 Вот уже два года как одна из лучших распределённых аналитических СУБД enterprise-уровня вышла в open source. Что изменилось за это время? Что дало открытие исходников проекту? Как дальше будет развиваться Greenplum?
Вот уже два года как одна из лучших распределённых аналитических СУБД enterprise-уровня вышла в open source. Что изменилось за это время? Что дало открытие исходников проекту? Как дальше будет развиваться Greenplum?Под катом я расскажу о том, что нового появилось в первом мажорном open source релизе СУБД, как развивается проект в текущих минорных версиях и каких нововведений стоит ждать в будущем.
Если вы ещё не знакомы с СУБД Greenplum, начать своё знакомство можно с этой обзорной статьи.
Релиз 5.0.0 состоялся 7-го сентября. Это первый релиз, который включает в себя доработки, внесённые сторонними разработчиками (community). Релизы версии 4.3, хотя и выкладывались в открытый репозиторий, разрабатывались только специалистами Pivotal.
Релиз принёс много нововведений, как мне кажется, основная причина этого в том, что пользователи, работающие с Greenplum достаточно давно, наконец-то получили возможность реализовать все свои хотелки, которые компания Pivotal не могла реализовать и которые копились так долго. Я приведу краткое описание, на мой взгляд, самых важных изменений в новом мажорном релизе и в последующих минорных апдейтах, так как изменений слишком много для того, чтобы рассказать про все. В конце статьи я приведу ссылки на Release Notes нового релиза и его минорных апдейтов.
Условно все нововведения можно разделить на три группы:
- Новые возможности, портированные из свежих версий PostgreSQL
- Нововведения Greenplum
- Новые дополнительные сервисы и расширения
Начнём по порядку.
1. Новые возможности, портированные из свежих версий PostgreSQL
- Rebase on PostgreSQL 8.3
В отличии от многих других проектов, основанных на PostgreSQL, Greenplum не стремится иметь в основе самую свежую версию PostgreSQL — до версии 5.0.0 Greenplum был основан на версии PostgreSQL 8.2, в текущем мажорном релизе версию подняли до 8.3. При этом в проект активно переносятся возможности более новых версий PostgreSQL; - Heap-таблицы теперь могут иметь контрольную сумму
Greenplum позволяет создавать два типа внутренних таблиц — heap-таблицы и append-optimized-таблицы. Если для вторых функция подсчёта контрольной суммы файлов на диске была доступна всегда, для heap-таблиц она появилась в текущем релизе. Функция включается параметром; - Анонимные блоки
Это нововведение было перетянуто из PostgreSQL без изменений. Не самая важная (блок кода всегда можно было обернуть в функцию), но так давно ожидаемая администраторами и разработчиками доработка.
DO $$DECLARE r record; BEGIN FOR r IN SELECT table_schema, table_name FROM information_schema.tables WHERE table_type = 'VIEW' AND table_schema = 'public' LOOP EXECUTE 'GRANT ALL ON ' || quote_ident(r.table_schema) || '.' || quote_ident(r.table_name) || ' TO webuser'; END LOOP; END$$; - DBlink
Механизм позволяет выполнять запросы во внешних сторонних СУБД и забирать результат. Казалось бы, этот механизм сильно расширяет возможности Greenplum, позволяя забирать данные в аналитическую СУБД напрямую из источников, однако применимость DBlink очень ограничена — ввиду архитектуры Greenplum передача данных при использовании DBlink осуществляется не сегментами впараллель, а однопоточно через мастер. Этот факт заставляет использовать DBlink только для управляющих запросов в сторонние базы, избегая передачи непосредственно данных. Справедливости ради стоит отметить, что с параллельным забором данных из сторонних СУБД поможет справиться ещё одно нововведение 5-ки, о котором мы поговорим в третьей части обзора новых функций.
