Если ваши релизы быстры как молния, автоматизированы и надежны, можете не читать эту статью.
Раньше наш процесс релиза был ручным, медленным и напичканным ошибками.
Мы проваливали спринт за спринтом, потому что не успевали сделать и выложить фичи к следующему Sprint Review. Мы ненавидели наши релизы. Часто они длились по три-четыре дня.
В этой статье мы опишем практику Stop the Line, которая помогла нам сфокусироваться на устранении проблем конвейера выкладки. Всего за три месяца нам удалось увеличить скорость деплоя в 10 раз. Сегодня наш деплой полностью автоматизирован, а релиз монолита занимает всего 4-5 часов.

Я помню, как мы придумали Stop the Line. На общей ретроспективе мы обсуждали долгие релизы, которые мешали нам достигать целей спринта. Один из наших разработчиков предложил:
Мы решили, что если релиз длится более 48 часов, то мы включаем мигалку и прекращаем работу всех команд над бизнес-фичами монолита. Все команды, работающие над монолитом, должны остановить разработку и сосредоточиться на проталкивании текущего релиза в прод или устранении причин, вызвавших задержку релиза. Когда релиз застрял, нет смысла делать новые фичи, ведь они все равно выйдут нескоро. В это время запрещается писать новый код, даже в отдельных ветках.
Мы также ввели «Stop the Line Board» на простом флипчарте. На нём мы пишем задачи, которые либо помогают дотолкать текущий релиз, либо помогают избежать причин его задержки.
Конечно, Stop The Line — это непростое решение, но эта практика является важным шагом на пути к непрерывной поставке и подлинному DevOps.
В Экстремальном Программировании (XP) есть золотое правило: если что-то причиняет боль, делайте это как можно чаще. Наши релизы всегда были болью. Мы тратили несколько дней, чтобы развернуть тестовую среду, восстановить базу данных, запустить тесты (обычно несколько раз), разобраться почему они упали, исправить баги и, наконец, зарелизить.
Спринт длится 2 недели, а релиз катится три дня. Чтобы успеть зарелизить до Sprint Review в пятницу, по-хорошему надо начинать релиз в понедельник. Это означает, что мы работаем над целью спринта только 50% времени. А если бы мы могли релизить каждый день, то продуктивный период работы вырос бы до 80-90%.
Наш средний релиз обычно занимал два-три дня. Сначала над кодом в общей ветке dev работало шесть команд (а с ростом компании число команд увеличилось до девяти). Непосредственно перед релизом мы бранчевали релизную ветку. Пока эта ветка тестируется и регрессится, команды продолжают разработку в общей ветке dev. Прежде чем релизная ветка достигнет прода, команды напишут довольно много кода.
Чем больше изменений в инкременте, тем больше шансов, что изменения, внесенные разными командами, повлияют друг на друга, а значит тем более тщательно инкремент должен быть протестирован, и тем больше времени будет занимать его релиз. Это самоусиливающий цикл (см. Рис. 2). Чем больше изменений в релизе («конский» релиз), тем дольше время регресса. Чем дольше время регресса, тем больше времени между релизами и тем больше изменений команды делают перед следующего релиза. Мы называли это «кони рождают коней». Следующая CLD-диаграмма (Causal Loop Diagram) иллюстрирует эту зависимость:
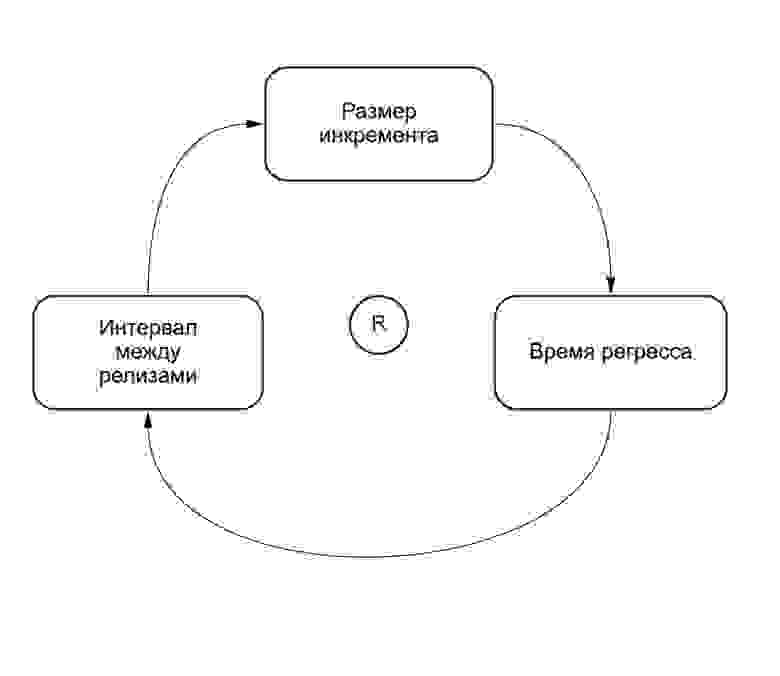
Рис. 2. CLD-диаграмма: длинные релизы приводят к еще более длинным релизам
Сначала мы решили избавиться от ручного регрессионного тестирования, но путь к этому был долгим и трудным. Два года назад ручной регресс Dodo IS длился целую неделю. Тогда у нас была целая команда ручных тестировщиков, которые проверяли одни и те же фичи в 10 странах неделю за неделей. Такой работе не позавидуешь.
