Привет, Хабр! Продолжаем публиковать рецензии на научные статьи от членов сообщества Open Data Science из канала #article_essense. Хотите получать их раньше всех — вступайте в сообщество!
Статьи на сегодня:
- Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization (Georgia Institute of Technology, Atlanta, USA, 2016)
- X3D: Expanding Architectures for Efficient Video Recognition (Facebook AI Research, 2020)
- Adaptive Attention Span in Transformers (Facebook AI Research, 2019)
- ResNeSt: Split-Attention Networks (Amazon, 2020)
- Weight Standardization (Johns Hopkins University, 2019)
- Supervised Contrastive Learning (Google Research, MIT, 2020)
- Improved Training Speed, Accuracy, and Data Utilization Through Loss Function Optimization (USA, 2019)
- TTNet: Real-time temporal and spatial video analysis of table tennis (OSAI, 2020)
- Learning in the Frequency Domain (Alibaba, Arizona, 2020)
- 2020 год: Январь — Февраль, Март ч1, ч2, Апрель ч1
- 2019 год: Январь — Июнь, Июль — Сентябрь, Октябрь — Декабрь
- Декабрь 2017 — Январь 2018, Февраль — Март 2018
- 2017 год: Август, Сентябрь, Октябрь — Ноябрь
1. Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization
Авторы статьи: Ramprasaath R. Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, Dhruv Batra (Georgia Institute of Technology, Atlanta, USA, 2016)
Оригинал статьи
Автор обзора: Александр Бельских (в слэке belskikh)
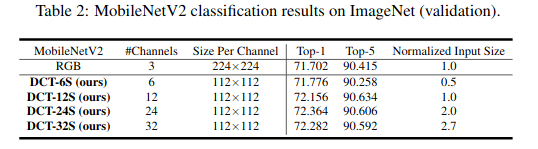
Самый простой и надёжный на данный момент способ визуализировать: «а куда же смотрит нейронка»?
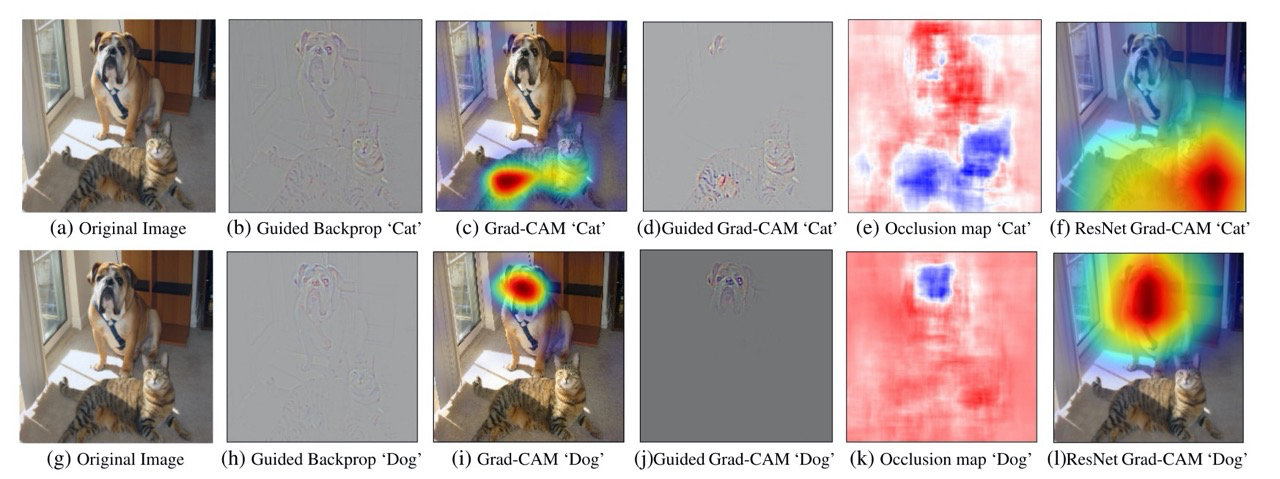
Этот многим известный подход позволяет получить некоторую интерпретацию работы модели, визуализировав хитмап активаций, которые сработали при предсказании конкретного класса.
Скомбинированный с Guided Backprop он позволяет ещё выделить на изображении фичи и грани, на которые триггерились сверточные фильтры. Все вместе это позволяет объяснить ошибки и успехи нейросети, поможет при дебаге и дотюнивании.
Суть метода:
- Берём изображение и выбираем какой-то класс, по которому будем делать визуализацию.
- Прогоняем изображение на форвард.
- Считаем градиент скора класса (до софтмакса) по фичемапу (зануляем градиенты остальных классов, а градиент по выбранному классу равен 1).
- Умножаем средний градиент по фичемапе на сам фичемап, суммируем по всем каналам и усредняем.
- Пропускаем через ReLU — так и получается хитмапа.
Если ещё посчитать Guided Backbropagation (который визуализирует градиенты по отношению к инпут изображению) и умножить его поэлементно на получившуюся хитмапу, то получится карта градиентов относительно конкретного класса.
Если же посчитать Grad-CAM с отрицательным градиентом для класса (-1 вместо 1), то подсветятся регионы, которые «мешают» или «смущают» сеть по этому классу.
Подсвечивание градиентов позволяет понять, почему же ошиблась сеть, даже если это с первого взгляда не видно, будет видно, на какие детали изображения она опиралась.

Также этот подход устойчив к adversarial атакам. На примере ниже сеть предиктит по adversarial изображению класс Airliner с уверенностью 0.9999, но если отрисовать Grad-CAM по классам Boxer или Cat, то отработает более-менее корректно.

Также можно искать bias в датасете, когда сеть явно оверфитится не на полезные признаки, а на часто сопутствующие.
В примере ниже видно, что сеть получила bias, глядя больше на лица и прическу, чем на атрибуты, предсказывая классы Doctor и Nurse.

В задачах Image Captioning можно визуализировать, какие слова были вызваны какими регионами.
