Предпосылкой к написанию данной статьи было вполне естественное желание улучшить производительность FineReader Engine.
Существует мнение, что компилятор от Intel производит гораздо более быстрый код, чем gcc. И ведь было бы неплохо увеличить скорость распознаванияничего не сделав просто собрав FR Engine другим компилятором.
На данный момент FineReader Engine собирается не самым новым компилятором – gcc 4.2.4. Пора переходить на что-то более современное. Мы рассмотрели две альтернативы – это новая версия gcc – 4.4.4, и компилятор от Интел – Intel C++ Compiler (icc).
Портирование большого проекта под новый компилятор может оказаться не самым простым делом, поэтому для начала мы решили протестировать компиляторы на бенчмарке.
Вот краткие результаты на процессоре Intel Core2 Duo:
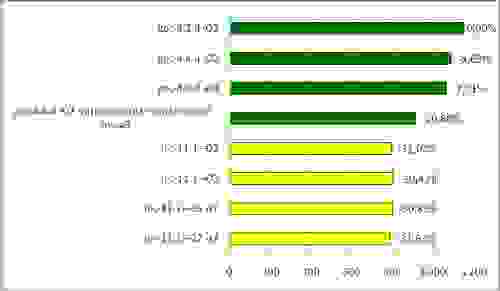
Время povray-теста на процессоре Intel (сек)
На AMD тоже было интересно посмотреть:

Время povray- теста на процессоре AMD (сек)
Кратко по поводу флагов:
-O1, -O2 и -O3 – различные уровни оптимизации.
Для gcc наилучшей опцией считается –O3, и она используется почти везде при сборке FineReader Engine.
Для icc оптимальной опцией считается -O2, а -O3 включает в себя некоторые дополнительные оптимизации циклов, которые, впрочем, могут не сработать.
-mtune=core2 -march=core2 -msse3 – оптимизация под конкретный процессор, в данном случае под Core2 Duo.
-xT – аналогичный флаг для компилятора от Intel.
-fprofile-use – PGO
Тесты с оптимизациями под конкретный процессор приведены just for fun. Бинарник, собранный с оптимизацией под один процессор, может не запуститься на другом. FineReader Engine не должен привязываться к определенному процессору, поэтому использовать подобные оптимизации нельзя.
Итак, судя по всему, прирост производительности возможен: icc очень значительно ускоряет на процессоре Intel. На AMD он ведет себя скромнее, но все равно дает неплохой прирост по сравнению с gcc.
Пришло время переходить к тому, ради чего мы все это затеяли, – к сборке FineReader Engine. Мы собрали FineReader Engine разными компиляторами, запустили распознавание на пакете изображений. Вот результаты:

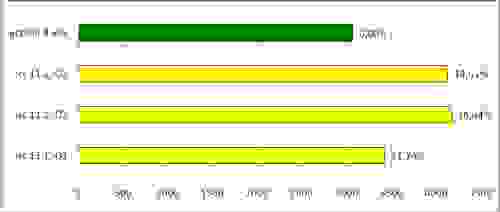
Время работы FREngine, собранного различными компиляторами (секунд на станицу)
Неожиданный результат. Соотношение gcc-4.4.4 / gcc-4.2.4 вполне согласуется с замерами на бенчмарке, и даже слегка превышает ожидания. Но что с icc? Он проигрывает не только новому gcc, но и gcc двухлетней давности!
Мы отправились за правдой к oprofile, и вот что удалось выяснить: в некоторых (достаточно редких) случаях icc испытывает проблемы с оптимизацией циклов. Вот код, который удалось написать, основываясь на результатах профайлинга:
Запустив функцию на разных входных данных, мы получили примерно такой результат:
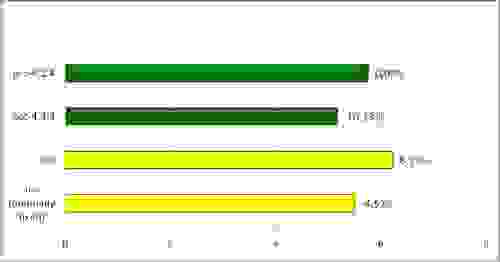
Время выполнения цикла (мс)
Добавление других флагов оптимизации не дало ощутимых результатов, поэтому я привел только основные.