SELECT * FROM dblink('host=remotehost port=5432 dbname=postgres', 'SELECT * FROM testdblink') AS dbltab(id int, product text); - Управление восприятием ORDER BY значений NULL
Теперь при запросе SELECT возможно задать блок [NULLS {FIRST | LAST}], управляющий тем, как будут отображаться NULL-значения — в начале или конце отсортированных значений.
SELECT * from my_table_with_nulls ORDER BY 1 NULLS FIRST; - Extensions (расширения)
Также портировано из PostgreSQL без изменений. Теперь именно этот механизм используется для создания, удаления и обновления различных сторонних расширений. По сути выражение CREATE EXTENSION выполняет указанный SQL-скрипт.
2. Нововведения Greenplum
- Доработки оптимизатора запросов — ORCA
Альтернативный стоимостный оптимизатор запросов существовал ещё в версии 4.3, однако там он включался опционально. В новом релизе оптимизатор был значительно доработан, в частности, повысилась производительность коротких лёгких запросов, запросов с очень большим количеством join и ряда других случаев. Был также доработан механизм отсечения лишних партиций при наличии в запросе условия по ключу партиционирования. Теперь по умолчанию используется именно этот оптимизатор; - Resource Groups
В Greenplum уже существует механизм управления нагрузкой — Resource queues (ресурсные очереди), однако он позволяет только ограничить запуск запросов исходя из их стоимости. Новый же механизм позволяет ограничивать запросы по потреблению памяти и CPU (но, увы, не по нагрузке на дисковую подсистему);
CREATE RESOURCE GROUP rgroup1 WITH (CPU_RATE_LIMIT=20, MEMORY_LIMIT=25); - PL/Python 2.6 -> 2.7
