
С каждым годом выходит всё больше инструментов, которые помогают автоматизировать часть рутинной работы программиста, — генераторы тестов, автодополнение кода, генераторы шаблонного кода. Мы воспринимаем как само собой разумеющееся, что условная IntelliJ IDEA предлагает нам после введения буквы метод, который мы и хотели.
А так ли нужен программист компаниям, если роботы становятся всё умнее и, казалось бы, вот-вот отправят разработчиков распахивать поля? Ведь компаниям важна прибыль, а дешёвый робот будет гораздо привлекательнее разработчиков, требующих огромные зарплаты.

Исследование этой проблемы провёл Тагир Валеев lany из JetBrains в докладе на Joker 2020. И результаты вышли весьма неоднозначными. Подробности — под катом, повествование далее будет от лица спикера.
Оглавление
- Вступление
- Code completion
- Whole line completion
- Code generation
- Automatic refactoring
- Automatic solution finding
- Automatic bug search
- Automatic bug fixing
- Automatic dependency updates
- Automatic tests development
- Solve human-specified problem in code
- Выводы
Вступление
Перед вами фрагмент исходников одной из инспекций IntelliJ IDEA — IDE, глядя на ваш код, решает, нужно ли подсветить определённую конструкцию и предложить упростить её:

Если посмотреть на код повнимательнее, то можно увидеть, что в нём очень часто используется if. По-моему, вся суть программирования состоит в условных переходах. Не было бы их, не было бы ничего. Даже когда вы складываете 2 + 2, внутри процессора происходит условный переход, когда решается, надо ли перенести бит в соседнюю ячейку памяти. По сути, транзистор — базовый элемент интегральных схем — это маленький примитивный if-else, который в зависимости от управляющего тока открывает или закрывает эмиттер. Миром правят условные переходы.
Позвольте представиться — я Тагир Валеев, senior if-else developer в JetBrains. Я достаточно хорошо пишу if, умею вкладывать их один в другой, аккуратно менять местами, группировать и даже дописывать ветку else при необходимости. За это меня терпят и даже платят зарплату.
Я всем доволен, но в последнее время появляются некоторые «звоночки», которые начинают беспокоить. Люди всё больше говорят, что роботы тоже могут писать свои if не хуже, чем живые программисты. Но при этом роботы не требуют повышения зарплат, не сидят в рабочее время в Твиттере и не ноют про выгорание. Сплошные плюсы. Не пора ли осваивать свиноводство или другую полезную профессию, чтобы не умереть в нищете?
Кажется, не меня одного волнуют такие вопросы. К примеру, в 2020 году JetBrains проводила исследование экосистемы разработки, в котором приняли участие аж 20 тысяч разработчиков. 50% из них допускают, что искусственный интеллект заменит программистов в будущем, а 4% опрошенных уверены в этом. В России люди настроены ещё оптимистичнее: 62% допускают, а 8% уверены.
Конечно, неизвестно, когда это будущее наступит, и можно уповать на то, что на наш век хватит, а свиноводством придётся заниматься нашим детям. Тем не менее стоит посмотреть, куда дует ветер, уже сегодня.
Чтобы понять текущее состояние дела, представить, что нас ждёт в будущем, давайте посмотрим, чем вообще занимаются программисты и как роботы нас пытаются заменить.
Деятельность программистов довольно разнообразна, и роботы пока не универсальны. Обычно они автоматизируют только один аспект деятельности.

Давайте сперва поговорим про написание кода. Основной помощник в написании кода — это автодополнение (code completion).
Code completion
Насколько мне известно, широкая публика увидела эту фичу в Microsoft Visual Studio 6.0 в конце прошлого века, хотя исследования и экспериментальные решения были и раньше.

Сейчас это выглядит устаревшим, но тогда это был довольно прорывной шаг. Я даже нашёл обзор тех лет, который вы можете посмотреть и представить, насколько это выглядело революционно и какие восторги вызывало. Оно показывает имена методов.
Мало того, оно показывает только те методы, которые есть в объекте. Более того, оно не только показывает, но и само вставляет их в код, и можно не печатать имя метода. И главное, оно работает не только со стандартной библиотекой, но ещё и с вашим кодом. Вы сделали объект, написали методы, и оно это поняло. Заметьте, в статье сплошной восторг и ни слова про то, что роботы могут отнять у нас хлеб.
С тех пор автодополнение кода шагнуло далеко вперёд. Сегодня автодополнение активируется автоматически и даже без горячей клавиши. Появилось много разных вариантов дополнения. Например, в документации к IntelliJ IDEA можно встретить целых 5 терминов на эту тему.
Чтобы оценить, как далеко шагнуло автодополнение, я написал маленькую стандартную программу, которая считает частоты встречаемости слов во входном файле и выводит 20 самых популярных вместе с количеством:
import java.io.IOException;
import java.nio.file.*;
import java.util.*;
import java.util.function.*;
import java.util.regex.Pattern;
import java.util.stream.Collectors;
public class WordCount {
public static void main(String[] args) throws IOException {
if (args.length != 1) {
System.err.println("File name required");
return;
}
Path path = Paths.get(args[0]);
Map<String, Long> counts = Files.lines(path)
.flatMap(Pattern.compile("\\W+")::splitAsStream)
.map(String::trim)
.filter(Predicate.not(String::isEmpty))
.collect(Collectors.groupingBy(Function.identity(), Collectors.counting()));
counts.entrySet().stream()
.sorted(Map.Entry.comparingByValue(Comparator.reverseOrder()))
.limit(20)
.map(e -> e.getKey() + "\t" + e.getValue())
.forEach(System.out::println);
}
}
Здесь 873 символа и 26 переводов строк. Далее я захотел проанализировать, как же я набираю такую программу в IDEA. Сперва я думал поставить кейлоггер, чтобы записать всё, что я нажимаю, а затем решил: «Зачем мне кейлоггер, если у меня есть IntelliJ IDEA со встроенным кейлоггером?» Я просто включил режим записи макроса, набрал текст этой программы (неидеально: я иногда ошибался, что-то стирал), сохранил этот макрос и получил XML-файл где-то в недрах папки IDEA. Затем я расковырял сохранённый макрос и посмотрел, что реально было набрано мной, а что — машиной. Результат был такой.
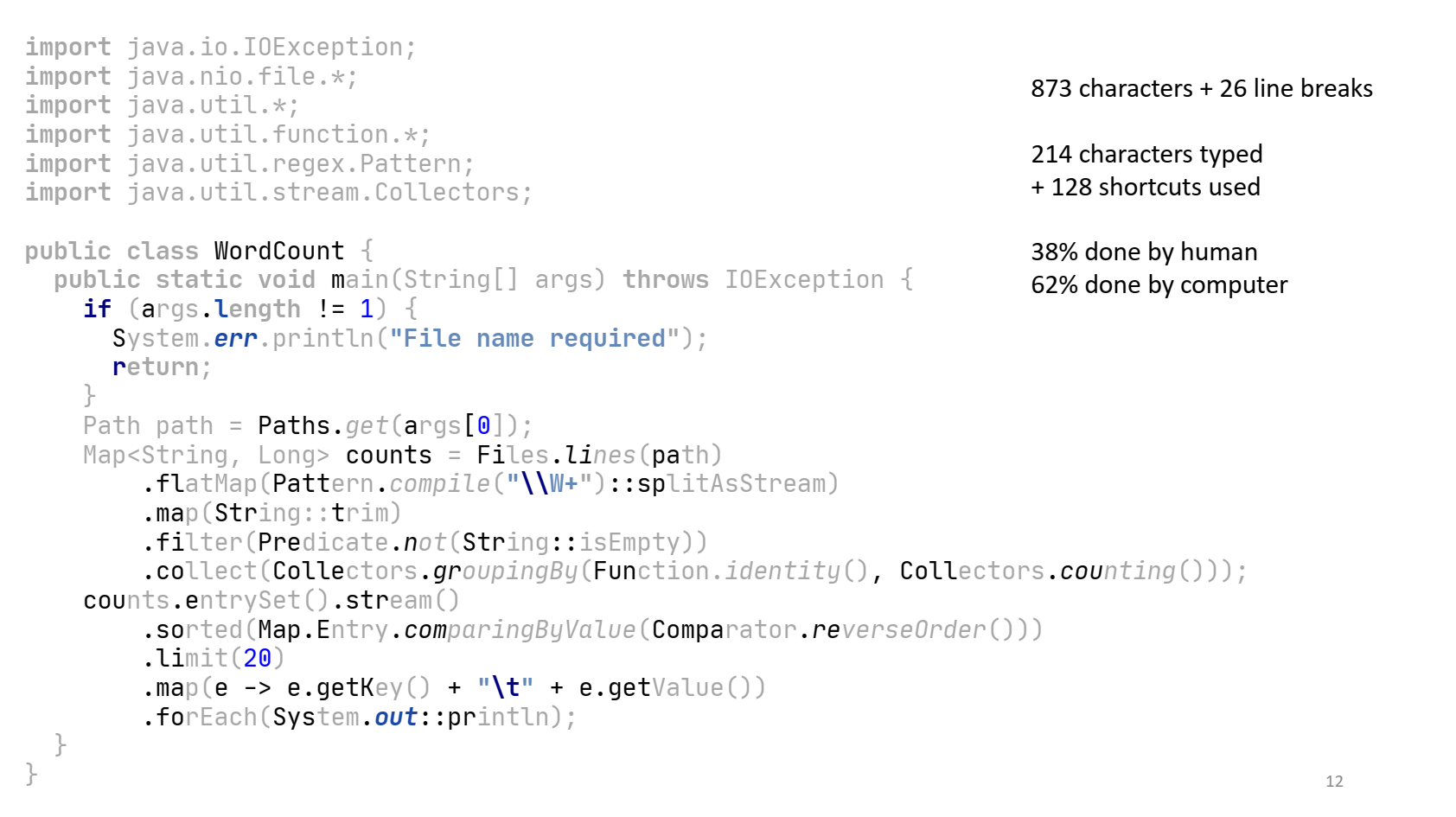
Весь серый код набран роботом, а код других цветов — мной. Импорт я вообще не набирал. Когда я стал писать main, я только нажал букву m, и мне сразу сказали «ты хочешь main». Потом я написал if и букву a, и автодополнение мне сразу предложило args, и так далее. Видно, что робот потрудился больше меня.
Если говорить в цифрах, то я набрал 214 символов, включая все опечатки. Также я использовал 128 специальных клавиш. Например, если мне выпадал список completion, я иногда нажимал стрелку вниз или Enter, чтобы выбрать нужный вариант. Можно по-разному считать, но если сложить все нажатые мной кнопки и поделить на размер результирующего файла, то оказывается, что я сделал только 38% работы, а робот сделал 62%. Если бы я это писал за деньги, то заплатили бы мне, а не компьютеру. Так что я доволен, ведь роботы забрали у меня часть работы, но не зарплату.
Эволюция автодополнения в чём-то похожа на развитие поисковых систем в Интернете. Изначально показать хоть какие-то результаты поиска было уже успехом, но со временем результатов стало слишком много, и появилась задача их ранжирования.
Например, я в случайном месте исходников IntelliJ IDEA написал букву e.

