
Николай Сивко ( NikolaySivko, okmeter.io )
Рассказ о том, как устроена эксплуатация в компании HeadHunter, и как используется мониторинг для того, чтобы следить за качеством эксплуатации.
Меня зовут Николай Сивко, я руковожу эксплуатацией в hh.ru. Доклад называется странно, но, по сути, мы говорить будем о следующем:

На этой конференции про мониторинг говорят на каждом докладе, я хотел бы осветить другую сторону — не как хранить метрики, а что хранить, зачем хранить, и какой профит из этого получить?
Начнем издалека — зачем, вообще, в компании нанимают админов, и какую задачу для бизнеса они решают. Дальше постараюсь осветить вопрос: как бизнесу понимать, хорошо работают админы или нехорошо? Мы внедрили KPI, и я расскажу немножко про него. Как мы мотивируем админов работать хорошо, и постарались связать это с профитом для бизнеса. Поговорим о том, как это все видят админы, т.е. изнутри. Уклон непосредственно сделан на мониторинг, чтобы было интересно как руководителям, так и технарям. Начнем.
В нашей ситуации бизнес компании связан с тем, что мы знакомим соискателя и работодателя. Это происходит на сайте. Соответственно, необходимым, но, естественно, не достаточным условием для того, чтобы бизнес зарабатывал деньги, является то, что сайт работает.

Также бизнесу нужно, чтобы был кто-то один, кто отвечает за то, что сайт работает. Групповой ответственности не существует, нужен конкретный человек на конкретной должности, с кого спросить прогноз, потребовать решения, потребовать, вообще, кардинально ситуацию исправить.
И есть еще у бизнеса требования такие, что скорость работы сайта влияет на деньги. И бюджет, все в рамках бюджета, без этого никак.

Дальше мы начали договариваться про то, что такое «сайт работает», вообще, потому что не понятно.
В первой версии мы договорились на том, что мы, директор наш, или кто-то там еще, считаем, что сайт работает, если раз в минуту проходят некие сценарии. Т.е. приходит соискатель, у него загружается Главная страница сайта, он делает поиск, поиск находит хоть одну вакансию, вакансия открывается. Аналогичный кейс по работодательскому сценарию. И на все это там есть рамки на время ответа — сколько-то секунд.
Такой подход у нас работал, это то, что можно прийти и сделать сразу. Прийти на какой-то сайт, который делает внешние чеки, запрограммировать там сценарий, он будет обрабатываться. Если что-то пойдет не так, вы получите SMS. Такой подход работает, но есть проблемы. Проблемы в том, что он не ловит все случаи, он не ловит весь функционал, который эти тести, чеки не затрагивают. Соответственно, мы пошли немножко дальше.

Это неидеальный вариант, это то, как пришлось объяснять бизнесу, что примерно означает «сайт работает». В данном случае количество ошибок на сайте меньше 20 в секунду. Число 20 берется из головы, потому что мы знаем, что когда их больше, то, как правило, у нас все взрывается. Когда их меньше, мы допускаем, что есть баги, и на какие-то редкие страницы, возможно, сайт пятисотит — мы их называем «фоновые ошибки», и с ними эксплуатация ничего не делает, их отдельно смотрят девелоперы, но мы по SMS’кам не просыпаемся, если на сайте 1 RPS пятисоток.
Дальше у нас есть критерий по времени ответа, он взят достаточно с запасом, потому что современные сайты работают быстро. У нас там грубо 500 мс, по факту основные страницы — 100 мс, и внешние чеки на случай проблем.
Этот сценарий мы сейчас эксплуатируем, т.е. у нас сейчас мониторинг в реалтайме читает логи, смотрит за этими показателями, и настроен триггер, т.е. если сайт начинает работать за рамками этого SLA, то мы получаем SMS’ки и вперед.

Это бизнес-ценности, по сути, отражает косвенно. И, вообще говоря, надо смотреть на бизнес-показатели. В нашем случае это активность по резюме, вакансиям и откликам. Но на самом деле это косвенно можно понять из access лога nginx. Бывают кейсы, когда на client side происходит какая-то ошибка, там баннер перекрывает форму отправки отклика или еще чего-нибудь, и со стороны nginx все хорошо, а на самом деле все плохо, пользователи страдают, и бизнес пользы не получает.

По факту, полностью отвечать за работоспособность могут два отдела. В нашем случае это служба эксплуатации и отдел разработки. Это никуда не годится и дальше будем придумывать, как решать. На инциденты, на SMS’ки разработчики никогда не подпишутся. Админы получают надбавку за вредность за то, что к ним по ночам приходят SMS. Попытаемся решить, как, вообще, это разрулить, чтобы было понятно и бизнесу, и эксплуатации, и девелоперам, что происходит.

Первая идея у нас была такая, что админы получают SMS’ку, идут чинить. У них есть телефоны самых крутых разработчиков. В случае, если они не понимают, что происходит, они им звонят, вместе чинят. Но в этом случае KPI показатели работы самих админов — здесь можно вычленить только время реакции на инцидент. Мы так жили, так было в годы, когда было проблем мало, когда мы чуть больше времени уделяли инфраструктуре, нормально жилось.

