
Обычно в термин «поддержка» вкладывают только один смысл — это реагирование на беды с хостингом, замена битых дисков, настройка веб-серверов и СУБД, общее повседневное администрирование. Но, на самом деле, это только первый уровень контроля стабильности работы любого интернет-проекта.
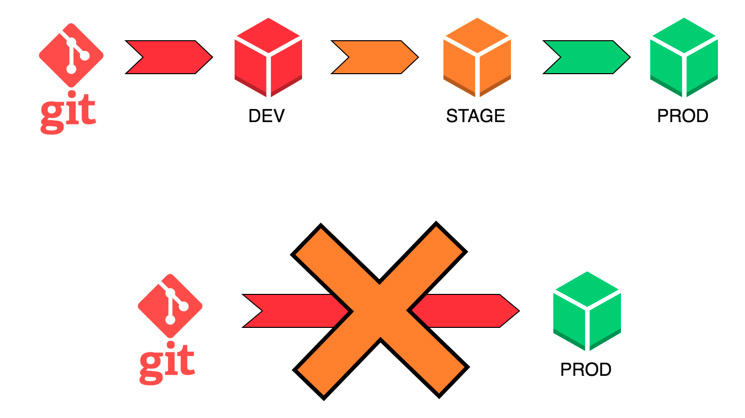
Ведь даже когда у вас уже настроен отказоустойчивый кластер из нескольких серверов в разных ЦОДах, с резервированием всех критичных данных и автоматическим фейловером, всё ещё остаются ситуации, когда отлаженная работа производственных площадок может быть серьёзно нарушена. Часто ли вам приходилось видеть вместо такого:
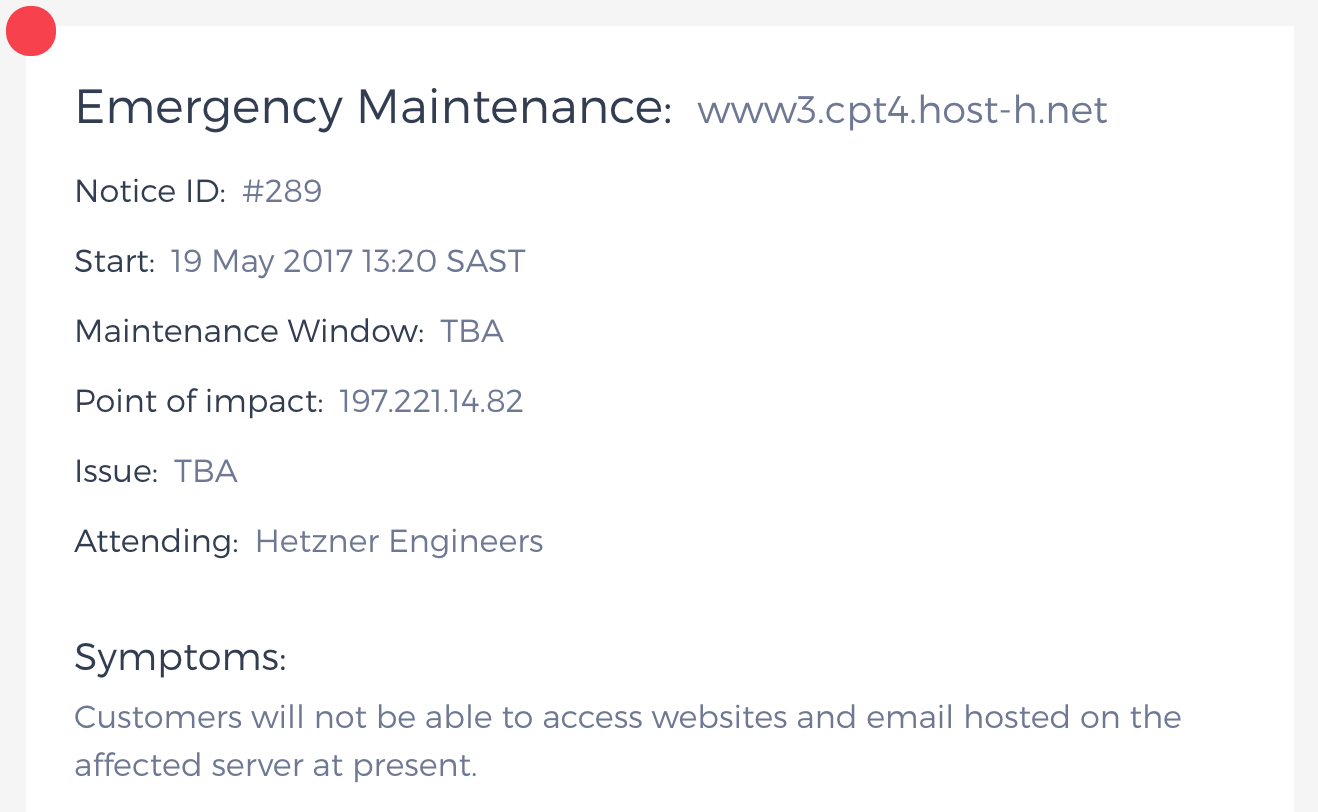
Вот такое:

И именно об этом пост — о безопасности и стабильности разработки и о том, какими системами и принципами их можно обеспечить. Или, если воспользоваться модными словами — о DevOps и CI/CD.
В базовой схеме, когда у нас есть только один сервер, на котором крутится и сам сайт, и база для него, и все остальные сопутствующие сервисы, типа кеширования и поиска, практически все вещи можно делать вручную — брать обновления кода из репозитория, перезапускать сервисы, переиндексировать поисковую базу и всякое такое.

