Comments 65
Интересно в домашних условиях кто-нибудь ее пробовал использовать?
Подобный, но упрощенный алгоритм используется в Seagate Momentus XT там 4Гб ssd. Он туда кешит часто используемые файлы.
Если под «ее» вы понимаете FlashCache, то это просто невозможно, это компонент стораджа, и его внутренней OS.
Но если как сам принцип, то отчего нет, я же привел в конце примеры с Adaptec MaxIQ и ZFS Cachezilla.
Но тут еще раз отмечу, что важну роль играет отсутствие random-записи в flash, на котором он обычно поразительно неэффективен.
Но если как сам принцип, то отчего нет, я же привел в конце примеры с Adaptec MaxIQ и ZFS Cachezilla.
Но тут еще раз отмечу, что важну роль играет отсутствие random-записи в flash, на котором он обычно поразительно неэффективен.
Зачем??? Поставьте небольшой SSD под систему и программы и он у вас 100 лет проживёт. Вот тут я раздаю хабровчанам утилитку для оценки жизни SSD — бесплатно. Запускаете, мониторите систему несколько дней — получаете результат. Пользователи linux'a и Mac'a могут ввести значения записей вручную на сайте и получить примерную калькуляцию.
Осталось совсем немного подождать — Intel уже выпускают новый чипсет с поддержкой подобной технологии — www.iguides.ru/forum/showthread.php?t=19955
Но только разница в том, что Intel еще только выпускают, а NetApp уже продал несколько десятков тысяч систем c FlashCache за два с половиной года, это значит, что основное количество проблем с ними уже решено, а вот что будет у Intel — я бы не был столь оптимистичен, считая, что сразу после выхода он будет готов в продакшен.
Интересно а какова стоимость этой штуки по сравнению с обычным DDR? ИМХО, сегодня проще взять и воткнуть 16Gb памяти. Или взять нормальный железный raid (если нужно работать с большими объемами) с приличным кешем и воткнуть в него обычные небольшие и очень дешевые диски, организовав raid-10, например…
Стоимость существенна, но значительно ниже, чем у сравнимого по результатам быстродействия количества жестких дисков (а в том числе не забывайте про энергопортебление и охлаждение всей кухни).
Примеры там выше в тексте приведены, когда сравнимое быстродействие получается на в 4 раза меньшем количестве дисков (при этом еще и на 54% дешевле, даже без учета электричества и охлаждения).
> Или взять нормальный железный raid
Примеры там выше в тексте приведены, когда сравнимое быстродействие получается на в 4 раза меньшем количестве дисков (при этом еще и на 54% дешевле, даже без учета электричества и охлаждения).
> Или взять нормальный железный raid
> Или взять нормальный железный raid
Что такое «нормальный железный raid», и чем он отличается от «ненормального»? ;)
Что такое «нормальный железный raid», и чем он отличается от «ненормального»? ;)
Например, наличием кеша.
Любая система хранения имеет кэш. Вопрос в его размере и в том, что происходит, если нужные данные в него не помещаются.
Сейчас DRAM примерно вдесятеро дороже эквивалентного объема на Flash.
Сейчас DRAM примерно вдесятеро дороже эквивалентного объема на Flash.
Не все raid'ы оснащены собственным кешем.
А вообще раньше были в продаже подобные штуки:
www.directcanada.com/products/?sku=11830DR4758&vpn=GC-RAMDISK&manufacture=GIGABYTE
Это PCI плата со слотами для DDR — в системе выглядит как SATA диск. Плата стоит совсем немного, а памяти такой навалом можно либо бесплатно нарыть, либо купить за сущие копейки. Поставить таких плат во все слоты и выдать эти ram-диски под системный кеш.
А вообще раньше были в продаже подобные штуки:
www.directcanada.com/products/?sku=11830DR4758&vpn=GC-RAMDISK&manufacture=GIGABYTE
Это PCI плата со слотами для DDR — в системе выглядит как SATA диск. Плата стоит совсем немного, а памяти такой навалом можно либо бесплатно нарыть, либо купить за сущие копейки. Поставить таких плат во все слоты и выдать эти ram-диски под системный кеш.
Ну ОК, уговорили. Рассчитайте, пожалуйста, сколько будет стоить ваше решение, емкостью, ну давайте, для простоты, равное емкости самого маленького FlashCache — 256GB.
Также не забудьте и то, что такую емкость должна поддерживать OS, а также то, что она должна быть энергонезависимой.
Также не забудьте и то, что такую емкость должна поддерживать OS, а также то, что она должна быть энергонезависимой.
Зачем ей быть энергонезависимой если это под кэш?
Но кэш-то у вас должен будет работать на запись и чтение, значит потеря данных в кэше, не попавших на диски, недопустима.
В случае FlashCache (к слову сказать FlashCache энергонезависим, так как flash) он не используется под запись потому что под ним WAFL, которой вследствие ее механизма работы кэш на запись не нужен, для любой другой файловой системы кэш на запись необходим, если мы только не делаем какой-то узкоспециальный продукт для read-only данных.
К тому же я сильно сомневаюсь, что «любая OS» сможет простым образом использовать такой RAM-SATA (как это происходит в случае FlashCache, который абсолютно прозрачен для операций системы и данных), значит поверх придется городить еще какую-то приблуду для автоматического tiering-а данных на него, о проблемах с этим связанных я уже тоже писал, частью в посте, частью в комментах ниже про EMC FAST.
В случае FlashCache (к слову сказать FlashCache энергонезависим, так как flash) он не используется под запись потому что под ним WAFL, которой вследствие ее механизма работы кэш на запись не нужен, для любой другой файловой системы кэш на запись необходим, если мы только не делаем какой-то узкоспециальный продукт для read-only данных.
К тому же я сильно сомневаюсь, что «любая OS» сможет простым образом использовать такой RAM-SATA (как это происходит в случае FlashCache, который абсолютно прозрачен для операций системы и данных), значит поверх придется городить еще какую-то приблуду для автоматического tiering-а данных на него, о проблемах с этим связанных я уже тоже писал, частью в посте, частью в комментах ниже про EMC FAST.
>SSD или Solid-State Disk (дословно: «Твердотельный диск»)
На самом деле расшифровка Solid-state drive т.к. ничего круглого подобного диску в них не имеется:)
На самом деле расшифровка Solid-state drive т.к. ничего круглого подобного диску в них не имеется:)
По этому поводу существуют разные мнения, одно из них озвучено выше, второе — вами. В принципе ваша поправка несущественна.
Замечание верно, но в слове «Disk» круглого не подразумевается. Вот если бы «Disc» написал, то 100% ошибка.
