Comments 87
Опечатка:
public void Undo() {
if (!CanRedo)
return;
items[items.Count — 1].Undo(document);
items.RemoveAt(items.Count — 1);
}
Кроме того:
У вас нарушена искапсуляция. List и currentIndex надо бы объединить в объект ActionHistortyStorage, так как их независимосе изменение может нарушить целостность данных. Но ещё лучше вместо List и currentIndex использовать два Stack.
public void Undo() {
if (!CanRedo)
return;
items[items.Count — 1].Undo(document);
items.RemoveAt(items.Count — 1);
}
Кроме того:
У вас нарушена искапсуляция. List и currentIndex надо бы объединить в объект ActionHistortyStorage, так как их независимосе изменение может нарушить целостность данных. Но ещё лучше вместо List и currentIndex использовать два Stack.
Инкапсуляция, не инкапсуляция, скриншот зацените. Красиво — же… Прям как новый твиттер!
Undo-redo — это частный случай реализации системы контроля версий. Если плясать от этого, то всё становится немного понятнее.
Кстати да, задачки родственные.
Более того, если смотреть с этого угла — то открываются широкие возможности в улучшении «стандартной» реализации. Например можно сделать бранчинг, можно хранить историю версий на диске, можно сделать синхронизацию.
Тут уже все зависит от поставленной задачи. Многим приложениям (и многим пользователям) такой навороченный инструмент не нужен. Не знаю, к сожалению или к счастью.
Многим да. Но вот в редакторах кода мне очень не хватает локального контроля версий, встроенного прямо в редактор, доступного по кнопкам undo-redo.
В простых текстовых редакторах это наверное не нужно, а вот сохранение истории правок на диск (тоже фича из VCS) — это нужно мне практически всегда.
В простых текстовых редакторах это наверное не нужно, а вот сохранение истории правок на диск (тоже фича из VCS) — это нужно мне практически всегда.
В ворде track changes для этого сделали. До тех пор, пока дело не доходит до серьезных изменений в таблицах даже работает адекватно. А вот мы у себя ещё не сподобились реализовать.
В vim'e, кстати, есть дерево изменений с возможностью перескакивать с ветки на ветку. И сохранение истории правок на диск тоже вроде появилась.
Local History есть у Eclipse и у NetBeans — изменения сохраняются на диск, можно просмотреть историю изменений, откатиться. Веток, вроде нет.
В графических редакторах такой инструмент (с бранчами, и возможностью сохранения истории на диск для последующего пользования) был бы просто незаменим.
Майкрософт в ворде в свое время баловался в ворде быстрым сохранением. Суть как раз и была в том, что в конец исходного документа писались изменения, доводящие документ до нужного результата. Но как-то не прижилось.
С бранчингом они заморачиваться не стали. Впрочем в текстовом редакторе это нечасто бывает нужно, а геммороя в реализации там вагон и маленькая тележка.
С бранчингом они заморачиваться не стали. Впрочем в текстовом редакторе это нечасто бывает нужно, а геммороя в реализации там вагон и маленькая тележка.
Если выполнение действия не удалось по какой-либо причине, последний элемент листа придется удалять. Логичнее было бы сначала попытаться выполнить а в случае успеха уже добавлять в лист.
Поразмыслив и посмотрев как сделано у других (всё уже украдено до нас) приходим к выводу, что в таком случае та часть истории действий, что находится после текущего индекса, должна быть потеряна
Порой это очень раздражает. Бывает, что хочется откатить процесс отката и изменения. В Фотошопе это сделано лучше всего — там отображается история действий.
Чтобы поддерживать операции Undo & Redo сначала нужно представить «документ» в виде набора объектов и определить атомарные операции над над ними. Затем для каждой такой операции разработать обратную ей (это можно сделать не всегда).
Невозможно обсуждать реализацию Undo & Redo, отдельно от типа документа и набора операций над ним.
