У нас есть шесть продуктов, которые используют в России и за рубежом. Это значит, что документация к ним должна быть в одном месте, но разделена по продуктам и языкам.
Раньше мы использовали MediaWiki, но со временем она устарела. От платформы мы ожидали так же хорошую вёрстку статей, гибкий поиск и внутренний редактор текстов. В качестве альтернативы выбрали Confluence.
В процессе стало ясно, что возможностей этой платформы из коробки тоже недостаточно для всех наших задач. Пришлось докупить плагин Scroll Viewport и потратить некоторое время на его настройку.
Вы можете посмотреть, что в итоге получилось, а я расскажу, как меняла дизайн, настраивала разделение по языкам, внутренний поиск и индексацию.

Компания начала переносить документацию с движка MediaWiki на Confluence год назад. Но когда я приступила к проекту, Confluence выглядел стандартно, предыдущий разработчик добавил наш логотип и скрыл ненужные анонимному пользователю элементы. К запуску надо было привести документацию к нашему стилю. Дизайнеры подготовили макеты, а я должна была их сверстать.
Но дело в том, что сам Confluence даёт очень мало гибкости в стилях и скриптах, а возможности из коробки нетривиальны для понимания и использования, да и непривычны веб-разработчику.
Отмечу, что Confluence — это Java-приложение, а вовсе не веб-сайт с привычными бэкендом и фронтендом. В разделе Внешний вид можно добавить таблицу стилей или настроить пользовательский HTML, но этого недостаточно для полноценного редизайна. Поэтому для вёрстки мы купили плагин Scroll Viewport. Тут-то и началось самое интересное.
Scroll Viewport — это плагин для Confluence, который позволяет создавать темы, используя привычный редактор кода и файловый менеджер. С его помощью можно писать стили, работать с шаблонами страниц, добавлять изображения, настраивать поиск.
Темы создаются для пространств. Пространства в Confluence — это сущности контента, в которых хранится информация по одному проекту. У нас есть пространство для продуктов: ISPmanager, BILLmanager и т. д., а также для главной страницы. У пространства есть ключ, заголовок, ряд настроек и, собственно, тема.
Начнём осваивать Scroll Viewport. Когда плагин установлен и включён, надо кликнуть на шестерёнку и далее — Основные настройки — раздел Scroll Viewport — Themes.
Выбираем, копируем или создаём тему и нажимаем Edit. Открывается редактор темы Scroll Viewport.
Обратите внимание, Scroll Viewport рекомендует не создавать тему с нуля, а брать за основу Scroll WebHelp Theme.
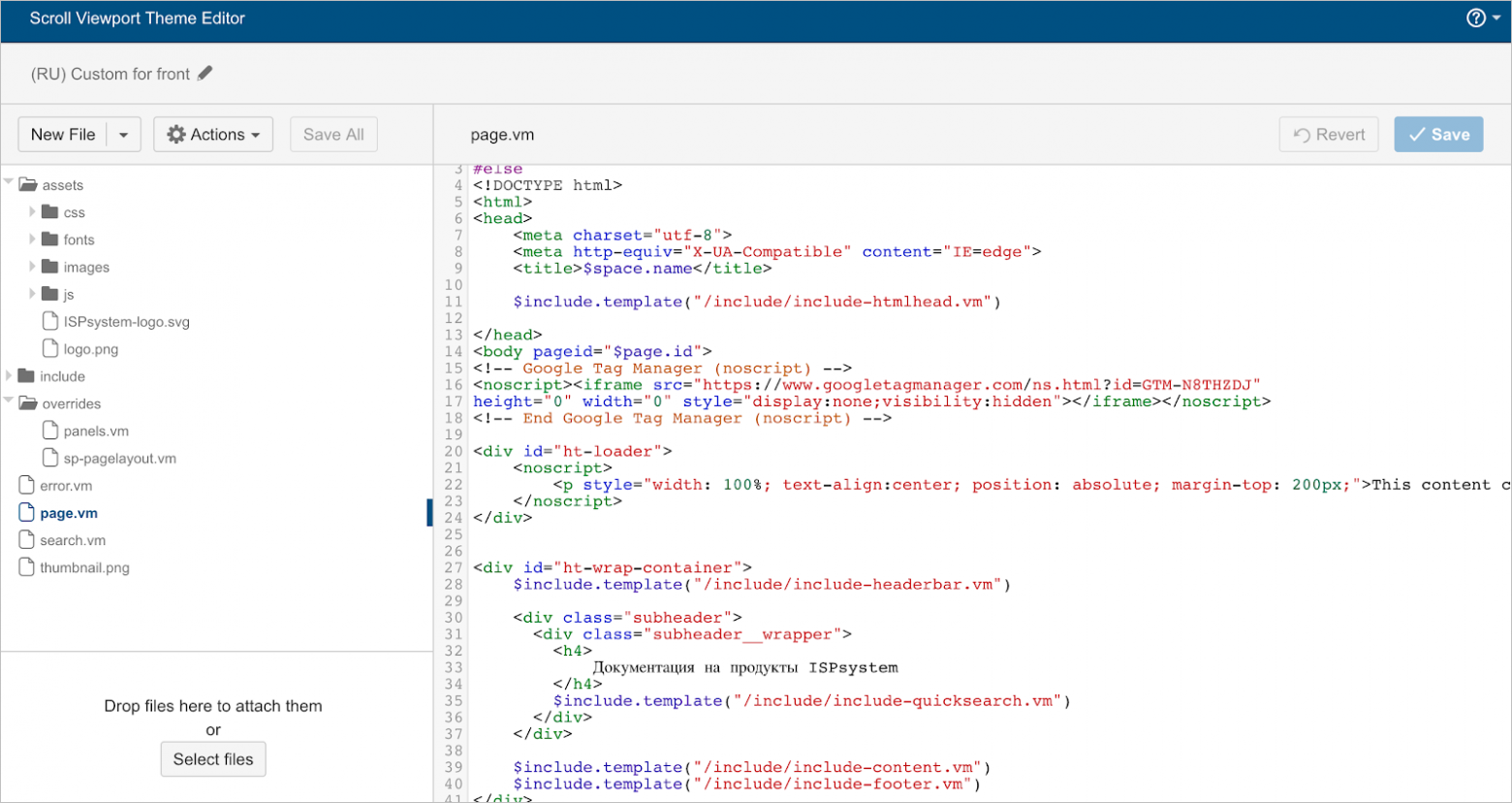
Редактор темы Scroll Viewport: слева структура темы, сверху название файла, в основной части сами файлы
Когда тема создана, можно приступить к её настройке. Зададим разметку и структуру страниц, добавим стили и скрипты, а потом перейдём к редактированию HTML-разметки элементов контента.
Структура страниц по типу
В корне темы находятся основные шаблоны: page.vm, search.vm, error.vm, а также изображение-обложка темы thumbnail.png.