Но что делать, когда проект вырастает? И вертикально, и горизонтально. Когда у нас уже есть десять серверов с вебом, три с базой, несколько серверов под поиск. А ещё мы решили понять, как именно нашим сервисом пользуются клиенты, завели отдельную аналитику со своими базами данных, фронтендом, периодическими задачами. И вот у нас уже не один сервер, а тридцать, к примеру. Продолжать делать все мелочи руками? Придётся увеличивать штат админов, т.к. у одного уже физически не будет хватать времени и внимания на все поддерживаемые системы.
Или же можно перестать быть админской ремесленной мастерской и начать налаживать производственные цепочки. Переходить на следующий уровень абстракции, управлять не отдельными сервисами или программами, но серверами целиком, как минимальной единицей общей системы.
Именно для этого и были придуманы методология DevOps и CI/CD. CI/CD подразумевает наличие отдельной площадки под разработку, отдельного стейджинга и отдельного прода.
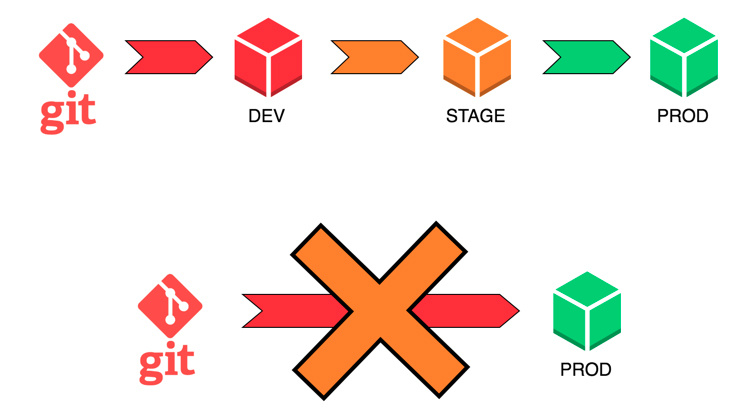
Также подразумевается, что каждый релиз обязательно проходит определённые стадии жизни, будь то ручное или автоматизированное тестирование, установка на stage для проверки работоспособности в окружении, идентичном продовому. Так исключается возможность того, что что-то пойдёт не так во время самого деплоя — пульнули не ту ветку, не из той репы, не на том сервере и пр. Всё заранее предусмотрено и структурировано, и влияние человеческого фактора минимально. Остаётся только следить за качеством самого кода и работой внутренней логики проекта.
Админам это позволяет никак не вмешиваться в сам процесс разработки и выкладки и заниматься своими непосредственными обязанностями по мониторингу и размышлению о том, как в дальнейшем расширять архитектуру.
Обычно о таких вещах говорят больше в теоретическом ключе. Вот, мол, есть такая штука, как Docker. Тут у нас можно недорого делать контейнеры. Создавать, обновлять, откатывать, всё можно делать безболезненно, не задевая жизненно важные части родительской системы, при этом не загружая ненужными прослойками и сервисами. А потом в другой статье — а вот есть Kubernetes. Он может вставлять и вытаскивать docker-кирпичи в вашем проекте самостоятельно, без ручного вмешательства, просто опишите ему конфигу, как он будет работать. Вот вам три строчки из официальной документации. И в таком вот стиле почти все материалы. Я же хотел бы рассказать о том, как всё это происходит в реальной жизни, отталкиваясь от реальной задачи обеспечения механик безопасной и стабильной разработки.
Рассказывать буду на примере сервиса Edwin, помогающего учить английский с помощью бота в Facebook Messenger. Бот @EnglishWithEdwin определяет уровень английского и персонализирует учебный план исходя из прогресса и скорости обучения каждого студента.
К этому моменту в компании уже несколько месяцев велась разработка, имелся работающий продукт, который быстро развивался, и компания готовилась к первому публичному релизу. На площадке, где велась разработка, уже были запущены сервисы в docker-контейнерах, подняты базы данных на AWS, и все это даже работало.
Руководитель разработки компании Edwin, Васильев Сергей, тщательно проанализировав существующие предложения на рынке, пришел к нам с описанием архитектуры своего продукта и требованиями к надежности в эксплуатации. Помимо нашей основной задачи — круглосуточной поддержки сервисов, — нам нужно было вникнуть в происходящее и организовать staging и production площадки с возможностью комфортных выкладок обновлений и общего управления инфраструктурой.
Использование контейнеров в production на тот момент не было массовым, а чат-боты только начинали развиваться. Таким образом, для нас это была отличная возможность попрактиковать современные инструменты на примере реального и интересного продукта.
Как Edwin устроен изнутри? Ключевые слова — Python, PostgreSQL, Neo4j, RabbitMQ. Условно архитектуру можно разделить на три больших блока: транспортный, логический и аналитический.
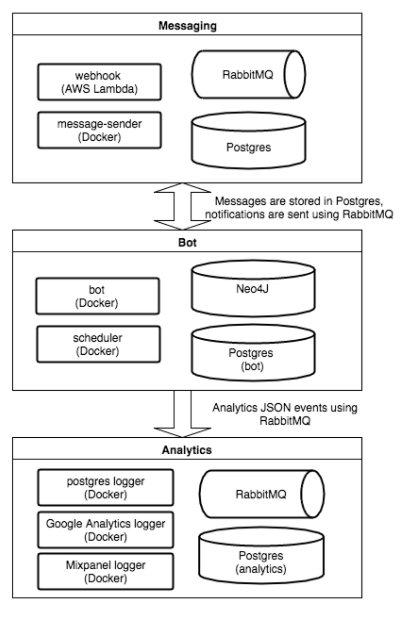
В первом блоке — докеризированное приложение-рассыльщик, написанное на питоне, которое через Facebook Gateway получает сообщения из социальной сети, сохраняет их в базу данных и добавляет событие в очередь RabbitMQ.
