Comments 710
Как раз таки "сложное" лучше писать в коде, который обмазывается тестами и кладется в CVS.
Особенно межмодульное соединение.
И обмазывание тестами межмодульное взаимодействие тоже из той же серии. Сделать и поддерживать DI для визуальщины даже проще, чем в коде. Пример — Unity Shader Graph который в режиме online использует облегченные ноды, а на этапе «рендринга» подсовывает нормальные классы.
Я частенько пользуюсь Together. Очень помогает в понимании именно общей концепции программы. Просто потому что кода не видно, но видны связи.
Вот пример: flows.nodered.org/flow/720044a3c587a310813a9326ed3cb08a
IEC 61131-3. Семейство языков для систем автоматизации. Обычный подход такой: структурный код на текстовых языках (ST, IL), блочный — на графических (FBD, LD), машины состояний и "шаговые программы" на SFC.
на мой взгляд с помощью визуального слишком сильно утрируют уход от кода. для начала достаточно создать инструмент в котором двигаешься по блокам кода, а не символа и входишь в разные режимы редактирования как в vim. Также люди сразу начинают спрашивать про csv и еще и про тестирование интересуются. Но не всякая задумка предназначена для решения больших задач лучше существующих инструментов в корпоративном сегменте. На этом в свободное время может кто-то захочет код писать, особенно если оно на отдельном устройстве реализовано.
>способность разбивать сложные задачи на совокупность простых.
Есть проверенные временем способы декомпозиции и композиции. Скажем, ФП как (упрощенно) композиция программ из функций, в их математическом виде. Основано на математике, по большей части — теории категорий. Есть ООП, под которую тоже подводили математический фундамент, но в целом тут с этим намного хуже.
Большинство же средств визуального программирования ни на чем не основаны. Как тут резонно пишут, есть области, где визуальные средства хорошо прижились. Но при этом очевидно есть и такие, где эти средства делают только хуже. То о чем автор пишет, к сожалению очень и очень типично, даже если он местами излишне обобщает.
Можно представить человека, не знакомого с математикой, но которому нужно рассчитать траекторию снаряда гаубицы например.
что же касается применения взрослыми в жизни, то если это решает задачи — почему бы и нет? (программированием чаще всего это не назвать)
А те, кто действительно когда-то писали код, окажутся на свалке истории как никому ненужные старперы, несущие какую-то пургу про «сборку мусора», «выделение памяти» и «приведение типов».
Эх, где моя муза, я бы такой рассказ на эту тему накатал!
— Сборка мусора?? Что это? Какое еще выделение памяти? Нет, это ты не понимаешь! А я все понимаю, я же программист! Вот смотри, я двигаю вот этот красный квадратик, видишь у него внизу черная фигнюшка. Я вот к ней прикрепляю чёрную стрелочку и веду вот сюда, к этому синему квадратику. Видишь в углу синего — кружочек? Я к нему прицепляю вот эту зеленую линию и веду вот сюда. Ага. А теперь я нажимаю на кнопку «BUILD PROGRAM» и оно работает. Работает же? Ну и зачем мне твои алгоритмы читать?
вспомни «Профессию» А.Азимова…
заодно можно вспомнить и «Основание» с жрецами Церкви Галактического Духа.
Считайте меня пессимистом и циником, но боюсь, рано или поздно (боюсь, что рано, лет через 15) придет к тому, что программистом будет считаться как раз человек, двигающий красивые квадратики в редакторе.Через 15 лет ещё не вымрут люди, всё это создавшие. Так что вряд ли. Но вот если соотнести тут обсуждаемое с вот этой вот статьёй… то есть ощущение, что хотя описанной проблемы и не возникнет… но мало кому понравится как её не возникнет.
Просто 90% населений (хорошо если не 99%) окажутся… ненужными. Просто — ненужными. Включая подавляющее большинство «программистов, двигающих квадритики».
И никто не будет им обеспечивать не «базовый безусловный доход», ни еду, ни что-либо ещё. Максимум — бетонную клетушку и небо в клеточку (хотя в этом случае какая-то еда им будет положена… хмм...).
Я бы сам был рад ошибаться — ибо вовсе не в восторге от подобного будущего… но пока не вижу что именно могло бы его остановить…
Таким людям не нужно рассчитывать траекторию.
У них есть математический фреймворк, который позволяет настраивать эту самую гаубицу так, чтобы снаряд попадал в нужную точку на нужном расстоянии.
Вы так говорите, как будто ставить и решать задачи — это проще, чем синтаксис, и синтаксис только этому и мешает :)
Ну да, я согласен (наверное частично), что при обучении детали синтаксиса могут мешать. Для первого-второго языка. Но вообще говоря, этому тоже надо научиться — потому что в профессиональном применении этих языков за много лет все равно будет десятки, если не сотни, и научиться приспосабливаться к синтаксису, понимать его — тоже полезно.
Визуальные инструменты типа Скратча — по максимуму отвязаны от деталей. Для детей (первоначального обучения алгоритмам) это замечательно. Дальше — можно уже учить языку (где-то видел толи плагин, толт нечто подобное для Скретча — показывает «нацарапанное» в виде Java). Это как раз этап роста программ, и то, что в визуальном виде занимает огромный объем — в текстовом получается весьма компактно. и этим переход от визуального к текстовому представлению (со всеми минусами типа бОльшего объема работы с клавиатурой, изучения синтаксиса) хорошо объясняется. Ну а обучение профессиональному применению — это уже отдельная тема.
Точно так же дети стремительно осваивают англоязычные менюшки в играх — потыркался и запомнил.
А текстовый он прямо на скриншоте:
when flag clicked
say Hello world
stop this script
наксолько я помню, объяснение были типа «вот когда нажмешь на флажок такого же цвета», «если тут числа равны, то выполняются шаги в этой части, а если не равны, то в этой», «сначала выполняются шаги, потом проверяется условие», «а вот сюда мы пишем то, что нам скажет кот в этом случае» (только мне кажется, что там был пес а не кот)
То есть, я к чему клоню — попробуйте скажем на Скретче описать простейшую вещь — выполнить REST запрос к какому-то сервису, получить ответ, распарсить JSON. Я боюсь, что почти ни один из визуальных языков не сможет вообще этого сделать, либо результат будет ужасен. При этом классические языки (не все, но многие) такие задачи решают на ура — то есть это однострочник, например.
Ну и второе — это обмен знаниями. Если мы про текстовое представление — то я могу вам прямо вот тут написать фрагмент кода:
a= 2*2
И вы его сможете применить (если не выполнить, то скопипастить). Расскажите, как это выглядит в визуальной среде? Многие ли из таких инструментов вообще хоть чего-то стоят без своей IDE?
Такой подход рекомендуют для детей 8 лет. Это вышеупомянутый Scratch или IDE для лего.
Обучение взрослых людей имеет такой контекст, что им нужно сразу давать промышленный язык программирования. Если бы им было целесообразно давать сначала визуальное программирование, то в интернете не было бы такого количества курсов по конкретным языкам.
Для алгоритмических задач весь синтаксис промышленных языков и не нужен. Объявление переменных, условия, циклы, массивы — не такой уж огромный объем. А вот исключения, абстрактные классы, интерфейсы и т.п. в концепцию визуального программирования хоть и вписываются (UML), но проще не становится.
Представим себе человека не знакомого с программированием, ему можно с помощью визуального программирования создать навык составления алгоритмов и быстро научить решать сложные задачи или долго топтаться на месте объясняя синтаксис,
Зачем представлять? Мы все были когда-то людьми, не знакомыми с программированием. Тяжко было начинать? Не очень, согласитесь?
«Долго топтаться на месте» — это минут 15, чтобы объяснить, как устроен хеллоуворлд. После этого можно писать простые алгоритмы, этого достаточно.
Мы все были когда-то людьми, не знакомыми с программированием. Тяжко было начинать? Не очень, согласитесь?
Верите — не помню! Девушка просит «научи», а я не знаю как, потому что кто бы мне рассказал, как я сам научился!
Зачем представлять? Мы все были когда-то людьми, не знакомыми с программированием. Тяжко было начинать? Не очень, согласитесь?
Если бы вы перенеслись в то время, когда вы действительно начинали, то вы бы себя настоящего послали, поскольку детали забываются, сложности сглаживаются в памяти со временем. Банальный алгоритм суммирования массива или работы с условиями не сразу даются и понимаются, их так же нужно тренировать и нарабатывать.
«Долго топтаться на месте» — это минут 15, чтобы объяснить, как устроен хеллоуворлд. После этого можно писать простые алгоритмы, этого достаточно.
Для того, чтобы «писать простые алгоритмы» нужно, чтобы человек понимал, что такое алгоритмы, как они строятся и как разбить элементарную операцию на алгоритм. А это не 15 минут времени. Далеко не 15 минут. Это такой же навык, который со временем нарабатывается.
Дальше — алгоритм, который есть в голове нужно изложить в программном коде. Это тоже не «15 минут ознакомления с синтаксисом и погнали». Этот самый синтаксис будет долго въедаться в память и человек будет учиться излагать свой алгоритм в программном языке.
Не помните, как вы или ваши одногруппники не знали, как выразить чётность числа?
Банальное if (num % 2 == 0)… не писалось, потому что не было понимания, что и как работает. Алгоритм в голове был(делится на 2 — чётное). По отдельности человек примерно понимал, как синтаксис выглядит. Но вот сесть и написать — ступор.
Не стоит недооценивать сложность входа в программирование. Это не так легко, как вам кажется.
Для того, чтобы «писать простые алгоритмы» нужно, чтобы человек понимал, что такое алгоритмы, как они строятся и как разбить элементарную операцию на алгоритм.
Нужно. Но разве есть какая принципиальная разница, на чём учиться плести алгоритмы, на цветных квадратиках, или на словах и математических знаках?
В случае визуалки — ты просто строишь алгоритмы из простых блоков, которые ты просто читаешь и видишь перед глазами. Если это какая-то игровая визуалка, то у тебя ещё и ограничены варианты блоков. Основной акцент идёт на алгоритм.
В случае ЯП — у тебя нет готовых простых блоков перед глазами, есть куча непонятных конструкций, которые нужно запомнить(!), нужно проассоциировать с своей логической моделью(чтобы, если грубо, знать, что условие когда\если — это if) и не забыть применить, когда требуется, не перепутать. Акцент с алгоритма смещается на борьбу с собой и языком и процесс идёт немного сложнее.
И в целом, я не защищал визуальный подход. Он при обучении может быть хорошим инструментом, которым можно пользоваться, но это всё зависит от человека, педагога и пр.
Меня зацепило ваше непонимание сложности обучения программированию.
У меня есть сотрудники, как дети, очень далёкие от программирования, алгоритм бизнес-процесса в текстовом виде не могут написать, а вот нарисовать его в draw.io у них получается. Если бы мне от них требовался алгоритм более сложный, я бы наверное им дал scratch и заставил там его описать.
Всему своё время и место.
SFC и FBD нормальные наглядные языки, которые точно требуют знания алгоритмизации, текстовые пошаговые языки тоже не плохи.
Графические схемы очень помогают в понимании, пока всякие ключевые слова и паттерны проектирования не выучены.
Но рассказывать про то, что на них можно хорошо и удобно сделать что-то сложное… ну не стоит.
{kind=link}
Попробуйте на досуге хорошо и удобно закодировать это. (Именно закодировать — потому, что кодогенератор реально даст оптимальный код, для конкретной целевой системы с учетом оптимального способа хранения весов и наличия-отсутствия FPU, чему не будет отвечать ни одна возможная реализация, кроме опять-же, вдруг написанных для целевой системы). Ну это конечно, если вы понимаете насколько прост серенький кубик… Хотя чего там понимать — простейшая моделька. 1 лист всего.
Визуализацию не забудьте закодировать — которая «MSE View», в 3 щелчка мышки там появилась — ибо средство языка.
И конечно ваш код должен быть столь же понятен, как эта картинка для
программиста на скажем — фортране…
А теперь вы представьте, что любого из этих прямоугольников на схеме язык не завезли, и попытайтесь реализовать его на основе базовых элементов…
А теперь вы представьте, что любого из этих прямоугольников на схеме язык не завезли, и попытайтесь реализовать его на основе базовых элементов…
Попробуйте на досуге хорошо и удобно закодировать это.
Если я правильно понял задачу, то вот тут описано как ее решать на Python
Только на питоне можно еще комментарии к коду писать с пошаговым объяснением своих мыслей.
import numpy as np
def sigmoid(x):
return 1.0/(1.0 + np.exp(-x))
def sigmoid_prime(x):
return sigmoid(x)*(1.0-sigmoid(x))
def tanh(x):
return np.tanh(x)
def tanh_prime(x):
return 1.0 - x**2
class NeuralNetwork:
def __init__(self, layers, activation='tanh'):
if activation == 'sigmoid':
self.activation = sigmoid
self.activation_prime = sigmoid_prime
elif activation == 'tanh':
self.activation = tanh
self.activation_prime = tanh_prime
# Set weights
self.weights = []
# layers = [2,2,1]
# range of weight values (-1,1)
# input and hidden layers - random((2+1, 2+1)) : 3 x 3
for i in range(1, len(layers) - 1):
r = 2*np.random.random((layers[i-1] + 1, layers[i] + 1)) -1
self.weights.append(r)
# output layer - random((2+1, 1)) : 3 x 1
r = 2*np.random.random( (layers[i] + 1, layers[i+1])) - 1
self.weights.append(r)
def fit(self, X, y, learning_rate=0.2, epochs=100000):
# Add column of ones to X
# This is to add the bias unit to the input layer
ones = np.atleast_2d(np.ones(X.shape[0]))
X = np.concatenate((ones.T, X), axis=1)
for k in range(epochs):
i = np.random.randint(X.shape[0])
a = [X[i]]
for l in range(len(self.weights)):
dot_value = np.dot(a[l], self.weights[l])
activation = self.activation(dot_value)
a.append(activation)
# output layer
error = y[i] - a[-1]
deltas = [error * self.activation_prime(a[-1])]
# we need to begin at the second to last layer
# (a layer before the output layer)
for l in range(len(a) - 2, 0, -1):
deltas.append(deltas[-1].dot(self.weights[l].T)*self.activation_prime(a[l]))
# reverse
# [level3(output)->level2(hidden)] => [level2(hidden)->level3(output)]
deltas.reverse()
# backpropagation
# 1. Multiply its output delta and input activation
# to get the gradient of the weight.
# 2. Subtract a ratio (percentage) of the gradient from the weight.
for i in range(len(self.weights)):
layer = np.atleast_2d(a[i])
delta = np.atleast_2d(deltas[i])
self.weights[i] += learning_rate * layer.T.dot(delta)
if k % 10000 == 0: print 'epochs:', k
def predict(self, x):
a = np.concatenate((np.ones(1).T, np.array(x)), axis=1)
for l in range(0, len(self.weights)):
a = self.activation(np.dot(a, self.weights[l]))
return a
if __name__ == '__main__':
nn = NeuralNetwork([2,2,1])
X = np.array([[0, 0],
[0, 1],
[1, 0],
[1, 1]])
y = np.array([0, 1, 1, 0])
nn.fit(X, y)
for e in X:
print(e,nn.predict(e))Только на питоне можно еще комментарии к коду писать с пошаговым объяснением своих мыслей.
Для таких алгоритмов пошагово мысли объясняли в конце 80-х, сейчас они вот так квадратом рисуются и все сразу ясно — а если не ясно с мелкими частными коэффициентами — можно в реализацию глянуть — все быстрее чем комментарии на не факт что родном языке читать.
Самое главное что вы глядя в квадрат с ходу поняли, что он делает а вот я глядя в ваш код с ходу этого не пойму и никто не поймет — от того вам так важны комментарии в этом коде.
У вас частный случай кастрированного серого квадрата реализованный в векторной форме занял аж 4 экрана текста… А квадрат — общий случай с матрицами произвольного размера. Представляю сколько экранов у вас именно прям его реализация займет?
Мне кажется тут какая-то путанница — вы сравниваете использование одного подхода с реализацией другого. Причем один из них проблемно-ориентированный язык, а другой — язык общего назначение.
А надо сравнивать графическое и текстовое представление. Т.е., например перевести схему в текстовый вид и сравнить запись (на языке того же уровня абстракции — то есть в этом случае текстовый DSL — если у вас там графы то будет внешнее подобие graphviz, или типа того) либо показать реализацию серого квадрата в виде графической схемы.
Вот текстовый вид модельки www.mathworks.com/matlabcentral/fileexchange/35781-multilayer-perceptron-neural-network-model-and-backpropagation-algorithm-for-simulink?focused=5228360&tab=model
Вот сам код www.mathworks.com/matlabcentral/fileexchange/36253-the-matrix-implementation-of-the-two-layer-multilayer-perceptron-mlp-neural-networks
И в решении своих конкретных проблем она и связанные с ней языки многократно мощнее любых языков общего назначения, именно поэтому она и доминирует в своих областях…
По каким критериям вы посчитали кратность мощности? Как убедились в доминировании?
Мы сейчас про Mathlab и Simulink? Они всего лишь конкурируют с питоном и скалой в области математических вычислений.
Я не исключаю, что вы используете визуальные языки для программирования в вашей суперсекретной и очень ответственной области. Но это совершенно не означает их превосходства. Просто у вас инерция системы.
Вот текстовый вид модельки…
Вот сам код
Как именно код соотносится с моделькой? Это ведь разные документы.
код ни на каком языке так изящно не способен это передать являясь одновременно и программой и инструкцией к симулятору и кодогенератору.
Код на питоне вполне себе инструкция к кодогенератору байткода.
Что вы понимаете под "симулятором"? Инструмент для запуска вашей модельки? В таком случае, код на питоне это еще и инструкция к симулятору.
По каким критериям вы посчитали кратность мощности? Как убедились в доминировании?
Убедится в доминировании очень не сложно — достаточно в этой области посмотреть на объем исходных текстов написанных живыми людьми и объем транслированных. Потом открыть описание и убедится, что все модели представлены в виде симулинковских файлов а в каком то другом виде не представлено извините нифига.
Мы сейчас про Mathlab и Simulink? Они всего лишь конкурируют с питоном и скалой в области математических вычислений.А в симулинке знают, что с ними питон конкурирует? ;) Ах ну да — в области «вычислений»… В которой может конкурировать любой «языкнейм».
Просто у вас инерция системы.
Напоминаю — это у вас инерция системы! Вы до сих пор пишите, что то там в тексте хотя есть ВП — БОЛЕЕ НОВАЯ и более совершенная технология создания ответственных и сложных программных продуктов!
Как именно код соотносится с моделькой? Это ведь разные документы.Так же как и матлаб соотносится с симулинком — это ведь разные продукты!
Код на питоне вполне себе инструкция к кодогенератору байткода.А картинка вполне может быть инструкцией к кодогенератору питона… И если вы против такого слоя то в вашей логике и С++ вообще не нужен ибо это просто инструкция к кодогенератору ассемблера!
ВП — БОЛЕЕ НОВАЯ и более совершенная технология создания ответственных и сложных программных продуктов!
Увы, нет. Вы продемонстрировали что некоторые продукты имеют преимущество в качестве DSL.
Но не объяснили, почему эти продукты должны быть визуальными.
Почему схема должна быть в виде картинки, а не в виде списка корпусов и списка порядка соединения пинов?
В кадах схема представлена в виде списка корпусов и порядка соединения пинов — но даже само слово «схема» говорит о генерируемой из этого текста картинке. Мы говорим «нарисуй мне схему» человеку — подразумевая конкретные действия и конкретный результат, а не «напиши мне схему».
Когда я впервые познакомился с словом алгоритм и всем из этого вытекающим — я никак не думал, что через каких то 30 лет с этим простым словом будет связанна не «схема алгоритма», а его извращенное описание на 100500 текстовых языках…
Какая разница, таскать провода мышкой, или писать строкой, что с чем должно быть соединено?
ИМХО, строкой удобнее и компактнее. А картинку можно и потом сгенерить.
что через каких то 30 лет с этим простым словом
По прежнему связано то же самое. Не путайте алгоритм и архитектуру приложения. Это вещи разного уровня.
Да, но при разработке схемы мы читаем спеку устройства и соединяем пины.
Какая разница, таскать провода мышкой, или писать строкой, что с чем должно быть соединено?
Как в вашем языке будут описываться резисторы и конденсаторы имеющие общепринятое в мире графическое изображение которое в школе проходят?!
Откуда следует очевидность вашего описания? (общепринятого — из школьного учебника следует).
Зачем это ваша никому не нужная сущность?
Почему графические элементы схем в любом каде одинаковые — а текст с ними же каждый фигачит кто во что горазд? Какой из диалектов этих текстов вы предлагаете познать для описания связей элементов текстом и почему?
Как в вашем языке будут описываться резисторы и конденсаторы имеющие общепринятое в мире графическое изображение которое в школе проходят?!
Так же как в вашем визуальном: использоваться готовые из внешней библиотеки.
Откуда следует очевидность вашего описания?
Оттуда же, откуда очевидность вашей схемы.
Зачем это ваша никому не нужная сущность?
Сущность — та же, что и у Вас, только без графического представления.
Почему графические элементы схем в любом каде одинаковые — а текст с ними же каждый фигачит кто во что горазд?
Потому что никто не озаботился разработать язык для этой задачи. Приходится пользоваться универсальными языками.
Убедится в доминировании очень не сложно — достаточно в этой области посмотреть на объем исходных текстов написанных живыми людьми и объем транслированных.
Вы серьезно предлагаете сравнивать языки по объему исходного кода? В любой технологии один и тот же код можно выразить несколькими способами с разной степенью наглядности и объемом кода.
А картинка вполне может быть инструкцией к кодогенератору питона…
На самом деле нет. Инструкцией к кодогенератору является модель, у которой есть графическое представление. Помимо графического представления, у нее еще есть какая-то структура данных для сохранения в файл. Вы ведь не можете взять фотографию этой модели и автоматически сгенерировать код по ней.
Вы серьезно предлагаете сравнивать языки по объему исходного кода? В любой технологии один и тот же код можно выразить несколькими способами с разной степенью наглядности и объемом кода.В мечтах адептов писания руками — да… В реальности — 90% написанного руками говнокод. Поэтому лучше выразить одним способом — и способ этот машинный.
Вы ведь не можете взять фотографию этой модели и автоматически сгенерировать код по ней.Это лишь вопрос сложности вашего кодогенератора. Вы все время забываете что квадратик может быть развернут.
В реальности — 90% написанного руками говнокод.
99% натыканного мышкой — тоже.
99% натыканного мышкой — тоже.
код написаный руками авторов «рисовалки» сильно снижает возможность «рисовальщиков» наговнокодить. Хотя не убирает полностью. Особенно в силу того, что рисовальщики просто не имеют представления о том, что происходит «внутри квадратика». уровень ардуинщиков.
Особенно в силу того, что рисовальщики просто не имеют представления о том, что происходит «внутри квадратика».
Вы путаете обучение детей в детском саду программированию и узких профессионалов в конкретных отраслях с многолетним опытом. Это программисты не понимают, что происходит внутри квадратика — поэтому им надо развернуть, поглядеть, подумать, погуглить, слова какие то знакомые поискать… Переписать все нафиг 10 раз потому что — ой а вот тут не понятно, ой а вчера вышел новый стандарт и так теперь не пишуть и вообще… И естественно наляпать ошибок в реализации не поняв и половину того, что нужно.
А специалист внутренности своих квадратиков с закрытыми глазами если надо нарисует. Вот хотя бы примерчик… Если вы знакомы с предметной областью этого квадратика — вы узнаете в нем абсолютно все! Если нет — даже вряд ли нагуглите, что это…

Кстати, варианта «программист со знанием предметной области» вы принципиально не рассматриваете?
Как бы внутренности ваших квадратиков писал какой-то программист. И он как раз знает что там внутри куда лучше вас.
Ну и пусть знает. Главное, что тому, кто этот блок использует не нужно знать специфику внутренностей. Ему главное, чтобы блок выполнял свою функцию, заложенную спецификацией. И чтобы блок выполнял ее безукоризненно.
Кстати, варианта «программист со знанием предметной области» вы принципиально не рассматриваете?
В некоторых отраслях это очень редкие экземпляры.
Наш оппонент же говорит про программирование в целом?Давайте лучше про «Копание ям в целом» поговорим — это лопатой в целом делают или экскаватором все же в целом? Надо ли уничтожить все лопаты — если экскаватор новее, и более лучше-быстрее копает? Или может все же грядку под клубнику будем копать лопатой а магистральный газопровод — экскаватором? Так вроде?
Так же я считаю, что если машина, что то может сделать вместо человека — именно она и должна это делать! Причем в любой области деятельности вообще. И последние 15 лет так или иначе занимаюсь именно этой проблематикой…
Ну а кто думает не так — пусть копает лопатой беломорканал — бо деды копали именно так, а значит в целом сие более универсально и лампово.
Приводите пример из своей области, но в упор не видите, что за её пределами, из-под «мышиных программ» выходит почти исключительно говнокод.
И добавляете, что кто с Вами не согласен «пусть копает лопатой беломорканал».
Короче, по Вам оргвыводы сделаны.
Я утверждаю, что это как раз не в целом — а в частном случае правильный метод — в моей области
Поздравляю, гражданит, соврамши.
Напоминаю — это у вас инерция системы! Вы до сих пор пишите, что то там в тексте хотя есть ВП — БОЛЕЕ НОВАЯ и более совершенная технология создания ответственных и сложных программных продуктов!
Ваши слова? Продолжите отпираться, будто говорили не «в целом»?
Ваши слова?А где здесь написано про целое? Это описание частного случая! Частный случай состоит в том что надо уволить всех программистов — которых можно заменить автогенерацией и оставить всех, что заменить нельзя! (с перспективой увольнения когда можно будет).
Мало того конкретно там речь шла про Матлаб. В котором легко пишется некий прикладной уровень но нельзя например написать драйвер! И прикладной уровень, что в матлабе занимает полэкрана самой сути алгоритма — в С занимает 15 экранов никому не понятного говнотекста. Следовательно не нужен.
И прикладной уровень, что в матлабе занимает полэкрана самой сути алгоритма — в С занимает 15 экранов никому не понятного говнотекста.
вам непонятного. в силу вполне понятных причин.
MATLAB не подходит для разработки больших программС подходом «возьмем дешевого программера и обучим новым трюкам» — никакой язык не подходит. Но если взять серьезного специалиста по матлабу а код С++ даст матлаб кодер — все прекрасно работает. «Большая программа» которую почему то пишет то ли 1 то ли 2 человека — тоже повеселило.
Мне любопытно, как вы определяете "говнокод".
Вы относите к нему фрагмент из комментария?
Если да, то по каким признакам?
Мне любопытно, как вы определяете «говнокод».По простым…
Вы относите к нему фрагмент из комментария?
Если да, то по каким признакам?
Есть некий язык, в котором вычисление гиперболического тангенса производится средствами языка — но при этом, он увы не является языком общего назначения.
Есть некий другой язык — где нет такого, но при этом он общего назначения…
Есть конкретная задача — вычислить гиперболический танегенс!
В первом случае это просто пишется в одну команду и не требует ничего кроме знания самого языка!
Во втором случае, вы тащите для этого какую то неясную сущность, тащите знание этой сущности, тащите знание языка… (в итоге, у вас как правило не остается место в голове на знание предметной области этого вычисления)…
Естественно, любые лишние сущности = говнокод! Если задача может быть решена без них. Конечно при этом в какой то другой задаче все будет строго наоборот но не в этой…
Все таки не понятно, что именно вы считаете говнокодом.
Судя по примеру с гиперболическим тангенсом получается, что говнокод для вас это все, что не предусмотрено стандартной библиотекой.
Возьмем тогда алгоритм обратного распространения, который вы упоминали выше.
Он есть в стандартной библиотеке? Нет.
Чтобы реализовать его вам нужно тащить новую сущность? Да — тот самый серый квадратик.
Нужно ли специалисту тащить с собой знание этого серого квадратика? Да, судя по вашим словам в комментарии.
Получается, что алгоритм обратного распространения был примером говнокода на Mathlab.
Если же тот серый квадрат не "лишняя сущность", то алгоритм обратного распространения на питоне тоже не является лишней сущностью, а значит он не говнокод.
Я ведь правильно понимаю вашу позицию, что на ВП и Mathlab в частности, говнокода быть не может?
Получается, что алгоритм обратного распространения был примером говнокода на Mathlab.Вы опять упустили самое важное — программа на матлаб не является конечным решением задачи. Она лишь разрабатывается и отлаживается в нем. Конечное решение — микроконтроллер. И говнокодом в данном случае будет любое нагромождение сущностей, которое нельзя поместить в микроконтроллер на любом языке который не транслируется в ПО миконтроллера. Потому что задачу они не решают! т.е. банально не работают.
Если же тот серый квадрат не «лишняя сущность», то алгоритм обратного распространения на питоне тоже не является лишней сущностью, а значит он не говнокод.
Я ведь правильно понимаю вашу позицию, что на ВП и Mathlab в частности, говнокода быть не может?На ВП вы можете нарисовать неадекватную объекту говномодель — это будет частный случай говнокода. В матлаб скажем так — говнокод создать несколько более сложновато…
если алгоритм может быть написан средствами языка — то язык это «молоток». А если нет то это «микроскоп». Микроскоп мощнее — им тоже можно забивать гвозди а рассматривать срезы тканей в молоток нельзя.
Какое то странное противопоставление. Можете привести примеры алгоритмов, которые нельзя выразить средствами тьюринг-полного языка?
На питоне (а также на C#, java, lua и многих других) можно при желании вызвать внешнюю нативную библиотеку. Например для реализации шифрования.
При этом, то же самое шифрование при желании можно написать средствами этих же языков, хоть это и нецелесообразно. Стал ли питон от этого микроскопом? Перестал ли он быть молотком?
И говнокодом в данном случае будет любое нагромождение сущностей, которое нельзя поместить в микроконтроллер на любом языке который не транслируется в ПО миконтроллера.
Технологии за пределами микроконтроллеров слишком разнообразны, чтобы клеймить говнокодом все, что не транслируется в микрокод.
Какое то странное противопоставление. Можете привести примеры алгоритмов, которые нельзя выразить средствами тьюринг-полного языка?Тьюринг полнота предполагает «беcконечность ленты». А когда у вас память 8-16-32кб, а библиотека — 10+мб, ваша Тьюринг полнота резко пропадает для любого языка в принципе!
У вас частный случай кастрированного серого квадрата
Что вы называете "частный случай"? Обработку массива 4х2?
В таком случае, вглядитесь в код. На питоне реализован не частный случай, а общий. Алгоритму можно подать на вход массив любого размера и он обучит сетку.
Кстати "серый квадрат" на питоне это только вот этот фрагмент:
# backpropagation
# 1. Multiply its output delta and input activation
# to get the gradient of the weight.
# 2. Subtract a ratio (percentage) of the gradient from the weight
for i in range(len(self.weights)):
layer = np.atleast_2d(a[i])
delta = np.atleast_2d(deltas[i])
self.weights[i] += learning_rate * layer.T.dot(delta)Для таких алгоритмов пошагово мысли объясняли в конце 80-х
Для таких алгоритмов мысли будут пошагово объяснять пока есть студенты, которые их изучают. Этот фрагмент кода — учебный и предназначен для увеличения наглядности и разжевывания материала.
сейчас они вот так квадратом рисуются и все сразу ясно
Из квадрата мне ничего не ясно. Я могу только верить и надеяться, что серый квадрат с надписью "backpropagation algorithm" это на самом деле алгоритм обратного распространения.
Самое главное что вы глядя в квадрат с ходу поняли, что он делает а вот я глядя в ваш код с ходу этого не пойму и никто не поймет — от того вам так важны комментарии в этом коде.
Я гуглил по заголовку диаграммы, плюс у меня есть немного знаний по теме. Что конкретно делает ваш квадрат я не знаю и из картинки для меня это не очевидно.
Если вы не хотите понимать код в текстовом виде, то это не значит, что никто другой его не поймет. Я ведь почему то понимаю текстовую версию этого кода. Наверняка я такой не один.
Кстати «серый квадрат» на питоне это только вот этот фрагмент:
Нет — поскольку используется сторонняя библиотека адового размера, из которой вы вызываете только вам ясные функции и по сути подменяете ими, а квадратик полностью самодостаточен и не использует ничего. Но самое главное даже не это… А то, что можно сделать с квадратиком вот так:


Нет — поскольку используется сторонняя библиотека адового размера, из которой вы вызываете только вам ясные функции и по сути подменяете ими, а квадратик полностью самодостаточен и не использует ничего
Что значит "квадратик самодостаточен"? Вы так говорите, как будто ваш визуальный язык не использует библиотеку компонентов.
Если бы ваш квадратик был самодостаточен, вы бы могли его в любом графическом редакторе нарисовать и запустить. Но это не так и квадратику для работы нужна специальная IDE и сопоставимая библиотека таких квадратиков.
Тот факт, что вы показываете результат кодогенератора из визуальной модели, говорит о том, что ваш визуальный язык вторичен и нужен только для создания текстового исходного кода.
В питоне у вас сразу текстовое представление и совсем не нужно упражняться с рисованием квадратиков мышкой.
Что значит «квадратик самодостаточен»? Вы так говорите, как будто ваш визуальный язык не использует библиотеку компонентов.
Я вам говорю что квадратик ее не использует — следовательно не эквивалентен вашему коду. Поэтому квадратик транслируется автоматом в реализацию самого себя на слабом микроконтроллере, а ваш код дальше вашего зоопарка определенной ветки питона никому не нужен (еще раз посмеялся про якобы конкуренцию питона с матлабом).
Тот факт, что вы показываете результат кодогенератора из визуальной модели, говорит о том, что ваш визуальный язык вторичен и нужен только для создания текстового исходного кода.
О боже — программист увидел что то знакомое. Только вот этот код не нужен! — нужен HEX ДЛЯ AVR! точнее даже нет — hex тоже не нужен — нужно устройство, решающую некую задачу, неким методом, где то в глубине которого находится AVR и в нем зашит некий HEX, который скомпилирован включая некий автоматически сгенерированный говнокод на С, который реализует алгоритм изначально нарисованый и отлаженный ИНЖЕНЕРОМ в виде квадратика и нужно что-б во всем этом процессе как можно меньше людей ерундой страдало ибо сие есть более дешево, многократно более надежно и конечно же практично!
Тот факт, что я создал 80кб исходник на си для целевой системы за 20 секунд нажатием пары кнопок говорит лишь о том что программист вторичен, нафиг не нужен а программы может писать любая домохозяйка! Ничего другого из этого факта никак не вытекает.
Тяжко было начинать? Не очень, согласитесь?
Ошибка выжившего. То что не было тяжело мне или вам вовсе не означает, что не будет тяжело кому-то другому. Это не в защиту визуальных языков, если что.
Тем не менее, хочу отметить, что по моим наблюдениям, те же редакторы на базе узлов и связей заметно сложнее для освоения пользователями, чем просто стеки модификаторов, ну а про текстовые скрипты и речи нет. Это логично, что, чем универсальнее и гибче инструмент, тем сложнее он в освоении.
Да, большинство нодовых систем в редакторах графики скорее ближе к функциональному программированию, но разве это плохо? Думаю ощущения от конструирования функции готовыми нодами, а не кодом весьма схожи и приятны программисту, по крайней мере это не зазорнее, чем «вешать на кнопки» короткий текстовый код, вызывающий мощные методы готовых объектов, фреймворков, библиотек и т.п. Ведь именно этим занимается приличная доля вполне себе достойных звания программиста людей? )
Мне кажется, что программировать можно только на чем-то Тьюринг-полном.
Конечные алгоритмы и регулярные выражения не являются тьюринг полными. однако специализированные языки для конечных автоматов и, особенно, регулярные выражения используются в IT постоянно.
Способ реализации – кто как хочет.
Удобна нодовая структура – окей, нравится много печатать – вперед, поизвращаться на пустом месте – есть Brainfuck и иже с ним )
На самом деле плевать.
Программист – человек понимающий суть процесса, в первую очередь!
Всеми лапами за блочное программирование, для простых вещей (сценариев, алгоритмов)
Потому что плохих примеров применения в других областях к сожалению навалом. Большую часть того, о чем автор пишет, я лично наблюдал многократно.
Кстати, было бы очень интересно понять, почему в промышленной автоматизации визуальные средства так востребованы, чем именно эта область отличается от множества других.
>Но видимо эта сфера очень далека от автора, раз в пример от приводит Scratch.
Ну я могу привести в пример BPMN и/или Информатику. На которых предлагается программировать бизнес-процессы, или ETL.
И пытаясь применять которые вы очень быстро натыкаетесь на ограниченность выразительных средств графического языка. Эта проблема решается как правило просто — добавляется второй (третий, пятый) язык, более обычный — Java, Javascript или что-то еще. На выходе получаем гибрид, который выглядит как результат визуального программирования, но процентов на 90 состоит из кода на более привычном языке. Профита от визуальных средств при этом что-то около нуля, а мешает он знатно.
Кстати, было бы очень интересно понять, почему в промышленной автоматизации визуальные средства так востребованы, чем именно эта область отличается от множества других.
1. Тематика. В автоматике рулит релейка. Все IL/STL, LD и прочие являются их прямым воплощением в контроллере.
2. Относительно низкий порог вхождения. Человек, знающий, как сделать запуск двигателя с самоподхватом на 1 контакторе и 2-х кнопках, сможет эту же схему воплотить и на контроллере (для примера) после изучения самых основ.
3. Лёгкость понимания. Почти везде в автоматике идут дискретные сигналы. И их проще отслеживать визуально в отладке — «ага, вот тут у нас сигнал дальше не идёт, надо посмотреть причину… а вот и она — один из входов в 0!». С аналоговыми величинами абсолютно аналогично — на входе блока X и Y, на выходе имеем Z как результат какой-либо мат. операции. Поищите в интернете ролики об отладке FBD/LAD ;)
FBD LAD — это условно параллельный порядок выполнения.
Пишут на ST скорее всего какие-нибудь функции обработки сигналов (ПИД регулятор тот же самый, разбор пакетов при организации протоколов связи). Но потом, на верхнем уровне, это всё упаковывается в FBD LAD.
Молодёжь в институтах учит С++ и Джаву по большей части. Может быть по началу (от неопытности или с непривычки) им легче в алгоритмической форме паскаля писать. Я думаю, потом перестроятся.