Допустим мы делаем вставку изображения в графическом редакторе по верх уже имеющегося, где «документ» представлен просто цельным изображением. Тогда при исполнении операции «вставка» нужно скопировать в буффер/запомнить ту часть изображения, которая была на этом месте. Если делать любую операцию, которая затрагивает весь документ (например размытие), придется хранить в history все старое изображение целиком. Расход памяти при этом так велик, что вам придется отказаться либо от данной структуры документа поддержки либо от поддержки операции Undo.
При нажатии Undo, возможно, нужно будет откатить парочку транзакций в локальной базе данных. Ваша модель к этому готова?
В вашем примере есть две функции CreateActionHistoryItem() & item.Redo(Document document). 90% времени вы проведете пытаясь написать их нормальную реализацию в любом реальном проекте.
Невозможно обсуждать реализацию Undo & Redo, отдельно от типа документа и набора операций над ним.
Допустим мы делаем вставку изображения в графическом редакторе по верх уже имеющегося, где «документ» представлен просто цельным изображением. Тогда при исполнении операции «вставка» нужно скопировать в буффер/запомнить ту часть изображения, которая была на этом месте. Если делать любую операцию, которая затрагивает весь документ (например размытие), придется хранить в history все старое изображение целиком. Расход памяти при этом так велик, что вам придется отказаться либо от данной структуры документа поддержки либо от поддержки операции Undo.
При нажатии Undo, возможно, нужно будет откатить парочку транзакций в локальной базе данных. Ваша модель к этому готова?
В вашем примере есть две функции CreateActionHistoryItem() & item.Redo(Document document). 90% времени вы проведете пытаясь написать их нормальную реализацию в любом реальном проекте.
А если добавить в список возможных операций перемещение по документу с выделениями, и объединением таких перемещений в одну операцию, то вобщем-то проблема легко решается. Кстати, многие редакторы так и делают — это заметно когда на Undo они просто перемещают курсор в старую позицию или возвращают выделение. Более серьезные вопросы возникают, когда программа имеет многодокументный интерфейс. Иметь ли Undo на все документы или на каждый? Включать ли в историю переключение между документами. Ответы зависят от задачи. Тут же еще могут возникнуть и другие задачи, когда редактирование одного текстового документа лишь часть сложного use case. Выделять ли редактирование документа в отдельный undo-список или вносить в общую кучу. Вобщем — да, задача Undo — не самая тривиальная область программирования интерфейса.
Вспомнил нашу реализацию Undo/Redo. «Склеивание операций» используется довольно часто. Даже если мы печатаем текст, то не каждую же букву Undo-шить? А т.к. я думаю ваши классы вы будете использовать и в своих других проектах, то стоит эту возможность включить в прототип.
С текстом да, в некоторых случаях можно подпатчивать последний элемент в буфере Undo, чтобы не добавлять туда лишнего. Мы не смогли (впрочем и не стояло такой задачи) затащить этот функционал именно в UndoManager, у нас на уровне редактирования модели решается, то ли новый элемент в Undo совать, то ли существующий править.
такая задача решается элементарно — делаемм снэпшоты с троттлинком миллисекунд в 200. то есть сохранение будет происходить между «сеансами ввода»
Ну какбы логичнее «засовывать» отдельные слова ;). А так «склеивать» нужно не только с текстом. Например может имеет смысл «склеивать» в векторном редакторе перетаскивание элемента клавишами, может даже мышкой.
нет, засовывать надо то, что для пользователя является атомарным действием. для текста — это сессия ввода/удаления, вставка/вырезка, изменение атрубутов
Я иногда пишу в течении большого времени " не отходя от кассы ". Что в этом случае делать? Могу написать целый обзац не отрываясь. ВОт этот коммент например я пишу не отрываясь. Т.е. если я нажму сейчас анду, то получится весь коммент исчезнет. Надо как-то совместить чтоли эти два подхода, пока не знаю.