Ну, это прикольно, что скорость выросла и задержки уменьшились. Но зачем хвастаться тем, что «на 67% улучшились показатели энергопотребления и занимаемого системой места в стойке.» при том, что система дала 16 Тб дискового пространства вместо 64 Тб в исходной. В чем заслуга то?
Тем, что за электричество потребляемое системой, и кондиционерами нужно платить. Иногда это бывают довольно существенные затраты. В рядовом датацентре затраты на охлаждение сегодня составляют примерно половину от общего его энергопотребления, то есть кондиционеры в нем потребляют столько же, сколько вся «IT-активка». Снизить этот процент было бы весьма заманчиво, так как отливается во вполне полновесных долларах экономии бюджета.
В арендованных же датацентрах расчет аренды идет из занятых «юнитов» в стойках, и уменьшение их количества также снижает затраты на эксплуатацию, подчас весьма существенно.
Выше же я уже писал, что емкость сегодня уже не главный параметр при выборе количества дисков, главный — быстродействие. Именно ради быстродействия берется так много дисков, а не потому, что нужно столько места. В сегодняшних системах хранения очень часто емкость дисков заполнена едва ли на 10% (и это еще одна проблема снижения эффективности традиционных систем), а много дисков покупаются ради IOPS.
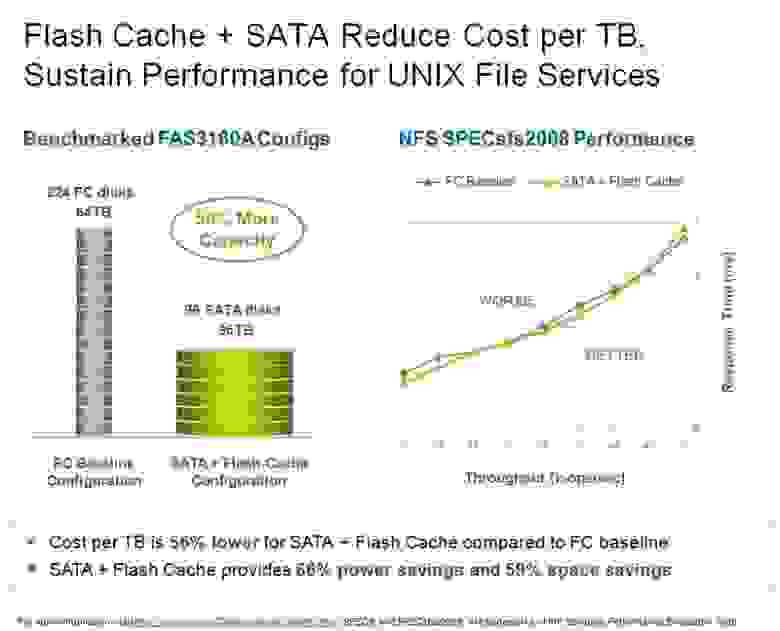
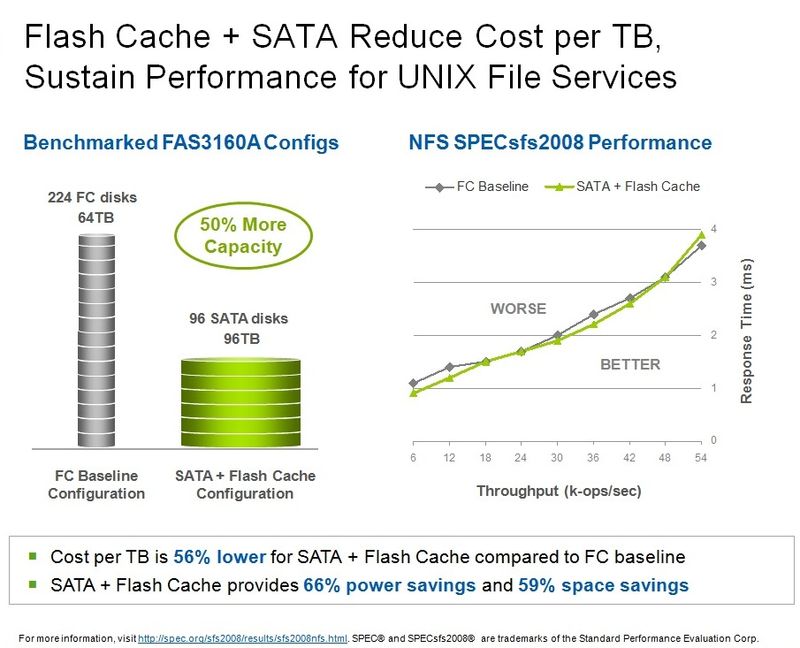
Если же важна именно емкость, то можно взять диски SATA, с ними, с использованием FlashCache, можно достичь того же быстродействия, но получить больше емкости, об этом третий пример. К сожалению на имеющейся у меня картинке рассматривалась другая система, FAS3160, под NFS, поэтому я не стал ее включать в пост, но смысл результата тот же.
В арендованных же датацентрах расчет аренды идет из занятых «юнитов» в стойках, и уменьшение их количества также снижает затраты на эксплуатацию, подчас весьма существенно.
Выше же я уже писал, что емкость сегодня уже не главный параметр при выборе количества дисков, главный — быстродействие. Именно ради быстродействия берется так много дисков, а не потому, что нужно столько места. В сегодняшних системах хранения очень часто емкость дисков заполнена едва ли на 10% (и это еще одна проблема снижения эффективности традиционных систем), а много дисков покупаются ради IOPS.
Если же важна именно емкость, то можно взять диски SATA, с ними, с использованием FlashCache, можно достичь того же быстродействия, но получить больше емкости, об этом третий пример. К сожалению на имеющейся у меня картинке рассматривалась другая система, FAS3160, под NFS, поэтому я не стал ее включать в пост, но смысл результата тот же.
Капец, вот это пропасть непонимания. Давайте рассмотрим приведенный Вами в статье пример.
В исходной системе было 64 Тб дискового пространства. Пусть на каждый ТБ приходилось х ватт питания — т.е. всего 64х. В полученной системе мы имеем 16 Тб дискового пространства и «на 67% сниженное энергопотребление» — т.е. 64х*0,33=21,12х общего потребления. И того энергопотребление на 1 Тб пространства увеличилось на 21,12 / 16 = 1,32х — это на 32%!
Я верю в эту классную технологию, но у Вас в статье какие-то не вяжущиеся с логикой цифры.
