Comments 331
BTW, оттуда же из статьи
Iterator found = Map.search("Jeffrey");
if (!found.hasNext()) {
throw new EmployeeNotFoundException();
}
return found.next();
имхо под этим куском кода маскируется желание использовать некий Optional<>, просто автор еще сам этого не понял ))
в Java 8, правда, Optional не следует этому на 100% и не предоставляет тот же набор API, что мы имеем для Stream API, из-за чего композиция Optional-ов например не возможна (в Java 9 добавили метод, но осадок остался)
TValue GetValue(TKey key, Action onNotFound);
return this.map.GetValue("Jeffrey", () => throw new EmployeeNotFoundException());
(value: TValue, found: bool) GetValue(TKey key);
(value, found) = this.map.GetValue("Jeffrey");
return found ? value : throw new EmployeeNotFoundException();
мы в курсе, что кремний для процов, а не силикон для сисек, чесслово. К сожалению, устоявщееся название региона это "Силиконовая Долина".
Так было лет 10 назад. Сейчас всё же грамотность побеждает. Это вы там в эмиграции отстаёте от российских трендов ;-)
Википедия всё еще перебрасывает "Кремниевую" на "Силиконовую".
Мне не нравится ни тот код, который я писал, ни та Java, которую я видел, ни библиотеки, с которыми я сталкивался, мне неприятно с ними работать. Не только мне, а людям, которые вокруг меня, программистам. Я вижу, какой код они пишут, как тяжело этот код потом понимать, поддерживать, как вообще неприятно программировать.
Но не ясно — нравится ли ему тот код, который он пишет «правильно»? Дальше он упоминает, что концепция in progress, что код, ушедший в продакшн, уже не такой «правильный». То есть я не вижу каких-то радикальных плюсов по сравнению с другими концепциями.
Каков вообще средний возраст его проектов? Если они пишут под заказ, то, я предполагаю, нет долгоживущих проектов. Тогда да, можно нагородить «ООП от Егора» и забыть, а в следующей проекте уже будет «ООП 2.0 от Егора», и так далее.
Есть ли у него код, которому, скажем, 5, 10 лет, и он ему все еще нравится? Есть ли реально большие и долгоживущие проекты, в котором «правильное ООП» показало себя на практике? Ну чтобы все было покрыто тестами, чтобы можно было спокойно менять устаревшие куски, чтобы глаза не болели? Как по мне, это недостижимый идеал.
Однако же мне это сильно напоминает мир Scala (не код, но, скажем, отличие от традиционного мира Java).
Свидетели Scala тоже говорят, что у них золотая таблетка, правильное ФП и вообще рай. Однако там точно такие же проблемы: высокий порог вхождения, сложность с поиском людей, сложность с чтением кода.
UPD Для улучшения читаемости я всегда в пул реквестах рекомендую дробить методы на более мелкие, а во многих случаях дробить нужно классы.
Совершенно аналогичные впечатления. Причем что характерно — не только код не читаем, не читается самое основное — задачи и цели фреймворка.
И таки да, все покрыто тестами
И что? Вот у меня нет никакой проблемы в жизни от того, что какой-нибудь сервлетный контейнер, Jetty там скажем, или еще какой-то, не покрыт тестами. Да пусть их хоть совсем там нет и не будет. Нисколько не страдаю от того, что в них много багов. Или они скажем медленные. Нету такой проблемы в природе. Незачем ее решать.
современный код на Java это почти всегда нечитаемый мусор.Ну это by design xD
“If Java had true garbage collection, most programs would delete themselves upon execution.”
— Robert Sewell
Конечно, к этому можно привыкнуть и даже начать считать удобным, если достаточно долго себя в этом убеждать… только какой в этом смысл?
public final class App {
public static void main(final String... args) {
new FtBasic(
new TkFork(
new FkRegex("/robots.txt", ""),
new FkRegex("/", new TkIndex()),
new FkRegex(
"/xsl/.*",
new TkWithType(new TkClasspath(), "text/xsl")
),
new FkRegex("/account", new TkAccount(users)),
new FkRegex("/balance/(?<user>[a-z]+)", new TkBalance())
)
).start(Exit.NEVER);
}
}
FtBasic — что это???
TkFork — что это???
Что такое Ft или Tk? Зачем эти префиксы из аббревиатур?
Этот код читаем только потому что там есть пути к ресурсам. Количество WTF на момент прочтения readme зашкаливает. Я очень надеюсь что мы не будем писать код с таким именованием классов больше никогда.
Fk это скорее всего Fake, по крайней мере так именовано в других проектах.
Еще есть например Comment и DyComment – это коммент в DynamoDB (реализация).
На самом деле названия очень нормальные, просто нужно иметь конвенцию. Вот меня раздражает стандартная многословность Java и необходимость все свои классы называть DynamoUser, PostgresUser и так далее. А тут DyUser, PgUser – все четко.
Upd: ой, ниже уже все ответили…
Вот пришел я к вам в команду и вижу что вы используете DyUser. Это DynamicUser ( ну какой-то может быть очень активный) или DynamoUser — структура записи пользователя в DynamoDB? Часто бывает что из контекста это не понятно. В лучшем случае — я час проведу изучая код и пытясь понять что такое Dy, в худшем — пойду пытать вас. А у вас релиз завтра и пара противных багов висит. Но это еще «хорошие обревиатуры». Предположим что у нас есть еще бизнес обьекты типа Route и класс DyRoute — и это как раз тот самы Dynamic Route — он вообще относится к инфраструктуре и определяет куда нужно сейчас оправлять ваш запрос в зависимости от загрузки нижележащих сервисов. И ваще жопа — тк какого художника одна и таже обревиатура в разных кусках одного проекта означает соовсем не связанные между собой вещи.
Когда я был маленький, деревья большие и code-competion был только в emacs и контекстный — тогда сокращения имели смысл. На текущем витке развития software development — это примерно такой-же атавизм как и Go-To. Лучше про него просто забыть.
PS: Я не считаю что имена классов, обьектов или методов должны быть длинными. Совсем наоборот — они должны быть максимально корткими — но при этом читаемые. Такая вот задача минимизации — как не выплеснуть ребенка читаемости вместе с водой.
У Егора есть целая заморока насчёт длины идентификаторов. Он в стопятом про это говорил. Мол, поля не длиннее восьми символов, хардлимит. Про классы, наверно, тоже такое есть.
Потому что альтернатива —
a.push(
b.pop)
А это ужас.
Я не хочу тут говорить вам, что можно придумать более информативные имена для «a» и «b», тк не знаю контекста.
Это условные обозначения, мне было лень придумать примеры.
Допустим, это было бы что-то типа
TConList = class //TConnectionList
или
lFIdx: integer; //lFirstElementIndex;
С появление intellisense я перестал думать о длинне имен и стараюсь писать читаемый код
Когда код не влазит в строку, и приходится его бить на несколько — это не сильно добавляет читаемости.
