Comments 93
При создании приложения, концепция которого подразумевает работу с документами, MongoDB будет хорошим выбором. К такому типу приложений можно отнести, к примеру, движок блог-платформы, где каждый автор сможет иметь по несколько блогов, и каждый из них будет содержать множество комментариев. База данных для обслуживания такого приложения должна быть легко расширяемой, и здесь MongoDB подойдет как рельзя лучше.
Так это как раз плохой пример. У монги же лок на запись на уровне документа. Причём как я понял из доков, лок на уровне документа доступен на движке WiredTiger, по-умолчанию лок на базу до сих пор (или я не там читал?)
Что если сразу куча народу захочет написать или подредактировать комменты? А если кто-то начнёт удалять свой коммент, а ему в этот момент начнут отвечать?
Комментарии можно хранить в отдельной коллекции. Удобней будет делать запросы, сортировки, поиск.
У каждого коммента хранить $dbref на пост и на родительский коммент? И как тогда строить дерево комментариев к посту?
Вот и вышло, что мы снова вернулись к плоским таблицам и связям между ними. Ну а зачем на монге (у которой нет нормальных транзакций и джойнов) пытаться эмулировать реляционные БД, если можно взять просто реляционную БД сразу.
Вот и вышло, что мы снова вернулись к плоским таблицам и связям между ними. Ну а зачем на монге (у которой нет нормальных транзакций и джойнов) пытаться эмулировать реляционные БД, если можно взять просто реляционную БД сразу.
MongoDB не подходит для хранения реляционных данных. Об этом говорят сами разработчики.
Вы привели самый простой способ организации хранения данных в данном случае, на самом деле их больше.
Обычно выбирают родительский пост и плоский список комментариев, затем их превращают в дерево уже на уровне языка программирования. Обычно комментариев немного, случаи вроде этого — исключения, но и они решаемы. В любом варианте, отдача десятков тысяч комментариев на странице просто убьет браузер, особенно на телефоне.
MongoDB используется на доске объявлений Craigslist, как вы понимаете, там особых связей не нужно. Плоская структура для сайта с гигантской посещаемостью и огромным количеством данных.
MongoDB подойдет там, где база растет, документы не требуют связности и их структура варьируется достаточно сильно. Представьте, что вам нужно добавить новое поле для 10 записей в таблице MySQL с триллионом записей. При этом у вас 100 обращений в секунду на чтение к этой таблице. Как вы будете решать такую задачу без блокировок? Предполагаю, что будет некоторый простой в работе сервиса.
Вы привели самый простой способ организации хранения данных в данном случае, на самом деле их больше.
Обычно выбирают родительский пост и плоский список комментариев, затем их превращают в дерево уже на уровне языка программирования. Обычно комментариев немного, случаи вроде этого — исключения, но и они решаемы. В любом варианте, отдача десятков тысяч комментариев на странице просто убьет браузер, особенно на телефоне.
MongoDB используется на доске объявлений Craigslist, как вы понимаете, там особых связей не нужно. Плоская структура для сайта с гигантской посещаемостью и огромным количеством данных.
MongoDB подойдет там, где база растет, документы не требуют связности и их структура варьируется достаточно сильно. Представьте, что вам нужно добавить новое поле для 10 записей в таблице MySQL с триллионом записей. При этом у вас 100 обращений в секунду на чтение к этой таблице. Как вы будете решать такую задачу без блокировок? Предполагаю, что будет некоторый простой в работе сервиса.
Я не знаю как в MySQL, а в MS SQL добавление колонки — не блокирующая операция, независимо от количества записей.
Кроме того, если вам не нужны предикаты и агрегации по новым полям, то поля можно и не добавлять, а воспользоваться полем типа json или xml.
Кроме того, если вам не нужны предикаты и агрегации по новым полям, то поля можно и не добавлять, а воспользоваться полем типа json или xml.
В PostgreSQL операция добавления в таблицу нового столбца с дефолтным значением NULL — не лочит таблицу.
Представьте, что вам нужно добавить новое поле для 10 записей в таблице MySQL с триллионом записей.
в реляционной схеме для этого лучше подходит создание новой таблицы связанную как 1:1. Это аналог ООП-шного наследования в реляционной нотации.
Это зависит от субд. В SQL Server при добавлении колонок меняются только метаданные. Данные пишутся в ROW_OVERFLOW страницы, которые работают как раз как связи 1:1, только скрыто от программиста. А если надо избавится от оверхеда таких "джоинов", то можно просто запустить rebuild таблицы.
В других базах механизмы аналогинчые.
В других базах механизмы аналогинчые.
Как всегда, во всех примерах комментарии добавляются прямо в документ, чтобы показать насколько это круто.
Наверное, людям нравится держать в голове (или они забивают на это), что размер документа не должен превышать 16МБ, а это не так много.