Мы видим, что здесь очень много результатов:
- ключевое слово else (я стою после if, поэтому, возможно, хотел else);
- локальные переменные из текущего метода, которые начинаются с e;
- методы текущего класса, которые начинаются с этой буквы;
- метод equals() из внешнего класса;
- методы, в названии которых какое-либо слово, кроме первого, начинается с e;

- методы, где e встречается на конце, потому что люди иногда вводят суффикс;
- методы суперкласса;
- методы внешнего класса;
- deprecated-методы;
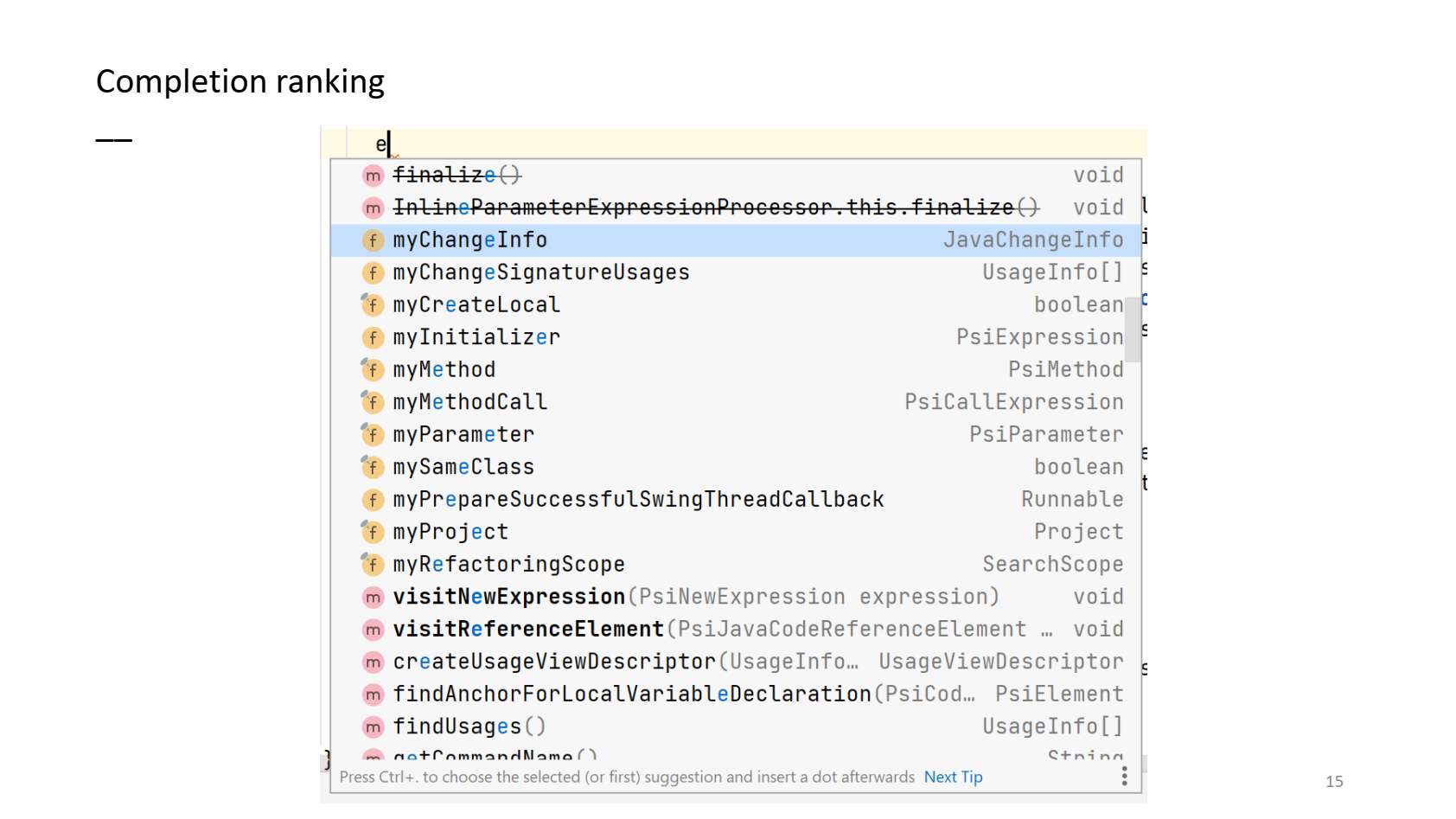
- поля и методы, где эта буква встречается вообще в произвольной позиции.
Как мы видим, есть разные критерии, по которым их можно отсортировать:
- степень совпадения;
- тип элемента;
- близость в его объявлениях точки использования;
- соответствие результирующего типа контексту;
- модификаторы;
- количество параметров метода;
- локальная статистика (если пользователь набирал метод часто, то его стоит поднимать).
Что делать, когда критериев много? Что поставить наверх? Метод, который идеально подходит по типу, или же метод, который по типу не подходит, но у него идеально совпадает префикс?
Оказывается, критерии сортировки тоже надо сортировать. Для Java эту работу аккуратно вели вручную почти 20 лет, пока вообще существует completion в IntelliJ IDEA. Причем это хрупкое равновесие, потому что если поменять логику в одном месте, чтобы улучшить приоритеты в каком-то конкретном случае, мы, вполне вероятно, ухудшим приоритеты в другом случае. И что бы мы ни сделали, всегда найдутся недовольные пользователи. Для других языков (вроде Python) IDE появилась позже, усилий на качество сортировки было потрачено меньше, и поэтому там недовольных больше.
Оказалось, что в этой области можно применить модный нынче data science (но сразу оговорюсь, что в data science, deep learning и ИИ я полный нуб и ничего не соображаю). Интересно, что здесь используется автоматизация программирования, то есть data science, для того чтобы автоматизировать программирование, то есть автодополнение. Сами фичи и критерии сортировки мы формируем всё ещё вручную, но для окончательной сортировки вариантов строим модель, которую тренируем на EAP-пользователях.
Как вы знаете, EAP-версии (Early Access Program) мы раздаём бесплатно, но кое-что требуем взамен. В частности, мы собираем анонимизированные данные о том, какие варианты автодополнения и с какими критериями пользователи выбирают чаще, а какие — реже. Никто не записывает точное название метода, который вы выбрали. Например, если вы предпочли статический метод нестатическому в каком-то контексте, то это будет записано.
На основании этих данных строится модель. Сейчас в IDEA используется random forest, но исследуются и другие подходы. На основании модели компилируется Java-код, и он же используется для ранжирования.
Надо убедиться, что ML-сортировка работает лучше обычной. Для офлайн-тестирования мы берём реальные проекты, в них ставим курсор на случайное слово, потом удаляем всё, кроме, например, первой буквы, и пытаемся дополнить. Понятно, что к такому тестированию много вопросов, но это позволяет убрать откровенные провалы и убедиться, что мы совсем всё не разломали.
Если здесь всё прошло нормально, то мы начинаем снова мучить EAP-пользователей, разделяя их на группы. Для одной группы мы включаем модель, а для другой группы оставляем традиционный completion, и смотрим, насколько успешнее какая из групп дополняет.
Есть много метрик, например:
- оказался ли искомый вариант первым в списке;
- попал ли вариант в топ-5 или топ-10;
- на какой средней позиции он оказался в списке;
- сколько символов пользователь набрал перед тем, как он выбрал нужный вариант (в идеале он должен набирать один символ или даже ничего не набирать);
- воспользовался ли пользователь completion или же он ввёл всё вручную.
Эти метрики показывают, что улучшения от ML есть не только для Python, но и для Java, хотя над Java работали вручную почти 20 лет. В PyCharm такое автозаполнение уже включено по умолчанию, в IntelliJ IDEA для Java в ближайшем релизе будет включено по умолчанию. Так мы все увидим, как работает машинное обучение.
Вот оно, светлое будущее! Оказывается, можно вообще не писать код, который будет заниматься сортировкой опций completion, а можно поручить это дело data science.
Меня в этом всём кое-что смущает. Вы же помните, что главное в программировании — это if-else? Именно это под капотом у так называемого ИИ. Это фрагмент, сгенерированный моделью completion на Java.
package com.jetbrains.completion.ranker.model.java;
/*
* WARNING: This file is a generated one, please do not edit it.
*/
public class Tree0 {
public static double calcTree(double[] fs) {
if (fs[54] <= 0.5) {
if (fs[59] <= 0.9736842215061188) {
if (fs[88] <= 0.5) {
if (fs[68] <= 25.0) {
if (fs[30] <= 0.41428571939468384) {
if (fs[38] <= 0.0005793680320493877) {
if (fs[84] <= 9953.5) {
if (fs[55] <= -903.5) {
if (fs[36] <= 0.00043574847222771496) {
if (fs[15] <= 0.5) {
if (fs[49] <= 0.5) {
if (fs[31] <= 0.31414473056793213) {
return 0.3141634980988593;
} else {
return 0.538899430740038;
}
} else {
Когда вы вызываете автодополнение в IntelliJ IDEA со включенной ML-сортировкой, по факту выполняется этот код. Эти 38 строчек — только начало, весь файл занимает 8923 строчки — мы просто упёрлись в размер class file, constant pool и так далее. Этих class file в модели около 60, то есть это более 100 000 строк. И меня это немного беспокоит.
Во-первых, меня беспокоит, что if пишут роботы, а не я сам. Причём робот пишет if гораздо быстрее, чем я. А значит, я могу остаться без работы. Представьте, придёт пользователь и скажет: «А почему вы этот пункт completion поставили выше, а тот ниже? Ведь тот, который ниже, главнее?». Мы смотрим на это и думаем, что пользователь, в принципе, прав, и хорошо бы починить этот баг. И это пугает даже сильнее безработицы. Что мы ему можем ответить, потому что отлаживать и редактировать это совершенно невозможно?
Любое изменение должно идти не привычным путём (найти какой-то if и поправить), а иным.

