В последнее время веб-разработка разделилась. Теперь мы все не full-stack программисты — мы фронтендеры и бэкендеры. А самое сложное в этом, как и везде, это проблема взаимодействия и интеграции.
Фронтенд с бэкендом взаимодействуют через API. И от того, какой это API, насколько хорошо или плохо бэкенд и фронтенд договорились между собой, зависит весь результат разработки. Если мы все вместе станем обсуждать, как сделать паджинацию, и потратим на её переделывание целый день, то можем и не добраться до бизнес-задач.
Чтобы не буксовать и не разводить холивары по поводу названия переменных, нужна хорошая спецификация. Давайте поговорим о том, какой она должны быть, чтобы всем жилось легче. Заодно станем экспертами по велосипедным сараям.

Начнем издалека — с проблемы, которую мы решаем.
Давным-давно, в 1959 году Сирил Паркинсон (не путать с болезнью, это писатель и экономический деятель) придумал несколько интересных законов. Например, что расходы растут вместе с доходами и т.д. Один из них называется Законом тривиальности:
Паркинсон был экономистом, поэтому он объяснял свои законы в экономических терминах, примерно так. Если вы придете в совет директоров и скажете, что вам нужны 10 млн долларов на строительство атомной электростанции, скорее всего, этот вопрос будет обсуждаться гораздо меньше, чем выделение 100 фунтов на велосипедный сарай для сотрудников. Потому что все знают, как строить велосипедный сарай, у всех есть свое мнение, все чувствуют себя важными и хотят поучаствовать, а атомная электростанция — это что-то абстрактное и далекое, 10 млн тоже никто никогда не видел — вопросов меньше.
В 1999 году закон тривиальности Паркинсона появился в программировании, которое тогда активно развивалось. В программировании этот закон встречался в основном в англоязычной литературе и звучал, как метафора. Назывался он The Bikeshed effect (эффект велосипедного сарая), но суть та же самая — велосипедный сарай мы готовы и хотим обсуждать гораздо дольше, чем строительство электростанции.
В программирование этот термин ввел датский разработчик Poul-Henning Kamp, который участвовал в создании FreeBSD. В процессе проектирования команда очень долго обсуждала то, как должна работать функция sleep. Это цитата из письма Poul-Henning Kamp (разработка тогда велась в e-mail переписке):
В этом письме он говорит, что есть куча гораздо более важных нерешенных задач: «Давайте не будем заниматься велосипедным сараем, уже что-нибудь с этим сделаем и пойдем дальше!»
Так Poul-Henning Kamp в 1999 году в англоязычную литературу ввел термин bikeshed effect который, можно перефразировать как:
Чем более простое добавление или изменение мы делаем, тем больше мнений по этому поводу мы должны выслушать. Думаю, многие с этим встречались. Если решаем простой вопрос, например, как именовать переменные, — для машины это без разницы — этот вопрос вызовет огромное количество холиваров. А серьезные, действительно важные для бизнеса проблемы не обсуждаются и идут фоном.
Как вы думаете, что важнее: то, как мы общаемся между бэкендом и фронтендом, или бизнес задачи, которые мы делаем? Все считают по-разному, но любой заказчик, человек, который ждет, что вы принесете ему деньги, скажет: «Сделайте мне уже наши бизнес-задачи!» Ему абсолютно все равно, как вы будете передавать данные между бэкендом и фронтендом. Возможно, он даже не знает, что такое бэкенд и фронтенд.
Подытожить вступление я хотел бы утверждением: API — это велосипедный сарай.
Ссылка на презентацию доклада
О спикере: Алексей Авдеев (Avdeev) работает в компании Neuron.Digital, которая занимается нейронками и делает для них классный фронтенд. Также Алексей уделяет внимание OpenSource, и всем советует. Занимается разработкой давно — с 2002 года, застал древний интернет, когда компьютеры были большими, интернет маленьким, а отсутствие JS никого не смущало и все верстали сайты на таблицах.
Как бороться с велосипедными сараями?
После того, как уважаемый Сирил Паркинсон вывел закон тривиальности, он много обсуждался. Оказывается, эффекта велосипедного сарая здесь можно легко избежать:
Anti-bikeshedding tool
Я хочу рассказать про объективные инструменты для решения проблемы велосипедного сарая. Чтобы продемонстрировать, что такое anti-bikeshedding tool, расскажу небольшую историю.
Представим, что у нас есть начинающий бэкенд-разработчик. Он недавно пришел в компанию, и ему поручили спроектировать небольшой сервис, например, блог, для чего нужно написать REST-протокол.
 Рой Филдинг, автор REST
Рой Филдинг, автор REST
На фото Рой Филдинг, который в 2000 году защитил диссертацию «Архитектурные стили и дизайн сетевых программных архитектур» и тем самым ввел термин REST. Более того, он придумал HTTP и, по сути, является одним из основателей Интернета.
REST — это набор архитектурных принципов, которые говорят, как нужно проектировать REST протоколы, REST API, RESTful сервисы. Это достаточно абстрактные и сложные архитектурные принципы. Уверен, что никто из вас ни разу не видел API, сделанного полностью по всем RESTful принципам.
Требования к архитектуре REST
Приведу несколько требований к REST протоколам, на которые потом буду ссылаться и опираться. Их довольно много, в Википедии можно прочитать про это подробней.
1. Модель клиент-сервер.
Самый главный принцип REST, то есть нашего с вами взаимодействия с бэкендом. По REST бэкенд является сервером, фронтенд — клиентом, и мы общаемся в формате клиент—сервер. Мобильные устройства тоже являются клиентом. Разработчики под часы, под холодильники, другие сервисы — тоже разрабатывают клиентскую часть. RESTful API — это сервер, к которому обращается клиент.
2. Отсутствие состояния.
На сервере обязательно должно отсутствовать состояние, то есть все, что нужно для ответа, приходит в запросе. Когда на сервере хранится сессия, и в зависимости от этой сессии приходят разные ответы, это нарушение принципа REST.
3. Единообразие интерфейса.
Это один из ключевых базовых принципов, по которым должны строиться REST API. Он включает в себя следующее:
Есть еще 3 принципа, которые я не привожу, потому что они не важны для моего рассказа.
RESTful-блог
Вернемся к начинающему бэкенд-разработчику, которого попросили сделать сервис для блога на RESTful. Ниже пример прототипа.

Это сайт, на котором есть статьи, их можно комментировать, у статьи и комментариев есть автор — стандартная история. Наш начинающий бэкенд-разработчик будет делать RESTful API для этого блога.
Со всеми данными блога мы работаем по принципу СRUD.

Должна быть возможность любой ресурс создавать, читать, обновлять и удалять. Попробуем попросить нашего бэкенд-разработчика построить RESTful AP Iпо принципу СRUD. То есть написать методы, чтобы создавать статьи, получать список статей или отдельную статью, обновлять и удалять.
Посмотрим, как он мог бы это сделать.

Здесь все неправильно относительно всех принципов REST. Самое интересное, что это работает. Я реально получал API, которые выглядели примерно таким образом. Для заказчика — это велосипедный сарай, для разработчиков — повод похоливарить и поспорить, а для начинающего разработчика — это просто огромный, дивный новый мир, на котором он каждый раз спотыкается, падает, разбивает себе голову. Ему приходится раз за разом переделывать.

