
Однажды я наткнулся на интерактивную карту lastfm и решил обязательно сделать подобный проект для фильмов. Под катом история о том, как собрать данные, построить граф и создать своё интерактивное демо на примере данных с кинопоиска и imdb. Мы рассмотрим фреймворк для скрапинга Scrapy, пробежимся по методам визуализации больших графов и разберёмся с инструментами для интерактивного отображения больших графов в браузере.
1. Сбор данных: Scrapy
В качестве источника данных я выбрал кинопоиск. Однако, потом оказалось, что этого очень мало и я соскрапил IMDb. Чтобы составить граф, для каждого фильма нужно знать список рекомендуемых фильмов. Если поискать, то можно найти достаточно парсеров кинопоиска и всевозможных неофициальных api, но нигде нет возможности достать рекомендации. IMDb открыто делится своим датасетом, но и там рекомендаций нет. Поэтому выбор остаётся только один: писать своего паука.
На хабре уже есть несколько статей о скрапинге, поэтому я пропущу обзор возможных подходов. В двух словах: если вы пишете на python и не хотите писать свой фреймворк, используйте Scrapy. Практически всё, что вам может понадобиться, в нём уже предусмотрено.
Scrapy действительно очень мощный и в то же время очень простой инструмент. Порог входа довольно низкий, но в то же время Scrapy легко масштабируется на проекты любого объёма и сложности. В нём действительно собрано всё что нужно. От инструментов непосредственно парсинга и HTTP запросов, обработки и сохранения полученных элементов, до управления работой проекта, включая способы обхода блока, паузы и возобновления скрапинга и т. д.
Создание проекта начинается с команды scrapy startproject mycoolproject, после чего вы получаете готовую структуру с шаблонами необходимых элементов и файлы минимальной рабочей конфигурации. Чтобы сделать из этого рабочий проект достаточно описать способ парсинга страницы — то есть создать паука и положить его в папку spiders внутри проекта, и описать какую именно информацию вы хотите извлечь — то есть унаследовать свой класс от класса scrapy.item в скрипте items.py. Таким образом можно сделать полностью рабочий проект меньше чем за час. Для сохранения результатов есть встроенные средства: например запись в csv или json, но лучше всё-таки использовать внешнюю БД, если проект не на пять минут. Поведение связанное с обработкой результатов, включая сохранение задаётся в pipelines.py. Остаётся последний важный файл — settings.py назначение которого понятно из названия. Здесь можно задать конфигурацию проекта связанную например с использованием прокси, таймингом между запросами и многим другим.
И так, по шагам:
- Смотрим в статьях раз, два и в документации как создавать проект для Scrapy. По аналогии создаём свой класс для items.
import scrapy
class MovieItem(scrapy.Item):
'''Movie scraped info'''
movie_id = scrapy.Field()
name = scrapy.Field()
like = scrapy.Field()
genre = scrapy.Field()
date = scrapy.Field()
country = scrapy.Field()
director = scrapy.Field()- Ищем нужные нам элементы на странице и достаём их xpath. Это можно сделать например через chrome: щёлкаем правой кнопкой мыши на элемент, выбираем inspect element, в коде снова щёлкаем правой кнопкой мыши, и ищем пункт copy -> xpath. Для отладки можно запустить scrapy-shell и передать в него url страницы:
scrapy-shell https://www.kinopoisk.ru/film/518214/. У вас будет инстанциирован объект response, из которого можно будет получать нужные элементы.
$scrapy-shell https://www.kinopoisk.ru/film/sakhar-i-korica-1915-201125/
$response.xpath('//span[@itemprop="director"]/a/span/text()').extract_first()
'Эрнст Любич'- Настраиваем обработку полученных объектов. Я выбрал для сохранения запись в базу sqlite, потому что это очень просто.
- Проверяем что всё работает, выставив при запуске параметр
CLOSESPIDER_PAGECOUNT=5, чтобы ограничить число запросов. - В бой! Создаём директорию для сохранения промежуточных результатов, например
crawls1. Запускаем паука с параметромscrapy crawl myspider -s JOBDIR=crawls1: теперь, если что-то пойдёт не так, мы сможем перезапустить паука с того же места, где он закончил. Соответствующий раздел в документации.
