
Обеспечение устойчивости к сбоям — задача нетривиальная. Для нее нет стандартного решения. Есть некие общие паттерны, компоненты. Но даже в рамках одной организации для обеспечения фолт-толерантности разных узлов применяются разные решения. Что уж говорить о сравнении подходов в разных организациях.
Кто-то оставляет проблему на «авось», кто-то вешает баннер на «пятисотку» и пытается зарабатывать на сбоях деньги. Кто-то пользуется стандартными решениями от поставщиков баз данных или сетевых устройств. А кто-то уходит в модные нынче «облака».

Ясно одно — по мере роста бизнеса обеспечение устойчивости к сбоям (даже не процедур восстановления после сбоев) становится всё более острой проблемой. От количества аварий в год начинает зависеть репутация компании, при больших временах простоя становится неудобно пользоваться сервисом, и т.д. Причин много.
В этой статье мы рассмотрим один из наших способов обеспечения устойчивости к сбоям. Под устойчивостью будем понимать сохранение работоспособности системы при выходе из строя как можно большего количества узлов этой самой системы.
Обычно архитектура веб-приложения устроена следующим образом (и наша архитектура не является исключением):
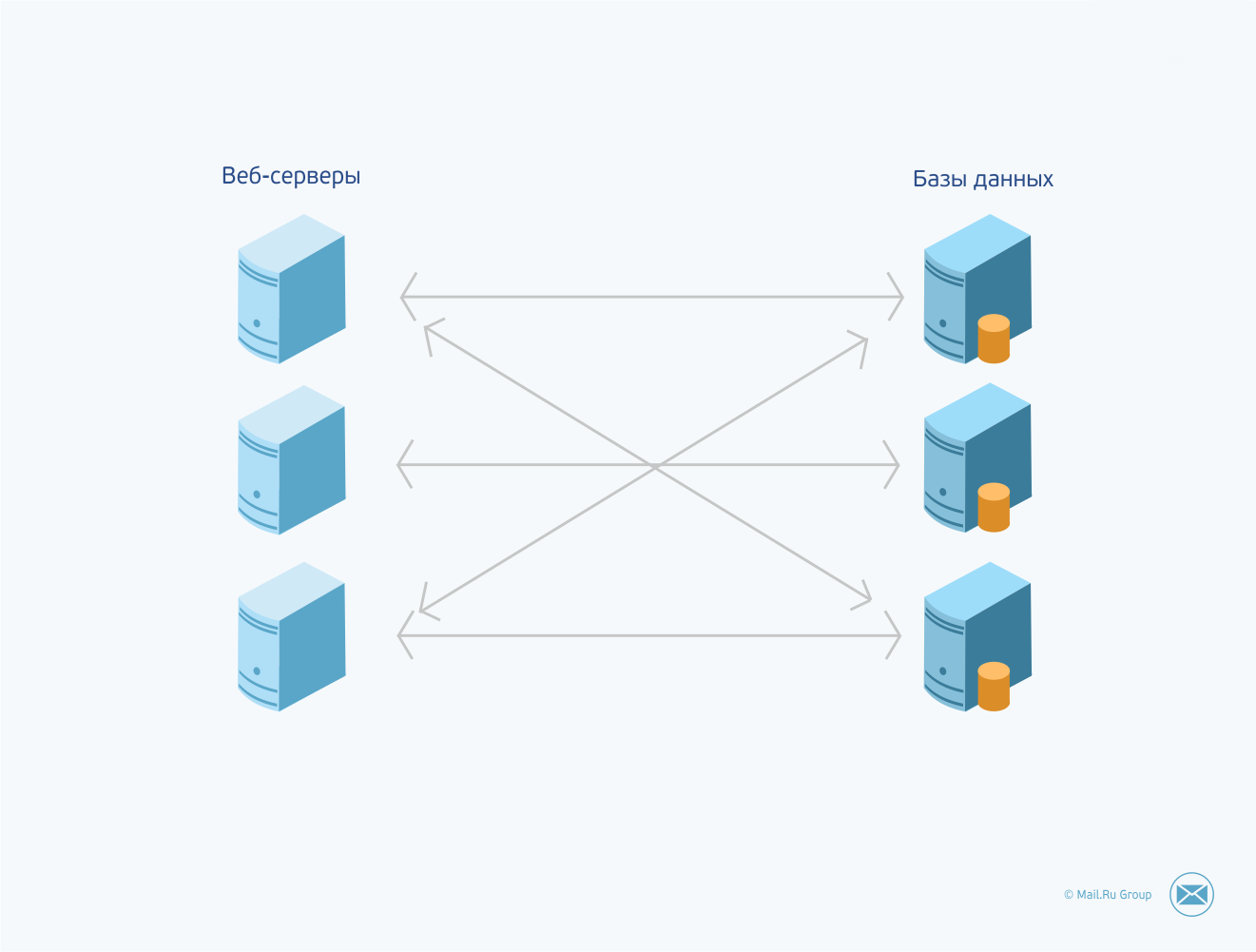
Веб-сервер занимается первичной обработкой и диспетчеризацией запросов, выполняет большую часть логики предметной области, он знает, откуда взять данные, что с ними сделать, куда положить новые данные. Не имеет особой разницы, какой конкретно веб-сервер будет обрабатывать пользовательский запрос. Если программное обеспечение написано более-менее корректно, любой веб-сервер успешно выполнит требуемую от него работу (если не будет перегружен, конечно). Поэтому выход из строя одного из серверов не приведет к серьезным проблемам: произойдет простое переключение нагрузки на оставшиеся в живых сервера, и веб-приложение продолжит свою работу (в идеале все незавершенные транзакции будут откачены, и пользовательский запрос можно будет повторно обработать на другом сервере).
