
Эта статья — практическая история о том, как мы столкнулись с проблемой разделения логов, хранимых в Elasticsearch, из-за которой пришлось поменять подход к бэкапам и управлению индексами.

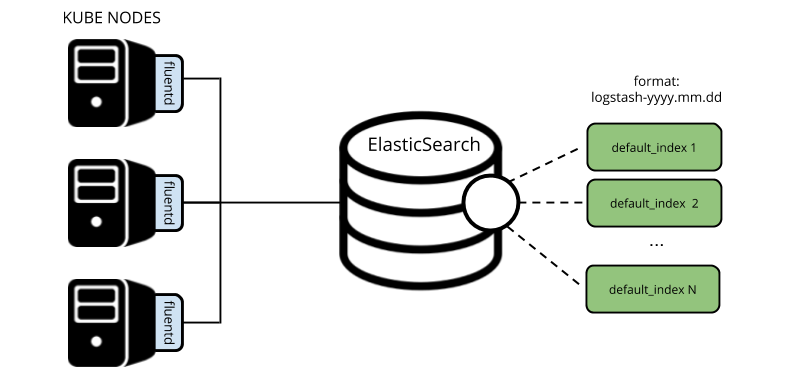
Всё началось вскоре после того, как было поднято production-окружение. У нас был «боевой» кластер Kubernetes, все логи из которого собирал fluentd и направлял их напрямую в индексы
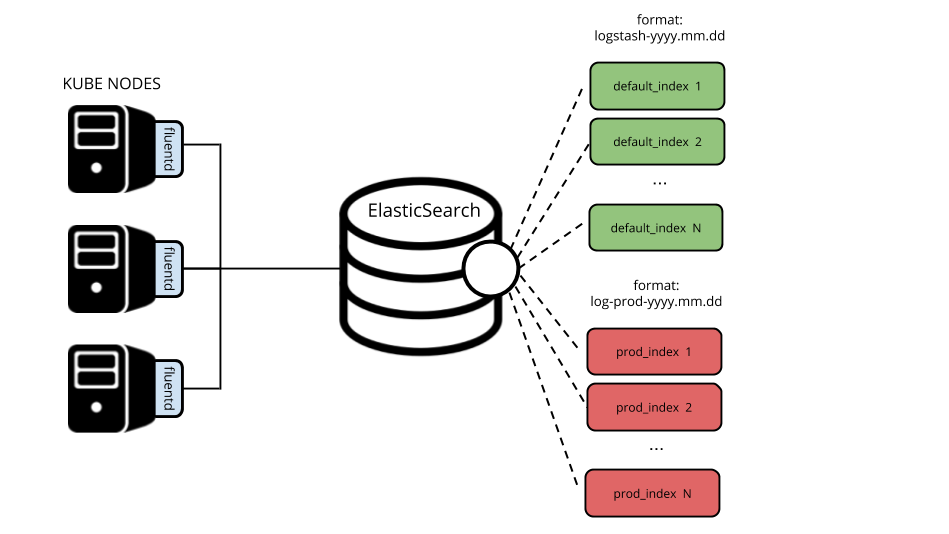
Однако появился запрос хранить некоторые логи приложений для поиска до 90 дней. На тот момент мы не могли себе этого позволить: хранение текущих индексов за такой период превысило бы все разумные меры. Поэтому было принято решение создать отдельный индекс-паттерн для таких приложений и настроить на него отдельный retention.
Чтобы выполнить такую задачу и отделить «нужные» логи от «ненужных», мы воспользовались параметром
Фрагменты получившегося
Итог — у нас два вида индексов (
На тот момент в кластере уже был настроен curator, который очищал индексы старше 14 дней. Он описывался как объект CronJob для разворачивания прямо в кластер Kubernetes.
Иллюстрация в
Однако мы решили, что вариант с куратором избыточен (запускается как отдельное ПО, требует отдельной настройки и запуска по крону) — ведь можно переделать очистку с помощью index lifecycle policy.
В Elasticsearch с версии 6.6 (вышла в январе 2019 года) появилась возможность прикрепления к index template политики, которая будет отслеживать время хранения для индекса. Политики можно использовать не только для управления очисткой, но и других задач, которые позволят упростить взаимодействие с индексами (например, выравнивание индексов по размеру, а не по дням).
