И снова здравствуйте!
Мы продолжаем расширение тем, которые преподаются у нас. Вот теперь разработали и вывели курс «Product Owner». Автор курса Екатерина Марчук предлагает вам ознакомится со своей авторской статьёй и приглашает на открытый урок.
Как нам интерпретировать фидбек?
О customer development или развитии пользователей в последнее время говорят все кому не лень. И каждый, кто знаком с понятием, осознает, насколько это важно, а если говорить прямо — жизненно необходимо для успешного запуска продукта.
Customer develoment помогает понять ценность продукта, выявить скрытые мотивы потребителей, их реальные проблемы и потребности. И самое главное, custdev позволяет нам проверять гипотезы. Без проверки гипотез сложно вести проект в правильном направлении, потому что, как показывает практика, голые цифры, увы, не репрезентативны.
Но, как водится, на чисто теоретическом понимании всё и заканчивается. У нас же ни на что не хватает времени, в том числе — и на такие важные задачи.
Почти у каждого есть плохая привычка, от которой хочется избавиться. Однако думать о плохой привычке и разбираться с ней — совершенно разные вещи. Так и здесь: мы вроде бы занимаемся развитием пользователей — собираем огромный объем обратной связи через колл-центры, социальные сети, тематические площадки, технические центры обслуживания и… не делаем ничего полезного. Вместо управляемого сбора и анализа пользовательского фидбека получаем хаотический поток неструктурированной информации и не получаем развития пользователей.
Когда мы говорим о сборе обратной связи, важно понимать, что у каждого канала контакта с пользователями своя аудитория и своя специфика. Наша основная задача — не просто собирать отзывы, а уметь правильно интерпретировать полученную информацию.

В погоне за количеством
или Почему не надо запускать MVP без проверок
Давайте поговорим о жизненном цикле пользовательской обратной связи, то есть отзывов, заявок и обращений. Как вы думаете, почему механизм обработки фидбека часто выходит из строя?
Простой пример. Давайте признаем: все мы обожаем KPI. И если посмотреть на Службу поддержки, одной из ключевых компонент KPI будет количество закрытых заявок.
На первый взгляд всё логично. Чем больше заявок обработано, тем выше будет лояльность. Чем выше лояльность, тем больше срок удержания пользователей. Так, да не так: индекс CSI (Customer Satisfaction Index, индекс удовлетворенности клиентов) не растет пропорционально количеству заявок, закрытых Службой поддержки. Почему?
Все довольно просто. При количественном подходе полученные заявки не валидируются должным образом, то есть никакой customer development не применяется. Это равноценно попытке реализовать идею, функцию или целый продукт без проверки ключевых гипотез: зачем мы всё это делаем? какую потребность, задачу или боль стараемся удовлетворить? какую выгоду хотим принести? Чем закончится такая попытка, думаю, всем очевидно.
Именно поэтому невероятно важно выстроить прозрачную систему обработки пользовательских запросов и обращений. О чем мы и поговорим сегодня.

Как мы дошли до жизни такой?
или о закономерных завалах в поддержке после запуска продукта
Возьмем стандартный сценарий. Владелец продукта Тимофей всегда полагается на свой опыт и чувство прекрасного. Так вышло, что при создании MVP сроки горели, стейкхолдеры лютовали, и Тимофей решил, что на глубинные исследования потребителей нет времени, можно обойтись без них. Каждому известно: опытная команда способна создать хороший и востребованный продукт самостоятельно. Исследования истинных потребностей не нужны! Особенно, когда нет времени.
Времени нет! Поэтому про A/B тест перед запуском забыли. А soft launch не провели, потому что времени нет. Вы же помните, да?
Результат закономерен: поток гневных обращений после релиза. Что делает Тимофей? Конечно, начинает в срочном порядке исправлять проблемы — все и сразу.
Метрик, само собой, у нас не было. В спешке забыли написать и прикрутить. А еще Тимофей решает загладить последний серьезный промах через добавление нового функционала. И вот, наконец, мы по-настоящему вышли в релиз! Ура? Благодарные пользователи несут нам деньги?
Вовсе нет! Вместо благодарности пользователи приносят еще больше заявок в Службу поддержки. Заявок становится всё больше, еще больше, и вот эта лавина обрушивается в наш бэклог… Ничего удивительного, служба поддержки работает хорошо, не то что наш Тимофей. Ему теперь разгребать сошедшую лавину и спасать продукт. Не будьте как Тимофей!
В нашем сценарии эффективнее всех работает Служба поддержки. Судите сами: было обработано огромное количество заявок. А что будет дальше? Появятся новые заявки, а потом еще — и цикл повторится. Чем больше пройденных циклов, тем сложнее контролировать ситуацию. Бэклог становится неуправляемым, обновлять его невозможно, как и проставлять приоритеты для всего, что туда попадает.
И вот когда количество обращений и заявок на новый функционал окончательно зашкаливает, приходит понимание, что так жить нельзя. А как нужно жить?

