Данный пост является переводом статьи «Flow Graphs, Speculative Locks, and Task Arenas in Intel Threading Building Blocks» из Parallel Universe Magazine, выпуск 18, 2014. Если вас интересует библиотека Intel TBB в частности, и интересные современные концепции параллельного программирования в общем, то добро пожаловать под кат.
Библиотека Intel Threading Building Blocks (Intel TBB) предоставляет С++ программистам решение для добавления параллелизма в их приложения и библиотеки. Широко известное преимущество библиотеки Intel TBB в том, что она делает легкодоступной для разработчиков масштабируемость и мощь параллельного выполнения их приложений, если их алгоритмы основаны на циклах или задачах. Общий обзор библиотеки можно увидеть под спойлером.
Далее, мы сфокусируемся на нескольких специфичных частях библиотеки. Сначала будет обзор вычислительного графа (flow graph), который доступен, начиная с версии Intel TBB 4.0. Затем будет рассказано о двух компонентах библиотеки, которые были впервые выпущены в версии Intel TBB 4.2. Это спекулятивные замки (speculative locks), которые используют преимущества технологии Intel Transactional Synchronization Extensions (Intel TSX) и управляемые пользователем арены для задач (user-managed task arenas), которые обеспечивают расширенный контроль и управление уровнем параллелизма и изоляции задач.
Хотя библиотека Intel TBB хорошо известна распараллеливанием циклов, интерфейс вычислительного графа [4] расширяет её возможности для быстрой и эффективной реализации алгоритмов, базируемых на графах зависимостей по данным и/или исполнению, помогая разработчикам использовать параллелизм в их приложениях на более высоком уровне.
Для примера рассмотрим простое приложение, которое последовательно выполняет четыре функции, как показано на Рис. 2(a). Подход распараллеливания по циклам подразумевает, что разработчик может рассмотреть каждую из этих функций на предмет распараллеливания с использованием таких алгоритмов, как parallel_for и parallel_reduce. Иногда этого может быть достаточно, но в других случаях этого может быть недостаточно. Например, на Рис. 2(b) показано, что удалось распараллелить по циклам функции B и D. Время выполнения в этом случае сократится, но что делать, если полученное увеличение производительности всё еще не достаточно?
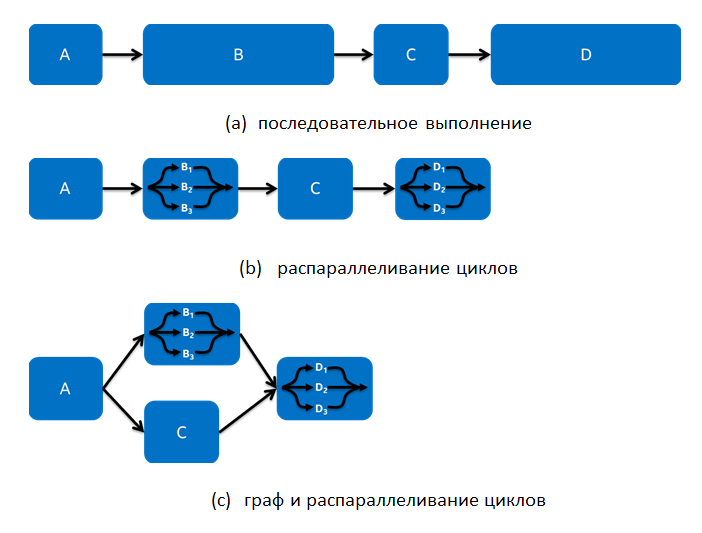
Рис. 2: Простой пример разных форм параллелизма
Иногда на вызов функций накладываются чрезмерные ограничения, как то: порядок вызова функций должен быть определенный, строго упорядоченный, вызовы один за другим, даже в случае не полных, а частичных зависимостей между функциями. На Рис. 2(а) функции расписаны разработчиком в таком порядке, чтобы функция выполнялась только после того, как все входные значения получены в процессе предыдущего выполнения. Но что делать, если функции B и C зависят от данных, вычисленных в функции A, а функция С не зависит от данных функции B? Рис. 2(с) показывает реализацию этого примера через граф и распараллеливание циклов. В этой реализации использовано распараллеливание на уровне циклов и полное упорядочивание заменено частичным, которое позволяет функциям B и C выполняться одновременно.