И здесь нет места обычному программированию, где мы пишем старые добрые if. И вот это меня беспокоит.
Whole line completion
Одно из модных сейчас направлений автодополнения — whole line completion. Даже с идеальным ранжированием обычный completion позволяет немного дополнить код. А давайте мы за пользователя будем писать приличный кусок программы с вызовом методов, аргументами и так далее.
Одно из доступных решений в продакшне — Codota. Можно установить плагин в IntelliJ IDEA, и он начинает предлагать интересные варианты, основываясь на имеющихся переменных и своём понимании.
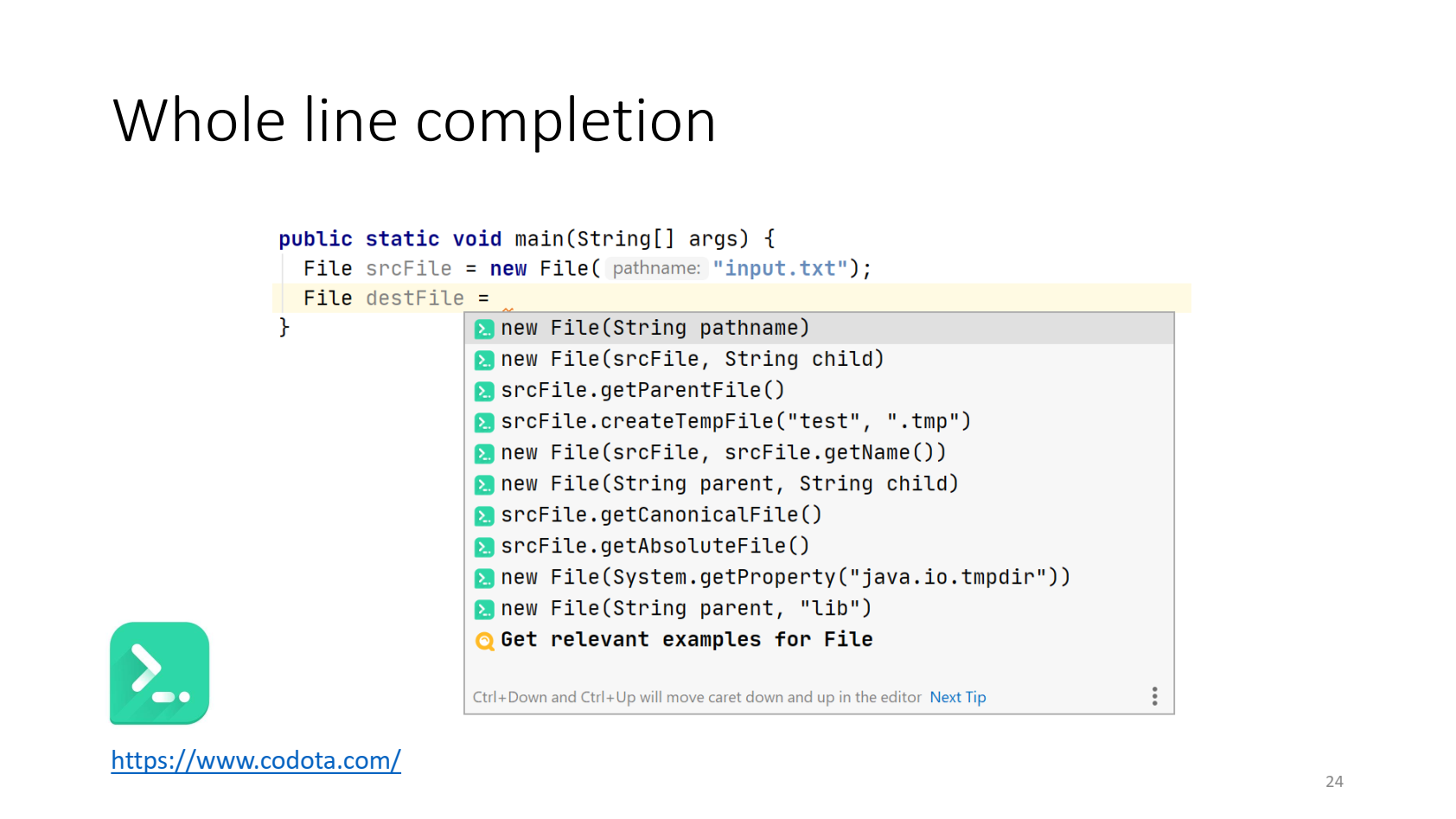
Как я понимаю, его модели обучаются на опенсорс-репозиториях и смотрят, что вообще люди пишут. Например, здесь плагин решил, что если мы хотим создать новый файл, то, возможно, мы хотим сделать его во временном каталоге, и за нас написал код.
С Codota вышла забавная и поучительная история. Помимо обычного дополнения, у них есть шаблоны: когда вы пишете название шаблона, то плагин вставляет какой-то boilerplate.
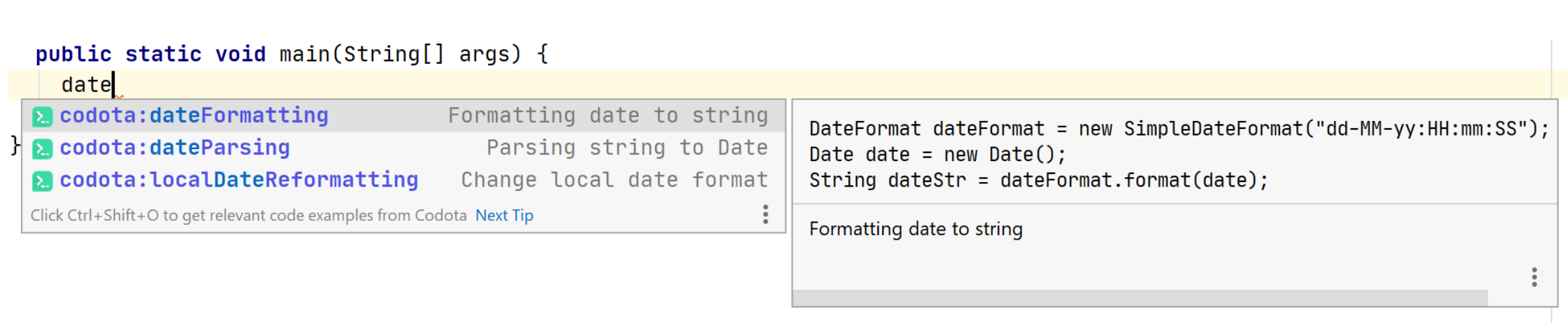
Вставим этот шаблон.

А почему SS выделено жёлтым? Недавно мы написали новую инспекцию для Java, которая разбирает эти строки форматирования и смотрит, нет ли чего странного. И раз встретились часы, минуты и миллисекунды рядом, а секунд нет, то это подозрительно выглядит, и мы предлагаем это исправить.

