Мы в X5 обрабатываем много данных в ERP-системе. Есть мнение, что больше нас в SAP ERP и SAP BW в России не обрабатывает никто. Но есть еще один момент – число операций и нагрузка на эту систему увеличивается быстро. 3 года мы «сражались» за производительность нашего ERP-тяжеловеса, набили немало шишек, а какими методами их лечили, рассказываем под катом.

Сейчас Х5 управляет более чем 13 000 магазинов. Большинство бизнес-процессов каждого из них проходит через единую ERP-систему. В каждом магазине может быть от 3 000 до 30 000 товаров, это создает проблемы с нагрузкой на систему, т.к. через неё проходят процессы регулярного пересчёта цен в соответствии с промо-акциями и требованиями законодательства и расчёта пополнения товарных запасов. Всё это критично, и если вовремя не будет посчитано, какие товары в каком количестве должны быть завтра доставлены в магазин либо какая цена должна быть на товары, покупатели не найдут на полках то, что искали, либо не смогут приобрести товар по цене действующей промо-акции. В общем, кроме учёта финансовых операций, ERP-система отвечает за многое в повседневной жизни каждого магазина.
Немного ТТХ ERP-системы. Её архитектура классическая, трехуровневая с сервисно-ориентированными элементами: сверху у нас более 5 000 толстых клиентов и терабайты информационных потоков от магазинов и распределительных центров, в слое приложений – SAP ABAP c более чем 10 000 процессами и, наконец, Oracle Database c более чем 100 Тб данных. Каждый процесс ABAP – это условно виртуальная машина, выполняющая бизнес-логику на языке ABAP, со своим DBSL и диалектом SQL, кэшированием, memory management, ORM и т.д. В день мы получаем больше 15 Тб изменений в логе базы. Уровень нагрузки – 500 000 запросов в секунду.
Эта архитектура – гетерогенная среда. Каждый из компонентов кроссплатформенный, мы можем перемещать его на разные платформы, выбирать оптимальные и т.д.
Масла в огонь добавляет то, что ERP-система находится под нагрузкой 24 часа в сутки 365 дней в году. Доступность — 99,9% времени в течение года. Нагрузка при этом разделена на дневной, ночной профили и house keeping в свободное время.
Но и это не всё. У системы жесткий и плотный релизный цикл. В год она переносит больше 2 000 пакетных изменений. Это может быть и одна новая кнопочка, и серьезные изменения в логике работы бизнес-приложений.

В итоге это большая и высоконагруженная, но при этом стабильная, прогнозируемая и готовая к росту система, способная «хостить» десятки тысяч магазинов. Но так было не всегда.
Для погружения в практический материал нужно перенестись в 2014 год. Тогда были самые сложные задачи по оптимизации системы. Магазинов было около 5 000.
Система в то время находилась в таком состоянии, что большинство критичных процессов были немасштабируемы и неадекватно отвечали на рост нагрузки (то есть на появление новых магазинов и товаров). Кроме того, за два года до этого был закуплен дорогой Hi-End, и на какое-то время апгрейд не входил в наши планы. При этом процессы в ERP были уже на грани нарушения SLA. Вендор дал заключение, что нагрузка на систему немасштабируема. Никто не знал, выдержит ли она еще хотя бы +10% прироста нагрузки. А магазинов планировалось открыть в два раза больше в течение трех лет.
Просто накормить ERP-систему новым железом было невозможно, да и не помогло бы. Поэтому в первую очередь мы решили включить в релизный цикл методику оптимизации ПО и следовать правилу: линейный рост нагрузки пропорционально росту драйверов нагрузки – залог прогнозируемости и масштабируемости.
В чем заключалась методика оптимизации? Это цикличный процесс, разбитый на несколько этапов:
Далее цикл повторялся.
В процессе мы поняли, что текущие инструменты мониторинга не позволяют нам быстро определять топовых потребителей, выявлять узкие места и голодающие по ресурсам процессы. Поэтому для ускорения попробовали инструменты elastic search и Grafana. Для этого самостоятельно разработали коллекторы, которые из стандартных инструментов мониторинга в Oracle/SAP/AIX/Linux передавали метрики в elastic search и позволяли в режиме реального времени отслеживать здоровье системы. Кроме того, обогатили мониторинг своими custom-метриками, например время отклика и пропускная способность специфичных компонентов SAP или раскладки профилей нагрузки по бизнес-процессам.