Интерфейс Intel TBB flow graph interface позволяет разработчикам легко выразить параллелизм на уровне графов. Он предоставляет поддержку для различных типов графов, которые могут быть найдены во многих областях, таких как обработка мультимедиа информации, игры, финансовые и высокопроизводительные вычисления, а также вычисления в здравоохранении. Этот интерфейс полностью поддерживается в библиотеке и доступен, начиная с Intel TBB 4.0.
При использовании Intel TBB flow graph вычисления представляются узлами, а каналы коммуникаций между этими узлами представляются ребрами. Пользователь использует ребра, чтобы задать зависимости, которые должны учитываться узлами при постановке в очередь на выполнение, предоставляя планировщику задач Intel TBB реализовать параллелизм на уровне топологии графа. Когда узел в графе получает сообщение, задача выполнить функтор над этим сообщением ставится в очередь на выполнение планировщиком Intel TBB.
Интерфейс flow graph поддерживает несколько различных типов узлов (Рис. 3): функциональные узлы (Functional nodes), которые выполняют пользовательские функции, буферные узлы (Buffering nodes), которые могут быть использованы для упорядочения и буферизации сообщений так, как они должны проходить через граф, узлы агрегации и де-агрегации (Aggregation / Deaggregation nodes), которые соединяют или разъединяют сообщения, а также другие полезные узлы. Пользователи соединяют объекты этих узлов ребрами, для того чтобы указать зависимости между ними, и предоставляют объекты, которые выполняют работу в этих узлах.
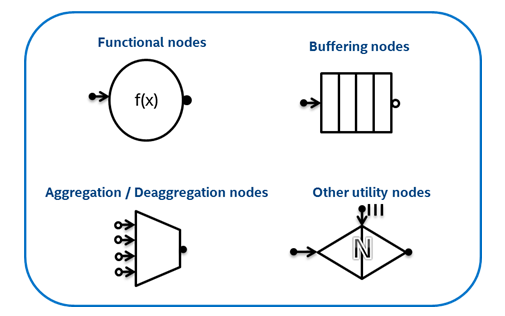
Рис. 3: Типы узлов (nodes), поддерживаемых интерфейсом flow graph
Рассмотрим исходный код для простого flow graph приложения “Hello World”. Этот пример очень простой и не содержит какого-либо параллелизма, но демонстрирует синтаксис данного интерфейса. В этом примере при помощи лямбда выражений создается два узла: hello и world, которые печатают, соответственно “Hello” и “World”. Каждый узел типа continue_node является функциональным узлом с типом, предусмотренным интерфейсом. Вызов make_edge создает ребро между узлами hello и world. Когда бы ни завершилась задача, запущенная узлом hello, она пошлет сообщение узлу world, заставив запустить задачу на выполнение его лямбда выражения.
В вышеизложенном коде вызов hello.try_put(continue_msg()) отправляет сообщение узлу hello, заставляя его вызвать задачу на выполнение тела объекта. Когда задача выполнена, она отсылает сообщение узлу world. Только когда все задачи, запущенные узлами, закончены, выполняется возврат из функции g.wait_for_all().
