PHP 7.4 только-только объявлена stable, а нам уже подавай еще больше усовершенствований. И лучше всех о том, что ждет PHP, может рассказать Дмитрий Стогов — один из ведущих разработчиков Open Source PHP и, наверное, старейший активный контрибьютор.
Все доклады Дмитрия только о тех технологиях и решениях, над которыми он работает лично. В лучших традициях Онтико под катом текстовая версия рассказа о самых интересных с точки зрения Дмитрия нововведениях PHP 8, которые могут открыть новые use-case-ы. В первую очередь JIT и FFI — не в ключе «потрясающих перспектив», а с подробностями реализации и подводными камнями.

Для справки: Дмитрий Стогов познакомился с программированием в 1984, когда еще далеко не все из читателей появились на свет, и успел внести существенный вклад в развитие инструментов разработки, и PHP в частности (хоть Дмитрий повышает производительность PHP не специально для российских разработчиков, они выразили свою благодарность в виде Премии HighLoad++). Дмитрий автор Turck MMCache для PHP (eAccelerator), майнтейнер Zend OPcache, лидер проекта PHPNG, легшего в основу PHP 7, и лидер разработки JIT для PHP.
Работать над производительностью PHP я начал 15 лет назад, когда пришел в Zend. Тогда мы выпустили версию 5.0 — первую, в которой язык стал по-настоящему объектно-ориентированным. С тех пор нам удалось повысить производительность на синтетических тестах в 40 раз, а на реальных приложениях в 6 раз.
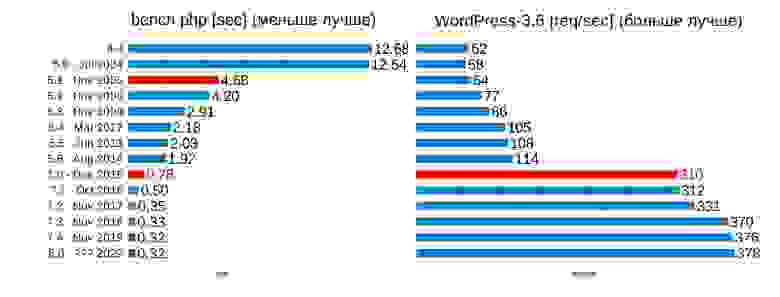
За это время было два прорывных момента:
Все остальные версии понемногу увеличивали производительность за счет реализации множества менее эффективных идей. В версии 7.1, например, большое внимание было уделено оптимизации байт-кода (статья, посвященная этим решениям).
На диаграмме видно, что как в конце разработки 5-й версии, так и в конце цикла разработки 7-й версии мы выходим на плато и замедляемся. Так за последний год работы над v7.4 удалось добиться только 2% прироста производительности. И это неплохо, потому что появились такие новые фичи как typed properties и ковариантные типы, которые замедляют PHP (об этих новинках на PHP Russia рассказывал Никита Попов).
И теперь всем интересно, что ждать от 8-й версии, сможет ли она повторить успех v7?
Идеи по усовершенствованию интерпретатора еще не исчерпаны, но все они требуют очень существенной проработки. Многие из них приходится отбросить на этапе proof of concept, потому что выигрыш, который удается получить, оказывается несоизмерим с усложнением или налагаемыми техническими ограничениями.
Но остается надежда на новую прорывную технологию — конечно, вспоминается JIT и история успеха JavaScript-движков.
На самом деле работы над JIT для PHP ведутся еще с 2012 года. Было 3 или 4 реализации, мы работали с коллегами из Intel, JavaScript-хакерами, но как-то все не получалось включить JIT в главную ветку. В конце концов в PHP 8 мы включили JIT в компилятор и увидели двукратное ускорение, но только на синтетических тестах, а на реальных приложениях наоборот — замедление.

Разумеется, это не то, к чему мы стремимся.
В чем же дело? Может, мы что-то делаем не так, может быть, WordPress такой плохой, и никакой JIT ему не поможет (да, на самом деле это так). Может, мы уже сделали слишком хороший интерпретатор, а в JavaScript он хуже. На вычислительных тестах это действительно так: интерпретатор PHP один из лучших.
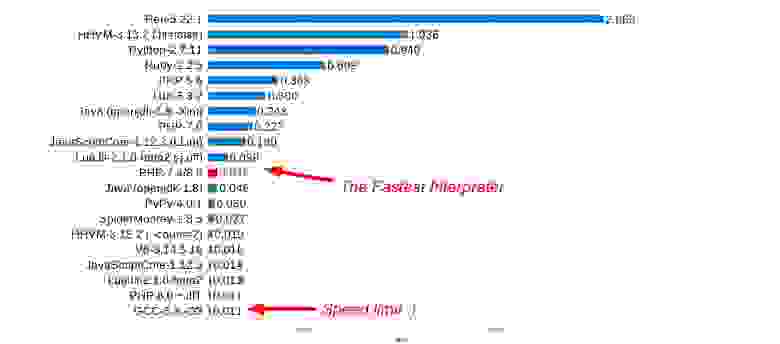
На тесте Mandelbrot он обгоняет даже такие жемчужины, как LuaJIT — интерпретатор, написанный на ассемблере. На этом тесте мы уступаем всего в 4 раза оптимизирующему компилятору GCC-5.3. С помощью JIT мы могли бы получить лучшие результаты в тесте Mandelbrot. Собственно, мы уже это делаем, то есть способны генерировать код, который конкурирует с компилятором C.
Почему же тогда мы не можем ускорить реальные приложения? Чтобы разобраться, расскажу, как мы делаем JIT. Начнем с самых азов.
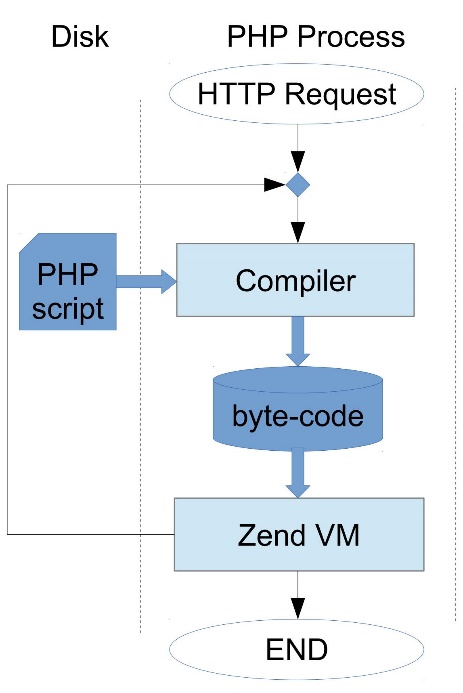
Сервер принимает запрос, компилирует его в байт-код, который в свою очередь поступает на исполнение виртуальной машине. Виртуальная машина, исполняя байт-код, может вызывать и другие PHP-файлы, которые опять перекомпилируются в байт-код и опять исполняются.
По завершению выполнения запроса вся информация, которая к нему относится, включая байт-код, удаляется из памяти. То есть каждый PHP-скрипт должен быть скомпилирован на каждом запросе заново. Разумеется, JIT-компиляцию в такую схему встроить просто невозможно, потому что компилятор должен быть очень быстрым.
Но скорее всего никто не использует PHP в голом виде, все его используют с OPcache.
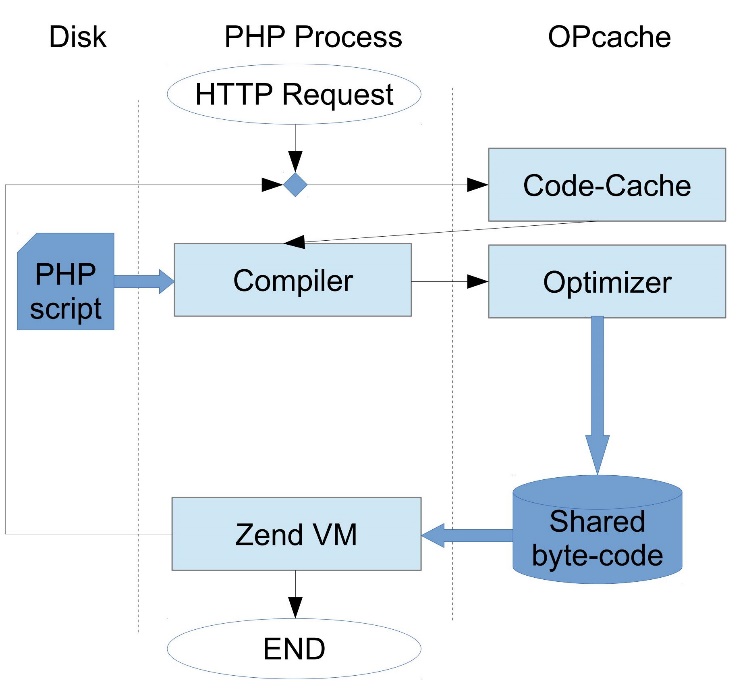
Главная задача OPcache — избавиться от перекомпиляции скриптов на каждом запросе. Он встраивается в специально предназначенную для него точку, перехватывает все запросы на компиляцию и кэширует скомпилированный байт-код в shared memory.
При этом экономится не только время компиляции, но и память, потому что раньше память под байт-код выделялся в адресном пространстве каждого процесса, а теперь он существует в единственном экземпляре.
В эту схему JIT уже можно встроить, что мы и сделаем. Но сначала покажу, как работает интерпретатор.