В первую очередь для меньшего влияния узких мест на быстродействие обеспечили более плавную подачу нагрузки на систему.
Большинство бизнес-процессов в нашей ERP-системе, например, такие как регулярный расчёт цен или планирование пополнения товарных запасов, представляют собой последовательную поэтапную обработку большого объёма данных (по всем товарам и всем магазинам). Для реализации обработки в рамках таких тяжёлых задач в своё время мы разработали собственный диспетчер пакетно-параллельной обработки (далее – планировщик нагрузки). В данном случае в виде пакета представляется обособленно выполняемый этап обработки по отдельному магазину.
Изначально логика планировщика была такова, что сначала выполнялись пакеты первого этапа обработки по всем магазинам, затем пакеты второго этапа и т.д. То есть в системе одновременно выполнялись процессы, создававшие однотипную нагрузку и вызывавшие деградацию определенных ресурсов (ввод-вывод на БД или CPU на серверах приложений, и т.д.).

Мы переписали логику планировщика таким образом, чтобы цепочка пакетов формировалась отдельно по каждому магазину и приоритет запуска новых пакетов выстраивался не по этапам, а по магазинам.

За счёт различной длительности выполнения пакетов по разным магазинам и регулируемого большого количества одновременно выполняемых процессов в рамках задач планировщика нагрузки мы достигли одновременного выполнения разнородных процессов, более плавной подачи нагрузки и устранения части узких мест.
Затем занялись оптимизацией отдельных конструкций. Каждый отдельный пакет рассматривали, профилировали и собирали неоптимальные конструкции и применяли подходы для их оптимизации. В дальнейшем эти подходы включили в регламент разработчика с целью предотвращения нежелательного роста нагрузки при развитии системы. Некоторые из них:
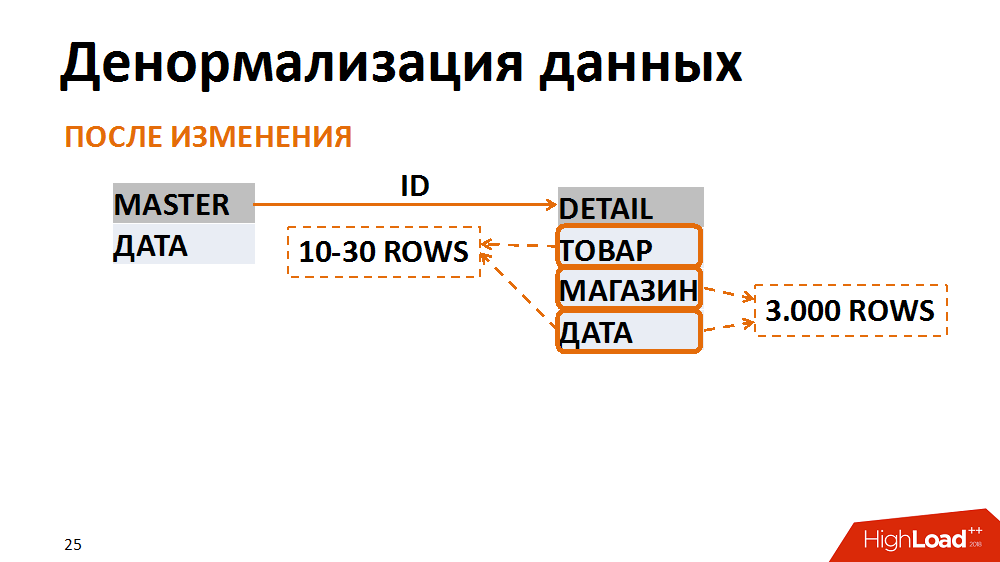
О последнем подробнее. В этом случае переводили модель данных в менее нормальную форму. Классический пример – выборка бухгалтерских документов за конкретную дату для отдельного магазина. Её запрашивают многие сотрудники. В master-таблице (таблице заголовков) хранятся даты документов, в таблице позиций — магазин и товар. Наиболее частые запросы – выборка всех документов по конкретному магазину за определённую дату. При таком запросе фильтр по дате по таблице заголовков выдаёт 500 тыс. записей, фильтр по магазину – аналогичный объём. При этом после склеивания по отдельному магазину за нужную дату мы имеем 3 тыс срок. Независимо от того, с какой таблицы мы начинаем фильтрацию и склеивание данных – всегда получаем много нежелательных операций ввода-вывода.