Потом перестало устраивать, мы пришли к ситуации, что реальный профит бизнес не получает, а админы свой KPI выполнили, т.е. просыпались быстро, жали на «OK» быстро — типа, мы проблемой начали заниматься. По сути, сайт долго лежал, потому что на то, сколько они будут чинить, они никак не были замотивированы.
Попытка №2, которую мы даже пробовать не стали:

Была идея сверху, сбоку, не помню, откуда она прилетела, что админы должны отвечать, вообще, за весь uptime. Но мои возражения о том, что: «Ребят, ну, есть большое сложное приложение, оно падает, течет… Админы не могут отвечать, они не могут на него влиять, это для них black box». Мне отвечали: «Давайте вам целый отдел QA в службу эксплуатации засунем. Все, что они тестировали — это ваша с ними ответственность». На самом деле, хороший QA, вообще, сделать сложно, дорого и слабо реально. В итоге решили, что делать этого ничего не будем. Я настоял на том, что хороший KPI можно сделать тогда, когда человек может на него влиять. Т.е. если он понял, что «тут я налажал, тут я исправился, я молодец, я получу бонус».
Вот к чему мы пришли:

Весь uptime мы поделили на классы, на зоны ответственности. Выделили какие-то классы проблем. Админы отвечают за то, что реально в их зоне ответственности, что реально можно взять и исправить. Что делать со всем остальным, не решалось, сейчас это такой подвешенный вопрос. Я не буду касаться, но там поймете, что примерно.

Итак, что нужно сделать?
Нужно задать какие-то рамки, условия, чтобы было всем все понятно и прозрачно. Мы договорились о SLA, что такое «сайт работает». Если показатели выполняются — все хорошо, если нет — инцидент. Если сайт не полностью в порядке, хоть и какой-то функционал по-прежнему работает, то мы считаем, что все равно проблема, downtime, и полностью сайт не живой.
На любой инцидент реагируют по-прежнему админы. По понятным причинам. У нас мы дежурных не выделяем, нас слишком мало, просыпаются все, но кто первый, тот и начинает. Если надо, то подтягивает остальных.
По каждому инциденту обязательно разбор. Мы должны, обязаны докопаться до причины, мы не можем сказать, что, типа, это был подземный стук и т.п., все, ничего не знаем. Мы обязаны это сделать. Дальше покажу как, с чем мы нарвались.
У нас отчетный период — квартал, мы фиксируем весь downtime за квартал, поделенный на классы. Делим по зонам ответственности. Админский downtime — на него завязаны классы проблем, какие мы выделили:

- Первое — это проблема во время релиза. Это либо плохой код выходит на продакшен, и все взрывается. Либо это процедура выкладки неправильная, и в момент выкладки чего-нибудь там пятисотит, или что-нибудь тупит. Такие штуки мы классифицируем как проблемы с релизом.
- Ошибка в приложении — это случай, когда приложение работало-работало, потом взорвалось и перестало работать. Причины могут быть самые разнообразные, начиная от утечки, кончая тем, что пришел запрос на какой-нибудь злой URL с какими-нибудь злыми параметрами и все уложил. Где-то там завис удаленный ресурс, timeout’ы не отработали и все такое…
- Железо, сеть, каналы, ДЦ — это то, что связано с хостингом, за это отвечаем мы, админы. Человеческая ошибка здесь только админская, потому что разработчики на прод, где можно накосячить, доступа не имеют.
- Проблемы с БД мы выделили отдельно, потому что мы аутсорсим DBA. Это интересный для нас класс проблем, мы хотим отдельно его считать, чтобы потом какие-то выводы делать.
- Плановый downtime мы сделали, потому что без этого никак. 100% доступности никто никому не гарантирует, но у планового downtime есть ограничения, и его надо заранее объявлять. Это нужно делать в часы, когда нагрузка совсем слабая, как правило, по ночам.
- Ошибка мониторинга — вынужденная мера, иногда бывает так, что пришел какой-нибудь бот, попятисотил 50 ошибок в секунду, пользователи не были затронуты, это вообще не проблема, он никого не поаффектил, но мы должны это по логам подтвердить. И чтобы ложные срабатывания не удалять, инциденты, никогда, мы сделали такой класс, он downtime’ом по факту не считается, но он есть.
Админы. В их зону ответственности входят эти три класса:

Это все, что связанно с хостингом, все, что связано с человеческой ошибкой, и проблемы с базами данных, потому что это почти хостинг, это инфраструктурная вещь, разработчики не отвечают за это.
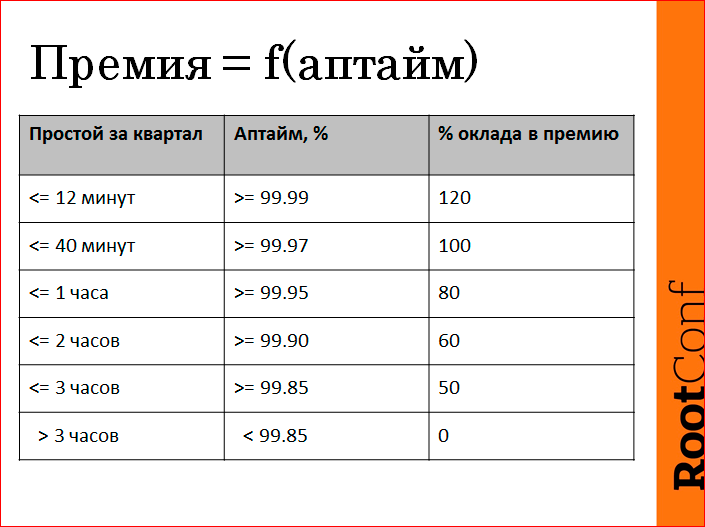
Вот, мы реально сделали KPI мотивацию. Премия, которую человек получит в конце квартала, — это реально функция от uptime, но в его зоне ответственности. Все по-честному. Табличка составлялась примерно из таких посылов, что больше трех часов в квартал лежать стыдно, поэтому бонус мы не получим. Если мы обеспечим в квартал по своим показателям 4 девятки, мы молодцы и получаем повышенный бонус. А потом серединку как-то пропорционально поделили. Вот так реально мы живем с января 2013 года.
Что, вообще, с этим делать? Как происходило внедрение, и что мы узнали? Мы в декабре, перед тем как уйти на Новый Год, долго-долго тестили мониторинг, включили и начали огребать. Если мы считаем все-все-все, мы поставили себе пороги, мы должны с этим справляться, нам реально пришлось работать, а до этого мы занимались непонятно чем.
В первые же недели мы поняли, что сильно лажаем в плане того, что на проди пускаем всякое, не думая, и это аффектит сайт. Все пятисоточки посчитаны, поэтому там не забалуешь. Научились думать, научились, если сомневаешься, бери плановый downtime и ночью чего-то делай. Это реально сняло много проблем, заметно. Также начали мы сомневаться в том, что у нас сделано все правильно, начали проводить реальные учения. Т.е. объявляем downtime, прибиваем мастер postgres. И засекаем, за сколько мы справимся все развернуть. Реплики есть, все гасим по-божески, но реальные боевые учения с падежом.

