Comments 51
Блин, пора менять работу.
Хочу такие же интересные штуки делать.
Хочу такие же интересные штуки делать.
Чтобы окончательно разочароваться в своей работе, рекомендую посмотреть ещё дневники (Development Updates) человека, который в одиночку под краудфандинг пилит космосим: www.youtube.com/user/LimitTheory/videos?shelf_id=0&view=0&sort=dd
Судя по FAQ на сайте игры ltheory.com/faq.html их там больше одного.
Текст повествуется от группы людей во множественном числе.
Текст повествуется от группы людей во множественном числе.
Multiplayer is not planned for the first release. We would love to...
Не всегда. У меня есть знакомый, который пилит на Ruby свой движок для блогов в одиночку, но во всех письмах говорит «Мы» и подписываться «Команда {ProjectName}»
Говорят это придает проекту оттенок зрелости и тп.
Говорят это придает проекту оттенок зрелости и тп.
Я так понял, что он один, но иногда нанимает подрядчиков (например, композитора для музыки и т. п.).
Справедливости ради упомяну, что есть еще один такой умелец www.youtube.com/watch?x-yt-ts=1422503916&x-yt-cl=85027636&v=rswRCT3097g
Что мешает делать интересные штуки не на работе?
Необходимость иногда спать.
Если после работы у вас остаётся время только на сон, то такую работу явно необходимо менять.
продавать бизнес вместе с командой пока не планирую
Так в вашем случае работа же интересная, иначе бы вы этим не занимались. Поэтому, не понимаю, почему про сон речь зашла. Ведь в вашем случае вы и на работе интересностями занимаетесь, следовательно на сон время есть.
Интересной работы остается процентов 10-15%, с начала этого года я занимался «интересными задачами»:
1. «выбиванием» денег с клиентов-должников на з/п сотрудников и аренду
2. реанимацией 3-х некросайтов
3. выполнением нескольких нетривиальных требований контролирующих организаций для клиентских сайтов
4. решением кадровых проблем
5. решением налоговых и организационных проблем
6. подготовкой к арбитражу
7. решением проблем с МТБ
8. резким поиском фрилансеров на задачи по которым подходит дедлайн и в рабочем порядке их делать не успеваем
9. бестолковой перепиской с объяснением почему вода мокрая, огонь горячий а воздух прозрачный
10. миграцией нескольких проектов, чувствительных к географии хостинга на отечественные сервера после соответствующих предписаний
Интересной работой последний раз занимался сегодня с часу ночи до четырех утра, и то по причине бессонницы чтобы немного перенаправить нервяк.
А вот занимался бы или нет — тут кроме интересности есть еще определенные существующие обязательства, которые просто так не разорвать, в том числе ипотечные.
1. «выбиванием» денег с клиентов-должников на з/п сотрудников и аренду
2. реанимацией 3-х некросайтов
3. выполнением нескольких нетривиальных требований контролирующих организаций для клиентских сайтов
4. решением кадровых проблем
5. решением налоговых и организационных проблем
6. подготовкой к арбитражу
7. решением проблем с МТБ
8. резким поиском фрилансеров на задачи по которым подходит дедлайн и в рабочем порядке их делать не успеваем
9. бестолковой перепиской с объяснением почему вода мокрая, огонь горячий а воздух прозрачный
10. миграцией нескольких проектов, чувствительных к географии хостинга на отечественные сервера после соответствующих предписаний
Интересной работой последний раз занимался сегодня с часу ночи до четырех утра, и то по причине бессонницы чтобы немного перенаправить нервяк.
А вот занимался бы или нет — тут кроме интересности есть еще определенные существующие обязательства, которые просто так не разорвать, в том числе ипотечные.
Воу-воу, полегче. Столько интересностей сразу. Глаза разбегаются.
Картинка в шапке — тоже рендер игровым движком?
Картинка в шапке это арт из игры. Что бы получить этот арт персонаж был выставлен в специальную позу в движке и картинка была отрендерена в движке, а после дорисована художниками.
Остальные картинки и видео это рендер движка. В некоторых картинках рендер на ultra high настройках, в некоторых просто на high.
Остальные картинки и видео это рендер движка. В некоторых картинках рендер на ultra high настройках, в некоторых просто на high.
Отличная статья!
Шероховатость (Roughness) — как вы его подбираете? Какие-то данные есть в «справочниках»?
Кстати, почему бы не хранить нормали в GBuffer XY в ViewSpace? А значение Z потом восстанавливать?
Шероховатость (Roughness) — как вы его подбираете? Какие-то данные есть в «справочниках»?
Кстати, почему бы не хранить нормали в GBuffer XY в ViewSpace? А значение Z потом восстанавливать?
И очень хотелось бы увидеть — как у вас организованно реализация PMREM (Prefiltered Mipmaped Radiance Environment map) и последующий просчет сферической гармоники.
В настоящий момент мы используем Modified AMD Cubemapgen и в нем Cosine filter и наша аналитическая модель освещения полностью совпадает с IBL частью освещения.
У него только один недостаток — очень долгое время работы. Есть несколько альтернатив и презентация от tri-Ace как это делать быстрее.