Интерфейс Intel TBB flow graph позволяет программировать очень сложные графы, включающие в себя тысячи узлов, ребер, циклов и прочих элементов. Рис. 4 показывает визуальное представление двух графов реализации Разложения Холецкого, которые используют алгоритм, похожий на тот, который можно найти в [5]. На Рис. 4(а) каждый вызов функций библиотеки Intel Math Kernel Library (Intel MKL) dpotf2m, dtrsm, dgemm и dsyrk — это отдельный узел в графе. В этом случае граф огромен, с множеством узлов на каждый блок матрицы, но он может быть легко реализован, модифицируя изначальные последовательные вложенные циклы Разложения Холецкого путем замены вызовов функций на создание узлов и ребер. В этом графе ребра использованы для указания связей зависимостей; каждый узел ждет, пока выполнятся все узлы, от которых он зависит. Легко видеть, как реализуется распараллеливание в этом графе.
Рис. 4(b) показывает альтернативную версию, которую тоже можно реализовать, используя интерфейс flow graph. В этой маленькой, более компактной версии графа, только удин узел, который отвечает за вызовы всех необходимых функций библиотеки Intel MKL. В этой реализации блоки передаются как сообщения между узлами в графе. Когда узел принимает набор блоков определенного типа, он вызывает задачу, которая обрабатывает эти блоки, и затем пересылает новый сгенерированный блок в другие узлы. Распараллеливание в таком графе будет реализовано из-за возможности библиотеки выполнять одновременно много экземпляров объектов каждого узла графа.
Хотя детали реализации, рассмотренные на Рис. 4, выходят за рамки этой статьи, данный пример демонстрирует, что интерфейс Intel TBB flow graph – это мощный и гибкий уровень абстракции. Он может быть использован для создания больших направленных ациклических графов, например, таких, как на Рис 4(а), где разработчик создает выделенный узел для каждого вызова библиотеки Intel MKL. С другой стороны, с помощью интерфейса Intel TBB flow graph можно создать компактный граф зависимостей по данным, который включает в себя циклы и условное выполнение, как показано на Рис. 4(b).
Больше информации об интерфейсах flow graph можно найти в справочном руководстве Intel TBB.
В следующей половине статьи мы рассмотрим спекулятивные замки (speculative locks), которые используют преимущества технологии Intel Transactional Synchronization Extensions (Intel TSX) и управляемые пользователем арены для задач (user-managed task arenas), которые обеспечивают расширенный контроль и управление уровнем параллелизма и изоляции задач.
Продолжение следует…
Введение
Библиотека Intel Threading Building Blocks (Intel TBB) предоставляет С++ программистам решение для добавления параллелизма в их приложения и библиотеки. Широко известное преимущество библиотеки Intel TBB в том, что она делает легкодоступной для разработчиков масштабируемость и мощь параллельного выполнения их приложений, если их алгоритмы основаны на циклах или задачах. Общий обзор библиотеки можно увидеть под спойлером.
О библиотеке
Библиотека включает в себя общие параллельные алгоритмы, планировщик и балансировщик задач, потокобезопасные контейнеры, диспетчер памяти, примитивы синхронизации и прочее (Рис. 1). Используя базовые шаблоны параллельного программирования совместно с этими строительными блоками, разработчики делают параллельные приложения, которые абстрагируются от проблем реализации механизма многопоточности на какой-то конкретной платформе, при этом получая производительность, которая масштабируется с увеличением числа ядер.