Дело в том, что Codota действительно вставил неправильный код, и никто этого не знал. Я сообщил им про этот баг, они его пофиксили, но мне эта история показалась очень интересной, ведь фактически подрались два робота. Программист говорит: «Я хочу отформатировать дату». Codota: «Я умею это делать, предоставь это мне, я сейчас за тебя всё напишу». И тут выскакивает второй робот: «Ты же неправ, так нельзя программировать, вот как надо!».
Многие уже видели чаты, где двух ботов стравливают друг с другом и смотрят, что получится. Кажется, что-то подобное мы начинаем наблюдать в IDE. Можем ли мы прийти к ситуации, когда вокруг нас будет ещё больше роботов? Разные инструменты, плагины. Каждый со своим ИИ и с пониманием, как писать код. Каждый будет давать вам свои советы. Начнут ли они ругаться друг с другом? И в чём тогда роль человека-программиста? Будет ли он больше разнимать ругающихся роботов, чем писать программы? Кто знает.
У Codota есть ещё один проект по автодополнению — Tabnine. И кажется, что он ещё более искусственный интеллект. Это независимый движок, он развивался отдельно, но затем Codota его купила. Иногда он действительно предлагает в топе тот вариант, который нам нужен.
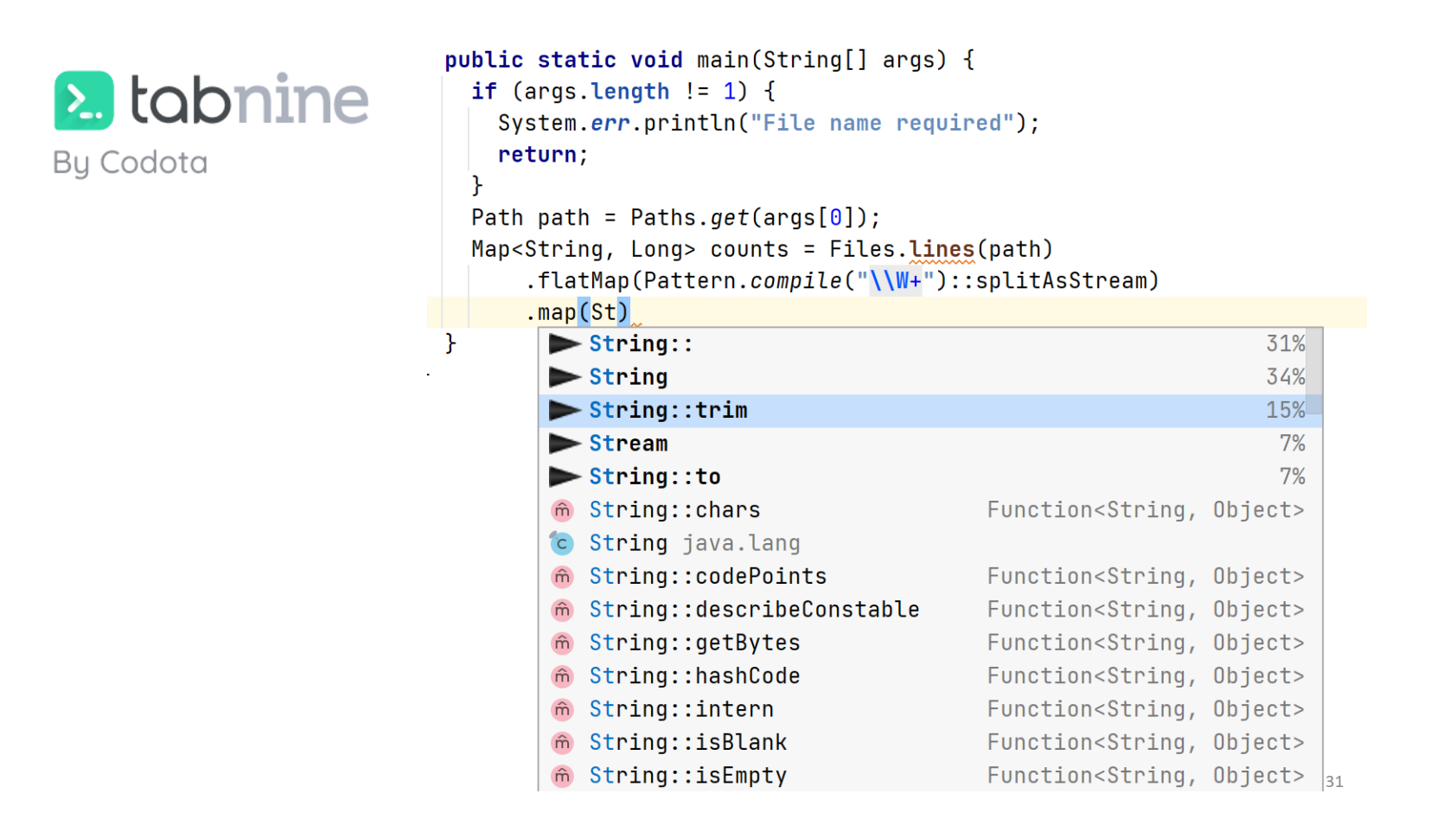
Например, здесь я хотел написать String::trim, и он вылез третьим пунктом, хотя completion от IDEA предложил этот вариант где-то внизу.

Но бывает и полная ахинея. Например, тут я хотел избавиться от пустых строк, и мне сразу предлагают Predicate.isNotBlank. Всё звучит как надо, плагин его вставляет, и тут Tabnine умывает руки, потому что никто не знает, что это за предикат и из какого класса.
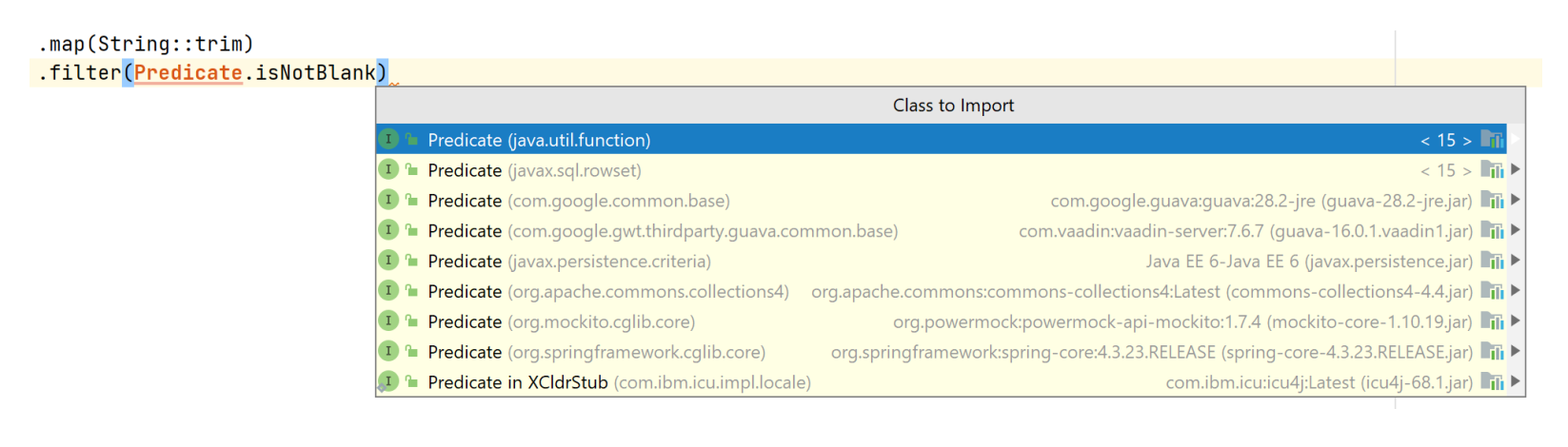
IDEA дальше предлагает импортировать его, но на самом деле ни в одном из этих классов нет подходящего метода isNotBlank. То есть Tabnine плевать, что это за предикат и откуда он взялся. Плагин просто видел его в каких-то опенсорс-проектах.

