
Привет, Хабр! Продолжаем публиковать рецензии на научные статьи от членов сообщества Open Data Science из канала #article_essense. Хотите получать их раньше всех — вступайте в сообщество!
Статьи на сегодня:
A Better Use of Audio-Visual Cues: Dense Video Captioning with Bi-modal Transformer (Tampere University, Finland, 2020)
Fast Bi-layer Neural Synthesis of One-Shot Realistic Head Avatars (Samsung AI Center, 2020)
Enhancing the Locality and Breaking the Memory Bottleneck of Transformer on Time Series Forecasting (University of California, USA, 2019)
Whitening for Self-Supervised Representation Learning (University of Trento, Italy, 2020)
MelGAN: Generative Adversarial Networks for Conditional Waveform Synthesis (Lyrebird AI and University of Montreal, 2019)
StyleFlow: Attribute-conditioned Exploration of StyleGAN-Generated Images using Conditional Continuous Normalizing Flows (KAUST, Adobe, 2020)
Ссылки на прошлые сборники серии:
2020 год: Январь — Февраль, Март ч1, ч2, Апрель ч1, ч2, Май ч1, ч2, Июнь, Июль-Август
2019 год: Январь — Июнь, Июль — Сентябрь, Октябрь — Декабрь
2017 год: Август, Сентябрь, Октябрь — Ноябрь
1. A Better Use of Audio-Visual Cues: Dense Video Captioning with Bi-modal Transformer
Авторы статьи: Vladimir Iashin, Esa Rahtu (Tampere University, Finland, 2020)
Оригинал статьи :: GitHub project :: Project :: Conference page :: Видео
Автор обзора и статьи: Владимир Яшин (в слэке vdyashin)
Проблема
Почти каждое видео, которое вы смотрите, еще имеет аудио дорожку. Чаще всего аудио синхронизировано с видео и может содержать важную информацию, которая поможет решить нашу задачу. Еще только пару лет назад в диплернинге использовали только RGB. Сейчас ситуация меняется и все больше SotA подходов используют две и даже несколько модальностей. Зачастую просто извлекают фичи из модальностей, применяют какую-нибудь RNN, и смешивают предсказания конкатенацией ближе к выходу. В этой работе мы показали, как можно адаптировать Энкодер и Декодер в Трансформере для входа с аудио и rgb, чтобы можно было смешивать информацию прямо внутри архитектуры. Получилось довольно элегантно.
Задача Dense Video Captioning
В отличии от Video Captioning, Dense Video Captioning требует:
найти "интересные" моменты в видео (proposal generation);
сгенерировать описание каждого из них (caption generation).

В чем заключается наш подход?
Наша модель состоит из двух частей: Bi-modal Transformer и Proposal Generator.

Начнем с первого. Давайте вспомним, как устроен Трансформер для перевода из немецкого в английски. Он состоит из Энкодера и Декодера. Энкодер принимает последовательность (source немецкий) размера T_src x D (количествослов x размерэмбеддинга) и возвращает последовательность того же размера. Каждый элемент из последовательности должен выучить, как смотреть по сторонам и на себя самого (за это отвечает self-attention). Декодер же принимает последовательность (target английский) размера T_trg x D и выход Энкодера T_src x D, и тоже возвращает T_trg x D с предсказаниями для следующего слова (последнего элемента при inference и каждого элемента при train). Получается, что каждый элемент последовательности должен выучить смотреть назад – что было сгенерировано ранее (self-attention) – и на каждую из позиций из Энкодера (encoder-decoder attention). D обычно одинаково для Энкодера и Декодера: тут и там текст.
Довольно просто это обобщить еще и до video captioning. То есть переводим теперь видео в английский. Source будет T_src x D_src, а target T_trg x D_trg (разные размеры эмбеддигнов). Хорошо. Теперь представим, что на вход мы получаем две модальности с размерами T_m1_src x D_m1_src и T_m2_src x D_m2_src, ну и T_trg x D_trg – что же делать с разными размерами?
Подбирать такие фичи, что бы T_m1_src == T_m2_src, тогда получится их сконкатенировать. В этом случае ваша модель ограничит вам выбор фичей (плохой вариант);
Придумать, что делать с таким входом в Энкодере и Декодере (Bi-modal Transformer).
Если взглянуть на Трасформер еще раз, то можно понять, что он же умеет обращаться с последовательностями разной длинны (T_src и T_trg) и за это отвечает encoder-decoder attention. Но получается, что ты, как ни крути, получаешь, что та модальность, которую подаешь в queries главнее другой, которая идет в keys и values – длина выхода будет как у queries. Итого, можно зафьюзить инфу по эмбеддингу (D_), потому что внутри scalled dot-product attention мы вход через dense-слои пропускаем, а вот по позиции (T_) никак, и придется выбирать, какая модальность для вас важнее. Этого хотелось бы избежать, потому авторы придумали Bi-modal Decoder, который берет оба зафьюженных между собой выхода из Bi-modal Encoder и воспринимает обоих как source, поэтому возвращает два представления размером T_trg x D_trg. А с этим уже гораздо проще работать. Эти представления комбинируются в Bridge слое, а дальше как привыкли. Смотри сравнение Ванилла Трансформера и нашего Би-модального Трансформера на картинке ниже.

