Централизация рабочих столов и клиентских ПК в центре обработки данных сегодня все чаще становится предметом обсуждения в IT-сообществе, особенно интересен такой подход для крупных организаций. Одной из наиболее «горячих» технологий в этом отношении является VDI. VDI позволяет централизовать обслуживание клиентских окружений, упростить развертывание приложений, их настройку и конфигурирование, а также обновление и контроль соответствия требованиям безопасности.
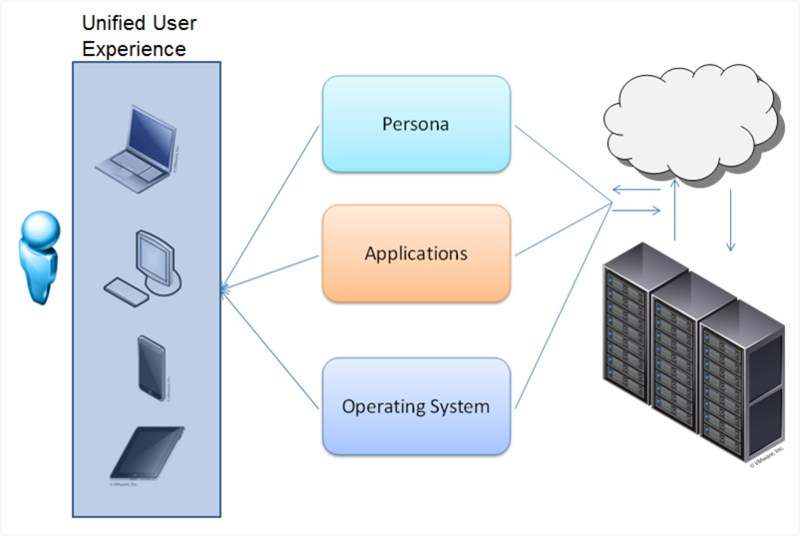
VDI «отвязывает» рабочий стол пользователя от аппаратного обеспечения. Развертывать можно как постоянный виртуальный рабочий стол, так и (наиболее частый вариант) гибкую виртуальную машину. Виртуальные машины включают индивидуальный набор приложений и настроек, который разворачивается в базовой ОС при авторизации пользователя. После выхода из системы, ОС возвращается в «чистое» состояние, убирая любые изменения и вредоносные программы.
Для системного администратора это очень удобно — управляемость, безопасность, надежность на высоте, обновлять приложения можно в едином центре, а не на каждом ПК. Офисные пакеты, интерфейсы к базам данных, интернет-браузеры и прочие нетребовательные к графике приложения могут работать на любом сервере (всем известные терминальные клиенты 1С).