В исходной системе было 64 Тб дискового пространства. Пусть на каждый ТБ приходилось х ватт питания — т.е. всего 64х. В полученной системе мы имеем 16 Тб дискового пространства и «на 67% сниженное энергопотребление» — т.е. 64х*0,33=21,12х общего потребления. И того энергопотребление на 1 Тб пространства увеличилось на 21,12 / 16 = 1,32х — это на 32%!
Я верю в эту классную технологию, но у Вас в статье какие-то не вяжущиеся с логикой цифры.
Вы забыли как минимум то, что электричество потребляют и тепло выделяют еще собственно сами дисковые полки, в которых установлены эти диски, там в них много чего, там два 15-портовых FC-коммутатора в них встроены, через которые FC-диски видятся, два redundant блока питания, два интерфейсных модуля FC, в каждой полке.
Хотите я вам все данные из техспек по ним запощу, проверите?
Хотите я вам все данные из техспек по ним запощу, проверите?
Ну не о том я, не о том, ну почему же Вы меня не слышите?
Уменьшение дискового массива в 4 раза (с 64 ТБ до 16 Тб) в любом случае повлекло бы за собой снижение количества полок и энергопотребления. И не важно FlashCache при этом используется или нет — все равно 16 Тб это в 4 раза меньше потребления, чем 64 Тб (т.е. на 75%). Я верю в цифру «на 67% меньше энергопотребление». Но это не преимущество FlashCache, а просто голый факт, основанный на том, что 64 Тб в 4 раза больше чем 16 Тб. А FlashCache даёт просто кеширование и минимизацию задержек, кушая при этом своих 75-67=8% питания.
Уменьшение дискового массива в 4 раза (с 64 ТБ до 16 Тб) в любом случае повлекло бы за собой снижение количества полок и энергопотребления. И не важно FlashCache при этом используется или нет — все равно 16 Тб это в 4 раза меньше потребления, чем 64 Тб (т.е. на 75%). Я верю в цифру «на 67% меньше энергопотребление». Но это не преимущество FlashCache, а просто голый факт, основанный на том, что 64 Тб в 4 раза больше чем 16 Тб. А FlashCache даёт просто кеширование и минимизацию задержек, кушая при этом своих 75-67=8% питания.
> И не важно FlashCache при этом используется или нет
Что значит «не важно», если именно за счет использования FlashCache это и было достигнуто без падения производительности?
Да, дисков стало меньше, а производительность, ради которой этих дисков взяли много — не упала, вот в чем вся суть-то!
То ли вы не умеете объяснить понятно, чего вы хотите, то ли я вообще тупой :)
Что значит «не важно», если именно за счет использования FlashCache это и было достигнуто без падения производительности?
Да, дисков стало меньше, а производительность, ради которой этих дисков взяли много — не упала, вот в чем вся суть-то!
То ли вы не умеете объяснить понятно, чего вы хотите, то ли я вообще тупой :)
Ладно, пойдем другим путем.
Имелась исходная система с 64 Тб дисков. Имелась новая система на FlashCache с 16 Тб дисков, которая кушала на 67% меньше энергии (т.е. 33% от базовой). Допустим, мы бы захотели увеличить количество винтов в системе на FlashCache до 64 Тб. При этом её потребление составит 33%*4=132% от базовой.
Да, я понимаю, что будет выше производительность, это ясно, это круто. Но писать в статье об энергоэффективности системы — по меньшей мере странно, ибо жрет она на 32% больше стандартных систем. Писать о высокой производительности И энергоэффективности решения нельзя. Можно писать о высокой производительности ЦЕНОЙ энергоэффективности.
Вот и все, что я хотел сказать.
Имелась исходная система с 64 Тб дисков. Имелась новая система на FlashCache с 16 Тб дисков, которая кушала на 67% меньше энергии (т.е. 33% от базовой). Допустим, мы бы захотели увеличить количество винтов в системе на FlashCache до 64 Тб. При этом её потребление составит 33%*4=132% от базовой.
Да, я понимаю, что будет выше производительность, это ясно, это круто. Но писать в статье об энергоэффективности системы — по меньшей мере странно, ибо жрет она на 32% больше стандартных систем. Писать о высокой производительности И энергоэффективности решения нельзя. Можно писать о высокой производительности ЦЕНОЙ энергоэффективности.
Вот и все, что я хотел сказать.
Нет, вы не с той стороны подходите.
Имелась исходная система, дающая 55 тысяч IOPS.
Для того, чтобы получить такие результаты, нам, идя традиционным путем, надо взять 224 диска FC, то есть 16 дисковых полок по 14 дисков.
Потому что именно дисковые шпиндели в традиционных системах определяют производительность в IOPS. В наших требованиях — обеспечить 55000 IOPS при максимум 4ms latency, остальное уже детали, а это — первичный критерий.
Емкость — это уже вторичное. Обычно база занимает сравнительно незначительный доступный объем таких систем.
Она больше чем кэш, но меньше, чем суммарная емкость дисков. Допустим она размером 1TB вся. Но при этом вынь и положь 55000 IOPS на 4ms при работе с ней.
Именно поэтому дисков столько много. Не потому, что нам надо на них много хранить, а потому что IOPS.
На этом этапе еще понятна ситуация?
В случае традиционных систем у нас нет другого способа обеспечить требования по быстродействию и задержкам, кроме как купить и поставить нужное количество дисковых шпинделей, между которыми будет распараллелена нагрузка ввода-вывода.
Но если у нас есть FlashCache, мы можем подойти по другому. Мы можем взять куда меньше дисков, все равно 1TB базы у нас на них поместится. А необходимую производительность обеспечить с помощью FlashCache.
Дисков стало меньше, полок стало меньше, потребление электричества уменьшилось, вся система стала дешевле (так как дисковых шпинделей и полок стало в 4 раза меньше) — но производительность, наш главный критерий для системы, не упала!
Понятно-ли в таком варианте о чем речь?
Имелась исходная система, дающая 55 тысяч IOPS.
Для того, чтобы получить такие результаты, нам, идя традиционным путем, надо взять 224 диска FC, то есть 16 дисковых полок по 14 дисков.
Потому что именно дисковые шпиндели в традиционных системах определяют производительность в IOPS. В наших требованиях — обеспечить 55000 IOPS при максимум 4ms latency, остальное уже детали, а это — первичный критерий.
Емкость — это уже вторичное. Обычно база занимает сравнительно незначительный доступный объем таких систем.
Она больше чем кэш, но меньше, чем суммарная емкость дисков. Допустим она размером 1TB вся. Но при этом вынь и положь 55000 IOPS на 4ms при работе с ней.
Именно поэтому дисков столько много. Не потому, что нам надо на них много хранить, а потому что IOPS.
