Comments 57
Взял себе домой 1080, так даже её частенько не хватает. Приходиться что-то на рабочих тэслах считать:)
А статья классная, побольше бы таких
дропаут — это штука для регуляризации по средствам добавления шума в сеть
бн — это штука для ускорения обучения, но тк он все таки нормализует батчи, а не весь датасет, то и шума он тоже добавляет, получается он еще немного и регулризатор
в больших датасетах вариации данных и так достаточно, так что бн важнее
есть статьи где используется и то и то, но суда по конкурсам — все перешли на бн вместо дропаута
ну и еще обратите внимание, что с появлением резнета сеть стала сама по себе как ансамбль, а дропаут вообще говоря и есть ансамбль, но не по построению, а изза алгоритма обучения, получается что резнет с бн и так обладает всем, что дает дропаут
Просто опыта у меня совсем мало, со всем зоопарком приемов для fine-tuning сетей я не знаком.
Для рекурентных сетей bn не очень удобно использовать, поэтому там недавно появился layer normalization (ln). ln это почти то же, самое, что и bn, только они считают среднее и отклонение по всем нейронам, а не по батчу. Для рекурентных сетей работает получше и в целом удобнее, чем bn. Вместе с этим ln вполне можно использовать дропаут и в рекурентных, и в нерекурентных соединениях. Но опять же, если данных немного — на огромных сложных датасетах дропаут не используется. Как пример — недавно выходила статья от гуглбрейн, в которой они поставили несколько state-of-the-art результатов на широко используемых небольших бенчмарках с дропаутом. В той же статье есть результаты на больших наборах, так там уже никакого дропаута.
Так что рано говорить, что dropout is dead, имхо.
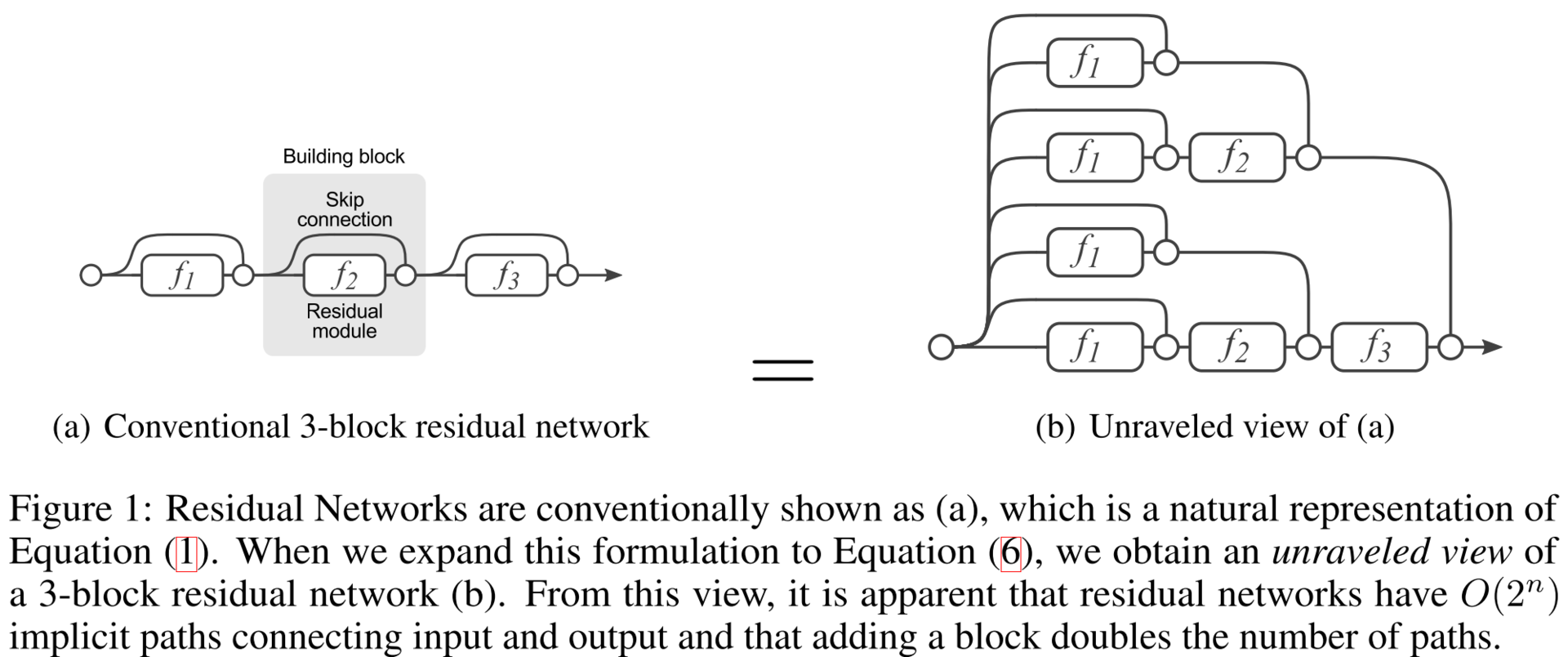
Если ResNet это что-то типа каскада, то такой результат довольно ожидаем. Каждый следующий уровень каскада просто улучшает результат предыдущего.
