Comments 59
Вы имеете в виду, что-то похожее на Sentry, но своё и заточенное под конкретный проект?
Что-то типа того. Elastic+kibana на старте могут дать быстрый результат


Kibana дает еще всякие дашборды с группировкой по сигнатуре/версии. Это не повод не лить в Sentry, если он дает дополнительный анализ.
Кстати, необязательно брать Sentry целиком. Можно взять только их клиент Raven.js, а приёмную сторону написать самостоятельно.
Месяц назад ребята из ВК на митапе в Новосибирске рассказывали о том, как они провернули такое у себя. Даже на их гигантских масштабах это сработало.
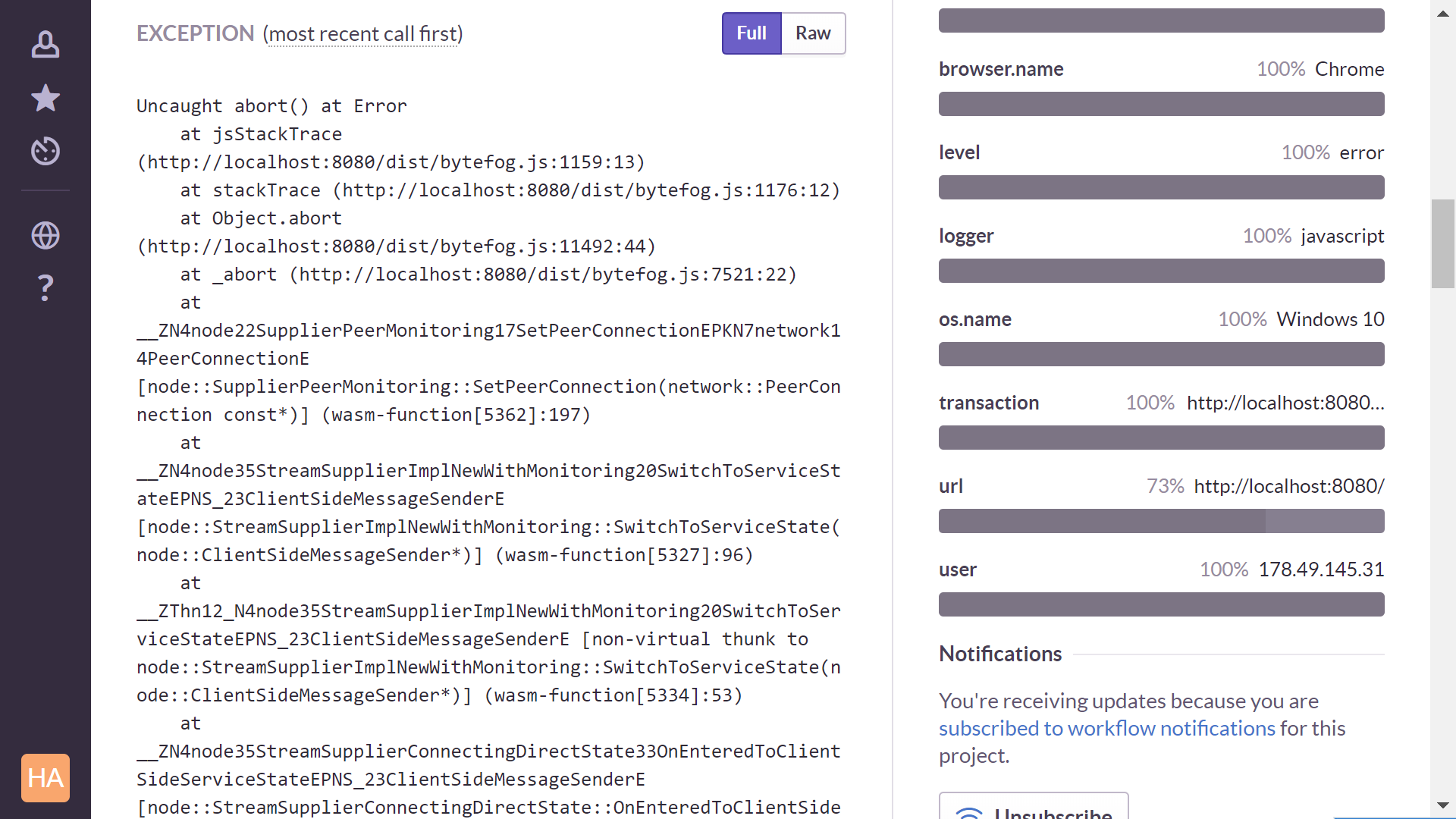
Так они и попадают в Sentry, от Debug-сборок. Выглядит это вот так.