Шаблон “page.vm” задаёт структуру всех страниц темы. Здесь можно редактировать html и с помощью переменных placeholders задавать, где будет выводиться контент. Плейсхолдеры обращаются к контенту пространства или данным пользователя (заголовок материала, название пространства, имя автора), с их полным списком можно ознакомиться в хелп-центре разработчика Scroll Viewport.
“page.vm” обращается к шаблонам, которые лежат на уровень ниже, в папке “include”, и оборачивает их в теги и блоки. В этом файле (page.vm) мы собираем страницу по кусочкам, и дополняем разметку всеми необходимыми атрибутами html-документа. Именно здесь мы указываем doctype, прописываем head и body.
Составные элементы страницы
В папке “include” лежат кусочки страницы. По названиям файлов можно догадаться, какой за что отвечает:
Синтаксис шаблонов Scroll Viewport прост для понимания. Операции начинаются с решётки, например “#if (условие)” или “#foreach($language in $languages.available)”, и заканчиваются с помощью “#end”, внутри — тело оператора. Всё остальное представляет собой html-теги.
Внутри папки “assets” хранятся файлы js и css. Так как мы не создавали тему с нуля, там уже содержатся файлы от разработчиков Scroll Viewport.
Чтобы кастомизировать стили, лучше создать новый css-файл и подключить его в head шаблона страницы. Файлы, которые начинаются на theme, содержат в себе правила базовой темы Scroll Viewport. Их стоит редактировать в случае, когда новые стили упираются в базовые. Будьте внимательны, удаляя и добавляя правила, помните об иерархии селекторов, она может выручить.
В “assets” я также добавила папку с изображениями и папку с файлами шрифтов. Файловый менеджер работает не идеально, добавить папку в нужную директорию нельзя, поэтому пришлось схитрить. Я создала папку на своём компьютере, добавила в неё файл, а потом загрузила в нужную директорию драг-энд-дропом. Как только папка создана, с загрузкой файлов проблем нет.
При создании нового дизайна мы учитывали возможности плагина и ориентировались на уже существующие темы в Scroll Viewport, поэтому внутри assets/js я задержалась ненадолго. Внесла небольшие изменения в существующие файлы скриптов и добавила файлы нужных библиотек. Если изменения будут более значительными, со скриптами придётся разобраться детальнее.
В процессе работы со Scroll Viewport выяснилось, что верстать мы можем, да не всё. Полномочия шаблона плагина заканчиваются на переменной $page.renderContent. Как верстать элементы главной с классами и ссылками? Непонятно. Где HTML? По умолчанию его там и нет. Переменная подсказывает, что нам предстоит выполнить часть вёрстки непосредственно на странице статьи, правда, пока там можно редактировать лишь текст, но не теги.

Благо, всегда можно поискать плагины, и, какая удача, нужный нашёлся почти сразу. Это Confluence Source Editor. После его установки можно в режиме редактирования статьи прошерстить и старый добрый гипертекст. Наконец-то!
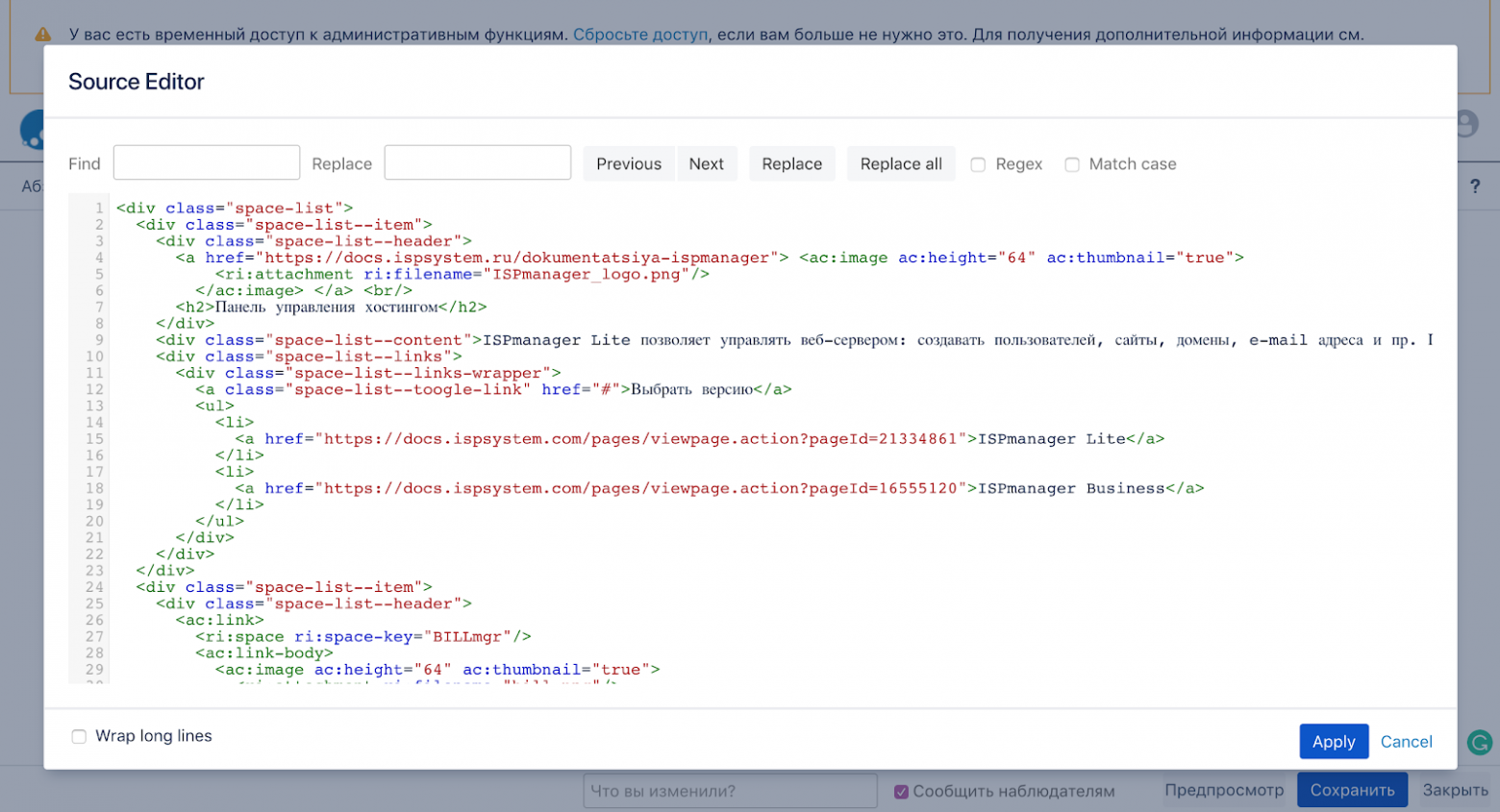
Плагин Source Editor
В Scroll Viewport верстаем шапку, сайдбар, футер и задаём стили. Контент верстаем с помощью Source Editor. Всего я создала две темы: для страниц статей и для главной страницы документации.