1.1 Обход ограничения на число запросов.
Кинопоиск забанил меня ещё на этапе отладки паука, когда я отправлял раз в несколько минут пачку из 5-ти запросов с таймаутом в 1 секунду. Чтобы обойти ограничания существует множество опций. Для скрапи легко нагугливаются готовые примеры использования тора, случайного перебора прокси из списка, либо подключения к платным сервисам rotating proxy. Так как у нас ”проект выходного дня”, я выбрал rotating proxy — самый быстрый в реализации вариант, правда приходится подключаться к платному сервису. Как это работает: вы подключаетесь к конкретному ip:port вашего провайдера прокси, а на выходе получаете новый ip на каждый запрос. Со стороны scrapy вам нужно добавить одну строку в файле settings.py своего проекта и в каждом запросе передавать параметр для пары ip:port.
Ищем в settings.py соответствующий раздел и добавляем туда строчку:
DOWNLOADER_MIDDLEWARES = {
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware':543
}Затем в каждом запросе вашего паука:
scrapy.Request(url=url, callback=self.parse,
meta={'proxy':'http://YOU_RPROXY_IP:PORT'})Автор вдохновившего меня проекта начал с Nightwish и дальше обходил рекомендации lastfm в ширину, как дерево — поэтому у него получился связный граф. Мой подход был похожим. С кинопоиска можно доставать фильмы по id, который судя по всему просто соответствует порядковому номеру фильма на сайте. Если просто брать все id подрят, то выйдет не очень хорошо, потому что большинство фильмов не имеют рекомендаций и будут одиночными точками, которые превратятся в шум на карте. ID свежих фильмов имеют порядок 500000 — это довольно много для наглядной отрисовки, поэтому начнём со списка топ 250 фильмов и будем итеративно обходить списки рекомендаций каждого фильма.
Я ожидал получить порядка 100 000 фильмов, но к после ночи скрапинга оказалось, что паук остановился на ~12600. Рекомендации в кинопоиске на этом кончаются. Как было упомянуто вначале, за новыми данными я полез на IMDb. Скрапинг IMDb оказался ещё проще. Пара часов на переписывание готового проекта и новый паук готов к старту. Через два-три дня кроулинга (8 запросов в секунду, чтобы не наглеть) паук остановился, собрав 173+ тысячи фильмов. Полный код пауков можно посмотреть на гитхабе: кинопоиск и IMDb.
2. Визуализация
С одной стороны, инструментов визуализации графов целый зоопарк. С другой стороны, когда у речь идёт об очень больших графах, этот зоопарк вдруг куда-то разбегается. Я выбрал для себя два инструмента на такие случаи: это sfdp из graphviz и gephi. SFDP — это CLI утилита с широким набором параметров, способен отрисовывать графы на миллион узлов, но в нашем случае — это не самый удобный инструмент, потому что нам нужно контролировать процесс укладки. Для случаев вроде нашего отлично подходит Gephi — это приложение с графическим интерфейсом и универсальным набором укладок, практически на любой вкус.
Экспорт данных для графа делаем простым скриптом на python. Я обычно использую формат dot, потому что он очень простой, что называется "human readable". Изначально формат предназначен для использования в graphviz, но сейчас поддерживается многими другими приложениями для работы с графами.
Описание формата
В начале мы пишем заголовок digraph kinopoisk {\n и не забываем в конце файла записать закрывающую скобку }. В каждой строке описываем рёбра графа node1 -> node2; и закрываем список. Описание формата здесь: официальные доки и простые примеры в википедии.
digraph sample {
1 -> 2;
1 -> 3;
5 -> 4 [weight="5"];
4 [shape="circle"];
}digraph — значит, что мы объявляем направленный граф. Если нужен не направленный, то пишем просто graph. sample — это имя нашего графа (не обязательно). В каждой строке обявлены рёбра или вершины. Если рёбра не направленные, то вместо -> пишем --. В квадратных скобках можно объявить параметры ребра или вершины. В этом примере мы задаём ребру между узлами 5 и 4 вес равный пяти, а вершине 4 форму круга. Имена вершин не обязательно обозначать числами, это могут быть и строки. Больше примеров и параметров смотрите в документации. В нашем случае вполне достаточно возможностей описанных выше.
