 В последнее время пользователи все чаще получают изображения документов при помощи фотокамер или мобильных устройств, прибегая к помощи сканера изредка, в особых случаях. В то же время, для изображений, получаемых фотокамерами, характерны следующие недостатки: геометрические искажения (о них мы говорили в статье про автоматическое выделение документа), неравномерность освещения (часто можно видеть тени или засветки при использовании вспышки), падение контраста, расфокусировка, смаз, цифровой шум при недостаточном освещении. Постараемся избавиться от этих недостатков, применяя некоторые преобразования к исходному изображению, чтобы приблизить его вид к отсканированному.
В последнее время пользователи все чаще получают изображения документов при помощи фотокамер или мобильных устройств, прибегая к помощи сканера изредка, в особых случаях. В то же время, для изображений, получаемых фотокамерами, характерны следующие недостатки: геометрические искажения (о них мы говорили в статье про автоматическое выделение документа), неравномерность освещения (часто можно видеть тени или засветки при использовании вспышки), падение контраста, расфокусировка, смаз, цифровой шум при недостаточном освещении. Постараемся избавиться от этих недостатков, применяя некоторые преобразования к исходному изображению, чтобы приблизить его вид к отсканированному.Прежде всего, отметим, что простое увеличение контраста относительно среднего уровня сигнала в большинстве случаев не работает, как видно на рисунке:


Слева – исходное изображение, справа – результат увеличения контраста.
Видно, что необходим более сложный алгоритм, учитывающий неравномерность освещения. Попробуем сделать адаптивное увеличение контраста относительно локального среднего значения. Локальное среднее значение вычисляется для каждого пикселя в пределах квадратной окрестности, центром которой он и является. Размер окрестности следует выбирать исходя из ожидаемых размеров букв и толщины штриха. Существуют алгоритмы для быстрого вычисления локальных средних значений, например, интегральная матрица (summed area table). Если перед увеличением контраста из локального среднего вычесть константу, соответствующую оценке уровня шума в изображении, то для простых документов результат может быть вполне удовлетворительным:


Слева – карта «порогов» (уровней яркости), относительно которых происходит увеличение контраста. Справа – результат применения.
Можно также увеличивать контраст относительно среднего значения между локальным минимумом и максимумом.
Все становится гораздо хуже, если документ содержит плоские участки, выворотки, или инвертированный текст, размер букв может отличаться в несколько раз, а рядом с текстом могут находиться фотографии. Вот так выглядит результат на сложной верстке:


Слева – исходное изображение, справа – результат увеличения контраста.
Видно, что на фотографиях значительная часть изображений потеряна, инвертированные участки текста, выворотки выглядят не так, как в оригинальном документе, большие буквы имеют контурное представление без заливки. Все это создает дополнительные сложности для последующего анализа и распознавания подобных документов.
Задача состоит в том, чтобы каким-то образом построить такую карту «порогов», относительно которой увеличение контраста приводило бы к повышению визуального качества, и которая учитывала бы особенности документов со сложной версткой. Такая карта порогов будет полезна и для получения бинаризованного (черно-белого) изображения документа. Процесс бинаризации можно рассматривать как частный случай, когда увеличение контрастов в изображении стремится к бесконечности.
Предлагаемый алгоритм позволяет построить приемлемую карту порогов для сложных документов. Чтобы учитывать объекты разных размеров на изображении, используется пирамидальное разложение изображения. Схематично этот процесс представлен на рисунке:
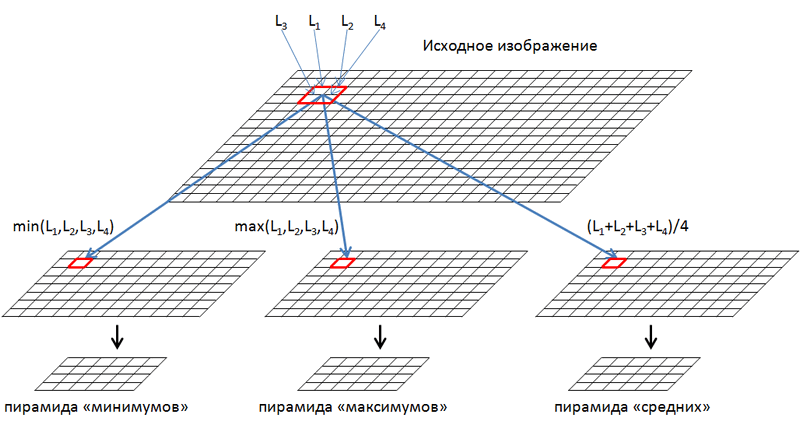
Разложение начинается с масштаба исходного изображения. Оно делится на непересекающиеся квадраты размером 2х2 пикселя, в каждом из которых мы получаем значения минимума, максимума и среднего из 4-х пикселей, его составляющих. Далее из этих значений формируем три изображения: минимумов, максимумов и средних, которые уменьшены в 2 раза по горизонтали и вертикали относительно исходного. Повторяем процедуру и раскладываем полученные изображения в пирамиды до уровня, на котором размер ещё составляет не менее 2 пикселей по горизонтали и вертикали.
При помощи пирамидального разложения мы получаем значения минимумов, максимумов и средних для исходных участков изображения, соответствующих различным масштабам его представления. Типичные изображения документов содержат 9-12 уровней разложения.
Алгоритм построения карты порогов на основе пирамидального разложения состоит в следующем:
- На нижнем уровне пирамидального разложения, где изображение состоит всего из нескольких пикселей, инициализируем карту порогов с использованием любой из двух гипотез:
- локальное среднее значение этого участка изображения (т.е. яркость пикселя из пирамиды средних)
- среднее между локальным минимумом и максимумом (среднее по яркости 2-х пикселей, взятых из пирамид минимумов и максимумов).
- Переходим на следующий уровень разложения, увеличивая карту порогов в 2 раза по горизонтали и вертикали с применением интерполяции со свертками [1 3], [3 1].
- В каждом пикселе на новом уровне пирамидального разложения вычисляем разницу между значением пикселя из пирамиды максимумов и значением из пирамиды минимумов. Если эта разница не превосходит шумовой порог, считаем, что полезного сигнала в этом участке изображения нет, причем как на этом, так и на последующих уровнях пирамидального разложения. Следовательно, значение порога, полученного на предыдущем уровне разложения, можно оставить без изменений. В противном случае вычисляем новое, уточненное значение порога, исходя из смеси двух гипотез, 1а и 1б.
- Шаги 2 и 3 повторяем до тех пор, пока не достигнем такого уровня разложения, на котором участки изображения, соответствующие пикселям в пирамиде, ещё обладают размером, превосходящим самые маленькие буквы, различимые на изображении. Обычно такие буквы имеют размер около 6-10 пикселей, этому соответствует 3-й или 4-й уровень пирамиды.
В результате получаем карту порогов, относительно которой увеличение контраста не приводит к потерям объектов различного размера, кроме того, плоские однородные участки на изображении не содержат шум:


Слева – карта порогов, справа – результат увеличения контраста относительно неё.
Остается решить, как быть в отношении цветных изображений, поскольку увеличение контраста часто приводит к потерям в цвете. Можно увеличивать контраст для компоненты яркости (серого изображения), учитывая участки с насыщенным цветом, снижая на них коэффициент увеличения контраста.
Используем своё цветовое пространство, похожее на HSL, но вместо яркости L будем работать с компонентой Y в цветовом пространстве YCbCr.
Для серого изображения контраст увеличивается так:
Y’ = k(Y – T) + T, где Т – значение яркости для этого же пикселя из карты порогов, Y и Y’ – исходное и получаемое значение яркости пикселя, k – коэффициент увеличения контраста, обычно его значение лежит в диапазоне от 3 до 6.
Для пикселей, у которых насыщенность S велика, мы будем часто получать неверный цвет, так как диапазон допустимых значений для цветовых компонент ограничен. Поэтому для цветного изображения коэффициент k в этой формуле необходимо сделать обратно пропорциональным насыщенности цвета. Дополнительные нормировочные коэффициенты несложно подобрать эмпирически.
Для участков со слабой насыщенностью можно, напротив, снижать насыщенность цвета вплоть до 0, подавляя цветовой шум на изображении. Это легко сделать, смешивая значения из цветовых каналов с яркостью в различной пропорции. Также полезно перед увеличением контраста сделать выравнивание баланса белого на изображении по гистограммам каналов R, G, B.


Слева – исходное изображение, справа – результат увеличения контраста с учетом насыщенности цвета.