Теперь второе: Proposal Generator. Он тоже дву-модальный. Принимаем на вход T_m1_src x D_m1_src и T_m2_src x D_m2_src, пропускаем через Bi-modal Encoder получаем зафьюженные представления и отдаем Proposal Generator. Он состоит из двух наборов из K_m1 = K_m2 "экспертов" (heads – не то же самое что в Multi-headed Attention).

Каждая голова похожа на слой YOLO и имеет параметр (k, receptive field) и делает предсказание для каждой позиции входа (T_m1_src или T_m2_src), для каждого прайора (anchor). Итого получается (T_m1_src * K_m1 * anchor_num_m1) + (T_m2_src * K_m2 * anchor_num_m2) пропозалов, из которых мы выбираем Топ-100 по "уверенности". Сама голова имеет простую архитектуру: три 1-D свертки, где первая имеет размер фильтра = k, а остальные – 1. Так как YOLO (v3) использует предсказания с разных скейлов, чтобы уметь находить объекты разного размера, мы это обходим просто большим количеством anchors. anchors (и K_m1) получаем из K-Means, как завещают великие.
Как тренировать теперь все это? Мы перепробовали несколько подходов и остановились на следующем:
тренируем Bi-modal Transformer (captioning module) на ground-truth отрывках видео – получаем хорошую captioning модель;
берем натренированных Bi-modal Encoder, замораживаем его веса, и тренируем Proposal Generator – получаем хороший генератор пропозалов.
Для предсказаний – все наоборот: берем исходное видео, получаем пропозалы, режем видео согласно пропозалам, пропускаем через Bi-modal Transformer.
Эксперименты и результаты
Применяем нашего красавца на Dense Video Captioning, где из видео достаем rgb (-> I3D) и аудио (-> VGGish) треки. Результаты приведены ниже. Мы сделали много ablation экспериментов и применяли части наших моделей в других моделях и получали улучшения.

2. Fast Bi-layer Neural Synthesis of One-Shot Realistic Head Avatars
Авторы статьи: Egor Zakharov, Aleksei Ivakhnenko, Aliaksandra Shysheya, Victor Lempitsky (Samsung AI Center, 2020)
Оригинал статьи :: GitHub project :: Blog
Автор обзора и статьи: Егор Захаров (в слэке e.zakharov)
Предложен новый метод, который делает упор на ускорение инференса при сохранении высокого качества, и побили SotA для сеттинга, в котором сложность инференса ограничена требованием real-time на девайсах.

Проблема
Аватары -- это модели, которые по одному или нескольким селфи могут анимировать человека с них в произвольной позе. В нашей работе мы фокусируемся на головах.
Проблема, которую мы увидели, такая SOTA методы тратят на прогон одного кадра в 3-5 раз больше времени, чем на инициализацию модели под конкретного человека. Понятно, что это очень неоптимально для системы, которую инициализируют всего один раз, а потом гоняют минимум 30 раз в секунду. В нашей работе мы предложили новую архитектуру генератора, в которой инференс занимает в 10 раз меньше времени, чем инициализация -- то, что надо.
Метод
Большая часть моделей в данной области имеют структуру энкодера-декодера: исходные картинки пропускаются через энкодер, а затем декодируются при заданной позе. Получается, чтобы ускорить инференс, в целом достаточно было бы пожать декодер. Сложность в том, что нейросеткам больно генерировать высокие частоты в данных, и по мере уменьшения размера декодера начинает ощутимо проседать качество.