Условно говоря,
lItem := lItem + some_func() + other_func();
лучше, чем
lSomeListItemWithNiceJavaStyleName :=
lSomeListItemWithNiceJavaStyleName +
SomeFunctionGivingResultWithNicejavaStyleName() +
OtherFunctionGivingResultWithNicejavaStyleName();
Если бы я использовал FirstElementIndex только внутри List, скорее я бы назвал его просто «first».
Здесь есть некоторая порция неоднозначности, потому что непонятно, индекс ли это, итератор ли, или сам элемент. Более того, непонятно даже, переменная ли это или формальный параметр. А уж в Delphi, на котором мне выпало сейчас писать, и вовсе может быть property объекта.
Это относится ко всему, кроме сеттеров и геттеров. С сеттерами и геттерами — недостаток языка. На самом деле, во всем вот этом сан и оракл виноваты, потому что не придумало нормальных сеттеров и геттеров. Это вызвало вот такие брожения, подсознательную ненависть к java. Это настроило мозги программистов на то, чтобы было желание придумывать новые языки, новые стили написания кода, новые фреймворки — лишь бы только уйти от сеттеров и геттеров.
Насчёт длины вообще — меньшая длина заставляет держать меньше идентификаторов в одном скоупе и больше дробить функции, что спасает от спагетти-кода.
К наименованиям полей и интерфейсных методов сокращение лучше, конечно, не применять.
https://github.com/yegor256/takes/blob/master/src/main/java/org/takes/Take.java
Response act(Request req) throws IOException;
Глагол в качестве имени класса? Я не сталкивался в литературе с take в форме существительного (хотя гугл-транслейт говорит, что таковое значение есть).
Действие «act»??? Что за хрень? Никак не получилось сделать нормальное имя действия?
https://github.com/yegor256/takes/blob/master/src/main/java/org/takes/misc/EnglishLowerCase.java
public String string()
Что за действие «string»?
Почему имя класса — какое-то действие/состояние, а не объект-субъект?
http://www.multitran.ru/c/m.exe?CL=1&s=take&l1=1
Чем это отличается от rich model? переименовали сеттеры? А что нам делать с DTO?
И очевидно предлагается научить обьект загружаться/сохраняться в базу/json/… минуя DTO
Book book = api.loadBookById(123);
database.saveNewBook(book);
А так хорошо:
Book book = api.bookById(123);
book.save(database);
Особой разницы нет. Разница лишь в том, кто выполняет действие. Либо база сохраняет книгу, либо книга сохраняется в базу.
Конечно, если бы это был реальный мир, то книгу на полку ставил бы человек. Или робот :)
Тогда следует писать
bookManager.saveToDb(book, db);
Что логически приводит к ORM системам :)
Что логически приводит к ORM системам :)
ORM низя — http://www.yegor256.com/2014/12/01/orm-offensive-anti-pattern.html
Это у товарищей АИС-программистов профдеформация — привычка раскидывать через ORM всякие таблицы вида «сотрудники», где все по колонкам разбито. А зачастую нужно просто хранить сериализованные объекты. У нас в системе, например, в виде сериализованных объектов хранятся всякие user-specific настройки для разных модулей.
Когда я писал о book.serialize я не думал о книге; ветка, в которой я писал, была об, условно, «сохранении объекта в базу данных» и я думал об этом в контексте своей текущей задачи, которая — о сериализации объекта и передаче по сети и/или сохранении в БД. Так что приношу извинения за не совсем корректный комментарий, написанный для иного контекста.
book.save() — это будет ActiveRecord, что, по крайней мере для языков со статической типизацией, давно признано антипаттерном.ЕслиbookManager.saveToDb(book, db);
db инкапсулировать в bookManager (например, через «фабрику»), то будет как раз тот подход, что применяется сегодня в использовании ORM.И получается, Request это лишь контейнер для данных. Почему он наружу свои данные выставляет? Это же нарушение инкапсуляции! :)
Вместо того, чтобы писать request.respond(outputStream), тут введен некий конвертер :)
Граница инкапсуляции есть всегда. И DTO есть в реальном мире (например, всяческие анкеты, фотографии, записи).
По статье: неприятное впечатление производят высказывания. То у них гадость, это — плохо, то — неправильно, се — неправильно. Очередная песня в стиле «крах ООП, победа ФП». А как правильно?
Software development — это инженерная наука, где практика — главный критерий. Что конкретно они сделали? Если своими эпатирующими провокационными заявлениями они выступают против ряда повсеместно используемых в современной разработке вещей — пусть покажут, как надо. Где их мега-крутой проект, супер-чистый код с джедайским подходом и космической производительностью? Если их подход — работает, почему они ездят по конференциям, а не создают стартап, который за несколько дней привлечет миллионы инвестиций? Заявлять можно много чего, пиар и коммерция это все…
Я уверен, что через 20 лет все актуальные ЯП (кроме самых low-level) будут придерживаться аналогичных подходов, потому что это позволит эффективно использовать все 1024 ядра (ну или сколько тысяч их там будет к тому времени) и управлять сотнями компонентов умного дома из одной программы.
которые перестанут тянуть идею «всё есть объект» куда не надо…
Действительно. ООП — это лишь метод, способ работы с данными. Есть ситуации, где это оправдано, есть, где нет. Где нет внутреннего состояния, где слои абстракции только скрывают суть действия ничем не помогая.
Егора, потому что тут больше про борьбу с оппонентами, чем про ООП. Возможности купить книгу в электронном варианте тоже нет,
поэтому пришлось собирать целостную картинку из записей в блоге, а не из книги.
Итак нам обещают ООП 2.0
1) Why NULL is Bad?
«null плохой». ок, но мы это уже давно знаем. эта тема обсосана со всех сторон.
2) Getters/Setters. Evil. Period.
«get/set плохо». суть статьи — вместо процедурного барахла, используйте ООП
3) Data Transfer Object Is a Shame
«DTO плохо» взамен предлагается переложить сериализацию/десериализацию на саму сущность, минуя DTO
4) ORM Is an Offensive Anti-Pattern
«ORM плохо» взамен предлагается active record и репозитарий для бедных
5) Objects Should Be Immutable
«all classes should be immutable in a perfect object-oriented world». эта тема обсосана со всех сторон.
6) OOP Alternative to Utility Classes
«Utility классы зло, каждому методу по обьекту». И такой код я тоже видел.
аргументы: SRP, удобнее писать тесты, «An object-oriented approach enables lazy execution». весьма слабо.
7) If-Then-Else Is a Code Smell
if — зло, vrtual dispatch — добро. где-то я это уже видел. может у Фаулера/Физерса/Кириевски?
8) Singletons Must Die
синглтоны зло.