Блин, хватит уже писать про JOIN в Mongo. Их там не должно быть, т.к ты не можешь быть уверен, что заJOIN'еный объект лежит на том же севере, на котором ты делаешь запрос. Mongo изначально делалась, чтобы решить проблемы, который у обычных RDBMS возникнут потом. Не у всех, правда.
То, что делается на Mongo максимально просто и понятно, а при возникновении проблем с объемом данных в реляционных БД будут изобретаться такие велосипеды, который все достоинства этих баз сведут к нулю.
Тяжело, вам, наверное делать изначально ограниченный проект на обычных реляционных базах, т.е не думать о том, что будет, когда все будет потихоньку накрываться…
Лучше побольше времени потратить на изначальное проектирование данных, которое снимет вообще все вопросы в будущем.
Наверное, людям нравится держать в голове (или они забивают на это), что размер документа не должен превышать 16МБ, а это не так много.
Блин, хватит уже писать про JOIN в Mongo. Их там не должно быть, т.к ты не можешь быть уверен, что заJOIN'еный объект лежит на том же севере, на котором ты делаешь запрос. Mongo изначально делалась, чтобы решить проблемы, который у обычных RDBMS возникнут потом. Не у всех, правда.
То, что делается на Mongo максимально просто и понятно, а при возникновении проблем с объемом данных в реляционных БД будут изобретаться такие велосипеды, который все достоинства этих баз сведут к нулю.
Тяжело, вам, наверное делать изначально ограниченный проект на обычных реляционных базах, т.е не думать о том, что будет, когда все будет потихоньку накрываться…
Лучше побольше времени потратить на изначальное проектирование данных, которое снимет вообще все вопросы в будущем.
https://docs.mongodb.org/ecosystem/use-cases/storing-comments/ вот так.
В статье как раз и говориться, что если у вас много сложных связей, тогда монго не ваш выбор.
В статье как раз и говориться, что если у вас много сложных связей, тогда монго не ваш выбор.
Вот и я не понимаю, почему в половине статей про монгу в качестве хорошего примера приводят блог и комментарии
Вот и я не понимаю, почему в половине статей про монгу в качестве хорошего примера приводят блог и комментарии
Извините мой слабый сарказм… :)
Но потому что популярных блогов мало на общем фоне. И большинство блогов как раз вялые — либо комментариев нет вообще, либо их там по пальцам рук можно пересчитать. :)
Они (проповедники MongoDB) сами говорят что если данных будет много то не надо их ложить массивом внутрь одного документа.
Люди просто берут mongo потому что 'модно, молодёжно', даже не задумываясь о том, что что-то подойдёт лучше для решения задачи.
Как только встречают элементарную задачу, комментарии те же, создают табличку и 'связывают'. И потом начинают всем рассказывать, что так делать — хороший вариант. Но вот взять реляционную бд, которая отлично справляется с этими проблемами — не вариант для любителей 'модно, молодёжно'. Mongo везде и всегда.
Как только встречают элементарную задачу, комментарии те же, создают табличку и 'связывают'. И потом начинают всем рассказывать, что так делать — хороший вариант. Но вот взять реляционную бд, которая отлично справляется с этими проблемами — не вариант для любителей 'модно, молодёжно'. Mongo везде и всегда.
Начиная с Mongo 3.2 Wired Tiger идет по умолчанию с декабря прошлого года.
Причём как я понял из доков, лок на уровне документа доступен на движке WiredTiger, по-умолчанию лок на базу до сих пор (или я не там читал?)
До версии 2.6 лок был на уровне базы.
Начиная с версии 2.6 (релиз 10 апреля 2014 года) лок стал на уровне коллекции.
Причем сделать они это хотели с 2010 года. :) И к 2014 осилили.
https://jira.mongodb.org/browse/SERVER-1240
Начиная с версии 3.0 (релиз 3 марта 2015 года) появился WiredTiger при использовании которого лок на уровне документа.
Начиная с версии 3.2 (релиз 8 декабря 2015 года) WiredTiger стал движком по-умолчанию.
Довелось побывать на встрече с одним из основателей компании WiredTiger — Dr. Michael Cahill — после того как их купила MongoDB.
И помню он говорил, загадочно улыбаясь, что WiredTiger как движок поддерживает транзакции.
Так что я ничему не удивлюсь. :)
Ну WiredTiger вроде как пилит бывший разраб постгреса. Так что да, ничего удивительного. Я знал, что тигра они должны впилить по дефолту, но когда читал faq я не просто не заметил...
Пересказ своими словами и лишь пара абзацев от себя %) Похоже надо ввести еще один тип статей помимо переводов — изложение.
Сам материал "пустой", местами даже вредный.
Если говорить о монге и проектировании приложений, то эта статья куда интереснее.
Сам материал "пустой", местами даже вредный.
Если речь иет о проекте в сфере «интернета вещей», где огромное количество всевозможных устройств и датчиков генерируют гигантские объёмы данных, вполне разумно будет использовать Cassandra.Ну вот как лишь по критерию объема данных делать выбор в пользу конкретной субд?
