В руках нашей команды из CleverDATA оказался уникальный материал – около 100 тыс. страниц англоязычных блогов, посвященных бьюти-сфере. Этот корпус к нам попал благодаря желанию одной косметической корпорации узнать законы, по которым «работает» блогосфера. Компания хотела эффективнее взаимодействовать с бьюти-блогерами – получать больший рекламный эффект, отдавая свои продукты в добрые руки лояльных авторов.

Источник
Большинство компаний пристраивают свои продукты в блогерские обзоры, опираясь на интуицию и профессионализм маркетологов. Фактически бренды двигаются вслепую, потому что личные знакомства с блогерами, дружеские связи и договоренности без статистических данных и аналитических выкладок иной раз оказываются очень ненадежными.
Скажу сразу, мы выяснили следующее:
Думаю, что наши наиболее интересные открытия, которым и посвящена эта статья, будут полезны всем, кто так или иначе соприкасается с продвижением продуктов в Сети. Например, зависит ли популярность блога от активности блогера и как аудитория реагирует на общее настроение поста. А мне, помимо этого, на примере анализа блогосферы хочется рассказать о возможностях Text mining.
Трудясь над проектом, мы выработали ряд подходов и приемов, которые в нашем случае показали хорошие результаты, но применять их на любом другом корпусе без калибровки малоэффективно. Поэтому я не стал приводить код, зато подробно рассказываю о самом корпусе, используемых методиках и главных выводах.
Итак, поехали!
Не секрет, что текстовая информация является одним из основных типов информации в современном обществе, поэтому анализ текстов способен не только раскрыть неявные закономерности, но и принести пользу в коммерческом приложении.
Нам не пришлось собирать данные – массив был собран ранее, в результате краулинга бьюти-блогов. Правда, для наших задач он оказался очень сырым и потребовал предварительной обработки. Кроме того, тексты естественно не были размечены, поэтому не было возможности использовать инструменты машинного обучения с учителем.

Источник
Массив бьюти-блогов состоял из порядка 100 тыс. страниц, а точнее 98 496. Мы сначала обрадовались: 100 тыс. страниц — это хороший корпус для предстоящего исследования. Но выяснилось, что он очень сильно зашумлен, и после очистки осталось только 59.6%, пригодных для анализа.
40.4% данных составили пустые страницы и страницы с ошибками, страницы не на английском языке (23,461), фото- и видеоматериалы без текста (2,315), статьи с ресурса techcrunch.com, не имеющего отношения к бьюти-индустрии (очевидно, это ресурс, на котором тестировался краулер, собирающий материал, и его вклад в общем корпусе оказался заметным – 3,402 страниц).
Конечно, получить в распоряжение почти 60 тыс. страниц, годных для анализа, тоже неплохо. Выяснилось, что этому объему текста соответствуют около 2 тыс. уникальных блогов, то есть за вычетом клонированных и схожих материалов этот объем текста создали две тысячи уникальных авторов.

Источник
Блоги на тему красоты и здоровья – это преимущественно женская тема. Если точный гендерный состав всей англоязычной блогосферы под вопросом, то в блогах о косметике и здоровом образе жизни всё однозначно: здесь большинство авторов и читателей – женщины. О чем говорят эти женщины в блогах? Это главный вопрос, который нам предстояло решить, чтобы понять, как наиболее эффективно продвигать товары бьюти-индустрии в блогосфере. Для ответа на этот ключевой вопрос, сначала попробуем исследовать, как говорят женщины в блогах.
Авторский стиль блогеров, конечно, различается. Но по размеру постов их авторов можно объединить в две группы: блогеры-миниатюристы с постами до 100 слов (20% всех авторов), и блогеры, предпочитающие полновесные тексты из 200-500 слов (~80%).
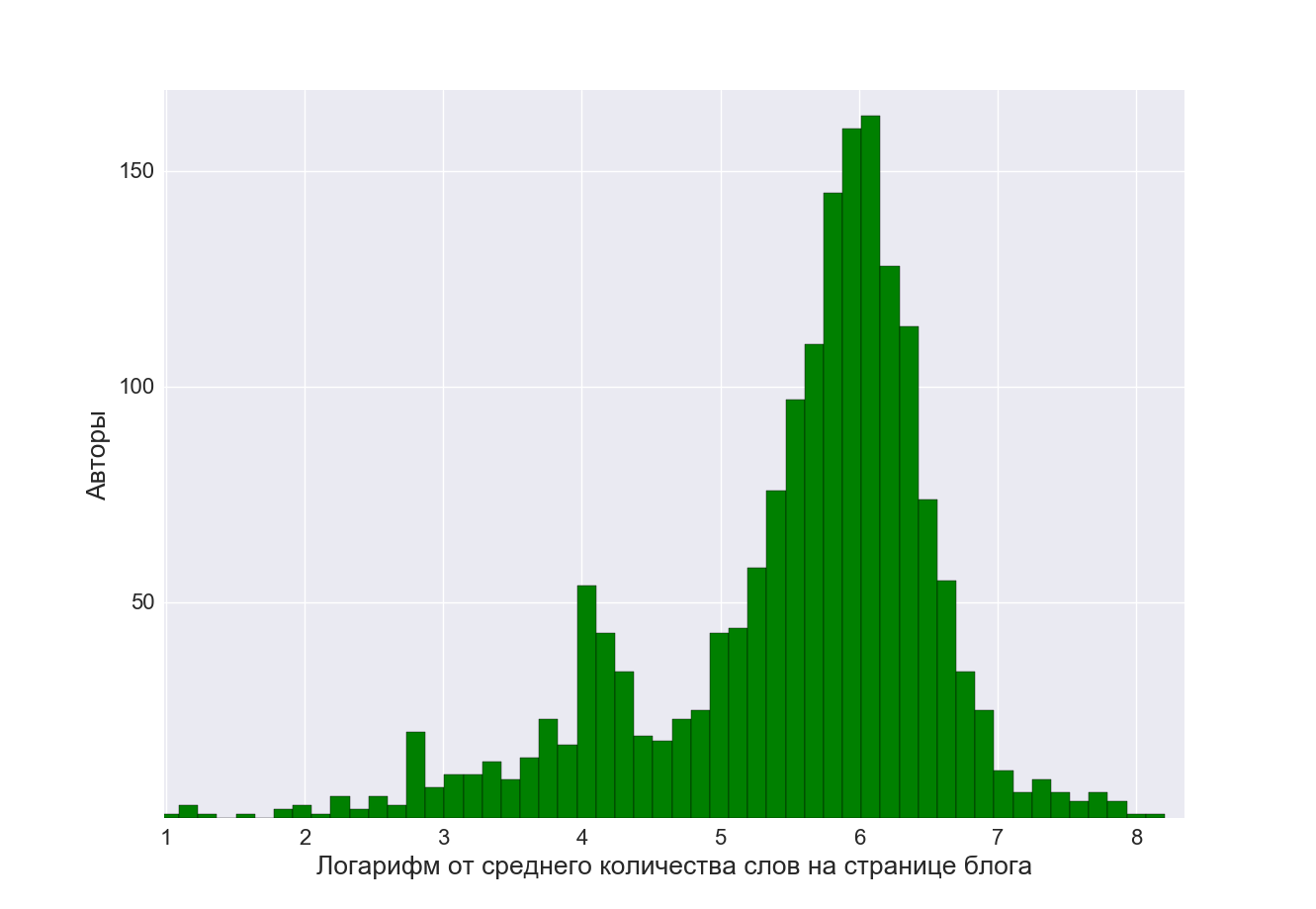
Любопытна корреляция между многословностью авторов и их активностью. Нельзя сказать, что коротеньких постов написано больше, чем многословных, и что любители писать в формате Твиттера берут количеством публикаций. Отнюдь. Мы увидели, что активность авторов из двух групп схожая.
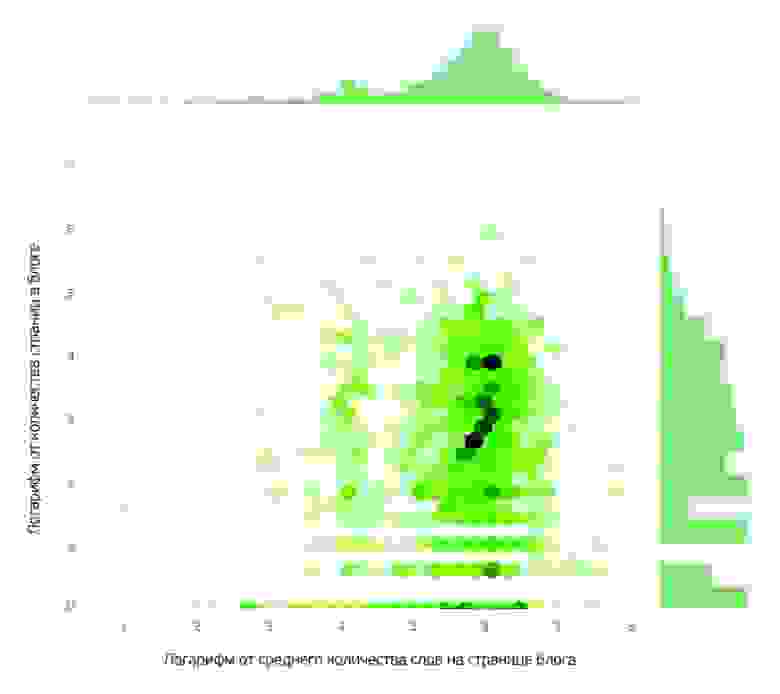
Анализ показал, что очень мало авторов пишут активно. Не более 20 авторов с момента появления блога успели написать свыше 300 постов, в большинстве блогов – до 100 постов, что укладывается в рамки обычной статистической закономерности.

Мы посмотрели на дискуссии в блогах и выяснили, что посты очень малого числа блогеров набирают более 40 комментариев. Статьи большинства авторов обсуждаются не столь активно, и на одну публикацию в среднем приходится 10-20 комментариев.

