Comments 15
Пост великолепен, абсолютно ничего лишнего и все по делу, с нетерпением жду следующей статьи!
Поделюсь одним своим опытом. Вдруг кому будет интересно, или пригодится. Извиняюсь за многобукафф — в двух словах не объяснить.
Одно время много занимался вопросом звукообразования — правда с противоположной стороны (т.е. в части вопроса распознавания речи, в основном гонял тесты на базе TIMIT). В попытках наиболее ёмко вычленить, что же превращает просто звук в речь — пробовал в том числе идти и от физики звукообразования (и много чего еще пробовал). Но все такого рода формальные теории давали слишком «грязные» результаты. После этого родилось у меня одно, так сказать, «асимметричное» решение.
Мысль была простая: коль скоро есть идеальный инструмент анализа звука, умеющий отлично отличать речь от обычного звука (моё ухо), то можно попробовать пойти от противного. Взять речь, то бишь вокализованные звуки, и начать глумиться над амплитудно-фазово-частотными характеристиками, прослушивая получившиеся результаты, и тем самым методом ручных тестов — определять, что же делает звук — фонемой.
Разумеется, для этого вначале была решена задача качественного автоматического разбиения речи на однократные периоды колебаний, далее в рамках каждого периода — делалось Фурье, на результаты Фурье — накладывались разные воздействия, далее производилось обратное преобразование, полученные кусочки «модернизированной» речи склеивались в итоговый сигнал, и производилось прослушивание.
В результате огромного кол-ва таких тестов (явно больше чем несколько сотен, скорее речь про пару тысяч прослушиваний по разному скорректированной речи, для широкого набора дикторов), мне стало очевидно, что стандартные применяемые алгоритмы распознавания речи — крайне далеки от реальности. Фактически, для уха, в части именно распознавания самой фонемы — значение имеет исключительно динамика изменения амплитуд фурье-спектра от колебания к колебанию. Всё остальное (конкретная форма амплитудной зависимости спектра, где находятся всеми любимые форманты, как меняются фазовые соотношения в сигнале и т.п.) не имеет совершенно никакого значения. Т.е. вообще не существенно. Максимум — всё это дает (на слух) просто другие обертона/половую принадлежность/оценку возраста, но при этом устойчиво распознается как речь — и смысл речи читается абсолютно однозначно. Даже когда сигнал превращается в хрип-писк, т.е. на каждом колебательном цикле — случайным образом изменены амплитуды и фазы, так что от «вокализованности» не остается и следа а сам сигнал слышится скорее как «звук тупой пилы по мокрому дереву» нежели как речь — всё равно этот шум-скрип однозначно складывается в уверенно распознанную речь, при совершенно невероятных амплитудах коррекции (по отношению к исходным амплитудам) — при которых там не то что формант различить нельзя, а вообще сам звук не имеет ничего общего с тем что может издавать человек. А вот обратная ситуация, т.е. плавное системное изменение динамики амплитуд частот (по мере «разворачивания» фонемы во временной области) резко ухудшает распознавание, вплоть до полной его невозможности.
Тем самым я пришел к простому выводу: увлечение формантным анализом, кепстральными коэффициентами и т.п. — изначально очень далеко от того, что нужно делать по крайней мере если говорить про задачу распознавания речи (все такого рода подходы конечно частично «цепляют» динамику изменения амплитуд частот, но именно что частично).
Соответственно, прочитав пост выше, возникла мысль, что в части генерации голоса, либо его изменения — наверное можно попробовать идти аналогичным путем. Т.е. не от теории, а от практики. Накладывать дополнительное преобразование на амплитуды и фазы частот исходного сигнала (разумеется с первоначальным разбиением на единичные колебательные циклы), и проводить опрос — что изменилось в характеристиках речи (стала ли она более женственной или мужественной, как изменился возраст распознаваемый из речи, и т.п. и т.д.). Для большого массива дикторов, и большого массива преобразований — снять ответы большого массива «инструментов» (т.е. слушателей). А далее уже на базе большого массива данных по такого рода «измерениям» — построить преобразователь, позволяющий «поправить» голос в сторону нужной характеристики (используя стандартные алгоритмы, вроде нечеткой логики/нейросетей/т.п.). Т.е. просто «измерить ухом» те изменения, которые необходимо вносить в сигнал, чтобы поменять речь в требуемую сторону. Вот такая мысль. Хотя, думается, чтобы реализовать подобный подход — наверное надо быть Гуглом.
Одно время много занимался вопросом звукообразования — правда с противоположной стороны (т.е. в части вопроса распознавания речи, в основном гонял тесты на базе TIMIT). В попытках наиболее ёмко вычленить, что же превращает просто звук в речь — пробовал в том числе идти и от физики звукообразования (и много чего еще пробовал). Но все такого рода формальные теории давали слишком «грязные» результаты. После этого родилось у меня одно, так сказать, «асимметричное» решение.
Мысль была простая: коль скоро есть идеальный инструмент анализа звука, умеющий отлично отличать речь от обычного звука (моё ухо), то можно попробовать пойти от противного. Взять речь, то бишь вокализованные звуки, и начать глумиться над амплитудно-фазово-частотными характеристиками, прослушивая получившиеся результаты, и тем самым методом ручных тестов — определять, что же делает звук — фонемой.
Разумеется, для этого вначале была решена задача качественного автоматического разбиения речи на однократные периоды колебаний, далее в рамках каждого периода — делалось Фурье, на результаты Фурье — накладывались разные воздействия, далее производилось обратное преобразование, полученные кусочки «модернизированной» речи склеивались в итоговый сигнал, и производилось прослушивание.
В результате огромного кол-ва таких тестов (явно больше чем несколько сотен, скорее речь про пару тысяч прослушиваний по разному скорректированной речи, для широкого набора дикторов), мне стало очевидно, что стандартные применяемые алгоритмы распознавания речи — крайне далеки от реальности. Фактически, для уха, в части именно распознавания самой фонемы — значение имеет исключительно динамика изменения амплитуд фурье-спектра от колебания к колебанию. Всё остальное (конкретная форма амплитудной зависимости спектра, где находятся всеми любимые форманты, как меняются фазовые соотношения в сигнале и т.п.) не имеет совершенно никакого значения. Т.е. вообще не существенно. Максимум — всё это дает (на слух) просто другие обертона/половую принадлежность/оценку возраста, но при этом устойчиво распознается как речь — и смысл речи читается абсолютно однозначно. Даже когда сигнал превращается в хрип-писк, т.е. на каждом колебательном цикле — случайным образом изменены амплитуды и фазы, так что от «вокализованности» не остается и следа а сам сигнал слышится скорее как «звук тупой пилы по мокрому дереву» нежели как речь — всё равно этот шум-скрип однозначно складывается в уверенно распознанную речь, при совершенно невероятных амплитудах коррекции (по отношению к исходным амплитудам) — при которых там не то что формант различить нельзя, а вообще сам звук не имеет ничего общего с тем что может издавать человек. А вот обратная ситуация, т.е. плавное системное изменение динамики амплитуд частот (по мере «разворачивания» фонемы во временной области) резко ухудшает распознавание, вплоть до полной его невозможности.
Тем самым я пришел к простому выводу: увлечение формантным анализом, кепстральными коэффициентами и т.п. — изначально очень далеко от того, что нужно делать по крайней мере если говорить про задачу распознавания речи (все такого рода подходы конечно частично «цепляют» динамику изменения амплитуд частот, но именно что частично).
Соответственно, прочитав пост выше, возникла мысль, что в части генерации голоса, либо его изменения — наверное можно попробовать идти аналогичным путем. Т.е. не от теории, а от практики. Накладывать дополнительное преобразование на амплитуды и фазы частот исходного сигнала (разумеется с первоначальным разбиением на единичные колебательные циклы), и проводить опрос — что изменилось в характеристиках речи (стала ли она более женственной или мужественной, как изменился возраст распознаваемый из речи, и т.п. и т.д.). Для большого массива дикторов, и большого массива преобразований — снять ответы большого массива «инструментов» (т.е. слушателей). А далее уже на базе большого массива данных по такого рода «измерениям» — построить преобразователь, позволяющий «поправить» голос в сторону нужной характеристики (используя стандартные алгоритмы, вроде нечеткой логики/нейросетей/т.п.). Т.е. просто «измерить ухом» те изменения, которые необходимо вносить в сигнал, чтобы поменять речь в требуемую сторону. Вот такая мысль. Хотя, думается, чтобы реализовать подобный подход — наверное надо быть Гуглом.