Если говорить о монге и проектировании приложений, то эта статья куда интереснее.
Вот перевод этой статьи.
Но авторы этой статьи снова взяли монгу там, где данные взаимосвязаны, а потом начали жаловаться, что БД плохая.
Но авторы этой статьи снова взяли монгу там, где данные взаимосвязаны, а потом начали жаловаться, что БД плохая.
Сталкивались со split brain? Или для вас это не критично
Мне очень http://arangodb.com/ нравится
OrientDB возможно получше монги субъективно, там есть связи, транзакции, schema-less и даже графы. Немного использовал и очень даже неплохо, но дальше hello world не заходил.
А минусовали то за Ориентир или за малоопытность? Хоть бы поясняли минусы. Ну народ, блин.
OrientDB — графовая субд, что уже переводит её в класс существенно более сложных систем. Она, мягко говоря, не вписывается в разговор.
Если говорить о применении. Пришлось недавно искать графовую базу и рассматривал в том числе OrientDB. Общая картина отзывов о ней — по началу безумный восторг, но когда проекты доходят до середины появляется ворох нерешаемых проблем. Создатели вкладываются в кучу фич, но до ума большинство не доводят, баги копятся. Принимать высокий риск вляпаться в проблемы желания не было.
Если уж очень хочется в сайтик вставить графовую базу, лучше посмотреть в сторону ArangoDB. Её позиционируют как универсальную базу удобную как раз для создания прототипов, когда модель данных может меняться. (Блин, ну 10 раз взвесьте сначала, нужна ли вам в проекте редкая сложная система, требующая других подходов. Все проблемы и вопросы придется задавать в гугл группе и ждать несколько дней ответ. При том, что в 99,99% случаев ваша модель не потребует ничего сложнее реляционности.)
з.ы. не минусовал.
Если говорить о применении. Пришлось недавно искать графовую базу и рассматривал в том числе OrientDB. Общая картина отзывов о ней — по началу безумный восторг, но когда проекты доходят до середины появляется ворох нерешаемых проблем. Создатели вкладываются в кучу фич, но до ума большинство не доводят, баги копятся. Принимать высокий риск вляпаться в проблемы желания не было.
Если уж очень хочется в сайтик вставить графовую базу, лучше посмотреть в сторону ArangoDB. Её позиционируют как универсальную базу удобную как раз для создания прототипов, когда модель данных может меняться. (Блин, ну 10 раз взвесьте сначала, нужна ли вам в проекте редкая сложная система, требующая других подходов. Все проблемы и вопросы придется задавать в гугл группе и ждать несколько дней ответ. При том, что в 99,99% случаев ваша модель не потребует ничего сложнее реляционности.)
з.ы. не минусовал.
Ну вообще я использовал OrientDB только как документно-ориентированную и она работает 1 в 1 как MongoDB на уровне кода и апи + даже есть возможность сделать схему данных. Читал про то что есть сырые фичи, которые выкатывают в релизы и просто с новыми фичами надо быть осторожнее.
Мне еще понравилось то, что она может встраиваться в Java проекты как embedded и работать без сервера. Отличный вариант для тех, кто ищет документно-ориентированную базу like MongoDB для проекта, но чтобы все работало как embedded из коробки.
P.S. Авторы OrientDB заявляют на сайте, что ее можно использовать и как графовую и как документно-ориентированную. Для каждого случая свое АПИ.
Мне еще понравилось то, что она может встраиваться в Java проекты как embedded и работать без сервера. Отличный вариант для тех, кто ищет документно-ориентированную базу like MongoDB для проекта, но чтобы все работало как embedded из коробки.
P.S. Авторы OrientDB заявляют на сайте, что ее можно использовать и как графовую и как документно-ориентированную. Для каждого случая свое АПИ.
Что ориент, что аранго, пытаются влезть в рынок баз и представляются как универсальные хранилища. Маркетинг. Графовая база более широкая (по разнообразию моделей данных) система, чем реляционные и NoSQL решения. Да, она может вместить в себя документо-ориентированную модель. Но её универсальность не позволяет быть оптимизированной под все случаи. Плюс одна из основных проблем графовых баз — это масштабируемость (заверяют, что решили её аранго и титан). Повторюсь, не стоит брать более сложный универсальный инструмент для относительно простой задачи, где есть специализированные инструменты.
Что сложного в графах? Это в таблицы раскладывать модели и джойнить талицы, чтобы получить данные обратно ложно. А пройтись по ссылкам — что может быть проще? Мои впежатления от использования графов очень положительные. И с какими-то нерешаемыми проблемами в ориенте я не стакивался.
Что сложного в графах?Из самого очевидного кластеризация.
Тут сложностей не больше, чем с таблицами. А в случае с ориентом даже меньше, так как он имеет встроенный map-reduce.