В июне 2017 года мы сформировали команду QA. Основной целью команды была автоматизация регресса наиболее важных бизнес-операций: прием заказа и производство продуктов. Как только у нас стало достаточно тестов, чтобы мы начали им доверять, мы полностью отказались от ручного тестирования. Но это произошло только спустя 1,5 года после того, как мы начали автоматизацию регресса. После этого мы распустили команду QA, и участники команды QA присоединились к командам разработки.
Однако, UI тесты имеют существенные недостатки. Поскольку они зависят от реальных данных в базе данных, эти данные надо настроить. Один тест может испортить данные для другого теста. Тест может упасть не только потому, что какая-то логика нарушена, но и из-за медленной сети или устаревших данных в кэше. Нам пришлось потратить много усилий, чтобы избавиться от мигающих тестов и сделать их надежными и воспроизводимыми.
Мы создали сообщество единомышленников #IReleaseEveryDay и провели мозговой штурм как ускорить deployment pipeline. Первые действия были такими:
Благодаря вышеперечисленным решениям, мы сократили среднее время релиза, но оно все еще было раздражающе долгим. Пришло время системных изменений.
Мы ввели правило, что если релиз длится более 48 часов, то мы включаем мигалку и прекращаем работу всех команд над бизнес-фичами монолита. Все команды, работающие над монолитом, должны остановить разработку и сосредоточиться на докатывании текущего релиза до прода или устранении причин, вызвавших задержку релиза.
Во время Stop the line, в офисе включается оранжевая мигалка. Тот, кто приходит на третий этаж, где работают разработчики Dodo IS, видит этот визуальный сигнал. Мы решили не сводить наших разработчиков с ума звуком сирены и оставили только раздражающий мигающий свет. Так задумано. Как мы можем чувствовать себя комфортно, когда релиз в беде?

Рис. 3. Мигалка Stop the Line
Сначала Stop the Line понравилась всем командам, потому что было весело. Все радовались как дети и выкладывали фотографии нашей мигалки. Но когда она горит 3–4 дня подряд, становится не смешно. Однажды одна из команд нарушила правила и залила код в ветку dev во время Stop the Line, чтобы спасти свою цель спринта. Легче всего нарушить правило, если оно мешает тебе работать. Это быстрый и грязный способ сделать бизнес-фичу, игнорируя системную проблему.
Как Скрам Мастер, я не мог мириться с нарушениями правил, поэтому поднял этот вопрос на общей ретроспективе. У нас был трудный разговор. Большинство команд согласились, что правила действуют на всех. Мы договорились, что каждая команда должна соблюдать правила, даже если она с ними не согласна. А заодно о том, как можно изменять правила, не дожидаясь следующей ретроспективы.
Изначально разработчики не фокусировались на решении системных проблем с deployment pipelint. Когда релиз застревал, вместо того, чтобы помочь устранить причины задержки, они предпочитали разрабатывать микросервисы, на которых не распространялось правило Stop the Line. Микросервисы это хорошо, но проблемы монолита сами себя не решат. Для того, чтобы решить эти проблему, мы ввели бэклог Stop The Line.
Некоторые решения были быстрофиксами, которые скорее скрывали проблемы, чем решали их. Например, многие тесты чинились путем увеличения таймаутов или добавления ретраев. Один из таких тестов выполнялся 21 минуту. Тест искал самого недавно созданного сотрудника в таблице без индекса. Вместо того, чтобы исправить логику запроса, программист добавил 3 ретрая. В результате медленный тест стал еще медленнее. Когда у Stop The Line появилась команда-владелец, которая сфокусированно занималась проблемами тестов, в течение следующих трех спринтов им удалось ускорить наши тесты в 2-3 раза.
Ранее только одна команда испытывала проблемы с релизом — та, которая поддерживала релиз. Команды старались как можно быстрее избавиться от этой неприятной обязанности, вместо того чтобы вкладываться в долговременные улучшения. Например, если тесты на тестовой среде упали, их можно перезапустить локально и если тесты пройдут, продолжить релиз. С введением Stop The Line у команд появилось время, чтобы стабилизировать тесты. Мы переписали код подготовки тестовых данных, заменили некоторые UI-тесты API-тестами, удалили ненужные таймауты. Теперь практически все тесты проходят быстро и на любом окружении.
Раньше команды не занимались техническим долгом систематически. Теперь у нас есть бэклог технических улучшений, которые мы анализируем во время Stop the Line. Например, мы переписали тесты на .Net Core, что позволило нам запускать их в Docker. Запуск тестов в Docker позволил нам использовать Selenium Grid для распараллеливания тестов и дальнейшего сокращения времени их выполнения.
Раньше команды полагались на команду QA для тестирования и команду инфраструктуры для развертывания. Теперь рассчитывать не на кого, кроме самих себя. Команды сами тестируют и релизят код в Production. Это подлинный, а не поддельный DevOps.