Когда тема создана, её надо связать с пространством. Для этого в настройках пространства нужно создать Viewport. Viewport — это то, что связывает пространство и тему. Только создав эту сущность, можно применить стили темы для пространства.
Войдите в пространство нужного продукта, откройте Настройки пространства — Дополнения. Здесь можно создать Viewport и управлять им: задавать темы, типы контента, разрешения, домен и путь.

Форма для связи пространства с темой, создания Viewport
На вкладке Themes представлены все созданные темы и одна тема по умолчанию, которая появляется вместе с плагином Scroll Viewport. Выберите тему и примените к пространству.
Вкладка Content позволяет выбрать тип контента, к которому будет применяться тема. Она нам наименее интересна, так как ключ пространства подтягивается автоматически.
На вкладке URL можно выбрать домен и путь, по которому будет открываться пространство, а также задать структуру адресов. Она так же понадобится, чтобы разделить документацию на два домена по языкам.
Есть два типа структуры URL:
С адресами страниц есть нюанс. Для статей на разных языках Confluence по-разному формирует URL. На английском выводит в адрес название, а на русском — несвязный набор букв, символов и чисел. Scroll Viewport позволяет привести адреса к одному виду. Если выбрать многоуровневую структуру, то в адресах русских статей будет отображаться название текста транслитом.
Но нужно учесть, что при выборе многоуровневых адресов URL будет зависим от названия статьи. Изменится название — изменится и адрес статьи. Если выбрать одноуровневую структуру, адрес будет менее читаем и понятен, но перестанет зависеть от заголовка страницы.
Мы выбрали многоуровневый тип структуры и читаемые адреса, но нам придётся следить за изменением названий статей и вовремя настраивать редиректы. И идеальный вариант мы всё ещё ищем. Мы также используем краткие ссылки, которые всегда ведут на статью и не меняются, такую ссылку можно найти в разделе Информация о странице.
Во вкладке Permissions можно обозначить, каким пользователям будет доступен просмотр пространства с применением Viewport.
Чтобы анонимные пользователи видели документацию только в заданном дизайне, нужно поставить две галочки:

Настройки вида пространства во вкладке Permissions
У нас документация на английском и русском, поэтому нужно, чтобы пространства на русском открывались на домене .ru, а на английском — на .com.
В Scroll Viewport такие настройки предусмотрены, но если просто ввести отличный от основного домен во вкладке URL в поле Domain Name, два домена не заработают. Это особенность плагина Scroll Viewport.
Надо настроить Reverse proxy, чтобы запросы пользователей передавались Confluence и там разруливались на два домена — см. инструкцию Scroll Viewport (конфигурации для Nginx и TOMCAT). После этого надо выключить режим совместного редактирования или внести дополнительные изменения. Теперь можно указывать один из двух доменов в настройках Viewport.
Применить одну тему к пространствам на разном языке не получится, потому что тема включает в себя не только стили, но и шаблоны страниц. Это означает, что язык элементов, которые выводятся не переменными, не меняется. Например, текст-плейсхолдер в строке поиска, контакты в футере и др. Так что пришлось делать отдельные темы для пространств на русском и английском языках.
Фактически я создаю идентичные по стилям темы, но вот шаблоны для них различны, в основном по части текста. Это излишество и дублирование, да, но иного способа я пока не нашла. К тому же тема регулирует и работу поиска тоже, а это ещё один аргумент в пользу разделения по языкам.
В итоге у меня получилось четыре темы: две для главных страниц на русском и английском, и ещё по две для страниц контента для каждого языка.
Параметры поиска настраиваются в файлах из папки “include”. Внутри них мы задаём параметры поиска:
По умолчанию поиск работает только по текущему пространству. Например, в пространстве ISPmanager — только по статьям об ISPmanager. Если нужен поиск по списку пространств, в настройках include-quicksearch.vm нужно указать их ключи.
Форма поиска для отдельного пространства
Форма поиска по списку пространств
Как будет выглядеть список с результатами поиска, задаёт шаблон include-search.vm. В моём случае у каждой найденной ссылки есть заголовок, описание и название пространства, к которому относится статья. Здесь же можно указать, что пользователь увидит, если поиск ничего не найдёт.
Из фрагмента шаблона ниже видно, что результаты поиска выводятся в цикле с использованием переменных-плейсхолдеров. Результатов поиска может быть довольно много, поэтому внизу страницы сделали пагинацию. Подробное руководство по шаблонам страниц поиска можно посмотреть в документации по поиску Scroll Viewport.
В шаблоне “search.vm” задаётся вся структура поисковых страниц, начиная от открывающегося тега . В этом шаблоне и следует собрать вместе форму поиска и его результаты. В итоге получим страницу типа “поиск”, которая включает в себя форму поиска и найденные совпадения, разбитые на несколько страниц.
Все шаблоны первого уровня, расположенные в структуре рядом с page.vm, переопределяют структуру страницы в зависимости от ее типа. Так search.vm задаёт вёрстку страниц поиска, а error.vm — страниц ошибок.
Остаётся задать стили элементам, возможно добавить скрипты, и наша тема становится функциональной, выполняет задачи и выглядит согласно дизайну.
Чтобы настроить индексацию, нужно положить карту сайта в корневую папку. Но у нас нет корневой папки, ведь Confluence — это Java-приложение, а не сайт. Что делать?
Подсказка нашлась в документации Scroll Viewport. Внутри пространства разводящих страниц, где хранится главная, надо создать новую статью, назвать её sitemap.xml и расположить на уровень ниже главной.
Расположение важно, потому что, как отмечают в документации, файл карты не будет доступен для Viewport с префиксом пути “/”. Как раз такой префикс у Viewport пространства главной страницы.

Статья sitemap.xml в структуре пространства
Мы помним, что в Confluence заголовок статьи и её URL связаны. Когда страница создана и уже открывается по адресу docs.ispsystem.com/sitemap-xml, займёмся её корректным отображением. Такой формат URL не совсем типичен, но вполне нам подойдёт.