Кажется мы о разном. Я говорил о СУБД с точки зрения построения самой СУБД, а не потребительском использовании.
Если у вас всё ок с ориентом, то я рад. При наличии других решений ввязываться я не захотел.
Если у вас всё ок с ориентом, то я рад. При наличии других решений ввязываться я не захотел.
В ArangoDB тоже не всё ладно.
Зато в PostgreSQL всё просто идеально.
И всё же я не вижу принципиальной сложности графовых перед табличными. Вот перед key-value, разумеется есть.
Зато в PostgreSQL всё просто идеально.
И всё же я не вижу принципиальной сложности графовых перед табличными. Вот перед key-value, разумеется есть.
13 открытых багов против 372. 412 закрытых против 567.
Реляционку или Key-Value можно "порезать" на части (с возможной денормализацией), отшардировать и реплицировать. Попробуйте по кластеру размазать произвольный граф. Ситуация, когда связанные компоненты окажутся на разных нодах, скорее нормальная. Это оказывает большое влияние на консистентность и производительность.
Реляционку или Key-Value можно "порезать" на части (с возможной денормализацией), отшардировать и реплицировать. Попробуйте по кластеру размазать произвольный граф. Ситуация, когда связанные компоненты окажутся на разных нодах, скорее нормальная. Это оказывает большое влияние на консистентность и производительность.
Число багов ни о чём не говорит. Важно что это за баги. Ну а если не светить багтрекер наружу, как PostgreSQL, то вообще всё шоколадно.
Вы сейчас стравниваете ручной шардинг и автоматический, а не таблицы и графы. Таблицы и графы в плане шардинга ничем не отличаются. А вот автоматический шардинг (в субд) разумеется сложнее в реализации, чем ручной (в приложении).
Вы сейчас стравниваете ручной шардинг и автоматический, а не таблицы и графы. Таблицы и графы в плане шардинга ничем не отличаются. А вот автоматический шардинг (в субд) разумеется сложнее в реализации, чем ручной (в приложении).
если в MongoDB нет связей и возможностей по объединению двух таблиц,
А как же аналог LEFT JOIN — $lookup?
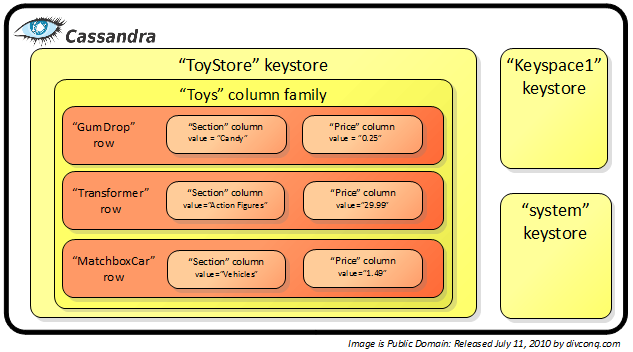
Строковые СУБД (например Cassandra)
С каких пор column-oriented называются строковыми? А традиционные РСУБД тогда что, интересно?
А column-family (которые теперь зовут просто таблицами) у неё просто так? И при использовании составных ключей wide rows лежат не в cf?
В документации на C* 1.0 они ещё говорили про column-oriented, упоминали column families и т. п. В 1.2 — уже нет. Но от того, что они поменляли терминологию суть не меняется.
В документации на C* 1.0 они ещё говорили про column-oriented, упоминали column families и т. п. В 1.2 — уже нет. Но от того, что они поменляли терминологию суть не меняется.
Колоночно-ориентированная субд отличается способом хранения данных. Она позволяет делать последовательные чтения с диска для получения данных из отдельных колонок. Предназначена для аналитических запросов. Часто умеет хорошо сжимать разреженные данные. Схема жестко задана. В качестве примера — формат хранения данных parquet. Данные бьются сначала на группы строк (это связанно с надежностью хранения), а внутри группы строк хранятся уже поколоночно. Схема внутри одной группы строк неизменяема.

Семейство колонок — это способ организации хранения в базах типа ключ-значение. Данные хранятся построчно. Доступ к строке по ключу. Внутри строки хранится список кортежей из двух элементов. Первый — имя колонки, второй — значение в данной строке и данной колонке. Это позволяет для каждого ключа иметь произвольный набор колонок.
Отличия между column и row oriented базами:

Семейство колонок — это способ организации хранения в базах типа ключ-значение. Данные хранятся построчно. Доступ к строке по ключу. Внутри строки хранится список кортежей из двух элементов. Первый — имя колонки, второй — значение в данной строке и данной колонке. Это позволяет для каждого ключа иметь произвольный набор колонок.
А column-family (которые теперь зовут просто таблицами) у неё просто так?Абсолютно верно, не просто так! Они потому и стали зваться таблицами, что это лучше отображает суть.

