В этом посте речь пойдет про пилотное ML-исследование для онлайн-гипермаркета «Утконос», где мы прогнозировали выкуп скоропортящихся товаров. При этом мы учли данные не только по остаткам на складе, но и производственный календарь с выходными и праздниками и даже погоду (жара, снег, дождь и град нипочем только «Taft’у Три погоды», но не покупателям). Теперь мы знаем, например, что «загадочная русская душа» особенно жаждет мяса по субботам, а белые яйца ценит выше коричневых. Но обо всем по порядку.

Пилот в ритейле больше чем пилот
В ритейле машинное обучение находится в двойственном положении. С одной стороны, ритейлеры накопили внушительные объемы данных за весьма впечатляющие промежутки времени: отдельные чеки покупок, данные с карт лояльности… С другой — ритейл существует настолько давно, что задачу прогнозирования спроса начал решать задолго до появления моды на data science и сегодня имеет в распоряжении необходимые BI-инструменты.
Получается, что ритейл — одно из наиболее перспективных полей для экспериментов датасайнтистов и внедрения машинного обучения, но бизнес смотрит на всё это со скепсисом: точно ли это хорошо для меня? Ведь уже есть работающие, проверенные многолетним опытом решения.
И вот тут самое время договориться о пилотном исследовании!
Сами по себе пилоты по сравнению с полноценным ML-проектом имеют понятные ограничения и специфику.
- Времени на пилотное исследование затрачивается достаточно, чтобы показать заказчикам возможности машинного обучения на их данных, но не настолько много, чтобы уйти в убытки.
- К тому же второго выстрела у датасайнтистов, как правило, уже не будет: если первые результаты бизнесу не кажутся интересными, то он сохранит скепсис и верность старым методикам прогнозирования. Так что целиться надо метко.
- За время пилотного проекта между заказчиком и датасайнтистом не может появиться никаких доверительных отношений. А подразделения и специалисты, владеющие важными для интерпретации данными, скорее всего, во время пилота недоступны, как и коммерчески важные инсайты.
Разумеется, эти особенности проявляются не в каждом пилотном проекте, но они составляют важную часть его рисков.
Немного о задаче
Задолго до знакомства с машинным обучением «Утконос» уже использовал собственную аналитическую систему, которая с весьма высокой точностью прогнозировала выкуп товаров на неделю. Тем не менее, ритейлера интересует возможность повышения эффективности планирования. В первую очередь это касалось скоропортящихся продуктов, многие из которых еще и весьма недешевы. Традиционная вилка: купишь много — будут убытки, купишь недостаточно — покупатель уйдет за своей любимой телячьей вырезкой, заготовленной при полной луне и слегка моросящем дожде, к конкуренту. Для достаточно точного прогноза на послезавтра лучше подходят решения на базе машинного обучения, позволяющие учитывать большее число факторов, чем классические BI-инструменты. «Утконос» согласился выступить нашим партнером для эксперимента, направленного на проверку гипотез применимости Machine Learning для e-commerce.
Чтобы показать возможности машинного обучения для решений этой задачи, по согласованию с бизнесом были выбраны несколько товарных наименований:
- два товара из категории «Охлажденное мясо» — как скоропортящиеся продукты, данные по которым наиболее важно обновлять оперативно;
- и два товара из категории «Яйцо куриное» — как товары со специфическим сезонным спросом, которые нельзя спрогнозировать просто как «в четверг все покупают X, а в пятницу — X умножить на коэффициент». Хотя куриные яйца не являются сложными для прогнозирования выкупа и как раз для них вполне приемлем недельный горизонт планирования, именно на этих товарах предстояло показать, что машинное обучение действительно видит сложные взаимосвязи и строит нетривиальный прогноз.
Конкретные товары мы выбрали уже на свой вкус, опираясь на полноту в исторических данных. Какие-то товары были введены в линейку достаточно недавно, какие-то — наоборот, продавались когда-то, но в настоящий момент уже были выведены из ассортимента, так что ценность данных по ним была только историческая.
Данные, предоставленные «Утконосом», содержали информацию о продажах четырех товарных наименований за предыдущие 2 года и о доступности этих товаров на складе в соответствующие периоды. От общего набора данных мы сразу «отрезали» последние полгода, с начала ноября по конец апреля — этот будет наш тестовый набор. В него вошли как относительно спокойные осенние месяцы, так и череда зимних каникул и весенних праздников.
Нас ожидало короткое, но увлекательное приключение.
Данные со складов: загадочные и необходимые
При работе с историческими данными первый же вопрос, который перед нами встал, — как отделить реальные продажи от «максимально доступных продаж» (т.е. случаев, когда заканчивающийся на складе товар был выкуплен на 100%, однако при его наличии объем продаж мог быть выше)? Такие неосуществленные желания покупателей ведь никак не отображаются в данных.
Доступность товаров на складе. К слову, по опыту предыдущих проектов в ритейле, мы ожидали, что это будут остатки, выраженные в единицах измерения. Однако в данном случае мы имели дело с относительным показателем «доступность», которая измерялась в процентах в течение дня. Что же касается наличия товара на складе, то этот показатель весьма относителен: то, что в какой-то промежуток товара не было, вовсе не означало, что его хотели купить.
Поэкспериментировав с разными вариантами (реконструкцией «действительного спроса» на основании по-разному рассчитанных коэффициентов и фильтрацией датасета продаж с разными порогами доступности), мы в итоге подобрали оптимальный порог, который не делал набор данных слишком узким. Идеал — наличие товара в течение всего дня — заметно сокращал данные даже для самых продаваемых товаров.
Товар 1: охлажденное мясо (необычной птицы)
Мы начали работать с охлажденным мясом, так как в прогностической способности модели, как только она будет готова в черновом варианте, не сомневались. (Спойлер: а вот и напрасно — в датасете с продажами яиц нас ждал интересный сюрприз, но об этом позже).
В целях экономии времени «из коробки» достали готовую библиотеку, хорошо работающую с временными рядами, — Prophet от Facebook.