А вот если Вам надо перевести значения энкодера в какую-то другую систему координат, посчитать кватернионы или рассчитать коэффициенты сплайна, то тут конечно проще на ST, C или чем-то подобным. На LAD, FBD и SFC простые циклы или цепочка вычислений превратится в программу на 100+ строчек с непонятной логикой, goto и т.п.
Для таких вещей лучше всего подходит Матлаб/симулинк, в котором вы можете построить графическую модель как алгоритма управления, так и самого объекта и все вместе промоделировать. А потом сгенерировать рабочий ST PLC Coderом. Я делал так несколько проектов, включая разные регуляторы в реальном времени и логику в Stateflow — очень неплохо получается. FBD и SFC просто дети по сравнению с Simulink/Stateflow
Тем не менее, FBD имеет ряд преимуществ. С помощью него очень наглядно можно представить логические схемы, которые не помнят своего предыдущего состояния. И отлаживать такие схемы легче в виде FBD. Но реальность такова, что все увиденные мной редакторы FBD (а это CodeSys, Schneider UnityPro, разное от Siemens) требуют какое-то нереальное количество кликов мыши и ужасно поддерживают размножение типовых кусков. Например, вызов одного и того-же блока, присоединенного к множеству разных входов/выходов контроллера станет головной болью в FBD.
LD же просто должен гореть в аду ))) Особенно, когда его лепят к аналоговым сигналам (Schneider это очень любит). Хотя это уже зависит от программиста больше.
Ну я могу привести в пример BPMN и/или Информатику. На которых предлагается программировать бизнес-процессы, или ETL.
ETL на BPMN? Я знаком с обоими, но вот такая комбинация выглядит странно. Может быть вы имели в виду ETL на DFD?
BPMN это ведь не средство программирования, а средство визуализации. Диаграммки рисуются в первую очередь для людей с целью улучшить понимание предметной области. Потом уже на основе таких диаграммок пишутся BRD на разработку и другие документы. Функционал по воспроизведению диаграмм BPMN в коде и их запуску — фичи конкретных инструментов, а не нотации.
>Функционал по воспроизведению диаграмм BPMN в коде и их запуску — фичи конкретных инструментов, а не нотации.
Разумеется. Но вполне конкретные вендоры преподносят BPMN как язык для разработки. Забывая при этом упомянуть, что без второго языка эта разработка реально невозможна.
В промышленной автоматизации широко применяются релейно-контактные схемы. Релейно-контактная схема обрабатывает сигналы с датчиков, кнопок и т.д. и включает/выключает какие-либо механизмы. Схему можно собрать либо из отдельных реле или применить программируемый логический контроллер. Релейно-контактная схема, в принципе, эквивалентна набору логических уравнений и их можно записывать в текстовом виде, но в виде схемы они смотрятся намного нагляднее. Поэтому в промышленности применяются два визуальных языка или представления логических уравнений: LD — выглядит, как релейно-контактная схема, FBD — выглядит, как графические обозначения из цифровой схемотехники. Обычно в средах программирования логических контроллеров есть возможность наблюдать, как выполняется программа. IDE подключается к контроллеру по сети и получает информацию о состоянии входов, выходов и внутренних переменных при этом элементы схемы подсвечиваются.
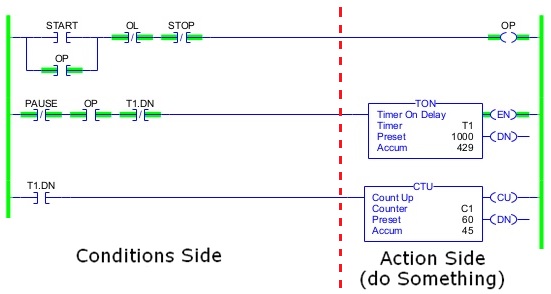
Также существует язык для описания последовательных процессов — SFC. Выглядит как блоксхема.
И поэтому там где продукт активно развивается, особенно многими людьми, такие инструменты заходят плохо — очень сложно понять, что изменилось с тех пор, как ты сюда заходил в последний раз, и почему тут что-то сломалось, при том что недавно работало.
Реальной проблемой может быть то, что графические языки заточены под описания жёстких схем. Когда что-то может меняться в процессе выполнения программы, визуальный язык скорее всего не имеет средств, чтобы это описать. Не могу привести пример графического языка, где предусмотрены символы, для описания какого-нибудь динамического создания объектов, выделения памяти, рекурсивных функций. В программировании систем управления это либо не нужно, либо
К тому же там где используются ПЛК обычно нет никакого активного развития. Установку привозят собирают, производят пусконаладку, возможно что-то исправляют в коде на месте. И потом возможно не трогают весь срок службы. Единственное, что нужно, чтобы проект с исходниками всегда был идентичен программе в контроллере, на случай если вдруг понадобится, что-то поменять. Средства для проверки этого есть, остальное не на столько критично.
В блендере есть аналогичный node editor для шейдеров. Поначалу я думал, что это наглядно и удобно, но потом понял, что реализация сколько-нибудь сложной функции занимает кучу места и оказывается сложной для восприятия. Переиспользовать код тоже неудобно — приходится создавать подграфы и переключаться между ними.
Например, простейшая модель освещения:
color = diffuseColor * (ambient + light * min(0, -dot(lightDir, normal)));Эта строчка легко читается, быстро печатается и занимает мало места: на экране без проблем поместится ещё 50-100 таких же. Если я захочу добавить зеркальное отражение — допишу ещё одну строчку.
А в нодах — выщеописанная функция уже содержит 5 операций и использует 5 переменных и одну константу. Т.е., в граф придётся добавить ещё 6 новых вершин и потом соединить их друг с другом и с пятью внешними вершинами. Это уже громоздко выглядит, не говоря уж о чём-то реально сложном.
Такой инструмент сильно снижает порог входа, но получается это за счёт ОЧЕНЬ сильного опускания потолка возможностей.
Автор, похоже, не знаком не только с промышленной автоматизацией, как указали выше, но и не в курсе, что с помощью Model-Based Design — тоже одного из видов визуального программирования, создается софт, который управляет автомобилями, самолетами, садит ракеты SpaceX, обрабатывает информацию с сонаров и радаров и передает гигаваты электричества на тысячи километров. В общем эти товарищи, похоже, выбрали плохую идею.
Ну а те, кто клепает проекты на Labview, вообще дети, наверное.
А вот да. :)
Но снова же — как только проект вырастает, проще все стереть и переписать в нормальной невизуальной среде
Если бы это автоматически могло происходить…
Но снова же — как только проект вырастает, проще все стереть и переписать в нормальной невизуальной среде,
Для многих проектов он не вырастает никогда, а вот наоборот, когда через несколько лет надо бы что-то подправить — Labview дает очень хороший результат
Намного проще посадить теоретиков с PhD в зарегулированную песочницу и встраивать результат их труда в системную обертку нежели пытаться найти людей с теми же скилами в прикладной области да плюс еще умеющих в C/C++.
LabView?
C++Builder/Delphi?
Ничего другого не знаю.
и оно успешно используется более 20 лет.
Ещё вот это: https://blueprintsfromhell.tumblr.com/
Я сильно извиняюсь — а что нынче есть визуальное программирование?
www.sidefx.com
www.foundry.com/products/nuke
www.blackmagicdesign.com/ru/products/fusion
www.allegorithmic.com/products/substance-designer
natrongithub.github.io
Очень много чего!
Я сильно извиняюсь — а что нынче есть визуальное программирование?
В отрасли embedded и микроконтроллеров это все, что позволяет получить исполняемый код из графических моделей.
Для Си кода у меня такой список:
MATLAB Embedded/Simulink Coder http://www.mathworks.nl/products/embedded-coder/
Gene-Auto http://geneauto.gforge.enseeiht.fr/
SCADE http://www.esterel-technologies.com/products/scade-suite/
dSPACE TargetLink http://www.dspace.com/en/inc/home/products/sw/pcgs/targetli.cfm
PLECS Coder http://www.plexim.com/products/plecs_coder
Synphony Model Compiler http://www.synopsys.com/Systems/BlockDesign/HLS/Pages/default.aspx
Evidence E4 Coder — http://www.e4coder.com/
National Instruments Labview — Z-brain — http://www.schmid-engineering.ch/de/151/ZBrain_System.htm
IMACS GmbH radCASE www.radcase.de
AdaCore QGen http://www.adacore.com/qgen
Для ПЛИСов — т.е. генерация VHDL/Verilog:
MATLAB HDL Coder http://www.mathworks.nl/products/hdl-coder
Xilinx System Generator for DSP http://www.xilinx.com/products/design-tools/vivado/integration/sysgen/index.htm
Altera DSP Builder http://www.altera.com/products/software/products/dsp/dsp-builder.html
Synphony Model Compiler http://www.synopsys.com/Tools/Implementation/FPGAImplementation/Pages/synphony-model-compiler.aspx
National Instruments LabView — only on LabView Hardware — http://www.ni.com/labview/fpga/
Altera Quartus II/prime (provides block diagram editor, Altera only) https://www.altera.com/products/design-software/fpga-design/quartus-prime/overview.html
Lattice Diamond(provides block diagram editor, Lattice only) http://www.latticesemi.com/en/Products/DesignSoftwareAndIP/FPGAandLDS/LatticeDiamond.aspx
Microsemi Libero SOC (provides block diagram editor, Microsemi only) http://www.microsemi.com/products/fpga-soc/design-resources/design-software/libero-soc
Xilinx Vivado IP integrator (provides block diagram editor, Xilinx only series 7 and up) http://www.xilinx.com/products/design-tools/vivado/integration.html
Mentor Graphics HDL Designer (provides block/state diagram editor) https://www.mentor.com/products/fpga/hdl_design/hdl_designer_series/
Aldec Active-HDL (provides block/state diagram editor) https://www.aldec.com/en/solutions/fpga_design/graphical_text_design_entry
HDL Works Ease (provides block/state diagram editor) https://www.hdlworks.com/
Языки программирования, такие как С, С++ и прочие, могут быть написаны в блокноте, где фон одним цветом, текст другим, контрастным с первым. Все. Это текстовые языки.
Но дальше мы визуализируем. Визуализация происходит статически и динамически. Статичная визуализация на самых верхних уровнях затронута у автора статьи. Что же динамичная визуализация и статическая визуализация на нижних уровнях?
Рассмотрим статическую визуализацию на нижних уровнях. О, чудо — это банальные отступы строк! И заметим, что отступы практически не влияют на работоспособность кода! Да простят меня программисты на Python, у которых отступы могут повлиять на работу их скрипта. Зачем нужны блоки? Они «визуализируют» блоки, выделяя псевдографическими средствами. И этим пользуются уже очень давно и доступно даже в ч/б режиме. Статическая — сохраняется в исходном коде.
С появлением цветных мониторов появилась динамическая визуализация — подсветка слов разными цветами в зависимости от предназначения. Динамическая, т.к. в исходный текст не сохраняется и каждый раз высчитывается заново. Конечно, некоторые могут пойти на ухищрения, чтобы сохранить разметку в отдельный файл, но мощности современных компьютеров хватает высчитывать это динамически, поэтому большинство не заморачивается.
И наступают еще два вида визуализации, одна статическая — специальным образом оформленные комментарии вначале процедуры, и одна динамическая — гипертекстовая с переходом к логически связанной области кода (например, объявление процедуры) с вариантом «отобразить в виде всплывающей подсказки».
И если первые два варианта доступны издавна и нынче доступны даже в продвинутых блокнотах (geany, notepad++ и т.д.), то следующие две стали распространены позже и требуют поддержки на уровне IDE и наличия исходного кода, на который ссылаться (хотя бы заголовочных файлов и/или комментариев/справки).
Можно даже представить развитие языков в виде линии 1D->2D->3D
Текст без отступов и переносов — это чистая 1D (одна длинная строка)
Отступы и переносы — 1,25D (условное деление, дабы 2D отдать полностью визуализированным языкам первого уровня)
Цвет текста (подсветка синтаксиса) — 1,5D
Гипертекстовые переходы и подсказки — 1,75D
Сверх-юникодная поддержка и Drag&Drop — 1,9D
Графическая автозамена — 2D
Поддержка слоев — 2,5D
… и т.д. вплоть до 3D и 4D!
Вышло много текста, поэтому остальное описание про 1,9D-4D с подробностями под спойлером!
Но как проставлять значки? На клавиатуре таких символов нет! Ответ: Drag&Drop поможет! Из готовых библиотек. Как значки, так и готовые куски текста — названия переменных, процедуры и т.д. Да хоть скопировать код, который находится чуть выше! Мне часто приходится копировать названия переменных, а так — навел, нажал клавишу мышки и перетащил куда надо, с зажатым Ctrl оно скопировалось. Но чаще привычка срабатывает Ctrl+C и Ctrl+V. Пока что надо предварительно выделять, нет возможности связать два названия переменной с указанием «это одно и то же» вплоть до одновременного редактирования (вместо пункта диалога — «заменить») и прочее.
Меня интересовала больше возможность заменить текст не на символьные примитивы, а на графические.
Как видим — сегодня мы пользуемся 1,75D языками, которые ближе к «чисто визуальным», нежели «чисто текстовым». И это считается нормой и является промышленным стандартом для многих серьезных проектов. В одну строчку код нынче не пишут, даже переносов людям стало нехватать! Поэтому и движутся по пути максимальной визуализации языка — отступы, подсветка синтаксиса и т.д.
А что же Scratch и прочие? Они сейчас больше похожи на ту одежду, которую демонстрируют на показах мод. Выглядят революционно, но в большинстве случаев имеют проблемы с применением в быту или вообще могут быть исключительно демонстрационными материалами (в мире визуальных языков — «для обучения»). Конечно, существуют и те языки, которые также используются в промышленном применении, но все же не стали всеобщим стандартом для большинства программистов.
Ах, да — визуальные языки еще помогут избавиться от наследия текстовых файлов — «все в один столбик». И если встречается ключевое слово «IF» («ЕСЛИ»), тогда дальше уже будет в 2 столбца, причем правый столбец — код, который записан в ветке «ELSE» («ИНАЧЕ»).
Но об этом уже на уровне 2D из представленной схемы.
Я для себя уже расписывал идеи по визуальному языку вплоть до 3D и 4D, но если 3D действительно в трех измерениях, то 4D — скорее маркетинг, нежели доп.измерение, и имеет интересные для меня свойства, которые «сделают этот жестокий мир программирования лучше» и позволят писать даже на машинных языках, т.е. нет необходимости компилировать код :D
Уточню про написание на машинных языках — 2D подготовит почву, благодаря замене машинного кода на граф.знаки, а вместо компиляции будет 2 файла — машинный код (готовый к исполнению) и файл привязки машинных кодов к граф.символам (нужен для IDE).
3D — упростит написание сложного кода на порядки, как это произошло с переходом от ассемблера на языки высокого уровня.
4D — позволит писать код тем, кто до этого не умел. И не обязательно что-то учить или даже знать как работает процессор для написания машинного кода!
Просматривая комментарий — надо было опубликовать как статью! Но я перфекционист и как-то не привык делиться концептами (описание у меня на уровне концептов), особенно для 3D и 4D, когда тут даже 2D подразумевает революционный подход (либо долгий эволюционный путь). Хотя, может кто-то согласится такое помочь реализовать или подсказать где искать? Тогда ради подсказок можно будет и попытаться поделиться своим видением «Next Gen» ЯП, которые будут визуальные на уровне IDE, но при этом все те же привычные С, Java, JS, C++, C# и любой другой текстовый язык, ассемблер или даже машинный код! Под спойлером я расписывал, но без подробностей и как оно так функционирует.
Вы забыли принцип «мухи отдельно, котлеты отдельно».
Т.е., для обычных ЯП (не визуальных), код и его «визуальное» представление отделены и не зависимы.
При этом как выглядит код, не сильно важно (кроме отчасти python'а)
В отличии от визуальных ЯП. Где все смешалось в кучу. Где визуальное представление не отделима от кода программы.
И да с текстом работать удобнее, чем с пиктаграммами.
Тупо за счет того, что текст компактнее.
Тупо за счет того, что текст компактнее.
Странно, обычно картинка favicon.ico (иконка сайта) компактнее названия всего сайта. Например, модуль подключения facebook можно обозначить двумя иконками — f (на синем фоне)+вилка (которую в розетку). 2 иконки будут короче целых слов, но могут посоревноваться по длине только с аббревиатурами, у которых есть ограничения по количеству допустимых вариантов — количество букв в алфавите всегда будет меньше количества доступных пиктограмм.
Мало того — есть много стандартных иконок, типа «сохранить» (дискета), «открыть» (папка), «создать» (лист с загнутым уголком или зеленый плюсик), «удалить» (красный минус). Соответственно, эти иконки будут заменами даже для слов «save», «open», «create», «delete». Можно набрать ключевое слово, которые позже будет отображаться иначе. Мало того — даже скобки можно представить в виде контейнеров, а это уже визуальщина. И Lisp благодаря этому может избавится от скобочек — в IDE отрисовывать выражение в скобках в виде выражения внутри прямоугольника или иной фигуры. И именно этот язык разбивает ваше утверждение про
с текстом работать удобнее, чем с пиктаграммами.
Опять же — ориентация на современные системы, в том числе сенсорные экраны, жесты и прочее, на которых с текстом работать уже хуже, чем с пиктограммами. Даже андроид-клавиатура предлагает ввод всяких смайликов. Только legacy клавиатуры до сих пор имеют неизменяемое нанесение букв одного-двух алфавитов с невозможностью динамической смены. На программном уровне клавиатуре все равно что за символы она передает. Она просто передает состояние типа «код нажатой клавиши» и «код клавиш-модификаторов», но никак не «код символа», это уже ОС сопоставляет «код нажатой клавиши» с «кодом символа» и это сопоставление зависит от раскладки клавиатуры, которая может быть любой пиктограмной.
И я приводил примеры, когда люди уже работают с пиктограммами — подсветка текста, отступы, переносы, сворачивания процедур и операторных блоков, базовые команды IDE или даже блокнота — везде пиктограммы. Даже Microsoft Word отказался от чисто текстового меню в пользу визуальных пиктограмм.
Сейчас в текст нельзя вставить картинку — она будет только в виде hex, base64 или иного варианта кодирования, который не воспринимается человеком как картинка.
И последний аргумент: символ — это частный случай пиктограммы из специального набора под названием «алфавит». Отсюда — любой текст — это набор пиктограмм. Отсюда ваше выражение приобретает противоречивый характер в стиле «с символами работать удобнее, чем с символами»
И последний аргумент: символ — это частный случай пиктограммы из специального набора под названием «алфавит». Отсюда — любой текст — это набор пиктограмм. Отсюда ваше выражение приобретает противоречивый характер в стиле «с символами работать удобнее, чем с символами»Пиктогра́мма (от лат. pictus — нарисованный и греч. γράμμα — запись) — знак, отображающий важнейшие узнаваемые черты объекта, предмета или явления, на которые он указывает, чаще всего в схематическом виде.
Буква алфавита такими свойствами не обладает, только набор букв формирующий слово целиком.
Также во многих языках существуют ситуации, когда буква может обозначать целое слово. Аббревиатуры
Не забываем, что многие народы «перескакивали» целые эпохи развития и могли получить свою письменность относительно недавно, особенно это касается малых народов, не являющимися на момент получения письменности государствообразующим.
И еще было упущено иероглифическое написание, когда даже сейчас можно каждой букве подставить свою пиктограмму-иероглиф, что даже так и делается — азбука для детей или шифрованные сообщения (простая замена написания), но особо не распространено среди остальных, т.к. является усложнением написания и влияет на скорость письма. Скорость письма отходит на второй план только при появлении доступного аудио- или иного фиксирующего оборудования, но до этого всю историю развития человечества именно скорость письма была критична, особенно до широкого распространения книгопечатания.
Соответственно, в будущем вполне возможен переход на иероглифичные стили письма. На это намекает широкое распространение эмоджи/смайликов, которые даже стало удобно набирать в различных мессенджерах/общалках/смс с поддержкой на уровне ОС (андроид и прочие). Но этому явлению в сверхшироком массовом сегменте буквально два десятилетия — первое десятилетие у каждого свои иероглифы-смайлики, второе — смайлики уже на уровне целых экосистем и операционных систем. Почему выделил только последние два десятилетия? До этого телефоны и компьютеры, как и интернет, не были доступны широкому кругу пользователей, в т.ч. домохозяйкам, обычным работникам, студентам, школьникам и другим не IT-специалистам, которым хочется писать в чате да котиков рассматривать, а не «изучать новое, неопознанное и очень сложное» без онлайн-сервисов, без связи с другими ПК, высокая стоимость этих самых ПК, никакая функциональность телефонов (максимум — телефонная книга в крошечном экране, и то не всегда). И т.д.
2) Смайлики не стоит рассматривать как альтернативу письменности, по сути это аналог жестов (типа рукопожатия, махания рукой) и невербальных эмоций (улыбка, нахмуривание и т.п.) при реальном общении. Полноценно на них никто не общается.
3) Абревиатуры — это не буквы алфавита сами по себе, это своего рода слова и они имеют смысл только в виде конкретного набора букв, но не сами буквы по отдельности.
4) Есть редкие исключения, когда одна буква может являться целым словом: я (местоимение), и (союз), о! а? (междометия), но сами буквы в составе слова не несут отдельного смысла.
Проще это демонстрировать на диаграмме Венна, когда по вложенности идут следующие множества:
Изображения/фото->рисунки->пиктограммы->иероглифы->базовые элементы->буквы->буквенные модификаторы (точки над ё).
Да, по мере вложенности часть информации теряется. И это больше похоже на слои абстракции, т.к. более вложенное множество не может продемонстрировать все достижения предыдущего слоя. Но получаем универсальность.
Картину зимнего леса не получится использовать для объяснения принципа работы компьютера. Но зато картина зимнего леса может эффективно заменить текст описания этого зимнего леса.
Имеет три параметра — скорость письма, универсальность применения, сложность обучения, сложность написания и информативность. Человечество ориентировалось на первые четыре в ущерб информативности, поэтому и дошли до букв. Тот же значок банана трудно нарисовать черным цветом, отсюда упрощение и сложность обучения иероглифу.
2.1) «Гулливер» Джонатана Свифта. Описание общения с помощью предметов. Они не знали про пиктограммы, поэтому таскали с собой целые мешки. А так достаточно одной книги со всеми возможными заменами слов в виде пиктограмм и просто тыкать на нужной странице.
2.2) Сейчас некоторые диалоги можно строить с помощью пиктограмм, этим даже пользуются. Например — когда пишут про 18+, используя (отпечаток помады от женских губ), (банан), (клубника) и т.д. IT специалисты пока вынуждены ждать, т.к. пиктограмм Shift, Ctrl, Tab и прочего еще не завезли. Названия клавиш не сильно интересны, а вот всякие faceboot, google и прочие значки могут пригодится.
2.3) Язык глухонемых. Извините, зашел с козыря. Мало того, язык глухонемых можно использовать для общения с теми существами, у которых человекопонятная речь в принципе невозможна из-за принципиально другого строения, например — собаки, обезьяны и прочие. Просто вместо жестов применять картинки.
3,4) некоторые иероглифы/пиктограммы могут не иметь самостоятельного значения или оно бессмысленно отдельно. Даже для слов встречается — есть слово «ненавидеть», но нет слова «навидеть». В остальном — повторение п.1.
5) Смысл букве именно сейчас обрести отдельный смысл?
6) Вы отрицаете, что буквы при ныне отсутствующем самостоятельном смысле когда-либо ранее имели отдельный смысл?
«собаки понимают язык глухонемых» — это сильное заявление…
«Значок банана трудно нарисовать черным цветом» — это почему?
В целом можно. Ч/б фотку сделать можем же. Есть лишь одна проблема — ложные пересечения, свойственные при упрощении. Например, как банан отличить от дольки мандарина, если пиктограмма будет элементарна и одинакова в обоих случаях.
Задачка посложнее — как отличить зеленое яблоко от красного? если оба нарисованы схематично черным цветом. Или красный от зеленого сигнала для горизонтально расположенного светофора, нарисованный черным цветом. А если не применять серый или доп.иконки — то задача действительно усложняется. Еще вариант — отличить полностью наполненную водой бутылку от пустой, тут даже фото не всегда поможет. Подразумеваю наполнение без воздушного промежутка сверху, т.е. до уровня крышки. Морскую волну и радиоволну, хотя тут можно выкрутится за счет широкой трактовки.
«собаки понимают язык глухонемых» — это сильное заявление…
Собаки поддаются дрессировке и способны понять 1-2 жеста и больше. Даже десяток вполне смогут. Или вы отрицали, что собаки могут понять до десятка жестов?
Я не говорил про всю полноту языка, тут даже люди не способны знать всю полноту родного языка, особенно всякой терминологии, названия инструментов и явлений и редко используемых слов. Максимум — художественную полноту осознают. А перечислить по памяти названия врачебных инструментов (кроме врачей и причастных)? Вряд ли рядовой обыватель справится. Я молчу про диалекты и местные наречия, когда одному и тому же явлению находятся разные слова.
Задачка посложнее — как отличить зеленое яблоко от красного? если оба нарисованы схематично черным цветом.
зато вы достаточно хорошо описали их текстом. Заметьте, текстом любого цвета. поэтому текстовое описание — более точное, позволяет выделять существенные признаки вещей.
Собаки поддаются дрессировке и способны понять 1-2 жеста и больше— понимание языка сильно отличается от запоминания жестов. Далеко не все слова в языке глухонемых описываются одним-двумя жестами. но немой вполне может одними и теми же жестами обьяснить, высокий или низкий он слышал звук, и высоко или низко прыгнула собака. вы можете выучить собаку в зависимости от жеста прыгать высоко или низко, но этим же жестом-модификатором вы не сможете ее заставить выть выше или ниже, и наоборот. Хотя вы можете заставить собаку запомнить названия медицинских инструментов (типа, «скальпель — гав», «шприц — гавгав»), но классифицировать иглу от шприца и иглу для взятия пункции как «иглы» она не сможет. а человек сможет выбрать иглу для пункции из груды скальпелей, зажимов и тампонов даже если никогда не знал о ее существовании.
текстом любого цвета. поэтому текстовое описание — более точное, позволяет выделять существенные признаки вещей.
Во-первых — не любого! Как минимум — не совпадающего с фоном, а желательно вообще контрастным
Во-вторых — позволяет абстрагироваться с потерей информации. Т.е. при описании фото растения вы можете пропустить информацию о том, что это растение болеет (нейросети уже учатся). Также вы не можете описать то, чего не знаете. Например, некоторые не знают что такое штангенциркуль, соответственно — не смогут его опознать.
В-третьих — занимает больше места. Одна иконка размером с 2-3 буквы заменит словосочетание «красное яблоко» (13 букв+спецсимвол пробела)
Еще пример — как мужчина попытайтесь описать название нескольких розовых помад разных оттенков и покажите это описание женщине. Тут большинство мужчин будет бессильно описать разницу между помадами, даже если вы ее заметите. Бессилие растет с ростом количества помад, для 2-3-х единиц могут и кое-как справится.
человек сможет выбрать иглу для пункции из груды скальпелей, зажимов и тампонов даже если никогда не знал о ее существовании.
Нет, не сможет. Если не знал даже очень похожих аналогов. Можете проверить — открыть рабочий набор инструментов перед студенткой гуманитарной специальности и попросить дать гаечный ключ, крестовую отвертку, различные биты для шуруповерта. Вот на словах «любой бит для шуруповерта» даже я засомневался, т.к. знаю про «насадки», но не про «биты», которые синонимы «насадкам», а не которые из IT.
Девушки, которые не от мира IT и специально или случайно не изучавшие, не смогут подать материнскую плату (которая не алименты), оперативную память (а отличить DDR2 от DDR3? DDR4? Или хотя бы ноутбучную DDR от полноразмерной?), процессор (который не системный блок под столом). А про всякие радиодетали — тут даже я буду бессилен, т.к. не всегда могу их различить, даже если видел их ранние версии, т.к. современные могут очень сильно отличаться или быть очень нестандартными в связи с миниатюризацией.
Еще пример с музыкой — тут первично графическое отображение (ноты). Не принято пытаться музыку записывать текстом. И обычный человек не способен описать музыку как она есть, максимум — выразить чувства и какие-то базовые характеристики — интонации, темп и прочее. Только для людей с абсолютным слухом возможно описать музыку «дословно», т.е. буквально каждую ноту.
Как минимум — не совпадающего с фоном, а желательно вообще контрастным— требованияе несовпадения с фооном есть требование выделения сигнала на фоне шума. Текст, кстати, отличается этим от картинок в лучшую сторону.
как вообще у пиктограмм с пмхозщищнстью?
В-третьих — занимает больше места. Одна иконка размером с 2-3 буквы заменит словосочетание «красное яблоко» (13 букв+спецсимвол пробела)— пожалуйста, нарисуйте всем понятную иконку, обозначающую «зеленое кисло-сладкое яблоко, весом 150 граммов, с плотной сочной мякотью, пролежавшее под деревом несколько дней в начале октября».
как мужчина попытайтесь описать название нескольких розовых помад разных оттенков и покажите это описание женщине.— колористами прекрасно работают и мужчины. и парфюмерами тоже. Более того, можно не «описывать словами» (аналог вашей «пиктограммы»), а указать конкретный цвет на палитре.
Еще пример с музыкой — тут первично графическое отображение (ноты). Не принято пытаться музыку записывать текстом.— «не принято» — это не значит, что невозможно (в студенчестве на Корветах вполне записывали в знаковом виде, взаимно однозначно переводимом в стандартную музыкальную нотацию). и более того, само понятие «нота»- это «знак». Т.е современная нотная нотация — это знаковое письмо. аналог формул — но не пиктограмм.
некоторые не знают что такое штангенциркуль, соответственно — не смогут его опознать.Это ндывается «бинго!». Давно-давно, несколько более 30 лет назад, ко мне в гости пришли одноклассники. на рабочем столе обычный рабочий беспорядок — паяльник, инструменты, детали… И вот девочка, гуманитарий, музыкантка-пианистка, ненавидящая естественные науки, задумчиво смотрит на стол и спрашивает — «это что, паяльник? — да. А это штангенциркуль? — да. Так вот он какой! — в смысле? — Ну, отец с кем-то говорил, сказал, что померил штангенциркулем. Я его никогда не видела, но поняла [тут описание цепочки рассуждений] что это штангенциркуль.» Вот так.
зеленое кисло-сладкое яблоко, весом 150 граммов, с плотной сочной мякотью, пролежавшее под деревом несколько дней в начале октября
Решается, но несколькими иконками (кроме цифр и единиц СИ):
(яблоко (зеленый; вкус: лимон, сахар; вес 150г; мякоть: сок, плотный; место: под деревом; срок давности: несколько дней; время года: октябрь)
Теперь каждое из слов можно заменить на свою иконку. Всего было 236 символов (включая пробелы), Русский язык. Можно заменить на 18 иконок + до 6-10 спецсимволов.
Вкус — рисунок губ+языка (на одной иконке)
Сахар — кубики сахара
Вес — Гиря+ перо (на одной иконке)
150г — остается без изменений, т.к. цифры и единицы СИ итак имеют максимальное сжатие, пиктограммами тут можно только увеличить размеры; также цифры общеприняты и не переводятся, кроме некоторых народов.
Мякоть — нож, воткнутый в арбуз
сок — стакан рядом с пакетом (одна иконка)
под деревом — стрелка вниз под кроной иконки дерева; посчитал за две иконки, но по факту тут одна
срок давности — часы и стрелка влево над часами, т.е. «в прошлое»
несколько дней — сдаюсь. Вот тут я не придумал что нарисовать.
Время года: октябрь — тут надо учитывать, что названия месяцев по звучанию — белиберда, т.к. никаких ассоциаций с реальными предметами. Логично, ведь название месяцев по факту — иностранные имена, числительные и прочее. Поэтому проще взять какие-нибудь народные названия, типа тех же украинских, у них «октябрь» = «жовтень». Итого 2 иконки — календарь отрывной + желтый цвет (можно совместить). Падающий лист уже будет «листопад» = «ноябрь»
Итого — не подобрал замену только для «несколько дней».
по «пиктограммам» — вы не смогли обойтись без знаков. Но даже с ними — проведите эксперимент: дайте ваш рисунок нескольким людям, померьте время на расшифровку «мгновенного восприятия образа», и сравните для смеха их понимание вашей пиктографики с тем, что вы пытались изобразить. ну, можете им еще сравнить их версии между собой — тоже весело будет.
я думаю, вывод понятен?
Но сейчас обнаружил и вариант получше:
ИИ! Точнее, пиктограммы/знаки для общения с ИИ.
Про собак — их вполне обучали даже вождению, например
У ИИ с этим некоторые сложности
Жаль, что все исследования носят локальный и ограниченный характер. Хотелось бы увидеть обучение в течении нескольких поколений. Правда, не исключено, что при положительном исходе обучения вполне возможно появление «нового разумного вида», даже если интеллект будет на уровне ребенка. И потом общение в интернете вплоть до споров, что когда-то люди считали этот вид не ровней человеку. Тут куча претендентов — дельфины, обезьяны, собаки и другие.
Что-то подобное уже было — всего пару столетий назад черные не считались за людей у белых европейцев или белых американцев. А до этого белые ученые пытались доказывать, что черные в принципе не могут разумно мыслить.
Согласно научному методу нужно это проверить. Предоставить равные права и возможности (с учетом особенностей строения) и посмотреть на результаты. Причем, стараться ради результата, а не бросая на самотек. Боюсь, результаты могут быть шокирующими и непривычным, особенно если интеллект этих животных превзойдет человеческий или будет сопоставим со взрослыми людьми или подростками.
I) Есть два принципиальных типа письменности
— Фонети́ческое письмо́ — вид письма, в котором графический знак (графема) привязан к определённому звучанию.
— Логографическое — главное отличие логограмм от других письменных систем состоит в том, что графемы напрямую не связаны с произношением.
У этих двух систем есть ряд вариаций, но это уже детали.
II) Я нигде не нашел детального обоснования того, что фонетическое письмо произошло от логографического, есть очень древние примеры и того и другого типа. Я склонен считать, что это две параллельные ветви письменности.
III) Язык глухонемых — это не козырь по следующим причинам:
— он очень специфичен и узкозаточен под конкретную задачу, точно также как и другие языки жестов.
— мы спорили не о языках, а о системах письменности. Какая письменность у языка глухонемых?
6) Вы отрицаете, что буквы при ныне отсутствующем самостоятельном смысле когда-либо ранее имели отдельный смысл?
Да, именно так и именно из этого началась наша дискуссия.
II) А я склонен, что это не просто параллельные, а одновременные. Т.е. грубо — 50% произошло от первого вида, 50% от другого. А у другого народа другие пропорции в пределах от (0%; 100%) до (100%; 0%). Мало того, в этих пропорциях могут быть поправки, например — третий вид, суррогатный. Когда и произношение, и письмо — заимствованное от более высокоразвитых цивилизаций, например — белые в Африке.
3) А тут небольшой подвох. Сейчас отдельной письменности у глухонемых нет, т.к. они используют принятую в обществе. Но они сами пользуются лишь ограниченным числом жестов, которые можно перевести в пиктограммы и мы получим письменность глухонемых, которую уже можно пользоваться наравне с обычно письменностью или даже вместо. В тех же смс/чате иной раз будет даже полезно. Или в инструкции. Кстати, в некоторых инструкциях действительно заменяют слова на иконки, например в инструкции к пульту управления будут не названия кнопок, а их графические изображения. Зависит от производителя и модели пульта. Возможно и для другой техники.
Отсюда — письменности пока что нет, но в этом направлении можно двигаться, он уже существует и даже немного работоспособен, пусть даже на базовом уровне и перевод в иконки должен быть «не дословным», т.е. как жест в реальности выглядит, а приблизительным или адаптированным для легкости понимания.
6) а я думал, что был иероглиф (который ближе к картинке), потом его расчленили на составные части, которые стали более универсальными, потом слишком сложные части еще раз порезали. И более простые элементы стали письменностью, как та же слоговая азбука в японском (хирагана и катакана). Я не утверждаю, что так появилось 100% букв. Мне для подтверждения хватит 1% от общего алфавита, причем для какого-нибудь одного языка. Тогда автоматически получается признание, что система работает и такое возможно. А дальше лишь установить точную границу в том, сколько именно букв получилось от иероглифов и когда-либо имели самостоятельно значение.
Эх, я сразу же выиграл. «Я» и сейчас имеет самостоятельное значение, а это более, чем 1%. Даже для пиктограмм свойственно утрачивать собственное значение, в зависимости от контекста и модификаторов, например — черта сверху может обозначать инверсию, т.е. было значение «красный», стало «не красный».
Кстати, в некоторых инструкциях действительно заменяют слова на иконки, например в инструкции к пульту управления будут не названия кнопок, а их графические изображения.Тут всё проще: иконки в инструкции позволяют её не переводить и, главное, не разделять модели с разными инструкциями. Сильно упрощает логистику.
— Врядли изображения их жестов будут простыми и удобными и легко читаемыми, так как там жесты объемные, а так же еще и масса жестов с движением.
— Интересно было бы услышать мнение человека владеющего и языком глухонемых и речью, насколько вообще этот язык удобен.
II) По поводу пультов, иконок и т.п.
Это все удобно в отдельных узких сферах, и даже там применяется частично, а не заменяет все.
Например есть дорожные знаки — визуально, удобно, понятно. Но, даже там есть еще доп. информационные таблички с текстом, хотя казалось бы, ну сделай знаков больше и откажись от текста вообще. Но ведь не отказываются, потому что это создаст больше путаницы, чем удобства.
III) В целом, я считаю, что есть отдельные задачи, где использование пиктограмм, иконок, смайликов и т.п. визуальных элементов очень удобны, но они удобны именно для узкого подмножества задач, но не формируют полноценный гибкий универсальный язык.
Эх, я сразу же выиграл. «Я» и сейчас имеет самостоятельное значение, а это более, чем 1%.В даном случае, я думаю просто была фонема означающая личное местоимение я и совпало что есть буква с таким звучанием (в английском тоже совпало, а вот в немецком и французском уже нет).
