Comments 134
Ах, отличная картинка, меня сразу привлекло. Спасибо за перевод.
Улыбнуло:
И тут я докрутил до формулы — и лег под стол. Посмеялся от души!
Материал отличный! Буду вспоминать математику и тестировать.
Спасибо.
Рейтинг = Нижняя граница доверительного интервала Вильсона (Wilson) для параметра Бернулли
И тут я докрутил до формулы — и лег под стол. Посмеялся от души!
Материал отличный! Буду вспоминать математику и тестировать.
Спасибо.
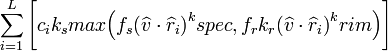
Картинка хорошая, конечно, но меня не покидает ощущение, что сиськи сейчас слипнутся под действием противоположных зарядов…
Зашел, чтобы прочитать первый комментарий.
world-art.ru применяет алгоритм Томаса Байеса для оценки аниме и фильмов по 10-балльной шкале, и, как мне кажется, она очень хорошо подходит для фильмов:
Для определения рейтинга применяется специальная статистическая техника, известная как байесовская оценка (по имени автора Томаса Байеса). Она призвана взять в расчёт не только среднее арифметическое оценок проголосовавших (средний балл), но и их количество.

30 — это необходимый минимум голосов, отданных за данное аниме. 7.2453 — некая усреднённая величина, принятая за основу метода. Суть заключается в том, что при небольшом количестве голосов расчётный балл будет близок к 7.2453. По мере увеличения отданных голосов роль среднего балла (среднего арифметического голосов) будет возрастать. Интересной особенностью является то, при одинаковой средней арифметической голосов больший расчётный балл имеют аниме с меньшим количеством голосовавших. Это искажение будет исправляться с поступлением новых голосов, хотя логика в нём есть — если при меньшем количестве голосовавших среднее арифметическое то же, то и низких баллов дано меньше.
Для определения рейтинга применяется специальная статистическая техника, известная как байесовская оценка (по имени автора Томаса Байеса). Она призвана взять в расчёт не только среднее арифметическое оценок проголосовавших (средний балл), но и их количество.
30 — это необходимый минимум голосов, отданных за данное аниме. 7.2453 — некая усреднённая величина, принятая за основу метода. Суть заключается в том, что при небольшом количестве голосов расчётный балл будет близок к 7.2453. По мере увеличения отданных голосов роль среднего балла (среднего арифметического голосов) будет возрастать. Интересной особенностью является то, при одинаковой средней арифметической голосов больший расчётный балл имеют аниме с меньшим количеством голосовавших. Это искажение будет исправляться с поступлением новых голосов, хотя логика в нём есть — если при меньшем количестве голосовавших среднее арифметическое то же, то и низких баллов дано меньше.
Да, этот метод похож. Его применяет IMDB.
При малом числе голосов такой рейтинг будет стремиться к заданному дефолтному значению. Насколько «малом» определяется константой (у вас 30). Я пробовал применить этот алгоритм к +/– голосованию, но тот что приведён в статье мне показался правильней. А только не на 100% понял почему так происходит и как он работает :)
Я где-то видел сравнение этих 2-х методов в обсуждении, если мне не изменяет память, на Reddit-е. Если найду — скину ссылку.
При малом числе голосов такой рейтинг будет стремиться к заданному дефолтному значению. Насколько «малом» определяется константой (у вас 30). Я пробовал применить этот алгоритм к +/– голосованию, но тот что приведён в статье мне показался правильней. А только не на 100% понял почему так происходит и как он работает :)
Я где-то видел сравнение этих 2-х методов в обсуждении, если мне не изменяет память, на Reddit-е. Если найду — скину ссылку.
Ага, нашёл. Там обсуждение как раз начинается с Bayesian average.
Алгоритм преподобного Томаса Байеса. Как звучит :)
По-моему, этот алгоритм не так хорош, как кажется. Слишком легко и высоко поднимаются новые аниме.
На кинопоиске по такой же формуле рассчитывается ТОП-250 (http://www.kinopoisk.ru/level/20/#formula)
«Если бы вы знали, что искать, то увидели бы, что алгоритм находится на окне в моей спальне.» (с) Марк Цукерберг из «Социальная сеть».
img-fotki.yandex.ru/get/6109/24951406.27/0_739ae_b9ed19d2_L
img-fotki.yandex.ru/get/6109/24951406.27/0_739ae_b9ed19d2_L
Отличная статья, спасибо за перевод. Сразу вспомнил одногруппника, который всегда говорил: «Я не математик, я программист». Даже в такой, на первый взгляд, тривиальной задаче ему бы пригодились тервер и матстат, чтобы взглянуть на проблему глубже.
С тем же успехом можно сказать, что ему помогли бы знания в лингвистике при написании компилятора или автоматического перевода. На самом деле математика и программирование софта связаны лишь в определенных местах. Та же теория графов не менее полезна.
Он прав. Математика нужна только инженерам-программистам. Инженер-программист отличается от программиста так же как инженер-конструктор самолетов, и рабочего собирающего самолеты в цеху. В обоих случаях требуется высокая квалификация специалистов. Но в разница способе производства огромна. Инженер это творец, а программист это ремесленник. Инженер сам не может знать, что ему нужно знать для своего труда. А программист четко знает, что ему нужно для создания конкретного продукта. Потому, что за него об этом подумал инженер или архитектор.
Хех. Как пример разности мнений, приведу свое. Всегда считал наоборот, т.к. из тех, кого знаю я, инженеры-программисты работали исключительно по тех заданию и по указаниям начальства, тогда как программисты имели простор для творчества и не ограничены в фантазии нуждами производства.
И да, в моем случае программист является и архитектором. Видимо вы про тех программистов, которые работают винтиками в каких то огромных компаниях.
И да, в моем случае программист является и архитектором. Видимо вы про тех программистов, которые работают винтиками в каких то огромных компаниях.
И как знания математики помогут инженеру-программисту написать какую-то предметную задачу? Ну скажем симулятор космического корабля (чтобы отладить на модели новую деталь, а не пускать спутники в океан). Тут очень сильно знание физики важны в первую очередь, а не математики. Или симулятор эволюционного развития, для биологии. Тут без генетических знаний — никуда, а математика нужна в объеме чуть выше чем «сдачу посчитать». В данном случае просто проблема, которую надо решить — математическая. При этом знания математики, конечно же, сильно помогают.