Встроенная версия Python теперь 2.7; - Доработки COPY
В и так не маленьком полку параллельных загрузок и выгрузок данных из Greenplum прибыло — теперь стандартная команда выгрузки данных из таблицы в плоский локальный файл поддерживает конструкцию ON SEGMENT — с ней данные выгружаются на всех сегментах БД в локальную файловую систему. Также появилась конструкция PROGRAM — забрать и отдать данные во внешнюю bash-команду. Кстати, эти две опции можно использовать вместе:
COPY mydata FROM PROGRAM 'cat /tmp/mydata_<SEGID>.csv' ON SEGMENT CSV;
3. Новые сервисы и расширения
- Поддержка PXF
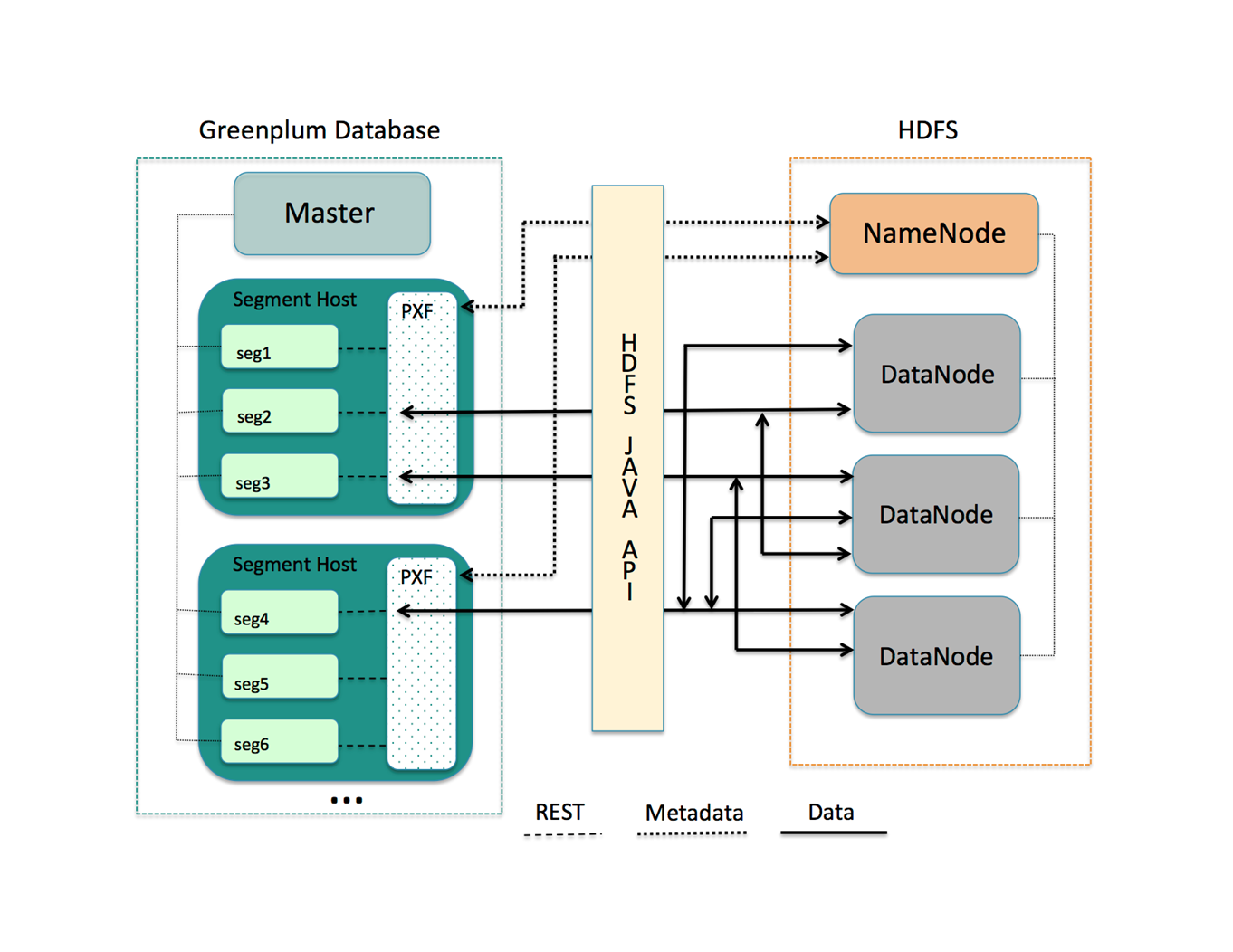
По моему мнению, это наиболее важная доработка Greenplum в новом релизе. PXF — фреймворк, позволяющий Greenplum параллельно обмениваться данными со сторонними системами. Это не новая технология, изначально он разрабатывался для форка Greenplum — HAWQ, работающего поверх кластера Hadoop. В Greenplum уже была параллельная реализация коннектора для кластера Hadoop, PXF же привносит в копилку интеграций гораздо большую гибкость и возможность подключать произвольные сторонние системы, написав свой коннектор.
Фреймворк написан на Java и представляет собой отдельный процесс на сервере-сегменте Greenplum, с одной стороны общающийся с сегментами Greenplum через REST API, с другой — использующий сторонние Java-клиенты и библиотеки. Так, например, сейчас имеется поддержка основных сервисов стека Hadoop (HDFS, Hive, Hbase) и параллельная выгрузка данных из сторонних СУБД через JDBC.
При этом сервис PXF должен быть запущен на каждом сервере в кластере Greenplum.