Также он предлагает какие-то куски выражений. Например, сама IDEA никогда не опустилась бы до того, чтобы предложить вставить вызов метода и не указать круглые скобки, тем более что у него нет аргументов.
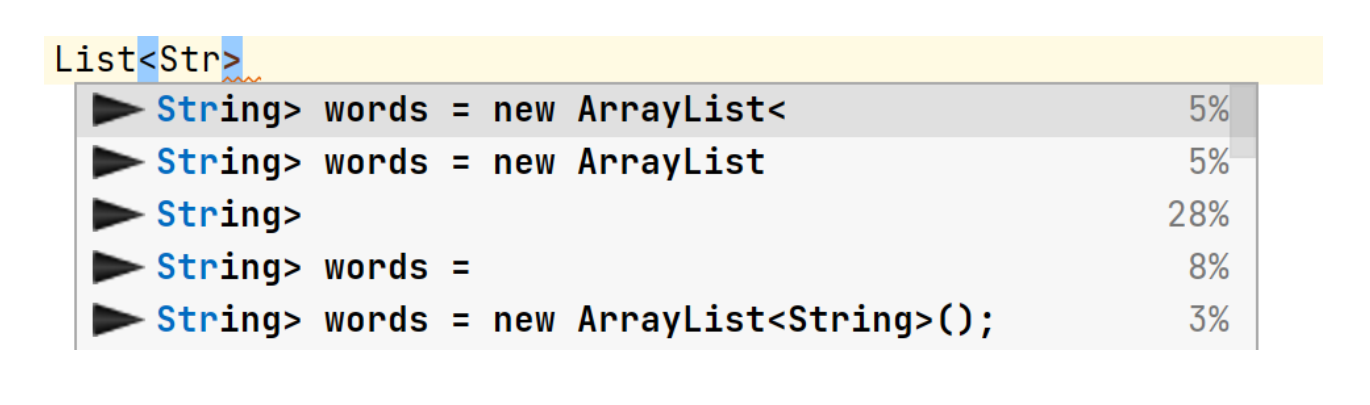
Вот ещё пример. Я только начал писать тип List, и он сразу предлагает new ArrayList и даже имя переменной придумал, хотя я хотел другое, но это неважно. Важно то, что он либо оставит меня без круглых скобок, если я выберу первый вариант, либо я могу выбрать последний вариант, но тогда Tabnine напишет тип справа, а у меня уже давно не Java 6.
Такое ощущение, что энергии у Tabnine много, он видел много исходного кода, и поэтому постоянно хочет что-то посоветовать. Но конкретно язык Java он не знает. А то, что мы вручную делали в IDEA с completion, очень хорошо знает язык.
Главное после Tabnine — никогда не знаешь, в каком ты месте окажешься после предложения, и что конкретно придётся дописать вручную. Может быть, я рано сдался, и надо было ему дать обучиться конкретно на моих «сорцах», но мне показалось, что с ним одно мучение. Здесь методы машинного обучения уступают completion, написанному вручную с любовью и заботой. Может, в других языках Tabnine более полезен, если вы очень медленно сами печатаете.
В общем, пока я не замечаю, чтобы code completion сам за вас написал всю программу. Программисту поработать всё равно придётся. А главное, эти технологии обычно экономят моторные действия, но не так уж экономят мысленную энергию. Вам всё равно придётся придумывать вашу программу самим. Так что пока рабочее место роботам не оставляем.
Code generation
Как насчёт автоматической генерации исходного кода? В целом, она близка к автозаполнению, но люди как-то разделяют эти понятия.
public class Person {
String firstName, lastName;
int age;
}
Мы начали писать класс мутабельного человечка, при этом нам completion почти не помогал. Что нужно дальше? Геттеры, сеттеры, конструкторы, equals(), hashcode(), toString() — скука смертная. Вы говорите компьютеру: «Я не хочу это писать, мне лень». Компьютер с радостью делает эту работу.
import java.util.Objects;
public class Person {
String firstName, lastName;
int age;
public Person(String firstName, String lastName, int age) {
this.firstName = firstName;
this.lastName = lastName;
this.age = age;
}
public String getFirstName() {
return firstName;
}
public void setFirstName(String firstName) {
this.firstName = firstName;
}
public String getLastName() {
return lastName;
}
public void setLastName(String lastName) {
this.lastName = lastName;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public boolean equals(Object o) {
if (this == o) {
return true;
}
if (o == null || getClass() != o.getClass()) {
return false;
}
Person person = (Person) o;
return age == person.age &&
Objects.equals(firstName, person.firstName) &&
Objects.equals(lastName, person.lastName);
}
@Override
public int hashCode() {
return Objects.hash(firstName, lastName, age);
}
@Override
public String toString() {
return "Person{" +
"firstName='" + firstName + '\'' +
", lastName='" + lastName + '\'' +
", age=" + age +
'}';
}
}
Любая IDE это сделает, не только IntelliJ IDEA. Было 4 строки, а стало гораздо больше. Если вам платят за строки, то этот день кажется особенно удачным. Впрочем, часто люди не хотят не только писать всё это, а даже читать. Вот настолько программисты обленились. Пусть компьютер пишет это где-нибудь у себя, но нам вообще не говорит, не показывает, мы этого не хотим видеть.
import lombok.*;
@Data
@AllArgsConstructor
public class Person {
String firstName, lastName;
int age;
}
Конечно, так тоже можно, и вот один из вариантов. Код появляется при компиляции автоматом, в исходниках его нет, и вы можете его не читать.
data class Person(
var firstName: String,
var lastName: String,
var age: Int)Другая альтернатива — перейти на язык, где этот код писать не нужно в принципе. И тут возникает философский вопрос: в данном случае писал ли робот код за вас или нет? Вы можете пользоваться геттерами, сеттерами, equals() и hashcode(), но язык не требует писать всё это.
Было ли здесь какое-то автоматическое программирование, сделанное за вас? Вообще термин «автоматическое программирование» — очень размытый. Он появился в 50–60-е годы XX века, и его использовали для обозначения программирования на языках высокого уровня типа Fortran, которые тогда появлялись. Мол, настоящее ручное программирование — это когда ты шпаришь в машинных кодах, и в самом крайнем случае — когда пишешь на Assembler.
А потом появились языки высокого уровня вроде Fortran, и программируем уже не мы, а транслятор. Настоящих программистов не осталось, и мы — лишь придатки к компиляторам. Мы описываем решение не в виде программы, а на каком-то высокоуровневом языке пишем алгоритмы, а сами общаться с машиной давно разучились.
Программистам от такого отношения обидно, и поэтому весь тот ужас, который мы пишем на высокоуровневых языках, называем программами. И несмотря на то что автоматическое программирование существует уже больше 60 лет, мы ещё не остались без работы.
Automatic refactoring
Предположим, что мы код тем или иным образом написали. Что же с ним надо сделать теперь? Правильно, переписать, потому что он написан плохо. Для того, чтобы переписывать код, придумали рефакторинг. Возможно, для вас будет звучать удивительно, но буквально 20 лет назад программисты рефакторили вручную.
Этому процессу посвящена монументальная книга Мартина Фаулера (Martin Fowler), Refactoring. Improving the Design of Existing Code. Некоторые говорят, что эта книга научила людей рефакторить, но главная её ценность в том, что она научила IDE рефакторить. По сути, эта книга — набор рецептов, как правильно написать IDE, чтобы она правильно рефакторила за вас. Когда книга вышла, производители инструментов для программирования бросились реализовывать эти алгоритмы и рецепты.
Ключевым моментом времени Фаулер назвал январь 2001 года, когда два инструмента преодолели рубикон рефакторинга и рефакторинг в Java получил серьёзную инструментальную поддержку. В этой заметке Мартин рассуждает, что ряд инструментов уже имел какую-то реализацию рефакторингов — очень простых вроде rename-методов. Но серьёзной заявкой на инструментальную поддержку была бы реализация Extract Method, потому что сделать реализацию этого метода — совсем не тривиальная задача. Я с удовольствием ссылаюсь на эту статью, потому что одним из двух инструментов, которые перешли Рубикон, являлась совершенно новая и малоизвестная среда разработки IntelliJ IDEA. Упоминание в статье Мартина Фаулера, конечно, стало большим успехом для JetBrains.
Сегодня автоматических рефакторингов в IDE довольно много. Есть какие-то популярные, например Rename, Change Signature, Move, Extract Variable, Inline, а есть такие, которые даже я не знаю, что делают, хотя я отвечаю за Java в IntelliJ IDEA. При этом самые популярные рефакторинги тоже прошли длинный путь от очень наивной реализации, которая часто ломалась, до очень умной, которая знает очень много частных случаев, корнер-кейсов, и они все покрыты разными if в коде.
Разберём несколько примеров с методом inline.
boolean checkValid(Data data) {
if (hasError(data.getContent())) return false;
return !hasError(data.getInheritedContent());
}
boolean hasError(List<String> content) {
for (String str : content) {
if (isInvalidString(str)) return true;
}
return false;
}Есть метод checkValid(), и в нём два вызова hasError(). По каким-то причинам мы решили, что метод hasError() лишний, и хорошо бы его заинлайнить. Сам метод hasError() выглядит несложно, но в нём две точки выхода, причём одна в цикле, а другая — снаружи. И в исходном методе checkValid() тоже две точки выхода.
Не так давно рефакторинг просто поднимал лапки вверх и говорил: «Не могу, не умею, слишком сложно для меня».
boolean checkValid(Data data) {
for (String str1 : data.getContent()) {
if (isInvalidString(str1)) return false;
}
for (String str : data.getInheritedContent()) {
if (isInvalidString(str)) return false;
}
return true;
} Однако сегодня вы получите аккуратный, будто написанный вручную код, и даже непонятно, где заканчивается предыдущий заинлайненный метод и начинается следующий. Это уличная магия, и иначе вообще не скажешь.