Здравствуйте!
Спасибо за интерес к статье и Ваши комментарии! Из большого количества высказанных Вами мыслей позволю себе ответить лишь на некоторые, но перед этим хотел бы задать несколько вопросов. За одно Вы меня поправите, если я Вас не правильно понял :) итак…
1) «Разумеется, для этого вначале была решена задача качественного автоматического разбиения речи на однократные периоды колебаний, далее в рамках каждого периода — делалось Фурье, на результаты Фурье — накладывались разные воздействия ....»
Не совсем понимаю о каких «однократных периодах » идет речь. Имеете ли Вы ввиду частоту основного тона или что-либо другое? Если первое, то смысл дальнейших преобразований более-менее понятен. Если нет — не могли бы Вы более подробно объяснить, на какие именно сегменты вы делили входной речевой сигнал?
2) Изменения проводились только на вокализованных образцах речи? На каких языковых единицах проводились преобразования? Отдельные фонемы? Слова? Предложения?
3) Вы были единственным слушателем синтезированных Вами звуков?
4) "… при совершенно невероятных амплитудах коррекции (по отношению к исходным амплитудам) ..." не могли бы Вы привести какие-либо конкретные числа? Или хотя бы их порядок односительно исходных амплитудных значений.
Прошу не думать, что я пытаюсь Вас на чем-то подловить! Мне действительно хотелось бы понять что именно Вы делали и к каким результатам в итоге пришли!
Спасибо за интерес к статье и Ваши комментарии! Из большого количества высказанных Вами мыслей позволю себе ответить лишь на некоторые, но перед этим хотел бы задать несколько вопросов. За одно Вы меня поправите, если я Вас не правильно понял :) итак…
1) «Разумеется, для этого вначале была решена задача качественного автоматического разбиения речи на однократные периоды колебаний, далее в рамках каждого периода — делалось Фурье, на результаты Фурье — накладывались разные воздействия ....»
Не совсем понимаю о каких «однократных периодах » идет речь. Имеете ли Вы ввиду частоту основного тона или что-либо другое? Если первое, то смысл дальнейших преобразований более-менее понятен. Если нет — не могли бы Вы более подробно объяснить, на какие именно сегменты вы делили входной речевой сигнал?
2) Изменения проводились только на вокализованных образцах речи? На каких языковых единицах проводились преобразования? Отдельные фонемы? Слова? Предложения?
3) Вы были единственным слушателем синтезированных Вами звуков?
4) "… при совершенно невероятных амплитудах коррекции (по отношению к исходным амплитудам) ..." не могли бы Вы привести какие-либо конкретные числа? Или хотя бы их порядок односительно исходных амплитудных значений.
Прошу не думать, что я пытаюсь Вас на чем-то подловить! Мне действительно хотелось бы понять что именно Вы делали и к каким результатам в итоге пришли!
По пунктам.
1. Да, разумеется речь про частоту основного тона. Но, поскольку даже в рамках одной фонемы эта частота непрерывно «плывет», то и говорить про частоту можно лишь довольно условно, корректнее говорить про локальную длительность разового размыкания голосовой щели. Что я и подразумеваю под «однократным периодом».
2. Я «игрался» и целиком над предложениями от разных дикторов (которые есть в базе TIMIT), и над отдельными словами, и над кусочками фонем. Всё пробовал в общем — что мог охватить технически, и на что хватало фантазии. Т.е. отдельно не разделял речь на вокализованные и не вокализованные куски, алгоритм разбивал на периоды — всё подряд, но, разумеется, на не вокализованных отрезках это разбиение носило достаточно условный характер (хотя тоже имело место, и получающаяся «длина окна» была одного порядка с той что возникала на вокализованных участках, чтобы сохранить единообразие).
3. Звуки не вполне синтезированные — ибо они всеж генерировались на базе реальной речи реальных людей. В качестве слушателей на начальном этапе привлёк родичей (брата и сестер, ну и родителей), но быстро выяснилось что значимых различий в восприятии в целом нет — так что достаточно одного меня. Так что бОльшую часть всех дальнейших экспериментов делал уже только «в одно ухо» — моё ).
4. Дело было примерно 3 года назад — точные цифры не назову конечно. Но насколько помню, амплитуда искажений примерно на порядок (т.е. в 10-20 раз больше исходного уровня) хотя и полностью убивала «человечность» звука, но оставляла его информационную составляющую.
Но все преобразования носили именно относительный характер. Т.е. просто накладывать шум (любой природы) на исходный сигнал — это не интересно (да и не соответствовало направлению поиска и задачи). Т.е. за условную единичную амплитуду брался именно исходный сигнал, и далее он изменялся в % от себя самого. Т.е. например — взять все амплитуды фурье-спектра, и домножить их на, скажем, синус, т.е. sin(f), где f — частота фурье-спектра. Или на экспоненту. Или на любую случайную функцию частоты (вплоть до шумовых функций). Но именно домножить а не прибавить. То же самое — с фазой.
На самом первом этапе таких измывательств над звуком — был сильно удивлен простому наблюдению. А именно, если взять просто один период колебаний (т.е. время одного размыкания голосовой щели), и «растиражировать» его вдоль временной оси, то вместо звука фонемы — возникает просто некое абстрактное гудение. Всегда — каков бы ни был вырезанный из реальной фонемы одиночный участок. Несколько периодов основного тона — тоже особо не спасают, просто гудение становится чуть сложнее — но остается гудением, а не звуком голоса.
Далее попросил родичей, и записал с микрофона длительно (постоянно в течение многих секунд) произносимую гласную букву. Типа «ааааааа» непрерывно секунд 10-15. И то же самое — с повышением и понижением частоты основного тона (т.е. звук «ааааа» начинающийся с очень низкого тона, плавно в течение 4-6 секунд поднимающийся вверх, и потом так же плавно спадающий). Проверял ряд идей по тому как меняются зависимости в рамках одного диктора — и одинаковые ли такие зависимости для разных дикторов…
Ну так вот, чтобы длительный просто постоянный звук «аааааа» воспринимался ухом именно как звук речи, а не как гудение, обязательно должны присутствовать определенные динамики амплитуд частот. Причем — не случайного характера. Т.е. если взять просто одно колебание, и далее его растиражировать с случайными небольшими отклонениями по амплитуде-фазе, то такая штука всё равно воспринимается как гудение — просто зашумленное. И только в малом % случаев от общей длительности синтезированного сигнала (видимо где случайные поправки «попадают» в естественные зависимости) это гудение распознается как звук речи (голос). Соответственно, общепринятые идеи о том, что мол линейная модель хорошо описывает речевой тракт — верны в смысле математики, но не верны в смысле информационной значимости того, что важно а что нет для уха человека. Для уха человека, де-факто, оказываются важны как раз вот эти самые «малые погрешности» такой модели (приводящие к тому, что именно малые но системные отклонения амплитуд и фаз частот от «идеальных» и распознаются ухом как речь, а не как металлизированное гудение), а основное «ядро» такой модели — как раз вторично (т.е. линейное «ядро» это всего-лишь «носитель» для информационно-значимых зависимостей, но не сама искомая зависимость; эдакая «канва», которая сама по себе не важна — т.е. вообще не важно какова она в моменте, а важна только её динамика).
Ну и много всякого такого пробовал. Например с шепотом — где источник возбуждения это вообще почти-что белый шум, но это совершенно не мешает уху выделять ровно те же самые зависимости что и на вокализованной речи (и «игры» с принудительными корекциями речи шепотом — приводят к тем же результатам что и для вокализованной речи). Хз, почему исследователи вообще не «роют» тему шепота, по идее это же как раз во многом более простая ситуация (постоянный источник возбуждения голосового тракта, с понятным распределением по частотам) — разобравшись в механизмах которой, можно намного продуктивнее работать с вокализованной речью…
Мои итоговые вывод — что искать надо именно в части относительной динамики амплитуд спектра. Грубо говоря, превращать спектр речи — в некую поверхность амплитуд (причем скользящее окно необходимо разумеется брать переменным — так чтобы в него всегда укладывался один период «мгновенного» основного тона), далее брать производную по времени для такой поверхности — отдельно для каждой частоты, и полученную поверхность из таких производных — уже описывать в терминах коэффициентов неких функций. И вот такие коэффициенты — уже будут иметь самое прямое отношение и к «очеловечиванию» синтезированной речи, и к распознаванию оной, и т.п.
