Python — классный. Мы говорим «pip install» и скорее всего нужная библиотека поставится. Но иногда ответ будет: «compilation failed», потому что есть бинарные модули. Они практически у всех современных языков страдают какой-нибудь болью, потому что архитектур много, что-то нужно собирать под конкретную машину, что-то нужно линковать с другими библиотеками. В целом интересный, но малоизученные вопрос: а как же их делать и какие там проблемы? На этот вопрос постарался ответить Дмитрий Жильцов (zaabjuda) на MoscowPython Conf в прошлом году.
Под катом текстовая версия доклада Дмитрия. Ненадолго остановимся на том, когда бинарные модули нужны, а когда от них лучше отказаться. Обсудим правила, которые стоит соблюдать при их написании. Рассмотрим пять возможных вариантов реализации:
О спикере: Дмитрий Жильцов занимается разработкой больше 10 лет. Работает в компании ЦИАН системным архитектором, то есть несет ответственность за технические решения и контроль сроков. В своей жизни успел попробовать и ассемблер, Haskell, C, а последние 5 лет активно программирует на Python.
О компании
Многие, кто живет в Москве и снимает жилье, наверное, знают про ЦИАН. ЦИАН это 7 миллионов покупателей и арендаторов в месяц. Все эти пользователи каждый месяц, с помощью нашего сервиса, находят себе жилье.
Про нашу компанию знают 75% москвичей, и это очень круто. В Санкт-Петербурге и Москве мы практически считаемся монополистами. В данный момент мы стараемся выйти в регионы, и поэтому разработка выросла в 8 раз, за последние 3 года. Это значит, что в 8 раз увеличилась команды, в 8 раз увеличилась скорость поставки ценностей до пользователя, т.е. от идеи продукта до того, как рука инженера выкатила build на production. Мы научились в своей большой команде очень быстро разрабатывать, и очень быстро понимать, что в данный момент происходит, но сегодня речь пойдет немного о другом.
Я буду рассказывать про бинарные модули. Сейчас практически 50% библиотек на Python имеют какие-то бинарные модули. И как оказалось, многие люди с ними не знакомы и считают, что это что-то заоблачное, что-то темное и ненужное. А другие люди предлагают лучше написать отдельный микросервис, и не использовать бинарные модули.
Статья будет состоять из двух частей.
Зачем нужны бинарные модули
Мы все прекрасно знаем, что Python интерпретируемый язык. Он почти самый быстрый из интерпретируемых языков, но, к сожалению, его скорости не всегда хватает для тяжелых математических расчетов. Тут же возникает мысль, что на C будет быстрее.
Но у Python есть еще одна боль — это GIL. Про него написано огромное количество статей и сделано докладов о том, как его обойти.
Также бинарные расширения нам нужны для переиспользования логики. Например, мы нашли сишную библиотеку, в которой есть вся необходимая нам функциональность, и почему бы нам этим не воспользоваться. То есть не надо писать заново код, мы просто берем готовый код и его переиспользуем.
Многие считают, что с помощью бинарных расширений можно скрыть исходный код. Вопрос очень и очень спорный, конечно с помощью каких-то диких извращений можно этого добиться, но 100% гарантии нет. Максимум, что можно получить, это не дать клиенту декомпилировать и посмотреть, что происходит в коде, который вы передали.
Когда бинарные расширения действительно нужны?
Про скорость и Python понятно — когда какая-то функция у нас работает очень медленно и занимает собой 80% от времени исполнения всего кода, мы начинаем подумывать о написании бинарного расширения. Но для того, чтобы принимать такие решения, нужно для начала, как говорил один известный спикер, подумать мозгом.
Для того чтобы писать сишные расширения, надо принять во внимание, что это, во-первых, будет долго. Сначала нужно «вылизать» свои алгоритмы, т.е. посмотреть нет ли каких-то косяков.
Второй случай, когда бинарные расширения действительно нужны, это использование multi threading для простых операций. Сейчас это уже не так актуально, но еще осталось в кровавом enterprise, в каких-нибудь системных интеграторах, где до сих пор пишут на Python 2.6. Там нет асинхронности, и даже для простых вещей, например, загрузить кучу картинок, поднимается multi-threading. Вроде бы кажется, что изначально это не несет никаких сетевых расходов, но, когда мы выгружаем картинку в буфер, приходит злополучный GIL и начинаются какие-то тормоза. Как показывает практика, такие вещи лучше решать с помощью библиотек, о которых Python ничего не знает.
Если нужно реализовать какой-то специфический протокол, может быть удобно сделать простой код на С/С++ и избавиться от большого количества боли. Я так делал в свое время в одном телеком-операторе, так как не оказалось готовой библиотеки, — пришлось самому писать. Но повторюсь, сейчас это не очень актуально, потому что есть asyncio, и для большинства задач этого достаточно.
Про заведомо тяжелые операции я уже заранее сказал. Когда у вас есть числадробилки, большие матрицы и подобное, то логично, что нужно делать расширение на C/C++. Хочу заметить, что некоторые люди считают, что не нужны нам тут бинарные расширения, лучше сделать микросервис на каком-нибудь «супербыстром языке», и передавать огромные матрицы по сети. Нет, лучше так не делать.
Еще один хороший пример, когда их можно и даже нужно брать, это когда у вас устоявшаяся логика работы модуля. Если у вас в компании какой-то модуль на Python или библиотека уже существует 3 года, изменения в ней бывают раз в год и то 2 строчки, то почему бы это не оформить в нормальную библиотеку на С, если есть свободные ресурсы и время. Как минимум получите увеличение в производительности. А еще будет понимание, что, если нужны какие-то кардинальные изменения в библиотеке, то это не так просто и, возможно, опять же стоит подумать мозгом и эту библиотеку как-то по-другому использовать.
