

Я работаю в Mail.ru Cloud Solutons архитектором и разработчиком, в том числе занимаюсь нашим облаком. Известно, что распределенной облачной инфраструктуре нужно производительное блочное хранилище, от которого зависит работа PaaS-сервисов и решений, построенных с их помощью.
Изначально при развертывании такой инфраструктуры мы использовали только Ceph, но постепенно блочное хранилище эволюционировало. Хотелось, чтобы наши базы данных, файловое хранилище и различные сервисы работали с максимальной производительностью, поэтому мы добавили локализованные хранилища и наладили расширенный мониторинг Ceph.
Расскажу, как это было — возможно, эта история, проблемы, с которыми мы столкнулись, и наши решения будут полезны тем, кто тоже использует Ceph. Кстати, вот видеоверсия этого доклада.
От DevOps-процессов к собственному облаку
DevOps-практики направлены на то, чтобы как можно быстрее выкатывать продукт:
- Автоматизация процессов — всего жизненного цикла: сборки, тестирования, доставки в тест и продуктив. Автоматизируют процессы постепенно, начиная с небольших шагов.
- Инфраструктура как код — модель, когда процесс настройки инфраструктуры аналогичен процессу программирования ПО. Сначала тестируют продукт, продукт предъявляет к инфраструктуре определенные требования, и нужно тестировать инфраструктуру. На этом этапе появляются пожелания к ней, хочется «подкрутить» инфраструктуру — сначала в тестовой среде, потом в продуктовой. На первом этапе это можно делать вручную, но потом переходят к автоматизации — к модели «инфраструктура как код».
- Виртуализация и контейнеры — появляются в компании, когда ясно, что нужно поставить процессы на промышленные рельсы, быстрее выкатывать новые фичи с минимальным ручным вмешательством.
 Архитектура всех виртуальных сред похожа: гостевые машины с контейнерами, приложения, публичная и приватная сети, хранилища.
Архитектура всех виртуальных сред похожа: гостевые машины с контейнерами, приложения, публичная и приватная сети, хранилища. Постепенно в виртуальной инфраструктуре, построенной в рамках и вокруг DevOps-процессов, разворачивают всё больше и больше сервисов, и виртуальная среда становится не только тестовой (используемой для разработки и тестирования), но и продуктивной.
Как правило, на начальных этапах обходятся простейшими базовыми инструментами автоматизации. Но по мере привлечения новых инструментов, рано или поздно возникает необходимость в развертывании полноценной облачной платформы, чтобы использовать наиболее развитые средства наподобие Terraform.
На этом этапе виртуальная инфраструктура из «гипервизоров, сети и хранилища» превращается в полноценную облачную инфраструктуру с развитыми инструментами и компонентами для оркестрации процессов. Тогда и появляется собственное облако, в котором происходят процессы тестирования и автоматизированной доставки обновлений существующих сервисов и развертывания новых сервисов.
Второй путь к собственному облаку — возникшая необходимость не зависеть от внешних ресурсов и внешних поставщиков сервисов, то есть обеспечение некоторой технической независимости для собственных сервисов.
 Первое облако выглядит почти как виртуальная инфраструктура — гипервизор (один или несколько), виртуальные машины с контейнерами, общее хранилище: если вы строите облако не на проприетарных решениях, это, как правило, Ceph или DRBD.
Первое облако выглядит почти как виртуальная инфраструктура — гипервизор (один или несколько), виртуальные машины с контейнерами, общее хранилище: если вы строите облако не на проприетарных решениях, это, как правило, Ceph или DRBD.Отказоустойчивость и производительность приватного облака
Облако растет, бизнес зависит от него всё сильнее, компания начинает требовать большей надежности.
Здесь к приватному облаку добавляют распределенность, появляется распределенная облачная инфраструктура: дополнительные точки, где размещено оборудование. Облако управляет двумя, тремя или более инсталляциями, построенными, чтобы получить отказоустойчивое решение.
При этом данные нужны со всех площадок, и тут есть проблема: внутри одной площадки нет больших задержек в передаче данных, а вот между площадками данные передаются медленнее.
 Инсталляционные площадки и общее хранилище. Красные прямоугольники — узкие места на уровне сети.
Инсталляционные площадки и общее хранилище. Красные прямоугольники — узкие места на уровне сети.Внешняя часть инфраструктуры с точки зрения сети менеджмента или публичной сети не так загружена, а вот по внутренней сети передаваемые объемы данных заметно больше. И у распределенных систем, начинаются проблемы, выражающиеся в большом времени обслуживания. Если клиент приходит на одну группу нод хранилища, данные должны моментально реплицироваться на вторую группу, чтобы изменения не были потеряны.