Если бы это не было случайностью, то скорей всего так было бы во многих языках и для многих местоимений.
habr.com/company/edison/blog/432334/?reply_to=19476468#comment_19480142
2) тут есть труднокодируемые сочетания: названия городов, улиц и т.д., аббревиатуры, числа, единицы СИ (скорость, масса) и т.п.
100% достигнуть не получится. Но заменять на слова типа «скользко», «ограничение скорости» и прочие — слова декодируются дольше, а сейчас еще и появляются те, кто читают с трудом. Видел одного, который до 11 класса читал по слогам, но сейчас нормально, т.к. научился из-за игровых чатов и субтитров к кинофильмам.
3) настаивал на том, что формируют, получаясь что-то вроде разборчивых иероглифов. 5-6 тыс таких знаков вполне могут дать адекватную замену для многих. А специализированные термины или редкие слова можно оставить текстом.
II) Я нигде не нашел детального обоснования того, что фонетическое письмо произошло от логографического, есть очень древние примеры и того и другого типа. Я склонен считать, что это две параллельные ветви письменности.Любой логографический язык неизбежно сталкивается с необходимостью фонетической записи тех слов, которые нельзя обозначить картинкой. Например имена в древнем египте.
Как правило — используется первая буква/слог
При «импорте» письменности иноязычным народом остаётся только фонетическая часть. А сами иероглифы упрощаются — ведь они теперь обозначают только звук, сохранять визуальное сходство уже не надо.
Любой логографический язык неизбежно сталкивается с необходимостью фонетической записи тех слов, которые нельзя обозначить картинкой.В Китае так и подбирают по созвучию, но стараются подобрать еще и иероглифы с положительным смыслом.
А в Японском изобрели дополнительную фонетическую запись. Кстати, сейчас посмотрел — она действительна произошла от иероглифов, это удачный пример появления фонетического письма из логографического. Но является ли это общей практикой или редким частным случаем?
При «импорте» письменности иноязычным народом остаётся только фонетическая часть.
Так как в случае китайских иероглифов пример прямо противоположный — они распространялись именно как графическое изображение слова, а вот их произношение в разных языках было совершенно разное. Что объяснимо, так как речь появилась раньше письменности.
Хотя да, в Японии паралельно с этим еще и создали слоговую азбуку упростив иероглифы.
А импорт (добровольный) был например в средиземноморье. Сначала финикийцы непонятно у кого, потом от них остальные.
И угадать вполне можно, если присмотреться
А — бык, D — дверь, М — вода(море), О — око, S — крючок, R — голова, W — зубы, Y — рука
В Китае — не было импорта, был навязываемый сверху государственный язык.Я говорю про экспорт китайских иероглифов в соседние регионы в дальнейшем — в Японию, в Корею. И они туда пришли именно как логографическая письменность, на слух их произносили так, как обозначаемое слово произносилось в языке нового региона, а не как в исходном Китайском.
Я нигде не нашел детального обоснования того, что фонетическое письмо произошло от логографического, есть очень древние примеры и того и другого типа.
Зато есть замечательный пример письма, которое является их гибридом: египетские иероглифы. Короткие слова обозначаются логограммами, а длинные — строятся из коротких по принципу ребуса.
Но зато картина зимнего леса может эффективно заменить текст описания этого зимнего леса.
Только ту часть, где даётся описание визуальной информации. А вот как на картине изобразить следующие фразы:
«В лесу раздавался топор дровосека.»
«Смолою и дымом пахнет зимний лес.»
Посмотрите на картинку нового процессора AMD:
 Там (в маленьких квадратиках по краям) 64 ядра. А вот та здоровенная хрень посередине — это хаб. Условно — «стрелочки», соединяющие эти ядра с шикой данных и друг другом. И нет — это не кеш.
Там (в маленьких квадратиках по краям) 64 ядра. А вот та здоровенная хрень посередине — это хаб. Условно — «стрелочки», соединяющие эти ядра с шикой данных и друг другом. И нет — это не кеш.Собственно из этой картинки понятно в чём беда «графических сред программирования».
Их бич — не пиктограммы. Они и компактнее текста могут быть.
Их бич — это рамочки и стрелочки. То есть то самое, что, собственно, и является основным достоинством и что помогает их освоить людям, незнакомым с программированием.
Когда задачи усложняются количество стрелочек возрастает — и довольно быстро вы достигаете состояния, где «за деревьями леса не видно».
А в тексте — никаких стрелочек нет. Они подразумеваются. Что, с одной стороны, позволяет делать всё компактнее, а с другой — требует обучения, да.
Теперь посмотрим на визуальные языки и видим, что им JMP/GOTO-инструкции не запретили, какого-либо обучения не дают и получаем спагетти-код или всякие другие варианты, в которых и похуже может получиться.
И видя, что и в тексте можно поломать и отстрелять себе ноги и все на свете, мы продолжаем ругать визуальные языки. Причем обучение не гарантирует получение знаний, которые позволят писать хороший и качественный код. Это не из-за «самоучителей для чайников», а просто потому, что чем сложнее создаваемая система, тем меньше людей, достигший того же уровня, соответственно — меньшему количеству людей потребуется решение. А сами решения могут быть сопоставимы по сложности с другими сложными системами, разве только на порядок проще, но все равно остаются на несколько порядков сложнее задач из самоучителей.
Отсюда преимущество визуальных языков ничуть не очевидно.
Правда, есть нюанс — в связи с низким порогом вхождения овнокодить на визуальном языке будет больше овнокодеров. Хорошо, если таковые вовремя остановятся, и не полезут овнокодить ответсвенные системы.
Хотя, безусловно, у визуальных систем есть куча применений, в которых они удобнее систем текстовых- только к программированию это никакого отношения не имеет.
Но ваш комментарий практически типичен (убрал одно слово):
в связи с низким порогом вхождения овнокодить на ______ языке будет больше овнокодеров. Хорошо, если таковые вовремя остановятся, и не полезут овнокодить ответсвенные системы.
Впишите любой язык «для широкого круга», типа PHP и прочие (извините, адепты языка PHP и языков из «прочие») и получите точно такую же ситуацию, с началом холивара в стиле «Язык для широкого круга VS некоторый другой более сложный язык», коих на просторах сети навалом.
Я чуть выше уже писал — мы уже пишем на визуальных языках, но видя текст, думаем, что это текст, набор строк. На самом деле уже давно нет и даже от иных авторов требуем добавить визуальные стили тегами Code lang=«язык программирования», чтобы удобнее читать, а это именно визуализация. Просто мы недалеки от того, что в том же ассемблере инструкцию MOV (переместить данные) можно заменить на обычную стрелочку, типа
Ячейка1 U--> Ячейка2 // да, я помню, что ранее нельзя было из оперативы в оперативу перемещать, только через регистр проца, как сейчас — не знаю. Вряд ли разрешили на х86. Поэтому просто немного пошалю
Ячейка2 += 115 // Вместо инструкции ADD, добавить
Ячейка2 =? Ячейка3 // вместо инструкции CMP, сравнить
(>0?)===> Goto1 // вместо JPM с условием (JMP с условиями забыл, поэтому тут для примера больше нуля)
Развить тему и мы получим действительно визуальный ассемблер с низким порогом вхождения. А вот как избавиться от кодинга Овнов — это сложнее, но реализуемо современными средствами. Точнее, если разработать на базе имеющихся средств. Правда, бюджет потребуется серьезный, а как привлечь деньги на подобные разработки я не знаю, где есть обязательное применение страхующих методов (для случаев невозрата инвестиций).
Продолжаю про ассемблер. По сути — мы пишем на макроязыках для ассемблера с расширенной поддержкой и некоторые компиляторы языка не переводит в машинные коды, а является трансляторами из «новомодного языка» в Си, из Си в какую-нибудь абстракцию машинных кодов или ассемблер, а оттуда уже происходит компиляция в… Машинные кода? Нет, в код, допустимой ОС и часть процедур внешние и ОС сама их предоставляет и выполняет, хотя часть полученного кода — вполне машинные инструкции. Различные программы на чисто машинных инструкциях ближе к эпохе DOS, а не современной с 101 изоляцией.
Кроме x86 существует много других систем. и у PDP-11, насколько помню, можно было и выполнять операции передачи память-память. Равно и как и ассемблеров существует много. И это дело автора ассемблера — как записать команду — словом MOV или словом-стрелочкой. Более того, такой «визуальный ассемблер» для атмеги существует. как думаете, кто им пользуется? :-) да-да-да, именно неспособные к нормальной записи нормальных слов. в полном соответствии с «принципом Шоу»: «Создайте систему, которой сможет пользоваться дурак, и только дурак захочет ею пользоваться».
вообще, у меня складывается ощущение, что вы плохо представляете себе, что такое «ассемблер», что такое «макрос», и что такое «компиляция» (и даже функционал опрационной системы)
«если так, то делаем это, а если иначе — то делаем то»
Учил только ASM (на базе TASM!), макросы и компиляцию в рамках университетского курса и самостоятельно для собственного интереса. ASM для х86. Позже FASM, но на уровне хобби.
Для Itanium не было визуального ассемблера, но архитектура приказала долго жить. Значит, не в визуальном ассемблере дело.
А кто пользуется обычным ассемблером? При написании веб-сайтов, веб-сервисов, игр, бизнес-приложений и т.д. И тут видно, что для сложных систем нужны слои абстракции, макросы и куча готовых компонентов с автоматизацией, чтобы не описывать «пересылку каждого байта».
неспособные к нормальной записи нормальных слов
А вот это недостаток, причем серьезный. Я за то, чтобы можно было переключить режим отображения. Хочешь — вот тебе ламповый текст, хочешь — вот картинками тоже самое. И если я в тексте что-то изменю, то картинки соответствующим образом изменятся. И обязательно — эквивалентность! Даже сейчас GUI для консольных программ чаще всего имеет усеченную функциональность по сравнению с написанием команд в консольке. Хотя для некоторых программ GUI может дать всю полноту управления при условии полного описания всех параметров либо с помощью читерского «добавить к команде» и дописывайте свои ключи и команды. Не касается вызова средств ОС.
«принцип Шоу»: «Создайте систему, которой сможет пользоваться дурак, и только дурак захочет ею пользоваться»
андроид, iOS изначально настроены дружелюбно, а еще MS-DOS(в виде первых Windows) и Linux получили графический интерфейс, дружелюбный пользователю. Вопрос — это считается за «систему, которой сможет пользоваться дурак»?
Я в курсе, что ныне Windows далеко ушла от MS-DOS и строится во многом на других принципах, хотя многие базовые понятия пока остались, типа — управление мышью и клавиатурой (сенсорный экран и жесты пока не всеохватывающие), хранение на жестком диске (а не в оперативной памяти — энергонезависимая память только-только появляется), 2D монитор, а не голографический или нейроинтерфейсный и т.д.
Из вики: транслятор исходного текста программы, написанной на языке ассемблера, в программу на машинном языке.
Макропроцессор — одни последовательности заменяются на другие, согласно заданным правилам. Ближе к трансляторам по логике работы. Отсюда — макрос — последовательность инструкций, которая будет заменена на другую последовательность (чаще всего такую же или более длинную).
Компиляция — анализ, компоновка исходного текста (если несколько файлов, которые не транслируются отдельно), трансляция и сборка. Анализ необходим для той же оптимизации.
функционал операционной системы… Вот тут вы задачку подбросили, т.к. по функционалу ОС для программистов написаны целые книги, причем что-то общее для всех ОС и для всех программистов (базовые понятия), а что-то различается (особенно куча нюансов). Современные ОС предоставляют свое окружение для программ и берут на себя — запросы к памяти (прямое обращение к любой физической области уже запрещено в той же Windows), отрисовку стандартных элементов и т.д., позволяя абстрагироваться от оборудования, используя средства ОС.
По-хорошему, тут надо ссылаться на книги соответствующей тематики, давая развернутый комментарий.
А как сами понимаете эти понятия?
Теперь посмотрим на визуальные языки и видим, что им JMP/GOTO-инструкции не запретили, какого-либо обучения не дают и получаем спагетти-код или всякие другие варианты, в которых и похуже может получиться.В ДРАКОНе вроде как раз запретили.
К сожалению, спагетти очень нравятся большинству именно из-за простоты создания. И я не про макаронные изделия, а про описание алгоритмов и схем. А некоторые топологии с определенного уровня даже распутать будет невозможно (в памяти всплыло число 19, но подробности той лекции уже утеряны).
Я расцениваю ДРАКОН именно как свод полезных правил, парадигма против спагетти. А его ругают как будто он самостоятельный язык. Почему ООП не ругают? У него вообще нет своего языка, все время какие-то посторонние языки его используют. Все потому, что ООП — не язык, а парадигма!
И получаем, что ДРАКОН — плохо, а ООП (ООяП) — хорошо. Но у обоих нет своих языков! Даже на Википедию зашел — вот там нету самостоятельного языка с названием "Объектно-Ориентированный язык Программирования", зато полно языков с поддержкой ООП (ООяП).
Тогда можно ввести понятие «Дракон-совместимость» и любой язык с поддержкой структурного программирования является ДРАКОН-совместимым.
Я расцениваю ДРАКОН именно как свод полезных правил, парадигма против спагетти.К сожалению это не просто «свод правил» — это некоторый, вполне определённый, язык. Там есть вполне определённые иконки, построенная над ними нотация и прочее.
Мало того — у ДРАКОН даже с типами более, чем никак, вообще никак. Поэтому типы берутся от языка-посредника, от которого берутся и ключевые слова.
Также у ДРАКОНа пока все плохо с процедурами и функциями. Нет, не с реализацией, а с логикой. Создается косвенная логическая связь, которая усложняет программу. Хотя ситуация типичная для всех языков программирования, но намного лучше неявных вызовов, т.к. есть хотя бы упоминания. При вызове процедуры вы по умолчанию считаете, что она работоспособна и без ошибок.
Еще у ДРАКОНа все плохо с ООП. Т.е. методы объекта описать еще можно, а вот объекты, их наследования и прочее — уже нет.
Было бы интересно увидеть сравнение на уровне ключевых слов/действий.
Например, ДРАКОН VS паскаль — у дракона определены циклы, ветвления, процедуры (с функциями беда — нет типов).
Никак с экспортом, операторами, типами, прерываниями и исключениями (как отдельные сущности), режимами работы.
Но я подразумевал не только символы <=, >=, !=, := и прочие, но и ключевые слова false, true, if then else, for и т.д. А также символы, определяемые пользователем или библиотекой — названия функций, переменных и т.д.
И тогда да, действительно будет близко даже к 1.85D, останется добавить Drag&drop панельки для готовых наборов. Еще пару деталей — и 2D, практически визуальный язык, который получили эволюционным путем, сохранив всю мощь по пути
Визуально — это медленно, а не быстро, академично, а не эффективно, упрощенно, а не универсально, мышь, а не клавиатура.
Да, визуалов большинство. Но даже им не понравится разглядывать граф исполнения сколь-нибудь сложной программы, считать черточки и не путаться в стрелочках.
От замечательного в своей концепции UML тошнит примерно всех, хоть некоторые по долгу службы и приспосабливаются незаметно сглатывать.
Специализированные средства разработки иногда прекрасны в своей области. Однако программирование неизмеримо шире любой из них, и натягивать конкретную сову на общемировой глобус — занятие неблагодарное.
Визуальный программист отличается от реального как ребенок, лепящий из Лего мафынку от технолога на заводе, который разработал техпроцесс для изготовления пластика деталек той леги.
Побольше бы научпопа про него.
Во-первых, сама концепция: она возникла в конце 70-х — начале 80-х годов, когда перелазить с традиционной электроники на программируемую уже понадобилось, а специалистов еще не было. А традиционные инженеры, особенно сформировавшиеся профессионально в середине -конце 60-х, хорошо воспринимали схемы, но не воспринимали программы. Вот и сделали это.
во-вторых, все эти притянутые за уши Паронджановым «исчисления икон» (несмотря на все «доклады и прочее»). Я не буду ничего криттиковаить — просто почитайте сами, вам этого будет достаточно.
в третьих, «заслуги» Дракона в создании того же Бурана сильно преувеличены. я попытал Паронджанова про использование… «мы нарисовали [на бумаге], и отдали программистам на кодирование». ну, и Дракон-Флокс почти из той же оперы (все переменные глобальны, формальная верификация не предусмотрена и т.п. Т.е. на уровне развития подходов к проограммированию — это 80-е годы прошлого века).
в четвертых, качество генерируемого «продукта» (извините, но кодом это язык не поворачивается назвать. хотя написать нормальный транслятор несложно. но нормальному человеку это не нужно, а авторы и пользователи «дракон-редакторов» не могут. Да, кстати, они делают свои дракон-редакторы без использования дракона.)
в пятых, использование Дракона хотя бы для описания бизнес-процессов (своего рода «русский BPMN»). Если примитивные процессы описать еще можно, то сложные (с передачей между зонами отвественности, и т.п.) — без извратов не получалось. Ну и, естественно, нет программного продукта для моделирования/симуляции.
Ну и самое главное: он метит не меньше чем на «спасителя мира». почитайте его «почему мудрец похож на обезьяну», «почему врачи калечат пациентов» и т.п. — и увидите, что это своего рода «юницкий в сфере программирования».
Читал книжки в меру и давно лишь с целью почерпнуть интересные идеи, которые можно применять сегодня или даже в качестве извращений аналогично Brainfuck. Си языки с их не всегда логичной работой (i++ + i++ и прочие) тоже являются своеобразным Brainfuck. Я молчу про регулярные выражения, которые больше инопланетный язык.
Часть транслятора была написана на ассемблере и поэтому летал он ласточкой.Вопрос: как права доступа к переменным нарисовать в «Драконе»? А никак. «Дракон» — это про алгоритмы. А права доступа — это про данные.
Для повышения надежности в языке ПРОЛ-2 описание нелокальных переменных должно было включать и права доступа в виде списка имен процедур, которым разрешается к этой переменной обращаться.
Так вот, проверочный транслятор выдал большое число сообщений, что идет обращение к переменным без права доступа. Штатный транслятор давно отлажен и многократно проверен. Таких нарушений он бы просто не пропустил. Откуда в проверенных программах взялись сотни ошибок доступа?
Но разбирательство показало, что таки-да, в штатном трансляторе помарка. Вероятно, она проникла в транслятор, когда выяснилось, что ресурсов одной БЦВМ не хватает и приняли решение поставить в «Буране» две машины, разделив ПО между ними. Транслятор подправили для двух ЭВМ, но он перестал проверять доступ переменной из процедуры на соседней БЦВМ. Выключилась одна из проверок.
После выяснения этого даже было совещание. Не столько на тему помарки в трансляторе, сколько на тему технологи разработки. Ведь рассчитывали на что? Что разработчики проанализируют сферу действия каждой переменной и явно и осмысленно укажут множество объектов, которые могут эту переменную читать/писать. А что получилось в реальности? Разработчики чихали на анализ и совали свои модули в транслятор. Ругнулся он по поводу прав — так и быть допишем список, не ругнулся — и так сойдет. В текстах даже нашли издевательские описания нелокальных переменных с пустыми списками, т.е. по правилам языка к ним вообще никто не мог обращаться. И при этом все работало нормально и казалось, что защита от порчи «чужих» данных хорошо обеспечена.
Лично я не считаю допустивших это программистов какими-то балбесами, не соблюдающими элементарные правила. Все силы и внимание уходили на разработку самих алгоритмов, отработку их взаимодействия, парирование нештатных ситуаций и т.п. На правила записи уже не хватало ни внимания, ни желания.
А что, разве при отработке не было случаев, когда один процесс портил переменную другому процессу? Конечно, были. Только во всех этих случаях как раз с доступом все было хорошо.
С тех пор прошло уже десятка три лет. Программирование и теоретически и практически ушло далеко вперед и добилось больших успехов.
Но когда я читаю о новом языке, который «просто не позволит вам написать ошибочную конструкцию», о том, что какая-нибудь инкапсуляция или запрет преобразования типов автоматически сделают вашу программу надежной и правильной и о прочих, ежедневно отливаемых «серебряных пулях», я нет-нет, да и вспомню ту давнюю историю, как иллюстрацию того, что формальные методы борьбы за правильность и надежность чаще всего дают и формальные же результаты.
В такой схеме например принципиально невозможна была бы авария разгонника на союзе — поскольку объект физический и реальный, в модели угол ограничен 360 градусами. И физическое представление тоже ограничивалось бы размерностью и диапазоном аргумента (например при uint16 представлении — преобразование K*360/65536) т.е. на второй круг ничего пойти не может по определению.
По поводу контроля версий тоже всё отлично: используется свой формат, а не xml/json:
object Form3: TForm3
Left = 0
Top = 0
Caption = 'Form3'
ClientHeight = 299
ClientWidth = 635
Color = clBtnFace
Font.Charset = DEFAULT_CHARSET
Font.Color = clWindowText
Font.Height = -11
Font.Name = 'Tahoma'
Font.Style = []
OldCreateOrder = False
PixelsPerInch = 96
TextHeight = 13
object Button1: TButton
Left = 280
Top = 137
Width = 75
Height = 25
Caption = 'Button1'
TabOrder = 0
end
endВот там как раз можно было «визуально» наваять приложение работающее с БД.
Причем было несколько шаблонов приложения, которые генерировались на основании структуры БД.
Когда работал с Delphi было ощущение «WTF?», все надо делать вручную :-)
(а сейчас там всё уже нормально)
Как и у многих «визуальных IDE», которые обычный блок с подсветкой синтаксиса и некоторыми базовыми настройками под конкретный язык. Все тот же текст, все тот же хардкор.
В одной мобильной игре было задание: «Напечатайте Название игры». Правильный ответ: «Название игры» (т.е. не надо было вспоминать, как называется игра, а просто набрать текст ответа посимвольно, который в кавычках, регистр неважен)
Но, поскольку внутрь DFM файлов всё равно никто не заглядывает (есть же визуальный редактор), новые версии Delphi/Lazarus мигрируют на XML.
но вопрос-то был в принципиальных отличиях, например,
Caption = 'Form3'
от
<_Caption>Form3</_Caption>
Да, xml многословнее… но опять же — текстовое (декларативное) описание графического элемента…
впрочем, еще до dfm в том же Clipper'е были конструкции типа
@ nRow, nCol PROMPT «QUIT» MESSAGE «RETURN TO DOS»
которые прекрасно выносились в отдельный «файл интерфейса»
2) Даже если при разработке не лазить руками в DFM файлы, при использовании контроля версий текстовой формат очень кстати.

вот dpr:
Кроме того, есть другие инструменты сравнения.
кроме того, вы можете опять же иметь схему для верификации xml. Ну и любой стандарт лучше, чем нестандарт.
Хотя сам я xml не люблю — «советское воспитание», когда занятые лишние сотни байт на диске считались почти что хищением социалистической собственности…
>с традиционным программированием что-то не так.
Ну, в каком-то смысле. Что вас удивляет? Традиционное программирование — оно неоднородно.
По сути только ФП основано на математических принципах, и к нему в итоге применимы как раз достаточно формальные методики, и иногда удается добиться того, что если продукт скомпилировался — то он работает. Но есть большая часть традиционного же программирования, включая скажем C++, где формальная верификация практически невозможна.
>систем из кубиков с взаимосвязями
Дайте угадаю? Из кубиков можно построить как ациклический граф (дерево), так и произвольный. По взаимосвязям можно передавать либо простой сигнал (0 или 1), так и произвольные структуры данных (в случае например BPMN). И это все в итоге очень разные вещи получаются. Обычное программирование, в его самом общем виде, оно местами просто сложнее, чем тот класс задач, который хорошо удается описывать в виде кубиков и связей.
Ну вот простой вопрос — связь передает от кубика к кубику какие-то данные. Какие? Какова их структура? Как вы их описываете (в терминах кубиков?). Как только встают подобные вопросы — так кубиков и стрелочек быстро становится недостаточно.
>Зачем описывать данные в терминах кубиков? Данные можно описать таблицей, например.
Ну, ок. Не вопрос. Я так понимаю, вы агитируете за визуальное программирование. Можете показать, как чисто визуально сделать простую вещь — выполнить REST (для определенности пусть будет POST и JSON body) запрос к какому-либо сервису, получить ответ в виде JSON, и распарсить его, попутно проверив на соответствие некой схеме? Зоть кубиками, хоть таблицами — но чтобы чисто визуально.
>математические формулы, для которых есть свой язык
Ну видите, вы согласны, что для формул свой язык. А я об этом с самого начала и толкую — что в большинстве так называемых «визуальных» средств НЕ удается обойтись без еще одного языка, причем хорошо если только одного. Что как только дело доходит до взаимодействия с чем-то еще (а оно доходит рано или поздно), так этот второй и третий язык становится абсолютно обязательным. И обходятся без этого только те применения, где нет этого взаимодействия, где есть некоторая замкнутая среда. Вполне возможно, что авиация и промышленная автоматизация — как раз из этой области.
в остальном — нарисовать некую фигуру с входящей стрелкой и двумя выходящими, и вписать туда текстовое условие — занимает больше времени, нежели написать «если-то-иначе» текстом. на экране это занимает больше места. «сворачиваются» графические ветки тоже хреновато.
то же самое относится и к описанию данных.
Как вы понимаете, можно и математические формулы записывать «визуально» — дерево для выражения вполне адекватное представление. Но попробуйте ответить, почему так почти никто их не пишет? На мой взгляд, по очень простой причине — так элементарно неудобно.
И да, к преимуществам текстового программирования я вообще-то отношу совсем другое. То что формулы встроены в большинство языков — это частность. Во многие языки еще и SQL встроен, или скажем XML с JSON. То есть, любое текстовое представление для чего угодно можно встроить в текстовый в основе язык. В этом смысле любая визуальная среда как раз оказывается замкнутой внутри себя — и это не очень хорошо.
Можете показать, как чисто визуально сделать простую вещь — выполнить REST (для определенности пусть будет POST и JSON body) запрос к какому-либо сервису, получить ответ в виде JSON, и распарсить его, попутно проверив на соответствие некой схеме? Зоть кубиками, хоть таблицами — но чтобы чисто визуально.
По моей прикидке визуально это будет автомат состояний, пара таблиц истинности и функция — парсер.
Вы приведите текст программы, если можно.
Текст того, как бы вы написали эти действия на удобном вам языке программирования.
println new JsonSlurper().parse(
new URL(«maps.googleapis.com/maps/api/geocode/json?latlng=?lat=${y},${x}»)
).formatted_address
Но это зависит от того, какие именно «эти» действия. Про это я и спрашивал.
maps.googleapis.com/maps/api/geocode/json?latlng=?вот тут координаты через запятую
Реальный парсер будет содержать что-то подобное реальной структуре JSON документа, а она сложнее, чем просто адрес. И тут на мой взгляд проблема в том, что в визуальном виде это удобно смотреть, но очень неудобно писать. Во-первых, не очень компактно (мягко говоря), во-вторых, это совершенно не поддается рефакторингу, в отличие от текста, в третьих, обычно очень плохо с поиском, автодополнением (и вообще навигацией) по такому виду кода.
Я не исключаю, что все эти проблемы можно решить — но мне ни одно такое решение не попадалось.
которые работают получше «этих ваших» Windows/Linux.А они точно «работают лучше»? Ну там, обрабатывают десятки тысяч сообщений в секунду, запускают тысячи потоков, рендерят 3D и т.д. и т.п.?
Или они делают что-то, что гораздо проще, на несколько порядков проще, чем задачи, которые решают «эти наши» Windows/Linux?
Ну так я вас разочарую: если задачи у вас на несколько порядков проще, чем в любой 3D игрушке — то вы можете и на текстовом языке всё прекрасно смоделировать и формально верифицировать.
А причина — уже приводилась выше: их использование позволяет «привлечь к делу» людей, которые схему обучены читать — а вот писать программы не хотят и не умеют. Вымрут динозавры — и эпоха завершится.
Тут, скорее, вопрос, в другом: что не так с обычным программированием, что к нему не подходят обычные способы проектирования систем из кубиков с взаимосвязями, которые широко применяются почти во всех областях техники?Очень просто: в каком-нибудь Боинге количество разных видов деталей — несколько десятков тысяч. В вашем смартфоне отдельных процедур — несколько миллионов (недавно как раз запускал Vulkan CTS… 285 388 тестов — и это только один компонент, хотя и довольно сложный). Проектирование самолёта — занимает лет 10, написание операционки для сматрфона — года 2-3… вот и всё.
На Земле просто нет достаточного количества конструкторов, чтобы писать код «обычными способами проектирования систем из кубиков» — а даже если кто-нибудь и смог создать мега-корпорацию с десятью миллионами конструкторов, то разработка занаяли бы столетия… потому приходится придумывать что-то и обходиться без формальной верификации, да…
и «все эти data-flow диаграммы» — всего лишь другое отображение формул. Для тех, кому проще работать с таким методом отображения.
во времена фортранов и алголов комптютеры были «однопоточными». современные — многопоточные. и как бы вы красиво не описывали в блок-схемах параллельное выполнение — оно может быть параллельным только в некоторых пределах, определяемых «железом»…
Поэтому в них и им подобных современных языках есть понятие и семантика вызова функции и последовательного выполнения, но семантика параллельного выполнения или событий эмулируется через те же вызовы функций.Нет, не поэтому. А потому что процессоры исполняют операции последовательно.
В Verilog, который тоже вполне себе текстовый, всё происходит параллельно.
В блок-схемах и текстовых языках, которые их описывают, блоки существуют параллельно и всегда реагируют на входные значенияСовершенно верно. А поскольку современные CPU (в отличие от FPGA, скажем) так не умеют, то всё это приходится эмулировать — с изрядной потерей эффективности.
в императивных языках это всё реализуется через циклы, потоки и прочие сложности, которые конфликтуют с изначально заложенными концепциями последовательного исполнения и состояния.Так SCADE или интерпретатору FBD приходится делать то же самое — причём они делают это куда менее эффективно.
И тем не менее они применяют гораздо более продвинутые инструменты и методики типа той же формальной верификацииНепонятно почему вы считаете интрументы и методики, которые могут решить меньше задач и с гораздо большими затратами считаете более продвинутыми.
Более надёжными? Да, наверное? Но и более ограниченными…
Графическое представление позволяет человеку оценить некий предмет гораздо быстрее. но для точного определения все равно потребуются текстовые описания.
именно поэтому для проектирования «в целом», на уровне взаимосвязей подсистем — графические представления применимы. а на уровне детального описания — они громоздки.
Посыл статьи в том, что графическое описание программ — фигня, потому что на нём плохо описываются любимые автором паттерны ООП и прочие традиционные подходы, при этом у автора не возникает мысли, что эти традиционные подходы, возможно, не самый лучший способ программирования.А какой ещё способ программирования вы знаете? Тот же самый SCADE, вокруг которого вы подняли столько шума — это всего-навсего графическая оболочка для тех, кто не освоил Lustra. А построен он поверх, вы не поверите, нифига не верифецированных C++ и/или Ada.
Там, куда индустрия движется, вполне обосновано применение графических описаний в том числеС этим я как раз согласен: в тех местах, где вы не можете найти нужных специалистов, могущих написать программу, а сама задача не очень сложна — графическое описание может быть уместно.
Но они ни в коем случае не может выступать как что-то самостоятельное. Так, в частности, мне не известна ни одна среда графического программирования, которая сама была бы написана на подобном же языке — это всегда такая маленькая примочечка сверху над кучей года, написанного традицонным способом. Ни одного исключения мне неизвестно.
Я так понимаю — в случае со SCADE он и написан и кодогенерирует. Второе, впрочем, не критично, можно тот же LLVM просто в среду влинковать.А построен он поверх, вы не поверите, нифига не верифецированных C++ и/или Ada«Поверх» — это в смысле «написан на них»? Или в смысле «поддерживает кодогенерацию в [верифицируемое подмножество] C++ и/или Ada»?
А вот так, чтобы подобное писалось без ООП — такого я не знаю.
Который может написать программу вместо того, чтобы тратить время на создание спецификаций.где вы не можете найти нужных специалистов, могущих написать программуА «нужный специалист» — это какой? Который перенесёт спецификацию в программный код быстрее, чем это сделает SCADE или Simulink?
То есть если у вас спецификация — неотъемлемая часть рабочего процесса (из-за требований сертификации или по иной причине), ничего страшного в графических примочках нет.
Вот только далеко не всегда люди могут себе позволить роскошь написания спецификации.
Вы слишком фиксируетесь на «графический vs. текстовый язык», это всё — разные способы представления одного и того же.Нет. Об этом и статья. Всё, что может быть выражено графически — можно записать и в текстовом виде. Кому что удобнее — это другой вопрос.
Однако не всё, что можно записать в виде текста, можно изобразить в виде обозримых графиков.
Java, как и многие современные языки, написана на C++, кодогенерирует в JIT, потом в ASM. Что это доказывает?Java-компилятор и среда таки написаны на Java. А что JIT написано на C++ — это показатель того, что да, Java хуже подходит для написания низкоуровневого кода.
Однако чисто теоретически написать JVM как Java class, выплёвыващий готовый JIT — я могу (ничем принципиально от Go не будет отличаться).
Когда-то ООП тоже было игрушкой для симуляции, не прошло и 30 лет — как получило широкое распространение.Не совсем так. Все «большие» операционки всегда пишутся с использованеим ООП. Даже MS-DOS начиная с версии 2.0.
Просто не всегда это делается на ООП-языках.
Если проект посерьёзнее и у вас один человек — ему просто придётся и писать спецификацию, и программировать.У нас проекты несколько посерьёзнее, мой сосед работает над одним из них — им миллиард человек пользуется. И никакой спецификации там нет. Есть отдельные документы описывающие как те или иные вещи должны быть изменены — но это не спецификация.
Если спецификация формально не описана — это не значит, что её вообще нет.Ну если рассматривать код в качестве специкации, тогда, наверное, да.
Поэтому хорошо бы, чтобы спецификация автоматически преобразовывалась в код и документацию.Далеко не всегда это возможно и не факт, что это приведёт к лучшему коду и к лучшей документации.
Например всё ту же SCADE. Почему она написана на ООП-языке?
MS-DOS написана с инкапсуляцией, полиморфизмом и наследованием?
А они-то тут причём? Может хватит тиражировать идиотизм, что ООП это про них?
Если у операционки есть драйвера (а если операционка не заточена строго под фиксированное железо без этого не обойтись), то у них будет абстрактный интерфейс и реализация, вся логика будет в них инкапсулирована и так далее.
Только учтите, что контекст — процедурное написание в однонитевой среде (соответственно, ООП стиля «рыбы в аквариуме», как в Simula и Smalltalk, не годится).
А про что тогда?
Побуду Капитаном Очевидность: про объекты, которые имеют внутреннее состояние и внешний интерфейс. Наследование и полиморфизм — штука полезная, но не обязательная — встречались языки без наследования и практически без полиморфизма (не считать же таковым позднее связывание?), приходилось крутиться.
Без инкапсуляции ООП, пожалуй, не выйдет, — она древнее.
MS-DOS написана с инкапсуляцией, полиморфизмом и наследованием?Именно так. Абстрактное устройство «диск» может иметь много реализаций: сетевой диск, электронный диск, CD-ROM и так далее.
Там у вас «классика жанра»: интерфейс, реализация и всё в этом духе. И в любой ОС, умеющей работать с железом, которого нет в момент её создания так же будет.
Наверное потому, что ООП подходит для создания пользовательского интерфейса также, как C++ — для создания JVM?Тогда что это за «более передовые методы», которые, оказывается, простых вещей не позволяют сделать?
1. MS-DOS сложно отнести к «большим» операционкам.
2. На самом деле, таки да. Потому что когда вы зовёте write (через какой-то вариант int 21h с конкретным AH) у конкретного хэндла, это инкапсуляция, потому что вам недоступны внутренние структуры напрямую, лишь через хэндл, и полиморфизм, потому что вы зовёте его универсально для файла на локальном диске, файла по SMB и вывода на экран.
Наследование, да, в этих реализациях обычно не присутствует, или очень урезанно. Но остальные два компонента есть в полный рост.
И это никак не «сову на глобус». Хотя именно у MS-DOS это слегка сбоку от основной логики (позаимствовали механизм из Unix, хоть и заметно испортили).
В B787 Dreamliner — 2.3 миллиона деталей, например. Это самолёт средних размеров.А в процессоре какого-нибудь iPhone — 10 миллиардов транзисторов. А там же ещё и память есть! Там их может и под триллион быть…
Но это как раз неважно. Номенклатура того же Боига — это таки десятки тысяч деталей, а не миллионы. А во флеш-памяти все транзисторы почти одинаковы, так что несмотря на их безумное количество она проще, чем процессор.
А вот отдельных процедур в операционке — миллионы. Более того — их были сотни тысяч уже в 90е. Иначе не поставлялся бы софт на 20-30-40 дискетах — это было для производителей довольно-таки накладно.
Вот софт начала 80х — тот сравним по сложности с самолётами… ну так он и умел много меньше…
Это только в вашем воспалённом воображении их разводят в графическом виде. В реальном мире существует Verilog и прочие разные HDL — такие же текстовые, как и языки программирования (хотя и со своими особенностями).А в процессоре какого-нибудь iPhone — 10 миллиардов транзисторовКоторые разводят в графическом виде.
В ядре Linux — около 400 системных вызовов.Вот только за многими из них стоят тысячи операций. Или вы хотите сравнить сложноть болтика или какого-нибудь элерона с каким-нибудь clone с десятком видов неймспейсов?
А когда хотят объяснить, как это всё работает — рисуют диаграммы на системном уровне — каких, например, много в документации Apple.Вот только все эти диаграммы, как правило, оказываются весьма и весьма упрощённым описанием реальности. Потому что если все детали в неё засунуть — её понять будет нельзя. И опять-таки, для clone вы получите несколько дюжин диаграмм — на каждый флаг плюс на некоторые «интересные» сочетания. Но чтобы понять всё до конца — всё равно придётся смотреть в исходники.
В реальном мире существует Verilog и прочие разные HDL — такие же текстовые, как и языки программирования (хотя и со своими особенностями).— более того, у них есть возможности верификации. В отличие от «графического вида»
Лабвью — неплохая система. но писана почему-то на «завещаных» методиках, но не на себе, новомодной…
Java написана на C++, а не на JavaКомпилятор Java написан-таки на C++.
Вывод — С++ единственный нужный язык программирования?:)Нет. Go написан на Go и C++ не требует. Тоже самое с FPC.