Отличия между column и row oriented базами:

Вижу, был неправ. Поглядел в исходники, table ещё много где называется cf и определяет директорию, где лежат sstable, а в sstable хранится уже по строкам. Видимо, их позиционирование во времени 0.6-0.8 и описания bigtable и hbase несколько смешало всё в кучу.
С тем что схема в column-oriented жестко задана не соглашусь. В паркете так, а в том же hbase — нет.
P. S. Похоже, теперь в комментариях нужно расставлять br руками..
С тем что схема в column-oriented жестко задана не соглашусь. В паркете так, а в том же hbase — нет.
P. S. Похоже, теперь в комментариях нужно расставлять br руками..
HBase тоже не колоночно-ориентированный.
Column-oriented — это еще один отдельный класс БД.
Хватит уже "раскапывать стюардессу". Какой MMAPv1 в 2016-м году?
Вот любят же про монгу писать статьи о старых версиях.
Лучше бы перешли на WiredTiger и написали — стало лучше или хуже. Было бы куда полезней, чем читать материал о практически устаревшем MMAPv1.
Вот любят же про монгу писать статьи о старых версиях.
Лучше бы перешли на WiredTiger и написали — стало лучше или хуже. Было бы куда полезней, чем читать материал о практически устаревшем MMAPv1.
Я стал использовать MongoDB только начиная с WiredTiger (3.2). Пока впечатления не очень хорошие из-за скорости Update.
на 700.000 записей toggle одного boolean поля занимает 3-5 секунд (Точнее запрос проекции {id, approve} и UpdateOne с {id,!approve}). Если сделать три таких запроса подряд, то 2-core Xeon на тестовом сервера умирает и захлебывается. Мне кажется, что это не очень хорошо.
Сами разработчики говорили, что будет минимум двукратная нагрузка на CPU по сравнению с MMAPv1.
на 700.000 записей toggle одного boolean поля занимает 3-5 секунд (Точнее запрос проекции {id, approve} и UpdateOne с {id,!approve}). Если сделать три таких запроса подряд, то 2-core Xeon на тестовом сервера умирает и захлебывается. Мне кажется, что это не очень хорошо.
Сами разработчики говорили, что будет минимум двукратная нагрузка на CPU по сравнению с MMAPv1.
Главное, что нужно понимать, это то, что не стоит использовать принципиально нереляционную БД в ситуации, когда у вас "реляционные" данные. А это, afaik, процентов так под 90 реальных кейсов в этом жестоком мире.
А то сначала они делают CRM на монге, а потом удивляются, почему для запроса "А покажи тех, кто зарегистрировался от полугода до года назад, живет в Москве, в последний месяц не делал заказов, а раньше делал в среднем на 1000 рублей в месяц или больше" требуется всё выкинуть, всех уволить и переписать заново...
Зато коллекции, json и schemaless, да.
А то сначала они делают CRM на монге, а потом удивляются, почему для запроса "А покажи тех, кто зарегистрировался от полугода до года назад, живет в Москве, в последний месяц не делал заказов, а раньше делал в среднем на 1000 рублей в месяц или больше" требуется всё выкинуть, всех уволить и переписать заново...
Зато коллекции, json и schemaless, да.
Данные не бывают реляционными, графовыми или еще какими-то. Реляционные они или нет — зависит от операций, об этом многие забывают. То, что сегодня укладывается в key-value запросы, завтра может потребовать джоинов, подзапросов, группировок.
Поэтому я бы перефразировал. Стоит использовать принципиально не реляционную СУБД, только если все сценарии работы с данными укладываются и будут укладываться в будущем в выборки по ключу и получение всей коллекции. Если такой уверенности нет, то лучше сразу взять РСУБД.
Поэтому я бы перефразировал. Стоит использовать принципиально не реляционную СУБД, только если все сценарии работы с данными укладываются и будут укладываться в будущем в выборки по ключу и получение всей коллекции. Если такой уверенности нет, то лучше сразу взять РСУБД.
Стоит использовать принципиально не реляционную СУБД, только если все сценарии работы с данными укладываются и будут укладываться в будущем в выборки по ключу и получение всей коллекции.
В этом случае стоит использовать kv storage. Но это далеко не все кейсы, когда необходимо использовать нереляционные СУБД.
Вопрос в подборе подходящей базы к задаче или её части. Где-то и графовые или rdf-движки нужны. А кому-то плевать на транзакции и strong consistency, но нужна хорошая горизонтальная масштабируемость и они берут кассандру, риак или ещё что-нибудь такое.
Еще раз. Способы обработки данных со временем меняются. На старте может казаться, что хватит и банального kv и обязательно будет 100500 миллионов пользователей и понадобится масштабирование.
Через год оказывается, что пользователей 10000, данные спокойно укладываются в sqlite, но нужны джоины для некоторых операций и транзакции.
Если на старте выбрать sql и правильно делать схему и запросы, то даже при 100500 миллионах пользователей приложения масштабируемость может не понадобиться.