Основные трудности начинаются на уровне хранения данных. Главная задача этой подсистемы — сохранить и приумножить информацию, необходимую для функционирования всей системы в целом. Часть этих данных можно иногда терять, а остальное является невосполнимым, и их потеря означает фактически смерть проекта. В любом случае, если данные частично потеряны, повреждены или временно недоступны, работоспособность системы резко снижается.
На самом деле, конечно, всё намного сложнее. При отказе веб-сервера система обычно не возвращается в предыдущую точку. Связано это с тем, что в рамках одной бизнес-транзакции необходимо внести изменения в нескольких различных хранилищах (при этом механизм распределенных транзакций в слое хранилищ данных обычно не реализован, да и слишком дорог в реализации и эксплуатации). Другими возможными причинами расхождения в данных являются ошибки в программном коде, неучтенные сценарии, безалаберность разработчиков и администраторов («человеческий фактор»), жесткие ограничения на сроки разработки и ещё куча других важных и неважных причин, по которым программисты пишут не совсем идеальный код. Но в большинстве ситуаций это и не нужно (не все же приложения пишутся для банковского и финансового сектора). Либо система автоматически умеет восстанавливать консистентность своих данных, либо существуют полуручные средства восстановления системы после сбоев, либо даже и этого не требуется (пример: пользователь отредактировал свои настройки, но из-за сбоя часть настроек не изменилась. В большинстве случаев это не смертельно, особенно если интерфейс честно скажет пользователю, что не смог применить изменения).
Учитывая все вышеизложенные соображения, наличие хорошей системы хранения и доступа к данным даёт ощутимый бонус к способности системы переживать аварии. Именно поэтому далее мы сконцентрируемся на том, как обеспечить устойчивость к сбоям в подсистеме доступа к данным.
В качестве базы данных в последние годы мы используем Тарантул (это наш опенсорсный проект, очень быстрая, удобная база данных, которая легко расширяется при помощи хранимых процедур. См. сайт http://tarantool.org).