9) Class Casting Is a Discriminating Anti-Pattern
cast зло
10) Composable Decorators vs. Imperative Utility Methods
Why Many Return Statements Are a Bad Idea in OOP
Разложим мир на микроскопические обьеты.
Итого: Либо банальные вещи, либо маргинальные экстремистские идеи. Так мы будем писать через 20 лет?
Так мы будем писать через 20 лет?
Тогда появится какой-то новый Егор, который будет ездить по конференциям и рассказывать, что «чистый ООП» — это ужасно, что все проекты плохие и что надо писать в процедурном стиле.
This is a classical example: public int max(int a, int b) { if (a > b) { return a; } return b; }
И пример «хорошего подхода»:
This is the code in a pure object-oriented world: public int max(int a, int b) { return new If( new GreaterThan(a, b), a, b ); }
What do you think now?
Ай финк нау, что это воняет за километр и двухметровой палкой это трогать нельзя. Нельзя гордиться тем, что ты навернул 4 абстракции вместо одной стандартной конструкции. Это технопорно вида «смотри, как я умею» — интересно, но непрактично и нечитаемо. Судя по всему, остальные предложения такие же гениальные.
This is the code in a pure object-oriented world:Такие примеры кода просто показывают полное непонимание сути ООП и для чего вообще нужна эта парадигма. Недавно обсуждали ООП вдоль и поперёк, начиная от самых истоков и заканчивая практической пользой в настоящем, не охота повторяться…public int max(int a, int b) { return new If( new GreaterThan(a, b), a, b ); }
Вот тут дело было.
new GreaterThan(a, b)
Интересно, а yegor256 смотрел scala? Там как раз сделано гораздо более ООПшно:
a.<(b)
И если это банальные вещи, то можно посмотреть на Ваш код, где все эти вещи реализованы?
вы этого не увидите, потому что я не согласен с вами полностью ни по одному из этих пунктов.
Более менее я стараюсь избавляться от проверок аргументов на null, это решается при помощи code contracts. null как результата функции тоже надо избегать, но все хорошо в меру.
Синглтон решается любым DI фреймворком. И то, пока проект маленький я даже и не подумаю что-то делать в этом направлении, у меня мало времени на перфекционизм
Immutable? все хорошо когда, у тебя value object, но как entity может быть immutable?
Можно увидеть, скажем, 5000 строк Java кода без NULL?
ну если бы вы читали мои комментарии, то знали бы что я пишу не на яве )) а в дотнете с этим попроще
Да, я надеюсь, что так мы будем писать через 20 лет. На самом деле, раньше
серьезно, вы правда думаете, что все будут делать так
return new If(
new GreaterThan(a, b),
a, b
);
?
Да ну, нет же. Никаким образом. Вы вместо того чтобы пару тройку инструкций воткнуть начинаете аллоцировать на управляемой куче. А вы не думали что будет если этот код часть итеративного алгоритма, запускается он 100500 раз? Ну тут и даже не по перформансу вопрос, а по логике вещей. Программирование — это математизация природы, а не ее антропоморфизация. Что нам дает одна точка выхода? Вот если бы вы писали статический анализатор — да, возможно это лучше. Но если нет, то вы рискуете превратить весь код в один цепочный fluent вызов, и ради чего? Where's the beef?
Скажите, а вы вот реально поставляете вашим заказчикам такой код? Это я к тому, что будь я вашим заказчиком то я бы, как вы в вашем подкасте и намекаете, справедливо задал бы вопрос "какого… вы мне код обфусцируете?" и ушел бы прямехонько к вашим конкурентам, рассказав им по пути о ваших протекционитстких практиках который сводят на нет 1) maintainability; и 2) возможность впоследствии передать этот код на суппорт кому-то ещё. Получается жесткий vendor lock без каких либо преимуществ.
Я бы вообще не был ни в чем убежден на 20 лет вперед. Это попахивает самоуверенностью.
А то что вы тут делаете, в конкретном примере — это простите, та еще чушь. Позволю себе как-бы похожий пример:
new If(new NotEqual(b, 0), a/b, b)
Java — это вообще-то не ленивый язык. Аргументы метода тут вычисляются всегда. Так что деление на ноль произойдет во всех случаях. И вообще исключения при их вычислении никто не отменял. Поэтому такие фокусы в реальной жизни прокатывают только тогда, когда аргументы являются лямбда-выражениями (т.е. в Java 8). Скажем, условный примерчик функциональщины в духе javaslang:
Try.of(()->Integer.valueOf("xyz")) — т.е. тут аргументом лямбда, которая будет вычислена лениво.
И только так реально можно делать в случаях, когда нужно либо-либо — либо один аргумент, либо другой. И я бы даже сказал, что я не против такого подхода в целом — но считать что через 20 лет мы будем писать только так — это сильно самоуверенно, потому что у этого подхода есть свои грабли, на которые можно наступать.
Ну в такой формулировке я могу быть убежден в чем угодно )))
Но реально глядя на вещи, и вспоминая скажем для верности 1986 (это правда не 20 лет, а уже 30), я могу твердо сказать, что любые тогдашние предсказания были глупостью. Т.е. тогда у меня были в качестве инструментов EC-1066, с 16 мегабайтами RAM, на которой работало человек 60, VM/SP как ОС, SQL/DS как база данных, REXX и PL/1 как языки разработки (были и другие, много, но они и тогда не заслуживали особого внимания), Script VS как средство подготовки документов, и XEDIT в качестве текстового редактора.
Ну и кому сейчас интересна машина с 16 мегабайтами и двумя процессорами, кроме историков?
Ну и кто из этих программ сегодня еще живой, так чтобы о них кто-то помнил, кроме ветеранов? Разве что SQL/DS под названием DB2 еще неплохо себя чувствует. Все остальные де факто сдохли, или чисто маргинальные.
Если вспомнить 1996, то все конечно ближе к сегодняшней жизни. Но вообразить себе скажем нынешние телефоны… их параметры и софт — я бы тогда не взялся. Поэтому не берусь и сегодня, все еще сто раз поменяется.
Я бы вообще не был ни в чем убежден на 20 лет вперед. Это попахивает самоуверенностью.
Через 20 лет либо падишах помрет, либо ишак :)
new If(new NotEqual(b, 0), a/b, b)
Извините, но это не ООП!
Вот ООП:
new If(new NotEqual(b, 0), new Divide(a, b), b)
new If(new NotEqual(b, new NumericalObjectZero()), new Divide(a, b), b)
Какие еще «0»? Автор же говорит — никаких NULL, используйте Null Object design, а с какой стати 0 тогда должен быть? 0 — это специальный случай — ведь на него делить нельзя. Следовательно, мы не можем использовать
Да, так и будет. Просто со временем люди придут к тому, что слишком много раз писать new смысла нет, ведь всё равно всё есть объект и это слово ничего не добавляет. И запятые уберут, они всё равно только загрязняют код. Будут писать просто
(if (greaterThan a b) a b)В данном примере мы исходим из того, что наши классы If и GreaterThan immutable by design и решают только одну задачу.