5 золотых правил
Эти правила я вывел на своей практике. Они касаются не только Python, но и других языков, для которых можно использовать бинарные расширения. Вы можете с ними поспорить, но может и задуматься и вывести свои.
Архитектура бинарных расширений
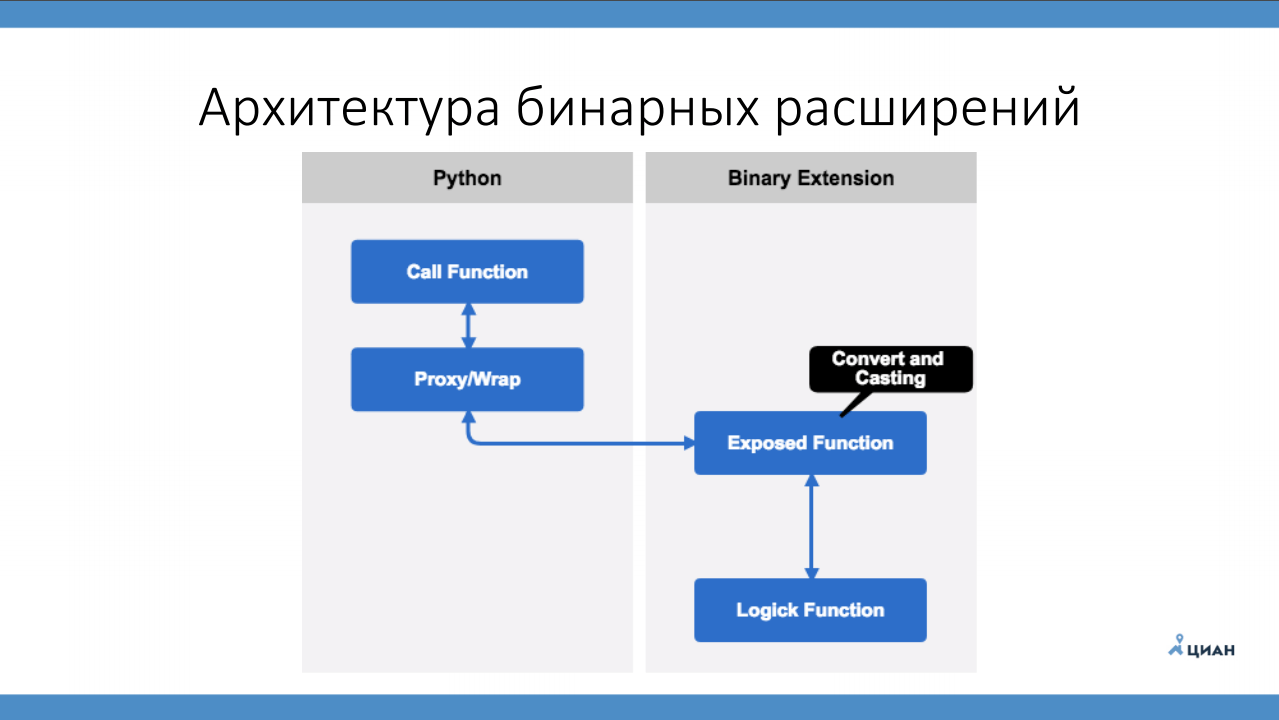
Собственно, ничего сложного в архитектуре бинарных расширений нет. Есть Python, есть вызывающая функция, которая приземляется на обертку, которая нативно вызывает сишный код. Этот вызов в свою очередь приземляется на функцию, которая экспортируется в Python, и которую он может напрямую вызвать. Именно в этой функции нужно привести типы данных до типов данных вашего языка. И только после того, как эта функция все нам перевела, мы вызываем нативную функцию, которая делает основную логику, в обратную сторону возвращает результат и прокидывает это в Python, переводя типы данных обратно.
Технологии и инструменты
Самый известный способ написания бинарных расширений это Native C/C++ extension. Только лишь потому, что это стандартная технология Python.
Native C/C++ extension
Сам Python реализован на С, и при написании расширений используются методы и структуры из python.h. Кстати, эта штука хороша еще тем, что её очень легко внедрять в уже готовый проект. Достаточно в setup.py указать xt_modules и сказать, что для сборки проекта нужно компилировать такие-то исходники с такими-то флагами компиляции. Ниже пример.
Плюсы Native C/C++ Extension
Минусы Native C/C++ Extension
По этой технологии, написано огромное количество документации, как стандартной, так и постов во всяких блогах. Огромный плюс и то, что мы можем делать свои типы данных Python и конструировать свои классы.
У этого подхода есть большие минусы. Во-первых, это порог входа — не все знают C настолько, чтобы кодить для production. Нужно понимать, что для этого недостаточно прочитать книжку и побежать писать нативные расширения. Если вы хотите этим заняться, то: для начала изучите C; потом начните писать командные утилиты; только после этого переходите к написанию расширений.
Boost.Python очень хорош для C++, он позволяет практически полностью абстрагироваться от всех этих оберток, которые мы используем в Python. Но минусом я считаю то, что взять какую-то его часть и импортировать в проект, не скачивая весь Boost, нужно очень сильно попотеть.
Перечисляя сложности в отладке в минусах, я имею ввиду то, что сейчас все привыкли использовать графический отладчик, а с бинарными модулями такая штука не пройдет. Скорее всего понадобится поставить GDB с плагином для Python.
Рассмотрим пример, как мы вообще это создаем.