Вот где-то на этом месте я и устал от данной темы, ну и отложил её в долгий ящик (во многом в связи с тем, что дальнейшие изыскания в таком направлении требуют уже команды, одному — стало тяжело, а свободное от работы время — не резиновое ). Т.е. софт до сих пор лежит на диске, равно как и база TIMIT, но энергия закончилась ). А тут наткнулся вдруг на Вашу статью, и «душа разбередилась». Потому и пишут так много наверное ).
1. Да, разумеется речь про частоту основного тона. Но, поскольку даже в рамках одной фонемы эта частота непрерывно «плывет», то и говорить про частоту можно лишь довольно условно, корректнее говорить про локальную длительность разового размыкания голосовой щели. Что я и подразумеваю под «однократным периодом».
2. Я «игрался» и целиком над предложениями от разных дикторов (которые есть в базе TIMIT), и над отдельными словами, и над кусочками фонем. Всё пробовал в общем — что мог охватить технически, и на что хватало фантазии. Т.е. отдельно не разделял речь на вокализованные и не вокализованные куски, алгоритм разбивал на периоды — всё подряд, но, разумеется, на не вокализованных отрезках это разбиение носило достаточно условный характер (хотя тоже имело место, и получающаяся «длина окна» была одного порядка с той что возникала на вокализованных участках, чтобы сохранить единообразие).
3. Звуки не вполне синтезированные — ибо они всеж генерировались на базе реальной речи реальных людей. В качестве слушателей на начальном этапе привлёк родичей (брата и сестер, ну и родителей), но быстро выяснилось что значимых различий в восприятии в целом нет — так что достаточно одного меня. Так что бОльшую часть всех дальнейших экспериментов делал уже только «в одно ухо» — моё ).
4. Дело было примерно 3 года назад — точные цифры не назову конечно. Но насколько помню, амплитуда искажений примерно на порядок (т.е. в 10-20 раз больше исходного уровня) хотя и полностью убивала «человечность» звука, но оставляла его информационную составляющую.
Но все преобразования носили именно относительный характер. Т.е. просто накладывать шум (любой природы) на исходный сигнал — это не интересно (да и не соответствовало направлению поиска и задачи). Т.е. за условную единичную амплитуду брался именно исходный сигнал, и далее он изменялся в % от себя самого. Т.е. например — взять все амплитуды фурье-спектра, и домножить их на, скажем, синус, т.е. sin(f), где f — частота фурье-спектра. Или на экспоненту. Или на любую случайную функцию частоты (вплоть до шумовых функций). Но именно домножить а не прибавить. То же самое — с фазой.
На самом первом этапе таких измывательств над звуком — был сильно удивлен простому наблюдению. А именно, если взять просто один период колебаний (т.е. время одного размыкания голосовой щели), и «растиражировать» его вдоль временной оси, то вместо звука фонемы — возникает просто некое абстрактное гудение. Всегда — каков бы ни был вырезанный из реальной фонемы одиночный участок. Несколько периодов основного тона — тоже особо не спасают, просто гудение становится чуть сложнее — но остается гудением, а не звуком голоса.
Далее попросил родичей, и записал с микрофона длительно (постоянно в течение многих секунд) произносимую гласную букву. Типа «ааааааа» непрерывно секунд 10-15. И то же самое — с повышением и понижением частоты основного тона (т.е. звук «ааааа» начинающийся с очень низкого тона, плавно в течение 4-6 секунд поднимающийся вверх, и потом так же плавно спадающий). Проверял ряд идей по тому как меняются зависимости в рамках одного диктора — и одинаковые ли такие зависимости для разных дикторов…
Ну так вот, чтобы длительный просто постоянный звук «аааааа» воспринимался ухом именно как звук речи, а не как гудение, обязательно должны присутствовать определенные динамики амплитуд частот. Причем — не случайного характера. Т.е. если взять просто одно колебание, и далее его растиражировать с случайными небольшими отклонениями по амплитуде-фазе, то такая штука всё равно воспринимается как гудение — просто зашумленное. И только в малом % случаев от общей длительности синтезированного сигнала (видимо где случайные поправки «попадают» в естественные зависимости) это гудение распознается как звук речи (голос). Соответственно, общепринятые идеи о том, что мол линейная модель хорошо описывает речевой тракт — верны в смысле математики, но не верны в смысле информационной значимости того, что важно а что нет для уха человека. Для уха человека, де-факто, оказываются важны как раз вот эти самые «малые погрешности» такой модели (приводящие к тому, что именно малые но системные отклонения амплитуд и фаз частот от «идеальных» и распознаются ухом как речь, а не как металлизированное гудение), а основное «ядро» такой модели — как раз вторично (т.е. линейное «ядро» это всего-лишь «носитель» для информационно-значимых зависимостей, но не сама искомая зависимость; эдакая «канва», которая сама по себе не важна — т.е. вообще не важно какова она в моменте, а важна только её динамика).
Ну и много всякого такого пробовал. Например с шепотом — где источник возбуждения это вообще почти-что белый шум, но это совершенно не мешает уху выделять ровно те же самые зависимости что и на вокализованной речи (и «игры» с принудительными корекциями речи шепотом — приводят к тем же результатам что и для вокализованной речи). Хз, почему исследователи вообще не «роют» тему шепота, по идее это же как раз во многом более простая ситуация (постоянный источник возбуждения голосового тракта, с понятным распределением по частотам) — разобравшись в механизмах которой, можно намного продуктивнее работать с вокализованной речью…
Мои итоговые вывод — что искать надо именно в части относительной динамики амплитуд спектра. Грубо говоря, превращать спектр речи — в некую поверхность амплитуд (причем скользящее окно необходимо разумеется брать переменным — так чтобы в него всегда укладывался один период «мгновенного» основного тона), далее брать производную по времени для такой поверхности — отдельно для каждой частоты, и полученную поверхность из таких производных — уже описывать в терминах коэффициентов неких функций. И вот такие коэффициенты — уже будут иметь самое прямое отношение и к «очеловечиванию» синтезированной речи, и к распознаванию оной, и т.п.
Вот где-то на этом месте я и устал от данной темы, ну и отложил её в долгий ящик (во многом в связи с тем, что дальнейшие изыскания в таком направлении требуют уже команды, одному — стало тяжело, а свободное от работы время — не резиновое ). Т.е. софт до сих пор лежит на диске, равно как и база TIMIT, но энергия закончилась ). А тут наткнулся вдруг на Вашу статью, и «душа разбередилась». Потому и пишут так много наверное ).
Большое спасибо за такой развернутый рассказ! Вы затронули очень много интересных моментов, которые исследовались и исследуются многими!
Вы совершенно справедливо отметили, что именно «неровности» и «шероховатости» в вокализованном сигнале возбуждения делают из него живой человеческий голос, а не монотонный роботизированный звук. Тут конечно уже встает вопрос цели исследования — синтезировать разборчивую речь (что уже вполне возможно), либо синтезировать натурально звучащую речь, что пока ещё нельзя назвать решенной задачей. В обоих случаях, эта «линейная модель» (назовем пока так) играет весьма значитеьную роль. В первом — её одной уже вполне достаточно для синтеза вполне разборчивой речи. Конечно параметров там будет значительно больше, нежели рассказано в статье, но это проблема статьи :) Во втором случае — она играет незаменимую роль в качестве некоторой исходной «точки отсчета», если можно так выразиться. Она дает базовые соотношения, над которыми можно уже экспериментировать, ставить опыты, делать выводы. Тяжело искать отличия в множестве объектов не имея никакого эталона. Данная линейная модель звукообразования и может быть этим базовым, максимально упрощенным эталоном.