Или вот здесь. У вас есть объект Person, вы вызвали конструктор и после этого вызываете геттер. Вы можете встать на конструктор и заинлайнить всё одним действием. Он понимает, что у вас есть объект, поля, и он всё это пропихнёт из параметров в поля, из полей перейдёт в геттеры, из геттера назад вытащит, поймёт, что возраст нам совершенно не нужен, и оставит только одно слово. Чудо же!
Что важно, здесь нет никакого новомодного ИИ и deep learning. Это всё нежно, аккуратно и заботливо написано вручную, то есть там много if, которые покрывают частные случаи. Конечно, это всё сильно помогает модифицировать уже написанный код, уменьшая количество работы, которое приходится делать вручную, а также количество ошибок, которое вы при этом сделаете.
Automatic solution finding
Часто программисту надо решать задачи, и очень часто они уже кем-нибудь решены. Казалось бы, зачем решать задачу, если её делал другой человек? Надо просто взять готовое решение. В принципе, все программисты этим пользуются: берут готовые библиотеки в зависимости от своих проектов, находят вопросы на StackOverflow, копипастят оттуда куски кода и так далее. Но всё равно это требует ручного труда, потому что нужно куда-то зайти, что-то поискать в Интернете, разобраться, что люди ответили… Могут ли роботы сами заниматься этой работой — искать готовые решения задач в Интернете?
Проверим, делится ли 15 на 3. Предположим, вы не умеете решать эту задачу или ваш язык программирования не умеет. Чтобы решить её, надо погуглить.
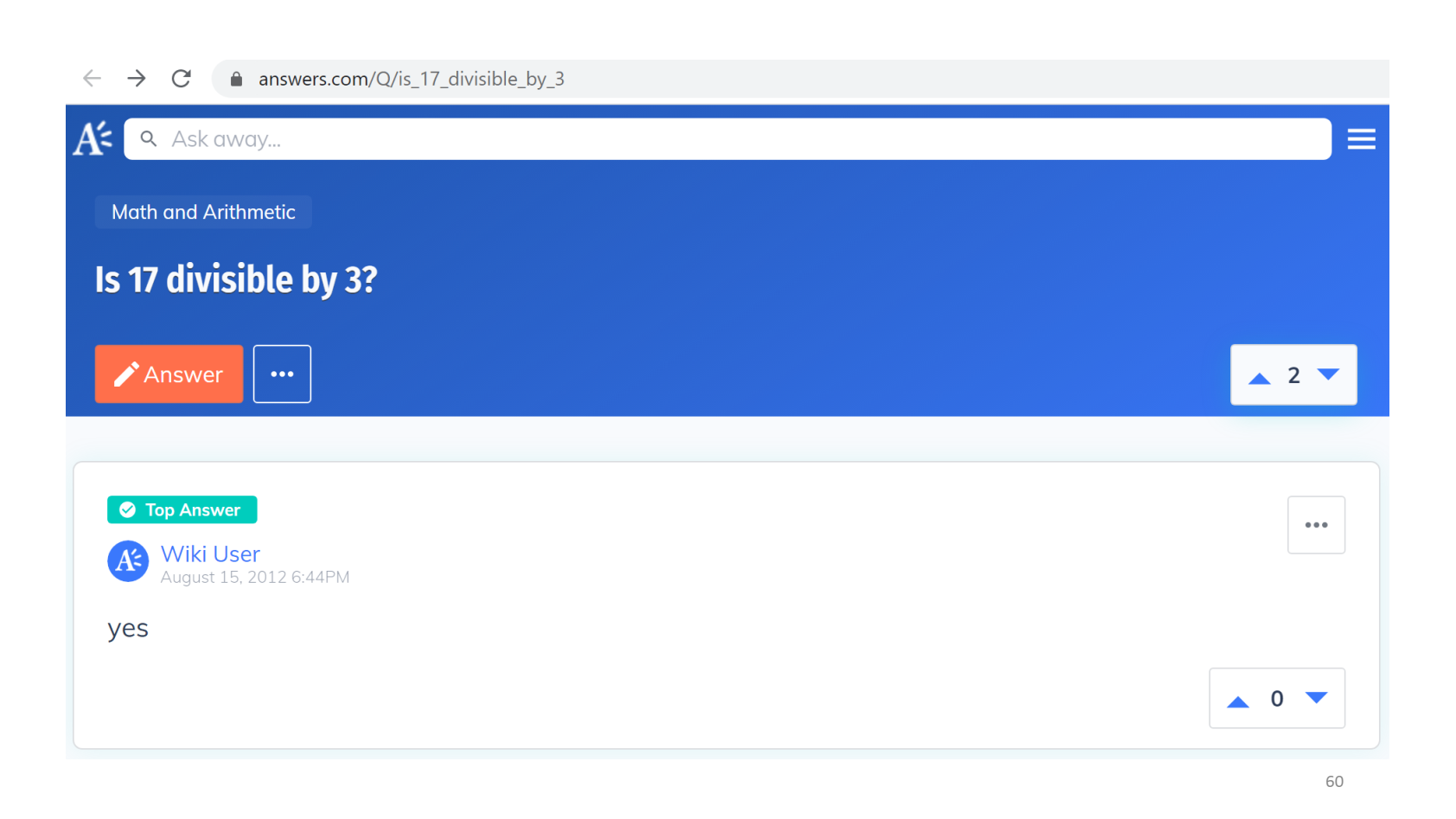
Сузим диапазон поиска и перейдём на сайт вопросов и ответов, где спросим «is 15 divisible by 3?».

Ответ выглядит так. Да, делится, задача решена. Нам не надо ничего самим считать — за нас уже решил другой человек, и мы ему поверим, ведь зачем делать работу во второй раз.
Один программист написал proof-of-concept решения задач FizzBuzz с использованием Automatic solution finding. Правда, написано на Python, но даже если никогда не видели Python, тут всё понятно.
if __name__ == '__main__':
divisors = [(3, 'fizz'), (5, 'buzz')]
for i in range(1, 101):
output = ''
for d in divisors:
if query_search_engine(i, d[0]):
output += d[1]
output = output or i
print(output)Проверку делимости мы не решаем, а делегируем Интернету, ведь она уже решена.
base_url = 'https://www.answers.com/Q/'
def query_search_engine(numerator, denominator):
''' ask a search engine if these numbers are divisible '''
question = 'is %d divisible by %d' % (numerator, denominator)
question = question.replace(' ', delimiter)
url = '%s%s' % (base_url, question)
request = Request(url)
request.add_header(
'User-Agent',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:72.0) ' \
'Gecko/20100101 Firefox/72.0')
response = urlopen(request)
# politeness -- wait a few seconds before the next query
time.sleep(3)
if url != response.url:
return False
text = response.read().decode('unicode-escape')
parser = SearchParser()
parser.feed(text)
return parser.conclude_yes_no()Здесь мы делаем такой запрос к answers.com. Парсер целиком показывать не буду, но суть здесь.
# words that indicate whether the answer is yes or no
self.positive_signs = ['yes', 'exactly', 'is divisible']
self.negative_signs = ['no', 'not', 'decimal']
…
def score_answer(self, answer):
''' evaluates an answer to determine if it's a yes or a no '''
score = 0
positive_signs = re.findall(
r'\b%s\b' % r'\b|\b'.join(self.positive_signs),
answer,
)
score += len(positive_signs)
negative_signs = re.findall(
r'\b%s\b' % r'\b|\b'.join(self.negative_signs),
answer
)
score -= len(negative_signs)
return scoreЕсли в ответе вы встречаете слова yes, exactly, is divisible, то вы добавляете очко. Если же встречаются no, not, decimal, то отнимаете очко. Эти очки суммируются по всем ответам, и вердикт выдаётся на базе общего количества ответов. В итоге программа делегирует задачу проверки делимости вселенскому разуму вместо того, чтобы решать её самостоятельно. И это работает! Вы можете не решать эту задачу у себя, то есть программа работает с точностью до того, что умеет вселенский разум, потому что встречается и такое.
Слепо доверять людям из Интернета, конечно, не стоит. Но в целом подход интересный, ведь в мире накоплено много решений типовых задач, и вполне можно взять готовое вместо того, чтобы платить программисту за то, чтобы он решал это снова.
Automatic bug search
Видя, что ошибки всё-таки бывают, мы переходим к вопросу о том, что программы часто работают неправильно. Чтобы программа начала работать правильно, надо искать в ней ошибки и исправлять. Люди могут искать ошибки и сами, но лучше, когда это делает машина.
Конечно, любой компилятор умеет искать ошибки, которые препятствуют исполнению программы. Но часто этим проблемы не ограничиваются.
Да, я слышал, что программисты на Haskell хвастаются, что если у них компилируется, значит, работает. Я даже видел простые примеры, подтверждающие этот тезис, но я им всё равно не верю. Так или иначе в более мейнстримных языках типа Java все прекрасно знают, что можно наделать кучу ошибок, которых компилятор не заметит.
Одним из знаковых инструментов, специально сделанных не для компиляции, а для поиска ошибок, является lint. Первая его версия вышла в 1978 году, так что в плане поиска ошибок в программах роботы уже очень давно отнимают наш хлеб.
Вот пример программы на C из книги Checking C Programs with Lint Яна Дарвина.
myfunc(s)
char *s
{
void a();
int i, j;
a("hello");
}Книга появилась в 1988 году, то есть на 10 лет позже, чем lint, но всё равно это доисторические времена. По крайней мере, в 1988 году я кушал кашу в детском саду, а не занимался проверкой задач на корректность.
Многие, глядя на листинг этой программы, даже не поймут, что здесь происходит, потому что это изначальный синтаксис языка Кернигана и Ритчи, когда типы параметров функции не писали в скобках.
При запуске lint выдаёт 3 предупреждения о неиспользуемом параметре функции и двух неиспользуемых локальных переменных.
% lint myfile.c
myfile.c:
myfile.c(2): warning: argument s unused in function myfunc
myfile.c(6): warning: i unused in function myfunc
myfile.c(6): warning: j unused in function myfunc
%То есть уже тогда lint умел определять, что переменная объявлена, но не используется. Могло оказаться, что она осталась после рефакторинга (это не ошибка, её просто надо удалить), но бывает и реальная ошибка. Например, мы хотели использовать какую-то переменную, но по ошибке случайно использовали одну из объявленных ранее.
Любопытно, что буквально с первых страниц книги поднимается вопрос о том, как собственно с роботами бороться.
Вот простой пример. Вы печатаете сообщение в стандартный поток ошибок с помощью fprintf(), а lint на ругается на то, мы не используем возвращаемое значение.
fprintf(stderr, "%s: -f argument %s invalid\n",
progname, optarg);
lint:
function returns value which is always ignored
fprintfВ C функция fprintf() возвращает количество выведенных символов либо отрицательное число в случае ошибки. Если даже случилась ошибка, это значит, что мы не смогли в stderr() что-то написать, то есть у нас сломан stderr(). Мы ничего не можем сделать, и даже пользователю не можем сообщить об ошибке. Поэтому мы вполне считаем себя вправе проигнорировать результирующее значение функции fprintf(). Так что тут глупый робот неправ. Как мы видим, уже в 1988 году программисты видели, что роботы не всесильны, и, бывает, глупость советуют.
Как же заткнуть робота и сказать, что всё нормально? Добавляем явный каст к типу void. В C и не такая жесть допустима. Зато lint теперь заткнулся.
(void) fprintf(stderr, "%s: -f argument %s invalid\n",
progname, optarg);
В этих случаях всегда возникает вопрос: а помогает ли статический анализатор или мешает? Ведь нам постоянно приходится бороться с предупреждениями, вставлять какие-то странные аннотации, комментарии или ещё что-то. Они загрязняют код, мешают его читать; если вы мёрджите что-то в Git или рефакторите, то эти комментарии могут случайно оторваться от нужного места и оказаться совсем не там, где надо. Получается полная ерунда, и вы тратите на это лишнее время вместо того, чтобы спокойно программировать.
Сегодня статический анализ ушёл далеко вперёд. Вместо десятков правил в самой IntelliJ IDEA, например, встроены уже тысячи. Но суть со времён lint не сильно изменилась — это поиск определённых шаблонов кода, которые считаются неправильными. И предупреждения тоже иногда приходится подавлять аннотациями или комментариями.
Конечно, не всегда это просто паттерны. Иногда за предупреждением стоит довольно сложная математическая теория, абстрактная интерпретация, widening, решётки и прочие страшные слова.
Например, на нашей конференции SnowOne я показывал такой код.