Графовые базы нужны в одном случае — если задача решается обходом графа. Таких задач на практике немного. Но плохая новость в том, что графовые движки, зачастую, кроме обхода графа делать ничего не умеют.
Для обхода графа данные из базы можно просто в память затянуть. Или делать обход графа при записи, а не при запросе. Необходимость применять графовый движок для обхода есть не всегда.
Через год оказывается, что пользователей 10000, данные спокойно укладываются в sqlite, но нужны джоины для некоторых операций и транзакции.
Если на старте выбрать sql и правильно делать схему и запросы, то даже при 100500 миллионах пользователей приложения масштабируемость может не понадобиться.
Графовые базы нужны в одном случае — если задача решается обходом графа. Таких задач на практике немного. Но плохая новость в том, что графовые движки, зачастую, кроме обхода графа делать ничего не умеют.
Для обхода графа данные из базы можно просто в память затянуть. Или делать обход графа при записи, а не при запросе. Необходимость применять графовый движок для обхода есть не всегда.
Если вы не поняли, я специально процитировал ложную дихотомию из вашего предыдущего сообщения. Вы делите все случаи на те, где достаточно kv и все остальные, утверждая, что для них необходимо использовать rdbms, выкидывая из рассмотрения множество других классов баз данных со своими плюсами и минусами.
если все сценарии работы с данными укладываются и будут укладываться в будущем в выборки по ключу и получение всей коллекции
Эм… это точно о монге, а не о memcached или редисе? Потому как это покрывает максимум процент от возможностей mongoDB.
Memcached вообще не сохраняет на диск. Redis действительно используют как замену монге. Он получается и быстрее, и имеет несколько полезных фич вроде time series.
Несмотря на все возможности монги основная операция с ней — выборка и запись по ключу. Все остальное имеет подводные камни.
Несмотря на все возможности монги основная операция с ней — выборка и запись по ключу. Все остальное имеет подводные камни.
Монга это не key-value база данных вообще.
А я писал что монга это key-value база данных вообще?
основная операция с ней — выборка и запись по ключу
Выборка по ключу подразумевает наличие ключа!
В монге выборка идет по запросу к содержимому документа.
В запросе могут использоваться OR,AND,<,<=,>,>=,not,exists и многое другое, включая поиск глубоко в подполях и подмассивах, полнотекстовый поиск, регулярные выражения, нахождение ближайших элементов по географическим координатам и так далее. К результатам выборки применяются сортировка, distinct, пагинация, объединение с данными из другой коллекции по LEFT JOIN, получение только выбранных полей документа, сложные группировки и агрегации, получение количества элементов в выборке и многое другое.
Все эти запросы делают полное сканирование коллекции.
Не делают, если настроены индексы для полей. Как и в SQL. Вы уделите время, ознакомьтесь с вопросом, монга это совсем не Redis.
Я в курсе как оно работает. Индексы в монге на порядок слабее, того что есть в любой рсубд.
Диалог в ветке шел о сравнении mongo с k/v хранилищами типа Redis, теперь вы зачем-то начинаете сравнивать монгу с реляционными базами, хотя я с ними не сравнивал. Ну допустим. В чем конкретно индексы на порядок слабее?
1) Не оценивается селективность индекса, используется первый подходящий, возможно не самый эффективный или даже бесполезный
2) Индексы должны влезать в память, чтобы быть эффективными
3) Нельзя сделать покрывающие multikey индексы
4) Про индексирование вычисляемых полей или индексированные представления молчу вообще
2) Индексы должны влезать в память, чтобы быть эффективными
3) Нельзя сделать покрывающие multikey индексы
4) Про индексирование вычисляемых полей или индексированные представления молчу вообще
1) Если по полям выборки существует несколько индексов, а проверить какой используется при конкретном запросе через explain лень, то достаточно легко в самом запросе указать, какой использовать, чтобы уж точно.
2) Здесь, пожалуй, соглашусь. Хотя оперативка сейчас довольно дешевый ресурс, можно и всю базу зачастую вытащить, не то, что индексы. Интересен механизм работы SQL, когда индексы находятся на диске и не влезают в оперативную память, на сколько понимаю, там производительность не проседает?
По остальным пунктам — решение задач реляционных баз данных. Не будем же мы считать отсутствие индексов представлений недостатком, если самого понятия представлений в mongo нет.
2) Здесь, пожалуй, соглашусь. Хотя оперативка сейчас довольно дешевый ресурс, можно и всю базу зачастую вытащить, не то, что индексы. Интересен механизм работы SQL, когда индексы находятся на диске и не влезают в оперативную память, на сколько понимаю, там производительность не проседает?
По остальным пунктам — решение задач реляционных баз данных. Не будем же мы считать отсутствие индексов представлений недостатком, если самого понятия представлений в mongo нет.