Написать большой кусок текста подряд без ошибок и не отрываясь, конечно можно, но чаще всё же в процессе то лишнюю буковку впишешь, то пропустишь чего. Приходится править. Любая такая правка атомарность разрывает. Начало нового абзаца также разрыв атомарности.
Вообще на эту тему забавно было наблюдать за вордом со включенной автозаменой. Пишешь предложение из нескольких слов с маленькой буквы. Откатываешь. Откатывает все слова, кроме первого. Потом замену малой буквы на большую откатывает. И наконец первую букву в слове. Т.е. автозамена тоже атомарность разорвала, что в общем-то логично.
Вообще на эту тему забавно было наблюдать за вордом со включенной автозаменой. Пишешь предложение из нескольких слов с маленькой буквы. Откатываешь. Откатывает все слова, кроме первого. Потом замену малой буквы на большую откатывает. И наконец первую букву в слове. Т.е. автозамена тоже атомарность разорвала, что в общем-то логично.
О да, какая знакомая проблема. В моём случае всё еще куда более запущено. Я пишу редактор языка блочных диаграмм передаточных функций для программирования контроллеров. Редактор сделан на WPF и использованием популярного паттерна M-V-VM. Собственно проблем возникло много, особенности реализации класса UndoRedoJournal самые мелкие из них.
Проблема №1 заключалась в том, что действия Undo/Redo не могли хранить ссылки на объекты модели, по тому что в ходе редактирования объекты удалялись из модели, а при необходимости откатить операцию удаления создавалась идентичная копия объекта. Пришлось ввести систему идентификации элементов, а в действиях отката вместо ссылок хранить идентификаторы.
Проблема №2 более интересная. Она была вызвана солидным количеством возможных типов элементарных модификаций модели (микро-действий) — около сотни. Т.е. действий типа «добавить», «удалить», «изменить свойство» и т.д. При том многие конечные операции модификации (макро-действия) состояли из десятка элементарных, количество возможных вариаций групповых модификаций стремилось к критическому количеству. Поэтому подход «1 класс действия на 1 макро-действие » никак не канал. С другой же стороны, не канал и подход «1 класс действия на 1 микро-действие», т.к. код макро-действия раздувался до совершенно неимоверных размеров из-за необходимости оперировать микродействиями.
И всё это усугублялось уже до совсем феерической сложности, тем отмеченным вами фактом, что следующая элементарная модификация должна была основываться на состоянии модели после выполнения предыдущей.
В итоге я решил эту проблему фундаментальным образом, вывернув описанный вами в статье паттерн на изнанку.
В саму модель я добавил функциональность транзактивной модификации, все изменения вносятся в модель в рамках транзакции. Код просто открывает транзакцию и изменяет состояние модели как хочет. При этом последовательность элементарных изменений автоматически «режется» кодом обработки изменений на действия отката с некоторой оптимизацией.
Гипотетический код, изменяющий модель выглядит так:
Проблема №1 заключалась в том, что действия Undo/Redo не могли хранить ссылки на объекты модели, по тому что в ходе редактирования объекты удалялись из модели, а при необходимости откатить операцию удаления создавалась идентичная копия объекта. Пришлось ввести систему идентификации элементов, а в действиях отката вместо ссылок хранить идентификаторы.
Проблема №2 более интересная. Она была вызвана солидным количеством возможных типов элементарных модификаций модели (микро-действий) — около сотни. Т.е. действий типа «добавить», «удалить», «изменить свойство» и т.д. При том многие конечные операции модификации (макро-действия) состояли из десятка элементарных, количество возможных вариаций групповых модификаций стремилось к критическому количеству. Поэтому подход «1 класс действия на 1 макро-действие » никак не канал. С другой же стороны, не канал и подход «1 класс действия на 1 микро-действие», т.к. код макро-действия раздувался до совершенно неимоверных размеров из-за необходимости оперировать микродействиями.