Интерпретатор — это в первую очередь цикл, который для каждой инструкции вызывает свой обработчик.
У нас используются два регистра:
Эти два вида регистров с помощью расширения gcc мапятся на реальные хардварные регистры, и за счет этого работают очень быстро.
В цикле мы просто вызываем обработчик для каждой инструкции, после чего в конце каждого обработчика сдвигаем указатель на следующую инструкцию.
Важно отметить, что адрес обработчика записывается непосредственно в байт-код. Для одной инструкции может быть несколько разных обработчиков. Первоначально это было придумано для специализации, чтобы обработчики могли специализироваться по типам операндов. Эта же технология используется для JIT, поскольку если записать в качестве обработчика адрес на новый сгенерированный код, то JIT-обработчики будут запускаться безо всякого изменения в интерпретаторе.
В примере выше справа представлен обработчик, написанный для инструкции сложения. Он принимает операнды (здесь первый и второй могут быть константой, временной или локальной переменной), читает операнды, проверяет типы, производит непосредственную логику — сложение — и дальше возвращается обратно в цикл, который передает управление на следующий обработчик.
Из этого описания генерируются специализированные функции. Так как было три возможных первых операнда, три возможных вторых, то получается 9 разных функций.

В данных функциях уже вместо универсальных методов для получения операндов используются конкретные, которые не делают никаких проверок.
Еще одно усложнение, которое мы сделали в версии 7.2 — это так называемая гибридная виртуальная машина.
Если раньше мы всегда вызывали обработчик с помощью косвенного вызова непосредственно в цикле интерпретатора, то теперь для каждого обработчика мы дополнительно в теле цикла ввели метку, на которую переходим с помощью косвенного перехода и где вызываем сам обработчик, но уже напрямую.

Казалось, раньше делали один косвенный вызов, теперь два: косвенный переход и прямой вызов, и такая система должна работать медленнее. Но на самом деле она работает быстрее, потому что мы помогаем процессору предсказывать переходы. Раньше была одна точка, из которой осуществлялся переход в разные места. Процессор часто ошибался, так как просто не мог запомнить, что надо прыгать сначала на одну инструкцию, потом на другую. Теперь после каждого прямого вызова идет косвенный переход на следующую метку. В результате, когда выполняется PHP-цикл, виртуальные PHP-инструкции выстраиваются в стабильные последовательности, которые потом выполняются практически линейно.
Гибридная виртуальная машина позволила поднять производительность еще на 5-10%.
JIT реализуется как часть OPcache.
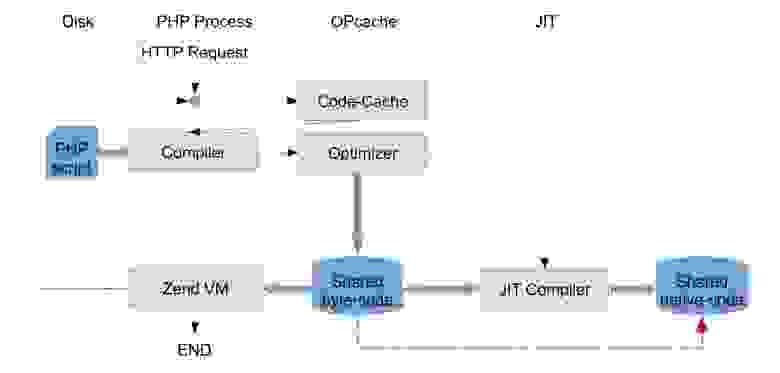
После того, как байт-код скомпилирован и оптимизирован, для него запускается JIT-компилятор, который уже не работает с исходными текстами. Из PHP байт-кода JIT-компилятор генерирует нативный код, после чего в байт-коде изменяется адрес первой инструкции (по сути дела функции).
После этого нативный, уже сгенерированный код начинает вызываться из существующего интерпретатора без каких-либо изменений. Покажу на простом примере.

Слева на PHP написана некая функция, которая считает сумму чисел от 0 до 100. Справа сгенерированный байт-код. Первая инструкция присваивает сумме 0, вторая то же делает для i, потом безусловный переход по метке. На метке L1 проверяется условие выхода из цикла: если оно выполнилось, то выходим, если нет, то идем в цикл. Дальше прибавляем к сумме i, записываем результат в сумму, увеличиваем i на 1.
Непосредственно отсюда генерируем ассемблерный код, который получается достаточно неплохим.