Но что делать, если хочется виртуализовать более серьезную графическую станцию?
Тут не обойтись без виртуализации графической подсистемы.
Есть три варианта работы:
Рассмотрим подробнее

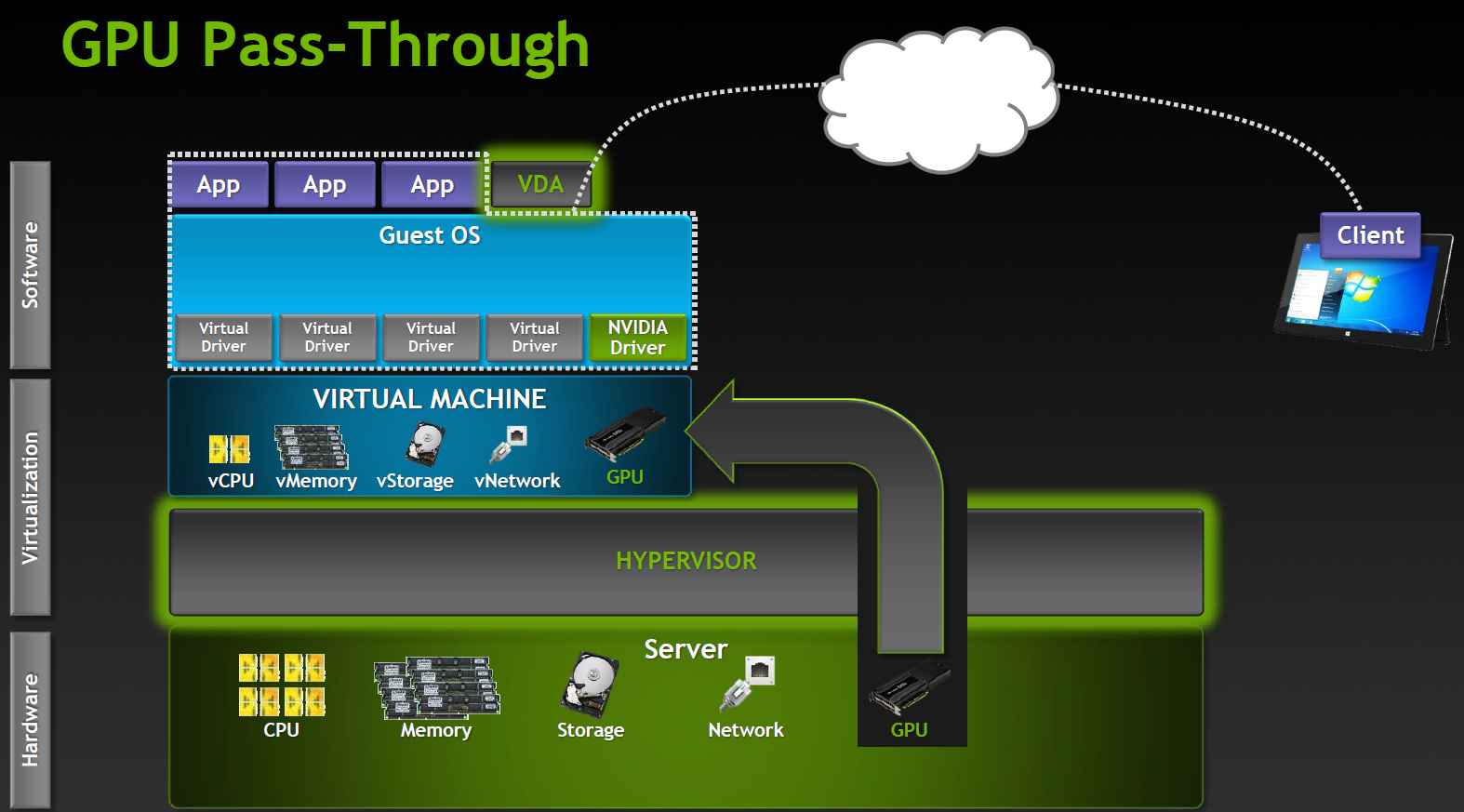
Выделенный GPU
Наиболее производительный режим работы, поддерживается в продуктах Citrix XenDesktop 7 VDI delivery и VMware Horizon View (5.3 or higher) with vDGA. Полностью работают NVIDIA CUDA, DirectX 9,10,11, OpenGL 4.4. Все остальные компоненты (процессоры, память, накопители, сетевые адаптеры) виртуализованы и разделены между инстансами гипервизора, однако один GPU остается одним GPU. Каждая виртуальная машина получает свой GPU практически без пенальти по производительности.
Очевидное ограничение — количество таких виртуальных машин ограничено количеством доступных графических адаптеров в системе.

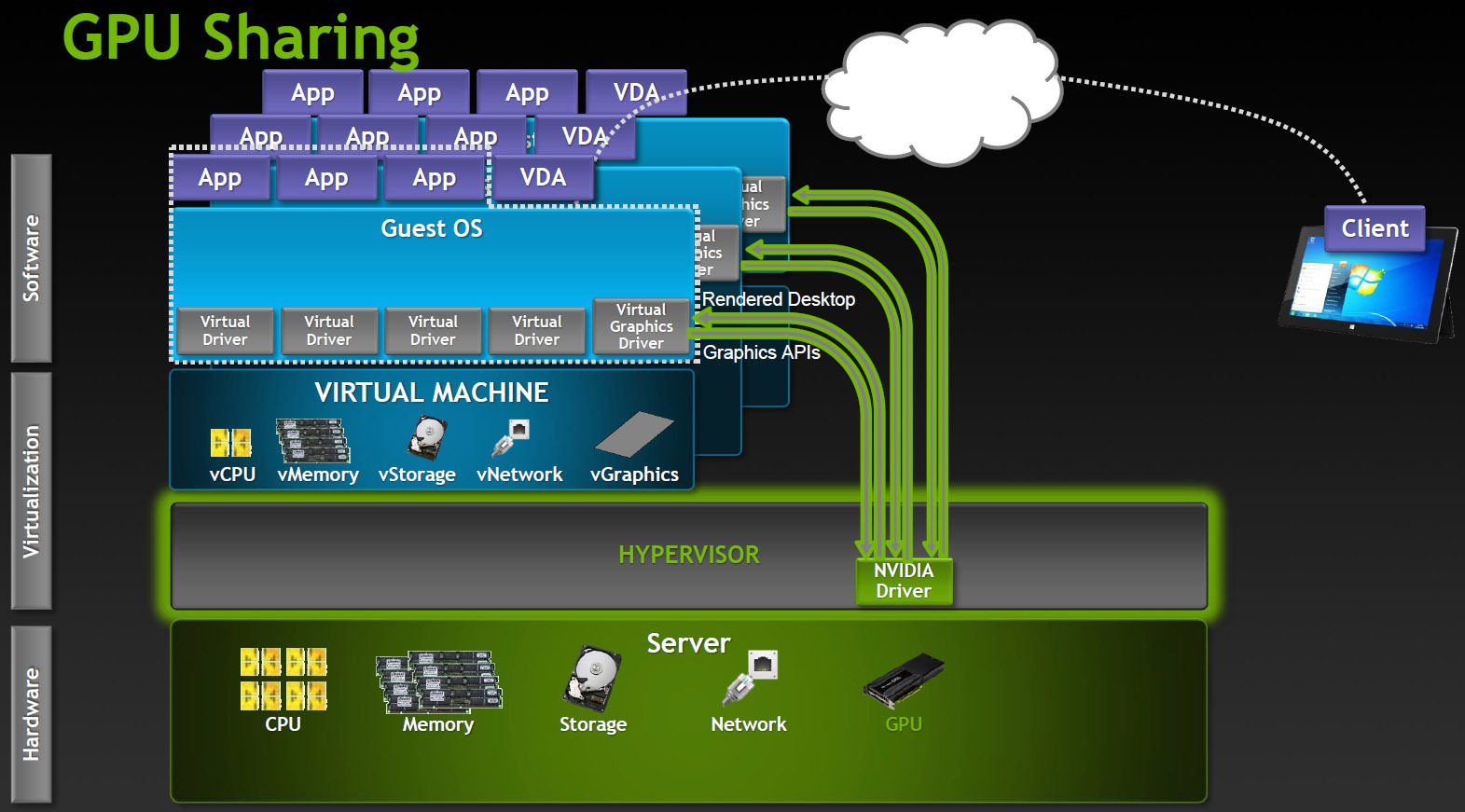
Shared GPU
Работает в Microsoft RemoteFX, VMware vSGA. Этот вариант полагается на возможности ПО для VDI, виртуальная машина работает как будто с выделенным адаптером и и серверный GPU также полагает, что работает с одним хостом, хотя на самом деле это уровень абстракции. Гипервизор перехватывает вызовы API и транслирует все команды, запросы отрисовки и прочее до передачи графическому драйверу, а хост машина работает с драйвером виртуальной карты.