Во втором блоке находятся контейнеры с самим ботом, который читает данные из очередей о пришедших сообщениях, обрабатывает, собирает данные для аналитики в третьем блоке, и с планировщиком — докеризированным приложением на Tornado, отвечающим за все периодические и отложенные задачи, вроде пуш-уведомлений и истечения времени жизни сессий.
В третьем блоке — базы с данными для аналитики и несколько контейнеров с сервисами, занимающимися агрегацией данных от ботов, и выгрузкой в Google Analytics и прочие места.
Но всё это только предполагаемая структура, т.к. Edwin пришёл к нам, ещё не имея релизной версии проекта, в продакшене он ни разу не светился. Именно настройкой stage-/prod- окружения мы и должны были заняться.
В целом, всё это выглядело не очень сложно, если бы не одно но — пока обсуждались все вводные детали, время дедлайна неумолимо приближалось, и у нас осталась всего неделя на то, чтобы реализовать все пожелания.
Настройка CI/CD
Первое, о чём нужно помнить — всё не так сложно, как кажется издалека. Главное — понимать, что вы делаете и зачем. Выбирать инструменты только под те нужды, которые действительно важны, адекватно оценивать свои реальные потребности и возможности.
Основа всей нашей системы — это docker-контейнеры с сервисами и бизнес-логикой. Контейнеры выбраны для большей универсальности и мобильности в управлении инфраструктурой. Самым популярным инструментом для жонглирования docker-контейнерами на данный момент является Kubernetes от Google (по крайней мере, он больше всех на слуху). Нам же он показался излишне замороченным и структурно переусложнённым, и потому требующим слишком много телодвижений для поддержания работоспособности (и слишком много времени на изначальное понимание). А т.к. сроки введения в строй всей системы CI/CD у нас были сжаты до минимума, мы решили поискать более простые и легковесные решения.
Для хранения шаблонов контейнеров было решено взять (на самом деле, даже не взять, а просто оставить уже выбранный до нас разработчиками) Amazon EC2 Container Registry. В целом, он мало чем отличается от собственноручно поднятого на локалхосте registry. В основном тем, что его не нужно собственноручно поднимать на локалхосте.
Итак, у нас есть репозиторий с шаблонами контейнеров. Как сделать так, чтобы развёрнутые контейнеры могли знать друг о друге всегда и могли связываться друг с другом даже при изменившейся конфигурации сети, к примеру? При этом, не вмешиваясь постоянно во внутренности самих контейнеров и их конфигурацию?
Для этого существует такой вид ПО, как service discovery — наверное, для простоты понимания его можно было бы назвать «маршрутизатором бизнес-логики», хотя технически это и не совсем корректное определение. Устанавливается единый распределяющий запросы центр, к которому обращаются все сервисы за данными о местонахождении соседей, внутри контейнеров изначально ставятся агенты этого центра. И все сервисы при запуске объявляют о своём местонахождении и статусе маршрутизатору.
Как быстро готовить новые машины под контейнеры? Ведь хосты тоже надо правильно настраивать под сетевые нагрузки и прочее, дефолтные параметры ядра тоже зачастую довольно далеки от того, что хотелось бы видеть у себя в продакшене. Для этого были написаны несколько Ansible-рецептов, которые сокращают время, затрачиваемое на подготовку новой площадки, на порядок.
Когда серверы под контейнеры настроены, все нужные сервисы докеризированы, остаётся только понять, как организовать, собственно, «непрерывную интеграцию», не нажимая по 500 кнопок каждые полчаса. По итогу остановились на такой системе, как GoCD и небольшой скриптовой обвязке. Почему GoCD, спросите вы меня, а не Jenkins? Ранее, в других проектах, нам приходилось сталкиваться и с тем, и с другим, и по совокупности взаимодействий GoCD показался более простым в настройке, чем Jenkins. Есть возможность создавать шаблоны задач и пайплайнов, на основе которых потом можно генерировать разные производственные цепочки для разных окружений.
Первый день выдался, в общем-то, спокойным. Мы, наконец, получили ТЗ на то, что должны были сделать.
Тут стоит, конечно, сделать оговорку, что ровно неделя — это всё же небольшая уловка. В конце концов, не в вакууме же мы существуем! Админы заранее были в курсе о том, какого рода проект придёт на поддержку, и какие, в общих чертах, будут стоять задачи в первую очередь. Так что у нас было некоторое время на то, чтобы немного сориентироваться в возможностях выбора инструментов.
В итоге тихо и размеренно изучаем уже имеющиеся сервера, на которых на тот момент велась разработка проекта. Обвешиваем мониторингами, разбираемся, где что запущено, как работает.
На основе полученной информации пишем Ansible-рецепты и начинаем установку серверов для продакшена, заводим в Амазоне отдельный VPC, который бы не пересекался с уже имеющимся dev-окружением во избежание неосторожных действий при разработке. Разворачиваем контейнеры со всеми нужными сервисами — PostgreSQL, Neo4j, кодом проекта.
Кстати сказать, при разработке коллеги пользовались PostgreSQL в виде Amazon RDS, но для продакшен-окружения, по совместной договорённости, решили перейти на обычные инстансы с PostgreSQL — это позволило сделать ситуацию более прозрачной для админов, которые могли бы максимально контролировать поведение всех элементов системы во время последующего роста нагрузок.
На самом деле, если проект вы делаете малыми силами, и у вас нет достаточного количества выделенных админочасов, то можно пользоваться и RDS’ом, он вполне себе пригоден, заодно позволит, в случае чего, высвободить ресурсы для более насущных задач.
На отдельном сервере устанавливаем в базовом варианте деплой-панель GoCD и сервис-дискавери Consul.
