

Netflix — лидер рынка интернет-телевидения — компания, создавшая и активно развивающая этот сегмент. Netflix известен не только обширным каталогом кино и сериалов, доступных с почти любого уголка планеты и любого устройства с дисплеем, но и надежной инфраструктурой и уникальной инженерной культурой.
Наглядный пример Netflix подхода к разработке и поддержке сложных систем на DevOops 2019 представил Сергей Федоров — директор по разработке в Netflix. Выпускник факультета ВМК ННГУ им. Лобачевского, Сергей один из первых инженеров в Open Connect — CDN команды в Netflix. Он построил системы мониторинга и анализа видеоданных, запустил популярный сервис для оценки скорости Интернет-соединения FAST.com и последние несколько лет работает над оптимизацией Интернет запросов, чтобы Netflix приложение работало как можно быстрее для пользователей.
Доклад получил лучшие отзывы от участников конференции, и мы подготовили для вас текстовую версию.
В докладе Сергей подробно рассказал
- про то, что влияет на задержку интернет запросов между клиентом и сервером;
- как эту задержку уменьшить;
- как проектировать, поддерживать и мониторить устойчивые к ошибкам системы;
- как достигать результата в сжатые сроки, и минимальным риском для бизнеса;
- как анализировать результаты и учиться на ошибках.
Ответы на эти вопросы нужны не только тем, кто работает в крупных корпорациях.
Представленные принципы и техники должен знать и практиковать каждый, кто разрабатывает и поддерживает интернет продукты.
Далее — повествование от лица спикера.
Важность скорости интернета
Скорость интернет-запросов напрямую связана с бизнесом. Рассмотрим сферу шопинга: компания Amazon в 2009 году говорила, что задержка в 100 мс приводит к потере 1% продаж.
Все больше становится мобильных устройств, а следом за ними мобильных сайтов и приложений. Если ваша страница загружается дольше 3 секунд, вы теряете около половины пользователей. С июля 2018 года Google учитывает скорость загрузки вашей страницы в поисковой выдаче: чем быстрее страница, тем выше ее позиция в Google.
Скорость соединения также важна и в финансовых организациях, где задержка критична. В 2015 году компания Hibernia Networks закончила прокладку кабеля между Нью-Йорком и Лондоном стоимостью 400 млн долларов, чтобы уменьшить задержку между городами на 6 мс. Представьте, 66 млн долларов за 1 мс уменьшения задержки!
Согласно исследованию, скорость соединения выше 5 Мбит/с перестает напрямую влиять на скорость загрузки типового сайта. Однако между задержкой соединения и скоростью загрузки страницы прослеживается линейная зависимость:

Однако Netflix — не типовой продукт. Влияние задержки и скорости на пользователя — активная сфера анализа и разработки. Есть загрузка приложения и выбор контента, зависящие от задержки, но загрузка статических элементов и стриминг также зависят и от скорости соединения. Анализ и оптимизация ключевых факторов, влияющих на качество сервиса для пользователя, — активная сфера разработки нескольких команд в Netflix. Одна из задач — уменьшение задержки запросов между Netflix устройствами и облачной инфраструктурой.
В докладе мы сфокусируемся именно на уменьшении задержки (latency) на примере инфраструктуры Netflix. Рассмотрим с практической точки зрения, как подходить к процессам проектирования, разработки и оперированию сложных распределенных систем и тратить время на инновации и результаты, а не диагностику операционных проблем и поломок.
Внутри Netflix
Тысячи различных устройств поддерживают Netflix приложения. Их разработкой занимаются четыре разные команды, которые делают отдельные версии клиента для Android, iOS, TV и веб-браузеров. И мы очень много сил тратим на то, чтобы улучшить и персонализировать пользовательский интерфейс. Для этого мы запускаем параллельно сотни A/B-тестов.
Персонализация поддерживается благодаря сотне микросервисов в облаке AWS, предоставляющие персонализированные данные для пользователя, диспетчеризацию запросов, телеметрию, Big Data и Encoding. Визуализация трафика выглядит так:
Ссылка на видео c демонстрацией (6:04-6:23)
Слева находится entry point, а затем трафик распределяется между несколькими сотнями микросервисов, которые поддерживаются разными backend командами.
Еще один важный компонент нашей инфраструктуры — это Open Connect CDN, который доставляет до конечного пользователя статический контент — видео, изображения, код для клиентов и т.д. CDN расположена на кастомных серверах (OCA — Open Connect Appliance). Внутри расположены массивы SSD и HDD-дисков под управлением оптимизированной FreeBSD, с NGINX и набором сервисов. Мы проектируем и оптимизируем аппаратные и программные компоненты таким образом, чтобы такой CDN сервер мог отправлять как можно больше данных пользователям.
«Стенка» из этих серверов в точке обмена интернет-трафиком (Internet eXchange — IX), выглядит так:

Internet Exchange предоставляет возможность интернет-провайдерам и поставщикам контента «подключиться» друг к другу для более прямого обмена данными в интернете. По всему миру есть примерно 70-80 Internet Exchange точек, где установлены наши сервера, и мы самостоятельно занимаемся их установкой и обслуживанием:

Помимо этого, мы также предоставляем серверы напрямую интернет-провайдерам, которые они устанавливают в свою сеть, улучшая локализацию Нетфликс трафика и качество стриминга для пользователей:

Набор AWS сервисов ответствен за диспетчеризацию видео запросов от клиентов к CDN серверам, а также конфигурирование самих серверов — обновление контента, программного кода, настроек и т.д. Для последнего мы также построили backbone network, которая соединяет сервера в Internet Exchange точках с AWS. Backbone network представляет из себя глобальную сеть из оптоволоконных кабелей и роутеров, которые мы можем проектировать и конфигурировать исходя из наших нужд.
По оценкам Sandvine, наша CDN инфраструктура доставляет в пиковые часы примерно ⅛ часть мирового интернет-трафика и ⅓ трафика в Северной Америке, где Netflix существует дольше всего. Впечатляющие цифры, но для меня одним из самых удивительных достижений является то, что вся CDN система разрабатывается и поддерживается командой из менее 150 человек.
Изначально, CDN инфраструктура была спроектирована для доставки видео данных. Однако, со временем мы поняли, что мы можем использовать ее и для оптимизации динамических запросов от клиентов в AWS облако.
Про ускорение интернета
Сегодня у Netflix 3 региона AWS, и задержка запросов в облако будет зависеть от того, насколько далеко клиент находится от ближайшего региона. При это у нас есть множество CDN серверов, которые используются для доставки статического контента. Можно ли как-то использовать эту инфраструктуру, чтобы ускорить динамические запросы? При этом кэшировать эти запросы, к сожалению, нельзя — API персонализированы и каждый результат уникален.
Давайте сделаем прокси на CDN-сервере и начнем через него прогонять трафик. Будет ли это быстрее?
Матчасть
Вспомним, как работают сетевые протоколы. Сегодня большая часть трафика в интернете использует HTTPs, который зависит от протоколов нижнего уровня TCP и TLS. Чтобы клиент подключился к серверу, он делает handshake, и для установки защищенного соединения клиенту нужно обменяться сообщениями с сервером три раза и еще как минимум один раз, чтобы передать данные. При задержке на один обмен (RTT) 100 мс нам понадобится 400 мс, чтобы получить первый бит данных:

Если сертификаты расположим на CDN-сервере, то время «рукопожатия» между клиентом и сервером можем существенно сократить, если CDN находится ближе. Предположим, что задержка до CDN-сервера составляет 30 мс. Тогда для получения первого бита потребуется уже 220 мс:

Но плюсы на этом не заканчиваются. После того, как соединение уже установлено, TCP увеличивает congestion window (количество информации, которое он может передавать по этому соединению параллельно). Если теряется пакет данных, то классические реализации TCP протокола (вроде TCP New Reno) уменьшают открытое «окно» в два раза. Рост congestion window, и скорость его восстановления от потери снова зависит от задержки (RTT) до сервера. Если это соединение идет только до CDN-сервера, это восстановление будет быстрее. При этом потеря пакетов — стандартное явление, особенно для беспроводных сетей.
Пропускная способность интернета может снижаться, особенно в пиковые часы из-за трафика от пользователей, что может приводить к «пробкам». При этом в интернете нет способа дать приоритет одним запросам по отношению к другим. Например, дать приоритет маленьким по объему и чувствительным к задержке запросам по отношению к «тяжелым» потокам данных, которые загружают сеть. Однако в нашем случае наличие собственной backbone сети позволяет это сделать на части пути запроса — между CDN и облаком, и мы ее можем полностью конфигурировать. Можно сделать так, чтобы небольшие и зависимые от задержки пакеты приоритизировались, а большие потоки данных пошли чуть позже. Чем ближе CDN к клиенту — тем больше эффективность.
Еще влияние на задержку оказывают протоколы application уровня (OSI Level 7). Новые протоколы, такие как HTTP/2, позволяют оптимизировать производительность параллельных запросов. Однако у нас есть Netflix есть клиенты со старыми устройствами, не поддерживающие новые протоколы. Не все клиенты можно обновить, или оптимально настроить. При этом между CDN прокси и облаком — полный контроль и возможность использовать новые, оптимальные протоколы и настройки. Неэффективная часть со старыми протоколами будет действовать только между клиентом и CDN-сервером. Более того, мы можем делать мультиплекс запросов на уже установленное соединение между CDN и облаком, улучшая утилизацию соединения на TCP уровне:

Измеряем
Несмотря на то, что теория обещает улучшения, мы не бросаемся сразу запускать систему в production. Вместо этого мы должны сначала доказать, что идея сработает на практике. Для этого нужно ответить на несколько вопросов:
- Скорость: будет ли прокси быстрее?
- Надежность: будет ли чаще ломаться?
- Сложность: как интегрировать с приложениями?
- Стоимость: сколько стоит развертывание дополнительной инфраструктуры?
Рассмотрим подробно наш подход к оценке первого пункта. Остальные разбираются похожим образом.
Для анализа скорости запросов мы хотим получить данные для всех пользователей, не тратить много времени на разработку и не сломать production. Для этого есть несколько подходов:
- RUM, или пассивное измерение запросов. Измеряем время выполнения текущих запросов от пользователей и обеспечиваем полное покрытие пользователей. Недостаток — не очень стабильный сигнал из-за множества факторов, например, из-за разных размеров запросов, времени обработки на сервере и клиенте. Кроме этого, нельзя протестировать новую конфигурацию без эффекта на production.
- Лабораторные тесты. Специальные сервера и инфраструктура, имитирующие клиентов. С их помощью проводим необходимые тесты. Так мы получаем полный контроль над результатами измерений и четкий сигнал. Но нет полного покрытия устройств и расположения пользователей (особенно с сервисом по всему миру и поддержкой тысяч моделей устройств).
Как можно объединить преимущества обоих методов?
Наша команда нашла решение. Мы написали небольшой кусочек кода — пробу — который встроили в наше приложение. Пробы позволяют нам делать полностью контролируемые сетевые тесты с наших устройств. Работает это следующим образом:
- Вскоре после загрузки приложения и завершения начальной активности мы запускает наши пробы.
- Клиент делает запрос на сервер и получает «рецепт» теста. Рецепт представляет собой список из URL-адресов, к которым нужно сделать HTTP(s) запрос. Помимо этого рецепт конфигурирует параметры запросов: задержки между запросами, объем запрашиваемых данных, HTTP(s) headers и т.д. При этом мы можем параллельно тестировать несколько разных рецептов — при запросе на конфигурацию мы случайным образом определяемся, какой рецепт выдать.
- Время запуска пробы выбирается так, чтобы не конфликтовать с активным использованием сетевых ресурсов на клиенте. По сути, выбирается время когда клиент не активен.
- После получения рецепта клиент делает запросы на каждый из URL-адресов, параллельно. Запрос на каждый из адресов может повторяться — т.н. «пульсы». На первом пульсе мы измеряем, сколько времени потребовалось для установки соединения и закачки данных. На втором пульсе мы измеряем время загрузки данных по уже установленному соединению. Перед третьим мы можем поставить задержку и измерить скорость установления повторного соединения и т.п.
Во время теста мы измеряем все параметры, которые может получить устройство:
- время DNS запроса;
- время установки соединения по TCP;
- время установки соединения по TLS;
- время получения первого байта данных;
- полное время загрузки;
- статус код результа.
- После окончания всех пульсов проба загружает результаты всех измерений для аналитики.

