Comments 40
Спасибо.
jfyi: на слайде What is a Bitmap Index? случайный набор нулей и единичек :)
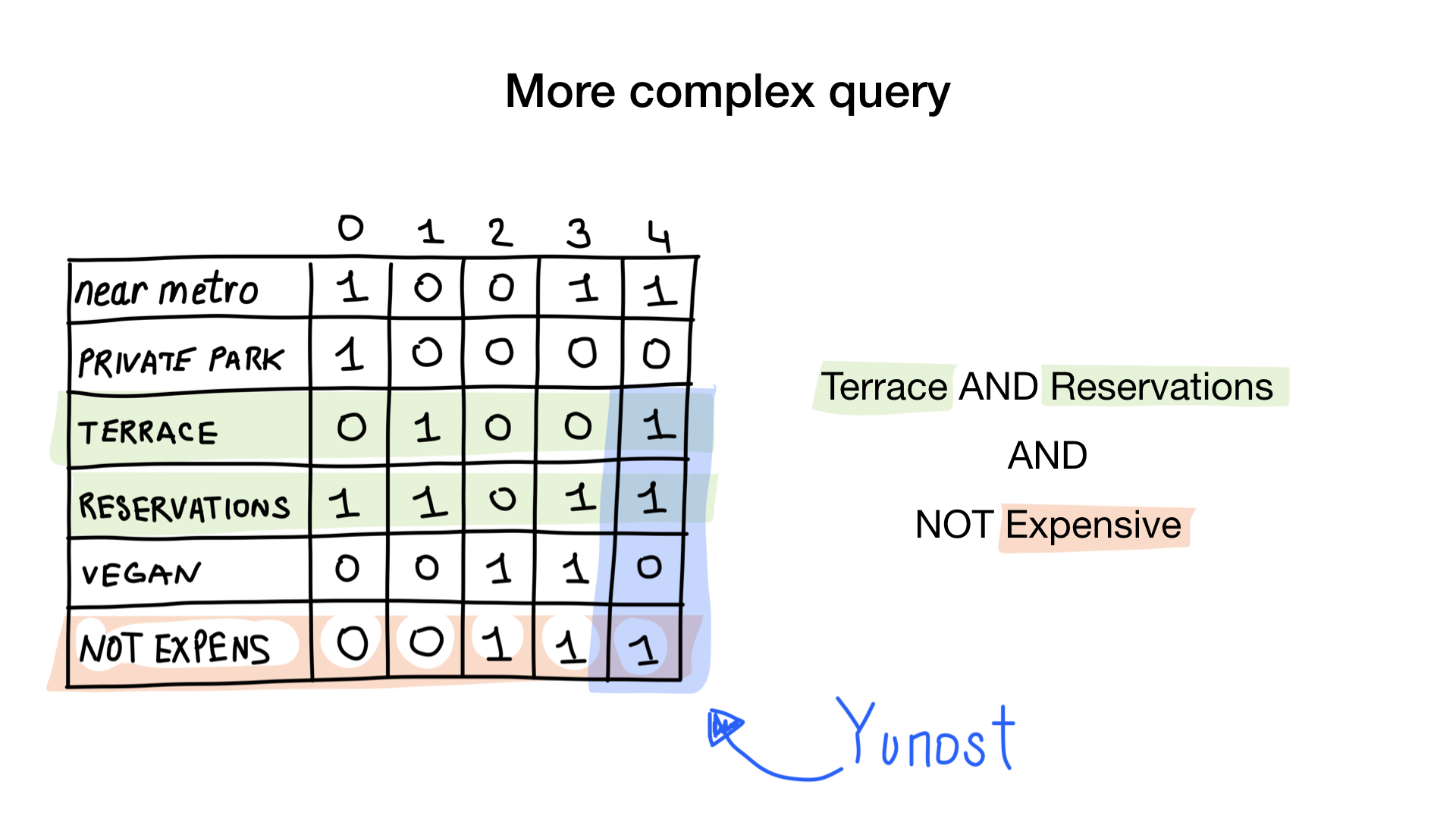
Второй запрос немного сложнее. Нам необходимо использовать битовую операцию NOT на битмапе «дорогой», чтобы получить список недорогих ресторанов, затем за-AND-ить его с битмапом «можно забронировать столик» и за-AND-ить результат с битмапом «есть веранда». Результирующий битмап будет содержать список заведений, которые соответствуют всем нашим критериям. В данном примере это только ресторан «Юность».

