Задумывались ли вы когда-нибудь, как работает голосовой поиск? Какая магия переводит ваши слова в поисковый запрос, причём практически в режиме реального времени? Сегодня мы расскажем, как «О’кей, Google!» стал ближе к вам на 300 миллисекунд и что именно позволяет вам разговаривать с вашим телефоном простым человеческим языком.

В основе актуальной версии голосового поиска Google лежит улучшенный алгоритм для обучения нейронных сетей, созданный специально для анализа и распознавания акустических моделей. В основу новых, Рекуррентных Нейронных Сетей (англ.: recurrent neural networks — RNN), легли Нейросетевая темпоральная классификация (англ.: Connectionist Temporal Classification — CTC) и дискриминантный анализ для последовательностей, адаптированный для обучения подобных структур. Данные RNN намного точнее, особенно в условиях посторонних шумов, а главное — они работают быстрее, чем все предыдущие модели распознавания речи.
Начать придётся с небольшого экскурса в историю. Почти 30 лет (по меркам IT-индустрии — целая вечность!) для распознавания речи использовались т.н. «модели смеси (многомерных) нормальных распределений» (англ.: Gaussian Mixture Model — GMM). Поначалу голосовой поиск Google также работал с этой технологией, пока мы не разработали новый подход к переводу звуковых волн в осмысленный набор символов, с которыми может оперировать «классический», текстовый поиск.
На тот момент (это случилось в 2012 году) перевод голосового поиска Google на технологию Глубоких Нейронных Сетей (англ.: Deep Neural Networks — DNN) осуществил настоящий прорыв в области распознавания речи. DNN лучше подходили для распознавания отдельных звуков, произносимых пользователем, чем GMM, благодаря чему точность распознавания речи значительно выросла.
В классической системе распознавания голоса записанный аудиосигнал делится на короткие (10 мс) фрагменты, каждый из которых затем анализируется на содержащиеся в нём частоты. Полученный в результате вектор характеристик прогоняется через акустическую модель (например, такую, как DNN), которая выдаёт набор вероятностных распределений среди всех возможных фонем. Скрытая Марковская модель (часто используемая в алгоритмах распознавания образов) помогает выявить последовательные структуры в этом наборе распределений вероятностей.
После этого данные анализа объединяются с другими данными, поступающими из альтернативных источников информации. Одним из них является Модель Произношения (англ.: Pronunciation Model), которая соединяет последовательность звуков в определённые слова предполагаемого языка. (прим.: Под «предполагаемым» языком понимается тот язык, который был выбран как «основной» в настройках голосового поиска). Другой источник — Языковая Модель: она обрабатывает полученные слова и анализирует фразу целиком, пытаясь оценить, насколько вероятна такая последовательность слов в искомом языке.
Далее вся информация попадает в систему распознавания, который согласует всю информацию, чтобы определить фразу, которую произносит пользователь. Например, если пользователь произносит слово «museum», то его фонетическая запись будет выглядеть следующим образом: /m j u z i @ m/.
Точно сказать, где закончился звук /j/ и начался /u/ может быть сложно, но на самом деле для алгоритма это не важно: главное, что все эти звуки были произнесены.
Наша улучшенная акустическая модель основана на Рекуррентных Нейронных Сетях (RNN). Их преимущество заключается в том, что они имеют циклы обратной связи в своей топологии, позволяющие им моделировать временные зависимости: когда пользователь произносит /u/ в предыдущем примере, его речевой аппарат одновременно выходит из процесса произношения предыдущих звуков /j/ и /m/. Попробуйте сказать вслух — «museum». Слово выходит моментально, на одном выдохе, и RNN могут это распознать.
RNN бывают разных типов, и для распознавания речи мы использовали специальные RNN с «длинной кратковременной памятью» (англ.: Long Short-Term Memory — LSTM). Эти ячейки памяти и сложный механизм гейтов позволяют LSTM RNN лучше других нейронных сетей запоминать информацию.
Использование одних этих моделей уже значительно улучшило качество нашей системы распознавания, но мы не остановились на этом. Следующим шагом стало обучение нейронных сетей распознаванию фонем во фразе без необходимости в постоянном выделении отдельных «предположений» о вероятностном распределении каждой из них.
С Нейросетевой темпоральной классификацией (CTC) модели научились выводить своеобразные «пики», которые и отображают последовательность различных звуков в звуковой волне. Они могут выделять различные фонемы в правильной с точки зрения языка последовательности звуков.
Самым сложным был вопрос «Как сделать так, чтобы распознавание происходило в реальном времени?». После множества попыток мы смогли научить потоковые однонаправленные модели обрабатывать более протяженные звуковые интервалы, чем те, что используются в «классических» моделях распознавания речи. В то время как сами вычисления происходят с меньшей частотой. При этом затраты вычислительных ресурсов на самом деле уменьшились, а скорость работы системы распознавания многократно увеличилась.