Хотя на самом деле, задача тут (которая формулой решается) вообще не программистская. Будто бы в ТЗ было прописано «вычислить оценку фильмам по оценкам пользователей, но так, чтобы лучшие фильмы имели более высокую оценку». Непонятно, что считать тут лучшими фильмами, и что если предложенный метод выглядит сложно, наукоемко (А раз так — то, значит, верен. Все сложное и непонятное всегда умнее простого и понятного), но при этом он не совсем хорош? Можно ведь и вообще по рандому выставлять оценки фильмам, товарам, итд, и тоже получим некий отсортированный список. Нужен какой-то четко прописанный принцип, какая оценка и сортировка нам кажутся правильными, и по каким критериям мы их оцениваем.
Вот самый грамотный подход (на мой взгляд конечно же) был бы тут такой, который бы с этого начинался. Сначала описываем критерии, по которым будем определять, какой результат работы считаем лучшим (а это уже заставляет задуматься, ведь непонятно почему эта схема хороша — показаны только минусы других простых подходов, а у этого и свои минусы могут быть). И потом уже пробуем разные алгоритмы, прогоняем через них разные данные, сравниваем результаты, «дефекты» каждого алгоритма, и в итоге получаем статистическое доказательство что выбранный алгоритм лучше. Предложденный же алгоритм лучше лишь тем, что не показывает иногда «яркие» положительные или отрицательные оценки при малом количестве отзывов. Но так же можно найти примеры, на которых он ошибается. Скажем, если алгоритм вам даст оценку шедевра кинематографа в «средние» 6 баллов, при том что проходная романтическая комедия (но не худшая) оценивается в 7, вы же не будете считать такой алгоритм правильным? А в данном случае этот алгоритм именно так и поступает, усредняя результат при малом количестве оценок.
Хотя на самом деле, задача тут (которая формулой решается) вообще не программистская. Будто бы в ТЗ было прописано «вычислить оценку фильмам по оценкам пользователей, но так, чтобы лучшие фильмы имели более высокую оценку». Непонятно, что считать тут лучшими фильмами, и что если предложенный метод выглядит сложно, наукоемко (А раз так — то, значит, верен. Все сложное и непонятное всегда умнее простого и понятного), но при этом он не совсем хорош? Можно ведь и вообще по рандому выставлять оценки фильмам, товарам, итд, и тоже получим некий отсортированный список. Нужен какой-то четко прописанный принцип, какая оценка и сортировка нам кажутся правильными, и по каким критериям мы их оцениваем.
Вот самый грамотный подход (на мой взгляд конечно же) был бы тут такой, который бы с этого начинался. Сначала описываем критерии, по которым будем определять, какой результат работы считаем лучшим (а это уже заставляет задуматься, ведь непонятно почему эта схема хороша — показаны только минусы других простых подходов, а у этого и свои минусы могут быть). И потом уже пробуем разные алгоритмы, прогоняем через них разные данные, сравниваем результаты, «дефекты» каждого алгоритма, и в итоге получаем статистическое доказательство что выбранный алгоритм лучше. Предложденный же алгоритм лучше лишь тем, что не показывает иногда «яркие» положительные или отрицательные оценки при малом количестве отзывов. Но так же можно найти примеры, на которых он ошибается. Скажем, если алгоритм вам даст оценку шедевра кинематографа в «средние» 6 баллов, при том что проходная романтическая комедия (но не худшая) оценивается в 7, вы же не будете считать такой алгоритм правильным? А в данном случае этот алгоритм именно так и поступает, усредняя результат при малом количестве оценок.
и все же, не каждый программист пишет игровой движок. В некоторых местах достаточно арифметики, логики и алгоритмов.
Спасибо за перевод.
Тема показалась не до конца раскрытой. Не хватило четких критериев, которым должна удовлетворять формула, т.е. критериев, по которым автор отделяет «правильно» от «не правильно». Именно поэтому, мне, например, не очень понятно, почему эта формула — то, что надо.
Тема показалась не до конца раскрытой. Не хватило четких критериев, которым должна удовлетворять формула, т.е. критериев, по которым автор отделяет «правильно» от «не правильно». Именно поэтому, мне, например, не очень понятно, почему эта формула — то, что надо.
Мы хотим знать следующее: «Обладая набором данных мне оценок, можно ли с вероятностью 95% сказать, какова будет „реальная“ доля положительных оценок?»
То есть матстатовыми методами оценивается, каков был бы рейтинг, если бы проголосовало больше людей — а именно меньшее/большее количество проголосовавших создаёт проблемы для очевидных способов ранжирования.
Если я сам правильно понял смысл такой. Пока оценок мало — мы не можем сказать каким будет отношение положительных и отрицательных голосов когда проголосует больше. Точнее, можем, но с определённой ±погрешностью. В данном алгоритме берётся нижняя граница этого диапазона. Т.е. если средний рейтинг = 10±5, то мы берём 5. В итоге учитывается и отношение голосов, и их число. Число голосов играет роль подтверждения достоверности результата.
Что мне не понятно, так это закон распределения. Тут используется именно нормальное распределение, и, по хорошему надо взять статистику голосов сайта и проверить как оно на самом деле. Берём объекты за которые проголосовало много людей. Вычисляем среднее значение голоса. И смотрим, по какому закону относительно числа голосов рейтинг приближался к своему среднему.
Будет время проанализирую голоса на Дару~даре. Или brutto с buxley проанализируют голоса Хабра.
Что мне не понятно, так это закон распределения. Тут используется именно нормальное распределение, и, по хорошему надо взять статистику голосов сайта и проверить как оно на самом деле. Берём объекты за которые проголосовало много людей. Вычисляем среднее значение голоса. И смотрим, по какому закону относительно числа голосов рейтинг приближался к своему среднему.
Будет время проанализирую голоса на Дару~даре. Или brutto с buxley проанализируют голоса Хабра.