Мы решили эту проблему разделением декодера на две части: первая сетка (толстая) генерирует высокочастотную текстуру для головы, а вторая сетка (тонкая) -- низкочастотную компоненту для выхода и варпинг поле. Выходная картинка получается после применения варпа к текстуре и складывания двух компонент. Архитектура подробнее изображена, а визуализация каждого выхода сеток -- ниже.
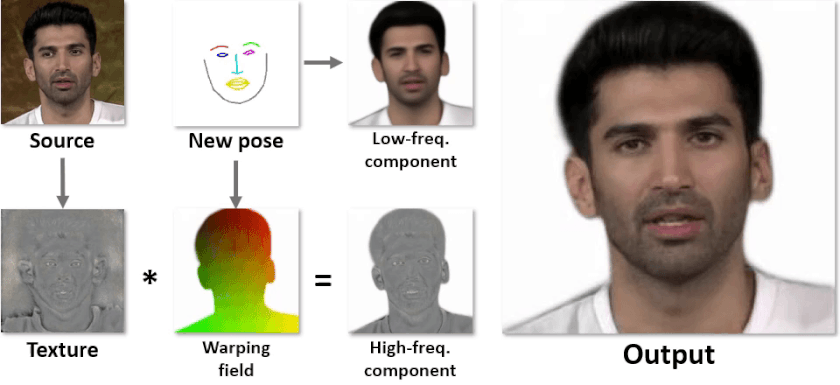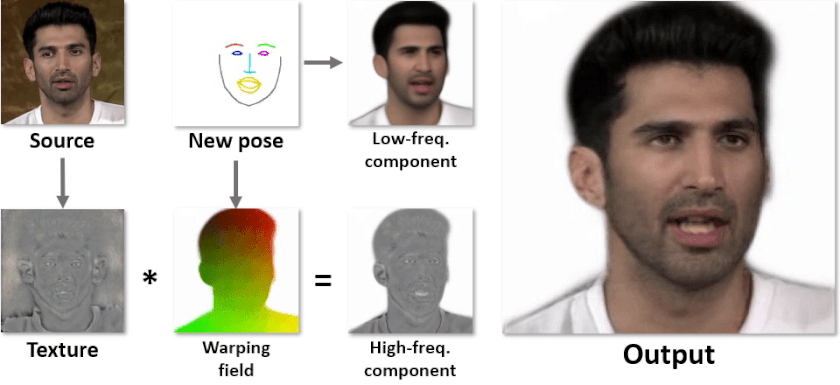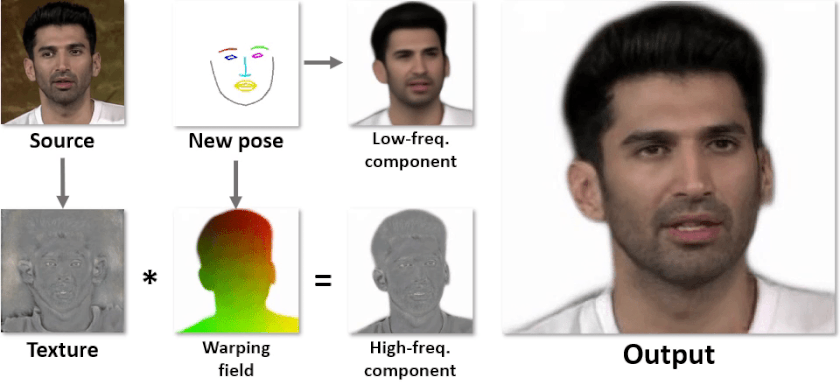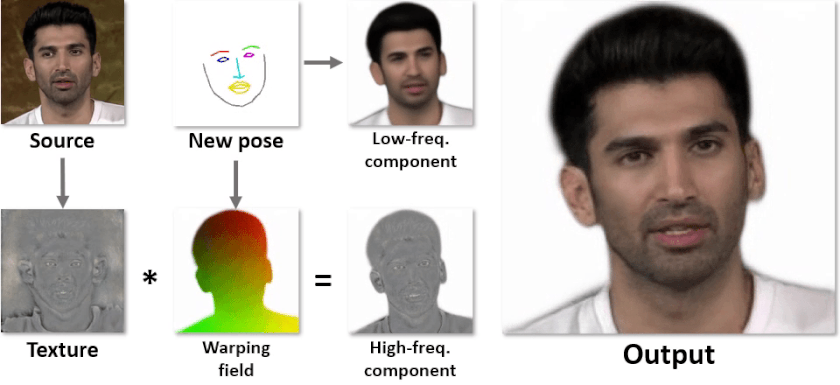
У такого подхода есть несколько преимуществ: текстура, которая генерируется первой сеткой (текстурным генератором), не зависит от позы, поэтому её нужно прогонять только один раз на аватар, а оба выхода второй сетки (инференс генератора) практически не имеют высоких частот, поэтому её можно существенно уменьшить. Бонусом является то, что всё учится end-to-end с минимальным супервиженом на геометрию.
Дальше мы подумали: если у нас теперь есть текстура, то её можно оптимизировать по исходным картинкам, чтобы ещё лучше зафитить мелкие детали, которые у метода не получилось научиться генерировать во время трейна. Проблема тут заключается в том, что на любой исходной картинке будет видна только часть лица, а значит текстура при оптимизации будет заполняться неравномерно. Здесь мы вдохновились методом [Learned Gradient Descent]() (а точнее, его крутым применением), и решили обучить для этого другую сетку: она принимает на вход текстуру, градиенты по текстуре, посчитанные с помощью простого лосса (например, sum of squared errors) и предсказывает для неё апдейт.
При этом она обучается при замороженной базовой модели бэкпропом через несколько копий (процесс апдейта текстуры итеративный). В итоге эта сетка становится частью инициализации и работает, по сути, в фидфорвард режиме. Процесс обучения описан и пример её работы продемонстрирован ниже. Видно, что она учится ещё лучше отрисовывать высокочастотные детали и убирать артефакты.