Первое, что приходит в голову, когда мы говорим об исследовании текста, – это анализ тональности текста, то есть оценка эмоций автора – положительные ли они или отрицательные. Моделей анализа эмоциональной окраски на сегодня предложено много. Поэтому мы не стали изобретать велосипед и использовали готовые модели:
Каждая модель оценки эмоционального окраса была натренирована на своем отдельном корпусе текстов. Одна давала хорошие результаты на коротких текстах (т.к. тренировалась на корпусе Твиттера), другая – на более развернутых текстах (корпус IMDB). У каждой из моделей свои сложности с окрасом нейтральных текстов, но поскольку мы использовали 4 модели, они сгладили некоторые недостатки друг друга и получилось гладкое распределение, где -1 означает крайне отрицательную эмоциональную оценку, а +1 крайне положительную.
Комбинация четырех независимых моделей дала следующее распределение текстов по эмоциональной окраске.
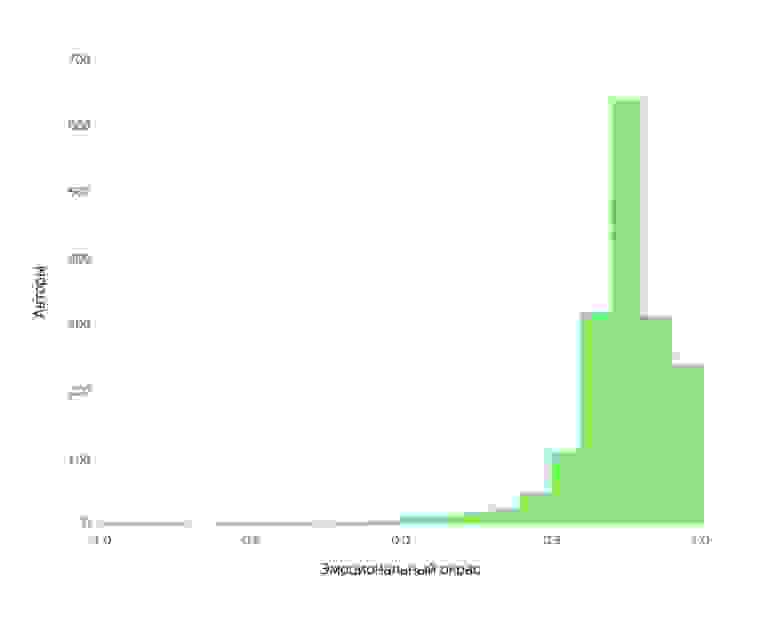
Мы видим ассиметричное квазинормальное распределение с центром в районе 0.72 и тяжелым правым хвостом. Это означает, что абсолютное большинство блогов имеют позитивную эмоциональную тональность. Смещение средней эмоциональной окраски в положительную область является удивительным фактом, о котором можно говорить с высокой статистической значимостью и который можно легко проверить самостоятельно, прочитав несколько взятых наугад женских блогов.
Если посмотреть, как распределены блогеры по их активности (анализ количества страниц), можно обнаружить, что самые плодовитые блогеры по эмоциональному окрасу работают в очень узком диапазоне: 0.74 ± 0.03.
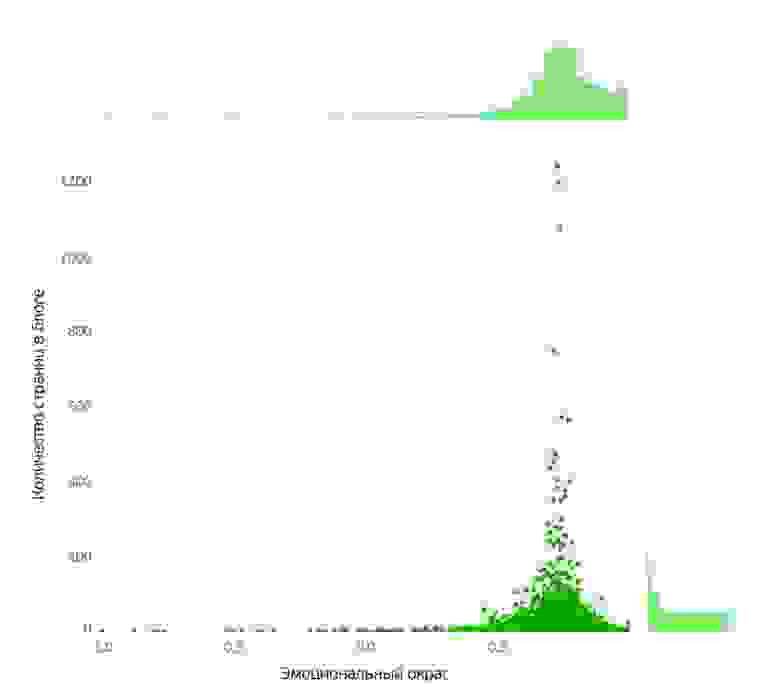
В данном случае очень любопытно, что профессиональные блогеры работают в столь узком диапазоне эмоциональной окраски – как будто используют некоторую резонансную частоту своей аудитории. Возможно, получается система с обратной связью: автор с нейтральной статьей получает обратную связь от читателей через комментарии и в следующий раз подстраивается под восторженное настроение аудитории.
Можно предположить, что столь узкий диапазон настроений связан с профдеформацией. Однако нашиконкуренты коллеги в своих исследованиях текстов в Интернете свидетельствуют, что позитивная окраска свойственна женской форме общения, в то время как эмоциональный оттенок мужских разговоров ближе к нейтральному.
Зависит ли обсуждаемость блога от его активности? К удивлению, нет. В наиболее активных блогах мы видим меньше комментариев.
Возможно, это связано с тем, что активные блогеры с большой аудиторией уже завоевали такой авторитет, что с ними тяжело спорить.
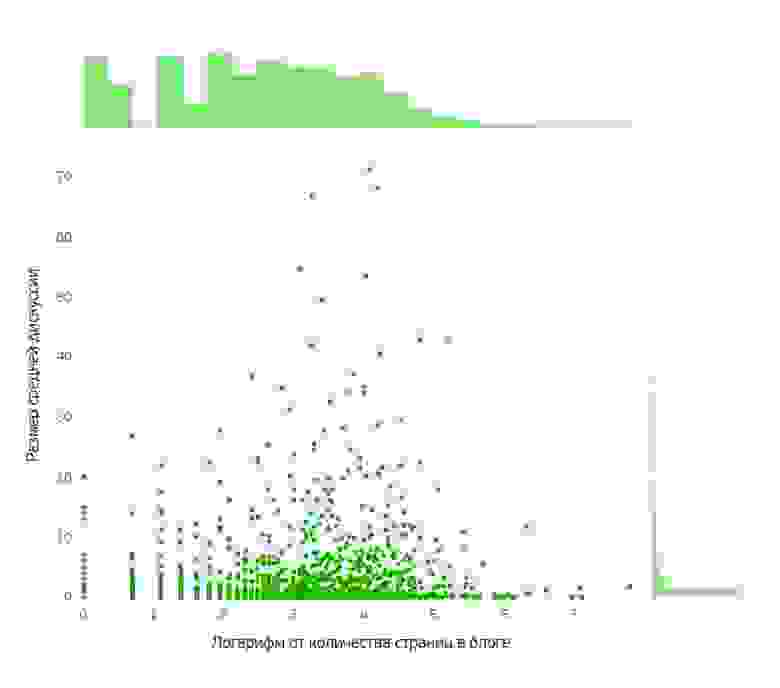
Зависимость обсуждения от эмоционального окраса стала для нас сюрпризом. Наиболее обсуждаемые блоги находятся в позитивной области эмоционального окраса. Стоит иметь в виду, что это (как показано на графиках выше) не самые активные блоги. Вывод очевиден: чтобы вызвать обсуждение, оказывается, достаточно просто что-нибудь похвалить не в меру.
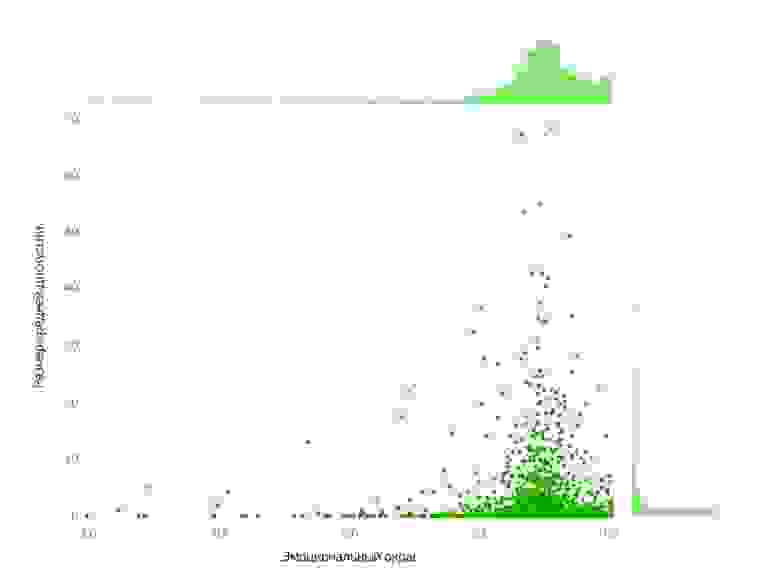
Чтобы оценить эффективность блогов, с точки зрения распространения информации (читают ли их, делают ли перепосты), мы попробовали воспользоваться готовыми инструментами для оценки Интернет-трафика.
Среди метрик, отражающих количество читателей и цитирования в сети, выделю следующие.
Alexa Rank – популярный счетчик числа посетителей и количества просмотров сайта, устанавливается далеко не на всех Интернет-ресурсах, поэтому не всегда можно воспользоваться его данными.
Yandex Thematic Citation Index (TIC, тематический индекс цитирования Яндекса) определяет «авторитетность» Интернет-ресурса с учетом качественной характеристики ссылок на него с других сайтов, однако не очень распространён в англоязычном сегменте Сети
Google Page Rank – подсчитывает количество и качество ссылок на блог, чтобы оценить значимость ресурса для аудитории; является основным показателем для раскрутки сайтов. Главное преимущество Google Page Rank в том, что он присутствует у всех сайтов, но у многих веб-страниц он явно неадекватный (и в этом его большой недостаток). Кроме того, из-за условий лицензионного соглашения есть ограничения на использование Google Page Rank, что затрудняет использование его даже для таких исследований, как наше.
Все вышесказанное определило наш выбор: мы попробовали YandexTIC и AlexaRank. Отмечу, что все эти метрики связаны с объемом аудитории (сколько раз автор цитируется, как много его читают), обладают своими недостатками и поэтому не могут претендовать на статус исчерпывающего. Поэтому стоит поискать дополнительные инструменты для оценки популярности автора.
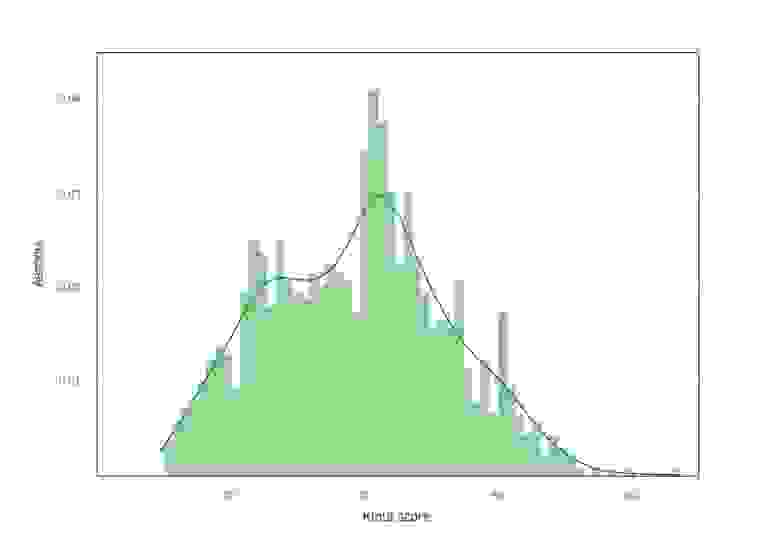
Чтобы как-либо еще измерить популярность авторов, мы прибегли к Klout score. Эта метрика используется в социальных сетях, чтобы оценить влияние человека: его социальные связи и цитируемость его постов. Эта, независимая от предыдущих, метрика оценивает и аудиторию читателей, и количество репостов именно в соцсетях. Примечательно, что с Klout score был связан громкий случай в 2011 году: на должность вице-президента одной из компаний претендовало два кандидата, один из которых 15 лет консультировал гигантов типа America Online, Ford и Kraft, второй же не мог похвастаться столь выдающимся опытом, но имел весомый козырь – Klout score, равный 67. В упомянутом случае позицию получил кандидат с более высоким Klout score. В нашем случае оказалось, что для наших авторов средний показатель Klout score составляет 40.1. Возможно, для вице-президента с пятнадцатилетним стажем такой Klout score будет низок, но для наших блогеров это нормальное значение: исследуемые бьюти-блогеры не являются центрами гигантских социальных скоплений, «наши» блогеры по своим характеристикам ближе к обычным людям со средней активностью в сети.
Если проследить взаимосвязь Klout score и эмоционального окраса, можно обнаружить интересную тенденцию.
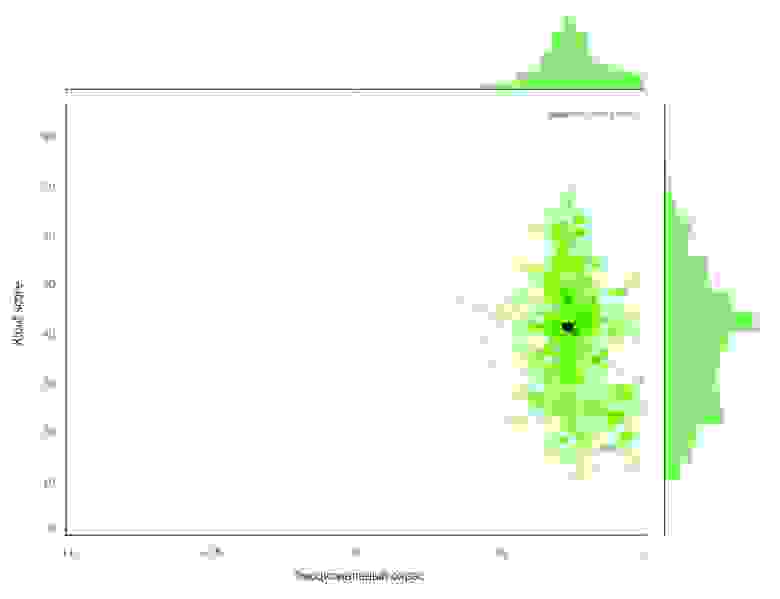
На графике видно, что есть группа блоггеров, у которых Klout score низкий, а эмоциональный окрас явно выше «резонансной» величины. Это значит, что такой автор только начинает писать (поэтому мало статей), но эмоциональный окрас текстов у него завышен. Возможно, это психологический феномен, связанный с новой деятельностью: автор пытается приукрашивать либо специально, либо у него «розовые очки», т.е. он сам находится в изрядно приподнятом настроении. В любом случае, если автор будет продолжать писать, он эволюционирует на более низкие эмоции по обратной связи в комментах.
Мы работали с торговой маркой, настоящее имя которой мы, конечно, не раскроем и в статье для удобства назовём ее «Баба Яга». Все продукты этой торговой марки имеют расширенные, многословные названия, например, «Крем для лица Баба Яга».
Мы применили технику Fuzzy String Matching на весь корпус текстов и попытались найти упоминания бренда и его продуктов во всех текстах.
Fuzzy String Matching основана на анализе расстояния Левенштейна, которое указывает на буквенные различия в словах. Строго говоря, расстояние Левенштейна определяет минимальное количество изменений одного символа (его удаления, замены, добавления), необходимых для превращения одного слова в другое. Расстояние, полученное с помощью модуля Python fuzzywuzzy, нормировано в диапазоне от 0 до 100. Таким образом, абсолютно различные слова будут иметь меру похожести, равную 0, а тождественные слова будут иметь меру похожести, равную 100. Например, в бородатом анекдоте о разнице между хлебом и пивом мера похожести будет равна нулю: чтобы из хлеба получить пиво, нужно заменить все четыре буквы.
Необходимо отметить, что нам повезло с названиями продуктов бренда, т.к. они не были односложными (как известное мыло «Удав»), а состояли из нескольких слов, по которым можно было понять тип и отчасти назначение продукта, например, «Масло для лица Баба Яга». Fuzzy String Matching позволяет с соответствующими настройками отлавливать частичное упоминание, например, «Face Oil», и мы пытались на этом играть.
Посты, в которых искомый продукт упоминался на 90% по метрике Fuzzy String Matching, отмечались в качестве «хороших». У бренда было около 100 продуктов, таким образом каждая статья проходила проверку для каждого продукта более 100 раз.
Рейтинг релевантности для автора брался как сумма всех «хороших» статей. Нормировка на количество статей не вводилась намеренно, чтобы авторы с бОльшим количеством статей вырвались вперед.
Впоследствии мы использовали натуральный логарифм от полученного рейтинга. Например, авторы с 30, 10 и пятью «хорошими» статьями получали соответствующий рейтинг релевантности 3.4, 2.3 и 1.6.
Подход несложный, однако за счет большого количества статей и большого количества продуктов начинали работать закон больших чисел и ЦПТ (центральная предельная теорема), и мы получали разумные оценки.
Чтобы ускорить процесс и повысить точность, мы перешли на использование расстояния, полученного с помощью модели Word2Vec, однако даже при первоначальном подходе мы получили результат, который можно использовать в дальнейшей работе.
На основе перечисленных техник мы построили рейтинг авторов. Он базируется на:

Следует обратить внимание, что мы не отдаём предпочтение блогерам с большим количеством страниц, потому что встречаются как активные блоги с объемом более 500 постов, так и малоактивные авторы с числом постов менее 100. Также нет предпочтений по количеству комментариев. Отмечу, что по уровню эмоционального окраса они все положительные и работают в диапазоне от 0.70 до 0.78.
Мы внимательно изучили лидера списка. Оказалось, что у него опубликована статья, посвященная нашему бренду. Это была хвалебная ода всему бренду, без анализа и описаний конкретных продуктов.
Итак, рейтинг блогеров построен, теперь нужно связать авторов и продукты, которые им можно отдать для обзора. Для этого нужно:
Продукты для продвижения были выбраны практически произвольно. Фактически выбор пал на них из-за того, что статистика их продаж серьезно выделялась на фоне остальных продуктов.
Первые два продукта пользовались большой популярностью, а значит, можно было еще больше увеличить число потенциальных покупателей.
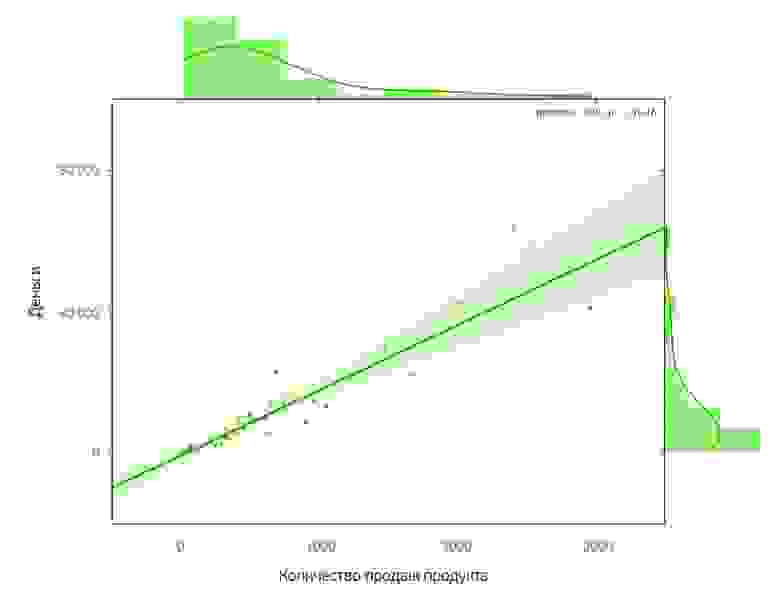
Вторые два выбранных продукта совсем недавно вышли на рынок и еще не успели показать себя в полной мере. Продвижение им точно не помешало бы. Эти продукты выделяются на графике зависимости стоимости продукта от количества его продаж.
 В принципе такой анализ можно провести для любого из продуктов. Выбор конкретного продукта не принципиален.
В принципе такой анализ можно провести для любого из продуктов. Выбор конкретного продукта не принципиален.
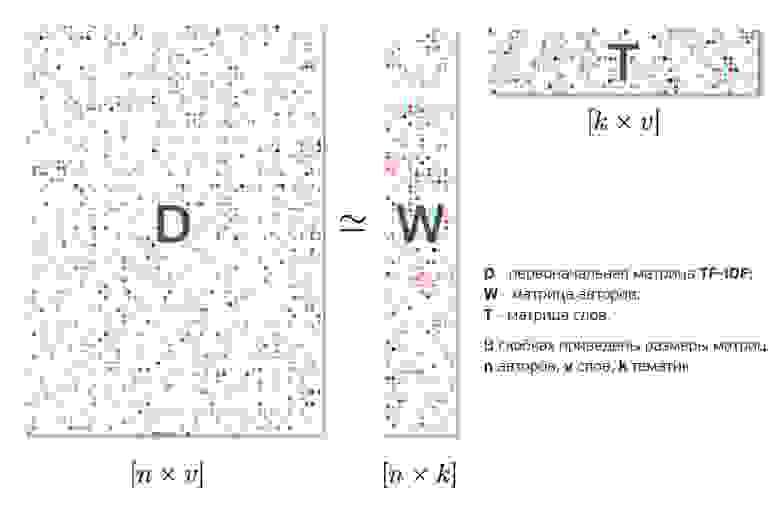
В блогах каждого автора можно найти темы, интересные для продвижения бренда. А о чем вообще пишут авторы? Чтобы узнать список тем каждого блога, составим матрицу, каждая строка которой будет соответствовать посту, в столбцах укажем ключевые слова, а цвет ячеек будет означать индекс TF-IDF (про применение метода TF-IDF можно почитать, например здесь и здесь) – частотную характеристику ключевого слова. Соответственно, чем более интенсивно окрашена ячейка, тем больше упоминаний слова мы нашли и тем важнее это слово в контексте. Примеры слов для формирования таблицы: «макияж», «лицо», «тело», «скраб», «лосьон», «масло», «очищение», «кондиционер» и т.д.
Далее применяется метод NMF, который позволяет разложить нашу матрицу на две поменьше: «авторы»/«промежуточное измерение» и «промежуточное измерение»/«слова». Единственное наложенное нами условие факторизации – величины должны быть не негативны, то есть они все должны быть больше либо равны 0.
«Промежуточное измерение» в данном случае можно интерпретировать как темы. Таким образом, мы разложили авторов на темы их текстов.
Используемый метод NMF для получения тематик текстов обычно может конкурировать с методами LDA и LSA (pLSA), однако нельзя не упомянуть еще один сильнейший инструмент в этой области: BigARTM, на который мы переходим в данный момент. Необходимо отметить, что базовая идея разложения матрицы присутствует и в методе BigARTM, однако его преимущество заключается в гибкой возможности использоваяния регуляризаторов
Теперь нужно сопоставить название продуктов бренда с выделенными темами. Это возможно сделать и с помощью уже использованного подхода Fuzzy String Matching, но лучше и точнее использовать дистанцию, измеренную с помощью модели Word2Vec.
Здесь следует учесть один момент: если название продукта полностью прописано в заголовке поста, скорее всего, это был обзорный пост, то есть автор уже писал о продукте и ему не стоит предлагать сделать это еще раз.
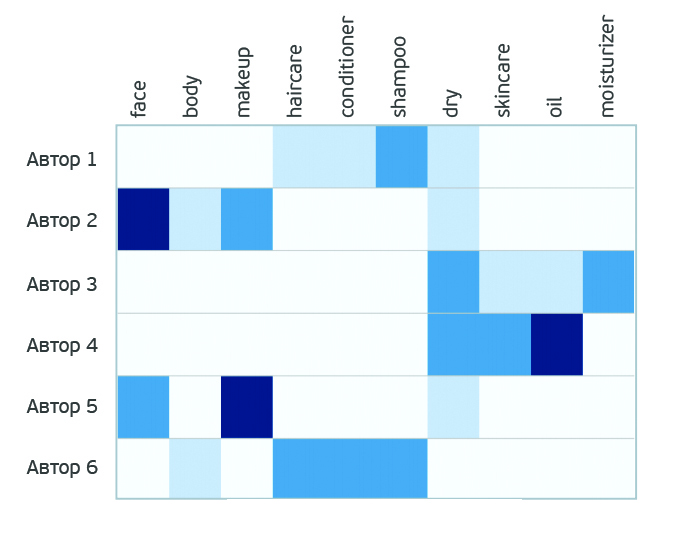
Получаем красочную матрицу, где цветом обозначена степень корреляции автора с продуктом. Матрица «авторы-продукты» отсортирована по нашему рейтингу авторов.
Рейтинг авторов отчасти базировался на упоминаемости продуктов бренда в текстах. После сортировки по рейтингу авторов можно наблюдать цветовое распределение, которое сосредоточено на авторах с высоким рейтингом и затухающее по мере уменьшения рейтинга.