Этого можно избежать, если представить данные в менее нормальной форме. В одном случае поле даты дублировали в таблице позиций, обеспечили его заполнение при создании документов, собрали индексы для быстрого поиска и фильтровали уже по таблице позиций. Таким образом, пожертвовав незначительными накладными расходами на хранение нового поля и индексов, мы в несколько раз сократили число операций ввода/вывода, порождаемых проблемными запросами.
За полтора года мы проделали большую работу по оптимизации системы, она стала более прогнозируемой. Тем не менее, планы по удвоению числа магазинов оставались актуальны, поэтому вызовы все еще стояли перед нами.
По пути «вверх» мы столкнулись с разными узкими местами. Например, в конце 2015 года осознали, что уперлись в производительность одного core-сервиса платформы. Речь идет о сервисе логических блокировок SAP ABAP. Из-за него система явно не выдержала бы роста нагрузки. На горизонте замаячили потери больших денег.
Уточним, задача сервиса – выносить логическую транзакционность на уровень сервера приложений. В ABAP одна транзакция может пройти в виде нескольких шагов на разных рабочих процессах. Для того чтобы транзакция была целостной, есть сервис блокировок и сопутствующие механизмы. Операции по блокировке и разблокировке в нем происходят быстро, но они атомарные, их нельзя разделять. При этом была проблема синхронного ввода-вывода.
Сервис немного ускорился после того, как разработчики SAP выпустили специальный патч, мы перевели сервис на другое железо и поработали над системными настройками, но этого по-прежнему было мало. Потолок сервиса по паспорту составлял примерно 7 тыс операций в секунду, а нам уже давно требовалось 10 тыс.
После синтетического нагрузочного теста выяснили, что деградация происходит нелинейно и мы все-таки находимся у границы производительности сервиса выше которой проявляется неприемлемая деградация всей ERP системы. Повторные обращения к разработчикам дали лишь неутешительный вердикт — сервис работает правильно, просто мы требуем слишком многого в текущей архитектуре решения. Даже если бы мы немедленно взялись переделывать всю архитектуру решения, нам потребовалось бы несколько месяцев поддерживать работоспособность текущей системы.
Один из первых вариантов действий в попытке продлить жизнь сервису блокировок – ускорить операции ввода-вывода и их запись в файловой системе. Чем? Экспериментами с альтернативой AIX. Перенесли сервис на Linux на самой мощной Power-машине, и выиграли очень много по времени отклика. Сервис с включенной работой с файловой системой вел себя так же, как на Aix с отключенной. Далее перенесли на один из x86_64 блейдов этот код и получили еще более фантастически пологую кривую производительности, чем раньше. Выглядело это забавно.
Можно было бы предположить, что разработчики на AIX и Linux в прошлом тесте кое-что делали по-разному, но здесь уже влияние оказывала и архитектура процессора.