2. X3D: Expanding Architectures for Efficient Video Recognition
Авторы статьи: Christoph Feichtenhofer (Facebook AI Research, 2020)
Оригинал статьи :: GitHub project
Автор обзора: Александр Бельских (в слэке belskikh)
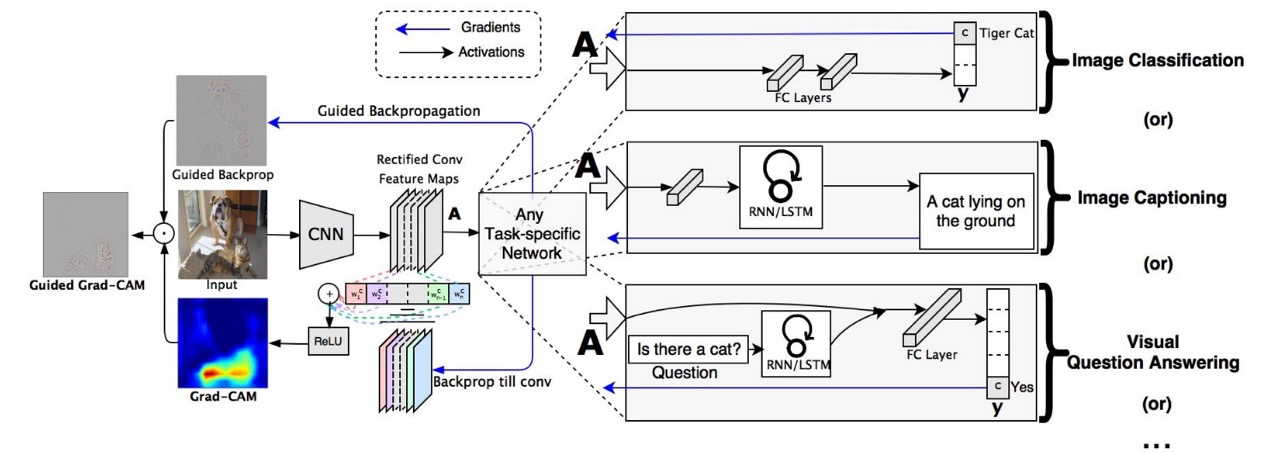
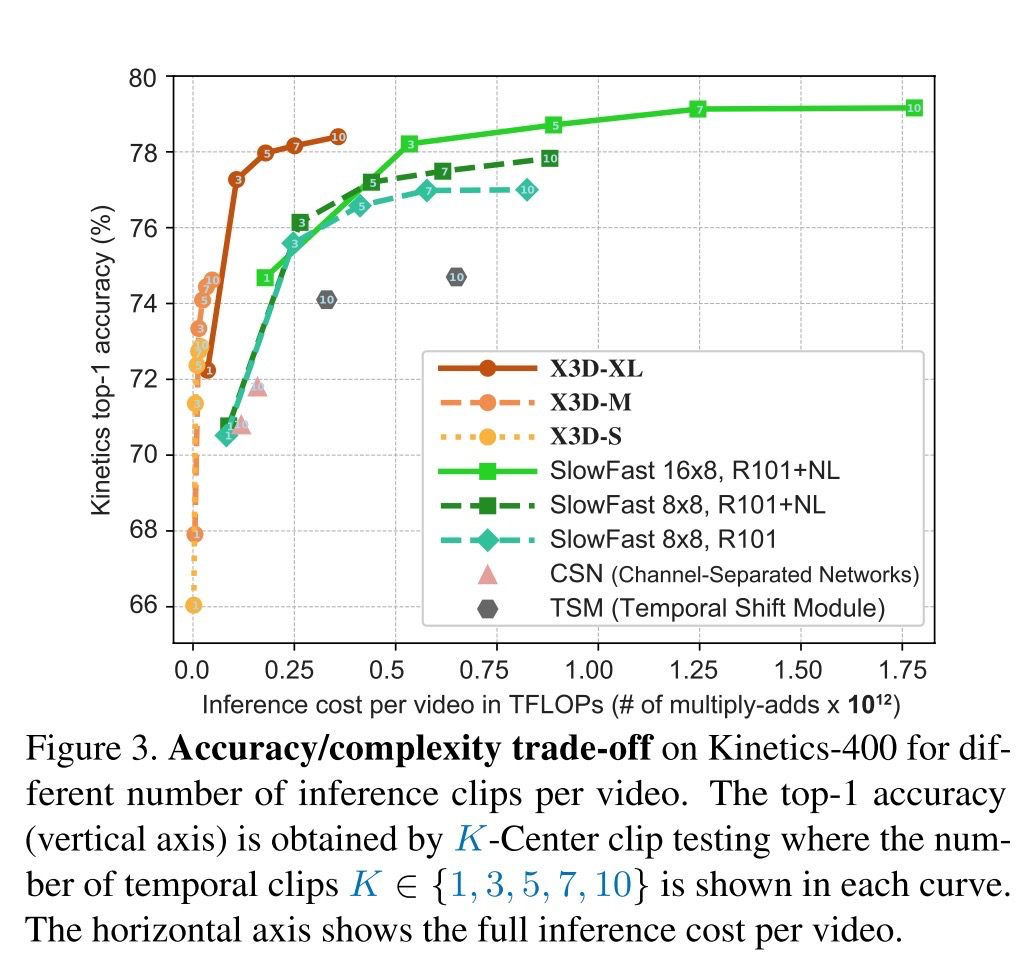
Ручной NAS архитектур для классификации видео от FAIR, в результате которого были получены на удивление тонкие архитектуры с хорошим перфомансом (до х5 меньше по параметрам предыдущей соты с той же точностью).
Автор отмечает, что большинство современных архитектур для классификации видео идут по пути адаптации существующих картиночных архитектур к 3D операциям (третье измерение в данном случае — время), в результате чего архитектуры получаются крайне жирные.
Автор решил пойти другим путём в поисках оптимальной архитектуры, обозначив базовую минимальную модель (за основу взял MobileNet с её depthwise конволюциями, но сделал её ещё в 10 раз меньше по параметрам), и задав ей ряд параметров:
- коэффициент продолжительности по времени;
- коэффициент сэмплирования из временного отрезка (сколько кадров брать);
- коэффициент пространственного разрешения (высота, ширина);
- коэффициент глубины сети;
- коэффициент ширины сети (кол-во каналов);
- коэффициент ширины ботлнека.
Эти шесть коэффициентов и определяют рост архитектуры. Чем-то напоминает коэффициенты роста EfficientNet.
У базовой модели все эти коэффициенты равны единице, это получается супер-легковесная сетка классификатор одного кадра.
Увеличение происходит следующим образом:
- на каждом шаге роста один из коэффициентов увеличивается, и полученная модель обучается, считается её качество и флопсы. (т.е. на каждом шаге учится шесть новых моделей, по одной на параметр);
- считается наиболее выгодный трейд-офф по увеличению сложности модели относительно возросшего качества;
- выбирается одна самая лучшая архитектура и проводится следующая итерация роста.
Так и были получены все архитектуры, лучшие из которых побили СОТУ при меньшем числе параметров.
3. Adaptive Attention Span in Transformers
Авторы статьи: Sainbayar Sukhbaatar, Edouard Grave, Piotr Bojanowski, Armand Joulin (Facebook AI Research, 2019)
Оригинал статьи :: GitHub project
Автор обзора: Юрий Кашницкий (в слэке yorko, на habr yorko)
Как известно, на данный момент трансформеры всем хороши, кроме того, что они дико прожорливы, но при этом не умеют съедать длинные куски текста. Не известно, что победит, реформеры или предлагаемый adaptive attention span, но идея парней из Facebook AI Research вот какая: модифицируем базовый блок self-attention так, чтоб он сам понимал, насколько далеко надо смотреть в прошлое.
Практический результат: можно поддерживать длинный вход (до 8к в их экспериментах), что хорошо в char-level language modelling. Выбили SOTА (на май 2019 г.) на text8k и enwiki8 да еще и меньше FLOPS понадобилось за счет того, что каждая голова в среднем смотрела всего на 300 символов.