Спасибо. На сколько я могу судить, понял смысл так же, как вы, и это хорошо :-) Что делает формула — понятно, наверняка она, даже крутая по всем параметрам, но это субъективная оценка: «да, формула большая, толстая и много чего учитывает».
Хотя, конечно, может автору и все равно на принятые в математике правила, и он просто хотел познакомить читателя с формулой, не вдаваясь в подробности. Я просто написал то, чего мне не хватило:
в постановке задачи, кроме субъективизма, я ничего не нашел (а ведь, как известно, постановка задачи — пол дела). Соответственно, после озвучки правильной формулы, никак не проверить её соответствие поставленной задаче. :-)
Хотя, конечно, может автору и все равно на принятые в математике правила, и он просто хотел познакомить читателя с формулой, не вдаваясь в подробности. Я просто написал то, чего мне не хватило:
в постановке задачи, кроме субъективизма, я ничего не нашел (а ведь, как известно, постановка задачи — пол дела). Соответственно, после озвучки правильной формулы, никак не проверить её соответствие поставленной задаче. :-)
Ну вы поробуйте, опять же, субъективную оценку. Поиграйтесь букмарклетом с комментами Хабра. В конце-концов основным критерием будет субъективная оценка создателей проекта. Если создателю/идеологу нравится результат — ок :) Хотя я конечно предпочёл бы встраивать в свой сайт не чёрный ящик, а что-то более прозрачное.
Тема подробно раскрыта в книге Building Web Reputation Systems. Написана разработчиками из Yahoo!
Спасибо. Любопытная книга. Только как я понял тут больше про пользовательскую репутацию и кармические механизмы. Там немного другая специфика.
Никогда не заказывал книги с Амазона. Не в курсе — насколько это сложно/долго и насколько большая выходит переплата?
Никогда не заказывал книги с Амазона. Не в курсе — насколько это сложно/долго и насколько большая выходит переплата?
Название книги может сбивать с толку, но в ней описаны практически все возможные рейтинговые системы, подпадающие под классификацию «A source» -> «makes a claim» — > «about a target», а также различнве методики сбора и подсчета статистики.
В Amazon я покупаю только электронные книги. Через Kindle эта процедура автоматизирована до одного клика, даже CVC-код карты никогда не запрашивается.
В Amazon я покупаю только электронные книги. Через Kindle эта процедура автоматизирована до одного клика, даже CVC-код карты никогда не запрашивается.
Вот уж действительно, где тема раскрыта! Целая книженция про рейтинги, для меня удивительно :-)
Область весьма нетривиальная, есть место для исследований. В книге, например, хорошо аргументируется, почему возможность прямого изменения рейтинга пользователя как на Хабре — простейшее и далеко не лучшее решение.
(фрагмент из первых абзацев главы про пользовательскую карму)
" — Rating a user directly should be avoided. Typical implementations require a user to click only once to rate another user and are therefore prone to abuse. When direct evaluation karma models are combined with the common practice of stream-lining user registration processes (on many sites opening a new account is an easier operation than changing the password on an existing account), they get out of hand quickly. See the example of Orkut in “Numbered levels” on page 186.
— Asking people to evaluate others directly is socially awkward. Don’t put users in the position of lying about their friends.
— Using multiple inputs presents a broader picture of the target user’s value.
— Economics research into “revealed preference,” or what people actually do, as opposed to what they say, indicates that actions provide a more accurate picture of value than elicited ratings."
(фрагмент из первых абзацев главы про пользовательскую карму)
" — Rating a user directly should be avoided. Typical implementations require a user to click only once to rate another user and are therefore prone to abuse. When direct evaluation karma models are combined with the common practice of stream-lining user registration processes (on many sites opening a new account is an easier operation than changing the password on an existing account), they get out of hand quickly. See the example of Orkut in “Numbered levels” on page 186.
— Asking people to evaluate others directly is socially awkward. Don’t put users in the position of lying about their friends.
— Using multiple inputs presents a broader picture of the target user’s value.
— Economics research into “revealed preference,” or what people actually do, as opposed to what they say, indicates that actions provide a more accurate picture of value than elicited ratings."
Карма на Хабре — забавная штука. Вроде бы, есть какой-то сложный рейтинг, который учитывает множество параметров, и формула которого известна одному НЛО. Но почему-то все права и ограничения завязаны на старую систему кармы, и от рейтинга не зависит ровным счётом ничего, кроме исключительно фаллометрического «топа».
Не понимаю.
Не понимаю.
А! Ну тогда я пошёл качать Kindle для iOS-а :) Спасибо.
Спасибо за наводку. Еще порекомендовал бы Programming Collective Intelligence (есть русское издание).
Отличная книга, давно есть в коллекции. Ещё есть хорошее дополнение — Алгоритмы интеллектуального Интернета
Да, я после её прочтения мигрировал на Python с PHP. Навсегда :)
А еще в фильме «Социальная сеть» на стекле в общаге они написали формулу для составления рейтинга девушек. Это как дополнительный вариант.
Всегда приходилось самому изобретать велосипед от необразованности. И как правило в сети толковоразжёванных статей не сыщешь. Спасибо за информацию.
Кстати в рейтингах приходится учитывать немного большее количество параметров, нежели + и -.
Открыл хабр после лепры и растерялся.
Readability — приводит текст веб-страницы к удобному для чтения виду.
Это вы про отображение в оверлее? Меня скорее плагин iReader для Хрома вдохновил :)
У всех рейтингов, какие бы формулы ни использовались, есть одна большая беда — «снежный ком» оценок. Есть 100500 объектов, у нескольких есть высокий рейтинг, и эти объекты, в общем-то, вполне удовлетворяют спрос. Все будут смотреть их, ставить плюсик и не обращать внимания на остальные. Однажды вырвавшиеся вперёд заплюсованные объекты застревают в Топе навечно, пока не случится какой-нибудь катаклизм.
Посмотрим на Хабр: когда к статье 300 комментариев, как много народа читает их все и объективно выставляет оценки? Скорее всего, есть несколько комментариев с рейтингом 20+, которые сразу бросаются в глаза, которые большинство плюсует, и эти комментарии быстро уходят ввысь. И, скорее всего, есть несколько комментариев в минусе, которые тоже хорошо бросаются в глаза благодаря серому тексту, и которые, скорее всего, скоро улетят в глубокий минус.