Первая инструкция
Дальше точно так же безусловный переход, проверяем, не произошло ли какое-то внешнее событие, проверяем условие цикла, идем в цикл. В цикле проверяется, является ли сумма целым: если да, то читаем целое значение, прибавляем к нему значение i, проверяем, не произошло ли переполнение, записываем результат обратно в сумму и прибавляем 1 к
Видно, что код близок к оптимальному. Можно было бы оптимизировать его еще больше, избавившись от проверки суммы на тип на каждой итерации цикла. Но это уже достаточно сложная оптимизация, мы пока таких не делаем. Мы развиваем JIT как достаточно простую технологию, не пытаемся делать то, что пытается делать Java HotSpot, V8 — у нас сил меньше.
Почему же при таком хорошем ассемблерном коде мы не можем ускорить реальные приложения?
Собственно, а должны ли?
Если приложение 80% времени ждет ответа от базы данных, то JIT не поможет. Если мы вызываем внешние ресурсоёмкие функции, например, сопоставление с регулярным выражением, то JIT точно также будет вызывать те же самые функции. Более того, если приложение строит большие структуры данных — деревья, графы, а потом читает их, то с помощью JIT мы генерируем код, который будет выполнять чтение за меньшее количество инструкций, но чтобы подгрузить сами данные, потребуется все то же время, а кроме того потребуется грузить еще и код.
Как вы уже видели, JIT даже может замедлить реальное приложение, потому что генерирует много кода и его чтение становится проблемой — при чтении больших объемов кода из кэша вытесняются другие данные, что и приводит к замедлению.
Одно из усовершенствований, которого мы хотим добиться в PHP 8, — это генерировать меньше кода. Сейчас, как я сказал, мы генерируем нативный код для всего скрипта, который грузим на этапе загрузки. Но половина функций наверняка не будет вызываться. Поэтому мы пошли немного дальше и ввели некий триггер, который позволяет сконфигурировать, когда мы хотим запускать JIT. Его можно запускать:
Такая схема может работать чуть лучше, но все равно не оптимальна, потому что в каждой функции опять есть пути, которые исполняются, и пути, которые никогда не исполняются. Поскольку PHP — динамический язык программирования, то есть каждая переменная может иметь разные типы, получается, что нужно поддерживать все типы, которые предсказывает статический анализатор. А он зачастую делает это с осторожностью, когда не смог доказать, что другой тип поступить не может.
В этих условиях мы собираемся уйти от честной компиляции и начать делать ее спекулятивно.
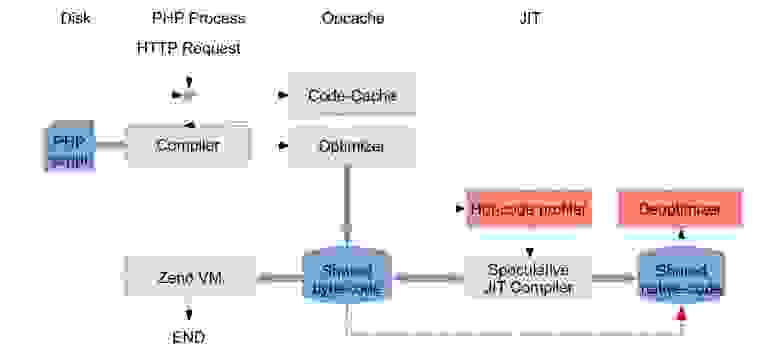
В будущем мы планируем сначала какое-то время в процессе работы приложения анализировать наиболее «горячие» функции, смотреть, по каким путям ходит программа, какие типы имеют переменные, может быть, даже запоминать граничные условия, и только потом генерировать код функций оптимальным для текущего исполнения образом — только для тех участков, которые реально исполняются.
Для всего остального будем ставить заглушки. Все равно будут проверки и возможные выходы, при которых будет запускаться процесс деоптимизации, то есть мы будем восстанавливать необходимое для интерпретации состояние виртуальной машины и отдавать на исполнение интерпретатору.
Подобная схема используется и в HotSpot Java VM, и в V8. Но адаптация технологии к PHP имеет ряд сложностей. В первую очередь это то, что мы имеем shared байт-код и shared нативный код, используемый из разных процессов. Мы не можем их менять непосредственно в shared memory, нужно сначала куда-то копировать, изменять, а потом уже коммитить обратно в shared memory.
На самом деле, многие идеи усовершенствований PHP, уже давно включенных в PHP 7 и даже PHP 5, пришли из работ, связанных с JIT. Сегодня я расскажу еще об одной такой технологии — это preloading. Эта технология уже включена в PHP 7.4 и дает возможность задать набор файлов, загрузить их при старте сервера и сделать все функции из этих файлов постоянными.
Одна из проблем, которую решает preloading-технология — это проблема связывания классов. Дело в том, что когда мы просто компилируем файлы в PHP, каждый файл компилируется отдельно от других. Делается это потому, что каждый из них может изменяться отдельно. Нельзя связать класс из одного скрипта с классом из другого скрипта, потому что при следующем запросе один из них может измениться, и что-то пойдет не так. Более того, в нескольких файлах может быть одноименный класс, и при одном запросе один из них используется в качестве parent, а при другом —используется другой класс из другого файла (с тем же именем, но совсем другой). Получается, что генерируя код, который будет выполняться на нескольких запросах, нельзя ссылаться ни на классы, ни на методы, потому что они каждый раз пересоздаются заново (время жизни кода превышает время жизни классов).
Preloading позволяет связать классы изначально и, соответственно, генерировать код более оптимально. Как минимум, для фреймворков, которые будут загружаться с помощью preloading’а.
Эта технология помогает не только для связывания классов. Что-то подобное реализовано в Java как Class Data Sharing. Там эта технология в первую очередь предназначена для ускорения старта приложений и уменьшения общего количества потребляемой памяти. Те же самые плюсы получаются и в PHP, поскольку теперь связывание классов не делается в runtime, а выполняется единожды. Кроме того связанные классы теперь хранятся не в адресном пространстве каждого процесса, а в shared memory, и следовательно общее потребление памяти падает.
Использование preloading так же помогает при глобальной оптимизации всех PHP-скриптов, полностью убирает накладные расходы OPcache и позволяет генерировать более эффективный JIT-код.
Но есть и минусы. Загруженные при старте скрипты нельзя заменить без рестарта PHP. Если мы что-то загрузили и сделали постоянным, то уже не можем это выгрузить. Поэтому технология может быть использована со стабильными фреймворками, но если вы деплоите приложение по нескольку раз в день, скорее всего, она вам не подойдет.
Технология задумывалась как транспарентная, то есть позволяла подгружать имеющиеся приложения (или их части) без каких-либо изменений. Но уже после реализации оказалось, что это не совсем так, Не все приложения работают так, как задумано, если они загружены с помощью preload. Например, если в приложении вызывается код по результатам проверки функции
Технически preloading включается с помощью всего одной директивы конфигурации opcache.preload, на вход которой вы даете файл сценария — обычный PHP-файл, который будет запущен на этапе старта приложения (не просто загружен, а именно выполнен).
Это один из возможных сценариев, который рекурсивно читает все файлы в какой-то директории (в данном случае ZendFramework). Можно реализовать абсолютно любой сценарий на PHP: читать списком, добавить исключения, или вообще скрестить с composer, чтобы он подсовывал файлы, которые нужны для preloading. Это всё дело техники, и более интересно не как грузить, а что грузить.