Реализация этого на ruby могла бы выглядеть примерно так:
class GreaterThan
def initialize(a, b)
@a = a
@b = b
end
def call
@a > @b ? @a : @b
end
end
class If
def initialize(condition, a, b)
@condition = condition
@a = a
@b = b
end
def call
@condition.call ? @a : @b
end
end
a = 1
b = 2
chain = If.new(GreaterThan.new(a, b), a, b)
chain.call # => 1Ок, мы устали писать new, ведь наши классы все равно решают только одну задачу:
class GreaterThan
def self.call(a, b)
a > b ? a : b
end
end
class If
def self.call(condition, a, b)
condition ? a : b
end
end
a = 1
b = 2
If.(GreaterThan.(a, b), a, b) # => 1В чем кардинальные отличия этого подхода от FP?
def _if(condition, a, b)
condition ? a : b
end
def greater_than(a, b)
a > b ? a : b
end
a = 1
b = 2
_if(greater_than(a, b), a, b) # => 1We do understand objects well, simply because they are real world entities and exist around of us. The function fibo(7) is exactly as understandable as the object Fibo(7), but objects are more convenient, because they take responsibility to know, what they are. A function lives within the confines of one statement and gives us a result as a successor. Probably a dumb one, which delegates a responsibility on knowing, what it is, to a programmer. This information gets lost in the code as soon as you leave a place of calling the function. In other words, an integer returned from fibo(7) cannot print itself as «Fibonacci number #7: 13» or find the subsequent Fibonacci number. An object (and an object composition) can be instantiated, passed to some function and expose its behaviour somewhere else. It has its own lifecycle, can be asked for its behaviour many times and knows exactly, what it is. Also, in some languages object interactions are way easier to test, thanks to interfaces and fake objects. I can’t remember a language, which allows to define such a separated schema for a function.
Also, in some languages object interactions are way easier to test, thanks to interfaces and fake objects. I can’t remember a language, which allows to define such a separated schema for a function.Ахах, т.е. заглушки — это просто, а заменить функцию в pipeline — сложно?
Впрочем, спору нет, что благодаря IoC и железной дисциплине в команде можно добиться от объектов того же уровня тестопригодности, который в любом функциональном языке присутствует by design (с нулевыми усилиями).
Это не так. Null не является Null Object, если бы он им являлся, можно было бы написать Foo foo = null; null.Bar() и это был бы no-op.
Ошибочными считаю предложения переносить инфраструктурные механизмы (сериализацию, работу с БД) в объект, это явно противоречит Domain-Driven Design, отголоски которого были слышны в посте «Геттеры\сеттеры — это плохо».
«ORM плохо» взамен предлагается active record и репозитарий для бедных
А вот нет. В ещё одной статье написано, что это всё зло.
А самое печальное, отсутствие электронной версии книги автора. Это ооооочень странно. Получается желание заработать преобладает над желанием распространить свои идеи и подходы.
Не хочу никого обижать, но все выглядит как какая-то популистика из разряда «давайте возьмем самые дискутируемые темы из ООП и покажем что все на-самом-деле-не-так».
Заменять null'ы NULL-объектами для меня крайне сомнительная затея.
Это нужно, чтобы вместо
Bean bean = repository.getBean();
if (bean == null) {
return null;
}
Data data = bean.getData();
if (data == null) {
return null;
}
return data.getName();Можно было написать что-то вроде.
return repository.getBean().getData().getName();Можно было написать что-то вроде.
return repository.getBean().getData().getName();
А зачем? Зачем нам getData от несуществующих данных? Зачем getName от несуществующих данных? Как отличить ситуацию, когда «имя» = "" и ситуацию, когда оно не найдено? Получается, что мы заменяем невалидный явно объект NULL на объект невалидный неявно — объект-пустышку, только для того, чтобы вызвать код, который по определению не может с пустышкой работать. Это еще не говоря про то, что где-то this может быть пустым и это сработает и так.
Мы собираемся вернут пустой объект, если хотя бы один объект в цепочке пустой. Так бы мы проверяли на null и возвращали null в конце концов. А так можно обойтись без проверок. Но это конечно не так интересно, как Optional, который поможет вернуть не null, а что-то кастомное, если хотя бы один объект в цепочке пустой. Или вообще не выполнять какую-нибудь операцию, если объект пустой.
А так можно обойтись без проверок.
Зачем две лишние
Зачем две лишниепроверкивозврата пустоты, если изначально ясно, что операция не удалась?
Возвраты пустоты для того, чтобы не писать проверки вручную. Код становится читать легче. Затраты — несущественно больше.
Еще вопрос: в стиле return repository.getBean().getData().getName();
вам нужно поставить breakpoint на вызов getName. Далеко не каждая среда разработки позволит отловить этот конкретный вызов. Уж не говоря о том, что с null мы можем поставиь точку останова именно на момент fail'а операции с целью просмотра каких-либо данных.
Я стараюсь без дебага обходиться. Но можно каждый вызов писать на отдельной строке — я только за. Опять же условный брейкпойнт поставить в джаве несложно. Но я стараюсь не дебажить.
Я стараюсь без дебага обходиться
О чем я и переживаю: «По-моему, код становится писать легче, а не читать»
Опять же условный брейкпойнт поставить в джаве несложно.
Условный — да, а можно ли в Java поставить BP на возврат объекта-пустышки из .getBean() в строке:
return repository.getBean().getData().getName();
Или все же потребуется
data = repository.getBean().getData();
return data.getName();
? И можете ли вы ловить именно объект-пустышку, а не null?
Код становится легче читать, потому, что бессмысленные проверки на null не мозолят глаз.
Вот с брейкпойнтами не уверен — нечасто я дебагом занимаюсь, юнит тесты всё решают. Думаю можно, но надо попробовать.
Код становится легче читать, потому, что бессмысленные проверки на null не мозолят глаз.
По-моему, читать «математическую» нотацию вида
bean = repository.getBean();
data = bean.getData();
outcome = data.getName();
return outcome;
легче, чем цепочку, и проверки никак не мешают — это обычный шаблон, который воспринимается совсем буднично, потому что код написан так же, как исполняется машиной, и читая его, ты следуешь ее логике: «получили — ошибка? выходим. Нет, смотрим дальше».
Наверное зависит от человека. Мне вот переменные мешают быстро понять, что там на самом деле цепочка вызовов и что outcome получилась из репозитория. Ну и в математике промежуточные переменные как правило убирают — оставляют только окончательную формулу.
Наверное зависит от человека.
Разумеется!