Для начала, мы подключаем заголовочные файлы Python. После этого описываем функцию addList_add, которую будет использовать Python. Самое главное называть функцию правильно, в данном случае addList — это у нас имя сишного модуля, _add имя функции, которая будет использоваться в Python. Передаем сам модуль PyObject и передаем аргументы тоже с помощью PyObject. После этого совершаем стандартные проверки. В данном случае, мы пытаемся распарсить аргумент tuple и говорим, что это object — литерал «О» нужно явно указать. После этого мы знаем, что в качестве объекта мы передали listObj, и пытаемся узнать его длину с помощью стандартных методов Python: PyList_Size. Заметьте, здесь мы еще не можем использовать сишные вызовы, чтобы узнать длину этого вектора, а используем функционал Python. Опустим реализации, после которой необходимо вернуть все значения обратно в Python. Для этого вызываем Py_BuildValue, указываем, какой тип данных мы возвращаем, в данном случае «i» — integer, и саму переменную sum.
В данном случае всем понятно — мы находим сумму всех элементов списка. Давайте пройдем чуть дальше.
Тут то же самое, на данный момент listObj — объект Python. И в данном случае мы пытаемся взять элементы списка. Для этого в Python.h есть все необходимое.
После того, как мы получили temp, мы пытаемся привести его к типу long. И только после этого можно что-то делать в С.
После того, как мы реализовали всю функцию, необходимо написать документацию. Документация — это всегда хорошо, и в этом инструментарии все есть для удобного ее ведения. Придерживаясь конвенции о названиях, именуем модуль addList_docs и сохраняем туда описание. Теперь нужно зарегистрировать модуль, для этого есть специальная структура PyMethodDef. Описывая свойства, мы говорим, что функция экспортируется в Python под именем «add», что эта функция вызывает PyCFunction. METH_VARARGS означает, что функция потенциально может принимать любое количество переменных. Еще мы записали дополнительные строки и описали стандартную проверку, на тот случай если мы просто импортировали модуль, но не обратились ни к какому методу, чтобы у нас все это не падало.
После того как мы это все объявили мы пытаемся делать модуль. Создаем moduledef и укладываем туда все, что уже сделали.
PyModuleDef_HEAD_INIT — это стандартная константа Python, которую всегда нужно использовать. —1 обозначает, что на этапе импорта не нужно выделять дополнительную память.
Когда мы создали сам модуль, нам нужно его инициализировать. Python всегда ищет init, поэтому создаем PyInit_addList для addList. Тепер из собранной структуры можно вызвать PyModule_Create и наконец создать сам модуль. Далее добавляем метаинформацию и возвращаем сам модуль.
Как вы уже заметили, здесь много чего надо преобразовать. Надо всегда помнить о Python, когда мы пишем на С/С++.
Именно поэтому, для облегчения жизни обычного смертного программиста, лет 15 назад появилась технология SWIG.
SWIG
Этот инструмент позволяет абстрагировать от биндингов Python и писать нативный сишный код. У него такие же плюсы и минусы как и у Native C/C++, но есть исключения.
Плюсы SWIG:
Минусы SWIG:
Первый минус в том, что пока его настроишь, то сойдешь с ума. Когда я настраивал его в первый раз, я потратил полтора дня, чтобы вообще его запустить. Потом уже, конечно, легче. В версии SWIG 3.x стало полегче.
Чтобы больше не вдаваться в код, рассмотрим общую схему работы SWIG.

example.c — это модуль на С, который про Python вообще ничего не знает. Есть интерфейсный файл example.i, который описывается в формате SWIG. После этого запускаем утилиту SWIG, которая из интерфейсного файла создает example_wrap.c — это та самая обертка, которую мы раньше делали руками. То есть SWIG нам просто создает файл обертку, так называемый мост. После этого с помощью GCC мы компилируем два файла и получаем два объектных файла (example.o и example_wrap.o) и уже потом создаем нашу библиотеку. Все просто и понятно.
Cython
Андрей Светлов сделал на MoscowPython Conf прекрасный доклад, поэтому я просто скажу, что это популярная технология с хорошей документацией.
Плюсы Cython:
Минусы Cython:
Минусы, как всегда, есть. Главный из них — свой синтаксис, который похож и на С/С++, и очень сильно на Python.
Но я хочу заострить внимание, что код Python можно ускорить с помощью Cython, написав нативный код.

Как вы видите очень много декораторов, и это не очень хорошо. Если захотите использовать Cython — обратитесь к докладу Андрея Светлова.
CTypes
CTypes — это стандартная библиотека Python, которая работает с Foreign Function Interface. FFI — это низкоуровневая библиотека. Это родная технология, ее до ужаса часто используют в коде, с ее помощью легко реализовать кроссплатформенность.
Но FFI несет с собой большие накладные расходы, потому что все мосты, все handler в runtime создаются динамически. То есть мы подгрузили динамическую библиотеку, а Python в этот момент вообще ничего не знает, что это за библиотека. Только при вызове библиотеки в памяти динамически конструируются эти мосты.
Плюсы CTypes:
Минусы CTypes:
Взяли adder.so и в runtime нативно вызвали. Мы даже можем передавать нативные типы Python.
После всего этого стоит вопроc: "Как-то все сложно, везде C, что же делать?".
Rust
В свое время я не предал это языку должного внимания, но теперь я практически на него перехожу.
Плюсы Rust:
Минусы Rust:
Rust — это безопасный язык с автоматическим доказательством правила работы. Сам синтаксис и сам препроцессор языка не позволяет сделать явную ошибку. В то же время он заточен на вариативность, то есть любой результат выполнения ветки кода он обязан обработать.
Благодаря команде PyO3, есть хорошие биндинги для Python для Rust, и инструментарий для интеграции в проект.
К минусам отнесу то, что для неподготовленного программиста его очень долго настраивать. Мало документации, но взамен в минусах у нас нет segmentation fault. В Rust, по-хорошему, в 99% случаях, получить segmentation fault программист может, только если сам явно указал unwrap и просто забил на этот случай.
Небольшой пример кода, того же самого модуля, который мы рассматривали до этого.