Я попробовал эту технологию на WordPress. Если просто загрузить все *.php файлы, то WordPress перестанет работать из-за упомянутой ранее особенности: в нем есть проверка function_exists, которая становится всегда истиной. Поэтому пришлось немного модифицировать сценарий из предыдущего примера (добавить исключения), и тогда, без каких-либо изменений в самом WordPress, он заработал.
В результате за счет preloading мы получили ~5% ускорение, что уже неплохо.
Я загрузил практически все файлы, но половина из них не использовалась. Можно сделать еще лучше — погонять приложение, посмотреть, какие файлы загрузились. Сделать это можно с помощью функции
Еще одна смежная c JIT технология, которая была разработана для PHP, — это FFI (Foreign Function Interface) или, говоря по-русски, возможность вызывать функции написанные на других компилируемых языках программирования без компиляции. Реализации подобной технологии в Python впечатлили моего шефа (Zeev Surazki), а сам я проникся, когда стал адаптировать ее к PHP.
В PHP уже было несколько попыток создать расширение для FFI, но все они использовали собственный язык или API для описания интерфейсов. Я же подсмотрел идею в LuaJIT, где для описания интерфейсов используется просто язык C (подмножество), и в результате получилась очень крутая игрушка. Теперь, когда мне нужно проверить как что-то работает на C, я пишу это на PHP — бывает, прямо в командной строке.
FFI позволяет работать со структурами данных, определенными на С, и может быть интегрирован с JIT для генерации более эффективного кода. Его реализация на основе libffi уже включена в PHP 7.4.
Но:
Хотя, может быть, для кого-то это будет удобно, потому что не нужен компилятор. Даже под Windows это будет работать безо всяких Visual-C из PHP.
Покажу, как использовать FFI, чтобы реализовать настоящее GUI-приложение под Linux.
Не пугайтесь С-кода, я сам GUI на С писал лет 20 назад, а этот пример нашел в интернете.
Программка создает приложение, навешивает на событие activate callback, запускает приложение. В callback создаем окошко, назначаем ему title размер и показываем.
А теперь, то же самое, переписанное на PHP:
Здесь в первую очередь создается FFI-объект. Ему на вход передается описание интерфейса — по сути дела h-файл — и библиотека, которую хотим загрузить. После этого все функции, описанные в интерфейсе, становятся доступны как методы объекта ffi, а все передаваемые параметры автоматически и абсолютно прозрачно транслируются в необходимое машинное представление.
Видно, что здесь все точно так же, как и в предыдущем примере. Отличие лишь в том, что в C мы посылали callback, как адрес, а в PHP связь происходит по имени заданному строкой.
Теперь посмотрим, как выглядит интерфейс. В первой части определяем типы и функции на С, а в последней строке подгружаем разделяемую библиотеку:
В данном случае эти С-определения скопированы из h-файлов библиотеки GTK, практически без изменений.
Чтобы не мешать в одном файле C и PHP, можно вынести весь С-код в отдельный файл, например, с названием gtk-ffi.h и добавить в начало пару специальных define’ов, которые задают имя интерфейса и библиотеку для загрузки:
Таким образом, мы выделили все описание С интерфейса в один файл. Этот gtk-ffi.h почти настоящий, но к сожалению, у нас пока не реализован С препроцессор, а значит макросы и include’ы работать не будут.
Теперь давайте загрузим этот интерфейс в PHP:
Поскольку FFI — достаточно опасная технология, мы не хотим давать ее в руки «кому попало». Давайте как минимум спрячем FFI-объект, то есть сделаем его приватным внутри класса. А создавать FFI-объект будем не с помощью
Остальной код практически не изменился, только в качестве обработчика события мы стали использовать безымянную функцию и передавать title с помощью лексического связывания. То есть мы используем и C, и сильные стороны PHP, которые в C недоступны.
Библиотеку, созданную подобным образом, можно было бы уже использовать в вашем приложении. Но хорошо, если она будет работать только в командной строке, а если засунуть её внутрь веб-сервера, то на каждом запросе будет читаться файл gtk_ffi.h, создаваться и загружаться библиотека, делаться биндинг… И вся эта повторяющаяся работа будет грузить ваш сервер.
Чтобы избежать этого и, по сути, позволить писать расширения PHP на самом PHP, мы решили скрестить FFI с preloading.
Код практически не изменился, только теперь h-файлы отдаем в preloading, и
В таком варианте FFI можно использовать из веб-сервера. Конечно, это не для GUI, но таким образом можно написать, например, биндинг к базе данных.
Созданное подобным образом расширение можно использовать прямо из командной строки:
Еще один плюс скрещивания FFI и preloading — это возможность запретить использовать FFI для всех user level скриптов. Можно указать ffi.enable = preload, что будет означать, что мы доверяем предзагружаемым файлам, но вызов FFI из обычных PHP-скриптов запрещен.
Еще одна интересная особенность FFI в том, что он умеет работать с нативными структурами данных. Можно в любой момент создать в памяти любую структуру данных, описанную на C.
Создаем массив из 100 структур (обратите внимание FFI::new != new FFI), содержащих два числа типа integer. Внутри памяти это будет представлено именно так, как написано на C. После этого можем работать с этой структурой данных с помощью обычных примитивов PHP, как будто это массив объектов. При этом можно использовать count, читать/писать элементы массива и даже итерировать с помощью foreach по ссылке. И эта структура занимает всего 800 байт, а если бы мы на PHP сконструировали подобную структуру данных из PHP’ых массивов и объектов, то она занимала бы раз в 10 больше.
Примеры использования FFI:
Python/CFFI используется для работы с: графикой (Cario, JpegTran), видео (ffmpeg), документами (LibreOfficeKit), в играх (SDL) и нейронных сетях (TensorFlow).
К сожалению, скорость работы FFI пока оставляет желать лучшего.
Происходит это из-за динамических особенностей PHP. Он просто не знает, что обращается к определенной структуре данных, и каждый раз с помощью callback’ов и загруженного описания структур данных определяет тип элемента, его размер и положение в памяти. Подобное происходит и в других динамических языках с FFI. Как говорится, чудес не бывает. Хотя если скрестить FFI c JIT, то, как показывает LuaJIT, можно добиться и чудес. Для нас эта планка пока недоступна, но это то направление, в котором мы предполагаем двигаться.
На таком простом примере использование FFI дает двукратное замедление.
Автор выражает благодарность: Zeev Surasky (Zend), Andi Gutmans (ex-Zend, Amazon), Xinchen Hui (ex-Weibo, ex-Zend, Lianjia), Nikita Popov (JetBrains), Anatol Belsky (Microsoft), Anthony Ferrara (ex-Google, Lingo Live), Joe Watkins, Mohammad Reza Haghighat (Intel) и команду Intel, Andy Wingo (JS hacker, Igalia), Mike Pall (автор LuaJIT).
В вопросах после доклада тоже есть много интересного, и не только связанного с темой доклада, послушать можно с этого момента.
Все доклады Дмитрия только о тех технологиях и решениях, над которыми он работает лично. В лучших традициях Онтико под катом текстовая версия рассказа о самых интересных с точки зрения Дмитрия нововведениях PHP 8, которые могут открыть новые use-case-ы. В первую очередь JIT и FFI — не в ключе «потрясающих перспектив», а с подробностями реализации и подводными камнями.