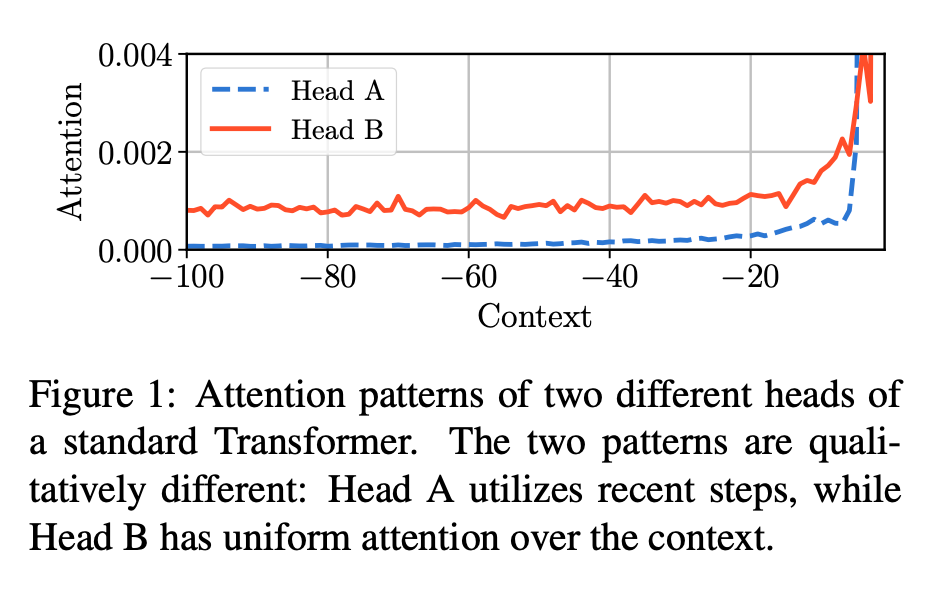
Self-attention heads учитывают контекст – для построения вектора, представляющего некоторый токен t. Проводится простая арифметика (точнее, немного матричных перемножений и софтмакс), суть которой в том, что каждому токену из прошлого “голова” назначит свой вес, с которым соответствующий токен будет учтен при построении представления токена t. Тут считаем, что токены упорядочены и алгоритм смотрит на S шагов назад, то есть до токена t-S (S – по сути размер окна, или длина контекста, для вычисления self-attention). Авторы углядели качественное отличие распределения этих весов для разных голов. На рисунке голова A “смотрит” по сути только в совсем недалекое прошлое, а вот голова B намного больше учитывает прошлое — веса, с которыми учитываются прошлые токены, намного “более равномерны“, чем у головы A.
Отсюда идея – пусть каждая голова (self-attention head) сама будет обучаться тому, насколько далеко в прошлое ей смотреть. То есть этот S, длина контекста, будет не гиперпараметром, а обучаемым параметром.
Чтоб избавиться от гиперпараметра S придется ввести новый гиперпараметр R. Но суть простая: теперь при вычислении представления токена t каждый прочий токен из прошлого будет учитываться с поправленным весом (обозвали это soft-masking):
- вплоть до z шагов в прошлое веса токенов равны 1 и self-attention считается как прежде, без поправок;
- от z до z+R (R мало, около 32) шагов в прошлое веса токенов начинают линейно падать;
- z – выучиваемый параметр, у каждой головы свой;
- R – гиперпараметр, в экспериментах 32.
Чтоб головы не обучились тому, чтоб смотреть в прошлое на миллиард шагов назад, добавляем сумму всех |z| как L1-регуляризацию в функцию потерь трансформера (которая cross-entropy при языковом моделировании).
Для еще большей параметризации сделали z динамическим, зависящим от t через пару обучаемых векторов.
В экспериментах максимальный размер контекста выставлялся очень большим: S = 8192. Но головы выучивались в среднем смотреть всего на 314 токенов в историю (благодаря описанной выше регуляризации).
Гоняли character-wise language modeling на двух датасетах – text8k и enwiki8 – и выбили SOTA с меньшей (в среднем) длиной контекста, необходимого для вычисления self attention и соответственно с меньшим FLOPS. За счет adaptive span ускорение на инференсе – вплоть до 70% FLOPS.
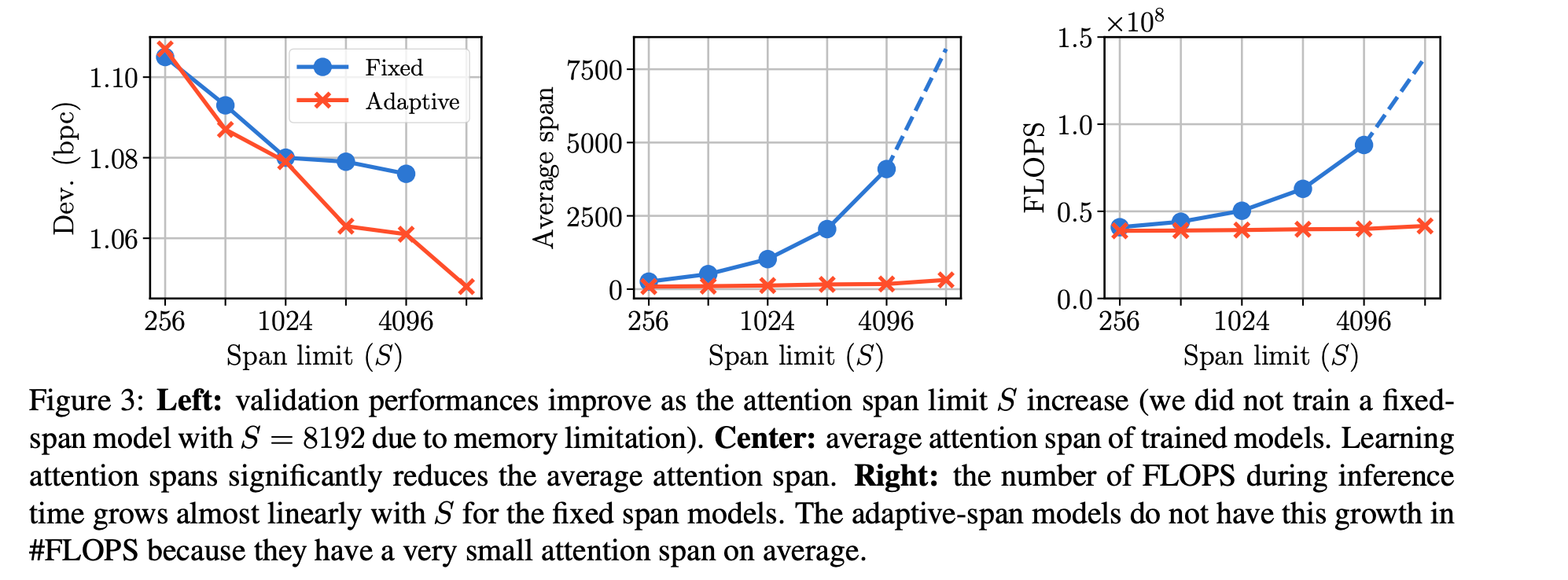
Картинка иллюстрирует все плюсы адаптивного vs. фиксированного размера окна (adaptive span vs. fixed span):
- (слева) лосс падает быстрее при увеличении максимального допустимого окна (span limit по оси иксов);
- (в центре) средний выучиваемый размер окна (который выше был z) несильно растет при росте S и остается малым, до нескольких сотен;
- (справа) то же самое по флопсам.
Вывод следующий – можно смотреть в прошлое всего примерно на 300 знаков и при этом добиваться SOTA в задачах посимвольного языкового моделирования.
От автора обзора осталась пара претензий к статье:
- Куча-куча гиперпараметров, перечисление как инициализировались всевозможные веса, дропауты, коэффициенты регуляризации и т.д. Впечатление, что без дикого grid search не заработало. Хотя кодом поделились, если приложить усилия, можно проверить, заходит ли оно при менее скрупулезном выборе гиперпараметров.
- Почему не обобщили на word-level LM? Значит, не смогли гиперпараметры подобрать.