1) Я видел в продакшене MongoDB на пяти разных проектах. Как ни странно, только в одном из них использовались индексы. Вообще есть тенденция, что на Mongo и другие NoSQL переходят те, кто не освоил SQL. Поэтому плотность правильного использования индексов в Монге в разы ниже, чем в РСУБД. А рассчитывать на то, что кто-то будет лезть с explain в монгу и выяснять какой там индекс, я бы вообще не стал.
2) Все РСУБД проектируются с рассчетом, что данные не влезают в ОП. Поэтому более-менее терпимо работают, когда индексы или данные не влезают в память. NoSQL базы обычно исходят из другого предположения — что данные и индексы будут находится в памяти в момент запроса. Если это так, то ответ отдается быстро, если нет, то давай до свидания. Монга в случае недостатка памяти тормозит очень сильно. Индексы съедают эту самую память, вытесняя данные.
2) Все РСУБД проектируются с рассчетом, что данные не влезают в ОП. Поэтому более-менее терпимо работают, когда индексы или данные не влезают в память. NoSQL базы обычно исходят из другого предположения — что данные и индексы будут находится в памяти в момент запроса. Если это так, то ответ отдается быстро, если нет, то давай до свидания. Монга в случае недостатка памяти тормозит очень сильно. Индексы съедают эту самую память, вытесняя данные.
Я видел в продакшене MongoDB на пяти разных проектах. Как ни странно, только в одном из них использовались индексы.
Может быть они воспринимают ее только как кейс для "выборки и запись по ключу" или считают, что "все запросы делают полное сканирование коллекции"?
В свое время я ознакомился с большим количеством чужих проектов, в основном php+mysql. Так вот индексы присутствовали немногим чаще, чем никогда. А вроде бы не mongo. Так-что вопрос квалификации разрабов наверное не связан с кокретной бд. Хотя монга действительно значительно проще в использовании, особенно если проект на node.js, и это оправдывает многие недостатки, если учесть их в процессе проектирования.
MongoDB использовать не стоит хотя бы по той причине, что до недавнего времени она не гарантировала strong consistency. База данных, которая возвращает клиенту ACK на запись, но при этом не гарантирует то, что эта запись на деле персистентна — это мусор, о ней нельзя говорить всерьез.
Как качественно бомбит у сторонников Mongo. Господа, не стесняйтесь, расскажите что у вас за кейсы где вы можете потерять часть данных и это не повлечет последствий.
меня вовсе не "бомбит", однако я подозреваю, что определенная неграмотность замечания и вызвала то, что ты видишь. Совсем непонятно о чем это ты говорил, если про write concern который в какой-то древней версии несколько лет назад был по умолчанию самый низкий — ну это вполне понятно удивляет некоторой… неактуальностью. Кроме того "не гарантировала strong consistency" видимо подразумевает что сейчас оно это гарантирует? Тут тоже много удивлений может быть вызвано у читателя, т.к. во первых там все не так прямо, а во вторых речь идет о продукте, который eventually consistent с разной степенью этой "eventually".
Я говорю о всем множестве «особенностей» mongo.
1. Про write concern, когда терялись записанные и ACK'нутые данные в самом строгом режиме записи. В середине 2013 (меньше 3 лет назад) он, насколько я вижу, был еще актуален. База к тому времени существовала 4 года (и видимо эти 4 года не гарантировала совсем ничего в смысле целостности данных). 3 года это вообще не срок, у иных традиционных БД аптайм больше.
2. Проблема eventual consistency в том, что это самое eventual может не наступить никогда. Я не зря спрашиваю про кейсы использования. По большому счету сценариев где можно взять и потерять часть данных — не так уж много. Я практически уверен, что существенная часть пользователей mongo плохо понимает этот ньюанс.
3. Отсутствие вменяемого, доказанного алгоритма согласования данных при передаче лидерства. Даже несмотря на то, что есть определенные проблески в виде мажорити и выбора лидера. Почему написал «не гарантировала» — потому что сейчас там Tokutek то ли пишет, то ли уже написал имплементацию движка, основанную на Raft, и дела пожалуй станут несколько лучше.
Вот хорошая ссылка по делу: https://aphyr.com/posts/284-jepsen-mongodb
1. Про write concern, когда терялись записанные и ACK'нутые данные в самом строгом режиме записи. В середине 2013 (меньше 3 лет назад) он, насколько я вижу, был еще актуален. База к тому времени существовала 4 года (и видимо эти 4 года не гарантировала совсем ничего в смысле целостности данных). 3 года это вообще не срок, у иных традиционных БД аптайм больше.
2. Проблема eventual consistency в том, что это самое eventual может не наступить никогда. Я не зря спрашиваю про кейсы использования. По большому счету сценариев где можно взять и потерять часть данных — не так уж много. Я практически уверен, что существенная часть пользователей mongo плохо понимает этот ньюанс.
