Сейчас, кажется, невозможно найти мессенджер без функции звонков. Это удобно для пользователей, потому что все коммуникации можно вести в одном приложении. Если объединить всю доступную в СМИ статистику, то получится, что люди разговаривают через интернет более миллиарда минут в день. И по мере развития технологий растет доля видеосвязи, потому что видео лучше передает эмоции собеседника и позволяет создать эффект присутствия.
Новый вызов для сервиса видеозвонков — собрать в одной конференции сразу всю семью или компанию друзей, находящихся в разных частях света, или коллег, работающих удаленно над одним проектом, на планерку.
Руководитель разработки платформ Видео и Лента Александр Тоболь (alatobol) покажет, что под капотом у сервиса видеозвонков, какие технологии и хаки применить, чтобы сделать свой сервер конференций, и как правильно передавать видео. Заходите под кат и узнаете, как перевести сервис звонков один на один к групповым звонкам на 100 человек и зачем вообще нужна поддержка такого количества участников.
Статья основана на докладе на HighLoad++ Siberia, в котором Александр Тоболь старается дать полную картину. Если вы уже знакомы с другими материалами по теме (например, об особенностях передачи видео и сетевых протоколах), то можете пропустить теоретическую часть и сразу перейти к решению.
План статьи:
Первым общеизвестным приложением для звонков, причем с видео, стал Skype, он появился в 2006 году. В Одноклассниках мы запускали звонки на базе решения от Adobe в 2010-2012 гг… Пару лет назад мы его полностью переделали на WebRTC (подробно об этом запуске здесь), в прошлом году добавили групповые звонки. Об этом переходе и пойдет речь в статье.
Почему я думаю, что могу рассказывать, как это нужно делать? Потому что наша ежемесячная аудитория, использующая звонки, превышает 10 млн человек, а в сутки у нас больше 2 млн звонков. Причем более половины из них совержаются через мобильные платформы.
Групповые звонки — самый быстрорастущий сервис, и наша цель — 100 одновременных участников конференции. Зачем так много? Во-первых, иногда хочется поделиться со своими друзьями и одноклассниками красивым кадром или провести семинар. Во-вторых, даже если вы считаете, что вашему сервису что-то не нужно, все может измениться.
Сейчас может казаться, что видеоконференции на 100 участников не нужны, а еще лет пять назад меня спрашивали, зачем мы запускаем видео в 4К. Сейчас телевизор с разрешением 4К — обыденность, а мы были готовы еще в 2014 году.
В каждом сервисе звонков есть 4 относительно независимых составляющих:
О любой из этих частей можно говорить отдельно. Но я хочу дать общую картину, как работают звонки, поэтому попробую уместить все в один рассказ.
Перед тем, как начать работу над сервисом, нужно обозначить требования:
Вот конкретные значения, в которых выражаются эти требования к групповым звонкам: старт звонка не больше 1 секунды; сеть, в которой стабильно работает видео 300 Кбит/с; latency от звонящего до слушателя не более 0,5 секунды; 100 пользователей в одном звонке.
Как известно, данные в сетях передаются пакетами: есть сокет, вы отправляете туда поток данных, все улетает, как в черный ящик, само собирается и работает.
Но сети бывают разные. Половина звонков совершается через мобильные сети, а они не всегда похожи на скоростное шоссе.

Сети могут быть перегружены, тогда данные будут теряться и их придется восстанавливать, еще больше нагружая сеть. Бывают сети, с которыми вроде все в порядке, но пакеты все равно пропадают — например, из-за того, что Wi-Fi-роутер находится за железобетонной стеной.
Разберем основные характеристики, которые описывают качество сети.
Round-trip time — время между тем, как сервер отправил данные клиенту и получил acknowledgement обратно.
Напоминаю, мы хотим установить соединение за 1 секунду. Если round-trip time составляет 200 мс, то с установкой соединения, например, по TCP, да плюс какой-нибудь TLS, можно потерять 500 мс только на установке соединения. Останется всего 500 мс, т.е. еще пара запросов, после которых соединение должно быть установлено. Поэтому с лишними запросами с RTT нужно работать очень аккуратно.
Пример:
При RTT = 220ms получение ответа по https занимает до 800 мс. Поэтому, если у вас вебсокетное безопасное соединение, то с таким ping вся секунда и уйдет.

В таблице представлены измеренные в мобильных сетях задержки на handshake (в этом докладе подробнее о работе приложений в мобильных сетях).
Вы можете отправлять в сеть пакеты как угодно: пачками или сразу забивать весь в буфер, они все равно будут приходить на клиент равномерно. Количество пакетов или данных в секунду и есть пропускная способность или bandwidth.
Проблема в том, что пропускная способность в мобильных сетях постоянно меняется. Если она резко упала, а данные передаются с тем же битрейтом, они, очевидно, пройдут с потерями, и звонок у пользователя «подвиснет». С этим тоже придется бороться.
При передаче данных пакет может потеряться. В этом случае есть выбор: или часть пакетов пропустить и получить искажения, или попытаться ретрансмитить пакеты и получить freeze кадра.
Дело в том, что пакеты приходят не равномерно по одному, а сгруппированными пачками с каким-то интервалом.
Jitter легко измерить:
Пинганули highload.ru несколько раз (ping — нестабильная величина, надо усреднять), получили средний jitter:
Предположим, мы передаем видео, и один кадр — это сетевой пакет. Несколько кадров проигрывается без перебоев, но третья птичка из-за jitter задерживается — получаем freeze кадра. Значит, надо где-то накапливать пакеты и выравнивать этот эффект.
То есть, чтобы характеризовать беспроводные сети, достаточно знать следующие величины:RTT (round-trip time); пропускную способность BW (bandwidth); процент потери пакетов (packet loss); jitter.
Перед тем, как приниматься оптимизировать работу с сетью, надо узнать, какой вообще интернет у пользователей — может, у всех сеть идеальная, любое решение будет работать.
В 80% случаев конечный пользователь использует беспроводное соединение: это или мобильная сеть, или Wi-Fi.

В России за пределами западного региона и крупных городов средние значения характеристик сети: RTT — 200 мс, bandwidth — 1,1 Мбит/с, packet loss — 0,6 %, jitter — 5мс.
Мы разбили эти значения по типам сетей и поняли, что учиться на этом работать необходимо.

Многие забывают, но LTE и 3G — это асимметричные каналы связи: downlink всегда больше, чем uplink. В зависимости от типа протокола это соотношение может меняться от 15/85 до 30/70. При разработке звонков это важно.
Как проверить, какой канал у ваших клиентов?

Можно посмотреть на speedtest, какое соотношение скорости в мире между мобильным и фиксированным интернетом. Оказалось, что по миру фиксированный интернет тоже ассиметричный. В России, к счастью, он оказался симметричным: соотношение uplink/downlink на фиксированном интернете через Wi-Fi в России 50/50. Будем ориентироваться на такие значения.

Промежуточный итог: беспроводные сети популярны и нестабильны.
С этим багажом знаний вернемся к реализации групповых звонков. Рассмотрим алгоритм простого группового звонка, который потом доработаем.
Шаг 1. Алиса хочет позвонить Борису и отправляет ему оффер, в котором сообщает все, что она умеет, какие поддерживает протоколы, настройки и т.д.
Шаг 2. Борис отвечает Алисе, после этого устанавливается транспортное соединение.
Шаг 3. После этого начинается обмен аудио/видео данными.
Архитектура любых звонков выглядит примерно так, как показано на схеме ниже.
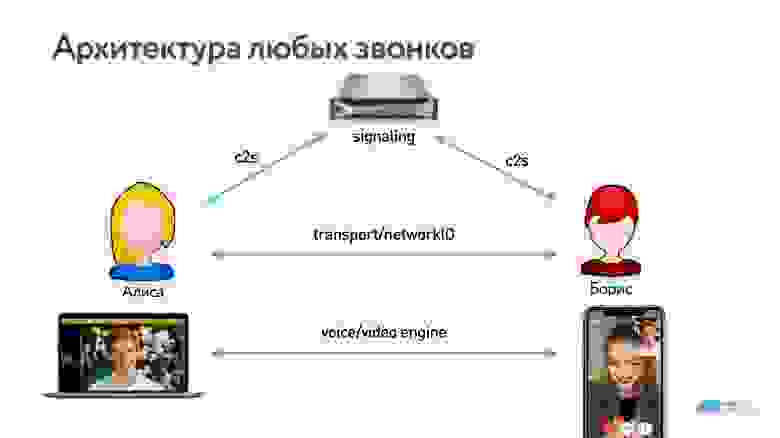
Всегда есть общий сервер, но когда соединение установлено, пользователи уже могут передавать данные p2p или через сторонние серверы.
Данные снимаются камерой, которая их кодирует на устройстве и отправляет в сокетное соединение. Они проходят по сети, воспроизводятся на другой стороне кодеком и отображаются на экране.
Рассмотрим все шаги алгоритма подробно и попробуем перейти от звонков 1-на-1 к групповым.
Задача: сообщить о звонке и установить data-соединения.
Все достаточно просто:
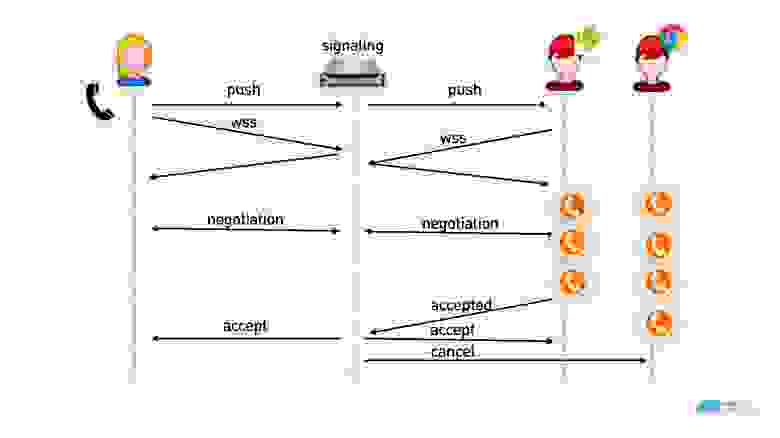
Платформа звонков в Одноклассниках поддерживает различные клиенты и транспорты. Они все замыкаются на какой-то сервер, который занимается обслуживанием звонка и пересылкой сообщений.

На случай сбоя на сервере или установки обновлений есть персистентное хранилище, в которое записываются все сообщения. В случае потери сервера можно легко переключиться на другой. Этим занимается ZooKeeper.
Единственная сложность — exactly-once. Мы не хотим применять некоторые сообщения два раза. Эта проблема решается просто: все сообщения имеют порядковый номер — два раза одно сообщение не придет.
Кроме того, нужно быть аккуратными при создании звонка. Человек может создать звонок, повесить трубку и создать еще один звонок. А может не повесить, но все равно создать еще один. Все эти звонки неуникальные — непонятно, это ретрансмит или пользователь два раза нажал на кнопку звонка. Чинится легко: на клиенте генерируется уникальный ID, и по нему производится дедупликация. В принципе, в signaling никаких сложностей нет.
p2p signaling до группового дорабатывается нетрудно.
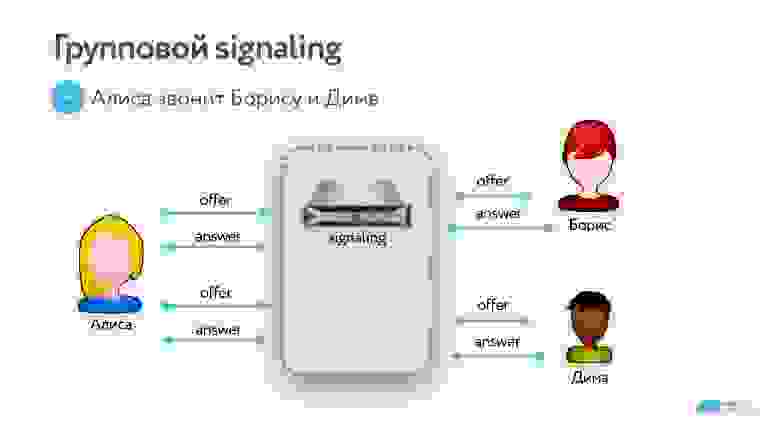
Те самые offers и answers Алиса теперь отправляет не только Борису, но и Диме. Они их получают, соглашаются, между ними появляются каналы обмена данными.
Для того, чтобы справиться с групповым звонком и понять, какие нужны технологии, нам придется чуть-чуть поговорить о том, что такое видео.
Видео — это 24 или 60 кадров в секунду. Для того, чтобы их сжимать, используются кодеки. Основная суть кодеков в том, что раз в несколько кадров есть опорный кадр (типа JPEG), а промежуточные кадры определяются через изменения.
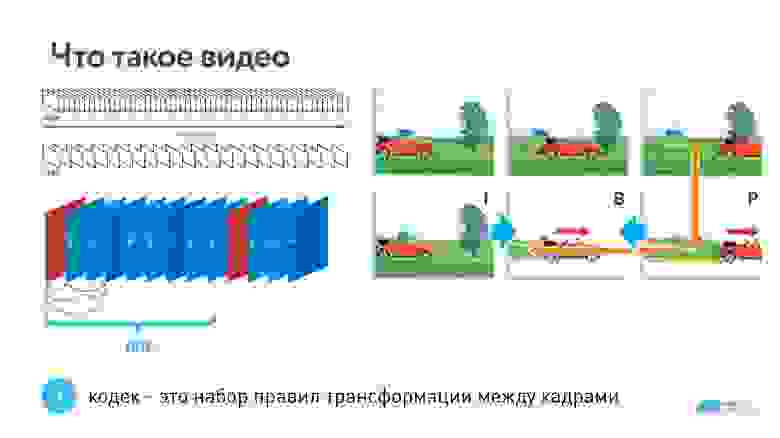
На картинке выше первый кадр с машиной опорный, а в следующем кадре кодируются только изменения (перемещение машины), и в следующий раз тоже только изменения.
Это называется group of picture — независимый набор взаимосвязанных фреймов, которые можно декодировать. Кодек — это алгоритм трансформации между кадрами. Чем круче кодек, тем он лучше сжимает данные, и тем больше ресурсов ему нужно.
Про соотношение битрейтов кодеков есть общие правила (см. ссылку).
Самые популярные кодеки, используемые для звонков, — это H.264 и VP8. H.264 хорош тем, что он везде хардварно работает и не жрет батарейку. Но обычно на телефонах один энкодер (кодировщик) и 4 декодеровщика. Для всего остального нужен софтверный VP8, который неплохо потребляет батарею. Стоит поменять приоритет на H.264 для групповых звонков (см. ссылку, как это сделать).
Кодек может кодировать с переменным (Variable bitrate) или постоянным битрейтом (Constant bitrate). Многие кодеки на устройствах не поддерживают постоянный битрейт, поэтому придется жить с картинкой слева.

Для аудио есть различные legacy-кодеки, например, G711. Очень популярен кодек Opus — он решает задачу кодирования и при низких битрейтах, и при высоких, потому что внутри содержит SILK из Skype и кодек CELT для музыки.
Стоит сказать, что в Opus есть алгоритм превентивного исправления ошибок Forward Error Correction (FEC). Для аудио этот алгоритм работает так: в каждом пакете есть данные в высоком качестве и данные предыдущих фреймов за какое-то время в низком качестве. Соответственно, если предыдущий пакет потерян, можно достать данные предыдущего пакета в низком качестве и как-то проиграть. В среднем получается довольно неплохо.
При работе с аудиокодеками интересно посмотреть на график, где представлено соотношение качества входного сигнала и битрейта.
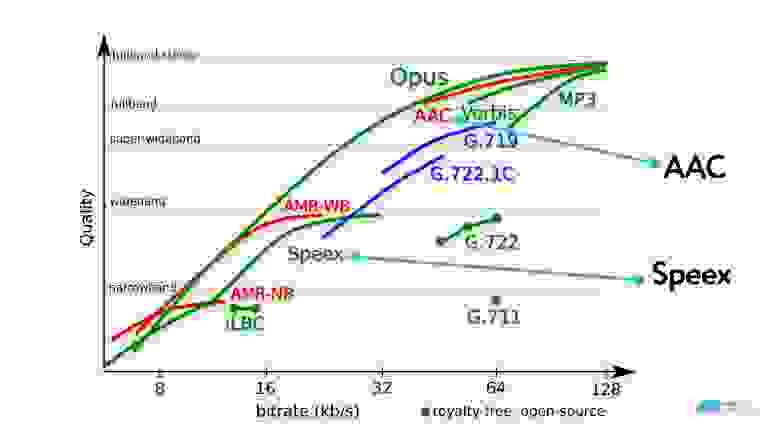
Видно, что Opus решает почти все проблемы. Любопытно обратить внимание на AAC, который используется при кодировании видео в различных хостингах и на старый кодек Speex, который использовался исключительно для аудио и до 32 Кбит/с отлично работает.
Для того, чтобы понять, как работают топологии, какие у них особенности, надо понять, как видеокодек справляется с потерями.
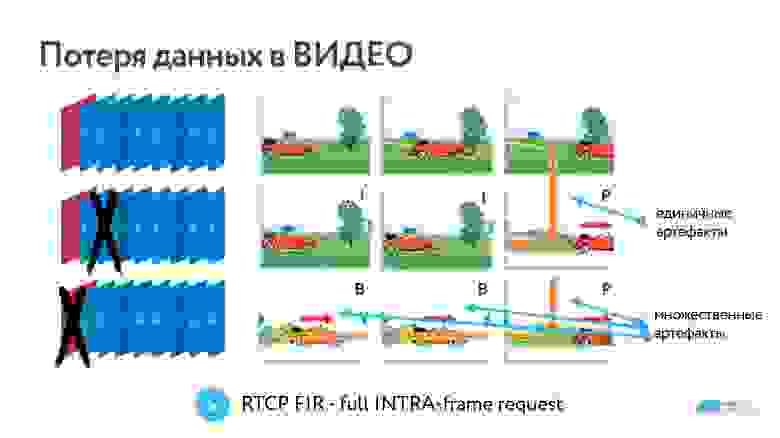
В первом случае ничего не пропало, и мы видим хорошую картинку. Во второй строке потерян один случайный кадр — на картинке есть небольшие артефакты. В третьем случае пропал опорный кадр, поэтому до следующего опорного будут показываться хаотично накладвающиеся друг на друга изменения.
Очевидно, делать опорные кадры часто — дорого, потому что растет битрейт. Поэтому почти все сервисы звонков так или иначе поддерживают возможность запросить опорный кадр в случае его потери. В WebRTC это называется full INTRA-frame.
Самая простая топология — это отправить все свое видео всем остальным участникам конференции.
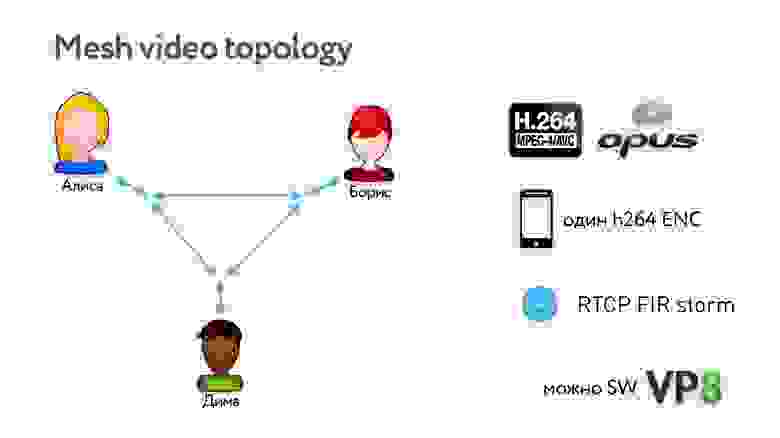
Запускаем один кодек и начинаем передавать видео. Алиса включает камеру, кодек, отправляет свое видео Борису и Диме. Но если у Димы плохой интернет, страдает Борис, потому что нужно понижать качество всего видео. А если Дима потерял кадр и запросил опорный, Борис тоже его получит, хотя ему он и не был нужен.
С другой стороны, можно все видео склеить в один поток. Для этого потребуется специальное оборудование и, возможно, будут дополнительные задержки, но такое решение тоже есть.
На выбор у нас есть TCP или UDP протоколы.
Наверное, все помнят, что TCP — это надежный протокол, который в случае потери пакетов пересылает их повторно. Именно поэтому возможен такой порядок кадров, как на картинке ниже.
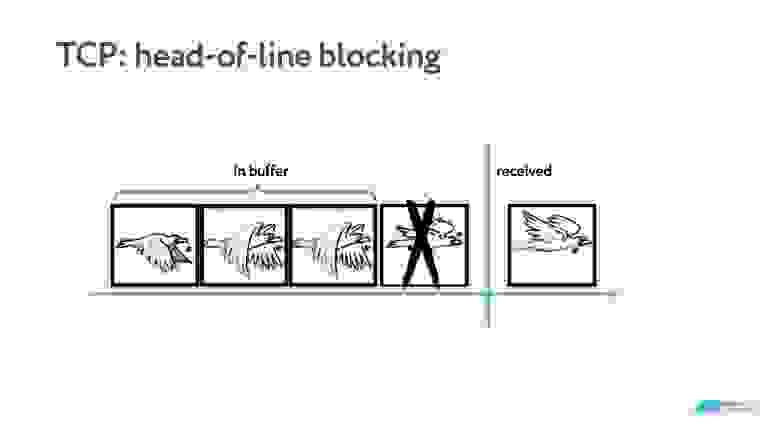
Если в пакете пропал кадр, на видео вы могли свободно бы пропустить этот один из 24 кадров, но TCP не даст получить следующие, пока не перешлет потерянный. Доставлять видео по TCP крайне неэффективно. Для таких задач рекомендован UDP, и все сервисы звонков используют именно его.
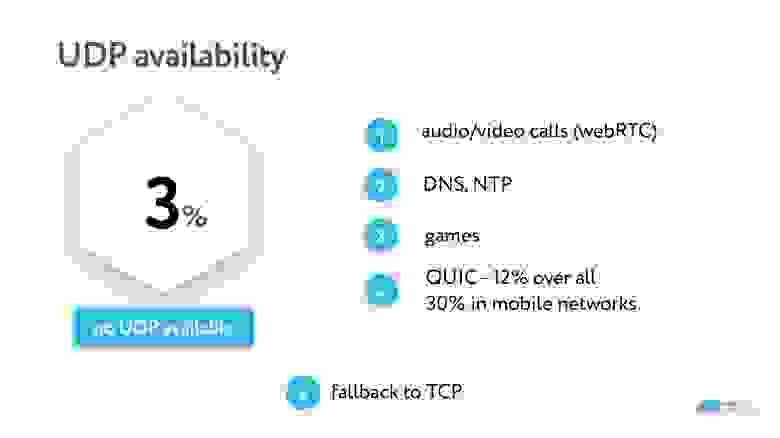
В этой статье приводятся все особенности обоих протоколов и объясняется, почему весь стриминг работает на UDP. В рамках сегодняшней темы нам достаточно знать, что UDP доступен не везде, он не работает в 3% сетей.
А вообще, пользователи могут между собой устанавливать р2р-соединения.
Это максимально выгодно, потому что если мы в Новосибирске звоним друг другу, то гораздо лучше общаться напрямую и не использовать дополнительный сервер, который даст плечо.
Но существует NAT, и больше 97% пользователей сейчас располагаются за ним — мало у кого есть внешние IP. Эту проблему с одной стороны рано или поздно решит IPv6. Кстати, в России его первым запустил МТС. Сейчас они полностью поддерживают IPv6, и у всех их клиентов белые IP.
NAT может пробиться, может не пробиться, и тогда придется использовать fallback через сервер. О том, как пробивать NAT тоже есть статья.
Двигаемся дальше. Теперь нам нужен jitter buffer, чтобы нивелировать эффект от jitter

Мы превентивно начинаем показывать кадры с какой-то задержкой и тем временем выстраиваем кадры через одинаковый интервал в буфере.
Буфер увеличивается динамически.
Если кадр пропал, и картинка заморозилась, то буфер увеличивается, и дальше мы работаем уже с буфером этого размера.
Но может быть и обратная ситуация, когда нужно уменьшить буфер. Например, сеть стабилизировалась, а время нужно нагнать. Если просто уменьшить буфер, получится смешно, люди начнут очень быстро говорить голосом гномика. Поэтому есть специальные алгоритмы, которые незаметно для вас подгоняют скорость аудио: убирают паузы между словами или схлопывают звуки, которые в речи слишком тянутся.
Если хотите транскодировать видео и что-то поправить, предварительно нужно иметь jitter buffer, и его latency будет не меньше, чем latency jitter этой сети. То есть это однозначно увеличивает latency, а мы помним, что очень хотим уложиться 0,5 с.
Выдыхаем — теория закончилась!
До групповых звонков у нас были p2p-звонки, использовалась библиотека WebRTC, были собраны веб и мобильные клиенты, написан signalling.
Когда не знаешь, что делать, — смотри конкурентов. Для ориентира мы выбрали набор: Skype, WhatsApp, Hangouts, ICQ, Zoom. Измеряли максимальное число участников в групповом звонке, задержки, потребление батарейки и качество.
Самое интересное — определить задержку. Делаем это так: включаем таймер, начинаем снимать видео, звоним.