На общей ретроспективе спринта мы пересматриваем эксперименты. За несколько последующих ретроспектив мы внесли множество изменений в правила Stop the Line, например:
Фактически, практика Stop the Line преобразует самоусиливающийся цикл (Рис. 2) в два балансирующих цикла (Рис. 4). Stop the Line помогает нам сосредоточиться на улучшении deployment pipeline, когда он становится слишком медленным. Всего за 4 спринта мы:
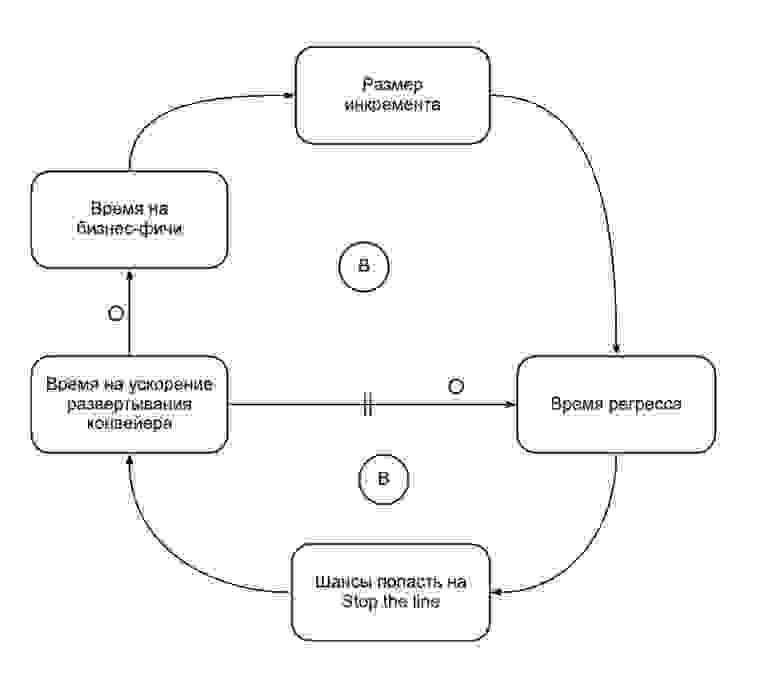
Рис. 4. CLD-диаграмма: Stop the Line уравновешивает время релиза
Stop The Line — яркий пример сильного решения, придуманного самими командами разработки. Скрам Мастер не может просто так взять и принести командам блестящую новую практику. Практика будет работать только если ее придумали сами команды. Для этого необходимы благоприятные условия: атмосфера доверия и культура экспериментирования.
Обязательно нужны доверие и поддержка со стороны бизнеса, что возможно только при полной прозрачности. Обратная связь, такая как регулярная общая ретроспектива со всеми представителями команд, помогает придумывать, внедрять и изменять новые практики.
Со временем практика Stop the Line должна сама себя убить. Чем чаще мы останавливаем линию, тем больше мы инвестируем в deployment pipeline, тем более стабильным и быстрым становится релиз, тем меньше причин для остановки. В конце концов линия никогда не будет останавливаться, если только мы не решим снизить порог, например, с 48 до 24 часов. Но, благодаря этой практике, мы здорово улучшили процедуру релиза. У команд появился опыт не только разработки, но и быстрой поставки ценности на прод. Это подлинный DevOps.
Что дальше? Я не знаю. Возможно, мы скоро откажемся от этой практики. Решать будут команды. Но очевидно, что мы будем продолжать двигаться в направлении Continuous Delivery и DevOps. Однажды моя мечта о релизе монолита несколько раз в день обязательно сбудется.
Раньше наш процесс релиза был ручным, медленным и напичканным ошибками.
Мы проваливали спринт за спринтом, потому что не успевали сделать и выложить фичи к следующему Sprint Review. Мы ненавидели наши релизы. Часто они длились по три-четыре дня.
В этой статье мы опишем практику Stop the Line, которая помогла нам сфокусироваться на устранении проблем конвейера выкладки. Всего за три месяца нам удалось увеличить скорость деплоя в 10 раз. Сегодня наш деплой полностью автоматизирован, а релиз монолита занимает всего 4-5 часов.
Stop the Line. Практика, придуманная командой
Я помню, как мы придумали Stop the Line. На общей ретроспективе мы обсуждали долгие релизы, которые мешали нам достигать целей спринта. Один из наших разработчиков предложил:
— [Сергей] Давайте ограничим объем релиза. Это поможет нам тестировать, исправлять баги и развертывать быстрее.
— [Дима] Может введем ограничение на работу в прогрессе (WIP limit)? Например, как только мы сделали 10 задач, останавливаем разработку.
— [Разработчики] Но задачи могут быть разными по размеру. Это не решит проблему больших релизов.
— [Я] Давайте введем ограничение, основанное на длительности релиза, а не на количестве задач. Будем останавливать разработку, если релиз занимает слишком много времени.
Мы решили, что если релиз длится более 48 часов, то мы включаем мигалку и прекращаем работу всех команд над бизнес-фичами монолита. Все команды, работающие над монолитом, должны остановить разработку и сосредоточиться на проталкивании текущего релиза в прод или устранении причин, вызвавших задержку релиза. Когда релиз застрял, нет смысла делать новые фичи, ведь они все равно выйдут нескоро. В это время запрещается писать новый код, даже в отдельных ветках.
Мы также ввели «Stop the Line Board» на простом флипчарте. На нём мы пишем задачи, которые либо помогают дотолкать текущий релиз, либо помогают избежать причин его задержки.
Конечно, Stop The Line — это непростое решение, но эта практика является важным шагом на пути к непрерывной поставке и подлинному DevOps.
История Dodo IS (техническая преамбула)
Dodo IS написана в основном на .Net framework с UI на React/Redux, местами на jQuery и вкраплениями Angular. Еще есть приложения для iOS и Android на Swift и Kotlin.
Архитектура Dodo IS – это смесь унаследованного монолита и около 20 микросервисов. Новые бизнес-фичи мы разрабатываем в отдельных микросервисах, которые деплоятся либо при каждом коммите (непрерывный деплой), либо по запросу, когда это необходимо бизнесу, хоть каждые пять минут (непрерывная поставка).