И всё это усугублялось уже до совсем феерической сложности, тем отмеченным вами фактом, что следующая элементарная модификация должна была основываться на состоянии модели после выполнения предыдущей.
В итоге я решил эту проблему фундаментальным образом, вывернув описанный вами в статье паттерн на изнанку.
// Интерфейс транзакции модификации модели.
public interface IModelEditTransaction : IDisposable
{
// Зафиксировать транзакцию.
UndoRedoOperation Commit(UndoRedoJournal journal, string name);
}
// Класс модели документа.
public sealed class DocumentModel
{
// Открыть транзакцию редактирования модели.
public IModelEditTransaction BeginEdit()
{
//...
}
// Изменить что-то.
public void ChangeXXX()
{
if (!IsEditing) throw new InvalidOperationException();
ProcessChangeXXX();
}
}
В саму модель я добавил функциональность транзактивной модификации, все изменения вносятся в модель в рамках транзакции. Код просто открывает транзакцию и изменяет состояние модели как хочет. При этом последовательность элементарных изменений автоматически «режется» кодом обработки изменений на действия отката с некоторой оптимизацией.
Гипотетический код, изменяющий модель выглядит так:
void EditModel(DocumentModel model, UndoRedoJournal journal)
{
using (IModelEditTransaction tran = model.BeginEdit())
{
model.ChangeXXX();
tran.Commit(journal, "Поменяли XXX").
}
}Вполно разумно сделано.
Но мы пошли по пути минимизации количества хранимых данных для каждого микродействия в вашей терминологии. Для этого пришлось переосмыслить строение внутренних структур данных. Зато когда переосмыслили, огромная куча микродействий как у Вас свелась к одному единственному базовому классу. Итого различных микродействий стало порядка десятка.
Кстати хранить ссылки на «живые» объекты иногда вполне допустимо, хотя мы вначале тоже от этого шарахались.
Но мы пошли по пути минимизации количества хранимых данных для каждого микродействия в вашей терминологии. Для этого пришлось переосмыслить строение внутренних структур данных. Зато когда переосмыслили, огромная куча микродействий как у Вас свелась к одному единственному базовому классу. Итого различных микродействий стало порядка десятка.
Кстати хранить ссылки на «живые» объекты иногда вполне допустимо, хотя мы вначале тоже от этого шарахались.