Это вариант по REST. По принципам идентификации ресурсов мы работаем с ресурсами — со статьями (articles) и пользуемся HTTP-методами, которые предложил Рой Филдинг. Он не мог не использовать свою предыдущую работу в своей следующей работе.
Для обновления статей многие используют метод PUT, у него немножко другая семантика. Метод PATCH обновляет те поля, которые были переданы, а PUT просто заменяет одну статью на другую. По семантике PATCH — это merge, а PUT — это replace.
Наш начинающий бэкенд-разработчик упал, его подняли и сказали: «Все в порядке, сделай так», и он честно переделал. Но дальше его ждет огромный большой путь через тернии.
Почему так правильно?
Однако это «велосипедный сарай», будет работать и предыдущий способ. Компьютеры общались до REST, и все работало. Но сейчас в индустрии появился стандарт.
Удаляем статью
Рассмотрим пример с удалением статьи. Допустим, есть нормальный, ресурсный метод DELETE /articles, который удаляет статью по id. HTTP содержит заголовки. Заголовок Accept принимает тип данных, которые клиент хочет получить в ответ. Наш джуниор написал сервер, который возвращает 200 OK, Content-Type: application/json, и передает пустой body:
Здесь допущена очень частая ошибка — пустой body. Вроде бы все логично — статья удалена, 200 ОК, присутствует заголовок application/json, но клиент, скорее всего, упадет. Он выкинет ошибку, потому что пустой body не валиден. Если вы когда-либо пробовали парсить пустую строку, то сталкивались с тем, что любой парсер json на этом спотыкается и падает.
Как можно исправить эту ситуацию? Самый, наверное, лучший вариант — это передать json. Если мы заявили: «Accept, отдай нам json», сервер говорит: «Content-Type, я вам отдаю json», отдайте json. Пустой объект, пустой массив — что-то туда положите — это будет решение, и оно будет работать.
Есть еще решение. Помимо 200 OK есть код ответа 204 — no content. С ним можно не передавать тело. Про это не все знают.
Так я подвёл к медиатипам.
MIME-типы
Медиатипы — это как расширение файлов, только в вебе. Когда мы передаем данные, мы должны сообщить или запросить, какой тип хотим получить в ответ.
Можно указать просто конкретный тип:
Заголовки Content-Type и Accept есть и важны.
Если у вас API построен на JSON, передавайте всегда Accept: application/json и Content-Type application/json.
Пример типов файлов.

Медиатипы аналогичны этим типам файлов, только в интернете.
Коды ответов
Следующий пример приключений нашего джуниор-разработчика — это коды ответов.

Самый смешной котд ответа — 200 ОК. Его все любят — он означает, что все прошло правильно. У меня даже был случай — мне приходили ошибки 200 ОК. Реально на сервере что-то упало, в ответ в response приходит HTML-страница, на которой в HTML сверстана ошибка. Я запрашивал application json с кодом 200 ОК, и думал, как же с этим работать? Идешь по response, ищешь слово «ошибка», считаешь, что это ошибка.
Это работает, однако в HTTP существует много других кодов, которые можно использовать, и по REST Рой Филдинг рекомендует их использовать. Например, на создание сущности (статьи) можно ответить:
Создание сущности
Следующий пример: мы создаем сущность, говорим Content-Type: application/json, и передаем этот application/json. Это делает клиент — наш фронтенд. Допустим, создаем эту самую статью:
В ответ может прийти код:
Но абсолютно непонятно, что конкретно произошло: какая сущность необрабатываемая, почему мне туда нельзя, и что в конце концов случилось с сервером?
Возвращайте ошибки
Обязательно (и об этом джуниоры не знают) в ответ возвращайте ошибки. Это семантично и правильно. Про это, кстати, не писал Филдинг, то есть это было придумано позже и построено поверх REST.
Бэкенд может в ответ вернуть массив с ошибками, их может быть несколько.
У каждой ошибки может быть свой статус и заголовок. Это здорово, но это уже идет на уровне соглашений поверх REST. Это может быть нашим anti-bikeshedding инструментом, чтобы перестать спорить, а делать сразу хороший правильный API.
Добавим паджинацию
Следующий пример: к нашему начинающему бэкенд-разработчику приходят дизайнеры и говорят: «У нас много статей, нам нужна паджинация. Мы нарисовали вот такую».

Рассмотрим ее подробней. Прежде всего в глаза бросается 336 страниц. Когда я это увидел, то подумал, как эту цифру вообще получить. Откуда взять 336, ведь на запрос списка статей мне приходит список статей. Например, их там 10 тысяч, то есть мне надо загрузить все статьи, поделить на количество страниц и узнать это число. Очень долго я буду грузить эти статьи, нужен способ получить количество записей быстро. Но если наш API отдает список, то куда это количество записей вообще засунуть, потому что в ответ приходит массив статей. Получается, раз количество записей нигде не ставится, то его надо в каждую статью добавлять, чтобы каждая статья говорила: «А нас всех столько-то!».
Однако есть соглашение поверх REST API, которое решает эту проблему.
Запрос списка
Чтобы API был расширяемый, можно сразу использовать GET-параметры для паджинации: размер текущей страницы и её номер, чтобы нам вернулся ровно тот кусок той страницы, который мы запросили. Это удобно. В ответ можно не сразу давать массив, а добавить дополнительную вложенность. Например, ключ data будет содержать массив, данные, которые мы запросили, а ключ meta, которого до этого не было, будет содержать общее количество.
Таким образом API может возвращать дополнительную информацию. Помимо count там может быть еще какая-то информация — это расширяемо. Сейчас, если джуниор не сделал так сразу, а только после того, как его попросили сделать паджинацию, то он совершил обратно несовместимое изменение, сломал API, и все клиенты должны переделываться — обычно это очень больно.
Паджинация бывает разная. Предлагаю несколько лайфхаков, которые можно использовать.
[offset]...[limit]
У тех, кто работает с базами данных, возможно, уже на подкорке [offset]...[limit]. Использовать его вместо page[size]...page[number] будет проще. Это немножко другой подход.
Курсорная паджинация
Курсорная паджинация использует указатель на сущность, с которой нужно начать подгружать записи. Например, она очень удобна, когда вы используете паджинацию или подгрузку в списках, которые часто меняются. Допустим, в наш блог постоянно пишут новые статьи. Третья страница сейчас — это не та же самая третья страница, которая будет через минуту, а перейдя на четвертую страницу, мы на ней получим часть записей с третьей страницы, потому что весь список сдвинется.
Эту проблему решает курсорная паджинация. Мы говорим: «Подгрузи статьи, которые идут после статьи, опубликованной в это время» — никакого сдвига уже быть не может чисто технологически, и это круто.
Проблема N +1
Следующая проблема, с которой обязательно столкнется наш джуниор-разработчик — это проблема N + 1 (бэкендеры поймут). Допустим, нужно вывести список из 10 статей. Мы загружаем список статей, у каждой статьи есть автор, и для каждой нужно загрузить автора. Мы отправляем:
Итого: 11 запросов, чтобы вывести небольшой список.
Добавляем связи
На бэкенде эта проблема решена во всех ORM — надо только не забывать дописывать эту связь. Эти связи можно использовать и на фронтенде. Делается это следующим образом:
Можно использовать специальный GET-параметр, назвать его include (как на бэкенде), говоря, какие связи нам нужно загрузить вместе со статьями. Допустим, мы загружаем статьи, и хотим вместе со статьями сразу же получить еще их автора. Ответ выглядит так:
В data перенесены собственные атрибуты статей и добавлен ключ relationships (связи). В этот ключ мы кладем все связи. Таким образом одним запросом мы получили все те данные, которые до этого получали 11 запросами. Это крутой лайфхак, который хорошо решает проблему с N + 1 на фронтенде.
Проблема дублирования данных
Допустим, нужно вывести 10 статей с указанием автора, у всех статей один автор, но объект с автором очень большой (например, очень длинная фамилия, которая занимает мегабайт). Один автор включен в ответ 10 раз, и 10 включений одного и того же автора в ответ займет 10 Мбайт.
Поскольку все объекты одинаковые, проблема, что один автор включен 10 раз (10 Мбайт), решается с помощью нормализации, которая используется в базах данных. На фронтенде в работе с API тоже можно использовать нормализацию — это очень здорово.
Мы помечаем все сущности каким-то типом (это тип репрезентации, тип ресурса). Рой Филдинг ввел понятие ресурса, то есть запросили статьи — получили «article». В relationships мы помещаем ссылку на тип people, то есть у нас еще где-то лежит ресурс people. А сам ресурс мы берем в отдельный ключ included, который лежит на одном уровне с data.
Таким образом, все связанные сущности в единственном экземпляре попадают в специальный ключ included. Мы храним только ссылки, а сами сущности хранятся в included.
Размер запроса уменьшился. Это лайфхак, про который начинающий бэкендер не знает. Он это узнает потом, когда нужно будет сломать API.
Нужны не все поля ресурса
Следующий лайфхак можно применить, когда нужны не все поля ресурса. Делается это при помощи специального GET-параметра, в котором через запятую перечисляются атрибуты, которые нужно вернуть. Например, статья большая, и в поле контента может быть мегабайт, а нам нужно вывести только список заголовков — нам не нужен контент в ответе.
Если нужна, например, еще и дата публикации, можно написать через запятую «published date». В ответ в attributes придет два поля. Это соглашение, которое можно использовать как anti-bikeshedding tool.
Поиск по статьям
Часто нам нужны поиски и фильтры. Для этого есть соглашения — специальные GET-параметры filters:
●
●
●
●
Сортировка статей
●
●
●
●
Нужно поменять URLs
Решение: гипермедиа, которое я уже упоминал, можно сделать следующим образом. Если мы хотим, чтобы объект (ресурс) был самоописываемый, клиент мог бы по гипермедиа понять, что с ним можно делать, и сервер мог бы развиваться независимо от клиента, то можно добавлять ссылки на список статей, на саму статью при помощи специальных ключей links:
Фронтенд с бэкендом взаимодействуют через API. И от того, какой это API, насколько хорошо или плохо бэкенд и фронтенд договорились между собой, зависит весь результат разработки. Если мы все вместе станем обсуждать, как сделать паджинацию, и потратим на её переделывание целый день, то можем и не добраться до бизнес-задач.
Чтобы не буксовать и не разводить холивары по поводу названия переменных, нужна хорошая спецификация. Давайте поговорим о том, какой она должны быть, чтобы всем жилось легче. Заодно станем экспертами по велосипедным сараям.

