Comments 52
UFO just landed and posted this here
Говорите: «Язык Си». Всё, контекст задан.
Ок. «Язык С». А ну-ка поведайте нам, например, размер типа int в «языке С»?
UFO just landed and posted this here
В том, что может быть 2, 4, 8 или вообще сколько угодно. Контекста «язык программирования» не достаточно. Нужен ещё как минимум компилятор и ОС. А иногда и другие параметры.
Это проблема (ок, гугл — это архитектура) реализации конкретного языка, который требует больше вводных для точного ответа. Int в контексте языка Java имеет конкретный железобетонный размер. Поэтому да, задание контекста в виде языка упрощает коммуникацию. К тому же, будет справедливо заметить, что команды редко включают разношёрстных спецов и ситуация «встретились инженеры на асме, питоне и го» больше соответствует курилке или интернет форуму. Внутри команды контекст известен день ото дня, поэтому всё не так плохо. Но сравнивать языка становится интересно и анекдотичные ситуации появляются. Спасибо за статью.
UFO just landed and posted this here
> размер типа int в «языке С»?
Стандарт выдвигает следующие требования:
1) sizeof(char) == 1 (char всегда 1 байт, число битов в байте не зафиксировано, но должно быть «достаточно, чтобы поместился описанный в стандарте набор символов»).
2) sizeof(char) <= sizeof(short) <= sizeof(int) <= sizeof(long) <= sizeof(long long)
Дальше все зависит от среды сборки/исполнения. Указать только язык в данном случае недостаточно для задания полного контекста.
Стандарт выдвигает следующие требования:
1) sizeof(char) == 1 (char всегда 1 байт, число битов в байте не зафиксировано, но должно быть «достаточно, чтобы поместился описанный в стандарте набор символов»).
2) sizeof(char) <= sizeof(short) <= sizeof(int) <= sizeof(long) <= sizeof(long long)
Дальше все зависит от среды сборки/исполнения. Указать только язык в данном случае недостаточно для задания полного контекста.
UFO just landed and posted this here
Ну серьезно. Сишной документации под рукой нет, но есть спек с++98, который вряд ли сильно отличается от с98 в этой части. Цитирую:
Параграф 1.7 дает определение байта в контексте языка С++, 3.9.1 предъявляет к char такие же требования по размеру, которые предъявлены к байту в параграфе 1.7, параграф 5.3.3 явно говорит, что размер char равен одному байту.
Судя по всему, вы думали о байте в контексте кодировок, а там в этот термин вкладывается немного другой смысл :)
1.7 The C++ memory model
The fundamental storage unit in the C++ memory model is the byte. A byte is at least large enough to contain any member of the basic execution character set and is composed of a contiguous sequence of bits, the number of which is implementation-defined.
3.9.1 Fundamental types
Objects declared as characters (char) shall be large enough to store any member of the implementation’s basic character set
5.3.3 Sizeof
The sizeof operator yields the number of bytes in the object representation of its operand. [...] sizeof(char), sizeof(signed char) and sizeof(unsigned char) are 1;
Параграф 1.7 дает определение байта в контексте языка С++, 3.9.1 предъявляет к char такие же требования по размеру, которые предъявлены к байту в параграфе 1.7, параграф 5.3.3 явно говорит, что размер char равен одному байту.
Судя по всему, вы думали о байте в контексте кодировок, а там в этот термин вкладывается немного другой смысл :)
UFO just landed and posted this here
2.2 Character sets
The basic source character set consists of 96 characters: the space character, the control characters representing horizontal tab, vertical tab, form feed, and new-line, plus the following 91 graphical characters [...]
[...]
The basic execution character set [...] shall [...] contain all the members of the basic source character set, plus control characters representing alert, backspace, and carriage return, plus a null character.
Про кодировки ни слова. Языку не интересно, как эти символы кодируются битами и машинными байтами, но байт в языке С определен как «at least large enough to contain any member of the basic execution character set». Если завтра авторы gcc решат заменить внутреннее представление символов с ASCII на UCS-2, — это их право. Тогда каждый символ будет занимать два машинных байта, но все еще один сишный байт.
> Так что я не вижу ошибки в своём мнении.
Ваше мнение прямо противоречит параграфу 5.3.3 стандарта.
Обратите внимание, что вы упали именно в ту яму, которая описана в посте: термин байт имеет множество смыслов в зависимости от контекста, и мы сейчас спорим о том, чем он является, а чем — нет, но используем разные контексты. Так что спорить мы можем бесконечно, пока не осознаем бессмысленность этого занятия (в контексте языка С прав я, в контексте UTF-8 правы вы: в RFC термины byte и octet используются как взаимозаменяемые, и octet определен как 8 бит).