Единственный недостаток нейросетей — это их высокая вычислительная сложность, поэтому спрос на более простые методы, не основанные на нейросетях, пока ещё есть, но и он сойдёт нет с развитием вычислительной техники.
мне вот кажется, что отлично, что и задвинули; компьютерное зрение стагнировало, из него выжали все что можно; и тут появляются модели которые «изобретают» все хэндкрафт методы сами
особенно мне например нравится подход R-CNN для детектирования, и то как сейчас делается сегментация
Хинтон давно писал "To Recognize Shapes, First Learn to Generate Images", и именно к этому мы и пришли со всеми современными нейрогенеративными моделями
на остальных данных лучше работает xgboost пока
так что это еще не паханное поле и еще дип лернингу туда предстоит зайти
если же примеров мало, и это картинки, то все вполне решаемо, но зависит от контекста задачи
- соседние пиксели не сильно отличаются друг от друга в изображении
- соседние значения звуковой волны голоса на оси времени не сильно отличаются друг от друга
- текст — это поток токенов, выстроенных в определенном порядке, и по корпусу текстов всегда можно вычислить какие слова более вероятно встретить после других и до, в каком то смысле это тоже корреляция локальная, тк мы больше знаем информации о соседних словах при данном слове, чем о других словах более удаленных от данного
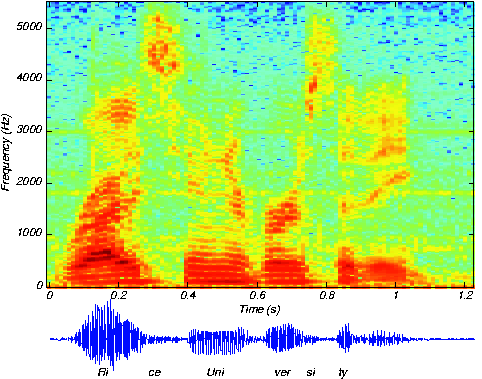
Для тех, кто хочет поиграться с этим подходом приведу ссылку на соревнование, которое проходит прямо сейчас.
Многие участники как раз и преобразуют временные ряды в спектрограммы, CNN на нижних слоях и рекурентные слои сверху.
https://www.kaggle.com/c/melbourne-university-seizure-prediction
Напомню, как выглядят рецепторные области нейронов на разных уровнях и какие признаки они извлекают.
А можно для забывчивых ссылку на то, как вычисляются эти картинки? Спасибо
полученная стеканием нескольких слоев, должна выучить тождественное преобразование, в случае если на предыдущих слоях был достигнут предел качества. Но этого не происходит по каким-то причинам,
Если задуматься над простой аналогией, то от сети, с не остаточной архитектуры, в которой следующий слой соединён только с предыдущими, ожидать увеличения качества с ростом количества слоёв — примерно то же самое, что ожидать лучшего результата от Ряда Тейлора, который раньше состоял из 4 членов, а теперь из шести начиная со второго.
По сути это то же самое, что вы сказали: «возможно, оптимизатор просто не справляется с тем, чтобы настроить веса так, чтобы сложная нелинейная иерархическая модель делала тождественное преобразование». Но только гораздо интуитивно проще и понятнее и требует меньше мат.подготовки чтобы понять.
Это, конечно, не так математически точно, зато позволяет дойти до идеи остаточных сетей на много быстрее и по более прямому пути.
примерно то же самое, что ожидать лучшего результата от Ряда Тейлора, который раньше состоял из 4 членов, а теперь из шести начиная со второго.