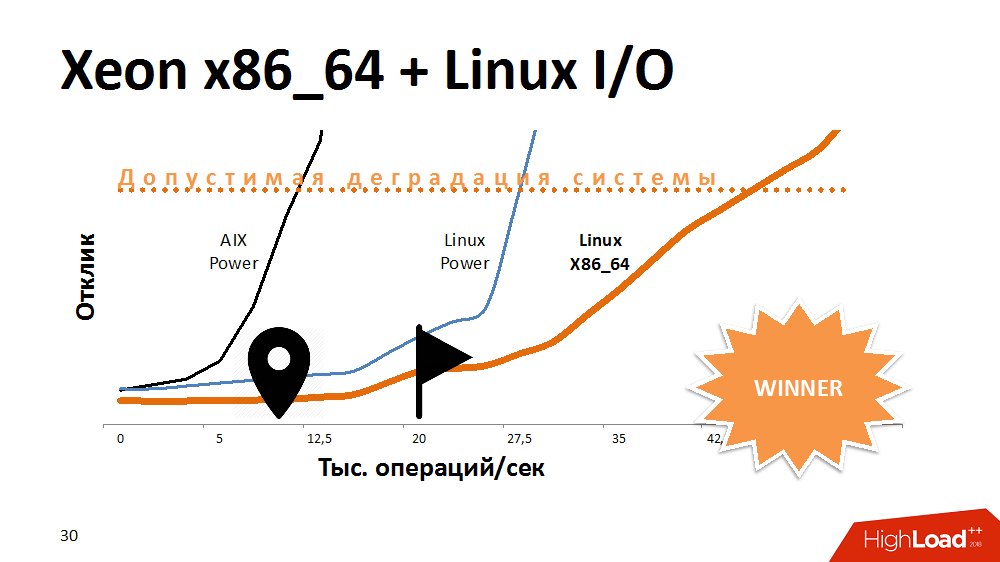
Какой был вывод? Какая-то платформа идеально подходит для многопоточных баз данных, обеспечивая и производительность, и отказоустойчивость, но со специфичными задачами процессор на другой архитектуре вполне может справиться лучше. Если на старте построения решения отказаться от кроссплатформенности, можно потерять пространство для маневров в будущем.
Тем не менее, с этой проблемой мы разобрались и сервис стал работать в 3-4 раза быстрее, что хватит на очень долгий рост.
Буквально через полгода стали ощущаться экзотические проблемы с ЦПУ на БД. Вроде бы понятно, что с ростом нагрузки растет потребление ресурсов процессора. Но все большую часть его стал занимать SysTime, и явно была проблема в ядре. Стали разбираться, делать синтетические нагрузочные тесты и поняли, что наша пропускная способность – 300 тыс операций в секунду, т.е. миллиард запросов в час, а дальше – деградация.
В итоге мы пришли к выводу, что идеальный запрос – тот, которого нет. Расширили свою методику оптимизации новыми подходами и провели ревизию ERP-системы: стали искать запросы, например, с низким КПД (100 тыс селектов – в результате 100 строк или вообще 0) — переделывать. Если «пустые» запросы не получается убрать, то пусть они уходят в «negative cache», если уместно. Если параллельно обрабатывается много запросов одних и тех же данных о товарах, то пусть они мучают сервер приложений, а не базу — кэшируем. Также большое количество частых единичных запросов по ключу в рамках одного процесса “укрупняем”, заменяя на более редкие выборки по части ключа. Или, например, для распределения нагрузки в цепочке обработки разные шаги могли выполняться на разных серверах приложений. Это хорошо, но на разных этапах они могут спрашивать одно и то же у базы. Тогда пусть первый шаг после старта на application кэширует часть запросов, и остается там доделывать всю остальную цепочку.

С помощью таких приемов мы выигрывали везде понемногу, но в итоге серьезно разгрузили базу. Система ожила. А мы тем временем занялись Aix.
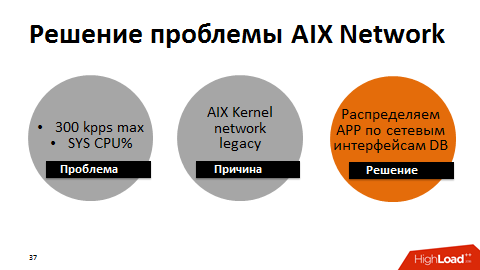
В ходе других экспериментов выяснили, что есть потолок производительности – уже упомянутые 300 000 DataBase-коллов в секунду. Корни проблемы были в производительности сетевого интерфейса, у которого был потолок – около 300 тыс пакетов в секунду в одну сторону. Как только потолок становился ближе, время системных вызовов росло. Как потом выяснилось, это также было наследие сетевого стека ядра ОС AIX.
В целом у нас никогда не было проблем с latency, ядро сети было производительным, все шнуры были собраны в большой неубиваемый канал на одном интерфейсе. Мы сделали обходное решение: разбили всю сеть между серверами приложений и базой данных на группы по разным интерфейсам. В итоге каждая группа серверов приложений общалась с БД по своему отдельному интерфейсу. Максимальная производительность каждого интерфейса немного снижалась, но суммарно мы разогнали сеть до 1 млн пакетов в секунду в одну сторону.
