В феврале в нашей новосибирской Точке кипения прошел тринадцатый митап JUGNsk, где Владимир Иванов, ведущий инженер Oracle из группы разработки виртуальной Java-машины HotSpot, рассказал, что сейчас приходит на смену JNI при взаимодействии Java-кода с native-кодом. Читайте далее о FFI (Foreign Function Interface), jextract, Memory Access API и Foreign ABI (Application Binary Interface).
Статья подготовлена по мотивам доклада, видеозапись которого с сессией вопросов-ответов можно найти тут. Это не просто расшифровка, а доработанная самим Владимиром версия исходного материала.
В целом, доклад посвящен довольно специфической теме: взаимодействию с платформенными (native) библиотеками из Java.

Видеозапись доклада Java Native Runtime with Charles Nutter
Разработка Java ведется в рамках OpenJDK, и любые нововведения в язык и платформу создаются в специализированных OpenJDK проектах. Для примера: лямбда-выражения и Stream API пришли из Project Lambda, система модулей (JPMS) создавалась в рамках Project Jigsaw, работа в Project Valhalla ведется над inline-типами (и всем, что с этим связано). Project Panama — один из таких мегапроектов, в рамках которого ведется разработка новых механизмов работы с платформенными библиотеками (и не только).
Текущее состояние (или «моментальный срез») проекта само по себе не столь интересно. Поэтому постараюсь не просто рассказать, где сейчас находится проект, но и дать некоторую перспективу: как проект начинался, что в нем происходило в последние годы, где он находится сейчас и куда планируется двигаться дальше.
Бывает, со стороны смотрят на проект и не понимают, что поменялось за последний год. Предположим, год назад рассказывали про Value Types, а теперь они называются по-другому — Inline Types. Со стороны может показаться, что это все изменения. Но если вглядеться в детали и проследить изменения год за годом, объем работы впечатляет.
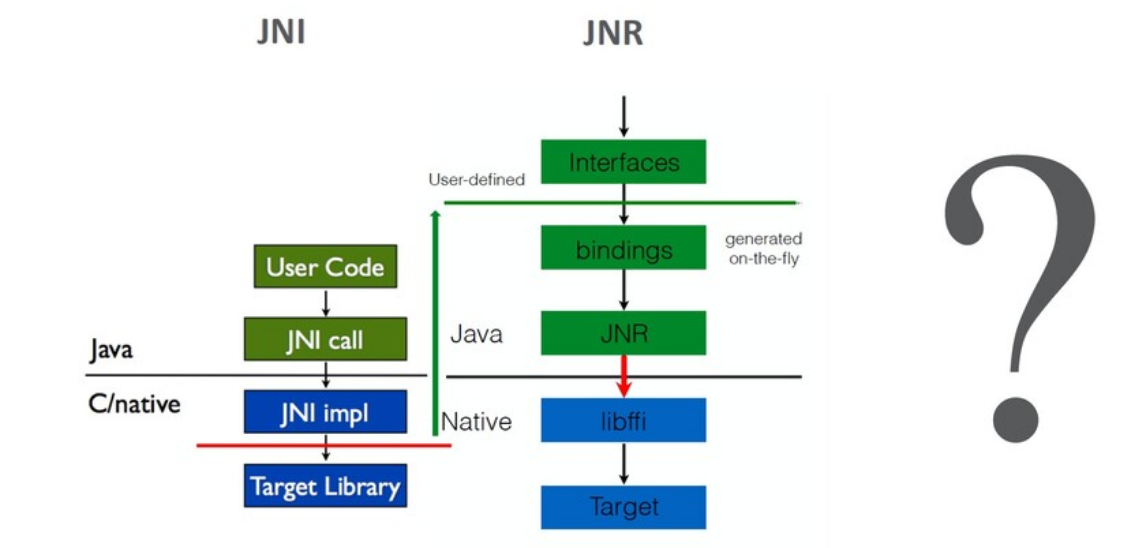
Возвращаясь к Panama: вдохновителем проекта стал Charles Nutter (@headius), который на конференции JVMLS 2013 сделал большой доклад про библиотеку JNR (Java Native Runtime), активно используемую JRuby для работы с платформой. В докладе он сравнил производительности JNR, JNI и JNA (еще одной библиотеки для взаимодействия с native-кодом).
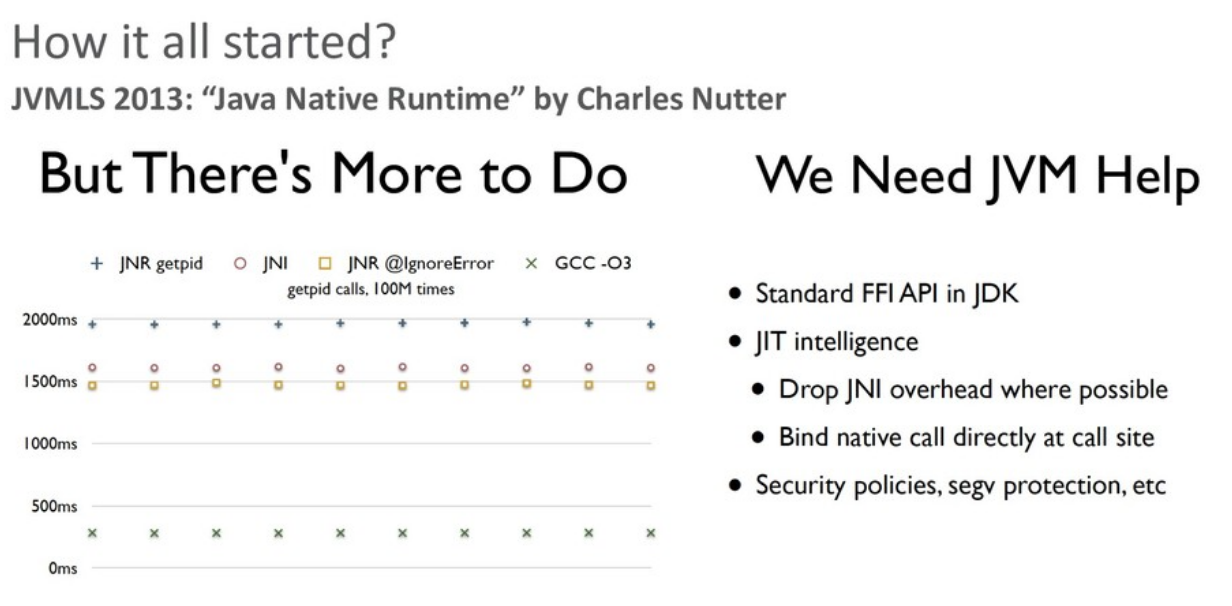
Производительность всех вариантов вызовов (через чистый JNI, через JNR и т.д.) была далека от прямого вызова native-функции, и повысить ее на уровне сторонней библиотеки было уже нельзя — необходима была помощь со стороны виртуальной машины Java (JVM). Идея Charles Nutter заключалась в том, чтобы создать новый API на замену JNI.

К слову, в то время разработка Java велась на основе JSR.
Призыв Чарльза был услышан, и в марте 2014 года было инициировано обсуждение нового OpenJDK-проекта. Предложение получило достаточный отклик в сообществе, так что датой старта проекта можно считать 18 марта 2014 года, когда John Rose инициировал официальное голосование о создании Project Panama.

Анонсированная «область ответственности» для проекта была выбрана гораздо шире, чем предлагал Чарльз. Для JNR было бы достаточно добавить низкоуровневый способ делать прямые вызовы библиотечных функций. Для прямого доступа в память уже был sun.misc.Unsafe. И для JNR было достаточно чего-то похожего: по входному адресу какой-либо native-функции виртуальная машина просто генерировала бы прямой вызов по этому адресу. Для целей JRuby (работы с интерфейсом POSIX) этого было более чем достаточно. Но не для Java-платформы и чего-то, рассматриваемого как замена JNI. Так что с самого начала для проекта были заявлены амбициозные цели: не просто работа с native-кодом, но и поддержка полностью программируемых представлений данных в памяти (memory layout) для более тесного взаимодействия. Проект не ограничивали жесткими рамками.
Не зря было выбрано «говорящее» название, напоминающее о Панамском проливе: проект Panama должен был сделать Java и native-код «ближе» друг к другу.
У проекта Panama есть свой репозиторий: http://hg.openjdk.java.net/panama/dev/
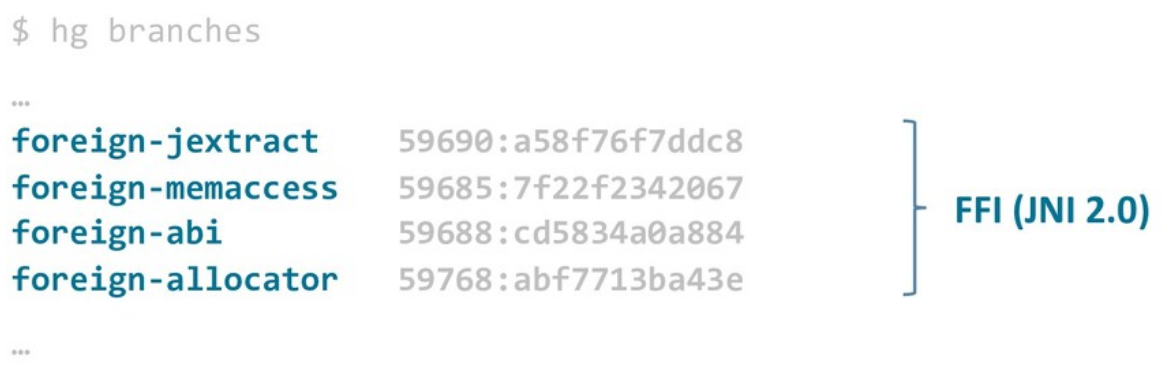
На текущий момент два основных направления работы — это замена JNI и Vector API.

Вот четыре основных ветки, которые можно отнести к FFI:
Но прежде чем говорить о деталях и особенностях нового FFI, я сначала расскажу о проблематике работы с native-кодом в Java: почему текущие решения выглядят именно так, что можно сделать лучше, а что исправить уже не получится.
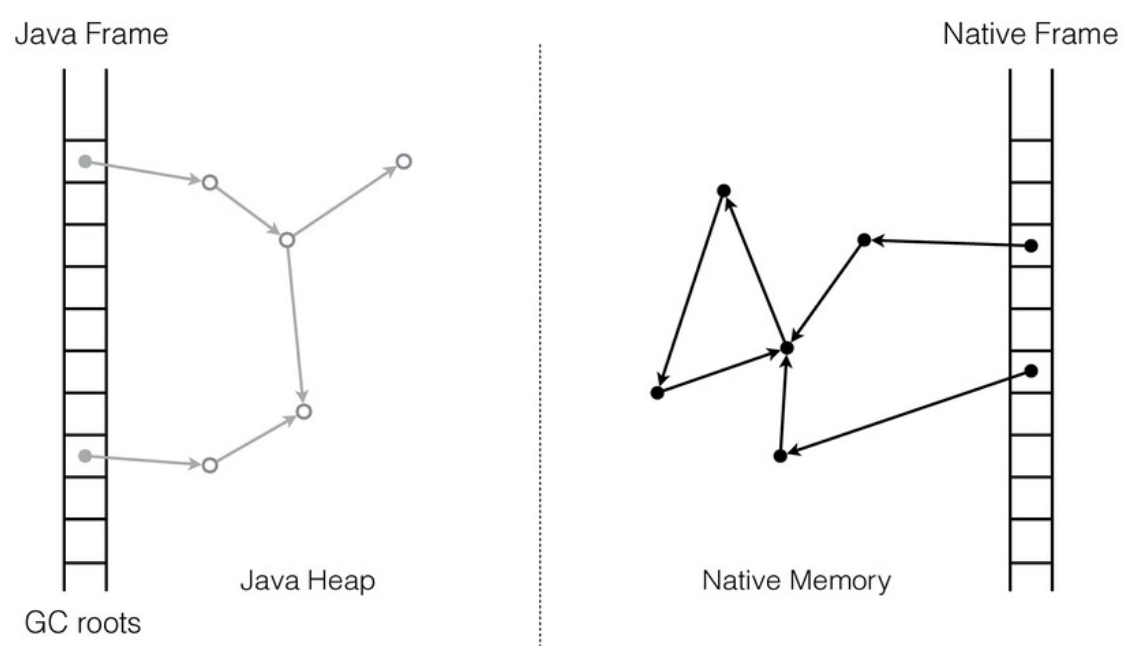
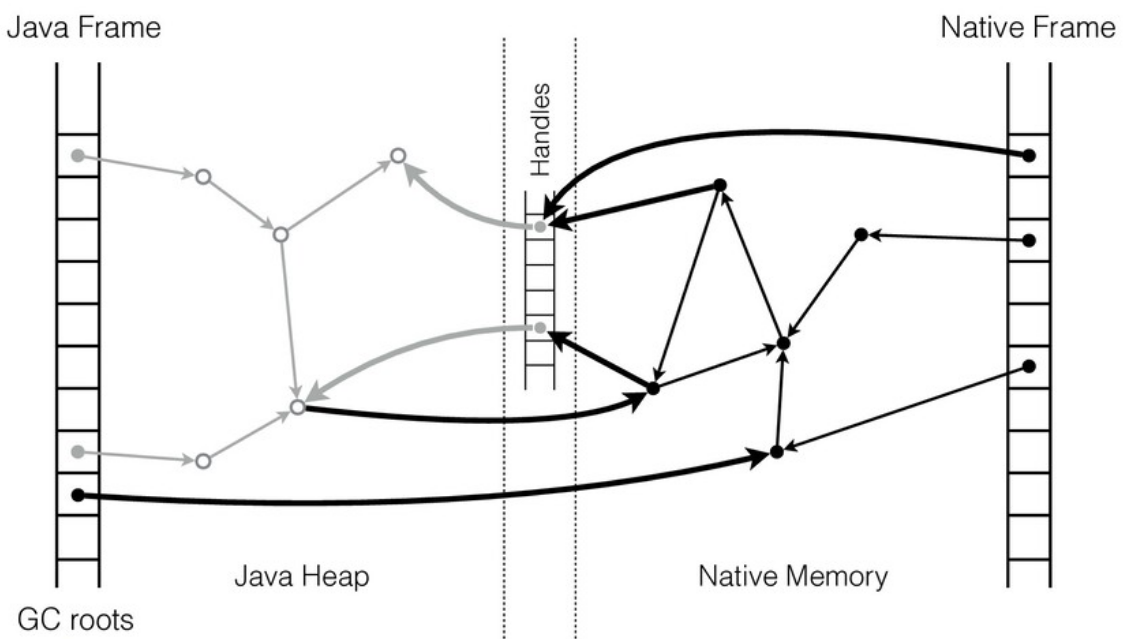
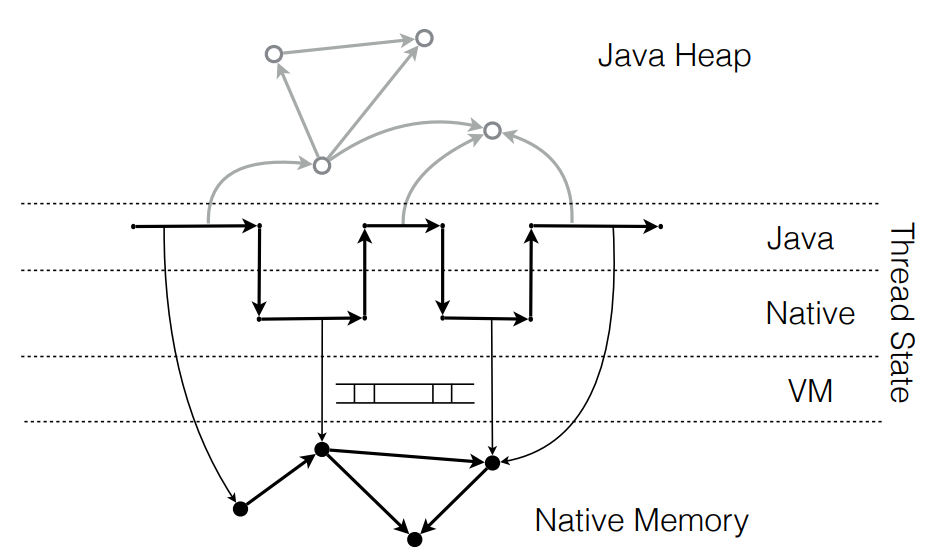
У native-кода есть своя область памяти и свои структуры данных. Java-код работает с Java-кучей. Если мы хотим, чтобы Java и native-код взаимодействовали, нам нужно найти способ ссылаться из одной области в другую. Т.е. native-код должен иметь возможность работать с Java-кучей, а Java-код — с native-кучей.
Какие тут могут быть проблемы? В native-коде указатели «стабильны», сами по себе, без ведома работающего с ними кода они не меняются. А Java-куча управляется сборщиком мусора (GC): объекты могут перемещаться по мановению волшебной палочки. Иными словами, в процессе освобождения памяти сборщик мусора вправе перемещать любой объект в памяти и все указатели на него должны быть корректно обновлены. По дизайну такая операция абсолютно прозрачна для Java-кода и им никак не контролируется.
Для памяти вне Java-кучи обновления не нужны, потому что структуры данных не двигаются. А если извне есть ссылки в Java-кучу, такого рода изменения нужно учитывать и обрабатывать.
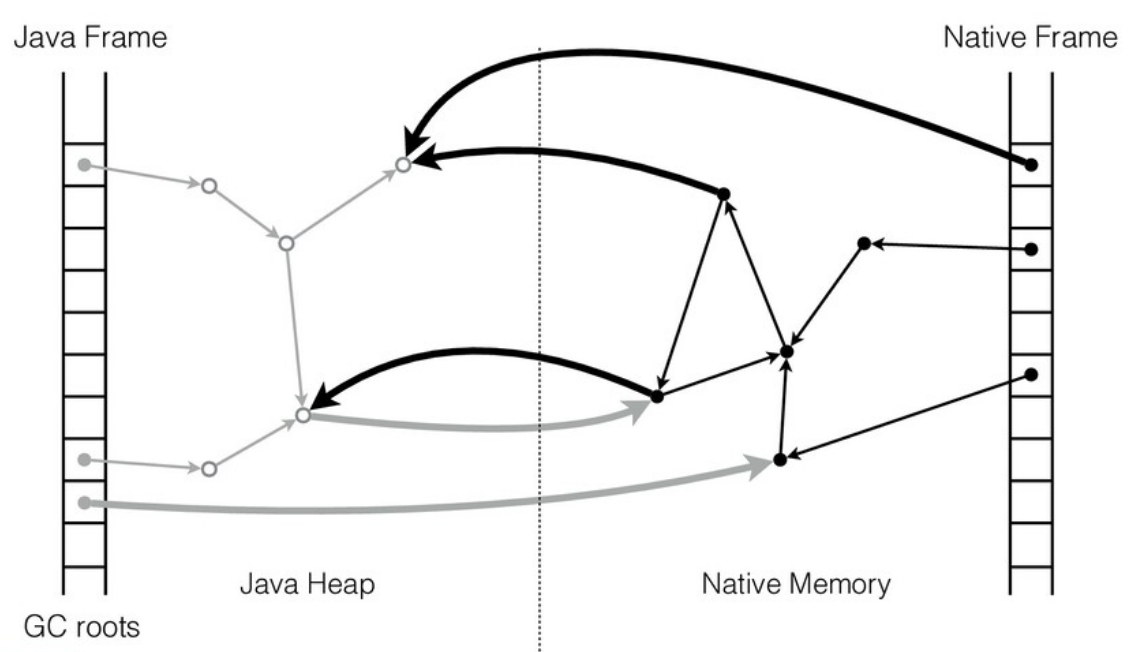
Одно из решений — это фиксирование положения объекта в Java-куче (object pinning), но это накладывает серьезные ограничения на реализацию GC и с точки зрения производительности имеет ряд неприятных последствий.
Альтернативный подход (который используется в JNI) заключается в работе с Java-объектами через таблицу стабильных указателей (handles), про которую знает GC.
При перемещении объекта сборщик мусора обновляет соответствующий слот таблицы, и native-код начинает работать с новым адресом. Но это требует определенных изменений на стороне native-кода: нельзя просто добавить дополнительный уровень косвенности без его ведома, требуется координация с GC.
В общих чертах дизайн взаимодействия native-кода и Java-кода на уровне данных выглядит следующим образом:
JNI появился практически сразу, начиная с версии 1.1 (технически API присутствовал и в 1.0, но не был частью стандарта.)
С точки зрения разработчика взаимодействие с JNI выглядит следующим образом:
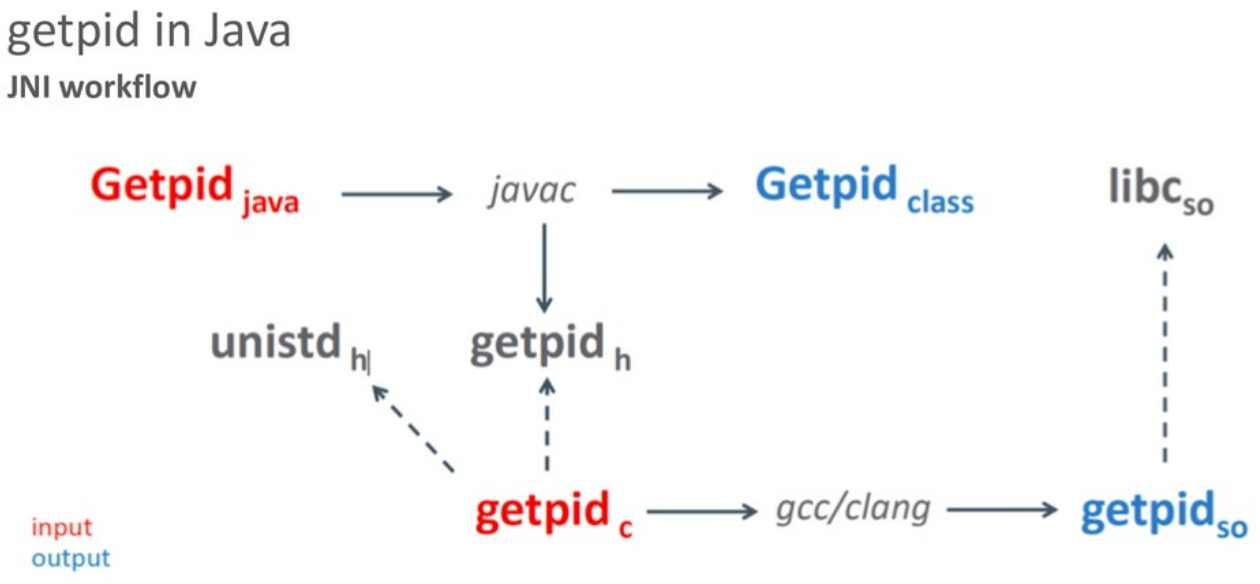
В Java-коде специальным образом (ключевое слово «native») объявляются методы и javac (java compiler) создает class-файл и header-файл. На основе header разработчик вручную пишет реализацию native-функций, компилирует с помощью компилятора С/C++ и получает на выходе готовую библиотеку. Таким образом получаем class-файл и библиотеку.
Для примера давайте посмотрим, как это выглядит на простом примере getpid — native-функции, которая не принимает никаких аргументов, а возвращает идентификатор текущего процесса.