UFO just landed and posted this here
> тема довольно мутная всё равно
Ну так пост именно об этом: у нас в обороте куча терминов, которые в разных контекстах имеют разное значение, и куча сущностей, которые в разных контекстах обозначаются разными терминами. И мы часто путаемся, потому что увидев термин, не знаем, какой контекст имелся ввиду, или сами используем термин не из того контекста, когда имеем ввиду какую-то сущность.
Ну так пост именно об этом: у нас в обороте куча терминов, которые в разных контекстах имеют разное значение, и куча сущностей, которые в разных контекстах обозначаются разными терминами. И мы часто путаемся, потому что увидев термин, не знаем, какой контекст имелся ввиду, или сами используем термин не из того контекста, когда имеем ввиду какую-то сущность.
Это хорошо, когда программист читает документацию на стандарт.
Но главное — читать документацию на конкретный компилятор!
Мы просто обалдели, когда компилятор выдал sizeof(char) = 1 и sizeof(double) = 2.
И ещё больше удивились, когда почитали
Но главное — читать документацию на конкретный компилятор!
Мы просто обалдели, когда компилятор выдал sizeof(char) = 1 и sizeof(double) = 2.
И ещё больше удивились, когда почитали
документацию на компилятор
Если честно, то «число битов в байте не зафиксировано» и потенциальное "=" с младшим типом — сбивает сильно с толку.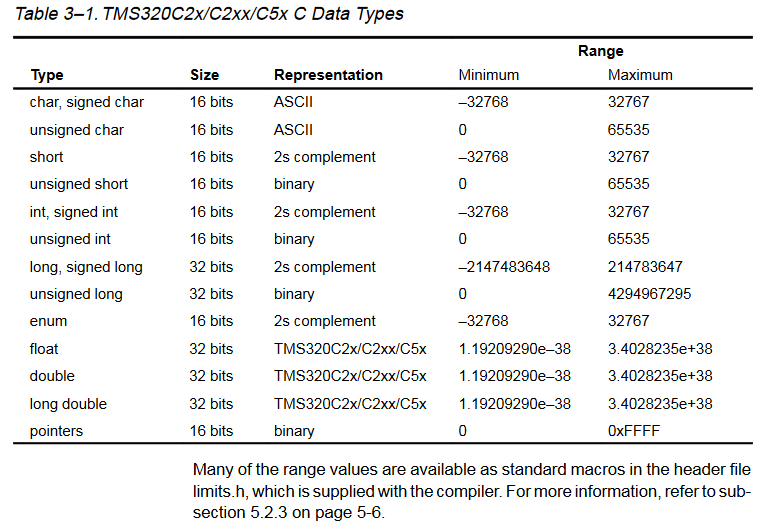
> Мы просто обалдели
> И ещё больше удивились
Для этого и нужно читать стандарт языка, чтобы не полагаться на имперические знания, почерпнутые из общения с одной платформой, при переходе на другую платформу. Там еще много таких интересных мест в стандарте есть, которые на вашем компайлере могут работать совсем не так, как вы привыкли на vc++/g++ ;)
> И ещё больше удивились
Для этого и нужно читать стандарт языка, чтобы не полагаться на имперические знания, почерпнутые из общения с одной платформой, при переходе на другую платформу. Там еще много таких интересных мест в стандарте есть, которые на вашем компайлере могут работать совсем не так, как вы привыкли на vc++/g++ ;)
Тогда в каждом языке программирования будет своя наука. Я против этого! Информатика (computer science) едина для всех программистов. Должна быть едина.
Хорошее описание проблемы.
Из-за сугобо эволюционного развития отрасли (да ещё и прямо от времён железа), копится огромный долг по стандартизации и сейчас нет организации, которая была бы в состоянии его закрыть.
Помочь может только появление какого-нибудь нового гуру, признанного всеми, который напишет умную книгу с логичным описанием соглашений по именованию.
Из-за сугобо эволюционного развития отрасли (да ещё и прямо от времён железа), копится огромный долг по стандартизации и сейчас нет организации, которая была бы в состоянии его закрыть.
Помочь может только появление какого-нибудь нового гуру, признанного всеми, который напишет умную книгу с логичным описанием соглашений по именованию.