Как я уже раньше упоминал, Edwin пришли к нам уже с готовой в какой-то степени инфраструктурой под разработку. Для жонглирования контейнерами они использовали Amazon ECS, он же EC2 Container Service. Что-то вроде Kubernetes-as-a-Service. После обсуждения с разработчиками пожеланий на тему будущей структуры проекта и работы с выкладками, было решено от ECS отказаться. Как и многие облачные штуки, он оказался недостаточно прозрачным для контроля происходящих внутри вещей, не хватало очень полезных в имеющейся ситуации вещей, типа задаваемых параметров окружения для одного и того же контейнера. Т.е. нет возможностей один и тот же контейнер использовать в разных пайплайнах, просто переопределив окружение. В амазоновой парадигме приходится создавать по отдельному контейнеру под каждое окружение.
Также нельзя по какой-то причине одни и те же задачи использовать в разных цепочках. В общем, GoCD нам показался гораздо более гибким.
Остаток дня занимаемся созданием и настройкой пайплайнов для продового окружения в GoCD — сборка кода, пересоздание контейнеров, выкатка новых контейнеров в прод, регистрация обновлённых сервисов в консуле.
Перепроверяем вчерашние настройки, проводим тестовые выкладки, проверяем связанность систем — что код корректно достаётся из репозитория, что этот же код потом правильно собирается в контейнер, контейнер запускается на правильном сервере, а потом объявляет о своём статусе консулу.
В целом, на данный момент у нас уже готова налаженная базовая инфраструктура, в рамках которой можно уже работать по новой парадигме. Деплой-панель GoCD есть, в ней настроены механики сборки и выкладки проекта в продакшн, Consul позволяет органично и без особых дополнительных временнЫх и трудовых затрат включать новые сервера и сервисы в уже имеющуюся инфраструктуру.
Удостоверившись, что всё работает как надо, настраиваем резервные репликации для баз данных в соседних Зонах Доступности, вместе с разработчиками заливаем рабочие данные в продовые базы данных.
Как я уже сказал, на этот момент, в общем-то, минимально необходимые элементы системы CI/CD у нас все установлены и настроены. Мы передаём разработчикам все данные по структуре получившейся системы, они со своей стороны приступают к тестированию всех механизмов сборки и выкладки проекта.
Тут, кстати, приходит осознание, что при составлении ТЗ забыли такой важный пункт, как централизованный сбор всех системных логов от всех контейнеров и сервисов. Это полезно для фонового анализа общей ситуации на проекте и отслеживания потенциальных узких мест и надвигающихся проблем.
Логи решено собирать в Kibana — очень удобный интерфейс для разного рода аналитики. Мы неоднократно сталкивались с ней как на сторонних проектах, так и использовали у себя на внутренних проектах.
За несколько часов поднимаем Kibana, настраиваем сбор логов с сервисов, настраиваем мониторинги всех критичных сервисов на проде.
По большей части, с организационной стороны в пятницу уже всё было готово. Нам, естественно, встретилась ещё куча разных мелких багов и глюков, но к системе непрерывной интеграции оно уже отношения не имело.
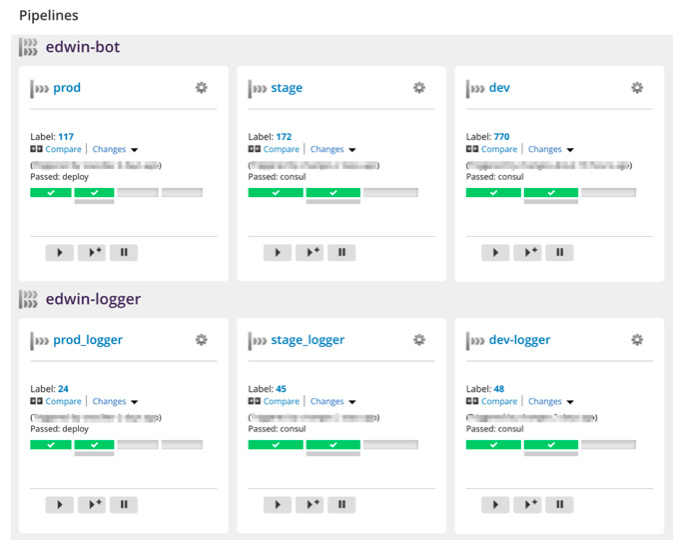
Что мы получили в итоге? Модульную систему разработки проекта, состоящую из трёх этапов и окружений — dev, stage и prod. Весь проект разделён на отдельные микросервисы, для каждого из которых заведены свои пайплайны.
Когда разработчики выпускают новую версию, они идут в панель GoCD и просто запускают соответствующий пайплайн. Например «раскатать новый логгер на stage», тестируют там, проверяют, что всё работает как надо, потом раскатывают на прод. Если вдруг что-то пошло не так, то опять же, самостоятельно через панель откатывают нужный сервис до нужной версии.

Все три окружения — и dev, и stage, и prod — изолированы в разных VPC. В Consul заведены под каждое окружение отдельные дата-центры, поэтому сервисы даже случайно не могут ходить между разными окружениями. И даже при большом желании в такой ситуации довольно сложно какими-либо действиями на деве например сломать прод.
Также, теперь можно легко увеличивать мощности под проект. Когда возникает нужда в новых вычислительных мощностях, новый инстанс можно запустить и подготовить к работе ориентировочно минут за десять.
Проблемы, с которыми столкнулись
В целом, несмотря на то, что сама область деятельности может показаться многим довольно сложной, с кучей подстерегающих проблем, у нас почти всё получилось сходу, за вычетом лишь пары вопросов. Которые, в общем-то, к continuous integration отношения толком и не имеют.
Проблем подкинул Amazon Web Services, на котором хостится этот проект.