На этом этапе еще понятна ситуация?
В случае традиционных систем у нас нет другого способа обеспечить требования по быстродействию и задержкам, кроме как купить и поставить нужное количество дисковых шпинделей, между которыми будет распараллелена нагрузка ввода-вывода.
Но если у нас есть FlashCache, мы можем подойти по другому. Мы можем взять куда меньше дисков, все равно 1TB базы у нас на них поместится. А необходимую производительность обеспечить с помощью FlashCache.
Дисков стало меньше, полок стало меньше, потребление электричества уменьшилось, вся система стала дешевле (так как дисковых шпинделей и полок стало в 4 раза меньше) — но производительность, наш главный критерий для системы, не упала!
Понятно-ли в таком варианте о чем речь?
Нет, ну если наш главный критерий одна только производительность, то Вы, конечно же, правы. Но я просто еще ни разу не встречал таких систем, где на размеры дискового массива было плевать абсолютно и между 1 Тб, 16 Тб и 64 Тб не было для заказчика никакой разницы. Обычно задача ставится в виде «обеспечить Х ТБ при скорости Y и latency Z».
А если нужна и емкость тоже, то тогда третий описанный вариант. Вместо 224 дисков FC ставим FlashCache и 93 емких, но медленных диска SATA, и получаем опять ту же высокую производительность (за счет FlashCache), и одновременно большую на 50% емкость и меньшую на 56% цену (за счет SATA).
И опять не теряем производительность, получая те же 55 тысяч (рисунок в комментах).
И опять не теряем производительность, получая те же 55 тысяч (рисунок в комментах).
Забили меня. Сдаюсь. :)
На запись то скорость теперь 93х«SATA disk IOPS» (скажем 93х80=7440, 80 IOPS это оптимистично, может и до 30 IOPS быть), а не 224x«FC IOPS» (скажем 224х150=33600).
Если у нас была OLTP база 66%/33% read/write и 11,2k (33,6k / 3) IOPS и были этими 33% writes то мы в пролете: 11200>>2480 (7440/3, если кэш не разогрет или ну вот плохое случилось идут запросы на отсутствующие в кэше данные и мы читаем все с дисков), 11200>7440 (идеальный случай когда все данные в кэше и 7440 IOPS мы 100% задействуем на write IOPS).
Поправьте если все запутал :).
Если у нас была OLTP база 66%/33% read/write и 11,2k (33,6k / 3) IOPS и были этими 33% writes то мы в пролете: 11200>>2480 (7440/3, если кэш не разогрет или ну вот плохое случилось идут запросы на отсутствующие в кэше данные и мы читаем все с дисков), 11200>7440 (идеальный случай когда все данные в кэше и 7440 IOPS мы 100% задействуем на write IOPS).
Поправьте если все запутал :).
Ну строго говоря там не IOPS, а спекмарковские «попугаи», я уж там так, для упрощения речи, сформулировал. За подробностями смотрите в описании тестов.
Строго говоря, на результат это не влияет, единицы одинаковые во всех трех случаях.
Но неправы в свою очередь и вы. Ситуация с записями в WAFL совсем иная.
Строго говоря, на результат это не влияет, единицы одинаковые во всех трех случаях.
Но неправы в свою очередь и вы. Ситуация с записями в WAFL совсем иная.
Я не придираюсь к тестам, там все понятно.
Мой пример конечно к этим тестам не относится — они NASовые для клиентского доступа по NFS и CIFS (не SAN и не vmdk на NFS например).
Что значит «иная»? Проблемы с raid penalty для RAID-6 решены, прироста IOPS это само по себе не дает.
Как говорит Recovery Monkey «There is no magic»: диски есть диски и больше чем теоретически возможно IOPS они не обслужат.
Попробую другой пример привести: если у нас было 33,6k IOPS при 100% writes (random, так конечно не бывает, просто для примера), перенесли все это с 224 FC на 93 SATA, стало 11,2k IOPS. Это не та же производительность на запись и FlashCache тут не поможет никак.
Мой пример конечно к этим тестам не относится — они NASовые для клиентского доступа по NFS и CIFS (не SAN и не vmdk на NFS например).
Что значит «иная»? Проблемы с raid penalty для RAID-6 решены, прироста IOPS это само по себе не дает.
Как говорит Recovery Monkey «There is no magic»: диски есть диски и больше чем теоретически возможно IOPS они не обслужат.
Попробую другой пример привести: если у нас было 33,6k IOPS при 100% writes (random, так конечно не бывает, просто для примера), перенесли все это с 224 FC на 93 SATA, стало 11,2k IOPS. Это не та же производительность на запись и FlashCache тут не поможет никак.
Я так понял, кэш используется на запись тоже. Проясните тогда, как защищены данные в Flash, пока они не сброшены на жесткие диски, где наверное RAIDы и все такое. Как обеспечивается безопасность новых записанных данных от сбоя Flash Cache?
Это еще один уровень со своим RAID?
Это еще один уровень со своим RAID?
FlashCache НЕ используется на запись. Только на чтение.
Системный кэш, в RAM, не используется на запись (вернее используется иным, чем обычно, образом, и преимущественно только на чтение).
Записываемые операции попадают в так называемый NVRAM (я о нем рассказывал, когда писал про WAFL), и NVRAM хранит в свой памяти с батарейкой операции между двумя «сбросами» на диски.
Данные в нем не хранятся продолжительное время, а каждые несколько секунд сбрасываются (flush) на диски.
Каждый flush завершается записью в файловую систему WAFL специальной отметки — consistency point, запись CP это «атомарная» процедура, она или есть, или ее нет. То есть данные пишем-пишем-пишем, и последним действием записываем CP. Затем, если она завершилась удачно, то очищаем относящуюся к этой порции страницу в памяти NVRAM.
Если CP есть, то валидны относящиеся к ней блоки записанных данных, если CP записать не удалось (например сбой питания или core dump), то остается валидной предыдущая CP. При этом неуспешно записанные данные в NVRAM не очищаются, а хранятся «под батарейкой». А записанные данные на дисках всегда консистентны.
Когда система поднялась, она обнаруживает неудачный flush, и начинает сброс его заново, с самого начала, после чего переставляет на новое состояние данных на дисках CP. До той поры записываемая порция находится в NVRAM.
Рекомендую, если интересны механизмы подробнее, сходить в статью про WAFL (ссылка на нее есть в посте), а там есть ссылка на перевод статьи об устройстве WAFL.
> Как обеспечивается безопасность новых записанных данных от сбоя Flash Cache?