2.1 Сравнение укладок
Для больших графов в gephi есть две разумные опции: OpenOrd и ForceAtlas 2. OpenOrd — очень быстрый приближённый алгоритм, но имеет мало настраиваемых параметров. ForceAtlas похож на другие классические force-directed алгоритмы, даёт более точные результаты, очень гибкий в настройке, но за это приходится платить временем. Ниже примеры работы обоих алгоритмов на графе, представляющем собой сетку.


Модельный граф-сетка. Слева OpenOrd, справа ForceAtlas.
Можно подумать, что OpenOrd вообще не стоит использовать если есть время ждать более точный результат. На самом деле не редки случаи графов, когда ForceAtlas собирает все узлы в один плотный комок, а OpenOrd показывает хоть какую-нибудь структуру.
Для ускорения процесса я использовал OpenOrd в качестве начального приближения и затем "размазывал" граф с помощью ForceAtlas. Чтобы на изображении было хоть что-то понятно, нужно устранить наложение узлов друг на друга. Для этого удобно использовать укладку Yifan Hu — чтобы немного размазать кластера, и noverlap, чтобы совсем устранить наложение. На устранение наложения в графе кинопоиска ушла ночь, с imdb не удалось справиться и за целые выходные.


3. Экспорт результатов: Интерактивная карта
Gephi умеет экспортировать картинки в svg, png и много других форматов. Но с большими данными приходят большие сложности. Одной только красивой картинки мало. Мы хотим видеть названия фильмов и как они связаны. Если рисовать метки узлов, то при таком их количестве мы получим совершенно нечитаемое облоко букв. Есть опции использовать SVG и масштабировать его пока не станет что-то видно, или рисовать только самые важные метки. Но есть вариант лучше, на котором я и решил сосредоточиться. Делаем интерактивную карту.
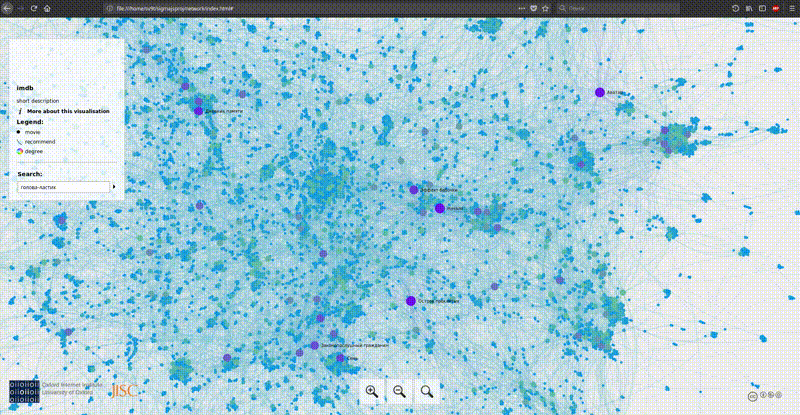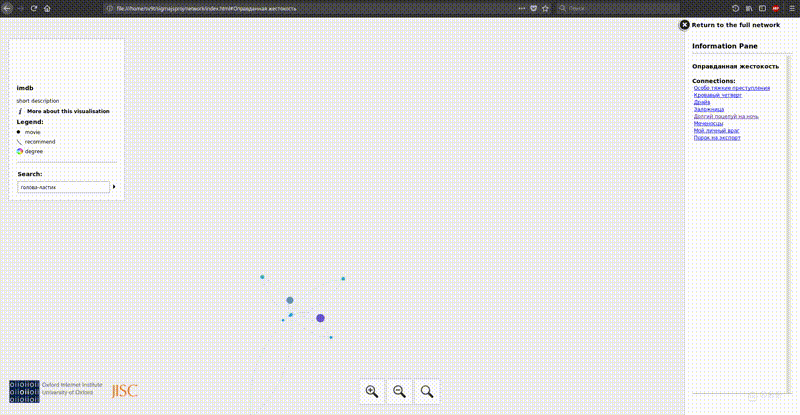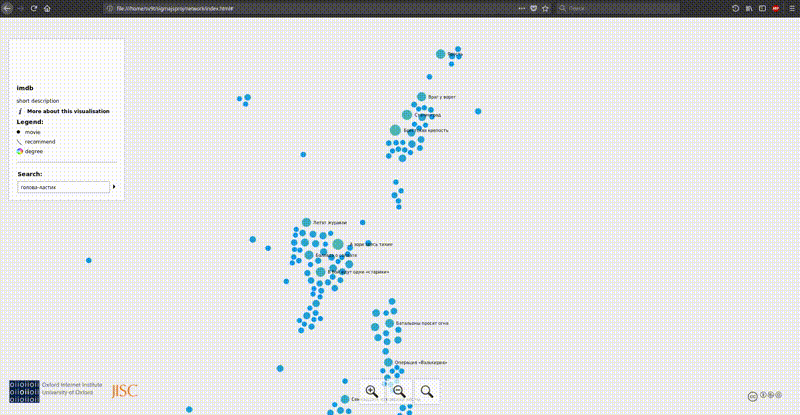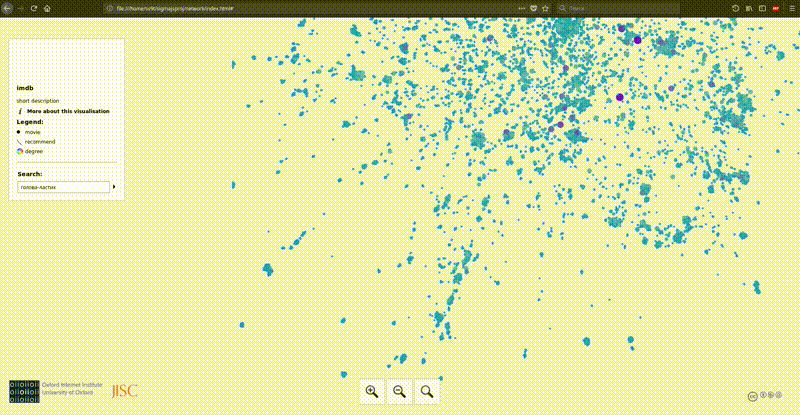
