Многие убеждены, что область Human Computer Interaction (HCI или человеко-компьютерное взаимодействие) сводится только к проектированию сайтов или приложений, а основная задача специалиста — удовлетворить пользователей, увеличивая на несколько пикселей кнопку лайка. В посте мы хотим показать, что это совсем не так, и рассказать, что происходит в HCI на стыке с исследованиями машинного обучения и искусственного интеллекта. Возможно, это позволит читателям посмотреть на эту область с новой для себя стороны.
Для обзора мы взяли труды конференции CHI: Conference on Human Factors in Computing Systems за 10 лет, и с помощью NLP и анализа сетей социтирования посмотрели на темы и области на пересечении дисциплин.

В России особенно силен фокус на прикладных задачах проектирования UX. Многие события, которые помогали росту HCI за рубежом, у нас не произошли: не появилось iSchools, ушли из науки многие специалисты, занимавшиеся близкими аспектами инженерной психологии, и т. д. В результате профессия возникала заново, отталкиваясь от прикладных задач и исследований. Один из результатов этого виден даже сейчас — это крайне низкая представленность российских работ по HCI на ключевых конференциях.
Но и за пределами России HCI развивался очень по-разному, фокусируясь на множестве тем и направлений. На магистерской программе «Информационные системы и взаимодействие человек-компьютер» в Питерской Вышке мы, в том числе, обсуждаем — со студентами, коллегами, выпускниками схожих специальностей европейских университетов, партнерами, которые помогают развивать программу, — что же относится к области человеко-компьютерного взаимодействия. И эти обсуждения показывают разнородность направления, в котором у каждого специалиста своя, неполная, картина области.
Время от времени мы слышим вопросы, как это направление связано (и связано ли вообще) с машинным обучением и анализом данных. Чтобы ответить на них, мы обратились к исследованиям последних лет, представленным на конференции CHI.
В первую очередь мы расскажем, что происходит в таких областях, как xAI и iML (eXplainable Artificial Intelligence и Interpretable Machine Learning) со стороны интерфейсов и пользователей, а также как в HCI изучают когнитивные аспекты работы специалистов data science, и приведем примеры интересных работ последних лет в каждой области.
Методы машинного обучения интенсивно развиваются и — что важнее с точки зрения обсуждаемой области — активно внедряются в автоматизированное принятие решений. Поэтому исследователи все чаще обсуждают вопросы: как пользователи, не являющиеся специалистами в машинном обучении, взаимодействуют с системами, где подобные алгоритмы применяются? Один из важных вопросов такого взаимодействия: как сделать, чтобы пользователи доверяли решениям, принятым на основе моделей? Поэтому с каждым годом все более горячей становится тематика интерпретируемого машинного обучения (Interpretable Machine Learning — iML) и объяснимого искусственного интеллекта (eXplainable Artificial Intelligence — XAI).
При этом, если на таких конференциях, как NeurIPS, ICML, IJCAI, KDD, обсуждают сами алгоритмы и средства iML и XAI, на CHI в фокусе оказываются несколько тем, связанных с особенностями дизайна и опытом использования этих систем. Например, на CHI-2020 этой тематике были посвящены сразу несколько секций, включая «AI/ML & seeing through the black box» и «Coping with AI: not agAIn!». Но и до появления отдельных секций таких работ было достаточно много. Мы выделили в них четыре направления.
Первое направление — это дизайн систем на основе алгоритмов интерпретируемости в различных прикладных задачах: медицинских, социальных и т. д. Такие работы возникают в очень разных сферах. Например, работа на CHI-2020 CheXplain: Enabling Physicians to Explore and Understand Data-Driven, AI-Enabled Medical Imaging Analysis описывает систему, которая помогает врачам исследовать и объяснять результаты рентгенографии органов грудной клетки. Она предлагает дополнительные текстовые и визуальные пояснения, а также снимки с таким же и противоположным результатом (поддерживающие и противоречащие примеры). Если система предсказывает, что на рентгенографии видно заболевание, то покажет два примера. Первый, поддерживающий, пример — это снимок легких другого пациента, у которого подтверждено это же заболевание. Второй, противоречащий, пример — это снимок, на котором заболевания нет, то есть снимок легких здорового человека. Основная идея — сократить очевидные ошибки и уменьшить число обращений к сторонним специалистам в простых случаях, чтобы ставить диагноз быстрее.