Для этого требовалось лишь создать две политики такого вида:
… и прикрепить их к требуемым index templates:
Теперь кластер Elasticsearch будет самостоятельно управлять хранением данных. Это означает, что все индексы, которые попадут под шаблон в
Но тут мы сталкиваемся с другой проблемой…
Созданные нами политики, шаблоны и те изменения, что были применены во fluentd, будут иметь эффект только для новых создаваемых индексов. Чтобы привести в порядок то, что уже имеем, придется запустить процесс переиндексации, обратившись к Reindex API.
Требуется выделить «нужные» логи из уже закрытых индексов и реиндексировать их самих, чтобы были применены политики.
Для этого достаточно двух простых запросов:
Теперь старые индексы можно удалить!
Однако есть и другие трудности. Как уже известно, ранее был настроен curator, который чистил кластер с retention в 14 дней. Таким образом, для актуальных для нас сервисов потребуется восстановить данные и из того, что уже было когда-то удалено. Здесь помогут бэкапы.
В простейшем случае, что применимо и к нашему, бэкапы делаются посредством вызова
Развернуть все, что было от запуска production, не представлялось возможным, т.к. в кластере банально не было столько места. К тому же, доступ к логам из бэкапа требовался уже сейчас.
Решение — развернуть временный кластер, в который восстанавливается бэкап, откуда уже и достаются нужные нам логи (способом, аналогичным уже описанному). А параллельно мы начали думать, как сделать снятие бэкапов более удобным способом — подробнее об этом см. ниже.
Итак, следующие шаги (по временному кластеру):
Этим запросом мы получаем из индексов в удаленном кластере документы, которые будут передаваться в production-кластер по сети. На стороне временного кластера все документы, не подходящие под запрос, будут отфильтрованы.
Параметры
На принимающем Elasticsearch мы настроили шаблоны индексов на максимальную производительность.
Когда все нужные логи оказались в одном месте полностью разделенными так, как требовалось, временный кластер можно удалять:
Самое время вернуться к бэкапам: запуск
Такую задачу можно «отдать» самому Elasticsearch — Snapshot Repository на базе S3. И вот основные причины, по которым мы сами выбрали такой подход:
Настройка бэкапа в S3 требует дополнительной установки плагина в Elasticsearch, чтобы Snapshot Repository мог общаться c S3. Вся конфигурация сводится к следующим шагам:
Статус снятия снапшота можно проверять по имени через API, вызвав информацию о снапшоте и посмотрев в поле
Статус восстановления же можно проверять из самого кластера: в начале восстановления кластер перейдет в статус
Также отслеживать статус можно с помощью
Результат — получаем точную копию индекса из сделанного снапшота:
Оптимальными для нас решениям в кластере Elasticsearch оказались:
Впрочем, полезно будет предостеречь, что изменения в политиках и шаблонах из-за изменяющихся потребностей в дальнейшем приведут к необходимости реиндексировать все индексы в кластере. А с бэкапами картина ещё дальше от идеала…
Несмотря на то, что мы «передали» выполнение бэкапов самому Elasticsearch, запуск снятия снапшота и наблюдение за его выполнением всё еще остается нашей задачей: обращение к API, отслеживание статусов (через
В целом, такая обособленность системы плохо ложится на использование централизованного подхода к бэкапам и мы пока не нашли (среди Open Source-инструментов) универсальное средство, которое бы это позволило.
Читайте также в нашем блоге:

Всё началось вскоре после того, как было поднято production-окружение. У нас был «боевой» кластер Kubernetes, все логи из которого собирал fluentd и направлял их напрямую в индексы
logstash-yyy.mm.dd…
Однако появился запрос хранить некоторые логи приложений для поиска до 90 дней. На тот момент мы не могли себе этого позволить: хранение текущих индексов за такой период превысило бы все разумные меры. Поэтому было принято решение создать отдельный индекс-паттерн для таких приложений и настроить на него отдельный retention.
Разделение логов
Чтобы выполнить такую задачу и отделить «нужные» логи от «ненужных», мы воспользовались параметром
match у fluentd и создали еще одну секцию в output.conf для поиска совпадений по нужным сервисам в пространстве имён production согласно тегированию, указанному для input-плагина (а также изменив @id и logstash_prefix, чтобы направить запись в разные места).Фрагменты получившегося
output.conf: <match kubernetes.var.log.containers.**_production_**>
@id elasticsearch1
@type elasticsearch
logstash_format true
logstash_prefix log-prod
...