Обзор инструментов:
sigma.js
Первая опция, одна из самых простых и в то же время самая наглядная — это плагин для gephi с экспортом в sigma.js шаблон. На гифке выше как раз оно. Устанавливаем плагин через меню gephi, после чего у нас появляется новый пункт меню экспорта во вкладке file. Заполняем форму, экспортируем и получаем готовую рабочую визуализацию. Просто и мощно. Результат можно посмотреть здесь. Недостаток: на больших графах браузер едва справляется.
gefx-js
Следующая опция ещё проще предыдущей и в целом очень похожа. gefx-js — нужно просто экспортировать ваш проект из gephi в формат gexf и положить в папку с шаблоном. Готово. Недостаток точно такой же как в предудщем случае. Более того, если с помощью sigmajs я мог просмотривать граф imdb хотя бы локально, то с gefx-js он просто не загрузился.
openseadragon
Для случаев, когда нужно показать очень большую картинку есть seadragon. Принцип точно такой же как при рендеринге географических карт: при масштабировании подгружаются новые тайлы, соответствующие текущему увеличению и области просмотра. Именно так и сделал автор вдохновившего меня проекта. Недостаток один: интерактивности минимум. Невозможно выделить узлы, сложно увидеть куда идут рёбра. Невозможно "заглянуть за" перекрытия узлов и рёбер.
shinglejs
А что, если сделать что-то вроде смеси предыдущих вариантов, чтобы при масштабировании граф подгружался тайлами, но не картинками, а как в первом случае, с интерактивностью узлов и рёбер? Готовое решение нашлось буквально чудом, это shinglejs.
Плюсы: можно рендерить очень (очень-очень) большие графы в браузере, сохраняя интерактивность.
Минусы: Не так красиво, как sigmajs, подготовка данных не тривиальна.

Не так красиво, зато очень шустро
Для визуализации графа imdb я выбрал последний вариант. Выбора в общем-то и не было. Результат можно посмотреть здесь, а дальше немного о том, как подготовить данные для такой визуализации.