Для справки: Дмитрий Стогов познакомился с программированием в 1984, когда еще далеко не все из читателей появились на свет, и успел внести существенный вклад в развитие инструментов разработки, и PHP в частности (хоть Дмитрий повышает производительность PHP не специально для российских разработчиков, они выразили свою благодарность в виде Премии HighLoad++). Дмитрий автор Turck MMCache для PHP (eAccelerator), майнтейнер Zend OPcache, лидер проекта PHPNG, легшего в основу PHP 7, и лидер разработки JIT для PHP.
Развитие производительности PHP
Работать над производительностью PHP я начал 15 лет назад, когда пришел в Zend. Тогда мы выпустили версию 5.0 — первую, в которой язык стал по-настоящему объектно-ориентированным. С тех пор нам удалось повысить производительность на синтетических тестах в 40 раз, а на реальных приложениях в 6 раз.

За это время было два прорывных момента:
- Версия 5.1, в которой мы смогли существенно повысить скорость интерпретации. Мы реализовали специализирующий интерпретатор, и это повлияло в первую очередь на синтетические тесты.
- Версия 7.0, в которой переработали все ключевые структуры данных и таким образом оптимизировали работу с памятью и кэшем процессора (подробнее об этих оптимизациях читайте здесь). Это привело к более чем двукратному ускорению и на синтетических тестах, и в реальных приложениях.
Все остальные версии понемногу увеличивали производительность за счет реализации множества менее эффективных идей. В версии 7.1, например, большое внимание было уделено оптимизации байт-кода (статья, посвященная этим решениям).
На диаграмме видно, что как в конце разработки 5-й версии, так и в конце цикла разработки 7-й версии мы выходим на плато и замедляемся. Так за последний год работы над v7.4 удалось добиться только 2% прироста производительности. И это неплохо, потому что появились такие новые фичи как typed properties и ковариантные типы, которые замедляют PHP (об этих новинках на PHP Russia рассказывал Никита Попов).
И теперь всем интересно, что ждать от 8-й версии, сможет ли она повторить успех v7?
To JIT or not to JIT
Идеи по усовершенствованию интерпретатора еще не исчерпаны, но все они требуют очень существенной проработки. Многие из них приходится отбросить на этапе proof of concept, потому что выигрыш, который удается получить, оказывается несоизмерим с усложнением или налагаемыми техническими ограничениями.
Но остается надежда на новую прорывную технологию — конечно, вспоминается JIT и история успеха JavaScript-движков.
На самом деле работы над JIT для PHP ведутся еще с 2012 года. Было 3 или 4 реализации, мы работали с коллегами из Intel, JavaScript-хакерами, но как-то все не получалось включить JIT в главную ветку. В конце концов в PHP 8 мы включили JIT в компилятор и увидели двукратное ускорение, но только на синтетических тестах, а на реальных приложениях наоборот — замедление.

Разумеется, это не то, к чему мы стремимся.
В чем же дело? Может, мы что-то делаем не так, может быть, WordPress такой плохой, и никакой JIT ему не поможет (да, на самом деле это так). Может, мы уже сделали слишком хороший интерпретатор, а в JavaScript он хуже. На вычислительных тестах это действительно так: интерпретатор PHP один из лучших.

На тесте Mandelbrot он обгоняет даже такие жемчужины, как LuaJIT — интерпретатор, написанный на ассемблере. На этом тесте мы уступаем всего в 4 раза оптимизирующему компилятору GCC-5.3. С помощью JIT мы могли бы получить лучшие результаты в тесте Mandelbrot. Собственно, мы уже это делаем, то есть способны генерировать код, который конкурирует с компилятором C.
Почему же тогда мы не можем ускорить реальные приложения? Чтобы разобраться, расскажу, как мы делаем JIT. Начнем с самых азов.
Как работает PHP

Сервер принимает запрос, компилирует его в байт-код, который в свою очередь поступает на исполнение виртуальной машине. Виртуальная машина, исполняя байт-код, может вызывать и другие PHP-файлы, которые опять перекомпилируются в байт-код и опять исполняются.
По завершению выполнения запроса вся информация, которая к нему относится, включая байт-код, удаляется из памяти. То есть каждый PHP-скрипт должен быть скомпилирован на каждом запросе заново. Разумеется, JIT-компиляцию в такую схему встроить просто невозможно, потому что компилятор должен быть очень быстрым.
Но скорее всего никто не использует PHP в голом виде, все его используют с OPcache.
PHP + OPcache
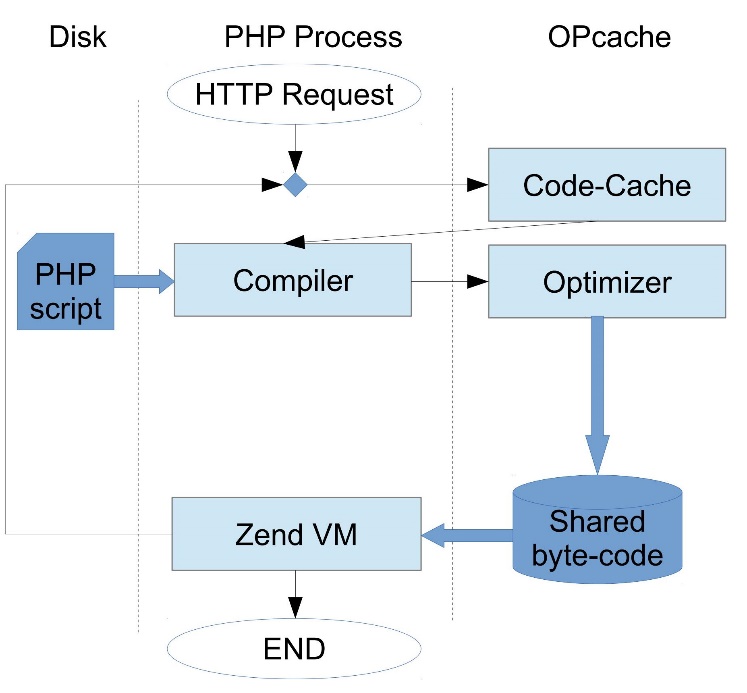
Главная задача OPcache — избавиться от перекомпиляции скриптов на каждом запросе. Он встраивается в специально предназначенную для него точку, перехватывает все запросы на компиляцию и кэширует скомпилированный байт-код в shared memory.
При этом экономится не только время компиляции, но и память, потому что раньше память под байт-код выделялся в адресном пространстве каждого процесса, а теперь он существует в единственном экземпляре.
В эту схему JIT уже можно встроить, что мы и сделаем. Но сначала покажу, как работает интерпретатор.

Интерпретатор — это в первую очередь цикл, который для каждой инструкции вызывает свой обработчик.
У нас используются два регистра:
- execute_data — указатель на текущий фрейм активации;
- opline — указатель на текущую исполняемую виртуальную инструкцию.
Эти два вида регистров с помощью расширения gcc мапятся на реальные хардварные регистры, и за счет этого работают очень быстро.
В цикле мы просто вызываем обработчик для каждой инструкции, после чего в конце каждого обработчика сдвигаем указатель на следующую инструкцию.
Важно отметить, что адрес обработчика записывается непосредственно в байт-код. Для одной инструкции может быть несколько разных обработчиков. Первоначально это было придумано для специализации, чтобы обработчики могли специализироваться по типам операндов. Эта же технология используется для JIT, поскольку если записать в качестве обработчика адрес на новый сгенерированный код, то JIT-обработчики будут запускаться безо всякого изменения в интерпретаторе.
В примере выше справа представлен обработчик, написанный для инструкции сложения. Он принимает операнды (здесь первый и второй могут быть константой, временной или локальной переменной), читает операнды, проверяет типы, производит непосредственную логику — сложение — и дальше возвращается обратно в цикл, который передает управление на следующий обработчик.
Из этого описания генерируются специализированные функции. Так как было три возможных первых операнда, три возможных вторых, то получается 9 разных функций.

В данных функциях уже вместо универсальных методов для получения операндов используются конкретные, которые не делают никаких проверок.
Гибридная виртуальная машина
Еще одно усложнение, которое мы сделали в версии 7.2 — это так называемая гибридная виртуальная машина.
Если раньше мы всегда вызывали обработчик с помощью косвенного вызова непосредственно в цикле интерпретатора, то теперь для каждого обработчика мы дополнительно в теле цикла ввели метку, на которую переходим с помощью косвенного перехода и где вызываем сам обработчик, но уже напрямую.

Казалось, раньше делали один косвенный вызов, теперь два: косвенный переход и прямой вызов, и такая система должна работать медленнее. Но на самом деле она работает быстрее, потому что мы помогаем процессору предсказывать переходы. Раньше была одна точка, из которой осуществлялся переход в разные места. Процессор часто ошибался, так как просто не мог запомнить, что надо прыгать сначала на одну инструкцию, потом на другую. Теперь после каждого прямого вызова идет косвенный переход на следующую метку. В результате, когда выполняется PHP-цикл, виртуальные PHP-инструкции выстраиваются в стабильные последовательности, которые потом выполняются практически линейно.
Гибридная виртуальная машина позволила поднять производительность еще на 5-10%.
PHP + OPcache + JIT
JIT реализуется как часть OPcache.