Для ряда процессов задержка репликации данных допустима, но в таких случаях, как транзакционный процессинг, транзакции терять нельзя. Если используется асинхронная репликация, возникает временной лаг, который может привести к потере части данных при отказе одного из «хвостов» СХД (системы хранения данных). Если же используется синхронная репликация, растет время обслуживания.
Также вполне естественно, что когда время обработки операций (latency) на хранилищах увеличивается, базы данных начинают подтормаживать и возникают негативные эффекты, с которыми приходится бороться.
В нашем облаке мы ищем сбалансированные решения, чтобы сохранить надежность и производительность. Самая простая методика — локализовать данные — и тогда мы добавили дополнительные локализованные кластеры Ceph.
 Зеленым цветом обозначены дополнительные локализованные кластеры Ceph.
Зеленым цветом обозначены дополнительные локализованные кластеры Ceph.Плюс такой сложной архитектуры в том, что те, кому нужен быстрый ввод/вывод данных, могут использовать локализованные хранилища. Данные, для которых критична полная доступность в рамках двух площадок, лежат в распределенном кластере. Он работает медленнее — но данные в нем реплицированы на обе площадки. Если его производительности не хватает — можно использовать локализованные кластеры Ceph.
Большинство публичных и частных облаков со временем приходят примерно к такой же схеме работы, когда в зависимости от требований нагрузка деплоится в разные типы хранилищ (разные типы дисков).
Диагностика Ceph: как выстроить мониторинг
Когда мы развернули и запустили инфраструктуру, настало время обеспечить ее функционирование, минимизировать время и количество отказов. Поэтому следующим шагом развития инфраструктуры стало построение диагностики и мониторинга.
Рассмотрим задачу мониторинга на всем протяжении — у нас есть стек приложения в виртуальной облачной среде: приложение, гостевая операционная система, блочное устройство, драйверы этого блочного устройства на гипервизоре, storage network и собственно СХД (система хранения данных). И всё это пока не покрыто мониторингом.
 Элементы, не покрытые мониторингом.
Элементы, не покрытые мониторингом.Мониторинг внедряют в несколько этапов, начинаем с дисков. Мы получаем количество операций чтения-записи, до некоторой точности время обслуживания (мегабайты в секунду), глубину очереди, прочие характеристики, также собираем SMART о состоянии дисков.
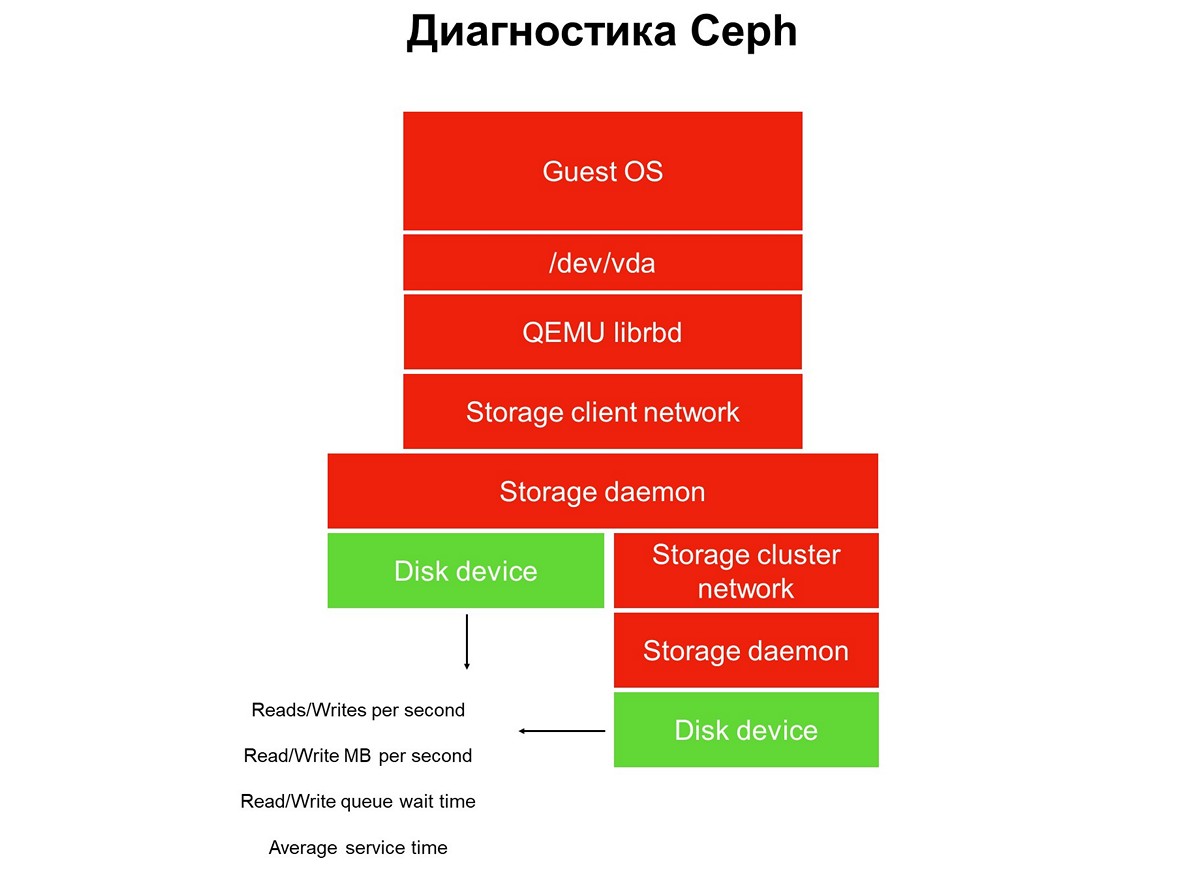 Первый этап: накрываем мониторингом диски.