{kind=link}
bnet.marlam.in/mv
Требует поддержи WebGL2.0 Управление для моделей M2 — мышкой + колесико мышки. Для моделей WMO — wasd + мышка.
Сначала программа разрабатывалась на C++ + OpenGL 3.3. А потом, как возникла идея — все с достаточно малыми усилиями было скомпилировано в WebAssembly. В основном благодаря тому, что использовались только те команды OpenGL 3.3, которые присутствовали и в WebGL 2.0
PS: Работает лучше всего в Chrome'е. У Safari сейчас вообще нет поддержки WebGL 2.0, поэтому Mac в пролете
73 Chromium, x64, Mint. Работает
path = project.wast project.wast project.js:1:6204
path = project.wasm project.wasm project.js:1:6204
path = project.temp.asm.js project.temp.asm.js project.js:1:6204
WebGL unmasked renderer: Radeon RX 560 Series (POLARIS11, DRM 3.27.0, 4.20.3-arch1-1-ARCH, LLVM 7.0.1) modelviewer.js:18:206
wasm streaming compile failed: RuntimeError: index out of bounds project.js:1:27187
falling back to ArrayBuffer instantiation project.js:1:27233
13 project.js:1:242622
13 project.js:1:242632
uncaught exception: abort(13). Build with -s ASSERTIONS=1 for more info.
assets.metacade.com/emulators/win311vr.html
Рекомендуется смотреть в FireFox.
А также, классный пример синтеза WebAssembly и Electron: Windows 95, аккуратно упакованная в Electron приложение, и доступная для запуска где угодно. (Можно рассматривать как альтернативу DOSBox).
github.com/felixrieseberg/windows95
Про неё кстати уже была статья здесь, на Хабре.
1) Нативная поддержка int64
2) Более быстрое выполнение кода
На этом все. Сейчас WebAssembly стоит воспринимать просто как байткод, который содержит типы, за счет чего может более быстро выдавать результат по сравнению с JS. На данном этапе WebAssembly не может делать напрямую вызовы браузерного API(делается через прослойки в виде js функций). Поэтому полезность минимальна.
С другой стороны, я имел опыт, когда программа скомпилированная в asm.js из С++ не работала, где-то внутри неправильно срабатывала математика и программа отказывалась правильно работать. При этом в таргете WebAssembly все работало как часы.
PS: с нетерпением жду когда сделают SIMD.JS в WebAssembly. Linked issue здесь: github.com/WebAssembly/proposals/issues/1
не может делать напрямую вызовы браузерного API
Это действительно так. То о чем вы говорите называется Host bindings и сейчас над ними ведётся активная работа. Когда их реализуют любой бэкенд компилирующийся в wasm сможет с низкими накладными расходами обращаться к функциональности хоста (это не обязательно будет браузер).
Но. В практическом смысле, подобное уже можно делать прямо сейчас. (Что мы и сделали в нашем проекте Bytefog. Оценить работу технологии можно, например, на сайте peers.tv). Технически, действительно, происходит проброс через JS. Но всю эту работу берет на себя Emscripten. На вход мы ему даём указания что именно мы хотим пробросить. Сделать это можно аж тремя разными способами. Мы выбрали Embind, и я подробно разбираю как его использовать в своём докладе.
FFMpeg в браузере уже реализовали, да не один раз. Думаю, вам будут полезны вот эти ссылки:
github.com/bgrins/videoconverter.js
github.com/sopel39/audioconverter.js
github.com/Kagami/ffmpeg.js
Буду благодарен вам, если расскажете о результатах своих экспериментов с ними.
Уже есть инструкция как скомпилировать под WebAssembly. OpenSSL — это надёжный код, проверенный тысячами приложений, не нужно ничего изобретать.