В результате возникает десяток комментариев с высокоми рейтингами по модулую, которые не обязательно самые выдающиеся и самые отвратительные, а большинство комментариев болтается в диапазоне ±1, иногда ±5.
Вот если бы знать, как бороться с этим, было бы круто.
Посмотрим на Хабр: когда к статье 300 комментариев, как много народа читает их все и объективно выставляет оценки? Скорее всего, есть несколько комментариев с рейтингом 20+, которые сразу бросаются в глаза, которые большинство плюсует, и эти комментарии быстро уходят ввысь. И, скорее всего, есть несколько комментариев в минусе, которые тоже хорошо бросаются в глаза благодаря серому тексту, и которые, скорее всего, скоро улетят в глубокий минус.
В результате возникает десяток комментариев с высокоми рейтингами по модулую, которые не обязательно самые выдающиеся и самые отвратительные, а большинство комментариев болтается в диапазоне ±1, иногда ±5.
Вот если бы знать, как бороться с этим, было бы круто.
Да, такая проблема безусловно есть. Но стоит ли считать её проблемой? Вот с фильмами, к примеру. Не будем же мы смотреть всё подряд, боясь пропустить что-то и зная о подобном эффекте? Скорее всего мы обратим внимание на уже оценённые фильмы. Это банально экономит время. Потом, мне кажется, действительно стоящие комментарии в конце концов всплывут, так как найдутся несколько энтузиастов прочиющих всё. Я иногда читаю по 500 комментариев, если мне интересна статья (хотя и редко).
Кстати, продолжая аналогию с фильмами, можно там же поискать решение. Помимо рейтинга IMDB, по которому вообще-то сложно понять насколько понравится фильм, существуют различные системы рекомендаций. Их можно взять на заметку, и, к примеру, делать колонку «комментарии которые могут вам понравится». В качестве алгоритма можно попробовать от Коллаборативной Фильтрации (предлагать высоко оцененные объекты от людей со схожими оценками), до Байесовской (выделяя в качестве независимых признаков объекта автора, ключевые слова и другие атрибуты). Как вам такая идея?
Кстати, продолжая аналогию с фильмами, можно там же поискать решение. Помимо рейтинга IMDB, по которому вообще-то сложно понять насколько понравится фильм, существуют различные системы рекомендаций. Их можно взять на заметку, и, к примеру, делать колонку «комментарии которые могут вам понравится». В качестве алгоритма можно попробовать от Коллаборативной Фильтрации (предлагать высоко оцененные объекты от людей со схожими оценками), до Байесовской (выделяя в качестве независимых признаков объекта автора, ключевые слова и другие атрибуты). Как вам такая идея?
Я экспериментировал с коллаборативной фильтрацией и в целом остался очень доволен. На одном из тематических арт-сайтов я сграбил все связи «юзер следит за работами юзера» и построил по ним рекомендации — сразу нашёл множество интересных мне художников. Судя по отзывам, эксперимент можно считать успешным. Что любопытно, некоторым интереснее оказалась обратная связь — кому порекомендовали их. Говорят, интересный народ нашли. :)
Для сравнения, другой программист сделал для того же сайта рейтинг с а-ля гугловским pagerank’ом — я прошёлся чуть ли не по тысяче из «топа», и толком ничего не нашёл.
В целом, да, считаю, что будущее за персонализацией рекомендаций под конкретного юзера. На крупных сайтах вываливаются тонны разнообразнейшей информации, поэтому любой «топ» в конце концов обессмысливается, а вариант просмотреть всё вообще выходит за рамки человеческих возможностей.
На том же Амазоне кроме его тупого рейтинга есть аналогичные «рекомендации» — можно сказать, что тебе нравится, и Амазон начнёт тебе советовать что-то похожее. Тытрубка — вообще ярчаший пример блестящей реализации рейтингов: есть и абсолютный топ, и результаты коллаборативной фильтрации, и «похожие» видео, и ещё чего только нет. Искать «хочу того, не знаю чего» становится весьма приятным занятием. :)
Но у коллаборативной фильтрации есть и минусы: во-первых, ресурсоёмко; во-вторых, нужно знать что-то о пользователе.
Для сравнения, другой программист сделал для того же сайта рейтинг с а-ля гугловским pagerank’ом — я прошёлся чуть ли не по тысяче из «топа», и толком ничего не нашёл.
В целом, да, считаю, что будущее за персонализацией рекомендаций под конкретного юзера. На крупных сайтах вываливаются тонны разнообразнейшей информации, поэтому любой «топ» в конце концов обессмысливается, а вариант просмотреть всё вообще выходит за рамки человеческих возможностей.
На том же Амазоне кроме его тупого рейтинга есть аналогичные «рекомендации» — можно сказать, что тебе нравится, и Амазон начнёт тебе советовать что-то похожее. Тытрубка — вообще ярчаший пример блестящей реализации рейтингов: есть и абсолютный топ, и результаты коллаборативной фильтрации, и «похожие» видео, и ещё чего только нет. Искать «хочу того, не знаю чего» становится весьма приятным занятием. :)
Но у коллаборативной фильтрации есть и минусы: во-первых, ресурсоёмко; во-вторых, нужно знать что-то о пользователе.
> Но у коллаборативной фильтрации есть и минусы: во-первых, ресурсоёмко; во-вторых, нужно знать что-то о пользователе.
Ресурсоёмкие — это по памяти или по времени?
Ресурсоёмкие — это по памяти или по времени?
В моём случае было и по времени (расчёт шёл несколько часов), и по памяти (все связи запихивались в оперативку). Есть какие-то специальные алгоритмы для очень больших наборов данных, но я в эту тему не влезал, да и давненько это уже было, деталей не помню. Уж в любом случае расчёт будет гораздо медленнее, чем подсчёт среднего.