Второе направление — разработка систем, которые помогают интерактивно сравнивать или объединять несколько методов и алгоритмов. Например, в работе Silva: Interactively Assessing Machine Learning Fairness Using Causality на CHI-2020 была представлена система, которая строит на данных пользователя несколько моделей машинного обучения и предоставляет возможность их последующего анализа. Анализ включает построение причинно-следственного графа между переменными и вычисление ряда метрик, оценивающих не только точность, но и честность (fairness) модели (Statistical Parity Difference, Equal Opportunity Difference, Average Odds Difference, Disparate Impact, Theil Index), что помогает находить перекосы в предсказаниях.
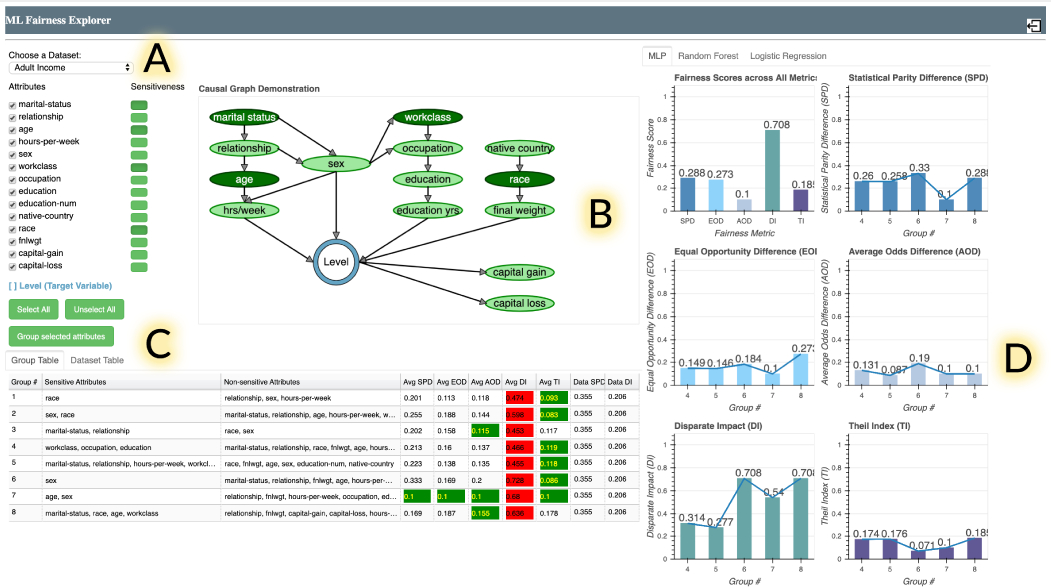
Silva: граф связей между переменными + графики для сравнения метрик честности + цветовое выделение влиятельных переменных в каждой группе
Третье направление — обсуждение подходов к задаче интерпретируемости моделей в целом. Чаще всего это обзоры, критика подходов и открытые вопросы: например, что понимать под «интерпретируемостью». Здесь хотелось бы отметить обзор на CHI-2018 Trends and Trajectories for Explainable, Accountable and Intelligible Systems: An HCI Research Agenda, в котором авторы рассмотрели 289 основных работ, посвященных объяснениям в искусственном интеллекте, и 12 412 публикаций, цитирующих их. С помощью сетевого анализа и тематического моделирования они выделили четыре ключевых направления исследований 1) Intelligent and Ambient (I&A) Systems, 2) Explainable AI: Fair, Accountable, and Transparent (FAT) algorithms and Interpretable Machine Learning (iML), 3) Theories of Explanations: Causality & Cognitive Psychology, 4) Interactivity and Learnability. Кроме того, авторы описали основные тренды исследований: интерактивное обучение и взаимодействие с системой.