Его еще надо довольно особенным способом скомпилировать дабы избежать атак по времени. Так что тут не все так однозначно. Вероятно имеет смысл либо не писать криптографию либо использовать использовать другие проверенные альтернативы.
Основной референс по constant time wasm
Там же ссылка на иследовательскую бумагу по теме и репу с портами и прочим необходимым.
Видео с пояснениями, какие проблемы с секьюрностью могут вызывать наивные порты кода в васм.
При просмотре поиска на Github по слову Forth встретился и проект конкатенавного, стекового языка Plorth github.com/RauliL/plorth основанного на языках программирования Forth и Factor.
и его WebAssembly репозиторий github.com/RauliL/plorth-webassembly
(Plorth interpreter as WebAssembly module, compiled with Emscripten)
P.S. Вероятно будут появлятся и другие подобные проекты.
Forth in JS github.com/hcchengithub/jeforth.3we (с красивыми примерами)
Запуск в браузере различных ОС copy.sh/v86 (например и KolibriOS)
github.com/drom/wast-forth
другая его разработка — QEMU. Возможно, мало кто о нем слышал, но на нем основана система виртуализации KVM, которая уж точно является лидером в своей области.
Поперхнулся смузи
KVM не основан на QEMU, и даже не наоборот. QEMU может использовать KVM для аппаратного ускорения, но он даже не требует его.
Спасибо за замечание. Возможно я неправильно понимаю сложные взаимоотношения KVM и QEMU. Я ориентировался на данные Википедии.
Программное обеспечение KVM состоит из загружаемого модуля ядра (kvm.ko), процессорно-специфического загружаемого модуля kvm-amd.ko либо kvm-intel.ko, и компонентов пользовательского режима (модифицированного QEMU).
Насколько я понимаю, KVM использует QEMU для паравиртуализации. Как-то так?

➜ qemu-system-x86_64 -h | grep accel
-accel [accel=]accelerator[,thread=single|multi]
select accelerator (kvm, xen, hax, hvf, whpx or tcg; use 'help' for a list)
use vhost=on to enable experimental in kernel accelerator
KVM это ускоритель, который может использоваться кем угодно (в том числе и qemu). Собственно, на приведённой Вами иллюстрации это и видно: есть hardware, поверх него ядро с kvm, поверх ядра qemu (или любой другой проект, который умеет в kvm), поверх уже гостевые системы.
А вот подскажите насчет криптографии. Почитал я про эту технологию и вознамерился сделать электронную подпись на x.509 сертификатах без плагина, прямо в браузере на стороне клиента. И, ясен пень, жестоко обломался с доступом к хранилищу сертификатов пользователя винды. Юзал c#, если это важно. Это когда-нить будет возможно?
Вы C# компилировали в Wasm? Расскажите об этом подробнее. Что вы использовали? Какие остались впечатления?
Не знаю, можно ли назвать это компиляцией, но пробовал собирать, отлаживать в браузере как в статье. Знатно подивился на шарп-код в отладчике браузера с возможностью пошаговой отладки. Как уже писал выше, задача была реализовать криптооперации в браузере без плагина и локального прокси, я прямо возбудился на эту тему, потому что она есть боль для меня лично (электронные торги и документооборот). И в итоге фиаско. Впечатление у меня лично такое: непонятно, зачем оно надо на прикладном уровне, с такими ограничениями. Разве что без смены ЯП фронтенд пилить, без перехода на javascript. Возможно, я неправильно понял или не дочитал, тогда сорян за тупизну.
Сделано что бы приложения типа Dead Trigger 2 быстрее стартовал в браузере
Кроме того, современный v8 постоянно делает сбор статистики по входным параметрам в функцию, на их основании компилирует js код в байткод процессора. Если какой-то параметр изменил тип — запускается неоптимизированная версия функции и статистика начинает собираться по новой.
А для WebAssembly этот функционал не нужен в принципе. Все статически скомпилировано и связано, как в обычном MZP\ELF исполняемом файле
Да, ну и вот эта цитата:
Но когда включается оптимизация (зеленый столбик), мы получаем время, практически совпадающее с JS. И, забегая вперед, мы получаем аналогичные результаты в нативном коде, если скомпилируем С++, как нативное приложение.