Экспорт данных в shinglejs:
Как я уже сказал, экспорт данных в последнем случае не очень простой, поэтому я приведу пример, как выгрузить граф из gephi для shinglejs.
- Экспортируем граф из gephi в формате gdf — это наверное единственный простой способ получить коордианты узлов в виде таблицы. Структура файла такая: сначала идёт таблица с описанием узлов, затем таблица с описанием рёбер.
- Читаем файл и достаём из него описание вершин и рёбер. Я делал это с помощью pandas, затем рубил датафрейм на два: рёбра и узлы. О работе с pandas.
- Меняем названия колонок в соответствии с доками shinglejs и экспортируем в json. Shinglejs не поддерживает прямого экспорта цветов, зато для каждого узла можно указать "communities" и раскрасить уже их. Поэтому рейтинги фильмов выгружаем как метки сообществ.
- В исходниках главной страницы не забудьте указать список цветов для сообществ. Для окрашивания узла из списка цветов берётся элемент с номером который вычисляется так:
id сообщества % количество цветов. - Склеиваем файлы в один. Я делал это через bash:
cat start imdbnodes.json middle imdbedges.json end > imdbdata.json, предварительно создав файлыstart, middle, stopсодержанием "{"nodes":", ", "relations":" и "}" соответственно. - Далее по инструкции с оф. сайта
- Не забудьте создать bitmap и положить его в папку с данными графа, иначе на большом отдалении будет видно только несколько узлов или вообще ничего. Автор проекта, кажется, не указал эту деталь, но по умолчанию пример будет пытаться подгрузить файлы
image_2400.jpgиimage_1200.jpg, а не npm как может показаться после сборки дефолтного проекта.
4. Интересные наблюдения
На графе lastfm есть явная кластеризация связанная со странами происхождения музыкальных коллективов, например японский поп и рок, греческий метал и т. д. В точности то же самое происходит с фильмами. Очень чётко отделяется корейское кино, турецкое, японское и бразильское. В imdb далеко от основной массы выделяется большой кластер мультфильмов. На обоих графах очень плотно собирается кластер фильмов о супергероях из комиксов. Вроде бы очевидно, но тем не менее неожиданно, что плохие фильмы собираются в одно большое облако. Есть отдельные кластера музыкальных клипов, детских youtube-блогов и фанатских фильмов по вселенной Гарри Поттера.
5. Что ещё можно делать с этими данными
Я уверен, что читатели смогут придумать и сделать на полученных данных ещё много интересных проектов. Мне в голову сразу приходят такие идеи:
- Кластеризовать и составлять тематические подборки. У меня отлично отработал DBSCAN почти с первого захода. (Пример будет дальше)
- Делать собственные рекомендательные системы
- Собирать интересные статистики о фильмах в целом
- Конечно же, расширять свою фильмотеку.
5.1 DBSCAN
Для кластеризации графов есть много специальных методов, и все они достойны отдельных статей. Я в качестве эксперимента использовал метод для графов не предназначенный. Рассуждения были такими: раз визуально граф разложился на облака похожих фильмов, то области где фильмы особенно плотно сблизились можно найти с помощью DBSCAN. Давайте разберёмся, что этот метод делает, не вдаваясь в глубокие подробности. Название DBSCAN расшифровывается как density-based scan, то есть применяя этот метод, мы объединяем точки, которые расположены друг к другу достаточно плотно. Формализуется это через два основных гиперпараметра — это радиус, в котором мы ищем соседей для каждой точки и минимальное число соседей.
1. Получаем координаты.
Для этого экспортируем наш граф из gephi в формате gdf. Читаем файл как csv с помощью pandas:
data = pd.read_csv('./kinopoisk.gdf')
# gdf содержит как-бы два файла в одном
# сначала описание вершин, а потом описание рёбер
# pandas читает это как целый файл, а недостающие поля в конце
# заполняет как nan поэтому можно достать информацию о вершинах например вот так
data_nodes = data[data['y DOUBLE'].apply(lambda x: not np.isnan(x))]Давайте теперь нарисуем и посмотрим, на что это похоже.
plt.figure(figsize=(7, 7))
plt.scatter(data['x DOUBLE'].values, data['y DOUBLE'].values, marker='.', alpha=0.3);
Отлично, DBSCAN с таким должен справиться.