Наконец, четвертое направление — это пользовательские исследования алгоритмов и систем, интерпретирующих модели машинного обучения. Другими словами, это исследования о том, становятся ли на практике новые системы понятнее и прозрачнее, какие сложности возникают у пользователей при работе с интерпретирующими, а не исходными моделями, как определить, используют ли систему так, как планировалось (или для нее нашли новое применение — может быть, некорректное), каковы потребности пользователей и предлагают ли им разработчики то, что действительно нужно.
Инструментов и алгоритмов интерпретации появилось очень много, поэтому возникает вопрос: как понять, какой же алгоритм выбрать? В работе Questioning the AI: Informing Design Practices for Explainable AI User Experiences как раз обсуждаются вопросы мотивации использования объясняющих алгоритмов и выделяются проблемы, которые при всем многообразии методов еще не решены в достаточной степени. Авторы приходят к неожиданному выводу: большинство существующих методов построены так, что отвечают на вопрос «почему» («почему у меня такой результат»), в то время как пользователям для принятия решений нужен еще и ответ на вопрос «почему нет» («почему не другой»), а иногда — «что сделать, чтобы результат изменился».
В работе говорится также о том, что пользователям нужно понимать, каковы границы применимости методов, какие у них есть ограничения — и это нужно явно внедрять в предлагаемые инструменты. Более ярко эта проблема показана в статье Interpreting Interpretability: Understanding Data Scientists' Use of Interpretability Tools for Machine Learning. Авторы провели небольшой эксперимент со специалистами в области машинного обучения: показали им результаты работы нескольких популярных инструментов для интерпретации моделей машинного обучения и предложили ответить на вопросы, связанные с принятием решения на основе этих результатов. Оказалось, что даже специалисты слишком доверяют подобным моделям и не относятся к результатам критически. Как любой инструмент, объясняющие модели можно использовать неправильно. При разработке инструментария важно учитывать это, привлекая накопленные знания (или специалистов) в области человеко-компьютерного взаимодействия, чтобы учитывать особенности и потребности потенциальных пользователей.
Еще одна интересная область HCI посвящена анализу когнитивных аспектов работы с данными. В последнее время в науке поднимается вопрос о том, как «степени свободы» исследователя — особенности сбора данных, дизайна экспериментов и выбора методов анализа — влияют на результаты исследований и их воспроизводимость. Хотя основная часть обсуждений и критики связана с психологией и социальными науками, многие проблемы касаются и надежности выводов в работе аналитиков данных в целом, а также сложностей при донесении этих выводов потребителям анализа.
Поэтому предметом этой области HCI становится разработка новых способов визуализации неопределенности в предсказаниях моделей, создание систем для сравнения анализа, проведенного разными способами, а также анализ работы аналитиков с инструментами, например с Jupyter notebooks.
Визуализация неопределенности — одна из особенностей, которые отличают научную графику от презентационной и бизнес-визуализации. Довольно долго ключевым в последних считался принцип минималистичности и фокуса на основных трендах. Однако это приводит к чрезмерной уверенности пользователей в точечной оценке величины или прогноза, что может быть критичным, особенно, если мы должны сравнивать прогнозы с разной степенью неопределенности. Работа Uncertainty Displays Using Quantile Dotplots or CDFs Improve Transit Decision-Making анализирует, насколько способы визуализации неопределенности в предсказании для точечных графиков и кумулятивных функций распределения помогают пользователям принимать более рациональные решения на примере задачи оценки времени прибытия автобуса по данным мобильного приложения. Что особенно приятно, один из авторов поддерживает пакет ggdist для R с различными вариантами визуализации неопределенности.

Примеры визуализации неопределенности (https://mjskay.github.io/ggdist/)
Однако часто встречаются и задачи визуализации возможных альтернатив, например, для последовательностей действий пользователя в веб-аналитике или аналитике приложений. Работа Visualizing Uncertainty and Alternatives in Event Sequence Predictions анализирует, насколько графическое представление альтернатив на основе модели Time-Aware Recurrent Neural Network (TRNN) помогает экспертам принимать решения и доверять им.