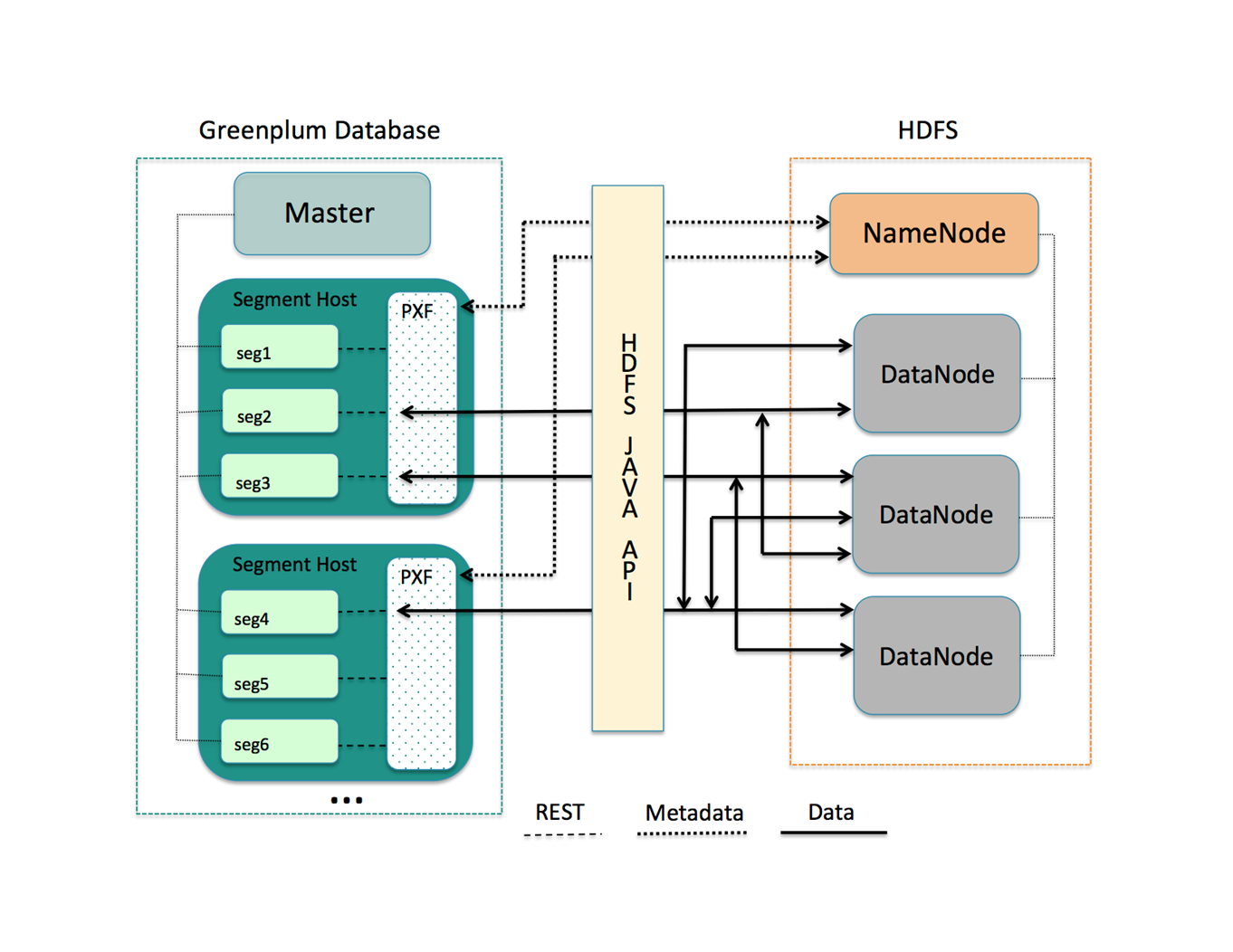
Схема взаимодействия PXF с HDFS
Как мне кажется, наиболее интересна возможность интеграции Greenplum со сторонними СУБД через JDBC. Так, например, добавив в CLASSPATH JDBC-thin-драйвер для Oracle Database, мы сможем запрашивать данные из таблиц одноимённой СУБД, при этом каждый сегмент Greenplum впараллель будет запрашивать свою шарду данных, исходя из логики, заданной во внешней таблице:
CREATE EXTERNAL TABLE public.insurance_sample_jdbc_ora_ro( policyid bigint, statecode text, ... point_granularity int ) LOCATION ('pxf://myoraschema.insurance_test?PROFILE=JDBC&JDBC_DRIVER=oracle.jdbc.driver.OracleDriver&DB_URL=jdbc:oracle:thin:@//ora-host:1521/XE&USER=pxf_user&PASS=passoword&PARTITION_BY=policyid:int&RANGE=100000:999999&INTERVAL=10000') FORMAT 'CUSTOM' (FORMATTER='pxfwritable_import');
С учётом возможности использовать в составе одной таблицы партиции (секции), являющиеся внешними таблицами, PXF позволяет строить на базе Greenplum удивительно гибкие и производительные платформы обработки данных — например, хранить горячие, свежие данные в Oracle, тёплые — в самом Greenplum и холодные, архивные — в кластере Hadoop, при этом пользователь будет видеть все данные в одной таблице; - Модуль passwordcheck
Данный модуль позволяет ограничить задание «слабых» паролей при создании или изменении роли (CREATE ROLE или ALTER ROLE); - PGAdmin 4
Популярный PostgreSQL-клиент теперь поддерживает расширенное взаимодействие с Greenplum. На борту поддержка DDL партиционированных таблиц, AO и Heap таблиц. DDL внешних таблиц пока не поддерживается.
