Всем привет, 30 апреля в ОТУС стартует курс «Алгоритмы для разработчиков», именно к этому приурочена публикация сегодняшнего материала. Начнём.

В этой статье вы узнаете, как в Python реализованы словари.
Словари индексируются с помощью ключей, и они могут рассматриваться в качестве ассоциированных массивов. Давайте добавим 3 пары ключ/значение (key/value) в словарь:
К значениями можно получить доступ следующим образом:
Ключа
Хэш-таблицы
Словари в Python реализуются с помощью хэш-таблиц. Они представляют собой массивы, индексы которых вычисляются с помощью хэш-функций. Цель хэш-функции – равномерно распределить ключи в массиве. Хорошая хэш-функция минимизирует количество коллизий, т.е. вероятность того, что разные ключи будут иметь один хэш. В Python нет такого рода хэш-функций. Его наиболее важные хэш-функции (для строк и целочисленных значений) выдают похожие значения в общих случаях:
Будем предполагать, что до конца этой статьи мы будем использовать строки в качестве ключей. Хэш-функция в Python для строк определяется следующим образом:
Если выполнить
Если для хранения пар значение/ключ используется массив размера

Как мы видим, хэш-функция в Python качественно выполняет свою работу, в случае, когда ключи последовательны, что хорошо, поскольку довольно часто приходится работать с такими данными. Однако, как только мы добавляем ключ
Мы могли бы использовать связанный список для хранения пар, имея при этом один и тот же хэш, но это бы увеличило время поиска, и оно бы не равнялось уже в среднем O(1). В следующем разделе описывается метод разрешения коллизий, используемый для словарей в Python.
Открытая адресация
Открытая адресация – это метод разрешения коллизий, в котором используется пробирование. В случае с
Для поиска свободных ячеек используется последовательность квадратичного пробирования. Реализуется она следующим образом:
Рекурсия в (5*j)+1 быстро увеличивает большие различия в битах, которые не повлияли на изначальный индекс. Переменная
Давайте из любопытства посмотрим, чтобы произойдет, если у нас будет последовательность пробирования с размером таблицы 32 и j=3.
3 -> 11 -> 19 -> 29 -> 5 -> 6 -> 16 -> 31 -> 28 -> 13 -> 2…
Вы можете узнать больше об этой последовательности пробирования, обратившись к исходному коду dictobject.c. Детальное объяснение работы механизма пробирования можно найти в верхней части файла.

Давайте с этим примером обратимся к исходному коду Python.
Структуры словаря С
Для хранения записи в словаре используется следующая структура C: пара ключ/значение. Хранятся хэш, ключ и значение.
Следующая структура представляет собой словарь.
Инициализация словаря
Когда вы только создаете словарь, вызывается функция
Функция
Добавление элемента
Когда добавляется новая пара ключ/значение, вызывается
Почему именно 2/3? Это необходимо, чтобы убедиться, что последовательность пробирования сможет найти свободные ячейки достаточно быстро. Позже мы рассмотрим функцию для изменения размера.
Мы хотим добавить следующие пары ключ/значение:
Структура словаря аллоцируется с размером таблицы равным 8.
PyDict_SetItem: key = ‘c’, value = 3
PyDict_SetItem: key = ‘x’, value = 24
Вот что у нас получается:
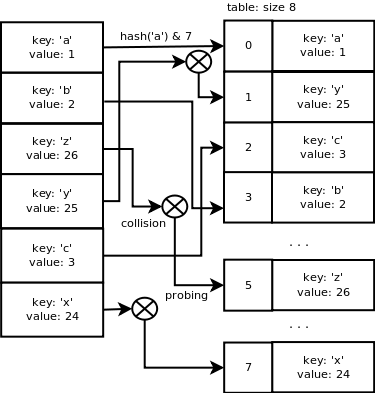
Сейчас используется 6 ячеек из 8, занято более 2/3 емкости массива.
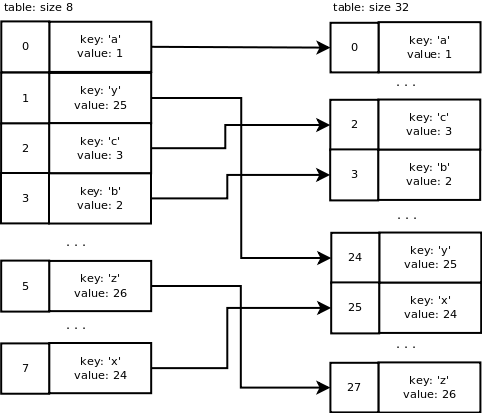
Новый размер таблицы должен быть больше 24, он рассчитывается путем смещения текущего размера на 1 бит влево до тех пор, пока размер таблицы не станет больше 24. В итоге он будет равен 32, например, 8 -> 16 -> 32.
Вот что происходит с нашей таблицей во время изменения размера: выделяется новая таблица размером 32. Старые записи таблицы вставляются в новую таблицу с использованием нового значения маски, равного 31. В итоге получается следующее:
Удаление элементов
Мы хотим удалить ключ «c» из нашего словаря. В итоге мы получаем следующий массив:
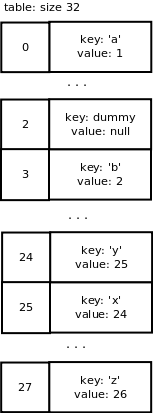
Обратите внимание, что операция удаления элемента не меняет размер массива, если количество используемых ячеек намного меньше, чем их общее количеств. Однако, когда добавляется пара ключ/значение, необходимость изменения размера зависит от количества используемых и неактивных ячеек, поэтому операция добавления также может уменьшить массив.
На этом публикация подошла к концу, а мы традиционно ждём ваши комментарии и приглашаем всех желающих на открытый урок, который пройдёт уже 18 апреля.