4. ResNeSt: Split-Attention Networks
Авторы статьи: Hang Zhang, Chongruo Wu, Zhongyue Zhang, Yi Zhu, Zhi Zhang, Haibin Lin, Yue Sun, Tong He, Jonas Mueller, R. Manmatha, Mu Li, Alexander Smola (Amazon, 2020)
Оригинал статьи :: GitHub project
Автор обзора: Андрей Лукьяненко (в слэке artgor, на habr artgor)
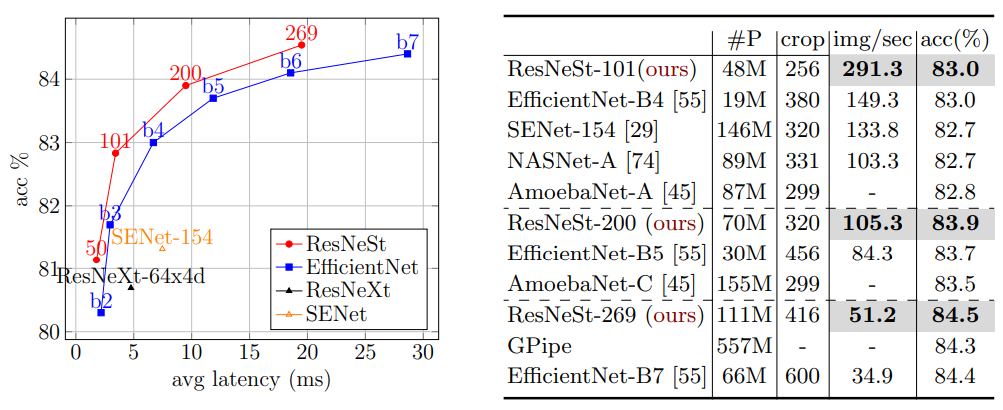
Новая модификация ResNet-архитектур: split-attention блок. Даёт высокое качество на ImageNet (например, ResNeSt-269 тренируется быстрее и чуть лучше, чем EfficientNet-B7). Но, что важнее, хорошо работает в качестве backbone для самых разных задач — например, для segmentation и object detection.
Обоснование исследования
В большинстве задач по работе с изображениями обычно используют ResNet или его варианты в качестве backbone, но эта архитектура была разработана именно для задач классификации, поэтому у неё ограниченный размер receptive field и нет взаимодействия между каналами. А это значит, что приходится применять разнообразные трюки, чтобы модель получше работала на конкретной задаче, такие как: модуль с пирамидой, long-range connections, cross-channel feature-map attention.
Авторы захотели поискать некий универсальный подход к решению этой проблемы. В результате в статье предлагается две новые вещи:
- встраивание feature-map split attention в отдельные блоки, вычислительные затраты не выше, чем у существующих вариантов ResNet, а качество лучше;
- много бенчмарков на больших датасетах по классификации и по transfer learning.
Архитектура блока
Новый блок называется Split-Attention Block. Каждая фича может быть разделена на K (cardinality) feature-map groups. И при этом внутри каждой группы можно сделать дополнительно R (radix) сплитов, таким образом общее число feature groups — G = K * R. К каждой группе можно применить какие-нибудь трансформации.
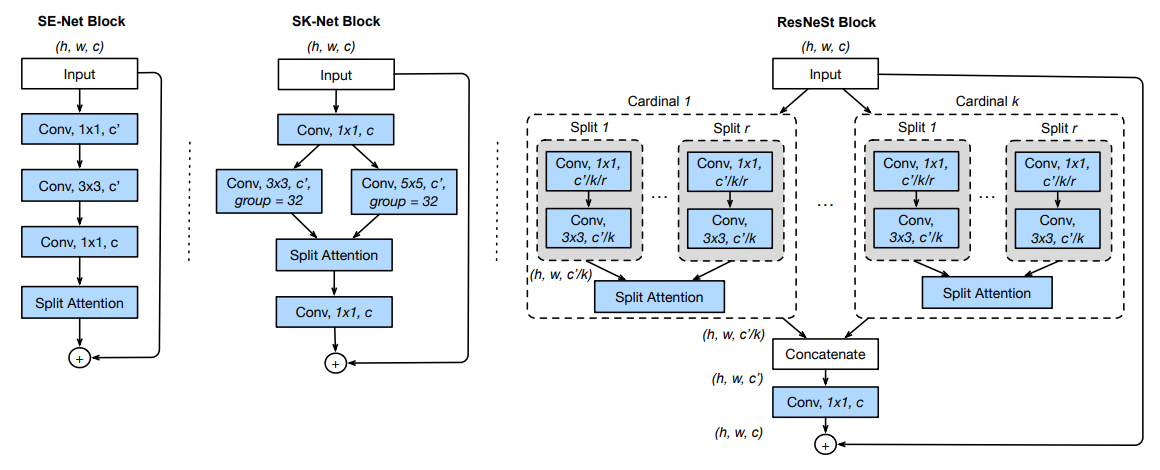
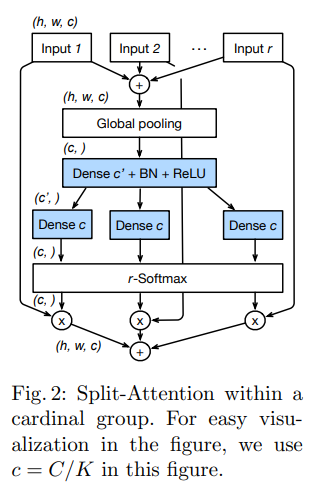
Добавили Split Attention in Cardinal Groups. Для каждой cardinal группы может быть получено объединение, используя поэлементное суммирование вдоль многих сплитов.
ResNeSt Block
После предыдущего шага все кардинальные группы можно сконкатенировать поканально. Финальный output делается как в residual блоках — shortcut connection, если размерность одинаковая, если же нет, то накладывается strided convolution или combined convolution-with-pooling.
Архитектура
- Average Downsampling: заменили strided convolution в transitioning block на average pooling layer с размером 3 × 3.
- Tweaks from ResNet-D: первый слой 7х7 заменили на 3 последовательных 3х3, что дает выигрыш в вычислениях.
- Добавили average pooling 2x2 к shortcut connection перед 1x1 convolution для transitioning blocks with stride of two.
Тренировка: Large Mini-batch Distributed Training
8 серверов по 8 GPU. Линейно скейлят начальную learning rate в зависимости от размера мини-батча. Вначале warm-up, потом cosine scheduler. BN параметр γ инициализируется равным 0 для каждой последней BN операции в каждом блоке. Label Smoothing, Auto Augmentation, Mixup, Large Crop Size (224 и 256), Regularization (dropout, dropblock, weight decay).
Тренировка на ImageNet
С каждым мини-батчем делают следующее:
- трансформации из autoaugment;
- дополнительные трансформации (random size crop, random horizontal flip, color jittering, and changing the lighting);
- нормализация через mean, std;
- mixup.
270 эпох, weight decay 0.0001, momentum 0.9, cosine learning rate schedule with the first 5 epochs reserved for warm-up. Размер мини-батча… 8192 for ResNeSt-50, 4096 for ResNeSt 101, and 2048 for ResNeSt-{200, 269}.
Для подсчета скора делают ресайз к 1/0.875 от размера кропа по короткой стороне и накладывают center crop.Тренировали на mxnet, glouncv.