Это цветовое распределение было получено с помощью отдельного математического подхода (TF-IDF, NMF, etc), и оно хорошо согласуется с нашим первоначальным результатом, полученным с помощью простых подсчетов упоминаний. Таким образом, мы с одной стороны подтверждаем адекватность своего рейтинга, а с другой стороны показываем разумность результатов, полученных с помощью ряда более сложных математических приемов. Согласованность результатов, полученных различными методами, говорит в нашу пользу.
Для продвижения продукта нам не нужно задействовать много человек. Возьмём первые сорок авторов. Для них матрица будет выглядеть следующим образом:

Из матрицы «автор-продукт» мы извлекаем наиболее резонансные пики, после чего колонка с пиком отбрасывается. Таким образом, для каждого автора мы получаем только один продукт. Итак, наша цель достигнута: связь авторов с продуктами установлена.
Таким образом, по результатам исследования первоначального корпуса статей бьюти-блогов с использованием метрики социальной активности Klout score, а также с учетом эмоционального окраса статей, нами был обнаружен ряд особенностей бьюти-блогеров. Эти особенности необходимо учитывать при организации рекламных компаний через бьюти-блогеров. Кроме того, мы нашли основные тематики статей блогов. По найденным тематикам мы соотнесли продукты с авторами таким образом, чтобы продукт был наиболее близок аудитории блога.
Первоначальный анализ мы сделали с помощью доступных и несложных методов работы с текстами (Fuzzy String Matching, TF-IDF, NMF), однако уже на этом уровне получили основные результаты, которые затем только уточнялись.
Оказалось, что данная косметическая компания работает с 30% исследованных авторов. Разумеется, бьюти-бренд был рад получить данные об оставшихся 70%, чтобы расширить своё влияние в блогосфере. В дальнейшем нам дали доступ к детальному описанию продуктов, данным о ингредиентах и другим характеристикам, что позволило перевести работу на новый уровень, мы стали активно использовать Word2Vec и BigARTM. Описанный анализ стал эволюционировать в инструмент, который прекрасно дополняет рекомендательную систему, подготовленную командой CleverDATA для бренда.
Демонстрация наших результатов привлекла еще четыре бьюти-бренда, с которыми мы сейчас сотрудничаем. Естественно, в блогосфере каждый бренд заинтересован исследовать и развивать свою собственную тему, соответствующую его продуктовой нише.
Рекомендации конкретных блогеров для продвижения продуктов со временем меняются, т.к. блогосфера растет и эволюционирует. Поэтому регулярный обзор авторов и мониторинг блогов важен брендам не только для продвижения продуктов, но и для понимания своего места в индустрии.
Сейчас мы работаем над тем, чтобы проводить краулинг блогов регулярно и разрабатываем возможность для оперативного отображения реакции аудитории на новые статьи с обзорами продуктов. Таким образом, бренд сможет быстро получать обратную связь на свои продукты, не заказывая дорогостоящие маркетинговые исследования. Также планируем подключить больше информации из социальных сетей: соцсети очень интересны брендам для привлечения новой аудитории.


Источник
Большинство компаний пристраивают свои продукты в блогерские обзоры, опираясь на интуицию и профессионализм маркетологов. Фактически бренды двигаются вслепую, потому что личные знакомства с блогерами, дружеские связи и договоренности без статистических данных и аналитических выкладок иной раз оказываются очень ненадежными.
Скажу сразу, мы выяснили следующее:
- блоги бьюти-индустрии пишутся преимущественно в позитивном эмоциональном окрасе;
- блогеры-новички склонны к завышенным эмоциям;
- блогеры-мастера работают в узком эмоциональном диапазоне;
- самые горячие обсуждения происходят в блогах среднего масштаба аудитории, а блоги-гиганты превращаются в вещательный инструмент;
- большинство бьюти-блогеров являются обычными людьми в социальных сетях.
Думаю, что наши наиболее интересные открытия, которым и посвящена эта статья, будут полезны всем, кто так или иначе соприкасается с продвижением продуктов в Сети. Например, зависит ли популярность блога от активности блогера и как аудитория реагирует на общее настроение поста. А мне, помимо этого, на примере анализа блогосферы хочется рассказать о возможностях Text mining.
Трудясь над проектом, мы выработали ряд подходов и приемов, которые в нашем случае показали хорошие результаты, но применять их на любом другом корпусе без калибровки малоэффективно. Поэтому я не стал приводить код, зато подробно рассказываю о самом корпусе, используемых методиках и главных выводах.
Итак, поехали!
Не секрет, что текстовая информация является одним из основных типов информации в современном обществе, поэтому анализ текстов способен не только раскрыть неявные закономерности, но и принести пользу в коммерческом приложении.
Нам не пришлось собирать данные – массив был собран ранее, в результате краулинга бьюти-блогов. Правда, для наших задач он оказался очень сырым и потребовал предварительной обработки. Кроме того, тексты естественно не были размечены, поэтому не было возможности использовать инструменты машинного обучения с учителем.
Отсекаем лишнее

Источник
Массив бьюти-блогов состоял из порядка 100 тыс. страниц, а точнее 98 496. Мы сначала обрадовались: 100 тыс. страниц — это хороший корпус для предстоящего исследования. Но выяснилось, что он очень сильно зашумлен, и после очистки осталось только 59.6%, пригодных для анализа.
40.4% данных составили пустые страницы и страницы с ошибками, страницы не на английском языке (23,461), фото- и видеоматериалы без текста (2,315), статьи с ресурса techcrunch.com, не имеющего отношения к бьюти-индустрии (очевидно, это ресурс, на котором тестировался краулер, собирающий материал, и его вклад в общем корпусе оказался заметным – 3,402 страниц).
Конечно, получить в распоряжение почти 60 тыс. страниц, годных для анализа, тоже неплохо. Выяснилось, что этому объему текста соответствуют около 2 тыс. уникальных блогов, то есть за вычетом клонированных и схожих материалов этот объем текста создали две тысячи уникальных авторов.
А автор кто?