означает, что у вас есть какие-то фундаментальные проблемы в вашем нативном C++ приложение. Т.е. мои тесты вполне подтверждают ваш результат, что WASM в данное время сравним по производительности с JS. Но при этом тот же C++ код скомпилированный в машинные коды всегда получается в разы быстрее. И на это есть две фундаментальные причины:
1. WASM с одной стороны предоставляет полный доступ к работе с указателями, а с другой должен гарантировать безопасное выполнение подобного кода внутри песочницы (у модуля не должно быть способа залезть в данные браузера или других модулей). Как следствие этого, IR код работы с памятью компилируется (при загрузке модуля в браузере) не в прямую инструкцию x86, а с дополнительной проверкой выхода за границы выделенной памяти. На активно работающем с памятью коде, это может давать просадку производительности х2 раза.
2. SIMD. В будущем в WASМ планируют завести поддержку SIMD инструкций, но пока этого нет. В JS этого нет тем более. А в любом приличном компиляторе C++ уже много лет как поддерживается автовекторизация циклов, которая может давать увеличение быстродействие вплоть до х7 раз (для самых подходящих циклов, но в коде графических фильтров изображений должно быть полно таких).
В общем не знаю где у вас там конкретные косяки с C++, но если у вас скомпилированное в машинные коды приложение исполняется столько же, сколько WASM и JS варианты, то эти косяки у вас однозначно есть.
есть какие-то фундаментальные проблемы в вашем нативном C++ приложение.
Все приложения разные, а JIT в браузерах творит чудеса.
Все приложения разные, а JIT в браузерах творит чудеса.
Нет там никаких чудес. Каждый раз, когда я видел утверждения о равенстве быстродействия с C++, всё сводилось к кривому использованию последнего (собственно иначе и быть не может, т.к. тогда бы уже давно писали бы браузеры на js). Для схожего с использованным в статье для тестов алгоритмом у меня были следующие результаты (это усреднённое время в мс):
JS 15,6
C# 15,1
ASM.JS (из C++) 12,5
WASM из ASM.JS 11,4
Java 10,1
C# unsafe 8,9
WASM 8,6
D 7,2
C++ nosimd 4,4
C++ 1,5
если у ребят получилась одинаковая производительность подобного алгоритма на JS, WASM (C++) и нативном C++, то практически гарантированно у них что-то очень не так в варианте нативного C++.
Но при этом тот же C++ код скомпилированный в машинные коды всегда получается в разы быстрее. И на это есть две фундаментальные причины
Мне кажется, что проверка на выход за границы heap-а в ряде случаев может убираться оптимизатором. Кроме того, часть работы по отлову выходов за границу хипа можно сделать через защиту памяти. Что касается SIMD, опять же, браузер может сам анализировать WASM и автоматом векторизовать его (для этого в WASM есть всё необходимое). По крайней мере, LLVM ровно так и делает. А вот ещё моменты, которые ещё, как мне кажется, могут сильно влиять на производительность:
- Нет возможности получить указатель на переменную в стеке. Если такой указатель где-то берётся, то приходится размещать переменную в shadow-стеке, со всеми накладными расходами на поддержание shadow-стека.
- Нет возможности вообще как-то погулять по стеку, чтобы, например, сгенерировать исключение. Да и нативную поддержку исключений пока не завезли. Так что единственная возможность — это вставлять всюду проверки.
Мне кажется, что проверка на выход за границы heap-а в ряде случаев может убираться оптимизатором.
Каким это образом, если и значение указателя и значения границ определены только в рантайме?
Кроме того, часть работы по отлову выходов за границу хипа можно сделать через защиту памяти.
Каким образом можно в рамках одного процесса закрыть некому коду доступ к какой-то области выделенной памяти?
Что касается SIMD, опять же, браузер может сам анализировать WASM и автоматом векторизовать его (для этого в WASM есть всё необходимое).
Нет там ничего необходимого. В будущем появится (соответствующие инструкции), но пока нет.
А если бы можно было делать автовекторизацию напрямую из машинных кодов, то такой алгоритм давным давно внедрили бы непосредственно в конвейер CPU.
По крайней мере, LLVM ровно так и делает.
Ээээ что? Где это он так делает?
Нет возможности получить указатель на переменную в стеке. Если такой указатель где-то берётся, то приходится размещать переменную в shadow-стеке, со всеми накладными расходами на поддержание shadow-стека.