Про JNI говорят много нехороших вещей, но, тем не менее, это оказался очень мощный API, предоставляющий богатый набор примитивов для взаимодействия
Например, вызов Java-метода:
Или доступ к полю в Java-объекте:
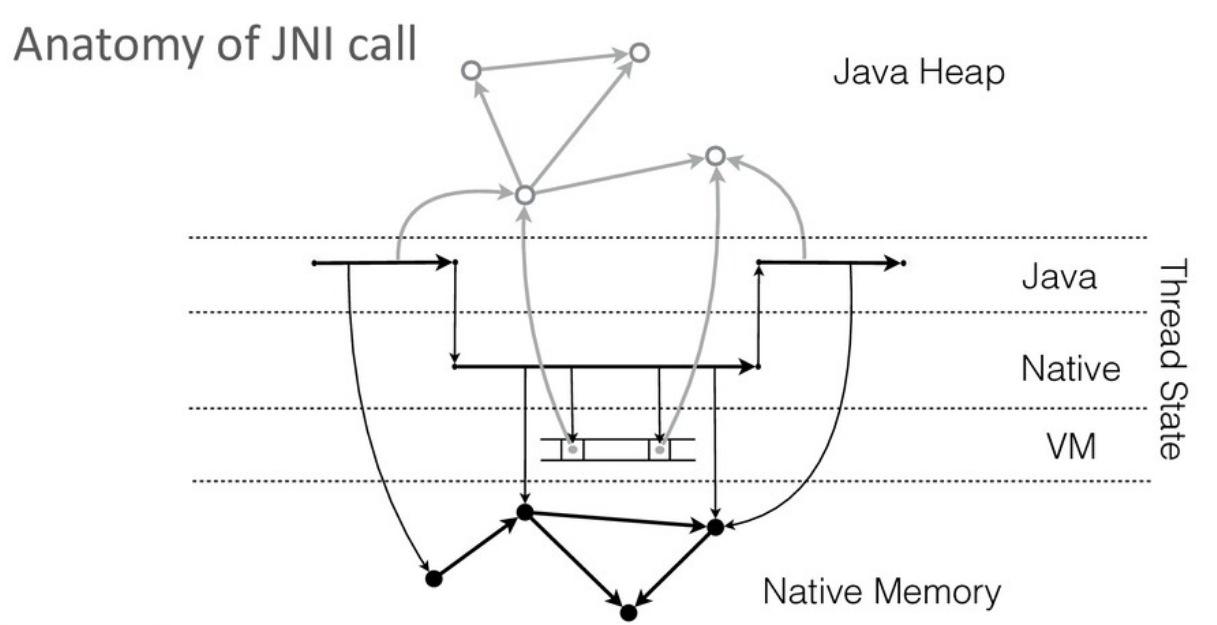
C точки зрения реализации, виртуальной машине полезно различать вызовы Java-кода, исполнение которого она полностью контролирует, и вызов native-кода, контроль которого в общем случае невозможен (за исключением строго определенных мест). Для JVM вызов native-кода — это «черный ящик».
Для стабильной работы виртуальной машине требуется иметь возможность оперативно остановить работу приложения в любой момент. Для этой цели JVM в сгенерированном коде выбирает и помечает места, в которых исполнение может быть безопасно остановлено (т.н. safe point).
В Java-коде виртуальная машина может эти точки расставлять по своему усмотрению. Поскольку у JVM нет возможности модифицировать native-код, при его вызове поток автоматически уходит в safe point (на всем протяжении вызова).
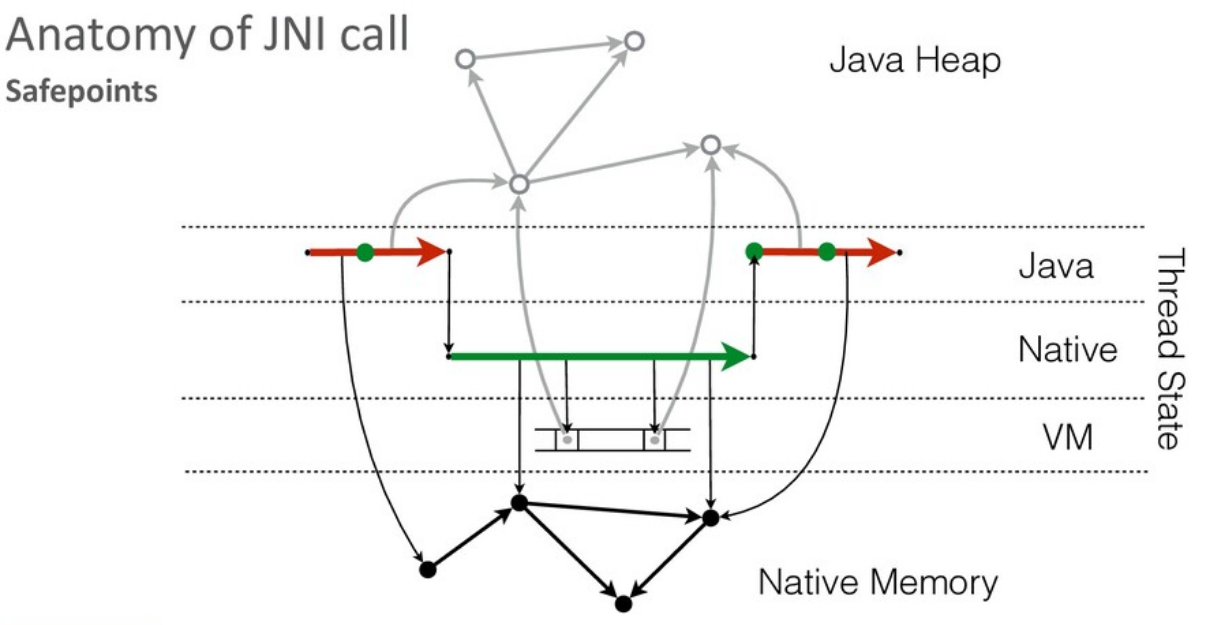
Инициируя safe point, виртуальная машина ждет остановки всех потоков, исполняющих Java-код, но это не относится к потокам, исполняющим native-код. Native-код может продолжать исполняться параллельно с работой сборщика мусора.
Подводя итоги:
Со временем реализация JNI в HotSpot была расширена. Например, появился Critical JNI.
Посмотрим на простой пример:
Предположим, у нас есть метод, в который в качестве параметра передается ссылка на массив из Java-кучи. Через JNI мы хотим получить доступ к содержимому этого массива. Сначала требуется узнать его длину, потом взять указатель на начало и только после этого можно начинать работать с данными.
Для небольших массивов эти два вызова через JNIEnv дают запредельный рост накладных расходов: по сравнению с вызовом пустого метода через JN, накладные расходы увеличиваются на порядок!

Связано это с тем, что, находясь в native-контексте, каждое обращение через JNIEnv требует проверки текущего состояния JVM (safepoint check). Иначе, например, может оказаться, что в это же время сборщик мусора куда-то передвигает наш массив.
Critical JNI решает эту проблему для примитивных массивов: JVM в процессе вызова извлекает всю нужную нам информацию (длина + указатель) и явно передает их в качестве аргументов.
Получаем существенную экономию. Наиболее ярко она проявляется для маленьких массивов, так как на больших объемах данных объем работы обычно доминирует над накладными расходами на вызовы.

У Critical JNI есть ряд ограничений. Это всего лишь небольшая надстройка (не являющаяся частью публичного API), которая не решает общих проблем самого JNI.
Как было отмечено выше, JNI — «Java-центричный» интерфейс. Как нам вызвать native-код, представления о вызовах в котором серьезно отличаются от Java? Например, printf:
На стороне Java-кода мы можем представить vararg-аргумент в виде Object[], но придется вручную взять все аргументы, распаковать их при необходимости, разложить на стек в соответствии с системным ABI и только после этого вызвать native-функцию. Написать JNI-«обертку» для printf вручную крайне непросто.
Следующий вопрос: что делать с вызовами из native-кода обратно в Java? Классический пример — qsort:
qsort получает в качестве аргумента указатель на функцию, используемую при сравнении элементов. Native-код делает вызов по указателю и передает необходимые аргументы, а мы хотим, чтобы в итоге исполнился Java-код. Как это сделать с помощью JNI? Однозначно нетривиально.
JNR решает часть проблем. JNI фактически ограничивался инструментами, предоставляемыми виртуальной машиной. Все остальное нам нужно было делать вручную. JNR поднимает все взаимодействия на уровень Java-кода.
Т.е. пользователю для getpid вообще не нужно больше писать native-код: набросал интерфейс, добавил аннотаций, и библиотека все делает за нас. И это неплохо работает.
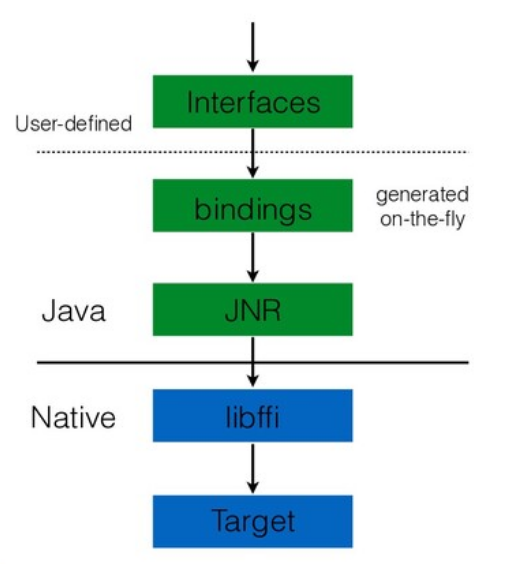
Как я упоминал, JRuby использует JNR для взаимодействия с платформенными библиотеками. Преимущество JNR — автоматическое связывание native-методов. Пользователю не надо писать native-код. Все «грязную» работу за него делает библиотека. Среди недостатков я бы выделил этап ручного написания интерфейса. Он не очень хорошо масштабируется. На практике библиотеки имеют достаточно обширный интерфейс, и его перевод на Java требует существенного объема. Кроме того, JNR — это библиотека, которая все равно базируется на JNI. Как говорил Charles Nutter, мы не можем быть быстрее JNI, хотя в некоторых случаях нам бы этого очень хотелось.
Можем ли мы в новом проекте быть быстрее JNI?
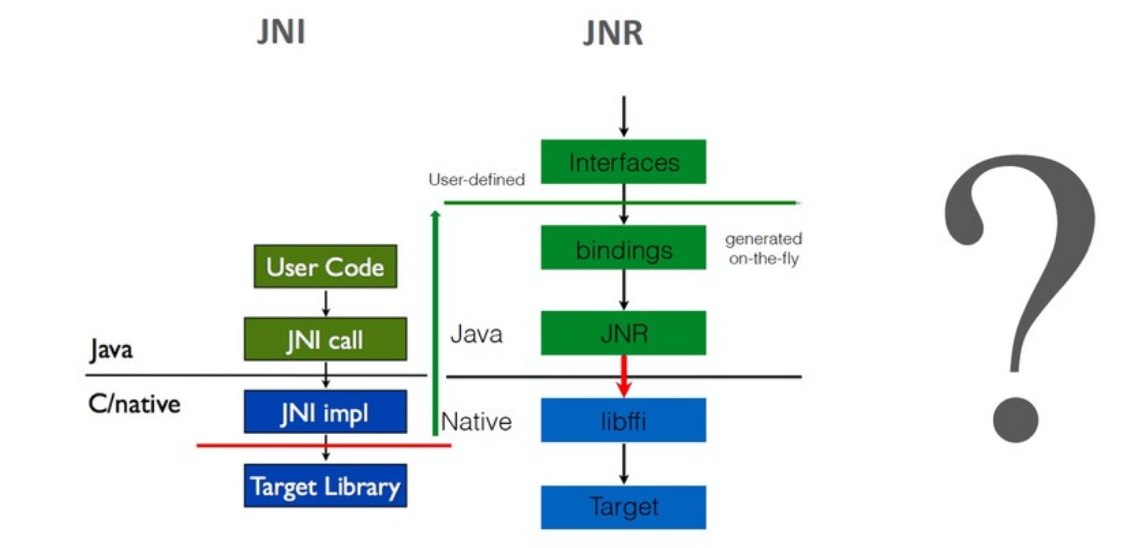
Выше я уже упоминал, что написание интерфейса для реальных библиотек крайне трудоемко. А миграция на новые версии становится еще более трудоемкой, сопоставимой с написанием интерфейса с нуля. В качестве примера рассмотрим популярную библиотеку TensorFlow:

C-интерфейс, который считается стандартом де-факто, актуален. У TensorFlow есть также Java-интерфейс, но он предоставляет ограниченный набор функциональности.
В цифрах C-интерфейс — это порядка 250 сущностей, которые нужно не только написать, но и «обернуть» аннотациями. Если вы что-то сделаете неправильно, скорее всего, вы получите труднодиагностируемую ошибку в процессе исполнения (crash), либо, что еще хуже, некорректный результат.
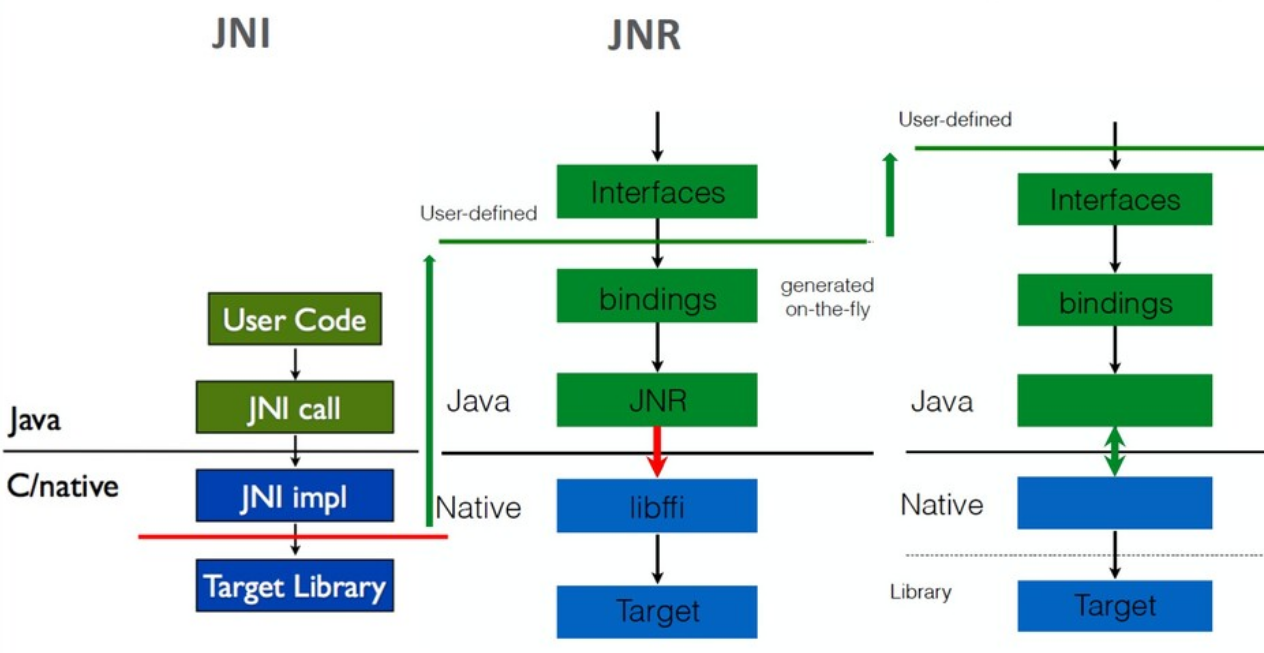
При миграции на новую версию вам нужно отследить все изменения в интерфейсе библиотеки и внести адаптировать Java-интерфейс. Даже ограниченный объем Java API, который предоставляет TensorFlow, — это уже более 10 тыс. строк native-кода и Java-кода. Поэтому имеют практический смысл более высокоуровневые механизмы работы с библиотеками. Так мы можем упростить работу с платформенными библиотеками для разработчика.
JNI нам мешает далеко не во всех случаях. Зачастую он достаточно быстр для большинства сценариев. Но вот вручную описать интерфейсы крайне трудозатратно.
Работа над FFI началась в конце 2014 года и активно развернулась в 2015.
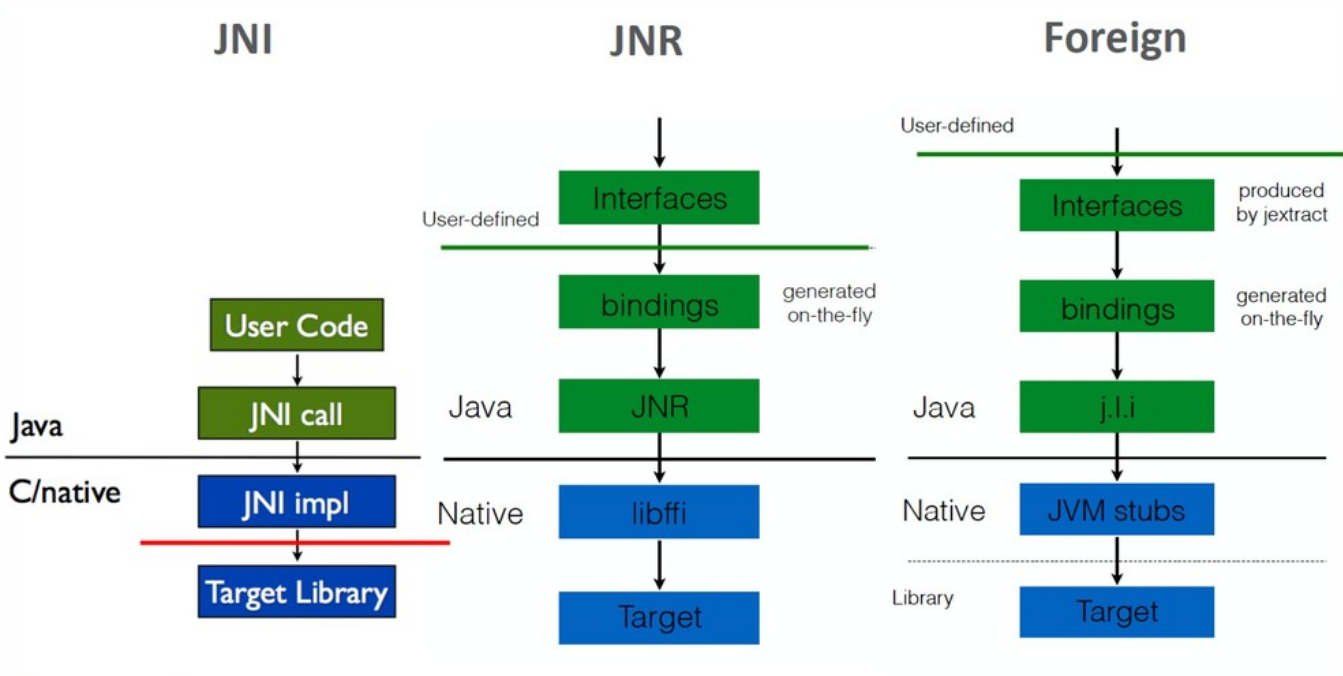
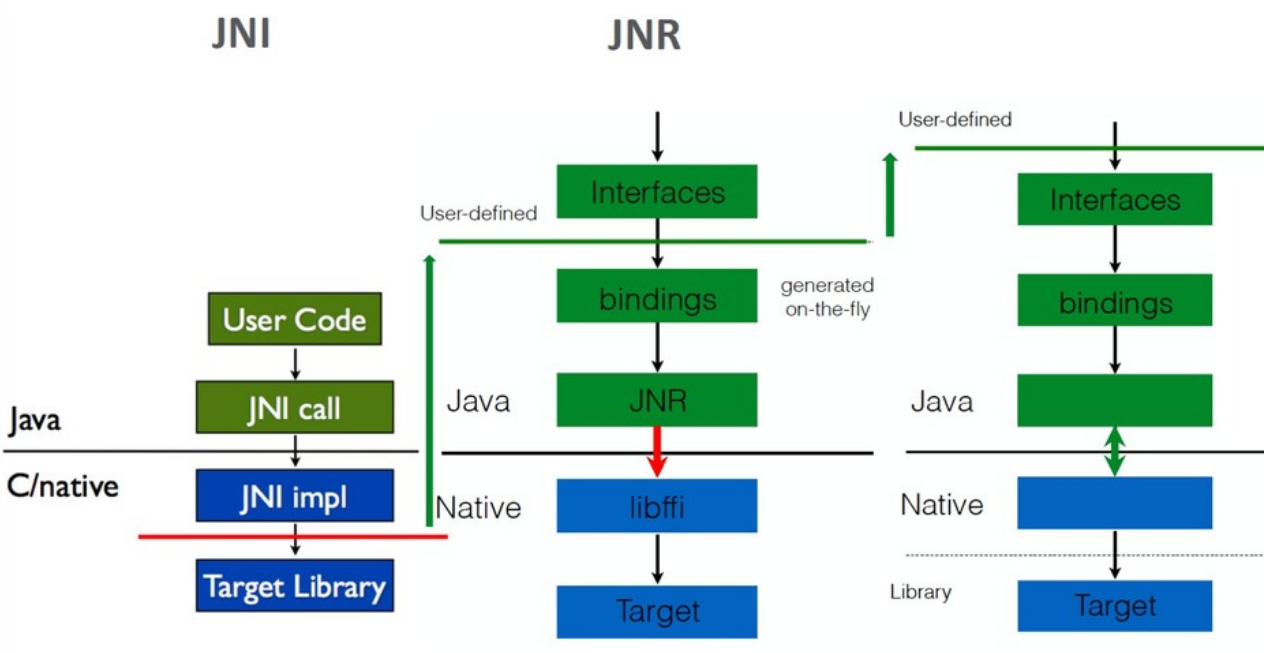
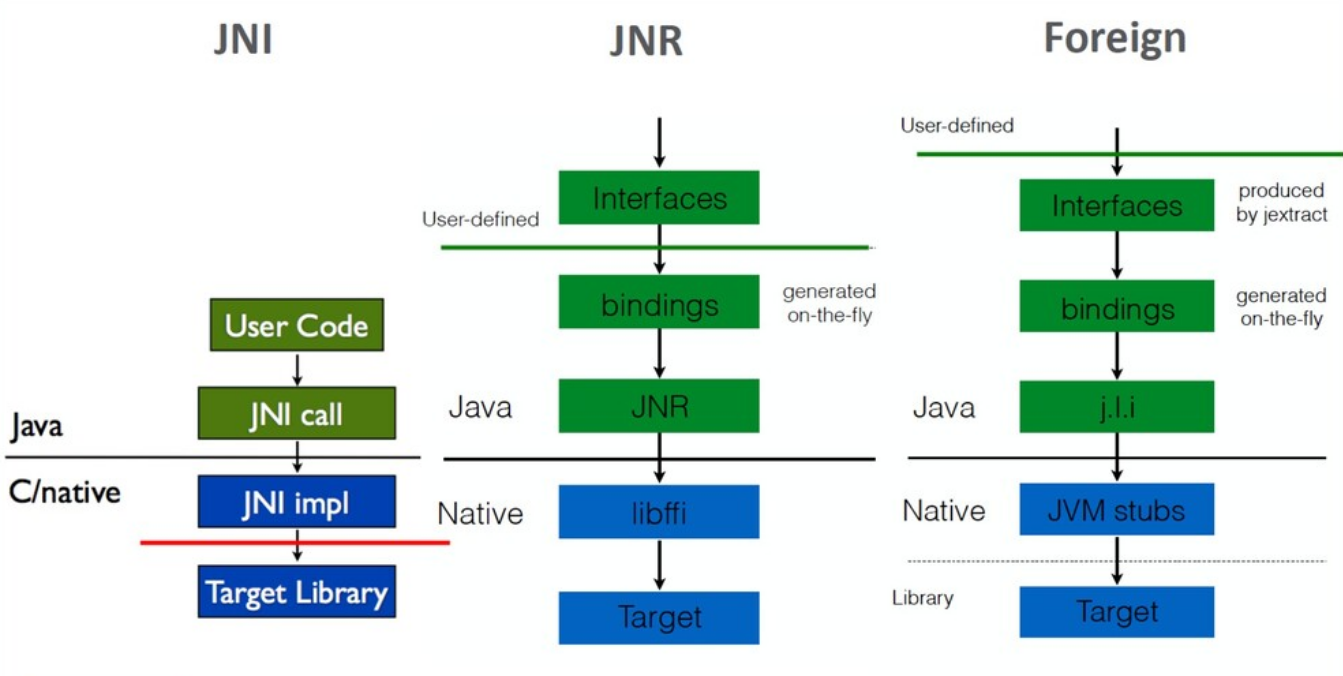
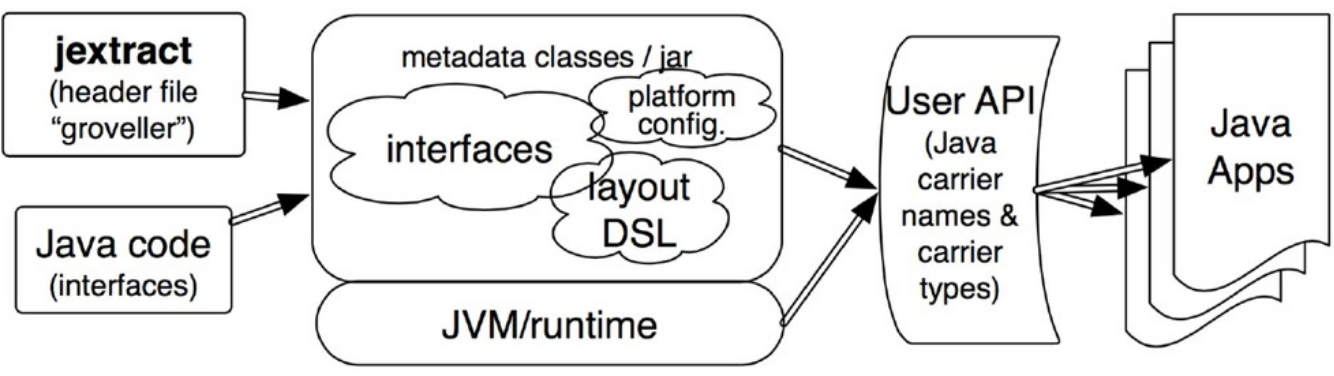
Результатом этой работы стало появление нового инструмента jextract, который на основе header-файла библиотеки автоматически создавал все необходимые интерфейсы. Т.е. в процессе разработки мы можем взять header-файл, извлечь из него интерфейсы, написать свое Java-приложение с использованием этих интерфейсов, скомпилировать и запустить. А все связывание интерфейсов с соответствующими частями native-библиотеки происходит «на лету» — в процессе исполнения. Нужные реализации создаются на основе мета-информации, собранной jextract.
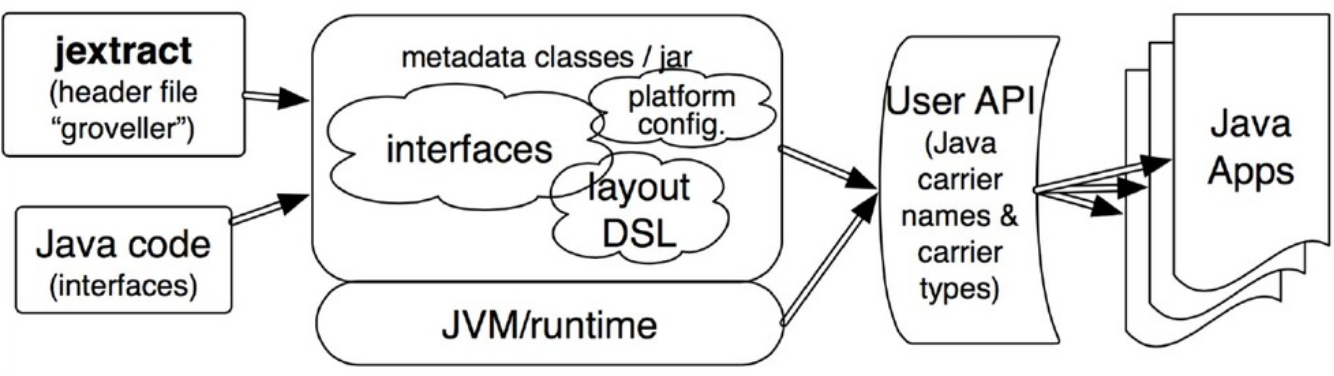
Рассмотрим это на примере getpid — аналога «hello world» для native-кода.
Для unistd.h jextract создает Java-интерфейс unistd (.h -> .class):

В аннотациях содержится вся необходимая информация, чтобы в процессе исполнения можно было найти и вызвать нужную native-функцию, а потом обработать возвращаемый результат. Все происходит автоматически: jextract генерирует интерфейс, а во время исполнения по нему создается реализация. Разработчику ничего не требуется делать.
Использовать это можно следующим образом:
Загружаем библиотеку и получаем реализацию ранее созданного интерфейса на её основе. unistd — это интерфейс, который jextract «извлек» из unistd.h. В итоге мы получаем объект, через который можем вызывать функции, объявленные в unistd.h.
Native-библиотеки содержат код, но на практике взаимодействие с ним подразумевает передачу данных. Поэтому вместе с jextract был добавлен новый API для работы с данными. Также появился класс Pointer, который представлял собой «типизированный» указатель: адрес плюс тип хранимого значения.
Класс Pointer предоставляет набор базовых операций: cast (привести к другому типу), offset (смещение указателя на константу), get/set (чтение/запись по адресу). По сути получился указатель в терминах C.
Также, в дополнение к Pointer, API содержит специальный класс Array, который представляет массив фиксированной длины. В принципе в C массивы — это просто синтаксический сахар поверх обычных указателей. Но есть ряд тонких различий, что и мотивировало появление новой сущности.
Для управления ресурсами появился класс Scope, представляющий некоторый контекст. Освобождение ресурсов происходит при закрытии контекста (Scope.close()), и try-with-resources позволяет удобно с ними работать в лексическом контексте: при выходе из контекста все использованные в данном контексте ресурсы будут автоматически освобождены. Кроме того, каждый Pointer «привязан» к некоторому Scope. На каждый доступ по указателю осуществляется проверка, не закрыт ли соответствующий Scope. Иначе бросается исключение, сигнализирующее ошибку доступа.
В этом примере мы передаем Java-строку в native-код. Поскольку представление строки в Java и native-коде различаются, требуется конвертация и— Scope предоставляет такую возможность (allocateCString()).
К 2018 году проект пришел в достаточно стабильное состояние. Был опробован ряд популярных библиотек, с которыми новые инструменты работали без особых проблем. Понятно, что не все было идеально, но это был период активного экспериментирования: каковы должны быть ключевые сценарии использования.
В таком контексте полученный результат был очень даже хорош. С точки зрения удобства использования это был гигантский шаг вперед по сравнению с JNI и существенное улучшение на фоне JNR.
Но если смотреть на проект как на пирамиду, то результат получился монолитным.
Не было четкого разделения на базовые и вспомогательные компоненты. Не было новых низкоуровневых платформенных API, которые можно было бы использовать, к примеру, в сторонних библиотеках (например, для поддержки C++ в JavaCPP).
Всё, за исключением jextract и Pointer API, было деталью реализации.
Это накладывало серьезные ограничения на дальнейшие шаги: если ставить вопрос об интеграции в JDK, то получалось «либо все, либо ничего».
John Rose (JVM Architect) в обсуждениях описал это так: «мы пытались получить все сразу, в случайном порядке, не выстраивая четкую пирамиду».
Наконец, пришло время структурировать дальнейшую разработку. В результате произошло разделение: jextract оформился как самостоятельный высокоуровневый инструмент, базирующийся на двух низкоуровневых платформенных API:
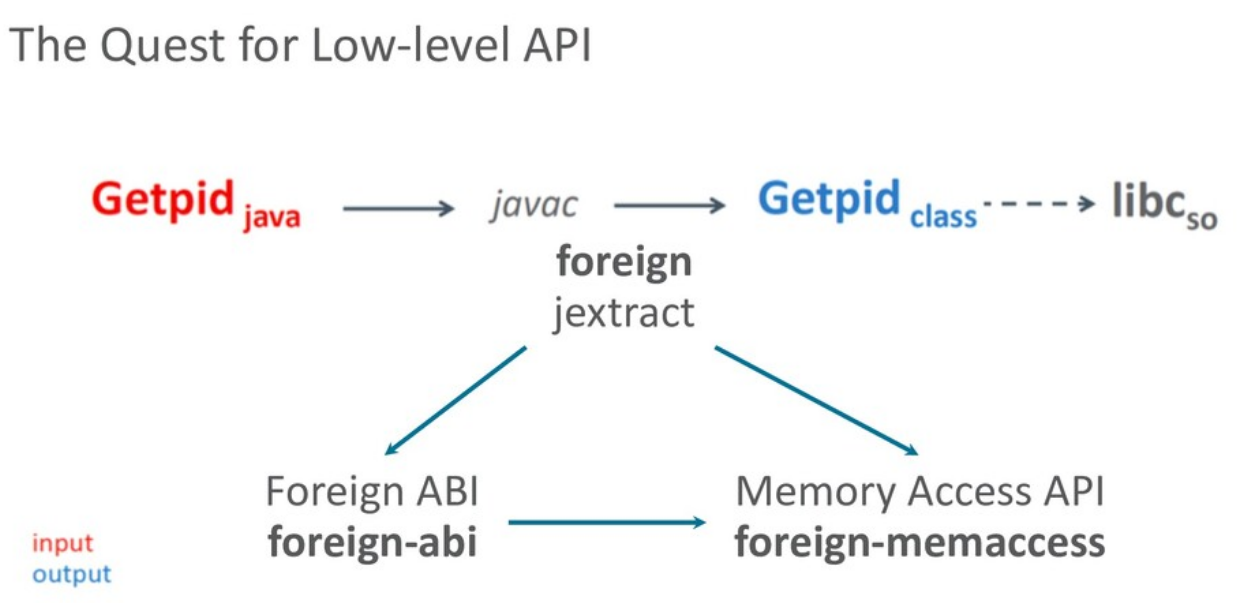
С точки зрения разработчика сценарий использования jextract остался прежним:
jextract на основе header-файла создает Java-интерфейс, а затем разработчик уже компилирует его как часть своей программы.

Но в новой реализации jextract генерирует не просто интерфейсы, а уже интерфейс с полной реализацией. Если заглянуть в unistd_h.java, то мы увидим там не просто интерфейс с аннотациями, как раньше, а реальный код, который исполняется и делает все то же самое, что раньше генерировалось на этапе исполнения.
Рассмотрим, каким образом данная реализация вызывает getpid:
Реализация базируется на новом типе MethodHandle (NativeMethodHandle) и расширяет существующий java.lang.invoke API.