Не менее важный, чем визуализация неопределенности, аспект работы аналитиков — сравнение того, как — часто скрытый — выбор исследователем разных подходов к моделированию на всех его этапах может вести к различным результатам анализа. В психологии и социальных науках набирает популярность предварительная регистрация дизайна исследования и четкое разделение эксплораторных и конфирматорных исследований. Однако в задачах, где исследование в большей степени основано на данных, альтернативой могут стать инструменты, позволяющие оценить скрытые риски анализа за счет сравнения моделей. Работа Increasing the Transparency of Research Papers with Explorable Multiverse Analyses предлагает использовать интерактивную визуализацию нескольких подходов к анализу в статьях. По сути, статья превращается в интерактивное приложение, где читатель может оценить, что изменится в результатах и выводах, если будет применен другой подход. Это кажется полезной идеей и для практической аналитики.
Последний блок работ связан с исследованием того, как аналитики работают с системами, подобными Jupyter Notebooks, которые стали популярным инструментом организации анализа данных. Статья Exploration and Explanation in Computational Notebooks анализирует противоречия между исследовательскими и объясняющими целями, изучая найденные на Github интерактивные документы, а в Managing Messes in Computational Notebooks авторы анализируют, как эволюционируют заметки, части кода и визуализации в итеративном процессе работы аналитиков, и предлагают возможные дополнения в инструменты, чтобы поддерживать этот процесс. Наконец, уже на CHI 2020 основные проблемы аналитиков на всех этапах работы, от загрузки данных до передачи модели в продакшн, а также идеи по улучшению инструментов обобщены в статье What’s Wrong with Computational Notebooks? Pain Points, Needs, and Design Opportunities.

Преобразование структуры отчетов на основе логов выполнения (https://microsoft.github.io/gather/)
Завершая часть обсуждения «чем же занимаются в HCI» и «зачем специалисту в HCI знать машинное обучение», хотелось бы еще раз отметить общий вывод из мотивации и результатов этих исследований. Как только в системе появляется человек, это сразу приводит к возникновению ряда дополнительных вопросов: как упростить взаимодействие с системой и избежать ошибок, как пользователь меняет систему, отличается ли реальное использование от запланированного. Как следствие, нужны те, кто понимает, как устроен процесс проектирования систем с искусственным интеллектом, и знают, как учесть человеческий фактор.
Всему этому мы учим на магистерской программе «Информационные системы и взаимодействие человек-компьютер». Если вы интересуетесь исследованиями в области HCI — заглядывайте на огонек (сейчас как раз началась приемная кампания). Или следите за нашим блогом: мы еще расскажем о проектах, над которыми студенты работали в этом году.
Для обзора мы взяли труды конференции CHI: Conference on Human Factors in Computing Systems за 10 лет, и с помощью NLP и анализа сетей социтирования посмотрели на темы и области на пересечении дисциплин.

В России особенно силен фокус на прикладных задачах проектирования UX. Многие события, которые помогали росту HCI за рубежом, у нас не произошли: не появилось iSchools, ушли из науки многие специалисты, занимавшиеся близкими аспектами инженерной психологии, и т. д. В результате профессия возникала заново, отталкиваясь от прикладных задач и исследований. Один из результатов этого виден даже сейчас — это крайне низкая представленность российских работ по HCI на ключевых конференциях.
Но и за пределами России HCI развивался очень по-разному, фокусируясь на множестве тем и направлений. На магистерской программе «Информационные системы и взаимодействие человек-компьютер» в Питерской Вышке мы, в том числе, обсуждаем — со студентами, коллегами, выпускниками схожих специальностей европейских университетов, партнерами, которые помогают развивать программу, — что же относится к области человеко-компьютерного взаимодействия. И эти обсуждения показывают разнородность направления, в котором у каждого специалиста своя, неполная, картина области.
Время от времени мы слышим вопросы, как это направление связано (и связано ли вообще) с машинным обучением и анализом данных. Чтобы ответить на них, мы обратились к исследованиям последних лет, представленным на конференции CHI.