Да, на счет ссылок я долго думал, но решил что проще всего от них отказаться. Реализация команды «Обновить» при хранении ссылок превращалась в настоящий кошмар, да и много чего еще усложнялось. Ссылки в действиях вполне допустимо хранить на неизменяетмые (immutable) объекты. А у меня «живое» почти всё.
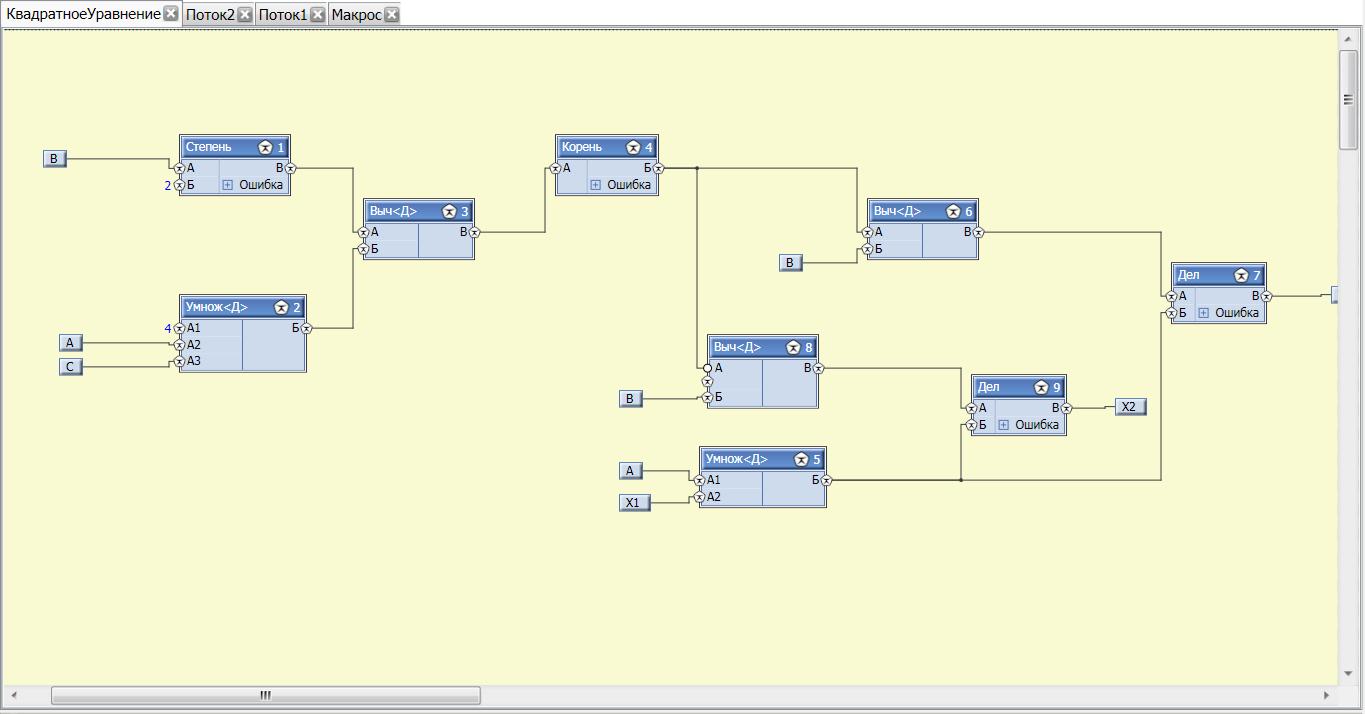
Это что бы было ясно о чем речь.
чем то похоже на www.ni.com/labview/whatis/graphical-programming/
Чем-то похоже. Это адаптация языка FBD стандарта IEC 61131-3.
Больше похоже на hiasm.
Точно так же работают стандартный IDesignerHost и DesignerTransaction.
Только текст транзакции задается вначале. UndoRedoService подписывается на события IComponentChangeService для регистрации изменений.
Только текст транзакции задается вначале. UndoRedoService подписывается на события IComponentChangeService для регистрации изменений.
это .NET?
разве там нету Undo/Redo framework`а?
разве там нету Undo/Redo framework`а?
хвост феи?
Мне давали как раз такую задачку (undo/redo для текстового редактора) на одном из собеседований для решения в уме (без компьютера и даже без бумажки).
Если честно, то довольно странно читать «Если сделаем вот так, то получим исключение, поэтому делаем вот так. И опять неправильно, потому что будет вызываться одно и то же, поэтому делаем вот так. И опять неправильно....»
Если честно, то довольно странно читать «Если сделаем вот так, то получим исключение, поэтому делаем вот так. И опять неправильно, потому что будет вызываться одно и то же, поэтому делаем вот так. И опять неправильно....»
надо же из чего-то статью высосать ;-)
Согласен, мне было не приятно читать статью в которой человек пишет заведомо кривой код, потом торжественно объясняет почему он кривой, исправляет… Но опять неверно. Почему нельзя сразу и правильно?!
>Почему нельзя сразу и правильно?!
Как правильно заметили выше, потому что в этом случае не получилось бы статьи. Ну сами подумайте: какая может быть статья, если бы автор написал «мы реализовали механизм undo/redo вот так-то» — и один листинг в 30-40 строк? Ну, реализовали, ну молодцы. Вот только задачи подобного уровня решаются тысячами программистов ежедневно, и ничего экстраординарного в ней нет. А тут и статья, и заодно ненавязчивая ссылка на проект.