Как начать жизнь с чистого листа?
или Возвращение к истокам — вводим метрики!
Начинать нужно с создания простых метрик. Обязательно до релиза первого MVP!
Когда вы собираете первый MVP, вы строите модель ценностного предложения по профилям пользователей. Сами профили вы должны предварительно собрать и сформировать.
Если по какой-то невероятной причине ничего такого не делалось, идем в самое начало и действуем по порядку: создаем профили, проверяем гипотезы, строим наше предложение и только потом — бизнес-модель! В противном случае все ваши усилия пойдут только на нагрев окружающей среды и никакого результата вы не получите.
В профилях вы описываете потребности, выгоды, задачи. У каждой из них свой приоритет, который находит отражение в MVP. Мы включили в MVP все самое ценное, а остальное откладываем на потом. Когда у нас есть хорошая система метрик, можно проверить, насколько та или иная функция важна сама по себе или относительно другой функции.
Может получиться так, что функция важна, но её не используют из-за убогой реализации. А еще мы делаем ошибки и можем не понять потребности пользователей. Тогда некоторыми функциями не будут пользоваться, потому что они не нужны. Всё это мы обязательно увидим в метриках, которые у нас есть. Ведь они у нас есть, правда?

Хорошо. А что делать, если вы проспали все полимеры и продукт увидел свет без положенной подготовительной работы? Не ставьте на продукте крест! Беритесь за создание метрик и общение с пользователями. Плавно выходите на следующий цикл: снятие сливок с метрик -> обработка обратной связи -> реализация фич по назначенным приоритетам -> релиз. И да пребудет с вами Сила!
Прекрасно, скажете вы. И зададите вот какой вопрос: а почему нельзя просто провести A/B тесты перед релизом? Посмотреть на их метрики, всё проверить, исправить погрешности и выйти в релиз?
Очень хороший вопрос. И вы, безусловно, правы… если речь идет о продукте, который уже вышел на рынок. Тогда вы четко понимаете целевую аудиторию, и когортные A/B тесты будут, пожалуй, одним из лучших инструментов для оценки.
Но если вы создаете инновационный продукт и у вас нет пользователей, остается только гадать, кто они и что им нужно. Бывает, что ничего. Тогда вам придется худо, но это уже совсем другая история… Лучше не будем об этом.

Итак, еще раз. Цель каждой вашей метрики — не просто показать цифры, а описать, что хорошо и что плохо, для чего мы придумали метрику и как будем ее использовать. Если одна метрика связана с другой, мы должны видеть, какая у них связь, как метрики влияют друг на друга и как мы можем применять их вместе.
Только не думайте, что с увеличением количества метрик общая картина обязательно станет яснее и вам будет проще исправлять ошибки. Возьмите на вооружение несколько правил, которые помогут структурировать метрики:
В метриках должна быть четкая структура и порядок. Избегайте метрик, за которыми не стоят конкретные цели и тех, которые вы не можете адекватно интерпретировать. Работа с такими метрикам грозит неверными выводами.
Когда мы разобрались с метриками и наш MVP уже готов увидеть свет, жмем на кнопку “Релиз!” и отправляемся нервно курить в сторонке. Ненадолго.

Получаем первые отзывы
или Шестой подвиг Геракла
Чтобы упростить жизнь себе и команде, а заодно предотвратить панику на корабле в период сразу после релиза, когда вас накрывает лавина отзывов, заявок и запросов от пользователей, нужно заранее продумать правила агрегации и аккумуляции поступающих данных. Зачем это нужно? Чтобы не допустить отзеркаливания всего полученного фидбека в бэклог под громкие призывы срочно пофиксить все проблемы и немедленно выкатить обновленное решение.
Если вы дочитали до этого момента, скорее всего, вы сталкивались с неверной приоритизацией багов. По своим характеру и последствиям входящая лавина неприоритезированных запросов это примерно то же самое.