Начнем издалека — с проблемы, которую мы решаем.
Давным-давно, в 1959 году Сирил Паркинсон (не путать с болезнью, это писатель и экономический деятель) придумал несколько интересных законов. Например, что расходы растут вместе с доходами и т.д. Один из них называется Законом тривиальности:
Время, потраченное на обсуждение пункта, обратно пропорционально рассматриваемой сумме.
Паркинсон был экономистом, поэтому он объяснял свои законы в экономических терминах, примерно так. Если вы придете в совет директоров и скажете, что вам нужны 10 млн долларов на строительство атомной электростанции, скорее всего, этот вопрос будет обсуждаться гораздо меньше, чем выделение 100 фунтов на велосипедный сарай для сотрудников. Потому что все знают, как строить велосипедный сарай, у всех есть свое мнение, все чувствуют себя важными и хотят поучаствовать, а атомная электростанция — это что-то абстрактное и далекое, 10 млн тоже никто никогда не видел — вопросов меньше.
В 1999 году закон тривиальности Паркинсона появился в программировании, которое тогда активно развивалось. В программировании этот закон встречался в основном в англоязычной литературе и звучал, как метафора. Назывался он The Bikeshed effect (эффект велосипедного сарая), но суть та же самая — велосипедный сарай мы готовы и хотим обсуждать гораздо дольше, чем строительство электростанции.
В программирование этот термин ввел датский разработчик Poul-Henning Kamp, который участвовал в создании FreeBSD. В процессе проектирования команда очень долго обсуждала то, как должна работать функция sleep. Это цитата из письма Poul-Henning Kamp (разработка тогда велась в e-mail переписке):
It was a proposal to make sleep(1) DTRT If given a non-integer argument that set this particular grass-fire off I’m not going to say any more about it than that, because it is a much smaller item than one would expect from the length of the thread, and it has already received far more attention than some of the *problems* we have around here.
В этом письме он говорит, что есть куча гораздо более важных нерешенных задач: «Давайте не будем заниматься велосипедным сараем, уже что-нибудь с этим сделаем и пойдем дальше!»
Так Poul-Henning Kamp в 1999 году в англоязычную литературу ввел термин bikeshed effect который, можно перефразировать как:
Количество шума, создаваемого изменением в коде, обратно пропорционально сложности изменения.
Чем более простое добавление или изменение мы делаем, тем больше мнений по этому поводу мы должны выслушать. Думаю, многие с этим встречались. Если решаем простой вопрос, например, как именовать переменные, — для машины это без разницы — этот вопрос вызовет огромное количество холиваров. А серьезные, действительно важные для бизнеса проблемы не обсуждаются и идут фоном.
Как вы думаете, что важнее: то, как мы общаемся между бэкендом и фронтендом, или бизнес задачи, которые мы делаем? Все считают по-разному, но любой заказчик, человек, который ждет, что вы принесете ему деньги, скажет: «Сделайте мне уже наши бизнес-задачи!» Ему абсолютно все равно, как вы будете передавать данные между бэкендом и фронтендом. Возможно, он даже не знает, что такое бэкенд и фронтенд.
Подытожить вступление я хотел бы утверждением: API — это велосипедный сарай.
Ссылка на презентацию доклада
О спикере: Алексей Авдеев (Avdeev) работает в компании Neuron.Digital, которая занимается нейронками и делает для них классный фронтенд. Также Алексей уделяет внимание OpenSource, и всем советует. Занимается разработкой давно — с 2002 года, застал древний интернет, когда компьютеры были большими, интернет маленьким, а отсутствие JS никого не смущало и все верстали сайты на таблицах.
Как бороться с велосипедными сараями?
После того, как уважаемый Сирил Паркинсон вывел закон тривиальности, он много обсуждался. Оказывается, эффекта велосипедного сарая здесь можно легко избежать:
- Не слушать советы. Я думаю, так себе идея — если не слушать советы, можно такого наворотить, особенно в программировании, и особенно если вы начинающий разработчик.
- Делать так, как хотите. «Я художник, я так вижу!» — никакого bikeshed эффекта, делается все, что нужно, но на выходе появляются очень странные вещи. Это часто встречается во фрилансе. Наверняка вы сталкивались с задачами, которые приходилось доделывать за другими разработчиком и реализация которых вызывала у вас недоумение.
- Спросить себя важно ли это? Если нет, можно просто не обсуждать, но это вопрос личного сознания.
- Использовать объективные критерии. Про этот пункт я как раз буду говорить в докладе. Чтобы избежать эффекта велосипедного сарая, можно использовать критерии, которые объективно скажут, что лучше. Они существуют.
- Не говорить о том, о чём не хочешь слушать советы. В нашей компании начинающие бэкенд-разработчики — интроверты, поэтому бывает, что они делают что-то, о чем не рассказывают остальным. В результате мы встречаем сюрпризы. Этот метод работает, но в программировании это не лучший вариант.
- Если вас не волнует проблема, ее можно просто отпустить или выбрать любой из предлагаемых вариантов, которые возникли в процессе холиваров.
Anti-bikeshedding tool
Я хочу рассказать про объективные инструменты для решения проблемы велосипедного сарая. Чтобы продемонстрировать, что такое anti-bikeshedding tool, расскажу небольшую историю.
Представим, что у нас есть начинающий бэкенд-разработчик. Он недавно пришел в компанию, и ему поручили спроектировать небольшой сервис, например, блог, для чего нужно написать REST-протокол.
 Рой Филдинг, автор REST
Рой Филдинг, автор RESTНа фото Рой Филдинг, который в 2000 году защитил диссертацию «Архитектурные стили и дизайн сетевых программных архитектур» и тем самым ввел термин REST. Более того, он придумал HTTP и, по сути, является одним из основателей Интернета.
REST — это набор архитектурных принципов, которые говорят, как нужно проектировать REST протоколы, REST API, RESTful сервисы. Это достаточно абстрактные и сложные архитектурные принципы. Уверен, что никто из вас ни разу не видел API, сделанного полностью по всем RESTful принципам.
Требования к архитектуре REST
Приведу несколько требований к REST протоколам, на которые потом буду ссылаться и опираться. Их довольно много, в Википедии можно прочитать про это подробней.
1. Модель клиент-сервер.
Самый главный принцип REST, то есть нашего с вами взаимодействия с бэкендом. По REST бэкенд является сервером, фронтенд — клиентом, и мы общаемся в формате клиент—сервер. Мобильные устройства тоже являются клиентом. Разработчики под часы, под холодильники, другие сервисы — тоже разрабатывают клиентскую часть. RESTful API — это сервер, к которому обращается клиент.
2. Отсутствие состояния.
На сервере обязательно должно отсутствовать состояние, то есть все, что нужно для ответа, приходит в запросе. Когда на сервере хранится сессия, и в зависимости от этой сессии приходят разные ответы, это нарушение принципа REST.
3. Единообразие интерфейса.
Это один из ключевых базовых принципов, по которым должны строиться REST API. Он включает в себя следующее:
- Идентификация ресурсов — то, как мы должны строить URL. По REST мы обращаемся к серверу за каким-то ресурсом.
- Манипуляция ресурсами через представление. Сервер возвращает нам представление, которое отличается от того, что лежит в базе данных. Неважно, храните вы информацию в MySQL или PostgreSQL — у нас есть представление.
- «Самоописываемые» сообщения — то есть в сообщении лежит id, ссылки, откуда можно еще раз это сообщение получить — все, что нужно, чтобы еще раз работать с этим ресурсом.
- Гипермедиа — это ссылки на следующие действия с ресурсом. Мне кажется, ни один REST API ее не делает, но она описана Роем Филдингом.
Есть еще 3 принципа, которые я не привожу, потому что они не важны для моего рассказа.
RESTful-блог
Вернемся к начинающему бэкенд-разработчику, которого попросили сделать сервис для блога на RESTful. Ниже пример прототипа.
Это сайт, на котором есть статьи, их можно комментировать, у статьи и комментариев есть автор — стандартная история. Наш начинающий бэкенд-разработчик будет делать RESTful API для этого блога.
Со всеми данными блога мы работаем по принципу СRUD.
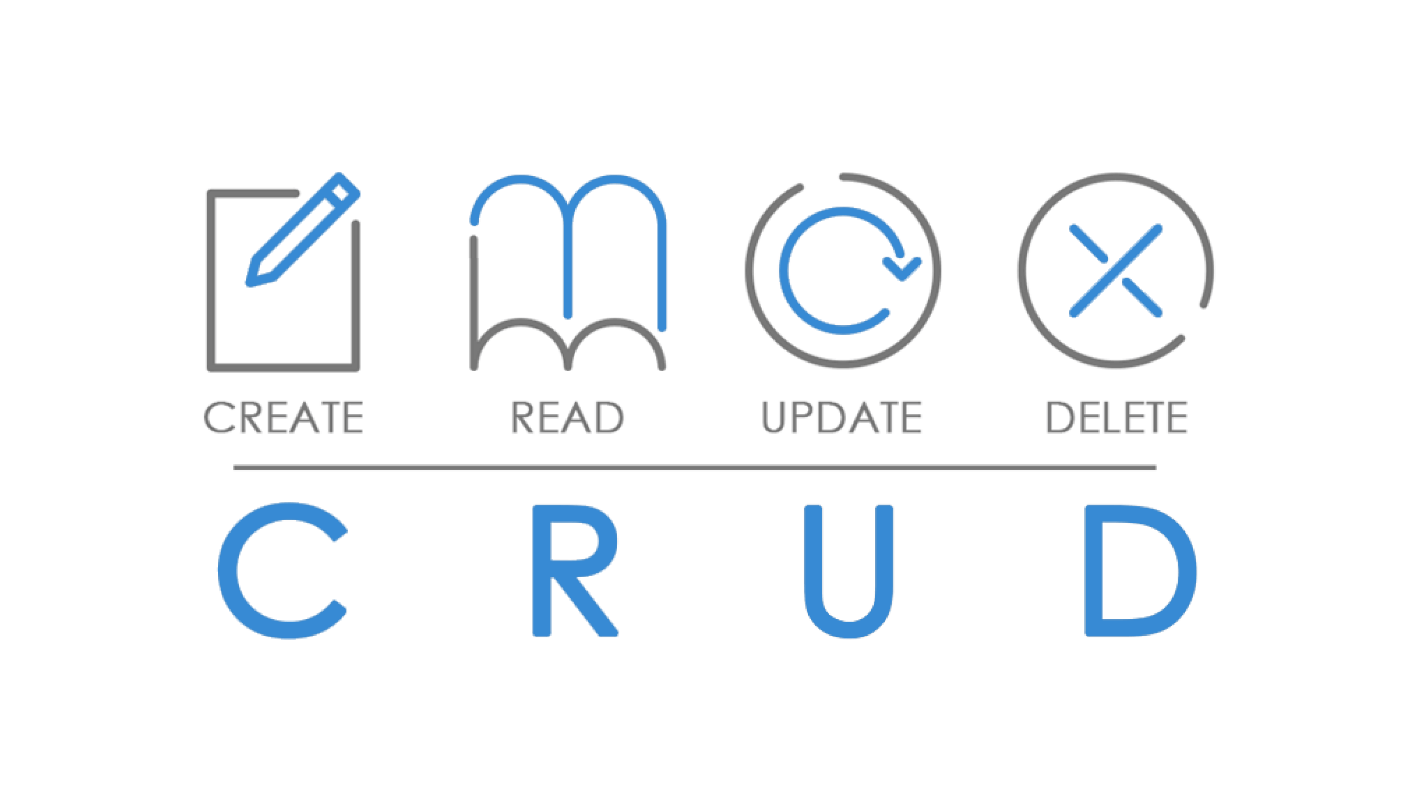
Должна быть возможность любой ресурс создавать, читать, обновлять и удалять. Попробуем попросить нашего бэкенд-разработчика построить RESTful AP Iпо принципу СRUD. То есть написать методы, чтобы создавать статьи, получать список статей или отдельную статью, обновлять и удалять.
Посмотрим, как он мог бы это сделать.