Разве не Тарас Бульба?
Я работал с roaring bitmaps в Си, поразительная штука, и, как мне кажется, недостаточно утилизированная в БД.
Но вы меня сильно удивили насчет варианта на Go. Один из авторов оригинальной либы в ее Си исполнении, некий Даниэль Лемирэ, — мирового уровня специалист по векторизации алгоритмов. Собственно, производительность библиотеки (на Си) определяется во многом именно использованием SIMD.
Неужели вариант на Го настолько слабей..? Вы как-нибудь сравнивали производительность? Я не смотрел код, но удивлюсь, если roaring на Go вообще обходится без SIMD.
Напрямую си и go версии я не сравнивал. В репозитории что к докладу есть сравнение cgo и go варианта, но это не совсем то.
В go реализациях в тикетах и пулл реквестах закопано несколько попыток добавить SIMD, но этот код, на сколько мне известно, еще никуда не замержен и нигде не используется.
Думаю что разработчики pilosa так или иначе в ближайшее время придут к тому, что без SIMD не обойтись. Идея и необходимость прямо витает в воздухе и, я уверен, скоро материализуется.
Я предложили к одной его либе (streamvbyte) расширить функционал, он подробно все со мной обсудил, комментировал изменения в алгоритмах, и в вообще буквально за руку держал в процессе приемки моего пулл-реквеста. С тех пор не пропускаю ничего из того, что он делает.
А если шире. Почему в roaring bitmaps на Го могли опустить SIMD? Я не слишком хорошо знаком с языком, чисто шапочно. Там есть что-то аналогичное SIMD intrisics в Си? Или надо на ассемблере делать?
Часть из этого я как раз описал в докладке и статье.
Все-таки Go довольно молодой язык. Но все будет, я уверен.
За ассемблер сейчас чаще всего берутся, когда пишут шифрование.
Появление avo/peachpy чуть приоткроет этот мир для более широкого круга лиц.
Тот же streamvbyte, или RoaringC, не используют ассемблер, это ж совсем болезненно, да и портируется тяжело, а пишут функциями, специфичными для каждой из платформ. А выбирают функции ifdef-ами.
А автовекторизация — священный грааль мира компиляторов. В сущности, никто не знает, как это правильно делать в нетривиальных случаях. Не думаю, что разработчики Го тут что-то неожиданное придумают.
Спасибо за ответы!
А что делать, если найдется amd64 без AVX инструкций?
ifdef или какой-нибудь аналог типа флагов времени компиляции?
Обычно делают скалярный вариант на случай CPU без SIMD вообще, и потом векторные — для актуальных процессоров. Или даже несколько: для ARM NEON, разных поколений Intel и т.д.
Удовольствия в этом мало, конечно. :-) Но когда оно надо, то оно надобно очень.
Представляю ситуацию. Заходит пользователь скачать minio, для файл помойки на core2quad, а там сборка под amd64, amd64-avx и т.д.
У вас это практические вопросы или риторические?
Сто лет в обед как единожды собранная glibc использует разные версии функций при использовании на разных машинах.
Если не подходят ifdef-ы, можно на лету выбирать необходимые функции: можно динамически линковать разные версии функций в зависимости от железа или даже атрибутами указывать под поколения процессоров версии одной и той же функции (https://lwn.net/Articles/691932/). В конце концов, можно вот прям кодом спросить есть ли у процессора соответствеующий набор инструкций.
Если уж хочется оптимизировать, то почему не использовать для сравнения gccgo, который куда охотнее оптимизирует пользовательский код?
Реально серьезная оптимизация алгоритмов компиляторами не делается, а делается людьми :-)
99% работы и активности приходится на основной компилятор.
спасибо!
А есть какие-то сравнительные тесты, которые показывают, как использование bitmap-индексов позволяет ускорить работу приложения по сравнению с "обычными" индексами?
Надо уточнить, какие именно операции вы хотите сравнить. Все-таки bitmap по определению это операции над множествами, что-то с ними принципиально не сделать.
Но если речь идёт об операциях вида and/or над множеством ключей, скажем, к таблице, то оно будет в десятки раз быстрей.
На простом Си пока ничего лучше roaring bitmap не придумали, и есть очень читаемая публикация в свободном доступе на эту тему. Там есть сравнения.