Хм, да это интересный момент. Я его не смотрел. Причём с учётом того, что итоговая машина всё же стековая, у WASM JIT'a в теории есть большое поле для оптимизации. А вот делается ли там сейчас что-то для этого или нет — не знаю. Хотя это не сложно посмотреть, т.к. исходники открыты.
Нет возможности вообще как-то погулять по стеку, чтобы, например, сгенерировать исключение. Да и нативную поддержку исключений пока не завезли. Так что единственная возможность — это вставлять всюду проверки.
С учётом того, что в наиболее требовательных к ресурсам приложениях (программирование различных МК, ядра ОС, дравейров и т.п.) как раз применяется режим C++ с отключёнными исключениями, то данная особенность если и влияет на производительность, то только положительно. )))
Каким это образом, если и значение указателя и значения границ определены только в рантайме?
Вот уж не знаю как. Я точно помню, как общался с сотрудниками Мозиллы и они мне говорили про багу в range analysis ещё в альфа-версии WebAssembly. Как минимум, нижняя граница определена в compile-time (в WebAssembly-модуле для heap необходимо указывать минимальный и максимальный размер хипа), а то, что указатель известен только в рантайме, ещё не значит, что его диапазон нельзя оценить с помощью статического анализа. Такое, например, реализовано в JVM для устранения проверки на выход за границу массива.
Каким образом можно в рамках одного процесса закрыть некому коду доступ к какой-то области выделенной памяти?
mprotect в POSIX. В Windows тоже был системный вызов, но я с ходу не вспомнил название.
Нет там ничего необходимого. В будущем появится (соответствующие инструкции), но пока нет.
Там есть всё необходимое. Вот как-то C-компиляторы делают это. А они, заметьте, никогда не оптимизируют непосредственно AST C. Т.е. они строят IR (промежуточное представление), которое как раз очень похоже на портабельный ассемблер, а потом уже находят в нём циклы, которые можно векторизовать. Для этого есть куча способов, есть много специализорованной литературы, которая рассказывает про это (вот даже последние редакции Dragon Book рассказывают про векторизацию), и есть ещё большая куча всяческих статей от авторов тех или иных компиляторов.
С учётом того, что в наиболее требовательных к ресурсам приложениях (программирование различных МК, ядра ОС, дравейров и т.п.) как раз применяется режим C++ с отключёнными исключениями, то данная особенность если и влияет на производительность, то только положительно. )))
Полагаю, что статья автора как раз не про драйвера и ядра ОС.
Вот уж не знаю как. Я точно помню, как общался с сотрудниками Мозиллы и они мне говорили про багу в range analysis ещё в альфа-версии WebAssembly. Как минимум, нижняя граница определена в compile-time (в WebAssembly-модуле для heap необходимо указывать минимальный и максимальный размер хипа), а то, что указатель известен только в рантайме, ещё не значит, что его диапазон нельзя оценить с помощью статического анализа. Такое, например, реализовано в JVM для устранения проверки на выход за границу массива.
Так нужны гарантии, что эти значения не меняются. Именно в этом проблема, а не в определение самих значений. Собственно единственная оптимизация, которую реально делают все подобные инструменты, это убирание повторных проверок (ну типа если мы дважды обращаемся по одному указателю внутри одной итерации цикла).
mprotect в POSIX. В Windows тоже был системный вызов, но я с ходу не вспомнил название.
VirtualProtect это в Винде. Только ничем эти функции не помогут для решения данной проблемы. Если закрыть с помощью них доступ к какой-то области памяти, то каким образом сам браузер будет работать с этой областью памяти?
Там есть всё необходимое. Вот как-то C-компиляторы делают это. А они, заметьте, никогда не оптимизируют непосредственно AST C. Т.е. они строят IR (промежуточное представление), которое как раз очень похоже на портабельный ассемблер, а потом уже находят в нём циклы, которые можно векторизовать. Для этого есть куча способов, есть много специализорованной литературы, которая рассказывает про это (вот даже последние редакции Dragon Book рассказывают про векторизацию), и есть ещё большая куча всяческих статей от авторов тех или иных компиляторов.
