
Я обожаю читать на хабре статьи про то, как устроены системы больших интернет-компаний. Кластеры SQL-серверов, монг и редисов. Тут у нас кластер ELK собирает трейсинг, там – сборка логов, здесь балансер выдает входящим запросам traceID и можно отслеживать, как запрос ходит по всем нашим микросервисам. Класс. Но, допустим, у вас совсем маленький проект и вы можете себе позволить лишь VPS минимальной конфигурации. Реально ли на ней сделать мониторинг не хуже, чем у больших проектов? Я решил – надо попробовать.
Создаем VPS
Сразу оговорюсь, что я ни разу не devops и не особо глубоко разбираюсь в Linux, поэтому, если что-то сделал неправильно, или у вас есть идеи, как можно было сделать то, что я делаю в этой статье проще и лучше – пишите в комментариях, буду рад любым вашим советам и замечаниям!
Для экспериментов я создал на Маклауде VPS следующей конфигурации: 1 CPU, 1 Гб RAM и 20 Гб диск.
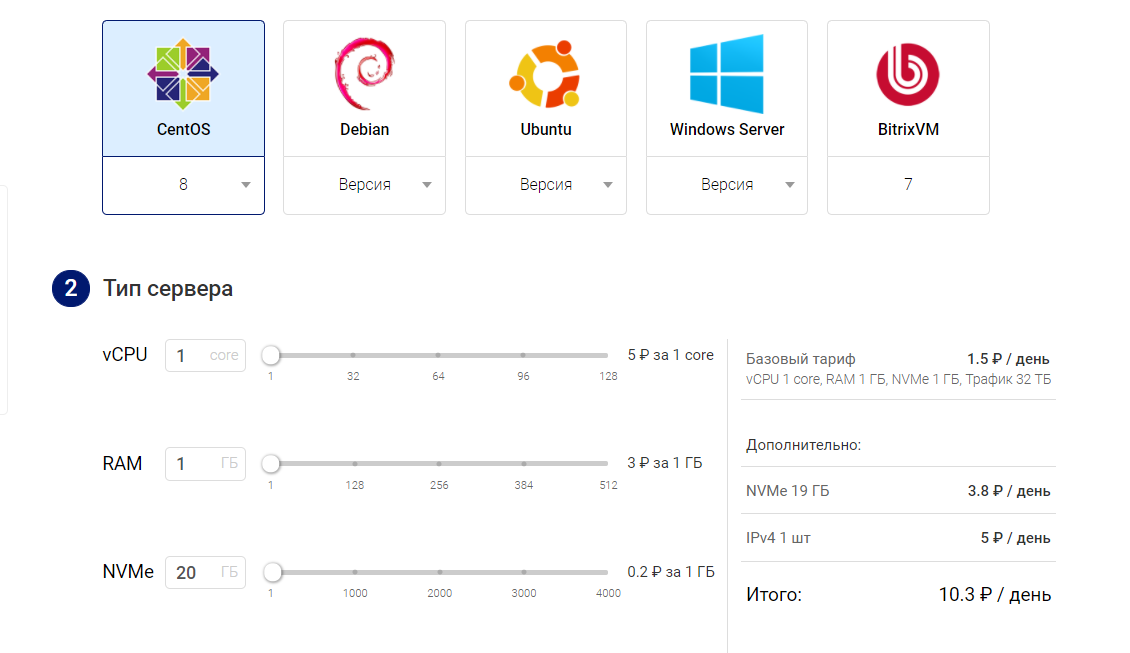
Для удобства я загрузил свой SSH ключ, и мог заходить в консоль сразу после запуска сервера. Также по умолчанию включено резервное копирование, я его отключил, так как в целях эксперимента мне оно было не нужно. Далее требовалось выбрать ОС. Для этого хотелось понять, какие ресурсы будут доступны на VPS сразу после создания. Меня интересовала свободная память и место на диске. Для этого, в панели управления можно инициировать переустановку ОС. Я поочередно установил доступные ОС и для каждой посмотрел, какие параметры она дает на старте:
CentOS 8:
[root@v54405 ~]# df
Filesystem 1K-blocks Used Available Use% Mounted on
devtmpfs 406744 0 406744 0% /dev
tmpfs 420480 0 420480 0% /dev/shm
tmpfs 420480 5636 414844 2% /run
tmpfs 420480 0 420480 0% /sys/fs/cgroup
/dev/vda1 20582864 1395760 18300472 8% /
tmpfs 84096 0 84096 0% /run/user/0
[root@v54405 ~]# free
total used free shared buff/cache available
Mem: 840960 106420 525884 5632 208656 600868
Swap: 0 0 0Debian 10
root@v54405:~# df
Filesystem 1K-blocks Used Available Use% Mounted on
udev 490584 0 490584 0% /dev
tmpfs 101092 1608 99484 2% /run
/dev/vda1 20608592 1001560 18736224 6% /
tmpfs 505448 0 505448 0% /dev/shm
tmpfs 5120 0 5120 0% /run/lock
tmpfs 505448 0 505448 0% /sys/fs/cgroup
tmpfs 101088 0 101088 0% /run/user/0
root@v54405:~# free
total used free shared buff/cache available
Mem: 1010900 43992 903260 1608 63648 862952
Swap: 0 0 0Ubuntu 20.04
root@v54405:~# df
Filesystem 1K-blocks Used Available Use% Mounted on
udev 473920 0 473920 0% /dev
tmpfs 100480 592 99888 1% /run
/dev/vda1 20575824 1931420 17757864 10% /
tmpfs 502396 0 502396 0% /dev/shm
tmpfs 5120 0 5120 0% /run/lock
tmpfs 502396 0 502396 0% /sys/fs/cgroup
tmpfs 100476 0 100476 0% /run/user/0
root@v54405:~# free
total used free shared buff/cache available
Mem: 1004796 65800 606824 592 332172 799692
Swap: 142288 0 142288
Итак, в CentOS не доложили оперативной памяти (кстати почему – хороший вопрос сервису), а Убунту занял на гигабайт больше места на диске. Так что я остановил свой выбор на Debian 10.
Для начала обновим систему:
apt-get update