Источник
Блоги на тему красоты и здоровья – это преимущественно женская тема. Если точный гендерный состав всей англоязычной блогосферы под вопросом, то в блогах о косметике и здоровом образе жизни всё однозначно: здесь большинство авторов и читателей – женщины. О чем говорят эти женщины в блогах? Это главный вопрос, который нам предстояло решить, чтобы понять, как наиболее эффективно продвигать товары бьюти-индустрии в блогосфере. Для ответа на этот ключевой вопрос, сначала попробуем исследовать, как говорят женщины в блогах.
Авторский стиль блогеров, конечно, различается. Но по размеру постов их авторов можно объединить в две группы: блогеры-миниатюристы с постами до 100 слов (20% всех авторов), и блогеры, предпочитающие полновесные тексты из 200-500 слов (~80%).
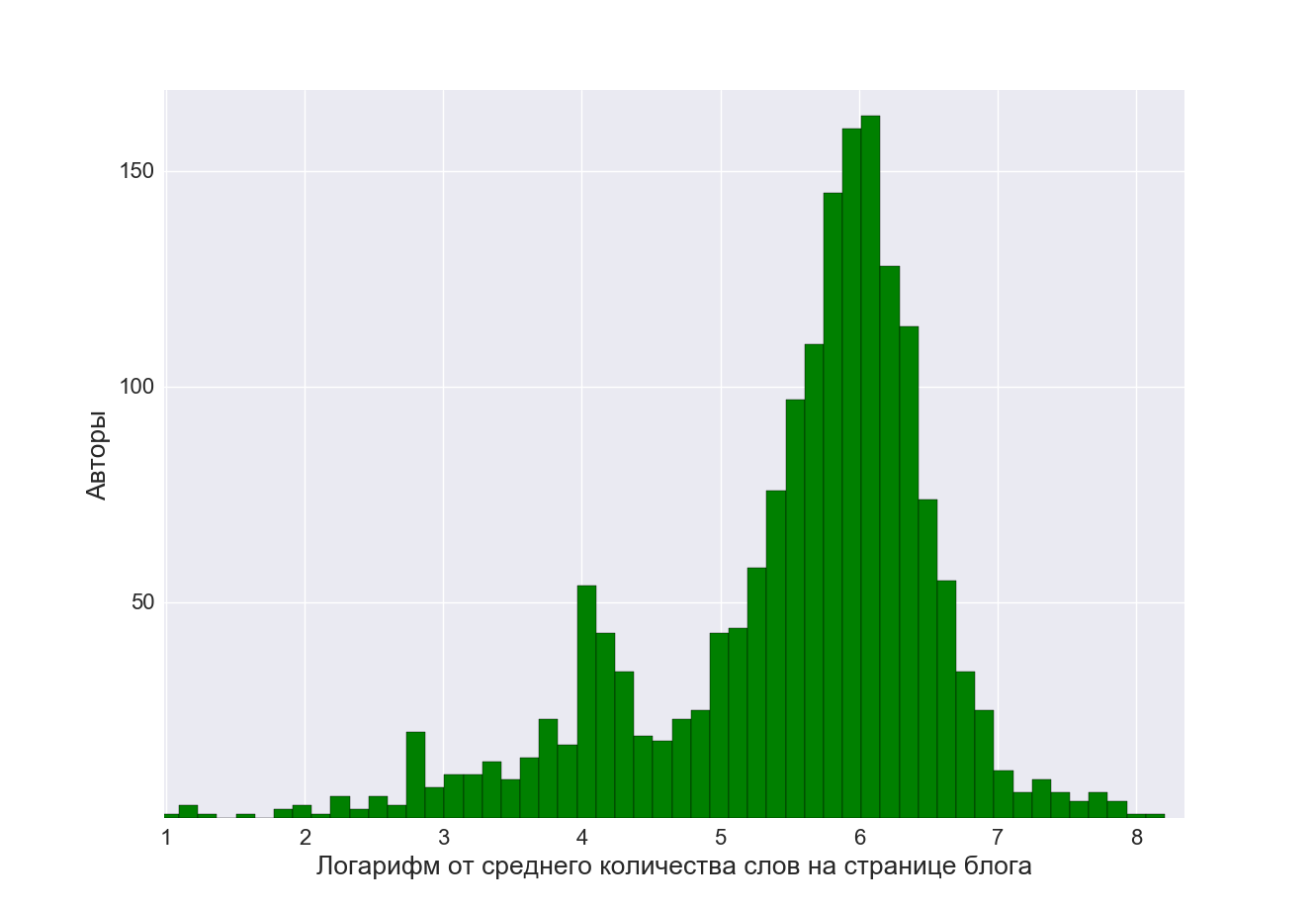
Любопытна корреляция между многословностью авторов и их активностью. Нельзя сказать, что коротеньких постов написано больше, чем многословных, и что любители писать в формате Твиттера берут количеством публикаций. Отнюдь. Мы увидели, что активность авторов из двух групп схожая.
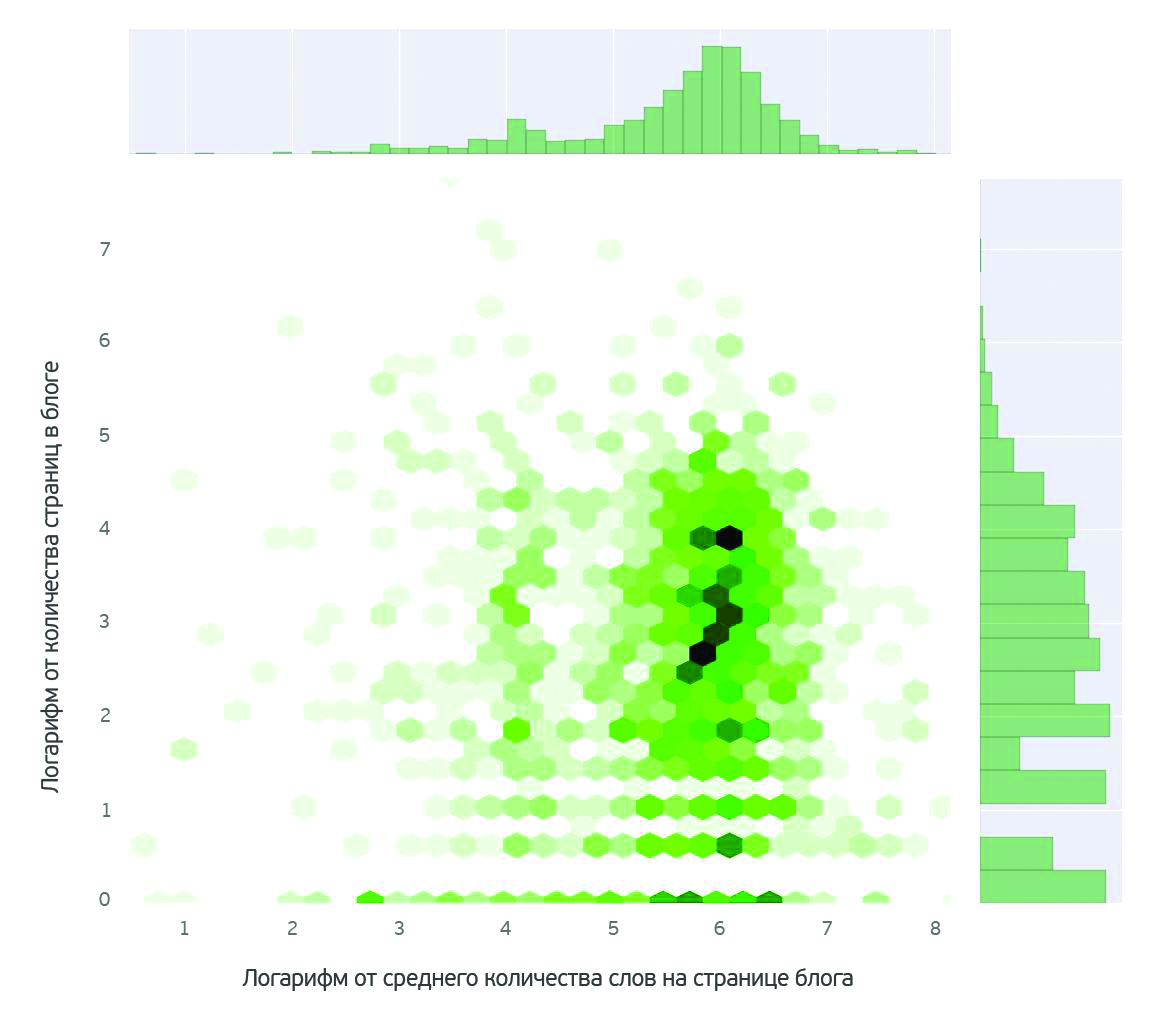
Анализ показал, что очень мало авторов пишут активно. Не более 20 авторов с момента появления блога успели написать свыше 300 постов, в большинстве блогов – до 100 постов, что укладывается в рамки обычной статистической закономерности.
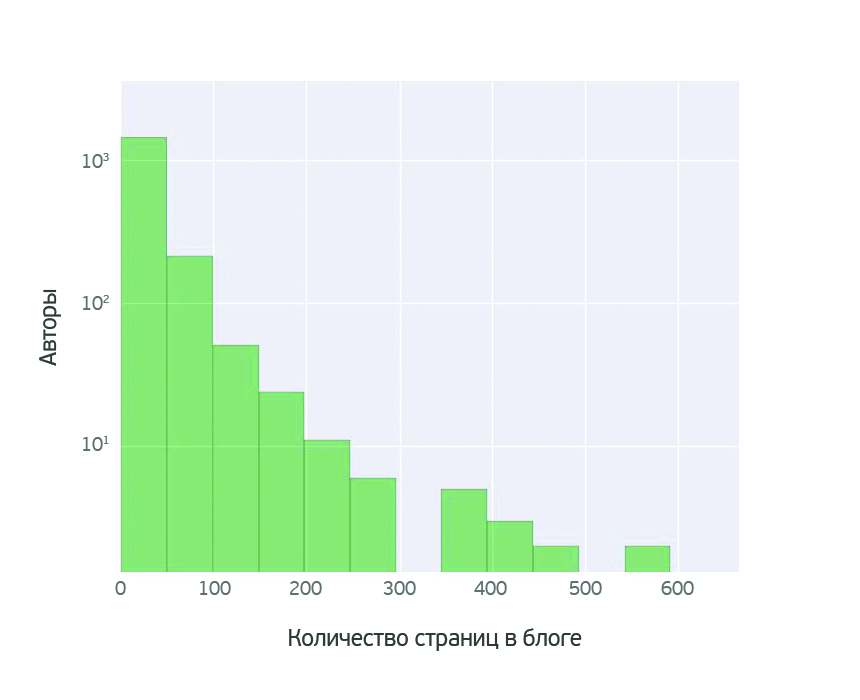
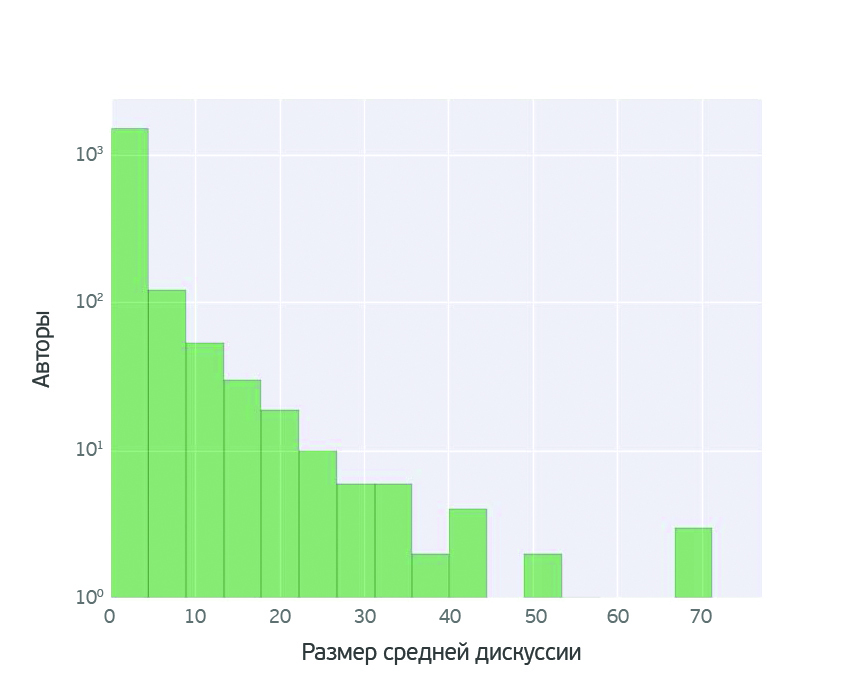
Разговорчики в блоге
Мы посмотрели на дискуссии в блогах и выяснили, что посты очень малого числа блогеров набирают более 40 комментариев. Статьи большинства авторов обсуждаются не столь активно, и на одну публикацию в среднем приходится 10-20 комментариев.
Эмоциональная подача
Первое, что приходит в голову, когда мы говорим об исследовании текста, – это анализ тональности текста, то есть оценка эмоций автора – положительные ли они или отрицательные. Моделей анализа эмоциональной окраски на сегодня предложено много. Поэтому мы не стали изобретать велосипед и использовали готовые модели:
- Sentity (https://sentity.io/),
- Twinword (https://www.twinword.com/),
- Textualinsights (http://www.textualinsights.com/),
- VivekN (https://github.com/vivekn/sentiment-web).
Каждая модель оценки эмоционального окраса была натренирована на своем отдельном корпусе текстов. Одна давала хорошие результаты на коротких текстах (т.к. тренировалась на корпусе Твиттера), другая – на более развернутых текстах (корпус IMDB). У каждой из моделей свои сложности с окрасом нейтральных текстов, но поскольку мы использовали 4 модели, они сгладили некоторые недостатки друг друга и получилось гладкое распределение, где -1 означает крайне отрицательную эмоциональную оценку, а +1 крайне положительную.
Комбинация четырех независимых моделей дала следующее распределение текстов по эмоциональной окраске.
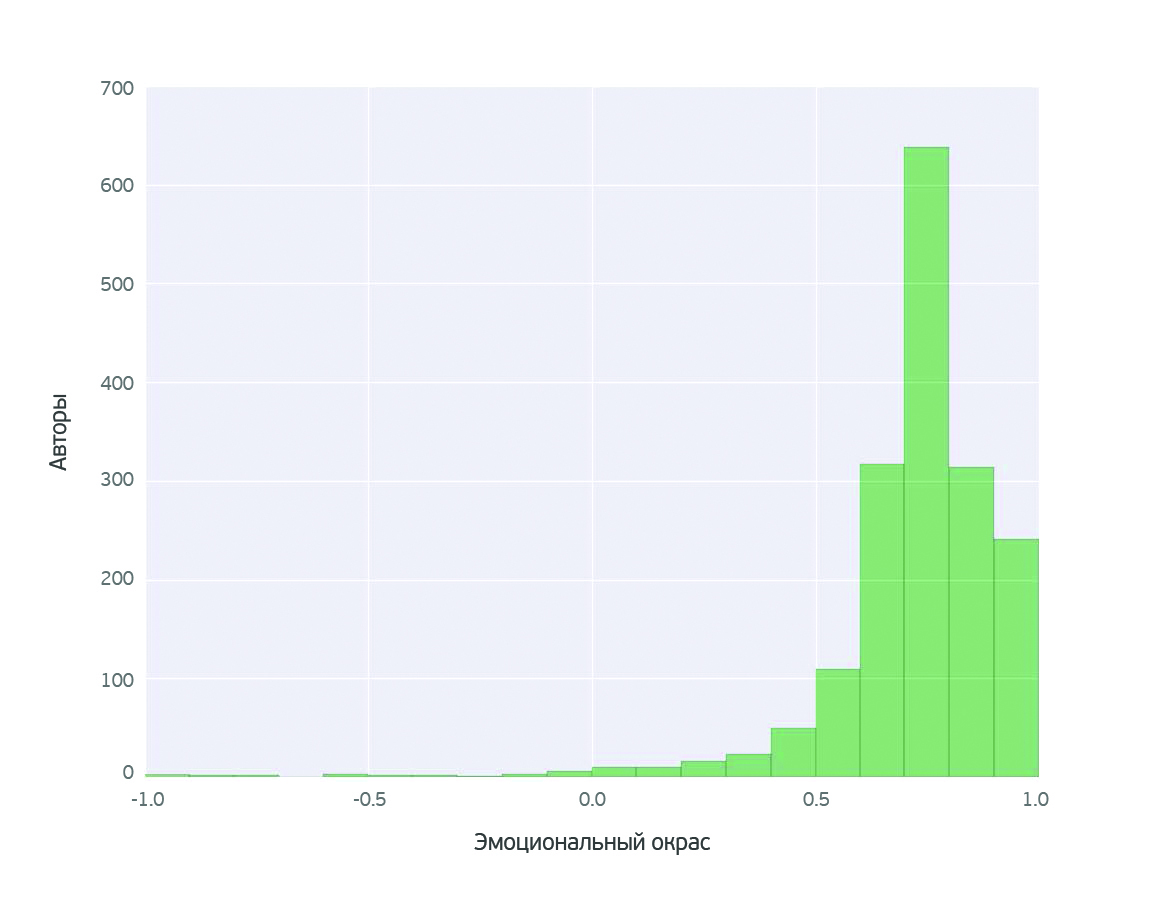
Мы видим ассиметричное квазинормальное распределение с центром в районе 0.72 и тяжелым правым хвостом. Это означает, что абсолютное большинство блогов имеют позитивную эмоциональную тональность. Смещение средней эмоциональной окраски в положительную область является удивительным фактом, о котором можно говорить с высокой статистической значимостью и который можно легко проверить самостоятельно, прочитав несколько взятых наугад женских блогов.
Если посмотреть, как распределены блогеры по их активности (анализ количества страниц), можно обнаружить, что самые плодовитые блогеры по эмоциональному окрасу работают в очень узком диапазоне: 0.74 ± 0.03.

