Сколько может рассказать о человеке профиль в соцсети? Фотографии, посты, комментарии, подписки – непаханное поле для анализа. Сегодня поговорим о том, как мы определяем интересы пользователей на основе их подписок в сети Instagram.
 Источник
Источник
Очевидный подход – разложить подписки человека по категориям. Допустим, среди подписок пользователя Ивана мы обнаружили двух автоблогеров и три аккаунта со смешными картинками, остальные профили не тематические (будем считать, что это друзья, родственники, коллеги и т. д.). Отсюда делаем вывод: Иван веселый человек, увлекается автомобилями. Профит. Все, что нам нужно – это соответствие “блогер + тематика контента”, но здесь не все так просто.
Кто такой блогер? Блогер в Instagram ничем не отличается от обычного аккаунта (и вообще, это что-то вроде состояния души). В идеале нас интересуют тематические аккаунты с большой долей живой аудитории, при этом не хотелось бы просто отсекать по числу подписчиков, можем что-то упустить.
Где взять хорошую таксономию? Если придумывать категории самостоятельно, то обязательно что-нибудь интересное затеряется в “разном”, а когда все будет готово, окажется, что категории слишком широкие. Мы же хотим получить естественное разбиение, а поэтому будем блогеров кластеризовать.
Может ли один блогер относиться к нескольким категориям? Еще как! Очень часто он одновременно и швец, и жнец, и на дуде игрец (а еще тревел, лайфстайл, жена и мама).
Итак, нам нужен датасет с очень большим числом блогеров и алгоритм кластеризации с пересекающимися кластерами на выходе.
К нам обращаются клиенты, которые хотят разместить свою рекламу у лидеров мнений в Instagram наиболее эффективно. Иногда есть список блогеров, и тогда мы решаем задачу оптимизации – охватить больше людей за меньшие деньги, а иногда списка нет и релевантных блогеров надо найти. На этот раз искали профили врачей-офтальмологов.
Мы использовали подход, похожий на рекомендательную систему:
Теперь подробнее на примере.
Шаг 1. С помощью поиска в Instagram отобрали 6 аккаунтов врачей-офтальмологов из разных регионов России:
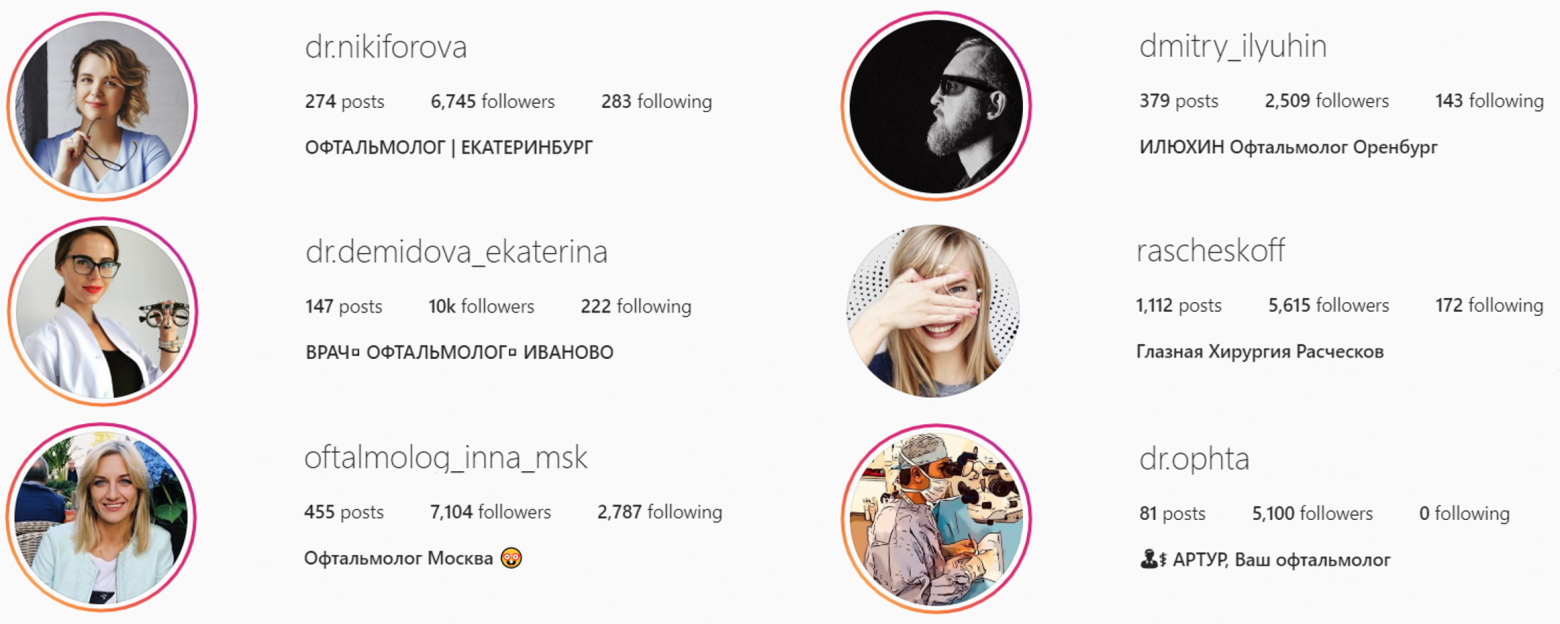
Список довольно случайный, но нам было достаточно того, что блог действительно соответствует тематике и подписчиков не меньше, чем 1000 человек.
Шаг 2. После пересечения всех подписчиков смотрим на распределение.
Ура! Пересечения есть.
Более того, есть два человека, которые подписаны на все шесть профилей! Итак, теперь нужно определить, кого считаем “увлеченными” офтальмологией. Мы решили, что берем всех, начиная с трех подписок. Как говорится, 1 раз — случайность, 2 раза — совпадение, 3 — уже закономерность. Таким образом, нашли 131 (2+3+24+102) “увлеченного” пользователя.
Шаг 3. Загружаем подписки “увлеченных” людей и опять всячески агрегируем.