Результаты
Сравнивать такую модель со state-of-the-art в лоб не получится: SotA выиграет по качеству, мы выиграем по скорости, непонятно, кто круче. Поэтому мы для каждого сравниваемого метода мы обучили 3 разные модельки: большую, среднюю и маленькую. При этом мы варьировали только те части, которые участвуют в инференсе, инициализацию оставляли без изменений. Получается, вместо отдельных методов мы можем сравнить их семейства, и в этом сравнении очень сильно выигрываем (численные результаты и визуальное сравнение представлено ниже).


Инференс генератор у нас получилось сконвертировать для использования в библиотеке SNPE, а остальные части вполне совместимы с PyTorch-Mobile. Все результаты в материалах показаны для нашей средней модельки, которая работает 42 миллисекунды на кадр на Snapdragon 855.
3. Enhancing the Locality and Breaking the Memory Bottleneck of Transformer on Time Series Forecasting
Авторы статьи: Shiyang Li, Xiaoyong Jin, Yao Xuan, Xiyou Zhou, Wenhu Chen, Yu-Xiang Wang, Xifeng Yan (University of California, USA, 2019)
Оригинал статьи
Автор обзора: Денис Воротынцев (в слэке tEarth, на habr tEarth)
Для предикта time series (далее: ТС) обычно используют ARIMA, RNN, LSTM. Проблема аримы состоит в невозможности уловить сложные паттерны в дате. Обучение RNN долго из-за затухающих и взрывающихся градиентов. LSMT решат эту проблему, но у этой архитектуры малый effective content size. Согласно этой работе, LSTM смотрит только на последние 200 токенов. Нужно больше.
Для решения этой проблемы можно использовать трансформер. Трансформер смотрит на всю историю ТС, вне зависимости от того, как давно это было, тем самым улавливая паттерны удаленные во времени. Однако у трансформера есть две проблемы: dot-product self attention нечувствителен к локальному контексту; и ограничения по памяти: затраты пропорциональны квадрату длины последовательности.
Авторы предложили две идеи: causal convolutional self attention и LogSparse Transformer. Первая идея состоит в замене Queries и Keys на свертки Queries и Keys. То есть раньше мы считали для одной точки, а теперь - для нескольких точек до данной. Авторы пишут, что такой подход может лучше улавливать не сами значения, но форму кривой. На картинке ниже изображено, что происходит (k - kernel size). В стандартной архитектуре трансформера сверток нет, но на картинке слева изображена свертка с ядром=1. По сути ничего не меняется. Это такая генерализация.

