Недавно BI.ZONE приняла участие в конференции HighLoad++. Понятное дело, что мы приехали туда не просто поглазеть на чужие стенды, а привезли кое-что интересное. Сотрудники из разных отделов компании приготовили для гостей конференции задачи, за решение которых мы предлагали призы. Одна из задач по Golang была посвящена распознаванию звука. Мы попросили ее автора рассказать о ней.
В нашей задаче требуется проиндексировать некоторое количество треков и научиться искать в базе оригинал композиции по ее сэмплу. При этом образец вполне может быть зашумлен, записан на плохой микрофон, у него может быть другая частота. За участника уже написана большая часть кода, ему нужно только реализовать функцию fingerprint, которая снимает с трека отпечаток.
Вполне понятно, что любой трек — механическая волна, которая имеет аналоговую природу. У волн в физике есть две характеристики: частота и амплитуда. Применительно к звуковым волнам можно для простоты считать, что амплитуда — это громкость, а частота — высота звучания, хотя на самом деле высокие звуки человеку кажутся громче при одинаковой амплитуде.
То есть, с точки зрения физики, каждая композиция описывается непрерывной функцией, а значит любой сколь угодно малый отрывок песни будет содержать в себе бесконечное количество информации (хотя, если это какой-нибудь пост-панк, то информации в треках, возможно, будет чуть меньше). Из-за этого аналоговый сигнал сохранить не получится, придется заниматься его оцифровкой. Основной подход к оцифровке аналоговых сигналов — импульсно-кодовая модуляция, о которой и пойдет речь в этом разделе. ИКМ состоит из трех этапов: дискретизация, квантование и кодирование. Давайте коротко разберем что происходит на каждом из них.
Итак, у нас есть функция амплитуды от времени. Если у кого-то возникает вопрос, где же частота, то она скрыта за изгибами графика функции. Ее пока не видно, но позже мы ее вытащим. Так как речь пока об аналоговом сигнале, функция непрерывна и определена на всем множестве возможных аргументов (любое действительное число от нуля до конца трека). То есть, мы знаем значение функции в любой момент времени, а моментов у нас очень много. Нам столько явно не надо, так что просто возьмем какое-то дискретное подмножество. Для этого будем сохранять значение сигнала через фиксированный маленький интервал. Он должен быть достаточно малым, чтобы мы на слух не заметили разницу, но достаточно большим, чтобы не сохранять слишком много лишнего, потому что это тоже нежелательно.
На самом деле при оцифровке задается не интервал, а частота, которая называется «частотой дискретизации». В зависимости от задач, частота дискретизации может быть от 8 кГц в телефонах до нескольких тысяч кГц в профессиональном звуковом оборудовании. Музыка для обычного прослушивания вне звукозаписывающих студий обычно сохраняется с частотой 44,1 кГц или 48 кГц.
Благодаря дискретизации у нас теперь есть куча точек вместо непрерывного графика функции, но с этим пока еще не получится работать, нужно попортить звук еще сильнее. Изначальная функция амплитуды от времени сопоставляла континуальному времени континуальную амплитуду. Со временем мы разобрались, а теперь нужно что-то придумать с амплитудой, ведь ее текущие значения разбросаны по множеству действительных чисел слишком хаотично, чтобы мы могли их без проблем сохранить. Например, среди них наверняка есть иррациональные, которые мы никак не сможем сохранить без округления.
Квантование — это процесс во время которого мы округляем амплитуды до значений из заранее выбранного множества. Конечно, мы хотим, чтобы количество амплитуд было степенью двойки. Для обычных аудиотреков используется 16-битное квантование, то есть количество амплитуд будет 65 536 (2 в 16 степени). Профессиональная звукозапись может выполняться с большей точностью, но мало кто на слух может отличить 16-битное квантование от 24-битного. Итак, берем степень двойки, берем кучу целочисленных амплитуд и называем их уровнями квантования. Тогда можно будет говорить, что сигнал квантуется по 65 536 уровням (авторитетно звучит, правда?). Каждая амплитуда округляется до одного из уровней, что в итоге позволяет хранить ее значение в 16-ти битах, а на слух такая запись неотличима от аналогового непрерывного звука.