</match>
<match kubernetes.**>
@id elasticsearch
@type elasticsearch
logstash_format true
logstash_prefix logstash
...
</match>Итог — у нас два вида индексов (
log-prod-yyyy.mm.dd и logstash-yyyy.mm.dd):
Очистка индексов
На тот момент в кластере уже был настроен curator, который очищал индексы старше 14 дней. Он описывался как объект CronJob для разворачивания прямо в кластер Kubernetes.
Иллюстрация в
action_file.yml:-
actions:
1:
action: delete_indices
description: >-
Delete indices older than 14 days (based on index name), for logstash-
prefixed indices. Ignore the error if the filter does not result in an
actionable list of indices (ignore_empty_list) and exit cleanly.
options:
ignore_empty_list: True
timeout_override:
continue_if_exception: False
disable_action: False
allow_ilm_indices: True
filters:
- filtertype: pattern
kind: prefix
value: logstash
- filtertype: age
source: name
direction: older
timestring: '%Y.%m.%d'
unit: days
unit_count: 14Однако мы решили, что вариант с куратором избыточен (запускается как отдельное ПО, требует отдельной настройки и запуска по крону) — ведь можно переделать очистку с помощью index lifecycle policy.
В Elasticsearch с версии 6.6 (вышла в январе 2019 года) появилась возможность прикрепления к index template политики, которая будет отслеживать время хранения для индекса. Политики можно использовать не только для управления очисткой, но и других задач, которые позволят упростить взаимодействие с индексами (например, выравнивание индексов по размеру, а не по дням).
Для этого требовалось лишь создать две политики такого вида:
PUT _ilm/policy/prod_retention
{
"policy" : {
"phases" : {
"delete" : {
"min_age" : "90d",
"actions" : {
"delete" : { }
}
}
}
}
}
PUT _ilm/policy/default_retention
{
"policy" : {
"phases" : {
"delete" : {
"min_age" : "14d",
"actions" : {
"delete" : { }
}
}
}
}
}… и прикрепить их к требуемым index templates:
PUT _template/log_prod_template
{
"index_patterns": ["log-prod-*"],
"settings": {
"index.lifecycle.name": "prod_retention",
}
}
PUT _template/default_template
{
"index_patterns": ["logstash-*"],
"settings": {
"index.lifecycle.name": "default_retention",
}
}Теперь кластер Elasticsearch будет самостоятельно управлять хранением данных. Это означает, что все индексы, которые попадут под шаблон в
index_patterns, указанный выше, будут очищаться после заданного в политике количества дней.Но тут мы сталкиваемся с другой проблемой…
Реиндексирование внутри кластера и из удаленных кластеров
Созданные нами политики, шаблоны и те изменения, что были применены во fluentd, будут иметь эффект только для новых создаваемых индексов. Чтобы привести в порядок то, что уже имеем, придется запустить процесс переиндексации, обратившись к Reindex API.
Требуется выделить «нужные» логи из уже закрытых индексов и реиндексировать их самих, чтобы были применены политики.
Для этого достаточно двух простых запросов:
POST _reindex
{
"source": {
"index": "logstash-2019.10.24",
"query": {
"match": {
"kubernetes.namespace_name": "production"
}
}
},
"dest": {
"index": "log-prod-2019.10.24"
}
}
POST _reindex
{
"source": {
"index": "logstash-2019.10.24"
"query": {
"bool": {
"must_not": {
"match": {
"kubernetes.namespace_name": "production"
}
}
}
}
},
"dest": {
"index": "logstash-2019.10.24-ri"
}
}Теперь старые индексы можно удалить!
Однако есть и другие трудности. Как уже известно, ранее был настроен curator, который чистил кластер с retention в 14 дней. Таким образом, для актуальных для нас сервисов потребуется восстановить данные и из того, что уже было когда-то удалено. Здесь помогут бэкапы.
В простейшем случае, что применимо и к нашему, бэкапы делаются посредством вызова
elasticdump для всех индексов разом:/usr/bin/elasticdump --all $OPTIONS --input=http://localhost:9200 --output=$Развернуть все, что было от запуска production, не представлялось возможным, т.к. в кластере банально не было столько места. К тому же, доступ к логам из бэкапа требовался уже сейчас.