Только чтение. Запись на WAFL практически нет необходимости кэшировать традиционным способом, в non-flushable RAM, (за подробностями снова в статью про WAFL), она и так идет практически на предельно возможной скорости, кэширование ее не ускорит, а алгоритмически сильно усложнит.
Кроме того, каждый сектор (512b) в WAFL дополнительно защищен CRC (8b, суммарно каждый сектор на дисках занимает 520b), это сквозная защита, до выхода байтов из стораджа.
Системный кэш, в RAM, не используется на запись (вернее используется иным, чем обычно, образом, и преимущественно только на чтение).
Записываемые операции попадают в так называемый NVRAM (я о нем рассказывал, когда писал про WAFL), и NVRAM хранит в свой памяти с батарейкой операции между двумя «сбросами» на диски.
Данные в нем не хранятся продолжительное время, а каждые несколько секунд сбрасываются (flush) на диски.
Каждый flush завершается записью в файловую систему WAFL специальной отметки — consistency point, запись CP это «атомарная» процедура, она или есть, или ее нет. То есть данные пишем-пишем-пишем, и последним действием записываем CP. Затем, если она завершилась удачно, то очищаем относящуюся к этой порции страницу в памяти NVRAM.
Если CP есть, то валидны относящиеся к ней блоки записанных данных, если CP записать не удалось (например сбой питания или core dump), то остается валидной предыдущая CP. При этом неуспешно записанные данные в NVRAM не очищаются, а хранятся «под батарейкой». А записанные данные на дисках всегда консистентны.
Когда система поднялась, она обнаруживает неудачный flush, и начинает сброс его заново, с самого начала, после чего переставляет на новое состояние данных на дисках CP. До той поры записываемая порция находится в NVRAM.
Рекомендую, если интересны механизмы подробнее, сходить в статью про WAFL (ссылка на нее есть в посте), а там есть ссылка на перевод статьи об устройстве WAFL.
> Как обеспечивается безопасность новых записанных данных от сбоя Flash Cache?
Только чтение. Запись на WAFL практически нет необходимости кэшировать традиционным способом, в non-flushable RAM, (за подробностями снова в статью про WAFL), она и так идет практически на предельно возможной скорости, кэширование ее не ускорит, а алгоритмически сильно усложнит.
Кроме того, каждый сектор (512b) в WAFL дополнительно защищен CRC (8b, суммарно каждый сектор на дисках занимает 520b), это сквозная защита, до выхода байтов из стораджа.
Тогда акценты в статье расставлены неверно, сбивают с толку.
Как раз при чтении начала статьи у меня было убеждение, что идет речь лишь о кэше на чтение. Но ни слова об этом явно не сказано.
Затем вдруг была поднята проблема random write на flash. Опять не прямо, явно, а коссвенно поднят вопрос записи. Стал думать, что все-таки запись проходит через FlashCache.
Теперь Ваш коммментарий возвращает к версии «только на чтение».
Тогда мой вопрос собственно снят.
PS. И статья, и комментарий могли бы быть гораздо короче. Как раз сложнее читать длинные абзацы для того, чтобы найти простую суть.
Как раз при чтении начала статьи у меня было убеждение, что идет речь лишь о кэше на чтение. Но ни слова об этом явно не сказано.
Затем вдруг была поднята проблема random write на flash. Опять не прямо, явно, а коссвенно поднят вопрос записи. Стал думать, что все-таки запись проходит через FlashCache.
Теперь Ваш коммментарий возвращает к версии «только на чтение».
Тогда мой вопрос собственно снят.
PS. И статья, и комментарий могли бы быть гораздо короче. Как раз сложнее читать длинные абзацы для того, чтобы найти простую суть.
Специально нужный фрагмент поста:
«Как же в данном случае «играет» WAFL?
Дело в том, что в системах NetApp, использующих WAFL, которая «оптимизирована на запись», а если подробнее, то записи, как я уже рассказывал, пишутся длинными последовательными «страйпами», а за счет того, что такая схема позволяет не держать записи в кэше, а записывать их непосредственно на диски, на максимально возможной для этих дисков скорости, кэш в системах NetApp практически не используется на запись. [b]Соответственно не используется на запись и FlashCache[/b], сильно упрощается и алгоритмическая часть, и решается проблема с низкой производительностью Flash на запись. [b]Flash в данном случае вообще не используется на запись[/b], записи прямиком, через буфер RAM, идут на диски, держать их в кэше просто не нужно, то есть мы используем Flash только в самом эффективно работающем у него режиме — random read»
«Как же в данном случае «играет» WAFL?
Дело в том, что в системах NetApp, использующих WAFL, которая «оптимизирована на запись», а если подробнее, то записи, как я уже рассказывал, пишутся длинными последовательными «страйпами», а за счет того, что такая схема позволяет не держать записи в кэше, а записывать их непосредственно на диски, на максимально возможной для этих дисков скорости, кэш в системах NetApp практически не используется на запись. [b]Соответственно не используется на запись и FlashCache[/b], сильно упрощается и алгоритмическая часть, и решается проблема с низкой производительностью Flash на запись. [b]Flash в данном случае вообще не используется на запись[/b], записи прямиком, через буфер RAM, идут на диски, держать их в кэше просто не нужно, то есть мы используем Flash только в самом эффективно работающем у него режиме — random read»
Спасибо, я абсолютно согласен, что пропустил текст.
Я лишь попытался объяснить «почему». Сейчас текст слишком большой. И как оказывается нагружен в том числе и информацией не относящейся к заголовку: «FlashCache».
Вместо того, чтобы в начале статьи сказать «Flash Cache — чудо-кэш только для для чтения. Запись через него не проходит», Вы предпочли добавить пять абзацев про WAFL, упомянули проблемы write для flash, и только где-то внутри можно было найти заветные слова. Явно перегруз лишней инфомрацией.
Было бы мило видеть в начале статьи лаконично сформулированные выделенные плюсы/минусы/назначения/. Любой из этих элементов сейчас надо вычитывать.
Общее впечатление: воды больше, чем нужно. Можно короче без потери смысла.
Хотя, это ИМХО. Думаю, что кому-то нравится.
Я лишь попытался объяснить «почему». Сейчас текст слишком большой. И как оказывается нагружен в том числе и информацией не относящейся к заголовку: «FlashCache».
Вместо того, чтобы в начале статьи сказать «Flash Cache — чудо-кэш только для для чтения. Запись через него не проходит», Вы предпочли добавить пять абзацев про WAFL, упомянули проблемы write для flash, и только где-то внутри можно было найти заветные слова. Явно перегруз лишней инфомрацией.