Но у нас еще есть огромная часть нашей бизнес-логики, реализованная в монолитной архитектуре. Монолит деплоить сложнее всего. Требуется время, чтобы собрать всю систему (артефакт сборки весит около 1 ГБ), запустить модульные и интеграционные тесты и выполнить ручной регресс перед каждым релизом. Сам по себе релиз тоже небыстрый. В каждой стране развернут свой экземпляр монолита, поэтому мы должны развернуть 12 экземпляров для 12 стран.
Непрерывная интеграция (CI) – это практика, которая помогает разработчикам постоянно поддерживать код в рабочем состоянии, выращивая продукт маленькими шагами, интегрируясь как минимум ежедневно в одной ветке при поддержке CI билда с множеством автотестов.
Когда несколько команд работают над одним продуктом и практикуют CI, количество изменений в общей ветке быстро растет. Чем больше изменений вы накапливаете, тем больше это изменение будет содержать скрытых дефектов и потенциальных проблем. Вот почему команды предпочитают деплоить изменения часто, что приводит к практике Continuous Delivery (CD) в качестве следующего логического шага после CI.
Практика CD позволяет развертывать код в прод в любое время. Эта практика основана на deployment pipeline — наборе автоматических или ручных шагов, которые проверяют инкремент продукта на пути к проду.
Наш пайплайн развертывания выглядит так:
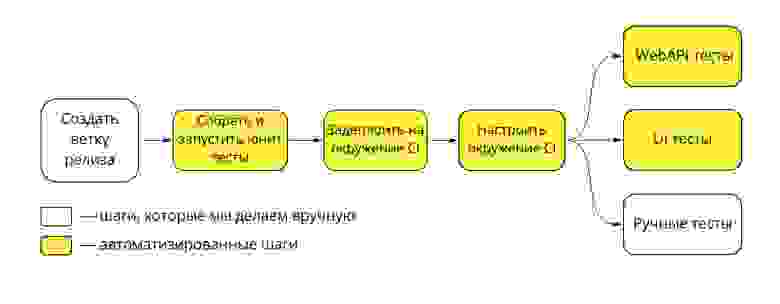
Рис. 1. Dodo IS Deployment Pipeline
Архитектура Dodo IS – это смесь унаследованного монолита и около 20 микросервисов. Новые бизнес-фичи мы разрабатываем в отдельных микросервисах, которые деплоятся либо при каждом коммите (непрерывный деплой), либо по запросу, когда это необходимо бизнесу, хоть каждые пять минут (непрерывная поставка).
Но у нас еще есть огромная часть нашей бизнес-логики, реализованная в монолитной архитектуре. Монолит деплоить сложнее всего. Требуется время, чтобы собрать всю систему (артефакт сборки весит около 1 ГБ), запустить модульные и интеграционные тесты и выполнить ручной регресс перед каждым релизом. Сам по себе релиз тоже небыстрый. В каждой стране развернут свой экземпляр монолита, поэтому мы должны развернуть 12 экземпляров для 12 стран.
Непрерывная интеграция (CI) – это практика, которая помогает разработчикам постоянно поддерживать код в рабочем состоянии, выращивая продукт маленькими шагами, интегрируясь как минимум ежедневно в одной ветке при поддержке CI билда с множеством автотестов.
Когда несколько команд работают над одним продуктом и практикуют CI, количество изменений в общей ветке быстро растет. Чем больше изменений вы накапливаете, тем больше это изменение будет содержать скрытых дефектов и потенциальных проблем. Вот почему команды предпочитают деплоить изменения часто, что приводит к практике Continuous Delivery (CD) в качестве следующего логического шага после CI.