Он говорит, что это условие всегда истинно. И тут реально без бутылки не разберёшься, почему; надо крепко задуматься, а робот вам подсказывает за долю секунды. Вы пишете код, а он — хоп! — и подсветил, что ты неправильно написал.
Подобных примеров я видел в своей жизни десятки, потому что я как раз занимаюсь инспекцией, которая это делает. Обычно подобное приносит пользователь и говорит: «Ха-ха, ваш анализатор ошибся! У меня в коде нет ошибок!». Потом я внимательно смотрю на этот код, где-то полчаса разбираю все возможные варианты, доказываю, что ни в каком варианте это условие не может быть ложно, и пишу длинный комментарий пользователю, где говорю: «Нет, извини, у тебя в программе ошибка, мой анализатор всё сделал правильно».
И тут снова встаёт философский вопрос. Роботы становятся всё умнее, и они могут стать даже умнее человека, но при этом роботы всё ещё могут ошибаться. Что делать человеку? Как понять, ошибается робот или нет, если задача для человека уже слишком сложна?
Чтобы как-то решить проблему с предупреждениями, я сделал объяснялку.

Честно говоря, в сложных случаях она работает так себе. Гораздо проще научить робота решать задачу, чем заставить робота объяснить своё решение человеку. Но даже здесь объяснение хоть и неполное, но оно всё равно может подсказать направление мысли.
В кусочке кода выше выражение всегда истинное, потому что робот решил, что в данной точке список всегда пустой, и значение max тоже всегда 0, поэтому истина.
А почему же всегда 0? Дальше, к сожалению, надо рассуждать человеку, ведь этого робот нам не говорит. Если список пустой, то max = 0, и мы в цикл не заходим. Переменная c будет первым символом из строчки CONF_NAME, и после этого условие действительно будет истинно.
Что же произойдёт, если мы зашли в цикл (список был всё-таки не пустой изначально)? Сразу же у нас идёт проверка, и в случае, если хоть одна строчка в списке не содержит подстроки SnowOne, то мы возвращаемся сразу из методов, а не только из цикла. Поэтому все строчки в этом списке должны содержать SnowOne, если мы вообще хотим дойти до нашего if.
Если же проверка прошла, это значит, что длина строки s как минимум 7 символов, а значит, max сразу прыгает от 0 минимум до 7, то есть он не может принять значения 1..6. Если список непустой, то max точно не меньше 7. А когда мы доходим до строчки char c = CONF_NAME.charAt(max); мы ищем в символьной строке символ с индексом 7 или больше, и мы точно упадём с IndexOutOfBoundsException и тоже не выполним if. То есть if у нас не выполнится, если список непустой. Единственный способ дойти до if — наш список пустой, но тогда условие будет всегда истинно.
Как видите, этого всего робот объяснить нам не смог, но он проделал всё это в своей голове, и нам приходится повторять путь за ним.
Automatic bug fixing
Роботы находят баги и даже объясняют, почему это именно баги. Дальше баги надо исправлять. Хорошо бы, чтобы роботы сами их исправляли.
В простых случаях роботы легко с этим справляются. Вот одна из моих любимых ошибок.

Что не так с getClass()? А service — это уже класс, и если мы у объекта типа класс вызываем getClass(), то мы получим класс от класса, то есть просто java.lang.Class. В результате сообщения в логах будут выглядеть всегда одинаково: Unable to instantiate a service of class class java.lang.Class. То есть мы не увидим настоящий класс service и не поймём, куда копать. Такие ошибки я встречал в реальном коде, и они возникают либо при логировании, либо в путях обработки исключений — это вещи, которые редко тестируются.
Статический анализатор не только указывает на ошибку, но и предлагает наиболее вероятный способ её исправить — убрать лишний getClass(). Нам остаётся только лениво согласиться с предложением ткнуть мышкой или даже не согласиться, потому что на самом деле решение за нами. И если вдруг мы решим неправильно, то спрашивать будут с нас.
Впрочем, бывает, что ошибка есть, но вариантов её исправления, возможно, много. Яркий пример — NullPointerException.

Здесь мы видим, что data проверяли на NULL выше, а значит, NULL там может быть. А здесь мы, безусловно, его разыменовываем. Явно что-то не так и подозрительно, но что конкретно?
Может быть, надо всё оставшееся тело поместить в if, тогда у нас ошибки не будет.
void processData(Data data) {
if (data != null) {
setHasData(true);
validate(data);
for (Item item : data.getItems()) {
processItem(item);
}
afterProcessing();
}
}
Может быть, afterProcessing() стоит оставить снаружи, потому что этот метод надо вызвать, даже если у нас был NULL.
void processData(Data data) {
if (data != null) {
setHasData(true);
validate(data);
for (Item item : data.getItems()) {
processItem(item);
}
}
afterProcessing();
}
А может быть, мы уверены, что validate() при передаче NULL выкинет исключение, он же валидирует что-то. Тогда, может быть, data = NULL, и поэтому всё нормально, и мы не дойдём до цикла. Нужно лишь написать assert, чтобы было точно понятно всем, кто читает код.
void processData(Data data) {
if (data != null) {
setHasData(true);
}
validate(data);
assert data != null;
for (Item item : data.getItems()) {
processItem(item);
}
afterProcessing();
}
А может, NULL и быть не могло, и ошибка на самом деле в первом условии.
void processData(Data data) {
if (!data.isEmpty()) {
setHasData(true);
}
validate(data);
for (Item item : data.getItems()) {
processItem(item);
}
afterProcessing();
}
Как мы видим, нелегко правильно выбрать фикс. Приходится думать, напрягать голову, а это неприятно. Чтобы избавить программиста от столь неприятного занятия, Facebook сделала Getafix. Программа специально ориентирована на баги, которые детектировать можно, но непонятно, как исправлять. В первую очередь, проверка на NullPointerException.

Эта штука обучается на истории коммитов каких-то проектов, где была исправлена аналогичная проблема. Getafix превращает текстовый diff в AST-diff, абстрагирует его от несущественных вещей типа имён переменных и обучает тоже какую-то модель. Так что по окружающему контексту кода эта модель может решить, какой фикс в данном случае наиболее подходит, основываясь на том, что программисты делали в похожих случаях раньше. Причём сами фиксы в модель не закладывались, то есть нам не надо даже перечислять все возможные фиксы. Просто если мы знаем, что NullPointerException здесь был (его раньше статический анализатор репортил), а после этого фикса его не было, то Getafix сама намайнит эти фиксы.
Getafix интегрирована с системой code review, используемой в Facebook. Реагируя на срабатывание статического анализатора, она прямо приносит pull request, который исправляет проблему.

Идея Getafix в том, чтобы предложить человеку один вариант исправления, чтобы человеку не приходилось выбирать. Остаётся только лениво нажать accept (или всё-таки reject).
К сожалению, как я понял, инструмент так и не стал публичным. Кроме того, о нём уже ничего не слышно почти два года. Неясно, действительно ли он хорош для продакшна или это был больше научный эксперимент.
Automatic dependency updates
Кстати, идея с автоматическими pull request в целом очень богатая. Если исправление багов в коде ещё ждёт своего часа, то такая фича, как автоматическое обновление зависимостей, неожиданно прочно вошла в нашу жизнь буквально за последние год-полтора.
Если у вас есть более или менее нетривиальный проект на GitHub, то к вам, скорее всего, уже приходил dependabot. Ко мне, например, в мой любимый проект StreamEx dependabot приходил в октябре 2020 года с целью поднять версию JUnit, где исправили уязвимость с временными папками.

Робот вполне приятный. Он сам пытается резолвить конфликты. У него есть всякие полезные команды. Его патч выглядит абсолютно тривиально — взял pom.xml, красиво его подправил, добавил номер версии.
<artifactId>junit</artifactId>
-<version>4.13</version>
+<version>4.13.1</version>
<scope>test</scope>Если у вас настроен CI, то в этот момент другой робот в ответ на этот pull request автоматически прогнал тесты и убедился, что ничего не сломалось. Вы проснулись, и вам приходит имейл, где робот предложил поднять зависимость, а другой робот сказал, что ничего не сломалось. Дальше уже слово за вами: принять pull request или нет.
С другой стороны, зачем вообще что-то решать? Когда вы поднимаете зависимость в связи с security-фиксом, вы же вряд ли идёте в исходный проект и проводите там полный аудит кода, чтобы проверить, действительно ли исправили проблему безопасности, и при этом они не накосячили. Обычно вы доверяете мейнтейнерам того проекта, от которого зависите. А раз вы им доверяете, тогда нет причин не доверять dependabot. Значит, можно принимать от него pull request автоматически. То есть человеку можно даже не одобрять решение робота.
Первая такая известная история произошла в проекте React Components 16 сентября 2019 года. Запомните эту дату. Возможно, она войдёт в школьные учебники истории как Рубикон автоматизированного программирования по аналогии с Рубиконом рефакторинга.
В проект React Components пришёл dependabot, который предложил поднять версию зависимости библиотеки mixin-deep с 1.3.1 до 1.3.2.
Другой бот прогнал билд на CI. Далее в проекте был настроен бот mergify, которому дозволено автоматически принимать коммиты от dependabot, если CI-билд прошёл успешно. Поэтому бот всё замёрджил.