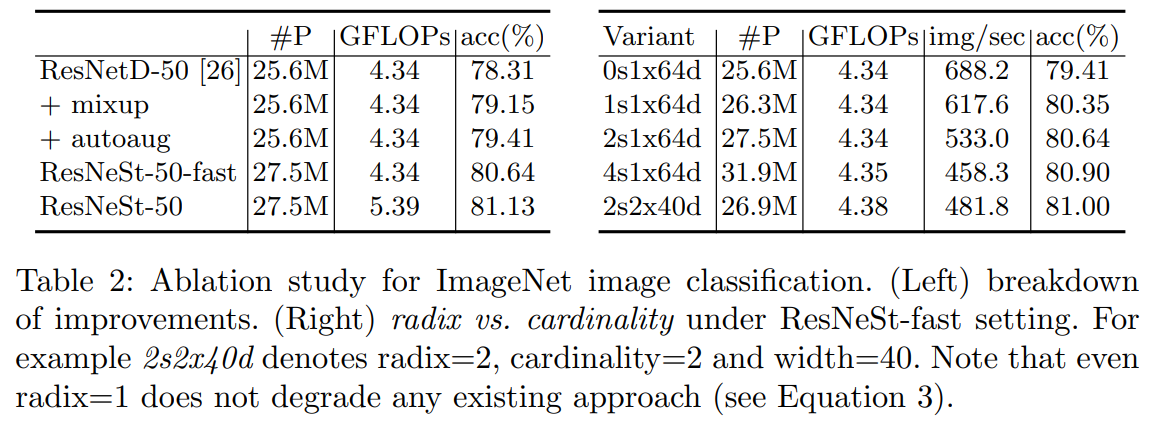
Ablation Study
Отдельно стоит отметить, что увеличение radix с 0 до 4 не только улучшает top-1 accuracy, но ещё и latency, а также memory usage.
5. Weight Standardization
Авторы статьи: Siyuan Qiao, Huiyu Wang, Chenxi Liu, Wei Shen, Alan Yuille (Johns Hopkins University, 2019)
Оригинал статьи :: GitHub project
Автор обзора: Эмиль Закиров (в слэке bonlime)
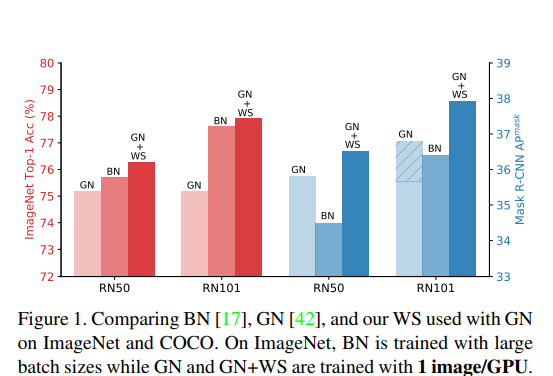
Авторы решают проблему micro-batch training, когда использование BatchNorm (BN) затруднено. GroupNorm в таком случае может служить хорошей альтернативой, но до сих пор он показывал себя хуже чем BN. Утверждается, что BN помогает тем, что сглаживает loss landscape и упрощает оптимизацию. Авторы предлагают другой способ сгладить loss landscape (и приводят теоретические доказательства того, что это действительно уменьшает константу Липшица). Как результат их подход + GroupNorm с BS=1 даёт качество лучше, чем BN + большой BS.
Статья с очень простой идеей и впечатляющими результатами, которая почему-то осталась без особого внимания.
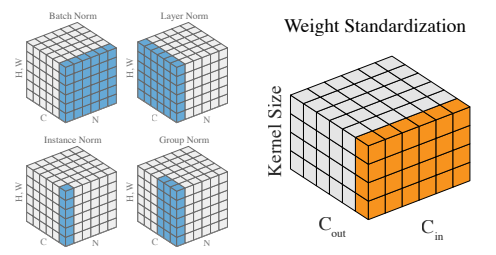
Основная идея: BN стандартизирует активации и как следствие упрощает оптимизацию. А давайте будем стандартизировать еще и веса у слоёв, чтобы еще сильнее упростить оптимизацию.
По сути главные результаты всей статьи: GN < BN < GN + WS < BN + WS. WS cтабильно докидывает.

Попробовали обучить ResNeXt 50 (101) только с GN — получили результаты хуже чем у ResNet 50 (101). А вот если добавить WS, то ResNeXt сразу начинает учиться гораздо лучше. Никаких гипер-параметров не тюнили, используют GN c groups=32.
По результатам сегментации на COCO WS опять стабильно докидывает и позволяет лучше обучать более глубокие сети.
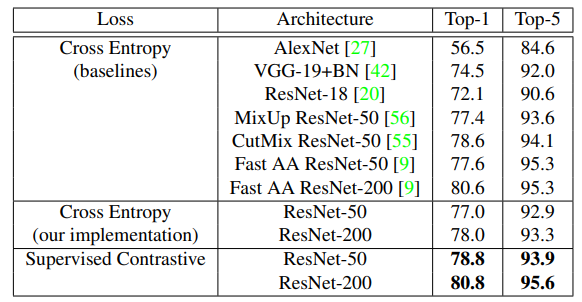
6. Supervised Contrastive Learning
Авторы статьи: Prannay Khosla, Piotr Teterwak, Chen Wang, Aaron Sarna, Yonglong Tian, Phillip Isola, Aaron Maschinot, Ce Liu, Dilip Krishnan (Google Research, MIT, 2020)
Оригинал статьи :: GitHub project
Автор обзора: Андрей Лукьяненко (в слэке artgor, на habr artgor)
Предлагают новый лосс на замену cross-entropy: модифицируют batch contrastive loss. Эмбеддинги одинаковых классов получаются схожими, эмбеддинги разных классов — разными. Ещё используют большой размер батча и нормализованные эмбеддинги.
Модельки получаются крутыми (по сравнению с другими моделями, использующими autoaugment) и робастными. В общем по сути похоже на triplet loss, но в нем не по одной паре позитивных-негативных примеров, а много позитивных и много негативных.
Cross-entropy активно используется в задачах с картинками, но у ней есть ряд известных проблем. Было сделано много попыток для их исправления, такие как label smoothing, self-distillation, mixup и другие.
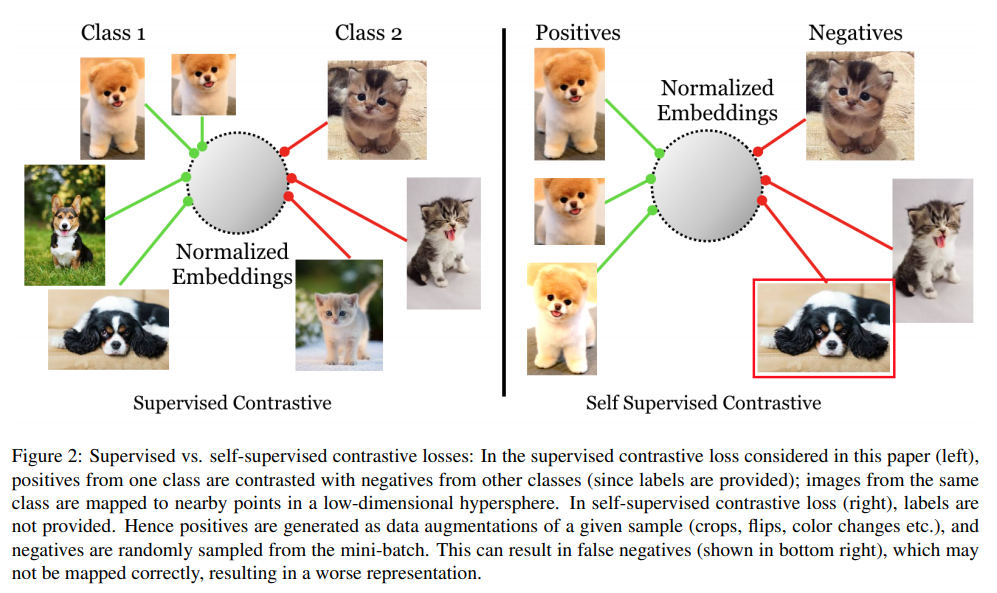
Авторы предлагают новый лосс, основная суть которого заключается в том, что нормализированные эмбеддинги одного класса должны быть ближе друг к другу, чем эмбеддинги разных классов. Этот лосс является по факту продолжением идеи contrastive objective functions, которые хорошо работают в self-supervised learning. Ну и логично, что есть связь с metric learning.