Ключевыми моментами являются минимальная зависимость от логики на клиенте, обработки данных на сервере и измерении параллельных запросов. Таким образом, мы получаем возможность изолировать и тестировать влияние различных факторов, влияющих на производительность запросов, варьировать их в пределах одного рецепта, и получать результаты с реальных клиентов.
Такая инфраструктура оказалась полезной не только для анализа производительности запросов. В данных момент у нас 14 активных рецептов, более 6000 проб в секунду, получающие данные со всех уголков земли и полным покрытием устройств. Если бы Netflix покупала бы подобный сервис у сторонних компаний, то он стоил бы миллионы долларов в год, при намного худшем покрытии.
Проверяем теорию на практике: прототип
С подобной системой мы получили возможность оценить эффективность CDN прокси на задержку запросов. Теперь нужно:
- создать прототип прокси;
- разместить прототип на CDN;
- определить, как направлять клиентов к прокси на конкретном CDN сервере;
- сравнить производительность с запросами в AWS без прокси.
Задача — как можно быстрее оценить эффективность предложенного решения. Для реализации прототипа мы выбрали Go, благодаря наличию хороших сетевых библиотек. На каждом CDN-сервере мы установили прототип прокси как static binary, чтобы минимизировать зависимости и упростить интеграцию. В начальной реализации мы по максимуму использовали стандартные компоненты и небольшие модификации для HTTP/2 connection pooling и request multiplexing.