В этой статье вы узнаете, как в Python реализованы словари.
Словари индексируются с помощью ключей, и они могут рассматриваться в качестве ассоциированных массивов. Давайте добавим 3 пары ключ/значение (key/value) в словарь:
>>> d = {'a': 1, 'b': 2}
>>> d['c'] = 3
>>> d
{'a': 1, 'b': 2, 'c': 3}К значениями можно получить доступ следующим образом:
>>> d['a']
1
>>> d['b']
2
>>> d['c']
3
>>> d['d']
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'd'Ключа
“d” не существует, поэтому появится ошибка KeyError. Хэш-таблицы
Словари в Python реализуются с помощью хэш-таблиц. Они представляют собой массивы, индексы которых вычисляются с помощью хэш-функций. Цель хэш-функции – равномерно распределить ключи в массиве. Хорошая хэш-функция минимизирует количество коллизий, т.е. вероятность того, что разные ключи будут иметь один хэш. В Python нет такого рода хэш-функций. Его наиболее важные хэш-функции (для строк и целочисленных значений) выдают похожие значения в общих случаях:
>>> map(hash, (0, 1, 2, 3))
[0, 1, 2, 3]
>>> map(hash, ("namea", "nameb", "namec", "named"))
[-1658398457, -1658398460, -1658398459, -1658398462]Будем предполагать, что до конца этой статьи мы будем использовать строки в качестве ключей. Хэш-функция в Python для строк определяется следующим образом:
arguments: string object
returns: hash
function string_hash:
if hash cached:
return it
set len to string's length
initialize var p pointing to 1st char of string object
set x to value pointed by p left shifted by 7 bits
while len >= 0:
set var x to (1000003 * x) xor value pointed by p
increment pointer p
set x to x xor length of string object
cache x as the hash so we don't need to calculate it again
return x as the hashЕсли выполнить
hash(‘a’) в Python, то отработает string_hash() и вернет 12416037344. Здесь мы по умолчанию используем 64-х разрядную машину.Если для хранения пар значение/ключ используется массив размера
Х, то для вычисления индекса ячейки пары в массиве будет использована маска, которая вычисляется как Х-1. Такой подход делает вычисление индексов ячеек быстрым. Вероятность найти пустую ячейку достаточно высока из-за механизма изменения размера, который описан ниже. Это означает, что простое вычисление имеет смысл в большинстве случаев. Размер массива равен 8, индекс для ‘a’ будет равен: hash(‘a’) & 7 = 0. Индекс для ‘b’ равен 2, индекс для ‘c’ – 3, индекс для ‘z’ равен 3, также как для ‘b’, и именно здесь у нас появляется коллизия.
Как мы видим, хэш-функция в Python качественно выполняет свою работу, в случае, когда ключи последовательны, что хорошо, поскольку довольно часто приходится работать с такими данными. Однако, как только мы добавляем ключ
‘z’, происходит коллизия, поскольку он не является последовательным по отношению к предыдущим. Мы могли бы использовать связанный список для хранения пар, имея при этом один и тот же хэш, но это бы увеличило время поиска, и оно бы не равнялось уже в среднем O(1). В следующем разделе описывается метод разрешения коллизий, используемый для словарей в Python.
Открытая адресация
Открытая адресация – это метод разрешения коллизий, в котором используется пробирование. В случае с
‘z’, индекс ячейки 3 уже используется в массиве, поэтому нам необходимо подыскать другой индекс, который еще не был использован. Операция добавления пары ключ/значение займет в среднем O(1), также как операция поиска.Для поиска свободных ячеек используется последовательность квадратичного пробирования. Реализуется она следующим образом:
j = (5*j) + 1 + perturb;
perturb >>= PERTURB_SHIFT;
use j % 2**i as the next table index;Рекурсия в (5*j)+1 быстро увеличивает большие различия в битах, которые не повлияли на изначальный индекс. Переменная
"perturb" при этом принимает в себя другие биты хэш-кода.Давайте из любопытства посмотрим, чтобы произойдет, если у нас будет последовательность пробирования с размером таблицы 32 и j=3.
3 -> 11 -> 19 -> 29 -> 5 -> 6 -> 16 -> 31 -> 28 -> 13 -> 2…
Вы можете узнать больше об этой последовательности пробирования, обратившись к исходному коду dictobject.c. Детальное объяснение работы механизма пробирования можно найти в верхней части файла.