И даже Java-машину можно написать на ассемблере и в комплекте с Java компилятором — это будет рабочая система.
При этом все используют как минимум один графический язык для описания интерфейса...Называть «языком» пассивный XML, гда написано какие кнолпочки где находятся — как-то странно.
Впрочем при желании всё те же самые кнопочки можно и вызовами функций создать, XML тут необязателен.
второй вывод — все Джавы/Джаваскрипты/Питоны — это надстройка для того, чтоб не писать на С++. Можно рассматривать как библиотеку, можно как кросс-компилятор. Этакое «средство для упрощения жизни». Утрированно, конечно.
Ну и xml, как вам справедливо заметили ниже — ничуть не графический язык, а совершенно текстовый. То, что описанное на нем можно представлять в т.ч. и в графическом виде — не делает его графическим.
И даже промежуточное представление
ну вот это промежуточное представление и является языком, который «описывает кнопки и меню».
Реализовано ли оно в виде , class Button или @nCol, nRow Say — уже не важно. Важно, что оно точнее, им можно манипулировать, его можно создать без графического представления на этапе создания.
Это следует из?...
Из того, что мышкой работать труднее и медленнее, чем пальцами.
Я думаю не случайно Boeing и Airbus пришли к SCADE.Они пришли к SCADE потому что им нужно решать простые задачи максимально надёжным образом.
Для них — это нормально. Среда, в которой «работает» самолёт — крайне проста (на самом деле нет, но все эти системы, созданные на SCADE, как раз сложные ситуации типа «мы попали в крайвой вихрь от A380» обрабатывают), а цена ошибки — очень высока.
В этой ситуации наглядные графические средства — могут иметь смысл.
Похожая ситуация также с АЭС (там тоже сложных ситуаций, где нужна мгновенная реакция на сложные исходные данные просто избегают) и некоторыми другими вещами.
А вот уже для самоуправляемых автомобилей — нет, потому как вся конструкция гораздо сложнее и в графические среды «не лезет».
Нет. Вот если бы машинный код его рантайма генерировался кодом на C#, вплоть до выходных бинарников — это было бы правда.
Сейчас это только полуправда — компилятор IL работает на C#, но дальше включается нижний уровень.
То же для Delphi.
> значит серьёзные, высокопроизводительные проекты на них нельзя написать
Ничего не значит. Реализация на себе же — достаточный, но не необходимый признак, причём _полноты_ реализации, а никак не высокопроизводительности, и тем более не какой-то неконкретной «серьёзности».
Рекомендую прекратить откровенные подтасовки, не получится.
> Python написан опять на C++, а не на Python
PyPy, к слову, существует давно и достиг вполне промышленного качества. Он не имеет собственный бутстрап вплоть до генерации бинарников, но такая задача и не ставилась.
Нет. Вот если бы машинный код его рантайма генерировался кодом на C#, вплоть до выходных бинарников — это было бы правда.
Почему вы так считаете? C# преобразуется в IL, IL преобразуется в машинный код, машинный код интерпретируется процессором переводя его в микрокод.
Почему "C# написан на С#" должно обозначать что-то кроме первой фазы?
см, кстати, статейку про то, какие усилия идут в этом направлении, но это не будет "C# на C#", это будет "IL на C#".
Delphi написан на Delphi.
IDE некоторых версий — возможно.
Компилятор написан точно на C.
Но все же паскаль использовался для написания компиляторов.
На объектном паскале написан компилятор FPC.
IDE некоторых версий — возможно.Насколько я знаю все Delphi IDE написаны на Delphi. Правда, в новых средах кода Delphi там не 100%.
Lazarus/FPC написан полностью на pascal. Компиляторы, среда. Среда, к слову, работает, в отличие от Delphi прямо по месту — Линукс, МакОС, Распбери. Работает почти на любом железе и операционках.
На самом деле это в чистом виде проблема бутстраппинга компилятора, а не самого языка. Сделать реализацию рантайма в машинном коде, который дальше запустит основной движок, который будет в состоянии компилировать и исполнять код на таком же языке — концептуально тривиально, и есть практические примеры перед глазами — Go создаёт свои бинарники сам, компилятор написан на том же Go, в Erlang часть сборки выполняется готовым кодом на Erlang. В случае managed языков (Java, Javascript...) потребуется прослойка unsafe-управления памятью, но она опять же может быть скомпилирована кодом на этом же языке.
Мешает этому лишь то, что аналогичная среда на C/C++ уже давно сделана, вылизана в деталях и мало кому хочется повторять этот путь и дублировать усилия.
И для графического языка было бы то же самое. Но — это значит, что он должен быть таким, чтобы уметь описать всё вплоть до команд ассемблера какого-нибудь аналога crt1.o (то, что в Unix подходе стартует первым в запущенном процессе и готовит среду для libc и main(), настраивая стек, формируя параметры argc/argv, и так далее). И к обычной сложности (не уровневой, а просто множества сущностей) добавляется ещё один очень специфический слой, потребность в котором у 0.0001% юзеров, а работы — много. Поэтому всем обычно облом, и используют C как базу.
А вот как берёшь Дракон, LabView, SCADE и прочее — так почему-то выясняется что нужен C++, Java или C#, но никак не Дракон, LabView или SCADE.
Это ни в коем случае не значит, то это плохие и бессмысленные вещи. Всего лишь значит, что они — не универсальные, вот и всё.
но на высоком уровне граф понятнее, чем страница текста
Граф, который понятен — эквивалентен максимум десятку строчек текста.
Кстати, в матричном виде ошибки вычисляются очень легко.
А теперь к вам встречное предложение — нарисуйте в графическом редакторе схему усилителя, и постройте его АЧХ.
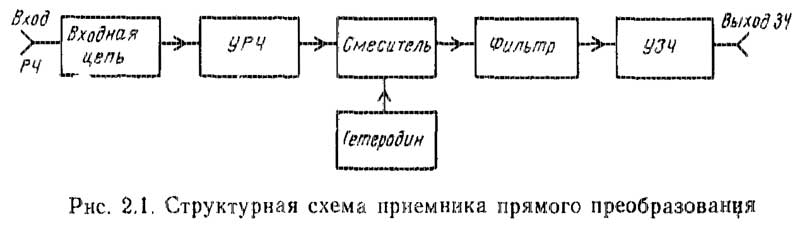
потом детализироовал каждый блок.
Есть языки для обработки данных. В случае радиоприемника — это технологические карты для его производства. На С++ можно описать последовательность инструкций для изготовления радиоприемника?
Вымрут динозавры — и эпоха завершится.
Мечты… мечты…
Один-два полномасштабных кризиса уровня «Великой Депрессии» — и динозавры вымрут.
Но это не так. Они, ДРАКОН, IBM Rational Real-time и т.п., ориентированны на весьма квалифицированых программистов, в частности, требуют владения C/C++/Python в совершенстве.
У них фишки совсем в ином. Задачи управления механикой, пилотирования и пр. в реальном времени формулирутся, верифицируются и тестируются в концепции конечных автоматов, функций управления, с одной стороны. Да и подход к повторному использованию кода там существенно отличается, с другой стороны.
Вот это IMHO уже слишком. Нет такого слова. Даже в жаргоне. Чем вас не устраивает «уменьшение связности» которое вы же и привели? Вполне устоявшийся и понятный термин.
Это обычный текстовый язык, но с какими то рамочками вокруг каждого слова.
Streambase уже уже упоминали?
Драконисты очень сильно нахваливают возможности своего дракона. но пишут свои поделки почему-то не на драконе
Это не так.
Степан Митькин (Норвегия, город Колсас Kolsås) разработал свой дракон-конструктор, используя язык ДРАКОН.
sourceforge.net/projects/drakon-editor/files
drakonhub.com
С уважением,
Владимир Данилович Паронджанов
Mobile: +7-916-111-91-57
Viber: +7-916-111-91-57
E-mail: vdp2007@bk.ru
Skype: vdp2007@bk.ru
Website: drakon.su
Webforum: forum.drakon.su
Человек мыслит образами, и визуальные языки — это попытка приблизить программирование к образному мышлению, это следующий эволюционный шаг, как в свое время языки высокого уровня были попыткой приблизить программирование к человеческому языку или к формальному языку.
Человек мыслит образами
А наиболее абстрактный образ — это слово.
Человек либо хорошо излагает свои мысли словами, и тогда ему не трудно описать их на любом языке, либо сам не понимает чего хочет, и тогда от его образов никакого толку.
на языке ДРАКОН можно делать лишь «поделки», «что называется, упаси господи»
Это не так. На визуальном языке ДРАКОН делаются серьезные вещи.
Вот две статьи, где говорится про применение языка ДРАКОН в серьезных космических проектах:
1. Морозов В. В., Трунов Ю. В., Комиссаров А. И., Пак Е. А., Жучков А. Г., Дишель В.Д, Залихина Е. Е., Паронджанов В. Д. Система управления межорбитального космического буксира «Фрегат» \ Вестник ФГУП «НПО им. С. А. Лавочкина», 2014, № 1. — С. 16-25.
bit.ly/2RtCdaU
2. Паронджанов В.Д. Визуальный алгоритмический язык ДРАКОН в ракетной технике и
медицине // Современные автоматизированные системы управления реального
времени как прикладное развитие научных достижений кибернетики» (К 100-летию со
дня рождения И.А. Полетаева). Материалы межведомственной конференции 24
марта 2016 г. — ФГБУ «3 ЦНИИ» Минобороны РФ, 2016. — 218 с. — С. 57-78.
bit.ly/2BDhYCB
Вот еще одна статья, где речь идет о применении языка ДРАКОН в Немецком космическом агентстве (German Aerospace Agency).
Marc Schwarzbach, Sven Wlach, Maximilian Laiacker. Modifying a Scientific Flight Control System for Balloon Launched UAV Missions // German Aerospace Center DLR // IEEE, 2015.
drakon.su/_media/ballon_ap_final.pdf
вообще, лучше всего знакомиться именно с проектами, ссылки на которые регулярно дают Паронджанов или Тышов. это как раз из принципа «с такими друзьями и враги не нужны».
ну, можете еще ознакомиться с системой Графит-Флокс. Видимо, из-за ее наличия в Лавочкине — «у буржуев» Куриосити на Марсе, а «у нас» Фобос-В-Грунт…
«Так что сейчас мы живем в мире 16-символьных идентификаторов. Из которых первые шесть символов отводятся на префикс. Префикс состоит из 5-символьного классификатора и эргономичного разделителя (точки). Точка-разделитель находится в 6-й позиции.
Вопрос. Что отсюда следует?
Ответ. На смысловую часть (то есть на описание ФИЗИКИ ОБЪЕКТА) остается всего 10 символов (16 — 6 = 10).
10 символов — это очень мало. Если бы идентификатор был 24-символьным, то смысловую часть пришлось бы 18 символов. 18 символов — почти вдвое больше чем 10. Но сегодня это только мечты.
Сегодня мы живем в трудных условиях. Приходится вводить режим жестокой экономии символов. Приходится ногами утаптывать СМЫСЛОВУЮ ЧАСТЬ (символы 7—16), чтобы поместить ее в узкое горлышко из 10 символов. Это очень трудно.»
© Паронджанов. О Графит-Флоксе.
добро пожаловать в волшебный мир ДРАКОНа…
зы. обсуждается «КС1УФ.ОТКЛЮЧИТЬ.ФИДЕР.УМ1»©
Вы повторяете недостоверные сведения (анекдоты), которые не имеют отношения к действительности и серьезной работе. Инженеры разрабатывают на языке ДРАКОН по методу " программирование без программистов" исходный код программы (а не картинки, как вы предположили). Прочитайте статьи, на которые я дал ссылки. После этого многие вопросы отпадут.
Вы правы, получаемая модель памяти загружается в БЦВМ (и НЦВМ) Бисер.
Именно для этого и служит дракон-технология в Роскосмосе.
Если же вы хотите работать не с Бисером, а с другим компьютером или контроллером,
надо использовать технологию Степана Митькина, как это делают в Немецком космическом агентстве (см. ссылку, которую я дал). Или технологию Геннадия Тышова. Или разработайте свою собственную.
надо использовать технологию Степана Митькина, как это делают в Немецком космическом агентстве (см. ссылку, которую я дал). Или технологию Геннадия Тышова. Или разработайте свою собственную.
Увы это будет «велосипед». Я не могу с специально обученными людьми соревноваться.

«Программирование без программистов» появилось очень давно — с появлением языка Фортран, идеей которого было дать математикам возможность общаться с машиной «без этих ваших программистов, которые бубнят об адресах и переходах». Только очень быстро оказалось, что составление инструкций на Фортране — это тоже программирование. У вас — программирование на ДРАКОНе, суть та же — есть специальное знание, которым надо овладеть. Поэтому «создание программ без программиста» в этом контексте — это утопия.
Приведенные статьи не дают обзора принимаемых при создании языка решений, нет сравнения с другими инструментальными средами при решении тех же задач.
Программирование — сложно, software engineering — ещё сложнее.
А транслятор во что нибудь кроме «бисера» (что обычный человек может руками пощупать) с него есть
Да, есть.
Посмотрите четыре видеоролика Сергея Ефанова (общая длительность 1 час).
Вот ссылка на 1-й видеоролик
Видео. Использование языка ДРАКОН для программирования микроконтроллеров. Часть 1. Разработка программы управления автоматическим дверным замком.
www.youtube.com/watch?v=Ua9dUUONjdk&feature=youtu.be
Если вам это интересно, я могу прислать вам книги по языку ДРАКОН
Чтоб все поняли, для «программистов» какого уровня необходим ваш ДРАКОН.
В чем-то лучше (проще мышкой соединить несколько блоков, чем писать многие строчки кода), в чем-то хуже (в системы контроля версий плохо кладется, всё равно не всё обозреть получается). Но вполне нормальный подход, который в некоторых случаях имеет право на жизнь.
Программирование под ПЛИС вообще неплохо поддается визуализации, так как там все также и работает, как мы представляем себе визуально — линия связи между блоками так и реализуется, как линия связи. Сигналы остаются сигналами. Все блоки работают параллельно и т.д.
Это ведь и немудрено — ПЛИС задумывались как замена железу, а железо изначально описывалось схемами, а не текстом. Это потом уже придумали VHDL, Verilog и т.д.
Поэтому в том же Vivado ихний Block Design был воспринят весьма положительно — намного визуальней отслеживать связи между блоками в виде линий, а не текста. Ну и возможности совершить ошибку стало гораздо меньше.
Вывод: графическое представление проще для понимания, но годится только для мелких несложных проектов. Для больших и сложных проектов лучше текст.
Как уже писали визуальное программирование понижает порог… Порог вхождения во что? Да ни во что, оно просто позволяет человеку сделать так, чтобы компьютер выполнил то, что он хочет, с наименьшими усилиями.
Вопрос — кто этот человек? Ребенок? Ученый? Менеджер? Электрик/Электронщик? Домохозяйка? Трудно сказать. Но что я знаю точно — это точно не программист. И поэтому оценивать значимость и преимущества визуального программирования программистам не стоит.
А теперь по поводу кто динозавр в этом мире.
Так вот предположим, что тот самый ученый, менеджер, электронщик и домохозяйка хотят сделать так, чтобы компьютер сделал то, что им надо. Без визуального программирования у них есть два варианта — выучить язык программирования и самим сделаться программистами(что им нафиг не надо, так как у них своих проблем достаточно), либо описать задачу знакомому программисту и попросить его запрограммировать ее в компьютер для них. Но тут мы сталкиваемся с классической проблемой — само по себе такое описание, это уже полно работы, причем часто это не текст, а диаграммы состояний, блок-схемы, формулы, стрелочки связей и прочее. Иначе программист не поймет и программа будет делать совсем не то, что надо человеку, а то, что понял программист.
И тут воаля — появилось решение — визуальное программирование! Вместо того, чтобы описывать задачу программисту, ученый, менеджер, домохозяйка, ребенок, могут описать ее сразу машине, причем в той форме, в какой они сами ее понимают и машина ее выполнит! Понимаете прикол? Программист исключен! Как и исключен порядок взаимодействия — ученый, менеджер, домохозяйка -> программист -> машина, на каждом этапе которого могут появиться ошибки! А еще у нас появляется одна единственная точка правды — исходное, одновременно и машино- и человекочитаемое описание работы (в простонародье — модель), и нет никаких разногласий между ней и исходным кодом. И эту модель может прочитать не-программист и внести в нее изменения, если нужно.
Насчет того, что это годится только для описания простых процессов — это все запугивания и непонимание. У меня в работе есть модель, которая генерит примерно 200 тысяч исходных строк Си-кода. Причем это очень оптимизированный код. А разрабатывает ее один кандидат наук — специалист по автоматической теории управления плюс один специалист по силовой электронике. То, что у них в этом тандеме выходит, не осилила бы команда даже из 10 программистов, хотя они ни Си, ни микроконтроллеры вообще не знают
Если вы их не видите, это не значит, что их нет. Просто их в этом случае надо меньше, чем обычно и работают они эффективнее, так как их идеи идут сразу в код.
Насчет того, что визуальное программирование не используют в продакшене — вы сильно ошибаетесь. Вопрос в том, что визуальное программирование нужно в первую очередь там, где программисты являются связующим звеном между изобретателем, ученым или инженером и компьютером.
А там, где программисты сами придумывают новые вещи, оно не приживется, так как для них это костыли. Поэтому и вряд ли вы увидите это в IoT или на серверах, например.
Хотя тойота отсталая… не удивлюсь если до сих пор все руками пишут…
Как насчет того, что тойота ЭБУ не производит — их Denso делает.
Денсо конечно игрок крупный, у меня нет достоверной информации по использованию ими MBD. Но если сложить Бош (с асцетом) и всех его лицензиатов и Континенталь-Сименс (с симулинком) и всех его лицензиатов — то это уже доля 2/3 рынка мира. Даже если предположить что Денсо там все руками пишет (что вряд ли) — технология MBD уже победила — и рыночек порешал.
Хотя я уверен что и denso MBD использует после тойотовских скандалов — японцы конечно тупые но отстают не далее 10-ти лет. А технология повсеместно используется уже 20лет.
К тому же тойота разная бывает — вся европейская тойота=бош. китайская=бош… денсо с их отсталостью это лишь американская и японская тойоты…
В том то и дело, что это реально в первую очередь инженерные либо научные вещи. Что IoT (это по сути дела следущее поколение АСУ ТП + аналитика), что сотовая связь (радио и телекоммуникации), что автопилоты (и автомобилестроение), что медицинские приборы. Поэтому, если следовать вашим словам, там оно должно использоваться в первую очередь и вообще на каждом шагу.
Нет, в первую очередь это те вещи, которые поддаются моделированию. Вот вы пробовали, например что-то промоделировать на компьютере? Например электрическую цепь, деталь или конструкцию в 3D, какой-нибудь алгоритм или функцию? Если да, то вы знаете, что для получения желаемого результата вам придется ее описать в определенном виде, чтобы компьютер понял, что вы от него хотите. И этим и занимаются ученые, математики и инженеры.
Вот тут народ и смякитил — раз задача уже описана в том виде, в котором ее понимает машина — почему бы не сделать из нее исполняемый код? Да, не слишком эффективный, но тем не менее вполне рабочий — вот вам и появилось визуальное программирование.
Просто я за свою профессиональную карьеру имел отношение к перечисленным выше вещам, либо близко знаком с людьми, которые этим занимаются. И графическими языками там даже близко вообще не пахло.
Собственно тут и ответ — если они не занимались моделированием, то естественно графических языков там тоже не будет. Те же космические и самолетные отрасли без моделирования сегодня никак — поэтому там этого полно. В автомобилестроении моделирование тоже важно из-за требований верификации — поэтому там тоже есть. Энергосистемы тоже моделируют.
Только вот какая странность: инженеры-схемотехники не катят бочки на инженеров низкого уровня которые разрабатывают эти самые микросхемы. А вот приверженцы "графического программирования" почему-то это делают.
А вот приверженцы "графического программирования" почему-то это делают.
Откуда вы это взяли?
так уж ли эти традиционные методики хороши? Может быть это «традиционные программисты», которые до сих пор кодят на вариантах Алгола и Фортрана, застряли в каменном веке?
Вы можете понять это как-то иначе?
И это в то время, как к традиционным методикам вопросов, на самом деле, немало.К современным методикам вопросы есть, но когда нам в качестве «супердостижения» преподносят некоторый аналог структурного программирования (основное достоинство ДРАКОНа) и говорят, что они, тем самым «опередили всех»… непонятно — то ли смеяться, то ли плакать.
Комменты под статьёй про «вымрут динозавры» не сильно лучше.Это простое применения принципа Планка: Не следует думать, что новые идеи побеждают путем острых дискуссий, в которых создатели нового переубеждают своих оппонентов. Старые идеи уступают новым таким образом, что носители старого умирают, а новое поколение воспитывается в новых идеях, воспринимая их как нечто само собой разумеющееся.
Вся эта возня вокруг визуальных языков и прочего существует только и исключительно из-за того, что сегодня носителями знаний в разных областях являются люди, которых, в своё время, учили рисовать чертежи, а не программировать на Бейске.
Массовое появление школьных компьютеров и соотвествующее обучение — это 90е. Соременные школы чертить на ватмане не учат, а программировать — таки учат (пусть не очень хорошо и формально, но учат). То есть лет ещё 20-30 мы будем вот-это-вот-всё наблюдать. Потом всё — вопросы использования «графических сред для программирования без программирования» будет закрыт.
Ну в моей области действительно были т.н. кодеры, целый отдел — им приносишь до ужаса разжеванную спецификацию софта, и они согласно ей пишут и отлаживают программу. А потом они все садились вместе с теми, кто писал спецификацию и втыкали сутками, пытаясь понять, что и где эта программа делает неправильно. Нашли баг — если дело в спецификации, подправляли ее, передавали кодерам, те исправляли программу и все по новой.
Когда подготовка спецификаций и такая отладка стала занимать более 80% времени, отведенного на софт, они перешли на визуальное программирование и уволили всех кодеров нафиг. В итоге затраты на софт уменьшились на 70%, как и время выполнения проекта с 1 года до 2-х месяцев. И это был достаточно сложный софт.
могут описать ее сразу машине, причем в той форме, в какой они сами ее понимают и машина ее выполнит!
Но машина выполнит задачу не так, как её понимают они, а так, как она описана. После чего «ученый, менеджер, домохозяйка, ребенок» или начинают исправлять формулировки, становясь неопытным «визуальным программистом»или идут к программисту чтобы он перевёл машине их пожелания.
А потом, когда сложность достигла определённого предела — всё кончилось. Нет больше никаких ватманов с графиками в разработке ПО.
И непонятно почему другие инженерные дисциплины, которые сейчас находятся в начале этого пути, пытаются сделать вид, что они тут — «в первых рядах».
В других инженерных дисциплинах самолёты не зависают на подлёте.И именно поэтому в других дициплинах люди могу экспериментировать и использовать новые технологии. В то время как в авиастоении и космосе используются проверенные временем технологии — слегка подрихтованные вещи из 60х-70х годов.
Может быть, есть чему поучиться?Тому как тратить 100 рублей на то, что в других отраслях делают за рубль? Да, может быть строителям АЭС и стоит поучиться. Но если ошибка не ведёт к катастрофическим последствиям — то можно использовать другие, более прогрессивные, подходы.
Среди визуальных сред выживаемость, кстати, значительно выше оказалась, хотя их и существенно меньше.Я вот в этом не уверен. У вас есть статистика? Или только «чуйка»?
Я бы посмотрел, сколько бы стоил тот сайт-визитка и на чём бы его писали, если бы ввели жесткую сертификацию как по авиационным стандартам.Нисколько не стоил бы. Его бы просто не было. И компьютера у вас, скорее всего, тоже не было. И смартфона. Были бы перфокарты, в лучшем случае. И ваших любимых визуальных языков бы, кстати, тоже не было. Ну может были бы вещи типа ДРАКОНа, которые бы на ватмане бы рисовались.
А много ли в современном программировании технологий, которым меньше 30-40 лет? Не языков и фрейморков, которые громко любят называть «технологиями», а технологий — в смысле способов и подходов?30-40 лет… от какого момента, извините? От момента, когда была высказана идея: «да, можно такую штуку сделать», до момента, когда она реально даст выхлоп часто десятилетия проходят. Нейронные сети какие-нибудь известны с 60х — но долгое время они не давали никакого выхлопа… а сейчас, наконец, «дозрели» — без них бы, скажем, самоуправляемые автомобили не появились бы.
Очень хороший, кстати, пример: ваши чудесные графические программы так и не привели к появлению чего-либо подобного — прищлось привлекать программистов с их «неправильными» технологиями…
Сколько сейчас используемых языков программирования и сколько их всего?Вопрос в том, что такое «используемые языки программирования» и «всего». Все языки, на которых было написано хоть сколько-нибудь осмысленное количество приложений — всё ещё в строю. Хоть dBase (нынче его величают Vulcan.NET), хоть Turbo Basic (сегодня его зовут PowerBasic), хоть Turbo Prolog (он получил приставку «Visual», но графическим языком от этого не стал).
Да, вокруг них мало Хайпа, но они — вполне живы. Умерли разве что совсем экзотические языки, на которых и в 80-то три с половиной разработчика писали.
А визуальных сред?А это уже у вас стоит спросить. Если вы так уверены, что у них «выживаемость лучше» — то, наверное, у вас есть какая-то статистика.
Причём выжившие языки программирования выжили не потому, что на них удобно и безопасно программировать синтаксически и семантически, а потому, что лучше всего подходят под конкретные задачи (вроде тех же C и C++).Нет, они выжили потому, что существует достаточное количество программистов, готовых за их разработку платить. То же и с графическими средами.
К качеству собственно языков всё это имеет весьма и весьма опосредованное отношение.
Бизнес-процессы: Как все запущено и запутано. Глава Третья. Общая классификация BPM и философия BPMS
habr.com/post/305720
см. в районе параграфа
3.4 Причины популярности BPMS или «на пути к великой цели человечества»: создание программ без программистов
Резюме. Визуализацию алгоритмов разделил бы на три направления (причем в обе стороны — прямая и обратная трансформация):
а) схема — код исполняемый, в том числе через промежуточную трансляцию в программный код высокого уровня (например, С++): CASE\UML, SCADA\TraceMode, BPMS\BPMN;
б) имитационное моделирование, сюlа же отнес бы и системы типа Graphviz;
в) схема — алгоритм человеческий (программа для человечка, в противовес — программа для машины): BPwin\IDEF, ARIS\EPC. Алгоритм человеческий — это фактически программа из русских букв для формализации регламентов взаимодействия и просто логики, в том числе, для целей дальнейшего ее программирования.
«схема — код исполняемый» — или «программирование без программирования»: ИТ-человечество к нему идет уже 30 лет. На смену CASE\UML пришел BPMS\BPMN и low code. Однако, они не оправдали наши ожидания и классическое программирование облегченно «выдохнуло». Но Эволюция продолжается и придут новые решения (не сомневаюсь), т.к. это востребовано и с каждым годом противоречия усугубляются.
Есть много программистов — сторонников «программирование без программирования» (их видимо обвинят в предательстве), но основным «клиентом» данной технологии будет бизнес-пользователь. Сейчас бизнес-пользователь пишет ТЗ и кидает его за стенку программерам. Те, что-то делают, но долго и не так и не за ту стоимость, особенно по «водопаду». Всемогущий ИГИЛе часто не помогает, а решиться на него в крупной компании совсем не просто.
Когда сам бизнес-пользователь сможет САМ своими руками менять бизнес-логику — тогда будет революция и классическое программирование вынуждено будет потесниться и уступить визуальному. Такое «nocode будущего» я сзываю с развитием визуального программирования. Картинки появились намного раньше алфавита — и намного более интуитивно понятны человеку, даже современному. Кроме того, что программы будут делать «люди из бизнеса», идея и в том, что сами программы станут понятны и пользователям, а не только программистам.
А может быть будет так: навел камерой смартфона на текст программы, а на экране отобразился сгенерированный алгоритм в виде схемы (или фрагмент). Или наоборот, навел на схему алгоритма — а смартфон запустил «на лету» сгенерированную программу.
«схема — алгоритм человеческий».
Пример. Есть подробный регламент взаимодействия подразделений компании только по одному направлению, но на 300- 400 листах. Понять, как по нему работать понятно, что непросто (совсем не понятно). Первое, что нужно сделать — упаковать его в формализованную таблицу. Далее из такой таблички автоматически строить схему процесса. И наоборот (BPwin так хорошо делал).
Однако нормально эту функцию сегодня никто делать не умеет (BPMS-BPA). Уверен, что со временем это станет «обычным делом», т.к. алгоритмы усложняются, но технологии их описания не развиваются.
Интересно, где раньше прорвет? В «схема — код исполняемый» или в «схема — алгоритм человеческий».
Вместо того, чтобы описывать задачу программисту, ученый, менеджер, домохозяйка, ребенок, могут описать ее сразу машине, причем в той форме, в какой они сами ее понимают и машина ее выполнит! Понимаете прикол? Программист исключен!
и я про это же (lingvo), но такие вещи на хабре говорить очень опасно, карму порежут — видимо от страха конца программирования (а когда то за подобные проповеди святая инквизиция вообще настоящей кармы лишала). Как не стало кочегаров и массы других профессий, видимо не станет и программистов.
Конечно сейчас и тем более программистам — в это не верится.
Конечно сейчас и тем более программистам — в это не верится.Вы не поверите — но верится. Очень даже верится. Но по-другому.
Как не стало кочегаров и массы других профессий, видимо не станет и программистов.А почему вы считаете, что профессия программиста исчезнет не как профессия кочегара, а как профессия писаря и секретаря? Я лично общался с дедом моего знакомого. Который был довольно-таки большим начальником в 80е. И даже перестройку умудрился пережить. Но он отказывался общаться с компьютерами. Приказы за него набирал секретарь и почту электронную он же читал. А потом, где-то ближе к концу 90х, он был поставлен перед фактом: с такого-то числа секретаря у него больше ну будет и он будет сам чистать почту и писать приказы… или он может уволиться. Так как ему оставалось до пенсии пару лет — он предпочёл уволиться.
«схема — код исполняемый» — или «программирование без программирования»: ИТ-человечество к нему идет уже 30 лет. На смену CASE\UML пришел BPMS\BPMN и low code. Однако, они не оправдали наши ожидания и классическое программирование облегченно «выдохнуло». Но Эволюция продолжается и придут новые решения (не сомневаюсь), т.к. это востребовано и с каждым годом противоречия усугубляютсяПочему в качестве решения не может подойти самое простое: уволить всех, кто не умеет программировать?
Программирование — не самая простая область человеческой деятельности, но освоить какиой-нибудь Python — не сложнее, чем изучить английский или немецкий. Тем не менее знание иностранного языка — не является чем-то редким и уникальным. А знание питона, скажем, для «бизнес-человека» считается немыслимым. Почему, собственно, и откуда уверенность, что так будет всегда?
Иными словами: почему вы считаете, что бизнес-люди, которым нужно писать программы будут всегда обходиться некоторым, специально для них созданным «языком-огрызком», возможно графическим — вместо того, чтобы воспользоваться инструментом, которым пользуются для написания программ программисты?
С учёными это уже зачастую так и происходит: всё больше учёных пользуются, когда им нужно, не всевозможными «научными языками», а банальным питоном (пусть и со специфическими библиотеками)
Тем не менее есть и обратный процесс — бухгалтерия автоматизируется, дизайн не знаю. Вот водителей скоро вытеснят автопилотами. С программированием тоже такой процесс существует.
А вот как раз спрос на людей, знающих и предметную область и умеющих программировать — только растёт. Кому-то же нужно поддерживать всё это в рабочем состоянии!
А вот как раз спрос на людей, знающих и предметную область и умеющих программировать — только растёт.
Ну так вот графическое программирование и позволяет параллельно решить и эту проблему — найти людей, просто знающих предметную область и обучить их клепать модели в том же Матлабе (который они и так обычно знают) гораздо легче, чем найти знающих и предметную область и умеющих программировать.
Понимаете — вот опять получается — вы смотрите на проблему со стороны программиста, а я смотрю на проблему со стороны бизнеса. И у нас разные цели.
Как пример — вот этот самый человек, знающий и предметную область и умеющий программировать — да это ж ужас для компании. Например, уволился он и привет, давайте-ка попытаемся разобраться, что он там по напридумывал и понапрограммировал. В результате в 90% его последователь начнет все переписывать с нуля, так как просто не сможет разобраться с исходниками. Ну да — с каким-нибудь вебсайтом или фреймворком этот номер пройдет на ура. Но вот с ПО для какой-нибудь системы управления самолетом — уже не очень.
Вы не знаете, но именно для этого многие большие фирмы придумывали свои внутренние графические языки программирования, которые вы никогда не увидите — они не выходят за пределы ихних отделов. Но они пытаются решить именно вышеуказанную проблему. Например — HiDraw от ABB Обратите внимание — там картинка от Windows 3.1.
Но вот с ПО для какой-нибудь системы управления самолетом — уже не очень.С чего вдруг? Люди, разрабатывающие эти системы не могут научиться программировакть? Извините — не верю. Возможно не все — но больша́я часть — могут это сделать.
Но они пытаются решить именно вышеуказанную проблему.Они делают то, что осмысленно делать в сегодняшнем мире. Где есть масса компаний, которые, по хорошему, давным-давно должны были бы стать банкротами.
Это, с одной стороны, даёт возможность держать людей, которые не слишком эффективны (могущих «склепать в Матлабе модель, не могущих её эффективно запрограммировать»), а с другой — «связывает» людей, которые могли бы их заменить в разного рода мелких фирмочках.
Однако если количество людей, умеющих программировать, будет расти (а оно таки растёт: количество таких людей в 70е измерялось десятками тысяч, сегодня — миллионами), то потребность в людей, не умеющих программировать будет, соотвественно, падать.
А наступление хорошего кризиса (сравнимого по масштабам с Великой Депрессией) — ускорит этот процесс. И очень сильно.
В любом случае это — гадание на кофейной гуще. С тем, что сегодня, сейчас, графические языки программирования сегодня всё ещё востребованы и закрывают определённую нишу — я согласен.
А вот с тем, что это какой-то «шаг вперёд» по сравнению с текстовыми языками — нет.
Графическими блок-схемами программисты развлекались 20-30-40 лет назад. Сегодня этим занимаются непрограммисты… но где уверенность, что они так и будут продолжать?
Программисты от этого давно отказались. Нет, не от схем вообще — на всяких конференциях и в документации вы их вполне можете увидеть. Но от идеи описывать задачи схемами полностью и до конца. Потому что в 90% случаев это — не нужно (задачи слищком простые), а в 90% оставшихся случаев — невозможно (задачи слишком сложные и полную схему будет невозможно ни нарисовать, ни понять… потому в документации — упрощённая схема, а за полным описанием — пожалуйте в исходники).
С тех пор появился WYSIWYG почти во всех местах: когда-то, чтобы сверстать документ, вы должны были знать теги LaTeX, сейчас все делают это кнопочками в Word.Что приводит к тому, что результат получается хуже и рождается дольше.
Но зато позволяет использовать менее квалифицированную рабочую силу, да.
То, что авиационная отрасль, бизнес-аналитика, промышленность уходят от прямого программирования — тоже звоночек: 20-30 лет назад игрались с Ada, теперь — со SCADE, Simulink и т.д.С Ada игрались совсем другие люди, извините. Те люди, которые сейчас что-то делают со SCADE и Simulink'ом 20-30 лет назад не общались с компьютерами вообще.
Собственно вопрос не в том «есть ли в графических языках смысл сейчас» а совсем в другом: «являются ли графические языки промежуточным шагом или чем-то, что будет использоваться в долгосрочной перспективе».
В 80е-90е — казалось, что за ними будущее… но в 2000е все эти среды, позволявшие программировать базы данных и прочее мышкой — оказались не у дел. Когда накопилась критическая масса людей, способных обходится без этих костылей.
Вопрос: почему в других отраслях всё должно будет на них остановиться?
Звучит довольно голословно
Так может сказать только тот, кто этот результат не видел. Если цель — получить распечатку, то да, Word покатит. Но если нужно получить код, который будет адекватно отрисовываться в разном окружении — то это адский ад.
А с преимуществом Word в скорости вы согласны?
Согласен. Но только в описанном случае.
PDF в помощь
Не всегда приемлем. В частности, нередко есть потребность отрисовать введённый пользователем текст с оформлением на встроенном фоне (различном в зависимости от окружения). Так же нередко этот текст (вместе с оформлением) требуется передать в теле XML, по возможности — не слишком тяжёлом: проблема в том, что при прочих равных визвиги создают очень большой код. Код, созданный Word-ом — приходится основательно чистить от мусора.
У Word-а кстати есть огромный недостаток — отсутствие возможности работать непосредственно с кодом. Я помню, как проклинал всё, при составлении более-менее сложных таблиц. Застрелишься, пока настроишь все ширины и высоты столбцов и строк, мышью — вообще невозможно (шаг сетки не позволяет), приходится вбивать через форму.
Это не совсем «управление оформлением». Хотя и это тоже можно делать.
Для особо продвинутых пользователей в Word-е вроде возможность кодить есть — правда мало кто пользуется.
Возможность верстать документ с помощью кода?
Который позволяет документы средней сложности редактировать почти так же быстро, как в LaTeX.
Однако ограниченность стилей и, главное, тот факт, что ими неудобно пользоваться на практике приводит к тому, что в сложных случаях тексты становятся просто уродливыми.
Собственно TeX был изначально создан именно потому, что после перехода с «ручной» литографии на машинную книги стали выглядеть хуже.
Другой вопрос, что тут, как бы, всегда всё упирается в «а что мы хотим в результате?»… если качественный результат нам не нужен и строки/таблицы с пробелами в километр нас устраивают, то Word и быстрее может быть…
знать теги LaTeX
Говорят, что в науке это стандарт де-факто. Сам утверждать не берусь, но от научных работников слышал.
С чего вдруг? Люди, разрабатывающие эти системы не могут научиться программировакть? Извините — не верю. Возможно не все — но больша́я часть — могут это сделать
Вы исходную предпосылку читали? Этих людей нет — они уволились. А новые должны мочь поддерживать существующий код, например. Который очень ответственный.