Итак, наша цель — максимальная доступность данных. Тарантул как программное обеспечение проблем обычно не вызывает, т. к. он стабилена, нагрузка на сервер хорошо прогнозируется, сервер не уйдет неожиданно из-за возросшей нагрузки. Перед нами встает проблема надежности оборудования. Иногда серваки сгорают, диски сыплются, стойки вырубаются, маршрутизаторы выходят из строя, линки к датацентрам пропадают… А нам нужно, несмотря ни на что, обслуживать наших пользователей.
Чтобы не потерять данные, нужно продублировать сервер базы данных, разместить его в другой стойке, за другим маршрутизатором или даже в другом центре обработки данных и настроить репликацию данных с основного сервера на дублирующий. Нельзя забывать и об обязательном и регулярном резервном копировании данных. В случае технической поломки данные останутся живыми и доступными. Но есть один нюанс: данные будут доступны по другому адресу. А приложения продолжат по привычке стучаться в сломанный сервер.
Самый простой и распространенный вариант — разбудить одного из системных администраторов, чтобы он разобрался в проблеме и перенастроил все наши приложения на использование нового сервера данных. Не самое лучшее решение: переключение занимает много времени, велика вероятность что-то забыть, да и ненормированный график работы — это очень плохо.
Есть менее надежный, но зато более автоматизированный вариант — использование специализированного ПО для определения того, жив ли сервер и не пора ли переключиться на дублирующий. Пусть меня поправят господа админы, но мне кажется, тут присутствует ненулевая вероятность ложных срабатываний, которая будет приводить к расхождениям в данных между разными хранилищами. Правда, количество ложных срабатываний можно уменьшить за счет увеличения времени реагирования системы на сбой (что, в свою очередь, приводит к увеличению времени простоя).
Как вариант, можно в каждом датацентре поставить по мастер-копии данных и написать ПО таким образом, чтобы все корректно работало в этой конфигурации. Но для большинства задач такое решение — просто фантастика.
Также хотелось бы уметь обрабатывать случаи расщепления сети, когда для части кластера мастер-копия данных остается доступной.
В результате нами был выбран компромиссный вариант — в случае проблем с доступом к базе данных автоматически переключаться на реплику (но уже в режиме доступа только на чтение). Причем каждый сервер принимает решение о переключении на реплику и обратно на мастер самостоятельно, на основании собственной информации о доступности мастера и реплик. Если сервер с мастер-копией данных действительно сломался, системные администраторы предпримут все необходимые действия для его починки, а система в это время будет работать с немного урезанным функционалом (например, у части пользователей будет недоступна функция редактирования контактов). В зависимости от критичности сервиса администраторы могут предпринимать разные действия по устранению проблемы — от немедленного введения в строй замены до «утром поднимем». Главное, что веб-приложение продолжает работать, пусть и в немного урезанном варианте. Автоматически.
Не могу не рассказать об одном повсеместно используемом у нас компоненте, который у нас стоит на каждом сервере. Мы его называем Капрон. Капрон выполняет функции мультиплексора запросов к базам данных (MySQL и Tarantool), поддерживая с ними пул постоянных соединений, инкапсулирует в себе всю информацию о конфигурации баз данных, шардинге и балансировке нагрузки. Капрон позволяет скрывать особенности протокола БД, предоставляя своим клиентам более простой и ясный интерфейс. Очень удобная штука. И идеальный кандидат для помещения туда описанной ранее логики.
Итак, приложению требуется произвести какие-то действия с данными. Оно формирует запрос и передает его Капрону. Капрон определяет, в какой шард нужно отправить запрос, устанавливает соединение (или использует уже созданное ранее соединение) с нужным сервером и отправляет ему команду. В случае недоступности сервера или превышения времени ожидания ответа запрос дублируется в одну из реплик. В случае неудачи запрос будет отправлен в следующую реплику и т. д., пока не кончатся реплики или запрос не будет обработан. Статус доступности серверов сохраняется между запросами. И в случае, если мастер был недоступен, следующий запрос сразу пойдет в реплику. Капрон в фоновом режиме продолжает стучаться в мастер-сервер и, как только он оживет, тут же снова начнет отправлять в него запросы. При попытке внесения изменений на реплике запрос фэйлится — это позволяет нам не беспокоиться о том, куда идет запрос, на мастер или реплику.