Вот только проиллюстрированный подход к разработке у меня очень, очень плохо увязывается с ценой продукта по ссылке. Нет-нет, я ни в коем случае не «считаю чужие деньги» и не «учу никого вести бизнес» — просто озвучиваю своё собственное впечатление от прочитанного и увиденного. Не более.
Как правильно заметили выше, потому что в этом случае не получилось бы статьи. Ну сами подумайте: какая может быть статья, если бы автор написал «мы реализовали механизм undo/redo вот так-то» — и один листинг в 30-40 строк? Ну, реализовали, ну молодцы. Вот только задачи подобного уровня решаются тысячами программистов ежедневно, и ничего экстраординарного в ней нет. А тут и статья, и заодно ненавязчивая ссылка на проект.
Вот только проиллюстрированный подход к разработке у меня очень, очень плохо увязывается с ценой продукта по ссылке. Нет-нет, я ни в коем случае не «считаю чужие деньги» и не «учу никого вести бизнес» — просто озвучиваю своё собственное впечатление от прочитанного и увиденного. Не более.
Не мучайтесь, gof всё придумали за вас.
Как же я рад, что пишу под Мак и мне не приходится выдумывать велосипед.
А под Мак подобные компоненты рождаются из вулканического пепла, что ли? Нет, товарищ, представьте себе: их тоже кто-то пишет. И в них тоже реализован обсуждаемый механизм. Схожим (или не очень) образом.
Поэтому Ваша ремарка немного (хотя лучше сказать совершенно) не в кассу.
Поэтому Ваша ремарка немного (хотя лучше сказать совершенно) не в кассу.
Написать свой NSUndoManager — задача 10 минут используя Objective-C, но этого не требуется — всё есть. Допустим есть метод addObject и обратный к нему — removeObject, тогда первая строка метода addObject будет выглядеть так:
[[_undoManager prepareWithInvocationTarget:self] removeObject:object];
И первая строка метода removeObject:
[[_undoManager prepareWithInvocationTarget:self] addObject:object];
Готово!
За что минуса?
[[_undoManager prepareWithInvocationTarget:self] removeObject:object];
И первая строка метода removeObject:
[[_undoManager prepareWithInvocationTarget:self] addObject:object];
Готово!
За что минуса?
Написать свой Undo/Redo Manager — «задача 10 минут» используя любой высокоуровневый язык (и об этом я, кстати, сказал где-то тут). Не вижу никакой «эксклюзивности» Мака в этой ситуации.
И уж тем более не вижу эксклюзивности в случае «не пишем сами, а используем готовые решения» — их есть у нас под любыми системами в достатке.
И уж тем более не вижу эксклюзивности в случае «не пишем сами, а используем готовые решения» — их есть у нас под любыми системами в достатке.
Видимо за то, что вы весело ворвались в тред для разработчиков .NET с комментарием «А я пишу под Мак а вы все умственно отсталые» ;)
А что, функционал Undo/Redo для произвольных объектов под Мак поддерживается уже на уровне операционной системы?
Я бы использовал двунаправленный список, ссылка на начало, ссылка на текущий HistoryItem. Итерация быстрее, «хвост отбрасывать» быстрее, навигация вперед — назад тоже. Ну и LOH не расходуется.
Сейчас Вам опять скажут «ну это же не боевой код, а всего лишь пример» ;)
Нет, сейчас неработающую фигню принято называть прототипом.
Это-ж сколько элементов надо будет сунуть в List чтобы он в LOH лёг? От 10-20 тысяч получается. Сдается мне документ всё же закроют раньше :)
Ну, LOH может и не станет проблемой, но вот разница между перемещением по массиву (и удалением элементов) по индексам супротив итеративного перемещения по двунаправленному списку (и «отбрасывания хвоста») будет весьма существенной во вполне реальных условиях более-менее продолжительной правки документа.