Здесь все неправильно относительно всех принципов REST. Самое интересное, что это работает. Я реально получал API, которые выглядели примерно таким образом. Для заказчика — это велосипедный сарай, для разработчиков — повод похоливарить и поспорить, а для начинающего разработчика — это просто огромный, дивный новый мир, на котором он каждый раз спотыкается, падает, разбивает себе голову. Ему приходится раз за разом переделывать.

Это вариант по REST. По принципам идентификации ресурсов мы работаем с ресурсами — со статьями (articles) и пользуемся HTTP-методами, которые предложил Рой Филдинг. Он не мог не использовать свою предыдущую работу в своей следующей работе.
Для обновления статей многие используют метод PUT, у него немножко другая семантика. Метод PATCH обновляет те поля, которые были переданы, а PUT просто заменяет одну статью на другую. По семантике PATCH — это merge, а PUT — это replace.
Наш начинающий бэкенд-разработчик упал, его подняли и сказали: «Все в порядке, сделай так», и он честно переделал. Но дальше его ждет огромный большой путь через тернии.
Почему так правильно?
- потому что так сказал Рой Филдинг;
- потому что это REST;
- потому что это архитектурные принципы, на которых строится наша профессия сейчас.
Однако это «велосипедный сарай», будет работать и предыдущий способ. Компьютеры общались до REST, и все работало. Но сейчас в индустрии появился стандарт.
Удаляем статью
Рассмотрим пример с удалением статьи. Допустим, есть нормальный, ресурсный метод DELETE /articles, который удаляет статью по id. HTTP содержит заголовки. Заголовок Accept принимает тип данных, которые клиент хочет получить в ответ. Наш джуниор написал сервер, который возвращает 200 OK, Content-Type: application/json, и передает пустой body:
01. DELETE /articles/1 НТТР/1.1
02. Accept: application/json01. HTTP/1.1 200 OK
02. Content-Type: application/json
03. null
Здесь допущена очень частая ошибка — пустой body. Вроде бы все логично — статья удалена, 200 ОК, присутствует заголовок application/json, но клиент, скорее всего, упадет. Он выкинет ошибку, потому что пустой body не валиден. Если вы когда-либо пробовали парсить пустую строку, то сталкивались с тем, что любой парсер json на этом спотыкается и падает.
Как можно исправить эту ситуацию? Самый, наверное, лучший вариант — это передать json. Если мы заявили: «Accept, отдай нам json», сервер говорит: «Content-Type, я вам отдаю json», отдайте json. Пустой объект, пустой массив — что-то туда положите — это будет решение, и оно будет работать.
Есть еще решение. Помимо 200 OK есть код ответа 204 — no content. С ним можно не передавать тело. Про это не все знают.
Так я подвёл к медиатипам.
MIME-типы
Медиатипы — это как расширение файлов, только в вебе. Когда мы передаем данные, мы должны сообщить или запросить, какой тип хотим получить в ответ.
- По умолчанию это text/plain — просто текст.
- Если ничего не указано, то браузер, скорее всего, будет иметь в виду application/octet-stream — просто поток бит.
Можно указать просто конкретный тип:
- application/pdf;
- image/png;
- application/json;
- application/xml;
- application/vnd.ms-excel.
Заголовки Content-Type и Accept есть и важны.
API и клиент должны передавать заголовки Content-Type и Accept.
Если у вас API построен на JSON, передавайте всегда Accept: application/json и Content-Type application/json.
Пример типов файлов.

Медиатипы аналогичны этим типам файлов, только в интернете.
Коды ответов
Следующий пример приключений нашего джуниор-разработчика — это коды ответов.

Самый смешной ко
Это работает, однако в HTTP существует много других кодов, которые можно использовать, и по REST Рой Филдинг рекомендует их использовать. Например, на создание сущности (статьи) можно ответить:
- 201 Created — успешный код. Статья создана, в ответ надо вернуть созданную статью.
- 202 Accepted означает, что запрос был принят, но его результат будет позже. Это долгоиграющие операции. На Accepted можно не возвращать никакого body. То есть если вы Content-Type в ответе не отдаете, то и body тоже может не быть. Или Content-Type text/plane — все, никаких вопросов. Пустая строка — это валидный text/plane.
- 204 No Content — тело может вообще отсутствовать.
- 403 Forbidden — вам нельзя создавать эту статью.
- 404 Not Found — вы залезли куда-то не туда, нет такого пути, например.
- 409 Conflict — крайний случай, который мало кто использует. Он бывает нужен, если вы на клиенте, а не на бэкенде генерируете id, а в это время кто-то уже успел создать эту статью. Конфликт — это правильный ответ в таком случае.
Создание сущности
Следующий пример: мы создаем сущность, говорим Content-Type: application/json, и передаем этот application/json. Это делает клиент — наш фронтенд. Допустим, создаем эту самую статью:
01. POST /articles НТТР/1.1
02. Content-Type: application/json
03. { "id": 1, "title": "Про JSON API"}В ответ может прийти код:
- 422 Unprocessable Entity — необрабатываемая сущность. Вроде бы все здорово — семантика, есть код;
- 403 Forbidden;
- 500 Internal Server Error.
Но абсолютно непонятно, что конкретно произошло: какая сущность необрабатываемая, почему мне туда нельзя, и что в конце концов случилось с сервером?
Возвращайте ошибки
Обязательно (и об этом джуниоры не знают) в ответ возвращайте ошибки. Это семантично и правильно. Про это, кстати, не писал Филдинг, то есть это было придумано позже и построено поверх REST.
Бэкенд может в ответ вернуть массив с ошибками, их может быть несколько.
01. HTTP/1.1 422 Unprocessable Entity
02. Content-Type: application/json
03.
04. { "errors": [{
05. "status": "422",
06. "title": "Title already exist",
07. }]}У каждой ошибки может быть свой статус и заголовок. Это здорово, но это уже идет на уровне соглашений поверх REST. Это может быть нашим anti-bikeshedding инструментом, чтобы перестать спорить, а делать сразу хороший правильный API.
Добавим паджинацию
Следующий пример: к нашему начинающему бэкенд-разработчику приходят дизайнеры и говорят: «У нас много статей, нам нужна паджинация. Мы нарисовали вот такую».

Рассмотрим ее подробней. Прежде всего в глаза бросается 336 страниц. Когда я это увидел, то подумал, как эту цифру вообще получить. Откуда взять 336, ведь на запрос списка статей мне приходит список статей. Например, их там 10 тысяч, то есть мне надо загрузить все статьи, поделить на количество страниц и узнать это число. Очень долго я буду грузить эти статьи, нужен способ получить количество записей быстро. Но если наш API отдает список, то куда это количество записей вообще засунуть, потому что в ответ приходит массив статей. Получается, раз количество записей нигде не ставится, то его надо в каждую статью добавлять, чтобы каждая статья говорила: «А нас всех столько-то!».
Однако есть соглашение поверх REST API, которое решает эту проблему.
Запрос списка
Чтобы API был расширяемый, можно сразу использовать GET-параметры для паджинации: размер текущей страницы и её номер, чтобы нам вернулся ровно тот кусок той страницы, который мы запросили. Это удобно. В ответ можно не сразу давать массив, а добавить дополнительную вложенность. Например, ключ data будет содержать массив, данные, которые мы запросили, а ключ meta, которого до этого не было, будет содержать общее количество.
01. GET /articles?page[size]=30&page[number]=2
02. Content-Type: application/json
01. HTTP/1.1 200 OK
02. {
03. "data": [{ "id": 1, "title": "JSONAPI"}, ...],
04. "meta": { "count": 10080 }
05. }
Таким образом API может возвращать дополнительную информацию. Помимо count там может быть еще какая-то информация — это расширяемо. Сейчас, если джуниор не сделал так сразу, а только после того, как его попросили сделать паджинацию, то он совершил обратно несовместимое изменение, сломал API, и все клиенты должны переделываться — обычно это очень больно.
Паджинация бывает разная. Предлагаю несколько лайфхаков, которые можно использовать.
[offset]...[limit]
01. GET /articles?page[offset]=30&page[limit]=30
02. Content-Type: application/json
01. HTTP/1.1 200 OK
02. {
03. "data": [{ "id": 1, "title": "JSONAPI"}, ...],
04. "meta": { "count": 10080 }
05. }
У тех, кто работает с базами данных, возможно, уже на подкорке [offset]...[limit]. Использовать его вместо page[size]...page[number] будет проще. Это немножко другой подход.
Курсорная паджинация
01. GET /articles?page[published_at]=1538332156
02. Content-Type: application/json01. HTTP/1.1 200 OK
02. {
03. "data": [{ "id": 1, "title": "JSONAPI"}, ...],
04. "meta": { "count": 10080 }
05. }Курсорная паджинация использует указатель на сущность, с которой нужно начать подгружать записи. Например, она очень удобна, когда вы используете паджинацию или подгрузку в списках, которые часто меняются. Допустим, в наш блог постоянно пишут новые статьи. Третья страница сейчас — это не та же самая третья страница, которая будет через минуту, а перейдя на четвертую страницу, мы на ней получим часть записей с третьей страницы, потому что весь список сдвинется.
Эту проблему решает курсорная паджинация. Мы говорим: «Подгрузи статьи, которые идут после статьи, опубликованной в это время» — никакого сдвига уже быть не может чисто технологически, и это круто.
Проблема N +1
Следующая проблема, с которой обязательно столкнется наш джуниор-разработчик — это проблема N + 1 (бэкендеры поймут). Допустим, нужно вывести список из 10 статей. Мы загружаем список статей, у каждой статьи есть автор, и для каждой нужно загрузить автора. Мы отправляем:
- 1 запрос на получение списка статей;
- 10 запросов для получения авторов каждой статьи.
Итого: 11 запросов, чтобы вывести небольшой список.
Добавляем связи
На бэкенде эта проблема решена во всех ORM — надо только не забывать дописывать эту связь. Эти связи можно использовать и на фронтенде. Делается это следующим образом:
01. GET /articles?include =author
02. Content-Type: application/json
Можно использовать специальный GET-параметр, назвать его include (как на бэкенде), говоря, какие связи нам нужно загрузить вместе со статьями. Допустим, мы загружаем статьи, и хотим вместе со статьями сразу же получить еще их автора. Ответ выглядит так:
01. НТТР/1.1 200 ОК
02. { "data": [{
03. { attributes: { "id": 1, "title": "JSON API" },
04. { relationships: {
05. "author": { "id": 1, "name": "Avdeev" } }
06. }, ...
07. }]}В data перенесены собственные атрибуты статей и добавлен ключ relationships (связи). В этот ключ мы кладем все связи. Таким образом одним запросом мы получили все те данные, которые до этого получали 11 запросами. Это крутой лайфхак, который хорошо решает проблему с N + 1 на фронтенде.
Проблема дублирования данных
Допустим, нужно вывести 10 статей с указанием автора, у всех статей один автор, но объект с автором очень большой (например, очень длинная фамилия, которая занимает мегабайт). Один автор включен в ответ 10 раз, и 10 включений одного и того же автора в ответ займет 10 Мбайт.
Поскольку все объекты одинаковые, проблема, что один автор включен 10 раз (10 Мбайт), решается с помощью нормализации, которая используется в базах данных. На фронтенде в работе с API тоже можно использовать нормализацию — это очень здорово.
01. НТТР/1.1 200 ОК
02. { "data": [{
03. "id": "1″, "type": "article",
04. "attributes": { "title": "JSON API" },
05. "relationships": { ... }
06. "author": { "id": 1, "type": "people" } }
07. }, ... ]
08. }Мы помечаем все сущности каким-то типом (это тип репрезентации, тип ресурса). Рой Филдинг ввел понятие ресурса, то есть запросили статьи — получили «article». В relationships мы помещаем ссылку на тип people, то есть у нас еще где-то лежит ресурс people. А сам ресурс мы берем в отдельный ключ included, который лежит на одном уровне с data.
01. НТТР/1.1 200 ОК
02. {
03. "data": [ ... ],
04. "included": [{
05. "id": 1, "type": "people",
06. "attributes": { "name": "Avdeev" }
07. }]
08. }Таким образом, все связанные сущности в единственном экземпляре попадают в специальный ключ included. Мы храним только ссылки, а сами сущности хранятся в included.
Размер запроса уменьшился. Это лайфхак, про который начинающий бэкендер не знает. Он это узнает потом, когда нужно будет сломать API.
Нужны не все поля ресурса
Следующий лайфхак можно применить, когда нужны не все поля ресурса. Делается это при помощи специального GET-параметра, в котором через запятую перечисляются атрибуты, которые нужно вернуть. Например, статья большая, и в поле контента может быть мегабайт, а нам нужно вывести только список заголовков — нам не нужен контент в ответе.
GET /articles?fields[article]=title НТТР/1.101. НТТР/1.1 200 OK
02. { "data": [{
03. "id": "1″, "type": "article",
04. "attributes": { "title": "Про JSON API" },
05. }, ... ]
06. }Если нужна, например, еще и дата публикации, можно написать через запятую «published date». В ответ в attributes придет два поля. Это соглашение, которое можно использовать как anti-bikeshedding tool.
Поиск по статьям
Часто нам нужны поиски и фильтры. Для этого есть соглашения — специальные GET-параметры filters:
●
GET /articles?filters[search]=api HTTP/1.1 — поиск;●
GET /articles?fiIters[from_date]=1538332156 HTTP/1.1 — загрузить статьи с определенной даты;●
GET /articles?filters[is_published]=true HTTP/1.1 — загрузить статьи, которые только опубликованы; ●
GET /articles?fiIters[author]=1 HTTP/1.1 — загрузить статьи с первым автором.Сортировка статей
●
GET /articles?sort=title НТТР/1.1 — по заголовку;●
GET /articles?sort=published_at HTTP/1.1 — по дате публикации;●
GET /articles?sort=-published_at HTTP/1.1 — по дате публикации в обратном направлении;●
GET /articles?sort=author,-publisbed_at HTTP/1.1 — сначала по автору, потом по дате публикации в обратном направлении, если статьи у одного автора.Нужно поменять URLs
Решение: гипермедиа, которое я уже упоминал, можно сделать следующим образом. Если мы хотим, чтобы объект (ресурс) был самоописываемый, клиент мог бы по гипермедиа понять, что с ним можно делать, и сервер мог бы развиваться независимо от клиента, то можно добавлять ссылки на список статей, на саму статью при помощи специальных ключей links:
01. GET /articles НТТР/1.1
02. {
03. "data": [{
04. ...
05. "links": { "self": "http://localhost/articles/1" },
06. "relationships": { ... }
07. }],
08. "links": { "self": "http://localhost/articles" }
09. }
Или related, если мы хотим подсказать клиенту, как загрузить комментарий к этой статье:
01. ...
02. "relationships": {
03. "comments": {
04. "links": {
05. "self": "http://localhost/articles/l/relationships/comments",
06. "related": "http://localhost/articles/l/comments"
07. }
08. }
09. }
Клиент видит, что есть ссылка, переходит по ней, загружает комментарий. Если ссылки нет, значит, комментариев нет. Это удобно, но так мало кто делает. Филдинг придумал принципы REST, но не все из них зашли в нашу индустрию. В основном мы пользуемся двумя-тремя.
В 2013 году все лайфхаки, о которых я вам рассказал, Steve Klabnik объединил в спецификацию JSON API и зарегистрировал как новый media type поверх JSON. Так наш джуниор бэкенд-разработчик, постепенно эволюционируя, пришел к JSON API.
JSON API
На сайте http://jsonapi.org/implementations/ всё подробно описано: есть даже список 170 различных реализаций спецификаций для 32 языков программирования — и это только добавленные в каталог. Уже написаны библиотеки, парсеры, сериализаторы и пр.
Поскольку эта спецификация опенсорсная, в неё все вкладываются. Я, в том числе, что-то сам написал. Уверен, таких людей много. Вы можете сами присоединиться к этому проекту.
Плюсы JSON API
Cпецификация JSON API решает ряд проблем — общее соглашение для всех. Раз есть общее соглашение, то мы не спорим внутри команды — велосипедный сарай задокументирован. У нас есть соглашение, из каких материалов делать велосипедный сарай и как его красить.
Теперь, когда разработчик делает что-то неправильно и я это вижу, то не начинаю дискуссию, а говорю: «Не по JSON API!» и показываю на место в спецификации. Меня ненавидят в компании, но постепенно привыкают, и JSON API всем начал нравиться. Новые сервисы по умолчанию мы делаем по этой спецификации. У нас есть ключ date, мы готовы добавлять ключи meta, include. Для фильтров есть зарезервированный GET-параметр filters. Мы не спорим, как назвать фильтр — используем эту спецификацию. В ней описано, как делать URL.
Поскольку мы не спорим, а делаем бизнес задачи, производительность разработки выше. У нас спецификации описаны, бэкенд разработчик прочитал, сделал API, мы его прикрутили — заказчик счастлив.
Популярные проблемы уже решены, например, с паджинацией. В спецификации много подсказок.
Поскольку это JSON (спасибо Дугласу Крокфорду за этот формат), он лаконичней XML, его довольно легко читать и понимать.
То, что это Open Source может быть и плюсом, и минусом, но я люблю Open Source.
Минусы JSON API
Объект разросся (date, attributes, included и пр.) — фронтенду надо парсить ответы: уметь перебирать массивы, ходить по объекту и знать, как работает reduce. Не все начинающие разработчики знают эти сложные вещи. Есть библиотеки сериализаторы/десериализаторы, можно пользоваться ими. Вообще это просто работа с данными, но объекты большие.
А у бэкенда начинается боль:
- Контроль вложенности — include можно залезть очень далеко;
- Сложность запросов к БД — они строятся иногда автоматически, и получаются очень тяжелыми;
- Безопасность — можно залезть в дебри, особенно если подключить какую-то библиотеку;
- Спецификация сложно читается. Она на английском, и это некоторых отпугнуло, но постепенно все привыкли;
- Не все библиотеки реализуют спецификацию хорошо — это проблема Open Source.
Подводные камни JSON API
Немножко хардкора.
Количество relationships в выдаче не ограничено. Если мы делаем include, запрашиваем статьи, добавляя к ним комментарии, то в ответ нам придут все комментарии этой статьи. Есть 10 000 комментариев — получи все 10 000 комментариев:
GET /articles/1?include=comments НТТР/1.1
01. ...
02. "relationships": {
03. "comments": {
04. "data": [0 ... ∞]
05. }
06. }
Таким образом на наш запрос в ответ пришло реально 5 Мбайт: «В спецификации так и написано — надо правильно переформулировать запрос:
GET /comments?filters[article]=1&page[size]=30 HTTP/1.1
01. {
02. "data": [0 ... 29]
03. }
Мы запрашиваем комментарии с фильтром по статье, говорим: «30 штучек, пожалуйста» и получаем 30 комментариев. Это и есть неоднозначность.
Одни и те же вещи можно неоднозначно сформулировать:
● GET /articles/1?include=comments HTTP/1.1 — запрашиваем статью с комментариями;
● GET /articles/1/comments HTTP/1.1 — запрашиваем комментарии к статье;
● GET /comments?filters[article]=1 HTTP/1.1 — запрашиваем комментарии с фильтром по статье.
Это одно и то же — одни и те же данные, которые получаются по-разному, возникает некоторая неоднозначность. Этот подводный камень сразу не видно.
Полиморфные связи «один ко многим» очень быстро вылезают в REST.
01. GET /comments?include=commentable НТТР/1.1
02.
03. ...
04. "relationships": {
05. "commentable": {
06. "data": { "type": "article", "id": "1″ }
07. }
08. }
На бэкенде есть полиморфная связь commentable — она вылезает в REST. Так и должно произойти, но ее можно замаскировать. В JSON API не замаскируешь — она вылезет.
Сложные связи «многие ко многим» с дополнительными параметрами. Тоже все связующие таблицы вылезают:
01. GET /users?include=users_comments НТТР/1.1
02.
03. ...
04. "relationships": {
05. "users_comments": {
06. "data": [{ "type": "users_comments", "id": "1″ }, ...]
07. },
08. }
Swagger
Swagger — это интерактивный инструмент для написания документации.
Допустим, нашего бэкенд-разработчика попросили написать документацию к его API, и он ее написал. Это легко, если API простой. Если же это JSON API, Swagger так легко не напишешь.
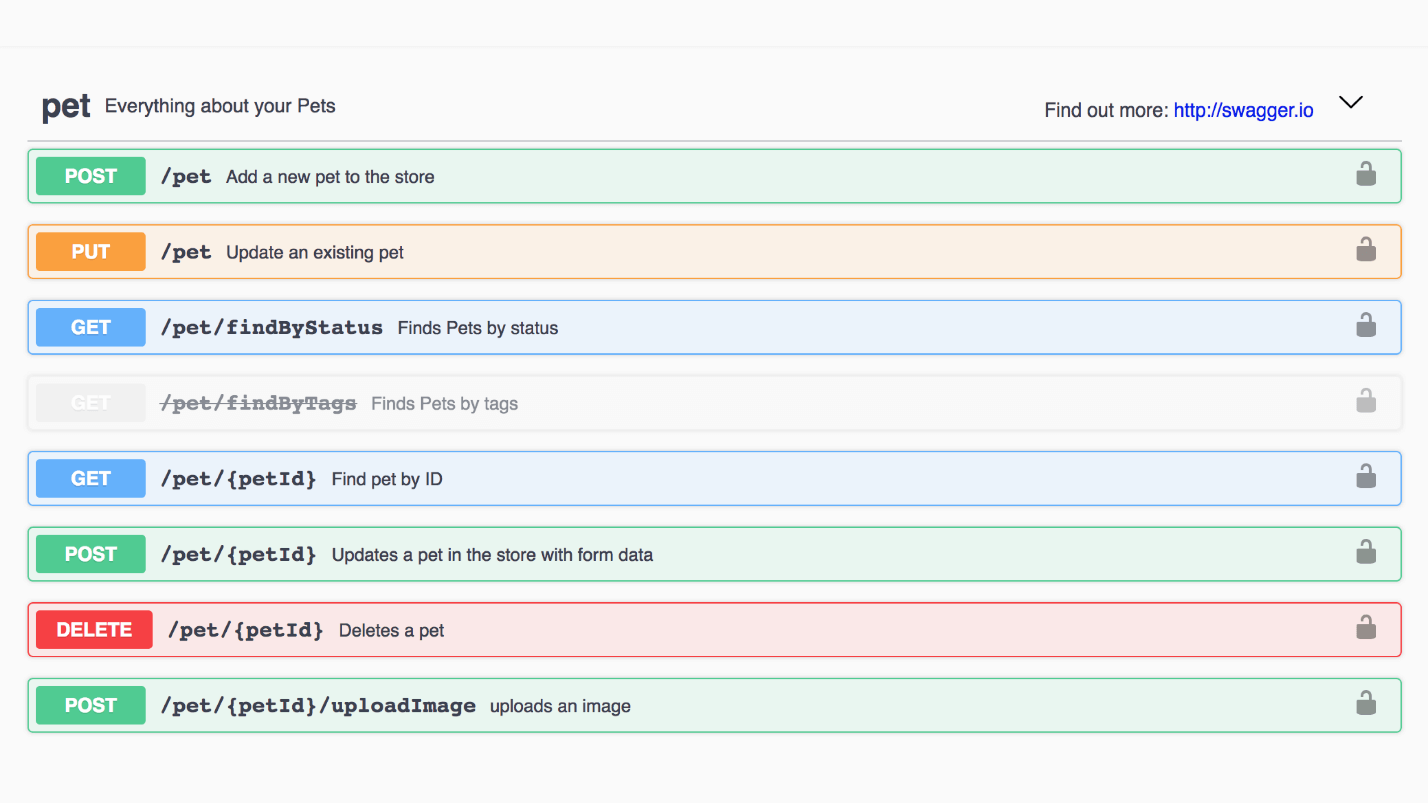
Пример: Swagger магазина животных. Каждый метод можно открыть, посмотреть response и примеры.