В лабораторных условиях распознавать речь достаточно легко: в полной тишине вы получаете качественную звуковую дорожку, которую потом анализируете. К сожалению, реальные условия эксплуатации голосового поиска существенно отличаются от эталонных. Кто-то говорит на заднем плане, мимо проезжают машины, где-то вдалеке гудит телевизор, в микрофон смартфона со свистом влетает порыв ветра… Все эти шумы затрудняют обработку речи нейронными сетями, так что мы научили их работать даже в таких тяжелых условиях.
В процессе обучения RNN мы подмешивали искусственные шумы, ревербацию, эхо и прочие типичные в повседневной эксплуатации «загрязнения» на обучающих сэмплах, что помогло сделать систему распознавания более устойчивым к фоновым шумам.
Теперь у нас был быстрый и точный распознаватель и мы готовы были запустить его на настоящих голосовых запросах, однако, нам предстояло решить ещё одну проблему.
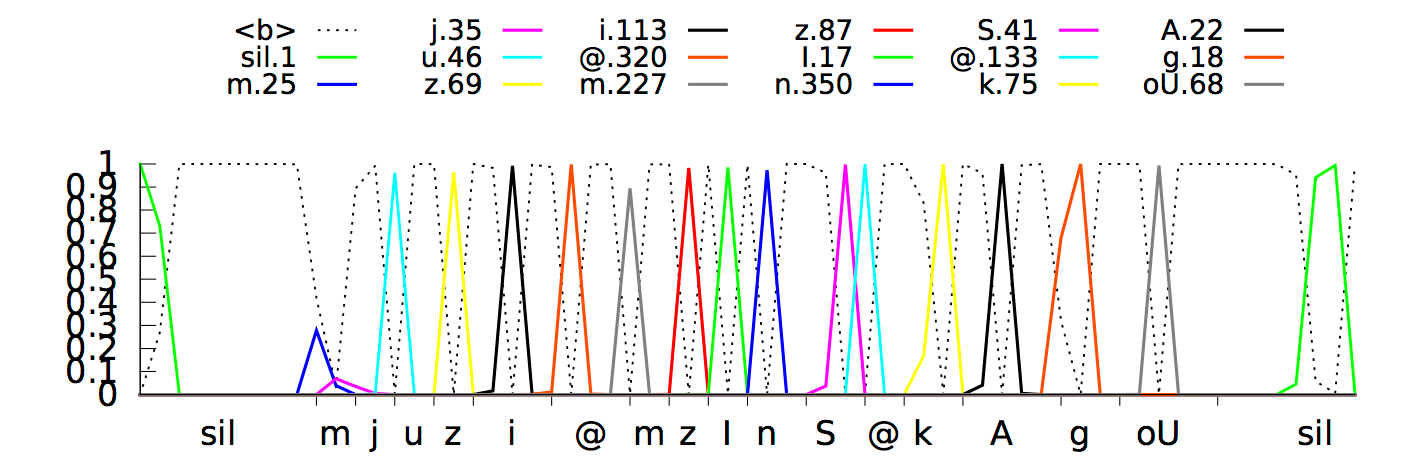
Модель выдавала прогноз фонем с задержкой примерно на 300 миллисекунд, так как нейронная сеть «поняла», что сможет лучше распознать фонемы, слушая сигнал чуть дольше. Вот так выглядит процесс распознавания в наглядной форме:
Нейросетевая темпоральная классификация пытается распознать фразу «How cold it is outside»
Такое поведение было логичным и отлично работало, но привело к более медленным ответам системы, чего мы совсем не хотели. Мы решили эту проблему путём длительного обучения нейронной сети выделению отдельных фонем как можно ближе к «срезу» сигнала. В результате распознавание речи происходит практически в режиме реального времени. Текущая модель на основе CTC выделяет «пики» отдельных фонем (отображены различными цветами) как только она определяет их во входящем звуковом потоке.
По оси X показаны определённые в каждый момент времени фонемы, а по оси Y — апостериорные вероятности распределения той или иной фонемы. Пунктиром отмечены те варианты, которые алгоритм решил не выделять / не распознавать как отдельные звуки.
Сейчас наш новый алгоритм используется в голосовом управлении и диктовке текста на ваших смартфонах (пока только на базе Android) и приложении Google на Android и iOS. Он не только использует меньше вычислительных ресурсов, но и точнее, работает быстрее, а ещё устойчив к шумам и помехам. Попробуйте, надеемся, вам понравится!