Выключать разные сервисы, без которых сайт должен работать, потому что мы в свое время завязались на Service-oriented architecture и разделили на сервисы, какие-то основные, какие-то не основные. Начали вырубать неосновные, а у сайта таймауты неправильно сделаны, поэтому все ложится. В общем, жуть, сколько мы всего исправили за первый квартал.

Logrotate давали пятисотки, потому что они начинались в одно и то же время. Cron’ы пятисотили… Т.е. чего мы только не выгребли. В nginx как-то были на полудефолты настроены ретраи, таймауты — все это пришлось выгребать, чинить. Мы сильно переделали деплой. Мы даже заставили разработчиков переделать всю работу с очередями, т.е. чтобы любую очередь можно было нормально погасить, и это не аффектило никого.
Самое сложное — это выяснять причину всех факапов. Т.е. что бы ни случилось, нужно докопаться. Конечно, поначалу не удавалось, логи пишутся не так подробно, как хотелось бы, приходилось как-то пытаться, какие-то гипотезы проверять на стенде, какие-то грузилки делать. Потом как-то за первый квартал все устаканилось, и мы начали примерно успешно справляться с задачей.
В частности, нас перестал устраивать текущий мониторинг. Требованием нашим было — узнать, что проблема случилась. Самое главное требование. Это надежно должно работать всегда, т.е. если за пределы SLA вышли, все, алерт, SMS’ки, все такое.

Видеть, что происходит, буквально за полминуты понять, насколько проблема затрагивает все или не все, какой примерно сервис… Потому что инфраструктура большая, гребать логи мы уже не успеваем. Иметь достаточно метрик, чтобы копаться задним числом — это то, что сыграло последнюю каплю. Нам не хватало метрик. Мы видим — CPU подскочил, а что это было, кто пришел, какой запустил скрипт, или что происходило на сервере, какой процесс съел этот CPU? Это нужно было делать задним числом, потому что бывает так, что есть проблема, в момент ее починки мы чего-то рестартим, мы понимаем, что где-то болит, мы это рестартим, исправляем, причину мы не знаем, но мы обязаны потом ее найти. Ускорять решение проблем, потому что время от uptime зависит, нам хочется денег больше. Мы какие-то типичные вещи из логов выносим на графики, чтобы тупо ускориться. И простота расширения, потому что кто-то предлагает, типа, разгребли какой-то инцидент, поняли, что эта метрика в следующий раз поможет, эта метрика, допустим, в логах пишется — надо иметь возможность быстро ее вкрячить на график.
Я, наверное, седьмой год в компании работаю… Что у нас за всю историю было:

У нас был Nagios, была такая штука, французская подделка, я не знаю, она жива до сих пор, centreon называется, это такие графики, которые на Nagios рисуются. Мы ее патчили, потом мы ее выкинули и написали свою. Потом у нас загибался Nagios, мы написали свой poller SNMP. В это время разработчики, когда им надо какую-то конкретную метрику свою нарисовать, они пилят какой-нибудь скрипт, который в cacti, graphite что-нибудь шлет… Потому что наш мониторинг, долго нас просить надо, чтобы мы там чего-то включили…
Свое решение. У нас был разработчик, он год пилил мониторинг. Все было хорошо, он удовлетворял нашим требованиям, потом они изменились, мы поняли, что нам надо выкинуть все нафиг.

И поняли, что надо написать заново, потому что вся концепция изменилась, наши требования изменились, все изменилось, мир поменялся.
Более того, тратить время на разработку мониторинга у нас не было времени, да и не хотелось это делать. Это достаточно интересная работа для тех, кто любит циферки пожать, в store положить-достать, все это вот. На самом деле, у нас много другой работы, нам надо чинить, нам надо где-то что-то оптимизировать, у нас гораздо больше кайфа возникает, когда гистограмма времени ответа зеленеет, нежели то, что у нас там новый красивый график появился. Мы хотели full-stack, т.е. собрать из графита и др., из пластилина и зубочисток, какое-то решение собрать можно, я не сомневаюсь. Но это надо посадить человека, чтобы он взял и все это собрал. Более того, у нас были такие решения, мы их собирали, но потом, когда это ломалось, чуваку уже не так интересно это чинить. Потому что он собрал, график нарисовал, но, по сути, когда там половина данных съехало, ему надо пойти в какие-то логи посмотреть, агенты проверить. В общем, жуть.
И у нас требования выше среднестатистических, мы много всего хотим смотреть, приходилось доделывать под себя.