Насчет важности анализа не только мгновенных характеристик сигнала, но и их поведения во времени — тоже абсолютно правильно. Тут можно много привести примеров, но раз уж затронули вопросы распознавания — в задачах распознавания речи, насколько я могу судить, именно поэтому и нашли широкое применение скрытые модели Маркова, которые в том числе отражают статистику изменения состояний системы, а не только вероятности каких-то мгновенных её состояний. В то время как попытки распознавать отдельные фонетический единицы в изоляции пришли в тупик и имеют смысл только при работе с известным голосом.
К вопросу модификации амплитуд/фаз при обработке коротковременного спектра. Соглашусь с Вами, что фазы модифицировать можно самым причудливым образом. Конечно с условием, что работаем на коротких временных отрезках, даже не обязательно кратных периоду основного тона. Собственно именно на этом построен т.н. эффект «whisperization». Разборчивость речи при этом вполне сохраняется, хотя конечно человеческим голосом подобный звуки назвать язык не повернется :) Насчет амплитуд — уже не так все очевидно. Модифицируя амплитуды испортить разборчивость значительно проще. Согнасен, что менять их можно, согласен, что порой весьма сильно и смысл речи при этом можно будет разобрать. Но именно, что порой… Говорить, что можно с ними делать практически все, что угодно, и при этом речь останется разборчивой — в общем случае я бы не рискнул… Тут пожалуй стоит говорить о конкретной реализации и параметрах: что менялось, по какому закону, как часто, какой входной сигнал… Непростой вопрос, чтобы сразу на него ставить какие-то штампы…
Ещё раз большое спасибо за столь развернутый ответ!
Вы совершенно справедливо отметили, что именно «неровности» и «шероховатости» в вокализованном сигнале возбуждения делают из него живой человеческий голос, а не монотонный роботизированный звук. Тут конечно уже встает вопрос цели исследования — синтезировать разборчивую речь (что уже вполне возможно), либо синтезировать натурально звучащую речь, что пока ещё нельзя назвать решенной задачей. В обоих случаях, эта «линейная модель» (назовем пока так) играет весьма значитеьную роль. В первом — её одной уже вполне достаточно для синтеза вполне разборчивой речи. Конечно параметров там будет значительно больше, нежели рассказано в статье, но это проблема статьи :) Во втором случае — она играет незаменимую роль в качестве некоторой исходной «точки отсчета», если можно так выразиться. Она дает базовые соотношения, над которыми можно уже экспериментировать, ставить опыты, делать выводы. Тяжело искать отличия в множестве объектов не имея никакого эталона. Данная линейная модель звукообразования и может быть этим базовым, максимально упрощенным эталоном.
Насчет важности анализа не только мгновенных характеристик сигнала, но и их поведения во времени — тоже абсолютно правильно. Тут можно много привести примеров, но раз уж затронули вопросы распознавания — в задачах распознавания речи, насколько я могу судить, именно поэтому и нашли широкое применение скрытые модели Маркова, которые в том числе отражают статистику изменения состояний системы, а не только вероятности каких-то мгновенных её состояний. В то время как попытки распознавать отдельные фонетический единицы в изоляции пришли в тупик и имеют смысл только при работе с известным голосом.
К вопросу модификации амплитуд/фаз при обработке коротковременного спектра. Соглашусь с Вами, что фазы модифицировать можно самым причудливым образом. Конечно с условием, что работаем на коротких временных отрезках, даже не обязательно кратных периоду основного тона. Собственно именно на этом построен т.н. эффект «whisperization». Разборчивость речи при этом вполне сохраняется, хотя конечно человеческим голосом подобный звуки назвать язык не повернется :) Насчет амплитуд — уже не так все очевидно. Модифицируя амплитуды испортить разборчивость значительно проще. Согнасен, что менять их можно, согласен, что порой весьма сильно и смысл речи при этом можно будет разобрать. Но именно, что порой… Говорить, что можно с ними делать практически все, что угодно, и при этом речь останется разборчивой — в общем случае я бы не рискнул… Тут пожалуй стоит говорить о конкретной реализации и параметрах: что менялось, по какому закону, как часто, какой входной сигнал… Непростой вопрос, чтобы сразу на него ставить какие-то штампы…
Ещё раз большое спасибо за столь развернутый ответ!
В задачах распознавания речи конечно используют цепи Маркова, но, насколько я в курсе, как правило в несколько другом контексте. Когда уже, в каком-то виде, найдены вероятность принадлежности локального речевого кусочка ко всем фонемам, тогда развертку таких вероятностей во времени — действительно можно использовать для цепей Маркова (для распознавания уже конкретных фонем). Но это — уже второй этап процесса распознавания. Если сами по себе вероятности принадлежности к фонемам найдены «грязно» — то цепи Маркова не смогут выдать хороший результат. Это, разумеется, просто моё мнение (я много работал и с первичной и со вторичной обработкой сигналов в разного рода задачах распознавания, и для себя пришел к выводу, что именно первичная обработка сигнала — это всегда самое «узкое место»).
Мне не приходилось встречать работ, где за точку фокуса брали бы именно относительные изменения амплитуд спектра. Причем использовались бы корректно найденные амплитуды — т.к. именно незначительные по амплитуде но системные/плавные изменения амплитуд и оказались решающими исходя из моих экспериментов, а делая поиск оных с окном фиксированной длины — этого никак не достичь. Далее строили бы динамику относительных изменений амплитуд спектра от периода к периоду, и искали бы общие паттерны такой динамики — для разных дикторов (в рамках одной фонемы). Такого — не находил.
Всем хочется простоты — т.е. малого кол-ва чисел, характеризующих динамику спектра. И в погоне за компактностью описания фич — по сути «гробят» значительную часть критичных (по информационной значимости) данных. Естественно, делая не вполне корректное сворачивание потока речи в фичи (с значительным % потери значимой информации) — в дальнейшем не получить качественного результата, какие бы методы не применялись…
На мой взгляд, компактное описание фич речи возможно (и фич «человечности» речи) — но его необходимо делать в терминах коэффициентов некоей общей формулы, задающей поверхность, образованную производными по времени — от правильно найденных амплитуд спектра речи, причем эти производные надо нормировать на сами амплитуды. Вот такие коэффициенты (задающие такую поверхность) — были бы необходимы и достаточны для полного описания речи, её паттернов, механизмов «очеловечивания» сигнала, его распознавания, и т.п.
Но и математически и алгоритмически — это весьма непростая постановка задачи, разумеется.
По амплитудам. Выше я описывал, что исходя из моих экспериментов, с ними можно делать все что угодно — но только если используется одинаковое преобразование, примененное к каждому периоду основного тона, т.е. преобразование не меняющее сколь-нибудь заметно график производных амплитуд по времени, нормированных на модуль амплитуд. Т.е. берем и умножаем фурье A(f,t) — на функцию S(f), не зависящую от времени (одинаковую для всех фурье). Тогда S(f) может быть практически «от балды». Это в том числе может быть например и функция, обратная амплитудам формант (т.е. по сути выравнивающая средний спектр на прямую линию). Главное чтобы она была одинакова — для всех периодов. А вот если мы берем функцию корректировки зависящую и от времени, т.е. корректировка спектра системно/плавно меняется с течением времени — это резко убивает информацию (для уха). Откуда собственно и следует явный вывод — что значимость имеет только относительное изменение амплитуды, а не абсолютное значение амплитуд. Абсолютное значение амплитуд спектра характеризует суммарно: речевой тракт + окружающую среду (например комнату с её характеристикой) + АЧХ сигнала накачки тракта. Т.е. даже по здравому смыслу — сама по себе амплитуда, и отношение амплитуд разных частот друг в другу «в моменте» — почти ничего не значит (зависит слишком от большого кол-ва параметров). Разумеется, это мои личные выводы — оформлять/доказывать их в виде диссертации я морально не готов.
Спасибо за Ваш комментарии и в равной степени развернутый ответ.
