25 и 26 января лаборатория проводит практический учебный курс по визуализации данных.

Весь прошлый год мы в лаборатории решали задачи по визуализации и придумывали новые форматы представления данных, я вела обычные и живые советы, читала лекции и проводила практические занятия со студентам МАИ, МГУ и участниками питерского «Дизайн-трека». Мы собрали огромное количество материала, которым не трепится поделиться, и подготовили двухдневный практический курс для тех, кто хочет перейти «на ты» со сложными данными и с головой погрузиться в тему.
На курсе участники учатся работать с данными с помощью дизайнерских инструментов. В первый день мы разберём хорошие и плохие примеры, по-новому взглянем на привычные таблицы, графики и диаграммы, познакомимся с необычными форматами — удавом, слоёным пирогом, мозаикой, домограммой. Во второй день Дима Тихвинский devgru, веб-технолог лаборатории, покажет как применить эти навыки при работе с библиотекой D3.js — самым современным и гибким инструментом интерактивных визуализаций. Все участники курса получат раздаточные материалы с кратким конспектом лекций:

Курс будет полезен дизайнерам, аналитикам, менеджерам, программистам, журналистам и редакторам онлайн-изданий. Предварительного знакомства с D3.js не требуется, опыт работы с HTML, CSS и JavaScript полезен, но не обязателен.
Чтобы заинтересовать хабровчан, я приготовила полезный и приятный сюрпризы. В этой заметке я поделюсь рецептами грамотной работы со сложными данными, которым мы учим на курсе, и расскажу, как получить скидку.
Этим летом я прошла на курсере курс «Data Science». В числе прочих там была тема «Data Visualization», которая по понятным причинам, меня очень заинтересовала. Лекции вела профессор Сесилия Арагон. Приведу краткий фрагмент одной из них.
В самом начале профессор говорит, что задача визуализации — выбрать наиболее эффективный способ визуального кодирования для конкретного набора данных, и обещает рассказать, как это делается. После нескольких, на мой взгляд неоднозначных, утверждений, в числе которых запрет на кодировании количественной информации цветом (привет, Яндекс-пробки), Сесилия демонстрирует все визуальные атрибуты, которые подходят для кодирования информации:

Затем она предлагает, в качестве упражнения, визуализировать с их помощью автомобильные данные:

В конце лекции Сесилия показывает вариант решения, предложенный её студентом:

Внимательно рассмотрите эту визуализацию. О чём она рассказывает? Какие закономерности вы видите? Какую пользу можете извлечь?
Всё визуальные атрибуты в этом примере выбраны произвольно. Оси демонстрируют очевидную закономерность — чем больше мощность двигателя, тем больше расход топлива. Данные сбиваются в кучу у нижней границы, ненулевая точка вертикального отсчёта нарушает масштаб (кажется, что самый «прожорливый» автомобиль отличается от экономичных раз в десять — на самом деле, в три). Сколько весят «крестик» и «треугольник»? О чём говорит скопление машин в верхнем левом углу? Визуализацию буквально приходится расшифровывать, постоянно обращаясь к легенде, но даже это не даёт сколько-нибудь интересных результатов.
Вот как эту задачу решала бы я.
Во-первых, необходимо изучить данные, понять, какие задачи они могут решать. Я не представляю, какие значимые выводы можно извлечь из данных об автомобилях и зачем их изучать, не беря в расчёт важнейший параметр автомобильной реальности — цену. Вы скажите, что это нечестно, и у автора первой визуализации этого параметра не было. Но именно эту проблему чаще всего таят в себе наборы данных, с которыми мы сталкиваемся в жизни: они неполны. Количество цилиндров и вес я, наоборот, опустила, они показались мне не интересным по сравнению с другими параметрами.
Итак, задача информационного дизайнера №1: изучить данные и сценарии работы с ними, собрать максимально полный набор и выделить в нём ключевые измерения. В своём примере я использую данные «Авто.ру»:

Задача информационного дизайнера №2: выбрать наиболее эффективный способ визуального кодирования, который учитывает смысл отображаемого параметра.
Я хочу узнать, как цена автомобилей зависит от других параметров, поэтому по оси Y я откладываю именно цену (в школе это называлось зависимая переменная). На горизонтальную ось просятся год или мощность — числовые параметры с более-менее равномерным распределением. Хотя график зависимости стоимости от года выпуска может оказаться интересным, я выберу мощность, а года покажу иначе. На этом шаге получаем простой двумерный график:
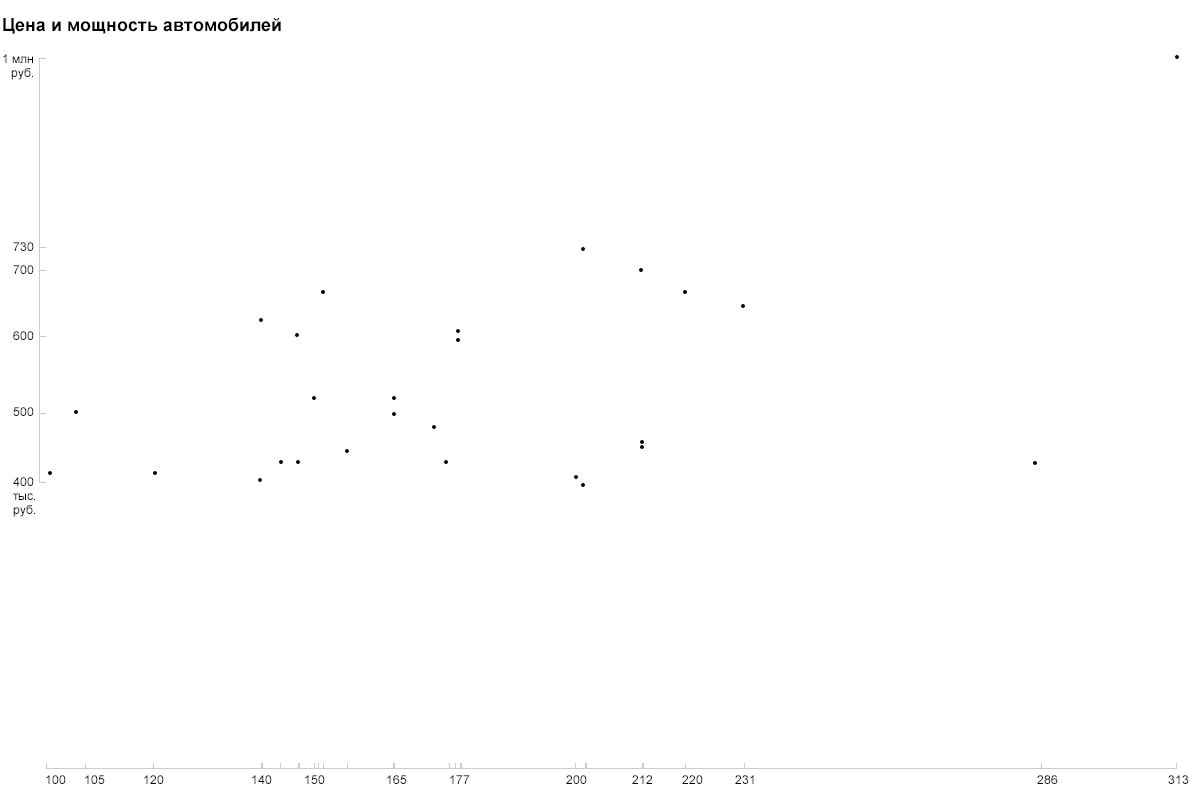
Как наглядно показать год? Цветом? Размером? Прозрачностью? Давайте попробуем просто подписать его цифрами:

Засчёт специфического формата годы считываются однозначно и не требуют легенды и расшифровки.
Наверное, вы уже догадались, как я предложу изобразить страны. Конечно, флагами:
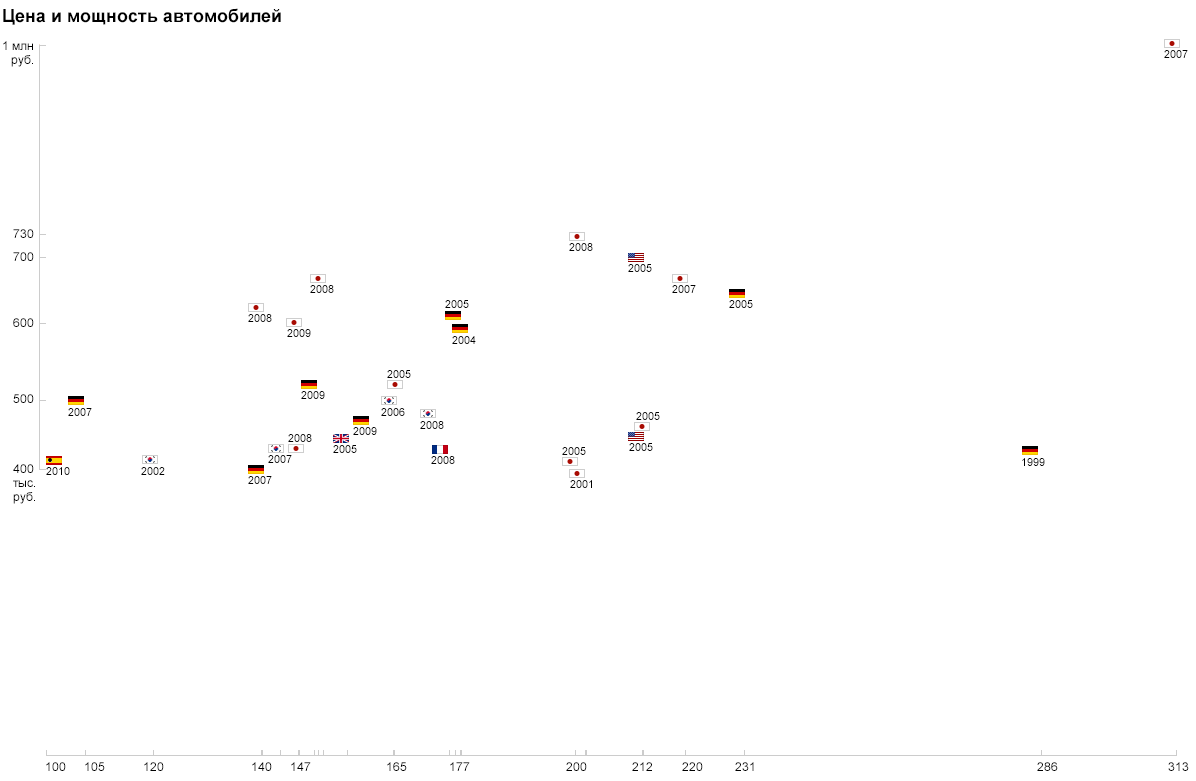
Обратите внимание на обилие азиатских марок, на то, что самый старый (немецкий) и самый дорогой (японский) автомобили опередили всех по мощности, на то, что цена корейцев держится ниже 500 тыс., что самая новая машина — испанская и одна из самых дешёвых. Все эти особенности считываются просто, засчёт естественных обозначений параметров.
Теперь разберёмся с расходом топлива. Пиктограммы, цветовое кодирование и другие графические штуки перегрузят нашу визуализацию. А что если использовать существующие измерения? Ведь расход — это не что иное, как регулярные затраты, которые добавятся к цене автомобиля после покупки. Но просто сложить рубли с литрами нельзя, поэтому, чтобы показать добавку на вертикальной оси, нам нужно перевести расход в рубли. Например, рассчитаем сколько владелец машины потратит на бензин, чтобы проехать 50 тыс. км: 50000/100*расход*стоимость литра бензина.

Так мы увидим сравним не только затраты на автомобиль, но и на его эксплуатацию. Аналогично можно показать стоимость обслуживания на 50 тыс. км — картина получится ещё полнее. На основании такой визуализации можно изучить тенденции на рынке и выбрать автомобиль по карману. На этом я закончу рассказ, а читателям предлагаю самостоятельно подумать, как на этом графике отобразить информацию о модели автомобиля. Участники курса узнаю правильный ответ в первый день занятий :-)
Курс стоит немало (я знаю, что многих это останавливает), но он того стоит. Чтобы сделать курс более доступным, мы придумали специальную акцию для пользователей Хабра. Каждый новый участник, который при записи сошлётся на эту заметку, получит скидку в (N-1) тысячу рублей, где N — это количество участников-хабровчан. То есть если с хабра придут два человека, то каждый получит скидку в 1 тыс. рублей, а если 11 — то скидка для каждого составит 10 тыс. Договаривайтесь, объединяйтесь в группы, записывайтесь и снижайте цену! (Оплатить курс нужно будет по первоначальной цене, мы рассчитаем скидку в день курса по количеству оплативших участников и возвратим деньги удобным вам способом. Максимальный размер группы — 16 человек, несколько мест уже занято.)
Я очень хочу, чтобы как можно больше ребят подружились с данными. Расскажите об акции свои друзьям и коллегам, которых курс может заинтересовать — так вы поможете всем желающим немного сэкономить!