100 мс — задержка камеры от момента, как видео попало на объектив, до того, как оно отрисовалось на матрице телефона. После этого видео отправляется в сеть, и мы видим задержку 310 мс уже в звонке.
Не забываем замерять использование CPU на устройстве. Начиная с iOS 12 появилась возможность делать это системно, но мы по старинке используем пирометр.
Получили следующие результаты:
У WhatsApp и ICQ максимальное количество участников звонка всего 4, у Skype — 25 (у Skype for Business 250), и по 100 участников у Hangouts и Zoom. У Hangouts раньше было порядка 35 участников, сейчас он перепрыгнул в раздел 100+.
У Zoom чуть больше задержка, но при этом Hangouts сильнее расходует батарейку. Мне показалось, что качество лучше у Zoom, но есть статьи, которые говорят обратное, — это субъективная метрика.

Часть сервисов используют открытый WebRTC, другие — проприетарные протоколы. Но очевидно, что то, какой транспорт вы используете внизу, никак не влияет на количество участников в звонке. Есть решения со 100 звонками и со своими протоколами (Zoom), и с WebRTC (Hangouts).
Рассмотрим интересный кейс: есть клиент, у которого асимметричный канал, вход 3 Мбит/с, выход 1.5 Мбит/с, packet loss 0,6%, jitter 50 мс. Есть видео в HD (1280х720) с битрейтом 1,5 Mбит/с и видео с разрешением 640х360 (назовем LOW) на 600 Кбит/с. Хотим передавать классные видео.
В случае, если два человека звонят p2p, то все просто. Им хватает входной сети, выходной сети хватает уже впритирку, потому что канал асимметричный, и с кодеками проблем нет — все кодеки свободны.
Когда мы начинаем делать групповые звонки, надо всех перезамыкать. Самый простой вариант топологии — это Mesh или «все ко всем».
Здорово, что не нужны промежуточные серверы, но раздать всем свое видео для клиентов с такими характеристиками становится проблематично. А если клиент не может раздать видео кому-то одному, то нужно понизить качество, потому что кодируется общий поток для всех.
В таком варианте для 5 участников уже ни 3, ни 4 Мбит/с не хватит.

Поэтому в WhatsApp в групповом звонке максимально 4 участника, и больше не будет до тех пор, пока они используют Mesh.
Другой вариант — всю картинку собрать на сервере. Для клиента это максимально выгодно: он имеет одно соединение с сервером, сервер собирает картинку, клиент получает ее обратно.

Но предположим, наши пользователи из Петропавловска-Камчатского, Комсомольска-на-Амуре и Новосибирска хотят пообщаться через московский сервер. Естественно, получится очень плохо. Наличие CDN чуть-чуть поможет, но все равно получится большой объем jitter-буферов, которые суммарно внесут приличную добавку к latency.
Следующая топология — End mixing — предлагает не собирать общую картинку на сервере, чтобы избежать этих задержек, а просто перекидывает пакеты.
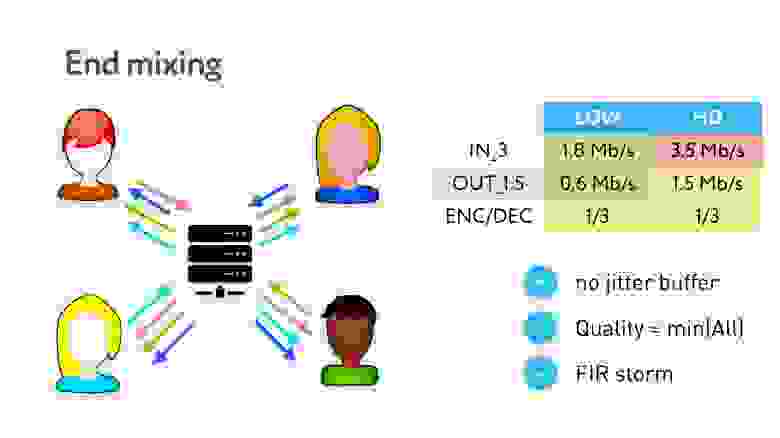
То есть сервер в этой топологии просто ретранслятор, который перебрасывает данные.
Всё становится несколько лучше: пользователь получает потоки всех других участников звонка и отправляет свой только один раз. Но опять есть проблемы:
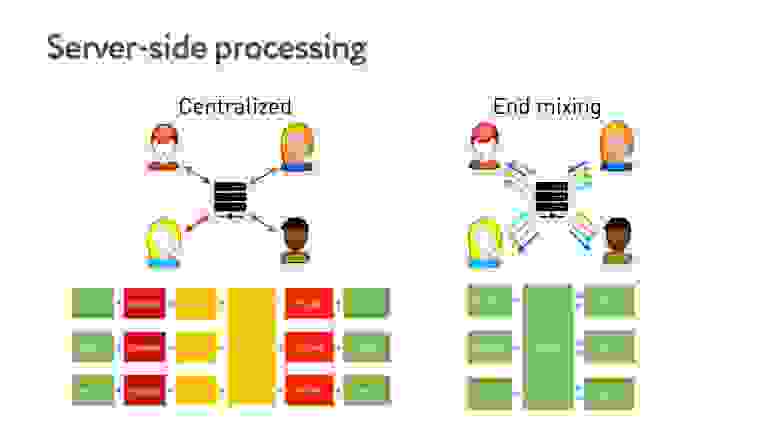
Если используется централизованная система, то есть все видео собирается на сервере. Это требует многих стадий кодирования, которые и latency добавляют, и требуют дополнительного оборудования. В End mixing, наоборот, все быстро и просто.
Минусы топологий:
На топологии Mesh работают только ICQ и Skype, у всех остальных End mixing. Но, как мы помним, все сервисы по характеристикам разные — значит, там не просто End mixing, а что-то еще.
Hangouts провернули такой трюк с End mixing.
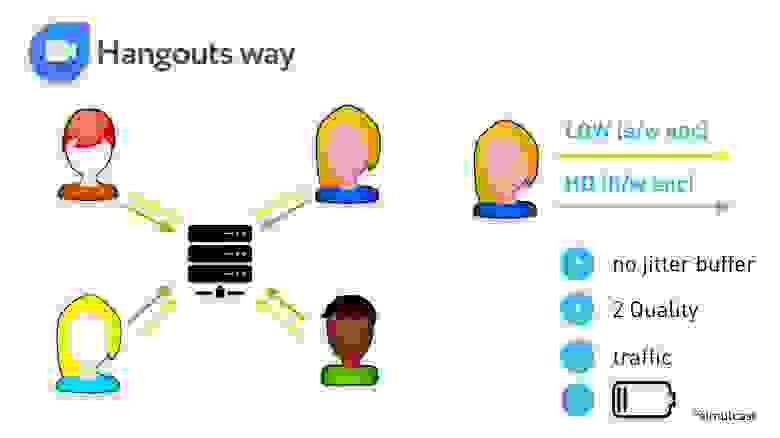
На каждом клиенте запускается два кодировщика: H.264 в высоком качестве, и VP8 — в низком. Соответственно, для пользователей с хорошим интернетом сервер передает видео в высоком качестве, для тех, у кого интернет плохой, — похуже, причем низкое качество адаптируется под худшую сеть. Два качества это хорошо, но это лишний трафик с клиентов и расход батареи. Зато нет jitter buffer
Из таблицы видно, что с работающим Hangouts телефон греется больше всего, в нем минимальные задержки, но страдает качество, потому что низким качеством все равно отъедается битрейт у высокого.
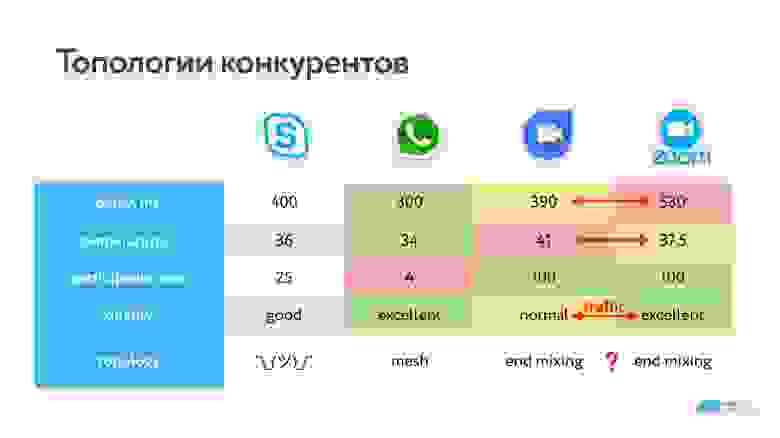
Мы решили шагнуть дальше, поиграть в такую игру: все-таки не запускать софтверные кодеки с клиента, кодировать H.264, использовать канал на всю катушку под один поток (это сэкономит батарею и трафик) по схеме End mixing для высокого качества. А для низкого качества использовать centralized-схему, но сервер вместо того, чтобы собирать общую картинку, будет видео высокого качества кодировать в то, которое нужно каждому конкретному пользователю.
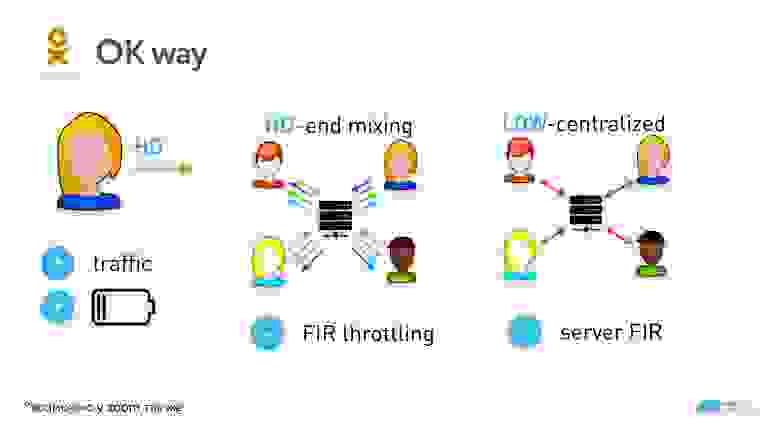
Правда, приходится бороться со штормом опорных кадров: для высокого качества мы их троттлим. То есть считаем, что если пользователь в состоянии получать высокое качество, наверное, у него мало пропадающих пакетов, и он как-то без этих опорников сможет справиться. На практике это означает, что мы не позволяем запрашивать опорный кадр чаще раза в секунду.
В итоге мы получили следующие варианты разных топологий.
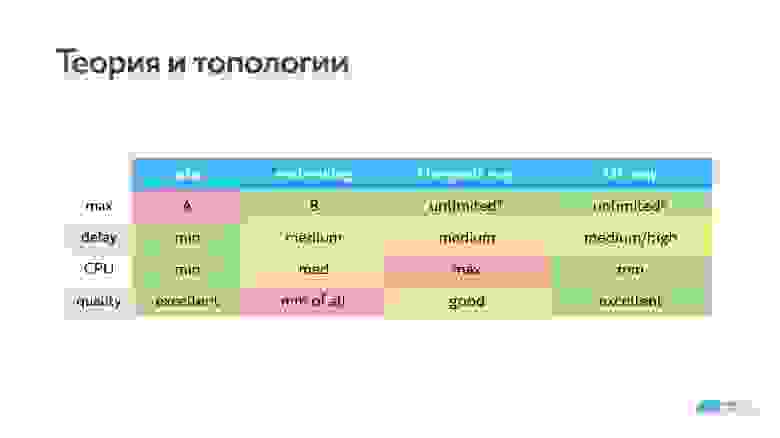
Конечно, мне кажется, наш вариант самый удачный, но у нас может быть большая latency для клиентов с плохой сетью. Мы решили этим пренебречь, потому что если у клиента низкое качество видео, возможно, ему даже выгоднее, когда нет второго плеча до раздающего видео. Потому что при такой топологии пропажа пакетов чинится на интервале между клиентом и сервером в топологии centralized, то есть есть сервер, который разбирает, имеет свой jitter-буфер и транскодирует. Сервер может отдать персональный опорный кадр или восстановить определенный кадр, и все эти действия по восстановлению пакетов никак не влияют на того, кто отдает видеопоток.
Формально в графе количество клиентов у нас «бесконечность», но со звездочкой. Это потому что никто не в состоянии отображать ни 100, ни 50, ни даже 20 собеседников за раз. На экране у нас обычно один говорящий и список остальных участников.

У всех клиентов разная сеть и разные устройства — есть такие, которые не в состоянии декодировать больше 5 видеопотоков. К каждому устройству нужен персональный подход. Мы это делаем так: устройство сообщает, сколько оно может проиграть потоков, мы ему их собираем на сервере, как в задаче о рюкзаке — сколько максимально можем впихнуть в сеть.
Самого «большого» пользователя мы выдаем в высоком качестве, тех, кто в окошках поменьше, — в низком. Также у нас есть режим настройки кодека: если мы понимаем, что участник отображается где-то далеко, мы включаем низкий fps. В принципе, если в превьюшках внизу картинка обновляются раз в секунду — это нормально. Если пользователи хоть как-то шуршат, добавляется звук. Если и это невозможно, мы их совсем не трогаем.
Так как топология Mesh до 3-4 участников работает очень хорошо в плане latency, батарейки и всего остального, то мы заморочились и до некоторой границы поддерживаем Mesh. Потом плавно переключаемся на серверную топологию, в которой HD отдаем через End mixing, a SD — через centralized.
В итоге получили характеристики близкие к Zoom.
Предположу, что они делают что-то схожее с той разницей, что у Zoom своё решение, частично несовместимое с WebRTC. А мы сохранили совместимость с WebRTC, поэтому поддерживаем групповые звонки еще и в браузере.
Куда же в разработке без них.
CPU может быть слабее, чем сеть. Мы передавали с сервера максимальный поток — столько, сколько влезает в сеть, но быстро выяснилось, что есть устройства, у которых CPU слабее, чем сеть. Тогда вроде бы кодировщики играют, но телефон начинает сильно тормозить или перегреваться.
Добавили дополнительную информацию: телефон может сказать, что он не справляется, и попросить понизить качество подаваемого видео.
При screen sharing плохого качества недостаточно. Если понизить битрейт screen sharing, то букв и цифр становится не видно, и весь смысл пропадает. Поэтому у screen sharing высокий приоритет. Кроме того, логично понизить fps — лучше, чтобы мышка двигалась медленно, но все было видно.
Один сервер не может транскодировать видео для всех клиентов. Еще одна особенность — если работать по схеме centralized, то рано или поздно возникнет ситуация, когда сервер не сможет транскодировать всех клиентов. Потому что невозможно предсказать, сколько их будет.
Таким образом, все приходящие стримы транскодируются тем или иным сервером, и есть сервер раздачи, который все транскодированное видео собирает. Поскольку мы не складываем все в одну большую картинку, а раздаем отдельными потоками, то можем позволить себе такую схему и не ограничены ресурсами одного сервера при транскодировании в нашей топологии.
Расскажу, как сделать сервер, если когда-нибудь захотите написать свой сервер конференцсвязи. Мы со всеми нашими претензиями к топологии ничего готового не нашли и решили делать сами.

Во-первых, открываете UDP-сокет и начинаете в него писать. Стандартно для UDP всегда нужен pacing. Не стоит отправлять UDP-пакеты большими пачками, если не хотите их потерять.
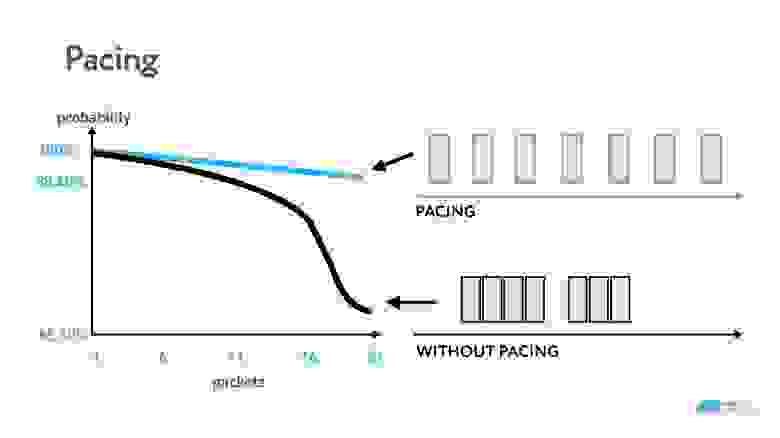
На графике показано, что если пересылать пакеты по UDP непрерывно, то к 21 пакету вероятность пропажи будет близка к 100%. Пакеты надо прорежать хотя бы раз в милли или наносекунду — это расстояние нужно вычислить эмпирически.
Для чего еще нужен pacing? Как я уже сказал, вы не можете заставить кодек выдавать константный битрейт (но иногда можете эмулировать) — если картинка меняется, битрейт растет. Поэтому если, после того как в канале установился примерно постоянный битрейт, потрясти камеру, то, скорее всего, картинка на другой стороне рассыпется, потому что из-за большого числа изменений вырастет битрейт и данные не пролезут в пропускную способность канала.
Есть два варианта:
Это отличный способ проверить клиент: если при встряхивании телефона на другой стороне тормозит, то pacing есть, если посыпались пакеты —нет.
Чем еще полезен packet pacing?

В реальной жизни, если вы (и с вами другие люди) передаете много данных за единицу времени, очередь может переполниться, и кого-нибудь дропнут. Поэтому считается (но не доказано), что если аккуратно все размазать, то вы ни с кем не пересечетесь, и вероятность пропадания пакетов снизится.
Единственный установленный факт — packet loss меньше, если есть pacing.
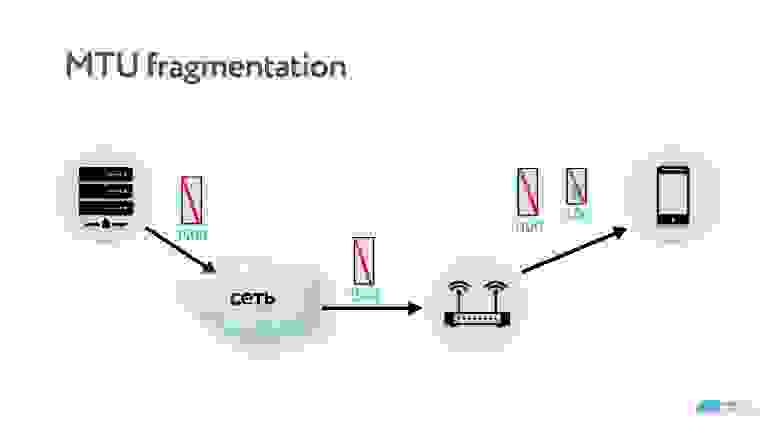
TCP нас избаловал, там никогда не нужно заморачиваться с MTU. Но если вы пишете сервер UDP, то как минимум придется вспомнить, что MTU — это максимальный размер пакета, который может быть передан в сети.
Если данные передаются по сети с MTU 1500, а потом на пути встречается сеть с MTU 1100, то пакет фрагментируется. Конечно, он потом соберется обратно, но если потеряется одна единственная часть этого пакета, то, считай, потеряются все пакеты (и весь оригинальный пакет). Поэтому оптимально работать с таким размером пакета, который соответствует MTU сети.
В TCP есть алгоритм, который определяет этот параметр при установке соединения. Можно повторить его, попробовать подобрать MTU: запуститься с каким-то значением по умолчанию, запустить параллельный процесс и, например, бинарным поиском подобрать MTU. Если передавать пакет с флагом запрета фрагментации размера большего, чем размер MTU, то он не фрагментируется, а дропается.
Картинка получится интересная.
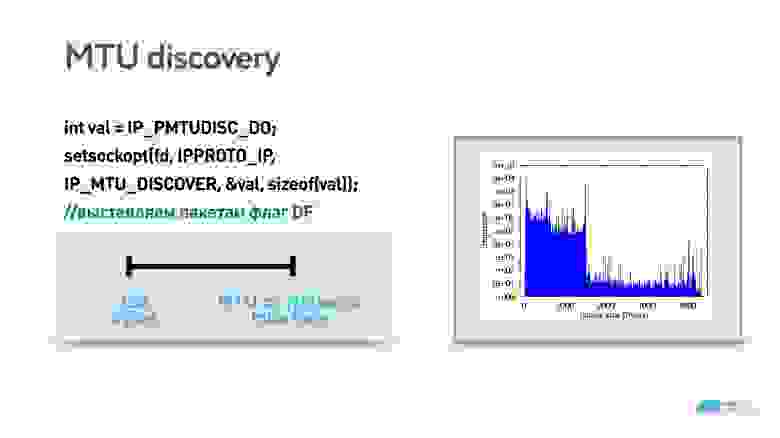
Так мы поняли, что достаточно провести такой эксперимент: отправлять пакеты с флагом запрета фрагментации, и считать, сколько из них дошло до сервера. В 98% случаев пакеты с запретом фрагментации проходят при размере до 1350. Можно спокойно установить MTU = 1350, снять флаг запрета фрагментации, и пусть в 2% случаев пакеты фрагментируются — не повезло, не страшно.
WebRTC поддерживает SACK, NACK, FEC. Придется прочитать спецификацию и научиться их исправлять.
Суть в том, что потеря 1–3% пакетов в беспроводных сетях — это нормально, и с этим нужно уметь работать.
В WebRTC для стриминга наиболее распространен подход negative acknowledgement (NACK).
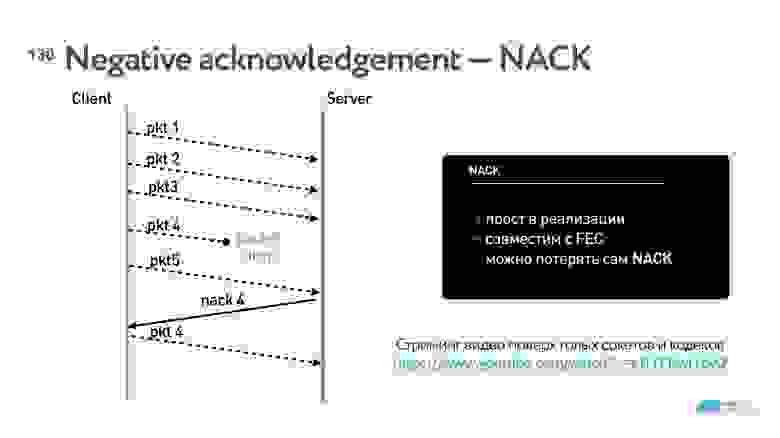
В этом случае порядок пакетов отслеживает принимающая сторона и, если понимает, что какой-то пакет пропущен, дозапрашивает его.
Как известно, TCP работает на acknowledgement, в том числе на selective acknowledgement. Особенность negative acknowledgement в том, что такой вид подтверждений хорошо работает с FEC (Forward Error Correction).
Если вам интересны детали того, как писать SACK, NACK, FEC, посмотрите этот доклад.
Технология FEC применяется, когда заранее известно, что сеть плохая. Работает так: в поток данных встраиваются дополнительные пакеты, когда обнаруживается ошибка, её можно исправить и не тратить время на ретрансмит. Потому что пока данные перезапросишь, перепошлешь, уже станет поздно — картинка уже замрет.

Самый простой вариант FEC — это XOR, но чаще используются более сложные варианты, например, ряды Соломона. К пачке пакетов добавляется пакет защиты избыточности, и при пропадании пакетов что-то можно восстановить.
Следующая фишка пока в драфте, но мы в своих протоколах её используем. Когда у вас есть предположение, что качество канала могло измениться в лучшую сторону, чтобы аккуратно в этом удостовериться, можно сначала добавить избыточных FEC-пакетов. Не жалко, если они пропадут, зато если они стабильно проходят через канал передачи данных, значит, можно поднимать битрейт в кодеке и использовать более широкий канал.
Итого, сложив все вышеописанное, мы запустили групповые звонки. Измерили характеристики работающего сервиса, получилось:
Что нужно не забыть при написании своего сервера групповых звонков:
Последний пункт очень важен, мы собирали логи всего signalling, все состояния WebRTC, все управляющие команды, которые были переданы, чтобы потом можно было что-то отладить.
У нас было много проблем с сетью, для каждой мы подобрали решение:
WebRTC — не самая удобная штука. Это RTP, поверх которого множество флагов и куча разных расширений, которые одни браузеры поддерживают, другие не поддерживают. На самом деле на WebRTC трудно работать.
Поэтому многие сервисы звонков, такие как Zoom, Skype и Line, пишут свой проприетарный протокол. У нас тоже было такое желание. Но тогда бы мы потеряли функциональность звонков из браузера. Поэтому, даже несмотря на то, что у нас есть опыт написания своего UDP-протокола (стриминг на нашем протоколе сейчас работает лучше, чем на WebRTC), мы решили подождать. Это действительно сложно, и пока мы решили, что не стоит торопиться. Например, потому что есть Google STADIA.
STADIA — это игровая консоль, которая позволяет онлайн играть на удаленном сервере. Она работает поверх WebRTC, и говорят, что там пропадает половина кадров. Поэтому Google сейчас очень активно лечит свой WebRTC. Среди решений по улучшению WebRTC даже предлагаются идеи перевести SRTP WebRTC на QUIC. Не знаю, как это будет работать, но это активно обсуждается.
Кстати о QUIC, он уже много где используется. Если вы с Chrome или c Android заходите в Google или YouTube, вы не пользуетесь TCP — там QUIC поверх UDP от Google. У мобильных операторов более 30% трафика через QUIC/UDP.
На плохих мобильных сетях QUIC доставляет данные быстрее на 20-30%, чем TCP. Поэтому просто включив где-то QUIC или переехав на него, вы можете дать своим пользователям неплохое ускорение.
В этой статье мы разобрали, как работают звонки через интернет и как написать свой сервер конференций. Вы узнали, что любые звонки состоят из: signaling; видео/аудио кодировщиков; сети и топологии. Надеюсь, у вас сложился общий пазл, как это все работает.
Что со всем этим делать?
А знания о сетях и видео/аудио кодеках пригодятся в любом случае.
Самое главное, что мы сегодня выяснили, — любые характеристики можно улучшить. В том числе увеличить количество пользователей в звонке, снизить latency, поднять качество. Помните, что нет предела совершенству! Но в какой-то момент все равно нужно будет остановиться :)
Новый вызов для сервиса видеозвонков — собрать в одной конференции сразу всю семью или компанию друзей, находящихся в разных частях света, или коллег, работающих удаленно над одним проектом, на планерку.