2. Кластеризуем.
Подбираем параметры и смотрим на распределение размеров кластеров. Никакой серьёзной работы не планировалось, поэтому качество я оценивал "на глаз".
from sklearn.cluster import DBSCAN
coords = data_nodes[['x DOUBLE', 'y DOUBLE']].values
dbscan = DBSCAN(eps=70, min_samples=5, leaf_size=30, n_jobs=-1)
labels = dbscan.fit_predict(coords)
plt.hist(labels, bins=50);
Распределение по размерам кластеров
Давайте раскрасим наши точки в цвета кластеров и посмотрим насколько результат похож на правду.
plt.figure(figsize=(8, 8))
for l in set(labels):
coordsm = coords[labels == l]
plt.scatter(coordsm[:,0], coordsm[:,1], marker='.', alpha=0.3);
Выглядит как то, что мы и хотели получить.
Попробуем получить кластер какого-нибудь фильма в виде списка. Я не позаботился о том, чтобы сделать удобный способ получения списка, поэтому в этот раз без кода. Ниже список фильмов, который попали в один кластер с "реальными упырями". По-моему неплохо.
| movie_id | name | date | genre | country | director |
|---|---|---|---|---|---|
| 271695 | Третья планета от Солнца | 1996-01-09 | фантастика | США | Терри Хьюз |
| 663135 | Соседи | 2012-09-26 | комедия | США | Крис Кох |
| 277375 | Инопланетяне | 1997-11-07 | мультфильм | Франция | Джим Гомез |
| 81845 | Суини Тодд, демон-парикмахер с Флит-стрит | 2007-12-03 | мюзикл | США | Тим Бёртон |
| 445196 | Руки-ноги за любовь | 2010-10-29 | триллер | Великобритания | Джон Лэндис |
| 271878 | Красный отель | 2007-12-05 | комедия | Франция | Жерар Кравчик |
| 3609 | Планкетт и Маклейн | 1999-01-22 | боевик | Великобритания | Джейк Скотт |
| 183497 | Бурк и Харе | 1972-02-03 | ужасы | Великобритания | Вернон Сьюэлл |
| 3482 | Доктор и дьяволы | 1985-10-04 | ужасы | Великобритания | Фредди Фрэнсис |
| 2528 | Ценности семейки Аддамс | 1993-11-19 | фэнтези | США | Барри Зонненфельд |
| 503578 | Колыбельная | 2010-02-12 | фэнтези | Польша | Юлиуш Махульский |
| 87404 | Красная харчевня | 1951-10-19 | комедия | Франция | Клод Отан-Лара |
| 5293 | Семейка Аддамс | 1991-11-22 | фэнтези | США | Барри Зонненфельд |
| 18089 | Похитители тел | 1945-02-16 | ужасы | США | Роберт Уайз |
| 271846 | Продавец мертвых | 2008-10-10 | ужасы | США | Гленн МакКвейд |
| 272111 | Свежезахороненные | 2007-09-09 | драма | Канада | Чаз Торн |
| 34186 | Эльвира: Повелительница тьмы | 1988-09-30 | комедия | США | Джеймс Синьорелли |
| 818981 | Реальные упыри | 2014-01-19 | комедия | Новая Зеландия | Джемейн Клемент |
| 8421 | Эдвард руки-ножницы | 1990-12-06 | фэнтези | США | Тим Бёртон |
| 5622 | Сонная Лощина | 1999-11-17 | ужасы | США | Тим Бёртон |
| 2389 | Битлджус | 1988-03-29 | фэнтези | США | Тим Бёртон |
Мне такой подход кажется интересным из-за того, что мы получаем список похожих фильмов, которые не обязательно связаны прямыми рекомендациями, и даже не обязательно достижимы за небольшое число шагов при обходе графа. То есть, так можно найти фильм, который попадётся если просто кликать похожие фильмы прямо на сайте.
P. S.
Спасибо всем друзьям, которые готовы были отвечать на мои вопросы, всем киноманам — новых открытий, а датасаентистам качественных данных!