Мы решили, что не будем этого делать больше. И успешно так полгода живем. Мы взяли SaaS. Во-первых, не нужно программировать — это кайф.
Во-вторых, мы не скованны никакими законами о банковской тайне, в мониторинге нет персональных данных, мы шлем туда обезличенные метрики, и мы не прочь их за свой периметр выпустить. Ну, RPS, ну что? Даже конкурентам они, в принципе, неинтересны.
Никогда мы себе не могли позволить надежного мониторинга. В частности, мониторинг мониторинга нужен, потому что у нас все на этом завязано. Если мы узнаем о проблеме не от SMS’ки, а от звонка саппорта, это стыд и позор.
Мониторинг требует тестов, это софт. Выпускать бажное, ломать, откатывать — это тоже задача. Мы можем прогибать подрядчика или сервис, потому что мы — не маленький клиент, у нас интересные задачи, у нас интересная экспертиза, мы даем интересный feedback. По сути, в итоге ценник сравним с выделенным разработчиком, учитывая, что у этого разработчика был я проджект менеджер, я QA, я эксплуататор мониторинга. Т.е. суммарно сервис обходится чуть ли не дешевле.
Мы используем okmeter.io. И нас все устраивает.
Дальше я бы хотел поговорить о том, не как метрики хранить, а что нужно снимать, на что нужно смотреть, чтобы проблемы решать. С метриками какие есть проблемы? Приходят люди и говорят: «Мы сейчас замониторим наше ядро». Мониторят основные сервисы, основные бэкенды, все остальное забывается, до конца доделать какую-то задачу людям очень сложно. Поэтому нужен тут какой-то подход.
Мы пробовали в регламенты включать покрытия мониторингом, это не работает, потому что чувак смотрит: «Ага, чтобы мне выпустить сервис, мне нужно его покрыть мониторингом. Что такое покрыть мониторингом веб-сервис? Наверное, прочекать, что у него порт открыт и все». Т.е. формально требование выполнено, но, по сути, голову не включил никто. Это, конечно, можно решать тем, что людей надо шлепать или еще что-то, но лучше это системно как-то решать.
Часто снимают не все, потому что некоторые подсистемы нуждаются в том, чтобы отдельно настроить съем метрик из них. В частности, в Java надо включить jmx, в postgres нужно пустить мониторингового пользователя и т.д.
Инфраструктура постоянно меняется. Т.е. запускаются сервисы, что-то переколбасили, новые виртуалки, новые сервисы, где-то бэкенд прикрыли nginx, где-то HAproxy поставили, много операций происходит в авральном режиме, поэтому уследить за всем — проблема. Бывает так, что метрики, вроде бы, собраны, но по ним ни хрена не поймешь задним числом, потому что они общие. Т.е. там кто-то сожрал диск IO, ну кто, я же не могу вернуться, linux лог не пишет, кто CPU жрал…

Подход у нас такой.
Все, что можем снять без конфига, мы снимаем всегда. Здесь я говорю о том, что мы попросили у нашего сервиса, чтобы сделали для нас. Эта концепция исходила от нас, реализация не наша. Я буду рассказывать, может быть, вы на своих решениях просто подход возьмете. Все, что можно снять без конфига, снимаем со всех машин. Надо или не надо — пусть будет.
Если агент видит, что нужна донастройка, или ему нужен доступ, это алерт в мониторинге. Админы классно чинят алерты, это то, что у них получается хорошо. Есть лампочка, он что-то сделал, лампочка погасла — кайф. Т.е. админ такую работу выполняет хорошо. Т.е. как test driven development, тест упал, тест починили, все, задача решена. В данном случае, примерно то же.
Метрики мы снимаем максимально детально, в пределах разумного, т.е. если речь идет о том, чтобы снять время ответа суммарное — хорошо, но мы хотим по URL’ам. URL’ов много, мы подумали-подумали и запросили сделать топ. Нам снимают тайминги по URL, но тех, которые больше чем 1%. Вот хорошо. Но мы можем докопаться, где тупило, где не тупило задним числом.
Ждем также, чтобы была autodiscovery, но не в терминах того, что принято, а мы много снимаем про TCP, мы видим, где сервисы, с кем взаимодействуют. Если мы поймали какой-то IP, которого нет в мониторинге, там не стоит агент, от него метрик нет — алерт. Нам мониторинг зажжет кучу лампочек, мы это все починим, и он будет каждую минуту это проверять, это классно.

Что мы снимаем? Я постоянно на собеседованиях спрашиваю админов, что надо снимать, чтобы было что-то понятно. Настала моя очередь отвечать на этот вопрос. Стандартные метрики, которые снимают все. CPU в процентах, memory всякие, шаред, кэш и прочее. Swap, swap i/o (обязательно). По сети — пропускная способность packet rate, ошибки. По диску — диск в емкости, использование inodes, i/o операции в секунду read/write. В трафике — read/write, и время, которое диск был занят i/o, т.е. это можно сказать, что это процент i/o. Со всех машин обязательно time offset относительно эталона, потому что это даже может бизнес зааффектить, если у вас время отстает. Проще просто один раз снимать это везде, настроить триггер, и чтобы все было хорошо. Состояния raid массивов, батарейки, и операции которые там идут.

Дальше интереснее. Про каждый процесс. Вернее, про каждый процесс, конкретно сгруппированный по executable и пользователю. Мы меряем CPU время, т.е. время, потраченное процессором в разрезе user/system; память, диск i/o на каждый процесс, сколько операций записи/чтения, сколько трафика на диск, swap на каждый процесс, swap rate на каждый процесс — это, вообще, нам сильно помогает. Количество thread, количество открытых файловых дескрипторов и лимит на файловые дескрипторы.

Про TCP. Если мы смотрим за всеми listen socket, если видим, что его соединения на той стороне имеют IP из нашей локалки, мы снимаем про каждый IP отдельно. Снимаем мы количество соединений в разных статусах: ESTABLISHED, TIME_WAIT, CLOSE_WAIT для каждого IP, опять же. Меряем RTT. RTT нам нужен, потому что, на самом деле, он абсолютно ничего не говорит о скорости вашей сети, потому что есть selective окно лишь TCP, но сравнивать, что вот тут сеть работала хорошо, а тут сеть работает плохо, по нему вполне себе нормально. Более того, имея хорошую детализацию метрик, мы можем судить о том, как работала сеть между двумя узлами в сети. Не абстрактно «у нас там ethernet свичился хорошо», а именно «эта машина с этой взаимодействовала до факапа вот так, во время факапа — так, после факапа — вот так». Также для всех listen мы снимаем размер backlog’а на accept и лимит его. Похожие метрики для исходящих соединений.