В качестве иллюстрации можно посмотреть картинку ниже, либо нагенерить собственных картинок на Питоне (код еще ниже). Справа вверху на иллюстрации видны пять уровней квантования. То есть, трек будет иметь всего пять уровней громкости.
Немного примеров
На этапе кодирования мы сохраняем результаты предыдущих шагов в понятной форме. Все действия до этого обычно выполняются специализированным оборудованием, нам же хочется иметь файл на компьютере или массив в памяти, где будут амплитуды. Соответственно, на этом этапе происходит преобразование сигналов оборудования в массив чисел, который мы в дальнейшем будем называть PCM (pulse code modulation). Его индексы — условное время (индекс интервала после дискретизации), а хранятся в нем амплитуды, округленные до целых чисел на этапе квантования.
Изначально у нас была механическая волна и желание ее оцифровать, а теперь есть оцифрованный сигнал и желание получить из него частоты. Добиться желаемого можно с помощью преобразования Фурье. На всякий случай перескажу его прикладное значение в этой задаче. Преобразование Фурье позволяет взять любую функцию и разложить ее на сумму синусов и косинусов. Нас это интересует, потому что синусоиды и косинусоиды — это про колебания, и звук — это про колебания. То есть, с помощью преобразования Фурье можно получить составные части сложного колебания, узнать их амплитуду и частоту, просто посмотрев, какие коэффициенты стоят перед синусом и аргументом синуса (или косинуса). Например, есть такая волна.

Волна
На самом деле мы знаем, что она задается функцией 10sin(3x) + sin(x) + 4sin(4x) + 20sin(2x), но это сейчас, а настоящая звуковая волна состоит из несметного множества таких слагаемых, и нам хотелось бы уметь с этим работать. Итак, прогоним эту функцию через преобразование Фурье с помощью программы FourierScope и посмотрим на амплитудный спектр.

Амплитудный спектр
Вот так выглядят четыре синуса. Нетрудно увидеть, что график соответствует коэффициентам при синусах и их аргументах.
Надо уточнить, что на самом деле это была демонстрация мощи не самого преобразования Фурье, а его дискретной версии, подходящей для сигналов, которые прошли через импульсно-кодовую модуляцию со всеми ее дискретизациями и квантованиями. Приводить алгоритм дискретного преобразования Фурье будет лишним, поэтому давайте просто сойдемся на том что есть такая штука, которая называется ДПФ, а также его модификация, быстрое преобразование Фурье (БПФ). В данном случае прикладной смысл у БПФ следующий: алгоритм получает на вход кусок PCM и отдает массив, в котором содержатся амплитуды, а индексами являются бины частоты. Речь идет именно о бинах частоты, а не просто о частотах, так как преобразование дискретное. В сущности, наивно было ожидать, что можно на протяжении всей статьи заниматься огрублением сигнала, а потом просто получить частоты без проблем и неточностей. По сути, бин частоты — это целый комок частот, которые БПФ не может отличить друг от друга.
Стоит отметить, что БПФ часто пишут неправильно, переписывая алгоритм из книжек и статей. Ниже приведен более корректный код для работы с БПФ, именно такой мы ожидали от участников в их решении.
Современные технологии позволяют написать быстрое преобразование Фурье всего в несколько строк. БПФ применяется для отрезков размером fftWindowSize и возвращает массив комплексных чисел, которые мы в дальнейшем используем для фингерпринтинга.
В целом преобразование Фурье является самым тонким местом во всей задаче. Во первых, размер бина равен $\frac{частота\ дискретизации}{размер\ окна}$. Соответственно, можно увеличить окно и получить больше частот, что приятно, но, разумеется, имеет негативные последствия. Рост размеров окна приводит к тому, что мы анализируем PCM большими промежутками и теряем звуки небольшой продолжительности. В разных обстоятельствах это может многократно ухудшить работу программы, если короткие звуки были частью композиции, а может и улучшить, если это просто шумы. А может вообще ни на что не повлиять. В такой сложной ситуации программист должен действовать решительно: взять какое-нибудь удачное число, вроде $2^9$ или $2^{10}$, и постараться не заморачиваться на тонкостях там, где этого не требуется. Для решения задачи хватит, а в серьезном приложении все равно придется использовать какое-нибудь окно Хэмминга и много еще над чем думать.