Shared GPU вполне разумное решение для многих случаев. Если приложения не слишком сложные, то одновременно может работать значительное число пользователей. С другой стороны, на трансляцию API тратится достаточно много ресурсов и при этом невозможно гарантировать совместимость с приложениями. Особенно с теми приложениями, которые используют более новые версии API, чем существовавшие на момент разработки VDI продукта.
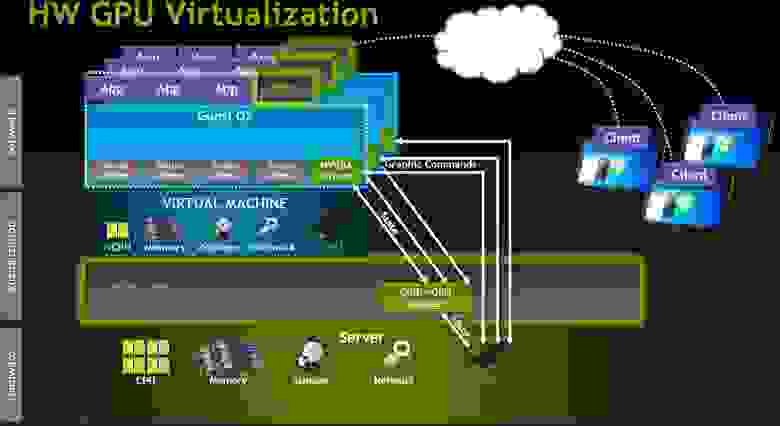
Virtual GPU
Наиболее продвинутый вариант разделения GPU между пользователями, поддерживается на данный момент только в продуктах Citrix.
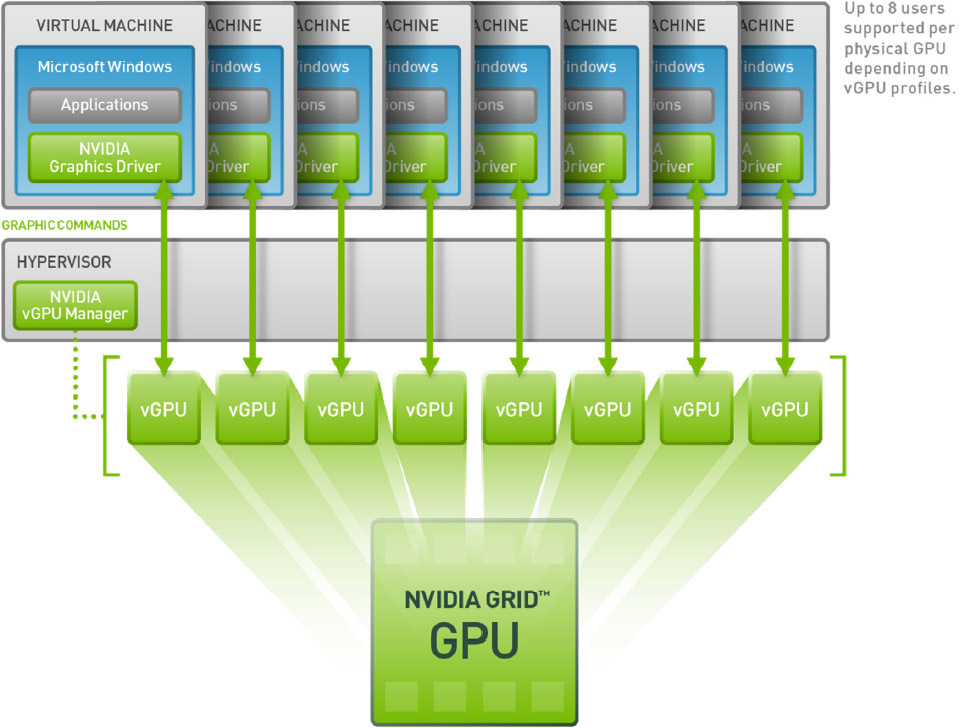
Как это работает? В VDI среде с vGPU каждая виртуальная машина работает через гипервизор с выделенным драйвером vGPU, который есть в каждой виртуальной машине. Каждый драйвер vGPU посылает команды и управляет одним физическим GPU, используя выделенный канал.
Обработанные кадры возвращаются драйвером в виртуальную машину для отправки пользователю.
Такой режим работы стал возможен в последнем поколении GPU производства NVIDIA — Kepler. В Kepler есть Memory Management Unit (MMU) который транслирует виртуальные адреса хоста в физические адреса системы. Каждый процесс работает в собственном виртуальном адресном пространстве, а MMU разделяет их физические адреса, чтобы не было пересечения и борьбы за ресурсы.