Руководитель разработки платформ Видео и Лента Александр Тоболь (alatobol) покажет, что под капотом у сервиса видеозвонков, какие технологии и хаки применить, чтобы сделать свой сервер конференций, и как правильно передавать видео. Заходите под кат и узнаете, как перевести сервис звонков один на один к групповым звонкам на 100 человек и зачем вообще нужна поддержка такого количества участников.
Статья основана на докладе на HighLoad++ Siberia, в котором Александр Тоболь старается дать полную картину. Если вы уже знакомы с другими материалами по теме (например, об особенностях передачи видео и сетевых протоколах), то можете пропустить теоретическую часть и сразу перейти к решению.
План статьи:
- История и устройство звонков.
- Переход от звонков один на один к групповым звонкам.
- Сервис групповых звонков своими руками.
- Сервер конференцсвязи: изучить конкурентов и сделать лучше.
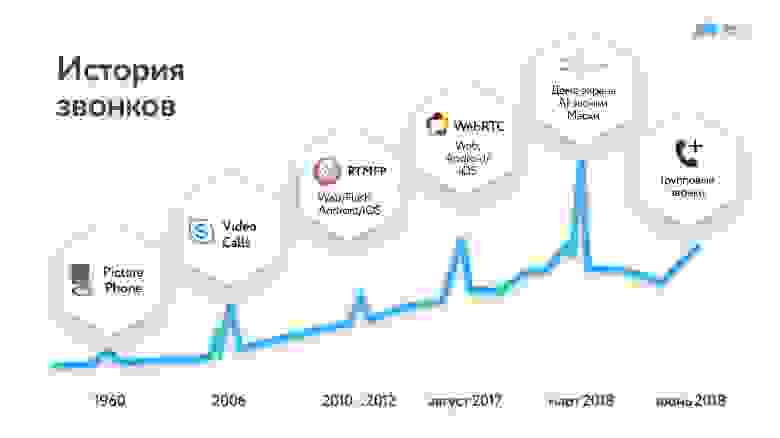
История звонков
Первым общеизвестным приложением для звонков, причем с видео, стал Skype, он появился в 2006 году. В Одноклассниках мы запускали звонки на базе решения от Adobe в 2010-2012 гг… Пару лет назад мы его полностью переделали на WebRTC (подробно об этом запуске здесь), в прошлом году добавили групповые звонки. Об этом переходе и пойдет речь в статье.
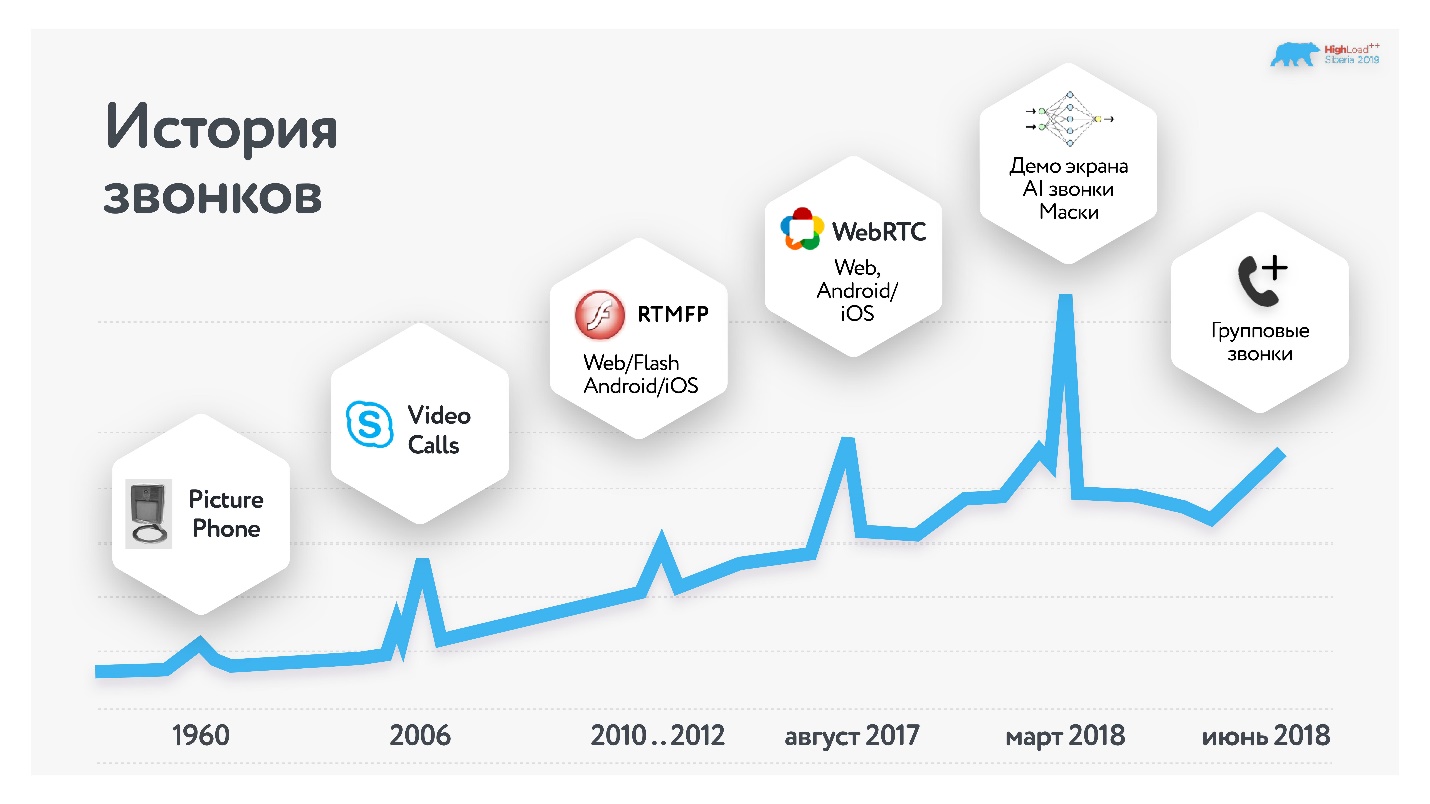
Почему я думаю, что могу рассказывать, как это нужно делать? Потому что наша ежемесячная аудитория, использующая звонки, превышает 10 млн человек, а в сутки у нас больше 2 млн звонков. Причем более половины из них совержаются через мобильные платформы.
Групповые звонки — самый быстрорастущий сервис, и наша цель — 100 одновременных участников конференции. Зачем так много? Во-первых, иногда хочется поделиться со своими друзьями и одноклассниками красивым кадром или провести семинар. Во-вторых, даже если вы считаете, что вашему сервису что-то не нужно, все может измениться.
Сейчас может казаться, что видеоконференции на 100 участников не нужны, а еще лет пять назад меня спрашивали, зачем мы запускаем видео в 4К. Сейчас телевизор с разрешением 4К — обыденность, а мы были готовы еще в 2014 году.
Дело не в опережении времени. Если хотите сделать хороший сервис, поднимите себе планку требований повыше.Если сможете добиться хорошо работающих звонков на 50-100 человек, то для 6-10 пользователей все будет работать просто отлично.
В каждом сервисе звонков есть 4 относительно независимых составляющих:
- Signaling. Задача — вызвонить абонента, обменяться начальными данными, сообщить, что умеет каждый абонент, и после этого наладить канал, через который можно передавать видеоданные.
- Видео/аудио. Видео и аудио данные сжимаются с помощью кодеков.
- Сеть. Нужно обеспечить работу в плохих сетях, реализовать восстановление пакетов, p2p -соединения и т.д.
- Топология — добавляется в случае групповых звонков.
О любой из этих частей можно говорить отдельно. Но я хочу дать общую картину, как работают звонки, поэтому попробую уместить все в один рассказ.
Перед тем, как начать работу над сервисом, нужно обозначить требования:
- Быстрая установка соединения, чтобы соединение устанавливалось сразу после того, как собеседник снял трубку.
- Высокое качество звонка, чтобы видео не рассыпалось и не замирало.
- Количество участников в звонке, чтобы можно было звонить в чаты, в которых до 100 участников.
- Низкие задержки между звонящими. Latency в 1,3 с как у Polycom нас совершенно не устраивает.
Вот конкретные значения, в которых выражаются эти требования к групповым звонкам: старт звонка не больше 1 секунды; сеть, в которой стабильно работает видео 300 Кбит/с; latency от звонящего до слушателя не более 0,5 секунды; 100 пользователей в одном звонке.
Что мешает?
Как известно, данные в сетях передаются пакетами: есть сокет, вы отправляете туда поток данных, все улетает, как в черный ящик, само собирается и работает.

Но сети бывают разные. Половина звонков совершается через мобильные сети, а они не всегда похожи на скоростное шоссе.

Сети могут быть перегружены, тогда данные будут теряться и их придется восстанавливать, еще больше нагружая сеть. Бывают сети, с которыми вроде все в порядке, но пакеты все равно пропадают — например, из-за того, что Wi-Fi-роутер находится за железобетонной стеной.
Характеристики сетей
Разберем основные характеристики, которые описывают качество сети.
RTT
Round-trip time — время между тем, как сервер отправил данные клиенту и получил acknowledgement обратно.
Напоминаю, мы хотим установить соединение за 1 секунду. Если round-trip time составляет 200 мс, то с установкой соединения, например, по TCP, да плюс какой-нибудь TLS, можно потерять 500 мс только на установке соединения. Останется всего 500 мс, т.е. еще пара запросов, после которых соединение должно быть установлено. Поэтому с лишними запросами с RTT нужно работать очень аккуратно.
Пример:
$ ping google.com
64 bytes from 173.194.73.139: icmp_seq=5 ttl=44 time=211.847 ms
round-trip min/avg/max/stddev = 209.471/220.238/266.304/19.062 ms
RTT = 220ms
$ curl -o /dev/null -w "HTTP time taken: %{time_connect}\nHTTPS time taken:
%{time_appconnect}\n" -s https://www.google.com
HTTP time taken: 0.231
HTTPS time taken: 0.797
HTTP = 230ms
HTTPS = 800msПри RTT = 220ms получение ответа по https занимает до 800 мс. Поэтому, если у вас вебсокетное безопасное соединение, то с таким ping вся секунда и уйдет.
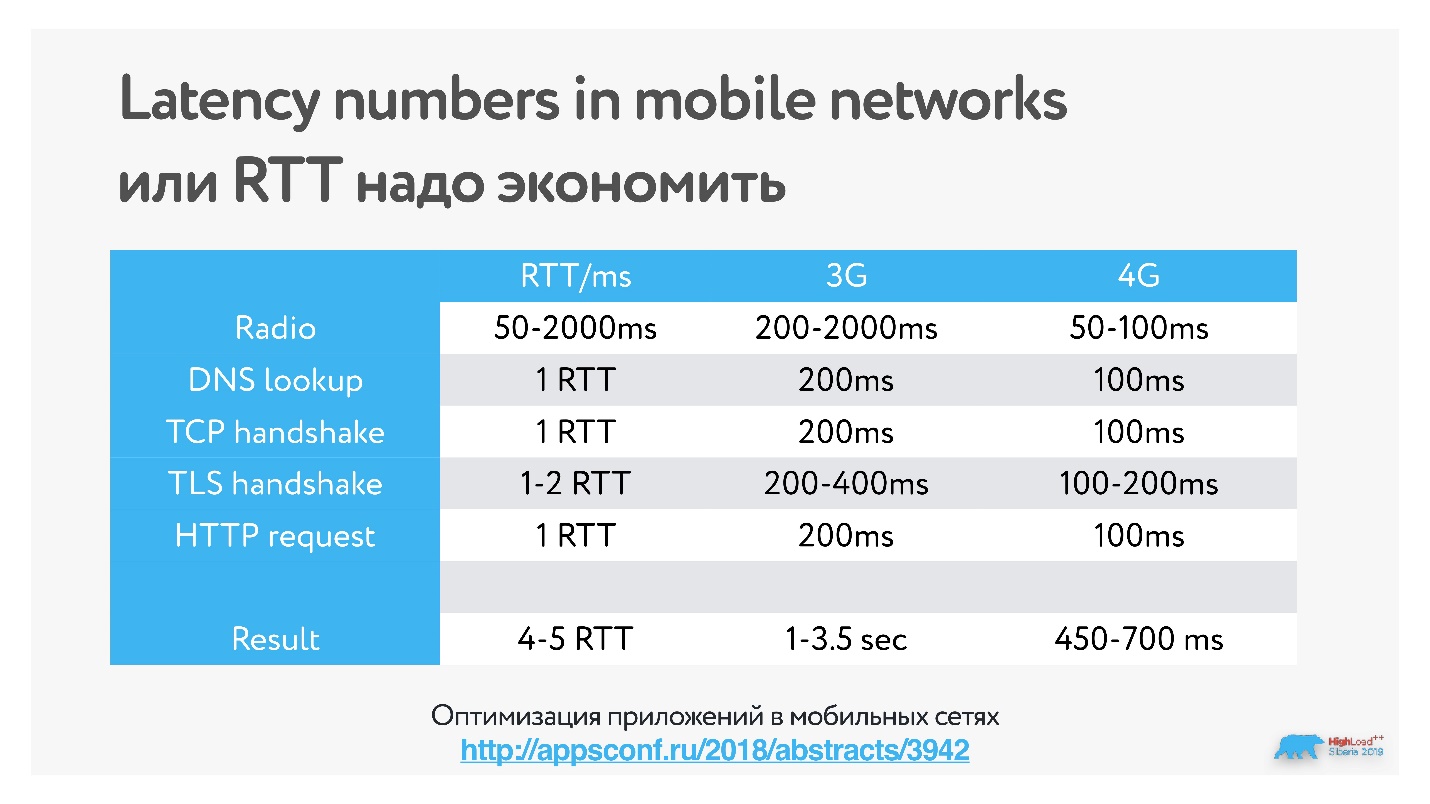
В таблице представлены измеренные в мобильных сетях задержки на handshake (в этом докладе подробнее о работе приложений в мобильных сетях).
Пропускная способность
Вы можете отправлять в сеть пакеты как угодно: пачками или сразу забивать весь в буфер, они все равно будут приходить на клиент равномерно. Количество пакетов или данных в секунду и есть пропускная способность или bandwidth.
Проблема в том, что пропускная способность в мобильных сетях постоянно меняется. Если она резко упала, а данные передаются с тем же битрейтом, они, очевидно, пройдут с потерями, и звонок у пользователя «подвиснет». С этим тоже придется бороться.
Потеря пакетов
При передаче данных пакет может потеряться. В этом случае есть выбор: или часть пакетов пропустить и получить искажения, или попытаться ретрансмитить пакеты и получить freeze кадра.
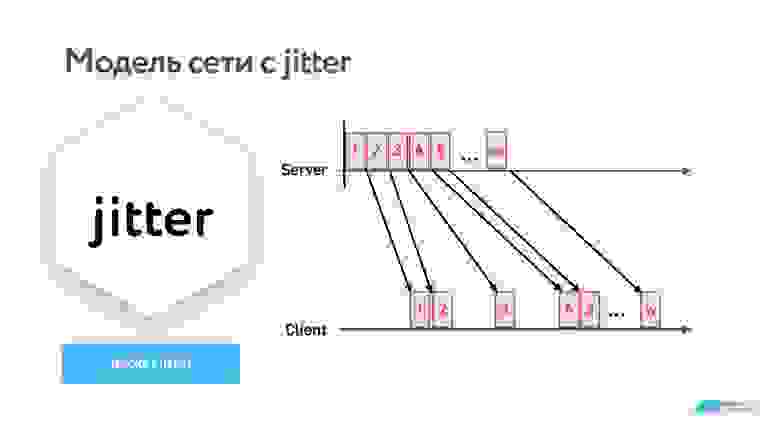
Jitter
Дело в том, что пакеты приходят не равномерно по одному, а сгруппированными пачками с каким-то интервалом.
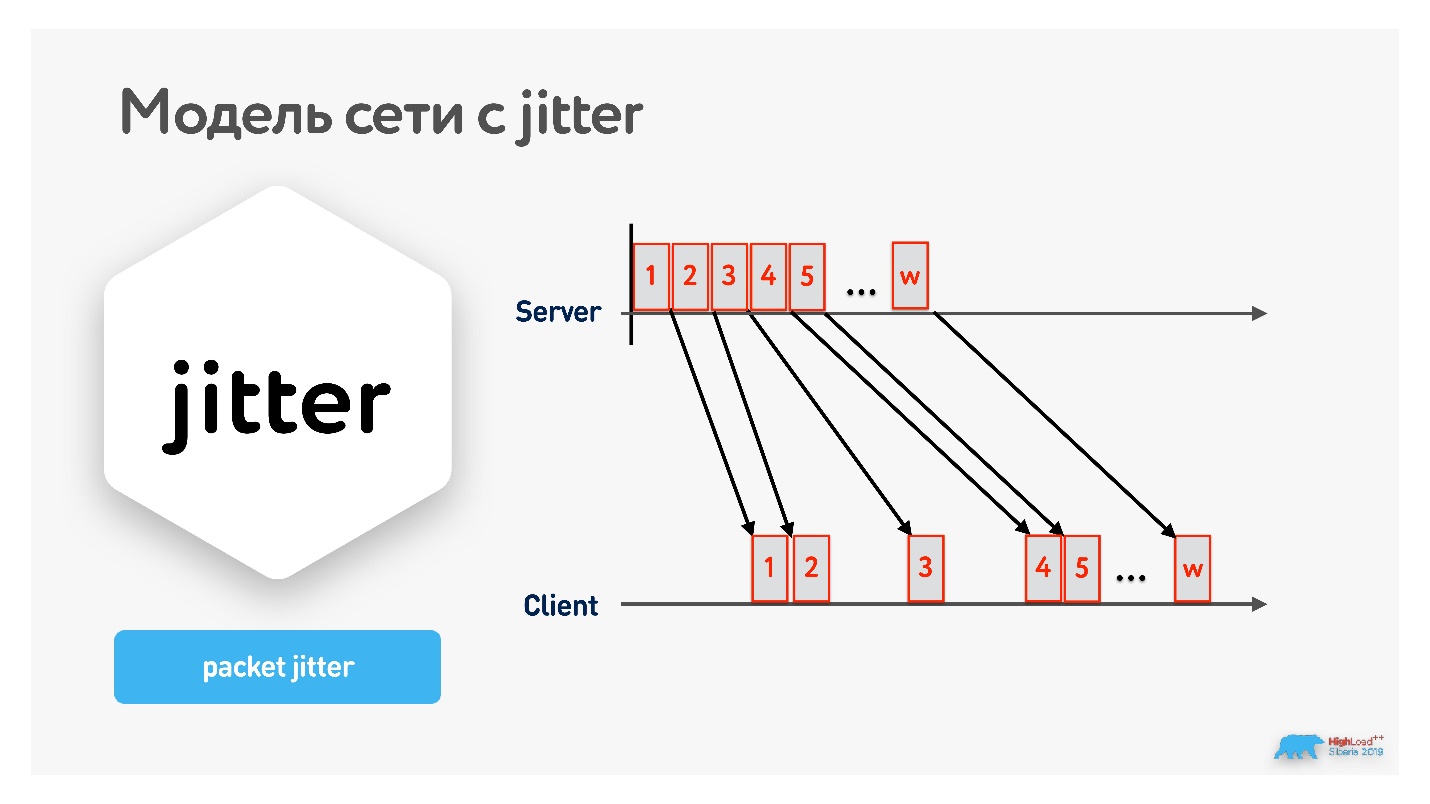
Jitter легко измерить:
PING highload.ru (178.248.233.16): 56 data bytes
icmp_seq=11 ttl=43 time=117.177 ms
icmp_seq=12 ttl=43 time=132.868 ms
icmp_seq=13 ttl=43 time=176.413 ms
icmp_seq=14 ttl=43 time=225.981 msПинганули highload.ru несколько раз (ping — нестабильная величина, надо усреднять), получили средний jitter:
((132-117)+(176-132)+(225-176)) / 3 = (14 + 44 + 79) / 3 = 46 мс.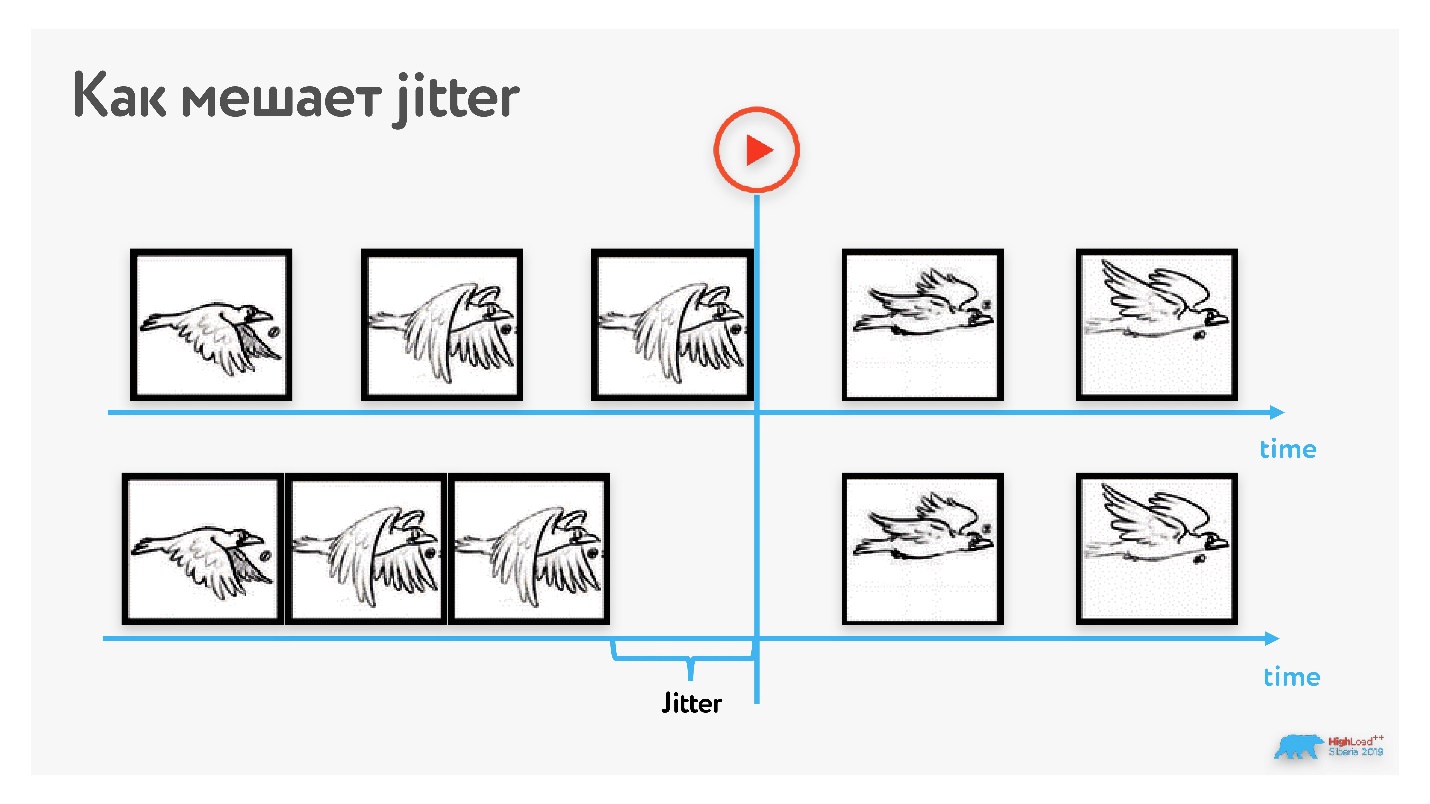
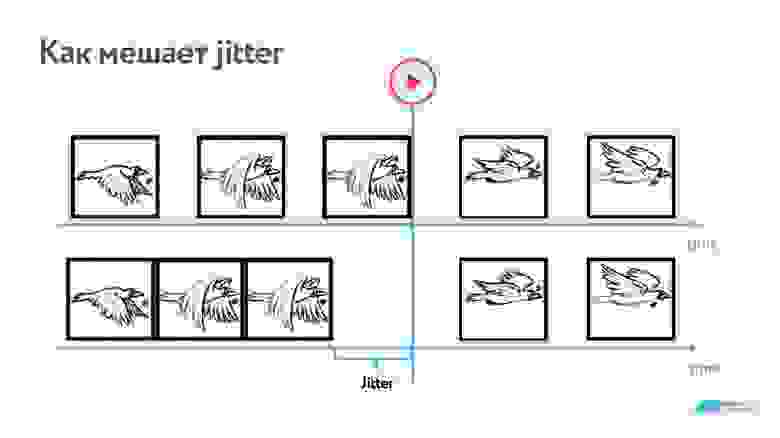
Предположим, мы передаем видео, и один кадр — это сетевой пакет. Несколько кадров проигрывается без перебоев, но третья птичка из-за jitter задерживается — получаем freeze кадра. Значит, надо где-то накапливать пакеты и выравнивать этот эффект.
То есть, чтобы характеризовать беспроводные сети, достаточно знать следующие величины:RTT (round-trip time); пропускную способность BW (bandwidth); процент потери пакетов (packet loss); jitter.
Как выглядит пользователь?
Перед тем, как приниматься оптимизировать работу с сетью, надо узнать, какой вообще интернет у пользователей — может, у всех сеть идеальная, любое решение будет работать.
В 80% случаев конечный пользователь использует беспроводное соединение: это или мобильная сеть, или Wi-Fi.