Задача сводится к тому, чтобы имея частоты и амплитуды композиции научиться получать хеш, который можно будет сопоставить треку и который будет нечувствителен к изменениям. Они могут быть самыми разными: небольшой шум, сдвиг всех частот, играющая параллельно другая песня и так далее. Также нужно учитывать, что в базе данных одновременно может лежать много похожих треков, которые надо отличить друг от друга. А может все треки будут разными, и проблема будет не в том, чтобы установить, какой подходит больше, а в том, чтобы понять, что не подходит ни один. В общем, тут есть определенный простор для творчества.
Снимать отпечаток можно по-разному. Скажем, составлять хеш в виде списка из нескольких разных показателей. Среди них могут быть, например, среднее количество пересечений нуля сигналом, BPM, средние значения частоты. Так делал в прошлых версиях Musicbrainz, а о проблемах этого подхода написано здесь. А можно рассматривать более абстрактные понятия, такие как ритм, анализируя трек с помощью алгоритма EM (статья). В общем, полная свобода самовыражения. К сожалению, большая часть предложенных алгоритмов, видимо, не имеет общедоступной реализации, поэтому просто взять и сравнить их не получится.
Самая мейнстримная реализация описана в этой статье. Особенно приятно, что реализовать этот алгоритм можно в несколько строк. Например, в оригинальной статье предлагается разбить частоты на 6 промежутков, найти в каждой максимальное значение амплитуды, взять среднее по всем шести и сохранить бины, которые оказались выше среднего, но возможно много других реализаций.
Приведенная выше функция реализует алгоритм снятия отпечатка. В конце массив частот (вернее, бинов) передается в функцию `hash()`, которая должна превратить массив из нескольких чисел в одно число. Сделать это можно любым подходящим способом, можно даже попробовать воспользоваться md5 (хотя это и плохая идея).
Было подготовлено несколько тесткейсов:
https://metacpan.org/pod/Audio::Ofa::Util
https://www.researchgate.net/publication/228347102_A_Review_of_Audio_Fingerprinting
http://www.freshmeat.net/projects/songprint
https://link.springer.com/article/10.1007/s11265-005-4152-2
https://github.com/acoustid/chromaprint
https://laplacian.wordpress.com/2009/01/10/how-shazam-works/
Постановка задачи
В нашей задаче требуется проиндексировать некоторое количество треков и научиться искать в базе оригинал композиции по ее сэмплу. При этом образец вполне может быть зашумлен, записан на плохой микрофон, у него может быть другая частота. За участника уже написана большая часть кода, ему нужно только реализовать функцию fingerprint, которая снимает с трека отпечаток.
Как записать звук
Вполне понятно, что любой трек — механическая волна, которая имеет аналоговую природу. У волн в физике есть две характеристики: частота и амплитуда. Применительно к звуковым волнам можно для простоты считать, что амплитуда — это громкость, а частота — высота звучания, хотя на самом деле высокие звуки человеку кажутся громче при одинаковой амплитуде.
То есть, с точки зрения физики, каждая композиция описывается непрерывной функцией, а значит любой сколь угодно малый отрывок песни будет содержать в себе бесконечное количество информации (хотя, если это какой-нибудь пост-панк, то информации в треках, возможно, будет чуть меньше). Из-за этого аналоговый сигнал сохранить не получится, придется заниматься его оцифровкой. Основной подход к оцифровке аналоговых сигналов — импульсно-кодовая модуляция, о которой и пойдет речь в этом разделе. ИКМ состоит из трех этапов: дискретизация, квантование и кодирование. Давайте коротко разберем что происходит на каждом из них.