Давайте с этим примером обратимся к исходному коду Python.
Структуры словаря С
Для хранения записи в словаре используется следующая структура C: пара ключ/значение. Хранятся хэш, ключ и значение.
PyObject является базовым классом для объектов в Python.typedef struct {
Py_ssize_t me_hash;
PyObject *me_key;
PyObject *me_value;
} PyDictEntry;Следующая структура представляет собой словарь.
ma_fill – это суммарное количество используемых и неактивных ячеек. Ячейка (slot) считается неактивной, когда удаляется ключевая пара. ma_used – это количество используемых (активных) ячеек. ma_mask равняется размеру массива -1 и используется для расчета индекса ячейки. ma_table – это массив, а ma_smalltable – изначальный массив размера 8.typedef struct _dictobject PyDictObject;
struct _dictobject {
PyObject_HEAD
Py_ssize_t ma_fill;
Py_ssize_t ma_used;
Py_ssize_t ma_mask;
PyDictEntry *ma_table;
PyDictEntry *(*ma_lookup)(PyDictObject *mp, PyObject *key, long hash);
PyDictEntry ma_smalltable[PyDict_MINSIZE];
};Инициализация словаря
Когда вы только создаете словарь, вызывается функция
PyDict_New(). Я удалил некоторые строки и преобразовал код на C в псевдокод, чтобы сосредоточиться на ключевых понятиях.Функция
PyDict_New():- Возвращает объект-словарь;
- Аллоцирует новый объект-словарь;
- Очищает таблицу словаря;
- Устанавливает количество используемых ячеек словаря и неиспользуемых ячеек (
ma_fill) в 0; - Устанавливает количество активных ячеек (
ma_used) в 0; - Устанавливает маску словаря (
ma_value) в значение равное размеру словаря – 1 = 7; - Устанавливает функцией поиска по словарю
lookdict_string; - Возвращает аллоцированный объект-словарь.
Добавление элемента
Когда добавляется новая пара ключ/значение, вызывается
PyDict_SetItem(). Эта функция принимает на вход указатель на объект-словарь и пару ключ/значение. Она проверяет, является ли ключ строкой и вычисляет хэш или повторно использует закэшированный, если такой существует. insertdict() вызывается для добавления новой пары ключ/значение и размер словаря меняется, если количество используемых и неиспользуемых ячеек больше 2/3 размера массива. Почему именно 2/3? Это необходимо, чтобы убедиться, что последовательность пробирования сможет найти свободные ячейки достаточно быстро. Позже мы рассмотрим функцию для изменения размера.
arguments: dictionary, key, value
returns: 0 if OK or -1
function PyDict_SetItem:
if key's hash cached:
use hash
else:
calculate hash
call insertdict with dictionary object, key, hash and value
if key/value pair added successfully and capacity over 2/3:
call dictresize to resize dictionary's tableinserdict() использует функцию поиска lookdict_string(), чтобы найти свободную ячейку. Эта же функция используется для поиска ключа. lookdict_string() вычисляет индекс ячейки, используя хэш и значения маски. Если она не может найти ключ по значению индекс ячейки = хэш & маска (slot index = hash & mask), она начинает пробирование, используя цикл, описанный выше, пока не найдет свободную ячейку. При первой попытке пробирования, если ключ равен null, она возвращает неиспользуемую ячейку, если он найден во время первого поиска. Таким образом обеспечивается приоритет для повторного использования ранее удаленных ячеек.Мы хотим добавить следующие пары ключ/значение:
{‘a’: 1, ‘b’: 2′, ‘z’: 26, ‘y’: 25, ‘c’: 5, ‘x’: 24}. Вот что произойдет:Структура словаря аллоцируется с размером таблицы равным 8.
- PyDict_SetItem: key = ‘a’, value = 1
- hash = hash(‘a’) = 12416037344
- insertdict
- lookdict_string
- slot index = hash & mask = 12416037344 & 7 = 0
- slot 0 не используется, возвращаем эту ячейку
- инициализация входа по индексу 0 с key, value и hash
- ma_used = 1, ma_fill = 1
- lookdict_string
- PyDict_SetItem: key = ‘b’, value = 2
- hash = hash(‘b’) = 12544037731
- insertdict
- lookdict_string
- slot index = hash & mask = 12544037731 & 7 = 3
- slot 3 не используется, возвращаем эту ячейку
- инициализация входа по индексу 3 с key, value и hash
- ma_used = 2, ma_fill = 2
- lookdict_string
- PyDict_SetItem: key = ‘z’, value = 26
- hash = hash(‘z’) = 15616046971
- insertdict
- lookdict_string
- slot index = hash & mask = 15616046971 & 7 = 3
- slot 3 используется, пробуем другую ячейку: 5 свободна
инициализация входа по индексу 5 с key, value и hash
ma_used = 3, ma_fill = 3
- lookdict_string
- PyDict_SetItem: key = ‘y’, value = 25
- hash = hash(‘y’) = 15488046584
- insertdict
- lookdict_string
- slot index = hash & mask = 15488046584 & 7 = 0
- slot 0 используется, пробуем другую ячейку: 1 свободна
- инициализация входа по индексу 1 с key, value и hash
- ma_used = 4, ma_fill = 4
- lookdict_string
PyDict_SetItem: key = ‘c’, value = 3
- hash = hash(‘c’) = 12672038114
- insertdict
- lookdict_string
- slot index = hash & mask = 12672038114 & 7 = 2
- slot 2 не используется, возвращаем эту ячейку
- инициализация входа по индексу 2 с key, value и hash
- ma_used = 5, ma_fill = 5
- lookdict_string
PyDict_SetItem: key = ‘x’, value = 24
- hash = hash(‘x’) = 15360046201
- insertdict
- lookdict_string
- slot index = hash & mask = 15360046201 & 7 = 1
- slot 1 используется, пробуем другую ячейку: 7 свободна
- инициализация входа по индексу 7 с key, value и hash
- ma_used = 6, ma_fill = 6
- lookdict_string
Вот что у нас получается:

Сейчас используется 6 ячеек из 8, занято более 2/3 емкости массива.
dictresize() вызывается для аллоцирования большего массива. Эта функция также занимается копированием записей из старой таблицы в новую.dictresize () вызывается с minused = 24 в нашем случае, где 4 * ma_used. 2 * ma_used используется, когда количество используемых ячеек очень велико (больше 50000). Почему в 4 раза больше ячеек? Это уменьшает количество шагов для реализации изменения размера и увеличивает разреженность.Новый размер таблицы должен быть больше 24, он рассчитывается путем смещения текущего размера на 1 бит влево до тех пор, пока размер таблицы не станет больше 24. В итоге он будет равен 32, например, 8 -> 16 -> 32.
Вот что происходит с нашей таблицей во время изменения размера: выделяется новая таблица размером 32. Старые записи таблицы вставляются в новую таблицу с использованием нового значения маски, равного 31. В итоге получается следующее:

Удаление элементов
PyDict_DelItem() вызывается для удаления записей. Для ключа записи вычисляется хэш, далее вызывается функция поиска, чтобы вернуть запись. Теперь ячейка пустая.Мы хотим удалить ключ «c» из нашего словаря. В итоге мы получаем следующий массив:

Обратите внимание, что операция удаления элемента не меняет размер массива, если количество используемых ячеек намного меньше, чем их общее количеств. Однако, когда добавляется пара ключ/значение, необходимость изменения размера зависит от количества используемых и неактивных ячеек, поэтому операция добавления также может уменьшить массив.
На этом публикация подошла к концу, а мы традиционно ждём ваши комментарии и приглашаем всех желающих на открытый урок, который пройдёт уже 18 апреля.