Nginx. У нас nginx не только на фронтендах, но еще внутри, у нас балансинг на нем внутренний сделан. И там хранилище всяких фоточек пользовательских, портфолио сделано на nginx. Часто случалась ситуация, когда мы забывали парсить логи, поэтому мы сделали парсинг логов автоматом. Если на машине работает nginx, агент находит его конфиг, читает access_log, понимает его формат, настраивает парсер, знает все access_log’и в лицо и начинает их парсить. Если нет таймеров, или log_format устроен так, что его нельзя распарсись, бывает такое в районе upstream_response_time, они через запятую с пробелами, в общем, бывает так, что его распарсить невозможно. В мониторинге появляется алерт, мы меняем log_format, алерт гаснет, все мы знаем, у нас полный access_log со всеми таймерами в хороших разрезах. Снимаем RPS по статусам, по топу URL, по кэш статусу, по методу. Примерно по тем же раскладкам мы снимаем тайминги.

Jvm. У нас больше половины — это Jvm. Jvm также автодетектим, пытаемся понять, где у него JMX. Если JMX выключен — алерт. Если внутри мы обнаруживаем чего-нибудь интересного (сassandra), то снимаются ее метрики, у нас есть инсталляция cassandra. Снимаем метрички про heap, про GC, про memory pools, про threads. Стандартно там не много вариантов, чего снять. Но мы требуем, чтобы JMX был включен везде, потому что где-то включено, а где-то есть подозрения на GC, приходим, метрик нет. Проблема.

Про Postgres. У нас Postgres. Также агент пытается законнектиться и снять все метрики. Если у него не получается, это алерт. Алерты чиним. Более того, мониторинг требует, чтобы там было влючено pg_stat_statements, потому что мы хорошую аналитику снимаем по sql-запросам, и это позволяет нам сильно сократить время починки базы. Не хватает прав — алерт. Снимаем про запросы, про таблички, про конкретные индексы. Там какая-то логика есть, это не столь важно. Важно, что много метрик, и копаться потом хорошо.
Метрики из логов снимаются примерно так.
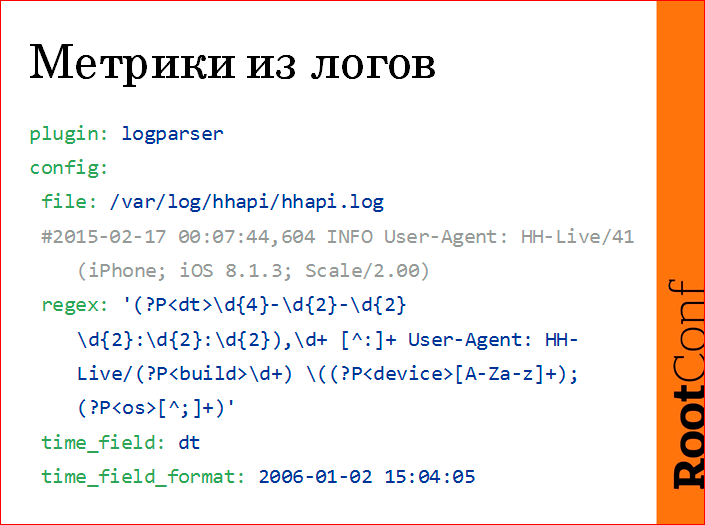
Есть лог, мы пишем regex с именованными группировками, потом из этих именованных группировок делаем метрику.

В данном случае это количество вызовов нашего API из мобильного приложения. Мы напарсили версию приложения, мы напарсили пользовательский девайс (iphone, ipad и т.д.), версию операционки.
После этого можем сделать из этого сразу же такой график:
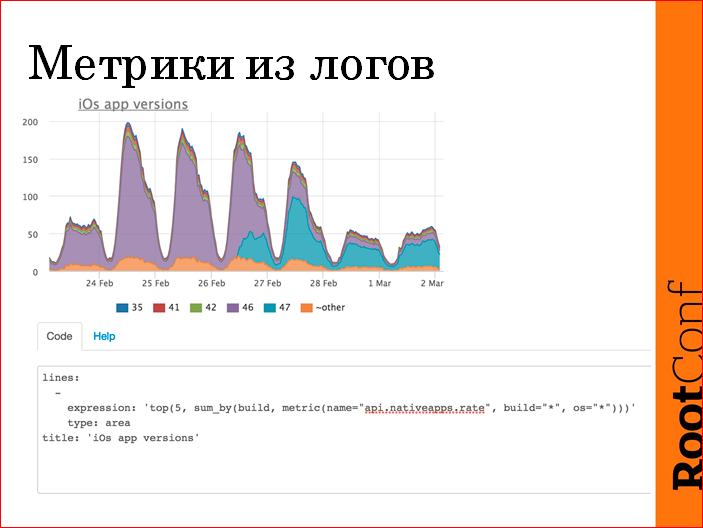
В данном случае лог просто распарсили, бизнес value нормально, мы выпустили новую версию приложения, и видим, как оно у пользователя апдейтилось во времени. Видим, что в первый день треть пользователей заапдейтилась, еще за три дня все на 47-ую приползли. Примерно в вебе это выглядит вот так. У нас там есть язык запросов, агрегация метрик сделана на лету. Соответственно, на все это мы вешаем триггеры потом.
Метрики из SLQ. Страшный запрос, но зато честный, как есть.