вот мне кажется ошибочно рассуждать о residual сети в аналогии с рядом Тейлора, каждый член разлодения в ряде Тейлора уточняет значение в смысле О(x^n), выкинув некий член мы сильно просядем в точности на выкинутом уровне
в то время как в резидуал сети каждый член он как бы уточняет весь ансамбль https://habrahabr.ru/company/mailru/blog/311706/#comment_9856086
Если человек будет думать о нелинейном слое не только как о апроксиматоре произвольной функции делающем всё лучше, но и как о изгибателе добавляющем изогнутости абсолютно всем признакам, выявленным слоем ниже, до него идея скипающихся слоёв дойдёт сильно быстрее. Потому что он будет понимать что в некоторых случаях он делает хуже, и даже интуитивно понятно в каких.
Также были применены другие трюки для избежания переобучения, и некоторые из них сегодня являются стандартными для глубоких сетей: DropOut (RIP), Data Augmentation и ReLu.
А что этим трюкам в сетях из живых нейронов соответствует?
ReLu не помню в какой статье, но сравнивают с осцилляциями и спайками в реальных нейронах, и показывают что РеЛу как бы лучше описывает динамику одного нейрона нежели другие
в общем в какой то лекции Салакхудинов, вроде, говорил, что бывает они что то придумывают и им биологи говорят, типа все так, и они вписывают в статью био обоснование; а бывает биологи смотрят на статью и говорят что нифига не так в мозге, а им математики говорят — ну и ладно, главное работает
https://habrahabr.ru/post/309508/#comment_9795718
Если вкратце: использование ReLU обусловлено существованием эффективных методов оптимизации коэффициентов свёрточных сетей, основанных на теории разреженных представлений. Ну а сравнение с осцилляциями и спайками — типичный случай, когда сначала идёт практика, а затем под неё подгоняется теория.
использование ReLU обусловлено существованием эффективных методов оптимизации коэффициентов свёрточных сетей, основанных на теории разреженных представлений. Ну а сравнение с осцилляциями и спайками — типичный случай, когда сначала идёт практика, а затем под неё подгоняется теория.
так там же обычный бекпроп, нельзя сказать что это новый метод эффективной оптимизации именно сверточных сетей; релу решает важную проблему — он отменяет понятие насыщенного нейрона, которое ведет к затуханию градиента, но добавляет еще больше шансов на exploding, что например в статье Mikolov'a решается методом cliping gradients; а все остальное про спарсность и спайки можно списать на «подтянутое за уши»
так там же обычный бекпроп, нельзя сказать что это новый метод эффективной оптимизации именно сверточных сетей… а все остальное про спарсность и спайки можно списать на «подтянутое за уши»
Я и не заявляю, что свёрточные нейросети имеют аналог в спарсе. Задача оптимизации коэффициентов нейросети — это просто задача минимизации функционала. В случае ReLU — задача L1-минимизации.
Просто в последнее десятилетие произошёл большой прогресс в области минимизации функционалов с L1-нормой благодаря теории разреженных представлений. Так что спасибо спарсу и товарищу Нестерову за то, что мы имеем сейчас эффективные математические методы обучения нейросетей, которые теперь называются «обычный бекпроп».
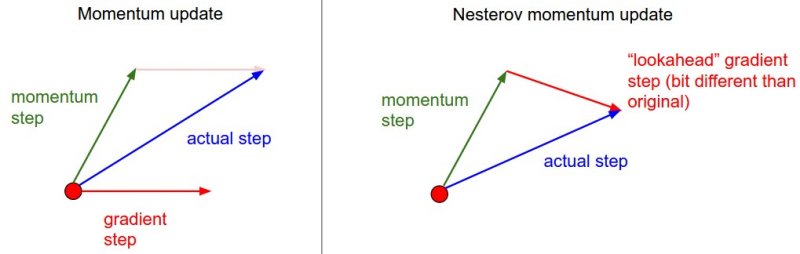
Ссылок полно, легко гуглятся по ключевым словам:
1. Просто Нестеров в Deep Learning (~400 цитирований):
http://www.jmlr.org/proceedings/papers/v28/sutskever13.pdf
2. Альтернативы методу Нестерова:
https://arxiv.org/pdf/1412.6980.pdf
3. Регуляризация:
http://cs231n.github.io/neural-networks-2/#reg
Благодаря Арнольду и Колмогорову мы и они в курсе, что нейросеть может аппроксимировать почти любую функциючто за теорема имеется ввиду?