В первую очередь мы расскажем, что происходит в таких областях, как xAI и iML (eXplainable Artificial Intelligence и Interpretable Machine Learning) со стороны интерфейсов и пользователей, а также как в HCI изучают когнитивные аспекты работы специалистов data science, и приведем примеры интересных работ последних лет в каждой области.
xAI и iML
Методы машинного обучения интенсивно развиваются и — что важнее с точки зрения обсуждаемой области — активно внедряются в автоматизированное принятие решений. Поэтому исследователи все чаще обсуждают вопросы: как пользователи, не являющиеся специалистами в машинном обучении, взаимодействуют с системами, где подобные алгоритмы применяются? Один из важных вопросов такого взаимодействия: как сделать, чтобы пользователи доверяли решениям, принятым на основе моделей? Поэтому с каждым годом все более горячей становится тематика интерпретируемого машинного обучения (Interpretable Machine Learning — iML) и объяснимого искусственного интеллекта (eXplainable Artificial Intelligence — XAI).
При этом, если на таких конференциях, как NeurIPS, ICML, IJCAI, KDD, обсуждают сами алгоритмы и средства iML и XAI, на CHI в фокусе оказываются несколько тем, связанных с особенностями дизайна и опытом использования этих систем. Например, на CHI-2020 этой тематике были посвящены сразу несколько секций, включая «AI/ML & seeing through the black box» и «Coping with AI: not agAIn!». Но и до появления отдельных секций таких работ было достаточно много. Мы выделили в них четыре направления.
Дизайн интерпретирующих систем для решения прикладных задач
Первое направление — это дизайн систем на основе алгоритмов интерпретируемости в различных прикладных задачах: медицинских, социальных и т. д. Такие работы возникают в очень разных сферах. Например, работа на CHI-2020 CheXplain: Enabling Physicians to Explore and Understand Data-Driven, AI-Enabled Medical Imaging Analysis описывает систему, которая помогает врачам исследовать и объяснять результаты рентгенографии органов грудной клетки. Она предлагает дополнительные текстовые и визуальные пояснения, а также снимки с таким же и противоположным результатом (поддерживающие и противоречащие примеры). Если система предсказывает, что на рентгенографии видно заболевание, то покажет два примера. Первый, поддерживающий, пример — это снимок легких другого пациента, у которого подтверждено это же заболевание. Второй, противоречащий, пример — это снимок, на котором заболевания нет, то есть снимок легких здорового человека. Основная идея — сократить очевидные ошибки и уменьшить число обращений к сторонним специалистам в простых случаях, чтобы ставить диагноз быстрее.
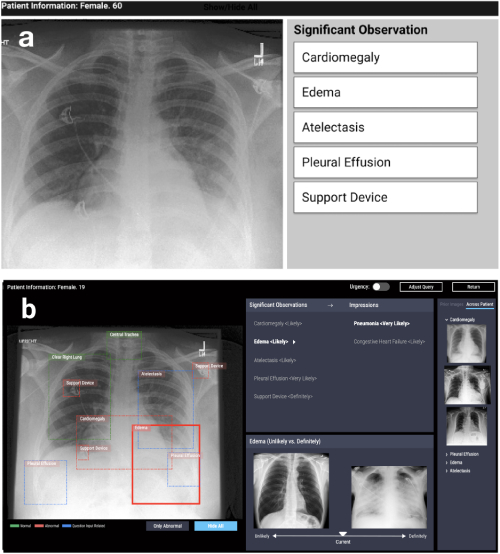
CheXpert: автоматизированное выделение областей + примеры (unlikely vs definitely)
Разработка систем для исследования моделей машинного обучения
Второе направление — разработка систем, которые помогают интерактивно сравнивать или объединять несколько методов и алгоритмов. Например, в работе Silva: Interactively Assessing Machine Learning Fairness Using Causality на CHI-2020 была представлена система, которая строит на данных пользователя несколько моделей машинного обучения и предоставляет возможность их последующего анализа. Анализ включает построение причинно-следственного графа между переменными и вычисление ряда метрик, оценивающих не только точность, но и честность (fairness) модели (Statistical Parity Difference, Equal Opportunity Difference, Average Odds Difference, Disparate Impact, Theil Index), что помогает находить перекосы в предсказаниях.