У него только один недостаток — очень долгое время работы. Есть несколько альтернатив и презентация от tri-Ace как это делать быстрее.
Если хранить нормали во ViewSpace то точность упаковки нормалей будет изменяться если вращать камеру. Для больших плоскостей (например пол) это выглядит бажно — вращаешь камеру, чуть плавает освещение.
Roughness для типичных материалов у нас указан в гайдлайне для художников. Насколько мне известно в «справочниках» таких данных нет, но можно попробовать использовать MERL BRDF Database и Disney's BRDF explorer что бы подобрать физичные значения.
Roughness для типичных материалов у нас указан в гайдлайне для художников. Насколько мне известно в «справочниках» таких данных нет, но можно попробовать использовать MERL BRDF Database и Disney's BRDF explorer что бы подобрать физичные значения.
Есть еще проблема в том, что иногда нормаль может иметь отрицательный Z во ViewSpace — например, из-за интерполяции вертексных нормалей или нормал мапа. Тогда придется, как минимум, еще где-то битик хранить и его распаковывать.
Не очень понял зачем вы делаете отдельный проход с восстановлением глубины? Можно ведь сразу писать глубину в R32F или восстанавливать уже в финальных шейдерах.
Разве не для того, что-бы потом в каком-нибудь SSAO не восстанавливать по сто раз эту глубину? :)
Не совсем очевидно какой из подходов быстрее. Я и сам склоняюсь к меньшему количеству проходов — это делает пайплайн рендеринга проще и универсальнее. Но на практике — все зависит от проекта. Возможно в данном случае это оправдано. Может быть автор прокоментирует?
На самом деле в дополнительном проходе ничего страшного нет. Но да, тут верно подмечено, что неизвестно — как по скорости будет дополнительный проход с последующим его использованием, либо каждый раз в финальных шейдерах восстанавливать.
И еще тут подумал, как написал sergey_reznik — почему бы в MRT не добавить еще один R32F, где мы уже будем писать восстановленную глубину (в хардварный по ряду причин писать не правильно).
Да, хотелось бы автора услышать :)
И еще тут подумал, как написал sergey_reznik — почему бы в MRT не добавить еще один R32F, где мы уже будем писать восстановленную глубину (в хардварный по ряду причин писать не правильно).
Да, хотелось бы автора услышать :)
почему бы в MRT не добавить еще один R32F
Думаю потому, что некоторые видеокарты поддерживают максимум 4 рендер-таргета. Выходить за эти рамки — значит либо уменьшать целевую аудиторию, либо поддерживать две версии
В таком раскладе у нас не будет 4 РТ:
Вариант для MRT (который сейчас):
1) Albedo RT
2) Normal RT
3) Depth DSV (hardware)
Два RT, глубина не относится к MRT.
Вариант с еще одной R32F:
1) Albedo RT
2) Normal RT
3) LDepth RT
4) Depth DSV (hardware)
Три RT, глубина опять же не относится к MRT.
Если MRT вообще поддерживается — то их кол-во точно уж не будет меньше четырех. Поэтому, не совсем вас понял :)
Вариант для MRT (который сейчас):
1) Albedo RT
2) Normal RT
3) Depth DSV (hardware)
Два RT, глубина не относится к MRT.
Вариант с еще одной R32F:
1) Albedo RT
2) Normal RT
3) LDepth RT
4) Depth DSV (hardware)
Три RT, глубина опять же не относится к MRT.
Если MRT вообще поддерживается — то их кол-во точно уж не будет меньше четырех. Поэтому, не совсем вас понял :)
Да, возможно использовать еще один R32F RT и рисовать в него линейную глубину.
Проблема в overdraw при заполнении G-Buffer. Во время заполнения G-Buffer, overdraw обычно больше 1, иногда значительно (например: деревья, трава и т.п.)
Это значит, что информация о глубине будет записана для каждого пикселя больше одного раза, а это неэффективное использование bandwidth.
В случае же «линеаризации» отдельным проходом, мы получаем гарантии, что запись в R32F текстуру будет выполнена один раз для каждого пикселя.
Проблема в overdraw при заполнении G-Buffer. Во время заполнения G-Buffer, overdraw обычно больше 1, иногда значительно (например: деревья, трава и т.п.)
Это значит, что информация о глубине будет записана для каждого пикселя больше одного раза, а это неэффективное использование bandwidth.
В случае же «линеаризации» отдельным проходом, мы получаем гарантии, что запись в R32F текстуру будет выполнена один раз для каждого пикселя.
Да, все сходится, не подумал. Спасибо за развернутые ответы!
Ага, логично.