Получили внушительный список аккаунтов, из которых теперь будем отбирать новых офтальмологов. Правый столбец показывает, сколько из 131 человека, которые отобраны на втором шаге, подписаны на профиль. В топе оказались профили из нашей изначальной шестерки, что неудивительно. Если мы сейчас подберем порог и скажем: “Все профили со значением count больше десяти – новые врачи”, то мы рискуем отнести популярные аккаунты вроде Ольги Бузовой к врачам-офтальмологам и в то же время потерять меленькие, но релевантные профили, поэтому добавим еще одним столбцом количество подписчиков и рассчитаем долю увлеченных пользователей среди подписчиков.

Для удобства доля умножена на 100 (так что share – это по факту процент). В итоге с условием count >= 6 и share >= 0.05 получили 166 новых врачей-офтальмологов. Класс!
Шаг 4. 172 аккаунта стали новым “ядром” сообщества, это помогло найти ещё примерно 500 новых офтальмологов, но результат уже смещался в зарубежные аккаунты.
Это все, конечно, интересно, и теперь мы умеем неплохо находить похожие друг на друга аккаунты, но мы все еще мечтаем получить разбивку всех инстаблогеров по категориям. И тут в голову пришла идея посмотреть на готовые рекомендации инстаграма.

Дело в том, что у тематических аккаунтов есть рекомендации, а у обычных людей – нет. Вот и ответ на вопрос, кого считать блогерами и минус одна головная боль. Ура!
В рекомендациях у одного блогера до 80 похожих профилей. У нас был список из 1000 российских блогов, начали с него. Взяли похожих, потом похожих похожих, потом … ну вы поняли:)
План был в том, что когда-нибудь этот процесс закончится, так как маленькие профили с парой сотен подписчиков в рекомендации не попадут, но фактически остановились мы, когда закончилось терпение. Всегда можно продолжить собирать датасет, но пока не пригодилось, с большой вероятностью почти всех российских блогеров мы охватили, и ладно.
Теперь у нас есть граф с 3 428 453 вершинами (блогеры) и 96 967 974 ребрами (похожесть двух блогеров между собой).
 Так выглядит наш граф на очень маленьком сэмпле
Так выглядит наш граф на очень маленьком сэмпле
Кстати, оказалось, мы не первые решили использовать такой подход.
Судя по всему, рекомендации в Instagram формируются, исходя из того, на кого еще подписаны подписчики этого профиля, поэтому у врача из Брянска в рекомендациях будут популярные брянские аккаунты и другие врачи. Это похоже на наш поиск офтальмологов, но теперь мы можем учитывать все сообщества, к которым одновременно принадлежит блогер. Плюс, скорость обработки увеличивается в разы, потому что нет необходимости анализировать всех подписчиков блогера, достаточно взять всего 80 рекомендованных аккаунтов.
Отлично! Данные подготовили, теперь надо выбрать инструмент и алгоритм, который справится с таким большим графом, желательно за адекватное время. Напомню, что на выходе мы хотим получить набор сообществ, где один блогер может принадлежать нескольким из них.
Мы остановили свой выбор на библиотеке Stanford Network Analysis Platform (SNAP)
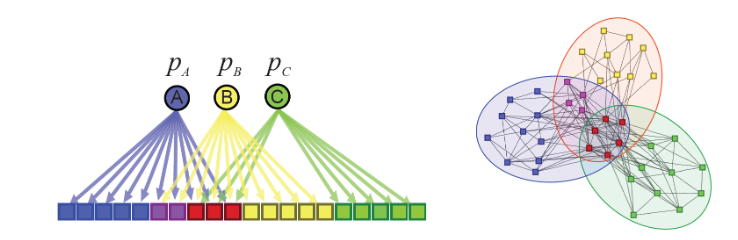
Основная и довольно интуитивная мысль: чем больше у двух узлов общих сообществ, тем больше вероятность связи между этими двумя узлами. В основе обоих алгоритмов лежит Affilated Graph Model, так что остановимся на ней подробнее:
Предположим, у нас есть двудольный граф, в котором круглые вершины – это сообщества ( и
и  ), а квадратные – пользователи соцсети, и каждый человек (
), а квадратные – пользователи соцсети, и каждый человек ( ) относится к разным сообществам с определенными весами (
) относится к разным сообществам с определенными весами ( и
и  ). Чем больше вес, тем больше вероятность того, что участник связан (знаком) с другими членами сообщества.
). Чем больше вес, тем больше вероятность того, что участник связан (знаком) с другими членами сообщества.

Пример: коллеги, которые учились в одном университете подписаны друг на друга в Instagram. Оба они являются выпускниками одного ВУЗа (сообщество 1) и работают в одной компании (сообщество 2), мы не знаем, что послужило причиной “дружбы” в сети и когда они познакомились. Пусть один только что окончил универ и устроился на работу, а второй выпустился пять лет назад и все это время работает в компании, тогда вес принадлежности первого к сообществу 1 будет больше, а к сообществу 2 – меньше и наоборот.
Для каждого общего сообщества пары человек мы получаем независимый шанс быть знакомыми:
Таким образом, чем больше общих сообществ, тем больше шансов знать друг друга:
Если посчитать вероятность связи между каждой парой пользователей, то на выходе получим граф, где вершины – это люди, а ребра между ними – это факт знакомства или подписка друг на друга.
Таким образом, от представления слева мы перешли к картинке справа.
Теперь поймем, как эта модель используется в обнаружении сообществ.
У нас есть граф похожих друг на друга блогеров и наша цель обнаружить сообществ с помощью модели описанной выше, путем подбора наиболее подходящей матрицы весов
сообществ с помощью модели описанной выше, путем подбора наиболее подходящей матрицы весов  (ее размерность
(ее размерность  узлов на сообществ) так, чтобы полученный на выходе граф был похож на наш исходный. Делается это с помощью максимизации функции правдоподобия
узлов на сообществ) так, чтобы полученный на выходе граф был похож на наш исходный. Делается это с помощью максимизации функции правдоподобия
А еще все это дело можно представить в виде неотрицательного матричного разложения, что как раз дает плюс в масштабируемости алгоритма BIGCLAM по сравнению с AGMfit.
Подробнее можно почитать здесь и здесь.
В BIGCLAM можно задать как точное число сообществ, так и интервал. Алгоритм выбирает 20% пар узлов на тест, а на 80% происходит подгонка модели с разным числом сообществ.
Сформировали входной файлик со списком ребер и запускаем:

Параметры позволяют задавать количество попыток, минимальное и максимальное число сообществ (или точное, если необходимо), количество тредов для параллелизации и префикс выходных файлов. В нашем случае мы задали интервал от 50 до 200 тысяч сообществ с 20 попытками на 10 тредах. Все это великолепие считалось пять дней на 2 Intel® Xeon® Gold 6150 CPU @ 2.70GHz. На выходе получили два файла один для Gephi, второй текстовый, в котором каждая строка – это сообщество.
На самом деле, мы запускали алгоритм дважды и первый раз уперлись в верхнюю границу в 50 тысяч сообществ, результат был неплохой, но часто попадались смешанные сообщества. В этот раз мы опять попали в максимальное значение в 200 тысяч сообществ, но они были гораздо более качественные, на этом и остановились. Вероятно, можно было получить результат еще лучше, но двести тысяч сообществ без названий и так пугали наше воображение.
 Красивая картинка
Красивая картинка
Что же теперь со всем этим делать?
С одной стороны, полученные сообщества помогают нам быстро искать узкие группы блогеров (как тогда с офтальмологами). Если есть парочка блогеров для примера, то берем все сообщества, в которые они входят, отбрасываем ненужные и все. Можно использовать поиск по названиям, вот, например, одно из сообществ про декор и дизайн интерьера:

С другой стороны, для определения интересов пользователей все эти сообщества надо как-то осмысленно назвать. А может быть, все и не нужно.
К сожалению, не все полученные сообщества одинаково хороши, и для обнаружения наиболее интересных решили попробовать использовать метод приоритезации CRank из той же библиотеки SNAP. Он призван автоматически на основе структуры графа сопоставить каждому сообществу ранг: чем больше значение, тем лучше сообщество.
На вход программе подаем найденные ранее сообщества, для каждого из них вычисляются метрики приоритизации (4 штуки), затем эти метрики агрегируются, и мы получаем оценку.