Погодите, скажете вы, ведь это задача службы поддержки — принести вам всё на блюдечке в лучшем виде.
Формально всё так. Но если посмотреть глубже, именно владелец продукта будет работать с информацией и разгребать последствия. Поэтому в ваших интересах позаботиться обо всём лично и заранее подготовить надежный плацдарм для быстрого и эффективного решения проблем. Поверьте, вам же будет проще.
Заблаговременно сформулируйте простые и понятные критерии, каким образом будут группироваться однотипные обращения. Не забудьте добавить счетчик этих обращений в вашу BTS (Bug tracking system). Идеально, если вы можете автоматически получать из CRM цифры по уже агрегированным обращениям.
Установите для счетчиков пороговые значения и назначьте соответствующие действия, которые нужно предпринимать по достижении каждого порога. Например: пока количество обращений по одной проблеме меньше 5 – не заносим её в бэклог, за исключением тех случаев, когда проблема блокирует наш основной сценарий. После 5 обращений заносим в бэклог и отслеживаем. Достигаем значения в 20 обращений — начинаем детальное изучение, общаемся с пользователями, пытаемся понять причину. Дошли до 50 – переводим в разряд критически важных, приоритезируем и берем в следующий спринт на проработку. Ваши цифры могут быть другими, а правила будут зависеть от специфики продукта, количества клиентов и прочих факторов. Но принцип вы поняли.
Важный момент: всё описанное выше не значит, что мы сразу делаем то, что хочет пользователь. Прежде необходимо понять, в чем заключается его настоящая боль.
Итак, ключевые шаги по приоритезации:
Механизм работы системы должен быть понятен не только вам как Владельцу продукта, но и Службе поддержки, и всем членам продуктовой команды.
После выполнения всех ключевых шагов обязательно обкатайте систему. Убедитесь, что все роли понимают, как она работает. Донесите до каждого члена команды важность и полезность этой информации. Эту работу достаточно сделать один раз — и она многократно окупится. Вы сэкономите кучу времени и нервов в будущем. Поверьте на слово.