При настройке Consul’а столкнулись с интересным затыком. Агенты и доступы к ним прописываются в контейнерах через системные резолверы. Но AMI Linux, используемый Амазоном по умолчанию, несколько отличается от дефолтной CentOS, и работа с резолверами там вынесена в настройки сети Virtual Private Cloud (VPC). При перезапуске сервера Amazon принудительно прописывает свои резолверы. Принудить его не ломать настройки резолва консула у нас пока так и не получилось, к сожалению. Но chattr +i всех спас, так теперь и живём.
Вообще структура VPC и его сетей довольно интересна, и там можно наткнуться на ограничения в очень неожиданных местах. Например, application balancer можно создать только мультизоне доступности, то есть бэкенды должны находиться сразу в нескольких разных availability zones. Для этого у VPC network должна быть разбивка, чтобы там присутствовали адреса в private/public и одной зоны, и другой. А менять разбивку VPC network можно только при создании. И менять VPC у инстансов тоже можно только при создании.
И получается, что когда у вас уже есть готовая инфраструктура с рабочими серверами в рамках одной зоны доступности, нет возможности модифицировать её, просто добавив ещё серверов в другой зоне и навесив впереди балансер. Увы, приходится полностью с нуля переделывать всю структуру.
Не стоит бояться расти и менять привычные рабочие процессы, если они перестают отвечать требованиям ситуации, текущего уровня развития вашего проекта. Не стоит бояться того, что переход на следующую ступень развития проекта обязательно будет для вас слишком обременительным. Если с толком подходить к собственным потребностям и не хвататься необдуманно за первые попавшиеся решения, о которых вы услышали, то эту дорогу вполне можно осилить даже в одиночку.
Хотя, конечно, многие могут сказать: «Ага-ага, они десять лет поддерживают проекты типа Хабрахабра и Нашего Радио, а нам тут разглагольствуют про простоту!». Да, действительно, на нашем веку мы видели много разного. И, возможно, как раз это и помогает нам отличать простое от сложного и не наступать на слишком большое количество граблей. Но опять же, если в самом начале разумно подойти к поставленной задаче и правильно подобрать инструменты, не гонясь за «крутостью», то можно значительно облегчить себе жизнь.
С другой стороны, обязательно стоит иметь ввиду, что описанная схема (да и любые другие, основанные на контейнеризации) подразумевает, что проект должен быть изначально готов к таким манипуляциям. Проект должен состоять из полноценных микросервисов, состояние которых можно не сохранять, чтобы они были мобильны и взаимозаменяемы. В рамках же монолитных систем внедрение такого подхода continuous integration представляется гораздо более трудозатратным и менее комфортным в дальнейшем применении.
Какие у нас дальнейшие планы по проекту?
После того, как была налажена базовая инфраструктура, есть желание подключить к ней ещё и багтрекер на основе Jira, чтобы можно было при выкатке новой версии в прод из Git-репозитория выбирать данные о заявках на баги, автоматически их закрывать и записывать в релиз-нотисы.
Также, похоже, приближается момент, когда нужно будет настраивать автоскейлинг на основных рабочих нодах, т.к. их общее количество постоянно растёт, и экономия на количестве активных серверов в часы минимальной нагрузки поможет сократить затраты.
Ведь даже когда у вас уже настроен отказоустойчивый кластер из нескольких серверов в разных ЦОДах, с резервированием всех критичных данных и автоматическим фейловером, всё ещё остаются ситуации, когда отлаженная работа производственных площадок может быть серьёзно нарушена. Часто ли вам приходилось видеть вместо такого:

Вот такое:

И именно об этом пост — о безопасности и стабильности разработки и о том, какими системами и принципами их можно обеспечить. Или, если воспользоваться модными словами — о DevOps и CI/CD.
Зачем?
В базовой схеме, когда у нас есть только один сервер, на котором крутится и сам сайт, и база для него, и все остальные сопутствующие сервисы, типа кеширования и поиска, практически все вещи можно делать вручную — брать обновления кода из репозитория, перезапускать сервисы, переиндексировать поисковую базу и всякое такое.

Но что делать, когда проект вырастает? И вертикально, и горизонтально. Когда у нас уже есть десять серверов с вебом, три с базой, несколько серверов под поиск. А ещё мы решили понять, как именно нашим сервисом пользуются клиенты, завели отдельную аналитику со своими базами данных, фронтендом, периодическими задачами. И вот у нас уже не один сервер, а тридцать, к примеру. Продолжать делать все мелочи руками? Придётся увеличивать штат админов, т.к. у одного уже физически не будет хватать времени и внимания на все поддерживаемые системы.
Или же можно перестать быть админской ремесленной мастерской и начать налаживать производственные цепочки. Переходить на следующий уровень абстракции, управлять не отдельными сервисами или программами, но серверами целиком, как минимальной единицей общей системы.
Именно для этого и были придуманы методология DevOps и CI/CD. CI/CD подразумевает наличие отдельной площадки под разработку, отдельного стейджинга и отдельного прода.
Также подразумевается, что каждый релиз обязательно проходит определённые стадии жизни, будь то ручное или автоматизированное тестирование, установка на stage для проверки работоспособности в окружении, идентичном продовому. Так исключается возможность того, что что-то пойдёт не так во время самого деплоя — пульнули не ту ветку, не из той репы, не на том сервере и пр. Всё заранее предусмотрено и структурировано, и влияние человеческого фактора минимально. Остаётся только следить за качеством самого кода и работой внутренней логики проекта.
Админам это позволяет никак не вмешиваться в сам процесс разработки и выкладки и заниматься своими непосредственными обязанностями по мониторингу и размышлению о том, как в дальнейшем расширять архитектуру.