К сожалению, Intel не указывает явно, что включают в себя -O1, -O2 и -O3, поэтому выяснить, какая именно оптимизация заставила код тормозить, не удалось. На самом деле в большинстве случаев icc оптимизирует циклы лучше, но в некоторых особых случаях (подобных приведенному выше) возникают трудности.
С помощью профайлинга удалось обнаружить еще одну, более серьезную проблему. В отчете профайлера для версии FineReader Engine, собранной icc, на достаточно высоких позициях находилась подобная строчка:
в то время как в версии от gcc такой функции вообще не было.
A::GetValue() возвращает простую структуру, содержащую несколько полей. Чаще всего этот метод вызывается для глобального константного объекта в конструкции вида
которая имеет тип int. Все приведенные методы Get..() тривиальны – они просто возвращают какое-то поле объекта (по значению или ссылке). Таким образом, GetValue() возвращает объект с несколькими полями, после чего GetField() вытаскивает одно из этих полей. В этом случае вместо постоянного копирования всей структуры с целью вытащить всего одно поле, вполне возможно цепочку превратить в один вызов, возвращающий нужное число. Кроме того, все поля объекта GlobalConstObject известны (могут быть вычислены) на этапе компиляции, поэтому цепочку этих методов можно заменить на константу.
gcc так и делает(по крайней мере, он избегает лишнего конструирования), однако icc с включенными оптимизациями -O2 или -O3 оставляет все, как есть. А учитывая количество таких вызовов, это место становится критическим, хотя здесь не выполняется никакой полезной работы.
Теперь о способах лечения:
1) Автоматический. У icc есть замечательный флаг -ipo, который просит компилятор выполнять межпроцедурную оптимизацию, к тому же между файлами. Вот что написано по этому поводу в мануалах Intel по оптимизации:
Кажется, это то, что нужно. Все было бы хорошо, но FineReader Engine содержит огромное количество кода. Попытка запустить его собираться с флагом -ipo привела к тому, что линковщик (а именно он выполняет ipo) занял всю память, весь swap и один только модуль распознавания страницы (впрочем, самый крупный) собирался несколько часов. Безнадежно.
2) Ручной. Если везде в коде вручную заменить цепочку вызовов на константу, на компиляторе Intel получается неплохой прирост производительности относительно старых результатов.
Последняя строчка – версия, собранная icc, где в самых критичных местах цепочка вызовов была заменена на константу. Как видно, это позволило версии icc работать быстрее gcc-4.2.4, но все еще медленнее gcc-4.4.4.
Можно попытаться выловить все подобные критические места и вручную поправить код. Очевиден недостаток — на это уйдет огромное количество времени и сил.
3) Комбинированный. Можно собирать с флагом -ipo не весь модуль, а только некоторые его части. Это даст приемлемое время компиляции. Однако какие именно файлы следует компилировать с этим флагом, придется определять вручную, что опять же потенциально приводит к большим трудозатратам.
Итак, резюмируем. Intel C++ Compiler потенциально хорош. Но из-за описанных выше особенностей и большого количества кода мы решили, что он не дает значительного выигрыша по скорости – достаточно значительного, чтобы оправдать трудозатраты по портированию и «заточке» кода под этот компилятор.
Существует мнение, что компилятор от Intel производит гораздо более быстрый код, чем gcc. И ведь было бы неплохо увеличить скорость распознавания
На данный момент FineReader Engine собирается не самым новым компилятором – gcc 4.2.4. Пора переходить на что-то более современное. Мы рассмотрели две альтернативы – это новая версия gcc – 4.4.4, и компилятор от Интел – Intel C++ Compiler (icc).
Портирование большого проекта под новый компилятор может оказаться не самым простым делом, поэтому для начала мы решили протестировать компиляторы на бенчмарке.