Silva: граф связей между переменными + графики для сравнения метрик честности + цветовое выделение влиятельных переменных в каждой группе
Общие вопросы интерпретируемости моделей
Третье направление — обсуждение подходов к задаче интерпретируемости моделей в целом. Чаще всего это обзоры, критика подходов и открытые вопросы: например, что понимать под «интерпретируемостью». Здесь хотелось бы отметить обзор на CHI-2018 Trends and Trajectories for Explainable, Accountable and Intelligible Systems: An HCI Research Agenda, в котором авторы рассмотрели 289 основных работ, посвященных объяснениям в искусственном интеллекте, и 12 412 публикаций, цитирующих их. С помощью сетевого анализа и тематического моделирования они выделили четыре ключевых направления исследований 1) Intelligent and Ambient (I&A) Systems, 2) Explainable AI: Fair, Accountable, and Transparent (FAT) algorithms and Interpretable Machine Learning (iML), 3) Theories of Explanations: Causality & Cognitive Psychology, 4) Interactivity and Learnability. Кроме того, авторы описали основные тренды исследований: интерактивное обучение и взаимодействие с системой.
Пользовательские исследования
Наконец, четвертое направление — это пользовательские исследования алгоритмов и систем, интерпретирующих модели машинного обучения. Другими словами, это исследования о том, становятся ли на практике новые системы понятнее и прозрачнее, какие сложности возникают у пользователей при работе с интерпретирующими, а не исходными моделями, как определить, используют ли систему так, как планировалось (или для нее нашли новое применение — может быть, некорректное), каковы потребности пользователей и предлагают ли им разработчики то, что действительно нужно.
Инструментов и алгоритмов интерпретации появилось очень много, поэтому возникает вопрос: как понять, какой же алгоритм выбрать? В работе Questioning the AI: Informing Design Practices for Explainable AI User Experiences как раз обсуждаются вопросы мотивации использования объясняющих алгоритмов и выделяются проблемы, которые при всем многообразии методов еще не решены в достаточной степени. Авторы приходят к неожиданному выводу: большинство существующих методов построены так, что отвечают на вопрос «почему» («почему у меня такой результат»), в то время как пользователям для принятия решений нужен еще и ответ на вопрос «почему нет» («почему не другой»), а иногда — «что сделать, чтобы результат изменился».
В работе говорится также о том, что пользователям нужно понимать, каковы границы применимости методов, какие у них есть ограничения — и это нужно явно внедрять в предлагаемые инструменты. Более ярко эта проблема показана в статье Interpreting Interpretability: Understanding Data Scientists' Use of Interpretability Tools for Machine Learning. Авторы провели небольшой эксперимент со специалистами в области машинного обучения: показали им результаты работы нескольких популярных инструментов для интерпретации моделей машинного обучения и предложили ответить на вопросы, связанные с принятием решения на основе этих результатов. Оказалось, что даже специалисты слишком доверяют подобным моделям и не относятся к результатам критически. Как любой инструмент, объясняющие модели можно использовать неправильно. При разработке инструментария важно учитывать это, привлекая накопленные знания (или специалистов) в области человеко-компьютерного взаимодействия, чтобы учитывать особенности и потребности потенциальных пользователей.
Data Science, Notebooks, Visualization
Еще одна интересная область HCI посвящена анализу когнитивных аспектов работы с данными. В последнее время в науке поднимается вопрос о том, как «степени свободы» исследователя — особенности сбора данных, дизайна экспериментов и выбора методов анализа — влияют на результаты исследований и их воспроизводимость. Хотя основная часть обсуждений и критики связана с психологией и социальными науками, многие проблемы касаются и надежности выводов в работе аналитиков данных в целом, а также сложностей при донесении этих выводов потребителям анализа.