Обычно о таких вещах говорят больше в теоретическом ключе. Вот, мол, есть такая штука, как Docker. Тут у нас можно недорого делать контейнеры. Создавать, обновлять, откатывать, всё можно делать безболезненно, не задевая жизненно важные части родительской системы, при этом не загружая ненужными прослойками и сервисами. А потом в другой статье — а вот есть Kubernetes. Он может вставлять и вытаскивать docker-кирпичи в вашем проекте самостоятельно, без ручного вмешательства, просто опишите ему конфигу, как он будет работать. Вот вам три строчки из официальной документации. И в таком вот стиле почти все материалы. Я же хотел бы рассказать о том, как всё это происходит в реальной жизни, отталкиваясь от реальной задачи обеспечения механик безопасной и стабильной разработки.
О ком?
Рассказывать буду на примере сервиса Edwin, помогающего учить английский с помощью бота в Facebook Messenger. Бот @EnglishWithEdwin определяет уровень английского и персонализирует учебный план исходя из прогресса и скорости обучения каждого студента.
К этому моменту в компании уже несколько месяцев велась разработка, имелся работающий продукт, который быстро развивался, и компания готовилась к первому публичному релизу. На площадке, где велась разработка, уже были запущены сервисы в docker-контейнерах, подняты базы данных на AWS, и все это даже работало.
Руководитель разработки компании Edwin, Васильев Сергей, тщательно проанализировав существующие предложения на рынке, пришел к нам с описанием архитектуры своего продукта и требованиями к надежности в эксплуатации. Помимо нашей основной задачи — круглосуточной поддержки сервисов, — нам нужно было вникнуть в происходящее и организовать staging и production площадки с возможностью комфортных выкладок обновлений и общего управления инфраструктурой.
Использование контейнеров в production на тот момент не было массовым, а чат-боты только начинали развиваться. Таким образом, для нас это была отличная возможность попрактиковать современные инструменты на примере реального и интересного продукта.
Структура проекта
Как Edwin устроен изнутри? Ключевые слова — Python, PostgreSQL, Neo4j, RabbitMQ. Условно архитектуру можно разделить на три больших блока: транспортный, логический и аналитический.

В первом блоке — докеризированное приложение-рассыльщик, написанное на питоне, которое через Facebook Gateway получает сообщения из социальной сети, сохраняет их в базу данных и добавляет событие в очередь RabbitMQ.
Во втором блоке находятся контейнеры с самим ботом, который читает данные из очередей о пришедших сообщениях, обрабатывает, собирает данные для аналитики в третьем блоке, и с планировщиком — докеризированным приложением на Tornado, отвечающим за все периодические и отложенные задачи, вроде пуш-уведомлений и истечения времени жизни сессий.
В третьем блоке — базы с данными для аналитики и несколько контейнеров с сервисами, занимающимися агрегацией данных от ботов, и выгрузкой в Google Analytics и прочие места.
Но всё это только предполагаемая структура, т.к. Edwin пришёл к нам, ещё не имея релизной версии проекта, в продакшене он ни разу не светился. Именно настройкой stage-/prod- окружения мы и должны были заняться.
В целом, всё это выглядело не очень сложно, если бы не одно но — пока обсуждались все вводные детали, время дедлайна неумолимо приближалось, и у нас осталась всего неделя на то, чтобы реализовать все пожелания.
Настройка CI/CD
Первое, о чём нужно помнить — всё не так сложно, как кажется издалека. Главное — понимать, что вы делаете и зачем. Выбирать инструменты только под те нужды, которые действительно важны, адекватно оценивать свои реальные потребности и возможности.
Основа всей нашей системы — это docker-контейнеры с сервисами и бизнес-логикой. Контейнеры выбраны для большей универсальности и мобильности в управлении инфраструктурой. Самым популярным инструментом для жонглирования docker-контейнерами на данный момент является Kubernetes от Google (по крайней мере, он больше всех на слуху). Нам же он показался излишне замороченным и структурно переусложнённым, и потому требующим слишком много телодвижений для поддержания работоспособности (и слишком много времени на изначальное понимание). А т.к. сроки введения в строй всей системы CI/CD у нас были сжаты до минимума, мы решили поискать более простые и легковесные решения.
Для хранения шаблонов контейнеров было решено взять (на самом деле, даже не взять, а просто оставить уже выбранный до нас разработчиками) Amazon EC2 Container Registry. В целом, он мало чем отличается от собственноручно поднятого на локалхосте registry. В основном тем, что его не нужно собственноручно поднимать на локалхосте.
Итак, у нас есть репозиторий с шаблонами контейнеров. Как сделать так, чтобы развёрнутые контейнеры могли знать друг о друге всегда и могли связываться друг с другом даже при изменившейся конфигурации сети, к примеру? При этом, не вмешиваясь постоянно во внутренности самих контейнеров и их конфигурацию?
Для этого существует такой вид ПО, как service discovery — наверное, для простоты понимания его можно было бы назвать «маршрутизатором бизнес-логики», хотя технически это и не совсем корректное определение. Устанавливается единый распределяющий запросы центр, к которому обращаются все сервисы за данными о местонахождении соседей, внутри контейнеров изначально ставятся агенты этого центра. И все сервисы при запуске объявляют о своём местонахождении и статусе маршрутизатору.
Как быстро готовить новые машины под контейнеры? Ведь хосты тоже надо правильно настраивать под сетевые нагрузки и прочее, дефолтные параметры ядра тоже зачастую довольно далеки от того, что хотелось бы видеть у себя в продакшене. Для этого были написаны несколько Ansible-рецептов, которые сокращают время, затрачиваемое на подготовку новой площадки, на порядок.