«Making native calls from the JVM», John Rose
В Java 7 в байт-код JVM была добавлена новая инструкция — invokedynamic, и вместе с ней появился новый java.lang.invoke API для работы с методами на уровне Java-кода. С точки зрения реализации java.lang.invoke, взаимодействие с native-кодом не сильно отличается от взаимодействия с Java-кодом, т.е. нам не составляет большого труда добавить поддержку native-функций.
Интерфейс между JVM и Java-кодом — это MethodHandle.linkToNative, специальный метод-адаптер, которому, наряду с аргументами функции, передается и адрес вызываемой native-функции (native entry point).
Посмотрим на это с точки зрения производительности. В машинном коде, сгенерированном JIT-компилятором JVM, вызов через MethodHandle был оптимизирован в прямой вызов:
Фактически мы получили то, о чем просил Charles Nutter.
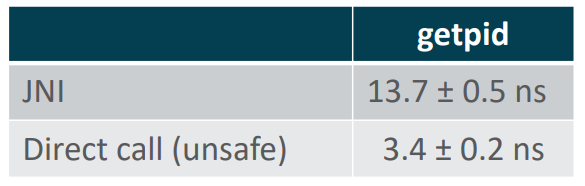
Если через JNI мы тратим на вызов getpid 12 — 13 нс, то при должной поддержке JIT-компилятора мы можем этот linkToNative call превратить в прямой вызов entry point. Понятно, он будет небезопасен. Но мы ранее обсуждали какие шаги делает JVM при вызове native-код: поток переводится в специальное состояние и с точки зрения виртуальной машины не должен быть остановлен при переходе в safe point.
А при прямом вызове этого работа не происходит. Соответственно, JVM будет думать, что поток исполняет Java-код и ждать его остановки.
Такая оптимизация работает для простых случаев вроде getpid. Но в более сложных ситуациях возможны проблемы. Например, если у вас есть блокирующий вызов внутри native-кода, JVM может просто «зависнуть», т.к. будет ожидать остановки потока, который заблокирован на неопределенное время.
И блокировки — не единственный источник проблем: в области сборщиков мусора с низким временем отклика (low latency GC) минимальные гарантированные паузы JVM были серьезно сокращены. Работа касалась не только GC, но и всей JVM, так что теперь можно гарантировать паузы порядка десятков миллисекунд, а говорить и о интервалах менее 1 миллисекунды. А за это время JVM должна не только достичь безопасного состояния, но и выполнить всю необходимую работу, чтобы не нарушить гарантии на паузы.
Мы рассмотрели подход с методом-адаптером linkToNative. Но параллельно разрабатывался альтернативный механизм — т.н. Universal Adapter. Это полностью программируемый API, который позволяет описывать произвольные native-вызовы.
У обычных Java-методов сигнатура фиксирована: в месте объявления метода четко описано, аргументы какого типа они принимают и результат какого типа возвращают. Для нужд java.lang.invoke и MethodHandle API этого недостаточно. Требуется через единый интерфейс иметь возможность вызывать любой метод. Из обычного Java-кода этого сделать нельзя, поэтому в спецификацию языка и платформы были добавлены так называемые signature-polymorphic методы, у которых может быть произвольная сигнатура (определяется в месте использования).
Проблема с linkToNative, который также является signature-polymorphic, в том, что его поведение описывается Java-сигнатурой. Предположим, мы хотим описать native-функцию с переменным числом аргументов (varargs). Нам потребуется описать, как именно в стеке располагаются параметры, что сделать в терминах Java-сигнатур теоретически возможно, но крайне неудобно. Другими словами Java-сигнатуры хороши для описания вызовов Java-методов, а для varargs нам лучше изъясняться в терминах C (или даже ABI платформы).
Universal Adapter API решает эту проблему. Он представляет из себя низкоуровневый механизм для описания состояния стека и регистров до и после вызова. Фактически Universal Adapter в качестве аргументов получает полное состояние регистров и вершины стека, а после возврата из вызова обрабатывает результат.
Хотя Universal Adapter — это очень мощный механизм, он плохо подходит для оптимизации JIT-компилятором. JIT-компилятору требуется много низкоуровневых деталей о вызове, чтобы подобрать оптимальный код. Так что с точки зрения производительности Universal Adapter оказался на порядок медленнее JNI.
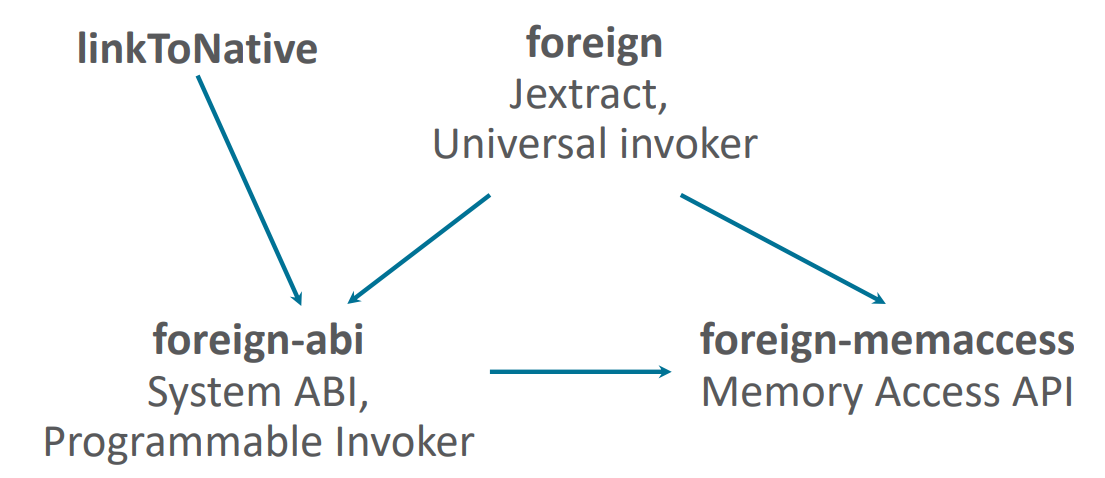
Описанные два подхода (linkToNative и Universal Adapter) не конкурируют, а взаимно дополняют друг друга. В идеале хотелось бы всегда демонстрировать максимальную производительность. Но, с практической точки зрения, имея возможность вызвать любой код, целесообразно сфокусироваться на оптимизации некоторых популярных случаев. Например, мы оптимизируем в JIT-компиляторе 90% наиболее часто используемых случаев, а для корректной работы остальных 10% будем использовать более простой альтернативный механизм, но пожертвовав скоростью вызова.
На текущий момент унифицировать linkToNative и Universal Adapter возможности нет, т.к. они предоставляют два абсолютно разных API. Нельзя в процессе работы с конкретным MethodHandle выбрать, какой интерфейс использовать. Это требуется указать в момент создания MethodHandle. Поэтому работа, которая идет сейчас в проекте, направлена на унификацию интерфейса между двумя механизмами. Цель — иметь возможность в момент JIT-компиляции выбрать конкретный механизм реализации вызова: есть ли возможность оптимизировать вызов или целесообразнее воспользоваться универсальным адаптером?
Далее я еще расскажу про вызовы из native-кода в Java-код (upcall), а пока переключимся на Memory Access API.
Memory Access API — это низкоуровневый, безопасный и в то же время эффективный API для доступа в память (как в Java-кучу, так и вне её). Он пришел на смену Pointer API как интерфейс взаимодействия с данными и больше не завязан на семантику языка C.
API предоставляет четыре ключевые абстракции:
Ключевой особенностью нового API является безопасность его использования. В отличие от sun.misc.Unsafe, новый API не должен допускать критических ошибок, ведущих к прекращению работы всей JVM. Вместо этого в случаях неправильного использования ошибки должны оставаться на уровне приложения или приводить к исключительным ситуациям (с возможностью их перехвата и обработки).
Например, при доступе к данным из многих потоков без должной синхронизации можно получить ошибки именно на уровне логики приложения (при чтении семантически некорректного значения или при неправильной интерпретации данных). С точки зрения среды исполнения это приводит к остановке всего Java-процесса.
В процессе исполнения Memory Access API предоставляет две ключевые гарантии.
Во-первых, контроль времени жизни ресурсов. Гарантируется, что память, к которой осуществляется доступ, все еще доступна. После закрытия соответствующего MemorySegment объекта память может быть освобождена, но все попытки получить к ней доступ приведут к исключительным ситуациям.
Во-вторых, для каждого обращения происходит проверка границ доступа. Попытка доступа вне границ сегмента также приведет к исключительной ситуации.
Разберем простой пример (в комментарии приведет эквивалентный код на C):
В примере объявляется массив из пяти элементов. Каждый элемент — это структура из двух элементов типа int (две координаты). Затем, перебирая элементы массива, в x-координату записывается определенное значение.
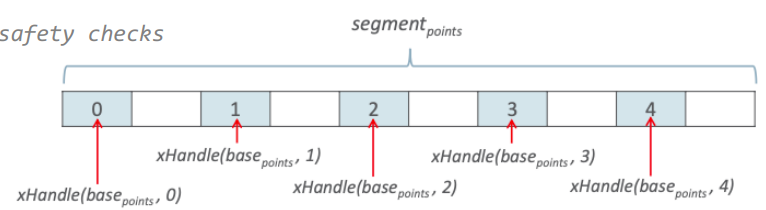
Чтобы написать эквивалентный код на основе Memory Access API, мы начинаем с того, что конструируем VarHandle, осуществляющий доступ к x-компоненте в i-ом элементе массива. В дальнейшем мы просто переиспользуем этот VarHandle. На вход он получает индекс элемента в массиве и записывает в него значение, переданное в другом аргументе.
VarHandle были добавлены в Java 9, и они очень похожи на MethodHandle. Есть даже возможность конвертировать VarHandle в эквивалентный MethodHandle. Но, по сравнению с MethodHandle, VarHandle API получился чуть выше уровнем и явно предоставляет 4 типа доступа к памяти.
В итоге мы имеем VarHandle объект, реализующий индексированный доступ к элементам массива. На основе комбинаторов для MemoryAddress можно строить достаточно сложные вычисления смещения.
После выхода у нас память освобождается за счет try-with-resources. Даже если созданный MemorySegment каким-либо образом покинет лексический контекст, он будет неявно закрыт при выходе из него. Любые попытки последующего доступа будут завершаться исключением. Т.е. проблема доступа к ресурсу после его освобождения (use after free) решена с помощью дополнительной проверки в процессе исполнения.
Memory Access API предоставляет возможность декларативно описывать раскладку структур данных в памяти. До этого, как мы видели в примерах, jextract добавлял специальные аннотации, в которых раскладка кодировалась с помощью специального языка (LDL = Layout Definition Language). LDL был построен на строках, и описания получались достаточно компактными, но достаточно неудобными для написания и последующего чтения.
На смену LDL пришел MemoryLayout с эквивалентной функциональностью:
Теперь
Структура — группа из двух элементов, каждый размером 32 бита — описывается с помощью MemoryLayout.ofStruct. Для удобства элементы структур можно именовать.
Это упрощает создание VarHandle на основе такого описания:
На основе такой раскладки с именованными полями можно получить тот же самый VarHandle в гораздо более наглядном виде.
К слову, Memory Access API уже доступен в JDK (как incubator модуль) начиная с 14 версии.
Ранее мы рассматривали сценарий работы с native-кодом из Java. Но иногда библиотека ожидает указатель на функцию в качестве параметра (callback), а мы хотим, чтобы вызван был Java-код. В контексте FFI это называется upcall.
«Hello world» для upcall — это qsort.
Фактически на каждое сравнение будет вызвана специальная функция сравнения значений, которая в C API передается в виде указателя на функцию. Но конструируя интерфейс для qsort, мы хотим оперировать в терминах языка Java. В этом случае jextract автоматически создаст для нас функциональный интерфейс (stdlib_h.qsort$__compar). Его можно явно реализовать, но в примере используется лямбда-выражение. На вход передается два MemoryAddress, из них нам нужно считать значения, сравнить и вернуть результат.
В примере просто возвращается разница значений. У нас есть объект, реализующий данный интерфейс. Но мы не можем передать результат в native-код напрямую. Native-код ожидает указатель, а в нашем случае это виртуальный вызов через Java-интерфейс. Нам нужно предварительно каким-то образом преобразовать объект в адрес, чтобы native-код может осуществить вызов. jextract помогает и в этом случае. Он добавляет специальный метод, возвращающий адрес, который мы можем использовать для вызова.
Как это выглядит в терминах Foreign ABI:
Здесь мы изначально создаем интерфейс, конструируем MethodHandle на метод в интерфейсе (для чего — увидим чуть позже):
Создаем MethodHandle для qsort:
Теперь описываем реализацию сравнения:
Здесь для простоты используем лямбда-выражения. Лямбда-выражения в Java представляются в виде объектов, реализующих некоторый функциональный интерфейс. Теперь нам нужно превратить объект в указатель (MemoryAddress) для передачи в native-код:
System ABI предоставляет такую возможность через upcallStub(). Фактически возвращается указатель на кусок машинного кода (stub), подготовленного JVM, который переводит поток в контекст исполнения Java-кода и вызывает MethodHandle, определенный при создании. Этот указатель native-код может использовать как указатель на функцию.
java.lang.invoke API поддерживает Java-семантику во всей её полноте, и использование MethodHandle позволяет нам делегировать исполнение в произвольный Java-код. Таким образом upcallStub() преобразовал вызов некоторого MethodHandle’а в указатель, т.е. для native-кода он выглядит как обычный указатель на функцию, а внутри происходит сложный процесс подготовки к исполнению Java-кода. Теоретически это можно сделать и с JNI, но придется все сделать вручную.
Теперь у нас есть возможность вызвать qsort:
Давайте теперь сравним производительность:
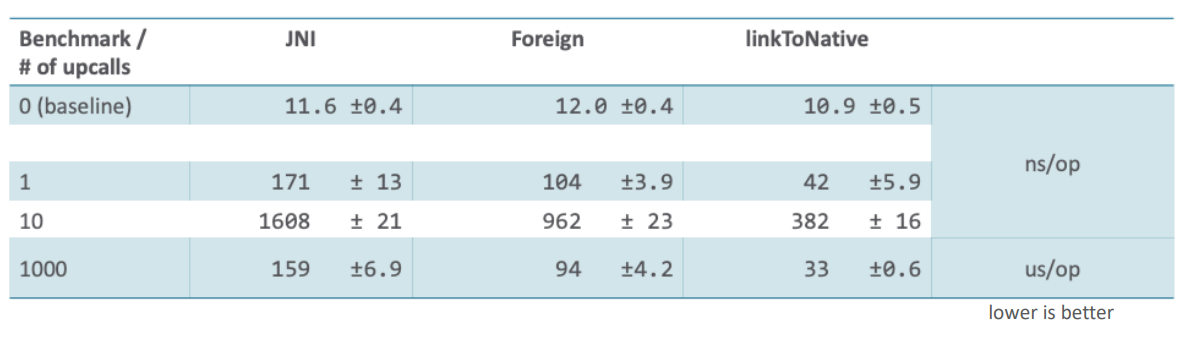
Первое, что бросается в глаза, это сравнительно низкая скорость вызова через JNI.
Как оказалось, режим вызова Java-кода через JNI не привлекал достаточного внимания JVM-инженеров и реализация может быть легко ускорена в разы за счет применения схемы со специальными адаптерами (по аналогии с вызовами native-кода из Java).
Эксперимент был проведен для linkToNative, потому что на тот момент все эксперименты с оптимизацией шли с реализацией на его основе. В Foreign на тот момент была своя реализация вызовов. Это не Universal Adapter, это своеобразный «небезопасный JNI», основанный на переиспользовании адаптеров для ситуаций с одинаковым представлением на уровне ABI. В JNI используются Java-типы (int, long, etc). А на уровне ABI аргументы типизированы на уровне регистров (integral, floating point) и значение занимает целый регистр. То есть, например, адаптеры для Java-сигнатур с параметромом типа int и long на Linux x64 (System V ABI) различаться не будут.
Вышеописанная схемы была использована (в foreign ветке) для вызовов native-кода из Java. Похожая схема применялась и для вызовов в обратную сторону. Она оказалась быстрее JNI, но не настолько, как специализированный адаптер.
Также на реализацию JNI влияет специфика HotSpot JVM.
В HotSpot в процессе исполнения одновременно могут использоваться интерпретатор и несколько JIT-компиляторов. Виртуальная машина свободно переключает исполнение между разными режимами. Для этого во внутреннем представлении каждого Java-метода хранятся два указателя на код, который должен исполняться: когда вызов приходит из интерпретатора (from interpreter entry) и когда вызов приходит из кода, сгенерированного JIT-компилятором (from compiled code entry).
Причина для этого следующая: соглашения о вызовах (calling conventions) существенно различаются между кодом, исполняемым в интерпретатором и кодом порожденным JIT-компиляторами. У JIT-компиляторов они приближены к системному ABI, у интерпретатора же свои соглашения: простые в реализации (активно используется стек потока), но довольно медленные при исполнении.
Если мы хотим вызвать скомпилированный код из интерпретатора, мы должны в процессе вызова перейти от одного соглашения к другому. Соответственно, вызов идет через специальный адаптер (interpreter-to-compiled или compiled-to-interpreter).
Соответственно, у native-кода свои соглашения о вызовах и тоже требуются специальные адаптеры. Для вызовов native-кода из Java у HotSpot реализованы специальные адаптеры для 2 других режимов (interpreter-to-native и compiled-to-native), а вот в обратную сторону адаптер есть только для интерпретатора (native-to-interpreter). Соответственно, если метод ранее был скомпилирован JIT-компилятором, то вызов из native-кода в Java идет через 2 адаптера: native-to-interpreter, а потом сразу в interpreter-to-compiled.
Получается, один лишний шаг и добавление нового адаптера специально для native-to-compiled позволило бы избавиться от лишней работы.
Посмотрим на производительность в более сложном случае:
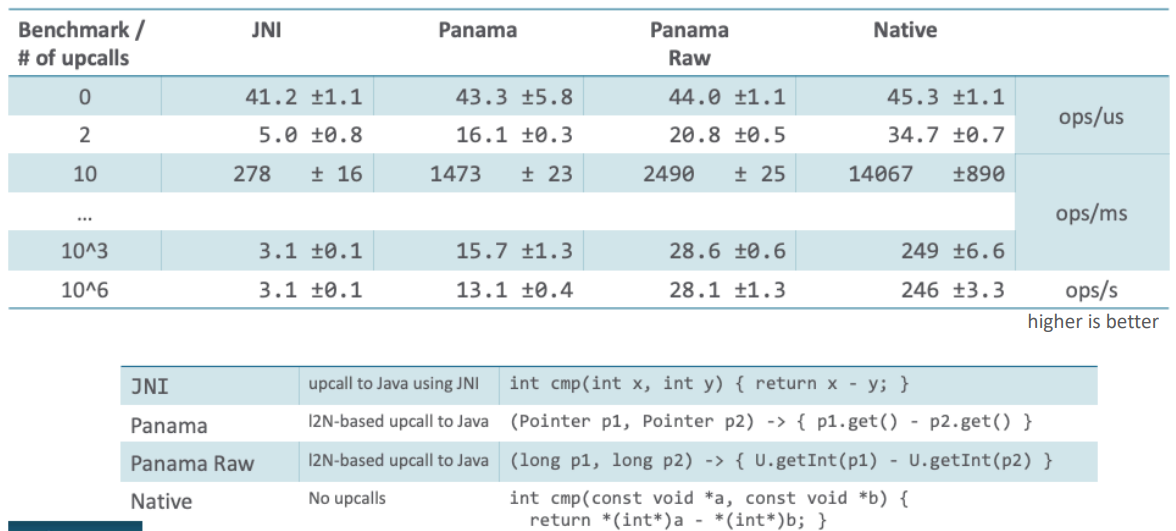
Здесь сравнивается qsort и варьируется количество вызовов из native-кода в Java: делается один downcall, а из него N upcall-ов).
Первая строчка — это некоторое базовое измерение: без вызовов в Java. Оно отражает «стоимость» одного вызова qsort: сколько операций в единицу времени (микросекунду) мы делаем. Как видим, стоимость одинакова для всех режимов.
Далее, варьируя количество вызовов из native-кода в Java, мы пытаемся измерить накладные расходы. JNI сравнивается с разными вариациями linkToNative-адаптера, а также присутствует режим с прямым вызовом native-кода.
При сравнении лучших результатов получается, что стоимость перехода из native-контекста в Java в 10 дороже, чем прямой вызов («Panama Raw» vs «Native»), хотя в обратную сторону разница не так разительна (как мы видели ранее, для getpid разница составляет порядка 3-4 раз).
Такое различие объясняется рядом нюансов.
Например, если посмотреть на реализацию адаптера для JNI, у каждого потока есть контекст исполнения (указатель на уникальную для потока внутреннюю структуру JVM). В случае JNI он очень легко восстанавливается, потому что хранится в JNIEnv.
А в оптимизированном адаптере доступа к JNIEnv уже нет, т.к. от native-кода больше не требуется взаимодействовать с JVM через JNIEnv. Чтобы восстановить контекст потока, нужно обратиться к JVM за помощью, и на текущий момент это требует дополнительного вызова.
(Есть вариант закодировать контекст напрямую в адаптер, но это потребует явно ограничить его использование только из этого потока.)
Несмотря на всю дополнительную работу, в данном конкретном случае скорость вызова из native-кода в Java получается в 10 раз быстрее, чем через JNI.
Но мы все равно остаемся на порядок медленнее прямого вызова, что оставляет большой задел для дальнейшей работы по оптимизации.
Одна из радикальных идей заключается в том, что можно не восстанавливать контекст исполнения для Java-кода, если он не требуется. Такое возможно для небольших методов, в которых нет обращений к Java-куче. Это позволило бы ускорить вызов еще на порядок и сравняться по стоимости с прямым вызовом native-кода.
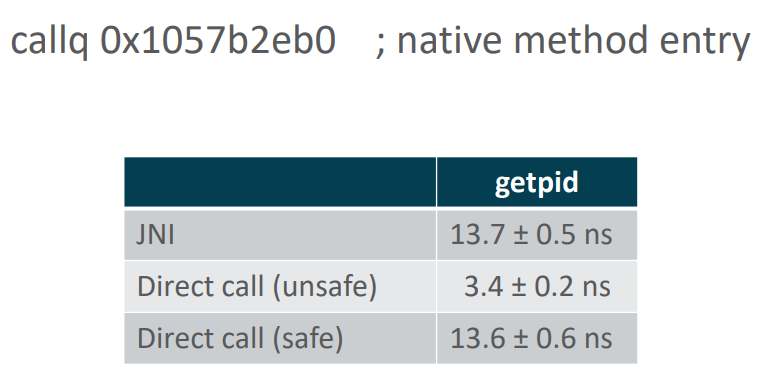
Для вызовов native-кода такого рода оптимизации сделать гораздо сложнее. Как только мы возвращаем переход в безопасное состояние для потока на время вызова native-кода, стоимость вызова становится сопоставимой с JNI. В этом режиме реализация JNI хорошо оптимизирована, и не осталось простых вещей, которые бы позволили существенно сэкономить на вызове.
src/hotspot/cpu/x86/sharedRuntime_x86_64.cpp:
«The Java calling convention is a «shifted» version of the C ABI. By skipping the first C ABI register we can call non-static jni methods with small numbers of arguments without having to shuffle the arguments at all. Since we control the java ABI we ought to at least get some advantage out of it.»
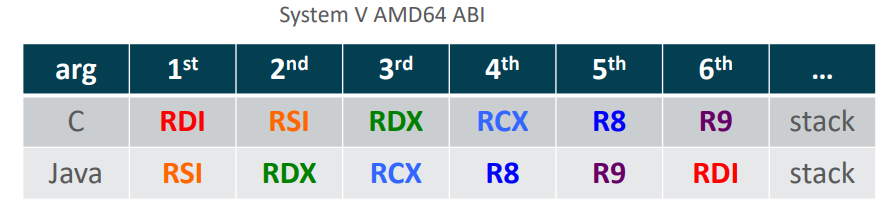
Для вызовов native-кода выбраны специальные соглашения, которые учитывают особенности JNI и для достаточно маленького количества аргументов совпадают с системным ABI. То есть при вызове native-кода из сгенерированного кода в адаптере требуется только положить первым аргументом указатель на JNIEnv (в JNI первым аргументом идет JNIEnv*, который используется для взаимодействия с виртуальной машиной). На Linux x64 (System V ABI) в случае если передается меньше 6 целочисленных аргументов, то все аргументы остаются на своих местах
На чем еще можно попытаться сэкономить? Можем ли мы сделать идущие подряд вызовы более эффективными? Каждый из вызовов делает определенный объем работы по подготовке к вызову, производит сам вызов, а потом возвращается к исполнению Java-кода.
Как мы посмотрели на тестах, для такого простого случая, как getpid, который из фиксированной области памяти читает одно значение и возвращает его, это примерно в 3-4 раза замедляет работу. Стоимость переходов туда-обратно для единичного вызова получается порядка 7-8 нс. Предположим, что это 20-25 тактов. Каким образом мы можем попытаться на этом сэкономить?
Давайте попытаемся сделать переход только один раз:
Здесь можно провести такую аналогию: в JIT-компиляторах (например, в C2) есть оптимизация Lock Coarsening. Предположим, у нас есть synchronized-методы, которые мы часто вызываем. По семантике при каждом вызове объект должен быть захвачен. Но спецификация явно не требует, чтобы попытка захвата происходила в точности на каждый вызов. Если несколько вызовов находятся рядом, то можно попытаться единожды захватить объект, выполнить вызовы, а затем отпустить объект. Таким образом можно сэкономить на множественных попытках захвата объекта. Похожую идею можно применить и для нескольких идущих подряд native-вызовов. В теории мы можем перейти в контекст исполнения native-кода единожды, затем напрямую вызвать N native-функций, а затем сделать обратный переход в контекст исполнения Java-кода.
Это будет выглядеть вот так:
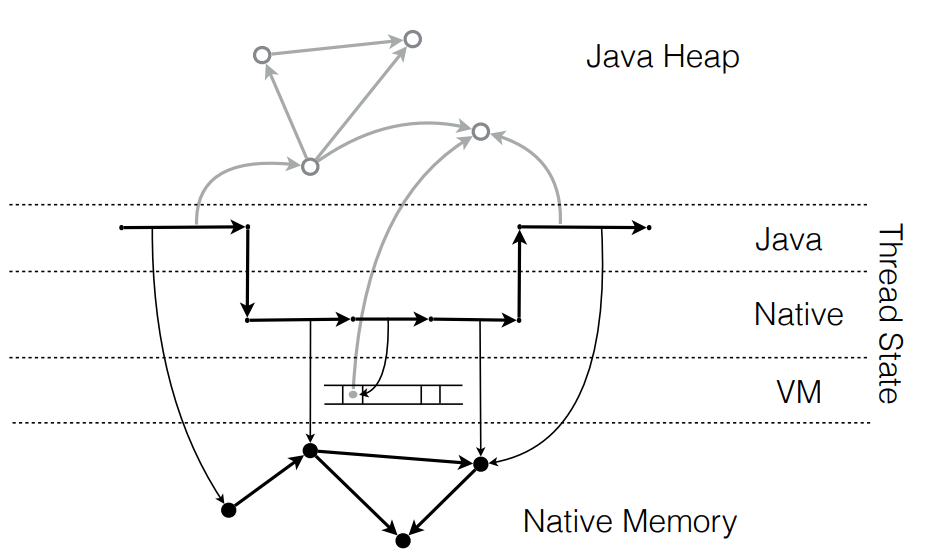
Проблема возникает в ситуации, когда между native-вызовами есть какие-то операции, требующие доступа в Java-кучу. Поскольку мы находимся в другом контексте исполнения, виртуальная машина может в процессе делать достаточно ряд небезопасных вещей (например, двигать объекты в Java-куче). Т.е. все доступы в Java-кучу должны быть обязательно синхронизированы с виртуальной машиной. Для этого либо требуется специальный код (как в JNI), либо мы не можем избавиться от смены контекста в этой ситуации и обязаны явно сменить контекст обратно на исполнение Java-кода.
В ходе экспериментов оказалось, что такой подход не очень хорошо масштабируется, поскольку native-вызовы достаточно жестко упорядочивают код вокруг себя и это мешает убрать операции с Java-кучей из промежутков между ними: с точки зрения разработчика, взаимодействие с native-функциями подразумевает какую-то адаптацию аргументов: принято работать не с последовательностями байт, а с какими-то более высокоуровневыми представлениями, поэтому между вызовами обычно присутствуют разные преобразования, которые легко ломают такого рода оптимизацию. В итоге получить прирост производительности относительно JNI оказалось непростой задачей.
Три параллельных мини-проекта в Panama —Memory Access API, Foreign ABI и jextract — выглядят очень перспективно как по производительности, так и с точки зрения удобства и безопасности.
С точки зрения производительности были достигнуты серьезные результаты, но еще осталось масса возможностей для дальнейших улучшений.
Отмечу, что до сего момента основной фокус проекта был на взаимодействии с языком C, как на lingua franca для взаимодействия между разными средами исполнения. Но С++ тоже популярен, и на текущий момент идут различные эксперименты по взаимодействию с библиотеками, написанными на С++.
Также Foreign-Memory Access API стал частью JDK 14 в виде incubator-модуля. (UPDATE: будет обновлен в JDK 15.)
Статья подготовлена по мотивам доклада, видеозапись которого с сессией вопросов-ответов можно найти тут. Это не просто расшифровка, а доработанная самим Владимиром версия исходного материала.
В целом, доклад посвящен довольно специфической теме: взаимодействию с платформенными (native) библиотеками из Java.
Как все начиналось