Первый этап: накрываем мониторингом диски.Мониторинга дисков недостаточно, чтобы получить полное представление о том, что происходит в системе. Поэтому переходим к мониторингу критичного элемента инфраструктуры — сети системы хранения. Их на самом деле две — внутренняя кластерная и клиентская, которая связывает кластеры хранения с гипервизорами. Здесь мы получаем скорости передачи пакетов данных (мегабайты в секунду, пакеты в секунду), размер сетевых очередей, буферов, возможно, тропы данных.
 Второй этап: мониторинг сетей.
Второй этап: мониторинг сетей.Часто на этом останавливаются, но так делать нельзя, ведь большая часть инфраструктуры пока не закрыта мониторингом.
Все распределенные хранилища, используемые в публичных и приватных облаках, — это SDS, software-defined storage. Они могут быть реализованы на решениях конкретного вендора, open source решениях, можно самостоятельно что-то сделать, используя стек знакомых технологий. Но это всегда SDS, и работу этих софтовых частей надо мониторить.
 Третий этап: мониторинг Storage daemon.
Третий этап: мониторинг Storage daemon.Большинство эксплуатирующих Ceph используют данные, собранные с демонов мониторинга и управления Ceph (monitor и manager, он же mgr). Изначально мы пошли тем же путем, но очень быстро поняли, что этой информации не хватает — предупреждения о зависших запросах появляются с опозданием: запрос завис на 30 секунд, только потом мы его увидели. Пока он дойдет до мониторинга, пока мониторинг поднимет тревогу — пройдет не меньше трех минут. В лучшем случае это значит, что часть хранилища и приложений три минуты будут простаивать.
Вполне естественно, что мы решили расширять мониторинг и опустились к главному элементу Ceph — демону OSD. От мониторинга Object Storage daemon мы получаем примерное время операции так, как его видит OSD, а также статистику по зависшим запросам — кто, когда, в какой PG, как долго.
Почему только Ceph недостаточно и что с этим делать
Только Ceph недостаточно по ряду причин. Например, у нас есть клиент с профилем баз данных. Он разворачивал все базы данных в кластере all-flash, задержка операций (latency), которая там выдавалась, его устраивала, однако, были жалобы на простои в работе.
Система мониторинга не позволяет видеть то, что происходит внутри виртуальной среды клиенты. В итоге для выявления проблемы мы воспользовались расширенным анализом, который запросили с помощью утилиты blktrace из его виртуальной машины.
 Результат расширенного анализа.
Результат расширенного анализа.В результатах анализа есть операции, помеченные флагами W и WS. Флаг W — запись, флаг WS — синхронная запись с ожиданием завершения операции устройстве. Когда мы работаем с базами данных, почти у всех баз данных SQL есть узкое место — WAL (write-ahead log).