Подробнее можно почитать тут.
Запуск
Во время запуска столкнулись с проблемой совместимости с Ubuntu 18.04, здесь предлагают решение.
Так как наш файл с полученными сообществами bloggers_cmtyvv.txt и список ребер query_graph_all.edgelist изначально содержали никнеймы (типа string), пришлось их захэшировать, чтобы было int, иначе crank ругается.
Посмотрим, как это работает на примере:
Выберем несколько сообществ, где встречаются профили, содержащие в названии строку “lokomotiv”, по задумке это должны быть сообщества футбольных болельщиков клуба “Локомотив”, посмотрим, что же на самом деле. Красным цветом обозначены участники сообщества, под каждой картинкой соответствующий score.
 Сообщество 1, score 0.4
Сообщество 1, score 0.4
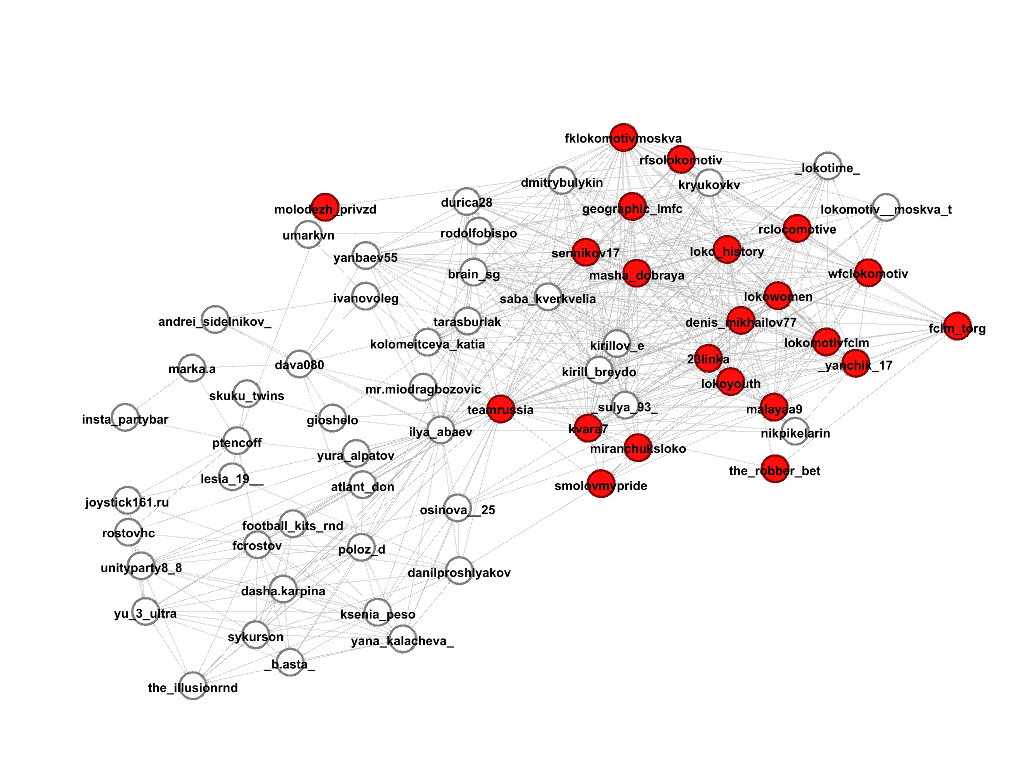 Сообщество 2, score 0.41
Сообщество 2, score 0.41
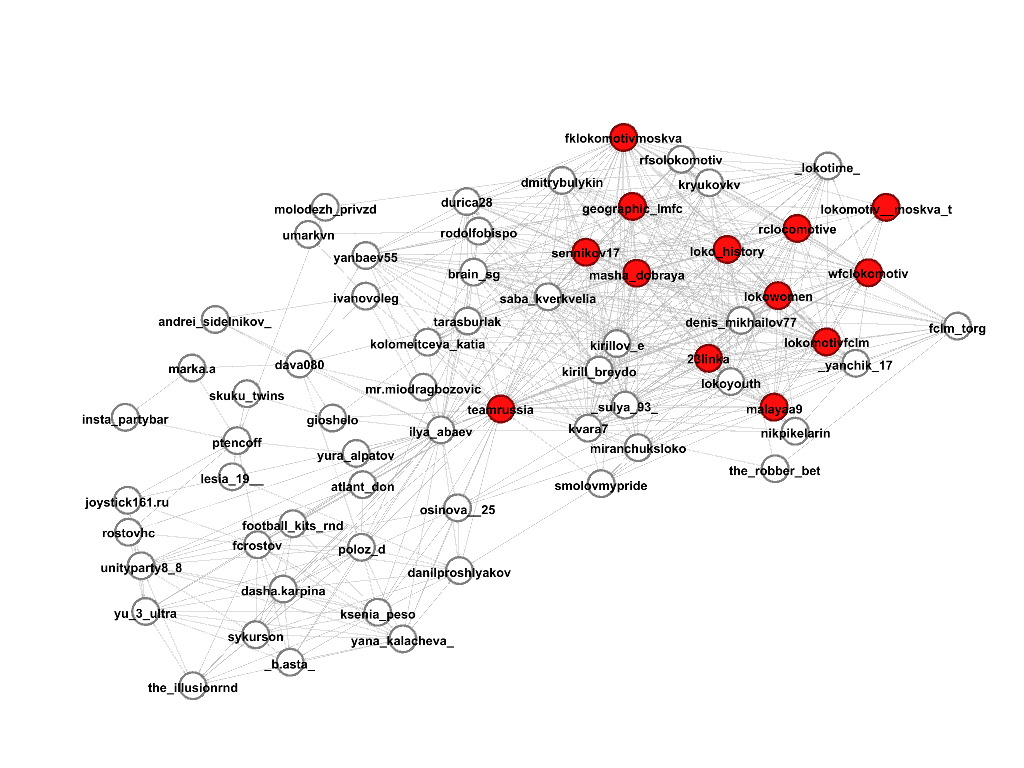 Сообщество 3, score 0.34
Сообщество 3, score 0.34
 Сообщество 4, score 0.13
Сообщество 4, score 0.13
Затем, просмотрев все профили из этого подграфа, выделяем тех, кто действительно относится к искомому сообществу, получилось вот так:
 Получается, что первые два сообщества на самом деле содержат то, что нам нужно, практически без ошибок (за исключением профиля сборной РФ по футболу teamrussia), третье сообщество хорошее, но покрывает меньше аккаунтов, чем первые два, поэтому и score поменьше, а четвертое сообщество хоть и состоит из аккаунтов на околофутбольную тему (здесь и футболисты других клубов, и их жены, и менеджеры), но мимо, нам не подходит.
Получается, что первые два сообщества на самом деле содержат то, что нам нужно, практически без ошибок (за исключением профиля сборной РФ по футболу teamrussia), третье сообщество хорошее, но покрывает меньше аккаунтов, чем первые два, поэтому и score поменьше, а четвертое сообщество хоть и состоит из аккаунтов на околофутбольную тему (здесь и футболисты других клубов, и их жены, и менеджеры), но мимо, нам не подходит.
Можно сделать вывод, что CRank работает весьма неплохо.
Для решения задачи раскраски пользователей по интересам, мы также анализируем тексты постов и нам хотелось посмотреть, где лучше/интереснее результат (в текстах или в подписках) и вообще есть ли совпадения. Для небольшой выборки людей пришлось самостоятельно разметить около 800 сообществ. Результатом мы остались более чем довольны и решили, что этот подход стоит развивать. Метод обнаружения сообществ позволяет находить очень узкие и необычные категории интересов, например, подписка на профили крыс (в смысле маленьких сереньких грызунов) и прочие удивительные вещи, можно узнать, каким именно видом спорта предположительно увлекается человек, а не запихивать всё в категорию “экстрим” и т д
Размечать все 200 тысяч сообществ мы, вероятно, не будем, но, может быть, поиграемся с результатами CRank и оставим только сообщества с высоким скором, а может, будем размечать по мере необходимости. Такие дела :)
Спасибо!
Статья написана совместно с моим руководителем Артёмом Королёвым (korolevart) R&D Dentsu Aegis Network Russia
 Источник
Источник