Думал я об этом вопросе и пришёл к выводу, что это не что иное, как несовершенство механизма ранжирования. Весь фокус в том, что для сообщества будет выгоднее ранжировать не по высшему рейтингу, а по несколько другому алгоритму. Проблема высокооценённых — этому яркое подтверждение. От этого же — попса не есть лучшее из искусства, топ фильмов не покажет все лучшие фильмы и топ компаний (по объёму поставок) не даст лучшие для пользователя компании. Чувствую, это — тема для ещё одной интересной статьи и отдельный вопрос.
У меня в топе игры была такая проблема — сильнейшие игроки застряли наверху и все видят только их, хотя они уже давно не посещают игру. Ввёл простое правило: кто не играл неделю — пошел вон из топа. И топ сразу ожил.
А вам, возможно что-то типа такого подойдёт. Сделать этот рейтинг основным, с возможностью сложного переключиться на «вневременный». Чтобы и тем с другим угодить.
Можно делить рейтинг на время, прошедшее с момента публикации оцениваемого комментария/статьи. Тогда новое интересное будет наверху, но чтобы оставаться наверху, ему надо быть ОЧЕНЬ интересным, получая всё новые плюсы.
есть несколько комментариев с рейтингом 20+, которые сразу бросаются в глаза, которые большинство плюсует, и эти комментарии быстро уходят ввысь
Это мне кажется вообще некошерным. Какая читателю разница какой рейтинг у комментария? Может быть разве что автору комментария стоит это показывать. А может быть даже и ему не показывать, а только для технической стороны дела использовать (удалять при -100 например).
Если кто-то написал «вася дурак», то для выставления оценки, читатель должен оценить, насколько это верно сказано, насколько тактично, насколько прямо итд. Но если ему при этом еще добавить лишней информации, типа «Кстати, 60% оценивают этот комментарий позитивно. Возможно вам интересно, но при этом 80% выставивших плюс имеют возраст до 20 лет, 75% проплюсовавших не имеют высшего образования, 77% из них часто употребляют мат в разговорной речи. Не будь быдлом как они, поставь другую оценку!», тогда человек уже не оценку утверждению выставляет, а оценку СЕБЕ, причисляя ее к той группе, которая ему более симпатична. На dirty слишком много такой информации дается. На хабре поменьше, но она тоже лишняя. Комментарий хороший или плохой, вне зависимости от того, нулевая у него пока что еще оценка, или его уже бешено заплюсовали (заминусовали).
Это мне кажется вообще некошерным. Какая читателю разница какой рейтинг у комментария? Может быть разве что автору комментария стоит это показывать. А может быть даже и ему не показывать, а только для технической стороны дела использовать (удалять при -100 например).
Если кто-то написал «вася дурак», то для выставления оценки, читатель должен оценить, насколько это верно сказано, насколько тактично, насколько прямо итд. Но если ему при этом еще добавить лишней информации, типа «Кстати, 60% оценивают этот комментарий позитивно. Возможно вам интересно, но при этом 80% выставивших плюс имеют возраст до 20 лет, 75% проплюсовавших не имеют высшего образования, 77% из них часто употребляют мат в разговорной речи. Не будь быдлом как они, поставь другую оценку!», тогда человек уже не оценку утверждению выставляет, а оценку СЕБЕ, причисляя ее к той группе, которая ему более симпатична. На dirty слишком много такой информации дается. На хабре поменьше, но она тоже лишняя. Комментарий хороший или плохой, вне зависимости от того, нулевая у него пока что еще оценка, или его уже бешено заплюсовали (заминусовали).
Тема рейтингов статей поднималась мной в недавней статье "Что у нас «Лучшего» на сегодня?". В ней приводится статистика оценивания 10-15 лучших статей на вечер пятницы на Хабре — 4 типа оценок: рейтинг, избранное, Гугл+ и число комментарии —
и названия с тематикой статей, ссылки на них. Стоит посмотреть, чтобы увидеть, что действительно интересные статьи для разработчиков надо искать по иным показателям, чем наивысшие какие-либо оценки. В конце я сформулировал мысль (уже ночью, поэтому не все, кто читал, её увидели. Если интересно — прошу обсудить), что надо построить иные формальные оценки статей на Хабре, и тогда каждая группа читателей (ведь кого-то устроит и рейтинг популярности) получит свою Ленту.
и названия с тематикой статей, ссылки на них. Стоит посмотреть, чтобы увидеть, что действительно интересные статьи для разработчиков надо искать по иным показателям, чем наивысшие какие-либо оценки. В конце я сформулировал мысль (уже ночью, поэтому не все, кто читал, её увидели. Если интересно — прошу обсудить), что надо построить иные формальные оценки статей на Хабре, и тогда каждая группа читателей (ведь кого-то устроит и рейтинг популярности) получит свою Ленту.
Появилась идея: из 5 показателей (включая число добавлений в избранное и число отрицательных ответов) пытаться угадать род статьи. Исходя ещё из заявленных хабов и иногда — автора, вполне можно классифицировать статьи гораздо точнее, чем сейчас. И ищущие серьёзных статей их будут получать.
Э… не надо пожалуйста про «свою ленту» :) Это больная тема. Я перед уходом из ТМ сделал тестовую версию Хаброленты 3.0, которая учитывала перечисленные вами и множество других признаков для персональной рекомендации статей. С тех пор я читал только её, т.к. для меня она работала великолепно. Но с миграцией на Хабы в её коде, видимо не разобрались, или сочли не порвостепенной задачей и выпилили. Хотя система Хабов, ИМХО, сама по себе замечательна. Но с ней я трачу горадо больше личного времени на прочтение неинтересных мне статей…
Так никто не предлагает уговаривать разработчиков Хабра поддержать придуманную систему. Есть более конструктивный путь.
Приятно услышать мнение из самых первых рук — от человека, который сражался с реальным потоком рейтингов на Хабре. Спасибо!
Приятно услышать мнение из самых первых рук — от человека, который сражался с реальным потоком рейтингов на Хабре. Спасибо!
Дело в том, что извне не вытащишь информацию о голосах пользователя. Только об избранном. Не уверен, что на одном избранном можно хорошо что-то порекомендовать.