В contrastive лоссах есть две "противоположные силы". Первая "сила" тянет якорь ближе к одним точкам, вторая толкает его подальше от других точек. Первые — позитивные семплы, вторые — негативные. Одно из ключевых новшеств статьи — в том, что у нас будет много позитивных и много негативных семплов на каждый якорь, причём выбираются лучше чем в предыдущих подходах.
Что полезного дает статья:
- вот этот самый лосс;
- демонстрация качества и робастности на Imagenet;
- этот лосс менее чувствительный к значениям гиперпараметров;
- доказывают аналитически, что градиент лосса способствует обучению на hard positive и hard negative;
- показывают, что triplet loss — частный случай предложенного.
Описание подхода
Вначале объясняется суть contrastive learning loss for self-supervised representation learning, а потом рассказывают о том, как его модифицировали.
Representation Learning Framework
Для начала в целом о том, как работают такие подходы:
- data augmentation module. Берем картинку и создаем из неё две аугментированных. Первый шаг такой аугментации — random crop, а затем resize до оригинального размера. Второй шаг — уже сама аугментация, авторы пробуют 3 варианта: autoaugment, randaugment, simaugment (random color distortion + Gaussian blurring + sparse image warp);
- encoder — просто backbone. Авторы брали ResNet-50 и ResNet-200, на выход берем последний pooling, т.е. вектор размером 2048;
- projection network. Берут output энкодера и пропускают через небольшую сеть. В данном случае MLP с одним скрытым слоем, размер выходного слоя — 128. Вектор ещё раз нормализуют для подсчета лосса. Этот MLP используется только для тренировки supervised contrastive loss. После тренировки MLP убирают и заменяют на обычный линейный слой. В результате энкодер дает более хорошие результаты на downstream задачах.
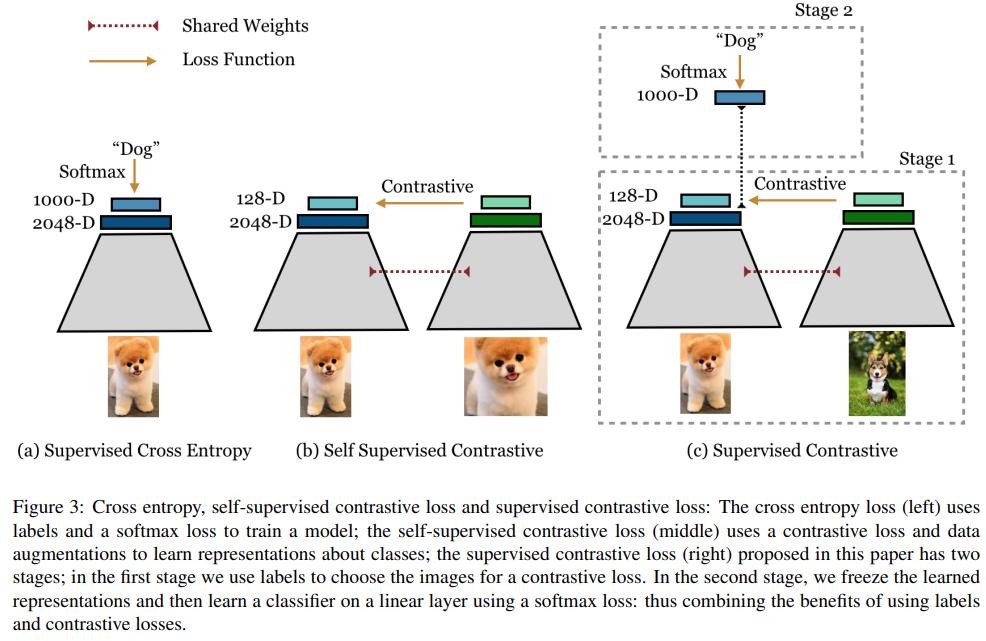
Contrastive Losses: Self-Supervised and Supervised
В целом подход заключается в том, что из каждого батча данных генерируется два новых — с разными аугментациями.
Self-Supervised Contrastive Loss
Пусть i — индекс аугментированной картинки, j(i) — индекс второй аугментированной картинки, при условии, что они были сгенерированы из одной картинки.
Лосс выглядит следующим образом. По факту у нас i — якорь, j(i) — позитивный семпл, а картинки с другими индексами — негативные семплы. Получается, что на каждый якорь у нас 1 позитивный семпл и 2N-2 негативных.

Supervised Contrastive Loss
Мы хотим изменить лосс так, чтобы он мог работать с несколькими позитивными кейсами.Теперь в числителе не только аугментированные картинки из одной оригинальной, но и картинки с таким же классом. И теперь выученные эмбеддинги сближают картинки одинаковых классов.

В работе показано, что:
- градиенты данного подхода обеспечивают фокусировку модели на сложных примерах, а не на легких;
- демонстрируется связь с триплет лоссом.
Эксперименты
Показывают качество на ImageNet и робастность к разным вариантам искажений изображений.
Effect of Number of Positives
Показывают, что увеличение количества позитивных семплов реально помогает.
Тренировка
Вначале 700 эпох тренировки с supervised contrastive loss. Но, как утверждают авторы, можно и "всего лишь" 350 — разница минимальна. Тренируется на 50% медленнее, чем просто cross entropy. Используют LARS оптимизатор. Тренировали с размером батча 8192, но пишут, что можно и 2048. Размер батча реально важен, ибо позволяет создать больше позитивных и негативных семплов. Ещё они используют температуру как гиперпараметр.
7. Improved Training Speed, Accuracy, and Data Utilization Through Loss Function Optimization
Авторы статьи: Santiago Gonzalez, Risto Miikkulainen (USA, 2019)
Оригинал статьи
Автор обзора: Денис Воротынцев (в слэке tEarth, на habr tEarth)
Итак, мы уже умеем оптимизировать гиперпараметры и архитектуру сетки через NAS, оптимизировать вес примеров через active learning и подбирать наиболее хорошие аугментации через autoaugment. Не так много параметров в пайплайне остались не оптимизированными и поэтому авторы статьи задаются вопросом, можем ли мы оптимизировать лосс для минимизации лосса? В качестве примера оптимизации лосса можно привести L1 или L2 регуляризации, которые помогают бороться с переобучением моделей.
Авторы в статье описывают Genetic Loss-function Optimization (GLO) стратегию оптимизации лосса — обычный генетический алгоритм оптимизации:
Задаем пространство поиска новых лоссов.
Unary Operators: log(◦), ◦2, √◦
Binary Operators: +, ∗, −, ÷
Leaf Nodes: x, y, 1, −1, где x — ground truth label, y — предсказание.
Пример нового лосса: log(y) + x/y
Семплим новые лоссы (популяция=80), обучаем сеть, смотрим целевую метрику на валидационном датасете (в данной задаче в качестве целевого лосса использовался logloss).
Оставляем fittest кандидатов, мутируем, рекомбинируем, переобучаем.