Мне не приходилось встречать работ, где за точку фокуса брали бы именно относительные изменения амплитуд спектра. Причем использовались бы корректно найденные амплитуды — т.к. именно незначительные по амплитуде но системные/плавные изменения амплитуд и оказались решающими исходя из моих экспериментов, а делая поиск оных с окном фиксированной длины — этого никак не достичь. Далее строили бы динамику относительных изменений амплитуд спектра от периода к периоду, и искали бы общие паттерны такой динамики — для разных дикторов (в рамках одной фонемы). Такого — не находил.
Всем хочется простоты — т.е. малого кол-ва чисел, характеризующих динамику спектра. И в погоне за компактностью описания фич — по сути «гробят» значительную часть критичных (по информационной значимости) данных. Естественно, делая не вполне корректное сворачивание потока речи в фичи (с значительным % потери значимой информации) — в дальнейшем не получить качественного результата, какие бы методы не применялись…
На мой взгляд, компактное описание фич речи возможно (и фич «человечности» речи) — но его необходимо делать в терминах коэффициентов некоей общей формулы, задающей поверхность, образованную производными по времени — от правильно найденных амплитуд спектра речи, причем эти производные надо нормировать на сами амплитуды. Вот такие коэффициенты (задающие такую поверхность) — были бы необходимы и достаточны для полного описания речи, её паттернов, механизмов «очеловечивания» сигнала, его распознавания, и т.п.
Но и математически и алгоритмически — это весьма непростая постановка задачи, разумеется.
По амплитудам. Выше я описывал, что исходя из моих экспериментов, с ними можно делать все что угодно — но только если используется одинаковое преобразование, примененное к каждому периоду основного тона, т.е. преобразование не меняющее сколь-нибудь заметно график производных амплитуд по времени, нормированных на модуль амплитуд. Т.е. берем и умножаем фурье A(f,t) — на функцию S(f), не зависящую от времени (одинаковую для всех фурье). Тогда S(f) может быть практически «от балды». Это в том числе может быть например и функция, обратная амплитудам формант (т.е. по сути выравнивающая средний спектр на прямую линию). Главное чтобы она была одинакова — для всех периодов. А вот если мы берем функцию корректировки зависящую и от времени, т.е. корректировка спектра системно/плавно меняется с течением времени — это резко убивает информацию (для уха). Откуда собственно и следует явный вывод — что значимость имеет только относительное изменение амплитуды, а не абсолютное значение амплитуд. Абсолютное значение амплитуд спектра характеризует суммарно: речевой тракт + окружающую среду (например комнату с её характеристикой) + АЧХ сигнала накачки тракта. Т.е. даже по здравому смыслу — сама по себе амплитуда, и отношение амплитуд разных частот друг в другу «в моменте» — почти ничего не значит (зависит слишком от большого кол-ва параметров). Разумеется, это мои личные выводы — оформлять/доказывать их в виде диссертации я морально не готов.
Спасибо за Ваш комментарии и в равной степени развернутый ответ.
Простите, что буду отвечать немного не по-порядку. Итак,
Если я правильно понял суть Ваших преобразований над спектром — Вы делали обыкновенную фильтрацию в частотной области. С помощью подобной операции действительно не так просто разрушить речевой сигнал до неузнаваемости. Если применялись мультипликативные изменения амплитуд вплоть до 10-20 раз, то это соответствует усилению или ослаблению сигнала на 10-13 дБ по амплитуде (20-26 по-мощности) — изменение весьма сильное, но не фатальное.
Анализ изменения амплитуд в спектре во времени производится в большом количестве работ по адаптивному шумоподавлению с 1 микрофоном, в работах, посвященных выделению отдельных дикторов из смешанного речевого сигнала, а также во многих работах, посвященных оценке и слежению за формантными частотами. Возможно там изменение амплитуд анализируется в несколько ином контексте, чем это предлагаете Вы, но сам факт анализа A(f,t) применяется во множестве работ.
Насчет распознавания речи — согласен, что в начальном формировании вектора фич для текущего анализируемого сегмента в классических подходах редко где фигурирует временной контекст. Но тут вопрос немного филосовский: если смотреть на систему распознавания в целом — то производится как раз контекстно-зависимый анализ, важно что было до и важно что идет после — на мой взгляд вполне подходит к понятию «анализ изменения во времени». Опять же если «расчленять» классическую систему распознавания и смотреть только на первичную обработку — соглашусь с Вами, что там контексту обычно уделяют значетельно меньше внимания.
Если я правильно понял суть Ваших преобразований над спектром — Вы делали обыкновенную фильтрацию в частотной области. С помощью подобной операции действительно не так просто разрушить речевой сигнал до неузнаваемости. Если применялись мультипликативные изменения амплитуд вплоть до 10-20 раз, то это соответствует усилению или ослаблению сигнала на 10-13 дБ по амплитуде (20-26 по-мощности) — изменение весьма сильное, но не фатальное.
Анализ изменения амплитуд в спектре во времени производится в большом количестве работ по адаптивному шумоподавлению с 1 микрофоном, в работах, посвященных выделению отдельных дикторов из смешанного речевого сигнала, а также во многих работах, посвященных оценке и слежению за формантными частотами. Возможно там изменение амплитуд анализируется в несколько ином контексте, чем это предлагаете Вы, но сам факт анализа A(f,t) применяется во множестве работ.
Насчет распознавания речи — согласен, что в начальном формировании вектора фич для текущего анализируемого сегмента в классических подходах редко где фигурирует временной контекст. Но тут вопрос немного филосовский: если смотреть на систему распознавания в целом — то производится как раз контекстно-зависимый анализ, важно что было до и важно что идет после — на мой взгляд вполне подходит к понятию «анализ изменения во времени». Опять же если «расчленять» классическую систему распознавания и смотреть только на первичную обработку — соглашусь с Вами, что там контексту обычно уделяют значетельно меньше внимания.
Формально — да, частотная фильтрация (хотя фильтрация подразумевает выделение узкой части спектра — я же использовал самые разные функции, не только локализованные на узкой частотной полосе).
Выше я не зря написал, что функция должна быть одного типа. Например, так же отлично подходят все функции типа (1+S(f)*Random()). Т.е. мультипликативная функция шумового характера, такая что амплитуда шумового мультипликатора фиксирована для каждой частоты (не меняется от времени) — но в каждом конкретном периоде основного тона используется своя конкретная случайная величина реализации шума, причем отдельно для каждой частоты — своя генерация ГСЧ. Можно использовать не только белый шум, но и любой другой, можно такую штуку в свою очередь множить на любой фиксированный мультипликатор, и т.п.
Так что вкупе с фазовыми искажениями, такого рода преобразования — действительно меняют сигнал до неузнаваемости (и в смысле математики/спектра, и в смысле его «похожести» на речевой сигнал), но — почти не меняют его информационной составляющей (видимо, все эти вариации амплитуд с фиксированной дисперсией — в итоге сглаживаются, и ухом «вытаскивается» именно общая средняя динамика амплитуд спектра — которая оказывается ключевой в смысле информационной значимости).
Сам по себе анализ поверхности вида A(f,t) — не будет осмысленным, т.к. сама по себе амплитуда (и отношения амплитуд друг к другу) на практике оказалась не важна. Важна лишь её динамика, т.е. производная амплитуды по времени, у которой исключен фактор масштаба. Например, должна хорошо работать функция вида A'(f,t)/A(f,t) (здесь ' — это производная по времени), т.к. для такой штуки во первых «выцепляется» именно динамика, во вторых именно динамика относительная (т.е. такое выражение будет инвариантом относительно домножения амплитуд на некий масштабный коэффициент, типа громкости голоса, или добротности резонанса речевого тракта на данной частоте).
В задаче «очеловечивания» синтезированной речи — на мой взгляд, при том подходе который использовал я, вопрос встает сугубо технический. Записать много разных вокализованных звуков большой длины (чтобы фонема непрерывно звучала нескольку секунд), сопоставить динамики «микро-дрожаний » амплитуд спектра (в виде указанном выше), и микро-вариаций частоты основного тона, ну и вывести итоговую эмпирическую зависимость, позволяющую «очеловечить» синтезированный звук. Потом повторить это же упражнение для заметно изменяющегося тона и/или громкости — доработать эмпирическую формулу для такого случая. Т.е. пойти чисто от практики — вывести требуемую зависимость из большого объема данных, не заморачиваясь на теоретизирование по этому поводу на первой фазе…
Ну это уже, так сказать, в порядке размышлизмов.