Когда серверы под контейнеры настроены, все нужные сервисы докеризированы, остаётся только понять, как организовать, собственно, «непрерывную интеграцию», не нажимая по 500 кнопок каждые полчаса. По итогу остановились на такой системе, как GoCD и небольшой скриптовой обвязке. Почему GoCD, спросите вы меня, а не Jenkins? Ранее, в других проектах, нам приходилось сталкиваться и с тем, и с другим, и по совокупности взаимодействий GoCD показался более простым в настройке, чем Jenkins. Есть возможность создавать шаблоны задач и пайплайнов, на основе которых потом можно генерировать разные производственные цепочки для разных окружений.
Процесс разработки
Понедельник, 6 февраля
Первый день выдался, в общем-то, спокойным. Мы, наконец, получили ТЗ на то, что должны были сделать.
Тут стоит, конечно, сделать оговорку, что ровно неделя — это всё же небольшая уловка. В конце концов, не в вакууме же мы существуем! Админы заранее были в курсе о том, какого рода проект придёт на поддержку, и какие, в общих чертах, будут стоять задачи в первую очередь. Так что у нас было некоторое время на то, чтобы немного сориентироваться в возможностях выбора инструментов.
В итоге тихо и размеренно изучаем уже имеющиеся сервера, на которых на тот момент велась разработка проекта. Обвешиваем мониторингами, разбираемся, где что запущено, как работает.
На основе полученной информации пишем Ansible-рецепты и начинаем установку серверов для продакшена, заводим в Амазоне отдельный VPC, который бы не пересекался с уже имеющимся dev-окружением во избежание неосторожных действий при разработке. Разворачиваем контейнеры со всеми нужными сервисами — PostgreSQL, Neo4j, кодом проекта.
Кстати сказать, при разработке коллеги пользовались PostgreSQL в виде Amazon RDS, но для продакшен-окружения, по совместной договорённости, решили перейти на обычные инстансы с PostgreSQL — это позволило сделать ситуацию более прозрачной для админов, которые могли бы максимально контролировать поведение всех элементов системы во время последующего роста нагрузок.
На самом деле, если проект вы делаете малыми силами, и у вас нет достаточного количества выделенных админочасов, то можно пользоваться и RDS’ом, он вполне себе пригоден, заодно позволит, в случае чего, высвободить ресурсы для более насущных задач.
Вторник, 7 февраля
На отдельном сервере устанавливаем в базовом варианте деплой-панель GoCD и сервис-дискавери Consul.
Как я уже раньше упоминал, Edwin пришли к нам уже с готовой в какой-то степени инфраструктурой под разработку. Для жонглирования контейнерами они использовали Amazon ECS, он же EC2 Container Service. Что-то вроде Kubernetes-as-a-Service. После обсуждения с разработчиками пожеланий на тему будущей структуры проекта и работы с выкладками, было решено от ECS отказаться. Как и многие облачные штуки, он оказался недостаточно прозрачным для контроля происходящих внутри вещей, не хватало очень полезных в имеющейся ситуации вещей, типа задаваемых параметров окружения для одного и того же контейнера. Т.е. нет возможностей один и тот же контейнер использовать в разных пайплайнах, просто переопределив окружение. В амазоновой парадигме приходится создавать по отдельному контейнеру под каждое окружение.
Также нельзя по какой-то причине одни и те же задачи использовать в разных цепочках. В общем, GoCD нам показался гораздо более гибким.
Остаток дня занимаемся созданием и настройкой пайплайнов для продового окружения в GoCD — сборка кода, пересоздание контейнеров, выкатка новых контейнеров в прод, регистрация обновлённых сервисов в консуле.
Среда, 8 февраля
Перепроверяем вчерашние настройки, проводим тестовые выкладки, проверяем связанность систем — что код корректно достаётся из репозитория, что этот же код потом правильно собирается в контейнер, контейнер запускается на правильном сервере, а потом объявляет о своём статусе консулу.
В целом, на данный момент у нас уже готова налаженная базовая инфраструктура, в рамках которой можно уже работать по новой парадигме. Деплой-панель GoCD есть, в ней настроены механики сборки и выкладки проекта в продакшн, Consul позволяет органично и без особых дополнительных временнЫх и трудовых затрат включать новые сервера и сервисы в уже имеющуюся инфраструктуру.
Удостоверившись, что всё работает как надо, настраиваем резервные репликации для баз данных в соседних Зонах Доступности, вместе с разработчиками заливаем рабочие данные в продовые базы данных.
Четверг, 9 февраля
Как я уже сказал, на этот момент, в общем-то, минимально необходимые элементы системы CI/CD у нас все установлены и настроены. Мы передаём разработчикам все данные по структуре получившейся системы, они со своей стороны приступают к тестированию всех механизмов сборки и выкладки проекта.
Тут, кстати, приходит осознание, что при составлении ТЗ забыли такой важный пункт, как централизованный сбор всех системных логов от всех контейнеров и сервисов. Это полезно для фонового анализа общей ситуации на проекте и отслеживания потенциальных узких мест и надвигающихся проблем.
Логи решено собирать в Kibana — очень удобный интерфейс для разного рода аналитики. Мы неоднократно сталкивались с ней как на сторонних проектах, так и использовали у себя на внутренних проектах.
За несколько часов поднимаем Kibana, настраиваем сбор логов с сервисов, настраиваем мониторинги всех критичных сервисов на проде.
Пятница, 10 февраля
По большей части, с организационной стороны в пятницу уже всё было готово. Нам, естественно, встретилась ещё куча разных мелких багов и глюков, но к системе непрерывной интеграции оно уже отношения не имело.