База всегда сначала пишет данные в журнал, получает подтверждение от диска со сбросом буферов, потом записывает данные собственно в базу. Если она не получила подтверждение о сбросе буферов, то считает, что сброс питания может стереть транзакцию, подтвержденную клиенту. Для базы это недопустимо, поэтому она выдает «write SYNC/FLUSH», потом пишет данные. Когда журналы заполняются, происходит их свитч, и все, что попало в page cache также принудительно флашится. Добавлено: на картинке нет собственно сброса — то есть операций с флагом pre-flush. Они выглядят как FWS — pre-flush + write + sync или FWSF — pre-flush + write + sync + FUA
Когда у клиента много мелких транзакций, фактически весь его ввод-вывод превращается в последовательную цепочку: write — flush — write — flush. Поскольку сделать что-то с базой данных нельзя, мы начинаем работать с системой хранения. В этот момент мы и понимаем, что возможностей Ceph недостаточно.
Для нас на этом этапе лучшим решением показалось добавление маленьких и быстрых локальных хранилищ, реализованных не средствами Ceph (его возможности мы, в общем-то, исчерпали). И мы превращаем СХД облака в нечто больше чем Ceph. В нашем случае мы добавили множество локальных стораджей (локальных с точки зрения дата-центра, а не гипервизора).
 Дополнительные локализованные хранилища Target A и В.
Дополнительные локализованные хранилища Target A и В.Время обслуживания такого локального хранилища порядка 0,3 мс в один поток. Если оно лежит в другом дата-центре, то работает медленнее — с производительностью примерно 0,7 мс. Это существенный прирост по сравнению с Ceph, который выдает 1,2 мс, а распределённый по дата-центрам — 2 мс. Производительность таких маленьких фабрик, которых у нас больше десятка, порядка 100 тысяч на модуль, 100 тысяч IOPS на запись.
После такого изменения инфраструктуры наше облако выжимает под миллион IOPS на запись или порядка двух-трех миллионов IOPS на чтение суммарно на всех клиентов:

Важно отметить, что такой тип хранилища — это не основной метод расширения, главную ставку мы делаем на Ceph, а наличие быстрых стораджей важно только для сервисов, требовательных ко времени отклика диска.
Новые итерации: доработка кода и инфраструктуры
Все наши стораджи — это shared (совместно используемые) ресурсы. Такая инфраструктура требует от нас внедрения политики уровня обслуживания: мы должны обеспечить определенный уровень сервиса и не допустить того, чтобы один клиент мог помешать другим случайно или специально, выведя из строя хранилище.
Для этого нам пришлось делать доработку и нетривиальную выкатку — итерационную доставку в продуктив.
Эта выкатка отличалась от привычных практик DevOps, когда все процессы: сборка, тест, выкатка кода, при необходимости рестарт сервиса, начинаются с нажатия кнопки, а потом всё работает. Если выкатывать DevOps-практиками на инфраструктуру, она живет до первой ошибки.
Именно поэтому в инфраструктурной команде не особенно прижилась «полная автоматизация». Конечно, есть определенный подход к автоматизации тестирования и доставки — но он всегда контролируется, и доставка инициируется SRE-инженерами команды облака.
Мы выкатили изменения в нескольких сервисах: в бэкенде Cinder, фронтенде Cinder (Cinder-клиенте) и в сервисе Nova. Изменения применялись за несколько итераций — одна итерация за раз. После третьей итерации соответствующие изменения применили на гостевые машины клиентов: чьи-то мигрировали, кто-то сам сделал перезапуск ВМ (hard reboot) или плановую миграцию для обслуживания гипервизоров.
Следующая проблема, которая возникла, — скачки скорости записи. Когда мы работаем с сетевыми хранилищами, гипервизор по умолчанию считает, что сеть медленная, поэтому кэширует все данные. Он пишет быстро, до нескольких десятков мегабайт, а потом начинает сбрасывать кэш. Из-за таких скачков было много неприятных моментов.
Мы выяснили, что если включить кэш, производительность SSD проседает на 15%, а если выключить кэш, производительность HDD проседает на 35%. Понадобилась очередная разработка, выкатили управляемое управление кэшированием, когда для каждого типа дисков кэширование назначается явно. Это позволило гонять SSD без кэша, а HDD — с кэшем, в итоге мы перестали терять в производительности.
Практика доставки разработки в продуктив аналогичная — итерациями. Выкатили код, перезапустили демон, потом по мере необходимости перезапускаем или мигрируем гостевые виртуальные машины, которые должны попасть под изменение. Мигрировали ВМ клиента c HDD, у него кэш включился — все работает, или, наоборот, клиента с SSD мигрировали, у него кэш отключился — все работает.