Выше я не зря написал, что функция должна быть одного типа. Например, так же отлично подходят все функции типа (1+S(f)*Random()). Т.е. мультипликативная функция шумового характера, такая что амплитуда шумового мультипликатора фиксирована для каждой частоты (не меняется от времени) — но в каждом конкретном периоде основного тона используется своя конкретная случайная величина реализации шума, причем отдельно для каждой частоты — своя генерация ГСЧ. Можно использовать не только белый шум, но и любой другой, можно такую штуку в свою очередь множить на любой фиксированный мультипликатор, и т.п.
Так что вкупе с фазовыми искажениями, такого рода преобразования — действительно меняют сигнал до неузнаваемости (и в смысле математики/спектра, и в смысле его «похожести» на речевой сигнал), но — почти не меняют его информационной составляющей (видимо, все эти вариации амплитуд с фиксированной дисперсией — в итоге сглаживаются, и ухом «вытаскивается» именно общая средняя динамика амплитуд спектра — которая оказывается ключевой в смысле информационной значимости).
Сам по себе анализ поверхности вида A(f,t) — не будет осмысленным, т.к. сама по себе амплитуда (и отношения амплитуд друг к другу) на практике оказалась не важна. Важна лишь её динамика, т.е. производная амплитуды по времени, у которой исключен фактор масштаба. Например, должна хорошо работать функция вида A'(f,t)/A(f,t) (здесь ' — это производная по времени), т.к. для такой штуки во первых «выцепляется» именно динамика, во вторых именно динамика относительная (т.е. такое выражение будет инвариантом относительно домножения амплитуд на некий масштабный коэффициент, типа громкости голоса, или добротности резонанса речевого тракта на данной частоте).
В задаче «очеловечивания» синтезированной речи — на мой взгляд, при том подходе который использовал я, вопрос встает сугубо технический. Записать много разных вокализованных звуков большой длины (чтобы фонема непрерывно звучала нескольку секунд), сопоставить динамики «микро-дрожаний » амплитуд спектра (в виде указанном выше), и микро-вариаций частоты основного тона, ну и вывести итоговую эмпирическую зависимость, позволяющую «очеловечить» синтезированный звук. Потом повторить это же упражнение для заметно изменяющегося тона и/или громкости — доработать эмпирическую формулу для такого случая. Т.е. пойти чисто от практики — вывести требуемую зависимость из большого объема данных, не заморачиваясь на теоретизирование по этому поводу на первой фазе…
Ну это уже, так сказать, в порядке размышлизмов.
Мне показалось, что S(f), не зависящая от времени — это, фактически, эквалайзер.
Только количество полос у него большое, да пределы усиления/ослабления можно сделать любыми. А так — просто регулировка тембра в магнитоле. Что наводит на мысль о том, что испортить голос он не должен, что согласуется с вашими экспериментами.
А вот S(f), меняющаяся во времени — это уже, боюсь, амплитудная модуляция (а то и с фазовой вместе).
Даже если пропустить простую синусоиду через S(f,t) [для синусоиды будет только одно значение f], то на выходе получим боковые полосы справа и слева от синусоиды, как у всех сигналов AM-радиостанций. Причём их спектр может быть гораздо шире, чем 1/T, где T-время ваших «однократных периодов». Ибо скачки амплитуды и фазы в S(t) — это, в общем случае, не синусоида с периодом Т, а вообще то, что вам в голову взбрело, меандр там, или что ещё.
Так что КАЖДАЯ частота из исходного спектра обрастает боковыми полосами, которых не было в исходном сигнале. Причём состав этих полос зависит от S(f,t). То есть в речь нещадно добавляется то, чего в ней не было, в отличие от S(f), не зависящей от времени. Неудивительно, что речь становится неразличимой.
То есть результаты экспериментов мне кажутся объяснимыми, но я их объясняю не так, как вы.
Но это на первый взгляд, возможно, я ошибаюсь. Что скажете?
P.S. Автору статьи большое спасибо за изложение полезных вещей человеческим языком.
Только количество полос у него большое, да пределы усиления/ослабления можно сделать любыми. А так — просто регулировка тембра в магнитоле. Что наводит на мысль о том, что испортить голос он не должен, что согласуется с вашими экспериментами.
А вот S(f), меняющаяся во времени — это уже, боюсь, амплитудная модуляция (а то и с фазовой вместе).
Даже если пропустить простую синусоиду через S(f,t) [для синусоиды будет только одно значение f], то на выходе получим боковые полосы справа и слева от синусоиды, как у всех сигналов AM-радиостанций. Причём их спектр может быть гораздо шире, чем 1/T, где T-время ваших «однократных периодов». Ибо скачки амплитуды и фазы в S(t) — это, в общем случае, не синусоида с периодом Т, а вообще то, что вам в голову взбрело, меандр там, или что ещё.
Так что КАЖДАЯ частота из исходного спектра обрастает боковыми полосами, которых не было в исходном сигнале. Причём состав этих полос зависит от S(f,t). То есть в речь нещадно добавляется то, чего в ней не было, в отличие от S(f), не зависящей от времени. Неудивительно, что речь становится неразличимой.
То есть результаты экспериментов мне кажутся объяснимыми, но я их объясняю не так, как вы.
Но это на первый взгляд, возможно, я ошибаюсь. Что скажете?
P.S. Автору статьи большое спасибо за изложение полезных вещей человеческим языком.
Вы разумеется правы — с формальной точки зрения. Но как обычно это бывает, «дьявол прячется в деталях».
1. Поскольку Вы говорите про спектр от всего отрезка речи (т.е. по сути крайне усредненное частотное описание, без учета временой зависимости), то «обрастание» частоты боковым спектром, с формальной точки зрения — тоже может быть рассмотрено как амплитудная модуляция (точнее — амплитудно-фазовая). Т.е. в принципе, любое оконное локальное преобразование можно свести к амплитудной (или фазовой) модуляции — если рассматривать итоговый суммарный (усредненный) спектр от всей речи, а не мгновенный спектр (найденный по малому окну). Фурье в этом смысле, как известно, имеет свои минусы, которые можно «забороть» например через вейвлеты, и для вейвлета — такое преобразование уже не будет выглядеть как добавление бокового спектра. Т.е. формально вы правы, но исходя из физической сути процесса — так рассуждать будет не вполне корректно.
2. Помимо указанного выше, есть еще один нюанс. А имеенно — разница амплитуд искажений. Даже очень большие, но постоянные амплитудные модуляции (в том числе — постоянно-шумовые, т.е. по сути резко различные от периода к периоду — но статистически одинаковые по дисперсии амплитуд искажений за большое кол-во периодов) — как-либо заметно не влияют на возможность распознавания речи, хотя для ряда таких преобразований (с использованием ГСЧ на каждом периоде основного тона) сигнал трансформируется в шумоподобный хрип (и для такого варианта преобразования — средний спектр разумеется изменяется до неузнавания, и по фазе и по амплитуде). Однако, даже слабые, но системно-постоянные изменения в амплитудах локального спектра (насколько помню, на уровне где-то 5% от исходной амплитуды и выше) — резко снижают читаемость речи. Хотя, с точки зрения локального фурье (или вейвлет) спектра, такие искажение малы.
Так что, учитывая установленную важность процесса «развертки» амплитуд во времени, согласится с Вашей трактовкой не могу. Дело явно в критичной значимости относительных изменений амплитуды, а абсолютное значение амплитуд (в т.ч. расположение формант, отношение амплитуд друг к другу и т.п.) — значения не имеет (если говорить про распознавание смысла речи, а не про вторичные признаки — типа пола человека, возраста, и т.п., т.к. для таких вторичных признаков — уже как раз важны именно абсолютные значения амплитуд, а их динамика вторична, что было очень хорошо слышно).