Дискретизация
Итак, у нас есть функция амплитуды от времени. Если у кого-то возникает вопрос, где же частота, то она скрыта за изгибами графика функции. Ее пока не видно, но позже мы ее вытащим. Так как речь пока об аналоговом сигнале, функция непрерывна и определена на всем множестве возможных аргументов (любое действительное число от нуля до конца трека). То есть, мы знаем значение функции в любой момент времени, а моментов у нас очень много. Нам столько явно не надо, так что просто возьмем какое-то дискретное подмножество. Для этого будем сохранять значение сигнала через фиксированный маленький интервал. Он должен быть достаточно малым, чтобы мы на слух не заметили разницу, но достаточно большим, чтобы не сохранять слишком много лишнего, потому что это тоже нежелательно.
На самом деле при оцифровке задается не интервал, а частота, которая называется «частотой дискретизации». В зависимости от задач, частота дискретизации может быть от 8 кГц в телефонах до нескольких тысяч кГц в профессиональном звуковом оборудовании. Музыка для обычного прослушивания вне звукозаписывающих студий обычно сохраняется с частотой 44,1 кГц или 48 кГц.
Квантование
Благодаря дискретизации у нас теперь есть куча точек вместо непрерывного графика функции, но с этим пока еще не получится работать, нужно попортить звук еще сильнее. Изначальная функция амплитуды от времени сопоставляла континуальному времени континуальную амплитуду. Со временем мы разобрались, а теперь нужно что-то придумать с амплитудой, ведь ее текущие значения разбросаны по множеству действительных чисел слишком хаотично, чтобы мы могли их без проблем сохранить. Например, среди них наверняка есть иррациональные, которые мы никак не сможем сохранить без округления.
Квантование — это процесс во время которого мы округляем амплитуды до значений из заранее выбранного множества. Конечно, мы хотим, чтобы количество амплитуд было степенью двойки. Для обычных аудиотреков используется 16-битное квантование, то есть количество амплитуд будет 65 536 (2 в 16 степени). Профессиональная звукозапись может выполняться с большей точностью, но мало кто на слух может отличить 16-битное квантование от 24-битного. Итак, берем степень двойки, берем кучу целочисленных амплитуд и называем их уровнями квантования. Тогда можно будет говорить, что сигнал квантуется по 65 536 уровням (авторитетно звучит, правда?). Каждая амплитуда округляется до одного из уровней, что в итоге позволяет хранить ее значение в 16-ти битах, а на слух такая запись неотличима от аналогового непрерывного звука.
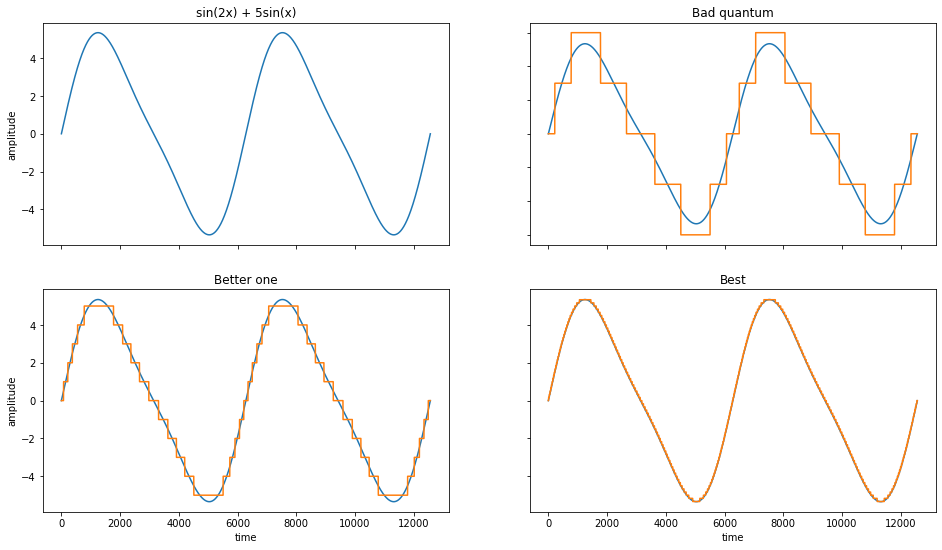
В качестве иллюстрации можно посмотреть картинку ниже, либо нагенерить собственных картинок на Питоне (код еще ниже). Справа вверху на иллюстрации видны пять уровней квантования. То есть, трек будет иметь всего пять уровней громкости.