За счет большого потока запросов знание о недоступности тех или иных серверов баз данных быстро обновляется, и это позволяет максимально быстро реагировать на смену обстановки.
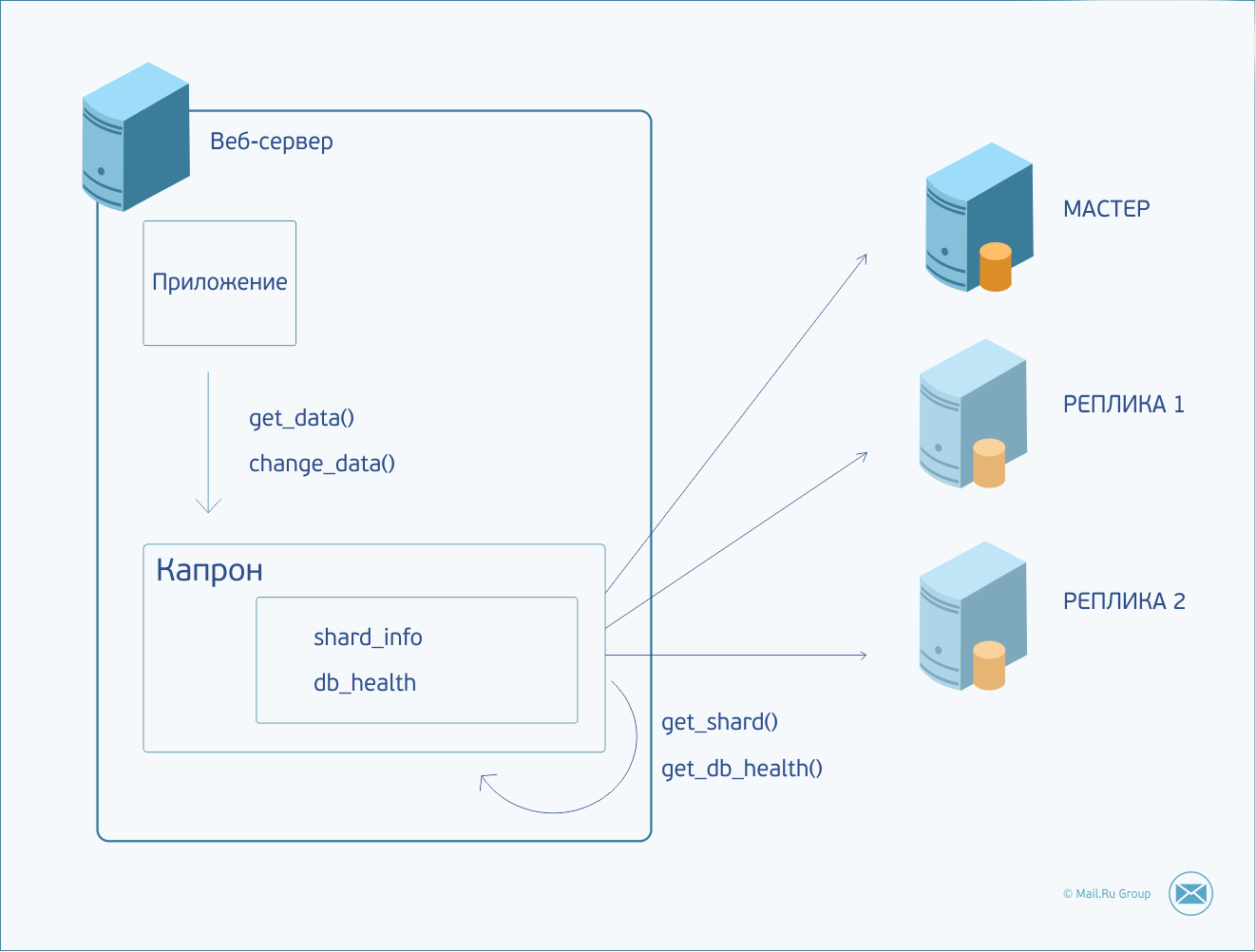
В результате получилась достаточно простая и универсальная схема. Прекрасно обрабатывает не только случаи падения мастер-копии данных, но и обычные сетевые задержки. Если мастер стаймаутил, запрос будет перенаправлен на реплику (и в случае неизменяющего запроса успешно ею обработан). В общем случае это позволяет уменьшить пороговые значения сетевых ожиданий для читающих запросов, и во время тормозов на мастер-сервере быстрее возвращать результат клиенту.