Видеозапись доклада Java Native Runtime with Charles Nutter
Разработка Java ведется в рамках OpenJDK, и любые нововведения в язык и платформу создаются в специализированных OpenJDK проектах. Для примера: лямбда-выражения и Stream API пришли из Project Lambda, система модулей (JPMS) создавалась в рамках Project Jigsaw, работа в Project Valhalla ведется над inline-типами (и всем, что с этим связано). Project Panama — один из таких мегапроектов, в рамках которого ведется разработка новых механизмов работы с платформенными библиотеками (и не только).
Текущее состояние (или «моментальный срез») проекта само по себе не столь интересно. Поэтому постараюсь не просто рассказать, где сейчас находится проект, но и дать некоторую перспективу: как проект начинался, что в нем происходило в последние годы, где он находится сейчас и куда планируется двигаться дальше.
Бывает, со стороны смотрят на проект и не понимают, что поменялось за последний год. Предположим, год назад рассказывали про Value Types, а теперь они называются по-другому — Inline Types. Со стороны может показаться, что это все изменения. Но если вглядеться в детали и проследить изменения год за годом, объем работы впечатляет.
Возвращаясь к Panama: вдохновителем проекта стал Charles Nutter (@headius), который на конференции JVMLS 2013 сделал большой доклад про библиотеку JNR (Java Native Runtime), активно используемую JRuby для работы с платформой. В докладе он сравнил производительности JNR, JNI и JNA (еще одной библиотеки для взаимодействия с native-кодом).
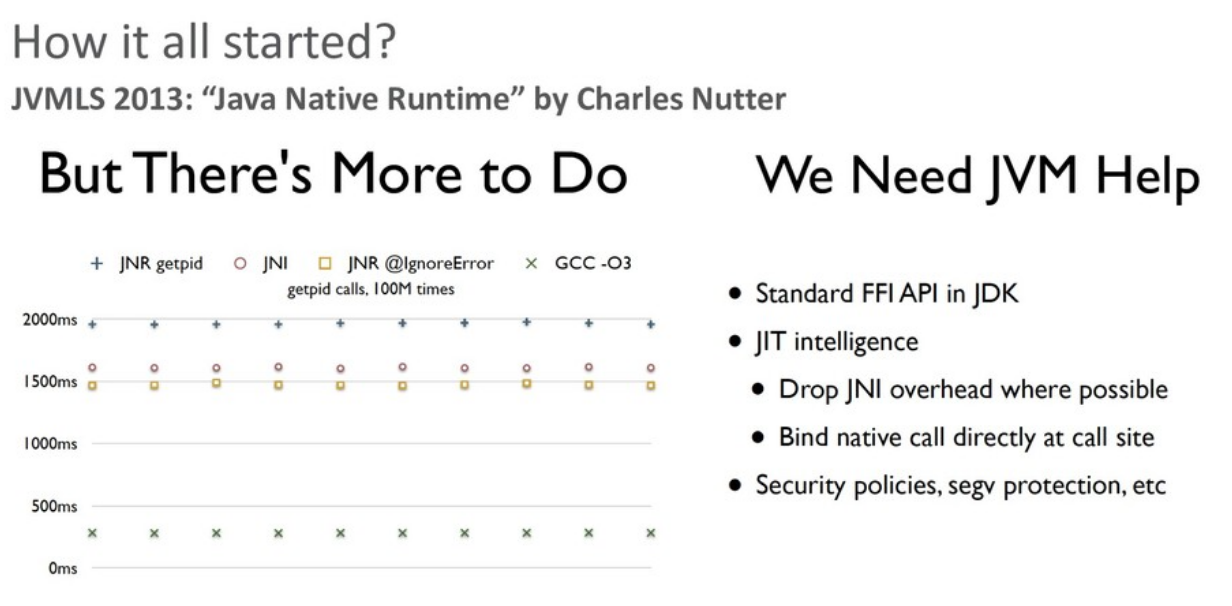
Производительность всех вариантов вызовов (через чистый JNI, через JNR и т.д.) была далека от прямого вызова native-функции, и повысить ее на уровне сторонней библиотеки было уже нельзя — необходима была помощь со стороны виртуальной машины Java (JVM). Идея Charles Nutter заключалась в том, чтобы создать новый API на замену JNI.

К слову, в то время разработка Java велась на основе JSR.
Призыв Чарльза был услышан, и в марте 2014 года было инициировано обсуждение нового OpenJDK-проекта. Предложение получило достаточный отклик в сообществе, так что датой старта проекта можно считать 18 марта 2014 года, когда John Rose инициировал официальное голосование о создании Project Panama.

Анонсированная «область ответственности» для проекта была выбрана гораздо шире, чем предлагал Чарльз. Для JNR было бы достаточно добавить низкоуровневый способ делать прямые вызовы библиотечных функций. Для прямого доступа в память уже был sun.misc.Unsafe. И для JNR было достаточно чего-то похожего: по входному адресу какой-либо native-функции виртуальная машина просто генерировала бы прямой вызов по этому адресу. Для целей JRuby (работы с интерфейсом POSIX) этого было более чем достаточно. Но не для Java-платформы и чего-то, рассматриваемого как замена JNI. Так что с самого начала для проекта были заявлены амбициозные цели: не просто работа с native-кодом, но и поддержка полностью программируемых представлений данных в памяти (memory layout) для более тесного взаимодействия. Проект не ограничивали жесткими рамками.
Не зря было выбрано «говорящее» название, напоминающее о Панамском проливе: проект Panama должен был сделать Java и native-код «ближе» друг к другу.
У проекта Panama есть свой репозиторий: http://hg.openjdk.java.net/panama/dev/
На текущий момент два основных направления работы — это замена JNI и Vector API.