После того, как байт-код скомпилирован и оптимизирован, для него запускается JIT-компилятор, который уже не работает с исходными текстами. Из PHP байт-кода JIT-компилятор генерирует нативный код, после чего в байт-коде изменяется адрес первой инструкции (по сути дела функции).
После этого нативный, уже сгенерированный код начинает вызываться из существующего интерпретатора без каких-либо изменений. Покажу на простом примере.

Слева на PHP написана некая функция, которая считает сумму чисел от 0 до 100. Справа сгенерированный байт-код. Первая инструкция присваивает сумме 0, вторая то же делает для i, потом безусловный переход по метке. На метке L1 проверяется условие выхода из цикла: если оно выполнилось, то выходим, если нет, то идем в цикл. Дальше прибавляем к сумме i, записываем результат в сумму, увеличиваем i на 1.
Непосредственно отсюда генерируем ассемблерный код, который получается достаточно неплохим.

Первая инструкция
QM_ASSIGN скомпилирована всего в две машинные инструкции (2-3 строка). В регистре %esi лежит указатель текущего фрейма активации. По смещению 30 лежит переменная сумма. Первая инструкция записывает значение 0, вторая записывает 4 — это идентификатор целого типа (IS_LONG). Для переменной i компилятор понял, что она всегда long, и для нее не нужно хранить тип. Более того, её можно хранить в машинном регистре. Поэтому здесь просто XOR регистра c самим с собой — самая простая и дешевая инструкция обнуления.Дальше точно так же безусловный переход, проверяем, не произошло ли какое-то внешнее событие, проверяем условие цикла, идем в цикл. В цикле проверяется, является ли сумма целым: если да, то читаем целое значение, прибавляем к нему значение i, проверяем, не произошло ли переполнение, записываем результат обратно в сумму и прибавляем 1 к
%edx.Видно, что код близок к оптимальному. Можно было бы оптимизировать его еще больше, избавившись от проверки суммы на тип на каждой итерации цикла. Но это уже достаточно сложная оптимизация, мы пока таких не делаем. Мы развиваем JIT как достаточно простую технологию, не пытаемся делать то, что пытается делать Java HotSpot, V8 — у нас сил меньше.
Что не так с JIT
Почему же при таком хорошем ассемблерном коде мы не можем ускорить реальные приложения?
Собственно, а должны ли?
- Если узкое место не в CPU, то JIT не поможет.
- Генерируется слишком много кода (code bloat).
- Статический вывод типов работает не всегда.
- Честный код (для случаев, которые никогда не исполняются).
- Поддержка консистентного состояния виртуальной машины (а вдруг exception).
- Классы живут только в течение одного запроса.
Если приложение 80% времени ждет ответа от базы данных, то JIT не поможет. Если мы вызываем внешние ресурсоёмкие функции, например, сопоставление с регулярным выражением, то JIT точно также будет вызывать те же самые функции. Более того, если приложение строит большие структуры данных — деревья, графы, а потом читает их, то с помощью JIT мы генерируем код, который будет выполнять чтение за меньшее количество инструкций, но чтобы подгрузить сами данные, потребуется все то же время, а кроме того потребуется грузить еще и код.
Как вы уже видели, JIT даже может замедлить реальное приложение, потому что генерирует много кода и его чтение становится проблемой — при чтении больших объемов кода из кэша вытесняются другие данные, что и приводит к замедлению.
Скромные планы на PHP 8
Одно из усовершенствований, которого мы хотим добиться в PHP 8, — это генерировать меньше кода. Сейчас, как я сказал, мы генерируем нативный код для всего скрипта, который грузим на этапе загрузки. Но половина функций наверняка не будет вызываться. Поэтому мы пошли немного дальше и ввели некий триггер, который позволяет сконфигурировать, когда мы хотим запускать JIT. Его можно запускать:
- для всех функций;
- только для функций при их первом вызове;
- можно навесить на каждую функцию счетчик и компилировать только те функции, которые действительно горячие.
Такая схема может работать чуть лучше, но все равно не оптимальна, потому что в каждой функции опять есть пути, которые исполняются, и пути, которые никогда не исполняются. Поскольку PHP — динамический язык программирования, то есть каждая переменная может иметь разные типы, получается, что нужно поддерживать все типы, которые предсказывает статический анализатор. А он зачастую делает это с осторожностью, когда не смог доказать, что другой тип поступить не может.
В этих условиях мы собираемся уйти от честной компиляции и начать делать ее спекулятивно.