Как не остаться с длинным релизом
или Не пытайтесь объять необъятное
Жесточайшая и вместе с тем классическая ошибка на этапе формирования релизного плана и цикла релизов — стараться включить как можно больше новых фич и исправленных багов в каждый релиз.
Обычно эта история развивается так: на этапе формирования плана включаем 10 фич, через две недели у нас их 12, потом 15, а на релиз выходит целых 25. Время до релиза растягивается, промежуточного фидбека нет, а после релиза получаем ту самую лавину отзывов. Красота!
И чем нам это грозит? А вот чем:
Смыть. Повторить. Итог очевиден.
Как же быть? Что делать? Релизиться как можно чаще. Вы скажете: похвальное намерение, но что-то не выходит! Соглашусь. Выйти на частый релизный цикл нелегко. Тут еще нужно понимать — это не просто частые релизы, это частые релизы с отработанной обратной связью.
Всё всегда зависит от специфики продукта. Но есть и общие моменты: через неделю после релиза у вас обычно есть четкая картина и по метрикам, и по полученным обращениям. Из этой информации вы можете понять, где есть проблемы.
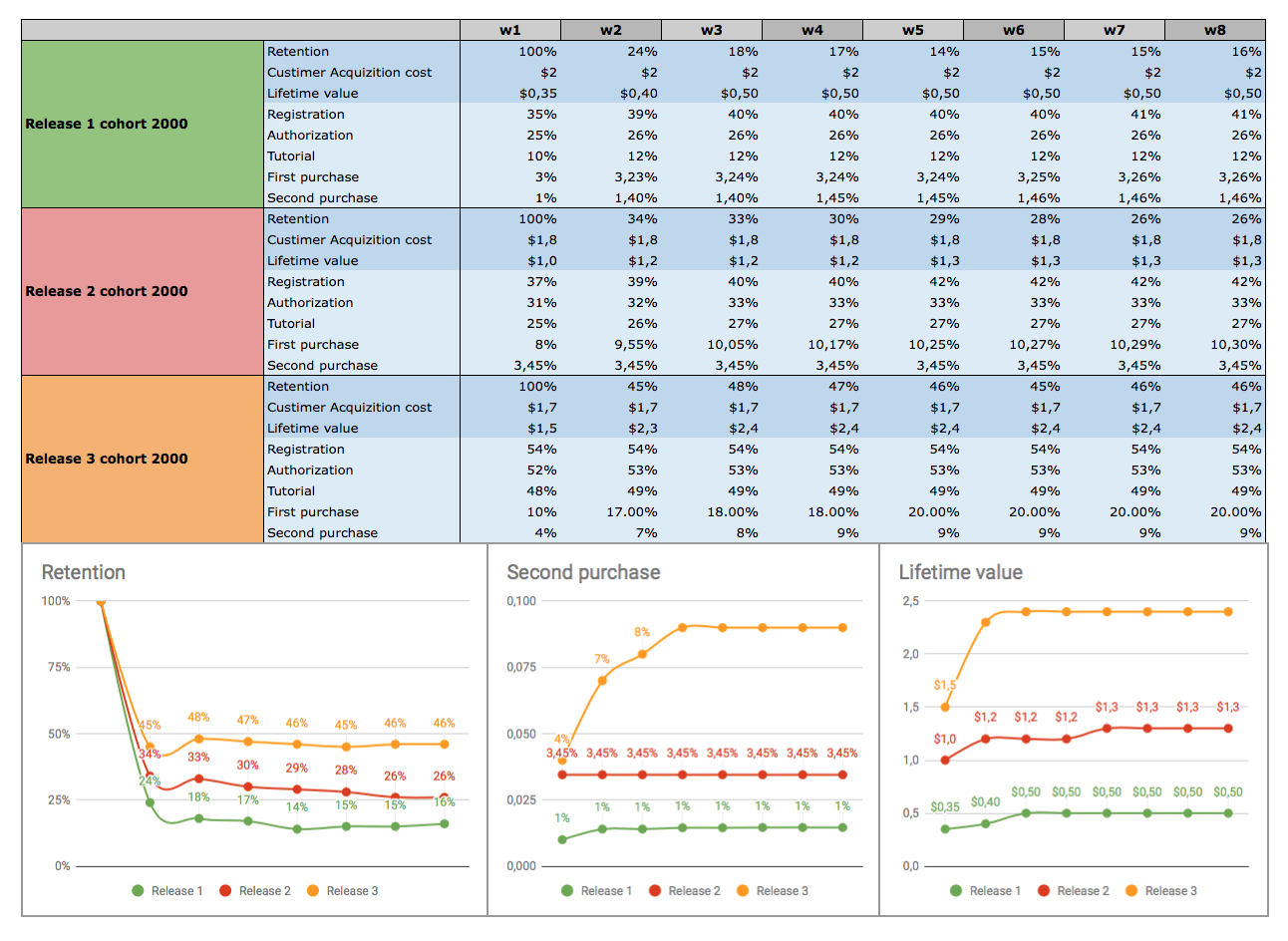
Главная и фатальная ошибка обычно в том, что мы не копаем вглубь, чтобы понять настоящую причину. Чаще всего мы стараемся исправить только последствия.
Беда в том, что исправление последствий работает только в одном случае — когда мы пропустили баги в релиз. Если мы говорим об удобстве использования и желаниях пользователей, нужны исследования и уточнение требований. Нужен диалог с клиентом.
Перед тем как вы начнете утрамбовывать в бэклог следующих спринтов новые фичи и хотелки, список которых вы получили из анализа метрик и разных счетчиков, выясните несколько вещей:
Как вы будете изучать клиентов — решать вам. Интервью, наблюдения, другие исследовательские методологии — на ваше усмотрение.
Вы должны быть готовы, что ни один из выбранных подходов не принесет мгновенных результатов. Тем не менее, это позволит изменить парадигму отношения к продукту. Шаг за шагом продукт начнет преображаться. У вас, с большой вероятностью, появятся:
Когда вы научитесь глубже и качественнее изучать клиентов, желание объять необъятное постепенно сойдет на нет. А зная приоритеты и ценности каждой фичи, вы сможете выстроить правильный цикл релизов, и обратная связь начнет работать на вас, а не против вас.
Что в остатке?
Один из самых тяжелых этапов во время разработки продукта – первые недели после релиза MVP. В это время идет поток отзывов и информации из метрик. Чем лучше вы подготовитесь, тем быстрее начнете улучшать показатели. Пройдите несколько итераций и верифицируйте выстроенный процесс сбора и обработки информации о поведении пользователей.
Для перехода к следующему этапу вам понадобится честно ответить на несколько вопросов:
Ответы на эти важные вопросы мы обязательно обсудим в следующих статьях. Без них наша история остается незаконченной.
И небольшое, но важное послесловие. Первый блин почти всегда выходит комом. Честно говоря, с первой попытки почти невозможно выбрать четко подходящие и эффективные метрики, идеально настроить механизм сбора и обработки отзывов. Так, чтобы потом не приходилось вносить уточнения и снова общаться с пользователями. Да, в первый раз может выйти полная ерунда, тут нечего скрывать. Надо пробовать снова, экспериментировать, переделывать и повторять еще раз. Только путём собственных проб и ошибок вы получите бесценный опыт развития потребителей и продуктов, начнете создавать личную философию работы, которая непременно приведет к успеху!
THE END
Ждём комментарии и вопрос тут или можете задать напрямую Екатерине на открытом уроке, который как раз и будет посвящён этой теме.
Мы продолжаем расширение тем, которые преподаются у нас. Вот теперь разработали и вывели курс «Product Owner». Автор курса Екатерина Марчук предлагает вам ознакомится со своей авторской статьёй и приглашает на открытый урок.
Как нам интерпретировать фидбек?
О customer development или развитии пользователей в последнее время говорят все кому не лень. И каждый, кто знаком с понятием, осознает, насколько это важно, а если говорить прямо — жизненно необходимо для успешного запуска продукта.
Customer develoment помогает понять ценность продукта, выявить скрытые мотивы потребителей, их реальные проблемы и потребности. И самое главное, custdev позволяет нам проверять гипотезы. Без проверки гипотез сложно вести проект в правильном направлении, потому что, как показывает практика, голые цифры, увы, не репрезентативны.
Но, как водится, на чисто теоретическом понимании всё и заканчивается. У нас же ни на что не хватает времени, в том числе — и на такие важные задачи.