С учётом того, что в LLVM IR имеются векторные типы, это конечно очень большая загадка, как это делается. ))) Кстати, ещё забавный вопрос: интересно, как укладывается в это ваше видение факт работы OpenMP SIMD (у уже молчу про intrinsics)?
Полагаю, что статья автора как раз не про драйвера и ядра ОС.
Речь о том, что отказ от исключений уж точно не ведёт к потере производительности. )
Так нужны гарантии, что эти значения не меняются. Именно в этом проблема, а не в определение самих значений.
Гарантий нет, но ведь всегда есть достаточно безопасные и предсказуемые кусочки программы, про которые что-то можно доказать. Кроме того, повторяю, что для верхнего лимита адресуемой памяти есть как минимум нижняя граница, которая указана просто в модуле. Для оптимизатора не важны точные значения. Для доказательства неравенства Amin < A < Amax, Bmin < B < Bmax, где Amin, Amax, Bmin, Bmax — константы, достаточно доказать, что Amax < Bmin. Если считать, что B — это размер хипа, то Bmin и Bmax тупо указаны в модуле. А Amax можно попытаться каким-то образом оценить, хотя бы сверху. Можно даже не с константами работать, а с инвариантами цикла. Ну например есть код:
while (start < end) {
*start++ = 0;
}компилятор вставит проверку
while (start < end) {
if (start >= wasm_upper_bound) generate_exception();
*start++ = 0;
}далее, у нас есть два инварианта цикла: wasm_upper_bound и end. К сожалению, start таковым не является, так что классический loop unswitching сделать не получится. Но известно, что он выполняется неравенство start < end с инвариантом цикла, так что можно попробовать модифицировать loop unswitching, чтобы он делал следующее
if (end < wasm_upper_bound) {
while (start < end) {
*start++ = 0;
}
} else {
while (start < end) {
if (start >= wasm_upper_bound) generate_exception();
*start++ = 0;
}
}VirtualProtect это в Винде. Только ничем эти функции не помогут для решения данной проблемы. Если закрыть с помощью них доступ к какой-то области памяти, то каким образом сам браузер будет работать с этой областью памяти?
А браузеру вовсе не нужно с данной памятью работать. Учитывая, что в WebAssembly пока размер кучи ограничен 2^32, а процессоры у нас 64-битные, можно тупо нарезервировать страниц как раз на 2^32, но на реальные физические отобразить ровно столько, сколько заявлено в дескрипторе wasm-модуля (ну и по мере вызова grow_memory отображать дополнительные).
С учётом того, что в LLVM IR имеются векторные типы, это конечно очень большая загадка, как это делается
Вы хотите сказать, что clang берёт и сам генерит векторные инструкции? Мне казалось, что они всё-таки получаются в процессе работы самого LLVM. Учитывая, что с точки зрения меня, как разработчика приложений, формат wasm является всего лишь форматом обмена данными, мне всё равно, в какой там IR браузер разворачивает мой wasm-модуль и как его оптимизировать. Или разработчики WebAssembly не хотят, чтобы браузер делал векторизацию и хотят переложить эту заботу на компилятор? Ну тогда я всё равно не вижу практической невозможности позволить генерацию быстрого кода, я вижу только невозможность сочетать это с быстрым запуском кода.
Учитывая, что в WebAssembly пока размер кучи ограничен 2^32, а процессоры у нас 64-битные
Chrome не даст более 2 Gb памяти.
В смысле? Chrome и не должен никому ничего давать. Это операционка должна давать Chrome-у. Есть какие-то причины, почему она не даст зарезервировать приложению (Chrome) страниц суммарно на 4Gb?
Код выполняется в V8, у которого свои лимиты:
By default v8 has a memory limit of 512MB on 32-bit systems, and 1.4GB on 64-bit systems. The limit can be raised by setting --max_old_space_size to a maximum of 1024 (1 GB) on 32-bit and 4096 (4GB) on 64-bit. источник
ok, во-первых, WebAssembly выполняется как раз в v8. Во-вторых, эти же лимиты они про то, как работает v8 с точки зрения юзера, а внутри он может что угодно и как угодно выделять. В третьих, зарезервировать в ОС страниц можно сколько угодно, пока в них процесс писать не будет, рельно память выделяться не будет. Впрочем, если резервировать с правильными флагами, то при попытке записи вообще будет генериться sigsegv (ну или как это называется в Windows), и никогда не будет выделяться физическая память. Что я, собственно, и предлагаю.
