Comments 10
Я понимаю, что статистика — это основа статистического обучения. Но такими темпами, скоро решение квадратного уравнения будем называть «машинным обучением». Имхо, корректное название статьи — «основы статистики»
Моя задача максимум — постепенно (по мере самообучения) сделать нормальный курс по современному «машинному обучению». Это — первая статья. Если посмотреть учебники, то они обычно начинаются как раз с регрессии. Вообще, насколько я понял, «машинное обучение» — это сборная солянка из разных областей: статистики, распознавания образов, обратных задач и т.д…
Было бы здорово сделать множественный выбор в опросе после статьи — мне, например, сразу несколько тем интересны.
Все же оставлю обычный выбор, для чистоты эксперимента. Опросы — большей частью для накапливания данных. А по перечисленным темам, рано или поздно, по всем напишу.
Было бы неплохо дать список литературы (сразу наперед)
В хвосте статьи (перед опросами) ссылки на бесплатные англоязычные книги.
Еще нашел русские ресурсы:
Еще нашел русские ресурсы:
- www.machinelearning.ru
- Машинное обучение (курс лекций, К.В.Воронцов)
- Дьяконов А.Г. Анализ данных, обучение по прецедентам, логические игры, системы WEKA, RapidMiner и MatLab // Учебное пособие
Я туплю, но разве 10 точек достаточно? Я просто помню, что у меня для n = 500 получалось расхождение АКФ уже при n > 40
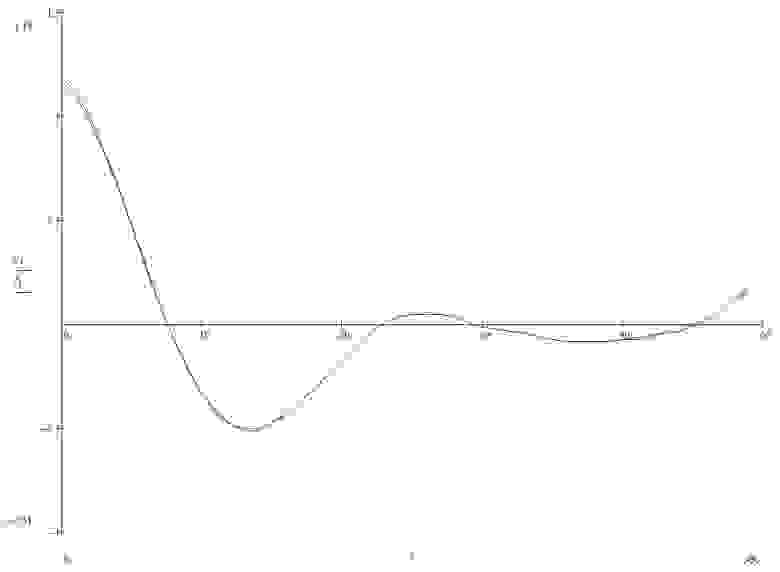
Вопрос тут скорее в том, сильно ли влияет количество точек на затухание АКФ (в среднем, конечно)?

Вопрос тут скорее в том, сильно ли влияет количество точек на затухание АКФ (в среднем, конечно)?
Спасибо за вопрос!
По 10 точкам я делаю регрессию, т.е. провожу прямую по МНК. Вообще говоря, ничего не мешает и по 3-м точкам провести. Будут разные оценки для стандартной ошибки регрессии (сигмы) — которая зависит в перую очередь от к-та корреляции.
Добавил в хвост статьи три графика для разного объема выборки N (10 и 100) и к-та корреляции R (два первых для 0.9, нижний — 0.5). Обратите внимание, на зависимость стандартной ошибки от R.
Про АКФ (автокорреляционная функция? По каким данным она у Вас нарисована?) будет во 2-й серии. Надо сказать, что датчики случайных чисел обычно дают не такие уж независимые данные. А в моей модели каждая пара данных (xi,zi) предполагается независимой (временной корреляции нет).
По 10 точкам я делаю регрессию, т.е. провожу прямую по МНК. Вообще говоря, ничего не мешает и по 3-м точкам провести. Будут разные оценки для стандартной ошибки регрессии (сигмы) — которая зависит в перую очередь от к-та корреляции.
Добавил в хвост статьи три графика для разного объема выборки N (10 и 100) и к-та корреляции R (два первых для 0.9, нижний — 0.5). Обратите внимание, на зависимость стандартной ошибки от R.
Про АКФ (автокорреляционная функция? По каким данным она у Вас нарисована?) будет во 2-й серии. Надо сказать, что датчики случайных чисел обычно дают не такие уж независимые данные. А в моей модели каждая пара данных (xi,zi) предполагается независимой (временной корреляции нет).
Данные я брал на кафедре, откуда они там получены, честно говоря, не знаю, но вроде это реальные данные (а не из ГПСЧ).
АКФ я рисовал для двух процессов — у меня было исследование возможностей численного нахождения коинтеграции для произвольных временных рядов. Поэтому я взял исходный стационарный процесс, разбил его на два нестационарных, затем подал его на вход моей программы, которая подобрала коэффициенты, по которым я построил новый процесс. Для него АКФ — синяя на графике, а для исходного процесса — красная. Забавно, что в итоге стат. характеристики полученного процесса оказались даже лучше, чем исходного :) (видно на графике, что дисперсия чуть-чуть ниже у синего).
АКФ я рисовал для двух процессов — у меня было исследование возможностей численного нахождения коинтеграции для произвольных временных рядов. Поэтому я взял исходный стационарный процесс, разбил его на два нестационарных, затем подал его на вход моей программы, которая подобрала коэффициенты, по которым я построил новый процесс. Для него АКФ — синяя на графике, а для исходного процесса — красная. Забавно, что в итоге стат. характеристики полученного процесса оказались даже лучше, чем исходного :) (видно на графике, что дисперсия чуть-чуть ниже у синего).
Sign up to leave a comment.
Машинное обучение — 1. Корреляция и регрессия. Пример: конверсия посетителей сайта