держать людей, которые не слишком эффективны (могущих «склепать в Матлабе модель, не могущих её эффективно запрограммировать»),
Унижаете, товарищ. Это часто очень эффективные люди, если их не отвлекать на такую мелочь, как программирование. Они думают другими категориями.
Однако если количество людей, умеющих программировать, будет расти (а оно таки растёт: количество таких людей в 70е измерялось десятками тысяч, сегодня — миллионами), то потребность в людей, не умеющих программировать будет, соотвественно, падать.
Не вижу здесь связи.
Графическими блок-схемами программисты развлекались 20-30-40 лет назад. Сегодня этим занимаются непрограммисты… но где уверенность, что они так и будут продолжать?
Количество новых продуктов и развитие старых позволяет судить о том, что продолжать будут еще долго.
Программисты от этого давно отказались. Нет, не от схем вообще — на всяких конференциях и в документации вы их вполне можете увидеть. Но от идеи описывать задачи схемами полностью и до конца.
Не знаю, но вот сравнительно недавно придумали же NodeRed — визуальный язык программирования? Не для программистов, случайно?
Не знаю, но вот сравнительно недавно придумали же NodeRed — визуальный язык программирования? Не для программистов, случайно?Нет. Всё для той же категории «людей, которым нужна программа, но лень учить python».
Унижаете, товарищ. Это часто очень эффективные люди, если их не отвлекать на такую мелочь, как программирование. Они думают другими категориями.Совершенно верно — и пока эти люди не уйдут на пенсию для них и будут делаться все эти кружочки и квадратики.
Количество новых продуктов и развитие старых позволяет судить о том, что продолжать будут еще долго.Можно даже сказать сколько. Лет 20-30 — пока люди, не общавшиеся с компьютером на уроках в школе не уйдут на пенсию.
Не вижу здесь связи.Связь — самая прямая: если у вас нет возможности взять на работу человека, который одновременно и разбирается в предметной области и умеет программировать — то вы начинается заниматься суррогатами. Если такая возможность появляется — вам это не нужно.
До какого-то уровня им хватит графических инструментов. после — наймут профессионалов, которые пользуются профессиональными инструментами.С такой постановкой — даже спорить нелепо. Вот только она немедленно сбрасывает «графические инструменты» с пьедестала и помещает их туда, где им и место: узкая ниша простых задач, где, действительно, может оказаться удобнее использовать не традиционные языки программирования, а что-то попроще.
А можно сделать молоток исключительно с помощью молотка?
Может отвертку, используя только отвертку?
Или нож используя нож?
Стоит ли отказаться от всех тех инструментов, используя которые, нельзя воспроизвести эти же инструменты?! Или может все таки для решения конкретной задачи, достаточно лишь способности к решению этой задачи. Это проблемно ориентированный язык — как молоток для гвоздей.
Посмотрим с другой стороны: В каком текстовом языке у нас например в стандартной библиотеке есть «PID регулятор» или набор из десятка фильтров? Выходит, что эти языки не пригодны для решения простейших задач построения управляющих систем и обработки данных, потому что инженер не должен изобретать эти штуки — ему хватит и проблемы подбора их параметров.
Так вот Cимулинк работает с потоком данных. Откуда эти данные будут получены и куда потом отправлены, вы конечно же можете написать самостоятельно в виде HAL и драйверов для своего железа или API для своей бизнес системы — чем полностью удовлетворить свое желание, написать что нибудь руками в виде печатного текста. Хоть на универсальных языках, хоть в той же среде матлаба.
На самый тяжелый случай — графическая модель ведь тоже в текстовом файле описана… Рассматривайте это как еще один узкоспециализированный текстовый язык.
Т.е. если по вашему на Simulink нельзя написать Simulink — то ой все что ли?Именно так.
Это проблемно ориентированный язык — как молоток для гвоздей.А кто и где с этим спорит, а?
Спор идёт как раз о сложности и унивесальности. На все попытки объяснить, что задача, которая 70 лет назад решалась с помощью палки и верёвки (шучу, шучу, там электромеханические приспособы были) ну аж никак не могу быть сложными — следует очередная попытка «задавить авторитетом». Ну как же: авия, атом, бальшие деньги… а что это говорит не о сложности задачи, а только лишь о её важности — aeeneas почему-то понять отказывается.
В каком текстовом языке у нас например в стандартной библиотеке есть «PID регулятор» или набор из десятка фильтров?А зачем вам нужен PID регулятор и этот десяток фильтров, извините? Не для того ли, чтобы превратить схему «из палок и верёвок» в что-то, что исполняется на компьютере? Ну так это — только первый этап. Дальше — нужно будет заставлять компьютер выдавать результат лучше, чем может «PID регулятор и десяток фильтров» (а иначе зачем вообще нужно было огород городить?).
И вот совершенно не факт, что графические схемы в этот момент по-прежнему будут адекватны.
На самый тяжелый случай — графическая модель ведь тоже в текстовом файле описана…Вопрос как она там описана. Вот тут про «новые технологии» спрашивали. Так их есть у меня. Правда новой её можно назвать только лишь с некоторой натяжкой, но… patch. Прошу любить и жаловать. Это — то, что убило нафиг все потуги что-то делать в графическом виде.
Вернее, конечно, не patch, как таковой, а то, что за ним последовало. Git и Mercurial. Это — то, что позволяет одному человеку рассмотреть (и принять или отвергнуть) десять тысяч изменений за пару недель.
Вася может добавить во все функции работы с диском новый параметр, а Петя — изменить что-то во всех функциях работы с памятью. И даже если у нас в системе есть функции работы и с диском и с памятью — проблем, в большинстве случаев, не будет. Сверху над этим были надстроены Coccinelle и прочие рефакторинги в IDE.
В некоторых современных визуальных средах тоже что-то подобное есть, но когда я общался с людьми их пользующими — они про них не знали. То есть они ими не пользуются. Что, собственно, и показывает, что они решают простые задачи — если бы речь шла о задачах сложных, то работать в одиночку над тем или иным проектом или использовать тыкву у них бы уже не получилось.
ну аж никак не могу быть сложными
Зачем мы платим летчикам по полмиллиона рублей?! (программистам не платим). Ведь задача которую решали братья Райт 120 лет назад никак не может быть сложной. Разве может быть сложным управляющий компьютер Буран-а который еще с магнитофона загружался и 25 лет назад ее решил?! Или может вся сложность, возникает где то совсем в другом месте — а вовсе не в превращении некоего алгоритма в некий код, и не в объеме того кода и алгоритма, и не в возможности молотка заворачивать шуруп…
А зачем вам нужен PID регулятор и этот десяток фильтров, извините? Не для того ли, чтобы превратить схему «из палок и верёвок» в что-то, что исполняется на компьютере?
Так они как средство обработки данных — тоже на палках и веревках нарисованы. А нужны они, чтоб не надо было инженеру велосипед изобретать — потому, что фильтры так или иначе используются в любой схеме оперирующей потоком данных. А ПИД в любой системе управления с замкнутой ОС. Именно потому и вынесены в стандартную библиотеку проблемно ориентированного языка.
Вернее, конечно, не patch, как таковой, а то, что за ним последовало. Git и Mercurial. Это — то, что позволяет одному человеку рассмотреть (и принять или отвергнуть) десять тысяч изменений за пару недель.
Вы не очень понимаете, что такое программирование на основе физических моделей и стараетесь сравнивать его с каким то говнокодингом (10тыс изменений в неделю)… Модель — это или труд огромного числа ученых, за много лет, или сложный вывод на базе автоматического анализа огромного потока данных — она обычно сразу получается в готовом виде и проходит верификацию. После этого либо принимается либо отвергается. На ее разработку, проверку адекватности объекту, и развитие могут тратится годы… Модель реализованная в неком релизном ПО сейчас — обычно разработана и проверена 5 лет назад и с тех пор в нее не внесено ни одного изменения. А на изменении (если его удастся внести на этапе разработки) диссертацию можно защитить… С того момента, как для модели выполнен весь набор тестов и доказана адекватность объекту — модель неприкасаема до момента, когда условия новой задачи вновь делают ее старую реализацию неадекватной текущему или новому объекту… Тогда модель усложняется и весь цикл разработки повторяется.
В этих условиях хорошо, если за всю свою жизнь вы накопите аж 5 версий модели…
Так вот задача трансляции финальной модели в живую полностью гарантированно реализующую ее копию железяку, очень плохо решается мешками с костями обладающими знаниями ЯП. И именно по этому фобосы грунты не летают. Молодежь туда тащит модные гиты и «10к вариантов говнокода» — а нужен один единственный вариант кода, на 100500% соответствующий модели движения КА, в котором вообще нельзя ничего менять под страхом расстрела. Поэтому не важно выполнен ли он в стиле спагетти или с goto или еще как — важно, что он обязан быть один и асболютно адекватен модели движения = нельзя его трогать, чтоб не сломать!
В частности в нейросети — можно потерять связь между нейронами. Можно напутать с весами — можно банально опечататься и применить 1 вес к 2-м связям… И в результате реализация будет работать, обучатся, проходить тесты — но не будет соответствовать исходной модели… Что приведет к тому, что потом придет инженер — загонит данные из исходной модели и все сломается непонятно почему…
Кроме того документация в этих языках генерируется автоматически (по сути модель это и есть документация лишь коментарии добавить).
Зачем мы платим летчикам по полмиллиона рублей?! (программистам не платим).Ну это у вас надо спросить. Вы ж платите. Средний инжинер в Гугле получает $141,614 в год, пилот в Американской Армии $75,540, а в American Airlines — $180,685. Вполне сравнимые величины.
Или может вся сложность, возникает где то совсем в другом месте — а вовсе не в превращении некоего алгоритма в некий код, и не в объеме того кода и алгоритма, и не в возможности молотка заворачивать шуруп…То, что простой код может потребовать, для своего написания, множество сложных исследований — не делает его, тем не менее, сложным.
А нужны они, чтоб не надо было инженеру велосипед изобретать — потому, что фильтры так или иначе используются в любой схеме оперирующей потоком данных.Совершенно верно. Но вы очень важное слово забыли: сегодня. Да, сегодня, сейчас, они используются в схемах. Потому что разработаны были эти схемы в докомпьютерную эпоху. Но из этого вовсе не следует, что там будет всегда.
Имея компьютер собирать схему из PID регуляторов и фильтров — несколько глупо. Гораздо разумнее описать то, что вы от него хотите — и, решив соотвествующую систему уравнений, разрешить ему делать то, что кажется самым разумным.
Но как первый шаг — да, воспроизвести то, что было наработано в докомпьютерную эпоху будет разумным. В конце-концов когда бухгалтерия на компьютеры периходила (исторически это проихошло задолго до того, как компьютеры стали встраиваться в разные железки) — вначале тоже начинали с того, что все формы перенесли с бумаги.
С того момента, как для модели выполнен весь набор тестов и доказана адекватность объекту — модель неприкасаема до момента, когда условия новой задачи вновь делают ее старую реализацию неадекватной текущему или новому объекту… Тогда модель усложняется и весь цикл разработки повторяется.А потом — ракета улетает неизвестно куда, и большинство запусков уходят к конкурентам.
Собственно вот всё что вы описали, почти 1-в-1 программная индустрия прошла в 70е годы.
Однако сейчас компьютер вполне может не только работать с жёсткой моделью, которую «разрабатывают за много лет» и «обычно сразу получается в готовом виде и проходит верификацию, после этого либо принимается либо отвергается» — но и строить эти модели на ходу, на основании тех данных, что у него есть.
И этот подход — уже начинают применять и в тех областях, про которые вы говорите. Вот, например. Да, конечно, аэрокосмческая отрасль и АЭС никак не могут тут быть в передовиках: потенциальный выигрыш невелик, а потенциальные потери — огромны. Но и говорить, что они находятся «впереди планеты всей» в области программирования — просто глупо. Нет — она аутсайдеры. По понятной и уважительной причине — но аутсайдеры.
В этих условиях хорошо, если за всю свою жизнь вы накопите аж 5 версий модели…Вы накопите их ещё меньше, когда люди, строящие свои модели не 5 лет, а 5 дней — вытеснят вас с рынка.
а нужен один единственный вариант кода, на 100500% соответствующий модели движения КА, в котором вообще нельзя ничего менять под страхом расстрела. Поэтому не важно выполнен ли он в стиле спагетти или с goto или еще как — важно, что он обязан быть один и асболютно адекватен модели движения = нельзя его трогать, чтоб не сломать!Аплодирую стоя. Вот ровно те же самые слова говорились людьми, которые объясняли что водопад — это то, что обеспечит нам всё, что нужно, если правильно его подготовить. Лет этак 20-30 тому назад. Большинство из них сейчас на пенсии, а их компании обанкротились… но вы верьте, что проблемы в Git'ах и неправильно сделанной «единственно верной» модели…
Молодежь туда тащит модные гиты и «10к вариантов говнокода» — а нужен один единственный вариант кода, на 100500% соответствующий модели движения КА, в котором вообще нельзя ничего менять под страхом расстрела.Объясните только мне, идиоту, почему у Space X как-то получается ракеты запускать без модели, которую они пять лет разрабатывает, а у Роскосмоса — нет?
И откуда уверенность в том, что если ещё сильнее опереться в технологии полувековой давности — то станет лучше, а не хуже?
То, что простой код может потребовать, для своего написания, множество сложных исследований — не делает его, тем не менее, сложным.
Для бизнеса нет понятия сложный-не сложный — есть понятие дешево или дорого. Этот код дорог… Автогенерация для него обеспечивает гарантированное отсутствие ошибок и ненадобность выплат кучи зарплат — так получается чуть дешевле, но все равно очень дорого.
Но из этого вовсе не следует, что там будет всегда.
Ну новую ТАУ то вряд ли в ближайшие 50 лет изобретут, она слишком фундаментальна — а вот новых ЯП точно придумают как грязи, так что выкинуть всегда успеют.
А потом — ракета улетает неизвестно куда, и большинство запусков уходят к конкурентам.
У конкурентов просто нет места программистам в текстовых редакторах. В спейс-x просто физически такого числа народу нет, сколько там работы по разработке ПО было произведено! Так что, там только ВП на физмоделях и место.
Вы накопите их ещё меньше, когда люди, строящие свои модели не 5 лет, а 5 дней — вытеснят вас с рынка.
30 лет слышу эти сказки — по факту только сложность растет. Цикл разработки год+ и одних экспериментов по неделе на модель.
Вот ровно те же самые слова говорились людьми, которые объясняли что водопад — это то, что обеспечит нам всё, что нужно, если правильно его подготовить.
Зачем его правильно готовить — если это промышленный стандарт разработки, благодаря которому все это 40 лет так работает! С «всем остальным» играться конечно можете — но вот когда стандартизируете, тогда и поговорим…
Объясните только мне, идиоту, почему у Space X как-то получается ракеты запускать без модели, которую они пять лет разрабатывает, а у Роскосмоса — нет?
Ровно потому, что это как раз у Space-X и MBD и автогенерация кода и тестирование а у Роскосмоса нормально ТЗ писать не кому — поэтому, что там дальше не важно.
«Простых задач» типа управления самолётами, атомными реакторами и бизнес-аналитики, с которыми почему-то не справились текстовые языки:)Во-первых — почему у вас там вдруг кавычки появились? И да, речь идёт о простых задачах типа управления самолётами и атомными реакторами.
Вы путаете сложность задачи и её важность. Автопилоты в авиации появились, я извиняюсь, в 40е годы, когда никаких компьютеров в самолётах и в помине не было. Управлять автомобилем сложнее и даже «тривальная» задача типа «взять бумажку с инструкцией и засунуть её в коробку с лекарством» или «взять конфетку с конвеера и положить в ячейку правильной формы» — далеко выходит по сложности за рамки того, что вы можете запрограммировать на ваших графических схемах.
А вот цена ошибки — тут ситуация совсем другая: если самолёт упадёт — то у вас десятки трупов, а если конфетку не в ту ячейку положили — ну и чёрт с ней, выкинули и забыли.
Просто потому, что в разработке серьёзного ПО коддинг занимает меньше половины ресурсов, соответственно скорость набивки программы, предоставляемая текстовыми языками, играет третьестепенную роль.Нет, важна не «серьёзность» ПО, а исключительно его сложность. Пока вы решаете простые (в программистском плане) задачи — вы можете себе позволить использовать графические среды и прочее. А поскольку сейчас — как раз время, когда комптютеры засовываются во всё — то решение простых задач востребовано. Всё равно это лучше, чем схемы, сделанные на релющках, которые эти компьютеры заменяют.
Но непонятно с какого перепугу вы решили, что решаемые задачи так и останутся простыми и через 20 лет и через 30.
А вот цена ошибки — тут ситуация совсем другая: если самолёт упадёт — то у вас десятки трупов, а если конфетку не в ту ячейку положили — ну и чёрт с ней, выкинули и забыли.
И почему вы вдруг выкидываете этот факт и начинаете говорить о том, что «серьёзность» ПО не важна, а важна исключительно его сложность? Что толку от сложного ПО, если оно не может выполнить "серьезную", хоть и простую задачу?
Я в пример всегда привожу домашнюю автоматизацию, куда с большим энтузиазмом всунулись всевозможные программисты — ну да ж, ведь появились всякие Arduino и ESP8266, которые можно запрограммировать на питоне, все супер.
Ну давайте, запрограммируйте-ка мне контроллер управления отопительным котлом на вашем питоне, чтобы измерял температуру и выключал котел, если она слишком высокая. Только котел у вас такой, что если его не выключить во время — он перегреется и выключится намертво. А еще все это дело должно работать автономно 24/7 и рядом людей нет.
И самое смешное — такие "простые" задачи останутся такими и через 10 и через 40 лет.
Что толку от сложного ПО, если оно не может выполнить «серьезную», хоть и простую задачу?Сейчас покажу на вашем же примере.
Ну давайте, запрограммируйте-ка мне контроллер управления отопительным котлом на вашем питоне, чтобы измерял температуру и выключал котел, если она слишком высокая. Только котел у вас такой, что если его не выключить во время — он перегреется и выключится намертво. А еще все это дело должно работать автономно 24/7 и рядом людей нет.А сколько у вас этих котлов? Если он вообще один — то не факт, что вся эта возня с Arduino и прочим вообще себя окупит. А вот если у вас их много и вы можете обеспечить достаточною экономию за счёт сложной программы на Питоне… то, возможно, общая цена всей конструкции даже с учётом страховки — будет дешевле, чем если вы сделаете всё в лоб с PID регуляторами…
И самое смешное — такие «простые» задачи останутся такими и через 10 и через 40 лет.А зачем вы туда вообще компьютеры пихаете, если они «останутся такими же»?
Или тут та же история, что и с Роскосмосом: пока Маск не сделал альтернативу (дешевле она реально или нет — сейчас оставим «за кадром»), так и «задачи оставлись такими и через 10 лет и через 40 лет»… а как рынок «ушёл» — так срочно движуха началась?
А сколько у вас этих котлов? Если он вообще один — то не факт, что вся эта возня с Arduino и прочим вообще себя окупит. А вот если у вас их много и вы можете обеспечить достаточною экономию за счёт сложной программы на Питоне… то, возможно, общая цена всей конструкции даже с учётом страховки — будет дешевле, чем если вы сделаете всё в лоб с PID регуляторами…
Подождите, а почему вы сразу спрашиваете о количестве котлов? Если программисту дают задачу "напиши программу", он же не спрашивает "а сколько у вас этих компьютеров"? Не надо гадать — вас просят, как программиста, решить задачу — напишите мне программу управления котлом по заданному алгоритму, чтобы я мог применить ее в контроллере. Даю подсказку — с Питона вам придется опуститься до уровня Си, а потом вам придется познакомиться и с ОСРВ. И "простая" задачка вдруг становится "сложной". Необычно, да?
А зачем вы туда вообще компьютеры пихаете, если они «останутся такими же»?
Потому что компьютеры могут часто решить эти задачи быстрее, одновременно, в них можно заложить гибкие, изменяемые алгоритмы.
Если программисту дают задачу «напиши программу», он же не спрашивает «а сколько у вас этих компьютеров»?Спрашивает, конечно. Потому что он этого сильно зависит вообще подход к решению задачи. Если мы делаем что-то, что будет работать на миллионе компютеров, то делать год что-то что даст экономию в один доллар — разумно. А если у нас этих компьютеров три штуку — то дешевле будет вместо ардуино туда какой-нибудь многоядерный процессор на пару гигагерц поставить.
Потому что компьютеры могут часто решить эти задачи быстрее, одновременно, в них можно заложить гибкие, изменяемые алгоритмы.И всё это можно сделать за совершенно разные деньги и с совершенно разными подходами. Если учесть, что в цена Arduino Uno (самая дешёвая модель) почти такая же, как цена Raspberry Pi Zero… с процессором 1GHz и памятью в 512MB… то вопрос «а сколько у нас будет этих котлов» становится отнюдь не праздным.
Спрашивает, конечно. Потому что он этого сильно зависит вообще подход к решению задачи.
Какой подход к решению? К программированию этой задачи? Вы же там выше писали про git, mercurial, "профессиональные решения" — ну так примените их здесь и решите простую задачу, как это сделал бы программист.
А не размышляйте, что тут лучше — Ардуино, Raspberry или многоядерный процессор — это же не компетенция программиста?
А не размышляйте, что тут лучше — Ардуино, Raspberry или многоядерный процессор — это же не компетенция программиста?Я такую фразу слышал несколько раз от потенциальных работодателей. Ни один из них не стал реальным — и я об этом не пожалел, так как все они закрылись через год-два после того, как я с ними разговаривал.
При этом я много чего видел: и реализацию AES на 4-битном процессоре и web-сервер на 8-битном… но всё это должно было получить экономическое обоснование. Ибо решение одной и той же программистской задачи может отличаться по цене на 4-5 порядка, в зависимости от того, под какое железо она делается — и вовсе не факт, что эти затраты окупятся.
Вы разбираетесь в системах управления самолётами или реакторами, что с такой уверенностью заявляете об их простоте?Я разбираюсь в истории. Не слишком сильно, да, но достаточно для того, чтобы понять что ни электромеханический автопилот, ни механические системы на Р-7 не могли решать сложных задач.
Как не может доказывать математические теоремы червь.
Конкретно в самолёте даже просто устройств ввода-вывода в несколько раз больше, чем в обычном компьютере, и связанность там гораздо выше: какой-нибудь датчик тангажа не получится просто абстрагировать от РЛС, например.Тем не менее вся эта информация невелика по объёму (одна-единственная USB-камера в роботе, который заворачивает конфетку даёт больше данных, чем все датчики самолёта, вместе взяты) и хорошо структурирована.
быструю сортировку или HTML-движок руками сейчас всё равно мало кто пишет, а вот собрать систему из блоков на графических языках — в самый раз.И, тем не менее, это «прокатывает» только в самых простейших случаях. Любой мало-мальски серьёзный сайт сибрается не из блоков на графических языках.
3.4 Причины популярности BPMS или «на пути к великой цели человечества»: создание программ без программистов
а потом выше.
Кстати, то, что я и многие остальные здесь не могут «буквами» донести ясно свои мысли — это как раз наглядное подтверждение ограничениям естественного «языка букв», поэтому к тексту часто и прикладывают схемы и чертежи. А если вместо чертежа токарю на стол положат талмуд с буквами, описывающими размер и форму детали, — то его работа займет намного больше времени и сил (а уж как он будет при этом материться ...). Это все про визуальное представление информации, алгоритмов и самих параметров изделий (деталей).
Визуальное программирование — примерно про это же: изготовление программных изделий по чертежам. А если посмотреть дальше — станки с ЧПУ, где ЧПУ изготавливает деталь не на основе программы, а классического чертежа, то мы фактически говорим о ситуации, когда бизнес-пользователь нарисовал на понятном ему языке схем, например, «BPMN ++», решение своей задачи (не постановку задачи), потом «по кнопке» отправил это решение в движок исполнения и радостно заявил (если получилось задуманное): наконец-то я обхожусь без программеров!
В принципе, может быть разработан алгоритмический язык бизнес-пользователя, который также будет компилиться в исполняемый код. Только схема чаще всего — наглядней. Может будет комбинация: бизнес-правила пишем на стандартном языке бизнес-правил (понятному бизнес-пользователю), а логика алгоритма — в графике. Точнее всегда будет возможность трансляции схемы процесса в таблицу или бизнес-код (алгоритмический язык бизнеса) и обратно.
Это было все про «схема — код исполняемый», в походе «схема — алгоритм человеческий» — немного другой подход.
Относительно «BPMN ++»: прогресс от от CASE\UML времен 2к (Rational Rose или ARIS с модулем кодо генерации в С++ силами ARIS script) до современных BPMS\BPMN и «low code \ no code» — колоссальный. Главное что есть большой интерес к этому направлению и появилось много инструментов (продуктов). Но это пока все еще инструменты скорее для программеров, нежели для бизнес — пользователя, поэтому «все еще впереди», но движение идет пусть и не так быстро, но в верном направлении.
Относительно обучить бизнес-пользователя — питону (хорошо, что не ассемблеру). Это утопия. Инженера по АСУТП без навыков программирования можно обучить Trace Mode (SCADA), исследователя — mathcad, схемотехника — LAbView и т.п.
Редкого Бизнес-пользователя можно обучить: а) хорошо пользоваться Excel и делать ровно такие же запросы (селекты и прочее) и обработку посредством связанных таблиц и другого инструментария Excel.
б) использовать подобное через встроенный инструментарий в генераторы отчетов, например, к хранилищам данных. Это тоже схожее направление к рассматриваемой теме — т.е. визуальное проектирование отчетов, когда селекты формируется без знания SQL.
Обучить бизнес — пользователя даже VBA — почти нерешаемая проблема, не говоря уже о питоне и т.п.
«Программирование без программистов» появилось очень давно — с появлением языка Фортран, идеей которого было дать математикам возможность общаться с машиной «без этих ваших программистов, которые бубнят об адресах и переходах». Только очень быстро оказалось, что составление инструкций на Фортране — это тоже программирование.
Это не совсем так.
История идеи «программирование без программистов» выглядит иначе.
ПРЕДЛОЖЕНИЕ ДЖЕЙМСА МАРТИНА
В 1982 году известный специалист по информатике Джеймс Мартин опубликовал книгу под названием «Прикладное программирование без программистов»:
James Martin. Application Development without Programmers, Prentice-Hall, Inc., Englewood Cliffs, New Jersey, 1982. 350 pp.
В этой книге Мартин утверждает, что с появлением непроцедурных языков появилась возможность предоставлять пользователям средства, которые позволяют им самим создавать программы.
Для справки приведу аннотацию к этой книге.
Applications development without programmers, James Martin, Prentice-Hall, Inc.,
Englewood Cliffs, NJ, 1982. 350 pp. (ISBN 0-13438943-9).
With the development of comprehensive nonprocedural languages, many organizations have found significant benefit in providing users with the tools to meet their own information processing requirements.
The author reviews the capability of such offerings including query facilities, report generators, graphics languages, applications generators, very-high-level programming languages, and parameter-driven applications packages.
Each development methodology is illustrated with scenarios from applications created using commercially available software. The implementation of these capabilities has significant implications for the entire data processing organization. Also discussed are management considerations for the implementation, control, and operation of an Information Center.
НОВОЕ НАПРАВЛЕНИЕ ИССЛЕДОВАНИЙ
Книга Мартина дала начало новому направлению исследований, которое обычно для краткости называют «Программирование без программистов» (хотя фактически речь идет только о программировании без ПРИКЛАДНЫХ программистов»).
Чтобы оценить масштаб и разнообразие ведущихся исследований, можно задать в Гугле запрос «Программирование без программистов»
С уважением,
Владимир Данилович Паронджанов
Mobile: +7-916-111-91-57
Viber: +7-916-111-91-57
E-mail: vdp2007@bk.ru
Skype: vdp2007@bk.ru
Website: drakon.su
Webforum: forum.drakon.su
Это не совсем так.
История идеи «программирование без программистов» выглядит иначе.
Это выглядит именно так, как я сказал.
A draft specification for The IBM Mathematical Formula Translating System was completed by November 1954.[8]:71 The first manual for FORTRAN appeared in October 1956,[8]:72 with the first FORTRAN compiler delivered in April 1957
John Backus said during a 1979 interview with Think, the IBM employee magazine, «Much of my work has come from being lazy. I didn't like writing programs, and so, when I was working on the IBM 701, writing programs for computing missile trajectories, I started work on a programming system to make it easier to write programs.»[12]
Как видите, «система трансляции математических формул для расчетов траекторий ракет» появилась в 1954 от того, что человек не хотел писать программы (в терминологии тех лет — на мнемокоде).
Продвигаемая вами идея отличается только способом формализации алгоритма — в виде блок-схемы.
Приведенные статьи не дают обзора принимаемых при создании языка решений, нет сравнения с другими инструментальными средами при решении тех же задач.
P.S. отвечайте, пожалуйста, ветками — так легче отслеживать беседу.
John Backus said during a 1979 interview with Think, the IBM employee magazine, «Much of my work has come from being lazy. I didn't like writing programs, and so, when I was working on the IBM 701, writing programs for computing missile trajectories, I started work on a programming system to make it easier to write programs.»[12]Спасибо за интересную цитату их Бэкуса. Но в этой цитате нет термина «программирование без программистов.
Как видите, «система трансляции математических формул для расчетов траекторий ракет» появилась в 1954 от того, что человек не хотел писать программы (в терминологии тех лет — на мнемокоде).Вы трактуете „программирование без программистов“ расширительно, я же склонен обращаться к первоисточнику (Джеймс Мартин), где этот термин впервые появился.
Продвигаемая вами идея отличается только способом формализации алгоритма — в виде блок-схемы.Моя идея — соединить идею алгоритма с идеей когнитивной эргономики. Полученный результат некорректно называть блок-схемами. Дракон-схемы принципиально отличаются от блок-схем.
Приведенные статьи не дают обзора принимаемых при создании языка решений, нет сравнения с другими инструментальными средами при решении тех же задач.Принимаемые при создании языка ДРАКОН решения описаны в моих книгах.
Наиболее полно — в книге
Паронджанов В.Д. Учись писать, читать и понимать алгоритмы. Алгоритмы для правильного мышления. Основы алгоритмизации. — М.: ДМК-Пресс, 2012, 2014, 2016. — 520 с. — Иллюстраций 272.
Спасибо за интересную цитату их Бэкуса. Но в этой цитате нет термина «программирование без программистов.
Это вопрос инженерного «маркетинга» и стремление назвать свое творение как-то иначе, даже если оно по сути, принципиально то же самое.
Вы трактуете „программирование без программистов“ расширительно, я же склонен обращаться к первоисточнику (Джеймс Мартин), где этот термин впервые появился.
Это лишь новое название для старого принципа — сведение программирования к языку, понятному предметникам. В случае Фортрана — математикам.
Моя идея — соединить идею алгоритма с идеей когнитивной эргономики. Полученный результат некорректно называть блок-схемами. Дракон-схемы принципиально отличаются от блок-схем.
Почему же, чем именно они отличаются? Судя по приведенным примерам (например, 4 видео про замок, рекомендованные вами) это именно блок-схемы. Не те, что гостированы, но вариация оных.
Принимаемые при создании языка ДРАКОН решения описаны в моих книгах.
Наиболее полно — в книге
Спасибо, но тем не менее — есть ли стандарт языка, инженерное (не учебное) описание и сравнение с аналогичными решениями? Все как всегда — предлагая новое, надо делать анализ имеющегося.
Это вопрос инженерного «маркетинга» и стремление назвать свое творение как-то иначе, даже если оно по сути, принципиально то же самое.Вы правы и я согласен с вами. Ваша трактовка насчет Бэкуса, Фортрана и математиков изящна и обогащает содержание обсуждения.
Это лишь новое название для старого принципа — сведение программирования к языку, понятному предметникам. В случае Фортрана — математикам.
Почему же, чем именно они отличаются? Судя по приведенным примерам (например, 4 видео про замок, рекомендованные вами) это именно блок-схемы. Не те, что гостированы, но вариация оных.Говоря кратко блок-схемы не эргономичны, не формализованы, не структурированы, не упорядочены.
Дракон-схемы, напротив, лишены подобных недостатков и во всех отношениях превосходят их. Чтобы пояснить эти слова, нужно ввести новую систему понятий, новые критерии и новую теорию. Для этой цели я написал ряд книг:
- Паронджанов В. Д. Как улучшить работу ума (новые средства для образного представления знаний, развития интеллекта и взаимопонимания). — М.: Радио и связь, 1998, 1999. — 352 с.
- Паронджанов В. Д. Как улучшить работу ума. Алгоритмы без программистов — это очень просто. — М.: Дело, 2001. — 360 с.
- Паронджанов В. Д. Дружелюбные алгоритмы, понятные каждому. Как улучшить работу ума без лишних хлопот. — М.: ДМК-пресс, 2010, 2014, 2016. — 464 с.
- Паронджанов В. Д. Учись писать, читать и понимать алгоритмы. Алгоритмы для правильного мышления. Основы алгоритмизации. — М.: ДМК Пресс, 2012, 2014, 2016. — 520 с.
- Паронджанов В.Д. Почему врачи убивают и калечат пациентов, или Зачем врачу блок-схемы алгоритмов? Иллюстрированные алгоритмы диагностики и лечения — перспективный путь развития медицины / Предисл. члена-корр. РАН Г.В. Порядина. — М.: ДМК Пресс, 2017. — 340 с.
- Паронджанов В. Д. Алгоритмы и жизнеритмы. Основы алгоритмизации. Быстрый способ изучить алгоритмы. — М.: ДМК Пресс, 2019. — 300 с. Это пока еще рукопись
есть ли стандарт языка, инженерное (не учебное) описание и сравнение с аналогичными решениями? Все как всегда — предлагая новое, надо делать анализ имеющегося.Сравнение с имеющимся в моих книгах есть. Формального стандарта языка нет, но есть почти равноценное стандарту техническое задание на разработку программы «дракон-конструктор».
Несколько энтузиастов создали свои варианты дракон-конструктора.
Например, дракон-конструктор Степана Митькина имеет открытый код и позволяет преобразовывать дракон-схемы в исходный код 13 целевых языков: Java, Processing, D, C#, C/C++ (with Qt support), Python, Tcl, JavaScript, Lua, Erlang, AutoHotkey и Verilog.
Благодарю вас.
Кое-что можно скачать бесплатно
Паронджанов В. Д. Как улучшить работу ума. Алгоритмы без программистов — это очень просто. — М.: Дело, 2001. — 360 с.
bit.ly/2AQaZV1
Паронджанов В. Д. Язык Дракон. Краткое описание.— М., 2009. — 124 с.
drakon.su/_media/biblioteka/drakondescription.pdf
Паронджанов В. Д. Алгоритмы и жизнеритмы. Основы алгоритмизации. Быстрый способ изучить алгоритмы. — М.: Препринт, 2018. — 313 с.
drakon.su/_media/zhizneritm.pdf
С уважением,
Владимир Данилович Паронджанов
Mobile: +7-916-111-91-57
Viber: +7-916-111-91-57
E-mail: vdp2007@bk.ru
Skype: vdp2007@bk.ru
Website: drakon.su
Webforum: forum.drakon.su
Но тем не менее есть области, где алгоритм очень сильно превалирует над данными — например real-time — там данные, если они не пришли во время, уже никому не нужны, а алгоритм в своей работе опирается только на самые свежие данные, которые попросту записываются поверх старых снова и снова. Также все структуры данных там четко определены до запуска программы и не меняются во время ее исполнения. Детерминизм требует.
Собственно в этом тоже одна из причин, почему визуальное программирование там более популярно — вы можете описать данные в виде статических связей между блоками на этапе проектирования, а в некоторых случаях вам вообще задают их сверху, так как это будет определено особенностями железа/интерфейсов и вы не в силах из изменить.
Автор этой заметки путается в определении базовых понятий. По своему определению Computer-aided software engineering (CASE) обозначает проектирование (конструирование/разработку) программного обеспечения, что с «визуальным программированием» связано лишь отдаленно.
Первая проблема заключена в buzzword'е CASE, в настоящее время исчезнувшем даже из рекламных материалов самих некогда «CASE» продуктов. Вероятно, автор имеет в виду не CASE вообще, а UML-средства проектирования. Возникает вопрос — считать ли UML-проектирование «программированием»?
Вторая проблема заключена в слишком обобщенном понятии «программирование», которым тоже можно назвать слишком многое. Отсюда второй вопрос — что именно понимать под «программированием», чтобы делать какие-то выводы?
Третье, это неправильное понимание «полного провала». UML-средства не провалились, они занимают свою нишу корпоративных инструментов с ценой аренды порядка ~$1500/мес.
Впрочем, все это риторика, с целью показать, что ложна уже сама изначальная постановка вопроса. При этом вряд ли стоит обвинять именно автора, т.к. у него указано: “Notepad, thoughts out loud, learning in public, misunderstandings, mistakes. undiluted opinions.”
P.S.
О «декуплицировать».
Крайне неудачное заимствование. Правильно — «ослабление взаимосвязи».
Как раз на той неделе наша группа выпускала второклашек.
4 урока на MS Codu Lab
4 урока на Scratch
Почти каждый ребёнок в итоге сумел сделать более-менее работоспособную игру в обеих средах.
На скратче предлагалось сделать лабиринт с бегающим котом, мимо которого нужно провести мышку до ключа, сделать открывающуюся при этом дверь в кладовку и по касанию сыра перейти на другой уровень или к победе.
Многие не плохо реализовали этот сценарий. Другие нагородили своих игровых концептов.
Второклашки.
За 4 полуторачасовых занятия.
С событиями, условиями, циклами, игровой концепцией и дизайном.
С любопытством посмотрю на автора, который за 4 занятия группу из десятка буйных втроклашей чему либо подобному научит на js или basic
Для обучения графические конструкторы — это прекрасные вещи.
Беда начинается в тот момент, когда над одним кодом нужно работать более, чем 2-3-5 разработчикам.
да беда начнется при простом росте проекта в эквиваленте строк на пару тысяч. либо при применении не примитивных типов данных.
Ну и, собственно, все, что делается «квадратиками» — текстом делается быстрее.
«ограниченая разработка» — это «узким кругом ограниченных людей»? :-)Люди могут быть «ограниченными» и «неограниченными» — это не так важно. Важно много их или мало работает над одним и тем же модулем.