Почти у каждого есть плохая привычка, от которой хочется избавиться. Однако думать о плохой привычке и разбираться с ней — совершенно разные вещи. Так и здесь: мы вроде бы занимаемся развитием пользователей — собираем огромный объем обратной связи через колл-центры, социальные сети, тематические площадки, технические центры обслуживания и… не делаем ничего полезного. Вместо управляемого сбора и анализа пользовательского фидбека получаем хаотический поток неструктурированной информации и не получаем развития пользователей.
Когда мы говорим о сборе обратной связи, важно понимать, что у каждого канала контакта с пользователями своя аудитория и своя специфика. Наша основная задача — не просто собирать отзывы, а уметь правильно интерпретировать полученную информацию.

В погоне за количеством
или Почему не надо запускать MVP без проверок
Давайте поговорим о жизненном цикле пользовательской обратной связи, то есть отзывов, заявок и обращений. Как вы думаете, почему механизм обработки фидбека часто выходит из строя?
Простой пример. Давайте признаем: все мы обожаем KPI. И если посмотреть на Службу поддержки, одной из ключевых компонент KPI будет количество закрытых заявок.
На первый взгляд всё логично. Чем больше заявок обработано, тем выше будет лояльность. Чем выше лояльность, тем больше срок удержания пользователей. Так, да не так: индекс CSI (Customer Satisfaction Index, индекс удовлетворенности клиентов) не растет пропорционально количеству заявок, закрытых Службой поддержки. Почему?
Все довольно просто. При количественном подходе полученные заявки не валидируются должным образом, то есть никакой customer development не применяется. Это равноценно попытке реализовать идею, функцию или целый продукт без проверки ключевых гипотез: зачем мы всё это делаем? какую потребность, задачу или боль стараемся удовлетворить? какую выгоду хотим принести? Чем закончится такая попытка, думаю, всем очевидно.
Именно поэтому невероятно важно выстроить прозрачную систему обработки пользовательских запросов и обращений. О чем мы и поговорим сегодня.

Как мы дошли до жизни такой?
или о закономерных завалах в поддержке после запуска продукта
Возьмем стандартный сценарий. Владелец продукта Тимофей всегда полагается на свой опыт и чувство прекрасного. Так вышло, что при создании MVP сроки горели, стейкхолдеры лютовали, и Тимофей решил, что на глубинные исследования потребителей нет времени, можно обойтись без них. Каждому известно: опытная команда способна создать хороший и востребованный продукт самостоятельно. Исследования истинных потребностей не нужны! Особенно, когда нет времени.
Времени нет! Поэтому про A/B тест перед запуском забыли. А soft launch не провели, потому что времени нет. Вы же помните, да?
Результат закономерен: поток гневных обращений после релиза. Что делает Тимофей? Конечно, начинает в срочном порядке исправлять проблемы — все и сразу.
Метрик, само собой, у нас не было. В спешке забыли написать и прикрутить. А еще Тимофей решает загладить последний серьезный промах через добавление нового функционала. И вот, наконец, мы по-настоящему вышли в релиз! Ура? Благодарные пользователи несут нам деньги?
Вовсе нет! Вместо благодарности пользователи приносят еще больше заявок в Службу поддержки. Заявок становится всё больше, еще больше, и вот эта лавина обрушивается в наш бэклог… Ничего удивительного, служба поддержки работает хорошо, не то что наш Тимофей. Ему теперь разгребать сошедшую лавину и спасать продукт. Не будьте как Тимофей!
В нашем сценарии эффективнее всех работает Служба поддержки. Судите сами: было обработано огромное количество заявок. А что будет дальше? Появятся новые заявки, а потом еще — и цикл повторится. Чем больше пройденных циклов, тем сложнее контролировать ситуацию. Бэклог становится неуправляемым, обновлять его невозможно, как и проставлять приоритеты для всего, что туда попадает.
И вот когда количество обращений и заявок на новый функционал окончательно зашкаливает, приходит понимание, что так жить нельзя. А как нужно жить?