Воплощение в карточках
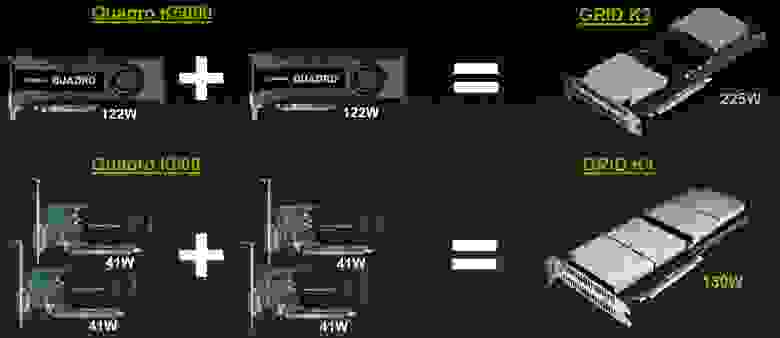
Модельный ряд
Разновидности для VDI
Но простого деления по характеристикам мало, для GRID доступно деление на виртуальные профили vGPU.
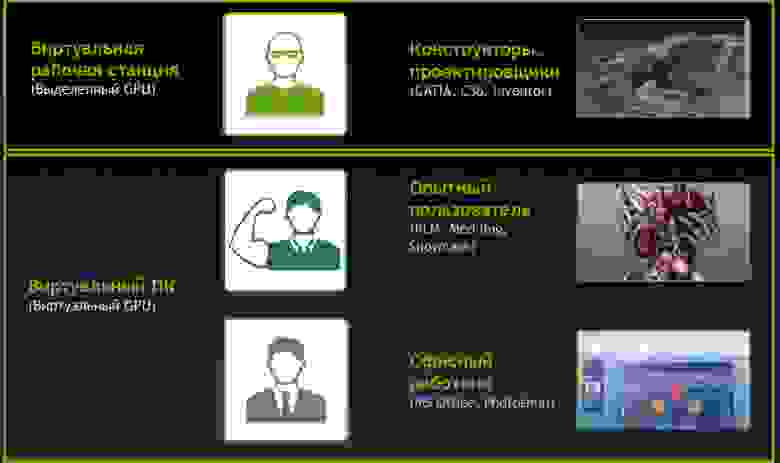
Видение типов пользователей
Профили и применения
Профили с индексом Q сертифицированы под ряд профессиональных приложений (например, Autodesk Inventor 2014 и PTC Creo) так же, как и карты серии Quadro.

Полное виртуальное счастье!
NVIDIA не была бы верна себе, если бы не подумала о дополнительных разновидностях. Определенную популярность набирают сервисы игр по запросу (Gaming-as-a-Service, GaaS), где тоже можно получить неплохой бонус от виртуализации и возможности разделить GPU между пользователями.
Разновидности для игр в облаках
Влияние виртуализации на производительность
Конфигурация сервера:
Intel Xeon CPU E5-2670 2.6GHz, Dual Socket (16 Physical CPU, 32 vCPU with HT)
Memory 384GB
XenServer 6.2 Tech Preview Build 74074c
Конфигурация виртуальных машин:
VM Vcpu: 4 Virtual CPU
Memory: 11GB
XenDesktop 7.1 RTM HDX 3D Pro
AutoCAD 2014
Бенчмарк CADALYST C2012
NVIDIA Driver: vGPU Manager: 331.24
Guest driver: 331.82
Методика измерений простая — в виртуальных машинах запускался тест CADALYST и сравнивалась производительность при добавлении новых виртуалок.




Как видно из результатов, для старшей модели K2 и сертифицированного профиля падение составляет порядка 10% при запуске 8 виртуальных машин, для модели K1 падение сильнее, но и виртуальных машин в два раза больше.
Абсолютный результат карт при максимальном числе виртуальных машин:

Куда ставить карты?
У нас представлена модель Hyperion RS225 G4, предназначенная для установки 4 Intel Xeon Phi или GPGPU карт.
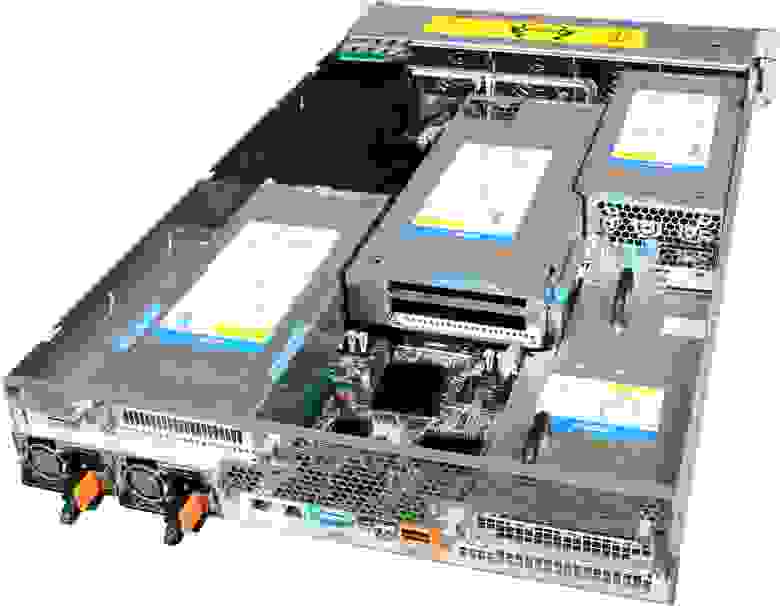
Два процессора Xeon E5-2600 v2, до 1 терабайта оперативной памяти, 4 посадочных места под жесткие диски, InfiniBand FDR или 40G Ethernet для подключения к высокоскоростной сети и пара стандартных гигабитных сетевых разъемов.