Очевидный подход – разложить подписки человека по категориям. Допустим, среди подписок пользователя Ивана мы обнаружили двух автоблогеров и три аккаунта со смешными картинками, остальные профили не тематические (будем считать, что это друзья, родственники, коллеги и т. д.). Отсюда делаем вывод: Иван веселый человек, увлекается автомобилями. Профит. Все, что нам нужно – это соответствие “блогер + тематика контента”, но здесь не все так просто.
Кто такой блогер? Блогер в Instagram ничем не отличается от обычного аккаунта (и вообще, это что-то вроде состояния души). В идеале нас интересуют тематические аккаунты с большой долей живой аудитории, при этом не хотелось бы просто отсекать по числу подписчиков, можем что-то упустить.
Где взять хорошую таксономию? Если придумывать категории самостоятельно, то обязательно что-нибудь интересное затеряется в “разном”, а когда все будет готово, окажется, что категории слишком широкие. Мы же хотим получить естественное разбиение, а поэтому будем блогеров кластеризовать.
Может ли один блогер относиться к нескольким категориям? Еще как! Очень часто он одновременно и швец, и жнец, и на дуде игрец (а еще тревел, лайфстайл, жена и мама).
Итак, нам нужен датасет с очень большим числом блогеров и алгоритм кластеризации с пересекающимися кластерами на выходе.
С чего все началось
К нам обращаются клиенты, которые хотят разместить свою рекламу у лидеров мнений в Instagram наиболее эффективно. Иногда есть список блогеров, и тогда мы решаем задачу оптимизации – охватить больше людей за меньшие деньги, а иногда списка нет и релевантных блогеров надо найти. На этот раз искали профили врачей-офтальмологов.
Мы использовали подход, похожий на рекомендательную систему:
- Выбираем 3-7 подходящих профилей руками (“ядро сообщества”)

- С помощью пересечения подписчиков определяем людей, которые интересуются темой (“увлеченные”)
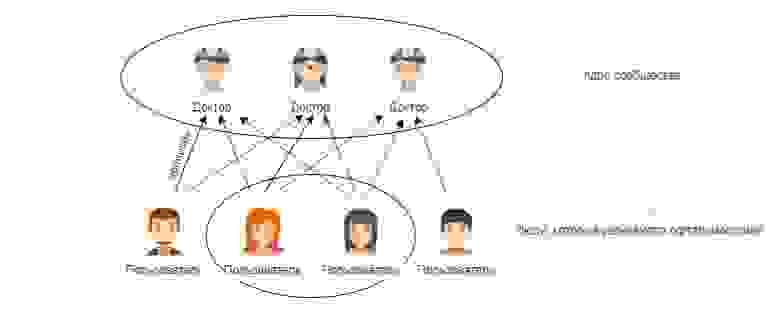
- Ищем в подписках “увлеченных” людей новых врачей

- В случае необходимости повторяем шаги 1-3 (добавляя новых врачей к “ядру” или меняя его)


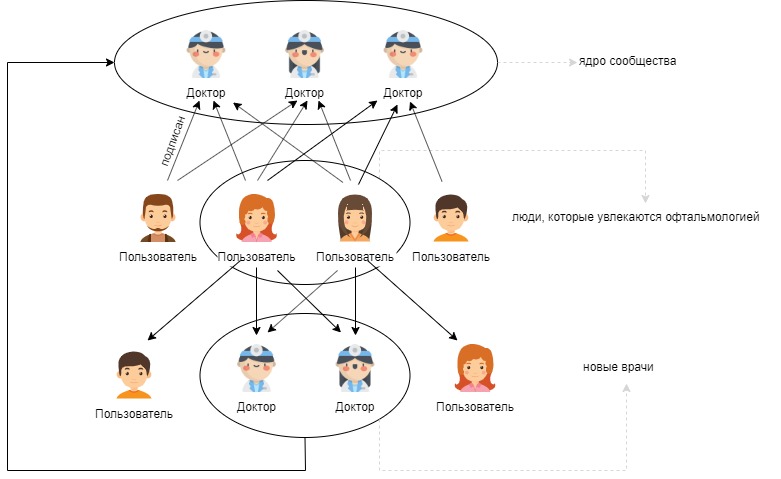
Теперь подробнее на примере.
Шаг 1. С помощью поиска в Instagram отобрали 6 аккаунтов врачей-офтальмологов из разных регионов России:

Список довольно случайный, но нам было достаточно того, что блог действительно соответствует тематике и подписчиков не меньше, чем 1000 человек.
Шаг 2. После пересечения всех подписчиков смотрим на распределение.
| Number of mutual followings | Number of accounts |
|---|---|
| 6 | 2 |
| 5 | 3 |
| 4 | 24 |
| 3 | 102 |
| 2 | 693 |
| 1 | 30025 |
Ура! Пересечения есть.
Более того, есть два человека, которые подписаны на все шесть профилей! Итак, теперь нужно определить, кого считаем “увлеченными” офтальмологией. Мы решили, что берем всех, начиная с трех подписок. Как говорится, 1 раз — случайность, 2 раза — совпадение, 3 — уже закономерность. Таким образом, нашли 131 (2+3+24+102) “увлеченного” пользователя.
Шаг 3. Загружаем подписки “увлеченных” людей и опять всячески агрегируем.

Получили внушительный список аккаунтов, из которых теперь будем отбирать новых офтальмологов. Правый столбец показывает, сколько из 131 человека, которые отобраны на втором шаге, подписаны на профиль. В топе оказались профили из нашей изначальной шестерки, что неудивительно. Если мы сейчас подберем порог и скажем: “Все профили со значением count больше десяти – новые врачи”, то мы рискуем отнести популярные аккаунты вроде Ольги Бузовой к врачам-офтальмологам и в то же время потерять меленькие, но релевантные профили, поэтому добавим еще одним столбцом количество подписчиков и рассчитаем долю увлеченных пользователей среди подписчиков.

Для удобства доля умножена на 100 (так что share – это по факту процент). В итоге с условием count >= 6 и share >= 0.05 получили 166 новых врачей-офтальмологов. Класс!
Шаг 4. 172 аккаунта стали новым “ядром” сообщества, это помогло найти ещё примерно 500 новых офтальмологов, но результат уже смещался в зарубежные аккаунты.
Похожие аккаунты в рекомендациях Instagram
Это все, конечно, интересно, и теперь мы умеем неплохо находить похожие друг на друга аккаунты, но мы все еще мечтаем получить разбивку всех инстаблогеров по категориям. И тут в голову пришла идея посмотреть на готовые рекомендации инстаграма.