UFO just landed and posted this here
Само собой пытаться описать всё не стоит. По мере развития отрасли, необходимо выделять устаканившееся ядро, которое уже не будет меняться. А фронтир технологий не ограничивать.
Например, в данный момент довольно легко сделать стандарт на именование машинных типов данных (например, int8, int16, etc...), но просто так массово на него переходить никто не будет, потому что крайне дорого.
Например, в данный момент довольно легко сделать стандарт на именование машинных типов данных (например, int8, int16, etc...), но просто так массово на него переходить никто не будет, потому что крайне дорого.
Какая бы гура не была, легаси никуда не денется. Нужны будут инструменты которые переведут всю имеющуюся базу кода к новому представлению, что конечно же не случится.
О переводе.
Вообще-то, говоря о функциях, "signature" переводится не как "интерфейс", а калькой — "сигнатура".
- "Передача дележом" — это "pass by sharing"? Устоявшегося перевода не назову, но такой перевод читаю первый раз.
Теперь о содержании.
Из какого такого языка пришел в Python человек, неправильно понимающий замыкания? Такого рода проблема существует либо когда-то существовала во всех известных мне языках...
- В PHP &-операторы не "заражают" никакие переменные ссылочностью. Ссылочность относится к значениям переменных!
Вообще-то, говоря о функциях, «signature» переводится не как «интерфейс», а калькой — «сигнатура».
Там в комментариях к оригинальной статье автор поясняет что он имел в виду под словом «signature», так вот он говорит «A function “signature” is just its interface: the arguments it takes, their names, their types, the return type, and exceptions that may be thrown.». А вообще, Ваш комментарий отличный пример той самой описанной в статье проблемы с именованием сущностей.
«Передача дележом» — это «pass by sharing»? Устоявшегося перевода не назову, но такой перевод читаю первый раз.
Да, это «pass by sharing». А если устоявшегося термина нет, то нужно же как-то первый раз это назвать. Можно ещё предложить «разделением доступа» или «одалживанием», но это не лучше и не хуже.
UFO just landed and posted this here
Проблема не столько с замыканиями, сколько с замыкаемыми переменными. Во многих языках вместо переменных используются неизменяемые величины, и таких проблем не возникает. Хотя в C++ и, в некоторой степени, в Rust поведением переменных в замыканиях можно явно управлять.
> C++: map (а на самом деле это двоичное дерево. С++11 добавляет unordered_map, который является хэш-таблицей)
Вроде бы, стандарт C++ не обязывает реализовывать map именно двоичным деревом, а unordered_map — хэш-таблицей.
Вроде бы, стандарт C++ не обязывает реализовывать map именно двоичным деревом, а unordered_map — хэш-таблицей.
Не обязывает, но это самый оптимальный способ и надо иметь веские причины делать как-то иначе. Вроде бы не один мейнстрим-компилятор таких причин не имеет.
Не уверен, что по всему спектру применений C++ этот способ оптимальный (без «самый»). Вполне могу предположить себе платформу, на которой реализация map может быть не деревом, а как раз хэш-таблицей.
Не думаю также, что мейнстримность чего-либо должна быть основанием стричь всё остальное под ту же гребёнку, в данном случае — менять терминологию из стандарта языка.
Не думаю также, что мейнстримность чего-либо должна быть основанием стричь всё остальное под ту же гребёнку, в данном случае — менять терминологию из стандарта языка.
map точно не обязывает, а еще его часто реализовывают красно-черным деревом
И это ещё не самый страшный случай, поскольку когда упоминается тип word — это вообще может подразумевать как минимум четыре различных толкования в плане его размера.Толкование одно — машинное слово
Само определение в статье, которую вы предложили, уже содержит как минимум одно «и/или» (размер регистров и/или размер шины данных). И потом, можно перебирать разные регистры. Итак, на самой популярной десктопной архитектуре, каков размер слова? 8? 16? 32? 64? 80? 128? 256? Или 512 бит?
Ну и, например, в контекте языка unix shell, word — совсем другое. :)
Ну и, например, в контекте языка unix shell, word — совсем другое. :)
Вспомнился комикс про философский смысл названий (сорри, нету ссылки на страничку):
http://static.existentialcomics.com/comics/philosophyFriends1.png
http://static.existentialcomics.com/comics/philosophyFriends2.png
http://static.existentialcomics.com/comics/philosophyFriends1.png
{kind=link}
http://static.existentialcomics.com/comics/philosophyFriends2.png
{kind=link}
С каких это пор Питон стал языком со строгой типизацией? (И, кстати — что это такое?)