Просто без этого напоминает старый анекдот: «С утра заехал, купил колодки, потом смотался на другой конец города, купил сцепление, потом заехал на мойку, потом в сервис, поменял колодки и сцепление, потом на техосмотр. Фффух, как бы я это успел, если бы не было машины». Здесь аналогично — если мы говорим, о том, что null это evil, потому что мы не можем с в стиле stream писать, то встает вопрос — а надо ли оно изначально.
return repository.getBean().getData().getName() должен быть возвращён не null, а экземпляр класса NotExistingName реализующий интерфейс IName. В этом как раз и заключается фундаментальное отличие от оператора ?..return repository.getBean().getData().getName();
Это же антипаттерн по Егору. Вы не уважаете объект. Лезете в его потроха.
return repository?.getBean()?.getData()?.getName();
Нет, это не так. Вам уже ответили тут
Разница в том, что попытка вызова метода у null приведёт к ошибке в рантайме.
Вы спорите о том, что крокодил длинный, я — о том, что зеленый. Вы говорите о том, что нельзя работать с null как с полноценным объектом, я о том, что null — специальная невалидная сущность (которую можно привести к объекту — и о чудо! это тоже будет полностью невалидный объект, невалидный вплоть до падения), которая в языке есть именно для того, чтобы понять, что результат не получен. Мне непонятно само желание выполнения последующих шагов обработки данных, если уже понятно, что операция не удалась изначально.
Статических методов у объекта не бывает, они у класса :). Но я не за Null Object, я за Optional, если что. Хотя Null Object всё равно лучше, чем Null, в случае, когда нужно просто написать цепочку вызовов и вернуть Null Object, если хотя бы один зафейлился. Шаги же не выполняются. Происходит несколько вызовов методов пустых объектов и всё. В случае с Optional — несколько вызовов одного метода одного и того же объекта.
Вы в дискуссиях про Go участвовали? Помните там обработка ошибок как устроена?
Статических методов у объекта не бывает, они у класса :)
Вроде я про статический метод объекта и не писал.
когда нужно просто написать цепочку вызовов и вернуть Null Object, если хотя бы один зафейлился.
null ничем концептуально не отличается — так же на каждой стадии при получении null мы можем прокидывать null наверх. Разница в написании в строку, но по мне, это сомнительное преимущество.
Вы в дискуссиях про Go участвовали? Помните там обработка ошибок как устроена?
Совсем немного.
Смотря где, постоянно вижу конструкции вида
err, res = function_name();
null ничем концептуально не отличается — так же на каждой стадии при получении null мы можем прокидывать null наверх. Разница в написании в строку, но по мне, это сомнительное преимущество.
Ну вот есть мнение, что огромное количество кода падает от того, что программист забыл проверку на null в цепочке. Которая вообще-то нужна только потому, что с null всё упадёт. Вон в С# целый оператор для этого придумали. ?.
Смотря где, постоянно вижу конструкции вида
err, res = function_name();
Я не совсем про это.
Там есть ещё про то, что в стрим какой-нибудь можно писать в цикле. И если на десятой записи будет ошибка, то остальные операции не отменяются, а просто проходят порожняком. А потом в стриме можно посмотреть была ли ошибка. Вот так.
b := bufio.NewWriter(fd)
b.Write(p0[a:b])
b.Write(p1[c:d])
b.Write(p2[e:f])
// and so on
if b.Flush() != nil {
return b.Flush()
}Принцип тот же. Вот ссылка на статью целиком, если я мутно написал.
Ну вот есть мнение, что огромное количество кода падает от того, что программист забыл проверку на null в цепочке.
Так это вообще-то замечательно — мы увидим, что есть ошибка(stacktrace прилагается), и исправим ее. В случае нульобджекта вы просто тихой сапой ничего не сделаете.
Которая вообще-то нужна только потому, что с null всё упадёт.
Да нет — это, например, просто символ ошибки операции. Вовсе не только потому что иначе упадет. Это может быть
someting = foo.bar();
if(something==null){
doThis();
doThat();
reportSomething();
return;
}
это может быть
data = foo.bar();
if(data==null){
data = new Data;
}
SomeClass someObject = null;
someObject.someStaticClassMethod();//code smell but works
Проблема в том, что статические методы не вызываются по ссылке объекта. Компилятор в процессе компиляции определяет, какой у объекта класс и заменяет
someObject.someStaticClassMethod();на
SomeClass.someStaticClassMethod();Вы совершенно правы (в том, что ?. решает тот кейс, который я привёл в пример). Единственное что это сильно зависит от точки зрения. По мне так синтаксический сахар, который вы показали это костыль, которым пытаются заменить Optional.
Поэтому там можно писать
repository.GetBean()?.GetData()?.GetName();
Без всякого нытья, какой null плохой.
Так-то.
Об этом уже говорили. Действительно решает проблему, но Optional лучше.
Тем, что позволяет вернуть что-то отличное от null.
object.getData().getOrElse("Bad Data");Да нет, не падаем. Просто дальше работаем с этой строкой.
В данном случае цель кода — вернуть строку в любом случае. Если мы знаем, что отсутствие data ведёт к исключительной ситуации, то мы напишем
object.getData().orElseThrow(IllegalStateException::new);Это вопрос из другого холивара :). В данном случае, если волнует дороговизна эксепшна — можно вернуть пустой Optional — по цене это тоже самое, что вернуть null, но дальше по цепочке есть все возможности, предоставляемые Optional.
В Java луше тк простой мапинг данных сделать в C# сложно
что-то из серии
Optional<User> user = ...;
Optional<UserName> name = user.map(u->new UserName(u.FirstName, u.LastName))
В C# будет выглядеть как
var user = ...
UserName name = null;
if(user != null) {
name = new UserName(u.FirstName, u.LastName);
}
Ну и в Java версии явно видно — может быть пустое значение или нет
UserName name = (u == null) ? null : new UserName(u.FirstName, u.LastName);
P.S.
Кстати map() можно добавить через метод расширения и будет вообще так же.
User user = ...
UserName name = user?.Map(u => new UserName(u.FirstName, u.LastName));
Хотя видел ещё разбиение на подстрочки вида:
(булево выражение)
? (операция один)
: (операция два)
в таком виде — тоже читабельность сохраняется (если выражение чётко влазит в строчку).
все уже давно есть ))
В Optional ещё можно лямбду выполнить если там пусто и ещё много чего можно. Кроме того Optional в сигнатуре медота означает, что метод может вернуть пустое значение. Синтаксис чище выходит. Не надо гадать, может там быть пустое значение, или нет.
А знаки вопроса эти на тернарный оператор похожи, будь он неладен. Хотя часть проблем снимают конечно. Но с таким подходом наверное лучше особый синтаксис делать для мест в которых null не может вернуться — их меньше.
В Optional ещё можно лямбду выполнить если там пусто и ещё много чего можно
все тоже самое, там должно быть просто выражение
Кроме того Optional в сигнатуре медота означает, что метод может вернуть пустое значение. Синтаксис чище выходит. Не надо гадать, может там быть пустое значение, или нет.