Перемещаться-то по массиву зачем? CurrentIndex есть, заинкрементить/задекрементить его недолго, а больше и не нужно ничего. Хвост обрезать тоже невелика беда, память-то выделять по-новой не надо, размер блока достаточно уменьшить. Вот когда массив растёт, realloc-и есть, но у List достаточно эффективный алгоритм внутри сидит, чтобы об этом не задумываться.
Да и в целом, менять подход есть смысл, когда профайлер покажет, что именно в данном месте есть проблема с производительностью. Если же брать то же текстовый редактор, то замеры кусков текста и отрисовка на многие порядки «тяжелее» любой модификации модели документа, не говоря уж об буфере undo.
Да и в целом, менять подход есть смысл, когда профайлер покажет, что именно в данном месте есть проблема с производительностью. Если же брать то же текстовый редактор, то замеры кусков текста и отрисовка на многие порядки «тяжелее» любой модификации модели документа, не говоря уж об буфере undo.
Насчет профайлера — это все так.
Но использовать List везде, где только не лень — это бомба замедленного действия :)
Когда начнутся якобы беспричинные OutOfMemoryException-ы, припомните мой совет ;)
Совет не относится к конкретному случаю (не боевой код), просто вспомнилось.
Но использовать List везде, где только не лень — это бомба замедленного действия :)
Когда начнутся якобы беспричинные OutOfMemoryException-ы, припомните мой совет ;)
Совет не относится к конкретному случаю (не боевой код), просто вспомнилось.
>Перемещаться-то по массиву зачем? CurrentIndex есть, заинкрементить/задекрементить его недолго, а больше и не нужно ничего.
После недолгого инкремента/декремента индекса наступает вполне себе долгая операция «получить элемент массива по этому индексу» — Вы об этом забыли?
А в случае двунаправленного списка получение предыдущего/следующего элемента осуществляется одной очень быстрой операцией: переходом по ссылке на предыдущий/следующий объект, которая хранится в каждом элементе двунаправленного списка. Причём скорость этой операции остаётся неизменной для списков любой длины (в отличие от).
После недолгого инкремента/декремента индекса наступает вполне себе долгая операция «получить элемент массива по этому индексу» — Вы об этом забыли?
А в случае двунаправленного списка получение предыдущего/следующего элемента осуществляется одной очень быстрой операцией: переходом по ссылке на предыдущий/следующий объект, которая хранится в каждом элементе двунаправленного списка. Причём скорость этой операции остаётся неизменной для списков любой длины (в отличие от).
Не пугайте меня. С каких пор конструкция pointer[index] стала работать кардинально медленнее, чем разыменовывание указателя (что суть *pointer или pointer[0]). И уж тем более как это от размера массива зависит?
Или вы думаете, что в .NET List это и вправду однонаправленный список? Так неправда это, там обычный массив внутри.
Или вы думаете, что в .NET List это и вправду однонаправленный список? Так неправда это, там обычный массив внутри.
Ну List делает проверку на попадание в используемую область массива. Плюс сам массив проверят доступ на безопасный диапазон.
Хотя соглашусь, на современном железе — это уже непринципиально
Хотя соглашусь, на современном железе — это уже непринципиально
Похоже мы друг друга поняли.
С определённого момента стал следовать правилу: 1. make it work; 2. make it work right; 3. make it work fast. А когда слез с C++ и пересел на C# осознал, что лучшая оптимизация — эффективный алгоритм. Никакой ассемблер не заменит правильно организованных структур данных и BinarySearch.
С определённого момента стал следовать правилу: 1. make it work; 2. make it work right; 3. make it work fast. А когда слез с C++ и пересел на C# осознал, что лучшая оптимизация — эффективный алгоритм. Никакой ассемблер не заменит правильно организованных структур данных и BinarySearch.