«Список инициализаторов» (как и список параметров функции") — это синтаксические конструкции языка, возможно вообще не имеющих однозначного представления в памяти.
Вообще, в тексте куча мелких шероховатостей и неясностей — непонятно откуда взявшихся, то ли из оригинала, то ли от переводчика.
«Список инициализаторов» (как и список параметров функции") — это синтаксические конструкции языка, возможно вообще не имеющих однозначного представления в памяти.
Вообще, в тексте куча мелких шероховатостей и неясностей — непонятно откуда взявшихся, то ли из оригинала, то ли от переводчика.
С каких это пор Питон стал языком со строгой типизацией?
С рождения.
> 3+"4"
< TypeError: unsupported operand type(s) for +: 'int' and 'str'Невозможность сложить число и строку — отличительный признак языка со строгой типизацией.
UPD: а, вы наверное имели в виду, что на русском обычно этот вид типизации называют сильным, а не строгим. Тогда согласен.
Примечание: В русскоязычной литературе часто встречается некорректный перевод[источник не указан 234 дня] термина «strong typing» как «строгая типизация»; корректный вариант «сильная типизация» используется лишь при противопоставлении «слабой типизации». Следует иметь в виду, что использование термина «строгий» в отношении системы типов языка может вызвать путаницу со строгой семантикой вычислений языка (англ. strict evaluation).
И таки да — вначале шла «сильная типизация» — а под конец пошла «строгая».
И таки да — вначале шла «сильная типизация» — а под конец пошла «строгая».
вообще-то именно разноообразие обеспечивает устойчивость разным систем
а языки надо просто учить, в том числе и вотношениие смысла моделей данных, используемых в них
А принцип — шаг влево — шаг вправо — попытка к бегству — стреляем без предупреждения — не очень правильный путь развития
Смысл развития в расширении, а не в сужении смыслов
а языки надо просто учить, в том числе и вотношениие смысла моделей данных, используемых в них
А принцип — шаг влево — шаг вправо — попытка к бегству — стреляем без предупреждения — не очень правильный путь развития
Смысл развития в расширении, а не в сужении смыслов
еще в тему… в таблицах Lua можно одновременно хранить и числовые, и строковые ключи, и для итерирования использовать два разных метода… очень «удобно»… ))
вся эта чехарда с понятиями воспринимается вполне естественно, если к данной области деятельности вместо термина «компьютерные ноуки» применить «компьютерные языки».
в естественных разговорных языках все то же самое, куча синонимов (много разных слов обозначают то же и так же), слов с множественной нагрузкой (коса, ключ...) и то же множество толкования понятия в зависимости от контекста использования, в толковых словарях много примеров.
и причина та же — языки программирования возникают не как науки ( не как специально организованное построение логически непротиворечивой, замкнутой и полной системы понятий), а как практики — как возникают и развиваются диалекты разговорных языков, стили живописи и музыки.
история развития и актуальное содержание языка PHP, наверное, ярчайший образец этого эволюционного процесса.
ПС. пользуясь случаем прошу поделиться ссылкой на материалы (если встречались) о теории информации (не теории о обработке и передаче данных, которую по ошибке називают теорией инф..)
в естественных разговорных языках все то же самое, куча синонимов (много разных слов обозначают то же и так же), слов с множественной нагрузкой (коса, ключ...) и то же множество толкования понятия в зависимости от контекста использования, в толковых словарях много примеров.
и причина та же — языки программирования возникают не как науки ( не как специально организованное построение логически непротиворечивой, замкнутой и полной системы понятий), а как практики — как возникают и развиваются диалекты разговорных языков, стили живописи и музыки.
история развития и актуальное содержание языка PHP, наверное, ярчайший образец этого эволюционного процесса.
ПС. пользуясь случаем прошу поделиться ссылкой на материалы (если встречались) о теории информации (не теории о обработке и передаче данных, которую по ошибке називают теорией инф..)
лично я уверен, что такой штуки как «свободная типизация» не существует
Лично я уверен, что все ассемблеры, которые я использовал — языки программирования со свободной типизацией или, другими словами, вообще без типизации. Данные в памяти или регистрах общего назначения нетипизированные и каждая инструкция их использующая как бы осуществляет неявное приведение этих данных к тому типу, с которым она работает. Результат инструкции, если он есть, также нетипизированный и уже следующая инструкция может использовать его данные совсем другого типа.