Решение — развернуть временный кластер, в который восстанавливается бэкап, откуда уже и достаются нужные нам логи (способом, аналогичным уже описанному). А параллельно мы начали думать, как сделать снятие бэкапов более удобным способом — подробнее об этом см. ниже.
Итак, следующие шаги (по временному кластеру):
- Установить еще один Elasticsearch на отдельный сервер с достаточно большим диском.
- Развернуть бэкап из имеющегося у нас dump-файла:
/usr/bin/elasticdump --bulk --input=dump.json --output=http://127.0.0.1:9200/ - Обратите внимание, что индексы в кластере не приобретут состояние green, т.к. мы переносим дамп в 1-узловую конфигурацию. Но переживать из-за этого не стоит: главное — вытащить только primal-шарды.
- Не нужно забывать, что для разрешения реиндексирования из удаленных кластеров нужно добавить их в whitelist в
elasticsearch.yaml:
reindex.remote.whitelist: 1.2.3.4:9200 - Далее произведем запрос на реиндексацию из удаленного кластера в текущем production-кластере:
POST _reindex { "source": { "remote": { "host": "http://1.2.3.4:9200" }, "size": 10000, "index": "logstash-2019.10.24", "query": { "match": { "kubernetes.namespace_name": "production" } } }, "dest": { "index": "log-prod-2019.10.24" } }
Этим запросом мы получаем из индексов в удаленном кластере документы, которые будут передаваться в production-кластер по сети. На стороне временного кластера все документы, не подходящие под запрос, будут отфильтрованы.
Параметры
size и slice используются для ускорения процесса реиндексации:-
size— для увеличения количества документов для индексации, передаваемых в пакете; -
slice— для деления этой задачи на 6 подзадач, которые будут параллельно заниматься реиндексированием. (Параметр не работает в реиндексации из удаленных кластеров).
На принимающем Elasticsearch мы настроили шаблоны индексов на максимальную производительность.
Когда все нужные логи оказались в одном месте полностью разделенными так, как требовалось, временный кластер можно удалять:

Бэкапы Elasticsearch
Самое время вернуться к бэкапам: запуск
elasticdump на все индексы — далеко не самое оптимальное решение. Хотя бы по той причине, что восстановление может занимать неприлично много времени, а бывают случаи, когда важен каждый час.Такую задачу можно «отдать» самому Elasticsearch — Snapshot Repository на базе S3. И вот основные причины, по которым мы сами выбрали такой подход:
- Удобство создания и восстановления из таких бэкапов, поскольку используется родной синтаксис запросов к Elasticsearch.
- Снапшоты накатываются инкрементально, т.е. добавляя новые данные к уже имеющимся.
- Возможность восстановить из снапшота любой индекс и даже восстановить глобальное состояние кластера.
- S3 кажется более надежным местом для хранения бэкапов, чем просто файл (в том числе и по той причине, что обычно мы используем S3 в режимах HA).
- Переносимость S3: мы не привязаны к конкретным провайдерам и можем развернуть S3 на новом месте самостоятельно.
Настройка бэкапа в S3 требует дополнительной установки плагина в Elasticsearch, чтобы Snapshot Repository мог общаться c S3. Вся конфигурация сводится к следующим шагам:
- Устанавливаем плагин для S3 на все узлы:
bin/elasticsearch-plugin install repository-s3
… и параллельно добавляем S3 в whitelist вelasticsearch.yml:
Repositories.url.allowed_urls: - "https://example.com/*" - Добавляем ключи
SECRETиACCESSв Elasticsearch keystore. По умолчанию для подключения к S3 используется пользовательdefault:
bin/elasticsearch-keystore add s3.client.default.access_key bin/elasticsearch-keystore add s3.client.default.secret_key
… и после этого поочередно перезапускаем сервис Elasticsearch на всех узлах. - Создаем репозиторий для снапшотов:
PUT /_snapshot/es_s3_repository { "type": "s3", "settings": { "bucket": "es-snapshot", "region": "us-east-1", "endpoint": "https://example.com" } }
В данном случае для создания снапшота хватит примеров из документации, где имя снапшота будет в формате:snapshot-2018.05.11,— т.е.:
PUT /_snapshot/my_backup/%3Csnapshot-%7Bnow%2Fd%7D%3E - Осталось лишь протестировать восстановление индекса:
POST /_snapshot/es_s3_repository/snapshot-2019.12.30/_restore { "indices": "logstash-2019.12.29", "rename_pattern": "logstash-(.+)", "rename_replacement": "restored_index_$1" }
Так мы восстанавливаем индекс «рядом», просто переименовав его. Однако можно восстановить его и в тот же индекс — только для этого индекс в кластере должен быть закрыт и иметь такое же количество шардов, что и индекс в снапшоте.