Третья проблема — некорректная работа виртуальных машин, развернутых с GOLD-образов на HDD.
Таких клиентов много, а особенность ситуации в том, что работа ВМ налаживалась сама собой: проблема гарантированно возникала при развертывании, но решалась, пока клиент доходил до техподдержки. Сначала мы просили клиентов подождать полчаса, пока работа ВМ стабилизируется, но потом начали работать над качеством сервиса.
В процессе исследований поняли, что возможностей нашей инфраструктуры мониторинга по-прежнему не хватает.
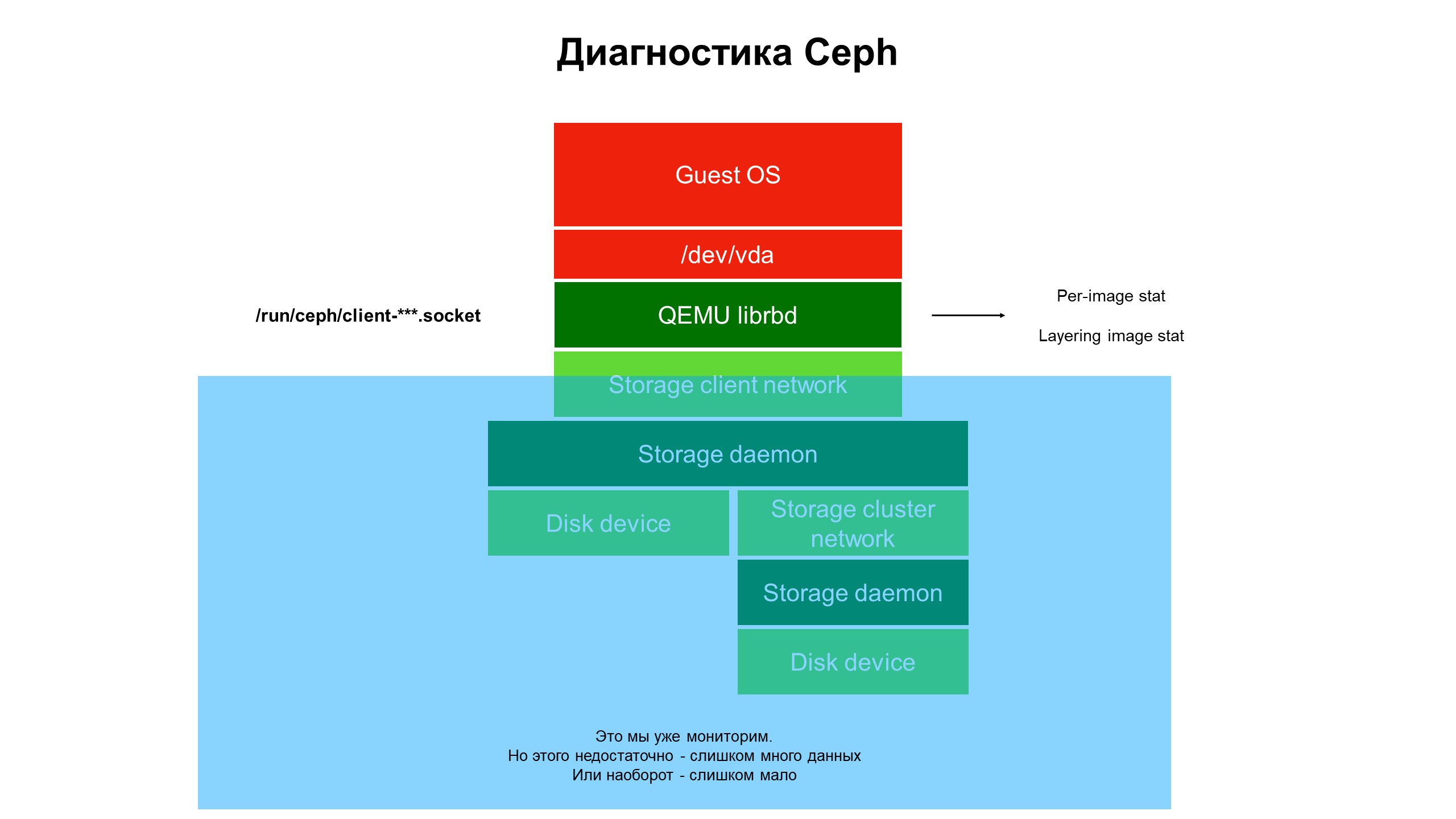 Мониторинг закрыл синюю часть, а проблема была в верхней части инфраструктуры, не накрытой мониторингом.