Просто пишем конфиг, пишем кастомный sql-запрос свой, он возвращает сколько-то строчек, одна колонка должна называться value…, а вторые колонки — это спецификация метрики. В данном случае мы считаем количество резюме, количество переходов резюме из одного статуса в другой за последнюю минуту. Снимаем это раз в минуту, получаем метрику resume.changes.count.
Делаем такой график:
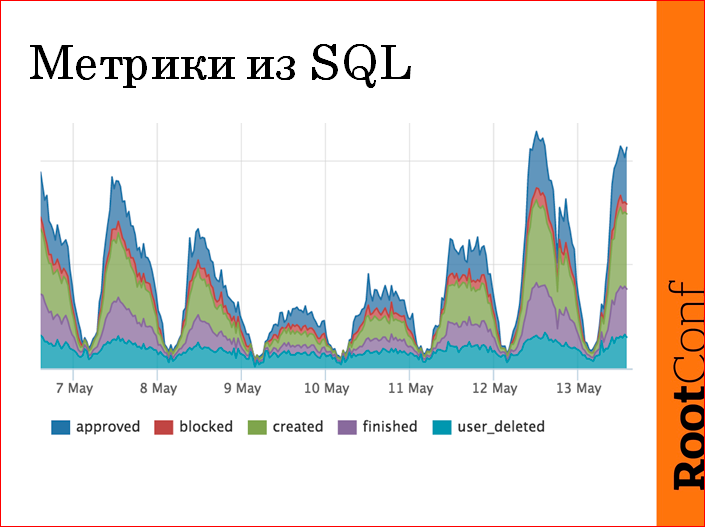
Т.е. сколько резюме, как меняются. Если где-то чего-то залипло — на этом графике провал, если мы пятисотим — на этом графике провал. Это основные наши показатели, я здесь оси не нарисовал, потому что мне сказали, что это секрет. Но зато, когда мы эту штуку проверяли, мы заметили, что у нас в 4 часа утра есть переходы резюме в отмодерированные, а модераторы у нас, в основном, в московской таймзоне. Мы начали разбираться, и реально, какая-то тетка (у нас модераторы, в основном, это тетеньки в декрете, HR’ы) стала кормить ребенка и решила отмодерировать резюме. Она была одна, поэтому мы поняли, что она модерирует 4 резюме за 10 минут. Зато реально нашло аномалию.
Дальше про триггеры. Начну с принципов. Потому что конкретные триггеры у всех свои.

У нас посылы такие:
- проактивного мониторинга не существует, это все фигня. Проактивный мониторинг может вам сказать, что у вас диск кончится скоро, и у него есть для этого данные.
- в веб-системе, особенно в нагруженной, все может меняться за секунду — у вас сейчас работает, через 100 мс не работает ни хрена. И вы никакими разладками, никакими Hadoop’ами это предсказать не могли. Поэтому давайте довольствоваться тем, что хотя бы мы узнаем, что сломалось, и постараемся причину найти.
- опять же, зависимости между алертами. Многие типа Zabbix заморачиваются: «если этот алерт зажегся, то этот мы не зажигаем, потому что это следствие». И хорошо это сделать невозможно, на мой взгляд. Поэтому мы это тоже пытаться делать не будем.
- в нормальном состоянии активных алертов быть не должно.

Critical событие — это то, что нужно починить прямо сейчас. Critical не может подождать, пока вы пообедаете. Если следовать этому принципу, вот у нас, допустим, CPU прямо сейчас чинить не нужно, если это не аффектит пользователей сайта. Поэтому никакие SMS’ки о том, что «Critical CPU» у нас нет.
У нас есть всего три critical триггера — это те, что были описаны для бизнеса. Это пятисотки, это время ответа, это внешние чеки. Все остальное — это подсказки, когда человек приходит чинить, или иногда в рабочее время чуваки заглядывают в мониторинг, и если какие-то warning загораются, то чиним. Но, по сути, мы даже на почту их не отправляем, потому что это нафиг не нужно.
Лучше зажечь много триггеров, в пределах разумного, потому что человек в пределах минуты 20-50 warning’ов парсит глазами нормально и может фигню от нефигни глазами отличить.

Часто бывает ситуация, что вы спите, вам приходит SMS, и вы не решаетесь вылезти из-под одеяла: «Ну, блин, если через минуту придет recovery, то я даже и не буду вставать». Мы эту обязанность отдали мониторингу, у нас нотификация идет, если алерт уже работает две минуты. Потому что даже если вы захотите, чтобы вас нотифицировали через 10 секунд, на самом деле вы доберетесь до компа за пять минут, потом пока вы проснетесь, пока откроете SSH, пока пропарсите алерты. Т.е. эти две минуты ни на что не влияют и, по сути, нет великой ценности алертить сразу. Поэтому мы решили вот так вот. Зато чуваки знают, если приходит SMS, все, надо чинить, уже все сломалось, уже recovery не будет.
Идеально, когда причина есть в списке алертов, warning’и. А если нет — есть дашборды, есть графики, потому что не для всего можно придумать адекватные пороги и всякую крутую математику, чтобы детектило провалы, спайки и т.д. Но мы стараемся, чтобы в следующий раз та же самая проблема была видна в алертах.

Важно: если горит алерт, и вы не собираетесь его чинить, выключайте, потому что, если вы знаете, что у вас мониторинг чистый, и начинают гореть какие-то лампочки, все, их надо починить, довести до чистого состояния. Это классный такой принцип, с ним иногда сложно, нужно перебороть себя. Но если мы не будем себя обманывать, это проще. Т.е. в данном случае, если вы постоянно от Zabbix или еще от какого-то невнятно настроенного мониторинга получаете тонну писем в папочку, которую никто никогда не читает, проще не обманывать себя, выключить, настроить у себя оповещение. Если CPU на какой-то машине вас не интересует… По сути, CPU — тоже хороший триггер, но он хороший, когда вы решаете проблему. Я не хочу получать письмо про CPU.
Наши триггеры, чтобы конкретику добить:

Все внутренние сервисы состоят за балансерами, у них такие же есть основные critical warning по логам nginx, пятисотки, timeout’ы, время ответа.
На все процессы open file usage — это отношение открытых дескрипторов к лимиту, потому что мы натыкались 25 раз на «too many open files» в логе. Все, мы закрыли для всех абсолютно процессов. Если загорается для чего-то неважного, мы просто руками, у нас есть возможность. Чистяков ругался, что надо подавить алерт, у нас такая фишка есть, мы просто гасим не нужный алерт, и все, он никогда больше не возникает.
Для всех LISTEN сокетов мы меряем backlog. Соответственно, если приложение начинает тупить и перестает аксептить соединение, мы знаем. Опять же, мы настроили один единственный конфиг для всех LISTEN сокетов. Если где-то какой-то второстепенный Redis начинает в это упираться, мы просто его закрываем. Но мы знаем, что если где-то произойдет задница, она нам высветится в мониторинге.
Про диски, мы снимаем usage. IO нас интересует только, если оно в планке 10 мин. и более. Это такие хинты, которые тоже помогают понять чего-то.
Про raid. Здесь стоит отметить, если идут какие-то операции consistency check, на софтовом raid это может зааффектить IO, поэтому у нас лампочка горит, если идет какая-то профилактика батарейки, там есть какие-то кейсы с железками, это может вырубить write кэш. Мы хотим просто знать, что это происходит.

- Живы все nginx, haproxy и важные процессы на машинах, где они были хоть раз запущены. Т.е. мы не пишем: «триггер, чекай на фронте таком-то, таком-то и таком-то». Мы говорим: «просто чекай все nginx». Если nginx на машине не стоял, и он там не был ни разу запущен, лампочка не зажжется. Если где-то вы руками запустите на тестовом nginx, который в мониторинге есть, и потом погасите, зажжется лампочка. Ничего, мы ее погасим руками, зато мы будем знать, что если где-то что-то потухнет, мы об этом узнаем.
- Давно нет данных от агента на каком-нибудь сервере — это warning.
- Нет данных от JVM, Postgres и т.д. — это warning.
- Heap usage > 99% — это warning на протяжении двух минут. Мы таким образом пытаемся поймать out of memory в Java, потому что есть опция, что она рестартует, а не все настроены. Мы просто настроили триггер и в следующий раз, если найдем такое место, мы его починим. Такой мониторинг driven эксплуатация.
Меряем time offset и важные очереди.
Инцидент примерный, что происходит?

Происходит SMS. Одновременно с этим мониторинг заводит задачу в JIRA. Обязательно. Для того, чтобы считать и вести там какой-то workflow. Тогда же считаем, что инцидент начался. Админы просыпаются, они должны в JIRA прийти и нажать «ок» — перевести задачу в статус «проблемой занимаются». Нужно это почему? Потому что в компании есть саппорт, которому звонят клиенты, он заходит в JIRA и видит: «Ага, есть проблема, реально, мониторинг запалил, что все плохо. И Коля Сивко проснулся и чинит». Он клиенту говорит: «Все чиним, скоро все будет». И никто никого не обманул. Классно.
Чиним примерно так:
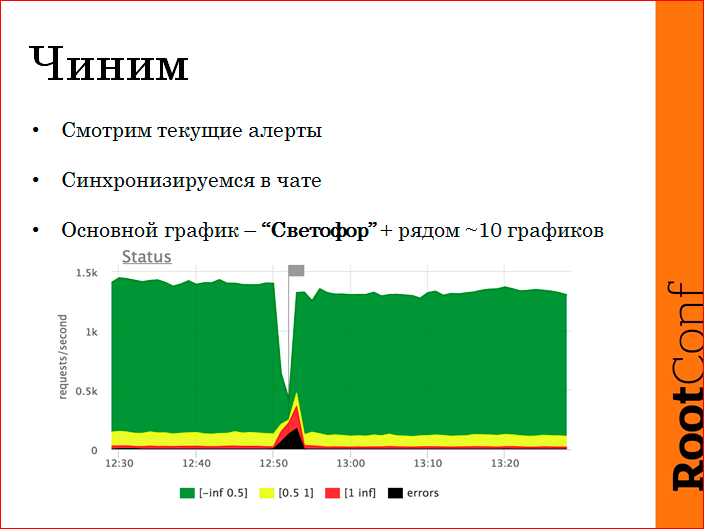
Смотрим текущие алерты, синхронизируемся в чатике. Пока инцидент не закрыт, в JIRA никто ничего не пишет, потому что долго, муторно, все это потом.
Основной график у нас, чтобы одним взглядом понять состояние — светофор. Зеленый — это быстрый запрос по шкале RPS. У нас где-то под 2000 RPS — это со всех логов, со всех фронтов проагрегрирован наш фронтсайд. Зеленая — быстрее чем полсекунды, желтая — помедленнее, до секунды, красная — тупящие запросы, черное — ошибки. Естественно, сразу видно, в каком масштабе сломалось, что произошло.
Есть дашборды, которые показывают взгляд на систему сверху, какие сервисы зааффекчены, какие URL зааффекчены, какие хэндлеры зааффекчены.
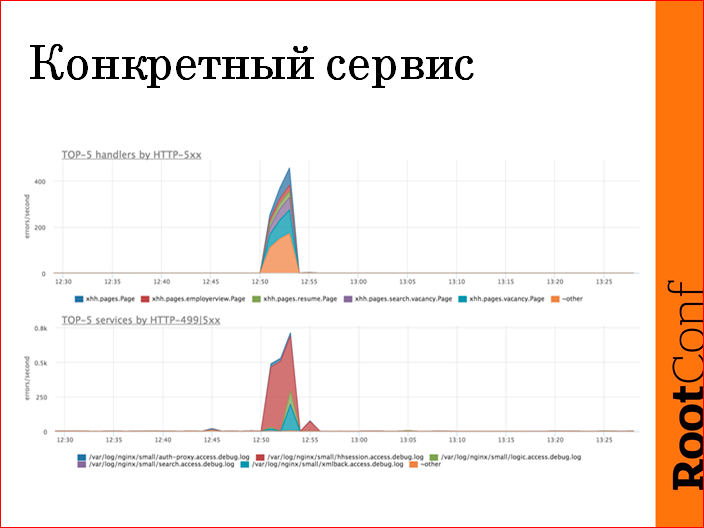
Очень у нас много сервисов, мы зачастую используем топ функции, потому что сервисов у нас, допустим, 40, на графике 40 areas выглядит плохо, мы используем «покажи нам топ 5 сервисов по пятисоткам, по ошибкам». В данном случае это нижний график — видно, что сервис hhsession пятисотит, и это вся проблема и есть. Т.о. одним взглядом на картинку мы сузили scope проблемы до конкретного сервиса, пошли в его дашборд, логи, не важно, починили.
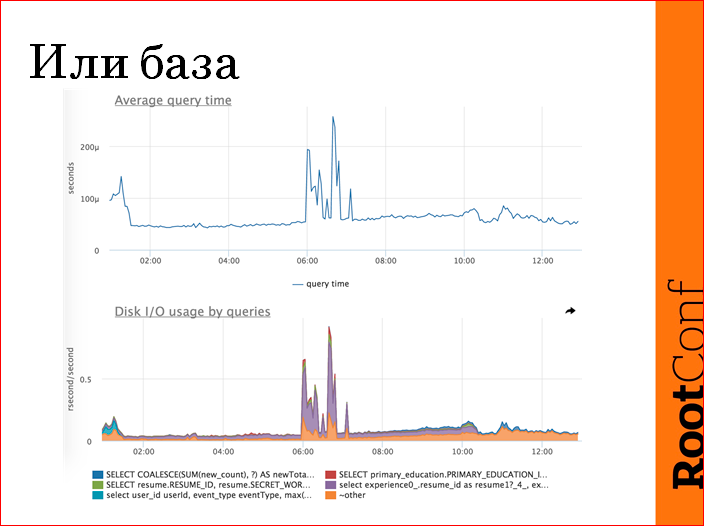
Если все равномерно аффектится, у нас есть такое правило — проверять, жива ли база. Базу мы проверяем по среднему времени ответа. Это, на самом деле, хреновая метрика, но она отлично справляется с задачей — показать, так же сейчас работает база или по-другому. В данном случае видны выбросы — это проблема. У нас есть детальные метрики по базе, чтобы не дергать попусту DBA, мы пытаемся понять, если там конкретный запрос вылез, мы либо релиз откатим, либо еще чего-нибудь, либо какой-нибудь крон выключим и т.д.