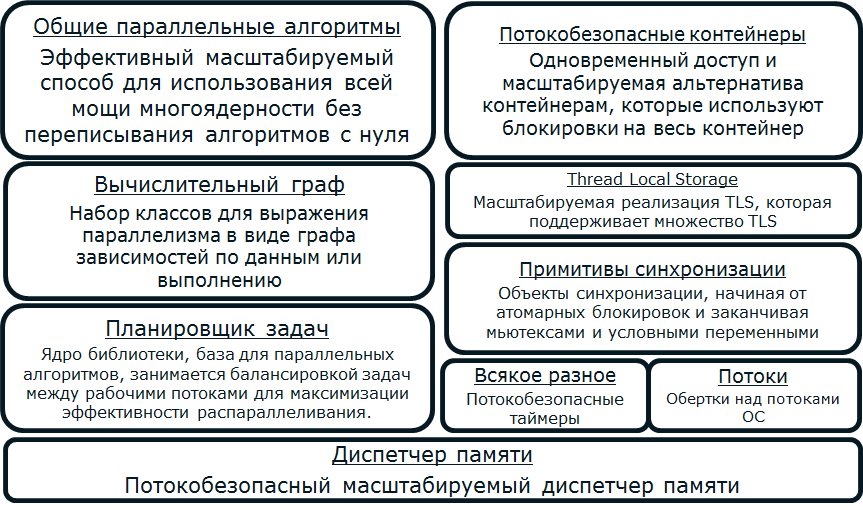
Рис 1: “Строительные блоки” Intel Threading Building Blocks
Книга “Structured parallel programming” [1] описывает ряд полезных параллельных шаблонов, которые хорошо ложатся на алгоритмы Intel TBB:
Библиотека Intel TBB может быть использована с любым С++ компилятором. Она также поддерживает стандарт С++11, например, лямбда выражения, что упрощает написание и читаемость кода, так как отпадает необходимость писать служебные функторные классы. Различные компоненты библиотеки могут быть использованы независимо и даже сочетаться с другими технологиями параллельного программирования.
Версия Intel TBB 4.2 внесла новый функционал, который включает в себя поддержку новейших функций архитектуры, таких как технология Intel Transactional Synchronization Extensions (Intel TSX) и поддержка сопроцессора Intel Xeon Phi на Windows*. Также появилась поддержка приложений для Windows Store* and Android* [2, 3]. Кроме того, были улучшены текущие компоненты (см. документацию). Intel TBB 4.2 доступен как отдельно, так и в составе таких продуктов, как Intel INDE, Intel Cluster Studio XE, Intel Parallel Studio XE, Intel C++ Studio XE, Intel Composer XE and Intel C++ Composer XE.
Версия библиотеки с открытым исходным кодом поддерживает больше архитектур, компиляторов и операционных систем, благодаря вкладу нашего сообщества. Библиотека может работать с операционной системой Solaris* и компилятором Oracle* C++ compiler for Intel Architecture и компилятором C++ для SPARC*-совместимых архитектур, IBM* Blue Gene* суперкомпьютеров и PowerPC*-совместимых архитектур. Она также работает с операционными системами Android*, Windows Phone* 8 и Windows RT* для ARM*-совместимых архитектур, FreeBSD*, Robot* и многих других платформ, где поддерживаются атомарные операции, встроенные в компилятор GCC*. Эта широкая кроссплатформенность означает, что приложение, однажды написанное с использованием библиотеки Intel TBB, может быть перенесено на многие другие операционные системы или архитектуры без переписывания основных алгоритмов.

Рис 1: “Строительные блоки” Intel Threading Building Blocks
Книга “Structured parallel programming” [1] описывает ряд полезных параллельных шаблонов, которые хорошо ложатся на алгоритмы Intel TBB:
- parallel_for: map, stencil (многомерная таблица данных)
- parallel_reduce, parallel_scan: reduce (редукция), scan (вычисление частичных редукций)
- parallel_do: workpile (многомерная таблица данных с неизвестным числом элементов на начало выполнения)
- parallel_pipeline: pipeline (конвейер)
- parallel_invoke, task_group: шаблоны fork-join
- flow_graph: шаблоны работы с вычислительным графом
Библиотека Intel TBB может быть использована с любым С++ компилятором. Она также поддерживает стандарт С++11, например, лямбда выражения, что упрощает написание и читаемость кода, так как отпадает необходимость писать служебные функторные классы. Различные компоненты библиотеки могут быть использованы независимо и даже сочетаться с другими технологиями параллельного программирования.