В основе актуальной версии голосового поиска Google лежит улучшенный алгоритм для обучения нейронных сетей, созданный специально для анализа и распознавания акустических моделей. В основу новых, Рекуррентных Нейронных Сетей (англ.: recurrent neural networks — RNN), легли Нейросетевая темпоральная классификация (англ.: Connectionist Temporal Classification — CTC) и дискриминантный анализ для последовательностей, адаптированный для обучения подобных структур. Данные RNN намного точнее, особенно в условиях посторонних шумов, а главное — они работают быстрее, чем все предыдущие модели распознавания речи.
Начать придётся с небольшого экскурса в историю. Почти 30 лет (по меркам IT-индустрии — целая вечность!) для распознавания речи использовались т.н. «модели смеси (многомерных) нормальных распределений» (англ.: Gaussian Mixture Model — GMM). Поначалу голосовой поиск Google также работал с этой технологией, пока мы не разработали новый подход к переводу звуковых волн в осмысленный набор символов, с которыми может оперировать «классический», текстовый поиск.
На тот момент (это случилось в 2012 году) перевод голосового поиска Google на технологию Глубоких Нейронных Сетей (англ.: Deep Neural Networks — DNN) осуществил настоящий прорыв в области распознавания речи. DNN лучше подходили для распознавания отдельных звуков, произносимых пользователем, чем GMM, благодаря чему точность распознавания речи значительно выросла.
Как это было раньше: работа DNN
В классической системе распознавания голоса записанный аудиосигнал делится на короткие (10 мс) фрагменты, каждый из которых затем анализируется на содержащиеся в нём частоты. Полученный в результате вектор характеристик прогоняется через акустическую модель (например, такую, как DNN), которая выдаёт набор вероятностных распределений среди всех возможных фонем. Скрытая Марковская модель (часто используемая в алгоритмах распознавания образов) помогает выявить последовательные структуры в этом наборе распределений вероятностей.
После этого данные анализа объединяются с другими данными, поступающими из альтернативных источников информации. Одним из них является Модель Произношения (англ.: Pronunciation Model), которая соединяет последовательность звуков в определённые слова предполагаемого языка. (прим.: Под «предполагаемым» языком понимается тот язык, который был выбран как «основной» в настройках голосового поиска). Другой источник — Языковая Модель: она обрабатывает полученные слова и анализирует фразу целиком, пытаясь оценить, насколько вероятна такая последовательность слов в искомом языке.
Далее вся информация попадает в систему распознавания, который согласует всю информацию, чтобы определить фразу, которую произносит пользователь. Например, если пользователь произносит слово «museum», то его фонетическая запись будет выглядеть следующим образом: /m j u z i @ m/.
Точно сказать, где закончился звук /j/ и начался /u/ может быть сложно, но на самом деле для алгоритма это не важно: главное, что все эти звуки были произнесены.
Что изменилось в голосовом поиске?
Наша улучшенная акустическая модель основана на Рекуррентных Нейронных Сетях (RNN). Их преимущество заключается в том, что они имеют циклы обратной связи в своей топологии, позволяющие им моделировать временные зависимости: когда пользователь произносит /u/ в предыдущем примере, его речевой аппарат одновременно выходит из процесса произношения предыдущих звуков /j/ и /m/. Попробуйте сказать вслух — «museum». Слово выходит моментально, на одном выдохе, и RNN могут это распознать.
RNN бывают разных типов, и для распознавания речи мы использовали специальные RNN с «длинной кратковременной памятью» (англ.: Long Short-Term Memory — LSTM). Эти ячейки памяти и сложный механизм гейтов позволяют LSTM RNN лучше других нейронных сетей запоминать информацию.
Использование одних этих моделей уже значительно улучшило качество нашей системы распознавания, но мы не остановились на этом. Следующим шагом стало обучение нейронных сетей распознаванию фонем во фразе без необходимости в постоянном выделении отдельных «предположений» о вероятностном распределении каждой из них.
С Нейросетевой темпоральной классификацией (CTC) модели научились выводить своеобразные «пики», которые и отображают последовательность различных звуков в звуковой волне. Они могут выделять различные фонемы в правильной с точки зрения языка последовательности звуков.
Прим.: RNN могут распознать слово «гидроэлектростанция», но не смогут верно выделить отдельные звуки в бессмысленной с точки зрения языка последовательности «йцукенфывапролдж».
Самым сложным был вопрос «Как сделать так, чтобы распознавание происходило в реальном времени?». После множества попыток мы смогли научить потоковые однонаправленные модели обрабатывать более протяженные звуковые интервалы, чем те, что используются в «классических» моделях распознавания речи. В то время как сами вычисления происходят с меньшей частотой. При этом затраты вычислительных ресурсов на самом деле уменьшились, а скорость работы системы распознавания многократно увеличилась.