И важно не это — а то сколько нужно другому человеку, чтоб продолжить эту работу. И в отдельных случаях это можно сделать хоть завтра — а в отдельных ему для этого понадобится вся жизнь. Но это не плохо, потому, что как правило, не надо ломать то, что работает в этой его жизни… Самолет завтра как то по другому не полетит и в атомном реакторе тоже ничего нового не отрастет даже через год…
Прелесть ВП в том, что метод решения задачи у ВП — как правило единственный поскольку базируется на чистой логике-математике-ТАУ. И какой то другой математики-логики на этом шаре нет… Т.е. это значит, что кто бы ее не решал — они решат одинаково, либо с незначительными различиями в не ключевых моментах. Поэтому модель и формализуется лишь 1 раз, и после, только лишь дополняется и расширяется вместе с расширением предметной области модели — т.е. возникновением каких то новых прикладных научных знаний в этой области.
Никаких проблем привнесенных стадом переводчиков с языков алгоритмов в машиночитаемые — нет от слова вообще.
Самолет завтра как то по другому не полетит и в атомном реакторе тоже ничего нового не отрастет даже через год…Вообще-то у самолёта каждый экземпляр уникален и у атомного реактора — тоже.
Пока вас удоевлетворяют простые, грубые, модели — вы можете обходиться ими и не учитывать все эти ньюансы. Но непонятно — зачем тогда вообще компьютер, если подобную грубую схему можно на релюшках собрать.
Прелесть ВП в том, что метод решения задачи у ВП — как правило единственный поскольку базируется на чистой логике-математике-ТАУ.Это только если вы точно знаете все параметры. А это, в свою очередь, обозначает, что вы работаете не с реальным объектом, а с его некоей идеальной аппроксимацией.
Это работает с самолётами, которые летают в воздухе и на дорожные знаки реагировать не должны — и совершенно не работает с автомобилями, скажем.
Да и с самолётами тоже — не факт, что упрощённых моделей, которые «все решат одинаково, либо с незначительными различиями в не ключевых моментах» будет продолждать хватать в будущем.
Вообще-то у самолёта каждый экземпляр уникален и у атомного реактора — тоже.
Любая уникальность закладывается апликаторами как параметры модели при например сборке самолета-реактора. Это низший уровень участников процесса создания подобного ПО. А модель на то и модель — что сферический реактор в вакууме описывает…
Это работает с самолётами, которые летают в воздухе и на дорожные знаки реагировать не должны — и совершенно не работает с автомобилями, скажем
А давно автомобили должны реагировать на дорожные знаки? Мой например не реагирует — хотя все его системы построены с использованием ВП.
упрощённых моделей
В большинстве своем они наоборот over-усложнены. Поскольку включают в себя всю прикладную область знаний доступную на данный момент — а как известно «люди научились строить дома из кирпичей за сотни лет до того, как поняли принципы, по которым работает цемент».
Мой например не реагирует — хотя все его системы построены с использованием ВП.Вот именно потому и не реагирует. Сложность системы, сопосбной это делать превышает возможности того, что можно написать в одиночку.
А с каких пор у нас вообще распознавание знаков — формализуемая задача? Это все пока игрушки на уровне навигации.
А с каких пор у нас вообще распознавание знаков — формализуемая задача? Это все пока игрушки на уровне навигации.И до каких пор вы будете считать это игрушками? До тех пор пока такси без водителей не появятся? Так уже близко
Такси без водителей появятся не раньше, чем программированию без программистов сотня лет стукнет… Потому, что вторая задача как раз формализуема на раз-два.
Хотя конечно периодические вылазки раз в пятилетку до очередного сбитого велосипедиста — несомненно и раньше будут происходить…
Вообще всё это мне напоминает историю столкнования телеком-мира с программистами в конце прошлого века.
У телекома — тоже были модели, всякие ISDN и ATM, красивые инструменты (частью графические) и прочее.
А у программистов — глючный Ethernet «в принципе не способный передавать аудио и видео из-за недетерменированности», какие-то глючащие «киски» и, конечно, идиоты-программисты, всё делающие «не по феншую».
Десять лет телеком-мир смеялся над идиотами, «лезущими не в свою тарелку», десять лет — сопротивлялся, но, в конце-концов — пришлось либо уходить с рынка, либо пользоваться «тем ужасом, которые эти идиоты-программисты разработали».
Подобная же история произошла на рынке сматфонов… достаточно сказать, что телеком-компания, которая смартфон, собственно, первый успешный смартфон создала — в далёком уже от нас 1996м году… больше никаких смартфонов не производит в принципе. Как и телефонов, кстати.
Причём во всех случаях всё идёт по одной и той же схеме: надо новичками долго смеются, объясняя, что многолетний опыт все их «дурацкие приёмчики» не заменят, что продолжается несколько лет, потом — начинают понимать что «что-то здесь не так», а затем, за несколько лет — вылетают с рынка. Или, в лучшем случае, уходят в другой, смежный — куда программисты с их «неправильными методами» ешё не добрались.
В случае с авиастроением и атомными станцими этого, впрочем, не произойдёт ещё много лет (как не произошло с медициной, хотя, казалось бы, там-то уж точно всё было должно давным-давно случится) — но не потому что все эти визуальные технологии лучше, а потому что сертификация… она может процесс очень сильно затормозить.
Если с помощью чиновников отгонять программистов (кроме случаев, когда всё уже совсем-совсем плохо), то можно долго свою кормушку иметь… но не надо это называть «передовыми методами», пожалуйста.
Потребность автопилотирования колымаг существовало за 100 лет пока никаких смартфонов не было. Но всегда находились какие то объективные причины не позволяющие ее осуществить.
Например все оборудование автомобиля обязано работать в температурном диапазоне -40 +125 с пассивным отводом тепла. Это в реальности значит, что температура кристалла работающего процессора может достигать +150. Очень немногие специально спроектированные для этого архитектуры, с технологиями от мамонтов способны работать в этих условиях. Понадобится 10 лет только для того, чтоб подобная архитектура стала обладать производительностью хотя бы ноутбука, который прямо сейчас стоит на витрине супермаркета в Бирюлево. Без этого, все эти уберы и гуглы — просто гаражные игрища по засовыванию компа с видеокартами в багажник и просверливанию дырок, чтоб не дохли…
Т.е. вы уже точно будете знать как делать — но 10 лет не сможете делать!
Не важно кто и когда придумал смартфон — важно кто и когда придумал потребность в смартфоне для каждого бомжа и смог осуществить эту потребность.А теперь… внимание вопрос: почему среди компаний из телекома таких не нашлось, а среди возящихся с компьютерами — нашлось аж две (и могли бы найтись и больше, если бы всё так быстро не случилось)?
Ваши же дальнейшие сентенции? Можно я их себе утащу? Потому что это настолько классика жанра, когда люди не хотят учиться на чужих ошибках и хотят наделать своих, что это даже не смешно.
А если по сути…
Без этого, все эти уберы и гуглы — просто гаражные игрища по засовыванию компа с видеокартами в багажник и просверливанию дырок, чтоб не дохли…Вы на 100% правы! Я даже спорить не буду. Прямо «не в бровь, а шлаз». Вот только… iPhone — был точно таким же экспериментом по сплющиваением Мака и засовываением его в маленькую коробочку.
Все, вот абсолютно все люди, которые что-то понимали в телефонах думали примерно как Баллмер: iPhone — это игрушка, у которой нет ну вот никаких шансов на рынке сотовых. Да, они получат свои 2-3% рынка и заработают на этом каких-то денег, но мы-то со своими 60%-70%-80% останемся. Ещё раз повторю: так думали если не все — то почти все. А до того, как выйдет Android и за один год увеличит свою рыночную долю с 4% до 23%, после чего станет ясно, что все, кто не возьмую его на вооружение окажутся за бортом… оставалось три года.
Например все оборудование автомобиля обязано работать в температурном диапазоне -40 +125 с пассивным отводом тепла.И телефон не должет превращаться в тыкву при минусовой температуре… во всяком случае до 2007го все разработчики телефонов считали — что это не просто важно, а чертовски важно.
Это в реальности значит, что температура кристалла работающего процессора может достигать +150.У производителей телефонов был другой бзик: они считали что телефон, который нужно заряжать каждый день — никто не купит. Ну, кроме 2-3% гиков, как говорил Балмер.
Очень немногие специально спроектированные для этого архитектуры, с технологиями от мамонтов способны работать в этих условиях.Угу. И с телефонами — та же история. Была. До 2007го.
Понадобится 10 лет только для того, чтоб подобная архитектура стала обладать производительностью хотя бы ноутбука, который прямо сейчас стоит на витрине супермаркета в Бирюлево.Угу. Любой чип, способный вытянуть операционку, портированную с PC — выжирал батарею космическими темпами. И да — эти изыски были им не страшны, потому что, по их рассчётам, потребовалось бы 10 лет (а то и больше), что чипы, способные проработать неделю от одной зарядки с небольшой батареей хотя бы приблизились по скорости к тому, что нужно, чтобы подобных монстров запускать. А пока… да, Symbian, JavaME и всё такое прочее. Пусть медленное и бес свистоперделок — зато делают то, что нужно от телефона «позарез».
Т.е. вы уже точно будете знать как делать — но 10 лет не сможете делать!Сделать так, чтобы удовлетворять «высоким стандартам автоиндустрии»? Несомненно. Но вот не окажется ли так, что взамен за то, что люди действительно хотят (сесть и проехать на машине из точку A в точку B не держась за руль, а смотря вместо этого фильмы, играя в игры, или, на худой конец, работая) — они откажутся от тех вещей, которые, на самом деле, им не слишком нужны?
Понимаете, пока телефоны отличались тем, что на одном в качестве игры была «змейка» (Nokia), а на другом — простенькие ралли (Ericcson), то да — пользователи упирались в то, что им нужно долгое время работы от батареии, возможность слетать в Сахару и в Якутск и всё такое прочее.
Но когда оказалось, что отказавшись от всех этих вещей они могут запостить фортки в Инстаграмм и поговорить с бабушкой «за копейки» через WhatsApp… выяснилось, что Сахара-то не так им и нужна.
Если вы прикините сколько стоит платить водителю каждый год зарплату — то поймёте, что ради избайления от этой статьи расходов владельцы таксопарков легко согласятся и с тем, что машина должна выключаться только в тёплом гараже, и в том, что в ней внушительный объём займёт отсек с электроникой… вопрос только в том, чтобы от водителя избавиться — и все эти «невероятно нужные» вещи окажутся так же важны, как и возможность пользоваться телефоном без подзарядки неделю. Что-то, о чём будут вспоминать с ностальгией — и только.
А теперь… внимание вопрос: почему среди компаний из телекома таких не нашлось, а среди возящихся с компьютерами — нашлось аж две
Встречный глупый вопрос — а почему компании телекомы: не торгуют семечками на базаре, не дают деньги в долг, и не проводят секс тренинги !? Несомненно все эти направления в бизнесе интереснее, чем какие то лопаты для тыканья пальцами.
И телефон не должен превращаться в тыкву при минусовой температуреКому не должен? Каким законодательным актом регулируется? Почему в реальности — превращается?
Сделать так, чтобы удовлетворять «высоким стандартам автоиндустрии»?Ваша проблема в том что вы сравниваете юзерскую игрушку, которая максимум прошла тест на электромагнитную совместимость и пожаро-безопасность (иногда не только лишь все прошли) и сертификацию на соответствие ее говнокода в телефонном модуле (а он чужой), стандарту ETSI бла бла бла — с «средством повышенной опасности». А его выпуск и производство регулируется совсем другими законами. С принципиально другими уровнями сертификации. Другими тестами, которые не способен пройти даже rugered телефон с кнопками — не то что смартфон! Где нагретую до 150 градусов железку с CPU (ваш смартфон уже стечет корпусом) обдают струей ледяной воды — и так 20 раз через 3 минуты… Потому, что машинки они по лужам ездят — когда не детские…
Эйпл поймали на читами с батарейкой — потрындели на форумах, говорящая голова ляпнула что то там дежурное — и все забыли… Кто то отозвал афйоны? нет… заменил батарейки? нет… пара дежурных обещаний — и все забыли… акции на бирже даже не шевельнулись особо…
Diselgate VW — ну чуток начитили, чуток изменили там в коде маленькую функцию добавили… всего лишь определяли что машина на стенде… немножечко по другому при этом работали… Задавили кого-то?! нет! кто то умер от этой фигни?! тоже нет! — итог: миллиардные штрафы, уволены сотни человек, некоторые арестованы, сотни тысяч уже собранных машин для белых людей, пришлось распихать по странам 3-го мира с более слабыми законами в области норм токсичности. Прогнозируемый убыток — десятки миллиардов долларов и прошли годы а скандал еще не закрыт…
Потому что нормы токсичности — закон! а время жизни батарейки лишь фантазии в инструкции к игрушке.
Если вы прикините сколько стоит платить водителю каждый год зарплатуЯ вам по секрету скажу. Каждый год зарплаты программиста в разы дороже обходится бизнесу чем каждый год зарплаты водителя — а следовательно данный вид деятельности людей стоит первым в очереди на его оптимизацию! Мало того бизнес уже оптимизировал водителей по максимуму путем аутсорса транспортно-курьерских услуг, и теперь его эта проблематика мало заботит.
Далее: Одна бабка с велосипедом — отбросила на пять лет… Что будет когда ребенка собьют? маленького в коляске (коих 100500 видов)… На поколение забудете, как водил оптимизировать (притом, что мешки с костями детей в колясках регулярно раскатывают — но это будет как с ГМО… Не докажете 100%-ю надежность и безопасность — давайте до свиданья с этого рынка… Статистика тут не сработает.)…
Так же рекомендую ознакомится с схемой работы такси в современном мире и почему «владельцы таксопарков» на самом деле НЕ ПЛАТЯТ водителям зарплату! Да и вообще, кто именно занимается проблематикой автопилотирования и кто будет выгодоприобретателем если оно вдруг появится…
Встречный глупый вопрос — а почему компании телекомы: не торгуют семечками на базаре, не дают деньги в долг, и не проводят секс тренинги !? Несомненно все эти направления в бизнесе интереснее, чем какие то лопаты для тыканья пальцами.Вы снова не можете разглядеть за деревьями лес. Секс-тренинги, может, и интереснее, чем «лопаты для тыканья пальцами» — но они не могут уничтожить производителя сотовых… А вышеупомянутые «лопаты» — могут… потому их и пытались разработать в телекомах в теченее более, чем 10 лет… вот только они пытались остаться в рамках телекомовских правил — потому и проиграли.
Потому что нормы токсичности — закон! а время жизни батарейки лишь фантазии в инструкции к игрушке.А почему собственно? Думаете миллиарды телефонов, выброшенных на свалку, меньше загрязняют окружающую среду, чем Фольксвагеновский дизель? Нет, конечо. Однако газеты про это не пишут, избирателям это неинтересно — и потому всё остаётся в рамках новостей, в законы не превращается.
Автокомпании уже почти проиграли эту игру, хотя она ещё, толком, не началась.
Далее: Одна бабка с велосипедом — отбросила на пять лет…Это как, я извиняюсь? Одна компания прекратила испытания на улицах на 9 месяцев и уже их возобновила, остальные продолжали без всяких проблем — и это дало вам задержку на пять лет? Странная у вас арифметика.
Что будет когда ребенка собьют? маленького в коляске (коих 100500 видов)…Зависит от того, сколько времени компания, автомобили которой это сделают, успеет накатать километров. Если там будет, условно, суммарный пробег в миллион километров — то сделать из этого бравурный репортаж в стиле «мясные водители всё равно в десять раз опаснее, чем роботы» — раз плюнуть.
Так же рекомендую ознакомится с схемой работы такси в современном мире и почему «владельцы таксопарков» на самом деле НЕ ПЛАТЯТ водителям зарплату!У меня есть знакомый, который таксистом работает. И он тоже на эти все схемы упирает… и не понимает, что это — абсолютно неважно. Неважно — поймут ли таксопарки что происходит или нет (скорее всего нет). В конечно итоге все деньги приходят от пассажира и часть их получает мясной водитель. Вся «алхимия» с перекладыванием денег из одного кармана в другое не может этого изменить.
Потому важно, что компании, которые не будут тратить на «мясных» водителей деньги — смогут обеспечить бо́льшую прибыли при более низких ценах. А будет это конкретно Uber, Waymo или кто-то ещё… какая разница? На кону — не просто большие деньги, а очень большие деньги… а потому и сбитый маленький ребёнок и все ваши регуляторы — не смогут с этим ничего поделать.
Да что ж вы так на законы то упираете? Законы — они, знаете ли, ручкой на бумаге пишутся. Ну Ok, в современном мире на принтере печатаются. Что написано в одну сторону — завегда можно переписать в другую.И телефон не должен превращаться в тыкву при минусовой температуреКому не должен? Каким законодательным актом регулируется?
Или уже забыли как развитие автономных увтомобилей должны было «встать намертво» из-за того, что нет законов, позволяющих их на дорогу выпускать? Когда время подошло — изменили законы и выпустили. Делов-то.
Всё это напоминает историю с «королями железных дорог» — они, в своё время, тоже уповали на разные законы (касающиеся, если память не изменяет, того, сколько часов в день может проводить водитель за рулём). Ну и где они сейчас?
Когда речь идёт не просто о деньгах, а о больших деньгах (а водители транспорта только в США получают больше 100 миллиардов долларов в год) — то оказывается, что и «опасность» «средства повышенной опасности» не так опасна… и законы можно трактовать весьма изощрённо… главное — чтобы оно работало.
А вот тут — у вашего любимого визуального программирования… полный швах. Нельзя с подходом модель реализованная в неком релизном ПО сейчас — обычно разработана и проверена 5 лет назад и с тех пор в нее не внесено ни одного изменения реализовать ничего подобного за разумные сроки.
Думаете миллиарды телефонов, выброшенных на свалку, меньше загрязняют
Больше! Но свалка где то далеко где бомжи живут в домах из мусора. А 10млн автомобилей вот они — в вашем городе!
Зависит от того, сколько времени компания, автомобили которой это сделают, успеет накатать километров.
Не зависит.
Сбивается ребенок — поднимается вой.
Кроме прямого ответственного назначаются с 10-к косвенных… Всем вдруг резко становится не интересно заниматься данным видом деятельности…
Или уже забыли как развитие автономных увтомобилей должны было «встать намертво» из-за того, что нет законов, позволяющих их на дорогу выпускать? Когда время подошло — изменили законы и выпустили. Делов-то
Ничего не изменили! Никакие законы не запрещали и не запрещают выпускать на дорогу автономные авто. Только вот в любом автомобиле все равно сидит двухногое животное, которое теперь называется не водитель а «оператор автопилота», и несет уголовную ответственность за несвоевременное нажатие красной кнопки СТОП — и сюрприз… он хочет денег за свой труд!
Так вот если законы изменят — эту самую ответственность просто переложат на «программистов автопилотов» причем как и в дизельгейте судить их будут сразу «всем отделом» — в результате они быстро кончатся…
Когда речь идёт не просто о деньгах, а о больших деньгах (а водители транспорта только в США получают больше 100 миллиардов долларов в год) — то оказывается, что и «опасность» «средства повышенной опасности» не так опасна… и законы можно трактовать весьма изощрённо… главное — чтобы оно работалоПомните историю с блаблакарами в Домодедово — люди выходят из самолета а блаблакары кучей стоят в 3км от аэропорта… Их таксисты отгоняли туда группами по одному возвращаясь кучей в 1 такси и сами ставили драконовские тарифы «за посадку».
Водители транспорта как только почувствуют реальную опасность увольнения, сразу же придумают способы с этим бороться — это даст еще лет 10 задержки для того чтоб общество подготовилось противостоять им…
А вот тут — у вашего любимого визуального программирования… полный швах
Проблема совсем в другом. В автопроме везде используются строго формализованные модели — это не вчера придумано. Даже нейросети используются лишь до того уровня, пока возможно формальное доказательство абсолютной корректности метода (т.е. по сути это очень простые вещи — типа многомерных аппроксимаций и local linear model tree). Автопилотирование на глобальном уровне очень легко формализуется с доказательством корректности (по сути это просто текст ПДД), но в локальных задачах — нет! Поэтому очень долго оно будет оставаться лишь игрушкой.
Ничего не изменили! Никакие законы не запрещали и не запрещают выпускать на дорогу автономные авто.А я-то, грешным делом, думал, что вы что-то знаете про авто…
Вот, почитайте — когда, кто и как менял законы.
Так вот если законы изменят — эту самую ответственность просто переложат на «программистов автопилотов» причем как и в дизельгейте судить их будут сразу «всем отделом» — в результате они быстро кончатся…Поживём — увидим. Пока вы громко верещите про то, что наезд на человека отбросит развитие на 10 лет, хотя по факту — машинки Uber'а снова катались, хотя и года не прошло. А все остальные компании даже не пристанавливали испытания.
Помните историю с блаблакарами в Домодедово — люди выходят из самолета а блаблакары кучей стоят в 3км от аэропорта… Их таксисты отгоняли туда группами по одному возвращаясь кучей в 1 такси и сами ставили драконовские тарифы «за посадку».Ну дык. Луддиты — они всегда такими были.
Водители транспорта как только почувствуют реальную опасность увольнения, сразу же придумают способы с этим бороться — это даст еще лет 10 задержки для того чтоб общество подготовилось противостоять им…Господи. Ну всё же уже было. Цитирую: Уничтожение машин (индустриальный саботаж) было объявлено преступлением, наказуемым смертной казнью, и 17 человек были казнены в 1813 году. Множество людей было отправлено в Австралию. В какое-то время войска занимались подавлением луддитских восстаний сильнее, чем сопротивлением Наполеону на Пиренейском полуострове.
В наше гуманное время вместо смертной казни людей будут сажать лет на 10 — вот и вся разница.
В автопроме везде используются строго формализованные модели — это не вчера придумано.Ну… примерно позавчена. Не забывайте, что меньше сотни лет назад Форд всё ещё производить свою пресловутую Модель T и ни о каким формализованных моделях и не думал.
А вы правила, которым всего лишь несколько десятилетий — вечными объявить хотите.
Поэтому очень долго оно будет оставаться лишь игрушкой.Поживём — увидим, как я сказал. Хотя есть подозрение что мы разнимся скорее не сроках, а в оценке: до конца этого десятилетия автономные авто будут экзотикой, а к концу следующего «мясной» шофёр — будет уже предметом роскоши, атрибутикой шейхов и королей…
Вот, почитайте — когда, кто и как менял законы.
Набор подзаконных актов. Там изменения уровня — 'давайте назовем автоплиот автопилотом'. 'подумаем что нам вообще делать с автопилотами'. 'надо испытать круиз для грузовиков' (хотя легковушки на этом уровне 20 лет продаются)… Очередная авария — те же говорящие головы наштампуют таких актов в обратную сторону.
Поживём — увидим. Пока вы громко верещите про то, что наезд на человека отбросит развитие на 10 лет, хотя по факту — машинки Uber'а снова катались, хотя и года не прошло
Ага — только теперь вместо одного водителя там ДВОЕ!
Настоящая автономность будет когда водителей станет 5 — и они будут отлично проводить время за чей то счет катаясь кругами…
Господи. Ну всё же уже было.А зачем что то уничтожать? — достаточно просто организованной группой ходить по пешеходному переходу непрерывным потоком — нормальные люди втиснутся и проедут а роботачки будут ждать, пока этот цирк не кончится.
А вы правила, которым всего лишь несколько десятилетий — вечными объявить хотите.
Тестам на боковой удар в столб нет и 10 лет — в то же время машины, системы безопасности которых спроектированны, без учета этих тестов, уже встречаются лишь в 3-х странах. Есть вещи которые очень быстро приживаются — и потом без них немыслимо выпускать авто.
Хотя есть подозрение что мы разнимся скорее не сроках,
Я считаю что автовождение (серийное — как опция в машине любого производителя) возникнет строго после того как возникнет автопрограммирование! Не важно когда — важно, что первыми вылетят на мороз оравы программистов — чуть погодя к ним присоединятся толпы водителей…
Я считаю что автовождение (серийное — как опция в машине любого производителя) возникнет строго после того как возникнет автопрограммирование!На всех машинах? Включая карьяерные экскаваторы и асфальтоукладчики?
У меня есть ощущение, что вы снова не можете увидеть за деревьями леса. Широкое распространение автономных автомобилей не приведёт к тому, что эта опция появится на «рядовых» легковушках. Оно приведёт к тому, что этот класс авто — просто отомрёт. Подавляющее большинство автомобилей покупается, чтобы ездить на работу и с работы — и очень небольшой процент людей делает это с удовольствием (такие люди существуют, но их мало...).
Если стоимость такси упадёт настолько, что ездить на такси будет дешевле, чем на своём собственном автомобиле — то очень много народу так и сделает. После чего «обычные легковушки» попадут в ту же категорию, что какие-нибудь дельтапланы — и будет у них у всех опция автопилота или нет… это будет уже не так важно.
Есть вещи которые очень быстро приживаются — и потом без них немыслимо выпускать авто.Ровно до того момента, пока покупатели готовы платить за все эти изыски.
А зачем что то уничтожать? — достаточно просто организованной группой ходить по пешеходному переходу непрерывным потоком — нормальные люди втиснутся и проедут а роботачки будут ждать, пока этот цирк не кончится.Это действительно сработает… какое-то время. Ровно такое, какое потребуется на то, чтобы изменить законы (хорошо, хорошо, «подзаконные акты») и отправить этих прохожих в уединённое место на 15 суток подумать — так ли сильно им хочется бороться с автономными авто.
Не важно когда — важно, что первыми вылетят на мороз оравы программистов — чуть погодя к ним присоединятся толпы водителей…А вот это уже — конкретный прогноз! Давайте обсудим его лет через 5-10. По моим прикидкам к тому моменту водители будут уже вполне в массовом порядке думать что они ещё умеют делать, а программисты… ну если не считать «программистами» окончивших двухнедельные курсы и умеющих только «натягивать CSS на CMS» — то нехватка всех остальных будет по-прежнему ощутима и за ними по-прежнему будут охотится рекрутеры…
На всех машинах?На предназначенных для движения по дорогам общего пользования. (для остальных то вообще никаких проблем нет — это уровень автономных тележек на складе).
ну если не считать «программистами» окончивших двухнедельные курсы и умеющих только «натягивать CSS на CMS» — то нехватка всех остальных будет по-прежнему ощутима и за ними по-прежнему будут охотится рекрутеры
Деятельность формализуемая многократно проще чем вождение автомобиля — следующая на очереди на улицу после нормального машинного перевода текста. Так что как увидите, что очередной гуглтранслит выкинул переводчиков из мяса и костей — пакуйте чемоданы. Вы следующий!
Деятельность формализуемая многократно проще чем вождение автомобиля — следующая на очереди на улицу после нормального машинного перевода текста.Мечты, мечты…
Я понимаю, что вам очень хочется в это верить… что «этих зазнаек» скоро поставят на место. Вот только… практика показывает — что всё происходит наоборот.
Так что как увидите, что очередной гуглтранслит выкинул переводчиков из мяса и костей — пакуйте чемоданы.А откуда, как вы думаете, возьмётся этот самый гуглтранслейт, извините? Его линвисты думаете делают или филилоги? Ха! Там в команде 100% программистов — хотя часть имеет второе, гуманитарное, образование.
И у ПРОМПТа то же самое. И у других. Просто потому что иначе — не выжить. «Накопленные столетиями» данные оказываются всегда в таких случаях всего лишь затравкой, которая используется для создания первой, черновой, версии. А дальше — работают програмисты.
Вы следующий!Увидим. Пока что мне не приходось сталкиваться с тем, чтобы у меня не было пары офферов в тот момент, когда вставал вопрос о том, что я могу уволиться. И за всё время я видел только всё более жестокие драки за «головы» программистов.
Но, возможно, в вашей вселенной всё не так и программисты со знанием нейросетей и прочего — просят милостыню, а «визуальные программисты» рисуют диаграммы, из которых получаются машинные переводчики… но вы точно уверено — что это в вашей вселенной просиходит, а не в вашем сне?
Я понимаю, что вам очень хочется в это верить… что «этих зазнаек» скоро поставят на место. Вот только… практика показывает — что всё происходит наоборот.Знаете почему вы не Греф. И не умеете в управление банком?.. Вы не видите будущее!
А откуда, как вы думаете, возьмётся этот самый гуглтранслейт,А откуда возьмется «цифровой гулаг»? — бла бла бла…
Да вы его сделаете! За хорошую заметим зарплату!
Естественно работы программисты лишат себя исключительно сами, по доброй воле, с песнями, плясками и в полной уверенности, что победит хорошее-светлое-вечное.
Увидим. Пока что мне не приходось сталкиваться с тем, чтобы у меня не было пары офферов в тот момент, когда вставал вопрос о том, что я могу уволитьсяВ 1991-м люди думали что СССР — это тоже навсегда. Ну вот они просыпались утром под гимн из радио — и так происходило все 70 лет — ничего более стабильного они не представляли. Лишь мелкая горстка понимала что жить этой конструкции оставались считанные месяцы… И скоро из радио прозвучит совсем другой гимн.
Я вам по секрету скажу. Каждый год зарплаты программиста в разы дороже обходится бизнесу чем каждый год зарплаты водителя — а следовательно данный вид деятельности людей стоит первым в очереди на его оптимизацию!Ну это уже вообще ни в какие ворота. Да, программист — стоит гораздо дороже, чем водитель. Но дело-то в том, что программистов для написания софта под самодвижущийся автомобиль требуются сотни, ну, может, тысячи, а водителей в одних Штатах — миллионы.
То же самое кассается грузчиков, кассиров и прочего. Будь иначе — не было бы кругом кучи открытых вакансий программистов (на таки да, очень и очень неплохую зарплату), а были бы кучи незакрытых вакансий водителей, поваров и бухгалтеров… их, впрочем, таки есть — но на такие смешные зарплаты, что часто возникают вопрос: а хлеб и вода к вакансии полагается? А то ж c голоду помереть можно…
Если бизнес завязан на программирование — то программистов там вагон. А водителей 0 потому, что давно уже есть транспортная компания на оутсорсе… Поэтому оптимизация программистов — прямые бабки! а автопилоты — ну, может быть чуть чуть на копейку транспортные услуги подешевеют, а может и не подешевеют — не интересно короче.
Выгодоприобреателя не там ищите. Вот Континенталю или Бошу какому нибудь, выгоден автопилот — он может продать оем-ам миллионы комплектов железа автопилотов за миллиарды долларов денег. Поэтому у них на полигонах автопилоты уже бороздят (толку пока не много, иначе бы орали об этом из каждой дыры)…
Например все оборудование автомобиля обязано работать в температурном диапазоне -40 +125 с пассивным отводом тепла. Это в реальности значит, что температура кристалла работающего процессора может достигать +150.Вот смотрю я на автомобиль — и спереди у него радиатор… для активного отвода тепла.
Я про то, что проще создать серийному оборудованию нужные условия, чем изобретать процессор на экзотике.
Как обеспечить скажем чипу от видеокарты внешний диапазон -40 +125 — причем все устройство должно быть герметичным?
Пока вы будете разрабатывать свою «опцию» люди, понимающие, что автопилот — это не «опция к автомобилю», а что автомобиль — это «опция к автопилоту»… сожрут вас с потрохами.
Посмотрите на рынок производителей сотовых телефонов. Кто там остался из «старичков» и смог нарастить продажи? Samsung? Так это потому, что он производит компьютерные компоненты и смог вовремя подсуетиться, когда парадигма изменилась!
Сейчас — вы не делаете телефон, а потом подбираете для него операционку, а берёте новую версию Андроида, смотрите на то, что она «умеет» — и выпускаете железо под неё.
То же самое будет и автопилотом: как только он станет нормой на дорогах (а не в каталогах производителей) главным (и основновным) фактором выживания для автопрозводителей станет умение обеспечить работу автопилота…
В конце-концов и в живой природе всё кончилось не тем, что были созданы разумные мозги, способные работать при температураз от -50 до +50, а тем, что весь организм был перекручен так, чтобы мозг всегда имел определённую температуру — буквально с точностью до долей градуса!
А почему, собственно, оно должно выдерживать диапазон от -40 до +125?
Потому что зимой когда вы приходите к машине в Салехарде под капотом -40 (и -50 бывает и она работает) а летом когда вы час простояли в пробке на солнце — под капотом только от радиатора +100 а блок может легко своим процессором догнать сам себя до +125.
И почему оно должно быть герметичным?Потому что при перепаде температур электроника проходит точку росы и на блоках есть постоянное напряжение. Если они будут не герметичными — они просто сгниют через неделю! (а должны отработать 10 лет или 100тыс км)
Так не будет этого!
Так я и говорю — не будет никакого вашего автопилота еще 10 лет от момента появления… А если как вы хотите из соплей — то он через неделю сдохнет. В результате озолотятся сервисы (чинить то эти автопилоты надо будет)…
С ремонтом вообще вопрос интересный — как автопилот поймет, что у него подшипник ступицы загудел в машине? Мешки с мясом понимают — автопилот видимо будет ездить пока колесо не отвалится… А колесо кривое (вибрация на руле?)… Посмотрим на реакцию пассажиров…
Пока вы будете разрабатывать свою «опцию» люди, понимающие, что автопилот — это не «опция к автомобилю», а что автомобиль — это «опция к автопилоту»… сожрут вас с потрохами.
Закон написан для производителей автомобилей — никаких производителей автопилотов нет… Создание автопилота компанией не производящей автомобили (прямо или косвенно) в текущем законодательном поле не возможно! Автомобиль должен быть одобрен для использования на дорогах общего пользования (сертифицирован). Все это требует формальных доказательств безопасности которые не могут быть предоставлены в текущей прадигме конструирования автопилотов. Поэтому про автопилоты пока вы можете помечтать или поиграться с ними в присутствии оператора (которому все равно платят). По сути — того же водителя.
А вообще в России например установка автопилота приравнивается к переоборудованию и влечет немедленный запрет эксплуатации (прекращение регистрации — так как отсутствуют основания для регистрации ТС) до демонтажа автопилота.
Потому что зимой когда вы приходите к машине в Салехарде под капотом -40 (и -50 бывает и она работает) а летом когда вы час простояли в пробке на солнце — под капотом только от радиатора +100 а блок может легко своим процессором догнать сам себя до +125.холод электронике не страшен — китайские **дуинки в жидкий азот кидали и ничо, работали.
Нагрев — вот это да… но можно и радиатор наружу вытащить и холодильник к нему прикрутить.
Потому что при перепаде температур электроника проходит точку росы и на блоках есть постоянное напряжение. Если они будут не герметичными — они просто сгниют через неделю! (а должны отработать 10 лет или 100тыс км)На радиаторе напряжения нет.
С ремонтом вообще вопрос интересный — как автопилот поймет, что у него подшипник ступицы загудел в машине?Дык датчик… их можно в каждый узел понапихать.
Закон написан для производителей автомобилейЗакон не догма, на него законодатели есть.
китайские **дуинки в жидкий азот кидали и ничо, работали.
А бессвинцовая пайка не отваливается? Или там пока ещё нормальная?
Дык датчик… их можно в каждый узел понапихать.
А что сейчас мешает напихать в каждый узел датчик? Например в газовых турбинах в каждый узел — сто лет как напихано…
А насколько дороже станет автомобиль — если в каждый узел пихать датчик определяющий износ-выход из строя?
И не вылетит ли экономия на мешках с костями в большую копеечку?
Создание автопилота компанией не производящей автомобили (прямо или косвенно) в текущем законодательном поле не возможно!Ух ты, сколько пафоса. Аж из ушей течёт. А что тогда ездит в Финиксе? Или у вас Alphabet уже автопроизводителем стал?
Все это требует формальных доказательств безопасности которые не могут быть предоставлены в текущей прадигме конструирования автопилотов.Нет — это всё требует бумажек, которые не вписываются «в текущую парадигму сертификации».
Мне всё это мне напоминает историю о том, как ИЛ-86 «пролетел» мимо трансатлантических перевозок. Его разрабатывали под 4 двигателя именно из-за того, что «всё это требовало формальных доказательств безопасности», которые требовали, чтобы у трансатлантических авиалайнеров было 4 двигателя.
А Боинг — разработал свой знаменитый Boeing 767 с двумя. А «формальные требования безопасности»? Ну их, эта, подправили чуток, когда нужно было — и всё.
Почему вы так уверены, что этого не может произойти с автопилотом?
А вообще в России например установка автопилота приравнивается к переоборудованию и влечет немедленный запрет эксплуатации (прекращение регистрации — так как отсутствуют основания для регистрации ТС) до демонтажа автопилота.И, тем не менее, Яндекс успешно автопилот испытывает тоже. Не являясь, заметим, автопроизводителем ни разу.
Или у вас Alphabet уже автопроизводителем стал?
А что не ясно, что это сопли прикрученные к серийному крайслеру и выпущенные на улицу по филькиной грамоте местной мерии (действующей ровно до очередного сбития очередной пьяной велосипедистки)?!
Ну их, эта, подправили чуток, когда нужно было — и всё.
Вот когда вы будете боингом.
И будете куда надо в правительство заносить N лярд $…
Тогда будете говорить о том, что «законодательство можно чуток подправить»…
А когда вы — мелкий стартап прикручивающий комп к рулю…
Максимум, что вам можно, виновато показывать местному полицейскому бумажку от местного мера и мечтать, чтоб вас побыстрее с потрохами купил General Motors… Только вот у General Motors есть свои MOP инженеры и купить он вас сможет скорее всего лишь для того, чтоб под ногами не мешались (закрыть)…
И, тем не менее, Яндекс успешно автопилот испытывает тоже. Не являясь, заметим, автопроизводителем ни разу.
Который 30км-ч быстрее не разгоняется? и не пересекает встречный поток?
так они и на мопеде могут его испытывать с двигателем 50сс — такому и регистрация то никакая не нужна…
Прелесть ВП в том, что метод решения задачи у ВП — как правило единственный поскольку базируется на чистой логике-математике-ТАУ. И какой то другой математики-логики на этом шаре нет… Т.е. это значит, что кто бы ее не решал — они решат одинаково, либо с незначительными различиями в не ключевых моментах. Поэтому модель и формализуется лишь 1 раз, и после, только лишь дополняется и расширяется вместе с расширением предметной области модели — т.е. возникновением каких то новых прикладных научных знаний в этой области.