Вот вам пара новинок после residual nets:
Deep Networks with Stochastic Depth
http://arxiv.org/pdf/1603.09382v1.pdf
Gao Huang, Yu Sun, Zhuang Liu, Daniel Sedra, Kilian Weinberger
Берут за основу Residual net, и пропускают при обучении целые слои аналогично dropout. Обычный dropout выполняется для отдельных связей или активаций, а здесь выкидываются целые фрагменты сети (слои) выбранные случайным образом, для каждого минибатча. При тестировании используются все слои, но их выходы модифицируются — умножаются на вероятность использования этого слоя при обучении.
Точность и скорость превосходят residual net, до 1202 слоев пробовали.
Фактически обучается ансамбль сетей 2^L т.к. возможно такое число комбинаций включенных и пропущенных слоев (L-общее число слоев).
FractalNet: Ultra-Deep Neural Networks without Residuals
http://arxiv.org/pdf/1605.07648v1.pdf
Gustav Larsson, Michael Maire, Gregory Shakhnarovich
Отказываются от residuals и конструируют “фрактальные” сети (структура самоподобная) эквивалентные очень большому числу слоев, и получают конкурентоспособную точность работы сети.
Очень хороший краткий обзор новых архитектур сетей с их недостатками.
Операция объединения у них — покомпонентное усреднение (объединяемых каналов). Это похоже на сложение в residual net, но способно работать при дропауте отдельных ветвей, вынуждая каждый канал обучаться надежному представлению данных.
>На следующем уровне логично взять чуть меньшую рецепторную область.
почему логично?
>Network can decide how deep it needs to be
А можно поподробнее как это реализуется на практике?
>Далее в статье идет множество картинок, которые еще больше подтверждают то, что их модель строится в полуавтоматическом режиме.
Откуда такие догадки?
p.s А как DL применяют в Mail.ru: поиск по картинкам, NLP, что еще?
Так как обучали до изобретения алгоритма обратного распространения ошибки?
тут стоит заметить, что сети не были популярны даже после публикации статьи про бэкпроп, не то что да
был например метод коррекции ошибки, который использовал Розенблатт для обучения персептрона (хотя он по сути и есть бекпроп, где значение производной просто очень грубо аппроксимируется); сеть Хопфилда обучалась оригинальным алгоритмом, который вроде нигде не используется больше, но заложил основу для energy-based learning; неокогнитрон обучался вообще наркоманским способом, и точно больше нигде не используется
>На следующем уровне логично взять чуть меньшую рецепторную область.
почему логично?
т.к. уменьшаетя плотность кореллированных участвков, и нет смысла охватывать их все; задача сверток и пулинга как раз развернуть оригинальное пространство в котором все координаты скореллированы в новое «хорошее» пространство
>Network can decide how deep it needs to be
А можно поподробнее как это реализуется на практике?
советую чуть более подробно разобраться в резнете, через этот пост или лучше через оригинальные статьи на которые указаны ссылки, тк ответ на этот вопрос это просто копипаста того что писал выше -)
>Далее в статье идет множество картинок, которые еще больше подтверждают то, что их модель строится в полуавтоматическом режиме.
Откуда такие догадки?
да это чистая догадка, доказательств нет, но я не могу себе представить ученого который занимается тем, что размышляет какие свертки, какого размера и в каком порядке применять, это была бы очень скучная работа; ну и стоит добавить, что в первой статье они сказали, что может быть когда-нибудть это можно будет автоматизировать
Каким же образом поймать такие корреляции и превратить их в один признак? На помощь приходит идея сверток 1 × 1 из предыдущей работы. Продолжая эту идею, можно предположить, что чуть меньшее количество коррелированных кластеров будет чуть большего размера, например 3 × 3. То же самое справедливо для 5 × 5 и т. д., но гугл решил остановиться на 5 × 5.
Не очень понятно, как свёртки 1 х 1 убивают/объединяют коррелированные признаки? Нам например известен эффект переобучения линейных классификаторов при наличии коррелированых признаков в объектах обучающей выборки.
Почему свёртка 1х1 не может в процессе обучения выучить какие-нибудь огромные веса (+10^9 и -10^9) для коррелированных признаков, став тем самым излишне чувствительной к шуму?