Версия Intel TBB 4.2 внесла новый функционал, который включает в себя поддержку новейших функций архитектуры, таких как технология Intel Transactional Synchronization Extensions (Intel TSX) и поддержка сопроцессора Intel Xeon Phi на Windows*. Также появилась поддержка приложений для Windows Store* and Android* [2, 3]. Кроме того, были улучшены текущие компоненты (см. документацию). Intel TBB 4.2 доступен как отдельно, так и в составе таких продуктов, как Intel INDE, Intel Cluster Studio XE, Intel Parallel Studio XE, Intel C++ Studio XE, Intel Composer XE and Intel C++ Composer XE.
Версия библиотеки с открытым исходным кодом поддерживает больше архитектур, компиляторов и операционных систем, благодаря вкладу нашего сообщества. Библиотека может работать с операционной системой Solaris* и компилятором Oracle* C++ compiler for Intel Architecture и компилятором C++ для SPARC*-совместимых архитектур, IBM* Blue Gene* суперкомпьютеров и PowerPC*-совместимых архитектур. Она также работает с операционными системами Android*, Windows Phone* 8 и Windows RT* для ARM*-совместимых архитектур, FreeBSD*, Robot* и многих других платформ, где поддерживаются атомарные операции, встроенные в компилятор GCC*. Эта широкая кроссплатформенность означает, что приложение, однажды написанное с использованием библиотеки Intel TBB, может быть перенесено на многие другие операционные системы или архитектуры без переписывания основных алгоритмов.
Далее, мы сфокусируемся на нескольких специфичных частях библиотеки. Сначала будет обзор вычислительного графа (flow graph), который доступен, начиная с версии Intel TBB 4.0. Затем будет рассказано о двух компонентах библиотеки, которые были впервые выпущены в версии Intel TBB 4.2. Это спекулятивные замки (speculative locks), которые используют преимущества технологии Intel Transactional Synchronization Extensions (Intel TSX) и управляемые пользователем арены для задач (user-managed task arenas), которые обеспечивают расширенный контроль и управление уровнем параллелизма и изоляции задач.
Вычислительные графы
Хотя библиотека Intel TBB хорошо известна распараллеливанием циклов, интерфейс вычислительного графа [4] расширяет её возможности для быстрой и эффективной реализации алгоритмов, базируемых на графах зависимостей по данным и/или исполнению, помогая разработчикам использовать параллелизм в их приложениях на более высоком уровне.
Для примера рассмотрим простое приложение, которое последовательно выполняет четыре функции, как показано на Рис. 2(a). Подход распараллеливания по циклам подразумевает, что разработчик может рассмотреть каждую из этих функций на предмет распараллеливания с использованием таких алгоритмов, как parallel_for и parallel_reduce. Иногда этого может быть достаточно, но в других случаях этого может быть недостаточно. Например, на Рис. 2(b) показано, что удалось распараллелить по циклам функции B и D. Время выполнения в этом случае сократится, но что делать, если полученное увеличение производительности всё еще не достаточно?