Установка карты в сервер:


Карта в сервере:


Также есть несколько типовых решений для различных случаев.
VDI «отвязывает» рабочий стол пользователя от аппаратного обеспечения. Развертывать можно как постоянный виртуальный рабочий стол, так и (наиболее частый вариант) гибкую виртуальную машину. Виртуальные машины включают индивидуальный набор приложений и настроек, который разворачивается в базовой ОС при авторизации пользователя. После выхода из системы, ОС возвращается в «чистое» состояние, убирая любые изменения и вредоносные программы.
Для системного администратора это очень удобно — управляемость, безопасность, надежность на высоте, обновлять приложения можно в едином центре, а не на каждом ПК. Офисные пакеты, интерфейсы к базам данных, интернет-браузеры и прочие нетребовательные к графике приложения могут работать на любом сервере (всем известные терминальные клиенты 1С).
Но что делать, если хочется виртуализовать более серьезную графическую станцию?
Тут не обойтись без виртуализации графической подсистемы.
Есть три варианта работы:
- GPU pass-through: 1:1 выделенный GPU на ВМ
- Shared GPU: Программная виртуализация GPU
- Virtual GPU: Аппаратная витруализация (HW&SW)
Рассмотрим подробнее
Выделенный GPU
Наиболее производительный режим работы, поддерживается в продуктах Citrix XenDesktop 7 VDI delivery и VMware Horizon View (5.3 or higher) with vDGA. Полностью работают NVIDIA CUDA, DirectX 9,10,11, OpenGL 4.4. Все остальные компоненты (процессоры, память, накопители, сетевые адаптеры) виртуализованы и разделены между инстансами гипервизора, однако один GPU остается одним GPU. Каждая виртуальная машина получает свой GPU практически без пенальти по производительности.
Очевидное ограничение — количество таких виртуальных машин ограничено количеством доступных графических адаптеров в системе.
Shared GPU
Работает в Microsoft RemoteFX, VMware vSGA. Этот вариант полагается на возможности ПО для VDI, виртуальная машина работает как будто с выделенным адаптером и и серверный GPU также полагает, что работает с одним хостом, хотя на самом деле это уровень абстракции. Гипервизор перехватывает вызовы API и транслирует все команды, запросы отрисовки и прочее до передачи графическому драйверу, а хост машина работает с драйвером виртуальной карты.
Shared GPU вполне разумное решение для многих случаев. Если приложения не слишком сложные, то одновременно может работать значительное число пользователей. С другой стороны, на трансляцию API тратится достаточно много ресурсов и при этом невозможно гарантировать совместимость с приложениями. Особенно с теми приложениями, которые используют более новые версии API, чем существовавшие на момент разработки VDI продукта.
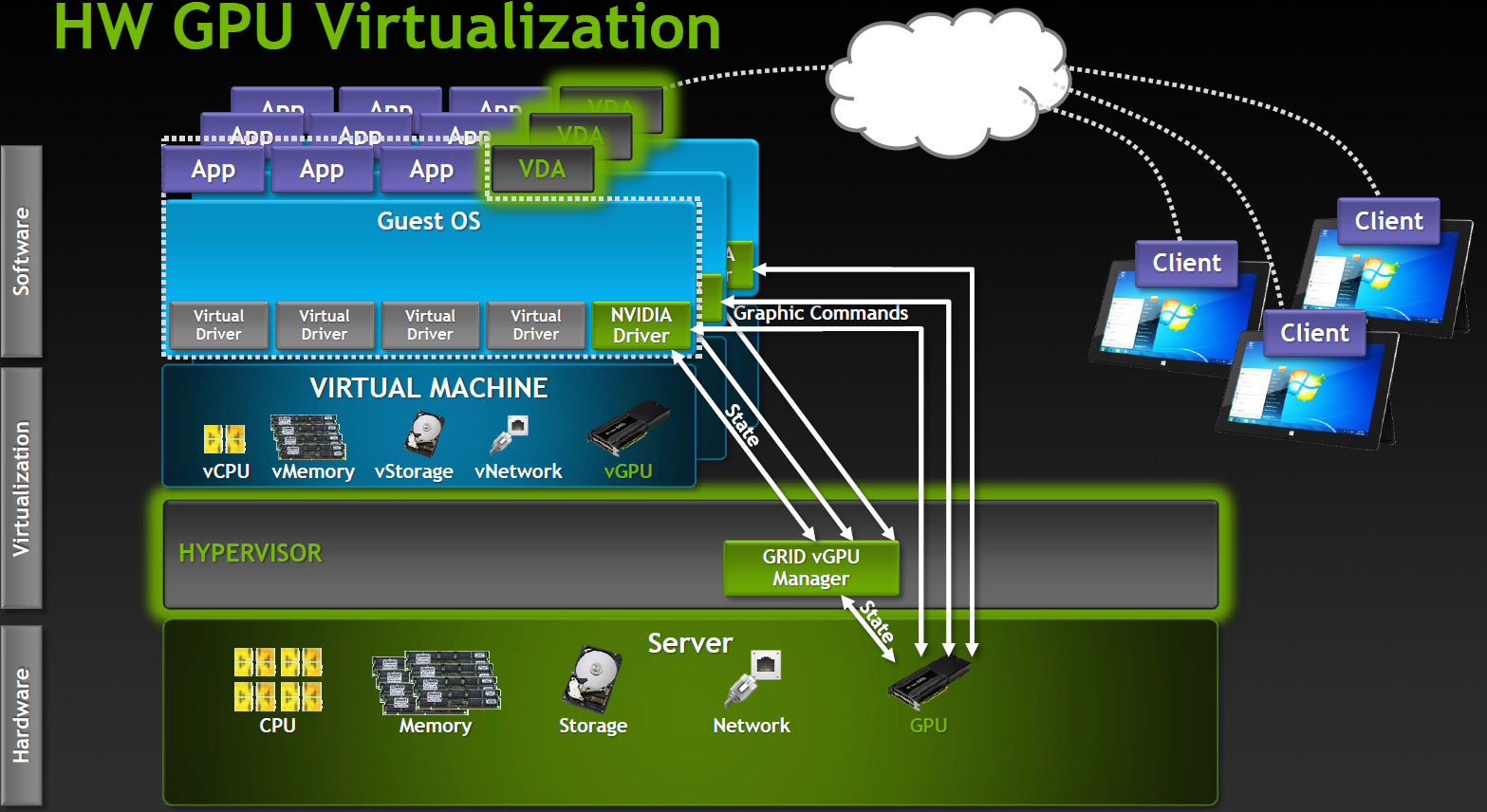
Virtual GPU
Наиболее продвинутый вариант разделения GPU между пользователями, поддерживается на данный момент только в продуктах Citrix.