Обобщить нововведения двухгодового пребывания в open source можно следующим:
- Архитектура Greenplum остаётся верной самой себе. Каких-либо существенных изменений (вроде негомогенных сегментов или переменного числа зеркал) не случилось
и слава Богу; - Развитие PostgreSQL-составляющей СУБД остаётся таким же — портирование новых функций вместо постоянного повышения версии за счёт rebase;
- Видно развитие в сторону интеграции со сторонними системами, и это, как мне кажется, очень и очень правильно;
- Greenplum обретает модульность и гибкость, старые, негибкие функциональности медленно убираются из системы (GPHDFS, Legacy Optimizer).
Что дальше?
Не так давно в официальном репозитории был тегирован релиз 6.0.0. Этот релиз должен выйти в сентябре следующего года, и вот какие (как минимум) нововведения в нём точно будут:
- PXF pushdown — передача на сторону СУБД-источника условий выборки данных (where-фильтров). Это позволит переносить часть нагрузки в сторонние системы и забирать из них готовый результат;
- PXF passing user identity — в дальнейшем PXF будет пробрасывать имя пользователя Greenplum, под которым работает запрос, во внешнюю систему. Безопасность, все дела. Возможно, эта доработка будет реализована в одном из минорных апдейтов «пятёрки»;
- Новый вид компрессии — Zstd. По результатам первых тестов, Zstd в Greenplum работает в 4 раза быстрее, при этом на 10% эффективнее сжимая данные в сравнении с Zlib. Особую гордость добавляет тот факт, что эта фича была разработана нашей командой (Arenadata);
- Дальнейшие доработки нового оптимизатора ORCA.
Как мне кажется, выход в open source однозначно пошёл Greenplum на пользу. Развитие проекта, оставшись верным прежнему курсу, сильно ускорилось и расширилось. Думаю, в ближайшее время мы увидим немало абсолютно новой для Greenplum функциональности.
Ссылки по теме:
Официальный репозиторий
5.0.0 Release notes
5.1.0 Release notes
5.2.0 Release notes
5.3.0 Release notes
Немного о нас: проект Arenadata был основан выходцами из компании Pivotal (компании-разработчика Greenplum и Pivotal Hadoop) в 2015 году, его целью было создание собственных дистрибутивов Greenplum и Hadoop enterprise-уровня для построения современных платформ хранения и обработки данных.
В начале 2017 года проект был приобретён компанией IBS.
Сейчас в портфеле проекта три собственных дистрибутива и все необходимые сервисы. В частности, по направлению Greenplum мы:
- Оказываем техподдержку;
- Предоставляем консалтинговые услуги;
- Выполняем миграцию данных и процессов из сторонних СУБД в Greenplum.
В комментариях постараюсь ответить на любые вопросы по проекту Arenadata и Greenplum в целом. Также будем рады видеть вас в канале пользователей Greenplum в Telegram. You are welcome!