А принцип «Лучший запрос — тот, которого нет» был добавлен в талмуд для разработчиков, чтобы это учитывалось при написании кода.
Ну и последний этап оздоровления нашей системы, пройденный в 2017 году. Оставалось дожить совсем немного до апгрейда и нужно было продержать SLA всего-то ничего. Код был оптимизирован, но мы видели, что чем выше нагрузка на ЦПУ базы данных, тем медленнее работают процессы, хотя запас утилизации составлял 10-20%. Изначально рассчитывали, что 100% — это в два раза больше, чем 50%. И когда есть запас 10-20%, это и есть 10-20%. На самом деле при нагрузке выше 67-80% длительность задач нелинейно росла, т.е. срабатывал закон Амдала. У системы был лимит параллелизации и при его превышении, при вовлечении всё большего числа процессоров в работу снижалась производительность каждого отдельно взятого процессора.
На тот момент мы использовали 125 физических процессоров, или 500 логических с учётом multithreading на уровне AIX. Что бы вы предложили? Апгрейд? Даже до окончания его согласования нужно было продержаться несколько месяцев и не уронить SLA.
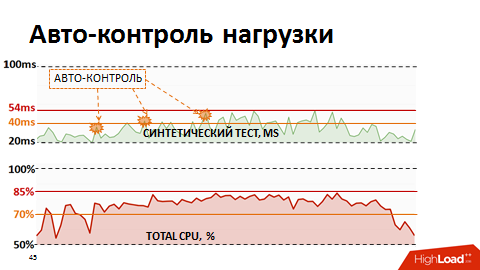
В какой-то момент поняли, что традиционные метрики утилизации процессора не показательны для нас – они не показывают фактическое начало деградации. Для реалистичной оценки здоровья системы мы начали использовать интегральную метрику – результат выполнения синтетического теста как метрики производительности процессора БД. Раз в минуту делали синтетический тест, замеряли его длительность и эту метрику выводили на наши мониторы. И реагировали, если метрика поднималась выше заявленной критической отметки. Мы немного придерживали нагрузку наших планировщиков нагрузки, чтобы она оставалась в зоне «максимального крутящего момента» базы данных.

Однако ручной контроль был неэффективным, да и просыпаться по ночам нам надоело. Тогда мы переписали планировщик нагрузки так, что у него появилась обратная связь по текущим метрикам производительности. Если метрики выходили за рамки желтого порога (см. картинку), планирование низкоприоритетных пакетов замораживалось и приоритет получали только бизнес-критичные процессы. Таким образом автоматически мы смогли управлять интенсивностью подачи нагрузки и ресурсы использовались эффективно. И самое интересное, что удерживая систему в пределах 80% нагрузки, в той самой зоне максимального крутящего момента, мы в итоге получили сокращение суммарного времени выполнения бизнес-процессов, т.к. каждый поток стал работать значительно быстрее.
Благодарим организаторов Highload за возможность поделиться этим опытом не только на Хабре, но и на сцене крупнейшего мероприятия по высоконагруженным системам.
Дмитрий Цветков, Александр Лищук, эксперты по SAP в #ITX5
Кстати, #ITX5 ищет консультантов SAP.

ERP X5
Сейчас Х5 управляет более чем 13 000 магазинов. Большинство бизнес-процессов каждого из них проходит через единую ERP-систему. В каждом магазине может быть от 3 000 до 30 000 товаров, это создает проблемы с нагрузкой на систему, т.к. через неё проходят процессы регулярного пересчёта цен в соответствии с промо-акциями и требованиями законодательства и расчёта пополнения товарных запасов. Всё это критично, и если вовремя не будет посчитано, какие товары в каком количестве должны быть завтра доставлены в магазин либо какая цена должна быть на товары, покупатели не найдут на полках то, что искали, либо не смогут приобрести товар по цене действующей промо-акции. В общем, кроме учёта финансовых операций, ERP-система отвечает за многое в повседневной жизни каждого магазина.