Было бы мило видеть в начале статьи лаконично сформулированные выделенные плюсы/минусы/назначения/. Любой из этих элементов сейчас надо вычитывать.
Общее впечатление: воды больше, чем нужно. Можно короче без потери смысла.
Хотя, это ИМХО. Думаю, что кому-то нравится.
Специально нужный фрагмент поста:
«Как же в данном случае «играет» WAFL?
Дело в том, что в системах NetApp, использующих WAFL, которая «оптимизирована на запись», а если подробнее, то записи, как я уже рассказывал, пишутся длинными последовательными «страйпами», а за счет того, что такая схема позволяет не держать записи в кэше, а записывать их непосредственно на диски, на максимально возможной для этих дисков скорости, кэш в системах NetApp практически не используется на запись. Соответственно не используется на запись и FlashCache[, сильно упрощается и алгоритмическая часть, и решается проблема с низкой производительностью Flash на запись. Flash в данном случае вообще не используется на запись, записи прямиком, через буфер RAM, идут на диски, держать их в кэше просто не нужно, то есть мы используем Flash только в самом эффективно работающем у него режиме — random read»
«Как же в данном случае «играет» WAFL?
Дело в том, что в системах NetApp, использующих WAFL, которая «оптимизирована на запись», а если подробнее, то записи, как я уже рассказывал, пишутся длинными последовательными «страйпами», а за счет того, что такая схема позволяет не держать записи в кэше, а записывать их непосредственно на диски, на максимально возможной для этих дисков скорости, кэш в системах NetApp практически не используется на запись. Соответственно не используется на запись и FlashCache[, сильно упрощается и алгоритмическая часть, и решается проблема с низкой производительностью Flash на запись. Flash в данном случае вообще не используется на запись, записи прямиком, через буфер RAM, идут на диски, держать их в кэше просто не нужно, то есть мы используем Flash только в самом эффективно работающем у него режиме — random read»
Подобное так же используется в ZFS, и например, в адаптеках с приставкой E.
Очень елегантное решение — SSD в продакшне пока кроме как на кеш использовать стрёмно.
Жду-не дождусь когда для венды что-то такое придумают
Очень елегантное решение — SSD в продакшне пока кроме как на кеш использовать стрёмно.
Жду-не дождусь когда для венды что-то такое придумают
Я написал о аналогичных решениях у других в последнем абзаце текста.
Но проблема еще уйти от использования random write в кэше, и если для ZFS это решается тем, что они используют те же принципы, что реализованы в WAFL у NetApp, то вот с другими системами будет сложнее.
Что же касается Windows, то разве поставив в Windows-сервер Adaptec с MaxIQ вы не добьетесь того, что хотели? (Я, к сожалению, довольно поверхностно знаю продукты Adaptec).
Опять же, NetApp, как производитель внешних, сетевых хранилищ, считает, что эта задача решается покупкой внешнего, сетевого хранилища, а не локальными дисками в каждом сервере.
Но проблема еще уйти от использования random write в кэше, и если для ZFS это решается тем, что они используют те же принципы, что реализованы в WAFL у NetApp, то вот с другими системами будет сложнее.
Что же касается Windows, то разве поставив в Windows-сервер Adaptec с MaxIQ вы не добьетесь того, что хотели? (Я, к сожалению, довольно поверхностно знаю продукты Adaptec).
Опять же, NetApp, как производитель внешних, сетевых хранилищ, считает, что эта задача решается покупкой внешнего, сетевого хранилища, а не локальными дисками в каждом сервере.
вот здесь в комментариях отметили недостаточный ресурс SSD для использования в качестве кеша.
гражданин трак опят маркитасит. :D
Уважаемый track.
1. Перемещение по «уровням хранения» автоматически есть у EMC.
2. Аналог FlashCache технологии есть как минимум у EMC и IBM, причем у последней бесплатно (лицензия бесплатно). Только они использую SSD в исполнении дисков, а не плат. В чем преимущества технологии FlashCache от NetApp перед конкурентами?
1. Перемещение по «уровням хранения» автоматически есть у EMC.
2. Аналог FlashCache технологии есть как минимум у EMC и IBM, причем у последней бесплатно (лицензия бесплатно). Только они использую SSD в исполнении дисков, а не плат. В чем преимущества технологии FlashCache от NetApp перед конкурентами?
Ну давайте по-порядку:
1. Китайская притча говорит, что у мастера Чжень Лун такое кунг-фу, что он может сражаться один против 30 воинов голыми руками. А у мастера Ли Бо — такое кунг-фу, что он никогда не попадет в ситуацию, когда приходится сражаться с 30 воинами голыми руками :)
EMC сперва использует SSD, а потом решает проблемы, вызванные этим использованием с помощью отдельного продукта — FAST. А NetApp просто не имеет этих проблем в принципе, так как не использует Flash в виде SSD, поэтому и FAST как средство tiered storage им не нужен.
Именно поэтому NetApp и говорит о FlashCache и системах с их использованием как о virtual tiered storage — хранилище с виртуальными «уровнями».
FAST постепенно улучшается (в v1 он был никуда не годен, говорят, в v2 уже получше, хотя по прежнему неидеален, сложен и с довольно высокими «накладными расходами», например оперирует «чанками» размером 1GB, против 4KB у NetApp), но NetApp с FlashCache в принципе не имеет тех проблем, которые нужно решать с помощью FAST.
Что выбрать — решать вам. Если у вас EMC, то выбора нет, конечно. Если не ограничиваться EMC, то есть варианты :)
2. Если под аналогом у IBM вы называете их N-series, то это тоже NetApp, IBM N-series это системы производства NetApp, продаваемые по OEM-соглашению. Разумеется они имеют все те же решения, что и «оригинальный NetApp», то есть тот же FlashCache. У IBM «своего» сейчас в стораджах — только DS8000 по-моему, все остальное с большей или меньшей степенью стороннее.
> причем у последней бесплатно (лицензия бесплатно).
FlashCache тоже бесплатен как лицензия, денег стоит только собственно сама физическая плата, соответствующий компонент в OS — FlexScale — встроен и бесплатен.
> В чем преимущества технологии FlashCache от NetApp перед конкурентами?
О преимуществах перед FAST я написал выше. Преимущества перед FASTcache, если вкратце, то большая достижимая емкость на системах верхнего уровня (до 8TB против 2TB), и лучшая производительность на flash в целом (пока демонстрируемые результаты на SSD, если рассмотреть их повнимательнее далеки от того, чтобы произвести впечатление, см. например разбор у recoverymonkey: раз и два.) То есть проблемы с производительностью на SSD у EMC на «системном уровне».