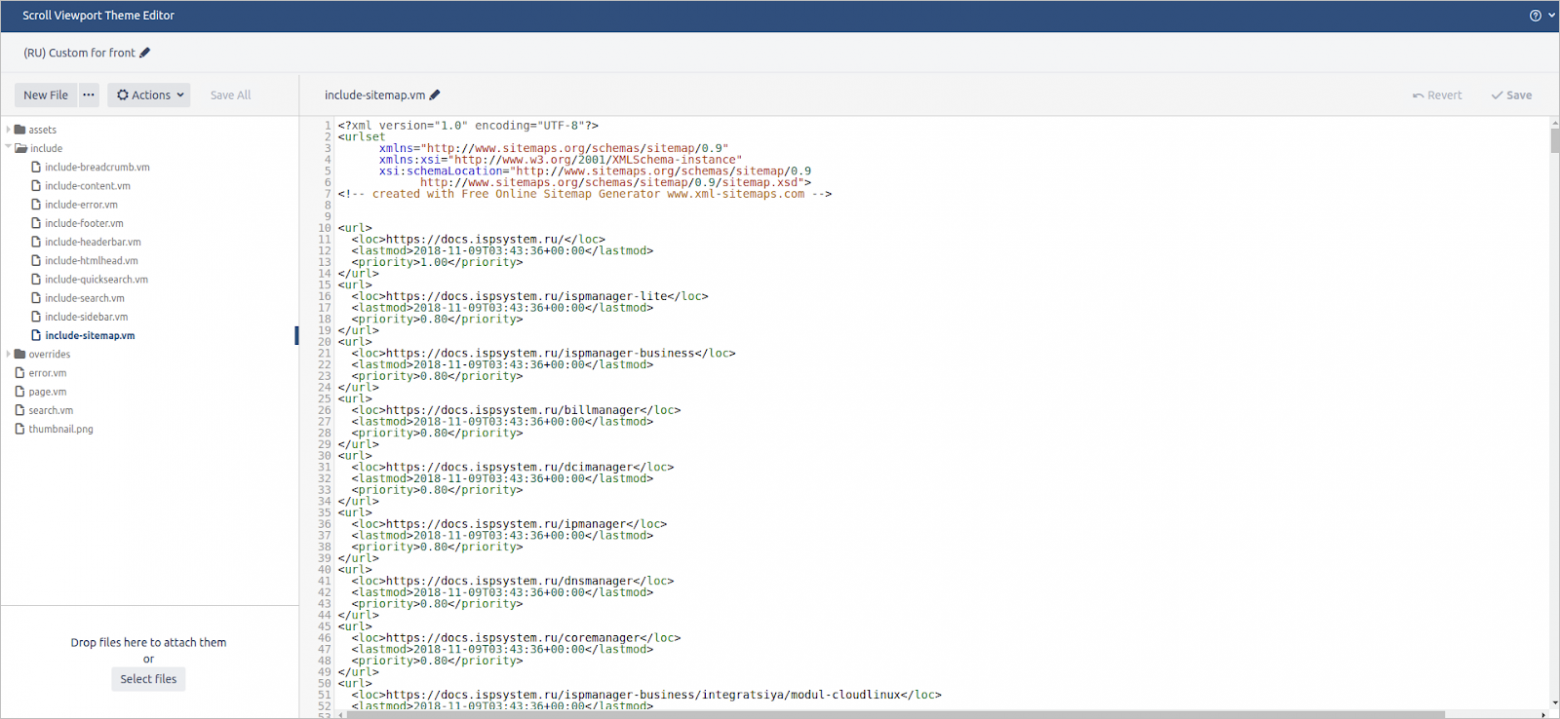
Карта сайта должна быть без лишних тегов и стилей, ведь она создаётся для поисковиков. Чтобы заданные раньше стили не применялись к карте сайта, надо создать шаблон include-sitemap.vm и скопировать в него содержимое подготовленной карты сайта — sitemap.xml. Это будет выглядеть следующим образом:
Теперь для страницы sitemap.xml создадим отдельное условие в шаблоне page.vm, чтобы стили и структура из шаблонов применялись для всех страниц, кроме карты сайта.
Для условия понадобится идентификатор. Узнать его можно, открыв страницу, а затем нажав Многоточие — Информация о странице, в конце адресной строки и будет идентификатор. Теперь пишем условие:
После описанных манипуляций путь к карте сайта можно указать в панелях вебмастера Яндекс и Google, и начнётся индексация.
В целом вопрос индексации для меня остаётся открытым. Не до конца понятно, как индексируются страницы контента Confluence. Нужно подумать, как автоматизировать процесс.
Вот так я настроила дизайн, локализацию, поиск и индексацию документации на Confluence. Понадобилось время и помощь техподдержки Scroll Viewport, чтобы разобраться с неочевидными вещами. Надеюсь, мой опыт будет полезен тем, кто столкнётся с похожей задачей.
Раньше мы использовали MediaWiki, но со временем она устарела. От платформы мы ожидали так же хорошую вёрстку статей, гибкий поиск и внутренний редактор текстов. В качестве альтернативы выбрали Confluence.
В процессе стало ясно, что возможностей этой платформы из коробки тоже недостаточно для всех наших задач. Пришлось докупить плагин Scroll Viewport и потратить некоторое время на его настройку.
Вы можете посмотреть, что в итоге получилось, а я расскажу, как меняла дизайн, настраивала разделение по языкам, внутренний поиск и индексацию.

Меняем дизайн
Компания начала переносить документацию с движка MediaWiki на Confluence год назад. Но когда я приступила к проекту, Confluence выглядел стандартно, предыдущий разработчик добавил наш логотип и скрыл ненужные анонимному пользователю элементы. К запуску надо было привести документацию к нашему стилю. Дизайнеры подготовили макеты, а я должна была их сверстать.
Но дело в том, что сам Confluence даёт очень мало гибкости в стилях и скриптах, а возможности из коробки нетривиальны для понимания и использования, да и непривычны веб-разработчику.
Отмечу, что Confluence — это Java-приложение, а вовсе не веб-сайт с привычными бэкендом и фронтендом. В разделе Внешний вид можно добавить таблицу стилей или настроить пользовательский HTML, но этого недостаточно для полноценного редизайна. Поэтому для вёрстки мы купили плагин Scroll Viewport. Тут-то и началось самое интересное.
Плагин Scroll Viewport
Scroll Viewport — это плагин для Confluence, который позволяет создавать темы, используя привычный редактор кода и файловый менеджер. С его помощью можно писать стили, работать с шаблонами страниц, добавлять изображения, настраивать поиск.
Темы создаются для пространств. Пространства в Confluence — это сущности контента, в которых хранится информация по одному проекту. У нас есть пространство для продуктов: ISPmanager, BILLmanager и т. д., а также для главной страницы. У пространства есть ключ, заголовок, ряд настроек и, собственно, тема.
Редактирование темы в Scroll Viewport: разметка, стили и html
Начнём осваивать Scroll Viewport. Когда плагин установлен и включён, надо кликнуть на шестерёнку и далее — Основные настройки — раздел Scroll Viewport — Themes.
Выбираем, копируем или создаём тему и нажимаем Edit. Открывается редактор темы Scroll Viewport.
Обратите внимание, Scroll Viewport рекомендует не создавать тему с нуля, а брать за основу Scroll WebHelp Theme.