Практика CD позволяет развертывать код в прод в любое время. Эта практика основана на deployment pipeline — наборе автоматических или ручных шагов, которые проверяют инкремент продукта на пути к проду.
Наш пайплайн развертывания выглядит так:
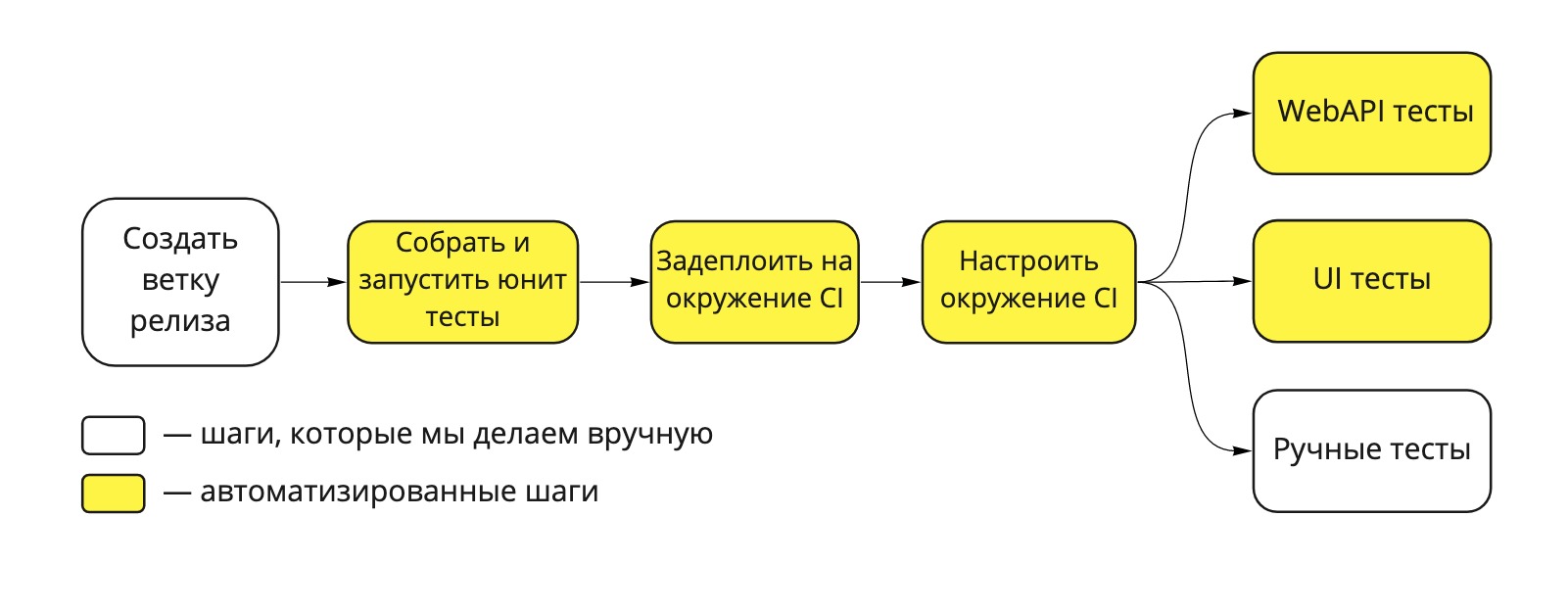
Рис. 1. Dodo IS Deployment Pipeline
Давайте релизить быстро: от проблемы к адаптированной практике Stop the line
Боль от медленных релизов. Почему они такие долгие? Анализ
В Экстремальном Программировании (XP) есть золотое правило: если что-то причиняет боль, делайте это как можно чаще. Наши релизы всегда были болью. Мы тратили несколько дней, чтобы развернуть тестовую среду, восстановить базу данных, запустить тесты (обычно несколько раз), разобраться почему они упали, исправить баги и, наконец, зарелизить.
Спринт длится 2 недели, а релиз катится три дня. Чтобы успеть зарелизить до Sprint Review в пятницу, по-хорошему надо начинать релиз в понедельник. Это означает, что мы работаем над целью спринта только 50% времени. А если бы мы могли релизить каждый день, то продуктивный период работы вырос бы до 80-90%.
Наш средний релиз обычно занимал два-три дня. Сначала над кодом в общей ветке dev работало шесть команд (а с ростом компании число команд увеличилось до девяти). Непосредственно перед релизом мы бранчевали релизную ветку. Пока эта ветка тестируется и регрессится, команды продолжают разработку в общей ветке dev. Прежде чем релизная ветка достигнет прода, команды напишут довольно много кода.
Чем больше изменений в инкременте, тем больше шансов, что изменения, внесенные разными командами, повлияют друг на друга, а значит тем более тщательно инкремент должен быть протестирован, и тем больше времени будет занимать его релиз. Это самоусиливающий цикл (см. Рис. 2). Чем больше изменений в релизе («конский» релиз), тем дольше время регресса. Чем дольше время регресса, тем больше времени между релизами и тем больше изменений команды делают перед следующего релиза. Мы называли это «кони рождают коней». Следующая CLD-диаграмма (Causal Loop Diagram) иллюстрирует эту зависимость:
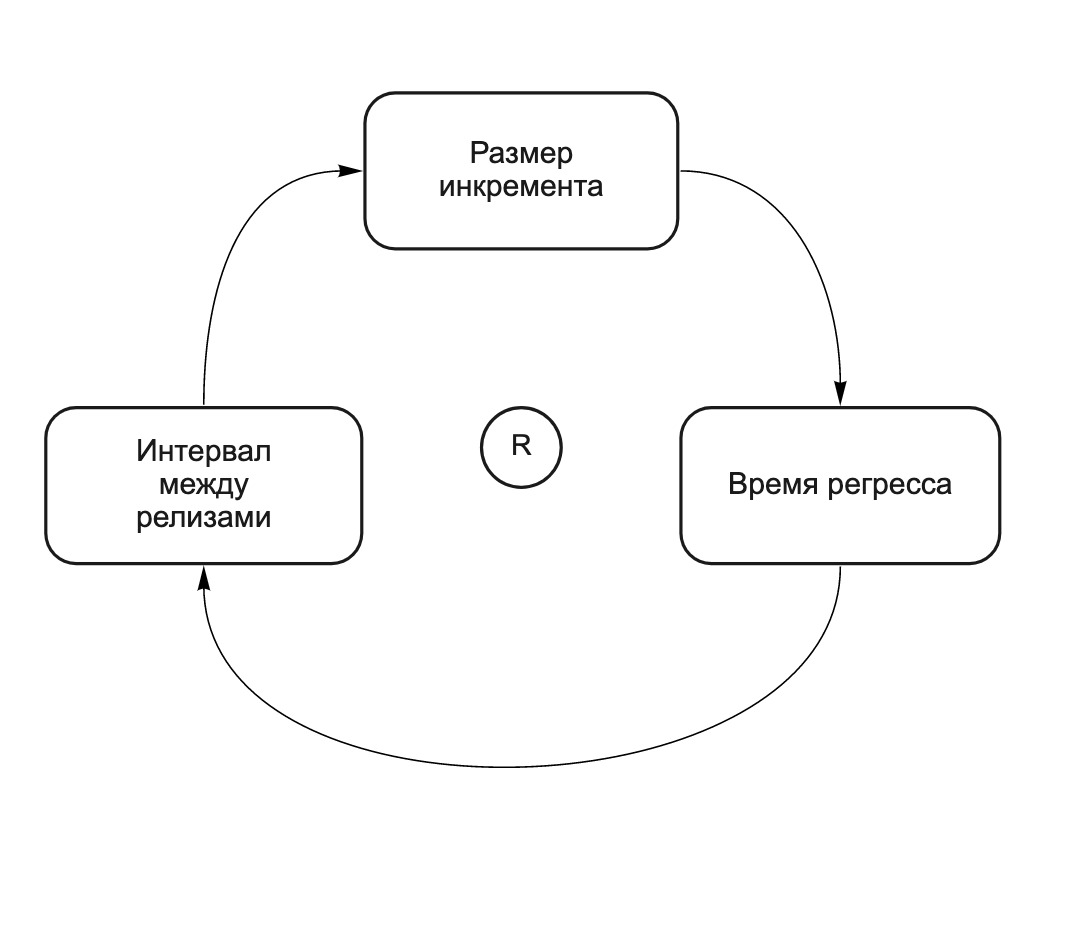
Рис. 2. CLD-диаграмма: длинные релизы приводят к еще более длинным релизам
Автоматизация регресса с помощью команды QA
Шаги, из которых состоит релиз
- Настройка среды. Восстанавливаем базу с прода (675 Гб), шифруем личные данные и чистим очереди RabbitMQ. Шифрование данных очень трудозатратная операция и занимает около 1 часа.
- Запуск автоматических тестов. Некоторые UI-тесты нестабильны, поэтому мы вынуждены запускать их несколько раз, пока не пройдут. Исправление мигающих тестов требует большого внимания и дисциплины.
- Ручные приемочные тесты. Некоторые команды предпочитают делать окончательную приемку до того, как код уйдет в прод. Это может занять несколько часов. Если они находят баги, мы даем командам два часа, чтобы исправить их, иначе они должны откатить свои изменения.
- Деплой на прод. Поскольку у нас отдельные экземпляры Dodo IS для каждой страны, процесс деплоя занимает некоторое время. После завершения деплоя в первой стране мы некоторое время смотрим логи, ищем ошибки, а затем продолжаем деплой в остальных странах. Весь процесс обычно занимает около двух часов, но иногда может занять и больше, особенно если придется откатывать релиз.
Сначала мы решили избавиться от ручного регрессионного тестирования, но путь к этому был долгим и трудным. Два года назад ручной регресс Dodo IS длился целую неделю. Тогда у нас была целая команда ручных тестировщиков, которые проверяли одни и те же фичи в 10 странах неделю за неделей. Такой работе не позавидуешь.
В июне 2017 года мы сформировали команду QA. Основной целью команды была автоматизация регресса наиболее важных бизнес-операций: прием заказа и производство продуктов. Как только у нас стало достаточно тестов, чтобы мы начали им доверять, мы полностью отказались от ручного тестирования. Но это произошло только спустя 1,5 года после того, как мы начали автоматизацию регресса. После этого мы распустили команду QA, и участники команды QA присоединились к командам разработки.
Однако, UI тесты имеют существенные недостатки. Поскольку они зависят от реальных данных в базе данных, эти данные надо настроить. Один тест может испортить данные для другого теста. Тест может упасть не только потому, что какая-то логика нарушена, но и из-за медленной сети или устаревших данных в кэше. Нам пришлось потратить много усилий, чтобы избавиться от мигающих тестов и сделать их надежными и воспроизводимыми.
За шаг до Stop the line. Инициатива #IReleaseEveryDay
Мы создали сообщество единомышленников #IReleaseEveryDay и провели мозговой штурм как ускорить deployment pipeline. Первые действия были такими:
- мы значительно сократили набор UI тестов, выбросив повторяющиеся и ненужные тесты. Это сократило время тестирования на несколько десятков минут;
- мы значительно сократили время на настройку среды благодаря предварительному восстановлению базы данных и шифрованию данных. Например, сейчас мы создаем резервную копию базы ночью, и как только начинается релиз, мы переключаем тестовую среду на резервную БД за несколько секунд.
Благодаря вышеперечисленным решениям, мы сократили среднее время релиза, но оно все еще было раздражающе долгим. Пришло время системных изменений.
А что если....
Мы ввели правило, что если релиз длится более 48 часов, то мы включаем мигалку и прекращаем работу всех команд над бизнес-фичами монолита. Все команды, работающие над монолитом, должны остановить разработку и сосредоточиться на докатывании текущего релиза до прода или устранении причин, вызвавших задержку релиза.
Когда релиз застрял, нет смысла делать новые фичи, ведь они все равно выйдут нескоро. В это время запрещается писать новый код, даже в отдельных ветках. Такой принцип описан в статье «Continuous Delivery» Мартина Фаулера: «В случае проблем с выкладкой ваша команда должна приоритезировать решение этих проблем выше работы над новыми фичами».
Антуражная мигалка
Во время Stop the line, в офисе включается оранжевая мигалка. Тот, кто приходит на третий этаж, где работают разработчики Dodo IS, видит этот визуальный сигнал. Мы решили не сводить наших разработчиков с ума звуком сирены и оставили только раздражающий мигающий свет. Так задумано. Как мы можем чувствовать себя комфортно, когда релиз в беде?