Я вообще пробовал 4 варианта: оценки постов, избранное, коллаборативную фильтрацию на основе оценок и на основе друзей. В итоге остановился на первых 2-х. Коллаборативная фильтрация вообще тут плохо подходит, т.к. в отличие от фильмов/музыки актуальность поста сильно зависит от времени. В итоге мы получаем сильно отстающую штуковину.
Я вообще пробовал 4 варианта: оценки постов, избранное, коллаборативную фильтрацию на основе оценок и на основе друзей. В итоге остановился на первых 2-х. Коллаборативная фильтрация вообще тут плохо подходит, т.к. в отличие от фильмов/музыки актуальность поста сильно зависит от времени. В итоге мы получаем сильно отстающую штуковину.
Суть статьи в трех предложениях:
Плохо: R = P+ — P-
Плохо: R = P+ / Pall
Хорошо: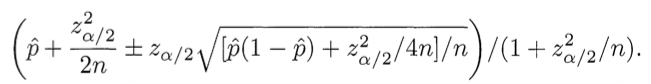
Плохо: R = P+ — P-
Плохо: R = P+ / Pall
Хорошо:
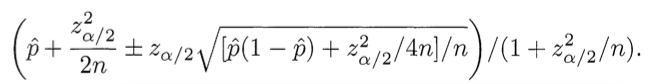
Короткий ответ на вопрос «Почему хорошо?»:
«Потому что кванти́ль!».
«Потому что кванти́ль!».
ахахаха))) да, здорово)
свои пять копеек:
давно интересовался проблемой, правда применимок спорту. И разработал прсотую, но как мне кажется, действенную систему (модификация второго варианта).
Берем две вещи с оценками (+/итого): 5/10 и 7/10. Получаем 50% и 70% положительных оценок. Вопросов не возникает — второе действительно лучше. Но что, если 50% получается из такого 100/200? Ведь навреное ценнее более расширенная выборка? Для этого нужно ввести дополнительный коэффициент — количество положительных оценок. (100 * 100) / 200 = 50 баллов, (7 * 7) / 10 = 4.9 балла похоже на истину?
Еще пример: 5/10 (2.5 балла), 5/11 (2.27 балла). По-моему здравое зерно в такой методике есть, т.к. основывается на процентовке, а для правильной оценки применяется количественный коэффициент.
Если я что-то неправильно думаю, поправьте. Мне это интересно.
По поводу снежного кома в рейтнгах (голосуют за ТОПовые позиции) могу предложить делать выборку за опеределнный срок, напрмиер месяц. Это не избавит от проблемы, но несколько снизит вред.
свои пять копеек:
давно интересовался проблемой, правда применимок спорту. И разработал прсотую, но как мне кажется, действенную систему (модификация второго варианта).
Берем две вещи с оценками (+/итого): 5/10 и 7/10. Получаем 50% и 70% положительных оценок. Вопросов не возникает — второе действительно лучше. Но что, если 50% получается из такого 100/200? Ведь навреное ценнее более расширенная выборка? Для этого нужно ввести дополнительный коэффициент — количество положительных оценок. (100 * 100) / 200 = 50 баллов, (7 * 7) / 10 = 4.9 балла похоже на истину?
Еще пример: 5/10 (2.5 балла), 5/11 (2.27 балла). По-моему здравое зерно в такой методике есть, т.к. основывается на процентовке, а для правильной оценки применяется количественный коэффициент.
Если я что-то неправильно думаю, поправьте. Мне это интересно.
По поводу снежного кома в рейтнгах (голосуют за ТОПовые позиции) могу предложить делать выборку за опеределнный срок, напрмиер месяц. Это не избавит от проблемы, но несколько снизит вред.
Хм… А почему именно p^2/n? И как вы эти 2 формулы потом объединили?
какие две формулы? у меня одна формула, которую вы написали.
нужен какой-то коэффициент. Если есть 5/10 и 10/20 (в обоих вариантах 50%), то более ценна оценка с большим количеством проголосовавших и соответственно положительных отзывов. Направшивается вывод: умножить на количество положительных.
5/10 и 10/20 => 2.5 и 5 — вторая оценка в два раза ценнее, т.к. в два раза больше проголосовавших.
нужен какой-то коэффициент. Если есть 5/10 и 10/20 (в обоих вариантах 50%), то более ценна оценка с большим количеством проголосовавших и соответственно положительных отзывов. Направшивается вывод: умножить на количество положительных.
5/10 и 10/20 => 2.5 и 5 — вторая оценка в два раза ценнее, т.к. в два раза больше проголосовавших.
UFO just landed and posted this here
А сиськи где?!!!
Я в своё время заморачивался, и обнаружил, что лучше всего работает вот такой тривиальный алгоритм: подбросить каждому элементу n-ое количество средних оценок.
Т.е. было среднее арифметическое = (сумма всех оценок) / (количество оценок)
Стало (для пятибальной системы) взвешенное среднее = (сумма всех оценок + 3n) / (число оценок + n)
n выбирается небольшое (я выбрал 2).
Просто для понимания, легко отсекает элементы с небольшим числом строго положительных/отрицательных оценок, почти не влияет на элементы с большим количеством оценок, очень легко вычисляется, в т.ч. SQL-запросом.
Т.е. было среднее арифметическое = (сумма всех оценок) / (количество оценок)
Стало (для пятибальной системы) взвешенное среднее = (сумма всех оценок + 3n) / (число оценок + n)
n выбирается небольшое (я выбрал 2).
Просто для понимания, легко отсекает элементы с небольшим числом строго положительных/отрицательных оценок, почти не влияет на элементы с большим количеством оценок, очень легко вычисляется, в т.ч. SQL-запросом.
Угу. Это у вас упрощённая версия вот этого. Для многих случаев она действительно неплохо работает. Когда нужно просто пессимизировать результаты с небольшим кол-вом голосов.
Если считать, что 3 — это средний балл, то да.
На самом деле смысл не в упрощении формулы, а в упрощении вычислительной сложности расчетов. В случае с Байесом приходится либо считать средние значения по всей базе «на лету», либо кэшировать их на какое-то время. А здесь всё просто и прозрачно.