1. Китайская притча говорит, что у мастера Чжень Лун такое кунг-фу, что он может сражаться один против 30 воинов голыми руками. А у мастера Ли Бо — такое кунг-фу, что он никогда не попадет в ситуацию, когда приходится сражаться с 30 воинами голыми руками :)
EMC сперва использует SSD, а потом решает проблемы, вызванные этим использованием с помощью отдельного продукта — FAST. А NetApp просто не имеет этих проблем в принципе, так как не использует Flash в виде SSD, поэтому и FAST как средство tiered storage им не нужен.
Именно поэтому NetApp и говорит о FlashCache и системах с их использованием как о virtual tiered storage — хранилище с виртуальными «уровнями».
FAST постепенно улучшается (в v1 он был никуда не годен, говорят, в v2 уже получше, хотя по прежнему неидеален, сложен и с довольно высокими «накладными расходами», например оперирует «чанками» размером 1GB, против 4KB у NetApp), но NetApp с FlashCache в принципе не имеет тех проблем, которые нужно решать с помощью FAST.
Что выбрать — решать вам. Если у вас EMC, то выбора нет, конечно. Если не ограничиваться EMC, то есть варианты :)
2. Если под аналогом у IBM вы называете их N-series, то это тоже NetApp, IBM N-series это системы производства NetApp, продаваемые по OEM-соглашению. Разумеется они имеют все те же решения, что и «оригинальный NetApp», то есть тот же FlashCache. У IBM «своего» сейчас в стораджах — только DS8000 по-моему, все остальное с большей или меньшей степенью стороннее.
> причем у последней бесплатно (лицензия бесплатно).
FlashCache тоже бесплатен как лицензия, денег стоит только собственно сама физическая плата, соответствующий компонент в OS — FlexScale — встроен и бесплатен.
> В чем преимущества технологии FlashCache от NetApp перед конкурентами?
О преимуществах перед FAST я написал выше. Преимущества перед FASTcache, если вкратце, то большая достижимая емкость на системах верхнего уровня (до 8TB против 2TB), и лучшая производительность на flash в целом (пока демонстрируемые результаты на SSD, если рассмотреть их повнимательнее далеки от того, чтобы произвести впечатление, см. например разбор у recoverymonkey: раз и два.) То есть проблемы с производительностью на SSD у EMC на «системном уровне».
>Если под аналогом у IBM вы называете их N-series, то это тоже NetApp
нет, я под аналогом называю IBM Storwize V7000. от представителей слышал, что это их разработка.
нет, я под аналогом называю IBM Storwize V7000. от представителей слышал, что это их разработка.
А, вы про Easy Tier. Я, увы, невеликий спец по конкурирующим решениям, я предпочитаю хорошо знать продукты одной компании, чем, одинаково плохо — всех. :)
Но основное возражение прежнее. Существуют два подхода: первый создать проблему неверным архитектурным решением (с точки зрения NetApp неверным, конечно же), а затем отдельным продуктом ее решать.
Второй — изначально, на уровне архитектуры системы не иметь этой проблемы в принципе.
Также обратите внимание, что Easy Tier это сравнительно молодой продукт, с которым еще нет достаточного опыта применения, малоизвестны его «узкие места» и слабости, в том время, как NetApp FlashCache продается уже около двух с половиной лет, и очень широко распространен, применяется и работает уже в тысячах стораджей компании у ее клиентов, хорошо протестирован и «пробенчмаркен».
Но основное возражение прежнее. Существуют два подхода: первый создать проблему неверным архитектурным решением (с точки зрения NetApp неверным, конечно же), а затем отдельным продуктом ее решать.
Второй — изначально, на уровне архитектуры системы не иметь этой проблемы в принципе.
Также обратите внимание, что Easy Tier это сравнительно молодой продукт, с которым еще нет достаточного опыта применения, малоизвестны его «узкие места» и слабости, в том время, как NetApp FlashCache продается уже около двух с половиной лет, и очень широко распространен, применяется и работает уже в тысячах стораджей компании у ее клиентов, хорошо протестирован и «пробенчмаркен».
У Netapp есть несколько проблем
1. Они НЕ умеют использовать SSD под запись и пишут, что оно какбэ и не надо, имхо бред, якобы у WAFL и так все хорошо с записью, но скорость записи на HDD, никак не сравнится со скоростью записи на флэши.
2. Такое преимущество как 8 Тб FlashCache — довольно наигранное, во-первых контроллеры mid-range СХД не прожрут такие IOPS, во-вторых, если даже брать что это 8Tb — незеркалируются, получается, при цене около 10K$ за 256Gb — 640K$, что неоправданно для mid-range СХД.
1. Они НЕ умеют использовать SSD под запись и пишут, что оно какбэ и не надо, имхо бред, якобы у WAFL и так все хорошо с записью, но скорость записи на HDD, никак не сравнится со скоростью записи на флэши.
2. Такое преимущество как 8 Тб FlashCache — довольно наигранное, во-первых контроллеры mid-range СХД не прожрут такие IOPS, во-вторых, если даже брать что это 8Tb — незеркалируются, получается, при цене около 10K$ за 256Gb — 640K$, что неоправданно для mid-range СХД.
> Они НЕ умеют использовать SSD под запись
Вы считаете, что постоянно писать на устройства, имеющие конечный ресурс на запись — это разумно?
> и пишут, что оно какбэ и не надо, имхо бред, якобы у WAFL и так все хорошо с записью, но скорость записи на HDD, никак не сравнится со скоростью записи на флэши.
Почитайте тут:
blog.aboutnetapp.ru/archives/936
в особенности вторую половину статьи.
> 2. Такое преимущество как 8 Тб FlashCache — довольно наигранное, во-первых контроллеры mid-range СХД не прожрут такие IOPS
Конечно не прожрут, тем более, что 8TB в них и не поставить, это только для 6200, hi-end, и вот для последних это весьма нужно.
Вы считаете, что постоянно писать на устройства, имеющие конечный ресурс на запись — это разумно?
> и пишут, что оно какбэ и не надо, имхо бред, якобы у WAFL и так все хорошо с записью, но скорость записи на HDD, никак не сравнится со скоростью записи на флэши.
Почитайте тут:
blog.aboutnetapp.ru/archives/936
в особенности вторую половину статьи.
> 2. Такое преимущество как 8 Тб FlashCache — довольно наигранное, во-первых контроллеры mid-range СХД не прожрут такие IOPS
Конечно не прожрут, тем более, что 8TB в них и не поставить, это только для 6200, hi-end, и вот для последних это весьма нужно.
Учитывая реальный ресурс при постоянно работающей СХД около 5 лет — вполне.