В России за пределами западного региона и крупных городов средние значения характеристик сети: RTT — 200 мс, bandwidth — 1,1 Мбит/с, packet loss — 0,6 %, jitter — 5мс.
Мы разбили эти значения по типам сетей и поняли, что учиться на этом работать необходимо.
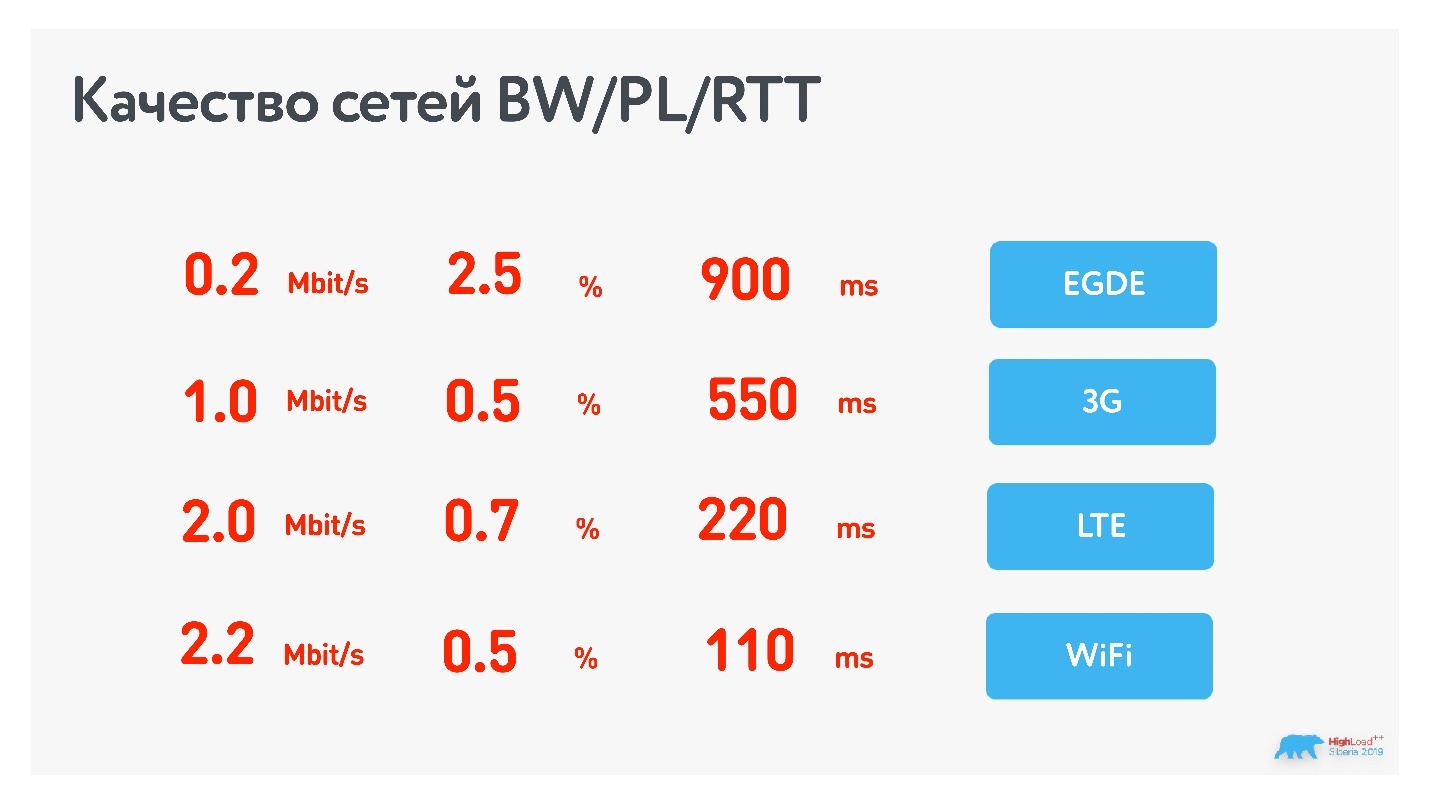
Особенности разработки звонков
Многие забывают, но LTE и 3G — это асимметричные каналы связи: downlink всегда больше, чем uplink. В зависимости от типа протокола это соотношение может меняться от 15/85 до 30/70. При разработке звонков это важно.
Как проверить, какой канал у ваших клиентов?
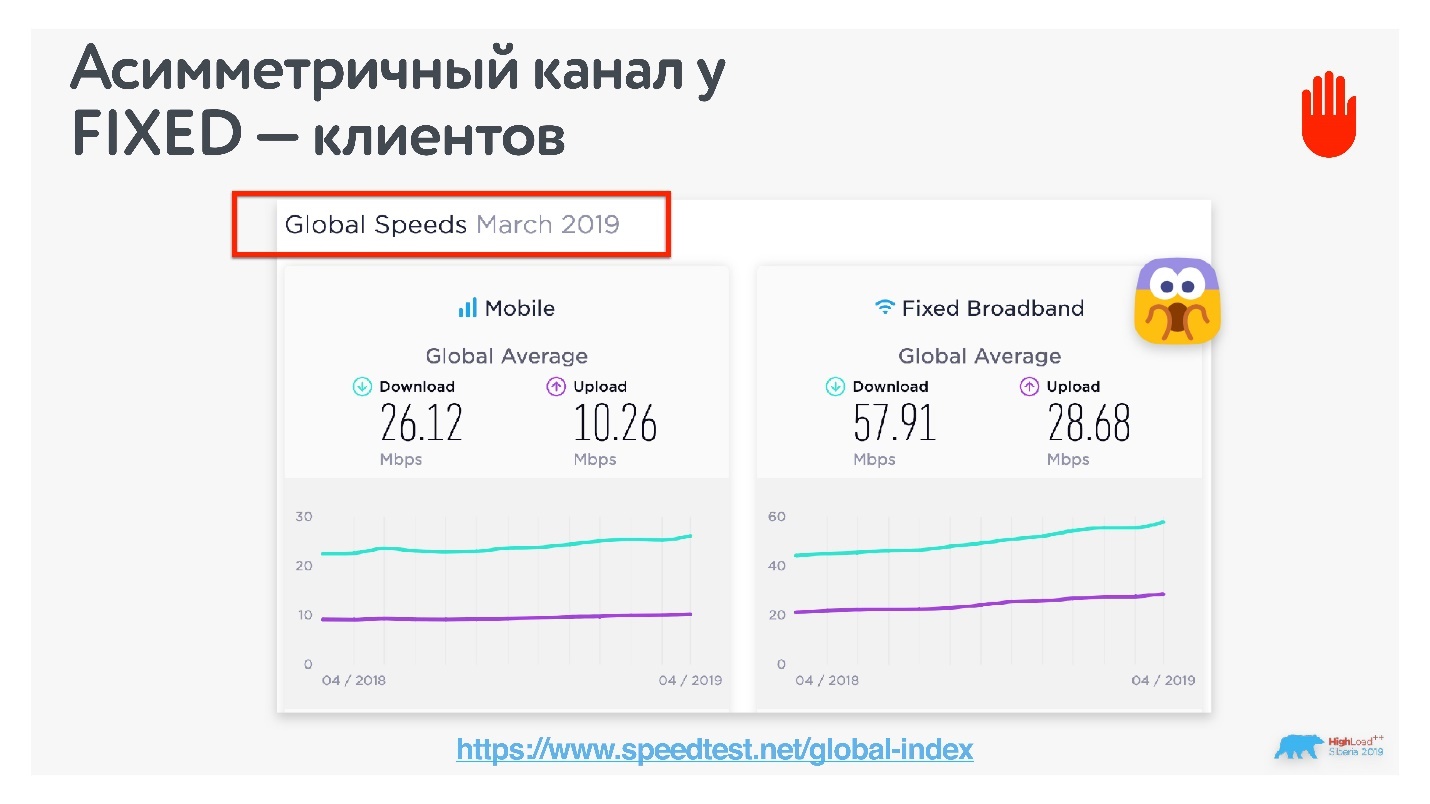
Можно посмотреть на speedtest, какое соотношение скорости в мире между мобильным и фиксированным интернетом. Оказалось, что по миру фиксированный интернет тоже ассиметричный. В России, к счастью, он оказался симметричным: соотношение uplink/downlink на фиксированном интернете через Wi-Fi в России 50/50. Будем ориентироваться на такие значения.

Промежуточный итог: беспроводные сети популярны и нестабильны.
- Больше 80% клиентов используют беспроводной интернет.
- Параметры беспроводных сетей динамично меняются.
- Беспроводные сети имеют высокие показатели packet loss, jitter, reordering.
- Асимметричный канал uplink/downlink в соотношении 30/70.
Звонки
С этим багажом знаний вернемся к реализации групповых звонков. Рассмотрим алгоритм простого группового звонка, который потом доработаем.
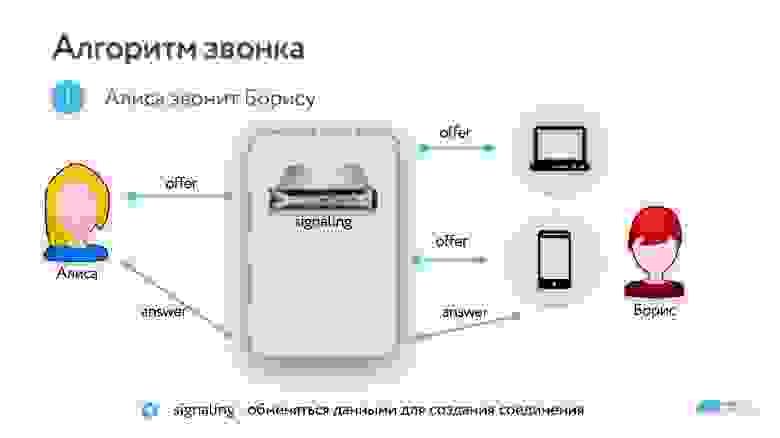
Шаг 1. Алиса хочет позвонить Борису и отправляет ему оффер, в котором сообщает все, что она умеет, какие поддерживает протоколы, настройки и т.д.
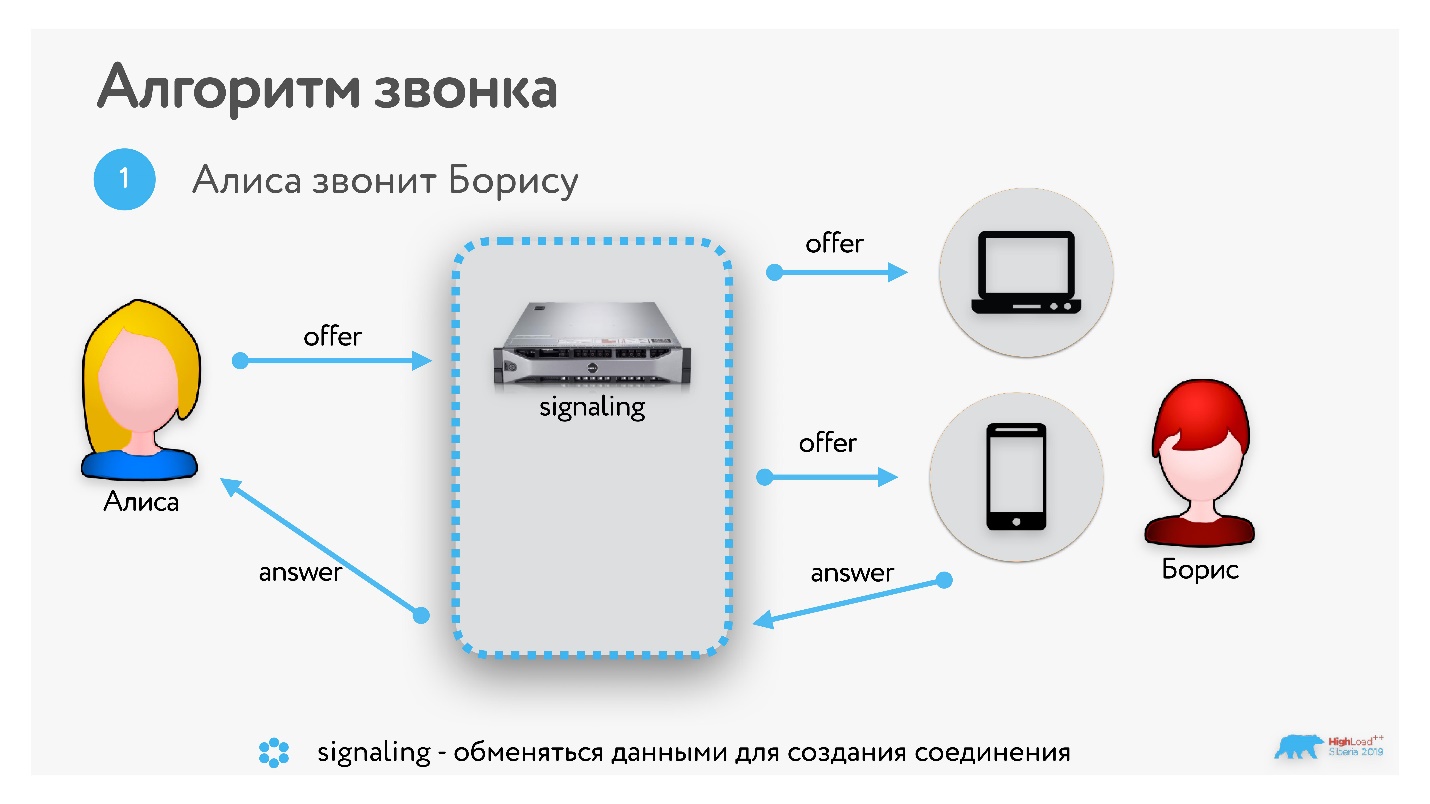
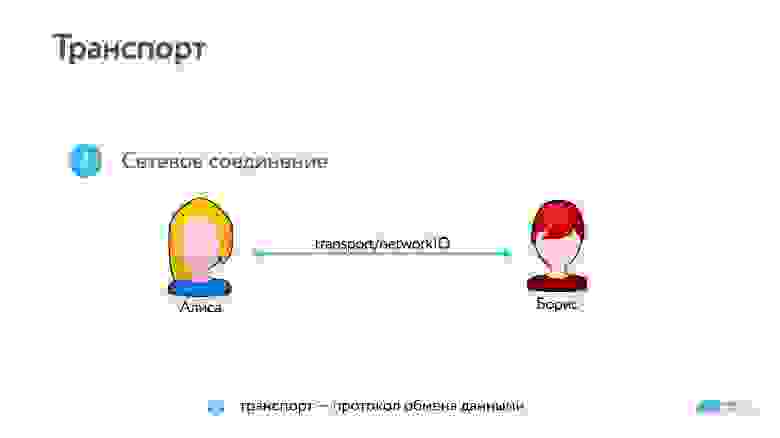
Шаг 2. Борис отвечает Алисе, после этого устанавливается транспортное соединение.
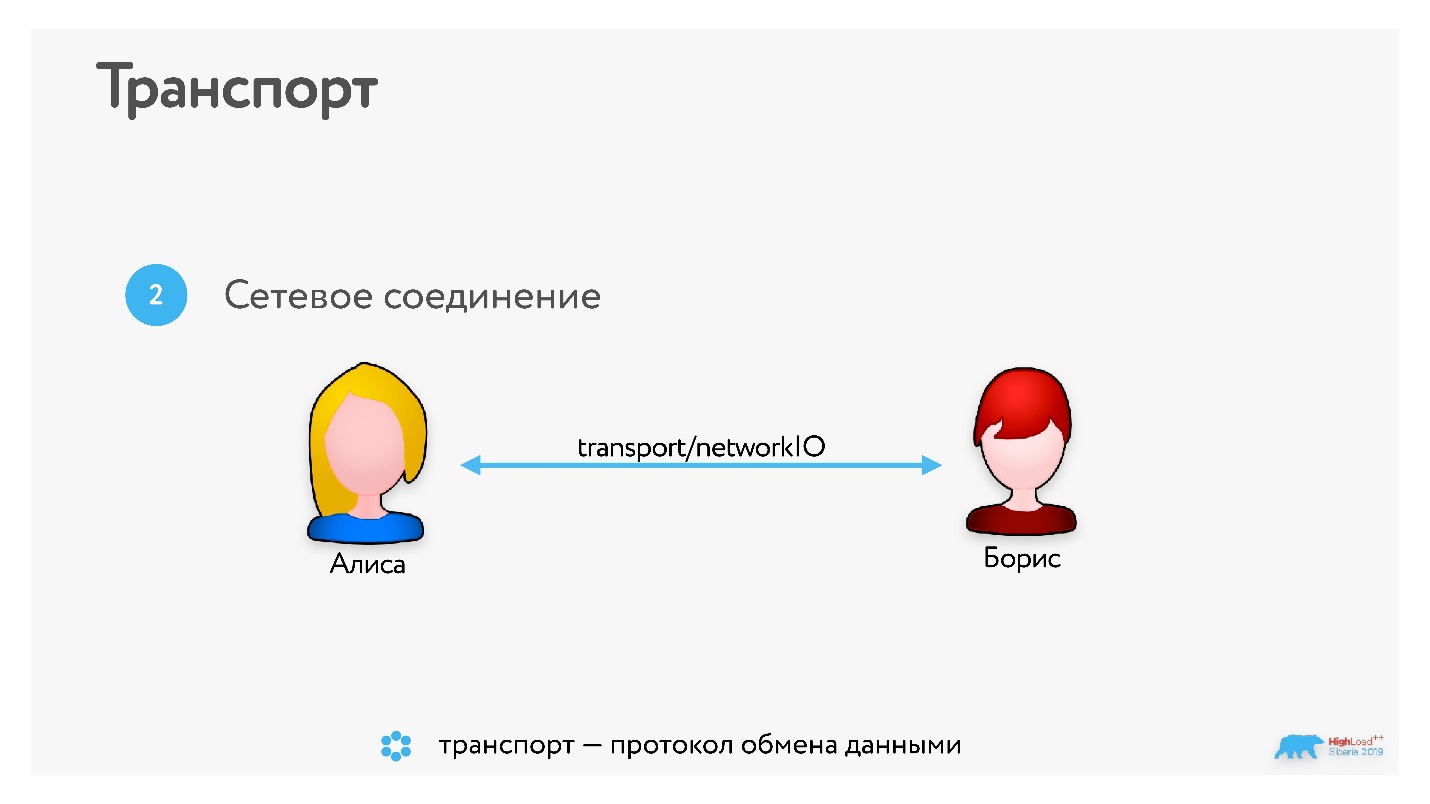
Шаг 3. После этого начинается обмен аудио/видео данными.

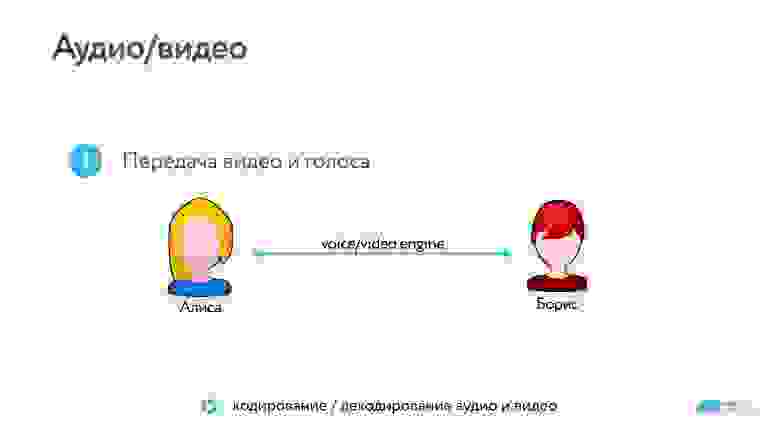
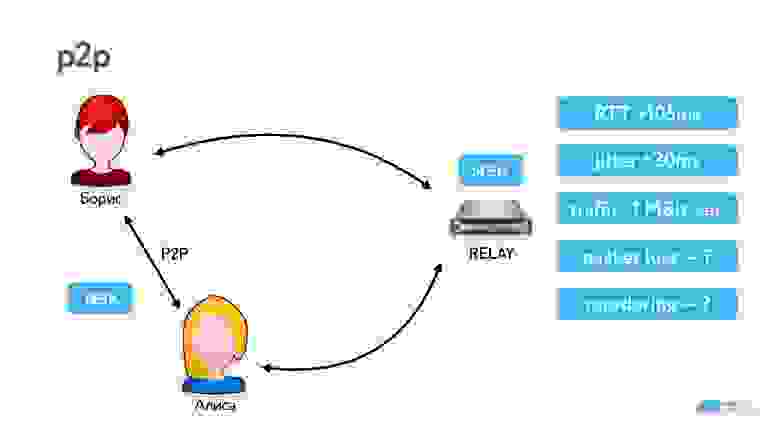
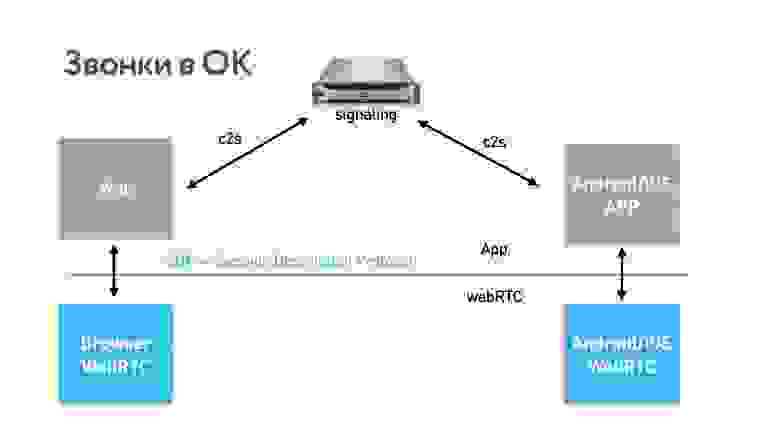
Архитектура любых звонков выглядит примерно так, как показано на схеме ниже.

Всегда есть общий сервер, но когда соединение установлено, пользователи уже могут передавать данные p2p или через сторонние серверы.
Данные снимаются камерой, которая их кодирует на устройстве и отправляет в сокетное соединение. Они проходят по сети, воспроизводятся на другой стороне кодеком и отображаются на экране.
Рассмотрим все шаги алгоритма подробно и попробуем перейти от звонков 1-на-1 к групповым.
Signaling
Задача: сообщить о звонке и установить data-соединения.
Все достаточно просто:
- Алиса звонит, Борису отправляется уведомление на мобильное устройство или в браузер.
- Устанавливается вебсокетное или любое другое соединение.
- После этого происходит negotiation — Алиса и Борис договариваются.
- Когда на одном устройстве сняли трубку, на другом звонок завершается автоматически.