В данном случае очень любопытно, что профессиональные блогеры работают в столь узком диапазоне эмоциональной окраски – как будто используют некоторую резонансную частоту своей аудитории. Возможно, получается система с обратной связью: автор с нейтральной статьей получает обратную связь от читателей через комментарии и в следующий раз подстраивается под восторженное настроение аудитории.
Можно предположить, что столь узкий диапазон настроений связан с профдеформацией. Однако наши
Обсуждаемость
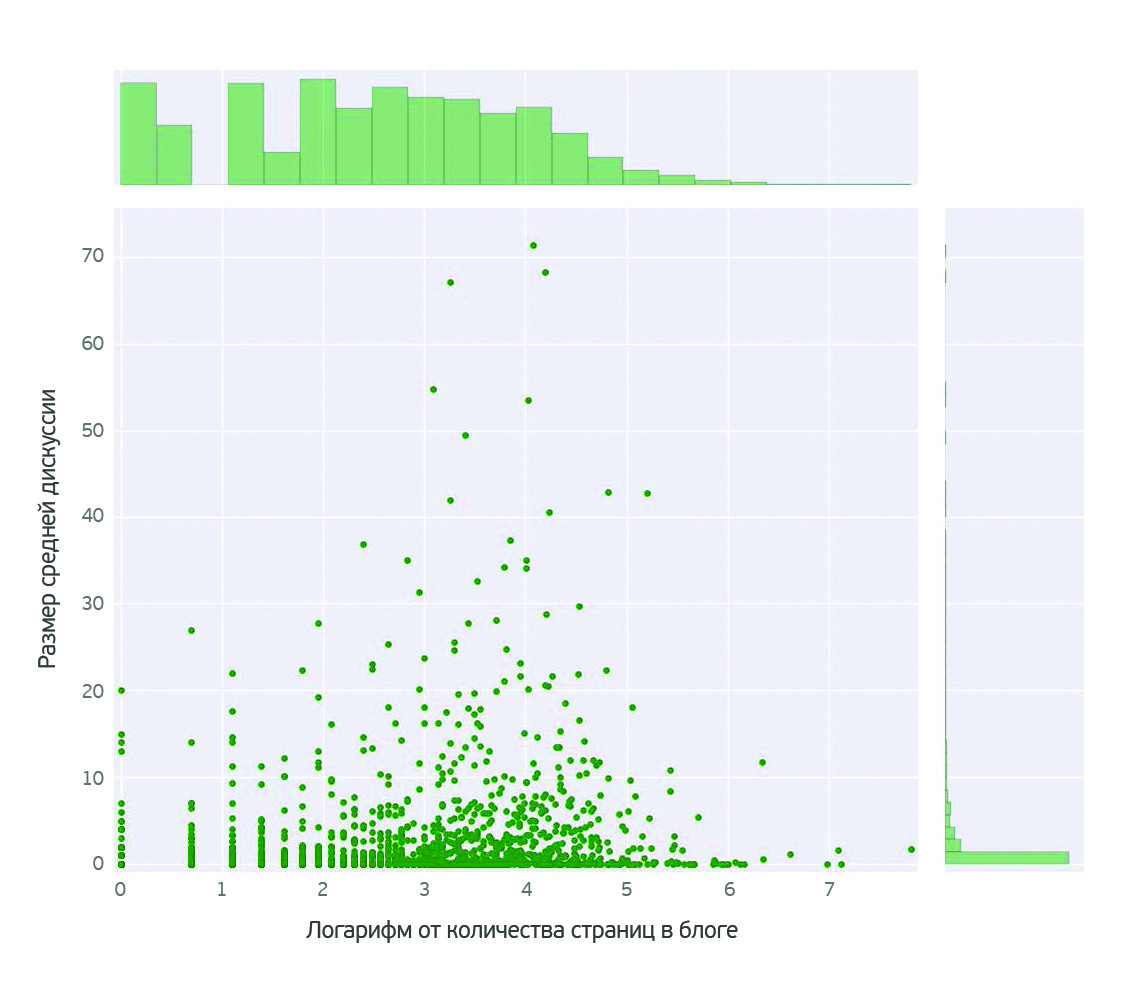
Зависит ли обсуждаемость блога от его активности? К удивлению, нет. В наиболее активных блогах мы видим меньше комментариев.
Возможно, это связано с тем, что активные блогеры с большой аудиторией уже завоевали такой авторитет, что с ними тяжело спорить.
Зависимость обсуждения от эмоционального окраса стала для нас сюрпризом. Наиболее обсуждаемые блоги находятся в позитивной области эмоционального окраса. Стоит иметь в виду, что это (как показано на графиках выше) не самые активные блоги. Вывод очевиден: чтобы вызвать обсуждение, оказывается, достаточно просто что-нибудь похвалить не в меру.
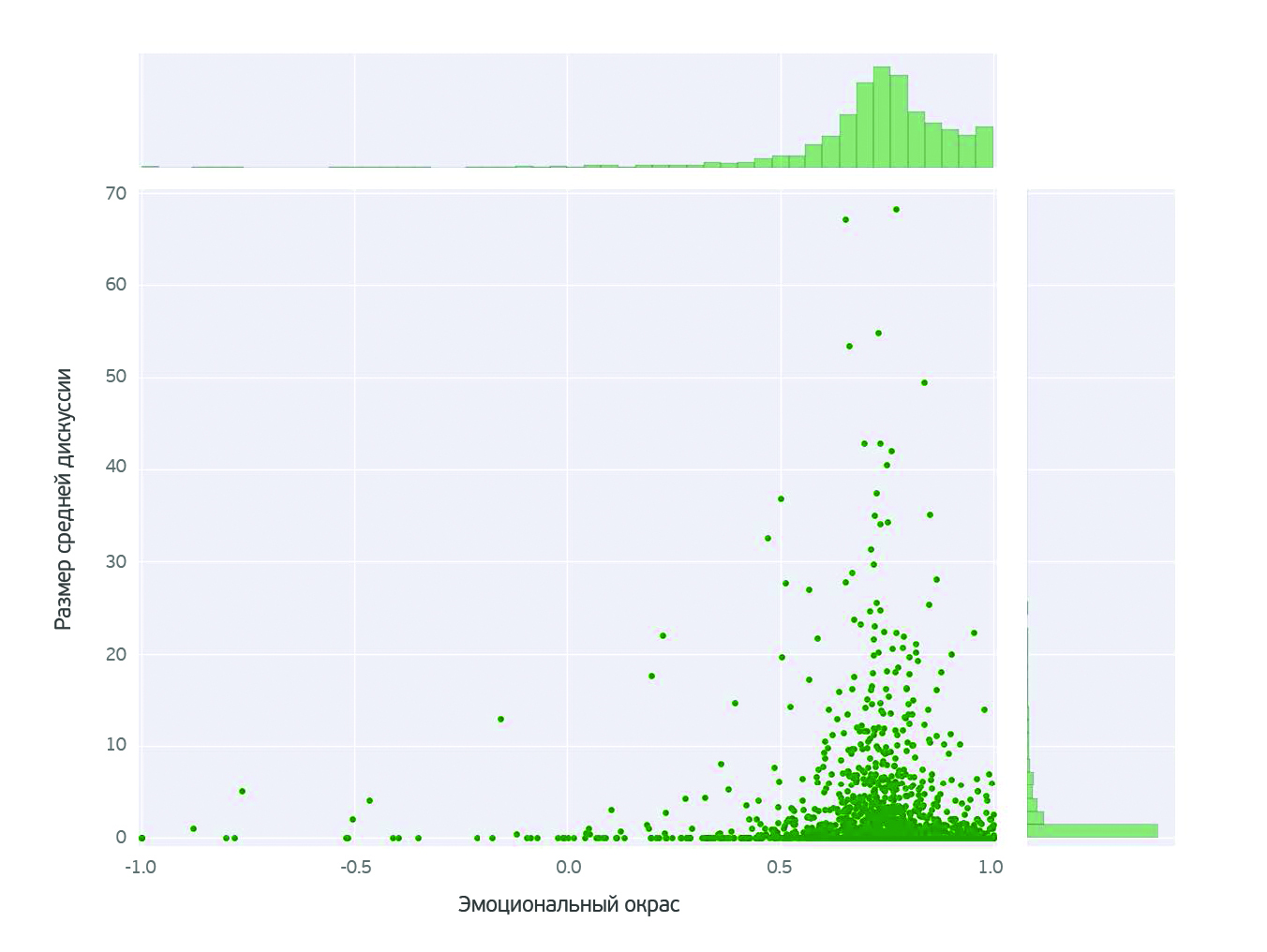
Популярность блога
Чтобы оценить эффективность блогов, с точки зрения распространения информации (читают ли их, делают ли перепосты), мы попробовали воспользоваться готовыми инструментами для оценки Интернет-трафика.
Среди метрик, отражающих количество читателей и цитирования в сети, выделю следующие.
Alexa Rank – популярный счетчик числа посетителей и количества просмотров сайта, устанавливается далеко не на всех Интернет-ресурсах, поэтому не всегда можно воспользоваться его данными.
Yandex Thematic Citation Index (TIC, тематический индекс цитирования Яндекса) определяет «авторитетность» Интернет-ресурса с учетом качественной характеристики ссылок на него с других сайтов, однако не очень распространён в англоязычном сегменте Сети
Google Page Rank – подсчитывает количество и качество ссылок на блог, чтобы оценить значимость ресурса для аудитории; является основным показателем для раскрутки сайтов. Главное преимущество Google Page Rank в том, что он присутствует у всех сайтов, но у многих веб-страниц он явно неадекватный (и в этом его большой недостаток). Кроме того, из-за условий лицензионного соглашения есть ограничения на использование Google Page Rank, что затрудняет использование его даже для таких исследований, как наше.
Все вышесказанное определило наш выбор: мы попробовали YandexTIC и AlexaRank. Отмечу, что все эти метрики связаны с объемом аудитории (сколько раз автор цитируется, как много его читают), обладают своими недостатками и поэтому не могут претендовать на статус исчерпывающего. Поэтому стоит поискать дополнительные инструменты для оценки популярности автора.
Чтобы как-либо еще измерить популярность авторов, мы прибегли к Klout score. Эта метрика используется в социальных сетях, чтобы оценить влияние человека: его социальные связи и цитируемость его постов. Эта, независимая от предыдущих, метрика оценивает и аудиторию читателей, и количество репостов именно в соцсетях. Примечательно, что с Klout score был связан громкий случай в 2011 году: на должность вице-президента одной из компаний претендовало два кандидата, один из которых 15 лет консультировал гигантов типа America Online, Ford и Kraft, второй же не мог похвастаться столь выдающимся опытом, но имел весомый козырь – Klout score, равный 67. В упомянутом случае позицию получил кандидат с более высоким Klout score. В нашем случае оказалось, что для наших авторов средний показатель Klout score составляет 40.1. Возможно, для вице-президента с пятнадцатилетним стажем такой Klout score будет низок, но для наших блогеров это нормальное значение: исследуемые бьюти-блогеры не являются центрами гигантских социальных скоплений, «наши» блогеры по своим характеристикам ближе к обычным людям со средней активностью в сети.