Результаты
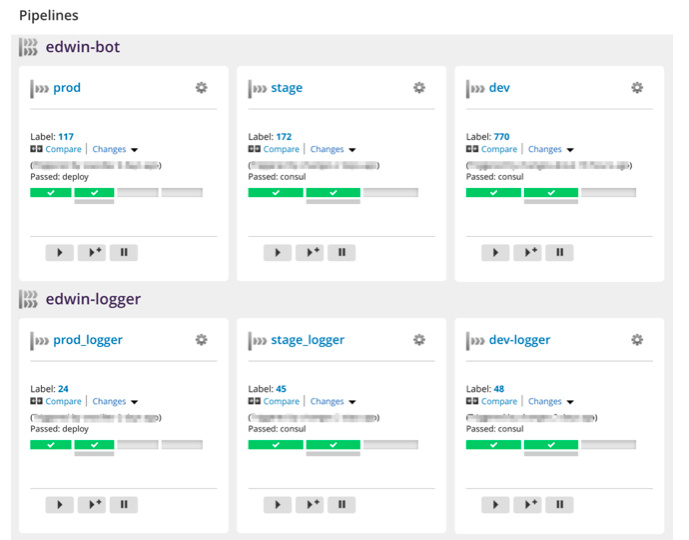
Что мы получили в итоге? Модульную систему разработки проекта, состоящую из трёх этапов и окружений — dev, stage и prod. Весь проект разделён на отдельные микросервисы, для каждого из которых заведены свои пайплайны.
Когда разработчики выпускают новую версию, они идут в панель GoCD и просто запускают соответствующий пайплайн. Например «раскатать новый логгер на stage», тестируют там, проверяют, что всё работает как надо, потом раскатывают на прод. Если вдруг что-то пошло не так, то опять же, самостоятельно через панель откатывают нужный сервис до нужной версии.

Все три окружения — и dev, и stage, и prod — изолированы в разных VPC. В Consul заведены под каждое окружение отдельные дата-центры, поэтому сервисы даже случайно не могут ходить между разными окружениями. И даже при большом желании в такой ситуации довольно сложно какими-либо действиями на деве например сломать прод.
Также, теперь можно легко увеличивать мощности под проект. Когда возникает нужда в новых вычислительных мощностях, новый инстанс можно запустить и подготовить к работе ориентировочно минут за десять.
Проблемы, с которыми столкнулись
В целом, несмотря на то, что сама область деятельности может показаться многим довольно сложной, с кучей подстерегающих проблем, у нас почти всё получилось сходу, за вычетом лишь пары вопросов. Которые, в общем-то, к continuous integration отношения толком и не имеют.
Проблем подкинул Amazon Web Services, на котором хостится этот проект.
При настройке Consul’а столкнулись с интересным затыком. Агенты и доступы к ним прописываются в контейнерах через системные резолверы. Но AMI Linux, используемый Амазоном по умолчанию, несколько отличается от дефолтной CentOS, и работа с резолверами там вынесена в настройки сети Virtual Private Cloud (VPC). При перезапуске сервера Amazon принудительно прописывает свои резолверы. Принудить его не ломать настройки резолва консула у нас пока так и не получилось, к сожалению. Но chattr +i всех спас, так теперь и живём.
Вообще структура VPC и его сетей довольно интересна, и там можно наткнуться на ограничения в очень неожиданных местах. Например, application balancer можно создать только мультизоне доступности, то есть бэкенды должны находиться сразу в нескольких разных availability zones. Для этого у VPC network должна быть разбивка, чтобы там присутствовали адреса в private/public и одной зоны, и другой. А менять разбивку VPC network можно только при создании. И менять VPC у инстансов тоже можно только при создании.
И получается, что когда у вас уже есть готовая инфраструктура с рабочими серверами в рамках одной зоны доступности, нет возможности модифицировать её, просто добавив ещё серверов в другой зоне и навесив впереди балансер. Увы, приходится полностью с нуля переделывать всю структуру.
Выводы и планы
Не стоит бояться расти и менять привычные рабочие процессы, если они перестают отвечать требованиям ситуации, текущего уровня развития вашего проекта. Не стоит бояться того, что переход на следующую ступень развития проекта обязательно будет для вас слишком обременительным. Если с толком подходить к собственным потребностям и не хвататься необдуманно за первые попавшиеся решения, о которых вы услышали, то эту дорогу вполне можно осилить даже в одиночку.
Хотя, конечно, многие могут сказать: «Ага-ага, они десять лет поддерживают проекты типа Хабрахабра и Нашего Радио, а нам тут разглагольствуют про простоту!». Да, действительно, на нашем веку мы видели много разного. И, возможно, как раз это и помогает нам отличать простое от сложного и не наступать на слишком большое количество граблей. Но опять же, если в самом начале разумно подойти к поставленной задаче и правильно подобрать инструменты, не гонясь за «крутостью», то можно значительно облегчить себе жизнь.
С другой стороны, обязательно стоит иметь ввиду, что описанная схема (да и любые другие, основанные на контейнеризации) подразумевает, что проект должен быть изначально готов к таким манипуляциям. Проект должен состоять из полноценных микросервисов, состояние которых можно не сохранять, чтобы они были мобильны и взаимозаменяемы. В рамках же монолитных систем внедрение такого подхода continuous integration представляется гораздо более трудозатратным и менее комфортным в дальнейшем применении.
Какие у нас дальнейшие планы по проекту?
После того, как была налажена базовая инфраструктура, есть желание подключить к ней ещё и багтрекер на основе Jira, чтобы можно было при выкатке новой версии в прод из Git-репозитория выбирать данные о заявках на баги, автоматически их закрывать и записывать в релиз-нотисы.
Также, похоже, приближается момент, когда нужно будет настраивать автоскейлинг на основных рабочих нодах, т.к. их общее количество постоянно растёт, и экономия на количестве активных серверов в часы минимальной нагрузки поможет сократить затраты.