apt-get upgrade
Также установим sudo
apt-get install sudoДля того, чтобы реализовать мою задумку первым делом я установил докер по инструкции с официального сайта.
Проверяем, что докер установлен
# docker -v
Docker version 20.10.6, build 370c289Также понадобится docker-compose. Процесс установки можно посмотреть тут.
Проверим, что докер установился:
# docker-compose -v
docker-compose version 1.29.1, build c34c88b2
Итак, все приготовления выполнены, посмотрим, сколько места осталось на диске:
Filesystem 1K-blocks Used Available Use% Mounted on
udev 490584 0 490584 0% /dev
tmpfs 101092 2892 98200 3% /run
/dev/vda1 20608592 1781756 17956028 10% /
tmpfs 505448 0 505448 0% /dev/shm
tmpfs 5120 0 5120 0% /run/lock
tmpfs 505448 0 505448 0% /sys/fs/cgroup
tmpfs 101088 0 101088 0% /run/user/0
Запускаем проект
Для эксперимента я написал на NestJS небольшой веб-сервис, который работает с изображениями. Он позволяет загружать изображения на сервер, извлекает из них метаданные, записывает их в MongoDB, а информация о сохраненных изображениях пишется в Postgres. Для каждого загруженного изображения можно получить метаданные и скачать само изображение. Изображения, к которым не обращались более 10 минут удаляются с сервера при помощи функции очистки, которая запускается раз в минуту.
Исходный код проекта на github.
Я клонировал его на сервер при помощи команды:
git clone https://github.com/debagger/observable-backend.git
Чтобы было удобно разворачивать сервис на сервере я написал файл
docker-compose.nomon.yml следующего содержания:version: "3.9"
volumes:
imagesdata:
grafanadata:
postgresdata:
mongodata:
tempodata:
services:
backend:
image: node:lts
volumes:
- ./backend:/home/backend
- imagesdata:/images
working_dir: /home/backend
environment:
OT_TRACING_ENABLED: "false"
PROM_METRICS_ENABLE: "false"
ports:
- 3000:3000
entrypoint: ["/bin/sh"]
command: ["prod.sh"]
restart: always
db:
image: postgres
restart: always
expose:
- "5432"
volumes:
- postgresdata:/var/lib/postgresql/data
environment:
POSTGRES_PASSWORD: password
POSTGRES_USER: images
adminer:
image: adminer
restart: always
ports:
- 8080:8080
mongo:
image: mongo
restart: always
volumes:
- mongodata:/data/db
mongo-express:
image: mongo-express
restart: always
ports:
- 8081:8081
Для запуска проекта переходим в его директорию
cd observable-backendИ запускаем:
docker-compose -f docker-compose.nomon.yml up -dСервису понадобится некоторое время чтобы стартовать, я настроил его таким образом, чтобы он при запуске автоматически загружал зависимости и собирался.
После запуска можно проверить что он работает в браузере по ссылке
http://<ip сервера>:3000/
Должна вывестись строка Hello World!
Для того, чтобы испытывать производительность сервиса при помощи библиотеки autocannon я написал нагрузочный тест. Он находится в том же репозитории, в директории autocannon. Его надо запускать на машине с установленным node.js предварительно установив адрес сервера, где запущен проект в .env файле.
После запуска двухминутного теста я получил следующий результат:

В процессе теста я мог наблюдать за поведением системы при помощи стандартной команды linux —
top, а также docker stats. Помимо этого можно смотреть логи, при помощи команды docker logs. Но этого недостаточно, хочется лучше понимать, что происходит с моим сервисом под нагрузкой. Поэтому следующим шагом я решил добавить к проекту сбор метрик.Настраиваем метрики
После недолгого гугления решений для сбора метрик я остановил свой выбор на связке Prometheus + Grafana.
Для использования этой связки я добавил в конфигурацию docker-compose следующее:
prometheus:
image: prom/prometheus
ports:
- 9090:9090
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
mongo-exporter:
image: bitnami/mongodb-exporter
ports:
- 9091:9091
command: [«--mongodb.uri=mongodb://mongo», «--web.listen-address=0.0.0.0:9091»]
pg-exporter:
image: bitnami/postgres-exporter
ports:
- 9092:9092
environment:
DATA_SOURCE_NAME: sslmode=disable user=images password=password host=db
PG_EXPORTER_WEB_LISTEN_ADDRESS: 0.0.0.0:9092
grafana:
image: grafana/grafana
ports:
- 3001:3000
volumes:
- grafanadata:/var/lib/grafana
Здесь минимальная конфигурация для запуска Prometheus и Grafana, а также экспортеры для метрик из Postgres и Mongo. Для Prometheus я написал конфиг prometheus.yml со следующим содержимым.
global:
scrape_interval: 10s
scrape_configs:
- job_name: 'nodejs'
honor_labels: true
static_configs:
- targets: ['backend:3000']
- job_name: «mongodb»
honor_labels: true
static_configs:
- targets: ['mongo-exporter:9091']
- job_name: «postgres»
scrape_timeout: 9s
honor_labels: true
static_configs:
- targets: ['pg-exporter:9092']
Чтобы собирать метрики из своего приложения я использовал библиотеку
express-prom-bundle, которая позволяет собирать стандартные метрики и создавать свои собственные. Также я добавил в свой сервис переменную окружения PROM_METRICS_ENABLE для того, чтобы можно было включать и отключать метрики из конфигурации контейнера. Если активировать данную функцию, метрики, собираемые приложением, будут доступны по адресу http://<ip сервера>:3000/metrics. Я включил сбор дефолтных системных метрик, метрики по запросам, обрабатываемым сервером Express, а также несколько своих, которые позволяют контролировать скорость и количество загружаемых и скачиваемых изображений, количество хранимых изображений и занимаемое ими место на диске.
Получившуюся конфигурацию я сохранил под именем
docker-compose.metrics.yml.Запустить эту конфигурацию можно командой
docker-compose -f docker-compose.metrics.yml up -dПосле запуска можно зайти в интерфейс Grafana по адресу
http://<ip сервера>:3001/Логин/пароль по умолчанию admin/admin.
Здесь в настройках я добавил источник данных Prometheus