Второй бонус. Теперь можно более безболезненно (менее болезненно) проводить на серверах баз данных обновление ПО и другие плановые работы. Так как запросов на чтение обычно подавляющее большинство, для большей части запросов перезапуск мастера не приведет к отказу в обслуживании.
Мы планируем не останавливаться на достигнутом и попытаемся устранить некоторые очевидные недоработки:
1) В случае сетевого таймаута, мы пробуем послать запрос в реплику. В случае модифицирующего запроса это напрасный труд, т. к. реплика не сможет его обработать. Имеет смысл не посылать в реплику априори модифицирующие команды. Решается на уровне ручного конфигурирования типов команд.
2) Сейчас сетевой таймаут не означает, что данные на мастере не будут изменены. Хоть мы и вернем клиенту, что не смогли обработать его запрос. Справедливости ради стоит отметить, что данный недостаток присутствовал и раньше. Ситуация может быть исправлена за счет введения на стороне Тарантула ограничения на время обработки команд (если изменения не применены за указанное время, они автоматически откатываются, и запрос фэйлится). Выставляем таймаут на обработку 1 секунду, а сетевой таймаут в Капроне — 2 секунды.
3) Ну и конечно, ждем от разработчиков Тарантула синхронную мастер-мастер-репликацию. Это позволит равномерно распределить запросы между несколькими мастер-копиями и успешно обрабатывать запросы даже в случае недоступности одного из серверов!
Дмитрий Исайкин, ведущий разработчик Почты Mail.Ru
Кто-то оставляет проблему на «авось», кто-то вешает баннер на «пятисотку» и пытается зарабатывать на сбоях деньги. Кто-то пользуется стандартными решениями от поставщиков баз данных или сетевых устройств. А кто-то уходит в модные нынче «облака».

Ясно одно — по мере роста бизнеса обеспечение устойчивости к сбоям (даже не процедур восстановления после сбоев) становится всё более острой проблемой. От количества аварий в год начинает зависеть репутация компании, при больших временах простоя становится неудобно пользоваться сервисом, и т.д. Причин много.
В этой статье мы рассмотрим один из наших способов обеспечения устойчивости к сбоям. Под устойчивостью будем понимать сохранение работоспособности системы при выходе из строя как можно большего количества узлов этой самой системы.
Обычно архитектура веб-приложения устроена следующим образом (и наша архитектура не является исключением):

Веб-сервер занимается первичной обработкой и диспетчеризацией запросов, выполняет большую часть логики предметной области, он знает, откуда взять данные, что с ними сделать, куда положить новые данные. Не имеет особой разницы, какой конкретно веб-сервер будет обрабатывать пользовательский запрос. Если программное обеспечение написано более-менее корректно, любой веб-сервер успешно выполнит требуемую от него работу (если не будет перегружен, конечно). Поэтому выход из строя одного из серверов не приведет к серьезным проблемам: произойдет простое переключение нагрузки на оставшиеся в живых сервера, и веб-приложение продолжит свою работу (в идеале все незавершенные транзакции будут откачены, и пользовательский запрос можно будет повторно обработать на другом сервере).
Основные трудности начинаются на уровне хранения данных. Главная задача этой подсистемы — сохранить и приумножить информацию, необходимую для функционирования всей системы в целом. Часть этих данных можно иногда терять, а остальное является невосполнимым, и их потеря означает фактически смерть проекта. В любом случае, если данные частично потеряны, повреждены или временно недоступны, работоспособность системы резко снижается.