Немного примеров
import numpy as np
import matplotlib.pyplot as plt
import math as m
def f(x):
return m.sin(x)
q = 1/2 # Неявно задает количество уровней квантования
k = 0 # Иногда бывает полезно написать сюда 1/2 или 1/4
vf = np.vectorize(f)
orig_f = vf(np.arange(0, 4 * m.pi, 0.001))
quanted_f = q * np.round(orig_f/q + k)
plt.plot(orig_f)
plt.plot(quanted_f)
Кодирование
На этапе кодирования мы сохраняем результаты предыдущих шагов в понятной форме. Все действия до этого обычно выполняются специализированным оборудованием, нам же хочется иметь файл на компьютере или массив в памяти, где будут амплитуды. Соответственно, на этом этапе происходит преобразование сигналов оборудования в массив чисел, который мы в дальнейшем будем называть PCM (pulse code modulation). Его индексы — условное время (индекс интервала после дискретизации), а хранятся в нем амплитуды, округленные до целых чисел на этапе квантования.
Преобразование Фурье
Изначально у нас была механическая волна и желание ее оцифровать, а теперь есть оцифрованный сигнал и желание получить из него частоты. Добиться желаемого можно с помощью преобразования Фурье. На всякий случай перескажу его прикладное значение в этой задаче. Преобразование Фурье позволяет взять любую функцию и разложить ее на сумму синусов и косинусов. Нас это интересует, потому что синусоиды и косинусоиды — это про колебания, и звук — это про колебания. То есть, с помощью преобразования Фурье можно получить составные части сложного колебания, узнать их амплитуду и частоту, просто посмотрев, какие коэффициенты стоят перед синусом и аргументом синуса (или косинуса). Например, есть такая волна.

Волна
На самом деле мы знаем, что она задается функцией 10sin(3x) + sin(x) + 4sin(4x) + 20sin(2x), но это сейчас, а настоящая звуковая волна состоит из несметного множества таких слагаемых, и нам хотелось бы уметь с этим работать. Итак, прогоним эту функцию через преобразование Фурье с помощью программы FourierScope и посмотрим на амплитудный спектр.

Амплитудный спектр
Вот так выглядят четыре синуса. Нетрудно увидеть, что график соответствует коэффициентам при синусах и их аргументах.
Надо уточнить, что на самом деле это была демонстрация мощи не самого преобразования Фурье, а его дискретной версии, подходящей для сигналов, которые прошли через импульсно-кодовую модуляцию со всеми ее дискретизациями и квантованиями. Приводить алгоритм дискретного преобразования Фурье будет лишним, поэтому давайте просто сойдемся на том что есть такая штука, которая называется ДПФ, а также его модификация, быстрое преобразование Фурье (БПФ). В данном случае прикладной смысл у БПФ следующий: алгоритм получает на вход кусок PCM и отдает массив, в котором содержатся амплитуды, а индексами являются бины частоты. Речь идет именно о бинах частоты, а не просто о частотах, так как преобразование дискретное. В сущности, наивно было ожидать, что можно на протяжении всей статьи заниматься огрублением сигнала, а потом просто получить частоты без проблем и неточностей. По сути, бин частоты — это целый комок частот, которые БПФ не может отличить друг от друга.
Стоит отметить, что БПФ часто пишут неправильно, переписывая алгоритм из книжек и статей. Ниже приведен более корректный код для работы с БПФ, именно такой мы ожидали от участников в их решении.
import "github.com/mjibson/go-dsp/fft"
...
blocksCount := len(pcm) / fftWindowSize
for i := 0; i < blocksCount; i++ {
complexArray := fft.FFTReal(pcm[i*fftWindowSize : i*fftWindowSize+fftWindowSize])
// use complexArray...
}
Современные технологии позволяют написать быстрое преобразование Фурье всего в несколько строк. БПФ применяется для отрезков размером fftWindowSize и возвращает массив комплексных чисел, которые мы в дальнейшем используем для фингерпринтинга.