Мониторинг закрыл синюю часть, а проблема была в верхней части инфраструктуры, не накрытой мониторингом.Мы стали разбираться с тем, что происходит в части инфраструктуры, не накрытой мониторингом. Для этого задействовали расширенную диагностику Ceph (а точнее, одной из разновидностей клиента Ceph — librbd). Используя инструменты автоматизации, внесли изменения в конфигурацию клиента Ceph, чтобы получить доступ к внутренним структурам данных через Unix domain socket, и начали снимать статистику с клиентов Ceph на гипервизоре.
Что мы увидели? Мы увидели статистику не по пулу/OSD/кластеру Ceph, а статистику по каждому диску клиентской виртуальной машины, чьи диски лежали в Ceph — то есть статистику, привязанную к устройству.
 Результаты статистики расширенного мониторинга.
Результаты статистики расширенного мониторинга.Именно расширенная статистика позволила понять, что проблема возникает только на дисках, клонированных с других дисков.
Далее мы посмотрели статистику по операциям, в частности операциям чтения-записи. Выяснилось, что по образам верхнего уровня нагрузка относительно небольшая, а по исходным, с которых идет клон, — большая, но неравновесная: большой объем чтения при полном отсутствии записи.
Проблема локализована, теперь требуется решение — код или инфраструктура?
С кодом Ceph сделать ничего нельзя, он «жесткий». Кроме того, от него зависит сохранность данных клиентов. Но проблема есть, ее надо решать, и мы изменили архитектуру хранилища. HDD-кластер превратился в гибридный кластер — к HDD добавили определенный объем SSD, затем изменили приоритеты OSD-демонов так, чтобы SSD был всегда в приоритете и становился первичным OSD внутри placement group (PG).
Теперь, когда клиент разворачивает виртуальную машину с клонированного диска, его операции на чтение попадают на SSD. В результате подъем с диска стал быстрым, а на HDD пишутся только клиентские данные, отличные от исходного образа. Мы получили трехкратный рост производительности практически бесплатно (относительно изначальных затрат на инфраструктуру).
Почему важен мониторинг инфраструктуры
- Инфраструктуру мониторинга надо включать по максимуму в весь стек, начиная с виртуальной машины и заканчивая диском. Ведь пока клиент, пользующийся частным или публичным облаком, доберется до своей инфраструктуры и даст нужную информацию, проблема изменится или переместится в другое место.
- Мониторинг всего гипервизора, виртуальной машины или контейнера «целиком» почти ничего не дает. Мы пробовали понять по сетевому трафику, что происходит с Ceph — это бесполезно, данные пролетают с высокой скоростью (от 500 мегабайт в секунду), крайне сложно выделить нужные. Понадобится чудовищный объем дисков для хранения такой статистики и много времени для ее анализа.
- Нужно собирать как можно больше данных мониторинга, иначе есть риск упустить что-то важное. И обратная сторона: если вы собрали много данных, но потом не можете их проанализировать и найти среди них то, что нужно — это делает накопленную статистику бесполезной, собранные данные просто бесцельно утилизируют ваше дисковое пространство.
- Цель мониторинга — не только определение отказа инфраструктуры. Отказ вы увидите, когда он случится. Главная цель — предсказать отказ и увидеть тренды, собрать статистику для улучшения качества сервиса. Для этого нужны стройные потоки данных в мониторинге, привязанные к инфраструктуре. В идеале от конкретного диска виртуальной машины и до самого низкого уровня — до тех дисков СХД, где лежат данные, к которым обращается виртуальная машина клиента.
- Облако MCS Cloud Solutions — это инфраструктура, решения об эволюции которой принимаются во многом на основе накопленных мониторингом данных. Мы улучшаем мониторинг и используем его данные для улучшения уровня сервиса для клиентов.
В нашем телеграм-канале — новости об этом и других сервисах на облачной платформе Mail.ru Cloud Solutions.
Что еще почитать:
1. «Смотри Mail.ru»: Как использовать объектное хранилище S3, чтобы быстро стартовать.
2. Работа с объектным S3-хранилищем Mail.ru Cloud Solutions как с файловой системой.
3. Пример event-driven приложения на основе вебхуков в объектном S3-хранилище Mail.ru Cloud Solutions.