На самом деле, конечно, всё намного сложнее. При отказе веб-сервера система обычно не возвращается в предыдущую точку. Связано это с тем, что в рамках одной бизнес-транзакции необходимо внести изменения в нескольких различных хранилищах (при этом механизм распределенных транзакций в слое хранилищ данных обычно не реализован, да и слишком дорог в реализации и эксплуатации). Другими возможными причинами расхождения в данных являются ошибки в программном коде, неучтенные сценарии, безалаберность разработчиков и администраторов («человеческий фактор»), жесткие ограничения на сроки разработки и ещё куча других важных и неважных причин, по которым программисты пишут не совсем идеальный код. Но в большинстве ситуаций это и не нужно (не все же приложения пишутся для банковского и финансового сектора). Либо система автоматически умеет восстанавливать консистентность своих данных, либо существуют полуручные средства восстановления системы после сбоев, либо даже и этого не требуется (пример: пользователь отредактировал свои настройки, но из-за сбоя часть настроек не изменилась. В большинстве случаев это не смертельно, особенно если интерфейс честно скажет пользователю, что не смог применить изменения).
Учитывая все вышеизложенные соображения, наличие хорошей системы хранения и доступа к данным даёт ощутимый бонус к способности системы переживать аварии. Именно поэтому далее мы сконцентрируемся на том, как обеспечить устойчивость к сбоям в подсистеме доступа к данным.
В качестве базы данных в последние годы мы используем Тарантул (это наш опенсорсный проект, очень быстрая, удобная база данных, которая легко расширяется при помощи хранимых процедур. См. сайт http://tarantool.org).
Итак, наша цель — максимальная доступность данных. Тарантул как программное обеспечение проблем обычно не вызывает, т. к. он стабилена, нагрузка на сервер хорошо прогнозируется, сервер не уйдет неожиданно из-за возросшей нагрузки. Перед нами встает проблема надежности оборудования. Иногда серваки сгорают, диски сыплются, стойки вырубаются, маршрутизаторы выходят из строя, линки к датацентрам пропадают… А нам нужно, несмотря ни на что, обслуживать наших пользователей.
Чтобы не потерять данные, нужно продублировать сервер базы данных, разместить его в другой стойке, за другим маршрутизатором или даже в другом центре обработки данных и настроить репликацию данных с основного сервера на дублирующий. Нельзя забывать и об обязательном и регулярном резервном копировании данных. В случае технической поломки данные останутся живыми и доступными. Но есть один нюанс: данные будут доступны по другому адресу. А приложения продолжат по привычке стучаться в сломанный сервер.
Самый простой и распространенный вариант — разбудить одного из системных администраторов, чтобы он разобрался в проблеме и перенастроил все наши приложения на использование нового сервера данных. Не самое лучшее решение: переключение занимает много времени, велика вероятность что-то забыть, да и ненормированный график работы — это очень плохо.
Есть менее надежный, но зато более автоматизированный вариант — использование специализированного ПО для определения того, жив ли сервер и не пора ли переключиться на дублирующий. Пусть меня поправят господа админы, но мне кажется, тут присутствует ненулевая вероятность ложных срабатываний, которая будет приводить к расхождениям в данных между разными хранилищами. Правда, количество ложных срабатываний можно уменьшить за счет увеличения времени реагирования системы на сбой (что, в свою очередь, приводит к увеличению времени простоя).
Как вариант, можно в каждом датацентре поставить по мастер-копии данных и написать ПО таким образом, чтобы все корректно работало в этой конфигурации. Но для большинства задач такое решение — просто фантастика.
Также хотелось бы уметь обрабатывать случаи расщепления сети, когда для части кластера мастер-копия данных остается доступной.