В целом преобразование Фурье является самым тонким местом во всей задаче. Во первых, размер бина равен $\frac{частота\ дискретизации}{размер\ окна}$. Соответственно, можно увеличить окно и получить больше частот, что приятно, но, разумеется, имеет негативные последствия. Рост размеров окна приводит к тому, что мы анализируем PCM большими промежутками и теряем звуки небольшой продолжительности. В разных обстоятельствах это может многократно ухудшить работу программы, если короткие звуки были частью композиции, а может и улучшить, если это просто шумы. А может вообще ни на что не повлиять. В такой сложной ситуации программист должен действовать решительно: взять какое-нибудь удачное число, вроде $2^9$ или $2^{10}$, и постараться не заморачиваться на тонкостях там, где этого не требуется. Для решения задачи хватит, а в серьезном приложении все равно придется использовать какое-нибудь окно Хэмминга и много еще над чем думать.
Снятие отпечатка
Задача сводится к тому, чтобы имея частоты и амплитуды композиции научиться получать хеш, который можно будет сопоставить треку и который будет нечувствителен к изменениям. Они могут быть самыми разными: небольшой шум, сдвиг всех частот, играющая параллельно другая песня и так далее. Также нужно учитывать, что в базе данных одновременно может лежать много похожих треков, которые надо отличить друг от друга. А может все треки будут разными, и проблема будет не в том, чтобы установить, какой подходит больше, а в том, чтобы понять, что не подходит ни один. В общем, тут есть определенный простор для творчества.
Снимать отпечаток можно по-разному. Скажем, составлять хеш в виде списка из нескольких разных показателей. Среди них могут быть, например, среднее количество пересечений нуля сигналом, BPM, средние значения частоты. Так делал в прошлых версиях Musicbrainz, а о проблемах этого подхода написано здесь. А можно рассматривать более абстрактные понятия, такие как ритм, анализируя трек с помощью алгоритма EM (статья). В общем, полная свобода самовыражения. К сожалению, большая часть предложенных алгоритмов, видимо, не имеет общедоступной реализации, поэтому просто взять и сравнить их не получится.
Самая мейнстримная реализация описана в этой статье. Особенно приятно, что реализовать этот алгоритм можно в несколько строк. Например, в оригинальной статье предлагается разбить частоты на 6 промежутков, найти в каждой максимальное значение амплитуды, взять среднее по всем шести и сохранить бины, которые оказались выше среднего, но возможно много других реализаций.
var freqBins = [...]int16{40, 80, 120, 180, 300}
func getKeyPoints(frame []freq_domain) int {
highScores := make([]float64, len(freqBins))
recordPoints := make([]uint, len(freqBins))
for bin := freqBins[0]; bin < freqBins[len(freqBins)-1]; bin++ {
magnitude := frame[bin]
binIdx := 0
for freqBins[binIdx] < bin {
binIdx++
}
if magnitude > highScores[binIdx] {
highScores[binIdx] = magnitude
recordPoints[binIdx] = (uint)(bin)
}
}
return hash(recordPoints)
}
Приведенная выше функция реализует алгоритм снятия отпечатка. В конце массив частот (вернее, бинов) передается в функцию `hash()`, которая должна превратить массив из нескольких чисел в одно число. Сделать это можно любым подходящим способом, можно даже попробовать воспользоваться md5 (хотя это и плохая идея).
О тестировании
Было подготовлено несколько тесткейсов:
- Обычный претест с одним треком. Оригинал и сэмпл полностью совпадали.
- Еще один претест с двумя треками. Оригиналы совпадали с сэмлами.
- Индексируется несколько большее количество треков, все поочередно ищутся.
- Загружается большое количество треков, ищутся они же, но после даунсемплинга.
- Индексируются треки после даунсемплинга, ищутся оригинальные.
- Индексируется несколько похожих треков, ищется похожий, но отсутствующий в базе.
- Индексируется несколько треков, ищутся они же, но с шумом.
Немного интересных ссылок
https://metacpan.org/pod/Audio::Ofa::Util
https://www.researchgate.net/publication/228347102_A_Review_of_Audio_Fingerprinting
http://www.freshmeat.net/projects/songprint
https://link.springer.com/article/10.1007/s11265-005-4152-2
https://github.com/acoustid/chromaprint
https://laplacian.wordpress.com/2009/01/10/how-shazam-works/