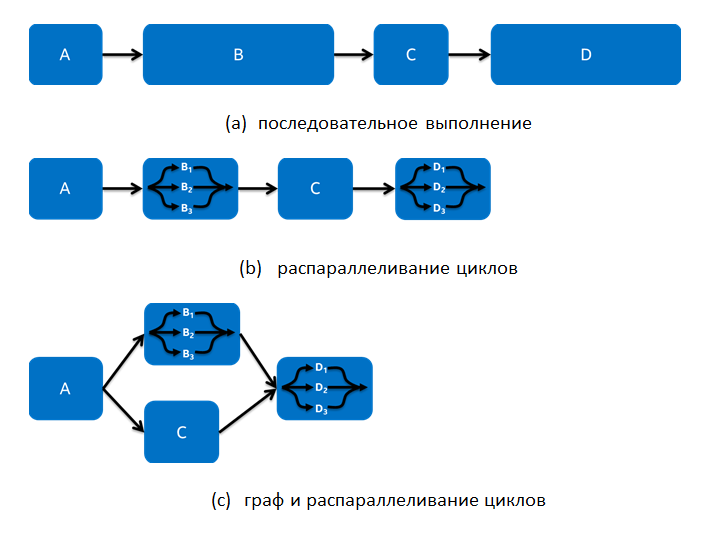
Рис. 2: Простой пример разных форм параллелизма
Иногда на вызов функций накладываются чрезмерные ограничения, как то: порядок вызова функций должен быть определенный, строго упорядоченный, вызовы один за другим, даже в случае не полных, а частичных зависимостей между функциями. На Рис. 2(а) функции расписаны разработчиком в таком порядке, чтобы функция выполнялась только после того, как все входные значения получены в процессе предыдущего выполнения. Но что делать, если функции B и C зависят от данных, вычисленных в функции A, а функция С не зависит от данных функции B? Рис. 2(с) показывает реализацию этого примера через граф и распараллеливание циклов. В этой реализации использовано распараллеливание на уровне циклов и полное упорядочивание заменено частичным, которое позволяет функциям B и C выполняться одновременно.
Интерфейс Intel TBB flow graph interface позволяет разработчикам легко выразить параллелизм на уровне графов. Он предоставляет поддержку для различных типов графов, которые могут быть найдены во многих областях, таких как обработка мультимедиа информации, игры, финансовые и высокопроизводительные вычисления, а также вычисления в здравоохранении. Этот интерфейс полностью поддерживается в библиотеке и доступен, начиная с Intel TBB 4.0.
При использовании Intel TBB flow graph вычисления представляются узлами, а каналы коммуникаций между этими узлами представляются ребрами. Пользователь использует ребра, чтобы задать зависимости, которые должны учитываться узлами при постановке в очередь на выполнение, предоставляя планировщику задач Intel TBB реализовать параллелизм на уровне топологии графа. Когда узел в графе получает сообщение, задача выполнить функтор над этим сообщением ставится в очередь на выполнение планировщиком Intel TBB.
Интерфейс flow graph поддерживает несколько различных типов узлов (Рис. 3): функциональные узлы (Functional nodes), которые выполняют пользовательские функции, буферные узлы (Buffering nodes), которые могут быть использованы для упорядочения и буферизации сообщений так, как они должны проходить через граф, узлы агрегации и де-агрегации (Aggregation / Deaggregation nodes), которые соединяют или разъединяют сообщения, а также другие полезные узлы. Пользователи соединяют объекты этих узлов ребрами, для того чтобы указать зависимости между ними, и предоставляют объекты, которые выполняют работу в этих узлах.
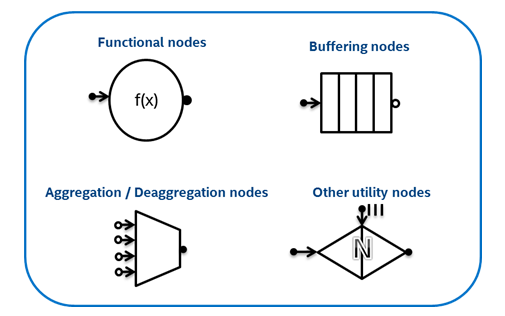
Рис. 3: Типы узлов (nodes), поддерживаемых интерфейсом flow graph
Рассмотрим исходный код для простого flow graph приложения “Hello World”. Этот пример очень простой и не содержит какого-либо параллелизма, но демонстрирует синтаксис данного интерфейса. В этом примере при помощи лямбда выражений создается два узла: hello и world, которые печатают, соответственно “Hello” и “World”. Каждый узел типа continue_node является функциональным узлом с типом, предусмотренным интерфейсом. Вызов make_edge создает ребро между узлами hello и world. Когда бы ни завершилась задача, запущенная узлом hello, она пошлет сообщение узлу world, заставив запустить задачу на выполнение его лямбда выражения.