В результате нами был выбран компромиссный вариант — в случае проблем с доступом к базе данных автоматически переключаться на реплику (но уже в режиме доступа только на чтение). Причем каждый сервер принимает решение о переключении на реплику и обратно на мастер самостоятельно, на основании собственной информации о доступности мастера и реплик. Если сервер с мастер-копией данных действительно сломался, системные администраторы предпримут все необходимые действия для его починки, а система в это время будет работать с немного урезанным функционалом (например, у части пользователей будет недоступна функция редактирования контактов). В зависимости от критичности сервиса администраторы могут предпринимать разные действия по устранению проблемы — от немедленного введения в строй замены до «утром поднимем». Главное, что веб-приложение продолжает работать, пусть и в немного урезанном варианте. Автоматически.
Не могу не рассказать об одном повсеместно используемом у нас компоненте, который у нас стоит на каждом сервере. Мы его называем Капрон. Капрон выполняет функции мультиплексора запросов к базам данных (MySQL и Tarantool), поддерживая с ними пул постоянных соединений, инкапсулирует в себе всю информацию о конфигурации баз данных, шардинге и балансировке нагрузки. Капрон позволяет скрывать особенности протокола БД, предоставляя своим клиентам более простой и ясный интерфейс. Очень удобная штука. И идеальный кандидат для помещения туда описанной ранее логики.
Итак, приложению требуется произвести какие-то действия с данными. Оно формирует запрос и передает его Капрону. Капрон определяет, в какой шард нужно отправить запрос, устанавливает соединение (или использует уже созданное ранее соединение) с нужным сервером и отправляет ему команду. В случае недоступности сервера или превышения времени ожидания ответа запрос дублируется в одну из реплик. В случае неудачи запрос будет отправлен в следующую реплику и т. д., пока не кончатся реплики или запрос не будет обработан. Статус доступности серверов сохраняется между запросами. И в случае, если мастер был недоступен, следующий запрос сразу пойдет в реплику. Капрон в фоновом режиме продолжает стучаться в мастер-сервер и, как только он оживет, тут же снова начнет отправлять в него запросы. При попытке внесения изменений на реплике запрос фэйлится — это позволяет нам не беспокоиться о том, куда идет запрос, на мастер или реплику.
