Довольно часто встречается задача классификации текстов — например, определение тональности (выражает ли текст позитивное мнение или отрицательное о чем-либо), или разнесения текста по тематикам. На Хабре уже есть хорошие статьи с введением в данный вопрос.
Сегодня я хочу поговорить о проблеме классификации отдельных предложений. Решение этой задачи позволяет делать много интересного, например, выделять положительные и отрицательные моменты из длинных текстов, определять тональность твитов, является компонентом многих систем отвечающих на естественно-языковые вопросы (классификация типа вопроса), помогает сегментировать веб-страницы на смысловые блоки и многое другое. Однако, классификация отдельных предложений значительно сложнее классификации больших блоков текста — в одном предложении значительно меньше полезных признаков, и велико влияние порядка слов. Например: «как положено фильму ужасов, этот фильм был ну очень жутким» — содержит негативные слова («ужас», «жуткий»), но выражает положительное мнение о фильме, «все было ужасно красиво», или даже «отличный фильм, ничего не скажешь, только зря деньги потратили».
Традиционно это затруднение стараются решать с помощью предварительной обработки текста и ручного выделения признаков. В предварительную обработку могут входить как относительно простые техники (учет отрицания путем приклеивания частицы «не» к следующим словам), там и более сложные наборы правил переключения тональности, а также построение дерева зависимостей, а в ручные признаки — словари положительных и отрицательных слов, место слова в предложении, и другие — насколько хватит фантазии. Ясно, что сей процесс нудный, требующий много сторонних функций (например, нужен парсер для грамматического разбора предложения, словари), и не всегда результативный. Например, если авторы предложений делали много грамматических ошибок, то парсер, строящий дерево зависимостей, начинает сильно путаться, и качество работы всей системы резко снижается.
Но дело даже и не в этом — а в том, что все это делать лень. Я глубоко убежден, что системы машинного обучения должны работать end-to-end – загрузили обучающие данные — получили работающую модель. Пусть даже качество упадет на пару процентов, но трудозатраты снизятся на порядок, и откроется путь для большого числа новых и полезных приложений (например, вот я нашел статью об интересном применении классификатора текстов ).
Теория: Но короче, от слов к делу. Чтобы предложение можно было подать на вход нейронной сети, надо решить несколько проблем. Во-первых, необходимо преобразовать слова в цифры. Первое желание, которое возникает — сопоставить каждому слову из словаря свое число. Скажем (Абрикос — 1, Аппарат — 2, …. Яблоко — 53845). Но делать так нельзя, потому что таким образом мы неявно предполагаем, что абрикос гораздо больше похож на аппарат, чем на яблоко. Второй вариант — закодировать слова длинным вектором, в котором нужному слову соответствует 1, а всем остальным — 0 (Абрикос — 1 0 0 …, Аппарат — 0 1 0 0 …, … Яблоко — … 0 0 0 1). Здесь все слова равноудалены и не похожи друг на друга. Этот подход гораздо лучше и в ряде случаев работает хорошо (если есть достаточно много примеров).
Но если набор примеров маленький, то весьма вероятно, что какие-то слова (например, «абрикос») в нем будут отсутствовать, и в результате встретив такие слова в реальных примерах, алгоритм не будет знать, что с ними делать. Поэтому оптимально кодировать слова такими векторами, чтобы похожие по смыслу слова оказывались близко друг к другу — а далекие, соответственно — далеко. Есть несколько алгоритмов, которые «читают» большие объемы текстов, и на основании этого создают такие вектора (самый известный, но не всегда самый лучший — word2vec). Подробности — тема для отдельного разговора, пока для понимания достаточно знать, что такие способы есть, они берут на вход длинные массивы текстов и выдают вектора фиксированной длины, соответствующие каждому слову.
Получив вектора слов, мы сталкиваемся с задачей номер два — как представить цельное предложение для нейронной сети. Дело в том, что обычные нейронные сети прямого распространения (feed-forward) должны иметь входные данные фиксированной длины (см картинку). Объяснять, как работает классическая искусственная нейронная сеть прямого распространения здесь не буду — на эту тему уже написано достаточно статей см, например. Для полноты картины вставлю только рисунок.