3. Отсутствие вменяемого, доказанного алгоритма согласования данных при передаче лидерства. Даже несмотря на то, что есть определенные проблески в виде мажорити и выбора лидера. Почему написал «не гарантировала» — потому что сейчас там Tokutek то ли пишет, то ли уже написал имплементацию движка, основанную на Raft, и дела пожалуй станут несколько лучше.
Вот хорошая ссылка по делу: https://aphyr.com/posts/284-jepsen-mongodb
Мне кажется, всю свою историю, человечество старалось систематизировать данные которые надо хранить и обрабатывать в дальнейшем. То есть связать их и упорядочить. Реляционные СУБД подходят для этого хорошо. К тому же сейчас уже, в них, для особых случаев, добавляют элементы документоориентированных БД (поля-массивы, поля-JSON).
Плюс, постоянно растут вычислительные и коммуникационные возможности, размеры и скорости хранилищ. Конечно, и объемы данных растут. Но кому они нужны если будут представлять собой, грубо, кучу, единственный плюс которой это возможность сравнительно задешево раскидать ее по нескольким свалкам :)
Плюс, постоянно растут вычислительные и коммуникационные возможности, размеры и скорости хранилищ. Конечно, и объемы данных растут. Но кому они нужны если будут представлять собой, грубо, кучу, единственный плюс которой это возможность сравнительно задешево раскидать ее по нескольким свалкам :)
Для логов лучше исспользовать time-series db.
Cassandra хороша когда нужна очень большая горизонтальная маштабируемость и гарантированое время записи.
Redis — если данные хорошо ложатся в парадигму ключ-значение, по факту это кеш в памяти с дублированием на диск. Возможно к вашему решению RADIUS были дополнительные требования не указанные в заметке, но согласно описания он вам подошёл бы лучше.
Для поднятия редко исспользуемых данных, можно реализировать сервис "прогрева", который поднимает данные с некоторой периодичностью.
Cassandra хороша когда нужна очень большая горизонтальная маштабируемость и гарантированое время записи.
Redis — если данные хорошо ложатся в парадигму ключ-значение, по факту это кеш в памяти с дублированием на диск. Возможно к вашему решению RADIUS были дополнительные требования не указанные в заметке, но согласно описания он вам подошёл бы лучше.
Для поднятия редко исспользуемых данных, можно реализировать сервис "прогрева", который поднимает данные с некоторой периодичностью.
А как можно совместить реляционные СУБД и документированные?
Я считаю, что пример с блогом не очень удачный. Если я хочу посмотреть все комментарии одного пользователя, как мне делать выборку и насколько это будет быстрым?
Кто-то может назвать более подходящий пример использования MongoDB?
Я сразу оговорюсь, я пользуюсь только SQL, но очень интересны случаи использования NoSQL и где это может реально пригодится. Спасибо
Кто-то может назвать более подходящий пример использования MongoDB?
Я сразу оговорюсь, я пользуюсь только SQL, но очень интересны случаи использования NoSQL и где это может реально пригодится. Спасибо
Если я хочу посмотреть все комментарии одного пользователя
db.comments.find({userID: 100500}).sort({date: -1})
Для комментариев отдельная коллекция что ли?
Ведь подразумевается, следующая структура: User -> Posts -> Comments
Ведь подразумевается, следующая структура: User -> Posts -> Comments
Сначала неверно истолковал вопрос, в таком случае требуется агрегация с группировкой:
Рабочая, проверил. Но если честно, впервые пишу выборку для такой структуры, может более опытные товарищи смогут написать агрегацию лаконичнее.
db.posts.aggregate([{
$project: {
items: {
$filter: {
input: "$comments",
as: "comm",
cond: {
$eq: ["$$comm.userID", 10]
}
}
}
}
}, {
$group: {
_id: "all",
messages: {
"$push": "$items"
}
}
}]);Рабочая, проверил. Но если честно, впервые пишу выборку для такой структуры, может более опытные товарищи смогут написать агрегацию лаконичнее.
А вот-так даже красивее гораздо:
db.posts.aggregate([{$unwind : "$comments"}, {$match: {"comments.userID": 10}}]);1) Как вытащить пост с комментами и их авторами для страницы поста?
2) Как вытащить пост с количеством комментов для главной?
2) Как вытащить пост с количеством комментов для главной?
1)
2)
db.posts.aggregate([
{$lookup: {"from": "comments", "localField": "_id", "foreignField": "postID", "as": "comments"}}, {$unwind : "$comments"},
{$lookup: {"from": "users", "localField": "comments.userID", "foreignField": "_id", "as": "comments.user"}},
{$group : { _id: "$_id", comments: {$push: "$comments"}}}
]);2)
db.comments.aggregate([
{$group: {_id: "$postID", count: { $sum: 1}}},
{$lookup: {"from": "posts", "localField": "_id", "foreignField": "_id", "as": "post"}},
]);Sign up to leave a comment.
За и против: Когда стоит и не стоит использовать MongoDB