да, это плюс
Но с таким подходом наверное лучше особый синтаксис делать для мест в которых null не может вернуться — их меньше.
в дотнете ровно все наоборот, обычно это нежданчик когда тебя null отдали, но в тех местах, где это есть, обьёмы кода впечатляют
Когда я читаю статьи Егора, мне вспоминается мультфильм про зайца, который всех учил чему-то. Сороконожка нормально ходила, никогда не задумываясь, как ходить, но как только начала ходить "правильно", оказалось, что она вообще не может ходить!
А всё потому, что он приводит короткие красивые примеры, где всё выглядит хорошо, но на практике, когда система начинает усложняться, писать, как он предписывает — равносильно самоубийству. Примеры? Пожалуйста (спасибо одному из комментаторов, дал хорошую подборку):
3) Data Transfer Object Is a Shame
«DTO плохо» взамен предлагается переложить сериализацию/десериализацию на саму сущность, минуя DTO
Да, вот только есть ещё такой подход, как single responsibility principle, такой важный, что является частью SOLID, и статьи, расписывающие преимущества SOLID, не менее логичны, чем статьи Егора. Вот только практика (именно практика, а не маленькие игрушечные примеры) показывает, что SOLID работает, а подходы Егора — нет.
Другой пример — Егор предлагает заменять utlity-методы объектами, т.е. вместо CollectionUtils.sort делать класс SortedList, и сортировать список, создавая экземпляр этого класса. Я не вижу никакой разницы, т.к. всё равно ничего не инкапсулируется, и более того, конструктор — это фактически и есть вызов статического метода (называемого <init>). Ну а уж по поводу критических по производительности кусках кода я вообще промолчу.
Так вот, проблема в том, что действительно, приходится писать не самые "чистые" вещи в коде. И это проблема не глупых разработчиков, это проблема глупых средств разработки. Были бы языки программирования повыразительнее, можно было бы включить перфекционизм на 142% и писать бескомпромиссно чистый код. Однако, тут проблема в том, что излишне выразительные языки программирования обладают тем недостатком, что их сложно выучить и сложно эффективно реализовать компиляторы и тулинг, но что ещё важнее, — они слишком непредсказуемые.
Были бы языки программирования повыразительнееПосмотрите Common Lisp или Racket. Выразительность ничем не ограничена. Описанных недостатков вроде не наблюдается.
Как раз Common Lisp — это плохой пример. В нём ровно две фатальные проблемы: динамическая типизация и макросы. Именно они делают код на CL совершенно нечитаемым и трудноподдерживаемым, уж не говоря о его минималистичном синтаксисе.
Ну а если код получился трудночитаемым даже на нём, то это уже «разруха в головах» (с).
Многим программистам нравится, когда выразительность искусственно ограничена, это помогает им структурировать свои мысли. Дальше всего по этому пути пошёл Go.
В первую очередь это помогает читать чужой код и упрощает командную разработку.
Например, я вижу в экосистеме Go большую тягу к велосипедостроительству… Это выражается в том, что для решения одной задачи создаются порой десятки вариантов решений, т.е. отсутвует консолидация усилий…
В языках, где можно легко и быстро включиться в разработку, наоборот преобладают тенденции к созданию де-факто стандартных пакетов под каждую задачу.
Мне эта идея нравится, когда в язык вшивается стиль, представьте язык, в который вшит, к примеру, гугло-джава-стиль https://google.github.io/styleguide/javaguide.html
А что касается функционала, если я правильно понял, в Go существует из коробки эдакий менеджмент зависимостей(я про import с git репозиториев) мне эта идея тоже нравится.
если я правильно понял, в Go существует из коробки эдакий менеджмент зависимостей(я про import с git репозиториев) мне эта идея тоже нравится.Поверьте, import тупо master-ветки с git репозиториев — это далеко не лучшая затея. Я давно не следил за прогрессом Go в этой области, но по крайней мере раньше у них даже не было штатного менеджера зависимостей. А когда у вас куча зависимостей на master-ветки репозиториев — это вообще не весело. Поэтому догадайтесь что там происходило пару лет назад… Правильно! Все, кому не лень, писали свои менеджеры зависимостей, коих было не меньше десятка.
CollectionUtils.sort и SortedList как раз очень показательные примеры в отношении инкапсуляции и SRP. С CollectionUtils.sort, на первый взгляд, всё нормально. Но мы никогда не используем этот метод сам по себе, мы применяем его к коллекции элементов, после чего она становится отсортированной. И у отсортированной коллекции уже другой набор инвариантов и свойств. Мы, к примеру, можем эффективно получать минимальный и максимальный элементы и производить поиск, но не можем просто добавлять новые элементы в конец списка. И если у нас имеется объект типа SortedList, то все эти инварианты поддерживаются самим объектом, а не хранятся в виде комментария, или вообще неявно, в голове писавшего этот кусок кода программиста.Насчёт производительности. В С++, к примеру, исходный список можно не копировать в
SortedList, а перемещать. И сам экземпляр класса SortedList можно при необходимости создавать на стеке, а не в куче. В Java, насколько я знаю, выбор, увы, не особенно велик, но небольшие объекты интерпретатор самостоятельно размещает на стеке, а семантику перемещения можно реализовать и вручную.вся красота ООП
Можно по пунктам? Или сравнение с текущим ООП.
Мы же даём программисту в Java управлять файлом на диске — открыли, закрыли. Почему то же самое нельзя делать с памятью?
Используйте C. Java ж вроде позиционируется как вещь, которой тяжелее выстрелить себе в ногу. Автоуборка мусора и все такое.
АОП
В Java нету чего-то типа dll? :)
И потом все практики за ними должны идти. А мы идём от практики к теории.
Есть много теоретически хороших, но мертвых языков. :)
А большинство языков программирования создаётся в битве за популярность. Они понимают, что если дать людям не 4 инструмента, а 14, упрощающих то, что и так делают, то их станут использовать с большим интересом.
Так ты сам такой. Хочешь разные фишки из коробки.
А чем плохи геттеры и сеттеры? :)
То что писал автор — ерунда.
Хотя я их практически не использую, так как использую ООП не фанатично, поэтому нужды в них нет.
Кстати, что думаете о goto? :^)
Там будет про ORM много
ОРМ — говно. +1
MVC
А что в нем плохого? Это всего лишь разделение кода. Или нужно все лепить в кучу?
Там будет про аннотации
Аннотации это фигня, код в комментариях, бред.
Относительно ф-и max. Это оверинжиниринг.
Основной язык — PHP.