За счет большого потока запросов знание о недоступности тех или иных серверов баз данных быстро обновляется, и это позволяет максимально быстро реагировать на смену обстановки.
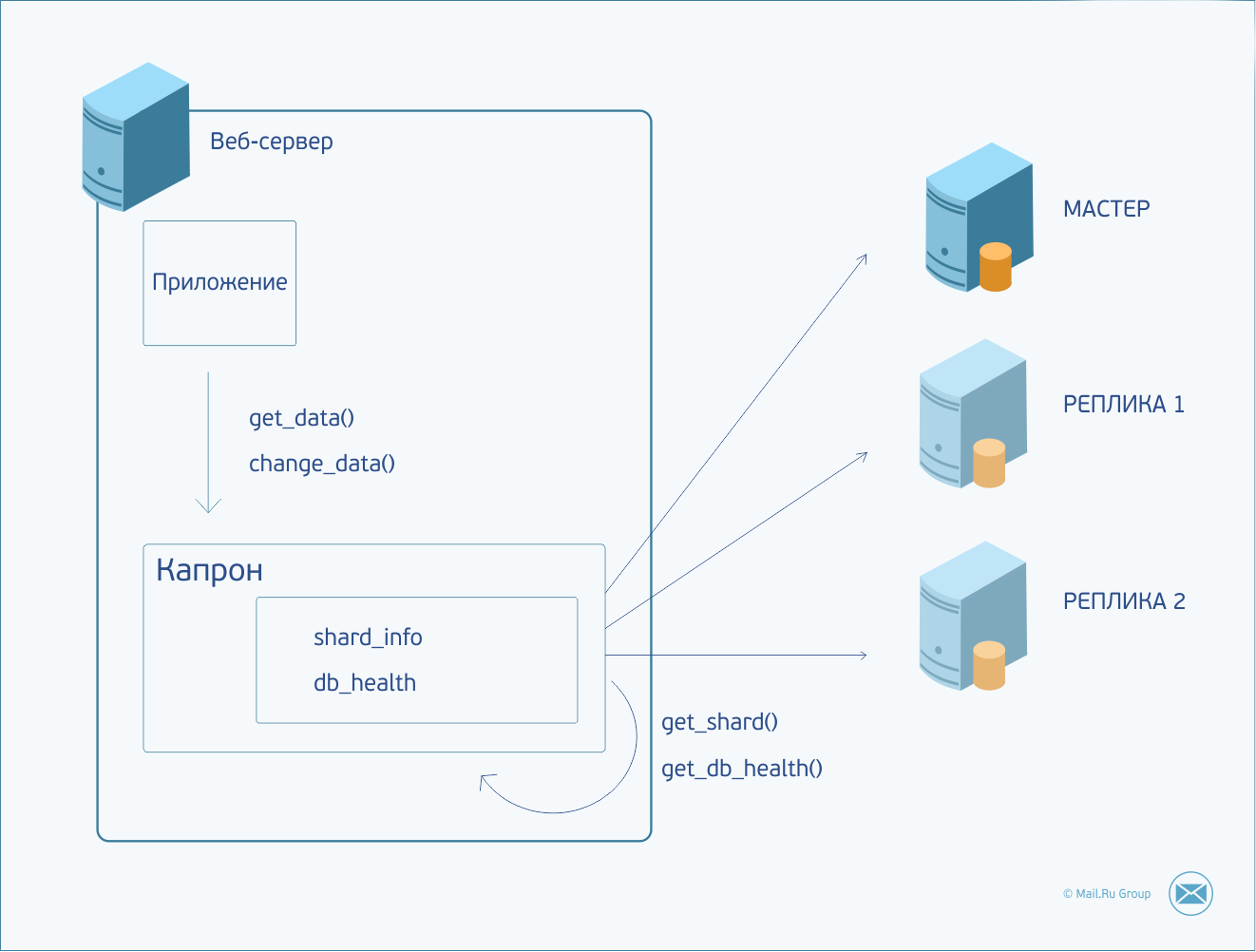
В результате получилась достаточно простая и универсальная схема. Прекрасно обрабатывает не только случаи падения мастер-копии данных, но и обычные сетевые задержки. Если мастер стаймаутил, запрос будет перенаправлен на реплику (и в случае неизменяющего запроса успешно ею обработан). В общем случае это позволяет уменьшить пороговые значения сетевых ожиданий для читающих запросов, и во время тормозов на мастер-сервере быстрее возвращать результат клиенту.
Второй бонус. Теперь можно более безболезненно (менее болезненно) проводить на серверах баз данных обновление ПО и другие плановые работы. Так как запросов на чтение обычно подавляющее большинство, для большей части запросов перезапуск мастера не приведет к отказу в обслуживании.
Мы планируем не останавливаться на достигнутом и попытаемся устранить некоторые очевидные недоработки:
1) В случае сетевого таймаута, мы пробуем послать запрос в реплику. В случае модифицирующего запроса это напрасный труд, т. к. реплика не сможет его обработать. Имеет смысл не посылать в реплику априори модифицирующие команды. Решается на уровне ручного конфигурирования типов команд.
2) Сейчас сетевой таймаут не означает, что данные на мастере не будут изменены. Хоть мы и вернем клиенту, что не смогли обработать его запрос. Справедливости ради стоит отметить, что данный недостаток присутствовал и раньше. Ситуация может быть исправлена за счет введения на стороне Тарантула ограничения на время обработки команд (если изменения не применены за указанное время, они автоматически откатываются, и запрос фэйлится). Выставляем таймаут на обработку 1 секунду, а сетевой таймаут в Капроне — 2 секунды.
3) Ну и конечно, ждем от разработчиков Тарантула синхронную мастер-мастер-репликацию. Это позволит равномерно распределить запросы между несколькими мастер-копиями и успешно обрабатывать запросы даже в случае недоступности одного из серверов!
Дмитрий Исайкин, ведущий разработчик Почты Mail.Ru