Эээ, вы немного преувеличиваете прелести ВП, рассказывая о модельно-ориентированном проектировании и его преемуществах. Но МОП — это только один из вариантов ВП. В том же Scratch или NodeRED никаких моделей нет, хотя они тоже являются средствами визуального программирования. Поэтому там прелестей логики/математики/ТАУ гораздо меньше.
может, это просто для сторонников ВП слишком сложно? ну, их «особенности».
Так так — и как вы собрались описать 1млн элементов с порядка 3млн связей в чисто HDLе без применения ВП?Во-первых не один миллион, а несколько миллиардов (если мы о GPU, скажем).
Если это сложно уже даже на уровне сотни…А во-вторых именно поэтому ВП там не применяется.
За последние несколько лет передо мной уже есть два примера, когда HDL полностью слился в сложных задачах:
- в проекте ЦОС надо было замутить на ПЛИС довольно сложную математически ФАПЧ, описанную вполне конкретным математическим языком — перемножениями матриц и т.д. По частоте никаких сложностей не было, но был вопрос о переводе все к фиксированной запятой. HDL программист кортел над задачей почти год, возился со своими симуляторами, но так и не смог запустить это дело в железе. С МОП человек решил задачу за 2 месяца и запустил в железе, где она и работает по сей день.
- в силовой электронике опять же надо было перенести алгоритм управления тиристорным инвертором с аналоговой + CPLD на чисто цифру + ПЛИС. HDLшики запросили 2 года. Товарищ на МОП выдал полностью рабочее железо за 4 месяца. При этом качество документации и тестирования на порядок превзошло ожидания всех. Они ожидали, что как обычно получится что-то нечитаемое и непонятное, а увидели абсолютно понятные графические модели. И в железе все заработало с первого раза.
вполне естественно, что использование готового серийного продукта оказалось дешевле, быстрее и качественнее.
О каком готовом серийном продукте вы говорите? Визуальный программист точно также начал все программировать с самых базовых логических кирпичиков, а для сложных операций использовались IP ядра, к которым HDL программист точно также имел свободный доступ и мог их использовать.
HDL программист был с хорошим стажем и квалификацией, если вы об этом.
Ваши действия по его визуальному программированию.
Код распространяется в виде кода — это базовый уровень. Компилятор для целевой архитектуры — там же распространяется!
В 21-м можно используя специальные инструменты создать сложнейшую embedded систему, не написав руками вообще ни строчки кода, а затем за полчаса перенести ее на абсолютно в принципе другую архитектуру контроллера, другого производителя с другой битностью, и порядком байт в слове…
И программы писал на бумаге, ноутбуков тогда не было. Достаточно сложный код текстом можно спокойно записать в тетради, а вот изобразить его визуально — надо будет ватман с собой таскать.
Си не возможен без ассемблера — вы знаете ассемблер целевой системы?
Ассемблер без машинных кодов — все их наизусть знаете?
А как вы коды запускаете без знания внутреннего устройства процессора?
А на схему вашего компа где можно посмотреть?
(у меня кстати моего есть — 170 листов А3 — и почему то не в виде текста нарисована)…
итд
Почему ваша абстракция колом встает именно на каком то уровне существования, какого то текста и каких то людей, что то там написавших. Не надо домохозяйке знать как устроен магнетрон в СВЧ печи и сколько народу работает на заводе самсунг, в цеху скручивания печей отвертками — она жмет кнопку и продукты греются = задача выполнена… Инженер рисует алгоритм в символике, жмет кнопку и получает hex для зашивки в устройство = задача так же выполнена. Бизнес видит что 1 человек работает за 10-рых — задача выполнена быстрее и дешевле… Какая кому разница, что там стоит посередине и сколько программистов пострадало когда написало весь этот набор… Для них всех эти программисты — обслуживающий персонал уровня — «ей слыш, у меня тут не работает че то — давай ка по быстрому разберись, чтоб работало как надо».
Инженер рисует алгоритм в символике, жмет кнопку и получает hex для зашивки в устройство = задача так же выполнена. Бизнес видит что 1 человек работает за 10-рых — задача выполнена быстрее и дешевле… Какая кому разница, что там стоит посередине и сколько программистов пострадало когда написало весь этот набор… Для них всех эти программисты — обслуживающий персонал уровня — «ей слыш, у меня тут не работает че то — давай ка по быстрому разберись, чтоб работало как надо».так и инженер для бизнеса тосно такой жке ресурс, стоящий деньги. И бизнесу неважо, «сколько инженеров там стоит посередине» — если бизнес сможет покупать, перекрашивать и продавать — он прекрасно обойдется без инженеров. а замена 10 программистов одним графическим редактором — если это выгодно (стоимость пакета проектирования позводит без увеличения стоимости платформы производить продукцию с такой же скоростью) — будут заменять. ситуация примерно как была с жесткой логикой и контроллерами/процессорами: до определенного уровня производства контроллеры были дороже. в общем, и сейчас есть отголоски — БМК/ASIC против CPLD/FPGA
Работает. только не надо называть это программированием.
А чем еще это называть, если на выходе — «программный продукт!?» Программировать можно как угодно и чем угодно. Начиная от ручки с тетрадкой в hex кодах. Нету «правильного» и «неправильного» программирования — и нету «правильных» и «неправильных» методов. Есть цена-качество-и сроки… Если окажется, что в тетрадке фигачить «дешевле-быстрее-лучше» — надо фигачить в тетрадке!
так и инженер для бизнеса тосно такой жке ресурс, стоящий деньги.
Вообще то инженеры разные бывают. Кады давно уже выставили армию расчетчиков на мороз. А те что проектируют системы — без сильного ИИ даже на горизонте не понятно как их заменить вообще…
Нету «правильного» и «неправильного» программирования — и нету «правильных» и «неправильных» методов. Есть цена-качество-и срокивот именно. приобретение визуального пакета переносит стоимость с конкретных кожаных программистов офиса на стоимость пакета (стоимость команды классных программистов «где-то там», которые работают на то, чтоб не слишком грамотный человек мог нарисовать то, что они пишут). качество — оно зависит от сложности проекта. управлять качеством (и сложностью) «в тексте» гораздо проще. Для этого есть системы хранения версий, системы статического и динамического анализа и т.п.
Вообще то инженеры разные бывают. Кады давно уже выставили армию расчетчиков на мороз.— и если окажется, что в тетрадке хренячить «дешевле-быстрее-лучше» — надо хренячить в тетрадке.
Только, как всегда, есть нюанс: инженер, умеющий «в тетрадке» — справится и с КАДом. а вот «современный передовой КАД-ориентированный, со ммузи и из коворкинга» без КАДа не сможет ничего вообще.
Если сборка из кубиков, которая вполне имеет место быть, выгоднее кодирования текстом — ее вполне можно применять. Но нужно представлять пределы применимости. Адепты визуальщины, для которых «программирование микроволновки на разморозку» есть достойная инженерная задача — это всего лишь мелкая часть инженеров.
пока вы не смогли показать, что на визуальщине можно разработать (коллективно), оттестировать и верифицировать (сначала — формально) достаточно сложное устройство.
Сложное — в смысле программного поведения, конечно.
А тестирование и верификация происходят САМИ! В этом то и прелесть.И документация еще САМА выпускается.
Да методами кодирования текстом на это надо 30 человеколет.
и верификация проводилась именно текста, а не картинок?
Верификация производилась — готового ПО. Тестовые скрипты для симулятора генерировались из картинок.
Лично у меня был точно такой пример в постановке бизнес-процессов: руководитель службы никак не мог словами полностью описать БП. Пришлось дать ему BizAgi, там не позволяются неоконченные процессы, ведущие в никуда маршруты и т.п. Он, конечно, долго матерился, что «глупая программа мешает полету мысли», но потом научился, а после даже стал нормально описывать БП текстом и отдавать «на отрисовку» девочке-секретарю.
Сделали возможность любому инженеру понимать это решение, при наличии всего лишь базового технического образования и отсутствии знания каких либо языков программирования вообще.
А программиста превратили в обслуживающий персонал сделав его навыки образование и опыт не нужными в массе.
Причем сделав это в юзерспейсе 20 лет назад (задача не сложная) — полезли делать то же самое в ядре методом создания единого апи ядра, абстрактно работающего c сотней живых архитектур — и тоже сделали это. И в итоге в блоки полгода один процессор пихают потом полгода другой, а потом снова первый. Потому что полгода контракт на 10 центов дешевле был из за низкой загрузки фаба — а разработка сделанная единожды, далее вообще не стоит ничего…
И, еще раз повторюсь, только для весьма ограниченного круга задач как по области, так и по сложности.
и не «сделали программиста обслуживающим персоналом», а перенесли центр разработки с «мест» в «центр», где и разрабатывается этот визуальный конструктор. И если там не будет «программистов текстом», то «инженеры-рисовальщики» уйдут лесом.
«продукт стоит космических денег» — ну вот эти деньги вы и платите обычным квалифицированным программистам… просто «не тут, а там».
Трубы действительно никуда не делись — в отличие от трубочистов…
Но как то пропала сама необходимость их чистить.
Так и с ПО — все будет. Кроме необходимости писать его руками с помощью людей.
Не, я тоже пользуюсь stm32cubemx, qtcreator'om и 1с, и считаю их вполне удобными в своей нише. только я представляю размер этих ниш.
а основной сдерживающий фактор именно в том, что большинство понимает, чем визуальщина в общем случае хуже. Хотя есть, безусловно, реальные преимущества в обучении, в исследованиях ака Матлаб и т.п. (хотя тоже с определенными ограничениями. про которые уже говорили неоднократно). Но некоторые, типа вас, парноджанова, разработчика «графического ассемблера» и т.п. продолжают пихать визуальщину в каждую дырку.
Вы же не берете excel под MsWin3.11 и не рисуете в нем поддержку xlsx. — нет таких задач. Вы просто берете тот excel который xlsx поддерживает!
Сравнивая визуальную систему с excel'ом вы уже переводите её из программирования в ограниченные прикладные средства разработки.
Все что вы перечислили — в стоках не существует и в актуальных разработках не используется.
И что с того? По сути вопроса это что-то меняет?
Большинство ПЛИС всё ещё слишком малы, чтобы разрабатывая под них вы могли упереться в ограничения ВП.
описанную вполне конкретным математическим языком— в матлабе? Что мешало ее там же сначала решить в целочисленном виде а потом уже переносить?
С МОП просто автоматически происходят преобразования систем счислений для фактического железа и любые пределы вычислений сами по себе отслеживаются, поэтому и половину работы за него кодогенератор выполнил — он просто типы вбил целые с нужной разрядностью…
Однако. Еще со времен блок-схем я понял простую вещь: визуальное представление выигрывает только на небольших объемах. Стоит блок-схеме разрастись на несколько листов, как наглядность полностью теряется.
Из этого и нужно исходить. Для задачек визуальное программирование годится. Для создания программного продукта — нет. Никто не строит из лего жилые дома, тем более крупные сооружения.
Если в алгоритме десяток шагов — можно его рисовать. Иначе придется писать.
Развитые среды программирования используют визуальный подход для отдельных изолированных задач. Но и только.
На тот момент только самые сложные модули (около 20%) были написаны визуально. Тогда это был ничтожный объем в рамках ПО… В современных системах — уже более 80% — объем увеличился в сотни раз…
Недавно анализировали одно сообщение (предельный момент) — весь механизм его вычисления. На выходе из принтера у нас получилась блоксхема из сотни страниц исчерченных ручкой во всех направлениях ;)
Стоит блок-схеме разрастись на несколько листов, как наглядность полностью теряется.
Из этого и нужно исходить.
Вы не правы в этом. Данная проблема возникала в период, когда все рисовали на бумаге и чтобы отобразить все связи, требовались чертежи формата А1 и больше. А многостраничные документы были практически нереализуемы из-за отсутствия возможности контролирования перекрестных ссылок и связей, невозможности создания библиотечных модулей, иерархии и т.д.
С появлением CADов эта проблема решена и принципиальная схема даже самой сложной платы спокойно рисуется на нескольких листах А4 и потом прекрасно читается.
То же самое и с алгоритмами. Разделить сложный алгоритм на несколько блок-схем сегодня можно без проблем.
Для задачек визуальное программирование годится. Для создания программного продукта — нет. Никто не строит из лего жилые дома, тем более крупные сооружения.
Авианосцы, ракеты, автомобили, роботы подойдут? Это, конечно, не визуальное программирование, а немного больше — модельно-ориентированный подход, где визуальное программирование является составной частью. Но не надо больше говорить, что нет реальных программных продуктов, ОК? В обычном автомобиле, на котором вы ездите, с 99% вероятностью используется автоматически сгенерированный код, нарисованный визуально.
Использовать Системы непрерывной интеграции и непрерывного развертывания?
Возможно ли использование какого-либо статического анализатора?
Как писать тесты (unit, модульные, итеграционные и пр.)?
С системами «визуального» программирования с которыми я встречался эти вопросы никак не решались, либо решались с такими «нюансами», что пользоваться не имело никакого смысла.
ИМХО «визуальное программирование» возможно только в очень узких нишах, где он является своего рода DSL (domain specific language).
А можно этот визуальный код загнать в систему контроля версий?
Конечно. В том числе можно визуально и программно отслеживать изменения в моделях.
Использовать Системы непрерывной интеграции и непрерывного развертывания?
Да. Мы используем непрерывную интеграцию.
Возможно ли использование какого-либо статического анализатора?
Да. В данном случае статический анализ применяется к самим визуальным моделям, проверяя правила применения систем и блоков.
В генерируемом коде статистический анализатор обычно находит 0 предупреждений, не говоря уже об ошибках.
Как писать тесты (unit, модульные, итеграционные и пр.)?
Мы пишем там же — в модели и в графическом виде. Позволяет отладить практически весь алгоритм вообще без железа. Но сам подход предполагает и модульные и итерационные и SIL и HIL тесты.
ИМХО «визуальное программирование» возможно только в очень узких нишах, где он является своего рода DSL (domain specific language).
Конечно. Но в данной нише — системах управления реального времени "визуальное программирование" это:
- далеко не игрушка для обучения или решения легких задач
- и именно в решении сложных задач оно вытеснило или стремительно вытесняет текстовые языки
Есть кстати еще одна ниша, где model-based design процветает — генерация кода для цифровой обработки сигналов.
А то, что в некоторых случаях удобно «нарисовать», чем «написать» — согласен.
Но этих случаев не так много.
И для того, чтобы они «заработали», нужно написать кучу кода, на «не визуальных» ЯП. ;-)
Конечно. Допустим стек TCP IP и в жизни не захочется писать на визуальном языке.
Но все дело в симбиозе технологий визуального программирования с классическим — при правильном применении вы получаете итоговый продукт гораздо более высокого качества и с гораздо меньшими затратами, чем если бы писали его только на не-визуальном ЯП. И под продуктом я подразумеваю не какую-то простую програмульку для ардуино, а вполне конкретный сложный production софт, работающий в той или иной железяке.
Поэтому «более высокое качество» это слишком сильное утверждение.
Т.к. качество визуальных компонент зависит от качества компонент написанных на не визуальном ЯП.
Что значит слишком сильное утверждение? Под качеством вы можете подразумевать любую характеристику программного продукта, например, количество выявленных багов после релиза и вы получите меньшее их количество при указанном подходе.
Т.к. качество визуальных компонент зависит от качества компонент написанных на не визуальном ЯП.
Тут есть особенность — каждая такая "визуальная компонента, написанная на невизуальном ЯП" это по сути своей функциональный библиотечный блок, протестированный и вылизанный в сотнях проектов производителем визуального ЯП.
Только не путайте "неспособных писать нормально" со "специалистами по теории автоматического управления с двумя высшими образованиями и 20-летним опытом разработки алгоритмов управления самолетами".
Вы действительно думаете, что им нужна эта возможность — "писать на невизуальных языках"?
Пусть этими компонентами занимаются айтишники. У них никто хлеб не забирает.
и косяки смещаются с уровня взаимодействия «постановщик-программист» на уровень «программист типовых модулей». С одной стороны, более качественный программист типовых модулей (а производитель конструктора может нанять высококлассных программистов, в отличие от пользователей конструктора) может написать и оттестировать более качественные модули. с другой стороны, при неочевидной ошибке в модулях будут проблемы у проекта из кубиков, когда все вроде бы правильно — а в целом не работает.
А для пассажирских полетов в воздухе от механики довольно быстро перешли к fly-by-wire и к компьютерным системам управления. Так что Союз тут малопоказателен.
при неочевидной ошибке в модулях будут проблемы у проекта из кубиков, когда все вроде бы правильно — а в целом не работает.
Нюанс в том, что данная прблема может встретиться и во вполне обычном проекте, написанном на невизуальном ЯП. Поэтому существуют вполне конкретные методики отладки и устранения таких ошибок.
Насчет вылизанности…
Мой опыт говорит, что Опять же это не понимание «Абстракции текут».
Например мне очень часто при работе с SOAP («типа вылизанная технология»), приходиться работать (знать) на уровене HTTP.
До уровня работы с TCP/IP не доходил, т.к. у меня не было таких нагрузок когда это было необходимо.
Как я понял, чем сложнее система, тем более глубинные слои абстракции надо знать.
А можно этот визуальный код загнать в систему контроля версий?Да и это очень удобно — сразу видно, что где поменялось. Я выше приводил пример. Delphi, DPR:
Тут я вижу код, а не картинку :-)
Как понять какая строка отвечает за какой визуальный элемент.
Т.е. для данного случая нужно знать два ЯП — визуальный и не визуальный.
Зачем?! Если можно сразу вести разработку и использовать инструменты для не визуального ЯП.
Если вам надо сравнить 2 картинки — вы их будете побайтно сравнивать или может каким то другим все же образом? Как дети умудряются «найти 10 отличий» в двух картинках, не зная минимум двух языков программирования?
Об этом и речь!
При визуальном программировании «засунуть» его в систему контроля версий становиться проблематичным.
Причем обычно теряется как раз визуальная составляющая. ;-)
Тут же можно и посмотреть:

А вообще версионность придумали задолго до систем контроля версий, поскольку версионность — это просто набор правил существующий сам по себе без какого либо софта… Например ничего не мешает в PCAD нафигачить 15 версий плат, что собственно в серийном производстве и делают — при том, что системы контроля версий там нет…
Когда-то всё (или почти всё) программирование было визуальным. Брались листы ватмана, на них рисповались разного рода схемы, всё это тщательно изучалось на этих картинках. Ну а потом, в конце-переводилось в текст, в код. Самый «плебейский» этап, когда специалисты не нужны, иногда даже школьникам это доверяли.
Я этого не застал, но моя сестра это всё видела.
А потом… потом оказалось, что если у вас «прогон программы» — не есть что-то, к чему вы готовитесь неделю, то вполне можно писать сразу код — без блок-схем и «визуального этапа». А уже следующий этап — это контроль версий. Потому что без паралльной работы многих разработчиков проекты больше определённого масштаба создать нельзя.
Именно поэтому «гордый ембеддед» сейчас активно подсел на Linux, который, собственно, и родил всю «шумиху вокруг контроля версий». Потому что решения созданные «традиционными способами» — не работают. Если бы работали — никто не стал бы отказываться от проверенных временем решений.
Фортран конечно уже нет — а вот Ассемблер например вполне используют — когда он в железе три доллара экономит… На партии 1млн устройств, 3 доллара превращаются в 3млн$. Сколько бы не стоили те кто, его используют и методы встраивания их кода в общий процесс — они не дороже 3млн$!
И линукс на 90% ембедед процессоров нельзя запустить физически — а в автомобильных системах всему этому набору говнокода вообще делать нечего дальше чем процессор в мультимедии… Опять же постановка линукса на IOT девайсы к разработке в узких конкретных направлениях мало отношения имеет…
У любого решения есть цена. Если какой то механизм не позволяет вам увеличить производительность в конкретных условиях но требует ресурсы для поддержания существования в виде набора знаний и компетенций — его цена отрицательная.
Применение СКВ требует разового вложения на изучение методов работы с ней. Поддержание — около нуля.
А это — да, довольно большая цена.
Применение СКВ требует разового вложения на изучение методов работы с ней. Поддержание — около нуля.Очень смешно. Процесс разработки в нормальных компаниях документирован. Применение в нем вообще «чего либо»-«шаг вправо-шаг в лево» требует внесение изменения в значительное количество документации, переобучение персонала и последующую переаттестацию этого персонала, согласно новым методам разработки — а все это очень дорого и непонято зачем и кому нужно, если действующие методы дают продукт без всех этих затрат.
«Процесс разработки в нормальных компаниях» обычно отдается на оутсорс тем компаниям, которые используют современные подходы к программированию и ЯПВы попутали современное с модным. Как раз ВП — современный подход, ибо решает конкретные задачи и экономит деньги на разработке, путем полного выкидывания не нужного в цикле разработки звена имплементации алгоритма в С-коде и специалистов этого дела на мороз. Система контроля версий никаких задач не решает и ничего не экономит — это вообще не подход а плюшка в виде 5-й ножки к стулу, потому что в нормальной системе поменять версию = поменять спецификацию и интерфейс модуля, а это делается раз в 5 лет, и поэтому всем вообще пофигу какими методами…
Система контроля версий решает одну главную задачу —
Позволяет распаралеллить работу над одной кодовой базой. Что позволяет ускорить и удешевить разработку.
ВП — экономит деньги на разработке в очень специфичных случаях.
В противном случае сейчас весь «кровавый Ынытрпрайз» был бы на ВП.
Но это не так. Хотя попытки внедрить ВП происходят регулярно. С неизменным результатам — дорого, глючно, долго. :-)
И если он хочет поменять интерфейс функции — он должен обратится к модератору проекта с докладной запиской объясняющей, «какого хрена он собирается все сломать» — в результате чего, его могут послать нафиг…
И если он хочет поменять интерфейс функции — он должен обратится к модератору проекта с докладной запиской объясняющей, «какого хрена он собирается все сломать» — в результате чего, его могут послать нафиг…Вы сейчас описали процесс разработки софта для сотовых телефонов лет этак 15 назад. Или 30. Где тоже люди были уверены, что так будет всегда.
А потом пришли разработчики из IT-индустрии со своим «говнокодом» и СКВ — и отправили большинство этих разработчиков искать другую работу.
Почему вы так уверены, что в других областях визуальное программирование — это то, за что стоит держаться и что вся история не кончится подобным же образом?
Инженеру не требуется распараллеливание работы над одной кодовой базой
Однако, системы контроля версий у них есть.
Инженеру не требуется распараллеливание работы над одной кодовой базой
Это не единственная причина, почему используется СКВ. СКВ имеет смысл использовать для сохранения истории, привязки изменений в коде к задачам. Даже если работает один человек. Это — тоже документирование. Считайте, журнал изменений.
но каждый над своими модулями
Вполне возможно, что код настолько плох, что инженеры просто не могут работать с кодом друг друга. Особенно весело, если речь идет о библиотечном модуле, а коллега, который ответственен за него, в отпуске или на больничном.
Или если человек поменялся и новому нужно посмотреть, почему внесено то или иное изменение.
Вы отстаиваете устаревшие методы, обосновывая тем, что вам и так неплохо, и устаревшие методы подходят вашим процессам. Вы не задумывались, что сами процессы И не могут быть иными при описанном подходе? «он должен обратится к модератору проекта с докладной запиской» — это не от хорошей жизни. Иначе будет невозможно понять, зачем принято то или иное решение. При современном подходе достаточно краткого устного или письменного (телеком) согласования. А «бамашка» и не нужна — вся фиксация с персоналиями осталась в СКВ и системе отслеживания задач. А изменение можно и откатить, причем частично.
Вообще, подобное отношение «спустя рукава» характерно для «железячников», считающих ПО чем-то вторичным и побочным.
Это не единственная причина, почему используется СКВ. СКВ имеет смысл использовать для сохранения истории, привязки изменений в коде к задачам. Даже если работает один человек. Это — тоже документирование. Считайте, журнал изменений.Журнал изменений ведется в исходнике в виде комментариев о внесенных изменениях и причинах их внесения в заголовке исходника — и сюрприз — так было принято, когда никаких СКВ не было!
Вполне возможно, что код настолько плох, что инженеры просто не могут работать с кодом друг друга
Не должны! Люди имеющие узкие знания в области сложных процессов не должны разбираться не с чьим кодом — это основной лозунг ВП. Инженеры пишут код только от безысходности, и это не есть нормально.
«он должен обратится к модератору проекта с докладной запиской» — это не от хорошей жизни.
От генерируемых сообщений в ваших модулях может зависеть сотни модулей, сотни других людей — вы не можете в одиночку сломать работающую систему, в двоем тоже, без очень веской на то причины… Даже когда вы все сломаете — скорее всего придется оставить сигнал с заглушкой, поскольку другие участники проекта, могут быть не готовы к его отсутствию из вашего модуля. Напоминаю — код как и весь процесс сертифицирован. Имеет законодательные требования — т.е. поведение части модулей может быть определено законом, без «бамажки» тут вообще никак.
ПО не вторично — методы его разработки зачастую вторичны и деструктивны… Никому не нужно, падающее глючное, жрущее 100мегабайт ОЗУ «тяп-ляп» из сотни версий, когда вы управляете ядерным реактором или газовой турбиной высокой мощности. Если вы в мелочах представляете динамику движения космического аппарата и 30 лет занимаетесь этим — учебник по С в вашей голове, это только мусорные знания, которые должны заменятся или ВП с автогенерацией кода, или студентом «подай-принеси-напиши ка говнокод» — но второй вариант хуже по понятным причинам!
Журнал изменений ведется в исходнике в виде комментариев о внесенных изменениях и причинах их внесения в заголовке исходника — и сюрприз — так было принято, когда никаких СКВ не было!
Именно — так было принято когда-то. Так же как — сюрприз! — было принято когда-то жить при свечах.
СКВ — это централизованный журнал. Индексированный, с возможностью поиска и наглядного сравнения. Комментарии по функциональности не стоят и близко — в СКВ я могу наглядно сравнить две версии side-by-side.
Не должны! Люди имеющие узкие знания в области сложных процессов не должны разбираться не с чьим кодом — это основной лозунг ВП.
А никто и не говорит про узко-специальные знания. Код не только из них состоит, значительная часть универсальна и перекрывается работниками. Пример — упомянутые выше библиотечные функции. Или обвязка какая-нибудь.
Инженеры пишут код только от безысходности, и это не есть нормально.
Программирование — это инженерная дисциплина. Так что программисты — тоже инженеры *глядит в свой диплом программиста — квалификация «инженер»*.
Когда я говорил выше про «инженеров, которые не могут понять код друг друга» я имел в виду инженеров-программистов, разумеется. Если кто-то иной пишет код, то он, кем бы он ни был, в это время выполняет работу инженера-программиста. А вот имеет ли он навыки для этого — вопрос.
От генерируемых сообщений в ваших модулях может зависеть сотни модулей, сотни других людей — вы не можете в одиночку сломать работающую систему, в двоем тоже, без очень веской на то причины…
ПО не вторично — методы его разработки зачастую вторичны и деструктивны…
Вот об этом я и говорю — вы относитесь к разработке ПО (методология сюда входит) как чему-то вторичному. Программирование — это отдельная сфера, отдельная дисциплина, требующая подготовки и актуальных профессиональных навыков. Но для инженеров-схемотехников это какая-то мелочь, которую можно делать на коленке, как-нибудь, устаревшими методами, которым можно придать надежность только жестко забюрократизировав и растянув тем самым разработку на более долгий срок. Методика разработки ПО совершенствуется, так же как и методы разработки электроники. Вряд ли кто-то возьмется сейчас проектировать крупный блок чисто на логической рассыпухе, руками на ватмане — методы поменялись, есть системы CAD, есть системы моделирования для виртуального тестирования работы устройства.
С программированием — то же самое. Методы изменились.
Вы говорите выше о «сломе модуля» — это решается сейчас элементарно. Каждый блок, имеющий спецификацию по входным-выходным данным, ожидаемой работе, покрывается тестами, проверяющими, работает ли программный блок в соответствии со спецификацией. Применяется Continous integration, что предполагает постоянное тестирование.
Скажем, у меня есть некоторый библиотечный модуль, в который я на работе вношу изменения. Каждые, скажем, 15 минут специальный демон берет актуальную копию кодовой базы, собирает ее и прогоняет тесты. Каждые 15 минут. Как только я «сломал» блок (он уже не отвечает заданной спецификации) максимум через 15 минут всем, втч мне придет e-mail, говорящий о том, что я — редиска — и сломал тесты.
При этом я могу либо поправиться, чтобы блок по-прежнему подходил под спецификацию, либо откатить изменения нажатием одной кнопки. Даже если это было изменение 100 разных файлов. И это все сохранится в истории. И человек, которому достанется мой код (когда, скажем, я уйду на пенсию) сможет легко разбираться в узких местах, опираясь на историю изменений и связанные с ней задачи в электронной системе отслеживания задач. Там же будут зафиксированы переговоры с коллегами по теме этой задачи, что даст контекст и так далее.
Никому не нужно, падающее глючное, жрущее 100мегабайт ОЗУ «тяп-ляп» из сотни версий, когда вы управляете ядерным реактором
Это софистика, даже комментировать не особо хочется. Вы зачем-то смешиваете современную методологию и некий конкретный плохой результат чьей-то работы. Пишите софт для управления ядерным реактором не жрущий 100 Мбт памяти просто так — кто ж за руки держит? Это не имеет никакого отношения к методологии. И так, на всякий случай, «версия» — это чисто внутреннее понятие, оно не соответствует релизной версии. Вы может разработать и выпустить одну-единственную версию своего встроенного ПО, на которую придется десять тысяч внутренних версий.
MacIn вы все пишите правильно. И СКВ применяется с визуальным программированием уже давно и очень успешно. Но тут такое дело — вы мало разбираетесь в особенностях промышленного embedded программирования, о чем твердят вам собеседники.
Чисто такая мелочь как Continous integration с embedded превращается в очень интересное занятие. Как вы, допустим собираетесь делать CI для ПО для микроконтроллера, которое работает на совершенно другой процессорной архитектуре, с реальными датчиками, АЦП, ЦАП, лампочками и моторами в реальном времени? В 99% случаев я вам отвечу — никак. Вы выберете очень простой подход — программируете, программируете, отлаживаете код в каком-нибудь симуляторе, насколько возможно, а потом… идете к своей железяке и пытаетесь запустить этот же код там. И если у вас с первого раза получится хоть помигать светодиодом (программа подала признаки жизни) — это уже огромная победа. А потом вы сидите часами и днями отлаживая одну-единственную версию вашей программы, пока она наконец не заработает в полном объеме на этом железе. Вот вам релиз v0.1. А до v0.2 вы дойдете еще через полгода, после полного цикла тестов на железе.
И все ваши внутренние десять тысяч версий при этом нафиг никому не нужны, даже вам самому, так как среди них есть только одна рабочая — та, что v0.1.
Как вы разворачиваете вашу программу на железке?
Насколько я понимаю, есть специальный порт для разрабочиков, через который в железку заливается бинарный файл. Верно?
Если так, то CI вполне себе жизнеспособен.
Процесс получается такой (на примере git):
- Вы (постоянно) подключаете свою железку к серверу, где находится основной репозиторий и CI-демон (не обязательно отдельный комп)
- Вы выполняете какие-то изменения в коде программы, проталкиваете коммит в основной репозиторий
- При получении коммита, демон компилирует бинарный файл, выполняет программные тесты, заливает бинарник на вашу железку и шлет вам email "все хорошо" или "ты редиска"
- Вы берете железку и начинаете ее проверять ручным способом
Тысяча внутренних версий вам нужна не для того, чтобы их отдавать клиентам, а для того, чтобы видеть какие подходы вы пробовали, что и где меняли в программе.
Как говорил Т. Эдисон: "Я не терпел поражений. Я просто нашёл 10 000 способов, которые не работают."
Как вы разворачиваете вашу программу на железке?
Насколько я понимаю, есть специальный порт для разрабочиков, через который в железку заливается бинарный файл. Верно?
Не всегда. Так же любой дурак захочет в нашу железку всунуть свою прошивку? Да, может быть такой метод, но часто микросхема памяти программируется отдельно на программаторе и потом вставляется в плату. Ну и OTP используется повсеместно.
Вы (постоянно) подключаете свою железку к серверу, где находится основной репозиторий и CI-демон (не обязательно отдельный комп)
Т.е. допустим если это холодильник или стиральная машина — она будет постоянно подключена к серверу? Ну ок, придется воду и слив провести, но что делать? А что делать с автомобилем, например?
При получении коммита, демон компилирует бинарный файл, выполняет программные тесты, заливает бинарник на вашу железку и шлет вам email "все хорошо" или "ты редиска"
После данного этапа вы сделали всего 1% тестовой работы.
Вы берете железку и начинаете ее проверять ручным способом
Вот это 99% всей тестовой работы, которая может занимать месяцы на проведение всех тестов. И она ручная!
Так же любой дурак захочет в нашу железку всунуть свою прошивку?
у вас железка для дураков, никакой защиты?
сли это холодильник или стиральная машина — она будет постоянно подключена к серверу? Ну ок, придется воду и слив провести, но что делать? А что делать с автомобилем, например?
а что мешает сделать стенд для автомобиля?
Да, может быть такой метод, но часто микросхема памяти программируется отдельно на программаторе и потом вставляется в плату.
знаете, у меня тема диплома была — эмулятор ПЗУ. Это было более 30 лет назад. после диплома это спаяли (правда, несколько доработали). и использовали лет 6 точно…
Вот это 99% всей тестовой работы, которая может занимать месяцы на проведение всех тестов. И она ручная!видимо, что-то в вашей консерватории надо менять…
у вас железка для дураков, никакой защиты?
Я образно упомянул "дураков" в смысле, что это будет какой-нибудь хакер с шеловливыми ручками, попытающийся взломать железяку ради спорта, и не понимающий всех последствий этого. Часто даже для его собственного здоровья. Проблема в том, что если с ним или другими случится что-то плохое, не ему за это отвечать, а мне, как изготовителю железки.
а что мешает сделать стенд для автомобиля?
Ну мешает стоимость и время — такой стенд стоит в десятки раз дороже самого автомобиля. И для каждой железяки он нужен свой, специфический.
знаете, у меня тема диплома была — эмулятор ПЗУ. Это было более 30 лет назад. после диплома это спаяли (правда, несколько доработали). и использовали лет 6 точно…
Тем не менее такие эмуляторы не появились для всего на свете.
видимо, что-то в вашей консерватории надо менять…
Ну предложите вы что-нибудь. Пока лучше, чем ручками, никто не предложил.
Проблема в том, что если с ним или другими случится что-то плохое, не ему за это отвечать, а мне, как изготовителю железки.с каких пор изготовители ножей отвечают за убийства, а нефтедобытчики — за сокрытие трупов путем сожжения, либо за токсикоманию?
с каких пор изготовители ножей отвечают за убийства, а нефтедобытчики — за сокрытие трупов путем сожжения, либо за токсикоманию?
Ну, а как выше написали, если холодильник сойдет с ума и заморозит все ваши продукты, кто будет отвечать? Или если барабан улетит из стиральной машины, так как кто-то задаст вместо 1500 об/мин 5000 об/мин?
Пользователь?
Хмм, вы понимаете вообще разницу между
Ну, а как выше написали, если холодильник сойдет с ума и заморозит все ваши продукты, кто будет отвечать? Или если барабан улетит из стиральной машины, так как кто-то задаст вместо 1500 об/мин 5000 об/мин?
между
ну так если я буду греть на газовой плите ведро с бензином — в этом будет виноват производитель плиты? Если я поставлю стиралку негоризонтированной — отвечать тоже будет производитель? если я включу ее в «бытовую» розетку? Если я буду мыть в ней домашних питомцев, или купать детей?
И кто в каких случаях за что отвечает?
Т.е. если кто-то сделает не по инструкции или вмешается в работу/конструкцию прибора.
Я ж и говорю, что этот кто-то — хакер, желающий потешить свое самолюбие. Не путайте с пользователем, который может вследствие этого пострадать.
покажите мне хакера, который попытается тайно взломать запаянное ПЗУ в моей стиральной машинке…
Возьмите вместо стиралки что-то более интересное — умный замок, систему сигнализации, автомобиль, самолет, систему защиты АЭС и таких желающих хакеров сразу станет гораздо больше. Возвращаясь к теме портов для заливки прошивки — да, доходит до того, что порт просто физически выламывается в цикле производства. Дешево, но сердито.
Выломаный порт достаточно легко обходится при наличии в прямых руках паяльника.
т.е. проектанты системы безопасности АЭС, или самолетов не могут позволить себе нанять нормальных программистов?
Коллега ниже с удовольствием описал нам сколько отделов программистов понадобится, чтобы выполнялись все методики проектирования ПО для таких ответственных систем. Да, денег легко может и не хватить.
покажите мне хакера, который попытается тайно взломать запаянное ПЗУ в моей стиральной машинке…Это сегодня там ПЗУ а завтра флешка с обновлением через инет…
Да, может быть такой метод, но часто микросхема памяти программируется отдельно на программаторе и потом вставляется в плату. Ну и OTP используется повсеместно.
Я думаю и с программатором можно организовать CI. Возможно там будет немного больше ограничений, чем в CI для веб-разработки, но все же. Программатор ведь все равно подключен к машине разработчика и ему передается бинарник. Ту часть CI, когда вы плату припаиваете к железке, пожалуй, не получится так просто автоматизировать.
При этом каждую такую плату можно маркировать точной внутренней версией вашей программы.
Будет не 100500 отработанных плат (если вдруг они одноразовые при тестировании) с пометкой (v0.1), а по 3 платы с пометками вроде 38bb561.
Т.е. допустим если это холодильник или стиральная машина — она будет постоянно подключена к серверу?
В чем проблема подключить стиралку к серверу (при наличии соответствующих интерфейсов)? Ну можно не к серверу, а к какому-нибудь агенту CI.
Вам ее всю вряд ли нужно подключать. Достаточно соорудить тестовый стенд, а к барабану прицепить тахометр. У вас наверняка он будет даже для ручного тестирования.
Для автомобиля то же самое. При разработке программы для управления подачей топлива вам не нужно тестировать электроусилитель руля и климат-контроль. Тестовый стенд будет включать в себя только то, что нужно и при этом управляться без вашего участия.