Рис. 3. Мигалка Stop the Line
Сопротивление команды и маленькие диверсии
Сначала Stop the Line понравилась всем командам, потому что было весело. Все радовались как дети и выкладывали фотографии нашей мигалки. Но когда она горит 3–4 дня подряд, становится не смешно. Однажды одна из команд нарушила правила и залила код в ветку dev во время Stop the Line, чтобы спасти свою цель спринта. Легче всего нарушить правило, если оно мешает тебе работать. Это быстрый и грязный способ сделать бизнес-фичу, игнорируя системную проблему.
Как Скрам Мастер, я не мог мириться с нарушениями правил, поэтому поднял этот вопрос на общей ретроспективе. У нас был трудный разговор. Большинство команд согласились, что правила действуют на всех. Мы договорились, что каждая команда должна соблюдать правила, даже если она с ними не согласна. А заодно о том, как можно изменять правила, не дожидаясь следующей ретроспективы.
Что не получилось так, как задумывалось?
Изначально разработчики не фокусировались на решении системных проблем с deployment pipelint. Когда релиз застревал, вместо того, чтобы помочь устранить причины задержки, они предпочитали разрабатывать микросервисы, на которых не распространялось правило Stop the Line. Микросервисы это хорошо, но проблемы монолита сами себя не решат. Для того, чтобы решить эти проблему, мы ввели бэклог Stop The Line.
Некоторые решения были быстрофиксами, которые скорее скрывали проблемы, чем решали их. Например, многие тесты чинились путем увеличения таймаутов или добавления ретраев. Один из таких тестов выполнялся 21 минуту. Тест искал самого недавно созданного сотрудника в таблице без индекса. Вместо того, чтобы исправить логику запроса, программист добавил 3 ретрая. В результате медленный тест стал еще медленнее. Когда у Stop The Line появилась команда-владелец, которая сфокусированно занималась проблемами тестов, в течение следующих трех спринтов им удалось ускорить наши тесты в 2-3 раза.
Как изменилось поведение команд после практики Stop the Line?
Ранее только одна команда испытывала проблемы с релизом — та, которая поддерживала релиз. Команды старались как можно быстрее избавиться от этой неприятной обязанности, вместо того чтобы вкладываться в долговременные улучшения. Например, если тесты на тестовой среде упали, их можно перезапустить локально и если тесты пройдут, продолжить релиз. С введением Stop The Line у команд появилось время, чтобы стабилизировать тесты. Мы переписали код подготовки тестовых данных, заменили некоторые UI-тесты API-тестами, удалили ненужные таймауты. Теперь практически все тесты проходят быстро и на любом окружении.
Раньше команды не занимались техническим долгом систематически. Теперь у нас есть бэклог технических улучшений, которые мы анализируем во время Stop the Line. Например, мы переписали тесты на .Net Core, что позволило нам запускать их в Docker. Запуск тестов в Docker позволил нам использовать Selenium Grid для распараллеливания тестов и дальнейшего сокращения времени их выполнения.
Раньше команды полагались на команду QA для тестирования и команду инфраструктуры для развертывания. Теперь рассчитывать не на кого, кроме самих себя. Команды сами тестируют и релизят код в Production. Это подлинный, а не поддельный DevOps.
Эволюция метода Stop the line
На общей ретроспективе спринта мы пересматриваем эксперименты. За несколько последующих ретроспектив мы внесли множество изменений в правила Stop the Line, например:
- Канал релиза. Вся информация о текущем релизе находится в отдельном канале Slack. В канале есть все команды, чью изменения вошли в релиз. В этом канале релизмен просит о помощи.
- Журнал релиза. Ответственный за релиз логирует свои действия. Это помогает найти причины задержки релиза и обнаружить закономерности.
- Правило пяти минут. В течение пяти минут после объявления Stop the Line представители команд собираются около мигалки.
- Бэклог Stop the Line. На стене есть флипчарт с бэклогом Stop The Line — списком задач, которые команды могут выполнять во время остановки линии.
- Не учитывать последнюю пятницу спринта. Несправедливо сравнивать два релиза, например, тот, который начался в понедельник, и другой, который начался в пятницу. Первая команда может потратить два полноценных дня на поддержку релиза, а во время второго релиза будет много мероприятий в пятницу (Sprint Review, Ретроспектива команды, Общая Ретроспектива) и в следующий понедельник (Общее и Командное Планирование Спринта), поэтому у пятничной команды меньше времени для поддержки релиза. Пятничный релиз будет остановлен с большей вероятностью, чем понедельничный. Поэтому мы решили исключить последнюю пятницу спринта из уравнения.
- Устранение технического долга. Спустя пару месяцев команды решили, что во время остановки можно работать над техническим долгом, а не только над ускорением deployment pipeline.
- Владелец Stop the Line. Один из разработчиков вызвался стать владельцем Stop The Line. Он глубоко погружается в причины задержки релизов и управляет бэклогом Stop the Line. Когда линия останавливается, владелец может привлекать любые команды для работы над элементами бэклога Stop the Line.
- Постмортем. Владелец Stop the Line проводит постмортем после каждой остановки.
Стоимость потерь
Из-за Stop the Line мы не выполнили несколько целей спринта. Представители бизнеса были не слишком обрадованы нашим прогрессом и задавали много вопросов на Sprint Review. Соблюдая принцип прозрачности, мы рассказали что такое Stop the Line, и почему стоит подождать еще несколько спринтов. На каждом Sprint Review мы показывали командам и заинтересованным лицам сколько денег мы потеряли из-за Stop the Line. Стоимость рассчитывается как суммарная зарплата команд разработки во время простоя.
• Ноябрь — 2 106 000 р.
• Декабрь — 503 504 р.
• Январь — 1 219 767 р.
• Февраль — 2 002 278 р.