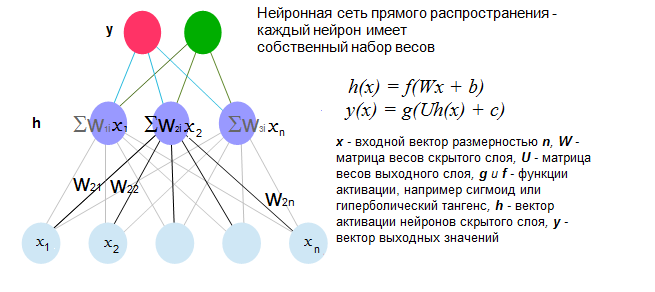
Так вот, наша проблема в том, что все предложения содержат разное число слов. Самый простой выход — сложить все вектора, получив таким образом результирующий вектор предложения. Приведя все такие вектора к единичной длине, получаем пригодные входные данные. Такое представление часто называется «neural bag of words” (NBoW) — «нейронная сумка слов», поскольку порядок слов в нем теряется. Плюсом данного алгоритма является крайняя простота реализации (имея под рукой вектора слов и любую библиотеку с реализацией нейронных сетей или другого классификатора, можно сделать рабочий вариант за 10 — 20 мин). При этом результаты иногда превосходят другие более сложные алгоритмы, оставаясь, правда, далеко от максимально возможных (сие, впрочем, зависит от задачи — например, при классификации текстов на отзывы о товарах/описания товаров/прочее, NBoW у нас показал 92% точности на тестовой выборке, против 86% алгоритма использующего логистическую регрессию и тщательно подобранный вручную словарь).
Однако, мы уже говорили о том, что для классификации предложений важен порядок слов. Чтобы сохранить порядок слов, вектор предложения можно образовать, соединив все вектора слов «голова к хвосту», в один длинный вектор, если конечно придумать, как передать нейронной сети входные данные разной длины.
Маленькое отступление — внимательный читатель должен возмутиться — я обещал классификатор предложений без предварительной обработки, но поделить предложение на слова и преобразовать в вектор — это уже предварительная обработка. Поэтому я должен был написать «с минимальной предварительной обработкой». Но это звучит не так хорошо, и к тому же по сравнению с обычными методами, такая обработка, в общем-то, и не считается. На сегодня есть методы, которые позволяют работать непосредственно с буквами, позволяя избежать деления предложения на слова и преобразования в вектора, но это опять отдельная тема.
Вернемся к проблеме разной длины входных данных. У нее есть разные решения, но мы пока рассмотрим одно — а именно сверточный фильтр. Идея простая — мы берем один нейрон и подаем на вход два (или более) слова (см. рис 2). Потом мы сдвигаем вход на одно слово и повторяем операцию. На выходе мы имеем представление предложения, которое в два (или в n) раз меньше оригинального. При этом таких фильтров обычно создается несколько (от 10 до 100). Далее операцию можно повторить, поставив над первым слоем, второй такой же, использующий входные значения первого пока все предложение не будет свернуто, либо, на определенном этапе выбрать максимальное значение активации нейрона (так называемый слой объединения — pooling layer). За счет этого, последний слой нейронов получает представление фиксированной длины, и уже он предсказывает нужную категорию предложения.

Главный результат — нейронная сеть получает возможность строить иерархические модели, формируя в каждом следующем слое более абстрактные представления предложения. Существует ряд модификаций, которые отличаются деталями архитектуры, при этом некоторые из них не только получают лучшие из известных результатов в классификации предложений на стандартных задачах, но и могут быть обучены для перевода с одного языка на другой.
Вообще такие сети похожи на те, которые успешно используются в распознавании изображений, что опять же приятно (одна архитектура на все задачи). Правда совсем одна не получается — у сетей обрабатывающих текст, все-таки есть свои особенности.
Опыты: Для опытов реализацию нейронной сети нам пришлось написать самостоятельно. Мы не хотели этого делать, но вышло так, что это проще, чем применить некоторые готовые библиотеки, которые к тому же сложно потом перенести в конечное приложение. Ну и полезно в плане самообразования. Тем более что данная реализация нам нужна не сама по себе (хотя и это полезно), а как часть большой системы.
В нашей тестовой реализации простой сверточной сети три слоя, — один сверточный слой, один слой объединения, и верхний полностью соединенный слой (как на первом рисунке), который выдает собственно классификацию. Все это следует примерно описанию системы из работы Kim et al, 2014 – там же есть и иллюстрация, которую я не буду копировать сюда, чтобы не думать про авторские права лишний раз.
В качестве объекта тестирования взяли стандартный набор положительных и отрицательных предложений о кинофильмах на английском языке. Вот что получилось:
В целом, получилось достаточно неплохо. Лучший опубликованный результат на этих данных для таких сетей сейчас составляет 83% с 100 фильтрами (см. статью выше), а лучший результат с помощью ручного подбора признаков — 77.3%.