Прочитал статью, она очень отдает «хьюлеттовщиной», то есть доводы все ну ооочень сомнительно для обычного человека, для инженера-стораджиста так вообще не доводы.
Ну что значит «По контрасту, если вы покупаете 256GB Flash Cache, вы можете использовать под кэширование и ускорение работы с данными все 256GB, сто процентов от затраченных на них денег,» а если погорит PAM-плата — останетесь без кэша?
Так можно и под FAST брать не 3, а 2 диска — причем появляется отказоустойчивость, а то что рекомендовано 3 флэша, так любой адекватный заказчик и возьмет 3 драйва, потому что данные уж куда важнее цены лишнего диска.
Опять же WAFL — это «надстройка» над классическим блочным уровнем, которая имеет свои плюсы так и минусы, атк как создание доп слоя создает свои задержки.
Ну и последнее, вы же сами знаете отличие Hi-End от mid-range — отсутсвие влияния на продакшен при выходе любой из компонент, 6200 никак не Hi, даже 3Par со своими 4-х контроллерными системами не зовет себя Hi-endом. Вот вылетит контроллер на 6200 груженной под 1000 дисков и что???
Прочитал статью, она очень отдает «хьюлеттовщиной», то есть доводы все ну ооочень сомнительно для обычного человека, для инженера-стораджиста так вообще не доводы.
Ну что значит «По контрасту, если вы покупаете 256GB Flash Cache, вы можете использовать под кэширование и ускорение работы с данными все 256GB, сто процентов от затраченных на них денег,» а если погорит PAM-плата — останетесь без кэша?
Так можно и под FAST брать не 3, а 2 диска — причем появляется отказоустойчивость, а то что рекомендовано 3 флэша, так любой адекватный заказчик и возьмет 3 драйва, потому что данные уж куда важнее цены лишнего диска.
Опять же WAFL — это «надстройка» над классическим блочным уровнем, которая имеет свои плюсы так и минусы, атк как создание доп слоя создает свои задержки.
Ну и последнее, вы же сами знаете отличие Hi-End от mid-range — отсутсвие влияния на продакшен при выходе любой из компонент, 6200 никак не Hi, даже 3Par со своими 4-х контроллерными системами не зовет себя Hi-endом. Вот вылетит контроллер на 6200 груженной под 1000 дисков и что???
> Ну что значит «По контрасту, если вы покупаете 256GB Flash Cache, вы можете использовать под кэширование и ускорение работы с данными все 256GB, сто процентов от затраченных на них денег,»
Вы сейчас кого цитируете? У меня в статье этой фразы нет.
> а если погорит PAM-плата — останетесь без кэша?
Не без кэша, а без Flash Cache, основной кэш в памяти работает по прежнему. Данные при выходе из строя Flash Cache не теряются, потому что кэш — только на чтение.
Если погорит плата — то происходит кластерный файловер, и клиенты переводятся на другой контроллер, на котором плата не погорела. Сама же плата доставляется курьерской службой со склада в режиме NBD Onsite, либо же, при наличии соответствующего уровня поддержки (до 50 км от сервисного склада), 4h 24x7.
> Так можно и под FAST брать не 3, а 2 диска — причем появляется отказоустойчивость, а то что рекомендовано 3 флэша, так любой адекватный заказчик и возьмет 3 драйва, потому что данные уж куда важнее цены лишнего диска.
Не вполне почем о чем вы, и к чему это. Переформулируйте.
> Опять же WAFL — это «надстройка» над классическим блочным уровнем, которая имеет свои плюсы так и минусы, атк как создание доп слоя создает свои задержки.
Это не вполне так.
Снова непонятно, что это, в процитированом виде, доказывает.
> Ну и последнее, вы же сами знаете отличие Hi-End от mid-range
Я знаю минимум три разных «определения» что такое hi-end. :)
Строго говоря, Hi-end это только лишь уровень производительности и уровень обеспечиваемого SLA.
> Вот вылетит контроллер на 6200 груженной под 1000 дисков и что???
Произойдет кластерный файловер, данные останутся доступны. При правильно сайзенной системе сохранится и гарантированный уровень производительности.
Вы сейчас кого цитируете? У меня в статье этой фразы нет.
> а если погорит PAM-плата — останетесь без кэша?
Не без кэша, а без Flash Cache, основной кэш в памяти работает по прежнему. Данные при выходе из строя Flash Cache не теряются, потому что кэш — только на чтение.
Если погорит плата — то происходит кластерный файловер, и клиенты переводятся на другой контроллер, на котором плата не погорела. Сама же плата доставляется курьерской службой со склада в режиме NBD Onsite, либо же, при наличии соответствующего уровня поддержки (до 50 км от сервисного склада), 4h 24x7.
> Так можно и под FAST брать не 3, а 2 диска — причем появляется отказоустойчивость, а то что рекомендовано 3 флэша, так любой адекватный заказчик и возьмет 3 драйва, потому что данные уж куда важнее цены лишнего диска.
Не вполне почем о чем вы, и к чему это. Переформулируйте.
> Опять же WAFL — это «надстройка» над классическим блочным уровнем, которая имеет свои плюсы так и минусы, атк как создание доп слоя создает свои задержки.
Это не вполне так.
Снова непонятно, что это, в процитированом виде, доказывает.
> Ну и последнее, вы же сами знаете отличие Hi-End от mid-range
Я знаю минимум три разных «определения» что такое hi-end. :)
Строго говоря, Hi-end это только лишь уровень производительности и уровень обеспечиваемого SLA.
> Вот вылетит контроллер на 6200 груженной под 1000 дисков и что???
Произойдет кластерный файловер, данные останутся доступны. При правильно сайзенной системе сохранится и гарантированный уровень производительности.
Существует ли возможность оценить потенциальную эффективность от установки Flash Cache ДО его приобретения? Если ли способ измерить объем читаемых со стораджа данных, которые могли бы принести пользу при их кэшировании на Flash Cache?
Боюсь, как бы не получилось так, что на флэшке будет данных храниться не более чем в RAM кэше контроллеров…
Боюсь, как бы не получилось так, что на флэшке будет данных храниться не более чем в RAM кэше контроллеров…
Да, такая возможность есть, она называется Predictive Cache Statistics (PCS). Посмотрите документ media.netapp.com/documents/tr-3801.pdf
Еще интересно тут:
ctistrategy.com/2009/02/27/netapp-cache-pcs/
ctistrategy.com/2009/02/27/netapp-cache-pcs/
Sign up to leave a comment.
FlashCache. Как использовать Flash в СХД НЕ как SSD?