• Март — 0 р.
• Апрель — 0 р.
• Май — 361 138 р.
Такая прозрачность создает здоровое давление и мотивирует команды сразу решать проблемы deployment pipeline. Наблюдая за этими цифрами, наши команды понимают, что ничего не дается бесплатно, и каждая Stop the Line встает нам в копеечку.
Результаты
Фактически, практика Stop the Line преобразует самоусиливающийся цикл (Рис. 2) в два балансирующих цикла (Рис. 4). Stop the Line помогает нам сосредоточиться на улучшении deployment pipeline, когда он становится слишком медленным. Всего за 4 спринта мы:
- Задеплоили 12 стабильных релизов
- Сократили время сборки на 30%
- Стабилизировали UI и API тесты. Теперь они проходят на всех окружениях и даже локально.
- Избавились от мигающих тестов
- Начали доверять нашим тестам
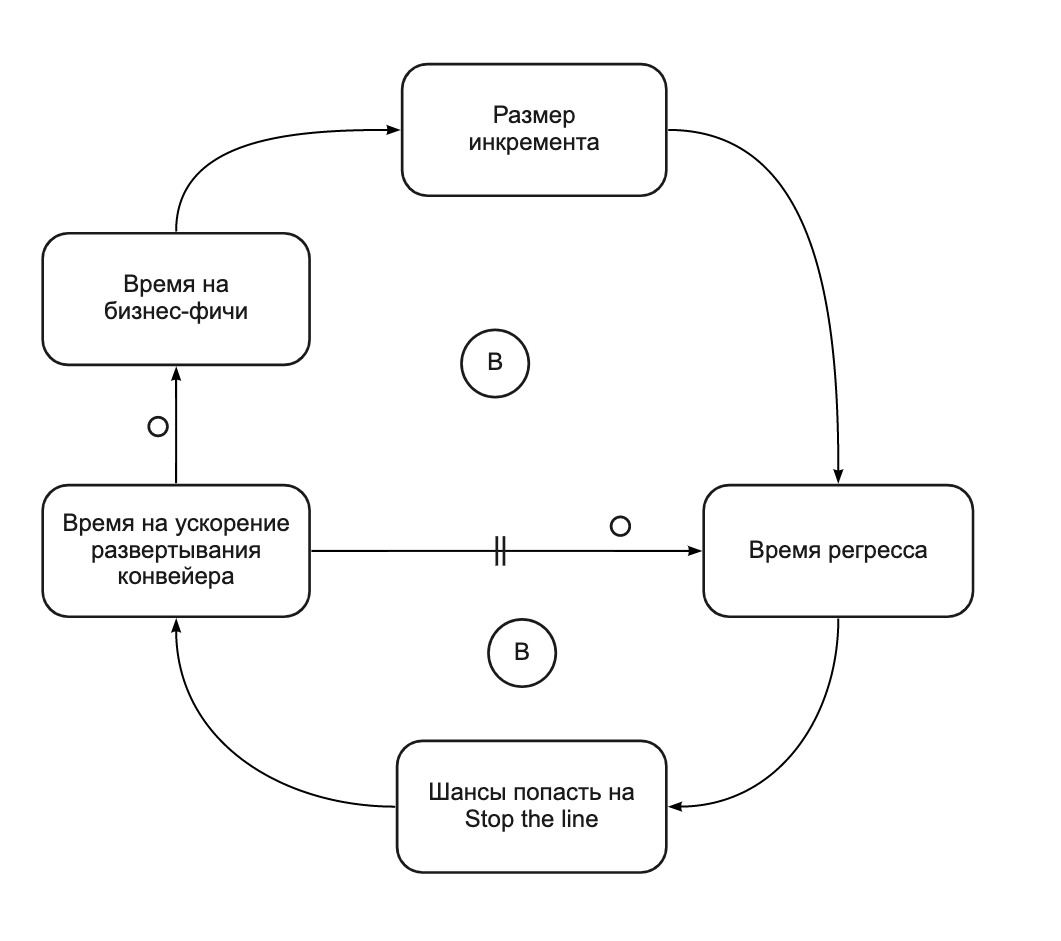
Рис. 4. CLD-диаграмма: Stop the Line уравновешивает время релиза
Выводы от Скрам Мастера
Stop The Line — яркий пример сильного решения, придуманного самими командами разработки. Скрам Мастер не может просто так взять и принести командам блестящую новую практику. Практика будет работать только если ее придумали сами команды. Для этого необходимы благоприятные условия: атмосфера доверия и культура экспериментирования.
Обязательно нужны доверие и поддержка со стороны бизнеса, что возможно только при полной прозрачности. Обратная связь, такая как регулярная общая ретроспектива со всеми представителями команд, помогает придумывать, внедрять и изменять новые практики.
Со временем практика Stop the Line должна сама себя убить. Чем чаще мы останавливаем линию, тем больше мы инвестируем в deployment pipeline, тем более стабильным и быстрым становится релиз, тем меньше причин для остановки. В конце концов линия никогда не будет останавливаться, если только мы не решим снизить порог, например, с 48 до 24 часов. Но, благодаря этой практике, мы здорово улучшили процедуру релиза. У команд появился опыт не только разработки, но и быстрой поставки ценности на прод. Это подлинный DevOps.
Что дальше? Я не знаю. Возможно, мы скоро откажемся от этой практики. Решать будут команды. Но очевидно, что мы будем продолжать двигаться в направлении Continuous Delivery и DevOps. Однажды моя мечта о релизе монолита несколько раз в день обязательно сбудется.