После восстановления мониторинг меняет статус задачи. Мониторинг фиксирует исправления, не человек, мониторинг. Для того чтобы точное время downtime прочитать.
Поиск причины идет постфактум. Потому что, опять же, починили не значит поняли суть. Нашли, в JIRA все записали, ставим класс задачи, закрываем задачу. Если там нужна разработка или еще что-то, есть продолжение workflow.
Вот примерно выглядит это в JIRA так:
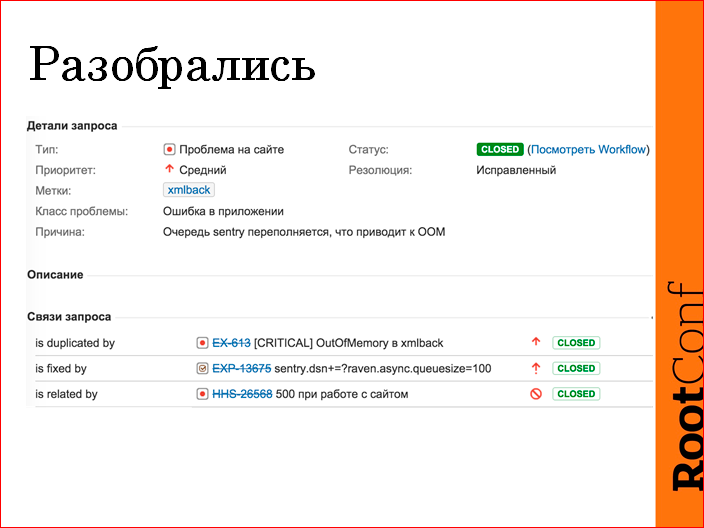
Была проблема, это резолюция «Ошибка в приложении». Криво внедрили sentry. Не поставили ограничения на очередь. Java упала с out of memory. Fixed by — задача в эксплуатации, поменять настройку, интеграция sentry. Связанная — ticket от саппорта. И, соответственно, проблема была второй раз, дубликат.

По результатам. Надо человеческие ошибки все обсудить. Поговорить с командой, посмотреть, может быть, человеку не надо в то место лезть, может, можно автоматизировать и т.д. Это важно.
Если проблема с релизом, может быть, как следствие изменений в автотестах либо в процедуре выкладки.
Проблема в приложении, как правило, выливается в задачу для разработки.
Железо/сеть — не всегда возможно что-то починить, но задачу нужно завести, можно уменьшить вероятность, можно сократить downtime в будущем, можно обеспечить там самовосстановление как-то. Т.е. какие-то меры, чтобы суммарный downtime снизить.

И не забываем про мониторинг. Может быть, добавить метрик, может быть, метрики сделать более детальными, может быть, новый триггер, либо какой-нибудь классный графичек.
Контакты
» NikolaySivko
» n.sivko@gmail.com
» Блог компании HeadHunter
» Блог компании okmeter.io
Этот доклад — расшифровка одного из лучших выступлений на конференции по эксплуатации и devops RootConf.
Также некоторые из этих материалов используются нами в обучающем онлайн-курсе по разработке высоконагруженных систем HighLoad.Guide — это цепочка специально подобранных писем, статей, материалов, видео. Уже сейчас в нашем учебнике более 30 уникальных материалов. Подключайтесь!
Ну и главная новость — мы начали подготовку весеннего фестиваля "Российские интернет-технологии", в который входит восемь конференций, включая RootConf. Мы, конечно, жадные коммерсы, но сейчас продаём билеты по себестоимости — можно успеть до повышения цен