После этого нам доступны все метрики, которые собирает Prometheus.
Для примера выведем графики загрузки процессора по всем сервисам:

Для своих целей я настроил такую панель:

Теперь мне стало гораздо проще разобраться, что происходит с сервисом.
ELK – неудача
Итак, я настроил метрики, и теперь мне хотелось заняться сбором логов. Я решил попробовать поднять для этих целей связку Elasticsearch + Logstash. Это просто первое, что пришло в голову, ибо читал много хорошего про эти инструменты. Особенно интересовало, удастся ли сделать сбор логов прямо с контейнеров, потому что у докера для этой целей есть встроенный плагин, позволяющий экспортировать вывод консоли сервисов в формате gelf, который поддерживает Logstash. Я добавил в docker-compose следующее
elasticsearch:
image: elasticsearch:7.12.1
environment:
- discovery.type=single-node
- ES_JAVA_OPTS=-Xms250m -Xmx250m
ports:
- 9200:9200
- 9300:9300
logstash:
image: logstash:7.12.1
links:
- elasticsearch
volumes:
- ./logstash.conf:/etc/logstash/logstash.conf
command: logstash -f /etc/logstash/logstash.conf
ports:
- 12201:12201/udp
depends_on:
- elasticsearchТакже для начала настроил экспорт логов из Mongo. Для этого описание сервиса mongo в файле docker-compose я дополнил следующим образом:
mongo:
image: mongo
restart: always
logging:
driver: gelf
options:
gelf-address: "udp://localhost:12201"Когда я запустил новую конфигурацию – я понял, что это конец. Ничего не работало. Сервер стал жутко тормозить, а kswapd0 периодически выходил на первое место по загрузке процессора, а свободная память была почти на нуле. Памяти для такой конфигурации явно не хватало.
Забегая вперед, когда я активировал файл подкачки, мне удалось запустить проект. Но все равно всё работало очень медленно, причем дольше всего запускался Logstash. Инструмент, задача которого всего лишь на всего грузить логи – стартовал минут 20. Хотя, когда он наконец запустился, работал как предполагалось, и я даже смог посмотреть в Grafana кусочек лога Mongo, так что, в принципе решение работало, просто для системы с таким объемом оперативной памяти оно не подходило, что не удивительно, ведь если погуглить, каковы минимальные требования для Elasticsearch, то ответ будет таким:

Я действительно этого не знал, поэтому немного приуныл, поскольку я хотел позже использовать Elasticsearch в качестве хранилища данных для jaeger, чтобы реализовать сбор трейсов приложения и поставить Kibana чтобы добить ELK стек. Но, как говорится, на нет и суда нет, поэтому я стал искать альтернативу.
Loki
И альтернатива нашлась! Искать, к слову, долго не пришлось, потому что в списке поддерживаемых источников данных Grafana обнаружился зверь под названием Loki. Это сборщик логов из той же эко-системы, что Prometheus и Grafana. Напомню, что моя идея была в том, чтобы писать логи из стандартного потока контейнеров. И для этого сценария тоже быстро нашлось решение. Оказалось, для докера есть плагин, который позволяет делать именно то, что мне надо – отправлять потоки стандартного вывода в Loki. Поставить его можно следующей командой:
# docker plugin install grafana/loki-docker-driver:latest --alias loki --grant-all-permissions
Я добавил в конфигурацию docker-compose сервис loki:
loki:
image: grafana/loki:2.0.0
ports:
- «3100:3100»
command: -config.file=/etc/loki/local-config.yaml
Кроме этого, я добавил ко всем сервисам, логи с которых хотел собрать, следующую секцию:
logging:
driver: loki
options:
loki-url: «http://localhost:3100/loki/api/v1/push»
А к своему приложению добавил еще
loki-pipeline-stages: |
- json:
expressions:
output: msg
level: level
timestamp: time
pid: pid
hostname: hostname
context: context
traceID: traceIDЧтобы из лога, который у меня в формате json парсились важные поля.
Получившийся конфиг я сохранил под именем
docker-compose.metrics_logs.yml.Теперь результат можно запустить при помощи команды
docker-compose -f docker-compose.metrics_logs.yml up -d
После запуска я понял, что что-то идет не так, потому что команда вылетела с сообщением Killed. Я попробовал еще раз – сервисы запустились частично. На третий раз все заработало, но когда я заглянул в top то увидел, что там периодически проскакивает
kswapd0, а это значило, что системе жестко не хватало памяти.
Простой выход – добавить в конфигурацию хотя бы гигабайт оперативной памяти, но по условиям эксперимента я хотел запустить все на VPS минимальной конфигурации. Поэтому я решил активировать swap-файл, который в системе по умолчанию отключен. Сколько было эпичных баттлов в комментариях про то, нужен ли файл подкачки в Linux, но у меня выбора особо не было. Заодно я решил проверить, как будет влиять наличие файла подкачки на производительность системы.
Включаем swap:
# sudo fallocate -l 1G /swapfile
# sudo chmod 600 /swapfile
# sudo mkswap /swapfile
# sudo swapon /swapfile
Проверяем про помощи команды
free: total used free shared buff/cache available
Mem: 1010900 501760 202344 26500 306796 353952
Swap: 4194300 0 4194300
В системе появился файл подкачки размером 4Гб. Должно хватить!
Снова пытаемся запустить нашу систему:
# docker-compose -f docker-compose.metrics_logs.yml up -dВсе работает! Теперь в Grafana добавляем в качестве источника логов Loki

Идем в Explore и видим, что логи начали подгружаться.

Проверим, что стало с производительностью.

Раз все работает, осталось закрепить файл подкачки в системе. Для этого надо в файле /etc/fstab добавить строку
/swapfile swap swap defaults 0 0
После этого файл подкачки останется в системе даже после перезагрузки.
Добавляем сбор трейсов при помощи Tempo
Для полного счастья мне нужна была система сбора трейсов. Чтобы не мудрить, раз уж так вышло, что я использую стек Grafana, можно добавить в качестве сборщика данных еще один инструмент от Grafana Lab – сервер для сбора трейсов Tempo. Он из коробки поддерживается Grafana, поэтому попробуем добавить его в систему.
Для того, чтобы приложение стало генерировать трейсы, его надо специальным образом инструментировать. Для этого есть замечательный проект под названием OpenTelemetry, который развивает систему спецификаций и библиотек для реализации трейсинга под различные платформы и системы. В нем есть готовые библиотеки для автоматической инструментации Node.js и сервера express.js, который работает под капотом у nest.js. Их я и добавил в свой проект.
Tempo может принимать трейсы про всем распространённым протоколам. Я выбрал протокол Jagger Trift binary – простой двоичный формат, передаваемый по UDP. Также, как и в случае с метриками, я в своем приложение я добавил переменную окружения
OT_TRACING_ENABLED, которая, если ее установить в true включает в приложении телеметрию.Для запуска Tempo я добавил в файл конфигурации docker-compose следующее:
tempo:
image: grafana/tempo:latest
command: [«-config.file=/etc/tempo.yaml»]
volumes:
- ./tempo-local.yaml:/etc/tempo.yaml
- tempodata:/tmp/tempo
ports:
- «6832/udp» # Jaeger - Thrift Binary
и сохранил его под названием
docker-compose.metrics_logs_tempo.ymlДля настройки Tempo я создал файл конфигурации tempo-local.yaml (на самом деле просто скопировал из репозитория Tempo подходящий и немного поправил). Запустим его командой
docker-compose -f docker-compose.metrics_logs_tempo.yml up -dТеперь осталось в Grafana настроить источник данных:

Чтобы было удобно переходить к просмотру трейсов из логов надо настроить источник данных Loki:

После такой настройки рядом с полем traceID появится ссылка:

По этой ссылке будет открываться окно с данным трейсом:

Испытываем производительность нашего сервиса.