В будущем мы планируем сначала какое-то время в процессе работы приложения анализировать наиболее «горячие» функции, смотреть, по каким путям ходит программа, какие типы имеют переменные, может быть, даже запоминать граничные условия, и только потом генерировать код функций оптимальным для текущего исполнения образом — только для тех участков, которые реально исполняются.
Для всего остального будем ставить заглушки. Все равно будут проверки и возможные выходы, при которых будет запускаться процесс деоптимизации, то есть мы будем восстанавливать необходимое для интерпретации состояние виртуальной машины и отдавать на исполнение интерпретатору.
Подобная схема используется и в HotSpot Java VM, и в V8. Но адаптация технологии к PHP имеет ряд сложностей. В первую очередь это то, что мы имеем shared байт-код и shared нативный код, используемый из разных процессов. Мы не можем их менять непосредственно в shared memory, нужно сначала куда-то копировать, изменять, а потом уже коммитить обратно в shared memory.
Preloading. Проблема связывания классов
На самом деле, многие идеи усовершенствований PHP, уже давно включенных в PHP 7 и даже PHP 5, пришли из работ, связанных с JIT. Сегодня я расскажу еще об одной такой технологии — это preloading. Эта технология уже включена в PHP 7.4 и дает возможность задать набор файлов, загрузить их при старте сервера и сделать все функции из этих файлов постоянными.
Одна из проблем, которую решает preloading-технология — это проблема связывания классов. Дело в том, что когда мы просто компилируем файлы в PHP, каждый файл компилируется отдельно от других. Делается это потому, что каждый из них может изменяться отдельно. Нельзя связать класс из одного скрипта с классом из другого скрипта, потому что при следующем запросе один из них может измениться, и что-то пойдет не так. Более того, в нескольких файлах может быть одноименный класс, и при одном запросе один из них используется в качестве parent, а при другом —используется другой класс из другого файла (с тем же именем, но совсем другой). Получается, что генерируя код, который будет выполняться на нескольких запросах, нельзя ссылаться ни на классы, ни на методы, потому что они каждый раз пересоздаются заново (время жизни кода превышает время жизни классов).
Preloading позволяет связать классы изначально и, соответственно, генерировать код более оптимально. Как минимум, для фреймворков, которые будут загружаться с помощью preloading’а.
Эта технология помогает не только для связывания классов. Что-то подобное реализовано в Java как Class Data Sharing. Там эта технология в первую очередь предназначена для ускорения старта приложений и уменьшения общего количества потребляемой памяти. Те же самые плюсы получаются и в PHP, поскольку теперь связывание классов не делается в runtime, а выполняется единожды. Кроме того связанные классы теперь хранятся не в адресном пространстве каждого процесса, а в shared memory, и следовательно общее потребление памяти падает.
Использование preloading так же помогает при глобальной оптимизации всех PHP-скриптов, полностью убирает накладные расходы OPcache и позволяет генерировать более эффективный JIT-код.
Но есть и минусы. Загруженные при старте скрипты нельзя заменить без рестарта PHP. Если мы что-то загрузили и сделали постоянным, то уже не можем это выгрузить. Поэтому технология может быть использована со стабильными фреймворками, но если вы деплоите приложение по нескольку раз в день, скорее всего, она вам не подойдет.
Технология задумывалась как транспарентная, то есть позволяла подгружать имеющиеся приложения (или их части) без каких-либо изменений. Но уже после реализации оказалось, что это не совсем так, Не все приложения работают так, как задумано, если они загружены с помощью preload. Например, если в приложении вызывается код по результатам проверки функции
function_exists или class_exists, а функция стала постоянной, соответственно, function_exists всегда возвращает true, и код, который раньше по задумке вызывался, вызываться перестает.Технически preloading включается с помощью всего одной директивы конфигурации opcache.preload, на вход которой вы даете файл сценария — обычный PHP-файл, который будет запущен на этапе старта приложения (не просто загружен, а именно выполнен).
<?php
function _preload(string $preload, string $pattern = "/\.php$/") {
if (is_file($path) && preg_match($pattern, $path)) {
opcache_compile_file($path) or die("Preloading failed");
} else if (is_dir($path)) {
if ($dh = opendir($path)) {
while (($file = readdir($dh)) !== false) {
if ($file !== "." && $file !== "..") {
_preload($path . "/" . $file, $pattern);
}
}
closedir($dh);
}
}
}
_preload("/usr/local/lib/ZendFramework");Это один из возможных сценариев, который рекурсивно читает все файлы в какой-то директории (в данном случае ZendFramework). Можно реализовать абсолютно любой сценарий на PHP: читать списком, добавить исключения, или вообще скрестить с composer, чтобы он подсовывал файлы, которые нужны для preloading. Это всё дело техники, и более интересно не как грузить, а что грузить.
Что загружать в preloading
Я попробовал эту технологию на WordPress. Если просто загрузить все *.php файлы, то WordPress перестанет работать из-за упомянутой ранее особенности: в нем есть проверка function_exists, которая становится всегда истиной. Поэтому пришлось немного модифицировать сценарий из предыдущего примера (добавить исключения), и тогда, без каких-либо изменений в самом WordPress, он заработал.
| Скорость [req/seq] | Память [MB] | Количество скриптов | Количество функций | Количество классов | |
| Ничего | 378 | 0 | 0 | 0 | 0 |
| Все (почти*) | 395 | 7,5 | 254 | 1770 | 148 |
| Только используемые скрипты | 396 | 4,5 | 84 | 1532 | 51 |
В результате за счет preloading мы получили ~5% ускорение, что уже неплохо.
Я загрузил практически все файлы, но половина из них не использовалась. Можно сделать еще лучше — погонять приложение, посмотреть, какие файлы загрузились. Сделать это можно с помощью функции
opcache_get_status(), которая выдаст все файлы, закэшированные OPcache, и создать из них список для preloading. Таким образом можно сэкономить 3 Мбайта и получить еще чуть-чуть ускорения. Дело в том, что чем больше требуется памяти, тем больше загрязняется кэш процессора, и тем он менее эффективно работает. Чем меньше памяти используется, тем выше скорость работы.FFI — Foreign Function Interface
Еще одна смежная c JIT технология, которая была разработана для PHP, — это FFI (Foreign Function Interface) или, говоря по-русски, возможность вызывать функции написанные на других компилируемых языках программирования без компиляции. Реализации подобной технологии в Python впечатлили моего шефа (Zeev Surazki), а сам я проникся, когда стал адаптировать ее к PHP.
В PHP уже было несколько попыток создать расширение для FFI, но все они использовали собственный язык или API для описания интерфейсов. Я же подсмотрел идею в LuaJIT, где для описания интерфейсов используется просто язык C (подмножество), и в результате получилась очень крутая игрушка. Теперь, когда мне нужно проверить как что-то работает на C, я пишу это на PHP — бывает, прямо в командной строке.
FFI позволяет работать со структурами данных, определенными на С, и может быть интегрирован с JIT для генерации более эффективного кода. Его реализация на основе libffi уже включена в PHP 7.4.
Но:
- Это 1000 новых способов выстрелить себе в ногу.
- Требует знания С и иногда ручного управления памятью.
- Не поддерживает С-препроцессор (#include, #define, ...) и С++.
- Производительность без JIT достаточно низкая.
Хотя, может быть, для кого-то это будет удобно, потому что не нужен компилятор. Даже под Windows это будет работать безо всяких Visual-C из PHP.
Покажу, как использовать FFI, чтобы реализовать настоящее GUI-приложение под Linux.
Не пугайтесь С-кода, я сам GUI на С писал лет 20 назад, а этот пример нашел в интернете.
#include <gtk/gtk.h>
static void activate(GtkApplication* app, gpointer user_data) {
GtkWidget *window = gtk_application_window_new(app);
gtk_window_set_title(GTK_WINDOW(window), "Hello from C");
gtk_window_set_default_size(GTK_WINDOW(window), 200, 200);
gtk_widget_show_all(window);
}
int main() {
int status;
GtkApplication *app;
app = gtk_application_new("org.gtk.example", G_APPLICATION_FLAGS_NONE);
g_signal_connect(app, "activate", G_CALLBACK(activate), NULL);
status = g_application_run(G_APPLICATION(app), 0, NULL);
g_object_unref(app);
return status;
}Программка создает приложение, навешивает на событие activate callback, запускает приложение. В callback создаем окошко, назначаем ему title размер и показываем.
А теперь, то же самое, переписанное на PHP:
<?php
$ffi = FFI::cdef("
… // #include <gtk/gtk.h>