Вторая идея - LogSparse Transformer - состоит в использовании при расчете не всех точки, а сэмпл. Пример приведен ниже. Потребление памяти снижается до O(L(log L)^2).

При таком подходе можно смотреть намного дальше в прошлое при тех же затратах памяти, при этом скор подрос.

Авторы сравнили свой подход с ARIMA, matrix factorization method - TRMF, autoregressive DeepAR (3-layers LSTM) и RNN-based state space model DeepState. Для сравнения использовалось два датасета: electricity-c, traffic-c (см. ниже), предсказывая на 7 дней вперед rolling окном (autoregressive model, последнее предсказание подается на вход; строки 1, 3) и на 7 дней вперед (seq2seq, строки 2, 4).

Предложенный подход показал лучшее качество, хотя тут есть две проблемы: авторы не сделали сравнение с обычным трансформером для предикта ТС, не указали параметры трансформера скоры которого указаны в таблице. Еще они писали, что для трансформера они оптимизировали параметры, но не упомянули, что делали это для других моделей. Нечестное сравнение. Авторы также продемонстрировали увеличение качества модели от размера свертки.

От автора обзора: В целом получилась хорошая работа. Мне нравится идея со сверткой, поскольку в своих задачах мне очень важен контекст, который плохо ловится dot-product.
4. Whitening for Self-Supervised Representation Learning
Авторы статьи: Aleksandr Ermolov, Aliaksandr Siarohin, Enver Sangineto, Nicu Sebe (University of Trento, Italy, 2020)
Оригинал статьи :: GitHub project
Автор обзора и статьи: Александр Ермолов (в слэке ermolov)
Кратко о self-supervised learning и contrastive loss (более полный обзор например у Дьяконова). Хорошо работает подход основанный на аугментации. Из исходного изображения с помощью случайного кропа и искажения цвета получаем пару новых изображений. Там изображен один и тот же объект, но сами изображения разные (позитивы). Используя cross-entropy loss (он же contrastive), мы тренируем классификатор, который определяет эту пару среди всех остальных сэмплов (негативов). Интуиция такая, если например на исходном изображении фото собаки, на первом сэмпле лапы, а на втором хвост, то энкодеру необходимо выучить семантику (само понятие собаки), чтобы сопоставить сэмплы. Таким образом мы получаем энкодер, сравнимый с обученным на лейблах. Для оценки качества результата, мы фиксируем энкодер и тренируем поверх него простой классификатор (линейный или k-NN) уже используя лейблы.

Эта статья основана на простой идее: вместо contrastive loss, давайте явно требовать, чтобы представления позитивов были максимально близкими друг с другом, уменьшая между ними MSE. Очевидно, если это делать напрямую, то мы получим плохое вырожденное решение, когда все представления соберутся в одной точке. Чтобы избежать этого, мы используем whitening transform, которое гарантирует некоррелированные представления с единичной дисперсией.
В качестве бонуса, так как мы не используем негативы, мы можем использовать больше позитивных пар: 2-м сэмплам соответствует 1 пара, а например из 4-х сэмплов можно составить 6 разных пар.

Пока мы готовили публикацию, вышел новый метод BYOL. Они также минимизируют расстояние между позитивами, но чтобы избежать вырожденное решение, используют эвристику, основанную на bootstrapping. Методы плюс-минус показывает одинаковые результаты, хотя я заметил, что для BYOL требуется некий разогрев, первые 120 эпох он отстаёт (полагаю связано с использованием скользящего среднего), а концу начинает лидировать. Эксперименты делали на CIFAR-10, CIFAR-100, STL-10, Tiny ImageNet для энкодера ResNet-18. Результаты для ImageNet не публикуем (у нас нет например 512 TPU v3 как у авторов BYOL), но текущих результатов достаточно, чтобы сравнить loss функции. Репозиторий кроме самого метода включает contrastive loss и BYOL, получился такой небольшой фреймворк.