> каждая инструкция их использующая как бы осуществляет неявное приведение этих данных к тому типу, с которым она работает
Правильнее будет сказать «интерпретирует данные, как данные того типа». Потому что приведение обычно подразумевает изменение формата и/или внутреннего представления (например: приведение int к string, приведение float к int), хотя и не всегда, а инструкция не меняет данные, а просто предполагает, что они уже в нужном ей формате.
Правильнее будет сказать «интерпретирует данные, как данные того типа». Потому что приведение обычно подразумевает изменение формата и/или внутреннего представления (например: приведение int к string, приведение float к int), хотя и не всегда, а инструкция не меняет данные, а просто предполагает, что они уже в нужном ей формате.
Спасибо, это очень хорошая статья.
Она могла бы быть отличным введением к разделу «Семантика языков программирования» в курсе «Теория ЯП». Теперь, по её прочтении, можно смело рассказывать студентам о том, зачем нужны такие «скучные» вещи, как операционная, аксиоматическая и денотационная семантика; что такое контракты, для чего появился язык Racket и чем силён Eiffel; почему в Haskell и Scala используют такие странные слова, как «моноид», «функтор» или «комонада» (что это не «хипстерская мода» и не умничание, а денотационная семантика соответствующих конструкций, которые можно обнаружить и в других языках); зачем, наконец, имея в своём распоряжении С, С++ и Java, сочинять и развивать новые языки программирования, подчас, странные, «академические» (с плохо проработанной операционной семантикой) или вовсе «фриковские».
Излагаемая в статье проблема — это проблема программирования, а не Computer Science. Параллельно с изобретением новых конструкций и концепций программирования (которое и порождает разнообразие и несогласованность терминов) идёт долгий и сложный процесс открытия этих концепций — поиск их денотационной семантики и доказательство точных связей между разными концепциями. Computer Science — это именно об этом, и там это не «сложнейшая проблема», а вполне решаемая задача.
Она могла бы быть отличным введением к разделу «Семантика языков программирования» в курсе «Теория ЯП». Теперь, по её прочтении, можно смело рассказывать студентам о том, зачем нужны такие «скучные» вещи, как операционная, аксиоматическая и денотационная семантика; что такое контракты, для чего появился язык Racket и чем силён Eiffel; почему в Haskell и Scala используют такие странные слова, как «моноид», «функтор» или «комонада» (что это не «хипстерская мода» и не умничание, а денотационная семантика соответствующих конструкций, которые можно обнаружить и в других языках); зачем, наконец, имея в своём распоряжении С, С++ и Java, сочинять и развивать новые языки программирования, подчас, странные, «академические» (с плохо проработанной операционной семантикой) или вовсе «фриковские».
Излагаемая в статье проблема — это проблема программирования, а не Computer Science. Параллельно с изобретением новых конструкций и концепций программирования (которое и порождает разнообразие и несогласованность терминов) идёт долгий и сложный процесс открытия этих концепций — поиск их денотационной семантики и доказательство точных связей между разными концепциями. Computer Science — это именно об этом, и там это не «сложнейшая проблема», а вполне решаемая задача.
Чтобы не было такого, что разные люди по-разному понимают термины, надо давать терминам формальные математические определения. В математике можно доказать, например, что понятия эквивалентны или одно понятие есть частный случай другого. Споров о том, верно ли доказательство, чаще всего не возникает.
Благодаря этому можно найти избыточные термины и прояснить связь между терминами, даже такими, которые употребляются в контексте разных япов.
Благодаря этому можно найти избыточные термины и прояснить связь между терминами, даже такими, которые употребляются в контексте разных япов.
В семантическом вебе пытаются бороться с проблемой разного именования сущностей в разных источниках. Надо попутаться описать разные языки и библиотеке средствами онтологий, должно получиться интересно.
В Perl также есть понятие «списка», но это лишь временный объект, существующий по ходу вычисления некоторого выражения, а не классический контейнерный тип данных.
Автор отжигает. В Perl список это вполне себе тип, которым можно инициализировать переменные «контейнерных» (кстати, а что значит это слово?) типов вроде hash или array, каковой array в свою очередь скорее list… Perl вообще интересный сорт травы, что да то да.
Автор отжигает. В Perl список это вполне себе тип, которым можно инициализировать переменные «контейнерных» (кстати, а что значит это слово?) типов вроде hash или array, каковой array в свою очередь скорее list… Perl вообще интересный сорт травы, что да то да.
Sign up to leave a comment.
Сложнейшая проблема компьютерных наук