Вот краткие результаты на процессоре Intel Core2 Duo:
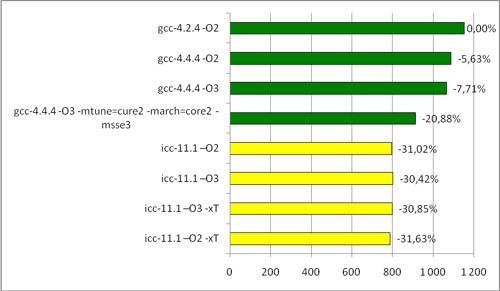
Время povray-теста на процессоре Intel (сек)
На AMD тоже было интересно посмотреть:
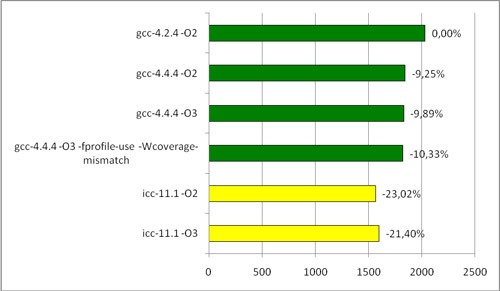
Время povray- теста на процессоре AMD (сек)
Кратко по поводу флагов:
-O1, -O2 и -O3 – различные уровни оптимизации.
Для gcc наилучшей опцией считается –O3, и она используется почти везде при сборке FineReader Engine.
Для icc оптимальной опцией считается -O2, а -O3 включает в себя некоторые дополнительные оптимизации циклов, которые, впрочем, могут не сработать.
-mtune=core2 -march=core2 -msse3 – оптимизация под конкретный процессор, в данном случае под Core2 Duo.
-xT – аналогичный флаг для компилятора от Intel.
-fprofile-use – PGO
Тесты с оптимизациями под конкретный процессор приведены just for fun. Бинарник, собранный с оптимизацией под один процессор, может не запуститься на другом. FineReader Engine не должен привязываться к определенному процессору, поэтому использовать подобные оптимизации нельзя.
Итак, судя по всему, прирост производительности возможен: icc очень значительно ускоряет на процессоре Intel. На AMD он ведет себя скромнее, но все равно дает неплохой прирост по сравнению с gcc.
Пришло время переходить к тому, ради чего мы все это затеяли, – к сборке FineReader Engine. Мы собрали FineReader Engine разными компиляторами, запустили распознавание на пакете изображений. Вот результаты:
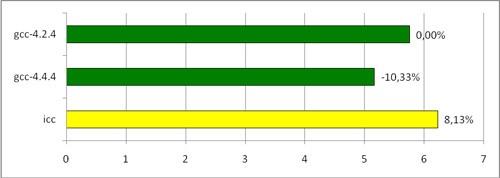
Время работы FREngine, собранного различными компиляторами (секунд на станицу)
Неожиданный результат. Соотношение gcc-4.4.4 / gcc-4.2.4 вполне согласуется с замерами на бенчмарке, и даже слегка превышает ожидания. Но что с icc? Он проигрывает не только новому gcc, но и gcc двухлетней давности!
Мы отправились за правдой к oprofile, и вот что удалось выяснить: в некоторых (достаточно редких) случаях icc испытывает проблемы с оптимизацией циклов. Вот код, который удалось написать, основываясь на результатах профайлинга:
static const int aim = ..;
static const int range = ..;
int process( int* line, int size )
{
int result = 0;
for( int i = 0; i < size; i++ ) {
if( line[i] == aim ) {
result += 2;
} else {
if( line[i] < aim - range || line[i] > aim + range ) {
result--;
} else {
result++;
}
}
}
return result;
}
* This source code was highlighted with Source Code Highlighter.Запустив функцию на разных входных данных, мы получили примерно такой результат:
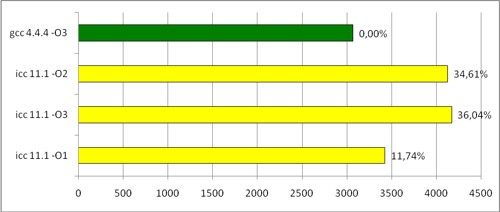
Время выполнения цикла (мс)
Добавление других флагов оптимизации не дало ощутимых результатов, поэтому я привел только основные.