ОРМ — говно. +1
Вы просто не умеете их готовить ) Не, серьезно, я знаю один аргумент, за ORM. А точнее даже за DAO. Он очень простой, но он применим далеко не ко всем проектам. DAO и ORM — это некоторый слой абстракции, куда можно засунуть часть логики приложения. И пилить его отдельно от других слоев. Это почти такое же разделение кода, как и MVC. Это позволяет данную (обычно рутинную) часть логики отдать отдельному человеку, сравнительно невысокой квалификации, ускорив таким образом разработку в этом месте.
Если вы пишете проект в одиночку, вам это скорее всего не нужно. Если у вас проект — репортинг, т.е. больше всего select — то опять же, вам ORM скорее всего не нужны. Но это далеко не все проекты.
Жрет память, иногда строит не совсем оптимальные или даже неадекватные запросы.
Зато не надо писать кучу кода. А неоптимальные запросы всегда можно переписать руками.
Зато не надо писать кучу кода.
Эту задачу решает не только ОРМ
А неоптимальные запросы всегда можно переписать руками.
Вот неоптимальные запросы как раз не хочется руками переписывать.
В одном случае пришлось просто явно разбить запрос на 2 вызова ORM, хотя под капотом там было тоже 2 запроса изначально.
Руками можно писать запросы, которые сложно выразить через абстракцию.
А что, помимо ОРМ помогает не писать эту кучу кода?
Но не нужно надеятся, что он сможет (легко) сконструировать сложный запрос. :)
Я иногда сложноватый запрос изначально пишу в sql, а потом уже транслирую для построителя запросов на языке программирования. :)
То есть sql-код не пишется вручную прежде всего потому, что неудобно работать с сырым текстом в языке программирования.
Если придерживаться логичного форматирования sql-кода, то нету ничего сложного в его написании, да и размер кода в чистом sql скорее всего будет меньшим. :)
ORM — как бы чуть для другого, оно даже расшифровывается для чего оно. :)
Ну такое, не всем дано понять. :) Особенно теперешней аудитории хабра.
Кто этот "он", и почему вы его недостатки обобщаете на все реализации?
Или JET Conf не проплатил? :trollface:
Выгнали его — за год он написал дико тормозящего монстра, в котором никто не мог разобраться, кроме него.
Мы этого монстра убили и за 1 месяц с нуля переписали 80% функционала, со слоями, DTO и JPA. Оставшиеся 20% допилили за еще месяца 4, причем уже не нужно быть супер опытным программистом, все в команде могут работать с этим кодом, в том числе и новички.
Покрытие тестами лучше, производительность лучше, читаемость лучше, новые люди без проблем разбираются в коде.
Вы видели проект, который Егор приводил в качестве идеала? Как вам?
Не до конца вы поняли каноны Егора, увидели что сожгло вам глаза и пошли хейтить, как и многие. Прочитайте книгу.
А без веры угодить Богу невозможно; ибо надобно, чтобы приходящий к Богу веровал, что Он есть, и ищущим Его воздаёт. Евр.11,6
Прочитайте книгу.Я бы вот с радостью почитал, да негде. В 21-ом веке не иметь цифровой версии книги — очень странно.
Программирование сложная инженерная область, потому как разработчик может сделать все что угодно и практически ни чем не ограничен. Единственный ресурс это время. Расходуя это время программист может строить людбые хрустальные замки и велосипеды, цена деньги в час — и все! При такой свободе действий создать шедевр может только гений, разумно используя весь технический арсенал, который со временем расширяется с гигантской скоростью. В шедевре ничего не бывает лишнего, не бывает избыточной красоты, ненужных вещей и красивости, красота в минимальности и простоте, достичь которую очень сложно. (Пример шедевра автоматическое оружие Калашникова)
Остальная серость, включая меня, ругает инструменты, не достаточно глубоко разбирается в сущности проблемы, назначении инструмента, кругозора инструментов и создает что-то монстроузное.
В начале 2000 когда язык придерживался только одной парадигмы, было трудно выйти за рамки. Сейчас C#, Java, C++ консолидируют возможности, которые должны быть использованы уместно. null reference это плохо, это не плохо, просто надо знать как им пользоваться и сейчас для этого куча готовых инструментов. If-Then-Else Is a Code Smell, г-но это тогда, когда он не уместно используется и так везде.
В отличии от программирования производство не позволяет создавать кучу инструментов и создание чего либо делается стандартным набором инструментов и стандартными процессами, по этому там революционеров меньше.
В общем всем радикалистам подумайте о том, для чего это создавалось, кем и какую проблему решали.
Не вижу нормального способа создать IOC-контейнером объект с циклическими ссылками без сеттеров в том или ином варианте.
Я думаю, идеями автора все же можно пользоваться, но без фанатизма — как и любыми инструментами.
Посмотрел видео… помоему, у автора просто депрессняк.
Не вижу нормального способа создать IOC-контейнером объект с циклическими ссылками без сеттеров в том или ином варианте.Через декорирование, проксирование и «одноразовые де-факто-сеттеры», типа ленивых инициализаторов.
Но автор же максималист. Он на «разборе полетов» утверждал, что геттер — это как если тебе в мозг втыкают электроды и вычитывают оттуда нужную инфу прямиком из мозга. А оопэшно — это если ты сам говоришь эту инфу попросившему ее сказать. То есть, геттеры тоже нельзя. Я его идею понял так.
Getter, который выдаёт наружу данные в своём внутреннем представлении, мешает сопровождению класса. Рефакторинг, например, гораздо проще, когда у объекта внутренние структуры не показываются наружу. Плюс, понимание чужого кода проще, если методы описывают, что объект может сделать, а не что он содержит.
"Хороший, умный и правильный" объект должен наружу показывать лишь те методы, которые от него требуются по контракту (также известному как "интерфейс"). Если разрабатывать архитектуру, отталкиваясь не от данных, а от задач, которые должны решаться, контракты большинства объектов не будут содержать getter'ов в значении "окна во внутреннее представление".
Иисус от ООП? Ну пусть сначала умрет за ваши программерские грехи))))
Я прям расстроен, что ваша подруга из пророков знает только Иисуса, который и пророком-то не был.
который и пророком-то не был.
Это смотря в какой религии.
Если я не ошибаюсь, то пророком он назван только у Бахай. У христиан он Бог, у остальных — "основатель кружка рыбной ловли"(с).
Зачем сразу кидаться в новомодную экзотику? Я имел в виду старый добрый ислам. Там он вполне себе пророк. Я бы даже сказал один из величайших пророков.
(+ vote 1)
(inc vote)
Я правильно понимаю, что функция вернёт vote + 1, а сам vote не изменится? Если так, то название inc вносит путаницу. Мне сразу кажется, что она увеличит аргумент.
И название типа inc или dec для функции, которая возвращает аргумент, увеличенный или уменьшенный на еденицу там общепринято?
В лиспе incf всё же имеет side effect.
Похожий подход предлагался уже на хабре для C++ 10 лет практики. Часть 1: построение программы.