Немного ТТХ ERP-системы. Её архитектура классическая, трехуровневая с сервисно-ориентированными элементами: сверху у нас более 5 000 толстых клиентов и терабайты информационных потоков от магазинов и распределительных центров, в слое приложений – SAP ABAP c более чем 10 000 процессами и, наконец, Oracle Database c более чем 100 Тб данных. Каждый процесс ABAP – это условно виртуальная машина, выполняющая бизнес-логику на языке ABAP, со своим DBSL и диалектом SQL, кэшированием, memory management, ORM и т.д. В день мы получаем больше 15 Тб изменений в логе базы. Уровень нагрузки – 500 000 запросов в секунду.
Эта архитектура – гетерогенная среда. Каждый из компонентов кроссплатформенный, мы можем перемещать его на разные платформы, выбирать оптимальные и т.д.
Масла в огонь добавляет то, что ERP-система находится под нагрузкой 24 часа в сутки 365 дней в году. Доступность — 99,9% времени в течение года. Нагрузка при этом разделена на дневной, ночной профили и house keeping в свободное время.
Но и это не всё. У системы жесткий и плотный релизный цикл. В год она переносит больше 2 000 пакетных изменений. Это может быть и одна новая кнопочка, и серьезные изменения в логике работы бизнес-приложений.

В итоге это большая и высоконагруженная, но при этом стабильная, прогнозируемая и готовая к росту система, способная «хостить» десятки тысяч магазинов. Но так было не всегда.
2014. Точка бифуркации
Для погружения в практический материал нужно перенестись в 2014 год. Тогда были самые сложные задачи по оптимизации системы. Магазинов было около 5 000.
Система в то время находилась в таком состоянии, что большинство критичных процессов были немасштабируемы и неадекватно отвечали на рост нагрузки (то есть на появление новых магазинов и товаров). Кроме того, за два года до этого был закуплен дорогой Hi-End, и на какое-то время апгрейд не входил в наши планы. При этом процессы в ERP были уже на грани нарушения SLA. Вендор дал заключение, что нагрузка на систему немасштабируема. Никто не знал, выдержит ли она еще хотя бы +10% прироста нагрузки. А магазинов планировалось открыть в два раза больше в течение трех лет.
Просто накормить ERP-систему новым железом было невозможно, да и не помогло бы. Поэтому в первую очередь мы решили включить в релизный цикл методику оптимизации ПО и следовать правилу: линейный рост нагрузки пропорционально росту драйверов нагрузки – залог прогнозируемости и масштабируемости.
В чем заключалась методика оптимизации? Это цикличный процесс, разбитый на несколько этапов:
- мониторинг (выявить узкие места в системе и определить топовых потребителей ресурсов)
- анализ (профилирование процессов-потребителей, выявление в них конструкций с наибольшим и нелинейным влиянием на нагрузку)
- разработка (снижение влияния конструкций на нагрузку, достижение линейной нагрузки)
- тестирование в среде оценке качества или внедрение на продуктивной среде
Далее цикл повторялся.
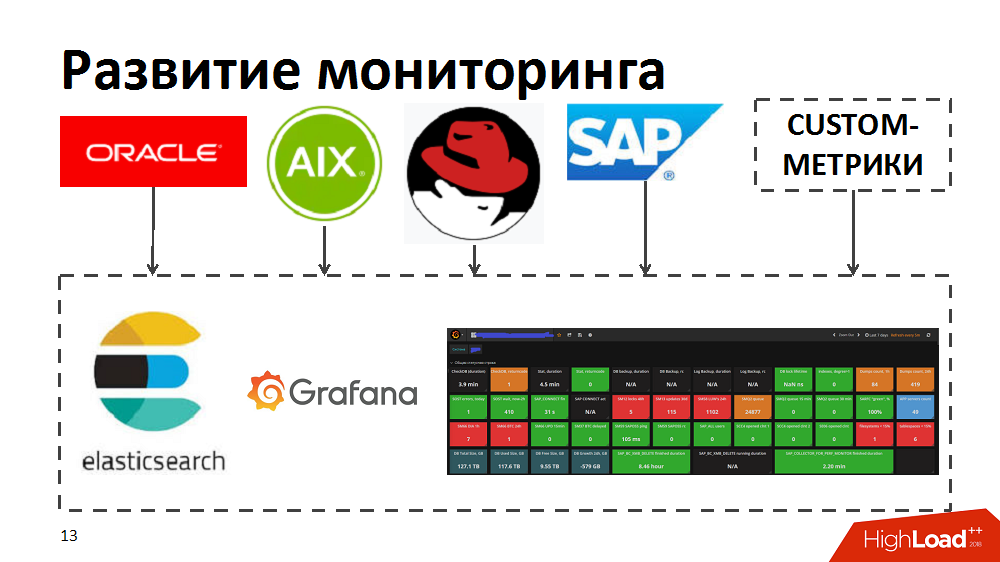
В процессе мы поняли, что текущие инструменты мониторинга не позволяют нам быстро определять топовых потребителей, выявлять узкие места и голодающие по ресурсам процессы. Поэтому для ускорения попробовали инструменты elastic search и Grafana. Для этого самостоятельно разработали коллекторы, которые из стандартных инструментов мониторинга в Oracle/SAP/AIX/Linux передавали метрики в elastic search и позволяли в режиме реального времени отслеживать здоровье системы. Кроме того, обогатили мониторинг своими custom-метриками, например время отклика и пропускная способность специфичных компонентов SAP или раскладки профилей нагрузки по бизнес-процессам.