Вот четыре основных ветки, которые можно отнести к FFI:
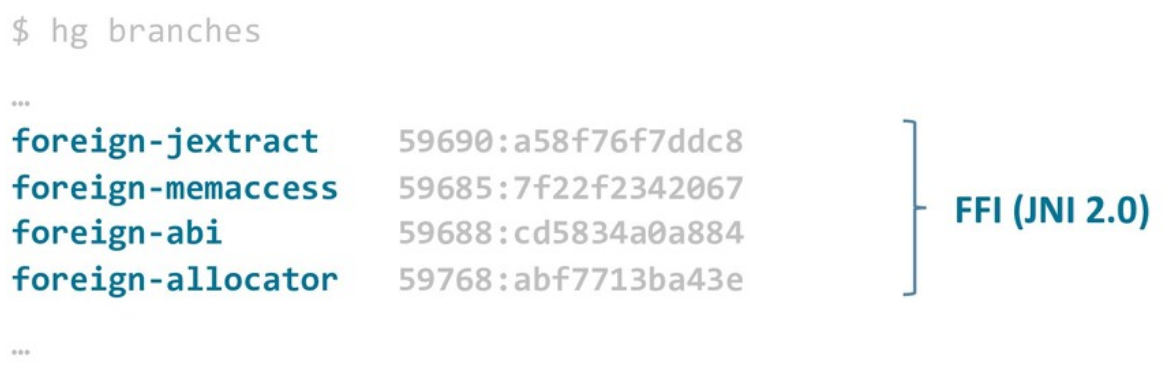
Но прежде чем говорить о деталях и особенностях нового FFI, я сначала расскажу о проблематике работы с native-кодом в Java: почему текущие решения выглядят именно так, что можно сделать лучше, а что исправить уже не получится.
Взаимодействие между Java и native-кодом
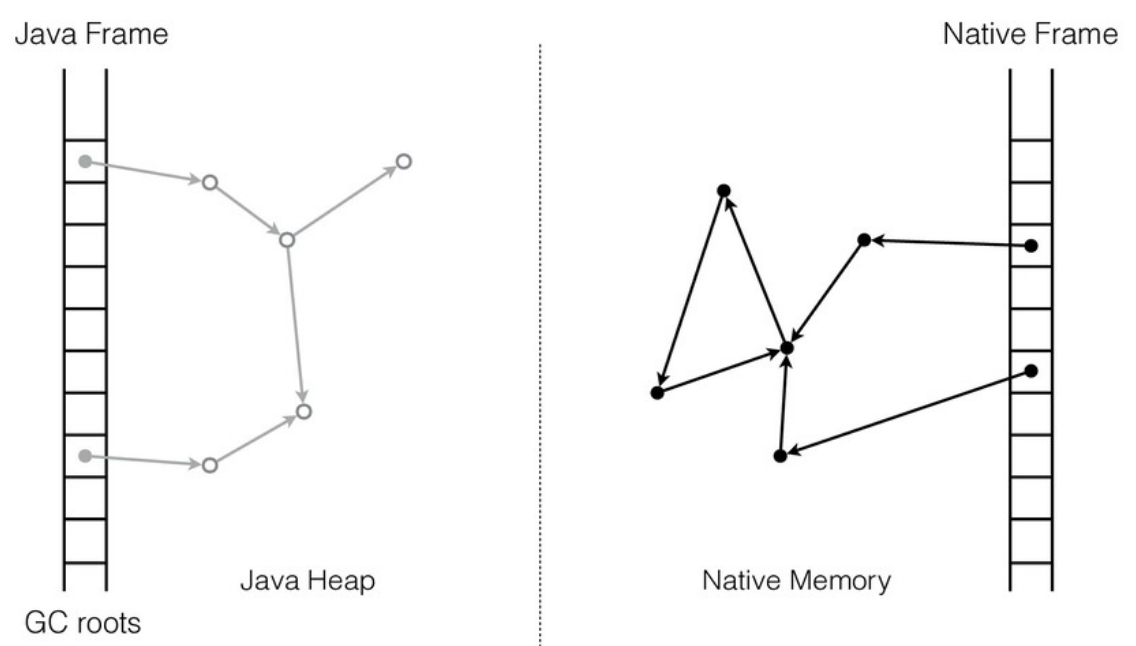
У native-кода есть своя область памяти и свои структуры данных. Java-код работает с Java-кучей. Если мы хотим, чтобы Java и native-код взаимодействовали, нам нужно найти способ ссылаться из одной области в другую. Т.е. native-код должен иметь возможность работать с Java-кучей, а Java-код — с native-кучей.
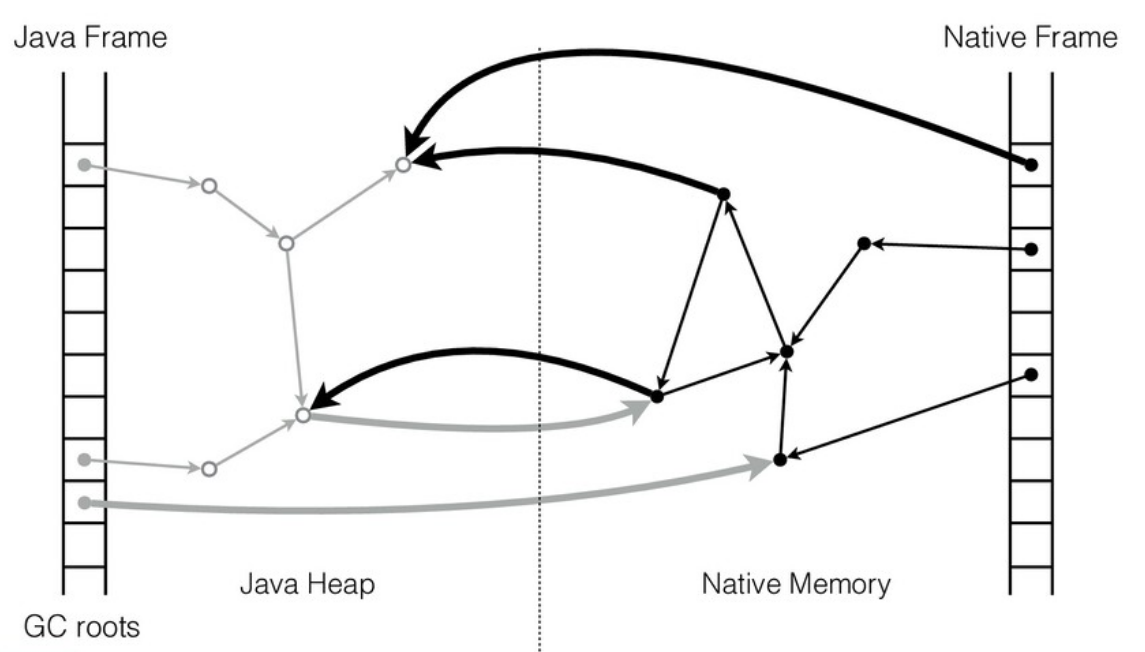
Какие тут могут быть проблемы? В native-коде указатели «стабильны», сами по себе, без ведома работающего с ними кода они не меняются. А Java-куча управляется сборщиком мусора (GC): объекты могут перемещаться по мановению волшебной палочки. Иными словами, в процессе освобождения памяти сборщик мусора вправе перемещать любой объект в памяти и все указатели на него должны быть корректно обновлены. По дизайну такая операция абсолютно прозрачна для Java-кода и им никак не контролируется.
Для памяти вне Java-кучи обновления не нужны, потому что структуры данных не двигаются. А если извне есть ссылки в Java-кучу, такого рода изменения нужно учитывать и обрабатывать.
Одно из решений — это фиксирование положения объекта в Java-куче (object pinning), но это накладывает серьезные ограничения на реализацию GC и с точки зрения производительности имеет ряд неприятных последствий.
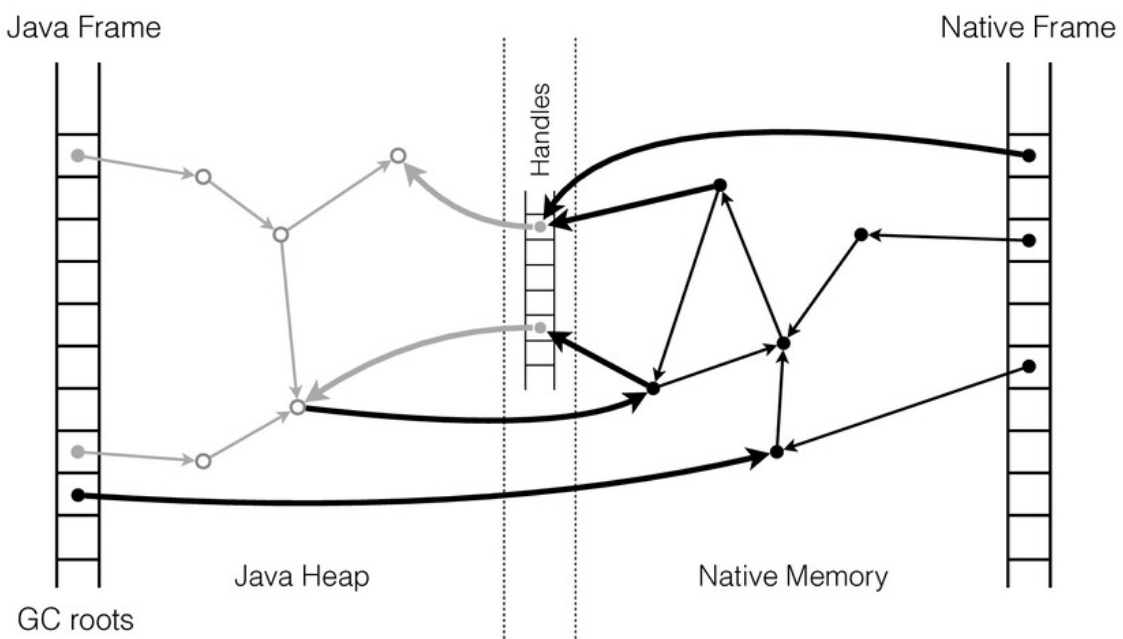
Альтернативный подход (который используется в JNI) заключается в работе с Java-объектами через таблицу стабильных указателей (handles), про которую знает GC.
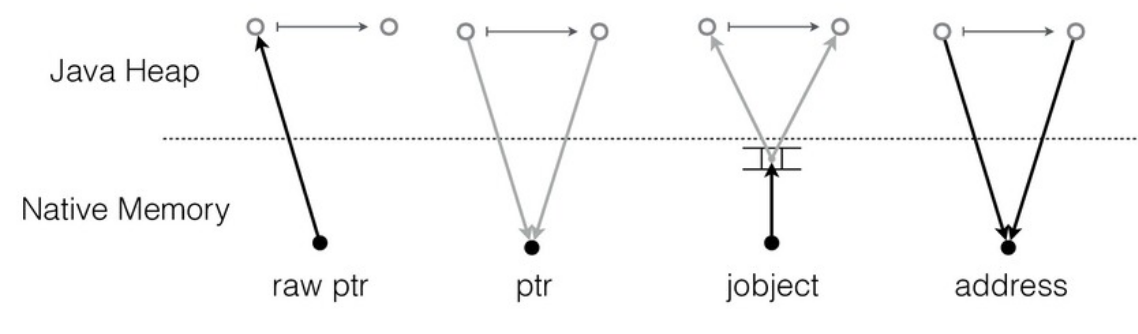
При перемещении объекта сборщик мусора обновляет соответствующий слот таблицы, и native-код начинает работать с новым адресом. Но это требует определенных изменений на стороне native-кода: нельзя просто добавить дополнительный уровень косвенности без его ведома, требуется координация с GC.
В общих чертах дизайн взаимодействия native-кода и Java-кода на уровне данных выглядит следующим образом:
JNI
JNI появился практически сразу, начиная с версии 1.1 (технически API присутствовал и в 1.0, но не был частью стандарта.)
С точки зрения разработчика взаимодействие с JNI выглядит следующим образом:
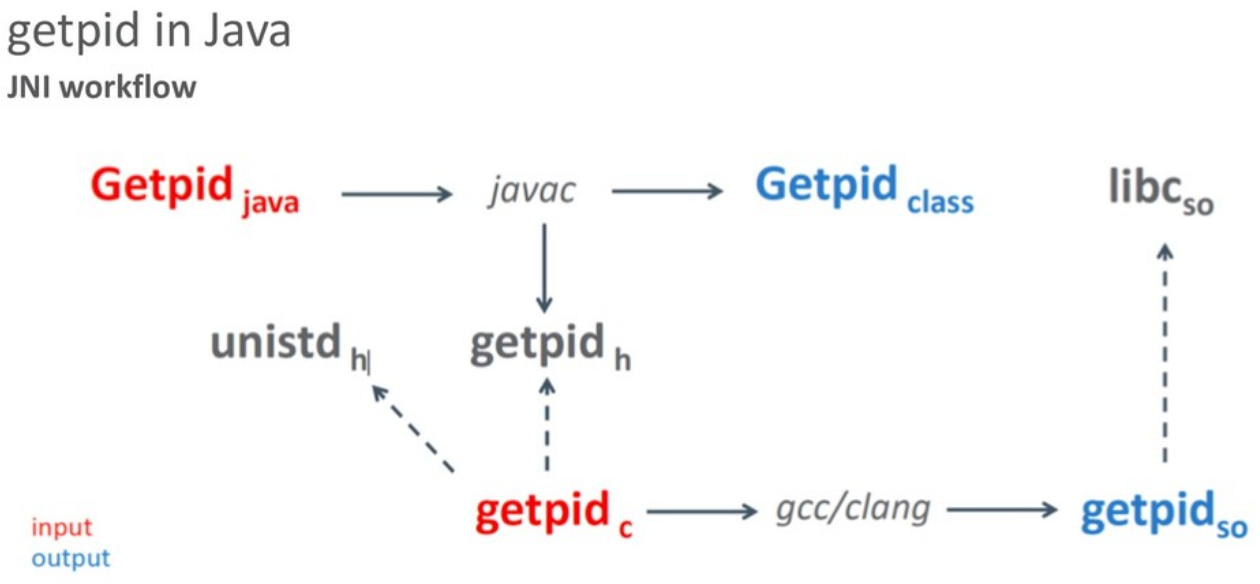
В Java-коде специальным образом (ключевое слово «native») объявляются методы и javac (java compiler) создает class-файл и header-файл. На основе header разработчик вручную пишет реализацию native-функций, компилирует с помощью компилятора С/C++ и получает на выходе готовую библиотеку. Таким образом получаем class-файл и библиотеку.
Для примера давайте посмотрим, как это выглядит на простом примере getpid — native-функции, которая не принимает никаких аргументов, а возвращает идентификатор текущего процесса.

class LibC {
static native long getpid();
}
jlong JNICALL Java_LibC_getpid(JNIEnv* env, jclass c) {
return getpid();
}
Про JNI говорят много нехороших вещей, но, тем не менее, это оказался очень мощный API, предоставляющий богатый набор примитивов для взаимодействия
Например, вызов Java-метода:
jlong JNICALL Java_... (JNIEnv* env,
jclass cls,
jobject obj) {
jmethodID mid = env->GetMethodID(cls, "m", "(I)J");
jlong result = env->CallLongMethod(obj, mid, 10);
Или доступ к полю в Java-объекте:
jlong JNICALL Java_...(JNIEnv* env,
jclass cls,
jobject obj) {
jfieldID fid = env->GetFieldID(cls, "f", "J");
jlong result = env->GetLongField(obj, fid);
jlong result = env->SetLongField(obj, fid, 10);
Детали реализации вызова через JNI
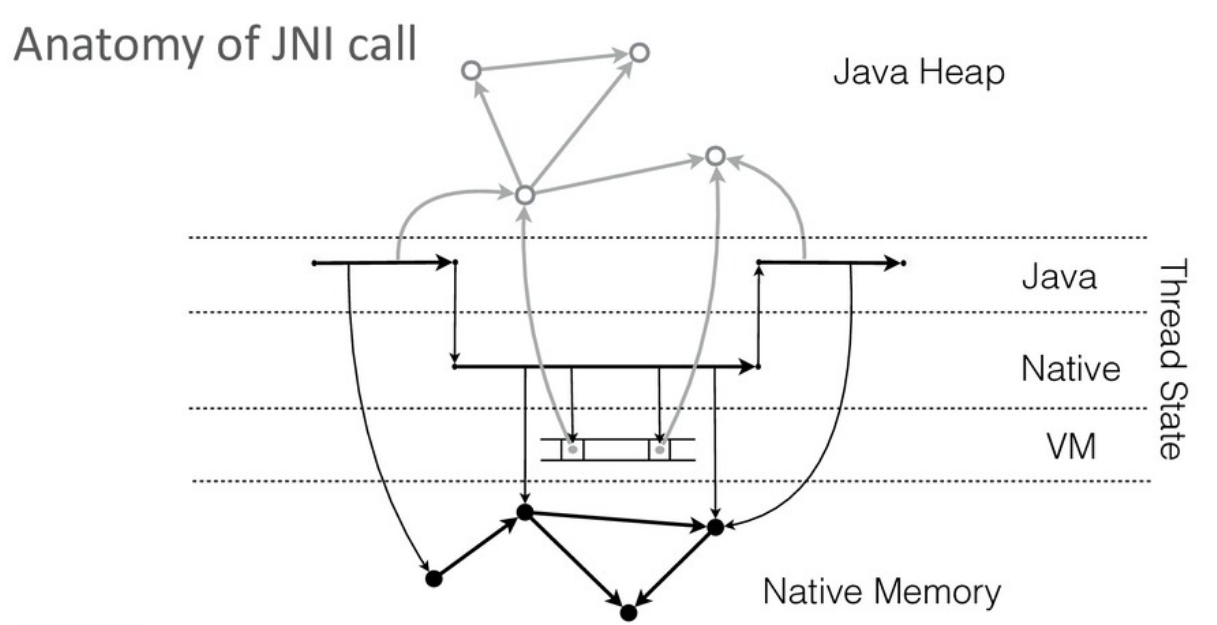
C точки зрения реализации, виртуальной машине полезно различать вызовы Java-кода, исполнение которого она полностью контролирует, и вызов native-кода, контроль которого в общем случае невозможен (за исключением строго определенных мест). Для JVM вызов native-кода — это «черный ящик».
Для стабильной работы виртуальной машине требуется иметь возможность оперативно остановить работу приложения в любой момент. Для этой цели JVM в сгенерированном коде выбирает и помечает места, в которых исполнение может быть безопасно остановлено (т.н. safe point).
В Java-коде виртуальная машина может эти точки расставлять по своему усмотрению. Поскольку у JVM нет возможности модифицировать native-код, при его вызове поток автоматически уходит в safe point (на всем протяжении вызова).
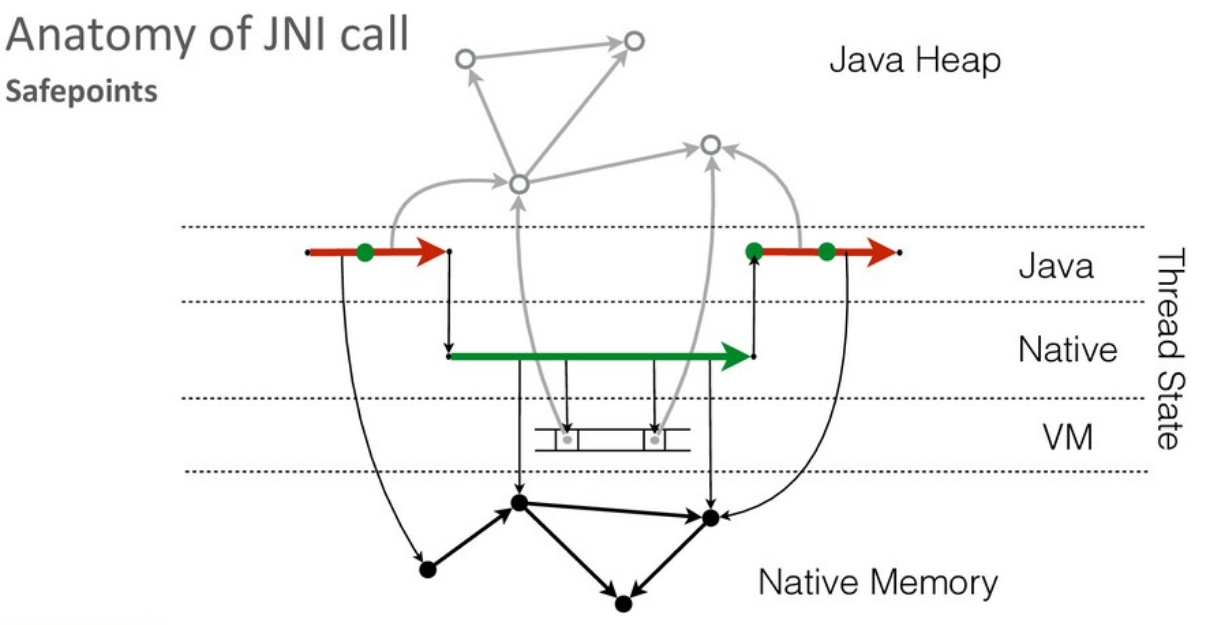
Инициируя safe point, виртуальная машина ждет остановки всех потоков, исполняющих Java-код, но это не относится к потокам, исполняющим native-код. Native-код может продолжать исполняться параллельно с работой сборщика мусора.
Подводя итоги:
- Плюсом JNI можно назвать хоть и не бесшовную, но хорошую интеграцию с Java. Этот API сфокусирован на Java, а не на native-коде, т.е. через него можно получить доступ к массе деталей Java-приложения.
- Минус: неудобство использования. Нужно вручную писать «обертки» и учитывать дополнительные расходы на вызов. Вполне можно представить доступ к данным вне Java-кучи доступ в виде JNI вызова, но это получается слишком накладно. (В этом основная причина популярности sun.misc.Unsafe.)
Critical JNI
Со временем реализация JNI в HotSpot была расширена. Например, появился Critical JNI.
Посмотрим на простой пример:
jint JNICALL Java_…(JNIEnv *env, jclass c, jobject arr) {
jint len = (*env)->GetArrayLength(end, arr);
jbyte* a = (*env)->GetPrimitiveArrayCritical(env, arr, 0);
…
return sum;
}
Предположим, у нас есть метод, в который в качестве параметра передается ссылка на массив из Java-кучи. Через JNI мы хотим получить доступ к содержимому этого массива. Сначала требуется узнать его длину, потом взять указатель на начало и только после этого можно начинать работать с данными.
Для небольших массивов эти два вызова через JNIEnv дают запредельный рост накладных расходов: по сравнению с вызовом пустого метода через JN, накладные расходы увеличиваются на порядок!

Связано это с тем, что, находясь в native-контексте, каждое обращение через JNIEnv требует проверки текущего состояния JVM (safepoint check). Иначе, например, может оказаться, что в это же время сборщик мусора куда-то передвигает наш массив.
Critical JNI решает эту проблему для примитивных массивов: JVM в процессе вызова извлекает всю нужную нам информацию (длина + указатель) и явно передает их в качестве аргументов.
jint JNICALL JavaCritical_…(jint length, jbyte* first) {
…
return sum;
}
Получаем существенную экономию. Наиболее ярко она проявляется для маленьких массивов, так как на больших объемах данных объем работы обычно доминирует над накладными расходами на вызовы.

У Critical JNI есть ряд ограничений. Это всего лишь небольшая надстройка (не являющаяся частью публичного API), которая не решает общих проблем самого JNI.
Как было отмечено выше, JNI — «Java-центричный» интерфейс. Как нам вызвать native-код, представления о вызовах в котором серьезно отличаются от Java? Например, printf:
int printf(const char *format, …)
На стороне Java-кода мы можем представить vararg-аргумент в виде Object[], но придется вручную взять все аргументы, распаковать их при необходимости, разложить на стек в соответствии с системным ABI и только после этого вызвать native-функцию. Написать JNI-«обертку» для printf вручную крайне непросто.
Следующий вопрос: что делать с вызовами из native-кода обратно в Java? Классический пример — qsort:
void qsort(
void* base,
size_t nel,
size_t width,
int (*cmp)(const void*, const void*));
qsort получает в качестве аргумента указатель на функцию, используемую при сравнении элементов. Native-код делает вызов по указателю и передает необходимые аргументы, а мы хотим, чтобы в итоге исполнился Java-код. Как это сделать с помощью JNI? Однозначно нетривиально.
Библиотека JNR (Java Native Runtime)
JNR решает часть проблем. JNI фактически ограничивался инструментами, предоставляемыми виртуальной машиной. Все остальное нам нужно было делать вручную. JNR поднимает все взаимодействия на уровень Java-кода.
public interface LibC {
@pid_t long getpid();
}
LibC lib = LibraryLoader
.create(LibC.class)
.load("c");
libc.getpid()
Т.е. пользователю для getpid вообще не нужно больше писать native-код: набросал интерфейс, добавил аннотаций, и библиотека все делает за нас. И это неплохо работает.
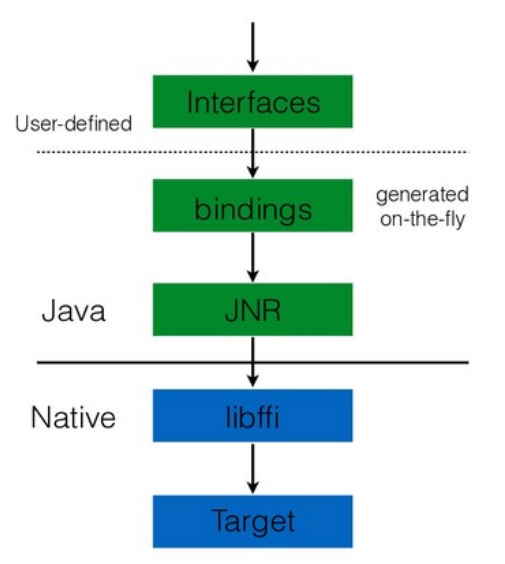
Как я упоминал, JRuby использует JNR для взаимодействия с платформенными библиотеками. Преимущество JNR — автоматическое связывание native-методов. Пользователю не надо писать native-код. Все «грязную» работу за него делает библиотека. Среди недостатков я бы выделил этап ручного написания интерфейса. Он не очень хорошо масштабируется. На практике библиотеки имеют достаточно обширный интерфейс, и его перевод на Java требует существенного объема. Кроме того, JNR — это библиотека, которая все равно базируется на JNI. Как говорил Charles Nutter, мы не можем быть быстрее JNI, хотя в некоторых случаях нам бы этого очень хотелось.
Куда двигаться дальше?
Можем ли мы в новом проекте быть быстрее JNI?
Выше я уже упоминал, что написание интерфейса для реальных библиотек крайне трудоемко. А миграция на новые версии становится еще более трудоемкой, сопоставимой с написанием интерфейса с нуля. В качестве примера рассмотрим популярную библиотеку TensorFlow:

C-интерфейс, который считается стандартом де-факто, актуален. У TensorFlow есть также Java-интерфейс, но он предоставляет ограниченный набор функциональности.
В цифрах C-интерфейс — это порядка 250 сущностей, которые нужно не только написать, но и «обернуть» аннотациями. Если вы что-то сделаете неправильно, скорее всего, вы получите труднодиагностируемую ошибку в процессе исполнения (crash), либо, что еще хуже, некорректный результат.
При миграции на новую версию вам нужно отследить все изменения в интерфейсе библиотеки и внести адаптировать Java-интерфейс. Даже ограниченный объем Java API, который предоставляет TensorFlow, — это уже более 10 тыс. строк native-кода и Java-кода. Поэтому имеют практический смысл более высокоуровневые механизмы работы с библиотеками. Так мы можем упростить работу с платформенными библиотеками для разработчика.
JNI нам мешает далеко не во всех случаях. Зачастую он достаточно быстр для большинства сценариев. Но вот вручную описать интерфейсы крайне трудозатратно.
Первая фаза проекта (2015 — 2018)
Работа над FFI началась в конце 2014 года и активно развернулась в 2015.
Результатом этой работы стало появление нового инструмента jextract, который на основе header-файла библиотеки автоматически создавал все необходимые интерфейсы. Т.е. в процессе разработки мы можем взять header-файл, извлечь из него интерфейсы, написать свое Java-приложение с использованием этих интерфейсов, скомпилировать и запустить. А все связывание интерфейсов с соответствующими частями native-библиотеки происходит «на лету» — в процессе исполнения. Нужные реализации создаются на основе мета-информации, собранной jextract.
Рассмотрим это на примере getpid — аналога «hello world» для native-кода.
Для unistd.h jextract создает Java-интерфейс unistd (.h -> .class):

В аннотациях содержится вся необходимая информация, чтобы в процессе исполнения можно было найти и вызвать нужную native-функцию, а потом обработать возвращаемый результат. Все происходит автоматически: jextract генерирует интерфейс, а во время исполнения по нему создается реализация. Разработчику ничего не требуется делать.
Использовать это можно следующим образом:
// Load native library
Library lib = NativeLibrary.load("c");
// Weave a class for the unistd interface,
// and return an instance
unistd unistd = NativeLibrary.create(lib, unistd.class)
// Call the system getpid() function
int pid = unistd.getpid();
Загружаем библиотеку и получаем реализацию ранее созданного интерфейса на её основе. unistd — это интерфейс, который jextract «извлек» из unistd.h. В итоге мы получаем объект, через который можем вызывать функции, объявленные в unistd.h.
Native-библиотеки содержат код, но на практике взаимодействие с ним подразумевает передачу данных. Поэтому вместе с jextract был добавлен новый API для работы с данными. Также появился класс Pointer, который представлял собой «типизированный» указатель: адрес плюс тип хранимого значения.
Класс Pointer предоставляет набор базовых операций: cast (привести к другому типу), offset (смещение указателя на константу), get/set (чтение/запись по адресу). По сути получился указатель в терминах C.
Также, в дополнение к Pointer, API содержит специальный класс Array, который представляет массив фиксированной длины. В принципе в C массивы — это просто синтаксический сахар поверх обычных указателей. Но есть ряд тонких различий, что и мотивировало появление новой сущности.
Для управления ресурсами появился класс Scope, представляющий некоторый контекст. Освобождение ресурсов происходит при закрытии контекста (Scope.close()), и try-with-resources позволяет удобно с ними работать в лексическом контексте: при выходе из контекста все использованные в данном контексте ресурсы будут автоматически освобождены. Кроме того, каждый Pointer «привязан» к некоторому Scope. На каждый доступ по указателю осуществляется проверка, не закрыт ли соответствующий Scope. Иначе бросается исключение, сигнализирующее ошибку доступа.
@NativeHeader(declarations=
"strlen=(u64:u8)i32")
interface Strings {
int strlen(Pointer<Byte> buf);
}
…
var lib = Libraries.bind(MethodHandles.lookup(),
Strings.class);
try (var scope = Scope.newNativeScope()) {
var strPtr = scope.allocateCString("Hello");
lib.strlen(strPtr);
}
В этом примере мы передаем Java-строку в native-код. Поскольку представление строки в Java и native-коде различаются, требуется конвертация и— Scope предоставляет такую возможность (allocateCString()).
Переосмысление подхода
К 2018 году проект пришел в достаточно стабильное состояние. Был опробован ряд популярных библиотек, с которыми новые инструменты работали без особых проблем. Понятно, что не все было идеально, но это был период активного экспериментирования: каковы должны быть ключевые сценарии использования.
В таком контексте полученный результат был очень даже хорош. С точки зрения удобства использования это был гигантский шаг вперед по сравнению с JNI и существенное улучшение на фоне JNR.
Но если смотреть на проект как на пирамиду, то результат получился монолитным.
Не было четкого разделения на базовые и вспомогательные компоненты. Не было новых низкоуровневых платформенных API, которые можно было бы использовать, к примеру, в сторонних библиотеках (например, для поддержки C++ в JavaCPP).
Всё, за исключением jextract и Pointer API, было деталью реализации.
Это накладывало серьезные ограничения на дальнейшие шаги: если ставить вопрос об интеграции в JDK, то получалось «либо все, либо ничего».
John Rose (JVM Architect) в обсуждениях описал это так: «мы пытались получить все сразу, в случайном порядке, не выстраивая четкую пирамиду».
Наконец, пришло время структурировать дальнейшую разработку. В результате произошло разделение: jextract оформился как самостоятельный высокоуровневый инструмент, базирующийся на двух низкоуровневых платформенных API:
- Memory Access API для работы с памятью;
- Foreign ABI API для вызовов native-кода.
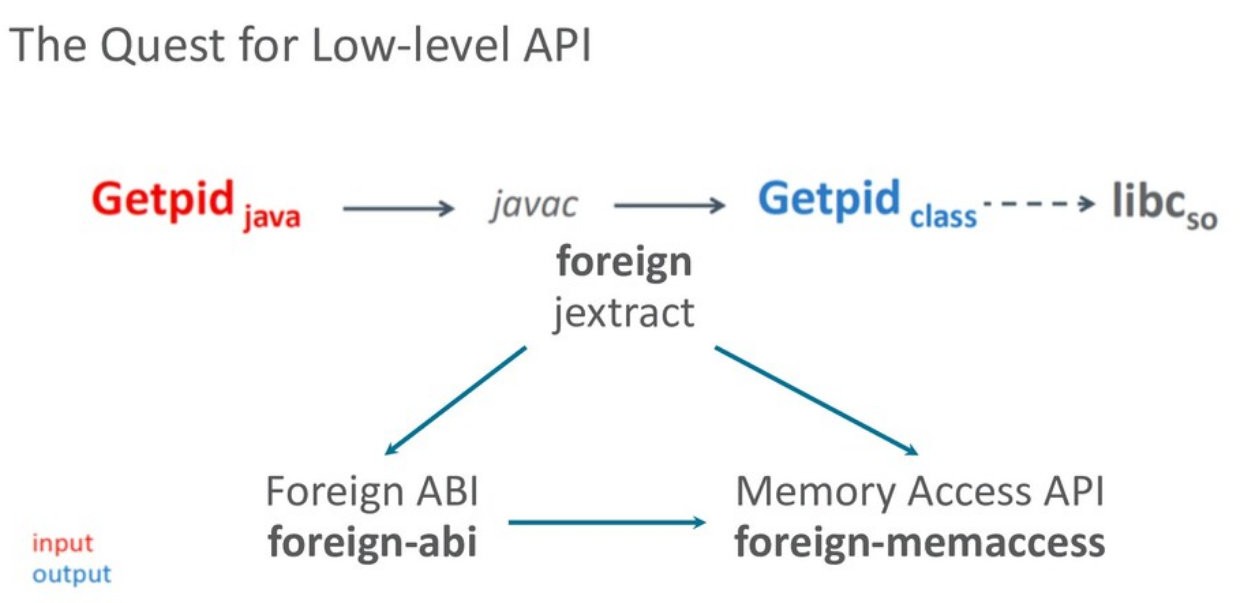
С точки зрения разработчика сценарий использования jextract остался прежним:
jextract на основе header-файла создает Java-интерфейс, а затем разработчик уже компилирует его как часть своей программы.

$ jextract … --source unistd.h
$ javac … unistd_h.java Getpid.java
$ cat Getpid.java
… unistd_h.getpid() ...
Но в новой реализации jextract генерирует не просто интерфейсы, а уже интерфейс с полной реализацией. Если заглянуть в unistd_h.java, то мы увидим там не просто интерфейс с аннотациями, как раньше, а реальный код, который исполняется и делает все то же самое, что раньше генерировалось на этапе исполнения.
pid_t getpid(void);
public final class unistd_h {
[...]
public static final MethodHandle getpid = RuntimeHelper.downcallHandle(
LIBRARIES, "getpid",
"()I",
FunctionDescriptor.of(C_UINT),
false);
public static final int getpid() {
try {
return (int)getpid.invokeExtract();
} catch (Throwable ex) {
throw new AssertionError(ex);
}
}
[...]
}
Рассмотрим, каким образом данная реализация вызывает getpid:
- System ABI
abi = SystemABI.getInstance();
У нас есть интерфейс System ABI, который используется для создания MethodHandle, с помощью которых можно взаимодействовать с native-кодом.
- MemoryAddress
entry = LibraryLookup.ofDefault().lookup("getpid");
Мы можем загружать библиотеки через LibraryLookup и делать поиск entry point по имени, на выходе получая адрес этого entry point.
- MethodType
type = MethodType.methodType(int.class);
Чтобы создать MethodHandle для native-функции, нам нужно описать, как он будет выглядеть на уровне Java-кода. Для этого мы используем MethodType. Все MethodHandle объекты динамически типизированы, несмотря на то, что на уровне системы типов Java эта информация отсутствует.
- FunctionDescriptor
desc = FunctionDescriptor.of(MemoryLayouts.C_INT);
Также требуется описание native-функции, которую мы хотим вызвать. Для этих целей используется новый класс FunctionDescriptor. В случае getpid требуется описать только тип возвращаемого значения, и для стандартных типов C уже есть набор готовых констант.
- MethodHandle
getpid = abi.downcallHandle(entry, type, desc);
Теперь на основе Java-типа (MethodType), native-типа (FunctionDescriptor) и адреса native-функции (MemoryAddress) SystemABI.downcallHandle() может сконструировать объект MethodHandle, реализующий вызов соответствующей native-функции.
Native Method Handles
Реализация базируется на новом типе MethodHandle (NativeMethodHandle) и расширяет существующий java.lang.invoke API.