Код имеет специфический синтаксис, но к нему очень быстро привыкаешь. На самом деле тут все то же самое. С помощью макросов делаем modinit, который за нас делает всю дополнительную работу по генерации всевозможных биндингов для Python. Помните я говорил, нужно делать handler обертку, вот здесь тоже самое. run_py конвертирует типы, потом вызываем нативный код.
Как вы видите, чтобы какую-то функцию экспортировать, есть синтаксическом сахаре. Мы просто говорим, что нам нужна функция add, и не описываем никаких интерфейсов. Мы принимаем list, который точно py_list, а не Object, потому что Rust в момент компиляции сам выставит необходимые биндинги. Если мы передадим неправильный тип данных, как в сишных расширениях, возникнет TypeError. После того как получили list, начинаем его обрабатывать.
Давайте посмотрим поподробнее что он начинает делать.
Тот же код который был на С/С++/ Ctypes, но только уже на Rust. Там я пытался привести PyObject к какому-то long. Чтобы было бы если к нам в list, кроме чисел попалась бы строка? Да, мы получили бы SystemEerror. В данном случае, через let mut sum : i32 = 0; мы также пытаемся из list получить значение и привести его к i32. То есть мы не сможем записать этот код без item.extract(), сотвесвенно и привести к нужному типу. Когда мы написали i32, в случае ошибки Rust, на этапе компиляции скажет: «Обработай случай, когда не i32». В таком случае, если у нас i32, мы возвращаем значение, если это ошибка — мы выкидываем исключение.
Что выбрать
После этого небольшого экскурса подумаем, что же выбрать в итоге?
Ответ на самом деле — на ваш вкус и цвет.
Я не буду пропагандировать какую-то конкретную технологию.

Просто обобщим сказанное:
Под катом текстовая версия доклада Дмитрия. Ненадолго остановимся на том, когда бинарные модули нужны, а когда от них лучше отказаться. Обсудим правила, которые стоит соблюдать при их написании. Рассмотрим пять возможных вариантов реализации:
- Native C/C++ Extension
- SWIG
- Cython
- Ctypes
- Rust
О спикере: Дмитрий Жильцов занимается разработкой больше 10 лет. Работает в компании ЦИАН системным архитектором, то есть несет ответственность за технические решения и контроль сроков. В своей жизни успел попробовать и ассемблер, Haskell, C, а последние 5 лет активно программирует на Python.
О компании
Многие, кто живет в Москве и снимает жилье, наверное, знают про ЦИАН. ЦИАН это 7 миллионов покупателей и арендаторов в месяц. Все эти пользователи каждый месяц, с помощью нашего сервиса, находят себе жилье.
Про нашу компанию знают 75% москвичей, и это очень круто. В Санкт-Петербурге и Москве мы практически считаемся монополистами. В данный момент мы стараемся выйти в регионы, и поэтому разработка выросла в 8 раз, за последние 3 года. Это значит, что в 8 раз увеличилась команды, в 8 раз увеличилась скорость поставки ценностей до пользователя, т.е. от идеи продукта до того, как рука инженера выкатила build на production. Мы научились в своей большой команде очень быстро разрабатывать, и очень быстро понимать, что в данный момент происходит, но сегодня речь пойдет немного о другом.
Я буду рассказывать про бинарные модули. Сейчас практически 50% библиотек на Python имеют какие-то бинарные модули. И как оказалось, многие люди с ними не знакомы и считают, что это что-то заоблачное, что-то темное и ненужное. А другие люди предлагают лучше написать отдельный микросервис, и не использовать бинарные модули.
Статья будет состоять из двух частей.
- Мой опыт: для чего они нужны, когда их лучше использовать, а когда нет.
- Инструменты и технологи, с помощью которых можно реализовать бинарный модуль для Python.
Зачем нужны бинарные модули
Мы все прекрасно знаем, что Python интерпретируемый язык. Он почти самый быстрый из интерпретируемых языков, но, к сожалению, его скорости не всегда хватает для тяжелых математических расчетов. Тут же возникает мысль, что на C будет быстрее.
Но у Python есть еще одна боль — это GIL. Про него написано огромное количество статей и сделано докладов о том, как его обойти.
Также бинарные расширения нам нужны для переиспользования логики. Например, мы нашли сишную библиотеку, в которой есть вся необходимая нам функциональность, и почему бы нам этим не воспользоваться. То есть не надо писать заново код, мы просто берем готовый код и его переиспользуем.
Многие считают, что с помощью бинарных расширений можно скрыть исходный код. Вопрос очень и очень спорный, конечно с помощью каких-то диких извращений можно этого добиться, но 100% гарантии нет. Максимум, что можно получить, это не дать клиенту декомпилировать и посмотреть, что происходит в коде, который вы передали.
Когда бинарные расширения действительно нужны?
Про скорость и Python понятно — когда какая-то функция у нас работает очень медленно и занимает собой 80% от времени исполнения всего кода, мы начинаем подумывать о написании бинарного расширения. Но для того, чтобы принимать такие решения, нужно для начала, как говорил один известный спикер, подумать мозгом.
Для того чтобы писать сишные расширения, надо принять во внимание, что это, во-первых, будет долго. Сначала нужно «вылизать» свои алгоритмы, т.е. посмотреть нет ли каких-то косяков.
В 90% случаев после тщательной проверки алгоритма необходимость в написании каких-то расширений отпадает.
Второй случай, когда бинарные расширения действительно нужны, это использование multi threading для простых операций. Сейчас это уже не так актуально, но еще осталось в кровавом enterprise, в каких-нибудь системных интеграторах, где до сих пор пишут на Python 2.6. Там нет асинхронности, и даже для простых вещей, например, загрузить кучу картинок, поднимается multi-threading. Вроде бы кажется, что изначально это не несет никаких сетевых расходов, но, когда мы выгружаем картинку в буфер, приходит злополучный GIL и начинаются какие-то тормоза. Как показывает практика, такие вещи лучше решать с помощью библиотек, о которых Python ничего не знает.