Для балансировки между AWS регионами мы использовали географическую базу данных DNS, ту же, что используется для балансировки клиентов. Для выбора CDN сервера для клиента используем TCP Anycast для серверов в Internet Exchange (IX). В этом варианте мы используем один IP-адрес на все CDN сервера, при этом клиент будет направлен к CDN серверу с наименьшим количеством IP hops. В CDN серверах установленных у интернет провайдеров (ISP) у нас нет контроля над роутером для настройки TCP Anycast, поэтому задействуем ту же логику, по которой клиенты направляются к интернет-провайдерам для видеостриминга.
Итак, у нас есть три типа путей для запроса: в облако через открытый интернет, через CDN-сервер в IX или через CDN-сервер расположенный у интернет-провайдера. Наша цель — понять какой путь лучше, и какая польза от прокси, по сравнению с тем, как запросы направляются в production. Для этого используем систему проб следующим образом:
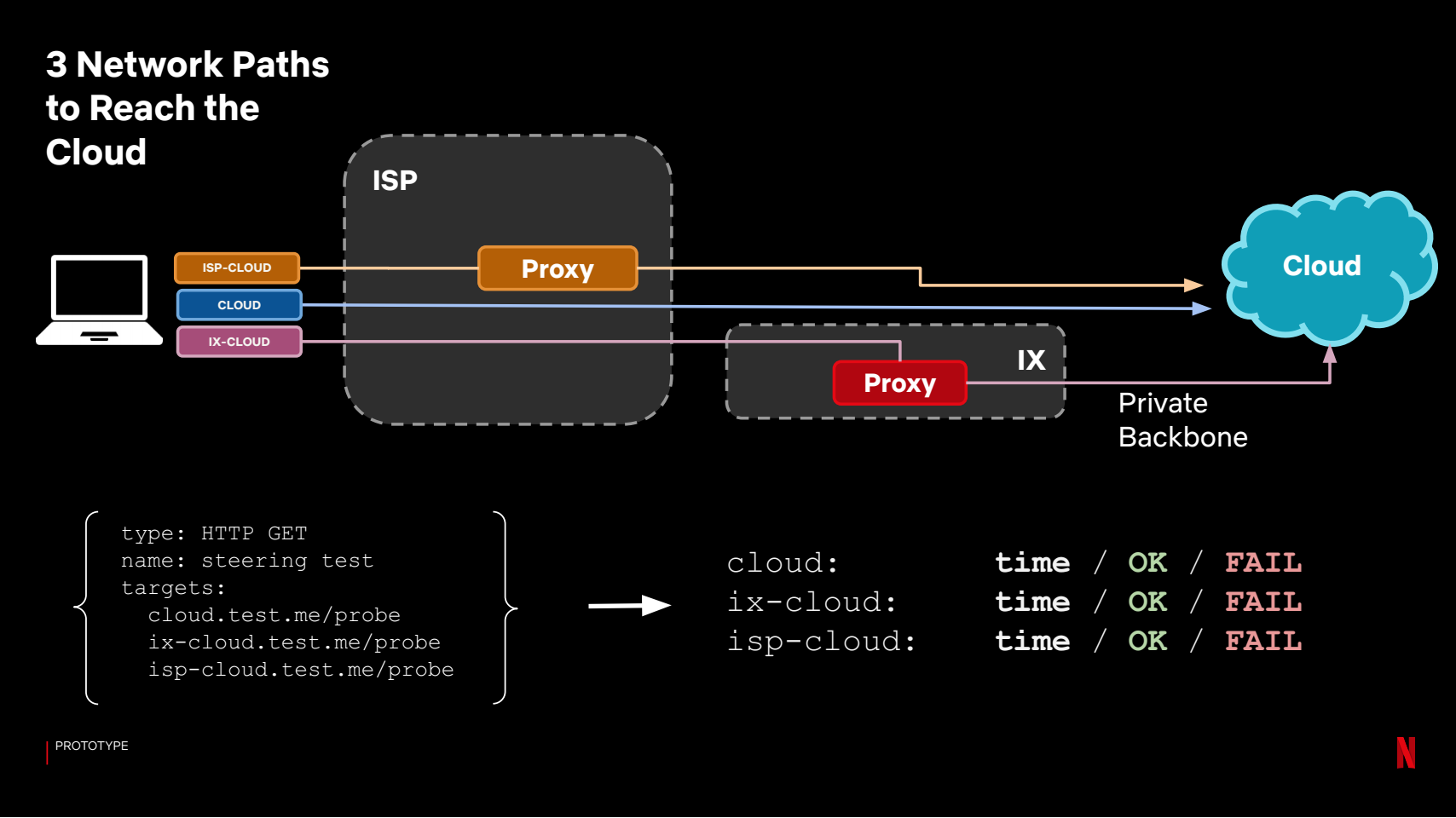
Каждый из путей становится отдельным таргетом, и мы смотрим на время, которое у нас получилось. Для анализа объединяем прокси результаты в одну группу (выбираем лучшее время между IX и ISP прокси), и сравниваем с временем запросов в облако без прокси:

Как видно, результаты оказались неоднозначны — в большинстве случаев прокси дает хорошее ускорение, но также есть достаточное количество клиентов, для которых ситуация значительно ухудшится.
В итоге, мы сделали несколько важных вещей:
- Оценили ожидаемую производительность запросов от клиентов в облако через CDN прокси.
- Получили данные от настоящих клиентов, со всех типов устройств.
- Поняли, что теория не подтвердилась на 100% и начальное предложение с CDN прокси для нас не сработает.
- Не рисковали — не меняли production конфигурации для клиентов.
- Ничего не сломали.
Прототип 2.0
Итак, возвращаемся к чертежной доске и повторяем процесс заново.
Идея — вместо 100% прокси будем для каждого клиента определим самый быстрый путь, и будем туда направлять запросы — то есть будем делать то, что называется client steering.

Как это реализовать? Мы не можем использовать логику на серверной стороне, т.к. цель — к этому серверу подключиться. Нужно каким-то образом делать это на клиенте. И идеально, сделать это с минимальным количеством сложной логики, чтобы не решать вопрос интеграции с обширным количеством клиентских платформ.
Ответ — использование DNS. В нашем случае у нас есть своя DNS инфраструктура, и мы может настроить доменную зону, для которой наши сервера будут авторитарными. Работает это так:
- Клиент делает запрос к DNS-серверу используя хост, например api.netflix.xom.
- Запрос поступает на наш DNS-сервер
- DNS-сервер знает какой путь для этого клиента самый быстрый и выдает соответствующий ip адрес.
В решении есть дополнительная сложность: авторитарные DNS-провайдеры не видят IP-адрес клиента и могут считать только IP-адрес рекурсивного resolver, которым пользуется клиент.
В итоге наш авторитарный resolver должен принимать решение не для отдельного клиента, а для группы клиентов на основе рекурсивного resolver.
Для решения мы используем те же пробы, агрегируем результаты измерений от клиентов по каждому из рекурсивных resolver и решаем, куда их эту группу направить — прокси через IX с помощью TCP Anycast, через ISP прокси или напрямую в облако.
Мы получаем такую систему:

Полученная модель DNS steering позволяет направлять клиентов на основе исторических наблюдений о скорости соединений от клиентов до облака.
Опять же, вопрос — насколько эффективно такой подход будет работать? Для ответа мы снова используем нашу систему проб. Поэтому мы настраиваем конфигурацию рецента, где один из таргетов следует направлению от DNS steering, другой — идет напрямую в облако (текущий production).

В итоге сравниваем результаты и получаем оценку эффективности:

В итоге, мы узнали несколько важных вещей:
- Оценили ожидаемую производительность запросов от клиентов в облако с использованием DNS Steering.
- Получили данные от настоящих клиентов, со всех типов устройств.
- Доказали эффективность предложенной идеи.
- Не рисковали — не меняли production конфигурации для клиентов.
- Ничего не сломали.
Теперь о сложном — запускаем в production
Самое легкое теперь позади — есть работающий прототип. Теперь сложная часть — запустить решение для всего Netflix трафика, развернуть на 150 млн пользователей, тысячи устройств, сотни микросервисов и постоянно меняющиеся продукт и инфраструктура. На сервера Netflix приходят миллионы запросов в секунду, и можно легко сломать сервис неосторожным действием. При этом мы хотим динамически направлять трафик через тысячи CDN серверов, в интернете, где что-то меняется и ломается постоянно и в самый неподходящий момент.
И при всем этом, в команде — 3 инженера, ответственные за разработку, развертывание и полную поддержку системы.
Поэтому дальше будем говорить о спокойном и здоровом сне.
Как продолжать разработку, а не тратить все время на поддержку? В основе нашего подхода лежат 3 принципа:
- Уменьшаем потенциальный масштаб поломок (blast radius).
- Готовимся к сюрпризам — ожидаем, что что-то сломается, несмотря на тестирование и личный опыт.
- Постепенная деградация (graceful degradation) — если что-то работает не так, оно должно чиниться автоматически, пусть и не самым эффективным способом.
Оказалось, что в нашем случае, при таком подходе к проблеме, можно найти простое и эффективное решение и значительно упростить поддержку системы. Мы поняли, что можем добавить в клиент небольшой кусочек кода и следить за ошибками сетевых запросов, вызванными неполадками с соединением. При сетевый ошибках делаем fallback напрямую в облако. Такое решение не требует значительных усилий для клиентских команд, но сильно уменьшает риск от неожиданных поломок и сюрпризов для нас.
Разумеется, несмотря на fallback, мы тем не менее следуем четкой дисциплине в ходе разработки:
- Тест на пробах.
- A/B-тестирование или Canaries.
- Постепенный выпуск (progressive rollout).
С пробами подход был описан — изменения сначала тестируются с помощью настроенного рецепта.
Для canary-тестирования нам нужно получить сравнимые пары серверов, на которых можно сравнить как работает система до и после изменений. Для этого из наших многочисленных CDN сайтов мы делаем выборку пар серверов, которые получают сравнимый трафик:

Затем мы ставим сборку с изменениями на Canary сервера. Для оценки результатов мы запускаем систему, которая сравнивает примерно 100-150 метрик с выборкой Control серверов:

Если Canary-тестирование прошло успешно, то мы делаем релиз постепенно, волнами. На каждом из сайтов мы не обновляем серверы одновременно — потеря целого сайта в случае проблем оказывает более значительное влияние на сервис для пользователей, чем потеря такого же количества серверов, но в разных местах.
В целом, эффективность и безопасность такого подхода зависит от количества и качества собранных метрик. Для нашей системы ускорения запросов мы собираем метрики со всех возможных компонентов:
- от клиентов — количество сессий и запросов, fallback rates;
- прокси — статистика по количеству и времени запросов;
- DNS — количество и результаты запросов;
- cloud edge — количество и время на обработку запросов в облаке.
Все это собирается в единый pipeline, и, в зависимости от нужд, мы решаем, какие метрики отправлять на real-time аналитику, а какие — в Elasticsearch или Big Data для более детальной диагностики.
Мониторим

В нашем случае мы делаем изменения на критическом пути запросов между клиентом и сервером. При этом количество различных компонент на клиенте, на сервере, и на пути через интернет — огромно. Изменения на клиенте и сервере происходят постоянно — в ходе работы десятков команд и естественных изменений в экосистеме. Мы посередине — при диагностике проблем велик шанс, что мы будем в этом участвовать. Поэтому нам нужно четко понимать, как определять, собирать и анализировать метрики для быстрой локализации проблем.
Идеально — полный доступ ко всем видам метрик и фильтрам в реальном времени. Но метрик очень много, поэтому встает вопрос стоимости. В нашем случае мы разделаем метрики и инструменты разработки следующим образом:

Для обнаружения и triage проблем мы используем собственную real-time систему с открытым исходным кодом Atlas и Lumen — для визуализации. Она хранит агрегированные метрики в памяти, надежна и интегрируется с alerting system. Для локализации и диагностики мы имеем доступ к логам с Elasticsearch и Kibana. Для статистического анализа и моделирования — задействуем big data и визуализацию в Tableau.
Кажется, что с таким подходом очень сложно работать. Однако при иерархической организации метрик и инструментов, мы можем быстро проанализировать проблему, определить тип проблемы и затем — углубиться в детальные метрики. Для выявления источника поломки мы в целом тратим около 1-2 минут. После этого мы уже работаем с конкретной командой над диагностикой — от десятков минут до нескольких часов.
Даже если диагностика делается быстро, мы не хотим, чтобы это происходило часто. В идеальном случае мы будем получать критический alert только тогда, когда есть значительное влияние на сервис. Для нашей системы ускорения запросов у нас всего 2 alert, которые будут уведомлять:
- процент Client Fallback — оценка поведения клиентов;
- процент Probe errors — данные стабильности сетевых компонент.
Эти critical alerts следят, работает ли система для большинства пользователей. Мы смотрим на то, сколько клиентов воспользовались fallback, если они не смогли получить ускорение запросов. У нас в среднем менее 1 критического оповещения в неделю, хотя в системе происходит огромное количество изменений. Почему нам этого достаточно?
- Есть client fallback в случае если наша прокси не работает.
- Есть автоматическая steering система, которая реагирует на проблемы.
О последнем поподробнее. Наша система проб, и система автоматического определения оптимального пути для запросов от клиента в облако, позволяют автоматически справляться с некоторыми проблемами.
Вернемся к нашей конфигурации проб и 3 категории путей. Помимо времени загрузки мы можем смотреть на сам факт доставки. Если не получилось загрузить данные, то, смотря на результаты по разным путям мы можем определить, где и что сломалось, и можем ли автоматически это починить, изменив путь запроса.
Примеры:



Этот процесс можно автоматизировать. Включить его в steering-систему. И научить ее реагировать на проблемы с производительностью и надежностью. Если что-то начинает ломаться — среагировать, если есть лучшая опция. При этом моментальная реакция не критична, благодаря fallback на клиентах.
Таким образом, принципы поддержки системы можно сформулировать так:
- уменьшаем масштаб поломок;
- собираем метрики;
- автоматически чиним поломки, если можем;
- если не может — оповещаем;
- работаем над dashboards и triage toolset для быстрой реакции.
Извлеченные уроки
Для написания прототипа не требуется много времени. В нашем случае он был готов уже через 4 месяца. С ним мы получали новые метрики, и через 10 месяцев с начала разработки мы получили первый production трафик. Затем началась нудная и очень сложная работа: постепенно продуктизировать и масштабировать систему, мигрировать основной трафик и учиться над ошибками. При этом этот эффективный процесс не будет линейным — несмотря на все усилия, нельзя все предугадать. Намного эффективнее — быстрая итерация и реагирование на новые данные.