На самом деле смысл не в упрощении формулы, а в упрощении вычислительной сложности расчетов. В случае с Байесом приходится либо считать средние значения по всей базе «на лету», либо кэшировать их на какое-то время. А здесь всё просто и прозрачно.
Да нет, оно считается один раз по проекту и прописывается как константа. Ну можно раз в год пересчитать
Ну я и говорю — кэшировать на год :)
Для проектов, которые быстро накапливают базу этот вариант неприемлем.
Для проектов, которые быстро накапливают базу этот вариант неприемлем.
Но IMDB его использует. Они посчитали один раз, и уже много лет не меняют. На самом деле не очень важно каков средний рейтинг по 5-и бальной шкале 4.123 или 4.124. Вообще если средний рейтинг оценки фильмов увеличится на 10 долю об этом напишут в новостях.
Между прочим при 0 голосов у вас выходит 3*2/2 = 3. Это и есть ваше среднее
Между прочим при 0 голосов у вас выходит 3*2/2 = 3. Это и есть ваше среднее
А, блин, да у вас же 1:1 формула :)
Разложите её на сумму
Разложите её на сумму
Всегда задавался этой проблемой, но никак не мог найти подходящего решения. Спасибо!
C такой нагрузкой дропбокс вам паблик на сутки закрутит, перезалейте.
Хорошая статья, возьму на заметку.
Я представил себе социальную сеть, где можно выбрать фотографии с 95% C.L. в ± 2σ вокруг оценённого пользователями балла 4.152.
Измерять вероятное количество положительных оценок — хорошо, но все равно не решает общую задачу. Нужно еще учитывать единодушие оценок, и, как здесь раньше написали в комментариях, предпочтения групп. Для чего мы строим систему рейтинга по объектам? Для того, чтобы потом тот или иной объект порекомендовать. Если оценки по объекту 98 положительных и 2 отрицательных, то порекомендовать его можно кому угодно. А если 1000 положительных и 1500 отрицательных? Да, рейтинг получается невысокий, но ведь 1000 человек это понравилось, значит, что-то в нем все-таки есть. Нужно пытаться сегментировать отрицательные и положительные оценки по объекту и выделять группы посетителей, которым он с большой вероятностью нравится и наоборот.
Что в итоге хотел сказать: рейтинг — это всего лишь примитивная система рекомендаций, как бы хитроумно он ни рассчитывался. И чтобы рейтинг получался правильным, его нужно рассчитывать для каждого персонально свой.
Что в итоге хотел сказать: рейтинг — это всего лишь примитивная система рекомендаций, как бы хитроумно он ни рассчитывался. И чтобы рейтинг получался правильным, его нужно рассчитывать для каждого персонально свой.
Согласен. Насчёт предпочтения групп — правильная идея. Но она тем более актуальна, чем менее тематичен ресурс. Т.е. если оценивать любые фильмы или музыку, то польза общего рейтинга невелика, а если у нас узко специализированное сообщество — то вполне подходит.
Я как раз привёл пример использования такого рейтинга для комментариев одной публикации, и тут он работает хорошо, т.к. публикация изначально сужает группу до тех, кому она интересна. В том числе на этой публикации букмарклет работает замечательно :)
Да, ещё помимо рекомендательной функции рейтинг выполняет функцию обратной связи. Это тоже важно.
Я как раз привёл пример использования такого рейтинга для комментариев одной публикации, и тут он работает хорошо, т.к. публикация изначально сужает группу до тех, кому она интересна. В том числе на этой публикации букмарклет работает замечательно :)
Да, ещё помимо рекомендательной функции рейтинг выполняет функцию обратной связи. Это тоже важно.
UFO just landed and posted this here
Не, я имел в виду обратную связь автору. Цифра рейтинга для него является показателем востребованности, одобрения его публикаций в сообществе.
Насчёт уведомлений — правильный подход. На Дару~даре вместо уведомлений есть лента даров/комментариев получивших определённое число минусов доступная «смотрителям». С комментариями фокус не пройдёт, а с публикациями можно делать плавающий порог для отправки уведомлений, на основе числа просмотров по приведённой формуле:
Насчёт уведомлений — правильный подход. На Дару~даре вместо уведомлений есть лента даров/комментариев получивших определённое число минусов доступная «смотрителям». С комментариями фокус не пройдёт, а с публикациями можно делать плавающий порог для отправки уведомлений, на основе числа просмотров по приведённой формуле:
Выявление спама или злоупотреблений. Сколько людей, увидевших сообщение, пометят его как спам?
Есть еще один фактор, который хотелось бы учесть — вещи, которые в топе рейтинга часто плюсуют просто так (принцип стада) — вот вес этих плюсов нужно уменьшать.
Вы наверно об этом? Я там написал свой комментарий.
Вы, наверное, про сиськи в этом посте? :)))
как по-поему, так картинка неправильная.
левая (с минусом которая) сиська должна быть нарисована большей, нежели правая (и дело тут вовсе не в том, что у реальных женщин левая грудь, обычно, немного больших размеров).
левая (с минусом которая) сиська должна быть нарисована большей, нежели правая (и дело тут вовсе не в том, что у реальных женщин левая грудь, обычно, немного больших размеров).

UFO just landed and posted this here
Я знаю 2 варианта:
- Рейтинг «самые трендовые», типа такого
- И ещё один забавный алгоритм. Можно просто к рейтингу прибавлять дату публикации на что-нибудь поделённую. В итоге вверх будут всплывать и более новые, и более рейтинговые (только нужно нормальный рейтинг тоже хранить, а этот использовать для сортировки)
Уже давали ссылку выше: amix.dk/blog/post/19588
См. раздел Effects of submission time
См. раздел Effects of submission time
ну как, как можно было на сиську "-" налепить? СИСЬКИ — это всегда "+"!
Статья отличная! Спасибо!
Статья отличная! Спасибо!
Скажите, пожалуйста, чем плох следующий велосипед. Выбираем некий шаг, например, 5%. Выбираем элементы, где процент положительных оценок ⊂ (95—100]. Сортируем по количеству положительных оценок. То же — для диапазона (90—95]. И так далее.