Платформа звонков в Одноклассниках поддерживает различные клиенты и транспорты. Они все замыкаются на какой-то сервер, который занимается обслуживанием звонка и пересылкой сообщений.
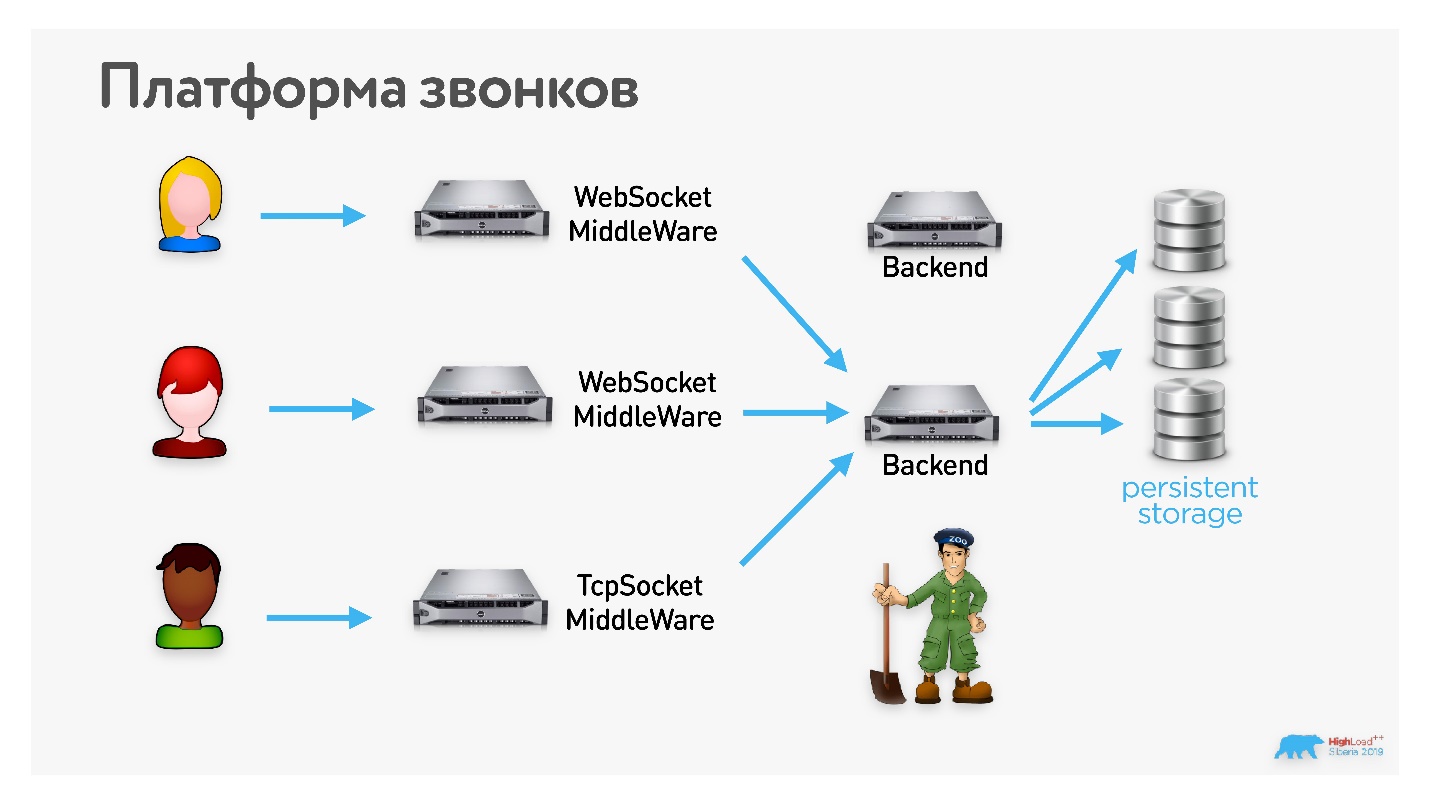
На случай сбоя на сервере или установки обновлений есть персистентное хранилище, в которое записываются все сообщения. В случае потери сервера можно легко переключиться на другой. Этим занимается ZooKeeper.
Единственная сложность — exactly-once. Мы не хотим применять некоторые сообщения два раза. Эта проблема решается просто: все сообщения имеют порядковый номер — два раза одно сообщение не придет.
Кроме того, нужно быть аккуратными при создании звонка. Человек может создать звонок, повесить трубку и создать еще один звонок. А может не повесить, но все равно создать еще один. Все эти звонки неуникальные — непонятно, это ретрансмит или пользователь два раза нажал на кнопку звонка. Чинится легко: на клиенте генерируется уникальный ID, и по нему производится дедупликация. В принципе, в signaling никаких сложностей нет.
p2p signaling до группового дорабатывается нетрудно.
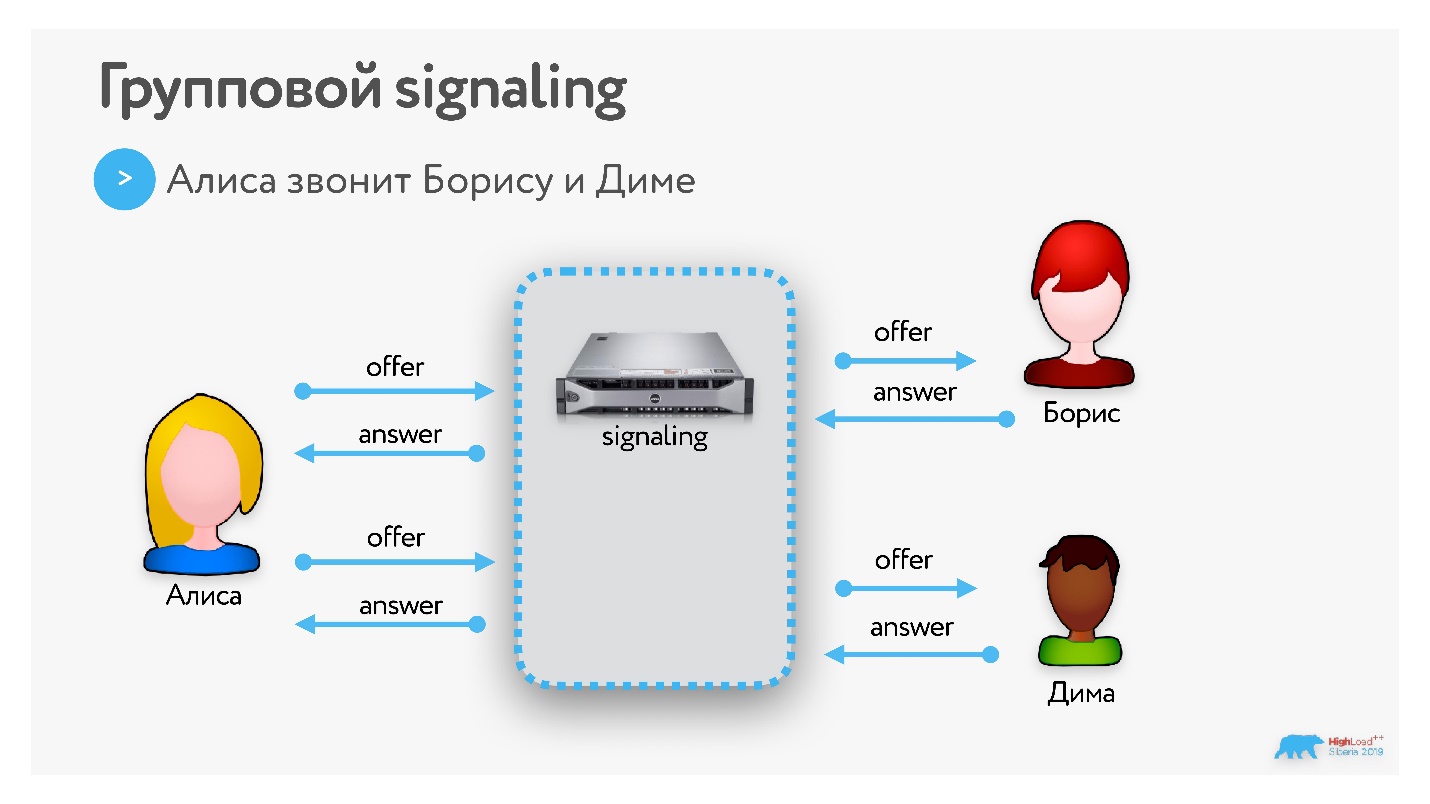
Те самые offers и answers Алиса теперь отправляет не только Борису, но и Диме. Они их получают, соглашаются, между ними появляются каналы обмена данными.
Аудио/Видео
Для того, чтобы справиться с групповым звонком и понять, какие нужны технологии, нам придется чуть-чуть поговорить о том, что такое видео.
Видео — это 24 или 60 кадров в секунду. Для того, чтобы их сжимать, используются кодеки. Основная суть кодеков в том, что раз в несколько кадров есть опорный кадр (типа JPEG), а промежуточные кадры определяются через изменения.
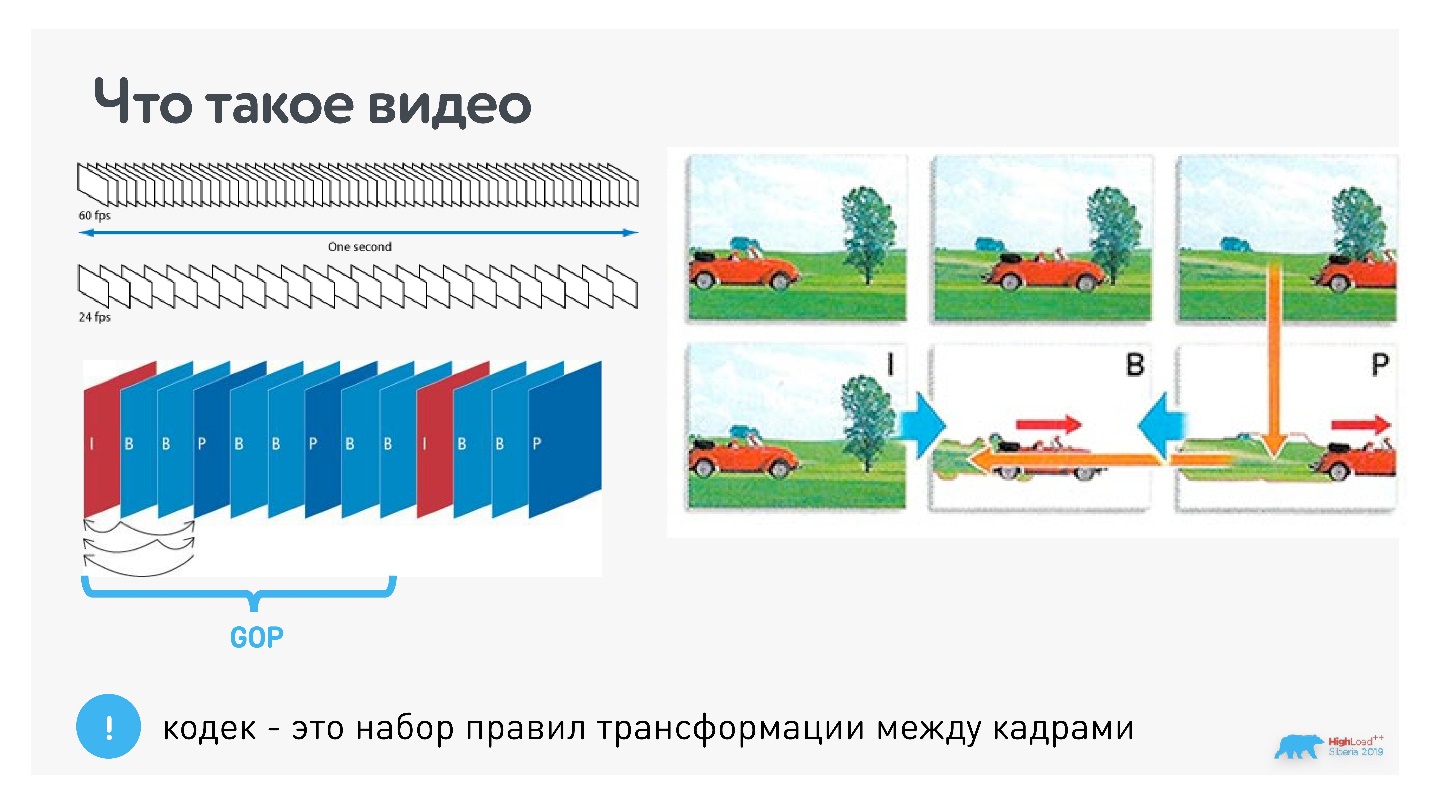
На картинке выше первый кадр с машиной опорный, а в следующем кадре кодируются только изменения (перемещение машины), и в следующий раз тоже только изменения.
Это называется group of picture — независимый набор взаимосвязанных фреймов, которые можно декодировать. Кодек — это алгоритм трансформации между кадрами. Чем круче кодек, тем он лучше сжимает данные, и тем больше ресурсов ему нужно.
| Качество | Разрешение | Минимальный битрейт |
| FullHD | 1920x1080 | 4 Мбит/с |
| HD | 1280x720 | 1,5 Мбит/с |
| low | 640x360 | 600 Кбит/с |
| lowest | 426x240 | 300 Кбит/с |
Самые популярные кодеки, используемые для звонков, — это H.264 и VP8. H.264 хорош тем, что он везде хардварно работает и не жрет батарейку. Но обычно на телефонах один энкодер (кодировщик) и 4 декодеровщика. Для всего остального нужен софтверный VP8, который неплохо потребляет батарею. Стоит поменять приоритет на H.264 для групповых звонков (см. ссылку, как это сделать).
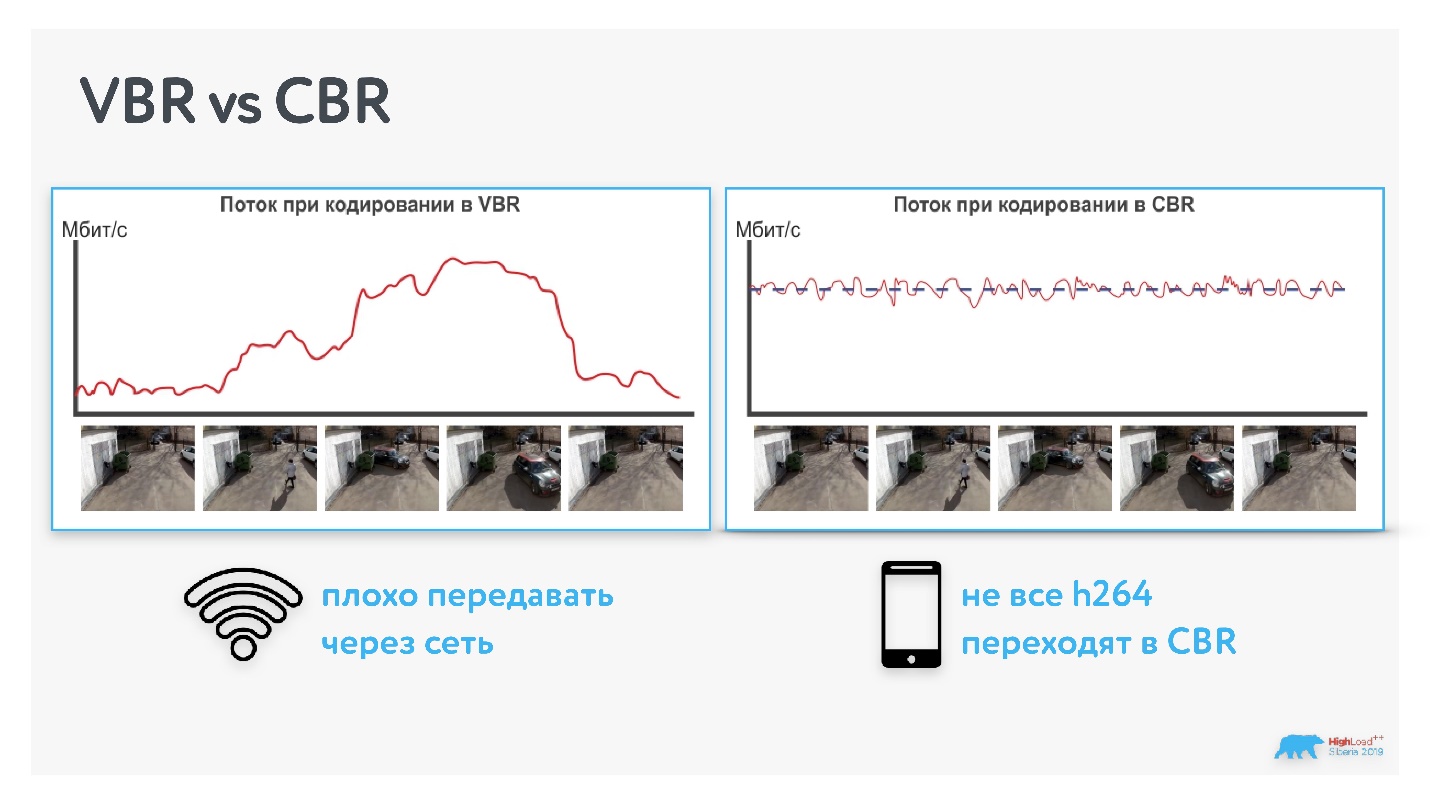
Кодек может кодировать с переменным (Variable bitrate) или постоянным битрейтом (Constant bitrate). Многие кодеки на устройствах не поддерживают постоянный битрейт, поэтому придется жить с картинкой слева.
Аудиокодеки
Для аудио есть различные legacy-кодеки, например, G711. Очень популярен кодек Opus — он решает задачу кодирования и при низких битрейтах, и при высоких, потому что внутри содержит SILK из Skype и кодек CELT для музыки.
Стоит сказать, что в Opus есть алгоритм превентивного исправления ошибок Forward Error Correction (FEC). Для аудио этот алгоритм работает так: в каждом пакете есть данные в высоком качестве и данные предыдущих фреймов за какое-то время в низком качестве. Соответственно, если предыдущий пакет потерян, можно достать данные предыдущего пакета в низком качестве и как-то проиграть. В среднем получается довольно неплохо.
При работе с аудиокодеками интересно посмотреть на график, где представлено соотношение качества входного сигнала и битрейта.
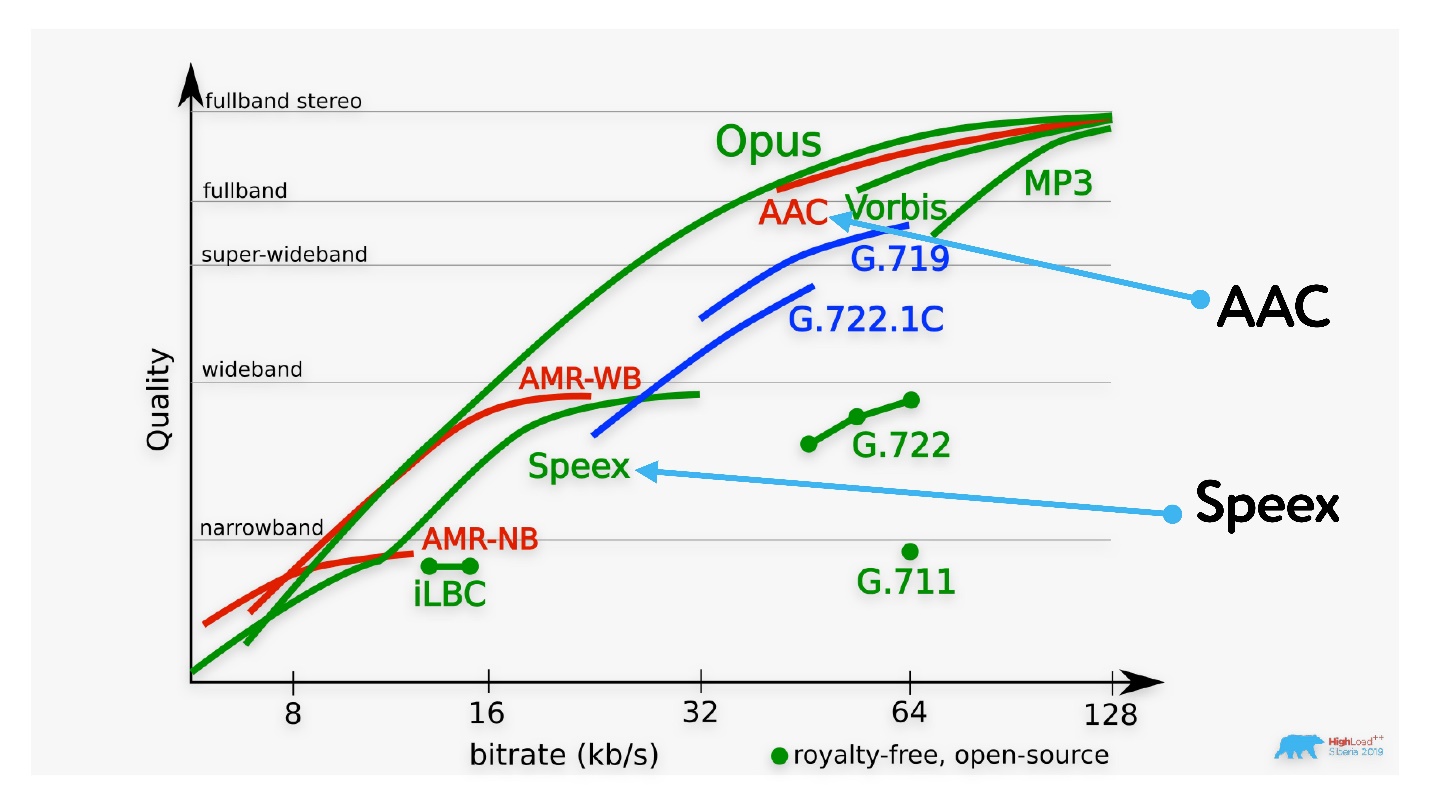
Видно, что Opus решает почти все проблемы. Любопытно обратить внимание на AAC, который используется при кодировании видео в различных хостингах и на старый кодек Speex, который использовался исключительно для аудио и до 32 Кбит/с отлично работает.
Медиатопологии данных
Для того, чтобы понять, как работают топологии, какие у них особенности, надо понять, как видеокодек справляется с потерями.

В первом случае ничего не пропало, и мы видим хорошую картинку. Во второй строке потерян один случайный кадр — на картинке есть небольшие артефакты. В третьем случае пропал опорный кадр, поэтому до следующего опорного будут показываться хаотично накладвающиеся друг на друга изменения.
Очевидно, делать опорные кадры часто — дорого, потому что растет битрейт. Поэтому почти все сервисы звонков так или иначе поддерживают возможность запросить опорный кадр в случае его потери. В WebRTC это называется full INTRA-frame.
Самая простая топология — это отправить все свое видео всем остальным участникам конференции.
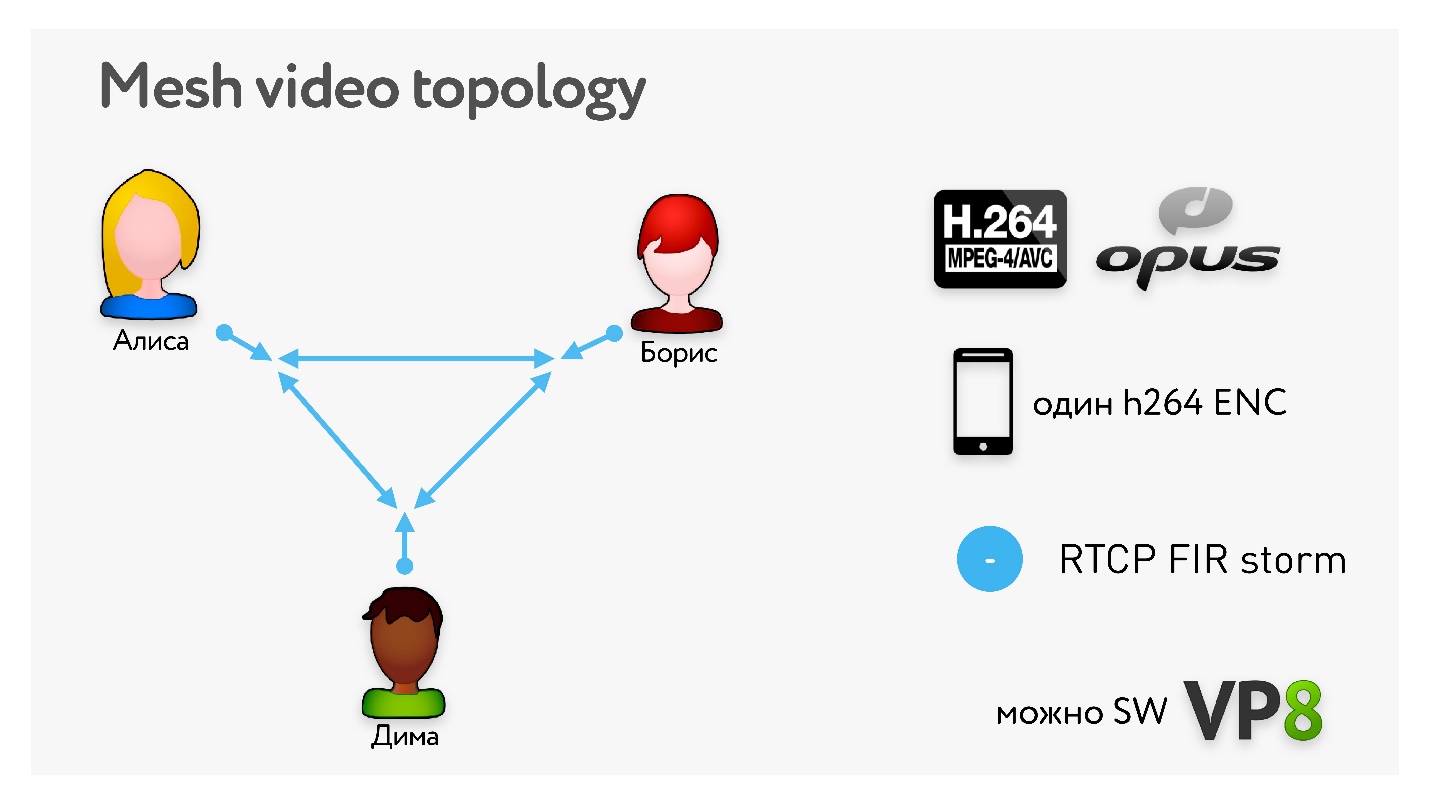
Запускаем один кодек и начинаем передавать видео. Алиса включает камеру, кодек, отправляет свое видео Борису и Диме. Но если у Димы плохой интернет, страдает Борис, потому что нужно понижать качество всего видео. А если Дима потерял кадр и запросил опорный, Борис тоже его получит, хотя ему он и не был нужен.
С другой стороны, можно все видео склеить в один поток. Для этого потребуется специальное оборудование и, возможно, будут дополнительные задержки, но такое решение тоже есть.
Транспорт или доставка видео и аудио с минимальной задержкой
На выбор у нас есть TCP или UDP протоколы.
| TCP | UDP |
| Reliable | Unreliable |
| Connection-oriented | Connectionless |
| Segment retransmission and flow control through windowing | No windowing or retransmission |
| Segment sequencing | No sequencing |
| Acknowledge sequencing | No acknowledgment |

Если в пакете пропал кадр, на видео вы могли свободно бы пропустить этот один из 24 кадров, но TCP не даст получить следующие, пока не перешлет потерянный. Доставлять видео по TCP крайне неэффективно. Для таких задач рекомендован UDP, и все сервисы звонков используют именно его.
В этой статье приводятся все особенности обоих протоколов и объясняется, почему весь стриминг работает на UDP. В рамках сегодняшней темы нам достаточно знать, что UDP доступен не везде, он не работает в 3% сетей.