Редактор темы Scroll Viewport: слева структура темы, сверху название файла, в основной части сами файлы
Когда тема создана, можно приступить к её настройке. Зададим разметку и структуру страниц, добавим стили и скрипты, а потом перейдём к редактированию HTML-разметки элементов контента.
Разметка: редактируем, добавляем классы и выводим однотипные элементы в цикле
Структура страниц по типу
В корне темы находятся основные шаблоны: page.vm, search.vm, error.vm, а также изображение-обложка темы thumbnail.png.
Шаблон “page.vm” задаёт структуру всех страниц темы. Здесь можно редактировать html и с помощью переменных placeholders задавать, где будет выводиться контент. Плейсхолдеры обращаются к контенту пространства или данным пользователя (заголовок материала, название пространства, имя автора), с их полным списком можно ознакомиться в хелп-центре разработчика Scroll Viewport.
“page.vm” обращается к шаблонам, которые лежат на уровень ниже, в папке “include”, и оборачивает их в теги и блоки. В этом файле (page.vm) мы собираем страницу по кусочкам, и дополняем разметку всеми необходимыми атрибутами html-документа. Именно здесь мы указываем doctype, прописываем head и body.
Составные элементы страницы
В папке “include” лежат кусочки страницы. По названиям файлов можно догадаться, какой за что отвечает:
- include-htmlhead.vm содержит всё то, что мы обычно указываем в head html-документа: обращения к таблицам стилей, файлам шрифтов, некоторым скриптам, включая стандартные скрипты Confluence и Scroll Viewport;
- include-headerbar.vm задаёт структуру хедера;
- include-footer.vm задаёт структуру футера;
- include-content.vm описывает структуру блока основного контента;
- include-sidebar.vm описывает разметку бокового меню, в котором обычно располагается список всех статей пространства.
Синтаксис шаблонов Scroll Viewport прост для понимания. Операции начинаются с решётки, например “#if (условие)” или “#foreach($language in $languages.available)”, и заканчиваются с помощью “#end”, внутри — тело оператора. Всё остальное представляет собой html-теги.
Стилизация: добавляем стили, изображения и скрипты
Внутри папки “assets” хранятся файлы js и css. Так как мы не создавали тему с нуля, там уже содержатся файлы от разработчиков Scroll Viewport.
Чтобы кастомизировать стили, лучше создать новый css-файл и подключить его в head шаблона страницы. Файлы, которые начинаются на theme, содержат в себе правила базовой темы Scroll Viewport. Их стоит редактировать в случае, когда новые стили упираются в базовые. Будьте внимательны, удаляя и добавляя правила, помните об иерархии селекторов, она может выручить.
В “assets” я также добавила папку с изображениями и папку с файлами шрифтов. Файловый менеджер работает не идеально, добавить папку в нужную директорию нельзя, поэтому пришлось схитрить. Я создала папку на своём компьютере, добавила в неё файл, а потом загрузила в нужную директорию драг-энд-дропом. Как только папка создана, с загрузкой файлов проблем нет.
При создании нового дизайна мы учитывали возможности плагина и ориентировались на уже существующие темы в Scroll Viewport, поэтому внутри assets/js я задержалась ненадолго. Внесла небольшие изменения в существующие файлы скриптов и добавила файлы нужных библиотек. Если изменения будут более значительными, со скриптами придётся разобраться детальнее.
Редактор html-разметки контента статьи
В процессе работы со Scroll Viewport выяснилось, что верстать мы можем, да не всё. Полномочия шаблона плагина заканчиваются на переменной $page.renderContent. Как верстать элементы главной с классами и ссылками? Непонятно. Где HTML? По умолчанию его там и нет. Переменная подсказывает, что нам предстоит выполнить часть вёрстки непосредственно на странице статьи, правда, пока там можно редактировать лишь текст, но не теги.

Благо, всегда можно поискать плагины, и, какая удача, нужный нашёлся почти сразу. Это Confluence Source Editor. После его установки можно в режиме редактирования статьи прошерстить и старый добрый гипертекст. Наконец-то!
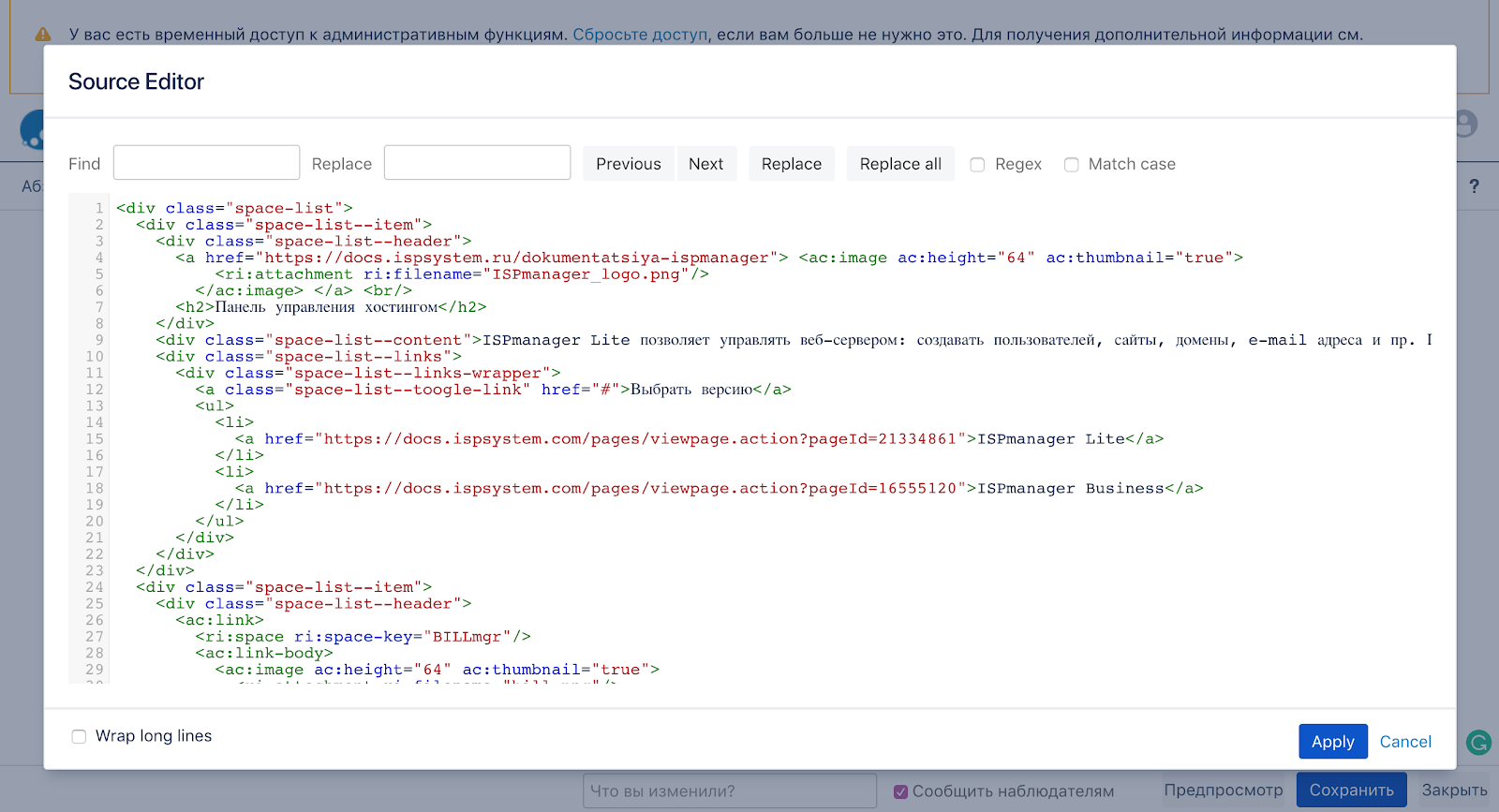
Плагин Source Editor
В Scroll Viewport верстаем шапку, сайдбар, футер и задаём стили. Контент верстаем с помощью Source Editor. Всего я создала две темы: для страниц статей и для главной страницы документации.