Весь прошлый год мы в лаборатории решали задачи по визуализации и придумывали новые форматы представления данных, я вела обычные и живые советы, читала лекции и проводила практические занятия со студентам МАИ, МГУ и участниками питерского «Дизайн-трека». Мы собрали огромное количество материала, которым не трепится поделиться, и подготовили двухдневный практический курс для тех, кто хочет перейти «на ты» со сложными данными и с головой погрузиться в тему.
На курсе участники учатся работать с данными с помощью дизайнерских инструментов. В первый день мы разберём хорошие и плохие примеры, по-новому взглянем на привычные таблицы, графики и диаграммы, познакомимся с необычными форматами — удавом, слоёным пирогом, мозаикой, домограммой. Во второй день Дима Тихвинский devgru, веб-технолог лаборатории, покажет как применить эти навыки при работе с библиотекой D3.js — самым современным и гибким инструментом интерактивных визуализаций. Все участники курса получат раздаточные материалы с кратким конспектом лекций:
Курс будет полезен дизайнерам, аналитикам, менеджерам, программистам, журналистам и редакторам онлайн-изданий. Предварительного знакомства с D3.js не требуется, опыт работы с HTML, CSS и JavaScript полезен, но не обязателен.
Чтобы заинтересовать хабровчан, я приготовила полезный и приятный сюрпризы. В этой заметке я поделюсь рецептами грамотной работы со сложными данными, которым мы учим на курсе, и расскажу, как получить скидку.
Сюрприз полезный
Этим летом я прошла на курсере курс «Data Science». В числе прочих там была тема «Data Visualization», которая по понятным причинам, меня очень заинтересовала. Лекции вела профессор Сесилия Арагон. Приведу краткий фрагмент одной из них.
В самом начале профессор говорит, что задача визуализации — выбрать наиболее эффективный способ визуального кодирования для конкретного набора данных, и обещает рассказать, как это делается. После нескольких, на мой взгляд неоднозначных, утверждений, в числе которых запрет на кодировании количественной информации цветом (привет, Яндекс-пробки), Сесилия демонстрирует все визуальные атрибуты, которые подходят для кодирования информации:

Затем она предлагает, в качестве упражнения, визуализировать с их помощью автомобильные данные:
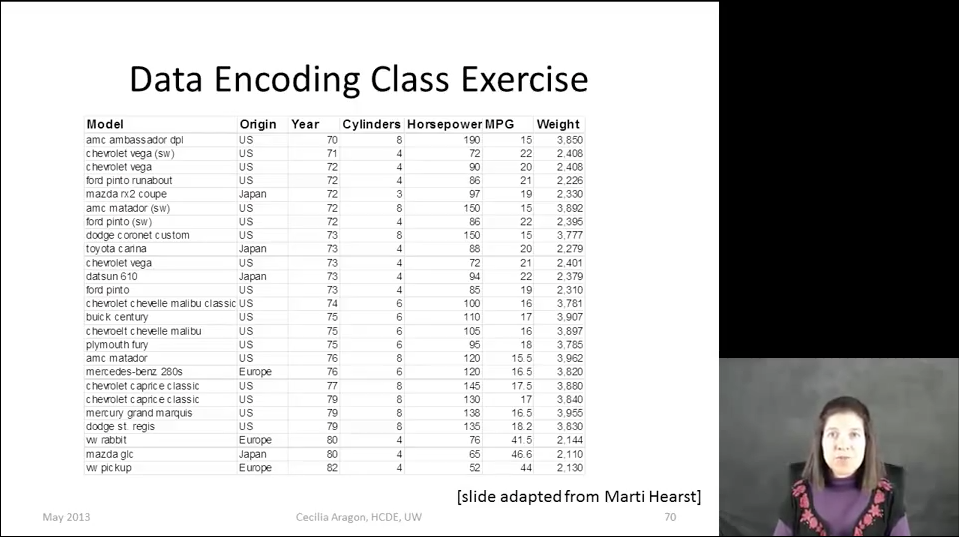
В конце лекции Сесилия показывает вариант решения, предложенный её студентом:
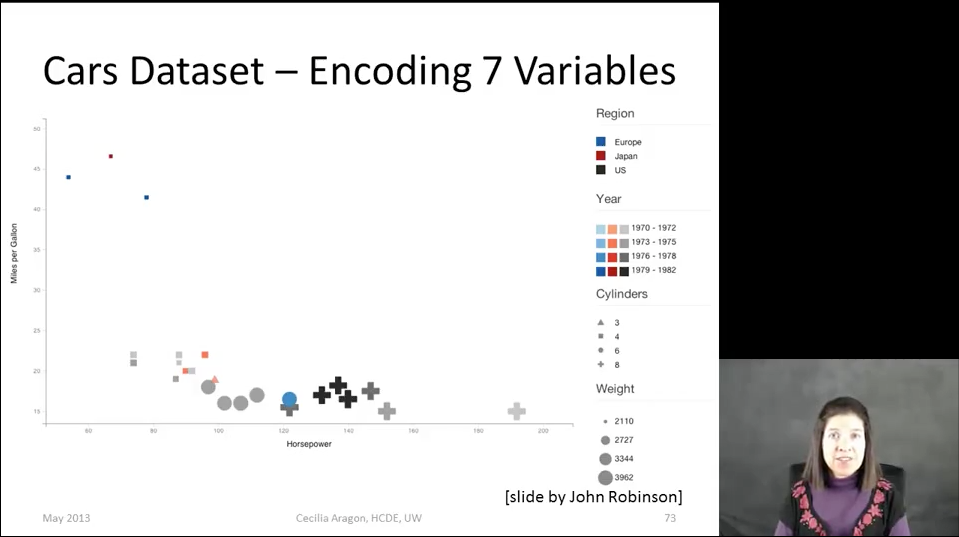
Внимательно рассмотрите эту визуализацию. О чём она рассказывает? Какие закономерности вы видите? Какую пользу можете извлечь?
Всё визуальные атрибуты в этом примере выбраны произвольно. Оси демонстрируют очевидную закономерность — чем больше мощность двигателя, тем больше расход топлива. Данные сбиваются в кучу у нижней границы, ненулевая точка вертикального отсчёта нарушает масштаб (кажется, что самый «прожорливый» автомобиль отличается от экономичных раз в десять — на самом деле, в три). Сколько весят «крестик» и «треугольник»? О чём говорит скопление машин в верхнем левом углу? Визуализацию буквально приходится расшифровывать, постоянно обращаясь к легенде, но даже это не даёт сколько-нибудь интересных результатов.
Вот как эту задачу решала бы я.
Во-первых, необходимо изучить данные, понять, какие задачи они могут решать. Я не представляю, какие значимые выводы можно извлечь из данных об автомобилях и зачем их изучать, не беря в расчёт важнейший параметр автомобильной реальности — цену. Вы скажите, что это нечестно, и у автора первой визуализации этого параметра не было. Но именно эту проблему чаще всего таят в себе наборы данных, с которыми мы сталкиваемся в жизни: они неполны. Количество цилиндров и вес я, наоборот, опустила, они показались мне не интересным по сравнению с другими параметрами.
Итак, задача информационного дизайнера №1: изучить данные и сценарии работы с ними, собрать максимально полный набор и выделить в нём ключевые измерения. В своём примере я использую данные «Авто.ру»:

Задача информационного дизайнера №2: выбрать наиболее эффективный способ визуального кодирования, который учитывает смысл отображаемого параметра.
Я хочу узнать, как цена автомобилей зависит от других параметров, поэтому по оси Y я откладываю именно цену (в школе это называлось зависимая переменная). На горизонтальную ось просятся год или мощность — числовые параметры с более-менее равномерным распределением. Хотя график зависимости стоимости от года выпуска может оказаться интересным, я выберу мощность, а года покажу иначе. На этом шаге получаем простой двумерный график:

Как наглядно показать год? Цветом? Размером? Прозрачностью? Давайте попробуем просто подписать его цифрами:
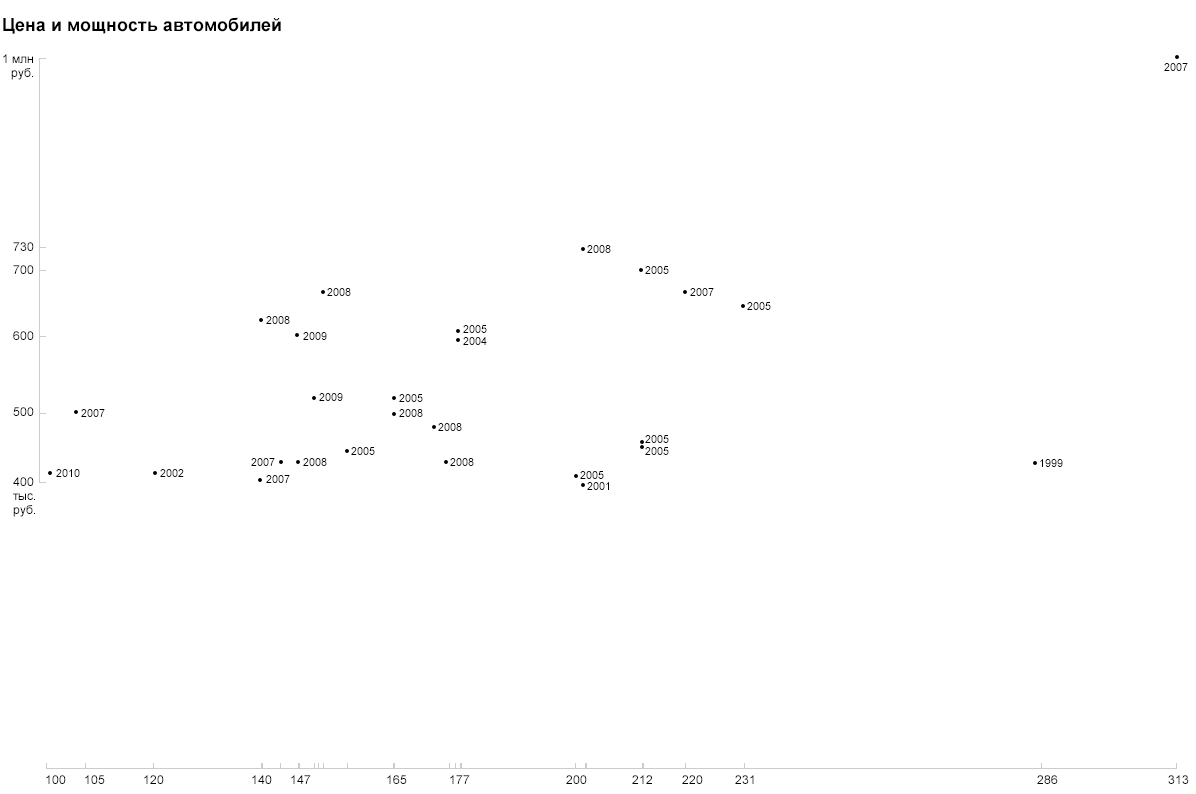
Засчёт специфического формата годы считываются однозначно и не требуют легенды и расшифровки.
Наверное, вы уже догадались, как я предложу изобразить страны. Конечно, флагами:

Обратите внимание на обилие азиатских марок, на то, что самый старый (немецкий) и самый дорогой (японский) автомобили опередили всех по мощности, на то, что цена корейцев держится ниже 500 тыс., что самая новая машина — испанская и одна из самых дешёвых. Все эти особенности считываются просто, засчёт естественных обозначений параметров.
Теперь разберёмся с расходом топлива. Пиктограммы, цветовое кодирование и другие графические штуки перегрузят нашу визуализацию. А что если использовать существующие измерения? Ведь расход — это не что иное, как регулярные затраты, которые добавятся к цене автомобиля после покупки. Но просто сложить рубли с литрами нельзя, поэтому, чтобы показать добавку на вертикальной оси, нам нужно перевести расход в рубли. Например, рассчитаем сколько владелец машины потратит на бензин, чтобы проехать 50 тыс. км: 50000/100*расход*стоимость литра бензина.
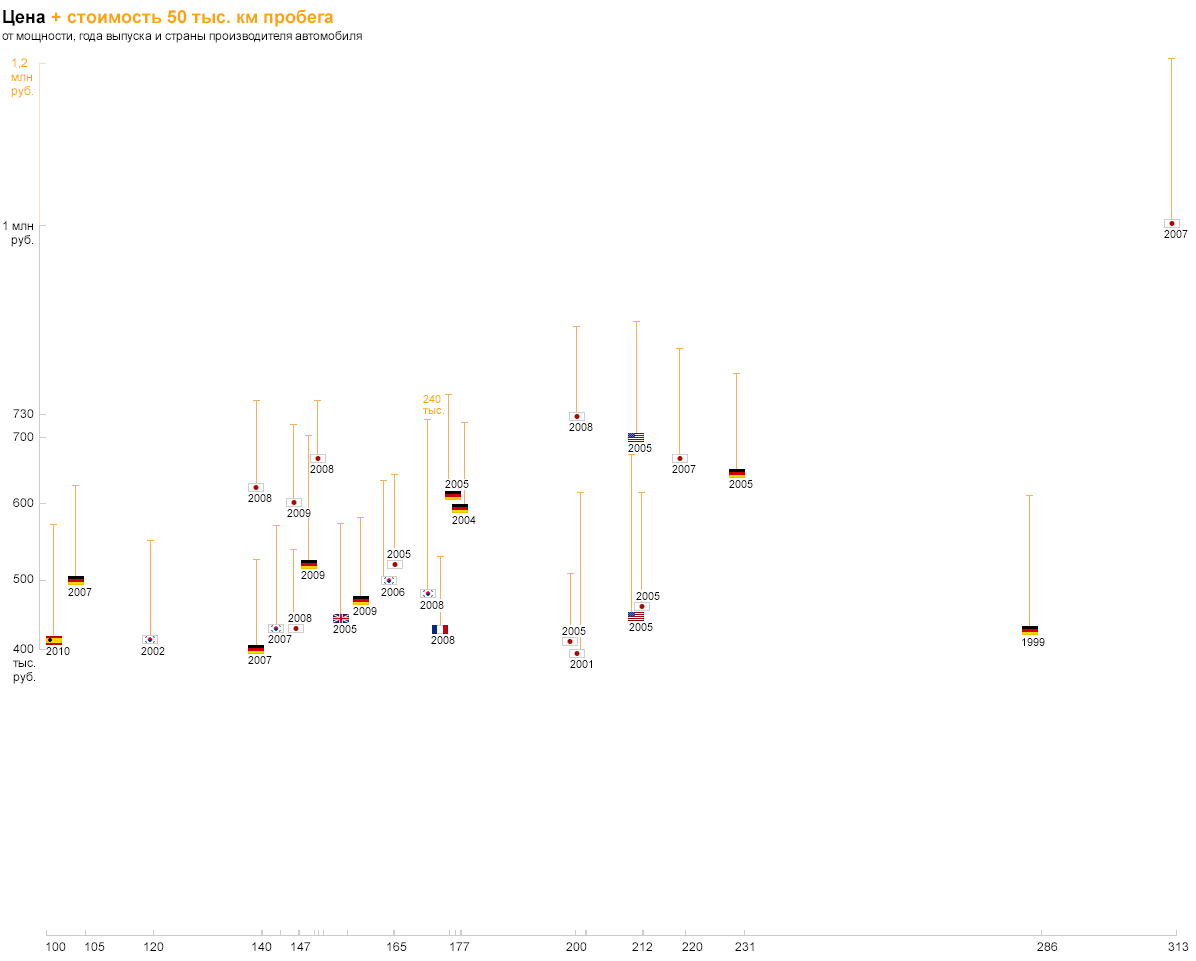
Так мы увидим сравним не только затраты на автомобиль, но и на его эксплуатацию. Аналогично можно показать стоимость обслуживания на 50 тыс. км — картина получится ещё полнее. На основании такой визуализации можно изучить тенденции на рынке и выбрать автомобиль по карману. На этом я закончу рассказ, а читателям предлагаю самостоятельно подумать, как на этом графике отобразить информацию о модели автомобиля. Участники курса узнаю правильный ответ в первый день занятий :-)
Сюрприз приятный
Курс стоит немало (я знаю, что многих это останавливает), но он того стоит. Чтобы сделать курс более доступным, мы придумали специальную акцию для пользователей Хабра. Каждый новый участник, который при записи сошлётся на эту заметку, получит скидку в (N-1) тысячу рублей, где N — это количество участников-хабровчан. То есть если с хабра придут два человека, то каждый получит скидку в 1 тыс. рублей, а если 11 — то скидка для каждого составит 10 тыс. Договаривайтесь, объединяйтесь в группы, записывайтесь и снижайте цену! (Оплатить курс нужно будет по первоначальной цене, мы рассчитаем скидку в день курса по количеству оплативших участников и возвратим деньги удобным вам способом. Максимальный размер группы — 16 человек, несколько мест уже занято.)
Я очень хочу, чтобы как можно больше ребят подружились с данными. Расскажите об акции свои друзьям и коллегам, которых курс может заинтересовать — так вы поможете всем желающим немного сэкономить!