Если нужно реализовать какой-то специфический протокол, может быть удобно сделать простой код на С/С++ и избавиться от большого количества боли. Я так делал в свое время в одном телеком-операторе, так как не оказалось готовой библиотеки, — пришлось самому писать. Но повторюсь, сейчас это не очень актуально, потому что есть asyncio, и для большинства задач этого достаточно.
Про заведомо тяжелые операции я уже заранее сказал. Когда у вас есть числадробилки, большие матрицы и подобное, то логично, что нужно делать расширение на C/C++. Хочу заметить, что некоторые люди считают, что не нужны нам тут бинарные расширения, лучше сделать микросервис на каком-нибудь «супербыстром языке», и передавать огромные матрицы по сети. Нет, лучше так не делать.
Еще один хороший пример, когда их можно и даже нужно брать, это когда у вас устоявшаяся логика работы модуля. Если у вас в компании какой-то модуль на Python или библиотека уже существует 3 года, изменения в ней бывают раз в год и то 2 строчки, то почему бы это не оформить в нормальную библиотеку на С, если есть свободные ресурсы и время. Как минимум получите увеличение в производительности. А еще будет понимание, что, если нужны какие-то кардинальные изменения в библиотеке, то это не так просто и, возможно, опять же стоит подумать мозгом и эту библиотеку как-то по-другому использовать.
5 золотых правил
Эти правила я вывел на своей практике. Они касаются не только Python, но и других языков, для которых можно использовать бинарные расширения. Вы можете с ними поспорить, но может и задуматься и вывести свои.
- Экспортировать только функции. Строить классы в Python в бинарных библиотеках довольно трудоемко: нужно описать очень много интерфейсов, нужно пересмотреть много ссылочных целостностей в самом модуле. Проще написать небольшой интерфейс для функции.
- Использовать классы обертки. Некоторые очень любят ООП и сильно хотят классы. В любом случае, даже если это не классы, лучше просто написать обертку Python: создаете класс, задаете класс-метод или обычный метод, вызываете нативно функции C/С++. Как минимум это помогает поддерживать целостность архитектуры данных. Если вы используете какое-то С/С++ стороннее расширение, которое вы не можете поправить, то в обёртке вы можете его хакнуть, чтобы это все работало.
- Нельзя передавать аргументы из Python в расширение —это даже не правило, а скорее требование. В некоторых случаях это может работать, но обычно это плохая идея. Поэтому в вашем сишном коде вы сначала должны сделать обработчик, который приводит тип Python в тип С. И только после этого вызывать какую-либо нативную функцию, которая уже работает с сишными типами. Этот же обработчик принимает ответ от исполняемой функции и переделывает в типы данных Python, и пробрасывает в код на Python.
- Учитывать сборку мусора. В Python есть всем известный GC, и про него не нужно забывать. Например, мы передаем по ссылке большой кусок текста и пытаемся найти какое-то слово в сишной библиотеке. Мы хотим это распараллелить, передаем ссылку именно на эту область памяти и запускам несколько потоков. В это время GC просто берет и решает, что на этот объект больше ничто не ссылается и удаляет его из области памяти. В сишном же коде мы просто получим null reference, а это обычно segmentation fault. Надо не забывать про такую особенность сборщика мусора и передавать в сишные библиотеки наиболее простые типы данных: char, integer и т.д.
С другой стороны, в языке, на котором пишется расширение может быть свой сборщик мусора. Сочетание Python и библиотеки на C# в этом смысле боль.
- Явно определять аргументы экспортируемой функции. Этим я хочу сказать, что эти функции надо будет качественно аннотировать. Если мы принимаем функцию PyObject, а мы в любом случае ее будем принимать в своих сишных библиотеках, то нам нужно будет явно указать, какие аргументы к каким типам относятся. Это полезно тем, что если мы передадим не тот тип данных, то получим ошибку в сишной библиотеке. То есть нужно для вашего же удобства.
Архитектура бинарных расширений

Собственно, ничего сложного в архитектуре бинарных расширений нет. Есть Python, есть вызывающая функция, которая приземляется на обертку, которая нативно вызывает сишный код. Этот вызов в свою очередь приземляется на функцию, которая экспортируется в Python, и которую он может напрямую вызвать. Именно в этой функции нужно привести типы данных до типов данных вашего языка. И только после того, как эта функция все нам перевела, мы вызываем нативную функцию, которая делает основную логику, в обратную сторону возвращает результат и прокидывает это в Python, переводя типы данных обратно.
Технологии и инструменты
Самый известный способ написания бинарных расширений это Native C/C++ extension. Только лишь потому, что это стандартная технология Python.
Native C/C++ extension
Сам Python реализован на С, и при написании расширений используются методы и структуры из python.h. Кстати, эта штука хороша еще тем, что её очень легко внедрять в уже готовый проект. Достаточно в setup.py указать xt_modules и сказать, что для сборки проекта нужно компилировать такие-то исходники с такими-то флагами компиляции. Ниже пример.
name = 'DateTime.mxDateTime.mxDateTime'
src = 'mxDateTime/mxDateTime.c'
extra_compile_args=['-g3', '-o0', '-DDEBUG=2', '-UNDEBUG', '-std=c++11', '-Wall', '-Wextra']
setup (
...
ext_modules =
[(name,
{ 'sources': [src],
'include_dirs': ['mxDateTime'] ,
extra_compile_args: extra_compile_args
}
)]
)
Плюсы Native C/C++ Extension
- Родная технология.
- Легко интегрируется в сборку проекта.
- Наибольшее количество документации.
- Позволяется создавать свои типы данных.
Минусы Native C/C++ Extension
- Высокий порог входа.
- Необходимо знание С.
- Boost.Python.
- Segmentation Fault.
- Сложности в отладке.