Поэтому предметом этой области HCI становится разработка новых способов визуализации неопределенности в предсказаниях моделей, создание систем для сравнения анализа, проведенного разными способами, а также анализ работы аналитиков с инструментами, например с Jupyter notebooks.
Визуализация неопределенности
Визуализация неопределенности — одна из особенностей, которые отличают научную графику от презентационной и бизнес-визуализации. Довольно долго ключевым в последних считался принцип минималистичности и фокуса на основных трендах. Однако это приводит к чрезмерной уверенности пользователей в точечной оценке величины или прогноза, что может быть критичным, особенно, если мы должны сравнивать прогнозы с разной степенью неопределенности. Работа Uncertainty Displays Using Quantile Dotplots or CDFs Improve Transit Decision-Making анализирует, насколько способы визуализации неопределенности в предсказании для точечных графиков и кумулятивных функций распределения помогают пользователям принимать более рациональные решения на примере задачи оценки времени прибытия автобуса по данным мобильного приложения. Что особенно приятно, один из авторов поддерживает пакет ggdist для R с различными вариантами визуализации неопределенности.

Примеры визуализации неопределенности (https://mjskay.github.io/ggdist/)
Однако часто встречаются и задачи визуализации возможных альтернатив, например, для последовательностей действий пользователя в веб-аналитике или аналитике приложений. Работа Visualizing Uncertainty and Alternatives in Event Sequence Predictions анализирует, насколько графическое представление альтернатив на основе модели Time-Aware Recurrent Neural Network (TRNN) помогает экспертам принимать решения и доверять им.
Сравнение моделей
Не менее важный, чем визуализация неопределенности, аспект работы аналитиков — сравнение того, как — часто скрытый — выбор исследователем разных подходов к моделированию на всех его этапах может вести к различным результатам анализа. В психологии и социальных науках набирает популярность предварительная регистрация дизайна исследования и четкое разделение эксплораторных и конфирматорных исследований. Однако в задачах, где исследование в большей степени основано на данных, альтернативой могут стать инструменты, позволяющие оценить скрытые риски анализа за счет сравнения моделей. Работа Increasing the Transparency of Research Papers with Explorable Multiverse Analyses предлагает использовать интерактивную визуализацию нескольких подходов к анализу в статьях. По сути, статья превращается в интерактивное приложение, где читатель может оценить, что изменится в результатах и выводах, если будет применен другой подход. Это кажется полезной идеей и для практической аналитики.
Работа с инструментами организации и анализа данных
Последний блок работ связан с исследованием того, как аналитики работают с системами, подобными Jupyter Notebooks, которые стали популярным инструментом организации анализа данных. Статья Exploration and Explanation in Computational Notebooks анализирует противоречия между исследовательскими и объясняющими целями, изучая найденные на Github интерактивные документы, а в Managing Messes in Computational Notebooks авторы анализируют, как эволюционируют заметки, части кода и визуализации в итеративном процессе работы аналитиков, и предлагают возможные дополнения в инструменты, чтобы поддерживать этот процесс. Наконец, уже на CHI 2020 основные проблемы аналитиков на всех этапах работы, от загрузки данных до передачи модели в продакшн, а также идеи по улучшению инструментов обобщены в статье What’s Wrong with Computational Notebooks? Pain Points, Needs, and Design Opportunities.