Дело в том, что у тематических аккаунтов есть рекомендации, а у обычных людей – нет. Вот и ответ на вопрос, кого считать блогерами и минус одна головная боль. Ура!
В рекомендациях у одного блогера до 80 похожих профилей. У нас был список из 1000 российских блогов, начали с него. Взяли похожих, потом похожих похожих, потом … ну вы поняли:)
План был в том, что когда-нибудь этот процесс закончится, так как маленькие профили с парой сотен подписчиков в рекомендации не попадут, но фактически остановились мы, когда закончилось терпение. Всегда можно продолжить собирать датасет, но пока не пригодилось, с большой вероятностью почти всех российских блогеров мы охватили, и ладно.
Теперь у нас есть граф с 3 428 453 вершинами (блогеры) и 96 967 974 ребрами (похожесть двух блогеров между собой).

Кстати, оказалось, мы не первые решили использовать такой подход.
Судя по всему, рекомендации в Instagram формируются, исходя из того, на кого еще подписаны подписчики этого профиля, поэтому у врача из Брянска в рекомендациях будут популярные брянские аккаунты и другие врачи. Это похоже на наш поиск офтальмологов, но теперь мы можем учитывать все сообщества, к которым одновременно принадлежит блогер. Плюс, скорость обработки увеличивается в разы, потому что нет необходимости анализировать всех подписчиков блогера, достаточно взять всего 80 рекомендованных аккаунтов.
Выбор и описание алгоритма
Отлично! Данные подготовили, теперь надо выбрать инструмент и алгоритм, который справится с таким большим графом, желательно за адекватное время. Напомню, что на выходе мы хотим получить набор сообществ, где один блогер может принадлежать нескольким из них.
Мы остановили свой выбор на библиотеке Stanford Network Analysis Platform (SNAP)
Stanford Network Analysis Platform (SNAP) is a general purpose network analysis and graph mining library. It is written in C++ and easily scales to massive networks with hundreds of millions of nodes, and billions of edges. It efficiently manipulates large graphs, calculates structural properties, generates regular and random graphs, and supports attributes on nodes and edges.Наше внимание привлек алгоритм AGMfit (AGM – Affilated Graph Model), а использовали в итоге BIGCLAM (Cluster Affiliation Model for Big Networks). Отличаются они лишь тем, что в первом случае задача оптимизации решается комбинаторно, что делает его менее масштабируемым, а второй как раз позволяет подавать на вход графы вроде нашего.
Основная и довольно интуитивная мысль: чем больше у двух узлов общих сообществ, тем больше вероятность связи между этими двумя узлами. В основе обоих алгоритмов лежит Affilated Graph Model, так что остановимся на ней подробнее:
Предположим, у нас есть двудольный граф, в котором круглые вершины – это сообщества (
и ), а квадратные – пользователи соцсети, и каждый человек () относится к разным сообществам с определенными весами ( и ). Чем больше вес, тем больше вероятность того, что участник связан (знаком) с другими членами сообщества.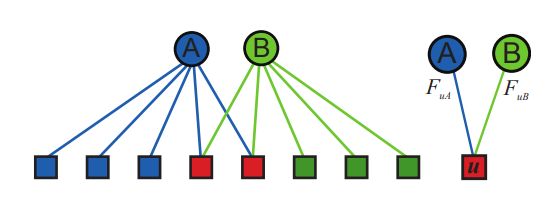
Пример: коллеги, которые учились в одном университете подписаны друг на друга в Instagram. Оба они являются выпускниками одного ВУЗа (сообщество 1) и работают в одной компании (сообщество 2), мы не знаем, что послужило причиной “дружбы” в сети и когда они познакомились. Пусть один только что окончил универ и устроился на работу, а второй выпустился пять лет назад и все это время работает в компании, тогда вес принадлежности первого к сообществу 1 будет больше, а к сообществу 2 – меньше и наоборот.
Для каждого общего сообщества пары человек мы получаем независимый шанс быть знакомыми:

Таким образом, чем больше общих сообществ, тем больше шансов знать друг друга:

Если посчитать вероятность связи между каждой парой пользователей, то на выходе получим граф, где вершины – это люди, а ребра между ними – это факт знакомства или подписка друг на друга.
Таким образом, от представления слева мы перешли к картинке справа.

Теперь поймем, как эта модель используется в обнаружении сообществ.
У нас есть граф похожих друг на друга блогеров и наша цель обнаружить
сообществ с помощью модели описанной выше, путем подбора наиболее подходящей матрицы весов (ее размерность узлов на сообществ) так, чтобы полученный на выходе граф был похож на наш исходный. Делается это с помощью максимизации функции правдоподобия
А еще все это дело можно представить в виде неотрицательного матричного разложения, что как раз дает плюс в масштабируемости алгоритма BIGCLAM по сравнению с AGMfit.
Подробнее можно почитать здесь и здесь.
Подбор числа сообществ и запуск
В BIGCLAM можно задать как точное число сообществ, так и интервал. Алгоритм выбирает 20% пар узлов на тест, а на 80% происходит подгонка модели с разным числом сообществ.
Сформировали входной файлик со списком ребер и запускаем:
./bigclam -o:bloggers -i:query_graph_all.edgelist -c:-1 -nc:20 -mc:50000 -xc:200000 -nt:10Параметры позволяют задавать количество попыток, минимальное и максимальное число сообществ (или точное, если необходимо), количество тредов для параллелизации и префикс выходных файлов. В нашем случае мы задали интервал от 50 до 200 тысяч сообществ с 20 попытками на 10 тредах. Все это великолепие считалось пять дней на 2 Intel® Xeon® Gold 6150 CPU @ 2.70GHz. На выходе получили два файла один для Gephi, второй текстовый, в котором каждая строка – это сообщество.
На самом деле, мы запускали алгоритм дважды и первый раз уперлись в верхнюю границу в 50 тысяч сообществ, результат был неплохой, но часто попадались смешанные сообщества. В этот раз мы опять попали в максимальное значение в 200 тысяч сообществ, но они были гораздо более качественные, на этом и остановились. Вероятно, можно было получить результат еще лучше, но двести тысяч сообществ без названий и так пугали наше воображение.

Что же теперь со всем этим делать?
С одной стороны, полученные сообщества помогают нам быстро искать узкие группы блогеров (как тогда с офтальмологами). Если есть парочка блогеров для примера, то берем все сообщества, в которые они входят, отбрасываем ненужные и все. Можно использовать поиск по названиям, вот, например, одно из сообществ про декор и дизайн интерьера:

С другой стороны, для определения интересов пользователей все эти сообщества надо как-то осмысленно назвать. А может быть, все и не нужно.
CRank
К сожалению, не все полученные сообщества одинаково хороши, и для обнаружения наиболее интересных решили попробовать использовать метод приоритезации CRank из той же библиотеки SNAP. Он призван автоматически на основе структуры графа сопоставить каждому сообществу ранг: чем больше значение, тем лучше сообщество.
На вход программе подаем найденные ранее сообщества, для каждого из них вычисляются метрики приоритизации (4 штуки), затем эти метрики агрегируются, и мы получаем оценку.
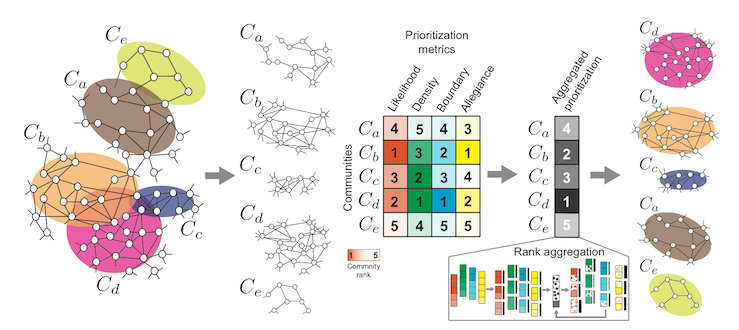
Подробнее можно почитать тут.
Запуск
./crank -i:bloggers_cmtyvv.txt -c:query_graph_all.edgelist -o:bloggers_prioritization.txt
Во время запуска столкнулись с проблемой совместимости с Ubuntu 18.04, здесь предлагают решение.
Так как наш файл с полученными сообществами bloggers_cmtyvv.txt и список ребер query_graph_all.edgelist изначально содержали никнеймы (типа string), пришлось их захэшировать, чтобы было int, иначе crank ругается.
Посмотрим, как это работает на примере:
Выберем несколько сообществ, где встречаются профили, содержащие в названии строку “lokomotiv”, по задумке это должны быть сообщества футбольных болельщиков клуба “Локомотив”, посмотрим, что же на самом деле. Красным цветом обозначены участники сообщества, под каждой картинкой соответствующий score.
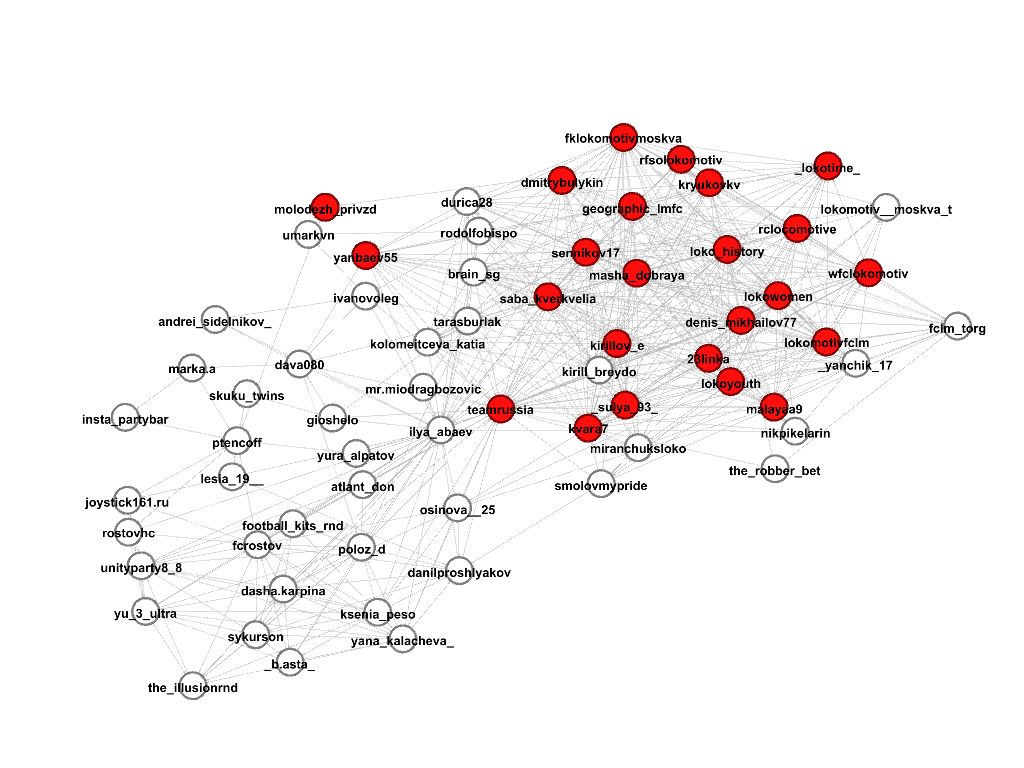
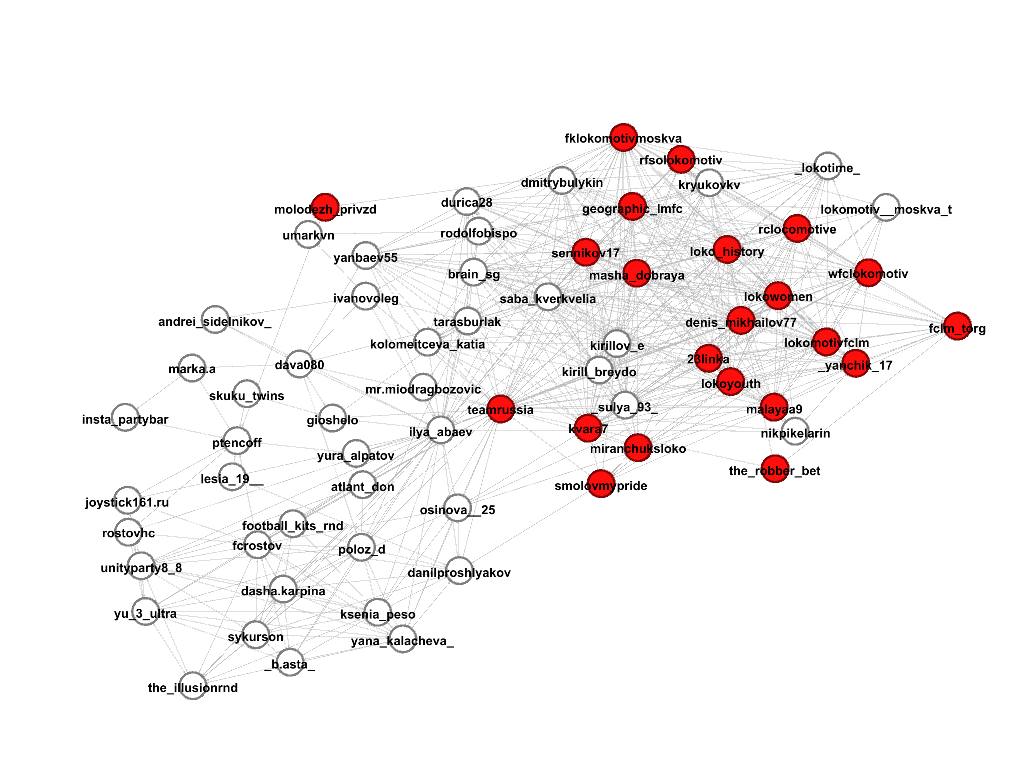

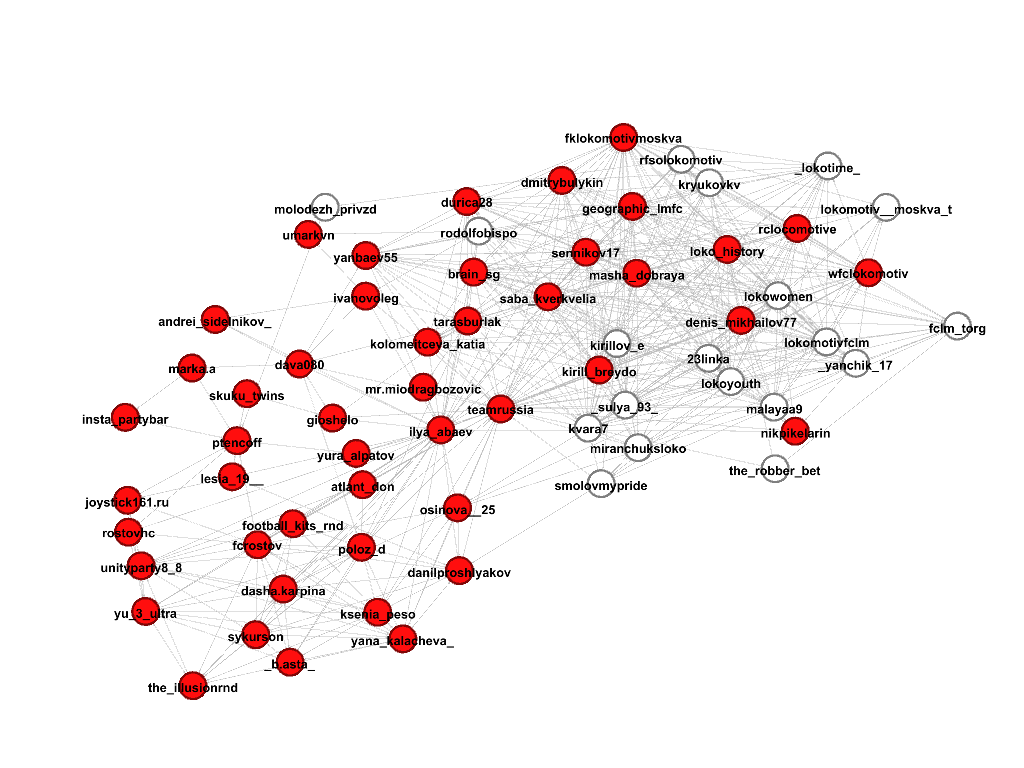
Затем, просмотрев все профили из этого подграфа, выделяем тех, кто действительно относится к искомому сообществу, получилось вот так:

Можно сделать вывод, что CRank работает весьма неплохо.
Ручная разметка для раскраски и результаты
Для решения задачи раскраски пользователей по интересам, мы также анализируем тексты постов и нам хотелось посмотреть, где лучше/интереснее результат (в текстах или в подписках) и вообще есть ли совпадения. Для небольшой выборки людей пришлось самостоятельно разметить около 800 сообществ. Результатом мы остались более чем довольны и решили, что этот подход стоит развивать. Метод обнаружения сообществ позволяет находить очень узкие и необычные категории интересов, например, подписка на профили крыс (в смысле маленьких сереньких грызунов) и прочие удивительные вещи, можно узнать, каким именно видом спорта предположительно увлекается человек, а не запихивать всё в категорию “экстрим” и т д
Размечать все 200 тысяч сообществ мы, вероятно, не будем, но, может быть, поиграемся с результатами CRank и оставим только сообщества с высоким скором, а может, будем размечать по мере необходимости. Такие дела :)
Спасибо!
Статья написана совместно с моим руководителем Артёмом Королёвым (korolevart) R&D Dentsu Aegis Network Russia