Настройки Viewport пространства: применяем тему
Когда тема создана, её надо связать с пространством. Для этого в настройках пространства нужно создать Viewport. Viewport — это то, что связывает пространство и тему. Только создав эту сущность, можно применить стили темы для пространства.
Войдите в пространство нужного продукта, откройте Настройки пространства — Дополнения. Здесь можно создать Viewport и управлять им: задавать темы, типы контента, разрешения, домен и путь.

Форма для связи пространства с темой, создания Viewport
Выбрать тему
На вкладке Themes представлены все созданные темы и одна тема по умолчанию, которая появляется вместе с плагином Scroll Viewport. Выберите тему и примените к пространству.
Вкладка Content позволяет выбрать тип контента, к которому будет применяться тема. Она нам наименее интересна, так как ключ пространства подтягивается автоматически.
Настроить адреса
На вкладке URL можно выбрать домен и путь, по которому будет открываться пространство, а также задать структуру адресов. Она так же понадобится, чтобы разделить документацию на два домена по языкам.
Есть два типа структуры URL:
- многоуровневая — путь отражает иерархию статей пространства и названия страниц,
- одноуровневая — все статьи доступны по адресам одинакового уровня с числовыми суффиксами
С адресами страниц есть нюанс. Для статей на разных языках Confluence по-разному формирует URL. На английском выводит в адрес название, а на русском — несвязный набор букв, символов и чисел. Scroll Viewport позволяет привести адреса к одному виду. Если выбрать многоуровневую структуру, то в адресах русских статей будет отображаться название текста транслитом.
Но нужно учесть, что при выборе многоуровневых адресов URL будет зависим от названия статьи. Изменится название — изменится и адрес статьи. Если выбрать одноуровневую структуру, адрес будет менее читаем и понятен, но перестанет зависеть от заголовка страницы.
Мы выбрали многоуровневый тип структуры и читаемые адреса, но нам придётся следить за изменением названий статей и вовремя настраивать редиректы. И идеальный вариант мы всё ещё ищем. Мы также используем краткие ссылки, которые всегда ведут на статью и не меняются, такую ссылку можно найти в разделе Информация о странице.
Включить тему
Во вкладке Permissions можно обозначить, каким пользователям будет доступен просмотр пространства с применением Viewport.
Чтобы анонимные пользователи видели документацию только в заданном дизайне, нужно поставить две галочки:
- Restrict access to Confluence UI,
- Automatically redirect users to viewport.
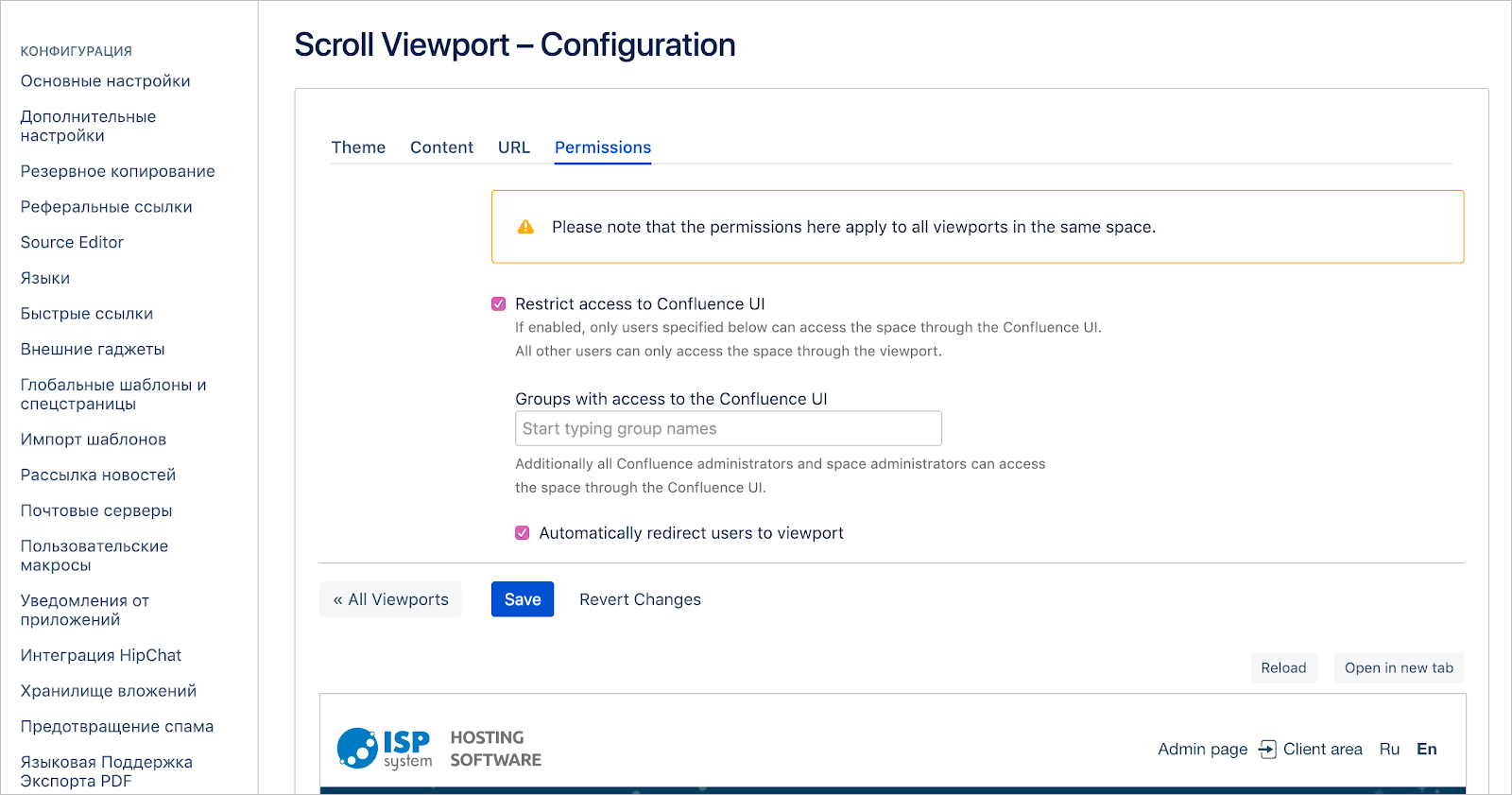
Настройки вида пространства во вкладке Permissions
Настраиваем разделение по языкам
У нас документация на английском и русском, поэтому нужно, чтобы пространства на русском открывались на домене .ru, а на английском — на .com.