Как начать жизнь с чистого листа?
или Возвращение к истокам — вводим метрики!
Начинать нужно с создания простых метрик. Обязательно до релиза первого MVP!
Когда вы собираете первый MVP, вы строите модель ценностного предложения по профилям пользователей. Сами профили вы должны предварительно собрать и сформировать.
Если по какой-то невероятной причине ничего такого не делалось, идем в самое начало и действуем по порядку: создаем профили, проверяем гипотезы, строим наше предложение и только потом — бизнес-модель! В противном случае все ваши усилия пойдут только на нагрев окружающей среды и никакого результата вы не получите.
В профилях вы описываете потребности, выгоды, задачи. У каждой из них свой приоритет, который находит отражение в MVP. Мы включили в MVP все самое ценное, а остальное откладываем на потом. Когда у нас есть хорошая система метрик, можно проверить, насколько та или иная функция важна сама по себе или относительно другой функции.
Может получиться так, что функция важна, но её не используют из-за убогой реализации. А еще мы делаем ошибки и можем не понять потребности пользователей. Тогда некоторыми функциями не будут пользоваться, потому что они не нужны. Всё это мы обязательно увидим в метриках, которые у нас есть. Ведь они у нас есть, правда?

Хорошо. А что делать, если вы проспали все полимеры и продукт увидел свет без положенной подготовительной работы? Не ставьте на продукте крест! Беритесь за создание метрик и общение с пользователями. Плавно выходите на следующий цикл: снятие сливок с метрик -> обработка обратной связи -> реализация фич по назначенным приоритетам -> релиз. И да пребудет с вами Сила!
Прекрасно, скажете вы. И зададите вот какой вопрос: а почему нельзя просто провести A/B тесты перед релизом? Посмотреть на их метрики, всё проверить, исправить погрешности и выйти в релиз?
Очень хороший вопрос. И вы, безусловно, правы… если речь идет о продукте, который уже вышел на рынок. Тогда вы четко понимаете целевую аудиторию, и когортные A/B тесты будут, пожалуй, одним из лучших инструментов для оценки.
Но если вы создаете инновационный продукт и у вас нет пользователей, остается только гадать, кто они и что им нужно. Бывает, что ничего. Тогда вам придется худо, но это уже совсем другая история… Лучше не будем об этом.

Итак, еще раз. Цель каждой вашей метрики — не просто показать цифры, а описать, что хорошо и что плохо, для чего мы придумали метрику и как будем ее использовать. Если одна метрика связана с другой, мы должны видеть, какая у них связь, как метрики влияют друг на друга и как мы можем применять их вместе.
Только не думайте, что с увеличением количества метрик общая картина обязательно станет яснее и вам будет проще исправлять ошибки. Возьмите на вооружение несколько правил, которые помогут структурировать метрики:
- собирайте требования с команд — вовлекайте представителей разных уровней и компетенций;
- делайте наброски метрик — не бойтесь использовать все, что приходит в голову;
- разбейте метрики на четкие категории — от бизнес-аспектов до интерфейса;
- выбросите из списка метрики, по которым у вас нет понимания, как их интерпретировать;
- после первого сбора метрик проведите ревизию — отбросьте те, что не можете интерпретировать, добавьте то, что упустили.
В метриках должна быть четкая структура и порядок. Избегайте метрик, за которыми не стоят конкретные цели и тех, которые вы не можете адекватно интерпретировать. Работа с такими метрикам грозит неверными выводами.
Когда мы разобрались с метриками и наш MVP уже готов увидеть свет, жмем на кнопку “Релиз!” и отправляемся нервно курить в сторонке. Ненадолго.

Получаем первые отзывы
или Шестой подвиг Геракла
Чтобы упростить жизнь себе и команде, а заодно предотвратить панику на корабле в период сразу после релиза, когда вас накрывает лавина отзывов, заявок и запросов от пользователей, нужно заранее продумать правила агрегации и аккумуляции поступающих данных. Зачем это нужно? Чтобы не допустить отзеркаливания всего полученного фидбека в бэклог под громкие призывы срочно пофиксить все проблемы и немедленно выкатить обновленное решение.
Если вы дочитали до этого момента, скорее всего, вы сталкивались с неверной приоритизацией багов. По своим характеру и последствиям входящая лавина неприоритезированных запросов это примерно то же самое.