Сегодня я хочу поговорить о проблеме классификации отдельных предложений. Решение этой задачи позволяет делать много интересного, например, выделять положительные и отрицательные моменты из длинных текстов, определять тональность твитов, является компонентом многих систем отвечающих на естественно-языковые вопросы (классификация типа вопроса), помогает сегментировать веб-страницы на смысловые блоки и многое другое. Однако, классификация отдельных предложений значительно сложнее классификации больших блоков текста — в одном предложении значительно меньше полезных признаков, и велико влияние порядка слов. Например: «как положено фильму ужасов, этот фильм был ну очень жутким» — содержит негативные слова («ужас», «жуткий»), но выражает положительное мнение о фильме, «все было ужасно красиво», или даже «отличный фильм, ничего не скажешь, только зря деньги потратили».
Традиционно это затруднение стараются решать с помощью предварительной обработки текста и ручного выделения признаков. В предварительную обработку могут входить как относительно простые техники (учет отрицания путем приклеивания частицы «не» к следующим словам), там и более сложные наборы правил переключения тональности, а также построение дерева зависимостей, а в ручные признаки — словари положительных и отрицательных слов, место слова в предложении, и другие — насколько хватит фантазии. Ясно, что сей процесс нудный, требующий много сторонних функций (например, нужен парсер для грамматического разбора предложения, словари), и не всегда результативный. Например, если авторы предложений делали много грамматических ошибок, то парсер, строящий дерево зависимостей, начинает сильно путаться, и качество работы всей системы резко снижается.
Но дело даже и не в этом — а в том, что все это делать лень. Я глубоко убежден, что системы машинного обучения должны работать end-to-end – загрузили обучающие данные — получили работающую модель. Пусть даже качество упадет на пару процентов, но трудозатраты снизятся на порядок, и откроется путь для большого числа новых и полезных приложений (например, вот я нашел статью об интересном применении классификатора текстов ).
Теория: Но короче, от слов к делу. Чтобы предложение можно было подать на вход нейронной сети, надо решить несколько проблем. Во-первых, необходимо преобразовать слова в цифры. Первое желание, которое возникает — сопоставить каждому слову из словаря свое число. Скажем (Абрикос — 1, Аппарат — 2, …. Яблоко — 53845). Но делать так нельзя, потому что таким образом мы неявно предполагаем, что абрикос гораздо больше похож на аппарат, чем на яблоко. Второй вариант — закодировать слова длинным вектором, в котором нужному слову соответствует 1, а всем остальным — 0 (Абрикос — 1 0 0 …, Аппарат — 0 1 0 0 …, … Яблоко — … 0 0 0 1). Здесь все слова равноудалены и не похожи друг на друга. Этот подход гораздо лучше и в ряде случаев работает хорошо (если есть достаточно много примеров).
Но если набор примеров маленький, то весьма вероятно, что какие-то слова (например, «абрикос») в нем будут отсутствовать, и в результате встретив такие слова в реальных примерах, алгоритм не будет знать, что с ними делать. Поэтому оптимально кодировать слова такими векторами, чтобы похожие по смыслу слова оказывались близко друг к другу — а далекие, соответственно — далеко. Есть несколько алгоритмов, которые «читают» большие объемы текстов, и на основании этого создают такие вектора (самый известный, но не всегда самый лучший — word2vec). Подробности — тема для отдельного разговора, пока для понимания достаточно знать, что такие способы есть, они берут на вход длинные массивы текстов и выдают вектора фиксированной длины, соответствующие каждому слову.
Получив вектора слов, мы сталкиваемся с задачей номер два — как представить цельное предложение для нейронной сети. Дело в том, что обычные нейронные сети прямого распространения (feed-forward) должны иметь входные данные фиксированной длины (см картинку). Объяснять, как работает классическая искусственная нейронная сеть прямого распространения здесь не буду — на эту тему уже написано достаточно статей см, например. Для полноты картины вставлю только рисунок.