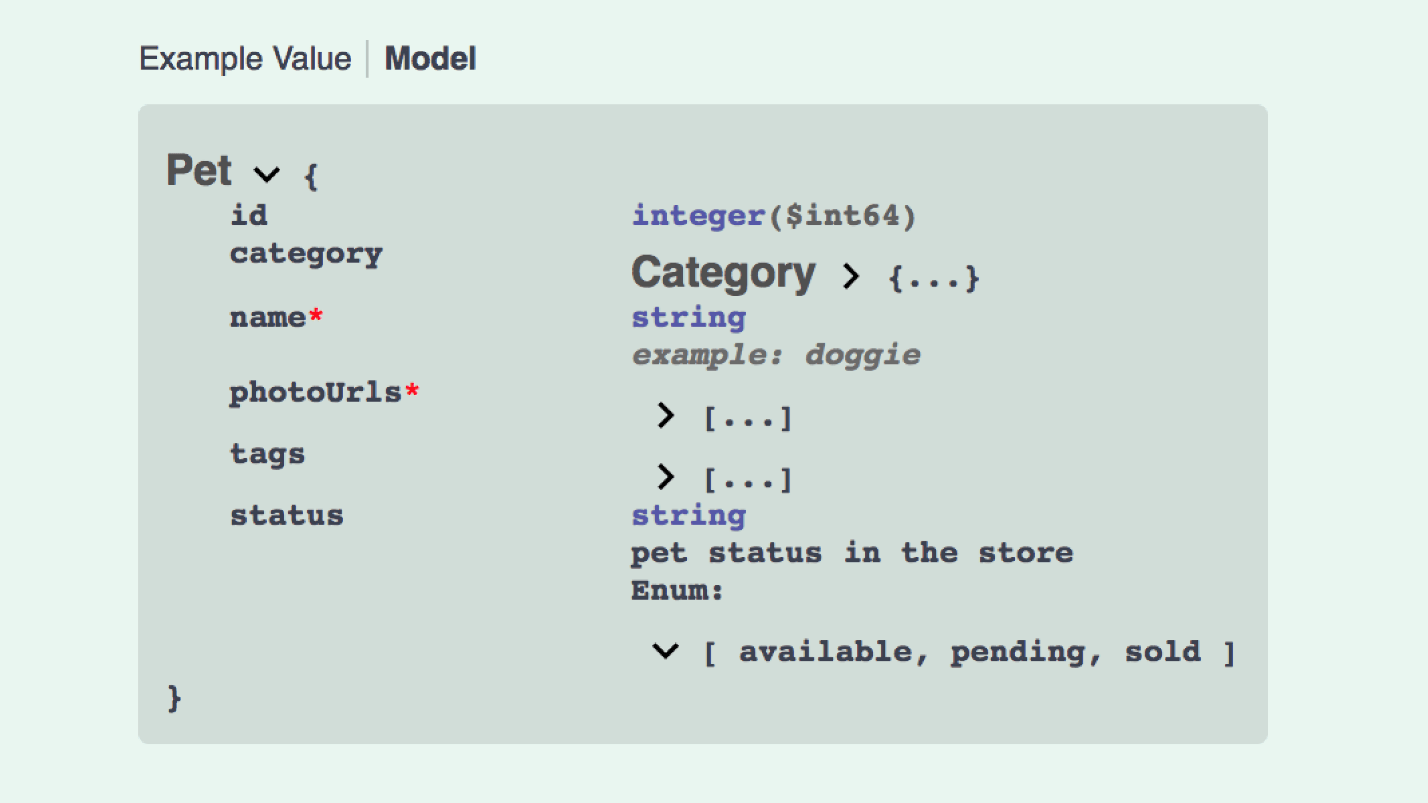
Так выглядит пример модели Pet. Здесь классный интерфейс, все просто читается.