Как это работает? В VDI среде с vGPU каждая виртуальная машина работает через гипервизор с выделенным драйвером vGPU, который есть в каждой виртуальной машине. Каждый драйвер vGPU посылает команды и управляет одним физическим GPU, используя выделенный канал.
Обработанные кадры возвращаются драйвером в виртуальную машину для отправки пользователю.
Такой режим работы стал возможен в последнем поколении GPU производства NVIDIA — Kepler. В Kepler есть Memory Management Unit (MMU) который транслирует виртуальные адреса хоста в физические адреса системы. Каждый процесс работает в собственном виртуальном адресном пространстве, а MMU разделяет их физические адреса, чтобы не было пересечения и борьбы за ресурсы.
Воплощение в карточках

Модельный ряд
| GRID K1 | GRID K2 | |
| Number of GPUs | 4 x entry Kepler GPUs | 2 x high-end Kepler GPUs |
| Total NVIDIA CUDA cores | 768 | 3072 |
| Total memory size | 16 GB DDR3 | 8 GB GDDR5 |
Разновидности для VDI
Но простого деления по характеристикам мало, для GRID доступно деление на виртуальные профили vGPU.
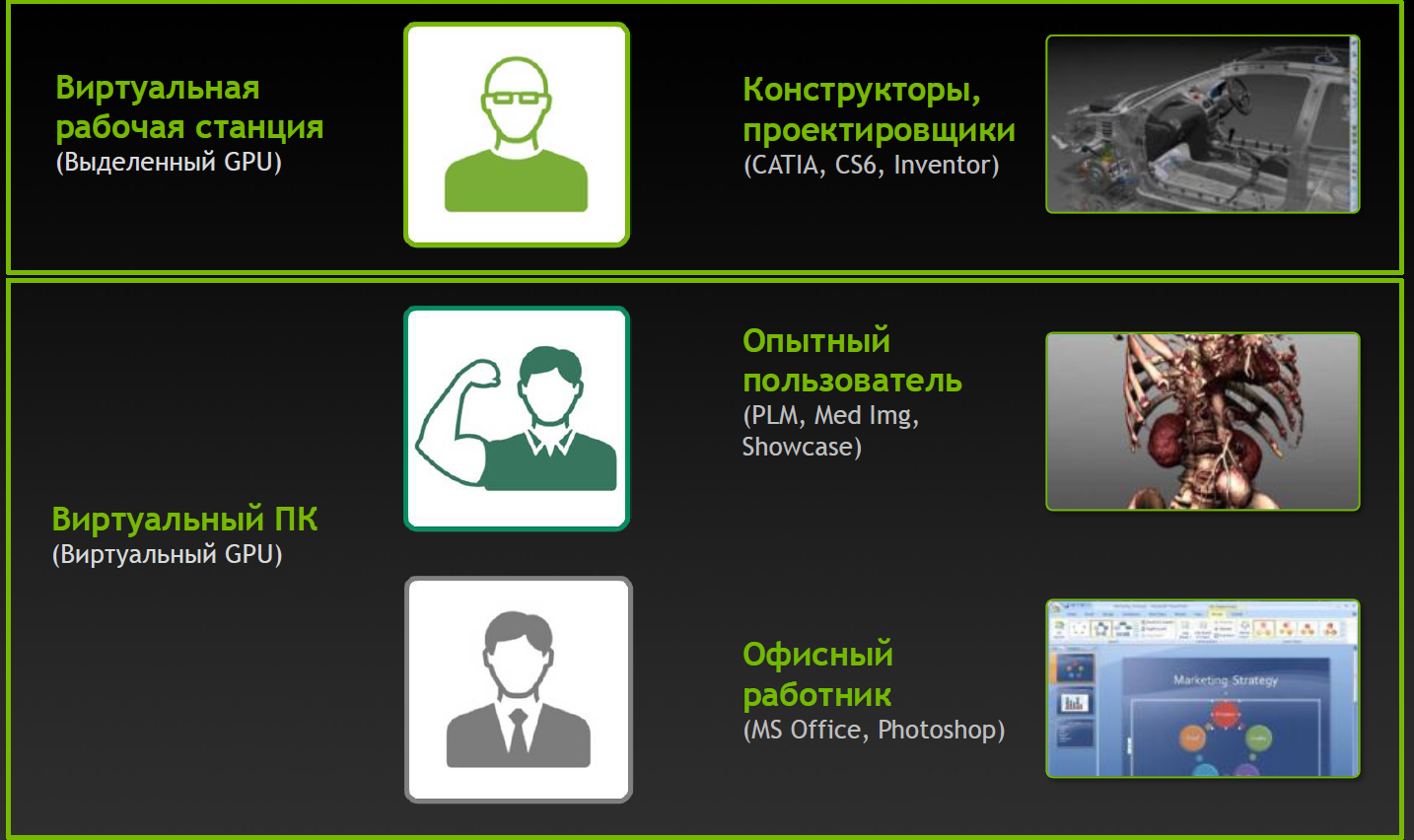
Видение типов пользователей
| Карта | Количество GPU | Виртуальный GPU | Тип пользователя | Объем памяти (МБ) | Количество виртуальных экранов | Максимальное разрешение | Max количество vGPU на GPU/карту |
| GRID K2 | 2 | GRID K260Q | Дизайнер/проектировщик | 2048 | 4 | 2560x1600 | 2/4 |