По этой технологии, написано огромное количество документации, как стандартной, так и постов во всяких блогах. Огромный плюс и то, что мы можем делать свои типы данных Python и конструировать свои классы.
У этого подхода есть большие минусы. Во-первых, это порог входа — не все знают C настолько, чтобы кодить для production. Нужно понимать, что для этого недостаточно прочитать книжку и побежать писать нативные расширения. Если вы хотите этим заняться, то: для начала изучите C; потом начните писать командные утилиты; только после этого переходите к написанию расширений.
Boost.Python очень хорош для C++, он позволяет практически полностью абстрагироваться от всех этих оберток, которые мы используем в Python. Но минусом я считаю то, что взять какую-то его часть и импортировать в проект, не скачивая весь Boost, нужно очень сильно попотеть.
Перечисляя сложности в отладке в минусах, я имею ввиду то, что сейчас все привыкли использовать графический отладчик, а с бинарными модулями такая штука не пройдет. Скорее всего понадобится поставить GDB с плагином для Python.
Рассмотрим пример, как мы вообще это создаем.
#include <Python.h>
static PyObject*addList_add(Pyobject* self, Pyobject* args){
PyObject * listObj;
if (! PyARg_Parsetuple( args, "О", &listObj))
return NULL;
long length = PyList_Size(listObj)
int i, sum =0;
// Опустим реализацию
return Py_BuildValue("i", sum);
}
Для начала, мы подключаем заголовочные файлы Python. После этого описываем функцию addList_add, которую будет использовать Python. Самое главное называть функцию правильно, в данном случае addList — это у нас имя сишного модуля, _add имя функции, которая будет использоваться в Python. Передаем сам модуль PyObject и передаем аргументы тоже с помощью PyObject. После этого совершаем стандартные проверки. В данном случае, мы пытаемся распарсить аргумент tuple и говорим, что это object — литерал «О» нужно явно указать. После этого мы знаем, что в качестве объекта мы передали listObj, и пытаемся узнать его длину с помощью стандартных методов Python: PyList_Size. Заметьте, здесь мы еще не можем использовать сишные вызовы, чтобы узнать длину этого вектора, а используем функционал Python. Опустим реализации, после которой необходимо вернуть все значения обратно в Python. Для этого вызываем Py_BuildValue, указываем, какой тип данных мы возвращаем, в данном случае «i» — integer, и саму переменную sum.
В данном случае всем понятно — мы находим сумму всех элементов списка. Давайте пройдем чуть дальше.
for(i = 0; i< length; i++){
// Получаем элемент из списка
// он также Python-объект
PyObject* temp = PyList_GetItem(listObj, i);
// Мы знаем, что элемент это целое число
// приводим его к типу C
long long elem= PyLong_AsLong(temp);
sum += elem;
}
Тут то же самое, на данный момент listObj — объект Python. И в данном случае мы пытаемся взять элементы списка. Для этого в Python.h есть все необходимое.
После того, как мы получили temp, мы пытаемся привести его к типу long. И только после этого можно что-то делать в С.
// Документация
static char addList_docs[] = "add( ): add all elements of the list\n";
// Регистрируем функции модуля
static PyMethodDef addList_funcs[] = {
{"add", (PyCFunction)addList_add, METH_VARARGS, addList_docs},
{NULL, NULL, 0, NULL}
};
После того, как мы реализовали всю функцию, необходимо написать документацию. Документация — это всегда хорошо, и в этом инструментарии все есть для удобного ее ведения. Придерживаясь конвенции о названиях, именуем модуль addList_docs и сохраняем туда описание. Теперь нужно зарегистрировать модуль, для этого есть специальная структура PyMethodDef. Описывая свойства, мы говорим, что функция экспортируется в Python под именем «add», что эта функция вызывает PyCFunction. METH_VARARGS означает, что функция потенциально может принимать любое количество переменных. Еще мы записали дополнительные строки и описали стандартную проверку, на тот случай если мы просто импортировали модуль, но не обратились ни к какому методу, чтобы у нас все это не падало.
После того как мы это все объявили мы пытаемся делать модуль. Создаем moduledef и укладываем туда все, что уже сделали.
static struct PyModuleDef moduledef = {
PyModuleDef_HEAD_INIT,
"addList example module",
-1,
adList_funcs,
NULL,
NULL,
NULL,
NULL
};
PyModuleDef_HEAD_INIT — это стандартная константа Python, которую всегда нужно использовать. —1 обозначает, что на этапе импорта не нужно выделять дополнительную память.
Когда мы создали сам модуль, нам нужно его инициализировать. Python всегда ищет init, поэтому создаем PyInit_addList для addList. Тепер из собранной структуры можно вызвать PyModule_Create и наконец создать сам модуль. Далее добавляем метаинформацию и возвращаем сам модуль.
PyInit_addList(void){
PyObject *module = PyModule_Create(&mdef);
If (module == NULL)
return NULL;
PyModule_AddStringConstant(module, "__author__", "Bruse Lee<brus@kf.ch>:");
PyModule_addStringConstant (Module, "__version__", "1.0.0");
return module;
}
Как вы уже заметили, здесь много чего надо преобразовать. Надо всегда помнить о Python, когда мы пишем на С/С++.
Именно поэтому, для облегчения жизни обычного смертного программиста, лет 15 назад появилась технология SWIG.
SWIG
Этот инструмент позволяет абстрагировать от биндингов Python и писать нативный сишный код. У него такие же плюсы и минусы как и у Native C/C++, но есть исключения.
Плюсы SWIG:
- Стабильная технология.
- Большое количество документации.
- Абстрагирует от привязки к Python.
Минусы SWIG:
- Долгая настройка.
- Знание C.
- Segmentation Fault.
- Сложности в отладке.
- Сложность интеграции в сборку проекта.