А вообще, пользователи могут между собой устанавливать р2р-соединения.

Это максимально выгодно, потому что если мы в Новосибирске звоним друг другу, то гораздо лучше общаться напрямую и не использовать дополнительный сервер, который даст плечо.
Но существует NAT, и больше 97% пользователей сейчас располагаются за ним — мало у кого есть внешние IP. Эту проблему с одной стороны рано или поздно решит IPv6. Кстати, в России его первым запустил МТС. Сейчас они полностью поддерживают IPv6, и у всех их клиентов белые IP.
NAT может пробиться, может не пробиться, и тогда придется использовать fallback через сервер. О том, как пробивать NAT тоже есть статья.
Jitter buffer между транспортом и кадрами
Двигаемся дальше. Теперь нам нужен jitter buffer, чтобы нивелировать эффект от jitter
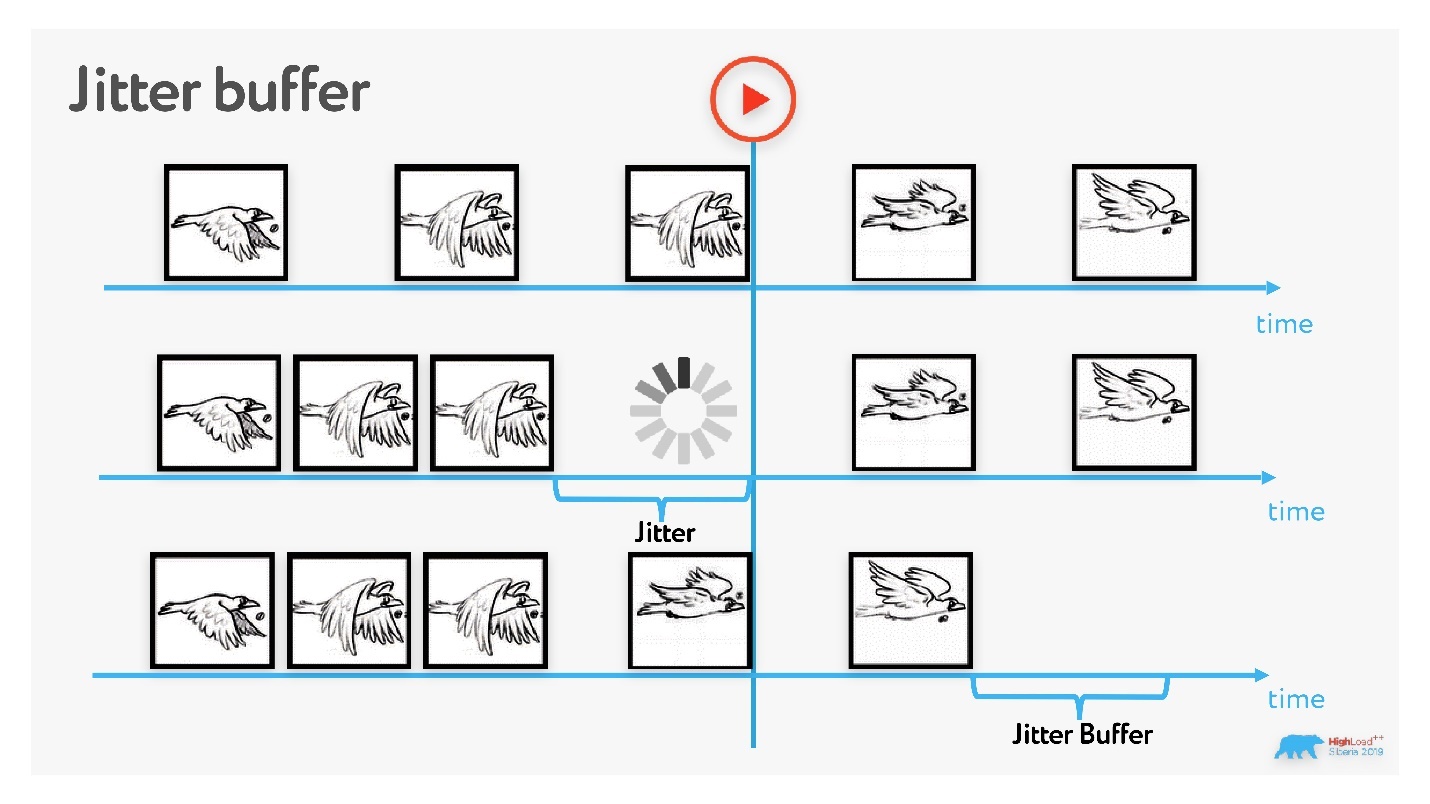
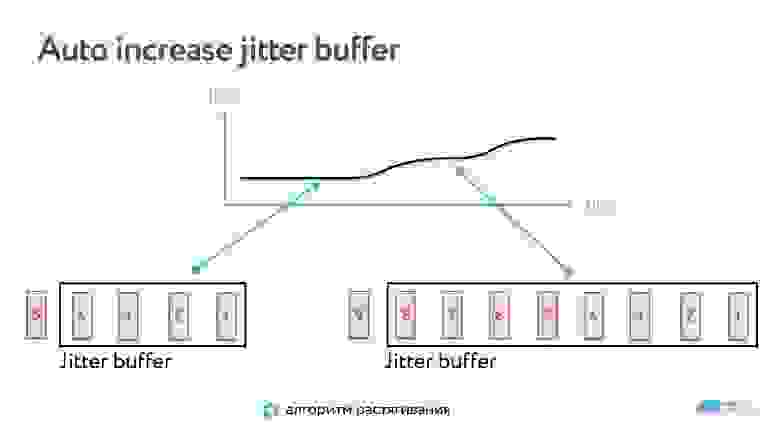
Мы превентивно начинаем показывать кадры с какой-то задержкой и тем временем выстраиваем кадры через одинаковый интервал в буфере.
Буфер увеличивается динамически.
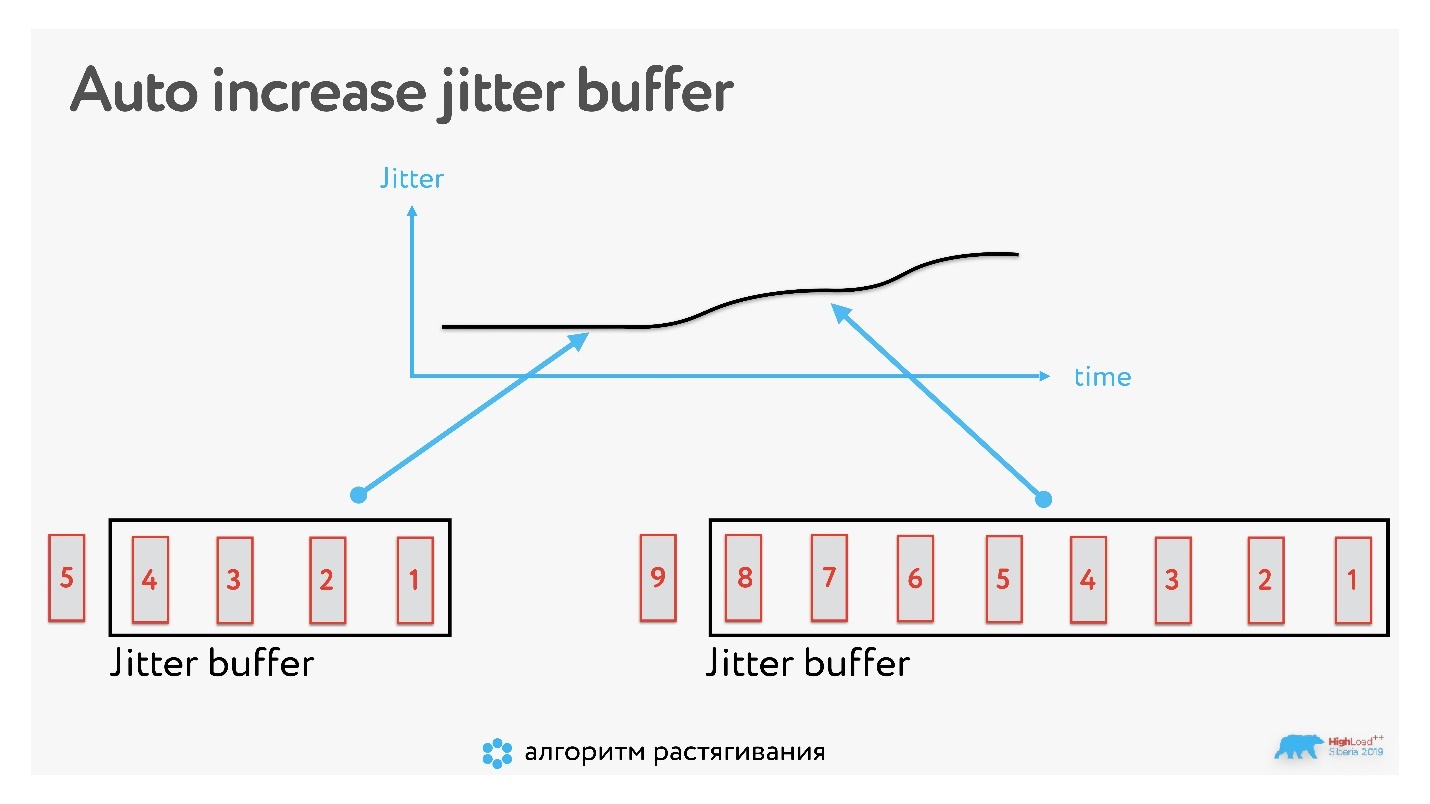
Если кадр пропал, и картинка заморозилась, то буфер увеличивается, и дальше мы работаем уже с буфером этого размера.
Но может быть и обратная ситуация, когда нужно уменьшить буфер. Например, сеть стабилизировалась, а время нужно нагнать. Если просто уменьшить буфер, получится смешно, люди начнут очень быстро говорить голосом гномика. Поэтому есть специальные алгоритмы, которые незаметно для вас подгоняют скорость аудио: убирают паузы между словами или схлопывают звуки, которые в речи слишком тянутся.
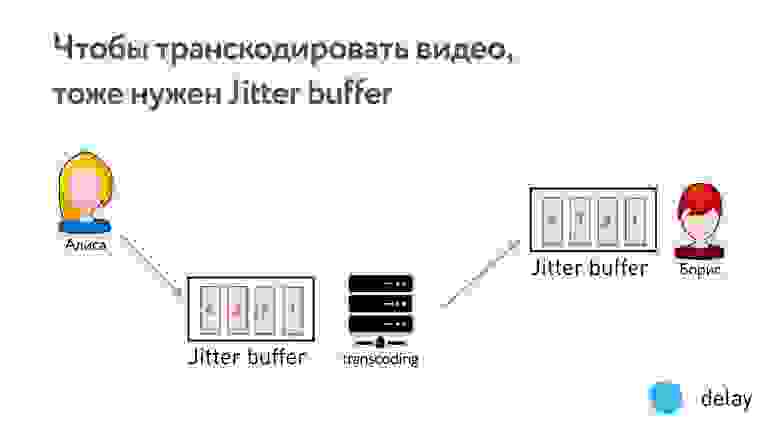
Если хотите транскодировать видео и что-то поправить, предварительно нужно иметь jitter buffer, и его latency будет не меньше, чем latency jitter этой сети. То есть это однозначно увеличивает latency, а мы помним, что очень хотим уложиться 0,5 с.
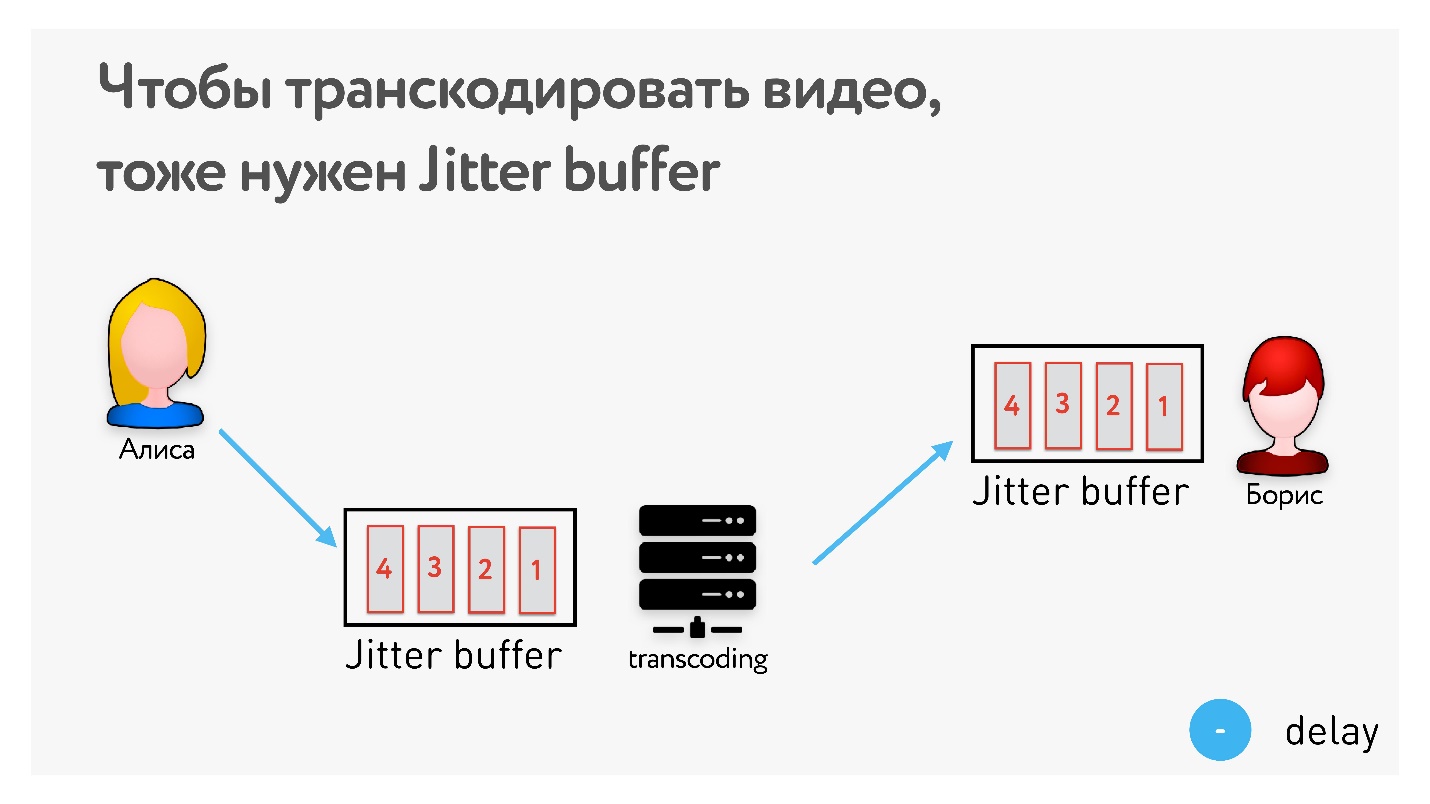
Выдыхаем — теория закончилась!
Звонки на OK
До групповых звонков у нас были p2p-звонки, использовалась библиотека WebRTC, были собраны веб и мобильные клиенты, написан signalling.

Анализ конкурентов
Когда не знаешь, что делать, — смотри конкурентов. Для ориентира мы выбрали набор: Skype, WhatsApp, Hangouts, ICQ, Zoom. Измеряли максимальное число участников в групповом звонке, задержки, потребление батарейки и качество.
Самое интересное — определить задержку. Делаем это так: включаем таймер, начинаем снимать видео, звоним.

100 мс — задержка камеры от момента, как видео попало на объектив, до того, как оно отрисовалось на матрице телефона. После этого видео отправляется в сеть, и мы видим задержку 310 мс уже в звонке.

Не забываем замерять использование CPU на устройстве. Начиная с iOS 12 появилась возможность делать это системно, но мы по старинке используем пирометр.
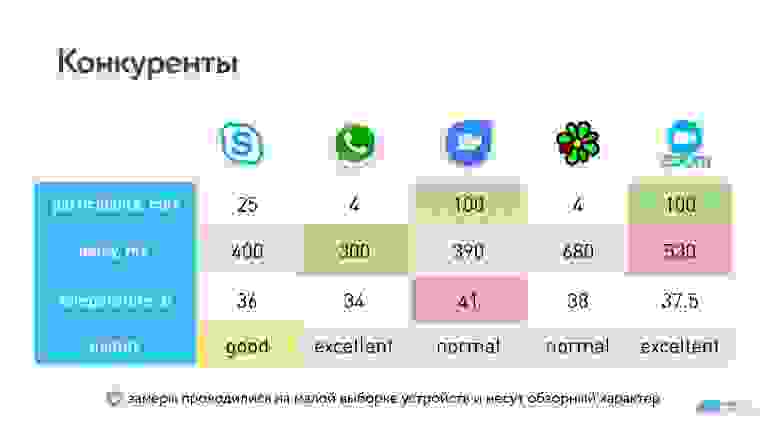
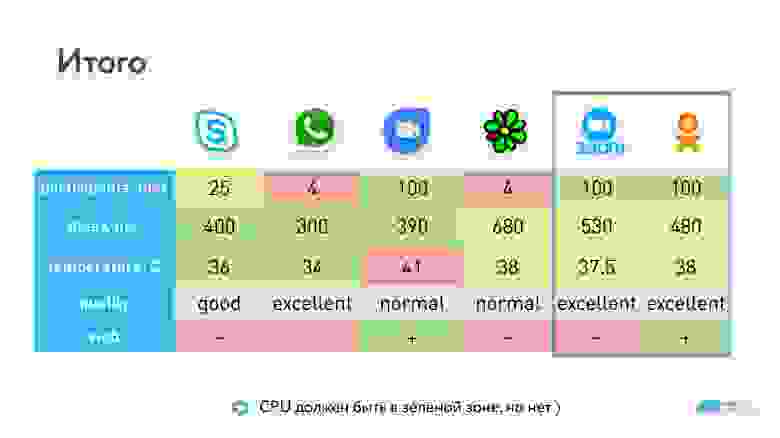
Получили следующие результаты:
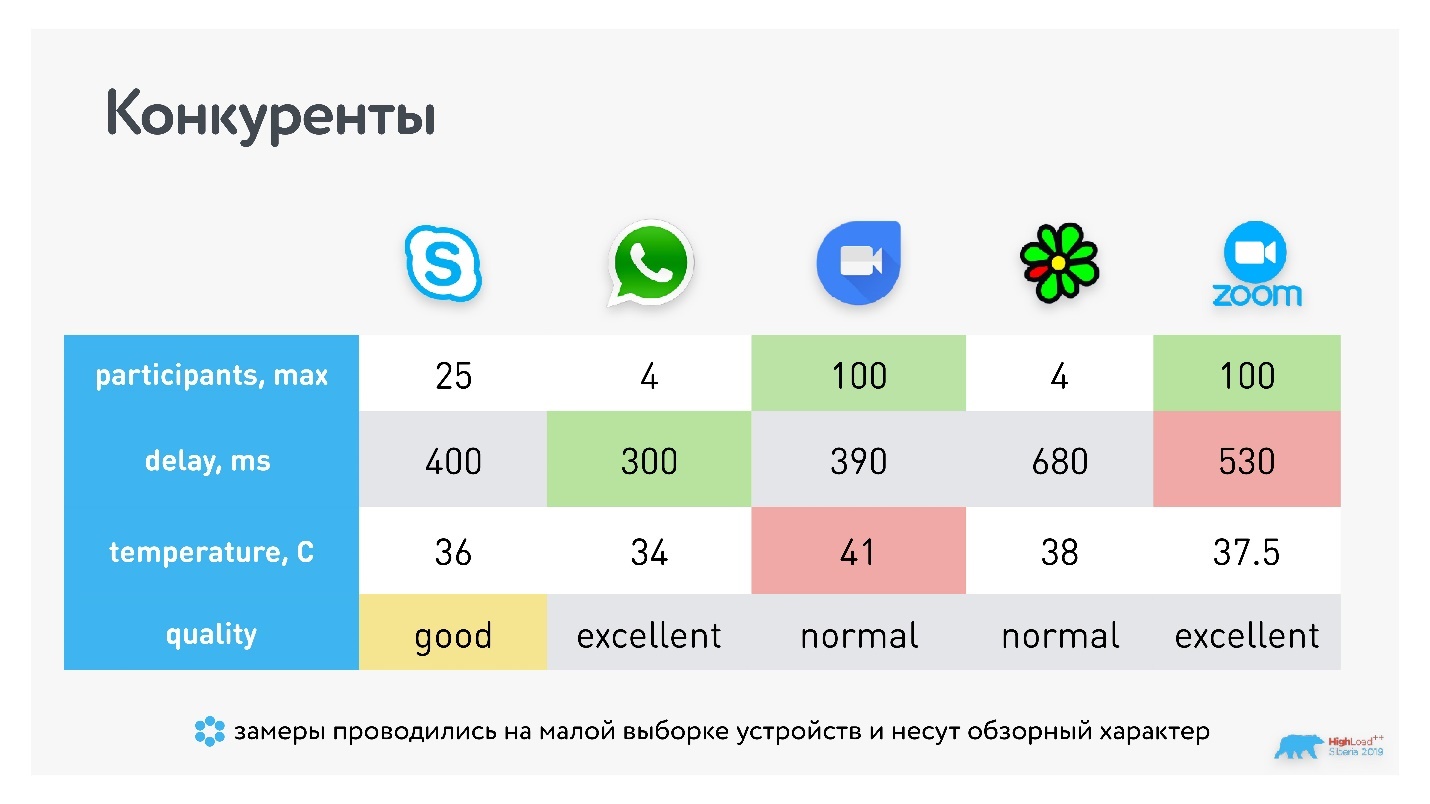
У WhatsApp и ICQ максимальное количество участников звонка всего 4, у Skype — 25 (у Skype for Business 250), и по 100 участников у Hangouts и Zoom. У Hangouts раньше было порядка 35 участников, сейчас он перепрыгнул в раздел 100+.
У Zoom чуть больше задержка, но при этом Hangouts сильнее расходует батарейку. Мне показалось, что качество лучше у Zoom, но есть статьи, которые говорят обратное, — это субъективная метрика.