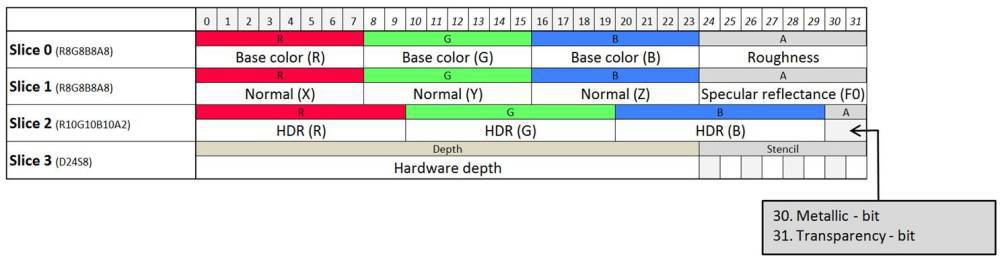
По поводу G-буфера — у вас не объяснено что такое HDR RGB в третьем таргете, поэтому складывается ощущение, что он лишний. Могу предположить, что это что-то вроде интенсивности освещения, тогда может стоит подумать о RGBM/RGBE?
И еще хорошо бы нормали упаковать в две компоненты, а на освободившееся место засунуть остальную информацию. По идее, можно было бы втиснуть в 2 таргета все.
Хотя, конечно, все зависит от железа, на которое вы целитесь.
По поводу G-буфера — у вас не объяснено что такое HDR RGB в третьем таргете, поэтому складывается ощущение, что он лишний. Могу предположить, что это что-то вроде интенсивности освещения, тогда может стоит подумать о RGBM/RGBE?
И еще хорошо бы нормали упаковать в две компоненты, а на освободившееся место засунуть остальную информацию. По идее, можно было бы втиснуть в 2 таргета все.
Хотя, конечно, все зависит от железа, на которое вы целитесь.
С двумя компонентами будут проблемы.
HDR это текущее значение буфера освещения. Туда например записывается информация для само-светящихся объектов и для global illumination.
RGBE/RGBM там к сожалению использовать нельзя, т.к. нужен аддитивный блендинг в этот таргет.
Мы сейчас пробуем еще ужать G-Buffer, например используя технику сжатия base color в два канала (YCoCg) как описано в статье
The Compact YCoCg Frame Buffer. В данный момент я уверен — наша текущая раскладка G-Buffer не финальная и мы будем её еще ужимать.
RGBE/RGBM там к сожалению использовать нельзя, т.к. нужен аддитивный блендинг в этот таргет.
Мы сейчас пробуем еще ужать G-Buffer, например используя технику сжатия base color в два канала (YCoCg) как описано в статье
The Compact YCoCg Frame Buffer. В данный момент я уверен — наша текущая раскладка G-Buffer не финальная и мы будем её еще ужимать.
Ужимание тратит инструкции на запаковку/распаковку. В одном малоизвестном проекте при переходе на ужимание потеряли 3% перфоманса. Пришлось делать без него, так как ни кто такой просадки не позволил :(
The AMD GCN Architecture — A Crash Course слайд #70
Export cost can be more costly than PS execution!
Each fast export is equivalent to 64 ALU ops on R9 290X
Обычно память (особенно на запись, где кеш не помогает) более ограниченный ресурс чем ALU, в том числе и на встроенных/мобильных GPU.
Export cost can be more costly than PS execution!
Each fast export is equivalent to 64 ALU ops on R9 290X
Обычно память (особенно на запись, где кеш не помогает) более ограниченный ресурс чем ALU, в том числе и на встроенных/мобильных GPU.
Круто, внушает.
Reversed Depth Buffer — гениально)
Очень круто
Вот бы ещё вся эта красота не тормозила — было бы совсем замечательно.
Мы сейчас практически все усилия направляем на оптимизацию, мы снимаем очень много метрик с ЗБТ который идет в данный момент и используем эти данные для оптимизации игры.
На мобильных видеокартах поведение к примеру оказалось не таким как мы расчитывали. Это для нас отдельный и очень важный фронт работ сейчас.
На мобильных видеокартах поведение к примеру оказалось не таким как мы расчитывали. Это для нас отдельный и очень важный фронт работ сейчас.
Спасибо за статью!
Очень классно все написано.
Буду надеяться, что это не последняя статья такого плана.
Очень классно все написано.
Буду надеяться, что это не последняя статья такого плана.
Круто! Если бы ещё понять всё это до конца!
На первых нескольких картинках очень резкие не естественные тени. Почему? Ведь судя по рендерам в конце статьи, движок умеет реалистичные мягкие тени
Мягкая тень или резкая это зависит от настроек которые сделали художники и от настроек качества графики — мягкие тени более дорогие для производительности.
Я на самом деле точно не помню какие именно настройки в первых картинках влияют на тени. Это либо настройки источников света либо настройки качества при снятии скриншота.
Я на самом деле точно не помню какие именно настройки в первых картинках влияют на тени. Это либо настройки источников света либо настройки качества при снятии скриншота.
Спасибо за шикарное описание PBR! Скрины красивые, особенно с далёким обзором. Проникаюсь уважением к Mail.Ru :)
Reverse depth подходит для любого движка, я бы рекомендовал его использовать во всех проектах.
Хорошо вам с Direct X. У меня проект на OpenGL, и там реверс z-буфер идёт лесом на Intel HD. Интелы до сих пор не добавили в драйвер расширение, приводящее z к диапазону [0, 1] вместо стандартного для GL [-1, 1]. По крайней мере на старых картах типа Intel HD 4000 его нет, и скорее всего не будет.
Sign up to leave a comment.
Skyforge: технологии рендеринга