Ну а при завершении работы над отдельными частями, потом уже провести интеграционные тесты.
Вот это 99% всей тестовой работы, которая может занимать месяцы на проведение всех тестов. И она ручная!
Что представляет из себя такое тестирование? Подача на плату каких-то исходных данных через какой-то порт и оценка того, что она выдает на другом порту?
В первый раз это может быть и можно сделать вручную, но во второй раз можно и эмулировать в автотестах.
При этом в третий и все последующие разы демон CI вам сможет сам выполнить этот тест при получении коммита.
Таким образом количество ручной работы у вас будет сокращаться с 99 до 40. Часть тестов просто не нужно будет повторять руками потому что они уже были выполнены автоматически.
40% потому что часть тестов наверняка завязана на физические процессы вроде "при подаче такого тока, плата перегревается и сгорает" или "при такой скорости вращения барабана, он вылетает и убивает мимо проходящего человека".
Что представляет из себя такое тестирование? Подача на плату каких-то исходных данных через какой-то порт и оценка того, что она выдает на другом порту?
Нет, и в этом есть одно из заблуждений программистов. Плата взаимодействует с окружающей средой и поэтому входные данные зависят от того, какой сигнал она выдаст в конкретный момент времени. Т.е. включила она нагрев — должна повышаться температура на входе, выключила — понижаться и все это по определенному закону. Если вы просто подадите записанный сигнал температуры без привязки к сигналу нагрева от платы — вы тестируете неправильно.
Самое смешное в этом деле, что согласно всяким теоремам Котельниковых, Найквистов и критериям устойчивости такой системы с обратными связями, ваш тестовый стенд должен работать хотя бы на порядок быстрее, чем контроллер. Т.е. например, если контроллер опрашивает температуру раз в секунду, то ее вычисление стендом и подача на вход контроллеру должно производиться 10 раз в секунду или чаще, чтобы сымитировать реальность. Иначе вы получите множество вопросов на тему "почему все прекрасно работает в реальности, но нифига не работает на стендах".
Именно поэтому тестирование с реальным объектом управления так важно. А визуальное программирование с моделированием дает возможность это сделать виртуально за два клика.
Именно поэтому тестирование с реальным объектом управления так важно. А визуальное программирование с моделированием дает возможность это сделать виртуально за два клика.
мы уже выяснили, что под слоем картинок прячется вполне себе текстовое представление «нарисованной» программы.
если скрытый от художника текст нарисованной программы может тестироваться в связке с реальным объектом — что мешает тестировать текст реальный?
Именно — так было принято когда-то.Вы работаете в фирме которой лет меньше чем России (потому что ни одна с развала СССР не сохранилась)… Очевидно, что для вас все, что было до момента вашего выпуска из института или не знаю там — курсов… находится в поле времени «когда то».
А теперь представьте себе, что задача именно программирования в данном понимании, существует ровно с момента изобретения микропроцессора +- т.е. с начала 1970х годов! И что существуют например изделия построенные на базе архитектуры образца 1983 года года+железа образца 1993 года с процессорами по технологии 1мкм просуществовавшего в активном виде десятилетия и последний раз выпущенного в партии 10млн штук в период 2008-2013 года. Так вот там 64к памяти и компилятор и код в базе — образца 1983 года! И все методики разработки образца 1983 года — с ассемблером. Рынок — Китай! Законодательно на рынке допустимо именно на этом железе решить задачу. И это очень выгодно…
Т.е. есть люди которые еще помнят боль перехода с ассемблера на С и сейчас ведут разработку только на С99 (а в некоторых случаях — даже на С89) потому, что еще раз эта боль — не нужна!
Программирование — это инженерная дисциплина. Так что программисты — тоже инженеры *глядит в свой диплом программиста — квалификация «инженер»*.
Знаете почему инженеров программистов с математическим образованием на мороз не выгоняют? их нельзя заменить системами кодогенерации. Никакая машина не способна решить задачу замены для реализации алгоритма 200байт ОЗУ на 100, или экономии каждого такта процессора там где надо его экономить — а это всегда надо, когда изделий миллионы…
Вот об этом я и говорю — вы относитесь к разработке ПО (методология сюда входит) как чему-то вторичному.
Давайте проще — собственно речь идет только о замене кодогенерации (на автомат) и исключения код-ревью (опять же ревью для правил автомата). Все это в целом 2-3% трудозатрат в подобных проектах… Основные затраты — сами модели управления (алгоритмы) и их ревью — вам может понадобится 2 недели, для разработки и верификации корректности и адекватности элементарного алгоритма и всего 5 минут для его кодирования руками (или 2 сек для автокодирования). И как в этом случае еще можно относится к этому процессу!? все это настолько рутина и настолько скучно и просто, что все эти методики выглядят как попытка раздуть слона из мухи.
Методика разработки ПО совершенствуется, так же как и методы разработки электроники. Вряд ли кто-то возьмется сейчас проектировать крупный блок чисто на логической рассыпухе, руками на ватмане — методы поменялись, есть системы CAD, есть системы моделирования для виртуального тестирования работы устройства.И они сокращают время и стоимость!
Выкидывание программистов на мороз с заменой на программу — резко сокращает стоимость. Применение СVS — ее увеличивает. (Поэтому программистов на мороз выкинули 20 лет назад а CVS ввели относительно недавно и не везде — причем в основном из за проблем в самих CVS с правами доступа, потому что модель из трех прав (нифига-RO-RW) не годится).
Каждый блок, имеющий спецификацию по входным-выходным данным, ожидаемой работе, покрывается тестами, проверяющими, работает ли программный блок в соответствии со спецификацией.
Визуальная модель является одновременно: спецификацией, исходником для кодогенератора, инструкцией для генератора автотестов, исходником генератора документации на программное обеспечение для пользователей более низкого уровня. Ваши 2 сущности заменены одной — вы уже проиграли по времени-стоимости. А еще даже документацию не наваяли и не выпустили ;)
Скажем, у меня есть некоторый библиотечный модуль, в который я на работе вношу изменения.Последнее изменение в библиотечных модулях одного визуального языка датировано 2004-м годом… Объясните — зачем вы ежедневно изменяете библиотечные модули?
Вы вообще понимаете, что такое библиотечный модуль и на каком уровне он должен быть реализован?! Если вы можете произвести рефакторинг библиотечного модуля — того кто его написал, надо под зад коленом выбросить за профнепригодность! Если кто то может сделать это с вашим — с вами надо проделать то же самое. Если вы на том же железе можете реализовать, что то быстрее-лучше-с меньшими затратами памяти, чем в библиотечном модуле — у вас очень серьезные проблемы внутри всего этого вашего «зоопарка новых технологий».
Каждые 15 минут
Вы знаете для меня не существует winapi выше XP-шной. Причина проста: 1) оно решает все задачи. 2) его 10 лет не трогали. 3) (специально для вас) «оно было когда никаких вас не было».
Мне не нужен API, у которого будет меняться интерфейс спецификация, реализация, или что то там еще в интервале 15-ти минут. И библиотеки такие тоже нафиг не нужны. Потому, что они не имеют абсолютно никакого отношения к библиотекам… Нет они конечно могут выглядеть как библиотеки, быть слинкованы как библиотеки, иметь интерфейс как у библиотек — но все равно — нафиг…
И все методики разработки образца 1983 года — с ассемблером. Рынок — Китай!
Как так получилось, что методики разработки у вас жестко привязаны к железу и софту?
Визуальная модель является одновременно: спецификацией, исходником для кодогенератора, инструкцией для генератора автотестов
Что именно вы называете автотестами?
Вы используете автотесты, чтобы оценить разницу между двумя версиями вашей модели?
Как так получилось, что методики разработки у вас жестко привязаны к железу и софту?Очень просто.
Если у вас 64к забиты под завязку — ни на чем кроме ассемблера это не пишется. И по сути все написание софта — косметическая доработка легаси кода, образца 93 года, собираемого компилятором 83 года. И что вы собрались поменять там? «рефакторинг» одного из эффективнейших by design кодов произвести? Или новый текстовый редактор прикрутить _не ДОСовый_… Ну это конечно мега задача…
Что именно вы называете автотестами?
Вы используете автотесты, чтобы оценить разницу между двумя версиями вашей модели?
Автотесты нужны, чтоб убедиться что реализация соответствует модели — если ее руками накодили. А если автоматом — вообще не нужны потому, что кодогенератор протестирован на 100500%.
Компилятор и стандарт языка это не методологии, а инструменты.
Методология это про то, как люди в вашей организации делают работу.
У вас наверняка проводятся испытания ваших моделей на реальном железе перед выпуском. Как происходит передача модели на испытания? Что вы делаете, чтобы убедиться что испытания проводятся именно над той моделью, которую вы считаете финальной?
Как защищаетесь от человеческого фактора при передаче?
Системы контроля версий ортогональны компиляторам и версиям стандартов языков. В СКВ можно положить исходники того артефакта, который вы меняете в процессе своей работы, в том числе вашу Модель.
Каждое сохранение в СКВ имеет свой номер и это здорово помогает в коммуникации.
А если автоматом — вообще не нужны
Как вы проверяете, что модель корректно решает поставленную в ТЗ задачу?
1) Модель алгоритма управления объектом прогоняется в симулинке (или аналоге) по модели самого объекта реализованного опять же в симулинке (или аналоге)… При этом выполняется часть адаптационных работ и система приводится в состояние, в котором она уже способна управлять реальным объектом (худо бедно).
2) Если в итоге модель алгоритма управления адекватна модели объекта — производится синтез системы управления на базе совокупности всех используемых моделей. В финише сборка семпла ПО c частью уже адаптированных данных.
3) Готовая в железе система тестируется на физической модели объекта (это шкаф с проводными выходами и входами, где на пачке xilinx-ов реализована та же симулинковская модель — но уже в виде железяки c напряжениями и частотами, а не в виде формул и сообщений). На этом этапе становится понятно, что НAL+драйверы (написанные всегда в ручную) и железо системы функционируют правильно. (и как тут уже было сказано — те версии, где не правильно, ни в каком виде не нужны! а те где правильно — не надо больше никогда трогать, чтоб не ломать!)
4) Если все ОК — добро пожаловать на реальный объект — в процесс адаптации.
Что вы делаете, чтобы убедиться что испытания проводятся именно над той моделью, которую вы считаете финальной?
Это не требуется — вы можете вернутся от 4 к 1 что то добавить и начать снова. (причем есть методы сделать это наглым хаком, прямо в собранном коде — специально предусмотренные в этом самом коде в апликационных версиях). Вы можете наоборот редуцировать модель на этапе адаптации, обнулив какие то коэффициенты. Модель как правило содержит сильно больше возможностей, чем реально надо для объекта… Т.е. она разрабатывается для абстрактного множества объектов и включает фундаментальные доступные научные знания в области управления, для данного класса объектов. Требуется, чтоб люди из 4 понимали, с чем именно они работают — а это обеспечивает документация, автоматом генерируемая из ФАКТИЧЕСКОЙ модели. И код из нее же… Задача адаптации — выполнение исходных требований (часть законодательно определена).
Как защищаетесь от человеческого фактора при передаче?Единственный человеческий фактор, как раз на этапе кодирования (не соответствие реализации на C исходной графической модели) — от него ревью и тесты… Если автомат — человеческого фактора нет.
Как вы проверяете, что модель корректно решает поставленную в ТЗ задачу?
Для отдельной модели можно измерить входные-выходные параметры в реализации и затем в симулинке опять же прогнать их по модели объекта, тупо вычислив среднеквадратичную ошибку на выходах… Если она у нуля болтается — все нормально. Хотя это уже не факт, что проблема модели — возможно проблема адаптации. Но это уже прям совсем финиш в верификации. Если уж ошибки у нулей — то «все работает».
Вообще, подобное отношение «спустя рукава» характерно для «железячников», считающих ПО чем-то вторичным и побочным— так об этом многократно сторонниками визуальщины говорилось… типа, они — Инженеры, а программеры — это обуза, которую надо нагнуть, а лучше — разогнать…
впрочем, подобный снобизм встречается и у программистов.
наиболее ярко, наверное, у Паронджанова с его Дураконом.
они просто не понимают, что программирование давно стало инженерной отраслью, со своими правилами, методологией, своими подходами в обеспечении качества и надежности…
они просто не понимают, что программирование давно стало инженерной отраслью, со своими правилами, методологией, своими подходами в обеспечении качества и надежности…
И очень дорогой отраслью. Я к тому, что профессиональный программист — это очень дорогой ресурс сегодня — нам приходится конкурировать с IT, где крутятся огромные бабки. Поэтому и получается, что в нашем бизнесе приходится иметь дело либо с а) самоучками-электронщиками, которые пишут спагетти-код корявыми ручками, либо б) профессионалами-фанатами, которые просто любят embedded. Но таких не найдешь днем с огнем. А все остальные — год-два и их переманивает IT. Поэтому и возникает стойкое желание избавиться от программистов совсем. Хотя бы в одной из задач. Вот народ и выходит из ситуации таким вот изощренным способом. И это, как ни странно для самих программистов, вполне неплохо работает.
Поэтому и возникает стойкое желание избавиться от программистов совсем.
Это скорее выглядит не как "избавиться от программистов", а как "выучить программистов на свой узкий стек, чтобы они не были востребованы во внешнем мире".
Возможно это одна из причин, по которым в таких конторах не используются общемировые практики типа СКВ и автотестирования.
Это скорее выглядит не как "избавиться от программистов", а как "выучить программистов на свой узкий стек, чтобы они не были востребованы во внешнем мире"
Открою тайну — на визуальное программирование я предпочитаю набирать людей с абсолютным незнанием программирования, но знакомыми с предметной областью, чем программистов и их переучивать. От программиста получается очень огромное сопротивление, которое мне не к чему.
нечто среднее между «вместо специалистов поставщика шеф-монтаж оборудования проведен силами наших среднеазиатских рабочих» и «Здравствуйте, я — молдавский вирус. В виду бедности моего создателя и общей отсталости развития высоких технологий нашей страны, я не в силах причинить какой-либо вред вашему компьютеру. Пожалуйста, сотрите сами несколько самых нужных вам файлов, а затем разошлите меня по почте своим друзьям»©
впрочем, проблема не нова — именно из-за такой же проблемы Паронджанов создавал свой Дуракон™. Только там причина была другая. помните, как у Стругацких, в «Понедельнике..»:
«Вам действительно так нужен программист?» — спросил я. «Нам позарез нужен программист». — «Я поговорю с ребятами, — пообещал я. — Я знаю недовольных». — «Нам нужен не всякий программист, — сказал горбоносый. — Программисты — народ дефицитный, избаловались, а нам нужен небалованный».©
Тогда начали появляться компьютеры, задачи для них — а пррграммистов никто не готовил. и вот для того, чтобы инженеры выкрутились, не изучая программирования — Паронджанов сотоварищи придумал это свою систему…
Но в силу того, что все-таки прогресс, в отличие о Паронджанова, не останавливался — у вас появился более приемлемый костыль — облегченный, анатомической формы, с мягкими ручками, напоминалкой, фонариком, держалкой для сотового телефона, кармашком для мелочи — но все равно костыль.
Хотя, честно говоря, я не знаю, на чем вы там развлекетесь — некоторые вещи «в графическом виде» вполне имеют право на жизнь, и облегчают работу (ну, упомянутый мной ранее STM32CubeMX, например. Матлаб.) но все равно есть границы…
ну то есть вы фактически согласились, что «визуальное программирование» — это не инженерный подход к решению задачи, а костыли, применяемые в связи с нехваткой денег на квалифицированный персонал. нечто среднее между «вместо специалистов поставщика шеф-монтаж оборудования проведен силами наших среднеазиатских рабочих»
Ну я бы сказал, что это когда "вместо высококвалифицированных людей, производивших расчеты вручную, мы закупили калькуляторы" или "автоматизировали работу котельной и уволили 10-ок высококвалифицированных надсмотрщиков".
Я бы назвал это автоматизацией. Часть этапов в "визуальном программировании" так и называется "автоматическая генерация кода".
И я бы сказал, что это вполне инженерный подход в вполне определенных отраслях, но можете считать это костылями.
Очень смешно. Процесс разработки в нормальных компаниях документирован. Применение в нем вообще «чего либо»-«шаг вправо-шаг в лево» требует внесение изменения в значительное количество документации
Это разовое мероприятие, как я писал выше.
переобучение персонала и последующую переаттестацию этого персонала, согласно новым методам разработки
Это разовое мероприятие и само обучение — не сложное. Вы пытаетесь, используя канцеляризмы, придать процессу весомость и несуществующую сложность. Такими формулировками очень удобно оправдываться перед несведущим начальством, здесь это неуместно.
Это разовое мероприятие,Божечки все эти методы «программистских гаражей» по созданию игрушек для айфончиков — так смешно мне делают…
Знаете, лицензия на Кейл бывает с кряком. Бывает честно купленная. А бывает — отдельная сборка Кейла, строго конкретных версий и линеек версий, специально для строго одной, конкретной фирмы, по определенным ей требованиям + круглосуточная! вечная! техническая поддержка этой сборки по отдельно выделенному телефонному номеру — не емейлу… не месенджеру… — а голосовому телефонному номеру, где отвечает отдельно выделенный для этой фирмы инженер-программист из Кейла, способный в любой момент сорваться на работу и решить любую проблему, в этой сборке Кейла в максимально кратчайшие сроки!.. Кстати удобная вещь — там менеджера лицензий нет, т.е. если у вас есть инсталятор, то она просто ставится и сразу работает, вечно, без каких либо ограничений в чем либо… При чем для остальных пользователей, этих версий, и линеек, и телефонов — не существует, ни за какие деньги. А по обычным телефонам в рабочее время отвечает либо секретарша, либо младший менеджер.
Так вот, ваше разовое мероприятие на 200 компов выйдет — лям долларов в год! Потому, что надо — «вот так»! Потому, что если что-то не так — то починить должны «вчера» и бегом, а не когда нибудь и может быть. Потому, что в документации разработчика ПО рядом с инструкцией в разделе CVS, указан круглосуточный телефон разработчика этой CVS, для поддержки по любым вопросам связанным с этой CVS — даже самым тупым. А так не бывает когда разворачиваешь «бесплатную фигню с гитхаба». Так бывает «за 1млн долларов в год»!
Вы не ответите на вопрос — как ваша CVS сэкономит 1.1m$ в год? — ну, чтоб менеджеру по внедрению было из чего себе потом премию выписать…
Вы как то слишком много пишете, чтобы троллить.
Как вы посчитали стоимость внедрения миллион долларов в год? Почему "в год"? Почему стоимость обучения людей у вас увеличивается от количества компов?
Git был выпущен в 2005 году, чтобы разрабатывать Linux. Это совсем не "игрушка для айфончика".
Честно не вычислял ROI от внедрения git на моей работе. Он у нас с самого начала проекта и приносит вот такую пользу:
- При передаче в тестирование все точно знают номер сборки и могут быть уверены, что тестируют именно то, что сделал разработчик.
- При передаче в релиз все точно уверены, что выпускают именно ту сборку, которая была протестирована.
- Есть возможность открыть файл и узнать, что строку №100 написал Вася в 2016 году. При этом он изменил еще вот эти файлы. Можно открыть ту версию из 2016 года и попробовать запустить ее (хоть в эмуляторе, хоть вживую). Это будет именно та версия, которую делал Вася.
Вы как то слишком много пишете, чтобы троллить. Как вы посчитали стоимость внедрения миллион долларов в год?Вполне себе типовая стоимость топовой лицензии и безлимитной поддержки на серьезное коммерческое ПО.
Git был выпущен в 2005 году, чтобы разрабатывать Linux. Это совсем не «игрушка для айфончика».Объясняю популярно.
Вы занимаетесь профессиональным производством ПО.
Для работы вы используете «инструменты» — и это профессиональные инструменты! Т.е. такие инструменты — которые люди их создавшие, умудрились ПРОДАТЬ, а не выложить куда либо бесплатно… Это очень существенное отличие — можно сказать решающее… (тут кстати стоит обратить внимание на % линукса на десктопах)…
У любого «инструмента» обязан быть метод «починки если сломается» и обязан быть тот, кто будет чинить (автор — как правило)…
Так вот — все ПО которое у вас прямо задействовано в техпроцессе, кроме конкретного доступного автора, должно иметь еще и поддержку — а следовательно оно может быть только коммерческое (купленное)!
ОС: коммерческая (win7 — и ее поддержка НЕ ЗАКОНЧИТСЯ для этого клиента, когда для остальных превратится в тыкву!)
Текстовый редактор: коммерческое решение из топ10 компаний производства текстовых редакторов! И если он вам не нравится, или в нем, что то по вашему не так — вам переделают по первому требованию! (хотя обычно текстовые редакторы подобного уровня, настраиваются как угодно и интегрируются с чем угодно — потому, что продать текстовый редактор в наше время, задача ну очень непростая)…
Компилятор: ТОП1 для заданной архитектуры. Ни о каких GCC даже речь не идет — Keil или Tasking или Metrowerks CW — смотря под что… (причем под капотом может быть GCC — но все равно по сути покупается «услуга»)
Система контроля версий: само собой тоже покупается (если надо). Что то там в jira встроенное — не помню.
На все это покупается полная поддержка на весь срок активной работы с выделением ПЕРСОНАЛЬНЫХ ОТВЕТСТВЕННЫХ в компаниях разработчиках этих продуктов.
Второй вариант — инструмент написан вашими инженерами. Соответственно — каждый скрипт, больше чем на три строки — имеет автора, код подразделения, местный телефон. Если его уволили а скрипт используется — тот кого взяли на его место, первым делом дописывает в скрипт свое имя и свой местный телефон и с этого момента ОТВЕЧАЕТ, за работу этого скрипта по этому телефону.
Третий вариант — софт написан компанией которая вашей принадлежит с потрохами (это как первый — только схема расчетов меняется)…
Так вот — чтоб вам скачать GIT, и настроить GIT, вам надо сначала завести целый отдел, где будут заниматься скачиванием-сборкой-развитием-интеграцией-поддержкой-серверами этого самого гита внутри компании, +выпуск документации (потому, что ordung — и никто не обязан знать то, чего нет в документации)… А это все стоит денег — и не понятно в каком месте их приносит… Хотя на самом деле конечно отделы занимающиеся игрушками на линуксах в подобных компаниях есть — и git они используют — и развивают, но это все «отделы игрушек» — магнитолок, мультимедий и планшетиков в Теслу на линуксе. Там уже другой уровень — как вы любите. Каждый добавляет, что хочет и когда хочет, у любой уборщицы R/W права и 100500версий — непонятно, какая из них работает — релиз подойдет разберутся.
Для работы вы используете «инструменты» — и это профессиональные инструменты! Т.е. такие инструменты — которые люди их создавшие, умудрились ПРОДАТЬ, а не выложить куда либо бесплатно…
Понял. В вашей организации на любой софт нужна поддержка и крайний ответственный.
Ну так есть вы тут не уникальны. Это почти всему крупному бизнесу нужно. У нас, например, выбрали вариант "свой отдел" и поддержкой сервера гита занимаются те админы, которые занимаются всей общей инфраструктурой, в т.ч. JIRA, confluence и т.п. На мой субъективный взгляд, поддержка гита сильно менее трудозатратна по сравнению с той же JIRA.
На гит тоже можно найти и поддержку и ответственного. Хоть по телефону, хоть по бумажной почте.
Если вам важна персональная ответственность за "скрипт", то гит может обеспечить вам ответственность на уровне каждой строчки в этом скрипте с историей и контактами человека, который последний раз менял его по существу.
Каждый добавляет, что хочет и когда хочет, у любой уборщицы R/W права и 100500версий — непонятно, какая из них работает — релиз подойдет разберутся.
СКВ это не про "кто угодно куда угодно пишет что вздумается". Это про то, что все знают кто, что, когда написал. Если культура развита, то понятно еще и почему.
В репозитории запросто может быть 100500 версий, но всегда понятно какая из них последняя и подлежит релизу. Разработчики в процессе своей работы при этом могут менять исходный код без риска что-либо серьезно испортить. Ну а когда приходит релиз, то у релизной версии в гите появляется минимум три ответственных:
- кто разрабатывал
- кто тестировал
- кто сделал эту версию новой релизной
СКВ это не проGIT про это.
СКВ прежде всего — это то где ты только «свое читаешь» и «в свое пишешь». А сборка на билд сервере. Чтоб не разбираться лишний раз, кто и что и какое на то имеет право… поэтому git даже за деньги не нужен — он для линускоидов only, где «все кругом колхозное-все кругом мое». Да он хороший удобный и классный — но в коммерческой разработке слабо пригодный, даже когда нужен.
Да он хороший удобный и классный — но в коммерческой разработке слабо пригодный, даже когда нужен.
Коммерческая разработка слишком большая и разная, чтобы делать такие категоричные заявления.
для линускоидов only, где «все кругом колхозное-все кругом мое»
В гите есть права доступа на репозитории. При желании можно организовать "свое читаешь и свое пишешь". Впрочем, мне нет нужны продавать вам именно гит. Я так понимаю, что СКВ у вас используется, просто какая-то другая.
Тогда возвращаемся к главному вопросу этой ветки комментариев: Ваша СКВ позволяет показать кто когда и как изменил каждый из блоков и связей в Визуальной Модели?
В гите есть права доступа на репозиторииА если у вас 100 человек на проекте — на каждого заведете репозиторий и будете из 100 репозиториев проект собирать или как?!
А модератор проекта у вас как в эти 100 репозиториев будет ходить?
А если у вас 100 человек на проекте — на каждого заведете репозиторий и будете из 100 репозиториев проект собирать или как?!Вы так говорите, как будто 100 репозиториев — это что-то большое и сложное…
Хотя на самом деле есть куда как более простое решение: Commi Queue. Бот, следящий за тестами и правами доступа. А на чтение — да, права будут у всех… но это редко когда бывает проблемой.
А модератор проекта у вас как в эти 100 репозиториев будет ходить?Кто такой «модератор проекта» и зачем ему в 100 репозиториев ходить?
Кто такой «модератор проекта» и зачем ему в 100 репозиториев ходить?
Подождите — а у вас что никакой иерархии нет? т.е. программисты это просто стадо которое пишет, что хочет и где хочет — а на следующий рабочий день следующая смена все еще раз заново переписывает, так что ли? Ну не мудрено.
Подождите — а у вас что никакой иерархии нет?Иерархия, конечно, есть. И именно поэтому нет какого-то загадочного модератора, которому нужно было сразу во все дырки затычкой быть.
Потому, что фирмы умеющие это делать, считаются по пальцам одной руки, системы умеющие это делать стоят очень дорого — и там применяют строгие меры к тому, чтоб впредь, в дальнейшем, так и оставалось. А значит вы не войдете ни в одну дверь, куда вам нельзя, и не увидите ни одной строчки кода, который лично вашей части проекта не касается, и не будете знать, над чем работает ваш сосед — и все это не сегодня придумано. А где то будет человек, который всегда будет знать больше и отвечать строже…
Да, когда у вас «бесплатное — скачать из интернета» — глупо хранить секреты. Но в мире есть и абсолютно полная противоположность. И конечно мир не черно-белый, и промежуточные варианты тоже есть…
Почитайте про утечку части кодов АVP — очень показательно и подумаете, что бы было — если бы там был git… а Касперский — не rocket science. Их в мире 150 штук…
Знаете почему ГТД высокой мощности запустить нельзя!?Знаю, конечно.
Потому, что фирмы умеющие это делать, считаются по пальцам одной руки, системы умеющие это делать стоят очень дорого — и там применяют строгие меры к тому, чтоб впредь, в дальнейшем, так и оставалось.Госсподи, какой бред. Вы ещё про «секретную» формулу кока-колы вспомните.
Турбины Siemens в Крыму работают — несмотря на все санкции, однако. А с выпуском — тут да, проблема. Только не та, о которой вы думаете.
Разработать и произвести ГТД высокой мощности — это экономическая проблема, а не технологическая. Грубо говоря вам нужно достаточно много заказчиков, чтобы это окупилось. Потому Китай или Индия — могут освоить такое производство, а России, увы, не может. Ну разве что с Индией договорятся (Китай наверняка сам захочет их делать научиться и ему, со временем, это удастся).
А все эти «секретные секреты» на 99% призваны прикрыть чью-то задницу, а не обеспечить эффективное производство.
не, тут явно «или крестик, или трусы...»©
А модератор проекта у вас как в эти 100 репозиториев будет ходить?
Зачем ему во всех репозитории ходить?
Это точно один человек и ему нужно 100 знать?
Казалось бы, если такая секретность, то почему есть один человек, который может везде читать?
Можно организовать специальный репозиторий для модератора, в который сабмодулями будут включены все другие репозитории. Модератор рекурсивно выкачивает один репозиторий и видит картину целиком.
Какой смысл может извлечь один человек из ста репозиториев сразу — вопрос очень интересный.
Зачем ему во всех репозитории ходить?У вас «не нужно» — это понятно… у вас его нет, чтоб ходить… потому что git — проходной двор. там все ходят. Вы говорите, что что-то можно организовать — так вот можно организовать доступ каждому юзеру, строго к строго определенному набору модулей с любого рабочего места (терминала), после аутентификации личной смарткартой — и такая CVS тупо покупается из коробки и это не git.
то, что его не используют в эмбеддинге — не делает его ненужным.
Если надо картинки, то их можно найти тут: https://de.mathworks.com/help/simulink/ug/merge-simulink-models-from-the-comparison-report.html
В Matlab/Simulink merge и diff делаются на уровне моделей полностью графически.
«Абстракции текут».
Для эффективной работы с ВП нужно знать его текстовое представление.
Тогда зачем нужна картинка, когда есть текст. :-)
вот если бы он на схеме подсветил измениния, тогда да, а так скорее текстовое представление…
Ну вообще-то он и подсвечивает.
Конечно есть. Это встроенные в среду инструменты.

Предугадывая вопросы — слева не выходной код, а просто меню навигации между изменениями. Клик выделяет отличия на моделях справа.
Если у вас есть Матлаб свежих версий можете запустить команду slxml_sfcar, чтобы попробовать самому.
Матлаб попробую поставить, все после смены компа как-то не нужен был…
Если алгоритм управления системой охлаждения токамака считать программным продуктом, то вот Вам и пример применения визуального программирования. Языки GRAPH (ага, блок-схемы) и FBD. Кстати, там даже в стандартах это описывают: вот. Не думаю, что коды там занимают меньше 100 страниц. А учитывая, что систем там много и они все взаимосвязаны.
Ну а если промышленная автоматизация это всего лишь «задачка». Ну а что тогда пишут на javascript?
Опять же, всё зависит от проблематики вопроса и области приложения. Где то удобнее так, а где — то этак.
Ну а если промышленная автоматизация это всего лишь «задачка».
Ну вот, сейчас вам начнут доказывать, что все трушные автоматизаторщики пишут только на ST и начнется еще 500 комментов холивара. :-)
типичный пользователь — студент или выпускник технического вуза… в рекордно короткие осваивает инструменты визуального программирования ..., после чего готов к реализации бизнес логики приложения, и даже логических блоков, которые в коде выглядят сложно и запутанно даже для опытного программиста. Но… большинство таких визуальных программистов быстро понимают базовые принципы программирования и… они быстро осваивают языки и больше визуальное программирование их не интересует. /blockquote>
грубо говоря, когда человек учится ходить — ходунки или костыли очень сильно помогают ему, снижают время на обучение/реабилитацию. как только человек научился ходить без ходунков и костылей — ходунки и костыли ему больше не нужны.
Необходимо, чтобы такие люди вовлекались в использование, но не уходили из него в «серьезное текстовое программирование».а вы их не хотите туда отпускать. приклеить костыли намертво. или ноги постоянно ломать.
А прежде всего, что глубокие, профильные специалисты в области, не связанной с программирование, но в тех областях, где программирование может улучшить их деятельность (математики, физики, инженеры электронной техники, бухгалтеры итп).
На примере 1С можно увидеть, что сложный инструмент "для профильных специалистов" порождает "программистов" этого самого инструмента с некоторым бэкграундом в профиле. Профильные специалисты при этом либо занимаются написанием ТЗ на естественном языке, либо не отвлекаются от своей работы и ТЗ пишут "программисты инструмента". При этом необходимость написания ТЗ тоже порождает отдельную специальность.
В итоге получается три роли, которые занимаются своим делом: профильные специалисты — своей непосредственной работой. Аналитики — выясняют потребности профильных специалистов и пишут ТЗ. Программисты — реализуют ТЗ в коде.
Вы же ожидаете от нормального специалиста некоей культуры поведения, грамотной речи, владения арифметикой? ну и тут примерно так же.
Например знание химии не поможет вам в создании, например, стирального порошка.
Точно так же основы программирования не помогут в создании программ. ;-)
основы программирования не помогут в создании программ — но они могут дать понять, какие действия можно автоматизировать/запрограммировать, и примерно оценить (и сформулировать) задачу по автоматизации. что уже будет шагом вперед.
Поэтому пользователю не нужен ЯП, ему нужен удобный инструмент для решения задач.
Это только во времена палеолита каждый мог делать сам себе инструмент.
С того времени специализация и индустриализация немного изменили подход к инструментам. :-)
изменили подход к инструментам
Но не ко всем. Когда тебе по силам сделать для себя некоторый инструмент — у тебя есть выбор, сделать его или купить. Исходя соображений рационального использования времени, сил и средств, выбор может быть разным.
Скажем, молоток для забивания гвоздей я скорее всего куплю, а молоток для отбивания шлака после сварки — сварю из арматуры не сходя с места.
и в то же время некоторые вещи перешли в «общую культуру» — уже не надо звать писца, чтоб написать письмо. не надо искать человека, умеющего читать, чтоб понять по газете, какими налогами тебя обложили. да и знающего арифметику для расчета оных тоже искать не надо — это все стало обычными общекультурными навыками обычного человека.
сокурсник производит мебель не имея форматно-раскроечного станка. а тот, кто имеет раскроечный станок, присадочный станок, кромочный станок — не занимается производством мебели, а занимается раскроем, кромлением и присадкой.
и даже в эмбеддинге уже становится вполне реальным разделение на проектировщиков «в целом», железячников и программистов.
Решение проблемы с моим отцом было простое — он ушёл на пенсию (хотя мог бы проработать ещё несколько лет… к нему хорошо относились, но оплавивать работу ещё и секретаря руководители предприятия не захотели).
И вот то же самое — и с визуальным программированием. Как только те люди, которые принципиально не хотят учиться программировать уйдут на пенсию — оно станет не нужным.
Как вы уже сами сказали: у молодого поколения панического страха перед программированием нету и для его использования костыли им особо не нужны…
Основная проблема «визуальных» языков заключается в том, что они по сути ничего и не визуализируют. Изображение исходного кода в виде квадратиков — это профанация, а не визуализация.
Визуализировать нужно данные, визуализировать нужно поведение. Например, вот так. Ну или хотя бы вот так или вот так.
«Визуальные» языки программирования не делают ни того, ни другого, и потому беспомощны в своей убогости.
Неплохая производительность плюс возможность вызывать любые функции из dll, удобное создание GUI, ориентация на функциональный стиль (как правило, «кубики» состояния не имеют), соответственно и отладка проблем не представляет. Для наших старых расчетных фортрановских модулей сделал оболочки на Labview, эффективность работы с ними возросла на порядок.
.
Вообще, из скратчеблоков (см. Blockly) можно сделать надстройку для [почти] любого формального языка (не только программирования, HTML, к примеру, тоже). Это довольно тонкая надстройка над языком, просто облегчающая составление синтаксически-правильных конструкций и затрудняющая (вплоть до полной невозможности) написания синтаксически ошибочных.
Ну и радикальное решение проблемы интернализации ключевых слов, пока программа в виде блоков — мы можем на лету переключаться между английскими/русскими да хоть китайскими ключевыми словами, главное, чтобы соответствующая (условно говоря) .po-шка была написана.
У инструментов визуального программирования очень редко есть эффективные механизмы для таких вещей, в результате «визуальный» разработчик оказывается в ловушке доступных возможностей, эквивалентной BASIC'у 1970-х годов.
Ну для оригинального Скретча/Блокли всё расширяется выходом на исходный язык. Smalltalk для старого Scratch 1.x, JS для третьего Скретча, а для Блокли есть вот такая предельно простая в использовании штука, пусть и требующая знания языка, на который транслируется блокли код.
Желаете не выходить за пределы графической парадигмы? Встречаем разработанный в другом ведущем техническом университете США форк Скретча — Snap! (во времена работы поверх смолтока назывался BYOB, что в данном случае означает build you own blocks). Объектно-ориентированный (с толикой функциональщины, как это сейчас и принято) визуальный язык программирования, где все общепринятые механизмы абстрагирования можно применять не выходя из
Отсутствие хорошего контроля над версиями — еще один серьезный недостаток большинства инструментов визуального программирования.
Для обучения программированию хорошие средства контроля версий не сильно и нужны. А так — формат хранения вполне себе текстовый, ну а если кто-то когда-то решит встроить нечто блоклиподобное в серьёзную расширяемую платформу (условный 1с), то разработать подсистему отображения диффов в графическом виде — реалистичная задача. Другое дело, что 1С-ники, кажется, до сих пор пишут внешние скрипты для разработки своих конфигураций с использованием git/svn (код — текстовый, формы и отчёты, ок — визуальные, ну так это в любом Delphi/Qt/.Net проекте так). Или уже нет, есть официальное решение от вендора?
И да — это одна из ниш где визуальное программирование в стиле блокли будет уместно. Возвращаясь к теме «условного» 1С — github.com/SPE-Systemhaus/blockly-sql-app — блокли-надстройка над SQL.
Задачи, решаемые в парадигме автоматного программирования и графическое представление конечных автоматов я в этом комментарии не затрагивал (я так понимаю, примерно это обозначил «предыдущий оратор» в качестве того, что лучше делать визуально), сосредоточившись на Блокли-подходе, который просто-напросто визуальное представление старой-доброй идеи структурного программирования.
Ну и да, возвращаясь к тому, с чего начал, скретчкод — это ведь просто текстовая программа, ну сами посмотрите на пример скретчкода на картинке. Ну и чем это принципиально отличается от языков с питоноподобным синтаксисом?
Визуальное программирование — почему это плохая идея