Первый минус в том, что пока его настроишь, то сойдешь с ума. Когда я настраивал его в первый раз, я потратил полтора дня, чтобы вообще его запустить. Потом уже, конечно, легче. В версии SWIG 3.x стало полегче.
Чтобы больше не вдаваться в код, рассмотрим общую схему работы SWIG.
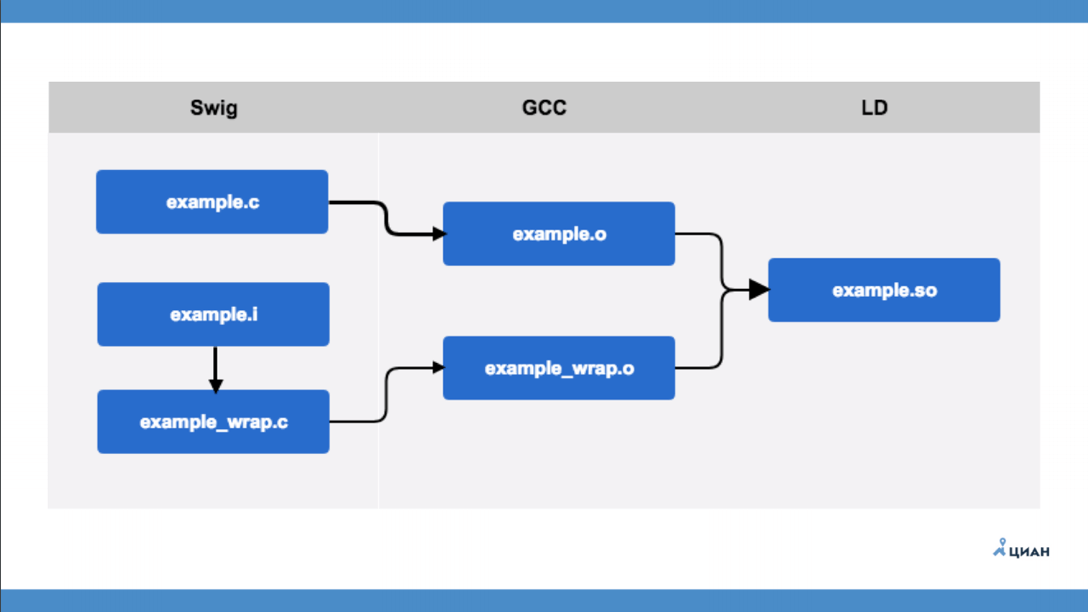
example.c — это модуль на С, который про Python вообще ничего не знает. Есть интерфейсный файл example.i, который описывается в формате SWIG. После этого запускаем утилиту SWIG, которая из интерфейсного файла создает example_wrap.c — это та самая обертка, которую мы раньше делали руками. То есть SWIG нам просто создает файл обертку, так называемый мост. После этого с помощью GCC мы компилируем два файла и получаем два объектных файла (example.o и example_wrap.o) и уже потом создаем нашу библиотеку. Все просто и понятно.
Cython
Андрей Светлов сделал на MoscowPython Conf прекрасный доклад, поэтому я просто скажу, что это популярная технология с хорошей документацией.
Плюсы Cython:
- Популярная технология.
- Довольно стабильно.
- Легко интегрируется в сборку проекта.
- Хорошая документация.
Минусы Cython:
- Свой синтаксис.
- Знание C.
- Segmentation Fault.
- Сложности в отладке.
Минусы, как всегда, есть. Главный из них — свой синтаксис, который похож и на С/С++, и очень сильно на Python.
Но я хочу заострить внимание, что код Python можно ускорить с помощью Cython, написав нативный код.

Как вы видите очень много декораторов, и это не очень хорошо. Если захотите использовать Cython — обратитесь к докладу Андрея Светлова.
CTypes
CTypes — это стандартная библиотека Python, которая работает с Foreign Function Interface. FFI — это низкоуровневая библиотека. Это родная технология, ее до ужаса часто используют в коде, с ее помощью легко реализовать кроссплатформенность.
Но FFI несет с собой большие накладные расходы, потому что все мосты, все handler в runtime создаются динамически. То есть мы подгрузили динамическую библиотеку, а Python в этот момент вообще ничего не знает, что это за библиотека. Только при вызове библиотеки в памяти динамически конструируются эти мосты.
Плюсы CTypes:
- Родная технология.
- Легко использовать в коде.
- Легко реализовать кроссплатформенность.
- Можно использовать практически любой язык.
Минусы CTypes:
- Несет накладные расходы.
- Сложности в отладке.
from ctypes import *
#load the shared object file
Adder = CDLL('./adder.so')
#Calculate factorial
res_int = adder.fact(4)
print("Fact of 4 = " + str(res_int))
Взяли adder.so и в runtime нативно вызвали. Мы даже можем передавать нативные типы Python.
После всего этого стоит вопроc: "Как-то все сложно, везде C, что же делать?".
Rust
В свое время я не предал это языку должного внимания, но теперь я практически на него перехожу.
Плюсы Rust:
- Безопасный язык.
- Мощные статические гарантии правильности поведения.
- Легко интегрируется в сборку проекта (PyO3).
Минусы Rust:
- Высокий порог входа.
- Долгая настройка.
- Сложности в отладке.
- Документации мало.
- В некоторых случаях накладные расходы.
Rust — это безопасный язык с автоматическим доказательством правила работы. Сам синтаксис и сам препроцессор языка не позволяет сделать явную ошибку. В то же время он заточен на вариативность, то есть любой результат выполнения ветки кода он обязан обработать.
Благодаря команде PyO3, есть хорошие биндинги для Python для Rust, и инструментарий для интеграции в проект.
К минусам отнесу то, что для неподготовленного программиста его очень долго настраивать. Мало документации, но взамен в минусах у нас нет segmentation fault. В Rust, по-хорошему, в 99% случаях, получить segmentation fault программист может, только если сам явно указал unwrap и просто забил на этот случай.