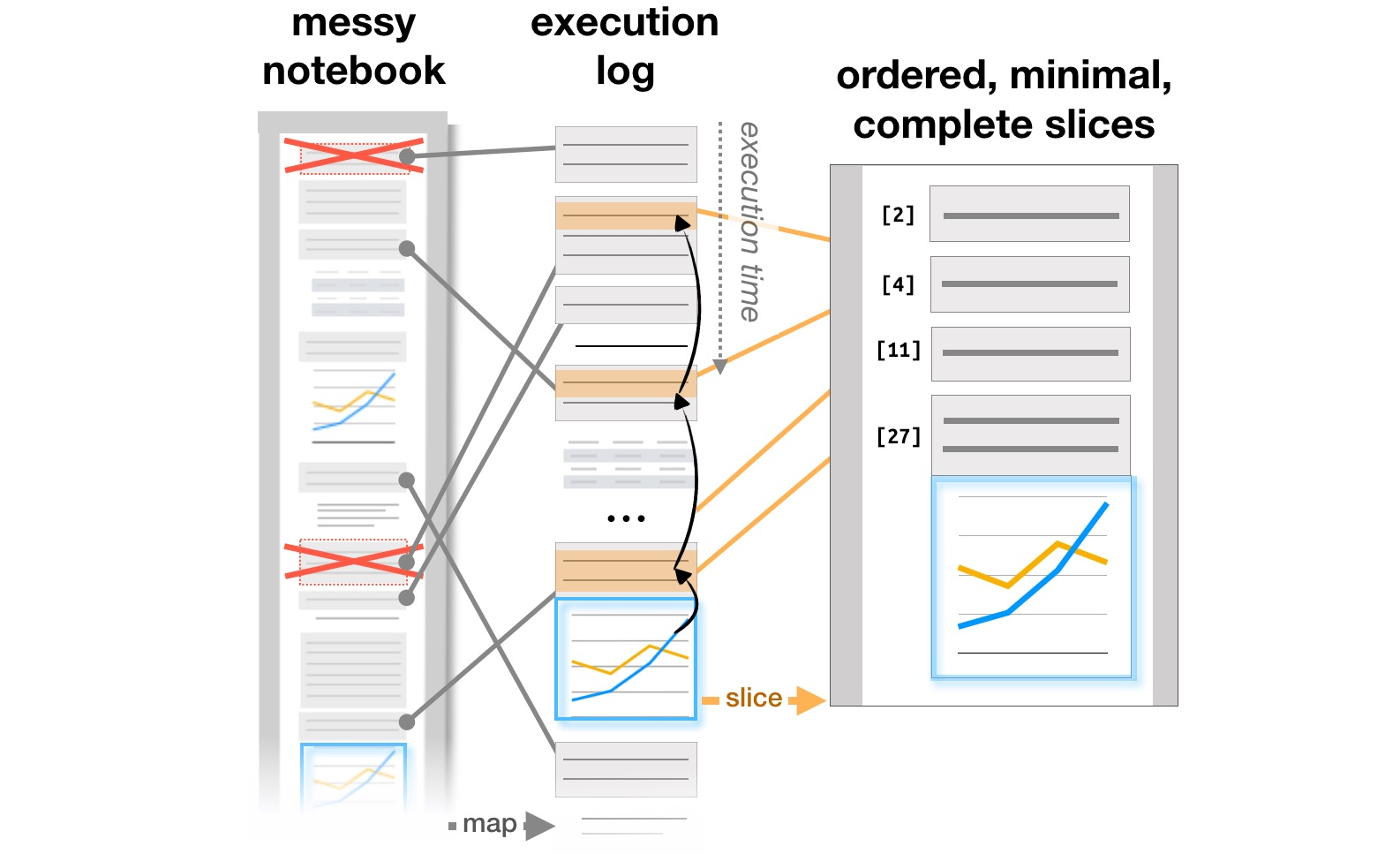
Преобразование структуры отчетов на основе логов выполнения (https://microsoft.github.io/gather/)
Подводя итог
Завершая часть обсуждения «чем же занимаются в HCI» и «зачем специалисту в HCI знать машинное обучение», хотелось бы еще раз отметить общий вывод из мотивации и результатов этих исследований. Как только в системе появляется человек, это сразу приводит к возникновению ряда дополнительных вопросов: как упростить взаимодействие с системой и избежать ошибок, как пользователь меняет систему, отличается ли реальное использование от запланированного. Как следствие, нужны те, кто понимает, как устроен процесс проектирования систем с искусственным интеллектом, и знают, как учесть человеческий фактор.
Всему этому мы учим на магистерской программе «Информационные системы и взаимодействие человек-компьютер». Если вы интересуетесь исследованиями в области HCI — заглядывайте на огонек (сейчас как раз началась приемная кампания). Или следите за нашим блогом: мы еще расскажем о проектах, над которыми студенты работали в этом году.