#include "tbb/flow_graph.h"
#include <iostream>
using namespace std;
using namespace tbb::flow;
int main() {
graph g;
continue_node< continue_msg> hello( g,
[]( const continue_msg &) {
cout << "Hello";
}
);
continue_node< continue_msg> world( g,
[]( const continue_msg &) {
cout << " World\n";
}
);
make_edge(hello, world);
hello.try_put(continue_msg());
g.wait_for_all();
return 0;
}
В вышеизложенном коде вызов hello.try_put(continue_msg()) отправляет сообщение узлу hello, заставляя его вызвать задачу на выполнение тела объекта. Когда задача выполнена, она отсылает сообщение узлу world. Только когда все задачи, запущенные узлами, закончены, выполняется возврат из функции g.wait_for_all().
Интерфейс Intel TBB flow graph позволяет программировать очень сложные графы, включающие в себя тысячи узлов, ребер, циклов и прочих элементов. Рис. 4 показывает визуальное представление двух графов реализации Разложения Холецкого, которые используют алгоритм, похожий на тот, который можно найти в [5]. На Рис. 4(а) каждый вызов функций библиотеки Intel Math Kernel Library (Intel MKL) dpotf2m, dtrsm, dgemm и dsyrk — это отдельный узел в графе. В этом случае граф огромен, с множеством узлов на каждый блок матрицы, но он может быть легко реализован, модифицируя изначальные последовательные вложенные циклы Разложения Холецкого путем замены вызовов функций на создание узлов и ребер. В этом графе ребра использованы для указания связей зависимостей; каждый узел ждет, пока выполнятся все узлы, от которых он зависит. Легко видеть, как реализуется распараллеливание в этом графе.
Рис. 4: Две параллельные реализации Разложения Холецкого на базе интерфейсов flow graph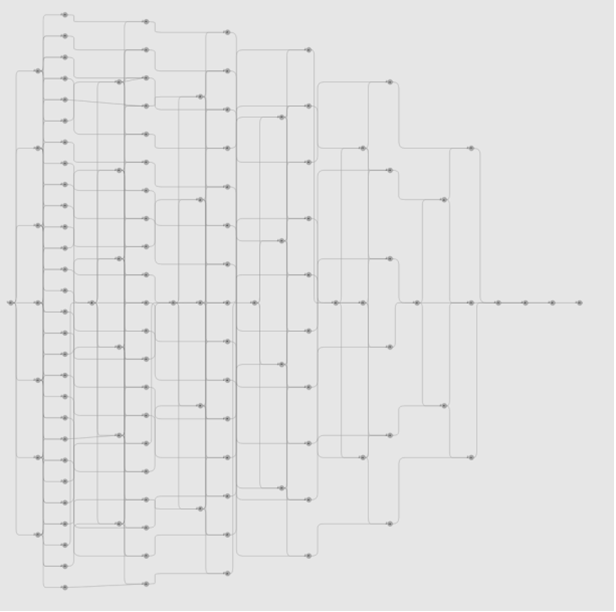
Рис. 4(a) Используя направленный ациклический граф
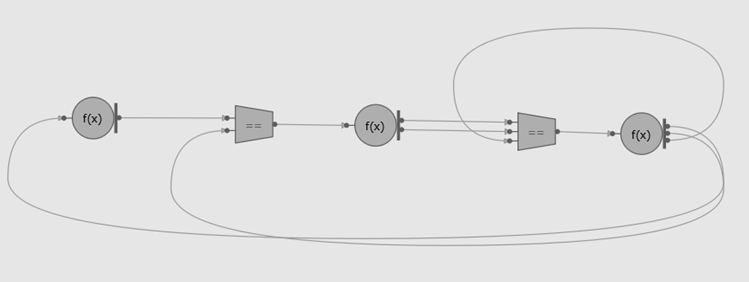
Рис. 4(b) Используя компактный граф зависимостей по данным

Рис. 4(a) Используя направленный ациклический граф

Рис. 4(b) Используя компактный граф зависимостей по данным
Рис. 4(b) показывает альтернативную версию, которую тоже можно реализовать, используя интерфейс flow graph. В этой маленькой, более компактной версии графа, только удин узел, который отвечает за вызовы всех необходимых функций библиотеки Intel MKL. В этой реализации блоки передаются как сообщения между узлами в графе. Когда узел принимает набор блоков определенного типа, он вызывает задачу, которая обрабатывает эти блоки, и затем пересылает новый сгенерированный блок в другие узлы. Распараллеливание в таком графе будет реализовано из-за возможности библиотеки выполнять одновременно много экземпляров объектов каждого узла графа.