Переход от конно-сферических условий к реальной эксплуатации
В лабораторных условиях распознавать речь достаточно легко: в полной тишине вы получаете качественную звуковую дорожку, которую потом анализируете. К сожалению, реальные условия эксплуатации голосового поиска существенно отличаются от эталонных. Кто-то говорит на заднем плане, мимо проезжают машины, где-то вдалеке гудит телевизор, в микрофон смартфона со свистом влетает порыв ветра… Все эти шумы затрудняют обработку речи нейронными сетями, так что мы научили их работать даже в таких тяжелых условиях.
В процессе обучения RNN мы подмешивали искусственные шумы, ревербацию, эхо и прочие типичные в повседневной эксплуатации «загрязнения» на обучающих сэмплах, что помогло сделать систему распознавания более устойчивым к фоновым шумам.
Теперь у нас был быстрый и точный распознаватель и мы готовы были запустить его на настоящих голосовых запросах, однако, нам предстояло решить ещё одну проблему.
Как голосовой поиск Google стал ближе к пользователю
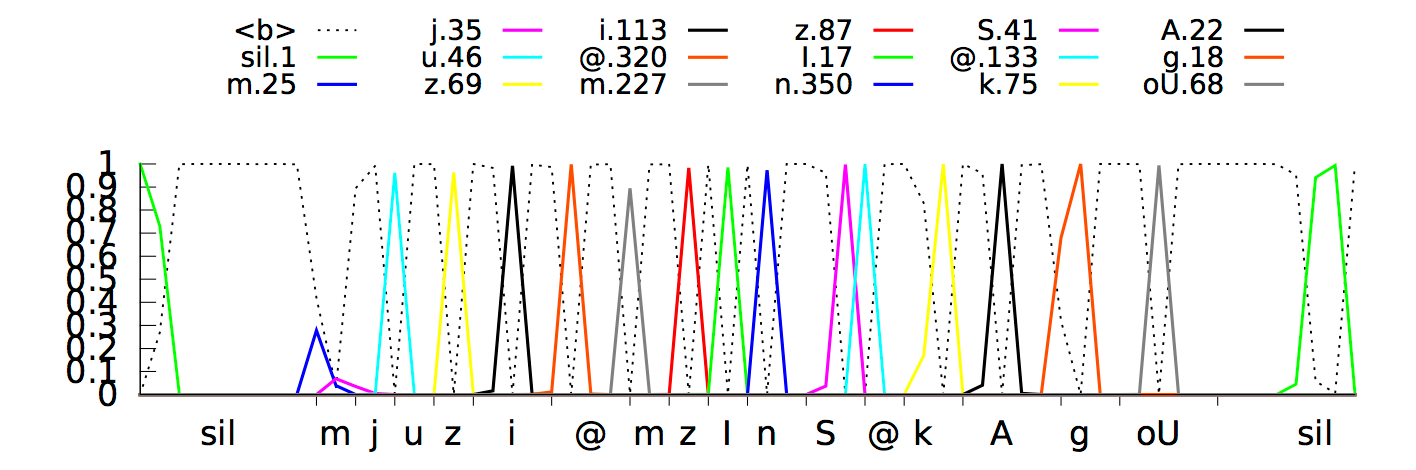
Модель выдавала прогноз фонем с задержкой примерно на 300 миллисекунд, так как нейронная сеть «поняла», что сможет лучше распознать фонемы, слушая сигнал чуть дольше. Вот так выглядит процесс распознавания в наглядной форме:
Нейросетевая темпоральная классификация пытается распознать фразу «How cold it is outside»
Такое поведение было логичным и отлично работало, но привело к более медленным ответам системы, чего мы совсем не хотели. Мы решили эту проблему путём длительного обучения нейронной сети выделению отдельных фонем как можно ближе к «срезу» сигнала. В результате распознавание речи происходит практически в режиме реального времени. Текущая модель на основе CTC выделяет «пики» отдельных фонем (отображены различными цветами) как только она определяет их во входящем звуковом потоке.
По оси X показаны определённые в каждый момент времени фонемы, а по оси Y — апостериорные вероятности распределения той или иной фонемы. Пунктиром отмечены те варианты, которые алгоритм решил не выделять / не распознавать как отдельные звуки.
Сейчас наш новый алгоритм используется в голосовом управлении и диктовке текста на ваших смартфонах (пока только на базе Android) и приложении Google на Android и iOS. Он не только использует меньше вычислительных ресурсов, но и точнее, работает быстрее, а ещё устойчив к шумам и помехам. Попробуйте, надеемся, вам понравится!