Ещё раз повторю важный момент: структура программы на С++ отличается от С с точностью до наоборот. Там у нас были структуры и общие переменные. Здесь у нас объекты, которые суть чёрные ящики. Каждый объект — сам себе жнец, швец, на дуде игрец…
Напоминаю, что get/set доступ — это чуть более завуалированный вариант открытого члена класса.… Вместо того чтобы запрашивать данные, просим объект сделать нужное действие самостоятельно. Это необходимое условие стабильности больших проектов на С++.
- уже звучало не первый раз, и в том числе и этом интервью — но мне до сих по не понятно — почему нельзя напилить свой язык, в java (как языке) много рудиментов и конструкционно не православных вещей — будь Бендром — сделай свой парк развлечений — как Одерский, Rick Hickey, авторы Kotlin (увы, не знаю их по именам) — инструменты доступны — оттранслировать в jvm не супер сложно (но не за 5 минут). Не нравится ООП в java, boiler plate, и что там еще — да черт бы с ними, покажи мир другой — как говорил Толкиен — не так сложно придумать мир с зеленым солнцем, сколько придумать мир в котором это солнце выглядело бы нормально. Покажи как надо делать правильно — и пусть даже используя новый язык — к чертям все эти компромиссы — я в своё время очень проникся clojure именно за то, что он был как глоток свежего (для меня) воздуха — почти чистый fp без лобызаний и сильных компромиссов — мой парк — мои женщины — что хочу — то ворочу
- почему нужен новый язык, а не пытаться реанимировать java? — была попытка обсуждения в чатике РП — говорят и на ассемлере можно писать ООП, но это мягко говоря не то удовольствие, которое хотелось бы иметь. Ладно бы в java был только один единстенный недостаток, но в силу истроческих причин их не мало. Не стоит использовать микроскоп для забивания гвоздей, а молоток для изучения бактерий. Не является ли java молотком для выражения идеологического (по Егору) верного ООП? Если существующие инструменты не позволяют выразить идеи — логично, что нужно создать новый инструмент
- да, я не читал книги Егора — но то, что я вижу в его коде — меня повергает в лёгкий шок — резонный вопрос — если через 5-10-15 минут мне не стало понятно, то зачем я буду тратить время, читая книгу, чтобы понять базовые вещи
- вполне допускаю, что в голове у Егора есть светлые идеи, но выразить их трудно покуда руки по локти в
гавjava, звучит критика, но звучащие предложения не убедительны и в чём-то даже вредны.
но мне до сих по не понятно — почему нельзя напилить свой язык
Так в статье есть вполне понятный ответ на это.
уже звучало не первый раз, и в том числе и этом интервью
объяснения, которые звучат — разумны, но не убедительны
«C++ is history repeated as tragedy. Java is history repeated as farce.»
– Scott McKay
«Java, the best argument for Smalltalk since C++»
– Frank Winkler
В принципе, можно у него самого уточнить…
В Вашей коллекции не хватает:
I'm sorry that I long ago coined the term «objects» for this topic because it gets many people to focus on the lesser idea. © http://c2.com/cgi/wiki?AlanKayOnMessaging
Ну и несколько статей на тему (хотя возможно Вы их уже читали):
Ten Things I Hate About Object-Oriented Programming
The Deep Insights of Alan Kay
Object Oriented Programming is an expensive disaster which must end
Fifty Questions for a Prospective Language Designer
P.S. Лично я считаю, что ООП не вредно, как средство высокоуровневого проектирования. Вред приносят попытки искусственно сделать всё объектами… Во-первых, они довольно корявы во всех мейнстрим-реализациях. Во-вторых, это не даёт никаких практических преимуществ.
Поэтому мне ближе ООП в том виде, в котором оно существует в BEAM (где в роли объектов выступают легковесные процессы, внутренняя реализация которых насквозь функциональна), а не то, что может предложить JVM.
Вам же, насколько я понял, нравится придерживаться идеи, что всё является объектами… Поэтому интересно было бы почитать Ваше мнение на тему Smalltalk.
it is an independent entity with its own life cycle, its own behavior, and its own habits.Я полностью согласен с таким определением объекта (впрочем, точнее было бы называть это субъектом или актором). Но вот дальнейшие примеры в статье показывают профессиональную деформацию от долгого программирования на мейнстрим-языках. Взять тот же файл, это совершенно пасивная сущность, без какого-либо собственного поведения, по сути тупо набор байтов. А XmlParser — это очевидно активная сущность, представляет она человека, читающего и интерпретирующего файл. Другими словами, любая человеческая активность может быть выражена объектом. Похожая метафора с того же OOPSLA97: «An object is a virtual server».
Таким образом, годный объект — это виртуальный сервер, обеспечивающий выполнение/автоматизацию некоторой активности, которая могла бы быть выполнена человеком, над некоторым набором данных (состояние объекта), на основании обработки входящих сообщений (аля приказы начальника, просьбы коллеги и т.п.)
Фиговые объекты сразу видно по действиям, которые описываются возвратными глаголами (с постфиксом -ся). Например, файл открывается, строка пишется, файл закрывается.
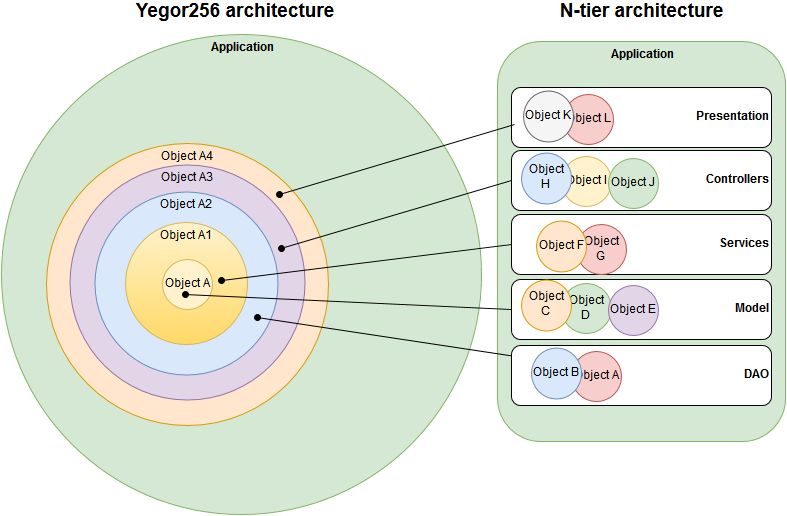
Возмущение в ответ Егору по причине, что это не удобно.
Выходит, Вы стремитесь к том, чтоб объекты представлющие модель содержали и всю бизнес-логику?
Объекты, отвечающие за сохранение в БД, например, у Вас тоже будут похожи на набор процедур.
Не получаем ли мы с Вашим подходом тоже самое?
ООП будущего: Барух Садогурский и Егор Бугаенко о том, как мы будем программировать через 20 лет