Хотя детали реализации, рассмотренные на Рис. 4, выходят за рамки этой статьи, данный пример демонстрирует, что интерфейс Intel TBB flow graph – это мощный и гибкий уровень абстракции. Он может быть использован для создания больших направленных ациклических графов, например, таких, как на Рис 4(а), где разработчик создает выделенный узел для каждого вызова библиотеки Intel MKL. С другой стороны, с помощью интерфейса Intel TBB flow graph можно создать компактный граф зависимостей по данным, который включает в себя циклы и условное выполнение, как показано на Рис. 4(b).
Больше информации об интерфейсах flow graph можно найти в справочном руководстве Intel TBB.
В следующей половине статьи мы рассмотрим спекулятивные замки (speculative locks), которые используют преимущества технологии Intel Transactional Synchronization Extensions (Intel TSX) и управляемые пользователем арены для задач (user-managed task arenas), которые обеспечивают расширенный контроль и управление уровнем параллелизма и изоляции задач.
Продолжение следует…
Библиография
[1] Michael McCool, Arch Robison, James Reinders “Structured Parallel Programming” parallelbook.com
[2] Vladimir Polin, “Android* Tutorial: Writing a Multithreaded Application using Intel Threading Building Blocks”. software.intel.com/en-us/android/articles/android-tutorial-writing-a-multithreaded-application-using-intel-threading-building-blocks
[3] Vladimir Polin, “Windows* 8 Tutorial: Writing a Multithreaded Application for the Windows Store* using Intel Threading Building Blocks”. software.intel.com/en-us/blogs/2013/01/14/windows-8-tutorial-writing-a-multithreaded-application-for-the-windows-store-using
[4] Michael J. Voss, “The Intel Threading Building Blocks Flow Graph”,
Dr. Dobb’s, October 2011, www.drdobbs.com/tools/the-intel-threading-building-blocks-flow/231900177.
[5] Aparna Chandramowlishwaran, Kathleen Knobe, and Richard Vuduc, “Performance
Evaluation of Concurrent Collections on High-Performance Multicore Computing Systems”,
2010 Symposium on Parallel & Distributed Processing (IPDPS), April 2010.
[2] Vladimir Polin, “Android* Tutorial: Writing a Multithreaded Application using Intel Threading Building Blocks”. software.intel.com/en-us/android/articles/android-tutorial-writing-a-multithreaded-application-using-intel-threading-building-blocks
[3] Vladimir Polin, “Windows* 8 Tutorial: Writing a Multithreaded Application for the Windows Store* using Intel Threading Building Blocks”. software.intel.com/en-us/blogs/2013/01/14/windows-8-tutorial-writing-a-multithreaded-application-for-the-windows-store-using
[4] Michael J. Voss, “The Intel Threading Building Blocks Flow Graph”,
Dr. Dobb’s, October 2011, www.drdobbs.com/tools/the-intel-threading-building-blocks-flow/231900177.
[5] Aparna Chandramowlishwaran, Kathleen Knobe, and Richard Vuduc, “Performance
Evaluation of Concurrent Collections on High-Performance Multicore Computing Systems”,
2010 Symposium on Parallel & Distributed Processing (IPDPS), April 2010.