Часть сервисов используют открытый WebRTC, другие — проприетарные протоколы. Но очевидно, что то, какой транспорт вы используете внизу, никак не влияет на количество участников в звонке. Есть решения со 100 звонками и со своими протоколами (Zoom), и с WebRTC (Hangouts).
Масштабирование от 2 к N
Рассмотрим интересный кейс: есть клиент, у которого асимметричный канал, вход 3 Мбит/с, выход 1.5 Мбит/с, packet loss 0,6%, jitter 50 мс. Есть видео в HD (1280х720) с битрейтом 1,5 Mбит/с и видео с разрешением 640х360 (назовем LOW) на 600 Кбит/с. Хотим передавать классные видео.
В случае, если два человека звонят p2p, то все просто. Им хватает входной сети, выходной сети хватает уже впритирку, потому что канал асимметричный, и с кодеками проблем нет — все кодеки свободны.
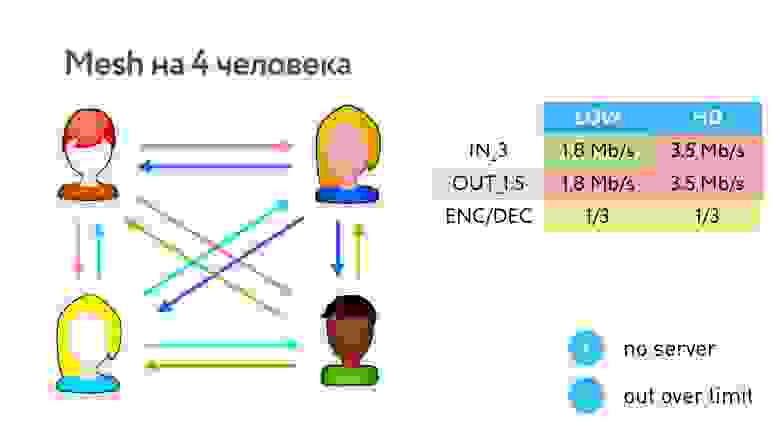
Когда мы начинаем делать групповые звонки, надо всех перезамыкать. Самый простой вариант топологии — это Mesh или «все ко всем».
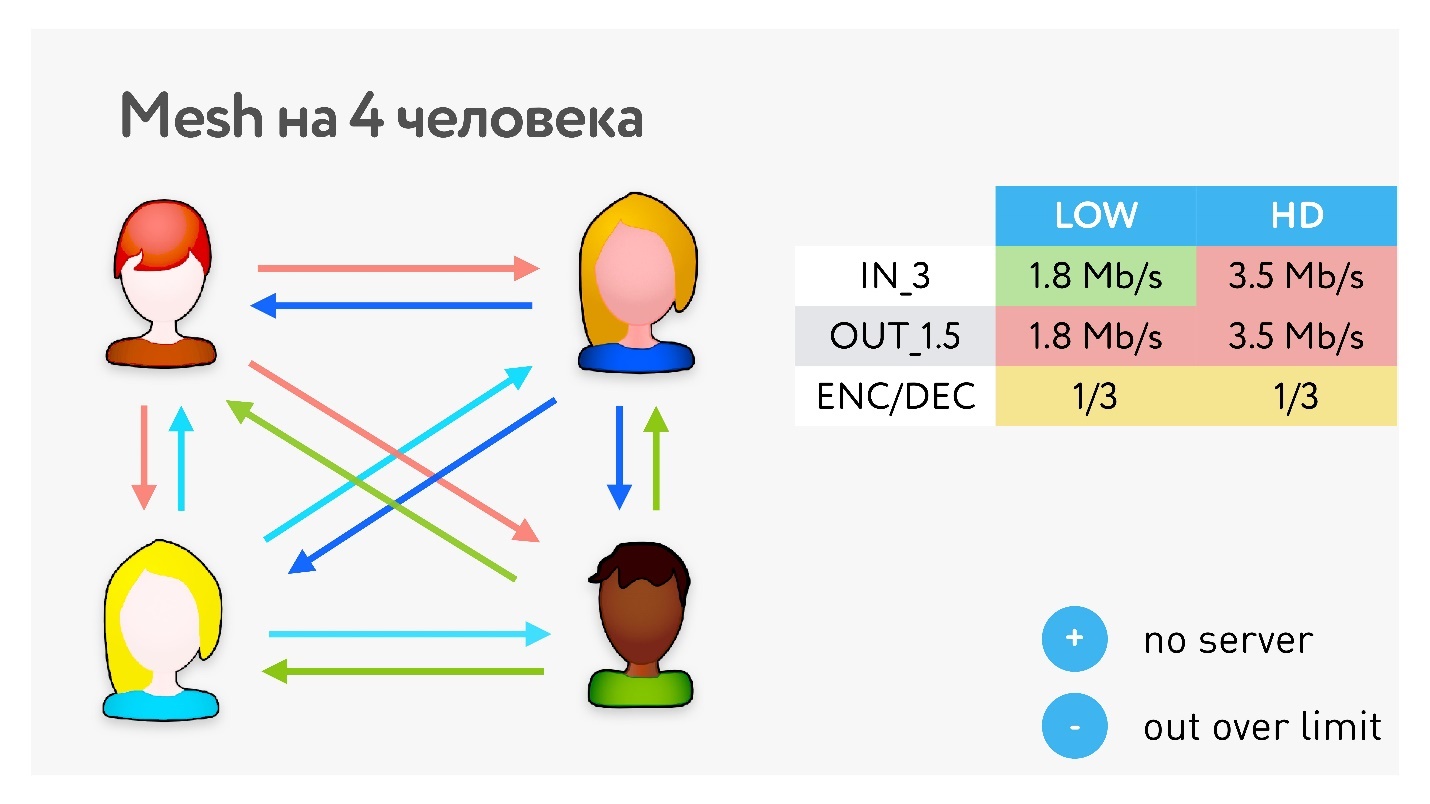
Здорово, что не нужны промежуточные серверы, но раздать всем свое видео для клиентов с такими характеристиками становится проблематично. А если клиент не может раздать видео кому-то одному, то нужно понизить качество, потому что кодируется общий поток для всех.
В таком варианте для 5 участников уже ни 3, ни 4 Мбит/с не хватит.

Поэтому в WhatsApp в групповом звонке максимально 4 участника, и больше не будет до тех пор, пока они используют Mesh.
Другой вариант — всю картинку собрать на сервере. Для клиента это максимально выгодно: он имеет одно соединение с сервером, сервер собирает картинку, клиент получает ее обратно.
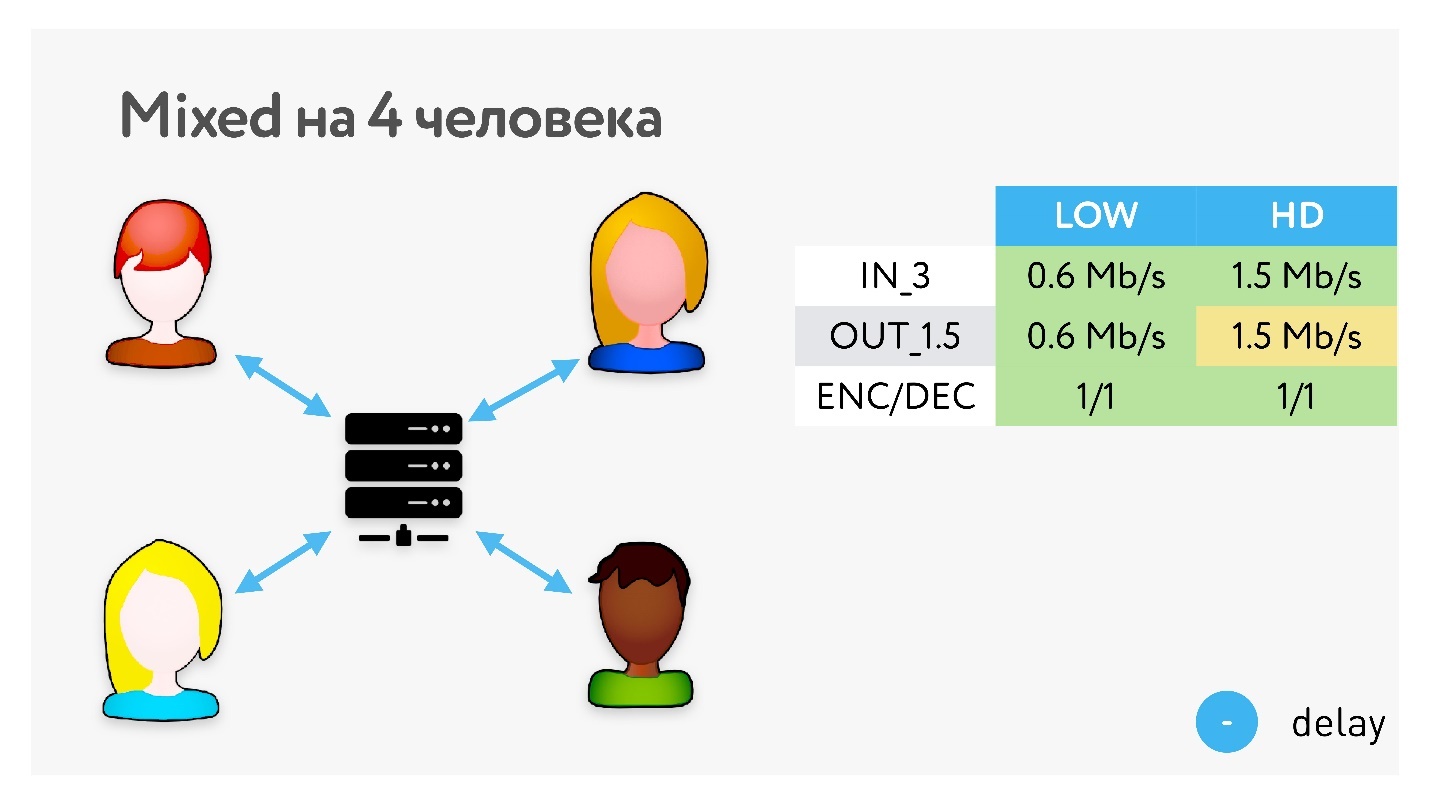
Но предположим, наши пользователи из Петропавловска-Камчатского, Комсомольска-на-Амуре и Новосибирска хотят пообщаться через московский сервер. Естественно, получится очень плохо. Наличие CDN чуть-чуть поможет, но все равно получится большой объем jitter-буферов, которые суммарно внесут приличную добавку к latency.
Следующая топология — End mixing — предлагает не собирать общую картинку на сервере, чтобы избежать этих задержек, а просто перекидывает пакеты.

То есть сервер в этой топологии просто ретранслятор, который перебрасывает данные.
Всё становится несколько лучше: пользователь получает потоки всех других участников звонка и отправляет свой только один раз. Но опять есть проблемы:
- Качество. Все получатели вашего потока имеют разную сеть. Если подключился один человек с плохим интернетом, то ему видео нужно доставить в низком разрешении и, соответственно, картинка испортится для всех.
- Шторм опорных кадров. Если человек с плохим интернетом постоянно просит опорный кадр, то все тоже начинают получать опорники. Это неэффективное использование битрейта, качество снова снижается.
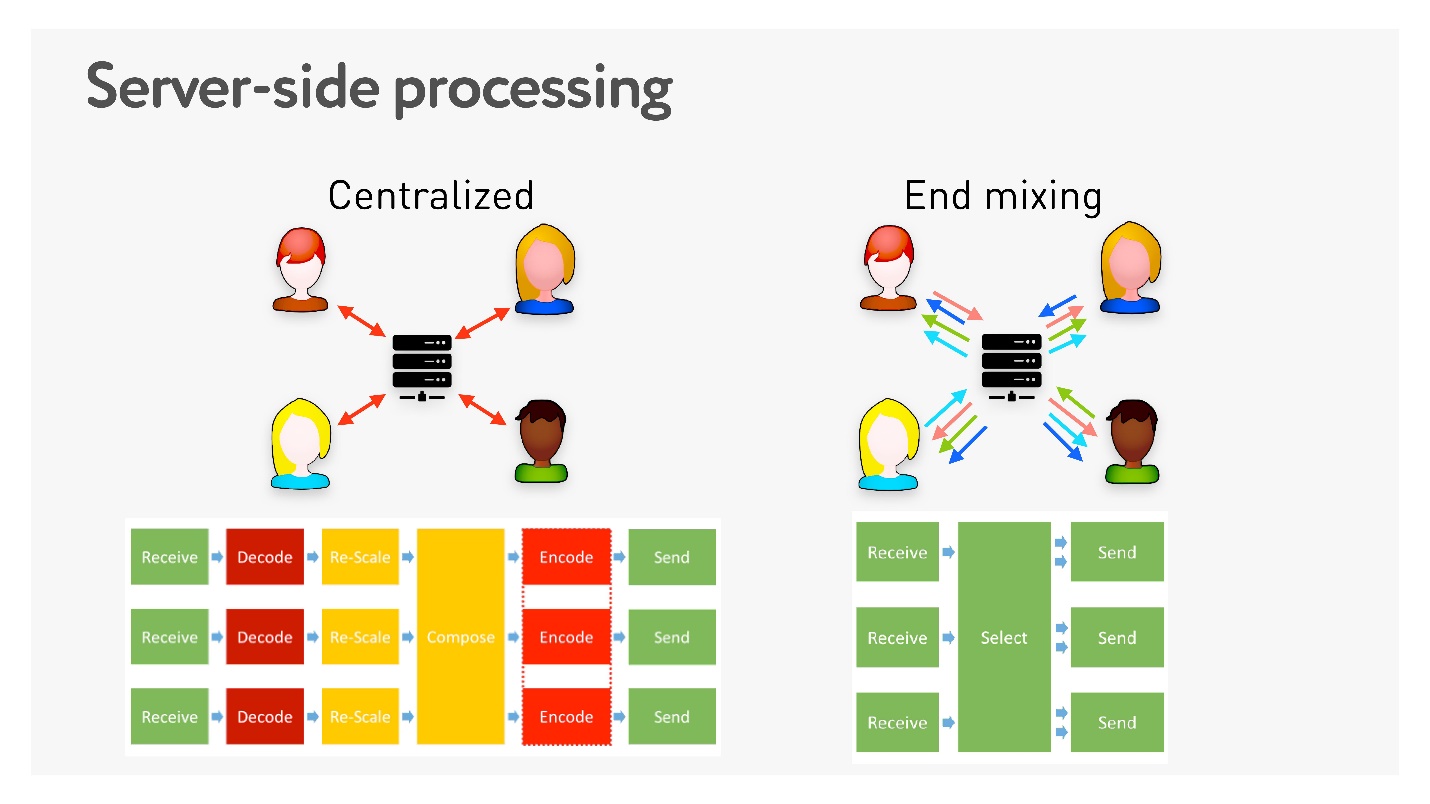
Если используется централизованная система, то есть все видео собирается на сервере. Это требует многих стадий кодирования, которые и latency добавляют, и требуют дополнительного оборудования. В End mixing, наоборот, все быстро и просто.
Минусы топологий:
- Mesh — максимум 4 участника.
- Centralized — проблемы с транскодированием и с jitter.
- End mixing — ограничение по качеству и шторм опорных кадров.
На топологии Mesh работают только ICQ и Skype, у всех остальных End mixing. Но, как мы помним, все сервисы по характеристикам разные — значит, там не просто End mixing, а что-то еще.
Hangouts провернули такой трюк с End mixing.
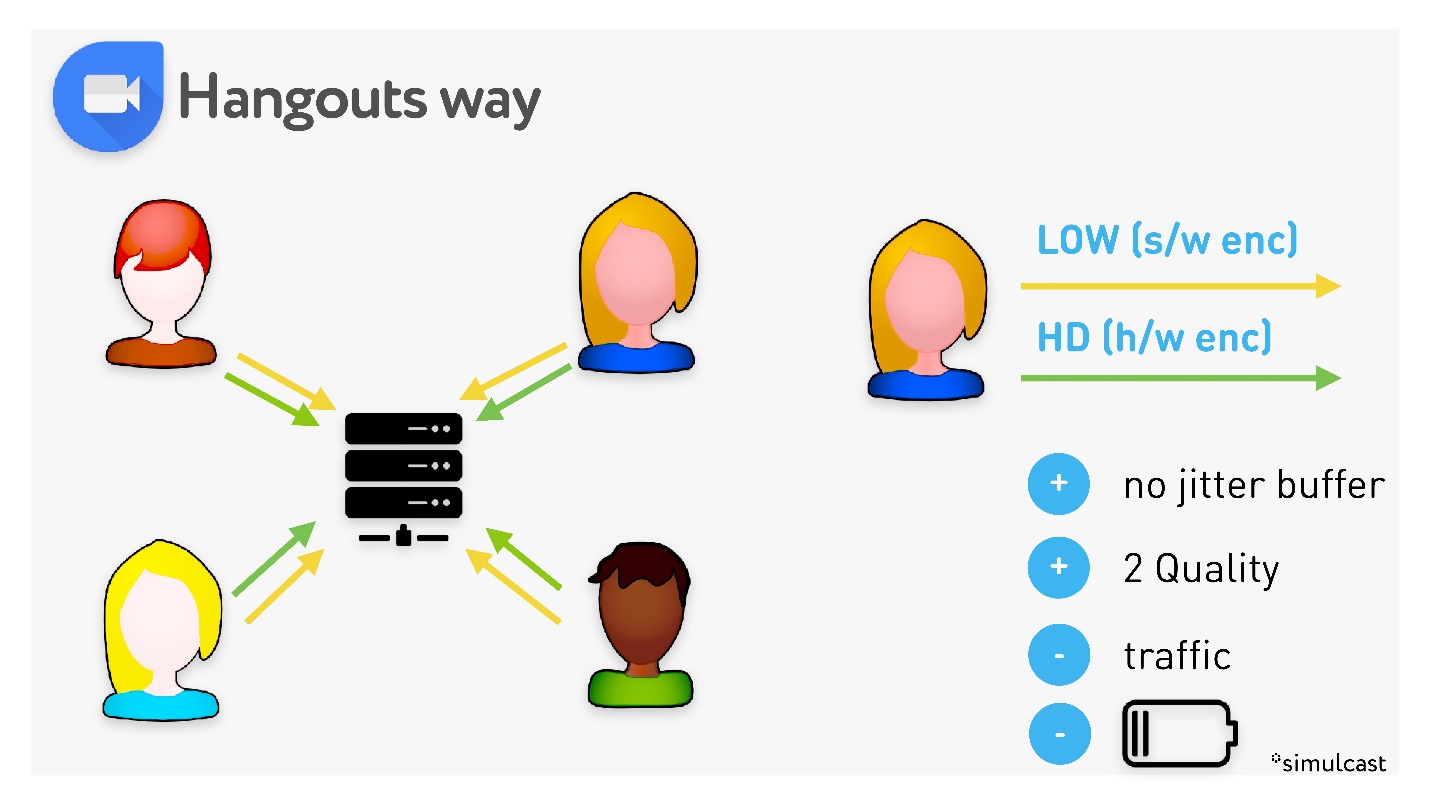
На каждом клиенте запускается два кодировщика: H.264 в высоком качестве, и VP8 — в низком. Соответственно, для пользователей с хорошим интернетом сервер передает видео в высоком качестве, для тех, у кого интернет плохой, — похуже, причем низкое качество адаптируется под худшую сеть. Два качества это хорошо, но это лишний трафик с клиентов и расход батареи. Зато нет jitter buffer
Из таблицы видно, что с работающим Hangouts телефон греется больше всего, в нем минимальные задержки, но страдает качество, потому что низким качеством все равно отъедается битрейт у высокого.

Мы решили шагнуть дальше, поиграть в такую игру: все-таки не запускать софтверные кодеки с клиента, кодировать H.264, использовать канал на всю катушку под один поток (это сэкономит батарею и трафик) по схеме End mixing для высокого качества. А для низкого качества использовать centralized-схему, но сервер вместо того, чтобы собирать общую картинку, будет видео высокого качества кодировать в то, которое нужно каждому конкретному пользователю.

Правда, приходится бороться со штормом опорных кадров: для высокого качества мы их троттлим. То есть считаем, что если пользователь в состоянии получать высокое качество, наверное, у него мало пропадающих пакетов, и он как-то без этих опорников сможет справиться. На практике это означает, что мы не позволяем запрашивать опорный кадр чаще раза в секунду.
В итоге мы получили следующие варианты разных топологий.
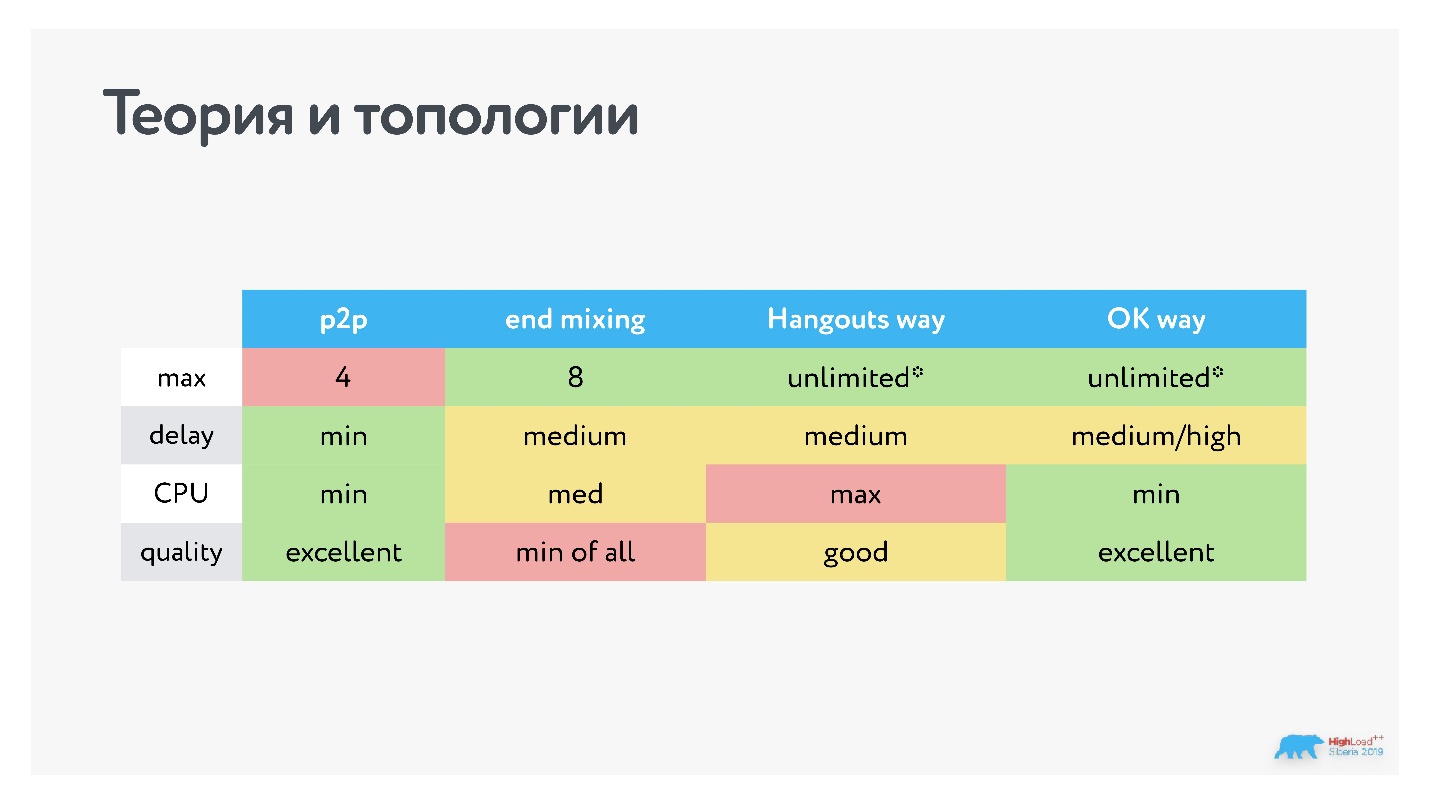
Конечно, мне кажется, наш вариант самый удачный, но у нас может быть большая latency для клиентов с плохой сетью. Мы решили этим пренебречь, потому что если у клиента низкое качество видео, возможно, ему даже выгоднее, когда нет второго плеча до раздающего видео. Потому что при такой топологии пропажа пакетов чинится на интервале между клиентом и сервером в топологии centralized, то есть есть сервер, который разбирает, имеет свой jitter-буфер и транскодирует. Сервер может отдать персональный опорный кадр или восстановить определенный кадр, и все эти действия по восстановлению пакетов никак не влияют на того, кто отдает видеопоток.
Формально в графе количество клиентов у нас «бесконечность», но со звездочкой. Это потому что никто не в состоянии отображать ни 100, ни 50, ни даже 20 собеседников за раз. На экране у нас обычно один говорящий и список остальных участников.