Погодите, скажете вы, ведь это задача службы поддержки — принести вам всё на блюдечке в лучшем виде.
Формально всё так. Но если посмотреть глубже, именно владелец продукта будет работать с информацией и разгребать последствия. Поэтому в ваших интересах позаботиться обо всём лично и заранее подготовить надежный плацдарм для быстрого и эффективного решения проблем. Поверьте, вам же будет проще.
Заблаговременно сформулируйте простые и понятные критерии, каким образом будут группироваться однотипные обращения. Не забудьте добавить счетчик этих обращений в вашу BTS (Bug tracking system). Идеально, если вы можете автоматически получать из CRM цифры по уже агрегированным обращениям.
Установите для счетчиков пороговые значения и назначьте соответствующие действия, которые нужно предпринимать по достижении каждого порога. Например: пока количество обращений по одной проблеме меньше 5 – не заносим её в бэклог, за исключением тех случаев, когда проблема блокирует наш основной сценарий. После 5 обращений заносим в бэклог и отслеживаем. Достигаем значения в 20 обращений — начинаем детальное изучение, общаемся с пользователями, пытаемся понять причину. Дошли до 50 – переводим в разряд критически важных, приоритезируем и берем в следующий спринт на проработку. Ваши цифры могут быть другими, а правила будут зависеть от специфики продукта, количества клиентов и прочих факторов. Но принцип вы поняли.
Важный момент: всё описанное выше не значит, что мы сразу делаем то, что хочет пользователь. Прежде необходимо понять, в чем заключается его настоящая боль.
Итак, ключевые шаги по приоритезации:
- установите критерии приоритезации;
- добавьте счетчики однотипных обращений;
- выделите зависимости;
- добавьте пороговые значения;
- определите конкретные действия, которые будут предприниматься при достижении каждого из пороговых значений;
- напишите подробную инструкцию, как должна работать система.
Механизм работы системы должен быть понятен не только вам как Владельцу продукта, но и Службе поддержки, и всем членам продуктовой команды.
После выполнения всех ключевых шагов обязательно обкатайте систему. Убедитесь, что все роли понимают, как она работает. Донесите до каждого члена команды важность и полезность этой информации. Эту работу достаточно сделать один раз — и она многократно окупится. Вы сэкономите кучу времени и нервов в будущем. Поверьте на слово.