Битмапы, думаю, имеет смысл использовать там, где много условий, много данных и требуется полный перебор. В таких задачах они могут давать колосальный выигрыш…
Точно! Исследуется эта тема давно, и прежде всего в контексте того, как битмапы сжимать эффективней, т.к. бит на ряд в наивной реализации — очень уж много.
Последние двадцать лет исследования в этой области сводились прежде всего к методам эффективного сжатия и распаковки таких индексов. У Оракла, кстати, есть патентованный алгоритм на эту тему; где-то есть обзорная научная публикация со сравнением традиционных методов и их производительности.
С распространением инструкций SIMD и расширением их возможностей появилось новое поколение алгоритмов, работающих с битмапами, которые практически разрешили основные из проблем битмапов. Прежде всего это roaring bitmaps, которые эффективно сжимаются/распаковываются, и на современных машинах работают поразительно эффективно.
Но вы зря про редкость объединений. Они в типичных запросах к бд встречаются постоянно.
Вы совершенно правы насчет главного ограничения индексов на битмапах: пространство значений типа колонки должно быть небольшой размерности. Битмапы — не универсальное решение. Я лишь хочу сказать, что в местах, где их можно использовать (операции над множествами), они будут вне конкуренции.
SIMD это хорошо, но в случае с БД любой дополнительный IO настолько больше ресурсов требует, > что любые выигрыши будут малозаметны.
Точно. В традиционных архитектурах БД, где память представляет собой просто кеш перед большим винтом, и у которых есть развитый менеджер буферов, преимущества векторизации ограничены скоростью шины памяти.
Но есть два "но"! :-) Во-первых, современные битмапы сильно ужаты, и умещаются в единицы кэш-линий. Для винта, тем более — SSD, это чтение одной страницы памяти; в то время как B-деревья трогают по крайней мере пару страницу.
Во-вторых, последнее поколение БД (https://en.wikipedia.org/wiki/NewSQL) использует винт исключительно для хранения лога (WAL), а данные хранятся почти полностью в памяти, и вот тут уже действуют совсем другие правила, и всякие там ускорения вычислений (векторизация запросов, jit-компиляция запросов, различные кеш-ориентированные индексы, безлоковые структуры данных) играют важную роль.
Вот и получается, что для того чтобы действительно получить хороший выигрыш, надо чтобы
звезды сошлись и человек понимал что и зачем он делает. Ну конечно IMHO.
Ну да, разумеется. Развитые структуры данных — дело такое, перед применением надо основательно разобраться с преимуществами или недостатками.
B-дерево — прекрасная и почти универсальная структура данных, я спорить тут не могу, но есть множество альтернатив, которые в отдельных слуаях будут себя показывать лучше. Например, MemSQL вообще решили обойтись скип-листом для своих индексов, т.к. решили, что корректно сделать безлоковое B-дерево им не по карману.
Я все это не на ровном месте говорю. Мы используем roaring bitmap для ускорения некоторых запросов к специлизированному индексу и удивительным образом он на профилях даже не появляется, памяти почти не ест. Данные у нас всегда в памяти, запросы часто фильтруют данные по полям малой размерности...
Не сказан главный недостаток таких индексов: сложность поиска по ним O(n) (линейно зависит от размера просматриваемой таблицы), тогда как деревья дают O(log n), а хэши чуть ли не O(1).
Если в таблице с миллиардами записей только 10 удовлетворяют условию, то нам придётся просмотреть весь индекс, в то время, как поиск по дереву пробежит только очень небольшую часть индекса.
Для разреженных данных проблема может быть решена сжатием, о котором писалось в статье, но тут возникают сложности с модификацией данных.
Для redis есть https://github.com/aviggiano/redis-roaring
Заюзал на коленке, поразительные результаты https://toster.ru/answer?answer_id=1201457
я не знаю, как работает модуль для Редис, но, если мне не изменяют память и разум, roaring должен возвращать значения из множества уже упорядоченные. Если значения это и есть ваши айдишники, то они должны быть уже упорядоченные.
А что именно вы хотите сортировать? сами айдишники?
Сортировать по характеристикам. Например, цена.
Если судить поверхностно, то битмапы тут никак не могут помочь по определению — это ж просто множества айдишников.
Опять же, сам Редис страшно не любит алгоритмы сложностью от O(n) и выше, т.к. работает в один поток, и такие алгоритмы просто заблокируют на ощутимое время весь процесс. А сортировка, как известно, это O(N*logN).
Так что тут вам традиционная БД в помощь.
Bitmap-индексы в Go: поиск на дикой скорости