У всех клиентов разная сеть и разные устройства — есть такие, которые не в состоянии декодировать больше 5 видеопотоков. К каждому устройству нужен персональный подход. Мы это делаем так: устройство сообщает, сколько оно может проиграть потоков, мы ему их собираем на сервере, как в задаче о рюкзаке — сколько максимально можем впихнуть в сеть.
Самого «большого» пользователя мы выдаем в высоком качестве, тех, кто в окошках поменьше, — в низком. Также у нас есть режим настройки кодека: если мы понимаем, что участник отображается где-то далеко, мы включаем низкий fps. В принципе, если в превьюшках внизу картинка обновляются раз в секунду — это нормально. Если пользователи хоть как-то шуршат, добавляется звук. Если и это невозможно, мы их совсем не трогаем.
Финальное решение
Так как топология Mesh до 3-4 участников работает очень хорошо в плане latency, батарейки и всего остального, то мы заморочились и до некоторой границы поддерживаем Mesh. Потом плавно переключаемся на серверную топологию, в которой HD отдаем через End mixing, a SD — через centralized.
В итоге получили характеристики близкие к Zoom.
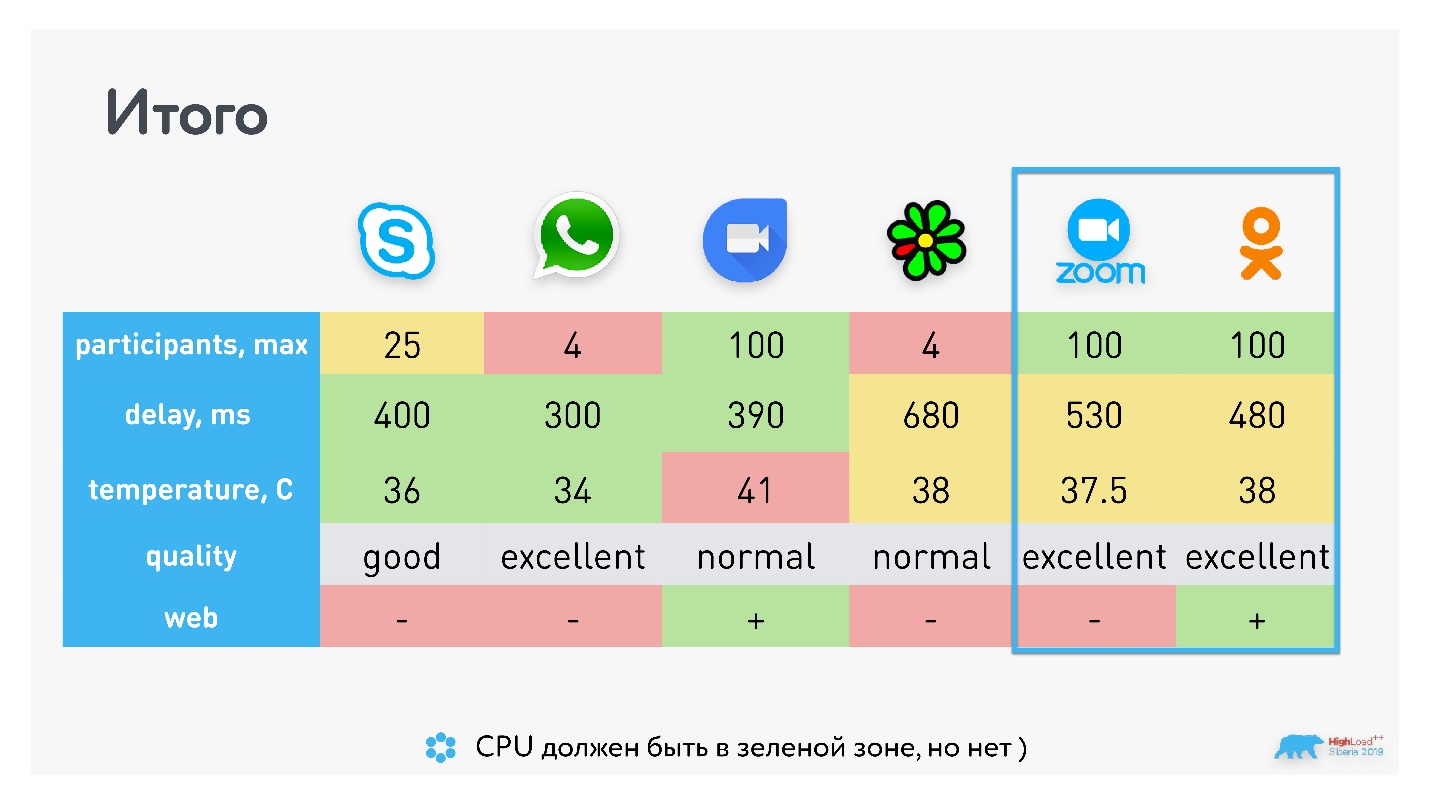
Предположу, что они делают что-то схожее с той разницей, что у Zoom своё решение, частично несовместимое с WebRTC. А мы сохранили совместимость с WebRTC, поэтому поддерживаем групповые звонки еще и в браузере.
Грабли
Куда же в разработке без них.
CPU может быть слабее, чем сеть. Мы передавали с сервера максимальный поток — столько, сколько влезает в сеть, но быстро выяснилось, что есть устройства, у которых CPU слабее, чем сеть. Тогда вроде бы кодировщики играют, но телефон начинает сильно тормозить или перегреваться.
Добавили дополнительную информацию: телефон может сказать, что он не справляется, и попросить понизить качество подаваемого видео.
При screen sharing плохого качества недостаточно. Если понизить битрейт screen sharing, то букв и цифр становится не видно, и весь смысл пропадает. Поэтому у screen sharing высокий приоритет. Кроме того, логично понизить fps — лучше, чтобы мышка двигалась медленно, но все было видно.
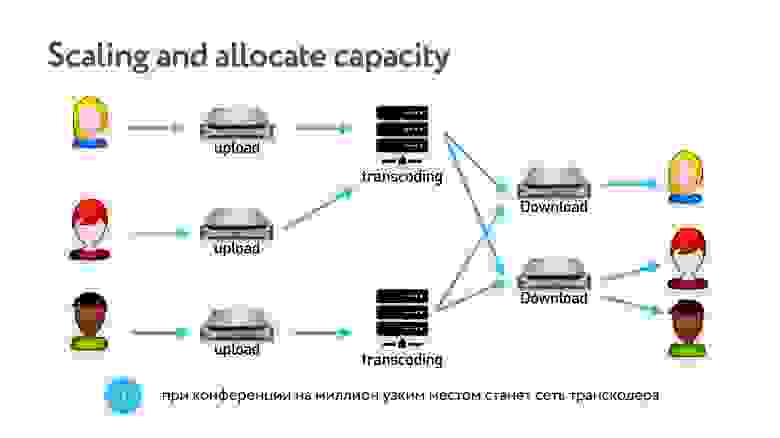
Один сервер не может транскодировать видео для всех клиентов. Еще одна особенность — если работать по схеме centralized, то рано или поздно возникнет ситуация, когда сервер не сможет транскодировать всех клиентов. Потому что невозможно предсказать, сколько их будет.

Таким образом, все приходящие стримы транскодируются тем или иным сервером, и есть сервер раздачи, который все транскодированное видео собирает. Поскольку мы не складываем все в одну большую картинку, а раздаем отдельными потоками, то можем позволить себе такую схему и не ограничены ресурсами одного сервера при транскодировании в нашей топологии.
Сервер конференцсвязи
Расскажу, как сделать сервер, если когда-нибудь захотите написать свой сервер конференцсвязи. Мы со всеми нашими претензиями к топологии ничего готового не нашли и решили делать сами.

Packet pacing
Во-первых, открываете UDP-сокет и начинаете в него писать. Стандартно для UDP всегда нужен pacing. Не стоит отправлять UDP-пакеты большими пачками, если не хотите их потерять.

На графике показано, что если пересылать пакеты по UDP непрерывно, то к 21 пакету вероятность пропажи будет близка к 100%. Пакеты надо прорежать хотя бы раз в милли или наносекунду — это расстояние нужно вычислить эмпирически.
Для чего еще нужен pacing? Как я уже сказал, вы не можете заставить кодек выдавать константный битрейт (но иногда можете эмулировать) — если картинка меняется, битрейт растет. Поэтому если, после того как в канале установился примерно постоянный битрейт, потрясти камеру, то, скорее всего, картинка на другой стороне рассыпется, потому что из-за большого числа изменений вырастет битрейт и данные не пролезут в пропускную способность канала.
Есть два варианта:
- Применить pacing, тогда видео будет немножко тормозить.
- Не применять pacing, тогда, скорее всего, потеряются избыточные пакеты, они начнут ретрансмититься и появятся искажения.
Это отличный способ проверить клиент: если при встряхивании телефона на другой стороне тормозит, то pacing есть, если посыпались пакеты —нет.
Чем еще полезен packet pacing?
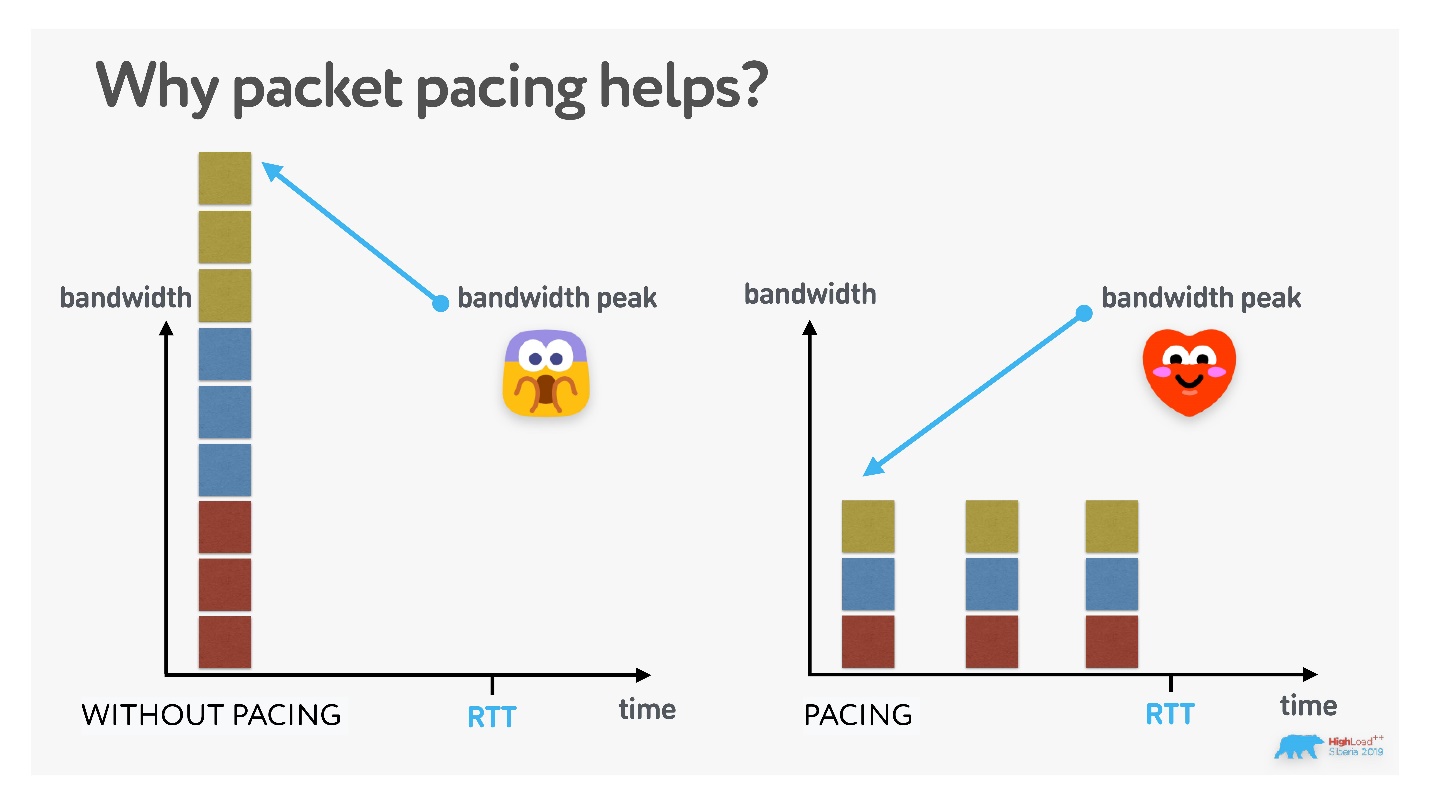
В реальной жизни, если вы (и с вами другие люди) передаете много данных за единицу времени, очередь может переполниться, и кого-нибудь дропнут. Поэтому считается (но не доказано), что если аккуратно все размазать, то вы ни с кем не пересечетесь, и вероятность пропадания пакетов снизится.
Единственный установленный факт — packet loss меньше, если есть pacing.
MTU
TCP нас избаловал, там никогда не нужно заморачиваться с MTU. Но если вы пишете сервер UDP, то как минимум придется вспомнить, что MTU — это максимальный размер пакета, который может быть передан в сети.
Если данные передаются по сети с MTU 1500, а потом на пути встречается сеть с MTU 1100, то пакет фрагментируется. Конечно, он потом соберется обратно, но если потеряется одна единственная часть этого пакета, то, считай, потеряются все пакеты (и весь оригинальный пакет). Поэтому оптимально работать с таким размером пакета, который соответствует MTU сети.
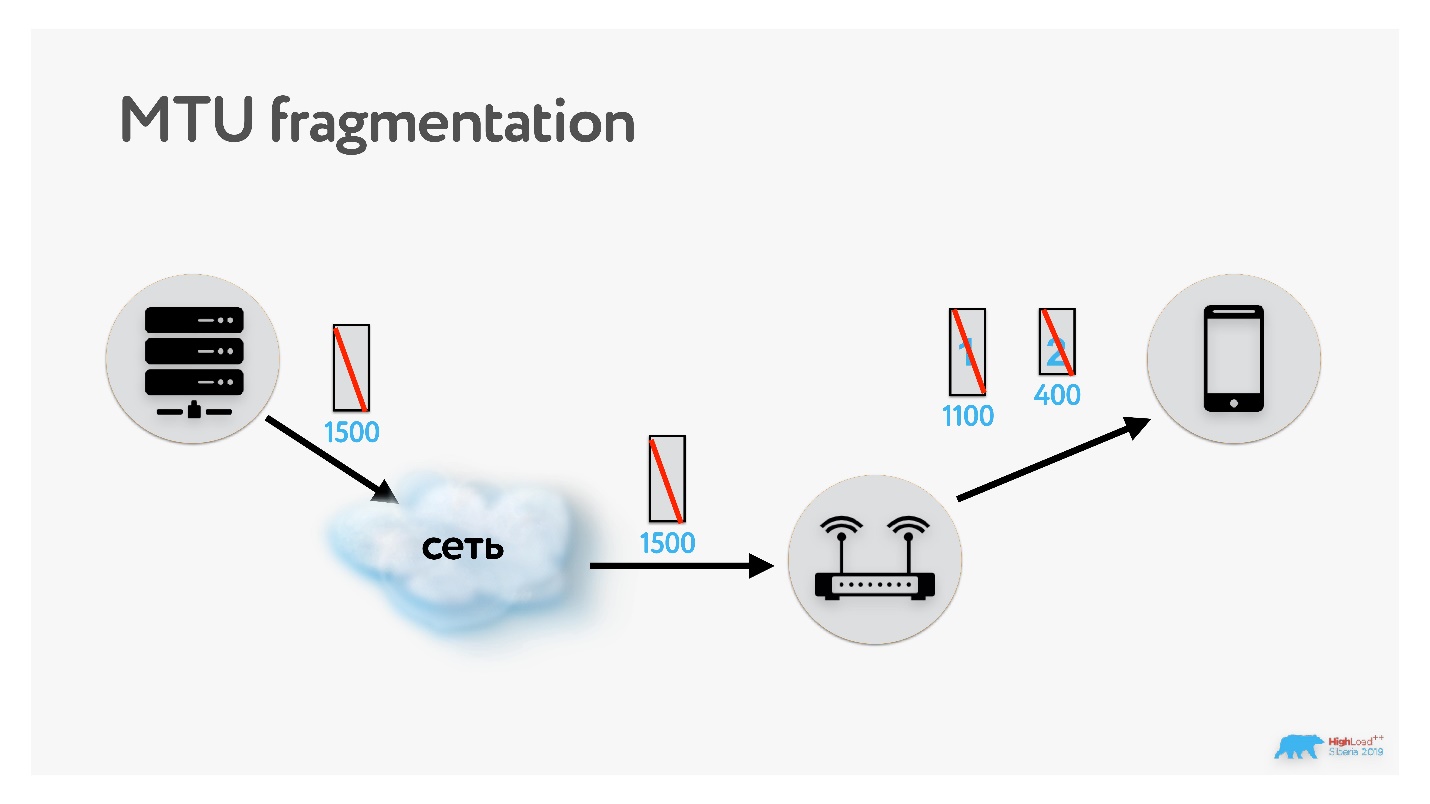
В TCP есть алгоритм, который определяет этот параметр при установке соединения. Можно повторить его, попробовать подобрать MTU: запуститься с каким-то значением по умолчанию, запустить параллельный процесс и, например, бинарным поиском подобрать MTU. Если передавать пакет с флагом запрета фрагментации размера большего, чем размер MTU, то он не фрагментируется, а дропается.
Картинка получится интересная.

Так мы поняли, что достаточно провести такой эксперимент: отправлять пакеты с флагом запрета фрагментации, и считать, сколько из них дошло до сервера. В 98% случаев пакеты с запретом фрагментации проходят при размере до 1350. Можно спокойно установить MTU = 1350, снять флаг запрета фрагментации, и пусть в 2% случаев пакеты фрагментируются — не повезло, не страшно.
Исправление ошибок
WebRTC поддерживает SACK, NACK, FEC. Придется прочитать спецификацию и научиться их исправлять.
Суть в том, что потеря 1–3% пакетов в беспроводных сетях — это нормально, и с этим нужно уметь работать.
В WebRTC для стриминга наиболее распространен подход negative acknowledgement (NACK).
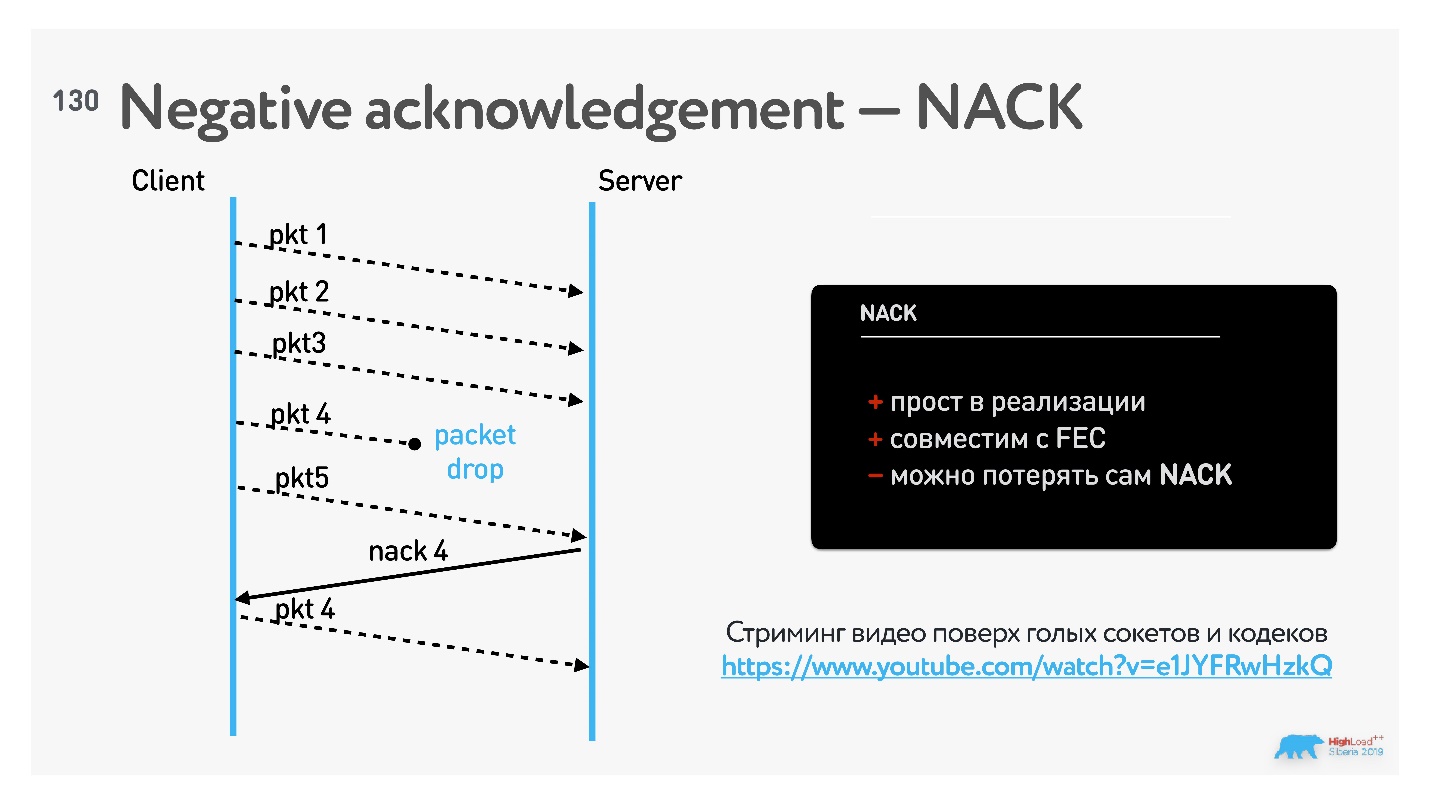
В этом случае порядок пакетов отслеживает принимающая сторона и, если понимает, что какой-то пакет пропущен, дозапрашивает его.
Как известно, TCP работает на acknowledgement, в том числе на selective acknowledgement. Особенность negative acknowledgement в том, что такой вид подтверждений хорошо работает с FEC (Forward Error Correction).
Если вам интересны детали того, как писать SACK, NACK, FEC, посмотрите этот доклад.
Технология FEC применяется, когда заранее известно, что сеть плохая. Работает так: в поток данных встраиваются дополнительные пакеты, когда обнаруживается ошибка, её можно исправить и не тратить время на ретрансмит. Потому что пока данные перезапросишь, перепошлешь, уже станет поздно — картинка уже замрет.

Самый простой вариант FEC — это XOR, но чаще используются более сложные варианты, например, ряды Соломона. К пачке пакетов добавляется пакет защиты избыточности, и при пропадании пакетов что-то можно восстановить.
Следующая фишка пока в драфте, но мы в своих протоколах её используем. Когда у вас есть предположение, что качество канала могло измениться в лучшую сторону, чтобы аккуратно в этом удостовериться, можно сначала добавить избыточных FEC-пакетов. Не жалко, если они пропадут, зато если они стабильно проходят через канал передачи данных, значит, можно поднимать битрейт в кодеке и использовать более широкий канал.
Итого, сложив все вышеописанное, мы запустили групповые звонки. Измерили характеристики работающего сервиса, получилось:
- У 90% наших пользователей скорость больше 500 Кбит/с.
- Среднее количество участников — 3-4, поэтому мы не зря сделали переключение между Mesh и End mixing.
- Среднее дневное максимальное число участников — примерно 27 человек (например, один класс).
Check List
Что нужно не забыть при написании своего сервера групповых звонков:
- Packet pacing.
- MTU discovery.
- Исправление ошибок.
- Cоберите максимум логов с клиентов.
Последний пункт очень важен, мы собирали логи всего signalling, все состояния WebRTC, все управляющие команды, которые были переданы, чтобы потом можно было что-то отладить.
У нас было много проблем с сетью, для каждой мы подобрали решение:
- Packet loss: ретрансмит, packet pacing, FEC, настройка MTU.
- Изменения пропускной способности сети: не забываем исправлять back pressure на кодек, а чтобы обратно повысить битрейт проверяем пропускную способность FEC-пакетами.
- Jitter лечится только с помощью jitter buffer, но все равно увеличивает latency.
- RTT: всегда нужно экономить, стараться минимизировать количество запросов на signaling.
Будущее или иногда нужно подождать
WebRTC — не самая удобная штука. Это RTP, поверх которого множество флагов и куча разных расширений, которые одни браузеры поддерживают, другие не поддерживают. На самом деле на WebRTC трудно работать.
Поэтому многие сервисы звонков, такие как Zoom, Skype и Line, пишут свой проприетарный протокол. У нас тоже было такое желание. Но тогда бы мы потеряли функциональность звонков из браузера. Поэтому, даже несмотря на то, что у нас есть опыт написания своего UDP-протокола (стриминг на нашем протоколе сейчас работает лучше, чем на WebRTC), мы решили подождать. Это действительно сложно, и пока мы решили, что не стоит торопиться. Например, потому что есть Google STADIA.
STADIA — это игровая консоль, которая позволяет онлайн играть на удаленном сервере. Она работает поверх WebRTC, и говорят, что там пропадает половина кадров. Поэтому Google сейчас очень активно лечит свой WebRTC. Среди решений по улучшению WebRTC даже предлагаются идеи перевести SRTP WebRTC на QUIC. Не знаю, как это будет работать, но это активно обсуждается.
Кстати о QUIC, он уже много где используется. Если вы с Chrome или c Android заходите в Google или YouTube, вы не пользуетесь TCP — там QUIC поверх UDP от Google. У мобильных операторов более 30% трафика через QUIC/UDP.
На плохих мобильных сетях QUIC доставляет данные быстрее на 20-30%, чем TCP. Поэтому просто включив где-то QUIC или переехав на него, вы можете дать своим пользователям неплохое ускорение.
Выводы
В этой статье мы разобрали, как работают звонки через интернет и как написать свой сервер конференций. Вы узнали, что любые звонки состоят из: signaling; видео/аудио кодировщиков; сети и топологии. Надеюсь, у вас сложился общий пазл, как это все работает.
Что со всем этим делать?
- Прикручивайте звонки, если есть чат или какое-то место, где их еще нет.
- Пишите свой сервер конференций или используйте готовый, если нужны групповые звонки.
А знания о сетях и видео/аудио кодеках пригодятся в любом случае.
Самое главное, что мы сегодня выяснили, — любые характеристики можно улучшить. В том числе увеличить количество пользователей в звонке, снизить latency, поднять качество. Помните, что нет предела совершенству! Но в какой-то момент все равно нужно будет остановиться :)
В следующем году HighLoad++ снова поедет в разные города. Питерская версия (а это всегда только полностью новая программа) уже в работе, можно подавать доклады и планировать 6-7 апреля 2020 года посвятить хайлоаду. А что еще готовится, узнаете из рассылки.