Статус снятия снапшота можно проверять по имени через API, вызвав информацию о снапшоте и посмотрев в поле
state:GET /_snapshot/es_s3_repository/snapshot_2019.12.30Статус восстановления же можно проверять из самого кластера: в начале восстановления кластер перейдет в статус
red, т.к. будут восстанавливаться primal-шарды ваших индексов. Как только процесс будет завершен, индексы и кластер перейдут в статус yellow — до того момента, как будет создано указанное количество реплик.Также отслеживать статус можно с помощью
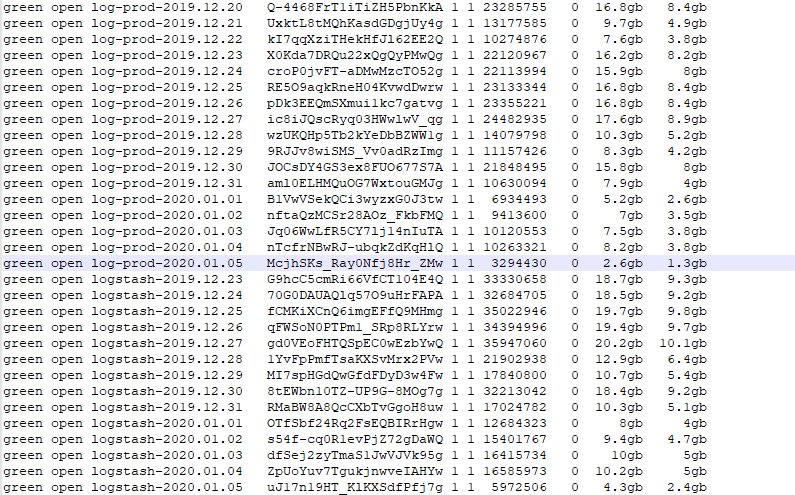
wait_for_completion=true, указанном прямо в строке запроса.Результат — получаем точную копию индекса из сделанного снапшота:
green open restored_index_2019.12.29 eJ4wXqg9RAebo1Su7PftIg 1 1 1836257 0 1.9gb 1000.1mb
green open logstash-2019.12.29 vE8Fyb40QiedcW0k7vNQZQ 1 1 1836257 0 1.9gb 1000.1mbИтоги и недостатки
Оптимальными для нас решениям в кластере Elasticsearch оказались:
- Настройка output-плагина в fluentd, с которой можно разделять логи прямо на выходе из кластера.
- Политика index lifecycle, позволяющая не заботиться о проблемах с местом, занятым индексами.
- Новый вид бэкапов через snapshot repository (вместо бэкапа целого кластера), с которым появилась возможность восстанавливать отдельные индексы из S3, что стало гораздо удобнее.
Впрочем, полезно будет предостеречь, что изменения в политиках и шаблонах из-за изменяющихся потребностей в дальнейшем приведут к необходимости реиндексировать все индексы в кластере. А с бэкапами картина ещё дальше от идеала…
Несмотря на то, что мы «передали» выполнение бэкапов самому Elasticsearch, запуск снятия снапшота и наблюдение за его выполнением всё еще остается нашей задачей: обращение к API, отслеживание статусов (через
wait_for_completion) и по статусу мы будем производить сами с помощью скриптов. При всей удобности backup repository есть у него и другая проблема: слишком мало плагинов. Например, нет возможности работать через WebDAV, если вместо S3 понадобится что-то совсем простое, но такое же мобильное.В целом, такая обособленность системы плохо ложится на использование централизованного подхода к бэкапам и мы пока не нашли (среди Open Source-инструментов) универсальное средство, которое бы это позволило.
P.S.
Читайте также в нашем блоге:
