Comments 10
UFO just landed and posted this here
alex005 У нас развернуто несколько инстансов Nagios — по одному на каждый дата-центр. Также используем HA Cluster: Pacemaker + Corosync + DRDB. Для автоматизированного добавления объектов в мониторинг мы используем связку наших скриптов, с помощью которых можно сгенерировать конфигурации для Nagios. Да, Вы правы, лучше иметь функцию автоматизации, уже встроенную в решение. Сейчас как раз смотрим и тестируем Check_MK. Спасибо за совет CEE с Micro Core. Попробуем и его.
«Предупреждение будет выдано на 3 мс, критическое пороговое значение установлено на 5 мс.»
продолжайте так думать
продолжайте так думать
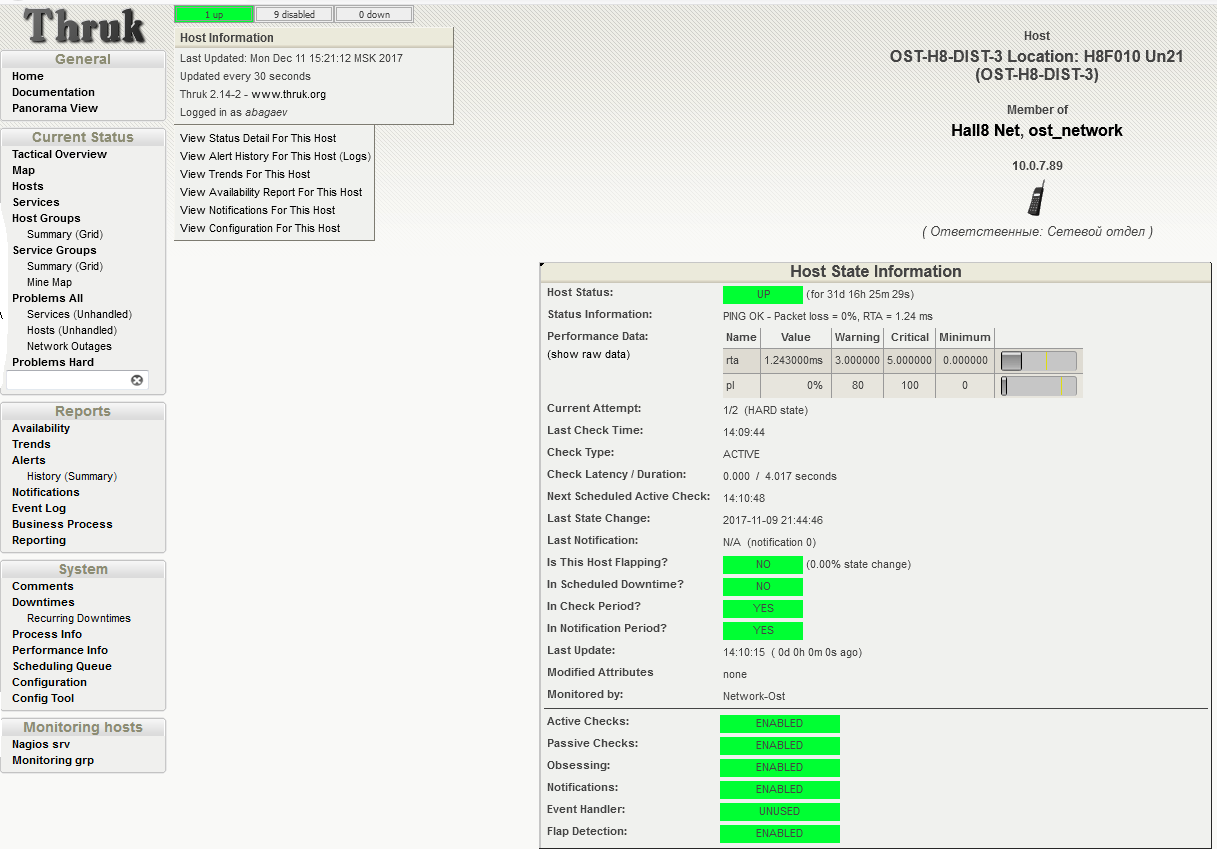
Если брать мониторинг физического оборудования в целом, то у него есть еще один аспект. Как-то решается учет точного размещения оборудования по юнитам стоек и учет подключений СКС?
Sign up to leave a comment.
Мониторинг инженерной инфраструктуры в дата-центре. Часть 4. Сетевая инфраструктура: физическое оборудование