Результаты работы модели на обучающих данных сразу показывают и достоинства, и недостатки. Модель хорошо улавливает «сезонность» спроса, но плохо — пики покупок. Также праздники, зашитые в Prophet по умолчанию. Относительное отклонение составляет 31.36%, будем его дальше использовать как базовый результат.
Встроенный инструмент визуализации сезонности, которую видит Prophet, позволяет сразу получить небольшой инсайт о том, как изменились покупки одного из товаров за два года, какие у них особенности в течение года и в течение недели:

У нашего охлажденного мяса четкий возрастающий тренд на общее число покупок, число покупок растет от понедельника к субботе и падает в воскресенье, летом покупки заметно «проседают». Плохо, что лето не попадает в наш тестовый период; с другой стороны — запомним, что период каникул и отпусков важен для уровня продаж, ведь летние каникулы — в России далеко не единственные.
Логичный вопрос: можно ли использовать эту модель сразу для прогноза на следующие полгода?
Интуитивно кажется, что нет. Эксперимент показал, что так и есть. Общий рисунок сезонности в течение недели верный. Но сразу стало очевидно, что от общего рисунка сезонности есть миллион отклонений как вверх, так и вниз, а среднее отклонение 45.71 % сильно превышает результаты на обучающих данных. Понятно, что это никуда не годится.
Для начала попробуем обучать модель ежедневно, представив, что каждый день после завершения работы магазина датасет дополняется продажами за «сегодня». Мы уже знаем, что в продажах есть восходящий тренд в целом — возможно, что оборот на наших тестовых данных растет с большей интенсивностью за счет более активной маркетинговой активности, чем было на обучающем наборе.
Относительный успех: при ежедневном дообучении модели относительное отклонение составляет 33.79%. Мы дополнили параметры модели информацией о перенесенных выходных, религиозных постах и праздниках, традиционных для России (таких как Новый год, Пасха и ряд других). Также были добавлены резкие изменения погоды: дни, когда температура скакала вверх или вниз на 10+ градусов или просто была заметно выше или ниже других дней этого месяца. Теперь в среднем за полгода наш прогноз отклонялся от реальных продаж на 28.48%, а в целом модель начала лучше учитывать всплески покупательской активности. Мы улучшили среднее отклонение на пять процентов! При том, что с выбросами Prophet в принципе работает плохо и данные рекомендуется от них очищать, — это было заметное движение вперед.


Прежде чем показывать предварительные результаты, встал вопрос: можем ли мы еще немного улучшить прогноз? Если посмотреть на корреляцию продаж товара и его средней цены в день — понятно, что это связанные признаки, а цена при построении модели никак не учитывается. Но, судя по набору данных, мы могли взять только некую «усредненную цену за единицу»: в заказах она нередко варьировалась в течение одного и того же дня, т.е. была записана с личной скидкой покупателя, а «витринные» цены в набор данных не входили.

Коэффициент корреляции между средней ценой за единицу в день и число проданного объема этого вида охлажденного мяса составил ¬–0.61 при p < 0.01. Понятно, что «средняя цена за единицу» — не идеальный показатель: в том случае, если в течение дня было много покупок от, скажем, партнеров с постоянной большой скидкой, в данные закрадутся опасные шумы. Мы же хотели выделить дни, когда были маркетинговые воздействия: общие скидки на группу товаров, скидки всем, кто введет свободно распространявшийся промокод и т.п.
Тем не менее, даже после выделения дней с усредненной ценой в 5-процентном квантиле как акционных, никакого прироста точности работы модели не вышло. Повысилась точность в дни экстремальных распродаж, а среднее относительное отклонение за полгода осталось прежним.
Но мысль про выраженную статистическую взаимосвязь с ценой сохранили для будущего.