Как не остаться с длинным релизом
или Не пытайтесь объять необъятное
Жесточайшая и вместе с тем классическая ошибка на этапе формирования релизного плана и цикла релизов — стараться включить как можно больше новых фич и исправленных багов в каждый релиз.
Обычно эта история развивается так: на этапе формирования плана включаем 10 фич, через две недели у нас их 12, потом 15, а на релиз выходит целых 25. Время до релиза растягивается, промежуточного фидбека нет, а после релиза получаем ту самую лавину отзывов. Красота!
И чем нам это грозит? А вот чем:
- сроки доставки фич не выдерживаются;
- не можем удержать клиентов/пользователей;
- не получается привлечь новых клиентов — срывается план продаж;
- доля рынка скукоживается;
- стейкхолдеры недовольны;
- демотивация всей команды.
Смыть. Повторить. Итог очевиден.
Как же быть? Что делать? Релизиться как можно чаще. Вы скажете: похвальное намерение, но что-то не выходит! Соглашусь. Выйти на частый релизный цикл нелегко. Тут еще нужно понимать — это не просто частые релизы, это частые релизы с отработанной обратной связью.
Всё всегда зависит от специфики продукта. Но есть и общие моменты: через неделю после релиза у вас обычно есть четкая картина и по метрикам, и по полученным обращениям. Из этой информации вы можете понять, где есть проблемы.
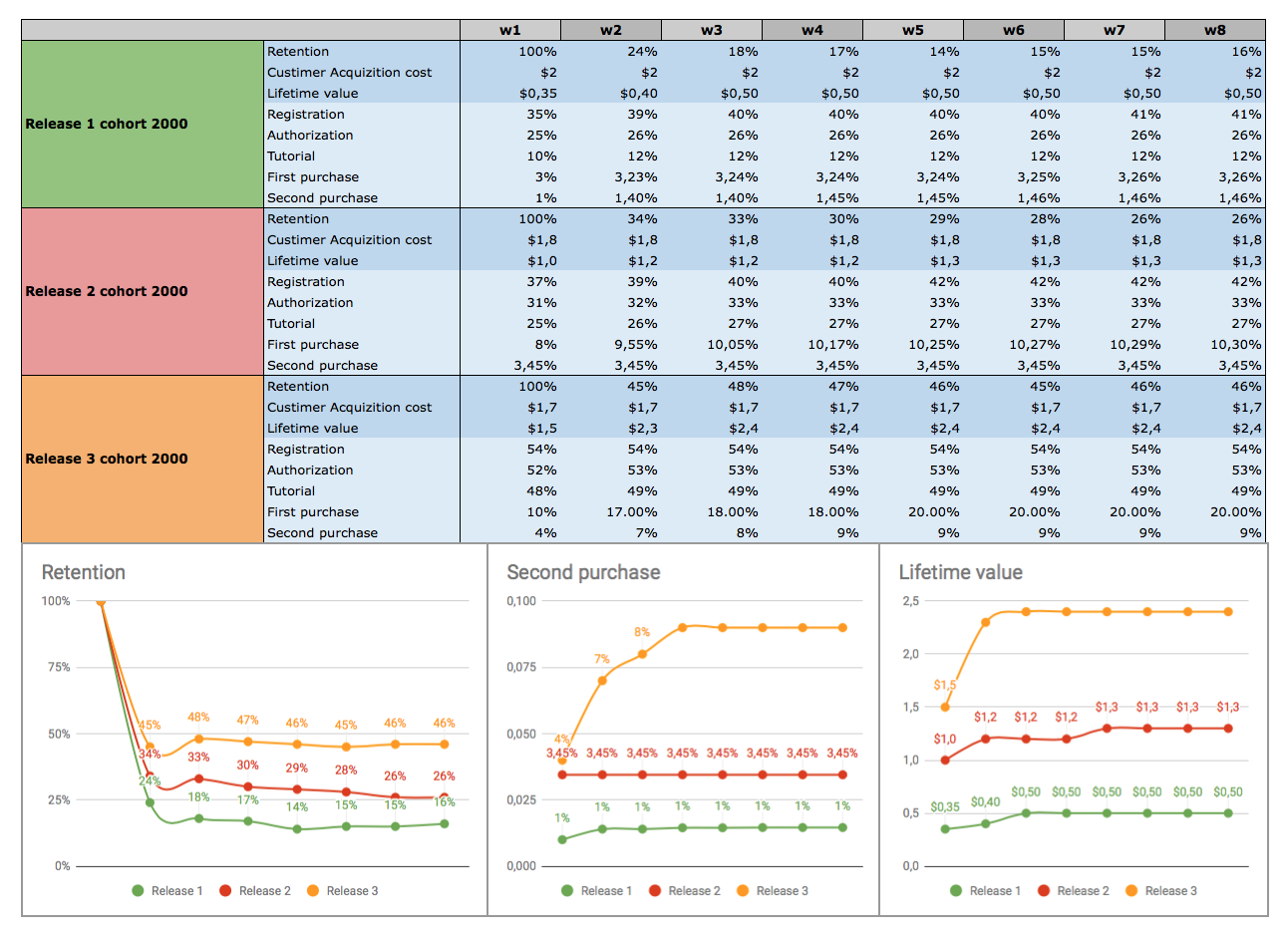
Главная и фатальная ошибка обычно в том, что мы не копаем вглубь, чтобы понять настоящую причину. Чаще всего мы стараемся исправить только последствия.
Беда в том, что исправление последствий работает только в одном случае — когда мы пропустили баги в релиз. Если мы говорим об удобстве использования и желаниях пользователей, нужны исследования и уточнение требований. Нужен диалог с клиентом.
Перед тем как вы начнете утрамбовывать в бэклог следующих спринтов новые фичи и хотелки, список которых вы получили из анализа метрик и разных счетчиков, выясните несколько вещей:
- правильно ли вы поняли проблему/задачу/хотелку?
- правильно ли назначили приоритет?
- не осталось ли за кадром что-то более важное и значимое, о чем вы не знаете?
- просчитали ли вы ценность от реализации той или иной фичи?
Как вы будете изучать клиентов — решать вам. Интервью, наблюдения, другие исследовательские методологии — на ваше усмотрение.
Вы должны быть готовы, что ни один из выбранных подходов не принесет мгновенных результатов. Тем не менее, это позволит изменить парадигму отношения к продукту. Шаг за шагом продукт начнет преображаться. У вас, с большой вероятностью, появятся:
- четкие приоритеты для каждой фичи;
- цели спринтов;
- оценка ценности каждого релиза.
Когда вы научитесь глубже и качественнее изучать клиентов, желание объять необъятное постепенно сойдет на нет. А зная приоритеты и ценности каждой фичи, вы сможете выстроить правильный цикл релизов, и обратная связь начнет работать на вас, а не против вас.
Что в остатке?
Один из самых тяжелых этапов во время разработки продукта – первые недели после релиза MVP. В это время идет поток отзывов и информации из метрик. Чем лучше вы подготовитесь, тем быстрее начнете улучшать показатели. Пройдите несколько итераций и верифицируйте выстроенный процесс сбора и обработки информации о поведении пользователей.
Для перехода к следующему этапу вам понадобится честно ответить на несколько вопросов:
- как вы оцениваете полученные показатели — они хорошие или плохие? гипотеза оправдывает ожидания или нет?
- какие метрики нужно исправить в первую очередь?
- как приоритезировать фичи?
Ответы на эти важные вопросы мы обязательно обсудим в следующих статьях. Без них наша история остается незаконченной.
И небольшое, но важное послесловие. Первый блин почти всегда выходит комом. Честно говоря, с первой попытки почти невозможно выбрать четко подходящие и эффективные метрики, идеально настроить механизм сбора и обработки отзывов. Так, чтобы потом не приходилось вносить уточнения и снова общаться с пользователями. Да, в первый раз может выйти полная ерунда, тут нечего скрывать. Надо пробовать снова, экспериментировать, переделывать и повторять еще раз. Только путём собственных проб и ошибок вы получите бесценный опыт развития потребителей и продуктов, начнете создавать личную философию работы, которая непременно приведет к успеху!
THE END
Ждём комментарии и вопрос тут или можете задать напрямую Екатерине на открытом уроке, который как раз и будет посвящён этой теме.