Но и это ещё не всё. В проекте есть ещё один бот, который постит мотивирующие гифки. И он тоже сделал успешно свою часть работы. В итоге выполнены абсолютно все функции, которые до этого делали люди.
Но в этой истории есть ложка дёгтя (или мёда, как посмотреть). Дело в том, что роботы на самом деле накосячили.

Дальше пришёл человек и сказал, что их зависимость не соответствует принципу semantic versioning, и помимо security-фикса они ещё и семантику немного поменяли, и поведение кода изменилось. Этот человек принёс новый тест, которого в проекте не было, и показал, что тест проходил до апдейта, а теперь падает. Так что даже если мы слепо доверяем ботам, люди всё равно нужны, потому что бывают нетривиальные случаи.
Другая интересная история с dependabot произошла в репозитории TruffleRuby вскоре после предыдущей истории.

Все мы слышали про GraalVM и проект Truffle. И вот как-то туда пришёл dependabot и предложил поднять зависимость, а то здесь не код, а решето.

Тут ему ответил бот проекта: а вы, собственно, кто такой? А документы у вас есть? А contribute agreement вы подписали? А с кем конкретно будет судиться Oracle, если вы нам свинью подложили? Ничего не подписали? Ну и идите отсюда со своим pull request.

Ну а dependabot в лучших традициях ответил: ну не хотите, как хотите, но I’ll be back.
Вообще тут сами роботы подняли важный юридический вопрос. Если робот приносит в вашу кодовую базу pull request, то вдруг он занесёт умышленно уязвимость? Или занесёт чужой код, покрытый копирайтом, и его лицензия несовместима с вашей, что ещё хуже.
Обычно серьёзные компании подписывают соглашение со внешними контрибьюторами (contributor license agreement). Но с кем его подписывать в случае бота? С его автором? А готов ли автор отвечать за весь код, написанный его ботом, как готов ли производитель роботизированных автомобилей отвечать за все аварии, в которые попал этот автомобиль? В общем, юристам и законотворцам ещё предстоит в этом разобраться.
Automatic tests development
Написали мы программу, отрефакторили, исправили баги, обновили зависимости. Теперь надо написать тесты. Да, сейчас придёт дядя Боб и скажет, что вы все дураки, и тесты надо было писать в самом начале. Но мы же не формалисты. Мы иногда пишем тесты и в конце.
Можно ли заставить бота писать тесты? Это интересный вопрос. Такие проекты тоже есть, и они неплохо развиваются.

Оксфордская компания Diffblue именно этим сейчас занимается. Причём они сделали ставку на Java, что для нас удобно.
Год назад у них была веб-песочница, в которой можно было написать код, и она покрывала его тестами. Я без задней мысли решил написать тривиальный метод.
public class Foo {
public static boolean check(String s) {
return s.matches("foo|bar");
}
}Давайте его покроем тестами. В итоге получил такой ад.

В секции Arrange вы видите оригинальный способ получить пустую строку. То есть мы обрабатываем строку с помощью PowerMockito, а потом с помощью reflection туда запихиваем пустой массив и длину. Причём видно, что код относится к Java 7, и сейчас это уже не сработает на свежих версиях. И вдобавок вам нужны зависимости на PowerMockito и ещё какой-то утилитный класс, который сам Diffblue провайдит.
Я посмеялся и забыл. А недавно вернулся к ним и оказалось, они не сидели на месте весь год. Во-первых, они выпустили плагин к IntelliJ IDEA, который стал генерировать тесты в самой IDEA. Во-вторых, он уже не такой глупый, и для того же самого метода тест выглядит так.
import static org.junit.Assert.assertFalse;
import org.junit.Test;
public class FooTest {
@Test
public void testCheck() {
assertFalse(Foo.check("s"));
}
}
Теперь никакой жести нет, всё красивенько и приятно. Вы можете сказать: «Ерунда, он написал false-тест, то есть он нашёл строчку, которая не матчится regexp. Сделать тест вообще пара пустяков, а вот найди строку, которая матчится».
Как я понимаю, это сделано так, потому что метрики Diffblue — это покрытие числа строк. И если все строки покрыты, то он успокаивается. Поэтому его можно заставить работать подольше, если мы немного поменяем метод.
public class Foo {
public static boolean check(String s) {
if (s.matches("foo|bar")) {
return true;
} else {
return false;
}
}
} Вот так мы растащим одну строку на пять благодаря функции Expand boolean return to ‘if else’ из IntelliJ IDEA. Теперь надо оба return покрыть тестами.
public class FooTest {
@Test
public void testCheck() {
assertFalse(Foo.check("s"));
assertTrue(Foo.check("foo"));
}
} И «сова» справилась! Она реально нашла, что строка foo матчится этим regexp.
Давайте усложним regexp.
public class Foo {
public static boolean check(String s) {
if (s.matches("\\da[X-Z]{2}\\d")) {
return true;
} else {
return false;
}
}
}И она нашла мне строчку, которую матчит, за полсекунды!
public class FooTest {
@Test
public void testCheck() {
assertFalse(Foo.check("s"));
assertTrue(Foo.check("9aYY9"));
}
}Давайте теперь попробуем с числами. Напишем какое-то ветвление.
public static String fizzBuzz(int x) {
if (x % 15 == 0) {
return "FizzBuzz";
}
if (x % 5 == 0) {
return "Fizz";
}
if (x % 3 == 0) {
return "Buzz";
}
return String.valueOf(x);
}
И «сова» покрыла все ветки! То есть она нашла все входные числа, которые заходят в каждую ветку.
@Test
public void testFizzBuzz() {
assertEquals("2", fizzBuzz(2));
assertEquals("FizzBuzz", fizzBuzz(0));
assertEquals("Fizz", fizzBuzz(5));
assertEquals("Buzz", fizzBuzz(3));
} Я попробовал сделать свой объект.
public class Person {
final String name;
final int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
boolean isValid() {
return !name.isEmpty() && age >= 0;
}
} Diffblue сам догадался, как его конструировать, и действительно написал 3 ассерта.
public class PersonTest {
@Test
public void testIsValid() {
assertTrue((new Person("name", 1)).isValid());
assertFalse((new Person("", 1)).isValid());
assertFalse((new Person("name", -1)).isValid());
}
}Diffblue вызывает конструктор с разными параметрами, и на самом деле она покрыла даже разные варианты, когда у вас разные ветки в true или false превращаются.
Я нашёл потом способы, как сломать «сову», но не буду показывать, потому что не хочу портить вам первое впечатление. Это уже совсем не игрушка, а полезный инструмент. Если быстро надо покрыть тестами домен или кодовую базу, в которой вообще нет тестов, инструмент вполне может пригодиться. Причём у них на сайте есть примеры генерации автотестов для Spring-приложений, которые выглядят именно так, как они канонически пишутся.
Рекомендую попробовать, а главное, вообще не надо никаких настроек: вы поставили плагин, нажали кнопку Write tests, и он пишет тест. В общем, если вас держат на работе только за то, что вы пишете подобные тривиальные тесты, вам стоит серьёзно подумать о завтрашнем дне.
Solve human-specified problem in code
Некоторые люди говорят, что ИИ никогда не заменит программистов полностью, потому что программистам приходится общаться с заказчиком и пытаться понять, что же ему надо. Мол, ИИ никогда не поймёт этих заказчиков и не сделает то, что они хотят, по обычной текстовой формулировке задачи. Есть ли подвижки в этом направлении?
Оказывается, кое-что есть. Думаю, многие уже слышали, что в мае 2020 года появилась новая языковая модель GPT-3, которая содержит 175 миллиардов параметров и может писать тексты, которые сложно отличить от написанных человеком.
В июне 2020 года появился доступ по API, через который модель может выполнить какие-то текстовые задания на английском языке. Оказалось, что она умеет генерировать не только английский текст, но и код на некоторых языках программирования.
В июле Шариф Шамим впервые показал, как оно работает для генерации лэйаутов на JSX:
А кого не впечатляют лэйауты, вот примеры полноценных интерактивных приложений на React.
Выводы
Что же нас ждёт? Выкинут ли роботы нас на свалку? У меня есть на этот счёт в чём-то оптимистичный взгляд. В программировании есть модная техника, называемая «парное программирование». Два человека работают за компьютером одновременно. Один из них, driver, пишет код, а другой, navigator, ревьюит, и они регулярно меняются местами.
Я не особо люблю парное программирование. Я очень редко его использовал даже до самоизоляции. А теперь мне всё больше кажется, что я давно занимаюсь парным программированием, просто мой партнёр — это робот. Он тоже может быть хоть драйвером, хоть навигатором.
При таком парном подходе оба участника обучаются чему-то. Так что будем работать рука об руку с роботом ещё много лет.
Чтобы не бояться роботов, можно повышать свою планку: чем более сложные вещи умеешь, тем сложнее тебя заменить. Один из способов оставаться на плаву — смотреть профильные конференции. Мы проводим как Java-конференции, где был сделан этот доклад Тагира, так и другие: сейчас анонсированы JPoint, Heisenbug (тестирование), HolyJS (JavaScript), DotNext (.NET), Mobius (мобильная разработка).
А если вы хотите ещё и помочь другим разработчикам опережать роботов, можете не просто посетить конференцию, а выступить на ней: сейчас на сайтах всех этих конференций открыт приём заявок на доклады.