Авторы использовали два датасета — MNIST и CIFAR-10, обучали простую AlexNet сетку. Авторам удалось найти два интересных лосса — Байкал и Байкал CMA. Оба лосса показали хорошие показатели на валидационном сете, и точность на отложенной выборке выше, чем при обучении с бейзлайн лоссом (logloss). Авторы исследовали полученные лоссы и пришли к выводу, что скорее всего, прирост точности получился из-за неявной регуляризации.

Лосс Байкал CMA отличается от представленного выше наличием дополнительных 6 коэффициентов.
8. TTNet: Real-time temporal and spatial video analysis of table tennis
Авторы статьи: Roman Voeikov, Nikolay Falaleev, Ruslan Baikulov (OSAI, 2020)
Оригинал статьи :: Dataset
Автор обзора: Роман Воейков (в слэке sparkling_brick)
В статье описывается архитектура сети и подход для решения трёх CV задач в видео анализе настольного тенниса: детекции событий, семантической сегментации и детекции мяча. Главным образом это инженерная статья, в которой демонстрируется, что можно добиться хорошей точности в мультитаск-подходе и при этом работать очень быстро (в 120 fps).
Проблема
Хотелось бы иметь одну систему, которая решает основные задачи аналитики для данного спорта, а как задача-максимум генерирует столько данных, чтобы понимать состояние игры и вести счёт без участия живого судьи. Для этого нужна информация об игровых событиях (отскоки от стола и попадания в сетку), координаты мяча и положение стола и игроков. При этом мяч в настольном теннисе порой летает со скоростью более 100 км/ч, поэтому на вход имеем видео в 120 fps и хотим обрабатывать его в реальном времени.
Архитектура
Для того, чтобы добиться быстрой работы сделали сеть с общим feature extractor’ом и 3-мя выходами под каждую из задач: object detection, semantic segmentation и event spotting (action recognition). В качестве бэкбона использовали VGG-like энкодер.
Для первой задачи после энкодера и пары фулл-конектед слоёв предсказываются вектора вероятностей координат мяча по каждой оси (x и y) и определяются грубые координаты, вокруг которых делается кроп из оригинальной стопки full HD изображений и подаётся во второй аналогичный feature extractor, откуда предсказываются уточнённые координаты мяча.
Для задачи семантической сегментации применяется стандартный Unet подход — фичи из энкодера разворачиваются в декодере с использованием skip-connections.
Далее самая главная задача — детекция событий (по этой причине на вход подаётся не одна картинка а последовательная стопка кадров, которая содержит также и временнУю информацию). Фичи из основного энкодера и энкодера, отработавшего на кропе из картинок с высоким разрешением, конкатинируются прогоняются через несколько свёрток и фулл-конектедов и в итоге получаются вероятности событий.
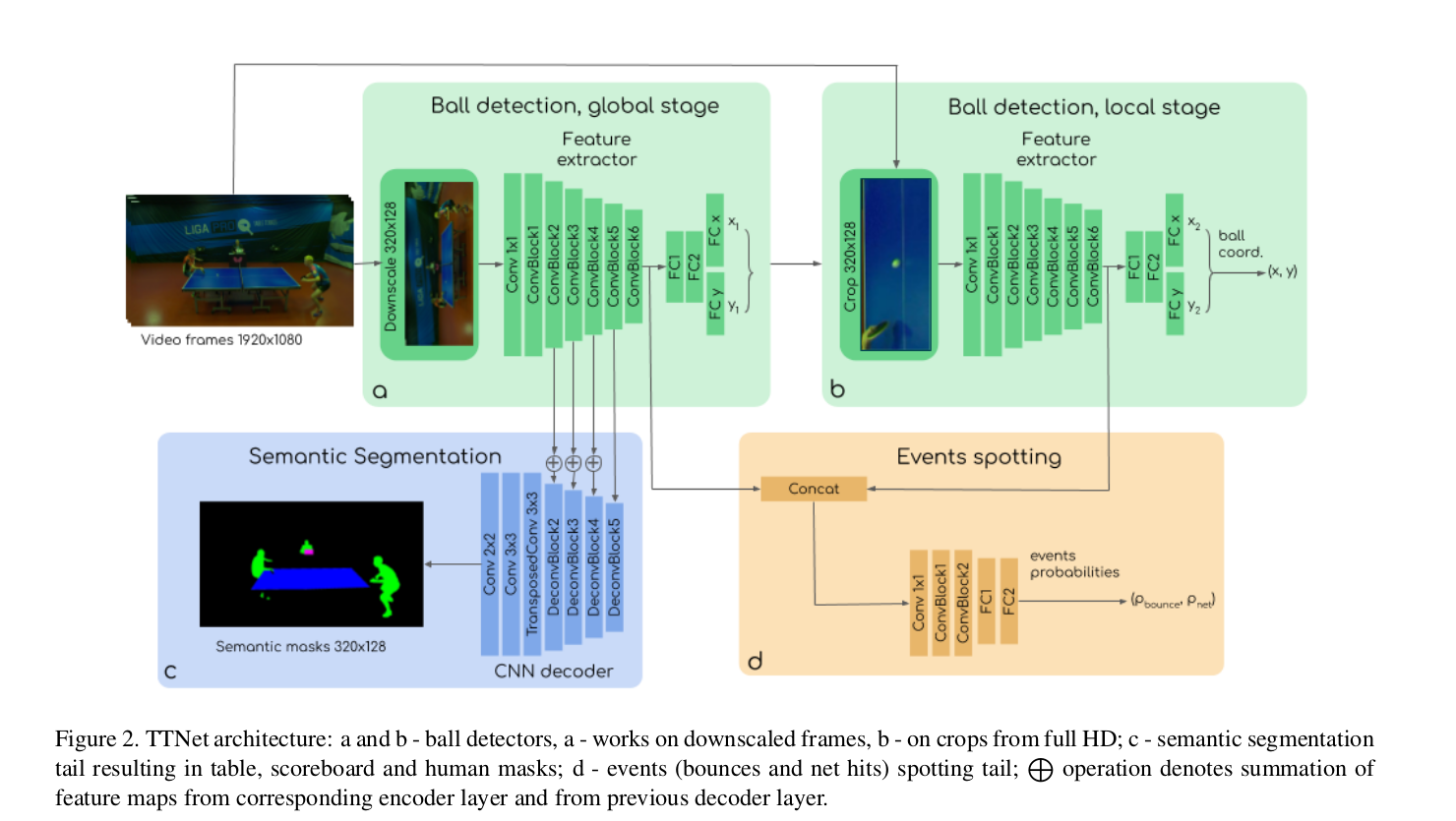
Особенности
По сути, для анализа временных событий используются не 3D свёртки, а обычные 2D над стакнутыми кадрами. Как показала практика (в experiments не вошло), модель с обычными свёртками демонстрирует такую же точность для наших применений.
Для детекции координат мяча таргет строится таким образом, что по каждой оси конструируется гауссиана вероятностей с центром там, где ground truth координаты.