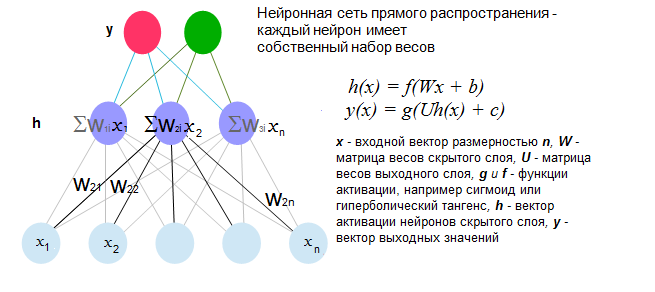
Так вот, наша проблема в том, что все предложения содержат разное число слов. Самый простой выход — сложить все вектора, получив таким образом результирующий вектор предложения. Приведя все такие вектора к единичной длине, получаем пригодные входные данные. Такое представление часто называется «neural bag of words” (NBoW) — «нейронная сумка слов», поскольку порядок слов в нем теряется. Плюсом данного алгоритма является крайняя простота реализации (имея под рукой вектора слов и любую библиотеку с реализацией нейронных сетей или другого классификатора, можно сделать рабочий вариант за 10 — 20 мин). При этом результаты иногда превосходят другие более сложные алгоритмы, оставаясь, правда, далеко от максимально возможных (сие, впрочем, зависит от задачи — например, при классификации текстов на отзывы о товарах/описания товаров/прочее, NBoW у нас показал 92% точности на тестовой выборке, против 86% алгоритма использующего логистическую регрессию и тщательно подобранный вручную словарь).
Однако, мы уже говорили о том, что для классификации предложений важен порядок слов. Чтобы сохранить порядок слов, вектор предложения можно образовать, соединив все вектора слов «голова к хвосту», в один длинный вектор, если конечно придумать, как передать нейронной сети входные данные разной длины.
Маленькое отступление — внимательный читатель должен возмутиться — я обещал классификатор предложений без предварительной обработки, но поделить предложение на слова и преобразовать в вектор — это уже предварительная обработка. Поэтому я должен был написать «с минимальной предварительной обработкой». Но это звучит не так хорошо, и к тому же по сравнению с обычными методами, такая обработка, в общем-то, и не считается. На сегодня есть методы, которые позволяют работать непосредственно с буквами, позволяя избежать деления предложения на слова и преобразования в вектора, но это опять отдельная тема.
Вернемся к проблеме разной длины входных данных. У нее есть разные решения, но мы пока рассмотрим одно — а именно сверточный фильтр. Идея простая — мы берем один нейрон и подаем на вход два (или более) слова (см. рис 2). Потом мы сдвигаем вход на одно слово и повторяем операцию. На выходе мы имеем представление предложения, которое в два (или в n) раз меньше оригинального. При этом таких фильтров обычно создается несколько (от 10 до 100). Далее операцию можно повторить, поставив над первым слоем, второй такой же, использующий входные значения первого пока все предложение не будет свернуто, либо, на определенном этапе выбрать максимальное значение активации нейрона (так называемый слой объединения — pooling layer). За счет этого, последний слой нейронов получает представление фиксированной длины, и уже он предсказывает нужную категорию предложения.

Главный результат — нейронная сеть получает возможность строить иерархические модели, формируя в каждом следующем слое более абстрактные представления предложения. Существует ряд модификаций, которые отличаются деталями архитектуры, при этом некоторые из них не только получают лучшие из известных результатов в классификации предложений на стандартных задачах, но и могут быть обучены для перевода с одного языка на другой.
Вообще такие сети похожи на те, которые успешно используются в распознавании изображений, что опять же приятно (одна архитектура на все задачи). Правда совсем одна не получается — у сетей обрабатывающих текст, все-таки есть свои особенности.
Опыты: Для опытов реализацию нейронной сети нам пришлось написать самостоятельно. Мы не хотели этого делать, но вышло так, что это проще, чем применить некоторые готовые библиотеки, которые к тому же сложно потом перенести в конечное приложение. Ну и полезно в плане самообразования. Тем более что данная реализация нам нужна не сама по себе (хотя и это полезно), а как часть большой системы.
В нашей тестовой реализации простой сверточной сети три слоя, — один сверточный слой, один слой объединения, и верхний полностью соединенный слой (как на первом рисунке), который выдает собственно классификацию. Все это следует примерно описанию системы из работы Kim et al, 2014 – там же есть и иллюстрация, которую я не буду копировать сюда, чтобы не думать про авторские права лишний раз.
В качестве объекта тестирования взяли стандартный набор положительных и отрицательных предложений о кинофильмах на английском языке. Вот что получилось:
| Алгоритм | Точность классификации |
| NBoW | 68% |
| Сверточная сеть, 8 фильтров | 74.3% |
| Сверточная сеть, 16 фильтров | 77.8% |
В целом, получилось достаточно неплохо. Лучший опубликованный результат на этих данных для таких сетей сейчас составляет 83% с 100 фильтрами (см. статью выше), а лучший результат с помощью ручного подбора признаков — 77.3%.