", "libgtk-3.so.0");
function activate($app, $user_data) {
global $ffi;
$window = $ffi->gtk_application_window_new($app);
$ffi->gtk_window_set_title($window, "Hello from PHP");
$ffi->gtk_window_set_default_size($window, 200, 200);
$ffi->gtk_widget_show_all($window);
}
$app = $ffi->gtk_application_new("org.gtk.example", 0);
$ffi->g_signal_connect_data($app, "activate", "activate", NULL, NULL, 0);
$ffi->g_application_run($app, 0, NULL);
$ffi->g_object_unref($app);Здесь в первую очередь создается FFI-объект. Ему на вход передается описание интерфейса — по сути дела h-файл — и библиотека, которую хотим загрузить. После этого все функции, описанные в интерфейсе, становятся доступны как методы объекта ffi, а все передаваемые параметры автоматически и абсолютно прозрачно транслируются в необходимое машинное представление.
Видно, что здесь все точно так же, как и в предыдущем примере. Отличие лишь в том, что в C мы посылали callback, как адрес, а в PHP связь происходит по имени заданному строкой.
Теперь посмотрим, как выглядит интерфейс. В первой части определяем типы и функции на С, а в последней строке подгружаем разделяемую библиотеку:
<?php
$ffi = FFI::cdef("
typedef struct _GtkApplication GtkApplication;
typedef struct _GtkWidget GtkWidget;
typedef void (*GCallback)(void*,void*);
int g_application_run (GtkApplication *app,
int argc, char **argv);
unsigned long * g_signal_connect_data (void *ptr, const char *signal,
GCallback handler, void *data,
GCallback *destroy, int flags);
void g_object_unref (void *ptr);
GtkApplication * gtk_application_new (const char *app_id, int flags);
GtkWidget * gtk_application_window_new (GtkApplication *app);
void gtk_window_set_title (GtkWidget *win, const char *title);
void gtk_window_set_default_size (GtkWidget *win, int width, int height);
void gtk_widget_show_all (GtkWidget *win);
", "libgtk-3.so.0");
...В данном случае эти С-определения скопированы из h-файлов библиотеки GTK, практически без изменений.
Чтобы не мешать в одном файле C и PHP, можно вынести весь С-код в отдельный файл, например, с названием gtk-ffi.h и добавить в начало пару специальных define’ов, которые задают имя интерфейса и библиотеку для загрузки:
#define FFI_SCOPE "GTK"
#define FFI_LIB "libgtk-3.so.0" Таким образом, мы выделили все описание С интерфейса в один файл. Этот gtk-ffi.h почти настоящий, но к сожалению, у нас пока не реализован С препроцессор, а значит макросы и include’ы работать не будут.
Теперь давайте загрузим этот интерфейс в PHP:
<?php
final class GTK {
static private $ffi = null;
public static function create_window($title) {
if (is_null(self::$ffi)) self::$ffi = FFI::load(__DIR__ . "/gtk_ffi.h");
$app = self::$ffi->gtk_application_new("org.gtk.example", 0);
self::$ffi->g_signal_connect_data($app, "activate",
function($app, $data) use ($title) {
$window = self::$ffi->gtk_application_window_new($app);
self::$ffi->gtk_window_set_title($window, $title);
self::$ffi->gtk_window_set_default_size($window, 200, 200);
self::$ffi->gtk_widget_show_all($window);
}, NULL, NULL, 0);
self::$ffi->g_application_run($app, 0, NULL);
self::$ffi->g_object_unref($app);
}
}Поскольку FFI — достаточно опасная технология, мы не хотим давать ее в руки «кому попало». Давайте как минимум спрячем FFI-объект, то есть сделаем его приватным внутри класса. А создавать FFI-объект будем не с помощью
FFI::cdef, а с помощью FFI::load, который читает как раз наш h-файл из предыдущего примера.Остальной код практически не изменился, только в качестве обработчика события мы стали использовать безымянную функцию и передавать title с помощью лексического связывания. То есть мы используем и C, и сильные стороны PHP, которые в C недоступны.
Библиотеку, созданную подобным образом, можно было бы уже использовать в вашем приложении. Но хорошо, если она будет работать только в командной строке, а если засунуть её внутрь веб-сервера, то на каждом запросе будет читаться файл gtk_ffi.h, создаваться и загружаться библиотека, делаться биндинг… И вся эта повторяющаяся работа будет грузить ваш сервер.
Чтобы избежать этого и, по сути, позволить писать расширения PHP на самом PHP, мы решили скрестить FFI с preloading.
FFI + preloading
Код практически не изменился, только теперь h-файлы отдаем в preloading, и
FFI::load выполняем непосредственно в момент preloading, а не когда создаем объект. То есть загрузка библиотеки, все разборы и связывания производятся один раз (при старте сервера), а с помощью FFI::scope("GTK") мы в своем скрипте получаем доступ к заранее загруженному интерфейсу по имени.<?php
FFI::load(__DIR__ . "/gtk_ffi.h");
final class GTK {
static private $ffi = null;
public static function create_window($title) {
if (is_null(self::$ffi)) self::$ffi = FFI::scope("GTK");
$app = self::$ffi->gtk_application_new("org.gtk.example", 0);
self::$ffi->g_signal_connect_data($app, "activate",
function($app, $data) use ($title) {
$window = self::$ffi->gtk_application_window_new($app);
self::$ffi->gtk_window_set_title($window, $title);
self::$ffi->gtk_window_set_default_size($window, 200, 200);
self::$ffi->gtk_widget_show_all($window);
}, NULL, NULL, 0);
self::$ffi->g_application_run($app, 0, NULL);
self::$ffi->g_object_unref($app);
}
}В таком варианте FFI можно использовать из веб-сервера. Конечно, это не для GUI, но таким образом можно написать, например, биндинг к базе данных.
Созданное подобным образом расширение можно использовать прямо из командной строки:
$ php -d opcache.preload=gtk.php -r 'GTK::create_window("Все просто!");'Еще один плюс скрещивания FFI и preloading — это возможность запретить использовать FFI для всех user level скриптов. Можно указать ffi.enable = preload, что будет означать, что мы доверяем предзагружаемым файлам, но вызов FFI из обычных PHP-скриптов запрещен.
Работа со структурами данных С
Еще одна интересная особенность FFI в том, что он умеет работать с нативными структурами данных. Можно в любой момент создать в памяти любую структуру данных, описанную на C.
<?php
$points = FFI::new("struct {int x,y;} [100]");
for ($x = 0; $x < count($points); $x++) {
$points[$x]->x = $x;
$points[$x]->y = $x * $x;
}
var_dump($points[25]->y); // 625
var_dump(FFI::sizeof($points)); // 800 байт
foreach ($points as &$p) {
$p->x += 10;
}
var_dump($points[25]->x); // 35Создаем массив из 100 структур (обратите внимание FFI::new != new FFI), содержащих два числа типа integer. Внутри памяти это будет представлено именно так, как написано на C. После этого можем работать с этой структурой данных с помощью обычных примитивов PHP, как будто это массив объектов. При этом можно использовать count, читать/писать элементы массива и даже итерировать с помощью foreach по ссылке. И эта структура занимает всего 800 байт, а если бы мы на PHP сконструировали подобную структуру данных из PHP’ых массивов и объектов, то она занимала бы раз в 10 больше.
Примеры использования FFI:
- Нейронные сети на PHP.
- Компилятор на PHP.
Python/CFFI используется для работы с: графикой (Cario, JpegTran), видео (ffmpeg), документами (LibreOfficeKit), в играх (SDL) и нейронных сетях (TensorFlow).
К сожалению, скорость работы FFI пока оставляет желать лучшего.
Происходит это из-за динамических особенностей PHP. Он просто не знает, что обращается к определенной структуре данных, и каждый раз с помощью callback’ов и загруженного описания структур данных определяет тип элемента, его размер и положение в памяти. Подобное происходит и в других динамических языках с FFI. Как говорится, чудес не бывает. Хотя если скрестить FFI c JIT, то, как показывает LuaJIT, можно добиться и чудес. Для нас эта планка пока недоступна, но это то направление, в котором мы предполагаем двигаться.
for ($k=0; $k<1000; $k++) {
for ($i=$n-1; $i>=0; $i--) {
$Y[$i] += $X[$i];
}
}На таком простом примере использование FFI дает двукратное замедление.
| Native Arrays | FFI Arrays | |
| PyPy | 0,010 | 0,081 |
| Python | 0,212 | 0,343 |
| LuaJIt -joff | 0,037 | 0,412 |
| LuaJit -jon | 0,003 | 0,002 |
| PHP | 0,040 | 0,093 |
| PHP + JIT | 0,016 | 0,087 |
Автор выражает благодарность: Zeev Surasky (Zend), Andi Gutmans (ex-Zend, Amazon), Xinchen Hui (ex-Weibo, ex-Zend, Lianjia), Nikita Popov (JetBrains), Anatol Belsky (Microsoft), Anthony Ferrara (ex-Google, Lingo Live), Joe Watkins, Mohammad Reza Haghighat (Intel) и команду Intel, Andy Wingo (JS hacker, Igalia), Mike Pall (автор LuaJIT).
В вопросах после доклада тоже есть много интересного, и не только связанного с темой доклада, послушать можно с этого момента.
PHP Russia 2020 быть! Следите за новостями в рассылке или telegram-канале, видео с конференции 2019 года смотрите на соответствующем youtube-канале и думайте, а чем вы можете поделиться с сообществом, — подать доклад уже можно.