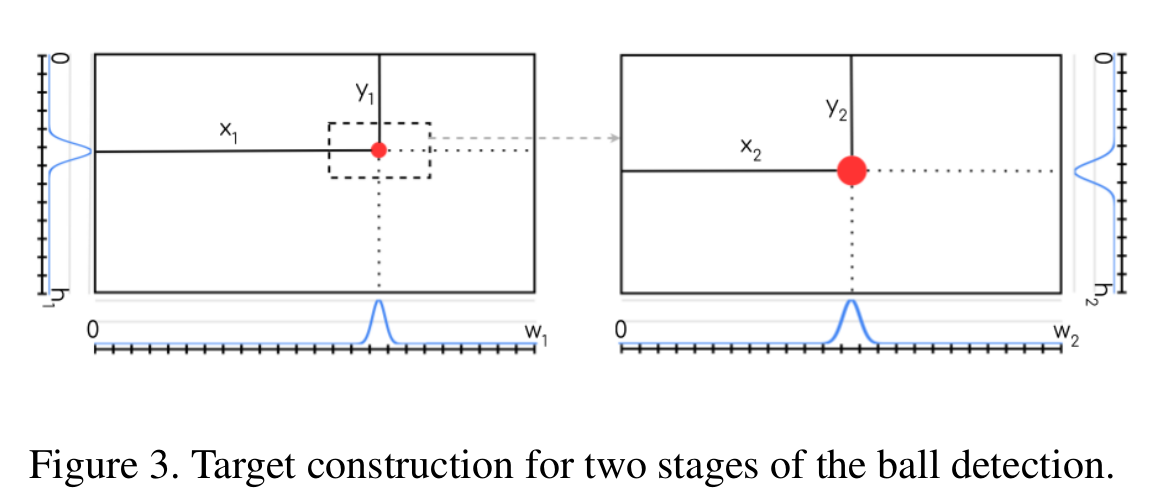
Лоссы
В качестве лоссов для сегментации использовался DICE + BCE, для предсказания гауссиан координат BCE и кросс-энтропия для вероятностей событий. Веса каждого лосса являлись оптимизируемым параметром в ходе обучения для автобалансировки.
Вход
Входной тензор — это стопка из 9 последовательных кадров. Временной таргет — событие происходит на 5-м кадре, а координаты мяча и маски нужно предсказать для последнего, 9-го кадра. Для того, чтобы сеть выучила гауссово распределение вероятности для обучения используются также стопки кадров, сдвинутые относительно кадра с событием вперёд и назад.
Результаты
В результате получилось сделать сетку, которая работает в 120 fps и на каждом кадре находит мяч с точностью 97.5% и среднеквадратичной ошибкой в 2 пикселя, предсказывает игровые события с точностью в 97%, а также предсказывает маски людей, стола и табло. Все результаты получены на совместно публикуемом датасете, так как под такую специфическую задачу не было представлено открытых данных.
9. Learning in the Frequency Domain
Авторы статьи: Kai Xu, Minghai Qin, Fei Sun, Yuhao Wang, Yen-Kuang Chen, Fengbo Ren (Alibaba, Arizona, 2020)
Оригинал статьи :: GitHub project
Автор обзора: Вадим Петров (в слэке graviton, на habr belgraviton)
Коротко
Переход из пространственного или временного представления данных в частотное (например, преобразование Фурье) используется в большом количестве приложений в науке и технике.
Данный переход позволяет избежать затратных вычислений:
- например, свертка с очень большим ядром заменяется на простое умножение в частотном пространстве;
- идеи также используются для сжатия изображений в JPEG файлы, где сохраняется низкочастотная составляющая снимков, которая важна для человеческого восприятия.
В работе предложен способ замены входного блока в нейронную сеть с применением этих же идей. Давайте переведем изображение в частотное представление и выбросим неинформативные каналы. И при этом за счет этого шага можно решить сразу несколько задач:
- сжатие высоты и ширины снимка (появляется возможность подачи на вход сети большИх изображений, не нужны MaxPooling в первых слоях сети);
- генерация большОго числа входных каналов (каналы соответствуют частотам), не нужен конволюционный слой (3->64) в первых слоях сети;
- так как количество каналов можно сокращать, можно добиться ускорения работы и всей сети (за счет уменьшения числа каналов) и только скорости загрузки данных на ГПУ.
Предшествующие подходы
- коэффициенты преобразования Фурье и косинусного преобразования используются издавна в классических подходах к компьютерному зрению в качестве фич;
- уже существуют работы предлагающие использовать частотные характеристики для нейронных сетей, но текущий подход предлагает их в обобщенном виде, что позволяет их использовать на более широком круге задач, что продемонстрировано в статье.
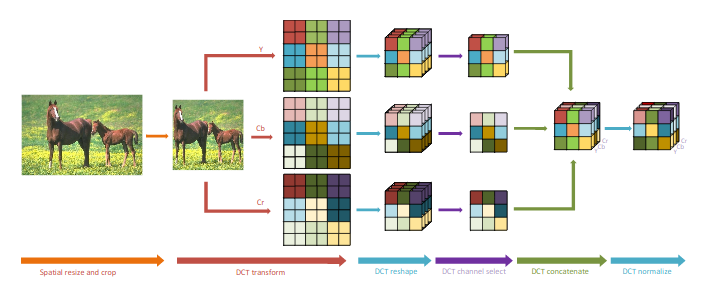
Предложенный препроцессинг изображения
Многие шаги препроцессинга взяты из JPEG.
- Входное RGB изображение преобразуется в YCbCr формат (Y — яркость, Cb и Cr — синяя и красная компоненты).
- Изображение разбивается на блоки 8х8, которые подвергаются косинусному преобразованию. В результате каждый блок 8х8 содержит уже не пространственную информацию, а частотную.
- Каждый блок 8х8, содержащий 64 компоненты амплитуд частот, трансформируется в 64 канала ("DCT reshape" на рисунке). Таким образом, высота и ширина уменьшается в 8 раз, а количество каналов увеличивается в 64 раза. Т.к. исходно было 3 канала, то всего получается 192 канала.
- Однако, из полученных каналов не все обладают хорошей информативностью. Часть каналов может быть удалена. Продемонстрирована возможность удаления 85% каналов без существенной потери точности.
- Полученные данные размера (H/8, W/8, 64C или XС при урезании каналов) можно подавать на вход стандартных блоков нейронной сети без применения MaxPooling и других сжимающих операций.
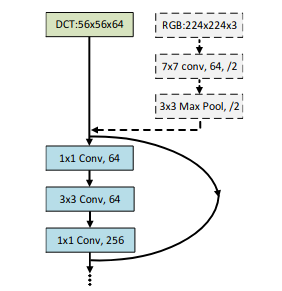
Выбор лучших каналов
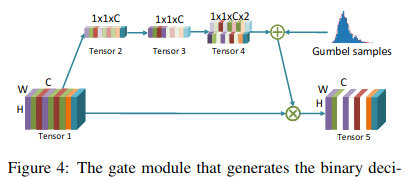
- Предложен динамический подход, обеспечивающий выбор лучших каналов динамически во время обучения с помощью gate-блока, похожего на SE-блок. Отличие состоит в том, что каналы не взвешиваются, как в SE-блоке, а включаются или исключаются полностью.
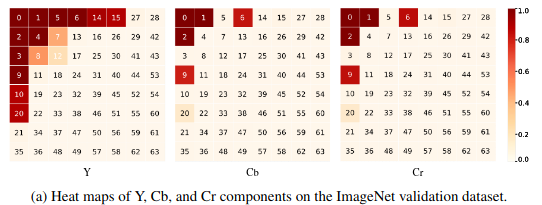
- Также возможен статический подход, в котором строятся heat maps для активации частотных каналов на наборе данных. По рисунку с хитмапами видно, что более низкочастотные компоненты используются чаще. Следует заметить, что указанные компоненты играют ключевую роль и для человеческого восприятия изображений.
Эксперименты
Для задач классификации (ImageNet), детекции и сегментации (COCO) подход позволяет добится улучшения в среднем в 1% за счет возможности использования входного (3-х канального) изображения большего размера. При этом существует возможность использования меньшего количества каналов при небольшом ухудшении точности.