А так выглядит создание модели JSON API:

Это уже не так здорово. Нам нужно data, в data что-то с relationships, included содержит 5 типов модели и т.д. Swagger можно написать, Open API — мощная вещь, но сложно.
Альтернатива
Есть спецификация OData, которая появилась чуть позже — в 2015 году. Это «The best way to REST», как заверяет официальный сайт. Выглядит следующим образом:
01. GET http://services.odata.org/v4/TripRW/People HTTP/1.1 — GET-запрос;
02. OData-Version: 4.0 — специальный заголовок с версией;
03. OData-MaxVersion: 4.0 — второй специальный заголовок с версией
Ответ выглядит так:
01. HTTP/1.1 200 OK
02. Content-Type: application/json; odata.metadata=minimal
03. OData-Version: 4.0
04. {
05. ’@odata.context’: ’http://services.odata.org/V4/
06. ’@odata.nextLink’ : ’http://services.odata.org/V4/
07. ’value’: [{
08. ’@odata.etag’: 1W/108D1D5BD423E51581′,
09. ’UserName’: ’russellwhyte’,
10. ...
Здесь расширенный application/json и объект.
Мы не стали использовать OData, во-первых, поскольку это то же самое, что JSON API, но он не лаконичный. Там огромные объекты и мне кажется, что все гораздо хуже читается. OData тоже вышел в Open Source, но он сложнее.
Что с GraphQL?
Естественно, когда мы искали новый формат API, мы нарвались и на этот хайп.
● Высокий порог входа.
С точки зрения фронтенда все выглядит круто, но нового разработчика не посадишь писать GraphQL, потому что его сначала нужно изучить. Это как SQL — нельзя сразу писать SQL, надо хотя бы прочитать, что это такое, пройти туториалы, то есть порог входа увеличивается.
● Эффект большого взрыва.
Если в проекте не было никакого API, и мы стали использовать GraphQL, через месяц мы поняли, что он нам не подходит, будет поздно. Придется писать костыли. С JSON API или с OData можно эволюционировать — простейший RESTful, прогрессивно улучшаясь, превращается в JSON API.
● Ад на бэкенде.
GraphQL вызывает ад на бэкенде — прямо один в один, как и полностью реализованный JSON API, потому что GraphQL получает полный контроль над запросами, а это библиотека, и вам нужно будет решать кучу вопросов:
- контроль вложенности;
- рекурсия;
- ограничение частоты;
- контроль доступа.
Вместо выводов
Рекомендую прекратить спорить по поводу велосипедного сарая, а взять anti-bikeshedding tool в качестве спецификации и просто делать API по хорошей спецификации.
Чтобы найти свой стандарт для решения проблемы велосипедного сарая, может посмотреть эти ссылки:
● http://jsonapi.org
● http://www.odata.org
● https://graphgl.org
● http://xmlrpc.scripting.com
● https://www.jsonrpc.org
Контакты Спикера Алексея Авдеева: alexey-avdeev.com и профиль на github.
Коллеги, мы открыли прием докладов на Frontend Conf, которая пройдет 27 и 28 мая в рамках РИТ++. Наш программный комитет начал работу, чтобы за следующие три месяца собрать классную программу.
Вам есть что рассказать? Хотите поделиться с сообществом вашим опытом? Ваш доклад может сделать жизнь многих фронтендеров лучше? Вы эксперт в узкой, но важной теме и хотите поделиться своим знанием? Подайте заявку!
Следите за ходом подготовки через рассылку, а идеи, кого стоит пригласить, о какой теме поговорить, пишите прямо в комментарии к статье.