1. Поскольку Вы говорите про спектр от всего отрезка речи (т.е. по сути крайне усредненное частотное описание, без учета временой зависимости), то «обрастание» частоты боковым спектром, с формальной точки зрения — тоже может быть рассмотрено как амплитудная модуляция (точнее — амплитудно-фазовая). Т.е. в принципе, любое оконное локальное преобразование можно свести к амплитудной (или фазовой) модуляции — если рассматривать итоговый суммарный (усредненный) спектр от всей речи, а не мгновенный спектр (найденный по малому окну). Фурье в этом смысле, как известно, имеет свои минусы, которые можно «забороть» например через вейвлеты, и для вейвлета — такое преобразование уже не будет выглядеть как добавление бокового спектра. Т.е. формально вы правы, но исходя из физической сути процесса — так рассуждать будет не вполне корректно.
2. Помимо указанного выше, есть еще один нюанс. А имеенно — разница амплитуд искажений. Даже очень большие, но постоянные амплитудные модуляции (в том числе — постоянно-шумовые, т.е. по сути резко различные от периода к периоду — но статистически одинаковые по дисперсии амплитуд искажений за большое кол-во периодов) — как-либо заметно не влияют на возможность распознавания речи, хотя для ряда таких преобразований (с использованием ГСЧ на каждом периоде основного тона) сигнал трансформируется в шумоподобный хрип (и для такого варианта преобразования — средний спектр разумеется изменяется до неузнавания, и по фазе и по амплитуде). Однако, даже слабые, но системно-постоянные изменения в амплитудах локального спектра (насколько помню, на уровне где-то 5% от исходной амплитуды и выше) — резко снижают читаемость речи. Хотя, с точки зрения локального фурье (или вейвлет) спектра, такие искажение малы.
Так что, учитывая установленную важность процесса «развертки» амплитуд во времени, согласится с Вашей трактовкой не могу. Дело явно в критичной значимости относительных изменений амплитуды, а абсолютное значение амплитуд (в т.ч. расположение формант, отношение амплитуд друг к другу и т.п.) — значения не имеет (если говорить про распознавание смысла речи, а не про вторичные признаки — типа пола человека, возраста, и т.п., т.к. для таких вторичных признаков — уже как раз важны именно абсолютные значения амплитуд, а их динамика вторична, что было очень хорошо слышно).
Пожалуй, спорить не буду. Ваши практические наблюдения перебивают все мои теории, как японская бензопила. Пока что. А, если не секрет, как вы искали частоту основного тона («была решена задача качественного автоматического разбиения речи на однократные периоды колебаний»)? Методов много, но хочется узнать, какой из них больше подошёл?
Конечно не секрет. Пичаль в том, что делал это всё много лет назад — совершенно не помню деталей реализации. Так что для ответа на Ваш вопрос пришлось поднять тулз, которым это всё делалось, и посмотреть по коду — что там у меня накручено… Делал сугубо свой вариант, по свои потребности, не вникая как это обычно делается — так что не в курсе как классифицируется такой метод, и есть ли похожие или нет в лит-ре.
Вот картинка: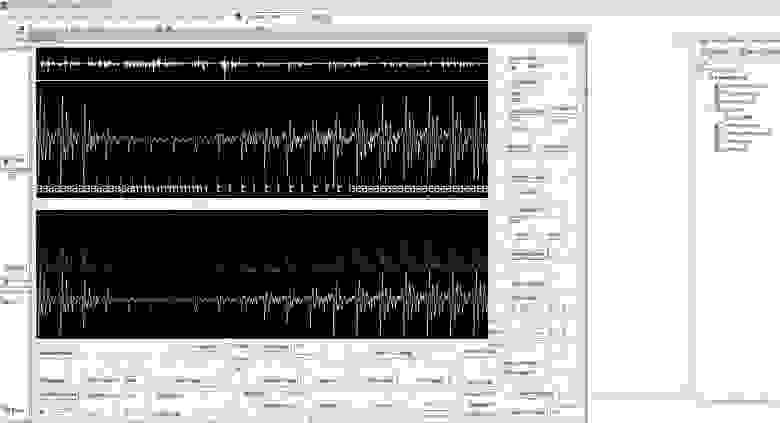
Это собственно вид моего… эээ… экспериментального сэтапа ))).
Вверху — выведен конкретный кусочек речи диктора из базы TIMIT (с разметкой на фонемы — из этой же базы). Т.е. непосредственно звуковые колебания (амплитуда отклонения мембраны микрофона в общем). В данном примере, в окно вывода попало 3000 точек ряда.
Что делает алгоритм в целом:
1) расчитывается скользящая дисперсия этого ряда, по малому окну (около 10 точек шириной). Это — зеленый график на нижнем окне.
2) очень грубо — определяется частота основного тона (из фурье-анализа), простейшим алгоритмом (могу пояснить каким — но это не существенно)
3) исходный сигнал «сканируется» окнами с длиной равной примерно полутора периодам основного тона (т.к. период основного тона определяется грубо — то такой запас необходим). Расположение таких окон идет с шагом, равным четверти длины период основного тона из п.2.
4) в каждом окне — находится экстремум дисперсии, но не просто экстремум — а с дополнительным условием. Условие состоит в том, что экстремуму должен предшествовать период с низкой дисперсией, т.е. должен наблюдаться резкий «взлет» средней величины дисперсии — и вот тогда такой экстремум дисперсии действительно принимается за «правильное» начало колебаний голосовой щели. Т.е. исхожу из физики — начало размыкания голосовой щели самое громкое, далее амплитуда колебаний спадает (а значит — так же спадает и скользящая дисперсия). Это позволяет игнорировать просто максимум дисперсии (т.к. максимум дисперсии — не обязательно означает начало колебания, как видно на левой части имаджа), и корректно находить именно начало колебаний голосовой щели.
5) найденные в п.4 точки таких экстремумов с доп. условием — накладываются друг на друга, и далее «чистятся» от случайных срабатываний такой логики (т.е. остаются только точки, которые алгоритм «видит» в нескольких перекрывающихся окнах, разовое «срабатывание» в конкретном окне — игнорируется). Т.е. простейшая фильтрация от ложных срабатываний установленных (эмпирически) порогов логики.
Как можно оценить по данному примеру (это типичный вариант — специально не подбирал), стабильность такого алгоритма отличная. Но, разумеется, он применим только для речи, в которой диктор говорит на хороший микрофон, и нет посторонних шумов. Поскольку у меня именно такая база (TIMIT), то для моих целей (игрищ с принудительным коверканьем речевого сигнала) такой алгоритм дает великолепный результат, не просто разбивая речь на четкие периоды основного тона, но даже — позволяет стабильно выделять именно начало колебаний (момент размыкания голосовой щели).
Вот картинка:

Это собственно вид моего… эээ… экспериментального сэтапа ))).
Вверху — выведен конкретный кусочек речи диктора из базы TIMIT (с разметкой на фонемы — из этой же базы). Т.е. непосредственно звуковые колебания (амплитуда отклонения мембраны микрофона в общем). В данном примере, в окно вывода попало 3000 точек ряда.
Что делает алгоритм в целом:
1) расчитывается скользящая дисперсия этого ряда, по малому окну (около 10 точек шириной). Это — зеленый график на нижнем окне.
2) очень грубо — определяется частота основного тона (из фурье-анализа), простейшим алгоритмом (могу пояснить каким — но это не существенно)
3) исходный сигнал «сканируется» окнами с длиной равной примерно полутора периодам основного тона (т.к. период основного тона определяется грубо — то такой запас необходим). Расположение таких окон идет с шагом, равным четверти длины период основного тона из п.2.
4) в каждом окне — находится экстремум дисперсии, но не просто экстремум — а с дополнительным условием. Условие состоит в том, что экстремуму должен предшествовать период с низкой дисперсией, т.е. должен наблюдаться резкий «взлет» средней величины дисперсии — и вот тогда такой экстремум дисперсии действительно принимается за «правильное» начало колебаний голосовой щели. Т.е. исхожу из физики — начало размыкания голосовой щели самое громкое, далее амплитуда колебаний спадает (а значит — так же спадает и скользящая дисперсия). Это позволяет игнорировать просто максимум дисперсии (т.к. максимум дисперсии — не обязательно означает начало колебания, как видно на левой части имаджа), и корректно находить именно начало колебаний голосовой щели.
