
С 7 по 11 сентября в Эдинбурге, Шотландия проходила 22-я международная конференция по параллельным архитектурам и методам компиляции (PACT). Конференция состояла из двух частей: Workshops/Tutorials и основной части. Мне удалось посетить основную часть, о которой хотелось бы рассказать.
Конференция PACT является одной из крупных и значимых в своей области. Список тем конференции весьма обширен:
- Параллельные архитектуры и вычислительные модели
- Инструментарий (компиляторы и прочее) для параллельных компьютерных систем
- Архитектуры: многоядерные, многопоточные, суперскалярные и VLIW
- Языки и алгоритмы для параллельного программирования
- И прочее, прочее, прочее, что связано с параллелизмом в software и в hardware
Конференция проводится под патронажем таких организаций, как IEEE, ACM и IFIP. В списке спонсоров прошедшей конференции присутствуют весьма известные корпорации:

Несколько слов о месте проведения. Конференция проводилась в исторической части Эдинбурга, старом городе, здании хирургов (Surgeons’ Hall):

Город поражает как своей красотой, так и числом известных людей, связанных с ним. Конан Дойль, Вальтер Скотт, Роберт Льюис Стивенсон, Джоан Роулинг, Шон Коннери. О них и других исторических личностях вам с удовольствием расскажут в этом городе. Первое, что приходит в голову, когда слышишь Шотландия – это виски. Здесь понимаешь, что виски – это неотъемлемая часть культуры Шотландии. Он повсюду, даже в наборе участника конференции присутствовала маленькая бутылочка односолодового виски:

Ключевые докладчики и победители студенческого конкурса получали полноразмерную бутылку отличного виски.
Ключевые доклады
A Comprehensive Approach to HW/SW Codesign
David J. Kuck (Intel Fellow) в своем докладе затронул тему анализа компьютерных систем формальными методами. Оптимизация параметров компьютерных систем проводится в основном эмпирическими методами. David Kuck предлагает методологию построения математических моделей HW/SW системы, описываемых системой нелинейных уравнений. Методология была реализована в программной системе Cape, которая ускоряет поиск оптимальных решений проблем дизайна компьютерных систем.
Parallel Programming for Mobile Computing
Câlin Caşcaval (Director of Engineering at the Qualcomm Silicon Valley Research Center) рассказывал о проблемах распараллеливания вычислений на мобильных устройствах. Проведя исследования сценариев использования мобильных устройств, Qualcomm предлагает свое видение стека мобильного ПО:
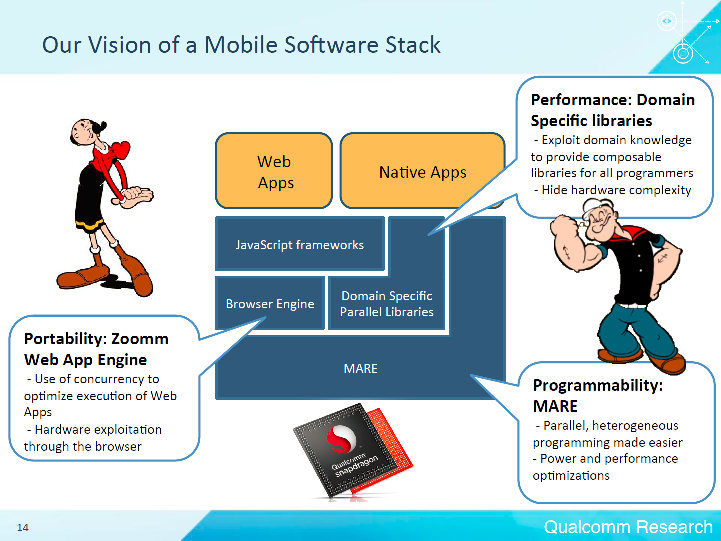
Ключевым компонентом системы является MARE — Multicore Asynchronous Runtime Environment. MARE предоставляет C++ API для параллельного программирования и runtime среду, которая оптимизирует исполнение программы по гетерогенный SoC. Можно сказать, что это аналог Intel Threading Building Blocks (Intel TBB).
Towards Automatic Resource Management in Parallel Architectures
Per Stenström (Chalmers University of Technology, Sweden) в своем докладе «Towards Automatic Resource Management in Parallel Architectures» рассмотрел некоторые проблемы, с которыми придется столкнуться в рамках текущих тенденций развития параллельных архитектур.
По прогнозам количество ядер в процессоре будет линейно расти в ближайшие годы и достигнет значения 100 ядер к 2020 году. При этом ограничения по энергопотреблению будут ужесточаться. Несмотря на рост количества ядер, рост пропускной способности памяти замедляется. Для достижения эффективного использования ресурсов процессора нужно по максимуму распараллеливать программы.
Программист распараллеливает программу, компилятор отображает программу на некую модель параллельных вычислений, среда исполнения осуществляет балансировку. Гетерогенные процессоры обладают хорошим потенциалом по энергоэффективности. Для параллельных архитектур скорость работы подсистемы памяти станет острой проблемой. Согласно исследованиям, большой процент данных в памяти и кэшах дублируются. Per Stenström предлагает в качестве кэшей последнего уровня (LLC) использовать кэш с сжатием. При использовании таких кэшей наблюдается двукратное ускорение исполнения программ.
Ключевые доклады
Доклады были распределены по секциям:
- Compilers
- Power and Energy
- GPU and Energy
- Memory System Management
- Runtime and Scheduling
- Caches and Memory Hierarchy
- GPU
- Networking, Debugging and Microarchitecture
- Compiler Optimization
Нужно было выбирать какие секции посетить, так как часть секций шли одновременно.
Ниже секции, которые я посетил и доклады, заинтересовавшие меня.
Compilers
Интересным был доклад «Parallel Flow-Sensitive Pointer Analysis by Graph-Rewriting» (Indian Institute of Science, Bangalore) о распараллеливании алгоритма анализа указателей на aliasing. «Flow-Sensitive Pointer Analysis» означает проведения анализа указателей с учетом порядка выполнения операций. В каждой точке программы вычисляется множество «points-to». В отличие от него при «Flow-Insensitive Pointer Analysis» строится одно множество «points-to» на всю программу. Анализ указателей на aliasing можно проводить на графе, где вершины — это переменные программы, а дуги — отношения между переменными одного из типов: взятие адреса, копирование указателя, загрузка данных по указателю, запись данных по указателю. Авторы доклада показали, что модифицируя этот граф по определенным правилам, можно получить граф, на котором можно проводить параллельный анализ указателей.
GPU and Energy
Интересный доклад «Parallel Frame Rendering: Trading Responsiveness for Energy on a Mobile GPU» (Universitat Politecnica de Catalunya, Intel) о распараллеливании расчета кадров на мобильных процессорах со встроенной графикой и проблемах с которыми столкнулись разработчики.
Доклад «Exploring Hybrid Memory for GPU Energy Efficiency through Software-Hardware Co-Design» (Auburn University, College of William and Mary, Oakridge National Lab) об исследовании гибридной памяти DRAM+PCM, которая потребляет меньше энергии, чем только DRAM или PCM, имея производительность всего на 2% меньше чем DRAM. Phase Change Memory (PCM) лучше DRAM по энергопотреблению, но хуже по производительности.
Runtime and Scheduling
«Fairness-Aware Scheduling on Single-ISA Heterogeneous Multi-Cores» (Ghent University, Intel) – традиционные методы диспетчеризации потоков не совсем подходят для гетерогенных многоядерных процессоров. В докладе описывается динамическая диспетчеризация потоков, позволяющая добиться одинакового прогресса исполнения каждого потока, что положительно сказывается на производительности приложения в целом.
«An Empirical Model for Predicting Cross-Core Performance Interference on Multicore Processors» (Institute of Computing Technology, University of New South Wales, Huawei) – применение методов машинного обучения для получения функции, предсказывающей падение производительности приложения при совместном исполнении с другими приложениями.
Networking, Debugging & Microarchitecture
В докладе «A Debugging Technique for Every Parallel Programmer» (Intel) было показано, как с помощью техники Concurrent Predicates(CP) можно существенно увеличить воспроизводимость багов в многопоточных приложениях. Впечатлили результаты применения этой техники для анализа реальных багов:
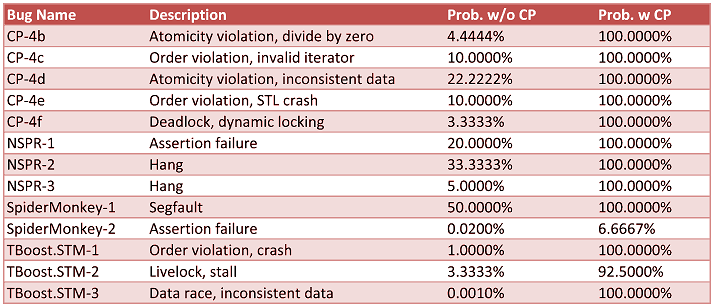
Третий столбец – это вероятность воспроизведения бага без техники CP. Четвертый столбец – с использованием техники CP.
Compiler Optimization
«Vectorization Past Dependent Branches Through Speculation» (University of Texas — San Antonio, University of Colorado) – доклад о SIMD векторизации циклов с простыми условными переходами в теле цикла. В цикле находится путь, который можно векторизовать и который исполняется в последовательных итерациях. На основе этого пути создается новый цикл. Если во время исполнения цикла возникает ситуация, когда в некоторых последовательных итерациях будут исполняться разные пути, то эти итерации будут исполнены исходным не модифицированным циклом.
Лучшие доклады
Отдельно от основных докладов проводилась сессия лучших докладов. Из них мне хотелось бы выделить два доклада:
- «A Unified View of Non-monotonic Core Selection and Application Steering in Heterogeneous Chip Multiprocessors» (Qualcomm, North Carolina State University) – исследование на тему нахождения оптимальных параметров гетерогенного процессора. Также описана система динамического обнаружения узких мест приложения и перемещения вычислительных потоков приложения с одного ядра на другое для устранения узких мест.
- «SMT-Centric Power-Aware Thread Placement in Chip Multiprocessors» (IBM) – в многоядерных процессорах снижение энергопотребления можно добиться путем динамического изменения напряжения/частоты ядер, либо отключением ядер. В докладе рассмотрено, как используя данные техники вместе и по отдельности можно добиться существенного улучшения соотношения power-performance.
Заключение
Общее впечатление от конференции положительное. Большое количество интересных докладов. Понимание, что происходит в академических кругах и в больших корпорациях. Люди, с которыми было интересно пообщаться. Завязались полезные контакты. Порадовала хорошо организованная культурная программа: ужины и экскурсии по городу, музеям. Бурные эмоции вызвала after-party в музее хирургии с обширной коллекцией экспонатов, лечащихся хирургическим путем. Для людей «с железными нервами» была организована ночная экскурсия по подземельям Эдинбурга. Приятно было встретить ребят из России (МФТИ и МЦСТ) на конкурсе студенческих работ.
В следующем году конференция будет проводиться в Эдмонтоне, Канада. Организаторы пообещали провести конференцию на таком же высоком уровне.
Ссылки
PACT 2013 Home
PACT 2013 Program
PACT 2014 Home