К сожалению, Intel не указывает явно, что включают в себя -O1, -O2 и -O3, поэтому выяснить, какая именно оптимизация заставила код тормозить, не удалось. На самом деле в большинстве случаев icc оптимизирует циклы лучше, но в некоторых особых случаях (подобных приведенному выше) возникают трудности.
С помощью профайлинга удалось обнаружить еще одну, более серьезную проблему. В отчете профайлера для версии FineReader Engine, собранной icc, на достаточно высоких позициях находилась подобная строчка:
Namespace::A::GetValue() const (На всякий случай все имена изменены на ничего не значащие)в то время как в версии от gcc такой функции вообще не было.
A::GetValue() возвращает простую структуру, содержащую несколько полей. Чаще всего этот метод вызывается для глобального константного объекта в конструкции вида
GlobalConstObject.GetValue().GetField()которая имеет тип int. Все приведенные методы Get..() тривиальны – они просто возвращают какое-то поле объекта (по значению или ссылке). Таким образом, GetValue() возвращает объект с несколькими полями, после чего GetField() вытаскивает одно из этих полей. В этом случае вместо постоянного копирования всей структуры с целью вытащить всего одно поле, вполне возможно цепочку превратить в один вызов, возвращающий нужное число. Кроме того, все поля объекта GlobalConstObject известны (могут быть вычислены) на этапе компиляции, поэтому цепочку этих методов можно заменить на константу.
gcc так и делает(по крайней мере, он избегает лишнего конструирования), однако icc с включенными оптимизациями -O2 или -O3 оставляет все, как есть. А учитывая количество таких вызовов, это место становится критическим, хотя здесь не выполняется никакой полезной работы.
Теперь о способах лечения:
1) Автоматический. У icc есть замечательный флаг -ipo, который просит компилятор выполнять межпроцедурную оптимизацию, к тому же между файлами. Вот что написано по этому поводу в мануалах Intel по оптимизации:
IPO allows the compiler to analyze your code to determine where you can benefit from a variety of optimizations:
• Inline function expansion of calls, jumps, branches and loops.
• Interprocedural constant propagation for arguments, global variables and return values.
• Monitoring module-level static variables to identify further optimizations and loop invariant code.
• Dead code elimination to reduce code size.
• Propagation of function characteristics to identify call deletion and call movement
• Identification of loop-invariant code for further optimizations to loop invariant code.
Кажется, это то, что нужно. Все было бы хорошо, но FineReader Engine содержит огромное количество кода. Попытка запустить его собираться с флагом -ipo привела к тому, что линковщик (а именно он выполняет ipo) занял всю память, весь swap и один только модуль распознавания страницы (впрочем, самый крупный) собирался несколько часов. Безнадежно.
2) Ручной. Если везде в коде вручную заменить цепочку вызовов на константу, на компиляторе Intel получается неплохой прирост производительности относительно старых результатов.
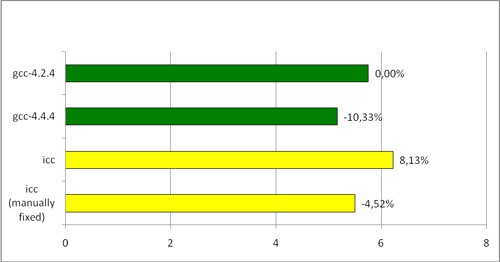
Последняя строчка – версия, собранная icc, где в самых критичных местах цепочка вызовов была заменена на константу. Как видно, это позволило версии icc работать быстрее gcc-4.2.4, но все еще медленнее gcc-4.4.4.
Можно попытаться выловить все подобные критические места и вручную поправить код. Очевиден недостаток — на это уйдет огромное количество времени и сил.
3) Комбинированный. Можно собирать с флагом -ipo не весь модуль, а только некоторые его части. Это даст приемлемое время компиляции. Однако какие именно файлы следует компилировать с этим флагом, придется определять вручную, что опять же потенциально приводит к большим трудозатратам.
Итак, резюмируем. Intel C++ Compiler потенциально хорош. Но из-за описанных выше особенностей и большого количества кода мы решили, что он не дает значительного выигрыша по скорости – достаточно значительного, чтобы оправдать трудозатраты по портированию и «заточке» кода под этот компилятор.