Кажется, я что-то не вполне верно понимаю :)
Почему свёртка 1х1 не может в процессе обучения выучить какие-нибудь огромные веса (+10^9 и -10^9) для коррелированных признаков, став тем самым излишне чувствительной к шуму?
ну во-первых есть регуляризаторы что бы не дать таким весам появиться, все так же как и в линейных моделях
Не очень понятно, как свёртки 1 х 1 убивают/объединяют коррелированные признаки? Нам например известен эффект переобучения линейных классификаторов при наличии коррелированых признаков в объектах обучающей выборки.
когда мы говорим о линейных моделях, то мы имеем в виду скореллированные признаки, т.е. колонки, которые при инвертировании матрицы дадут высокодисперсионное решение
в случае 1х1 свертки мы убираем корреляцию не соседних признаков на одной фича мапе, а в «глубину»; например, допустим что в мире всего 10 цветов и никаких оттенков нет, а у вас слой из 20ти нейронов, и допустим что нейроны этого слоя выучивают только детекторы определенного цвета, на выходе такого слоя будет тензор WxHx20, где WxH это размер картинки, допустим нам повезло и 10 нейронов выучили 10 цветов, а что выучат остальные? вероятно они выучат тоже самое, и если взять любую колонку глубины 20, т.е. сквозь фича мапы, то в ней будет всего 10 уникальных значений, тогда свертка 1х1 это просто сложит их что бы получить более высокоуровневую фичу (например градиентный переход), но вероятно веса на повторных цветах из этих 20ти будут нулевые
пока нейросети работают хорошо только там, где данные обладают одним свойством — локальная корреляция: картинки, текст, звук
на остальных данных лучше работает xgboost пока
Понятно объясняете.
Во временных рядах (мне интересная тема) может быть локальная корреляция… Но есть и много нюансов. Например, во-первых, надо стационаризовать ряд, иначе локальная корреляция будет наведенная от трендов. Ок, сделали это. Теперь может не быть локальной корреляции (линейной). Но может быть корреляция локальной дисперсии (по второму моменту), не объясняя знак приращения. Не совсем понятно, поможет ли свертка в таком случае. ARCH процесс… Сезонность с большим лагом…
Но есть и много нюансов. Например, во-первых, надо стационаризовать ряд, иначе локальная корреляция будет наведенная от трендов. Ок, сделали это. Теперь может не быть локальной корреляции (линейной).… Не совсем понятно, поможет ли свертка в таком случае.
да тут вы правы, зависимость может быть не линейной, так что скорее мне нужно говорить про локальную «корреляцию» в кавычках, все таки нейросеть машина нелинейная и можно надеяться что всякие нелинейные зависимости будут найдены; свертка тут как механизм который «декоррелирует» данные, в локальной корреляции мы подразумеваем, что чем точки ближе друг к другу тем они «зависемее» друг от друга, и свертка тогда объединяет несколько похожих признаков в один
на счет трендов и предобработки, то теоретически если свертка на всю длину ряда то никакой предобработки не нужно (в этом и есть фазовый переход от классического машинного обучения=feature extraction + model, к дип лернингу = raw data + deep model), но это естественно не выход, ресурсоемко слишком; но можно юзать например рекуррентные сети, где на каждом шаге вычисляется например свертки по окну и информация о признаках окна заносится в долгосрочную память, вот тут можно глянуть визуально как RNN выявляют такие зависимости http://karpathy.github.io/2015/05/21/rnn-effectiveness/
Я вот на что хотел обратить внимание. Нормальным является первичная предобработка в виде компонента d(x) (порядок дифференцирования). Можно сделать d(log(x)), если приращения не стационарны по дисперсии. Это легко.
Далее, может быть следующая вещь. Например, сезонность на лаге 1000, то есть, автокорреляция значимая. Но не будешь же делать окно свертки таким большим… Возможно, несколько слоев с окном 200 помогут, но не факт (не очевидно). Здесь только экспериментально можно понять?
но вообще я не имею большого опыта с рекуррентными сетями, если вам интересна эта тема, то советую зарегаться тут ods.ai, это самый большой русскоговорящий слак по датасаенсу, там есть канал про таймсерии и дип лернинг
Обзор топологий глубоких сверточных нейронных сетей