| GRID K2 | 2 | GRID K240Q | Дизайнер/проектировщик среднего уровня | 1024 | 2 | 2560x1600 | 4/8 |
| GRID K2 | 2 | GRID K200 | Офисный сотрудник | 256 | 2 | 1920x1200 | 8/16 |
| GRID K1 | 4 | GRID K140Q | Дизайнер/проектировщик начального уровня | 1024 | 2 | 2560x1600 | 4/16 |
| GRID K1 | 4 | GRID K100 | Офисный сотрудник | 256 | 2 | 1920x1200 | 8/32 |
Профили и применения
Профили с индексом Q сертифицированы под ряд профессиональных приложений (например, Autodesk Inventor 2014 и PTC Creo) так же, как и карты серии Quadro.
Полное виртуальное счастье!
NVIDIA не была бы верна себе, если бы не подумала о дополнительных разновидностях. Определенную популярность набирают сервисы игр по запросу (Gaming-as-a-Service, GaaS), где тоже можно получить неплохой бонус от виртуализации и возможности разделить GPU между пользователями.
| Product Name | GRID K340 | GRID K520 |
| Target Market | High-Density Gaming | High-Performance Gaming |
| Concurrent # Users1 | 4–24 | 2–16 |
| Driver Support | GRID Gaming | GRID Gaming |
| Total GPUs | 4 GK107 GPUs | 2 GK104 GPUs |
| Total NVIDIA CUDA Cores | 1536 (384/GPU) | 3072 (1536/GPU) |
| GPU Core Clocks | 950 MHz | 800 MHz |
| Memory Size | 4 GB GDDR5 (1 GB/GPU) | 8 GB GDDR5 (4 GB/GPU) |
| Max Power | 225 W | 225 W |
Разновидности для игр в облаках
Влияние виртуализации на производительность
Конфигурация сервера:
Intel Xeon CPU E5-2670 2.6GHz, Dual Socket (16 Physical CPU, 32 vCPU with HT)
Memory 384GB
XenServer 6.2 Tech Preview Build 74074c
Конфигурация виртуальных машин:
VM Vcpu: 4 Virtual CPU
Memory: 11GB
XenDesktop 7.1 RTM HDX 3D Pro
AutoCAD 2014
Бенчмарк CADALYST C2012
NVIDIA Driver: vGPU Manager: 331.24
Guest driver: 331.82
Методика измерений простая — в виртуальных машинах запускался тест CADALYST и сравнивалась производительность при добавлении новых виртуалок.
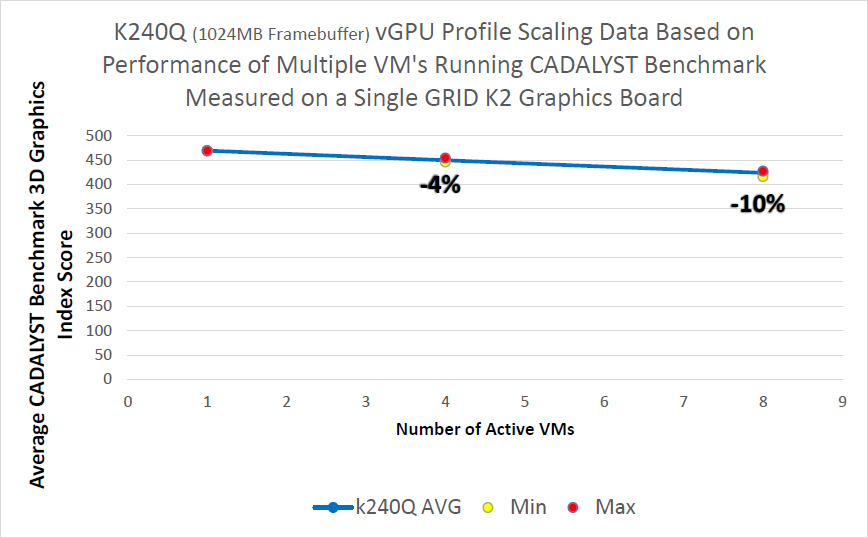
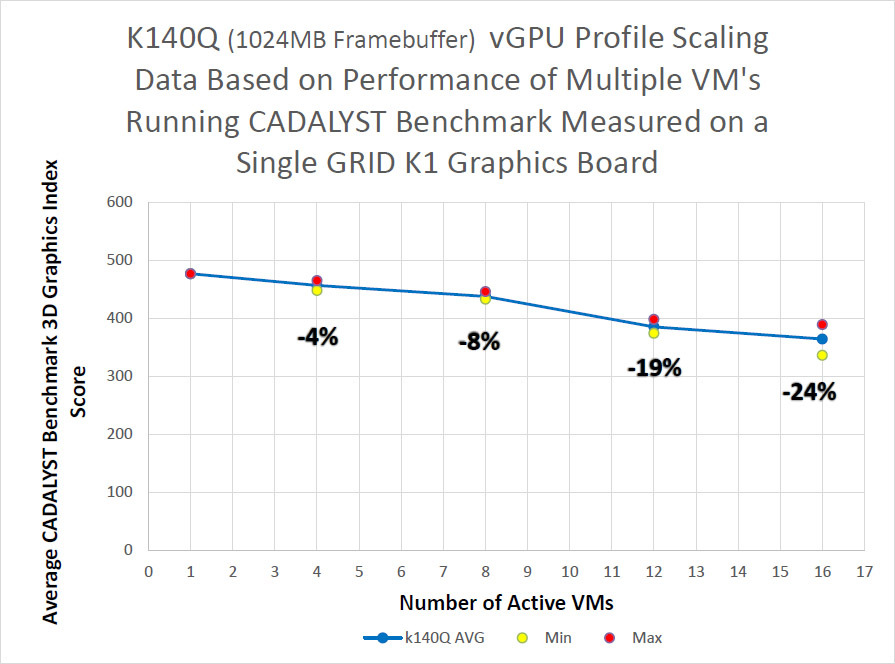

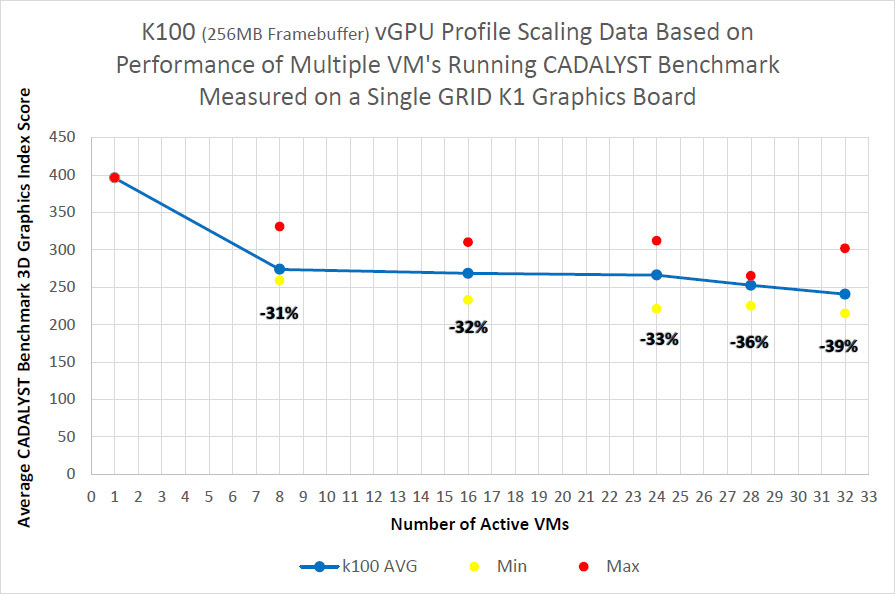
Как видно из результатов, для старшей модели K2 и сертифицированного профиля падение составляет порядка 10% при запуске 8 виртуальных машин, для модели K1 падение сильнее, но и виртуальных машин в два раза больше.
Абсолютный результат карт при максимальном числе виртуальных машин:
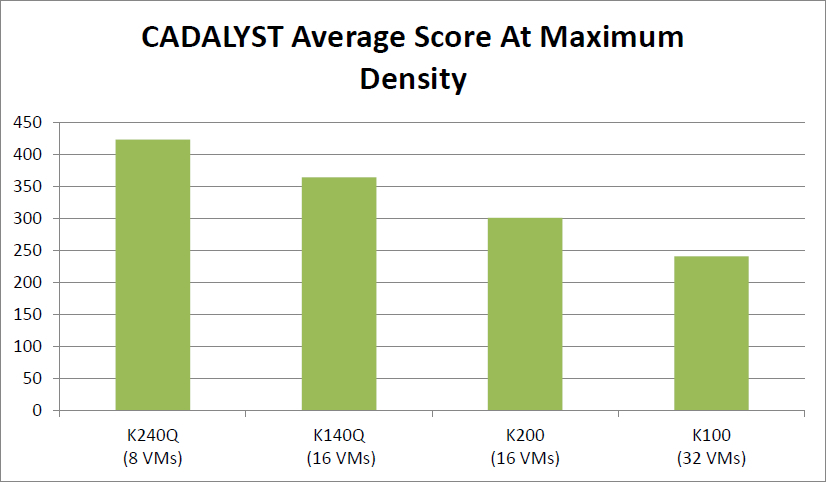
Куда ставить карты?
У нас представлена модель Hyperion RS225 G4, предназначенная для установки 4 Intel Xeon Phi или GPGPU карт.

Два процессора Xeon E5-2600 v2, до 1 терабайта оперативной памяти, 4 посадочных места под жесткие диски, InfiniBand FDR или 40G Ethernet для подключения к высокоскоростной сети и пара стандартных гигабитных сетевых разъемов.
Установка карты в сервер:


Карта в сервере:


Также есть несколько типовых решений для различных случаев.