Гарантий нет, но ведь всегда есть достаточно безопасные и предсказуемые кусочки программы, про которые что-то можно доказать.
Проблема в том, что на уровне машинных кодов невозможно получить гарантии. Потому как JIT компилятору неоткуда знать, что к данной ячейки памяти нет доступа у какого-то другого кода. Т.е. тот же C++ компилятор ещё может делать подобные выводы например по отсутствию ссылок (или операций взятия адреса) на данную переменную. А при просто потоке машинных кодов, обращающихся к каким-то произвольным участкам памяти, как гарантированно понять, что какой-то посторонний код (в худшем случае вообще в параллельном потоке — этого сейчас в WASM нет, но планируется в ближайшее время) не поправит данную ячейку памяти (которая потом используется как указатель)?
А браузеру вовсе не нужно с данной памятью работать. Учитывая, что в WebAssembly пока размер кучи ограничен 2^32, а процессоры у нас 64-битные, можно тупо нарезервировать страниц как раз на 2^32, но на реальные физические отобразить ровно столько, сколько заявлено в дескрипторе wasm-модуля (ну и по мере вызова grow_memory отображать дополнительные).
Ээээ что? Что значит браузеру не нужно с данной памятью работать? Ему не нужна вообще никакая память для своей личной работы или как? А если хоть какая-то нужна, то как её защитить от доступа из WASM модуля с помощью защиты страниц виртуальной памяти?
Вы хотите сказать, что clang берёт и сам генерит векторные инструкции? Мне казалось, что они всё-таки получаются в процессе работы самого LLVM. Учитывая, что с точки зрения меня, как разработчика приложений, формат wasm является всего лишь форматом обмена данными, мне всё равно, в какой там IR браузер разворачивает мой wasm-модуль и как его оптимизировать.
Ни в какой IR модули WASM в браузере не разворачивается. Формат wasm — это по сути и есть IR, представляющее собой ассемблерные инструкции некого виртуального процессора. Причём этот формат является чуть изменённой (упрощённой и с большей безопасностью) версией IR из LLVM. К сожалению векторные типы LLVM не вошли в первую версию WASM.
Или разработчики WebAssembly не хотят, чтобы браузер делал векторизацию и хотят переложить эту заботу на компилятор? Ну тогда я всё равно не вижу практической невозможности позволить генерацию быстрого кода, я вижу только невозможность сочетать это с быстрым запуском кода.
Не нехотят, а это единственное разумное решение. И собственно говоря уже все материалы (типы, инструкции) для реализации подготовлены: github.com/WebAssembly/simd/blob/master/proposals/simd/SIMD.md. Но в текущий «стандарт» WASM это пока не входит.
А при просто потоке машинных кодов, обращающихся к каким-то произвольным участкам памяти, как гарантированно понять, что какой-то посторонний код (в худшем случае вообще в параллельном потоке — этого сейчас в WASM нет, но планируется в ближайшее время) не поправит данную ячейку памяти (которая потом используется как указатель)?
Таки WASM — это не машинные коды, про него очень много всего можно сказать. Аналогичная проблема в JVM решается с помощью memory model. Собственно, там предполагается, что один поток может не увидеть изменений в памяти, сделанные другим потоком. Причём, на некоторых процессорных архитектурах это прямо аппаратно так (вроде на MIPS было
так).
Ээээ что? Что значит браузеру не нужно с данной памятью работать? Ему не нужна вообще никакая память для своей личной работы или как? А если хоть какая-то нужна, то как её защитить от доступа из WASM модуля с помощью защиты страниц виртуальной памяти?
Ещё раз — браузер мапит где-то для себя страницы. При этом для WASM он резервирует страниц на 4Гб, что никак не противоречит тому, что ещё какие-то страницы памяти выделены под сам WASM. При этом для доступа к WASM-хипу можно использовать что-то вроде такого: wasm_heap[ptr & 0xFFFFFFFF], поэтому мы гарантированно либо попадём в хип, либо получим sigsegv.
Формат wasm — это по сути и есть IR, представляющее собой ассемблерные инструкции некого виртуального процессора
WASM — это очень неудобный IR. Как минимум, потому что не SSA. Держу пари, что WASM машины внутри себя его во что-то более удобное преобразуют.