Предварительный результат нас вполне устроил, пора было переходить к другим товарам, прежде чем кончится отведенное на пилотный проект время.
Товар 2: яйцо куриное
Нас сразу предупредили, что яйца являются одной из наиболее показательных товарных категорий с точки зрения влияния внешних событий. В первую очередь объем покупок вырастает на Пасху: яйца красят и с яйцами готовят. Но больше, конечно, красят. Это легко понять, сравнив продажи белых и коричневых яиц.

В целом наша модель ожидает, что некоторое повышение спроса в Пасху будет, но ее прогноз меньше реального показателя почти в 2 раза (и это отклонение в ~100% во время пасхальной недели делает среднее отклонение за полгода невероятно большим). Почему? Ведь пасхальная неделя случается ежегодно — в данных предыдущих 2 лет должен быть паттерн!
Исследовательский анализ показал, что паттерна нет. В 2018 году (это наши тестовые данные) пик покупок приходится на всю неделю перед Пасхой вплоть до 7 апреля. В саму Пасху (8 апреля в 2018) покупки яиц всегда падают, что совершенно корректно видит модель. А вот в 2017 году Пасха приходится на 16 апреля, а пик покупок в исторических данных — 8 апреля, и в этом году пик — один день. В 2016 году Пасха приходится на 1 мая. Пик покупок — 29 апреля, с подъемами на день до и день после. В 2015 году Пасха приходится на 12 апреля, пик покупок снова один день, 9 апреля.

Нашей первой версией было влияние дней недели (и воображение рисовало родителей, которым к завтрашнему дню надо покрасить десяток яиц, потому что тематическое занятие, а ребенок сказал об этом сегодня). Увы, это не так. Вероятно, во время Пасхи есть какие-то факторы, которые мы пока не нашли (и не учли) — как внешние, так связанные и с маркетингом самой компании.
Сможем лучше!
Эта история — про работу с данными ритейлера в ограниченные сроки, а не про тайные техники машинного обучения. Но и в работе с данными есть возможность улучшить результат.
После работы с товарами из категории «Яйцо куриное» стало понятно, что модель можно улучшить за счет добавления факторов, которые мы не использовали в пилотном проекте. Поэтому было решено провести небольшой эксперимент со случайным лесом и данными, которые мы можем собрать из открытых источников. Плюс так мы сможем посмотреть, как поведет себя модель, где у дней продажи будет разносторонний набор признаков, а не только набор «особенных дней», выделенных на тех или иных основаниях.
В набор данных о «внешнем мире» была собрана следующая информация:
- полный производственный календарь на каждый год;
- религиозные посты и праздники, светские праздники;
- погодные условия и их отклонения от средних значений для месяца в регионе, а также колебания в течение последних месяца, дня и недели;
- курсы доллара и евро по Центробанку и их колебания как показатели общего экономического состояния.
Отдельно были добавлены признаки проведения отдельных маркетинговых акций и цена за единицу товара.
На расширенном наборе данных мы снова построили модель, ежедневно дообучавшуюся на новых данных, теперь уже используя RandomForestRegressor. Относительное отклонение немного улучшилось: до 27.29%. На графике видно, что новая модель лучше прогнозирует влияние маркетинговых акций, но хуже — недельную сезонность.

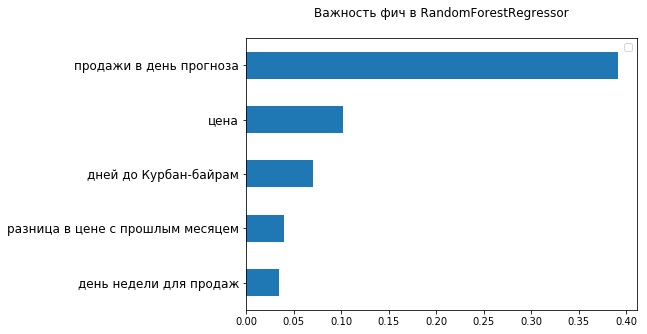
Посмотрев на топ–5 наиболее важных признаков с точки зрения использованного RandomForestRegressor, можно убедиться, что в него попали аж два признака, связанных со стоимостью товара, — текущая цена и ее изменения по сравнению с прошлым месяцем. Очевидно, то, что ценовой диапазон не удалось хорошо уложить в FB Prophet, сказалось на его точности.
На проверке, можем ли мы еще немного подумать и улучшить результат, пилотное исследование завершилось. Главные цели были достигнуты: мы показали, что машинное обучение в принципе применимо для данных ритейлера и показывает неплохие результаты даже в режиме «быстрого пуска».
Александра Царева, специалист отдела интеллектуального анализа «Инфосистемы Джет»