5. MelGAN: Generative Adversarial Networks for Conditional Waveform Synthesis
Авторы статьи: Kundan Kumar, Rithesh Kumar, Thibault de Boissiere, Lucas Gestin, Wei Zhen Teoh, Jose Sotelo, Alexandre de Brebisson, Yoshua Bengio, Aaron Courville (Lyrebird AI and University of Montreal, 2019)
Оригинал статьи :: GitHub project
Автор обзора: Артем Грибуль (в слэке Datasciensyash)
Генерация аудио-сигналов - очень непростая задача, в первую очередь из-за очень большой длины выходной последовательности. Поэтому в Text-To-Speech задачах как правило не генерируют аудио напрямую из текста одной моделью, а используют две модели, которые учатся отдельно. Первая из них переводит текст в сжатое представление, как правило, в mel-спектрограмму, и именуется энкодером. Вторая же восстанавливает mel-спектрограмму в аудио и называется вокодером. И у энкодеров, и у вокодеров есть одна существенная проблема - практически все современные подходы являются авторегрессионными, или просто медленные в силу своей архитектуры, и не могут качественно запускаться на CPU из-за низкой скорости работы (а очень бы хотелось!).
В представленной выше статье авторы предлагают новую Fully-Convolutional GAN архитектуру для вокодера, которая работает x520 Realtime на GPU и x10 Realtime на CPU.
MelGAN Generator
Идейно, генератор MelGAN'a - очень простая архитектура. Так как мы всегда знаем параметры, с помощью которых получаем mel-спектрограмму, мы можем точно определить исходный размер аудио-сигнала, который был использован для её получения. Если немного вдаться в детали, то ключевым параметром, который влияет на временной размер спектрограммы является hop_length , который мы можем называть stride, если мы рассматриваем STFT-преобразование как одномерную свертку. Очевидно, что mel-спектрограмма в hop_length раз меньше, чем сигнал, который мы хотим получить на выходе.

Для того, что бы получить из исходной mel-спектрограммы аудио, авторы предлагают использовать ряд последовательных Transposed Convolutions. Количество и параметры таких upsampling-операций определяются параметром hop_length . В оригинальной статье авторы работали с hop_length = 256 , и стратегия увеличения строилась следующим образом: x8 -> x8 -> x2 -> x2. Для того, что бы увеличить корреляцию между фичами между Upsampling блоками, авторы предлагают использовать стак из Dilated Convolutions слоев с Residual Connections между ними. В отличии от обычных сверток, использование dilation позволяет собрать информацию между очень далекими семплами из-за большого receptive field.
Однако, обязательно следует учесть пару важных нюансов, которые авторы жирным шрифтом выделили в статье:
Необходимо тщательно подбирать параметры kernel_size и stride в Transposed Convolution слоях, чтобы избежать такого явления как checkerboard artifacts, которые ведут к появлению высокочастотных шумов в выходном аудиосигнале. Впрочем, рецепт достаточно прост и описывается простой взаимосвязью: kernel_size = N * stride .
Лучше использовать Dilated Convolutions для увеличения скоррелированности между фичами перед Transposed Convolutions из-за лучшего Receptive Filed, относительно обычных сверток.
В стэке Dilated Convolutions важно повышать dilation с каждым шагом таким образом, чтобы каждая фича во входных данных была использована сверточным слоем одинаковое количество раз. Игнорирование этого также приводит к различного рода высокочастотным артефактам. Для того, чтобы это сделать, существует простая взаимосвязь: если мы выберем начальный dilation как dilation_0, то dilation_i = dilation ** i.
Batch Normalization / Instance Normalization или любая иная попытка нормализовать фичи приводит к потере информации о pitch, делая голос в выходном аудио неестественным и металлическим. Вместо этого для стабилизации процесса обучения авторы предлагают использовать технику weight normalization.
Использование функций активаций стандартно для GAN: LeakyReLU везде, Tahn на выходе.
MelGAN Discriminator и loss-функция
В MelGAN используется хитрая стратегия использования сразу нескольких однотипных дискриминаторов, которые оперируют разными масштабами в аудио-сигнале. Идея заключается в том, чтобы использовать стак дискриминаторов, причем каждый последующий будет принимать аудио меньшего масштаба. Выход генератора так же не совсем классический, в статье используют Hinge Loss (или MSE Loss из LSGAN, авторы отмечают, что разницы практически нет), поэтому расчет лосса происходит без взятия сигмоиды в конце. Дополнительным выходом дискриминатора являются так называемые Feature Maps, то есть, активации в промежуточных слоях всех дискриминаторов. На их основе формируется Feature Matching Loss, который является своеобразным Metric Learning'ом: генератор штрафуется, если активации сгенерированного аудио-сигнала не похожи на активации настоящего. Использование этой дополнительной лосс-функции крайне важно, так как без неё процесс обучения крайне нестабилен и не дает хороших результатов.
Results
MOS сравним, но все же меньше, чем у WaveGlow (SOTA).
Скорость x10 выше, чем у самой быстрой модели вокодера до MelGAN на RTX 1080 Ti (x520 Realtime).
Скорость x25 выше, чем у самой быстрой модели вокодера до MelGAN на CPU (x10 Realtime).
Количество параметров у генератора всего 5.2 млн. Для сравнения, у WaveGlow - 87 Млн.
Модель генерализуется на новых спикерах, если была обучена на multispeaker датасете.
6. StyleFlow: Attribute-conditioned Exploration of StyleGAN-Generated Images using Conditional Continuous Normalizing Flows
Авторы статьи: Rameen Abdal, Peihao Zhu, Niloy Mitra, Peter Wonka (KAUST, Adobe, 2020)
Оригинал статьи
Автор обзора: Григорий Рашков (в слэке logogriph)
Авторы решали задачу изменения атрибутов изображения в stylegan1/2. В отличии от interfacegan, подхода Харконена с PCA и др. подходов, где к вектору изображения в W пространстве добавлялся вектор изменения атрибута, авторы решили получать новый вектор в W из вектора исходного изображения в Z-пространстве и желаемых параметров атрибута с помощью условного нормализационного потока.