Причём этот формат является чуть изменённой (упрощённой и с большей безопасностью) версией IR из LLVM
Да вообще достаточно мало общего. Если для вас это "чуть изменённая" версия LLVM-биткода, то можно и JVM-байткод или MSIL назвать "чуть изменённой" версией LLVM.
а это единственное разумное решение
А обоснование какое?
Я действительно сильно забежал вперед анонсировав результаты нашего нативного теста, поэтому немного расскажу про него.
1. Исполняется тот же код, что в бенчмарке с графическими фильтрами.
2. Никаких особых оптимизаций в C++ мы не делали. Мы согласны с тем, что если покрутить правильные ручки у компилятора, то можно выжать совсем другие цифры.
3. Одна из этих ручек, например, SIMD, который мы не использовали. А для обработки изображений он значит многое. Хотя, на мой взгляд, это уже будет не совсем верное сравнение технологий. Другая весовая категория.
4. Мы очень бегло потестировали код, не проверили все кейсы. Именно поэтому я не стал включать результаты в доклад.
Лично я ожидал, что нативный код будет выполняться значительно быстрее Wasm. Но первые полученные результаты показали, что это не так. И это меня довольно сильно удивило. Планирую вернуться к этому бенчмарку позже.
Что касается нашего продукта, то все замеры производительности значат мало что, т.к. на сетевых задержках мы потеряем гораздо больше времени. Мы честно пытались найти хоть какой-то мало-мальски вычислительный код в продукте. Взяли например обработчик плейлистов. Но на реальных данных код выполняется микросекунды, поэтому бенчмаркать там нечего. К тому же, это совсем не критический участок кода.
Никаких особых оптимизаций в C++ мы не делали. Мы согласны с тем, что если покрутить правильные ручки у компилятора, то можно выжать совсем другие цифры.
Делать тесты производительности с C++ без хотя бы опции "-O3" — это уже довольно странная трата времени…
Лично я ожидал, что нативный код будет выполняться значительно быстрее Wasm. Но первые полученные результаты показали, что это не так. И это меня довольно сильно удивило. Планирую вернуться к этому бенчмарку позже.
И правильно что удивило — там точно что-то не так. )
Что касается нашего продукта, то все замеры производительности значат мало что, т.к. на сетевых задержках мы потеряем гораздо больше времени.
Ну я говорил только про обсуждаемый в статье тест — для него очевидно и тесты производительности актуальны и SIMD и т.д. Про продукт в контексте производительности вроде речи не было, так что мои замечания относились не к нему.
Мы честно пытались найти хоть какой-то мало-мальски вычислительный код в продукте. Взяли например обработчик плейлистов. Но на реальных данных код выполняется микросекунды, поэтому бенчмаркать там нечего. К тому же, это совсем не критический участок кода.
Если у вас там видео воспроизводится, то можно посмотреть различные латентности, особенно в 4K и со сложными кодеками. )
тесты производительности с C++ без хотя бы опции "-O3"
Мы мерили с -O2, из тех соображений, что при -O3 компилятор уже жертвует размером файла ради скорости (если я ничего не путаю). -O2 ближе к тому, что будет в реальном проекте.
Более подробно «методика» тестирвоания описана в репозитории проекта github.com/andrnag/wasm_cpp_bench Мы не выкладывали ещё нативную реализацию (забежал вперед, как я уже сказал), но вычислительное ядро там то же самое, что и для wasm. Добавлена просто CLI обёртка и работа с файлами, за рамками измеряемого кода.
И правильно что удивило — там точно что-то не так. )
Очень даже может быть :-) Буду рад вашим замечаниям к коду проекта.
Если у вас там видео воспроизводится, то можно посмотреть различные латентности, особенно в 4K и со сложными кодеками. )
Да, если бы мы воспроизводили видео, то это был бы хороший стресс-тест. Но непосредственным воспроизведением видео занимается браузер с помощью HTML-элемента <video> и нативных кодеков.
Наша разработка только поставляет данные для браузерного плеера. Поэтому больше всего времени мы занимаемся пересылкой по сети.
Разработка под WebAssembly: реальные грабли и примеры