Чем меньше шаг, тем выше точность. Из плюсов вижу интуитивную понятность, какие минусы?
Чем меньше шаг, тем выше точность. Из плюсов вижу интуитивную понятность, какие минусы?
Судя по рейтингу поста, вся статичтика — туфта. Сиськи рушат любые формулы и планы ))
Для получения объективных результатов нужно учитывать психологическую составляющую. Например то что отрицательные оценки люди склонны ставить гораздо чаще положительных.
Можно домножать количество отрицательных оценок на некий коэффициент (k>=1). На общий рейтинг это не влияет.
Может всё-таки реже? Давайте посмотрим на число людей с положительной кармой и число с отрицательной, первое явно выше. Про миллионы фотографий «я и ковёр», получающих на Однокласниках только 5 баллов (за 4 наверняка обижаются ещё) я уж молчу.
Но стоит ли придавать отрицательным оценкам больший вес из-за того что они встречаются реже? Скорее стоит сегментировать аудитории, но это уже путь к рекомендательному сервису. В целом же, 10-бальная шкала выглядит более полезной, чем + и — (по сути — двубальная шкала без градаций, как сильно вам что-то нравится или не нравится).
Но стоит ли придавать отрицательным оценкам больший вес из-за того что они встречаются реже? Скорее стоит сегментировать аудитории, но это уже путь к рекомендательному сервису. В целом же, 10-бальная шкала выглядит более полезной, чем + и — (по сути — двубальная шкала без градаций, как сильно вам что-то нравится или не нравится).
Статья была бы ещё лучше, если бы было поменьше «воды», и побольше математики. Я понимаю, что перевод, но всё же.
Есть у нас 10 картинок, за которые голосовали 1 год. А потом добавилась еще одна картинка и стало их 11. В результате в нашей системе образовалось 2 эпохи, когда оценок X, а количество картинок N и N+1. И получается, что формулу используем с допущениями, на которые она не рассчитана…
И может сохраниться вселенская несправедливость (мы же не исследовали наше допущение), когда отстойнейшая картинка, провисевшая год и набравшая по случайности K оценок, будет иметь лучший рейтинг, чем новая, провисевшая 10 дней и набравшая K/2 оценок.
А как же быть с сезонностью? Когда 31 декабря популярна картинка со Снегуркой в полупрозрачном красном пеньюаре, а летом популярна та же Снегурка, но в купальнике?
Вот и мыслится, что нужно в формулах учитывать ещё и возраст выставленной оценки: Чем древнее оценка, тем меньший коэффициент значимости ей присваивать. Таким образом оценки, выставленные недавно, будут больше влиять на рейтинг, чем оценки выставленные давно.
И может сохраниться вселенская несправедливость (мы же не исследовали наше допущение), когда отстойнейшая картинка, провисевшая год и набравшая по случайности K оценок, будет иметь лучший рейтинг, чем новая, провисевшая 10 дней и набравшая K/2 оценок.
А как же быть с сезонностью? Когда 31 декабря популярна картинка со Снегуркой в полупрозрачном красном пеньюаре, а летом популярна та же Снегурка, но в купальнике?
Вот и мыслится, что нужно в формулах учитывать ещё и возраст выставленной оценки: Чем древнее оценка, тем меньший коэффициент значимости ей присваивать. Таким образом оценки, выставленные недавно, будут больше влиять на рейтинг, чем оценки выставленные давно.
Хорошая статья, я даже успел забыть про завлекающую картинку.
Очень полезная статья и вполне достойный перевод. Спасибо.
Есть мысль, что если сразу задвигать вниз элементы с низким (отрицательным) рейтингом, то они никогда и не поднимуться. Тоже самое касается и популярных элементов.
Мне лично очень хотелось бы добавить в рассчет рейтинга нормирование всех элементов на общее кол-во оценок, или даже на количество оценок за последние Х дней. (Пример — рейтинги Ebay за год и месяц)
Т.е. по сути — заменить рейтинг на скорость наростания рейтинга…
Тогда новые элементы, вообще не имеющие оценок тоже будут иметь шанс быть увиденными а топам придется «прилагать усилия» для поддержания позиции.
Очень похоже на пример с выкидыванием из топа неигравших игроков.
Мне лично очень хотелось бы добавить в рассчет рейтинга нормирование всех элементов на общее кол-во оценок, или даже на количество оценок за последние Х дней. (Пример — рейтинги Ebay за год и месяц)
Т.е. по сути — заменить рейтинг на скорость наростания рейтинга…
Тогда новые элементы, вообще не имеющие оценок тоже будут иметь шанс быть увиденными а топам придется «прилагать усилия» для поддержания позиции.
Очень похоже на пример с выкидыванием из топа неигравших игроков.
Верная мысль, так и делал «заменить рейтинг на скорость наростания рейтинга…» но тут возникает большая проблема в подборе эмпирических коэффициентов и адекватных зависимостей, которые для каждого из сервиса могут быть свои. Например что будет выше в топе +1000 набранные год назад, или +10 набранные месяц назад, или +1 но сегодня.
По переводу названия — на мой взгляд, более подходящая форма для нас, русскоговорящих: Как НЕ нужно сортировать контент на основе оценок пользователей.
Слегка некропостинг, но похоже в оригинальной статье есть опечатка, просочившаяся и в перевод:
Если я правильно понял — это про значение квантили стандартного нормального распределения.
1.96 — это значение для 97,50%, а для 95% — 1,645 (пруф).
(Используйте 1.96 для доверительного уровня в 0.95)
Если я правильно понял — это про значение квантили стандартного нормального распределения.
1.96 — это значение для 97,50%, а для 95% — 1,645 (пруф).
Опечатки нет. Вернее она есть, но как раз наоборот там, где в примерах реализации в комментариях к коду написано, что «1.0 = 85%, 1.6 = 95%». Потому что квантиль в данном случае определяется не уровнем доверия непосредственно, а формулой 1−α/2, где α=1−confidence (уровень доверия). Наверняка во избежание именно такой путаницы и добавили в формуле под буквой z индекс α/2.
Sign up to leave a comment.
Как правильно сортировать контент на основе оценок пользователей