Для того, чтобы обучить поток между Z и W, авторы сэмплировали 10к векторов из Z, получили для них W и сгенерили изображения, которые прогнали через сетки для получения атрибутов изображений. Для изображений с помощью Face API получили атрибуты: возраст, пол, очки, усы/борода/щетина, экспрессивность выражения лица (не конкретизируя эмоции), лысину, поворот и наклон головы. Также с помощью DPR получали 9 атрибутов изображения, связанных с освещением (сферические гармоники). То есть всего 17 атрибутов.
Для моделирования самого потока использовали gate-biased modulation networks (ConcatSquash из работы PointFlow на базе FFJORD), т.к.авторы предполагали, что bias-часть будет лучше учить направление для семантического атрибута, а gate-часть — величину сдвига по этому направлению.
Чтобы поток учитывал информацию об атрибуте, авторы расширяют переменную времени t до размерности пространства атрибутов, покомпонентно конкатенируют с вектором атрибутов и отправляют полученную переменную в поток в качестве условия.
Авторы отмечают, что если поток будет учить только один атрибут за раз, то векторные поля будут запутанными и это скажется на качестве изменения, поэтому они объединят атрибуты в один тензор.
На инференсе при редактировании они используют линейную интерполяцию в домене атрибутов для более гладкого перехода.

Авторы использовали 4 CNF-блока и 2 moving batch нормализации — до и после CNF. Модель только с 2-3 CNF блоками переобучается.
Для редактирования изображений на инференсе авторы предлагают процедуру из трех шагов:
Joint Reverse Encoding (JRE) нужна, чтобы получить для изображения тройку w, a и z. С помощью Face API и DPR нужно получить атрибуты a. Если вектор w неизвестен (например, для реального изображения), то авторы предлагают получить его с помощью энкодеров для стайлгана. По векторам w и a с помощью потока можно получить z0.
Conditional Forward Editing (CFE). Для найденного на предыдущем шаге z0 и желаемых атрибутах a’ получаем новый вектор w’.
Edit Specific Subset Selection. Этот шаг используется при последовательном редактировании нескольких атрибутов. Авторы предлагают два варианта. В медленном варианте после каждого преобразования w-вектор проецируется обратно в Z. В быстром преобразования просто накладываются друг на друга, что приводит к нежелательным эффектам из-за того, что атрибуты пересекаются по слоям в W+.