В Scroll Viewport такие настройки предусмотрены, но если просто ввести отличный от основного домен во вкладке URL в поле Domain Name, два домена не заработают. Это особенность плагина Scroll Viewport.
Надо настроить Reverse proxy, чтобы запросы пользователей передавались Confluence и там разруливались на два домена — см. инструкцию Scroll Viewport (конфигурации для Nginx и TOMCAT). После этого надо выключить режим совместного редактирования или внести дополнительные изменения. Теперь можно указывать один из двух доменов в настройках Viewport.
Темы для разных языков
Применить одну тему к пространствам на разном языке не получится, потому что тема включает в себя не только стили, но и шаблоны страниц. Это означает, что язык элементов, которые выводятся не переменными, не меняется. Например, текст-плейсхолдер в строке поиска, контакты в футере и др. Так что пришлось делать отдельные темы для пространств на русском и английском языках.
Фактически я создаю идентичные по стилям темы, но вот шаблоны для них различны, в основном по части текста. Это излишество и дублирование, да, но иного способа я пока не нашла. К тому же тема регулирует и работу поиска тоже, а это ещё один аргумент в пользу разделения по языкам.
В итоге у меня получилось четыре темы: две для главных страниц на русском и английском, и ещё по две для страниц контента для каждого языка.
Настраиваем поиск по сайту
Параметры поиска настраиваются в файлах из папки “include”. Внутри них мы задаём параметры поиска:
- include-quicksearch.vm отвечает за поле поиска на всех страницах контента,
- include-search.vm задаёт структуру страниц с результатами поиска.
Где искать
По умолчанию поиск работает только по текущему пространству. Например, в пространстве ISPmanager — только по статьям об ISPmanager. Если нужен поиск по списку пространств, в настройках include-quicksearch.vm нужно указать их ключи.
<div id="ht-search">
#set($search = "/search")
#if ($stringUtils.equals(${viewport.link}, "/") == false)
#set($search = "${viewport.link}/search")
#end
<div class="ht-search-input">
<form action="$search" method="GET">
<input class="search-input" type="text" autocomplete="off" name="q" value="$!searchRequest.queryString" placeholder="Что вы ищете?"/>
<input type="hidden" name="max" value="20" />
<input type="submit" style="display:none" value="Submit">
## --- START --- Scroll Versions and Scroll Translations Integration -------------------------------------------
#if ($versions || $variants || $languages)
#if($versions)
<input id="version" type="hidden" name="scroll-versions:version-name"
value="$versions.current.value"/>
#end
#if($variants)
<input id="variant" type="hidden" name="scroll-versions:variant-name"
value="$variants.current.value"/>
#end
#if($languages)
<input id="language" type="hidden" name="scroll-translations:language-key"
value="$languages.current.value"/>
#end
#end
## --- END -----------------------------------------------------------------------------------------------------
</form>
</div>
</div>
Форма поиска для отдельного пространства
<div id="ht-search">
#set($search = "/search")
#if ($stringUtils.equals(${viewport.link}, "/") == false)
#set($search = "${viewport.link}/search")
#end
<div class="ht-search-input">
<form action="$search" method="GET">
<input class="search-input" type="text" autocomplete="off" placeholder="Что вы ищете?" name="q" value="$!searchRequest.queryString" />
<input type="hidden" name="s" value="BILLmgr" />
<input type="hidden" name="s" value="VMKVM" />
<input type="hidden" name="s" value="VMmgr5Cloud" />
<input type="hidden" name="s" value="VMmgr5OVZ" />
<input type="hidden" name="s" value="DCImgr" />
<input type="hidden" name="s" value="IPmgr5" />
<input type="hidden" name="s" value=" ISPmgr5BUSINESS" />
<input type="hidden" name="s" value="ISPmgr5Lite" />
<input type="hidden" name="s" value=" DNSmgr" />
<input type="hidden" name="s" value=" COREmgr" />
<input type="hidden" name="max" value="20" />
<input type="submit" style="display:none" value="Submit">
## --- START --- Scroll Versions and Scroll Translations Integration -------------------------------------------
#if ($versions || $variants || $languages)
#if($versions)
<input id="version" type="hidden" name="scroll-versions:version-name"
value="$versions.current.value"/>
#end
#if($variants)
<input id="variant" type="hidden" name="scroll-versions:variant-name"
value="$variants.current.value"/>
#end
#if($languages)
<input id="language" type="hidden" name="scroll-translations:language-key"
value="$languages.current.value"/>
#end
#end
## --- END -----------------------------------------------------------------------------------------------------
</form>
</div>
</div>
Форма поиска по списку пространств
Как выводить результаты
Как будет выглядеть список с результатами поиска, задаёт шаблон include-search.vm. В моём случае у каждой найденной ссылки есть заголовок, описание и название пространства, к которому относится статья. Здесь же можно указать, что пользователь увидит, если поиск ничего не найдёт.
Из фрагмента шаблона ниже видно, что результаты поиска выводятся в цикле с использованием переменных-плейсхолдеров. Результатов поиска может быть довольно много, поэтому внизу страницы сделали пагинацию. Подробное руководство по шаблонам страниц поиска можно посмотреть в документации по поиску Scroll Viewport.