Если проследить взаимосвязь Klout score и эмоционального окраса, можно обнаружить интересную тенденцию.
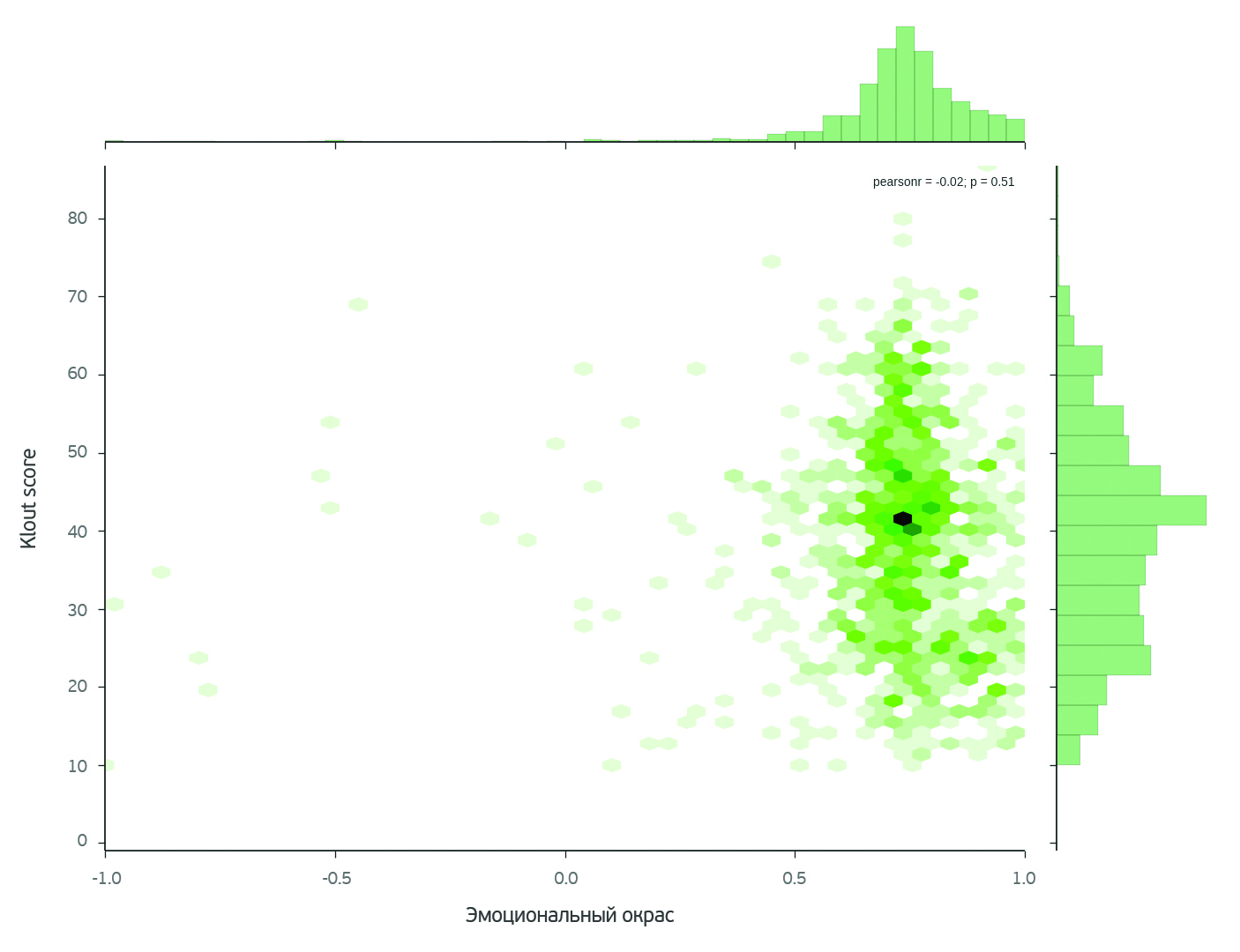
На графике видно, что есть группа блоггеров, у которых Klout score низкий, а эмоциональный окрас явно выше «резонансной» величины. Это значит, что такой автор только начинает писать (поэтому мало статей), но эмоциональный окрас текстов у него завышен. Возможно, это психологический феномен, связанный с новой деятельностью: автор пытается приукрашивать либо специально, либо у него «розовые очки», т.е. он сам находится в изрядно приподнятом настроении. В любом случае, если автор будет продолжать писать, он эволюционирует на более низкие эмоции по обратной связи в комментах.
Работа с брендом
Мы работали с торговой маркой, настоящее имя которой мы, конечно, не раскроем и в статье для удобства назовём ее «Баба Яга». Все продукты этой торговой марки имеют расширенные, многословные названия, например, «Крем для лица Баба Яга».
Мы применили технику Fuzzy String Matching на весь корпус текстов и попытались найти упоминания бренда и его продуктов во всех текстах.
Fuzzy String Matching основана на анализе расстояния Левенштейна, которое указывает на буквенные различия в словах. Строго говоря, расстояние Левенштейна определяет минимальное количество изменений одного символа (его удаления, замены, добавления), необходимых для превращения одного слова в другое. Расстояние, полученное с помощью модуля Python fuzzywuzzy, нормировано в диапазоне от 0 до 100. Таким образом, абсолютно различные слова будут иметь меру похожести, равную 0, а тождественные слова будут иметь меру похожести, равную 100. Например, в бородатом анекдоте о разнице между хлебом и пивом мера похожести будет равна нулю: чтобы из хлеба получить пиво, нужно заменить все четыре буквы.
Необходимо отметить, что нам повезло с названиями продуктов бренда, т.к. они не были односложными (как известное мыло «Удав»), а состояли из нескольких слов, по которым можно было понять тип и отчасти назначение продукта, например, «Масло для лица Баба Яга». Fuzzy String Matching позволяет с соответствующими настройками отлавливать частичное упоминание, например, «Face Oil», и мы пытались на этом играть.
Посты, в которых искомый продукт упоминался на 90% по метрике Fuzzy String Matching, отмечались в качестве «хороших». У бренда было около 100 продуктов, таким образом каждая статья проходила проверку для каждого продукта более 100 раз.
Рейтинг релевантности для автора брался как сумма всех «хороших» статей. Нормировка на количество статей не вводилась намеренно, чтобы авторы с бОльшим количеством статей вырвались вперед.
Впоследствии мы использовали натуральный логарифм от полученного рейтинга. Например, авторы с 30, 10 и пятью «хорошими» статьями получали соответствующий рейтинг релевантности 3.4, 2.3 и 1.6.
Подход несложный, однако за счет большого количества статей и большого количества продуктов начинали работать закон больших чисел и ЦПТ (центральная предельная теорема), и мы получали разумные оценки.
Чтобы ускорить процесс и повысить точность, мы перешли на использование расстояния, полученного с помощью модели Word2Vec, однако даже при первоначальном подходе мы получили результат, который можно использовать в дальнейшей работе.
Рейтинг авторов
На основе перечисленных техник мы построили рейтинг авторов. Он базируется на:
- количестве постов в блоге,
- числе комментариев,
- метриках AlexaRank + YandexTIC,
- степени релевантности блога товарам бренда,
- эмоциональном окрасе,
- Klout score.