Здесь уже видно заметное падение производительности сервиса, но надо понимать, что эта плата за детальную телеметрию.
Дополнение: уже когда я прогнал нагрузочные тесты, результаты которых приведены ниже и дописывал статью, изучая документацию Jaeger я выяснил, что он может использовать для хранения данных локальное хранилище на основе key-value базы данных Badger, и, таким образом, может работать без Elasticsearch. Я добавил в репозиторий файл конфигурации для docker-compose где вместо tempo используется jaeger (
docker-compose.metrics_logs_jaeger.yml), но не проводил всего набора тестов. Я запустил тест производительности только на базовой конфигурации, и в этом режиме получилось 19,92 запроса в секунду, что несколько больше по сравнению с вариантом, где используется tempo — 18,84. В отличии от tempo, который позволяет искать трейсы только по traceID, jeaeger дает возможность поиска по различным параметрам и у него есть собственный, достаточно удобный интерфейс для просмотра трейсов.
Результаты тестов
Итак, мне удалость запустить все необходимые компоненты мониторинга и телеметрии. Осталось понять, насколько использование различных компонентов влияет на производительность системы.
Для каждого из перечисленных выше вариантов я запускал нагрузочный тест продолжительностью 20 минут. Для того, чтобы задействовать все компоненты системы, включая сетевой интерфейс я запускал тест autocannon со своей VPS размещённой у другого провайдера, предварительно проверив скорость соединения при помощи iperf – она составила 90 Мбит/сек. Так же между запусками тестов я дожидался, пока отработает функция удаления старых изображений, полностью удалив загруженные в предыдущем тесте файлы с диска и информацию из баз данных.
Результаты я свел в таблицу. Для оценки производительности я решил ориентироваться на число запросов в секунду, которое может обрабатывать система. Конечно, есть куча других метрик, но именно эта наиболее наглядно, на мой взгляд, показывает общее влияние различных факторов на производительность системы. Вот что получилось.
| Запросов в секунду | Снижение производительности | |
| Без мониторинга | 28,07 | 100% |
| Prometheus | 27,19 | 97% |
| Prometheus+Loki | 25,47 | 91% |
| Prometheus+Loki+Tempo | 18,84 | 67% |
Выходит, что только использование трейсинга приводит к значительным потерям производительности, а в случае со сбором метрик и логов потери составляют менее 10%.
Добавляем ядра и память
Также я решил посмотреть, как будет влиять на производительность сервиса увеличение объема памяти и количества ядер процессора. Macloud.ru позволяет менять параметры тарифа и я решил посмотреть как работает эта функция. Первым делом я добавил еще 1 Гб оперативной памяти.

После нажатия кнопки «Сменить тариф» сервер перезагрузился и вот что получилось:
total used free shared buff/cache available
Mem: 2043092 309876 1190416 14284 542800 1576804
Swap: 4194300 0 4194300
Все правильно. Теперь можно отключить файл подкачки.
swapoff /swapfile
Посмотрим, что покажут тесты:
| Запросов в секунду | Снижение производительности | |
| Без мониторинга | 27,52 | 100% |
| Prometheus | 24,78 | 90% |
| Prometheus+Loki | 21,58 | 78% |
| Prometheus+Loki+Tempo | 21,44 | 78% |
Почему-то производительность в целом стала немного ниже, но не так сильно зависит от включения функций мониторинга. Я предположил, что может быть дело все-таки в файле подкачки и включил его обратно. Вот что получилось:
| Запросов в секунду | Снижение производительности | |
| Без мониторинга | 29,64 | 100% |
| Prometheus | 26,97 | 91% |
| Prometheus+Loki | 25,7 | 87% |
| Prometheus+Loki+Tempo | 22,95 | 77% |
Выводы такие – добавление памяти улучшает производительность системы, наличие файла подкачки также влияет положительно. Почему так происходит, требует более детального изучения, могу лишь предположить, что менеджер памяти при наличии файла подкачки имеет возможность вытеснить на диск малоиспользуемые данные чтобы дать больше места активным приложениям. Я оставил файл подкачки включенным несмотря на то, что памяти в принципе хватало для работы системы и без него.
После этого мне стало интересно – а как повлияет на производительность добавление второго ядра CPU? Сказано-сделано:

После добавления второго ядра я погнал всё те же тесты и вот какой результат получился.
| Запросов в секунду | Снижение производительности | |
| Без мониторинга | 49,05 | 100% |
| Prometheus | 44,52 | 91% |
| Prometheus+Loki | 45,64 | 93% |
| Prometheus+Loki+Tempo | 40,34 | 82% |
Производительность увеличилась в 1,75 раза если сравнивать с базовым вариантом. Это хорошо, ведь если нагрузка на сервер будет расти, я могу просто докупить второе ядро, когда в этом появится необходимость.
Дальше я экспериментировать не стал, мне понятно, что, если продолжить добавлять память и процессорные ядра, производительность системы не будет расти так заметно. Чтобы обеспечить прирост производительности в этом случае нужно будет организовать запуск приложения в режиме кластера и внести еще ряд архитектурных изменений.
Выводы
Начиная этот эксперимент, я задался целью проверить, возможно ли на VPS c очень ограниченными ресурсами (я знаю, что можно найти предложения с еще более скромными параметрами, но 1 CPU + 1 Гб RAM – это доступный минимум у большей части провайдеров) запустить полноценную систему мониторинга для приложения. Как видите, это оказалось вполне возможно. Конечно, не все инструменты, которые используют крупные компании, применимы, но вполне можно найти такой набор, который позволит организовать мониторинг вашей системы не сильно влияя на ее производительность.
Также в ходе эксперимента я смог ответить для себя на ряд вопросов:
Стоит ли заморачиваться с настройкой мониторинга для совсем небольшого проекта?
Я считаю, что да, стоит. Мониторинг помогает понять, как ведет себя ваш проект в рабочей среде и дает информацию для дальнейшего улучшения качества кода. Я в процессе данного эксперимента, благодаря изучению данных мониторинга я смог заметить ряд недостатков в своем приложении, которые мне бы вряд ли удалось выявить другим способом.
Нужно ли делать нагрузочное тестирование?
Однозначно да. Во-первых, это позволяет найти узкие места в вашем приложении. Во-вторых, позволяет оценить, с какой нагрузкой сможет справиться система. Ну и в-третьих, имея настроенный мониторинг очень интересно наблюдать как система ведет себя под нагрузкой, это дает очень много пищи для размышлений и позволяет улучшить понимание того, как взаимодействуют компоненты системы.
Сложно ли настроить мониторинг
Ох, хотел бы я сказать, что это просто, но нет. Если делаешь это впервые, скорее всего придется вдоволь походить по граблям. Тут нет единого рецепта, как построить работающую систему, которая будет делать то, что вам нужно. Часто приходится собирать необходимую информацию по крупицам, и действовать интуитивно, потому что какие-то важные для тебя моменты не озвучиваются в документации. Если вы решите пойти этим путем, надеюсь, что данная статья и прилагающийся репозиторий поможет вам пройти его быстрее, чем мне.
А почему не облачные решения?
Мне просто спокойней платить фиксированную сумму и иметь в своем распоряжении все ресурсы, которые дает VPS. Истории, как разработчик что-то сделал неправильно и получил многотысячный счет – пугают. Хотя возможно, что в облаке все, что я описываю в этой статье настраивается за пару кликов мышкой, и тогда это, конечно, огромный плюс.
В заключении хотелось бы сказать – даже если у вас небольшой проект, и еще нет мониторинга, имеет смысл задуматься о его внедрении. Если вы опасаетесь, что это сложно сделать, или что у вашей системы недостаточно ресурсов для его реализации – можете использовать в качестве отправной точки материалы данной статьи и пример реализации, который я разместил в репозитории.
Репозиторий можно посмотреть по этому адресу: github.com/debagger/observable-backend
Облачные серверы от Маклауд быстрые и безопасные.
Зарегистрируйтесь по ссылке выше или кликнув на баннер и получите 10% скидку на первый месяц аренды сервера любой конфигурации!