Исходя из нашего опыта, можем посоветовать следующее:
- Не верьте интуиции.
Наша интуиция подводила нас постоянно, несмотря на огромный опыт членов команды. Например, мы неправильно предсказывали ожидаемое ускорение от использования CDN прокси, или поведение TCP Anycast. - Получайте данные из production.
Важно как можно быстрее получить доступ хотя бы к небольшому количеству production данных. Количество уникальных случаев, конфигураций, настроек в лабораторных условиях получить практически невозможно. Быстрый доступ к результатам позволит быстрее узнать о потенциальных проблемах, и учесть их в архитектуре системы. - Не следуйте чужим советам и результатам — собирайте свои данные.
Следуйте принципам по сбору и анализу данных, но не берите слепо чужие результаты и утверждения. Только вы можете точно знать, что работает для ваших пользователей. Ваши системы и ваши клиенты могут существенно отличаться от других компаний. Благо, инструменты для анализа сейчас доступны и легки в использовании. Полученные вами результаты могут не совпадать с тем, что утверждают Netflix, Facebook, Akamai и другие компании. В нашем случае, производительность TLS, HTTP2 или статистика по DNS запросам отличается от результатов Facebook, Uber, Akamai — потому что у нас другие устройства, клиенты и потоки данных. - Не стремитесь за модными трендами без нужды и оценки эффективности.
Начинайте с простого. Лучше сделать простую рабочую систему за короткое время, чем потратить огромное количество времени на разработку ненужных вам компонентов. Решайте задачи и проблемы, которые важны на основе ваших измерений и результатов. - Будьте готовы к новым применениям.
Также, как сложно предугадать все проблемы — сложно заранее предугадать преимущества и применения. Берите пример со стартапов — их способность адаптироваться под условия клиентов. В вашем случае — вы можете обнаружить новые проблемы и их решения. В нашем проекте мы ставили цель уменьшить задержку запросов. Однако, в ходе анализа и обсуждений, мы поняли, что прокси-серверы мы можем применять также:
- для балансировки трафика по AWS регионам, и уменьшения расходов;
- для моделирования стабильности CDN;
- для конфигурирования DNS;
- для конфигурирования TLS/TCP.
Заключение
В докладе я описал как Netflix решает задачу ускорения интернет запросов между клиентами и облаком. Как мы собираем данные с помощью системы проб на клиентах, и используем собранные исторические данные, чтобы направлять production запросы с клиентов через наиболее быстрый путь в интернете. Как мы используем принципы работы сетевых протоколов, нашу CDN инфраструктуру, backbone сеть, и DNS сервера, для достижения этой задачи.
Однако, наше решение — это всего лишь пример того, как мы в Netflix реализовали такую систему. Что сработало для нас. Прикладная часть моего доклада для вас — принципы разработки и поддержки, которым мы следуем и достигаем хороших результатов.
Наше решение проблемы вам может не подойти. Однако теория и принципы разработки остаются, даже если у вас нет собственной CDN инфраструктуры, или если она существенно отличается от нашей.
Также остается важность скорости запросов на бизнес. И даже для простого сервиса нужно делать выбор: между «облачными» провайдерами, местоположением серверов, CDN и DNS провайдерами. Ваш выбор будет влиять на эффективность интернет запросов для ваших клиентов. И для вас важно это влияние измерять и понимать.
Начинайте с простых решений, заботьтесь о том, как вы изменяете продукт. Учитесь в процессе и совершенствуйте систему на основе данных с ваших клиентов, вашей инфраструктуры, и вашего бизнеса. Думайте о возможности неожиданных поломок в процессе проектирования. И тогда вы сможете ускорить ваш процесс разработки, улучшить эффективность решения, избежать излишней нагрузки на поддержку и спать спокойно.
В этом году конференция пройдет с 6 по 10 июля в онлайн-формате. Можно будет задать вопросы одному из отцов DevOps, самому Джону Уиллису!