Следует обратить внимание, что мы не отдаём предпочтение блогерам с большим количеством страниц, потому что встречаются как активные блоги с объемом более 500 постов, так и малоактивные авторы с числом постов менее 100. Также нет предпочтений по количеству комментариев. Отмечу, что по уровню эмоционального окраса они все положительные и работают в диапазоне от 0.70 до 0.78.
Мы внимательно изучили лидера списка. Оказалось, что у него опубликована статья, посвященная нашему бренду. Это была хвалебная ода всему бренду, без анализа и описаний конкретных продуктов.
Итак, рейтинг блогеров построен, теперь нужно связать авторов и продукты, которые им можно отдать для обзора. Для этого нужно:
- выбрать продукты для обзора,
- выделить основные темы авторов,
- сопоставить выделенные темы с названиями продуктов,
- найти оптимальную связь между продуктом и блогом.
Выбор продуктов для продвижения
Продукты для продвижения были выбраны практически произвольно. Фактически выбор пал на них из-за того, что статистика их продаж серьезно выделялась на фоне остальных продуктов.
Первые два продукта пользовались большой популярностью, а значит, можно было еще больше увеличить число потенциальных покупателей.
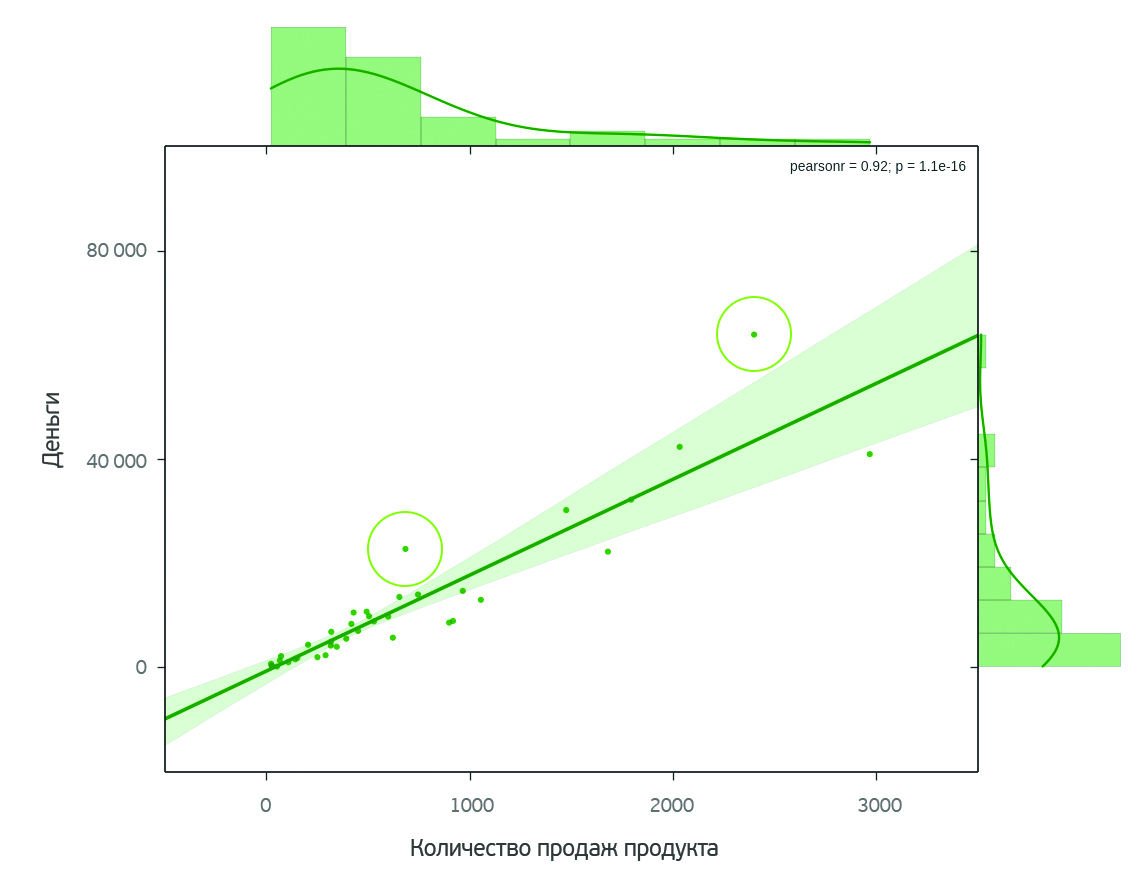
Вторые два выбранных продукта совсем недавно вышли на рынок и еще не успели показать себя в полной мере. Продвижение им точно не помешало бы. Эти продукты выделяются на графике зависимости стоимости продукта от количества его продаж.
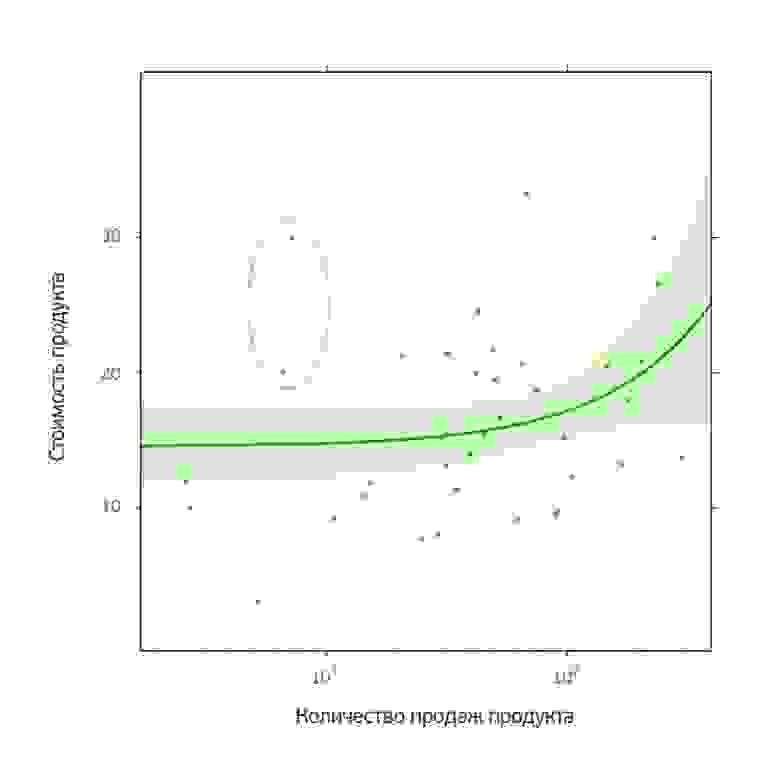
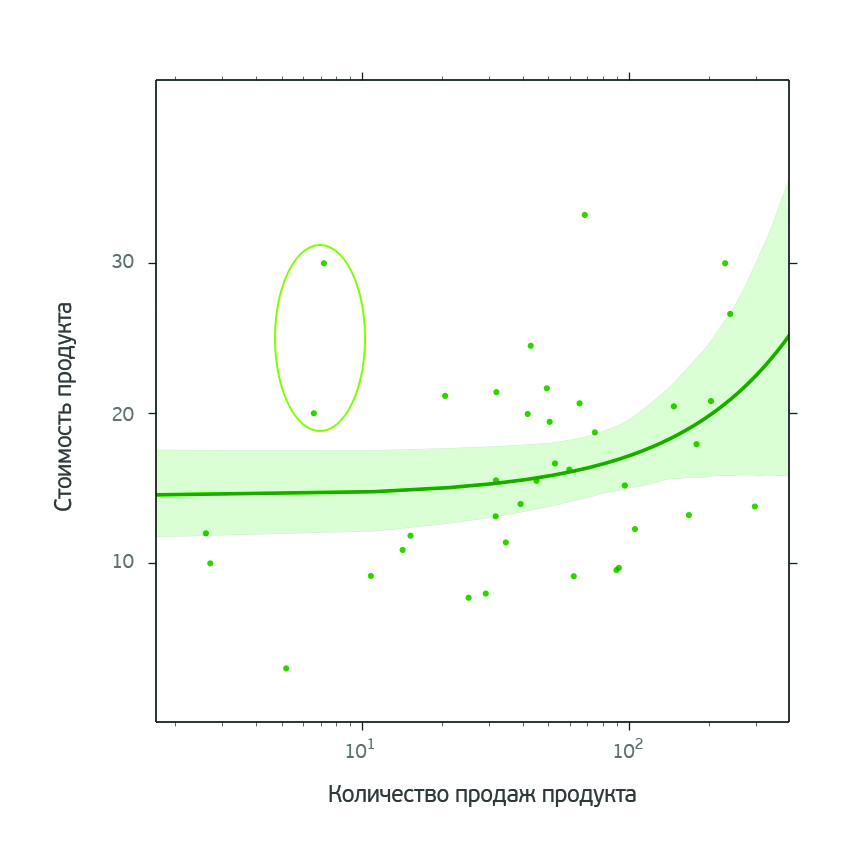 В принципе такой анализ можно провести для любого из продуктов. Выбор конкретного продукта не принципиален.
В принципе такой анализ можно провести для любого из продуктов. Выбор конкретного продукта не принципиален.Авторы и их темы
В блогах каждого автора можно найти темы, интересные для продвижения бренда. А о чем вообще пишут авторы? Чтобы узнать список тем каждого блога, составим матрицу, каждая строка которой будет соответствовать посту, в столбцах укажем ключевые слова, а цвет ячеек будет означать индекс TF-IDF (про применение метода TF-IDF можно почитать, например здесь и здесь) – частотную характеристику ключевого слова. Соответственно, чем более интенсивно окрашена ячейка, тем больше упоминаний слова мы нашли и тем важнее это слово в контексте. Примеры слов для формирования таблицы: «макияж», «лицо», «тело», «скраб», «лосьон», «масло», «очищение», «кондиционер» и т.д.
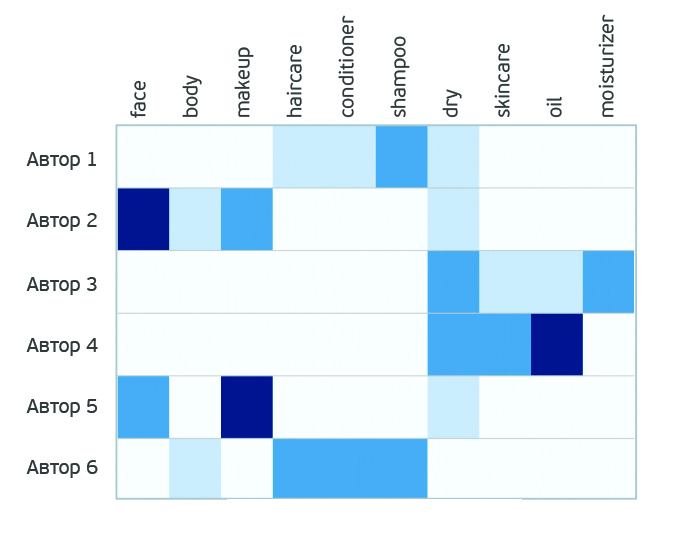
Далее применяется метод NMF, который позволяет разложить нашу матрицу на две поменьше: «авторы»/«промежуточное измерение» и «промежуточное измерение»/«слова». Единственное наложенное нами условие факторизации – величины должны быть не негативны, то есть они все должны быть больше либо равны 0.
«Промежуточное измерение» в данном случае можно интерпретировать как темы. Таким образом, мы разложили авторов на темы их текстов.
Используемый метод NMF для получения тематик текстов обычно может конкурировать с методами LDA и LSA (pLSA), однако нельзя не упомянуть еще один сильнейший инструмент в этой области: BigARTM, на который мы переходим в данный момент. Необходимо отметить, что базовая идея разложения матрицы присутствует и в методе BigARTM, однако его преимущество заключается в гибкой возможности использоваяния регуляризаторов

Каждому по возможностям
Теперь нужно сопоставить название продуктов бренда с выделенными темами. Это возможно сделать и с помощью уже использованного подхода Fuzzy String Matching, но лучше и точнее использовать дистанцию, измеренную с помощью модели Word2Vec.
Здесь следует учесть один момент: если название продукта полностью прописано в заголовке поста, скорее всего, это был обзорный пост, то есть автор уже писал о продукте и ему не стоит предлагать сделать это еще раз.
Получаем красочную матрицу, где цветом обозначена степень корреляции автора с продуктом. Матрица «авторы-продукты» отсортирована по нашему рейтингу авторов.
Рейтинг авторов отчасти базировался на упоминаемости продуктов бренда в текстах. После сортировки по рейтингу авторов можно наблюдать цветовое распределение, которое сосредоточено на авторах с высоким рейтингом и затухающее по мере уменьшения рейтинга.

Это цветовое распределение было получено с помощью отдельного математического подхода (TF-IDF, NMF, etc), и оно хорошо согласуется с нашим первоначальным результатом, полученным с помощью простых подсчетов упоминаний. Таким образом, мы с одной стороны подтверждаем адекватность своего рейтинга, а с другой стороны показываем разумность результатов, полученных с помощью ряда более сложных математических приемов. Согласованность результатов, полученных различными методами, говорит в нашу пользу.
Для продвижения продукта нам не нужно задействовать много человек. Возьмём первые сорок авторов. Для них матрица будет выглядеть следующим образом:

Из матрицы «автор-продукт» мы извлекаем наиболее резонансные пики, после чего колонка с пиком отбрасывается. Таким образом, для каждого автора мы получаем только один продукт. Итак, наша цель достигнута: связь авторов с продуктами установлена.
Подводя итоги
Таким образом, по результатам исследования первоначального корпуса статей бьюти-блогов с использованием метрики социальной активности Klout score, а также с учетом эмоционального окраса статей, нами был обнаружен ряд особенностей бьюти-блогеров. Эти особенности необходимо учитывать при организации рекламных компаний через бьюти-блогеров. Кроме того, мы нашли основные тематики статей блогов. По найденным тематикам мы соотнесли продукты с авторами таким образом, чтобы продукт был наиболее близок аудитории блога.
Первоначальный анализ мы сделали с помощью доступных и несложных методов работы с текстами (Fuzzy String Matching, TF-IDF, NMF), однако уже на этом уровне получили основные результаты, которые затем только уточнялись.
Оказалось, что данная косметическая компания работает с 30% исследованных авторов. Разумеется, бьюти-бренд был рад получить данные об оставшихся 70%, чтобы расширить своё влияние в блогосфере. В дальнейшем нам дали доступ к детальному описанию продуктов, данным о ингредиентах и другим характеристикам, что позволило перевести работу на новый уровень, мы стали активно использовать Word2Vec и BigARTM. Описанный анализ стал эволюционировать в инструмент, который прекрасно дополняет рекомендательную систему, подготовленную командой CleverDATA для бренда.
Демонстрация наших результатов привлекла еще четыре бьюти-бренда, с которыми мы сейчас сотрудничаем. Естественно, в блогосфере каждый бренд заинтересован исследовать и развивать свою собственную тему, соответствующую его продуктовой нише.
Рекомендации конкретных блогеров для продвижения продуктов со временем меняются, т.к. блогосфера растет и эволюционирует. Поэтому регулярный обзор авторов и мониторинг блогов важен брендам не только для продвижения продуктов, но и для понимания своего места в индустрии.
Сейчас мы работаем над тем, чтобы проводить краулинг блогов регулярно и разрабатываем возможность для оперативного отображения реакции аудитории на новые статьи с обзорами продуктов. Таким образом, бренд сможет быстро получать обратную связь на свои продукты, не заказывая дорогостоящие маркетинговые исследования. Также планируем подключить больше информации из социальных сетей: соцсети очень интересны брендам для привлечения новой аудитории.