<div id="ht-wrap-container">
<div id="search-results">
#if ($searchResults.total > 0)
#foreach($result in $searchResults.items)
<section class="search-result">
#set( $space = '' )
#if( $result.type == 'page' )
#set( $space = $result.getObject().fromConfluence.getSpace().getName() )
#end
<header>
<h4>
<a href="$result.link">$result.displayTitle</a>
</h4>
</header>
<div class="search-result-content">
<p class="search-result-desc">$result.getDescription(280)</p>
#if( $space )
<p class="search-result-space">$space</p>
#end
</div>
</section>
#end
#else
<h4>Мы ничего не нашли :(</h4>
<p>Проверьте запрос на ошибки, измените его или воспользуйтесь содержанием.</p>
#end
<div class="search-results-pager">
#if($pager.hasPrev)
<a class="back" href="$pager.prevLink">Назад</a>
#end
#foreach ($pagerPage in $pager.pages)
<a href="$pagerPage.link"
#if ($pagerPage.current)
class="current"
#end>$velocityCount</a>
#end
#if($pager.hasNext)
<a class="next" href="$pager.nextLink">Дальше</a>
#end
</div>
</div>
</div>
</div>
</section>
Как выглядит страница поиска
В шаблоне “search.vm” задаётся вся структура поисковых страниц, начиная от открывающегося тега . В этом шаблоне и следует собрать вместе форму поиска и его результаты. В итоге получим страницу типа “поиск”, которая включает в себя форму поиска и найденные совпадения, разбитые на несколько страниц.
Все шаблоны первого уровня, расположенные в структуре рядом с page.vm, переопределяют структуру страницы в зависимости от ее типа. Так search.vm задаёт вёрстку страниц поиска, а error.vm — страниц ошибок.
Остаётся задать стили элементам, возможно добавить скрипты, и наша тема становится функциональной, выполняет задачи и выглядит согласно дизайну.
Настраиваем индексацию
Чтобы настроить индексацию, нужно положить карту сайта в корневую папку. Но у нас нет корневой папки, ведь Confluence — это Java-приложение, а не сайт. Что делать?
Подсказка нашлась в документации Scroll Viewport. Внутри пространства разводящих страниц, где хранится главная, надо создать новую статью, назвать её sitemap.xml и расположить на уровень ниже главной.
Расположение важно, потому что, как отмечают в документации, файл карты не будет доступен для Viewport с префиксом пути “/”. Как раз такой префикс у Viewport пространства главной страницы.
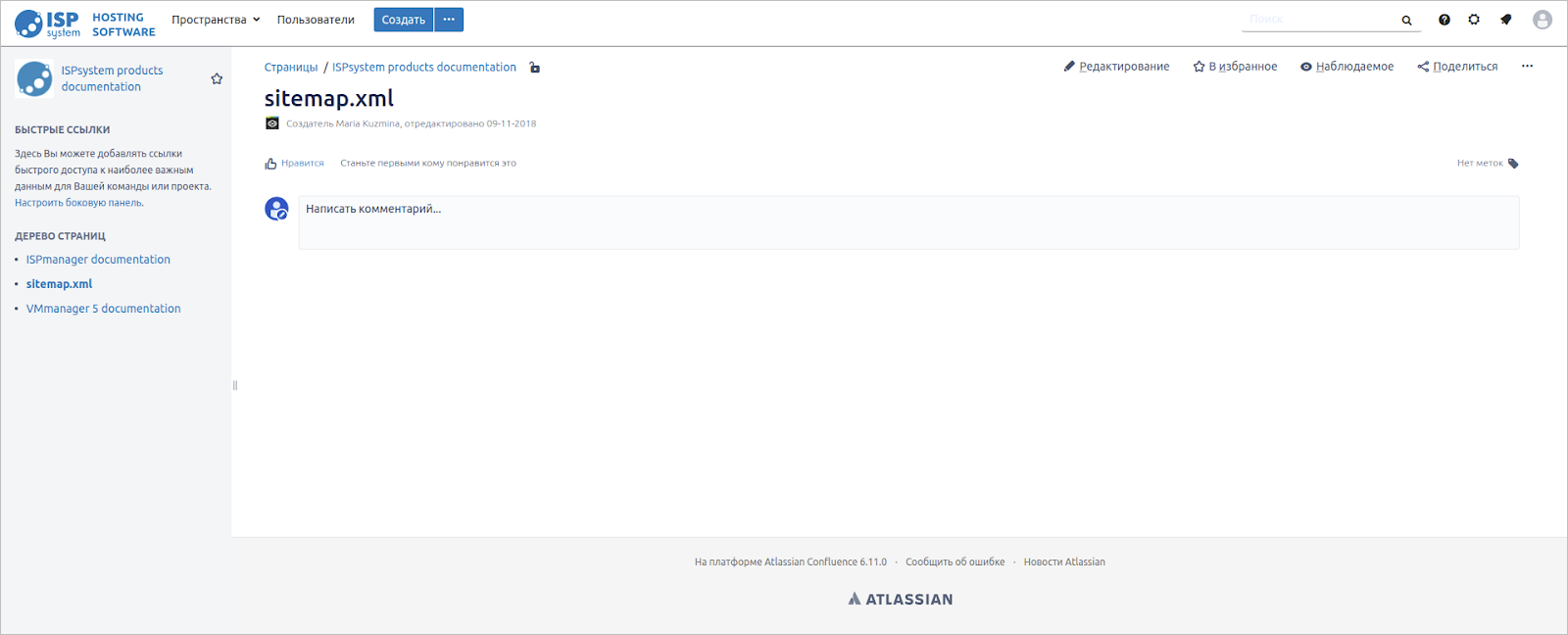
Статья sitemap.xml в структуре пространства
Мы помним, что в Confluence заголовок статьи и её URL связаны. Когда страница создана и уже открывается по адресу docs.ispsystem.com/sitemap-xml, займёмся её корректным отображением. Такой формат URL не совсем типичен, но вполне нам подойдёт.
Карта сайта должна быть без лишних тегов и стилей, ведь она создаётся для поисковиков. Чтобы заданные раньше стили не применялись к карте сайта, надо создать шаблон include-sitemap.vm и скопировать в него содержимое подготовленной карты сайта — sitemap.xml. Это будет выглядеть следующим образом:

Теперь для страницы sitemap.xml создадим отдельное условие в шаблоне page.vm, чтобы стили и структура из шаблонов применялись для всех страниц, кроме карты сайта.
Для условия понадобится идентификатор. Узнать его можно, открыв страницу, а затем нажав Многоточие — Информация о странице, в конце адресной строки и будет идентификатор. Теперь пишем условие:
#if ($page.id == 25370522)
$include.template("/include/include-sitemap.vm")
#else
/Разметка для остальных страниц/
После описанных манипуляций путь к карте сайта можно указать в панелях вебмастера Яндекс и Google, и начнётся индексация.
В целом вопрос индексации для меня остаётся открытым. Не до конца понятно, как индексируются страницы контента Confluence. Нужно подумать, как автоматизировать процесс.
Такие дела
Вот так я настроила дизайн, локализацию, поиск и индексацию документации на Confluence. Понадобилось время и помощь техподдержки Scroll Viewport, чтобы разобраться с неочевидными вещами. Надеюсь, мой опыт будет полезен тем, кто столкнётся с похожей задачей.