5) найденные в п.4 точки таких экстремумов с доп. условием — накладываются друг на друга, и далее «чистятся» от случайных срабатываний такой логики (т.е. остаются только точки, которые алгоритм «видит» в нескольких перекрывающихся окнах, разовое «срабатывание» в конкретном окне — игнорируется). Т.е. простейшая фильтрация от ложных срабатываний установленных (эмпирически) порогов логики.
Как можно оценить по данному примеру (это типичный вариант — специально не подбирал), стабильность такого алгоритма отличная. Но, разумеется, он применим только для речи, в которой диктор говорит на хороший микрофон, и нет посторонних шумов. Поскольку у меня именно такая база (TIMIT), то для моих целей (игрищ с принудительным коверканьем речевого сигнала) такой алгоритм дает великолепный результат, не просто разбивая речь на четкие периоды основного тона, но даже — позволяет стабильно выделять именно начало колебаний (момент размыкания голосовой щели).
Большое спасибо, что нашли время покопаться в старом коде, и за подробное описание использованных методов.
Буду признателен также за пояснения по п.«2) очень грубо — определяется частота основного тона (из фурье-анализа), простейшим алгоритмом (могу пояснить каким — но это не существенно)».
Если я правильно понял, то определение частоты основного тона основано на том, что каждый «однократный период» имеет специальный участок, где он наиболее сильно меняется, подобный импульсу. На нём дисперсия максимальна.
На всякий случай посмотрел свои звуки, и нашел в них, например, звук «у», произнесённый мной же, в котором явного импульса нет:
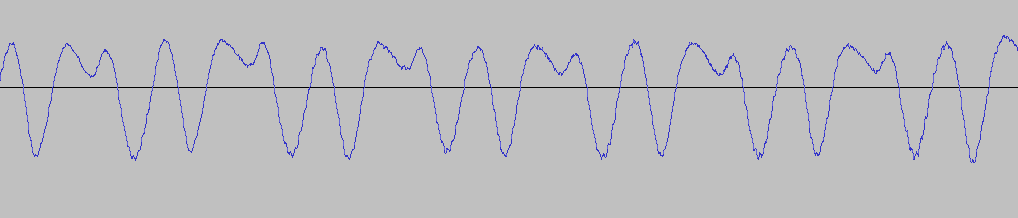
Может, у меня «голосовая щель» по другому устроена.
И мне кажется, что для такого звука больше подошли бы общепринятые методы поиска ЧОТ, вплоть до простейшей автокорреляции.
Тем не менее, было необычайно приятно почитать о нестандартном подходе к распознаванию речи.
Всё, что приходилось читать ранее, основано на неприкасаемых методах Рабинера & Co.
То, что было хорошо для обработки и компрессии звука, подавалось, как единственный метод для распознавания.
И кочуют из одной публикации в другую: Фурье, полосовые фильтры, квадратурные зеркальные фильтры, дискретное косинусное преобразование, вейвлеты, линейное предсказание, кепстры, модели Маркова. А воз и ныне там.
То есть не у всех он там. Есть люди, которые в этом разобрались втихаря, например Гугл или Нюанс Софтвер. Но это остаётся их коммерческой тайной, а остальных кормят неадекватными моделями.
В общем, успехов Вам, и надеюсь, что начатое когда-то не уйдёт в песок.
Буду признателен также за пояснения по п.«2) очень грубо — определяется частота основного тона (из фурье-анализа), простейшим алгоритмом (могу пояснить каким — но это не существенно)».
Если я правильно понял, то определение частоты основного тона основано на том, что каждый «однократный период» имеет специальный участок, где он наиболее сильно меняется, подобный импульсу. На нём дисперсия максимальна.
На всякий случай посмотрел свои звуки, и нашел в них, например, звук «у», произнесённый мной же, в котором явного импульса нет:

Может, у меня «голосовая щель» по другому устроена.
И мне кажется, что для такого звука больше подошли бы общепринятые методы поиска ЧОТ, вплоть до простейшей автокорреляции.
Тем не менее, было необычайно приятно почитать о нестандартном подходе к распознаванию речи.
Всё, что приходилось читать ранее, основано на неприкасаемых методах Рабинера & Co.
То, что было хорошо для обработки и компрессии звука, подавалось, как единственный метод для распознавания.
И кочуют из одной публикации в другую: Фурье, полосовые фильтры, квадратурные зеркальные фильтры, дискретное косинусное преобразование, вейвлеты, линейное предсказание, кепстры, модели Маркова. А воз и ныне там.
То есть не у всех он там. Есть люди, которые в этом разобрались втихаря, например Гугл или Нюанс Софтвер. Но это остаётся их коммерческой тайной, а остальных кормят неадекватными моделями.
В общем, успехов Вам, и надеюсь, что начатое когда-то не уйдёт в песок.
Буду признателен также за пояснения по п.«2) очень грубо — определяется частота основного тона (из фурье-анализа), простейшим алгоритмом (могу пояснить каким — но это не существенно)».
Ну тут всё просто и действительно очень грубо ).
1. Строится фурье по периоду, включающему большой кусок речи диктора (как минимум десятков периодов ОЧТ), с наложенной оконной функцией типа окна Хэмминга (т.е. интересует именно средняя ОЧТ для данного диктора, за большой кусок его речи).
2. Рассчитывается средняя амплитуда AF нижних частот (т.е. полоса Фурье в которой лежит ОЧТ у людей).
3. Далее иду по амплитуде Фурье слева направо, и тупо ищу первый попавшийся экстремум амплитуды спектра — такой, что он больше AF (либо AF*k, k>1 и подбирается эмпирически). На практике, такой простейший алгоритм дает отличные результаты в подавляющем большинстве случаев (т.к. используется большой кусок речи диктора, и — мне не нужно точное попадание в ОЧТ, хватит и приблизительного, т.е. с точностью до нескольких раз).
Если я правильно понял, то определение частоты основного тона основано на том, что каждый «однократный период» имеет специальный участок, где он наиболее сильно меняется, подобный импульсу. На нём дисперсия максимальна.
Почти так. Суть идеи — в то, что добротность голосового резонатора весьма низка. Так что колебания (возникшие от разового размыкания голосовой щели) чисто из физики — носят быстрозатухающий характер. И то что я делал как раз и было (весьма грубым) способом измерения динамики локальной энергии колебаний. Можно разумеется сделать и более точную меру энергии колебаний, но мне не потребовалось.
Ваш пример звука — действительно необычен. Очень большая разница в амплитуде низких частот и высоких. Вообще, что-то похожее я получал когда на первых порах производил запись своего голоса с некоторыми неаккуратностями (брал совсем простейший микрофон, и к тому же подносил его близко к губам — так что на него банально «дул» воздух при произнесении звука, и получался подобный перекос по амплитуде низких частот).
С другой стороны, если применить мою идею к этому ряду, то она всё равно должно сработать: дисперсия ряда тут явно не равномерная, и явно есть тенденция к затуханию. Т.е. для приведенного Вами сигнала, даже если не сработает «втупую» — можно немного адаптировать алгоритм исходя из его идеи: вместо дисперсии как меры энергии колебаний, находить совсем короткое Фурье (или вейвлеты) и из него рассчитывать локальную энергию колебаний, ну а дальше применять всю ту же идею — что должен быть резки рост энергии после относительного «плато», и начало точки такого роста энергии — это и есть момент размыкания голосовой щели.
Общепринятые методы ЧОТ, насколько я в курсе, не позволяют находить именно начало колебательного цикла — а мне это было важно для проверки ряда идей…
Да, согласен, в смысле идей — поле распознавания звука крайне бедное, все крутят одни и те же по своей сути подходы, и при этом почему-то надеются получить что-то принципиально новое… После определенного анализа лит-ры я сделал для себя вывод что это бесперспективно и надо искать свой подход, что и вылилось в исследование по «коверканию» звуков.
Спасибо за пожелание успехов. Может быть когда-нибудь и вернусь к этой теме. Хотя, думаю, не раньше чем найду единомышленника, одному уже тяжко стало такие проекты тащить — и времени катастрофически не хватает. Работа, семья, всё как у всех…
del
Sign up to leave a comment.
Задача изменения голоса. Часть 3. Прикладные модели представления речевого сигнала: LPC