«Making native calls from the JVM», John Rose
В Java 7 в байт-код JVM была добавлена новая инструкция — invokedynamic, и вместе с ней появился новый java.lang.invoke API для работы с методами на уровне Java-кода. С точки зрения реализации java.lang.invoke, взаимодействие с native-кодом не сильно отличается от взаимодействия с Java-кодом, т.е. нам не составляет большого труда добавить поддержку native-функций.
// int pid = mh.invokeExact();
$ java … -XX:+PrintInlining ...
...
@ 8 LambdaForm$MH::invokeExact_MT (29 bytes) force inline by annotation
@ 11 Invokers::checkExactType (17 bytes) force inline by annotation
@ 1 MethodHandle::type (5 bytes) accessor
@ 15 Invokers::checkCustomized (23 bytes) force inline by annotation
@ 1 MethodHandleImpl::isCompileConstant (2 bytes) (intrinsic)
@ 25 LambdaForm$NMH::invokeNative_I (27 bytes) force inline by …
@ 7 NativeMethodHandle::internalNativeEntryPoint (8 bytes) force inline …
@ 23 MethodHandle::linkToNative(L)I (0 bytes) direct native call
Интерфейс между JVM и Java-кодом — это MethodHandle.linkToNative, специальный метод-адаптер, которому, наряду с аргументами функции, передается и адрес вызываемой native-функции (native entry point).
Посмотрим на это с точки зрения производительности. В машинном коде, сгенерированном JIT-компилятором JVM, вызов через MethodHandle был оптимизирован в прямой вызов:
callq 0x1057b2eb0; native method entryФактически мы получили то, о чем просил Charles Nutter.
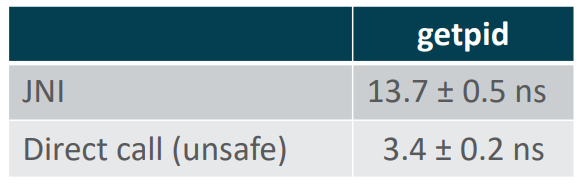
Если через JNI мы тратим на вызов getpid 12 — 13 нс, то при должной поддержке JIT-компилятора мы можем этот linkToNative call превратить в прямой вызов entry point. Понятно, он будет небезопасен. Но мы ранее обсуждали какие шаги делает JVM при вызове native-код: поток переводится в специальное состояние и с точки зрения виртуальной машины не должен быть остановлен при переходе в safe point.
А при прямом вызове этого работа не происходит. Соответственно, JVM будет думать, что поток исполняет Java-код и ждать его остановки.
Такая оптимизация работает для простых случаев вроде getpid. Но в более сложных ситуациях возможны проблемы. Например, если у вас есть блокирующий вызов внутри native-кода, JVM может просто «зависнуть», т.к. будет ожидать остановки потока, который заблокирован на неопределенное время.
И блокировки — не единственный источник проблем: в области сборщиков мусора с низким временем отклика (low latency GC) минимальные гарантированные паузы JVM были серьезно сокращены. Работа касалась не только GC, но и всей JVM, так что теперь можно гарантировать паузы порядка десятков миллисекунд, а говорить и о интервалах менее 1 миллисекунды. А за это время JVM должна не только достичь безопасного состояния, но и выполнить всю необходимую работу, чтобы не нарушить гарантии на паузы.
Universal Adapter
Мы рассмотрели подход с методом-адаптером linkToNative. Но параллельно разрабатывался альтернативный механизм — т.н. Universal Adapter. Это полностью программируемый API, который позволяет описывать произвольные native-вызовы.
У обычных Java-методов сигнатура фиксирована: в месте объявления метода четко описано, аргументы какого типа они принимают и результат какого типа возвращают. Для нужд java.lang.invoke и MethodHandle API этого недостаточно. Требуется через единый интерфейс иметь возможность вызывать любой метод. Из обычного Java-кода этого сделать нельзя, поэтому в спецификацию языка и платформы были добавлены так называемые signature-polymorphic методы, у которых может быть произвольная сигнатура (определяется в месте использования).
Проблема с linkToNative, который также является signature-polymorphic, в том, что его поведение описывается Java-сигнатурой. Предположим, мы хотим описать native-функцию с переменным числом аргументов (varargs). Нам потребуется описать, как именно в стеке располагаются параметры, что сделать в терминах Java-сигнатур теоретически возможно, но крайне неудобно. Другими словами Java-сигнатуры хороши для описания вызовов Java-методов, а для varargs нам лучше изъясняться в терминах C (или даже ABI платформы).
Universal Adapter API решает эту проблему. Он представляет из себя низкоуровневый механизм для описания состояния стека и регистров до и после вызова. Фактически Universal Adapter в качестве аргументов получает полное состояние регистров и вершины стека, а после возврата из вызова обрабатывает результат.
Хотя Universal Adapter — это очень мощный механизм, он плохо подходит для оптимизации JIT-компилятором. JIT-компилятору требуется много низкоуровневых деталей о вызове, чтобы подобрать оптимальный код. Так что с точки зрения производительности Universal Adapter оказался на порядок медленнее JNI.
Foreign ABI: В поиске низкоуровневого API
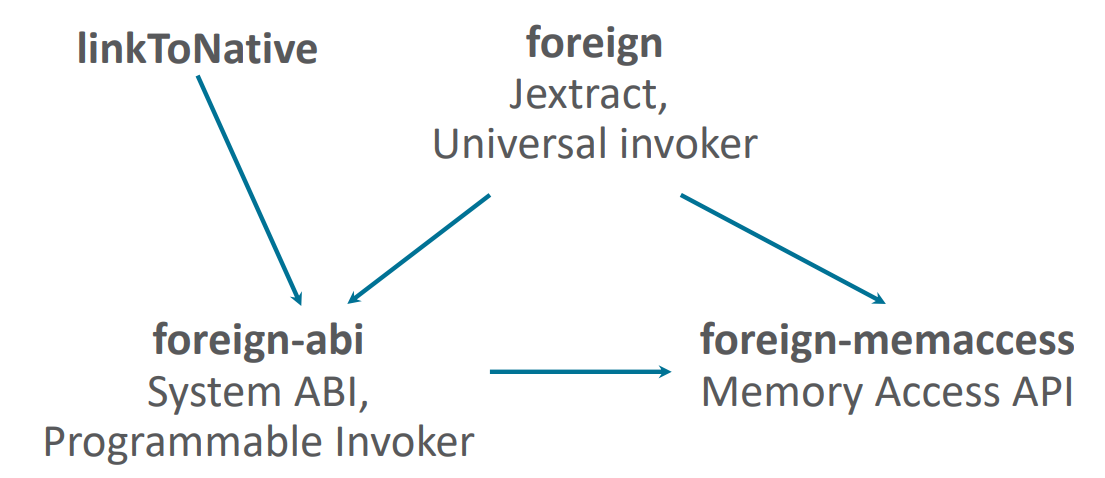
Описанные два подхода (linkToNative и Universal Adapter) не конкурируют, а взаимно дополняют друг друга. В идеале хотелось бы всегда демонстрировать максимальную производительность. Но, с практической точки зрения, имея возможность вызвать любой код, целесообразно сфокусироваться на оптимизации некоторых популярных случаев. Например, мы оптимизируем в JIT-компиляторе 90% наиболее часто используемых случаев, а для корректной работы остальных 10% будем использовать более простой альтернативный механизм, но пожертвовав скоростью вызова.
На текущий момент унифицировать linkToNative и Universal Adapter возможности нет, т.к. они предоставляют два абсолютно разных API. Нельзя в процессе работы с конкретным MethodHandle выбрать, какой интерфейс использовать. Это требуется указать в момент создания MethodHandle. Поэтому работа, которая идет сейчас в проекте, направлена на унификацию интерфейса между двумя механизмами. Цель — иметь возможность в момент JIT-компиляции выбрать конкретный механизм реализации вызова: есть ли возможность оптимизировать вызов или целесообразнее воспользоваться универсальным адаптером?
Далее я еще расскажу про вызовы из native-кода в Java-код (upcall), а пока переключимся на Memory Access API.
Memory Access API
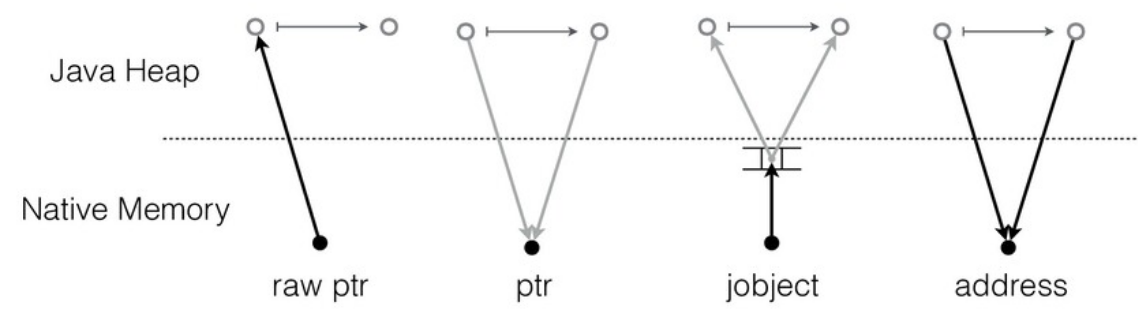
Memory Access API — это низкоуровневый, безопасный и в то же время эффективный API для доступа в память (как в Java-кучу, так и вне её). Он пришел на смену Pointer API как интерфейс взаимодействия с данными и больше не завязан на семантику языка C.
API предоставляет четыре ключевые абстракции:
- MemorySegment: описывает область памяти;
- MemoryAddress: адрес в MemorySegment;
- MemoryLayout: описание раскладки структур данных в памяти;
- MemoryHandles: фабрика VarHandle’ов для доступа к данным через MemoryAddress.
Ключевой особенностью нового API является безопасность его использования. В отличие от sun.misc.Unsafe, новый API не должен допускать критических ошибок, ведущих к прекращению работы всей JVM. Вместо этого в случаях неправильного использования ошибки должны оставаться на уровне приложения или приводить к исключительным ситуациям (с возможностью их перехвата и обработки).
Например, при доступе к данным из многих потоков без должной синхронизации можно получить ошибки именно на уровне логики приложения (при чтении семантически некорректного значения или при неправильной интерпретации данных). С точки зрения среды исполнения это приводит к остановке всего Java-процесса.
В процессе исполнения Memory Access API предоставляет две ключевые гарантии.
Во-первых, контроль времени жизни ресурсов. Гарантируется, что память, к которой осуществляется доступ, все еще доступна. После закрытия соответствующего MemorySegment объекта память может быть освобождена, но все попытки получить к ней доступ приведут к исключительным ситуациям.
Во-вторых, для каждого обращения происходит проверка границ доступа. Попытка доступа вне границ сегмента также приведет к исключительной ситуации.
Разберем простой пример (в комментарии приведет эквивалентный код на C):
// struct { int x; int y; } points[5];
// for (int i = 0; i < 5; i++) { points[i].x = i; }
VarHandle intHandle = MemoryHandles.varHandle(int.class, ByteOrder.nativeOrder());
VarHandle xHandle = MemoryHandles.withStride(intHandle, 8);
try (MemorySegment points = MemorySegment.allocateNative(4 * 2 * 5)) {
MemoryAddress base = points.baseAddress();
for (long i = 0 ; i < 5 ; i++) {
xHandle.set(base, i, (int)i); // safety checks
}
} // points.close() frees memory
В примере объявляется массив из пяти элементов. Каждый элемент — это структура из двух элементов типа int (две координаты). Затем, перебирая элементы массива, в x-координату записывается определенное значение.
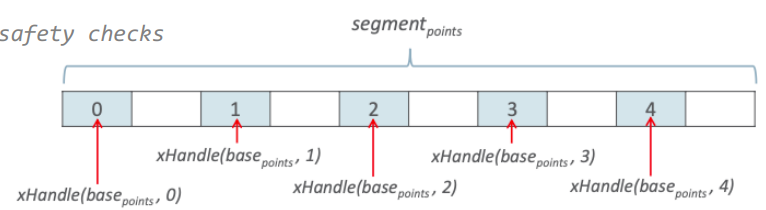
Чтобы написать эквивалентный код на основе Memory Access API, мы начинаем с того, что конструируем VarHandle, осуществляющий доступ к x-компоненте в i-ом элементе массива. В дальнейшем мы просто переиспользуем этот VarHandle. На вход он получает индекс элемента в массиве и записывает в него значение, переданное в другом аргументе.
VarHandle intHandle = MemoryHandles.varHandle(int.class, ByteOrder.nativeOrder());
VarHandle xHandle = MemoryHandles.withStride(intHandle, 8);
VarHandle были добавлены в Java 9, и они очень похожи на MethodHandle. Есть даже возможность конвертировать VarHandle в эквивалентный MethodHandle. Но, по сравнению с MethodHandle, VarHandle API получился чуть выше уровнем и явно предоставляет 4 типа доступа к памяти.
В итоге мы имеем VarHandle объект, реализующий индексированный доступ к элементам массива. На основе комбинаторов для MemoryAddress можно строить достаточно сложные вычисления смещения.
После выхода у нас память освобождается за счет try-with-resources. Даже если созданный MemorySegment каким-либо образом покинет лексический контекст, он будет неявно закрыт при выходе из него. Любые попытки последующего доступа будут завершаться исключением. Т.е. проблема доступа к ресурсу после его освобождения (use after free) решена с помощью дополнительной проверки в процессе исполнения.
MemoryLayout
Memory Access API предоставляет возможность декларативно описывать раскладку структур данных в памяти. До этого, как мы видели в примерах, jextract добавлял специальные аннотации, в которых раскладка кодировалась с помощью специального языка (LDL = Layout Definition Language). LDL был построен на строках, и описания получались достаточно компактными, но достаточно неудобными для написания и последующего чтения.
На смену LDL пришел MemoryLayout с эквивалентной функциональностью:
struct Point {
int x;
int y;
} pts[5];
Теперь
MemoryLayout.ofSequence(5,
MemoryLayout.ofStruct(
MemoryLayout.ofValueBits(32)
.withName("x"),
MemoryLayout.ofValueBits(32)
.withName("y")
)
);
Структура — группа из двух элементов, каждый размером 32 бита — описывается с помощью MemoryLayout.ofStruct. Для удобства элементы структур можно именовать.
Это упрощает создание VarHandle на основе такого описания:
// struct { int x; int y; } points[5];
SequenceLayout seq = MemoryLayout.ofSequence(5,
MemoryLayout.ofStruct(
MemoryLayout.ofValueBits(32, ByteOrder.nativeOrder()).withName("x"),
MemoryLayout.ofValueBits(32, ByteOrder.nativeOrder()).withName("y")));
// i -> points[i].x
VarHandle seqXHandle = seq.varHandle(int.class,
MemoryLayout.PathElement.sequenceElement(),
MemoryLayout.PathElement.groupElement("x"));
// for (int i = 0; i < 5; i++) { points[i].x = i; }
try (MemorySegment points = MemorySegment.allocateNative(seq)) {
MemoryAddress base = points.baseAddress();
long size = seq.elementCount().getAsLong();
for (long i = 0; i < size; i++) {
seqXHandle.set(base, i, (int) i);
}
}
На основе такой раскладки с именованными полями можно получить тот же самый VarHandle в гораздо более наглядном виде.
К слову, Memory Access API уже доступен в JDK (как incubator модуль) начиная с 14 версии.
Вызовы из native-кода в Java (Upcalls)
Ранее мы рассматривали сценарий работы с native-кодом из Java. Но иногда библиотека ожидает указатель на функцию в качестве параметра (callback), а мы хотим, чтобы вызван был Java-код. В контексте FFI это называется upcall.
«Hello world» для upcall — это qsort.
// void qsort(void* base, size_t nel, size_t width,
// int (*compar)(const void*, const void*));
// public interface stdlib_h.qsort$__compar {
// int apply(MemoryAddress x0, MemoryAddress x1);
// }
stdlib_h.qsort$__compar comparator =
(addr1, addr2) -> {
int e1 = (int)INT_VH.get(addr1.rebase(segment));
int e2 = (int)INT_VH.get(addr2.rebase(segment));
return e1 - e2; };
MemoryAddress comparatorAddr = stdlib_h.qsort$__compar$make(comparator);
stdlib_h.qsort(arrayBase,
elementCount,
elementSize,
comparatorAddr);
Фактически на каждое сравнение будет вызвана специальная функция сравнения значений, которая в C API передается в виде указателя на функцию. Но конструируя интерфейс для qsort, мы хотим оперировать в терминах языка Java. В этом случае jextract автоматически создаст для нас функциональный интерфейс (stdlib_h.qsort$__compar). Его можно явно реализовать, но в примере используется лямбда-выражение. На вход передается два MemoryAddress, из них нам нужно считать значения, сравнить и вернуть результат.
В примере просто возвращается разница значений. У нас есть объект, реализующий данный интерфейс. Но мы не можем передать результат в native-код напрямую. Native-код ожидает указатель, а в нашем случае это виртуальный вызов через Java-интерфейс. Нам нужно предварительно каким-то образом преобразовать объект в адрес, чтобы native-код может осуществить вызов. jextract помогает и в этом случае. Он добавляет специальный метод, возвращающий адрес, который мы можем использовать для вызова.
Как это выглядит в терминах Foreign ABI:
MethodHandle qsort = abi.downcallHandle(lookup.lookup("qsort"),
MethodType.methodType(void.class, MemoryAddress.class,
long.class, long.class,
MemoryAddress.class),
FunctionDescriptor.ofVoid(false, C_POINTER, C_ULONG, C_ULONG,
C_POINTER));
// Upcall handler
static int qsortCompare(MemoryAddress addr1, MemoryAddress addr2) {
return (int)intHandle.get(addr1) - (int)intHandle.get(addr2);
}
MethodHandle compar = MethodHandles.lookup().findStatic(StdLibTest.class, "qsortCompare",
MethodType.methodType(int.class, MemoryAddress.class,
MemoryAddress.class));
MemoryAddress qsortUpcallAddr = abi.upcallStub(compar, qsortFunction);
// qsort call
qsort.invokeExact(nativeArr.baseAddress(),
seq.elementsCount().getAsLong(),
C_INT.byteSize(), qsortUpcallAddr);
Здесь мы изначально создаем интерфейс, конструируем MethodHandle на метод в интерфейсе (для чего — увидим чуть позже):
interface QsortComparator { int compare(MemoryAddress addr1, MemoryAddress addr2); }
Создаем MethodHandle для qsort:
MethodHandle qsortCompare = MethodHandles.lookup().
findVirtual(QsortComparator.class, "compare",
methodType(int.class, MemoryAddress.class, MemoryAddress.class));
MethodHandle qsort = abi.downcallHandle(library.lookup("qsort"),
methodType(void.class,
MemoryAddress.class, long.class, long.class, MemoryAddress.class),
FunctionDescriptor.ofVoid(C_POINTER, C_ULONG, C_ULONG, C_POINTER));
Теперь описываем реализацию сравнения:
QsortComparator comparator = (addr1, addr2) -> ... // user-defined comparator
Здесь для простоты используем лямбда-выражения. Лямбда-выражения в Java представляются в виде объектов, реализующих некоторый функциональный интерфейс. Теперь нам нужно превратить объект в указатель (MemoryAddress) для передачи в native-код:
MemoryAddress comparatorAddr = abi.upcallStub(
qsortCompare.bindTo(comparator),
FunctionDescriptor.of(C_INT, C_POINTER, C_POINTER));
System ABI предоставляет такую возможность через upcallStub(). Фактически возвращается указатель на кусок машинного кода (stub), подготовленного JVM, который переводит поток в контекст исполнения Java-кода и вызывает MethodHandle, определенный при создании. Этот указатель native-код может использовать как указатель на функцию.
java.lang.invoke API поддерживает Java-семантику во всей её полноте, и использование MethodHandle позволяет нам делегировать исполнение в произвольный Java-код. Таким образом upcallStub() преобразовал вызов некоторого MethodHandle’а в указатель, т.е. для native-кода он выглядит как обычный указатель на функцию, а внутри происходит сложный процесс подготовки к исполнению Java-кода. Теоретически это можно сделать и с JNI, но придется все сделать вручную.
Теперь у нас есть возможность вызвать qsort:
qsort.invokeExact(arrayAddr, elemCount, elemSize, comparatorAddr);
Давайте теперь сравним производительность:

Первое, что бросается в глаза, это сравнительно низкая скорость вызова через JNI.
Как оказалось, режим вызова Java-кода через JNI не привлекал достаточного внимания JVM-инженеров и реализация может быть легко ускорена в разы за счет применения схемы со специальными адаптерами (по аналогии с вызовами native-кода из Java).
Эксперимент был проведен для linkToNative, потому что на тот момент все эксперименты с оптимизацией шли с реализацией на его основе. В Foreign на тот момент была своя реализация вызовов. Это не Universal Adapter, это своеобразный «небезопасный JNI», основанный на переиспользовании адаптеров для ситуаций с одинаковым представлением на уровне ABI. В JNI используются Java-типы (int, long, etc). А на уровне ABI аргументы типизированы на уровне регистров (integral, floating point) и значение занимает целый регистр. То есть, например, адаптеры для Java-сигнатур с параметромом типа int и long на Linux x64 (System V ABI) различаться не будут.
Вышеописанная схемы была использована (в foreign ветке) для вызовов native-кода из Java. Похожая схема применялась и для вызовов в обратную сторону. Она оказалась быстрее JNI, но не настолько, как специализированный адаптер.
Также на реализацию JNI влияет специфика HotSpot JVM.
В HotSpot в процессе исполнения одновременно могут использоваться интерпретатор и несколько JIT-компиляторов. Виртуальная машина свободно переключает исполнение между разными режимами. Для этого во внутреннем представлении каждого Java-метода хранятся два указателя на код, который должен исполняться: когда вызов приходит из интерпретатора (from interpreter entry) и когда вызов приходит из кода, сгенерированного JIT-компилятором (from compiled code entry).
Причина для этого следующая: соглашения о вызовах (calling conventions) существенно различаются между кодом, исполняемым в интерпретатором и кодом порожденным JIT-компиляторами. У JIT-компиляторов они приближены к системному ABI, у интерпретатора же свои соглашения: простые в реализации (активно используется стек потока), но довольно медленные при исполнении.
Если мы хотим вызвать скомпилированный код из интерпретатора, мы должны в процессе вызова перейти от одного соглашения к другому. Соответственно, вызов идет через специальный адаптер (interpreter-to-compiled или compiled-to-interpreter).
Соответственно, у native-кода свои соглашения о вызовах и тоже требуются специальные адаптеры. Для вызовов native-кода из Java у HotSpot реализованы специальные адаптеры для 2 других режимов (interpreter-to-native и compiled-to-native), а вот в обратную сторону адаптер есть только для интерпретатора (native-to-interpreter). Соответственно, если метод ранее был скомпилирован JIT-компилятором, то вызов из native-кода в Java идет через 2 адаптера: native-to-interpreter, а потом сразу в interpreter-to-compiled.
Получается, один лишний шаг и добавление нового адаптера специально для native-to-compiled позволило бы избавиться от лишней работы.
Посмотрим на производительность в более сложном случае:

Здесь сравнивается qsort и варьируется количество вызовов из native-кода в Java: делается один downcall, а из него N upcall-ов).
Первая строчка — это некоторое базовое измерение: без вызовов в Java. Оно отражает «стоимость» одного вызова qsort: сколько операций в единицу времени (микросекунду) мы делаем. Как видим, стоимость одинакова для всех режимов.
Далее, варьируя количество вызовов из native-кода в Java, мы пытаемся измерить накладные расходы. JNI сравнивается с разными вариациями linkToNative-адаптера, а также присутствует режим с прямым вызовом native-кода.
При сравнении лучших результатов получается, что стоимость перехода из native-контекста в Java в 10 дороже, чем прямой вызов («Panama Raw» vs «Native»), хотя в обратную сторону разница не так разительна (как мы видели ранее, для getpid разница составляет порядка 3-4 раз).
Такое различие объясняется рядом нюансов.
Например, если посмотреть на реализацию адаптера для JNI, у каждого потока есть контекст исполнения (указатель на уникальную для потока внутреннюю структуру JVM). В случае JNI он очень легко восстанавливается, потому что хранится в JNIEnv.
А в оптимизированном адаптере доступа к JNIEnv уже нет, т.к. от native-кода больше не требуется взаимодействовать с JVM через JNIEnv. Чтобы восстановить контекст потока, нужно обратиться к JVM за помощью, и на текущий момент это требует дополнительного вызова.
(Есть вариант закодировать контекст напрямую в адаптер, но это потребует явно ограничить его использование только из этого потока.)
Несмотря на всю дополнительную работу, в данном конкретном случае скорость вызова из native-кода в Java получается в 10 раз быстрее, чем через JNI.
Но мы все равно остаемся на порядок медленнее прямого вызова, что оставляет большой задел для дальнейшей работы по оптимизации.
Одна из радикальных идей заключается в том, что можно не восстанавливать контекст исполнения для Java-кода, если он не требуется. Такое возможно для небольших методов, в которых нет обращений к Java-куче. Это позволило бы ускорить вызов еще на порядок и сравняться по стоимости с прямым вызовом native-кода.
Оптимизация вызовов native-кода из Java

Для вызовов native-кода такого рода оптимизации сделать гораздо сложнее. Как только мы возвращаем переход в безопасное состояние для потока на время вызова native-кода, стоимость вызова становится сопоставимой с JNI. В этом режиме реализация JNI хорошо оптимизирована, и не осталось простых вещей, которые бы позволили существенно сэкономить на вызове.
Соглашения о вызовах в HotSpot JVM
src/hotspot/cpu/x86/sharedRuntime_x86_64.cpp:
«The Java calling convention is a «shifted» version of the C ABI. By skipping the first C ABI register we can call non-static jni methods with small numbers of arguments without having to shuffle the arguments at all. Since we control the java ABI we ought to at least get some advantage out of it.»

Для вызовов native-кода выбраны специальные соглашения, которые учитывают особенности JNI и для достаточно маленького количества аргументов совпадают с системным ABI. То есть при вызове native-кода из сгенерированного кода в адаптере требуется только положить первым аргументом указатель на JNIEnv (в JNI первым аргументом идет JNIEnv*, который используется для взаимодействия с виртуальной машиной). На Linux x64 (System V ABI) в случае если передается меньше 6 целочисленных аргументов, то все аргументы остаются на своих местах
На чем еще можно попытаться сэкономить? Можем ли мы сделать идущие подряд вызовы более эффективными? Каждый из вызовов делает определенный объем работы по подготовке к вызову, производит сам вызов, а потом возвращается к исполнению Java-кода.
void run() {
nativeFunc1(); // checks & state trans.
nativeFunc2(); // checks & state trans.
nativeFunc3(); // checks & state trans.
}

Как мы посмотрели на тестах, для такого простого случая, как getpid, который из фиксированной области памяти читает одно значение и возвращает его, это примерно в 3-4 раза замедляет работу. Стоимость переходов туда-обратно для единичного вызова получается порядка 7-8 нс. Предположим, что это 20-25 тактов. Каким образом мы можем попытаться на этом сэкономить?
Давайте попытаемся сделать переход только один раз:
void run() {
transitionJavaToNative();
call nativeFunc1();
call nativeFunc2();
call nativeFunc3();
transitionNativeToJava();
}
Здесь можно провести такую аналогию: в JIT-компиляторах (например, в C2) есть оптимизация Lock Coarsening. Предположим, у нас есть synchronized-методы, которые мы часто вызываем. По семантике при каждом вызове объект должен быть захвачен. Но спецификация явно не требует, чтобы попытка захвата происходила в точности на каждый вызов. Если несколько вызовов находятся рядом, то можно попытаться единожды захватить объект, выполнить вызовы, а затем отпустить объект. Таким образом можно сэкономить на множественных попытках захвата объекта. Похожую идею можно применить и для нескольких идущих подряд native-вызовов. В теории мы можем перейти в контекст исполнения native-кода единожды, затем напрямую вызвать N native-функций, а затем сделать обратный переход в контекст исполнения Java-кода.
Это будет выглядеть вот так:

Проблема возникает в ситуации, когда между native-вызовами есть какие-то операции, требующие доступа в Java-кучу. Поскольку мы находимся в другом контексте исполнения, виртуальная машина может в процессе делать достаточно ряд небезопасных вещей (например, двигать объекты в Java-куче). Т.е. все доступы в Java-кучу должны быть обязательно синхронизированы с виртуальной машиной. Для этого либо требуется специальный код (как в JNI), либо мы не можем избавиться от смены контекста в этой ситуации и обязаны явно сменить контекст обратно на исполнение Java-кода.
В ходе экспериментов оказалось, что такой подход не очень хорошо масштабируется, поскольку native-вызовы достаточно жестко упорядочивают код вокруг себя и это мешает убрать операции с Java-кучей из промежутков между ними: с точки зрения разработчика, взаимодействие с native-функциями подразумевает какую-то адаптацию аргументов: принято работать не с последовательностями байт, а с какими-то более высокоуровневыми представлениями, поэтому между вызовами обычно присутствуют разные преобразования, которые легко ломают такого рода оптимизацию. В итоге получить прирост производительности относительно JNI оказалось непростой задачей.
Вместо итогов
Три параллельных мини-проекта в Panama —Memory Access API, Foreign ABI и jextract — выглядят очень перспективно как по производительности, так и с точки зрения удобства и безопасности.
С точки зрения производительности были достигнуты серьезные результаты, но еще осталось масса возможностей для дальнейших улучшений.
Отмечу, что до сего момента основной фокус проекта был на взаимодействии с языком C, как на lingua franca для взаимодействия между разными средами исполнения. Но С++ тоже популярен, и на текущий момент идут различные эксперименты по взаимодействию с библиотеками, написанными на С++.
Также Foreign-Memory Access API стал частью JDK 14 в виде incubator-модуля. (UPDATE: будет обновлен в JDK 15.)