>Хотя соглашусь, на современном железе — это уже непринципиально
Да знаю я, знаю: я старый, упёртый ретроград, напрочь испорченный программированием под встраиваемые системы и мобильные девайсы :)
Да знаю я, знаю: я старый, упёртый ретроград, напрочь испорченный программированием под встраиваемые системы и мобильные девайсы :)
Так, стоп машина. Я с другой реализацией попутал (давно шарпа не касался, каюсь).
Внутри, разумеется, обычный массив, и что касается скорости доступа Вы абсолютно правы. Однако, во-первых нас всё равно подстерегают прелести переаллокации (прозрачной и незаметной, но всё же). Ну либо резервирования массива «достаточного» размера, что тоже не фонтан. А второй момент касается не самого списка, а конкретной реализации в обсуждаемой статье: отбрасывание хвоста путём откусывания по одному элементу в цикле вместо list.RemoveRange() — хм…
Да, я помню, что «это не боевой код, а всего лишь пример», но я не понимаю, зачем в «примере» использовать заведомо неоптимальное решение.
Внутри, разумеется, обычный массив, и что касается скорости доступа Вы абсолютно правы. Однако, во-первых нас всё равно подстерегают прелести переаллокации (прозрачной и незаметной, но всё же). Ну либо резервирования массива «достаточного» размера, что тоже не фонтан. А второй момент касается не самого списка, а конкретной реализации в обсуждаемой статье: отбрасывание хвоста путём откусывания по одному элементу в цикле вместо list.RemoveRange() — хм…
Да, я помню, что «это не боевой код, а всего лишь пример», но я не понимаю, зачем в «примере» использовать заведомо неоптимальное решение.
В крайнем случае можно было бы использовать итераторы — те же яйца, вид в профиль. Но уж точно не числовые индексы.
На x64 по идее = массив поинтеров на 10K… А учитывая, что List растит массив каждый раз в два раза больше — то 5К записей.
5К записей — это всегод лишь 2-3 страницы текста набрать. И это не учитывая опечатки, коррективы и т.д.
Другое дело, что в 4 версии дотнета вроде бы LOH границу увеличили…
5К записей — это всегод лишь 2-3 страницы текста набрать. И это не учитывая опечатки, коррективы и т.д.
Другое дело, что в 4 версии дотнета вроде бы LOH границу увеличили…
Насчёт LOH: объекты в списке могут быть разные. К примеру, если у нас не plain text, а ещё и стили/цвета/размеры/етц, то загреметь в LOH можно куда раньше, чем на 10-20 тысячах объектов.
Вовсе необязательно так все разжевывать:
Вы же пишете статью, рассчитанную на аудиторию имеющую определенные профессиональные. А то получается что вы общаетесь с читателем как с воспитанником кружка лепки из пластилина для дошкольников. Или, как выше правильно заметили, просто нужно было растянуть 35-40 строк исходного кода на «годную» статью.
ЗЫ Вы бы лучше сконцентрировали внимание на HistoryItem и записи сложных элементов в буфер истории. И рассказали о том, как вы это делаете, какие сложности. Вот это было бы действительно интересно.
public void Undo() {
items[items.Count — 1].Undo(document);
}
Лаконично, изящно… но совершенно неправильно.
Для начала, при попытке вызвать метод Undo при пустом списке, вылетит исключение. Исправляем:
Вы же пишете статью, рассчитанную на аудиторию имеющую определенные профессиональные. А то получается что вы общаетесь с читателем как с воспитанником кружка лепки из пластилина для дошкольников. Или, как выше правильно заметили, просто нужно было растянуть 35-40 строк исходного кода на «годную» статью.
ЗЫ Вы бы лучше сконцентрировали внимание на HistoryItem и записи сложных элементов в буфер истории. И рассказали о том, как вы это делаете, какие сложности. Вот это было бы действительно интересно.
Ссылка на статью в NYT побилась: https://www.nytimes.com/2009/09/20/magazine/20FOB-onlanguage-t.html
Sign up to leave a comment.
Undo/Redo — Иллюзия простоты