Небольшой пример кода, того же самого модуля, который мы рассматривали до этого.
#![feature(proc_macro)]
#[macro_use] extern crate pyo3;
Use pyo3::prelude::*;
/// Module documentation string 1
#[py::modinit(_addList)]
fn init(py: Python, m: PyModule) -> PyResult <()>{
py_exception!(_addList, EmptyListError);
/// Function documentation string 1
#[pufn(m, "run", args= "*", kwargs="**" )]
fn run_py(_py: Python, args: &PyTuple, kwargs: Option<&PyDict>) -> PyResult<()> {
run(args, kwargs)
}
#[pyfn(m, "run", args="*", kwatgs="**")]
fn run_py(_py: Python, args: &PyTuple, kwargs: Option<&PyDict>) -> PyResult<()>{
run(args,kwargs)
}
#[pyfn(m,"add")]
fn add(_py: Python, py_list: &PyList) -> PyResult<i32>{
let mut sum : i32 = 0
match py_list.len() {
/// Some code
Ok(sum)
}
Ok(())
}
Код имеет специфический синтаксис, но к нему очень быстро привыкаешь. На самом деле тут все то же самое. С помощью макросов делаем modinit, который за нас делает всю дополнительную работу по генерации всевозможных биндингов для Python. Помните я говорил, нужно делать handler обертку, вот здесь тоже самое. run_py конвертирует типы, потом вызываем нативный код.
Как вы видите, чтобы какую-то функцию экспортировать, есть синтаксическом сахаре. Мы просто говорим, что нам нужна функция add, и не описываем никаких интерфейсов. Мы принимаем list, который точно py_list, а не Object, потому что Rust в момент компиляции сам выставит необходимые биндинги. Если мы передадим неправильный тип данных, как в сишных расширениях, возникнет TypeError. После того как получили list, начинаем его обрабатывать.
Давайте посмотрим поподробнее что он начинает делать.
#[pyfn(m, "add", py_list="*")]
fn add(_py: Python, py_list: &PyList) -> PyResult<i32> {
match py_list.len() {
0 =>Err(EmptyListError::new("List is empty")),
_ => {
let mut sum : i32 = 0;
for item in py_list.iter() {
let temp:i32 = match item.extract() {
Ok(v) => v,
Err(_) => {
let err_msg: String = format!("List item {} is not int", item);
return Err(ItemListError::new(err_msg))
}
};
sum += temp;
}
Ok(sum)
}
}
}
Тот же код который был на С/С++/ Ctypes, но только уже на Rust. Там я пытался привести PyObject к какому-то long. Чтобы было бы если к нам в list, кроме чисел попалась бы строка? Да, мы получили бы SystemEerror. В данном случае, через let mut sum : i32 = 0; мы также пытаемся из list получить значение и привести его к i32. То есть мы не сможем записать этот код без item.extract(), сотвесвенно и привести к нужному типу. Когда мы написали i32, в случае ошибки Rust, на этапе компиляции скажет: «Обработай случай, когда не i32». В таком случае, если у нас i32, мы возвращаем значение, если это ошибка — мы выкидываем исключение.
Что выбрать
После этого небольшого экскурса подумаем, что же выбрать в итоге?
Ответ на самом деле — на ваш вкус и цвет.
Я не буду пропагандировать какую-то конкретную технологию.

Просто обобщим сказанное:
- В случае SWIG и C/C++, надо знать C/C++ очень хорошо, понимать, что разработка этого модуля понесет какие-то дополнительные накладные расходы. Зато будет использовано минимум инструментария, и мы будем работать в родной технологии Python, которая поддерживается разработчиками.
- В случае с Cython мы имеем малый порог входа, мы имеем большую скорость разработки, а также это обыкновенный кодогенератор.
- На счет CTypes, хочу предостеречь, относительно больших накладных расходов. Динамическая подгрузка библиотек, когда мы не знаем, что это за библиотека, может повлечь массу неприятностей.
- Rust я бы посоветовал взять тому, кто плохо знает C/C++. Rust в production действительно несет меньше всего проблем.
Полезные ссылки
https://github.com/zaabjuda/moscowpythonconf2017
https://docs.python.org/3/extending/building.html
https://cython.org
https://docs.python.org/376/library/ctypes.html
https://www.swig.org
https://www.rust-land.org/en-US/
https://github.com/PyO3
https://www.youtube.com/watch?v=5-WoT4X17sk
https://packaging.python.org/tutorials/distributing-packages/#platformwheels
https://github.com/PushAMP/pamagent (боевой пример сипользования)
https://docs.python.org/3/extending/building.html
https://cython.org
https://docs.python.org/376/library/ctypes.html
https://www.swig.org
https://www.rust-land.org/en-US/
https://github.com/PyO3
https://www.youtube.com/watch?v=5-WoT4X17sk
https://packaging.python.org/tutorials/distributing-packages/#platformwheels
https://github.com/PushAMP/pamagent (боевой пример сипользования)
Call for Papers
Принимаем заявки на Moscow Python Conf++ до 7 сентября — напишите в этой простой форме, что вы знаете о Python такого, чем очень нужно поделиться с сообществом.
Для тех, кому интереснее слушать, могу рассказать о классных докладах.
- Donald Whyte любит рассказывать про ускорение математики на Python и готовит для нас новую историю: как с помощью популярных библиотек, хитрости и коварства делать математику в 10 раз быстрее, а код — понятным и поддерживаемым.
- Артём Малышев собрал весь свой многолетний опыт разработки Django и представляет доклад-путеводитель по фреймворку! Все, что происходит между получением HTTP запроса и отправкой готовой веб страницы: разоблачение магии, карта внутренних механизмов фреймворка и много полезных советов для ваших проектов.