Оптимизация кода и процессов
В первую очередь для меньшего влияния узких мест на быстродействие обеспечили более плавную подачу нагрузки на систему.
Большинство бизнес-процессов в нашей ERP-системе, например, такие как регулярный расчёт цен или планирование пополнения товарных запасов, представляют собой последовательную поэтапную обработку большого объёма данных (по всем товарам и всем магазинам). Для реализации обработки в рамках таких тяжёлых задач в своё время мы разработали собственный диспетчер пакетно-параллельной обработки (далее – планировщик нагрузки). В данном случае в виде пакета представляется обособленно выполняемый этап обработки по отдельному магазину.
Изначально логика планировщика была такова, что сначала выполнялись пакеты первого этапа обработки по всем магазинам, затем пакеты второго этапа и т.д. То есть в системе одновременно выполнялись процессы, создававшие однотипную нагрузку и вызывавшие деградацию определенных ресурсов (ввод-вывод на БД или CPU на серверах приложений, и т.д.).
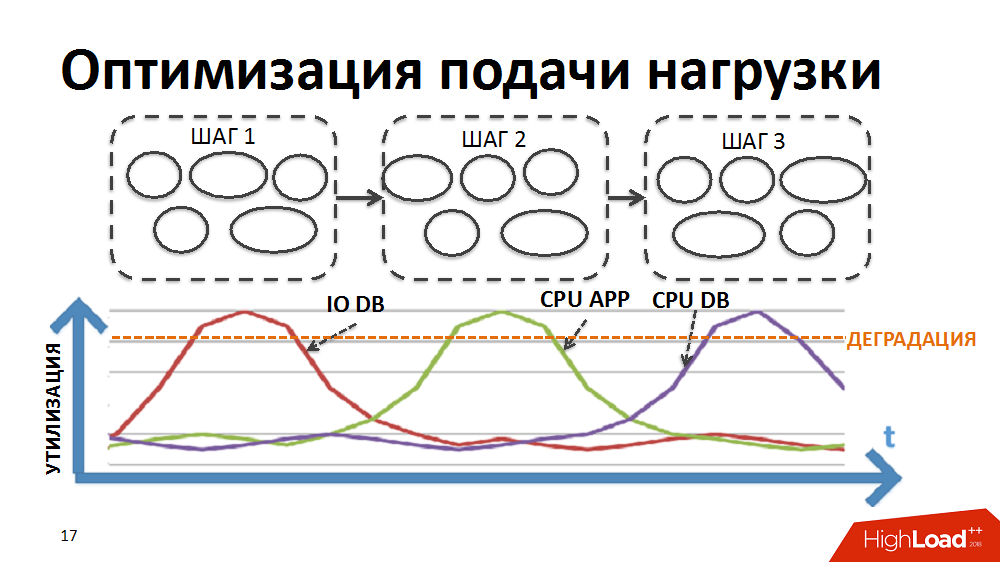
Мы переписали логику планировщика таким образом, чтобы цепочка пакетов формировалась отдельно по каждому магазину и приоритет запуска новых пакетов выстраивался не по этапам, а по магазинам.
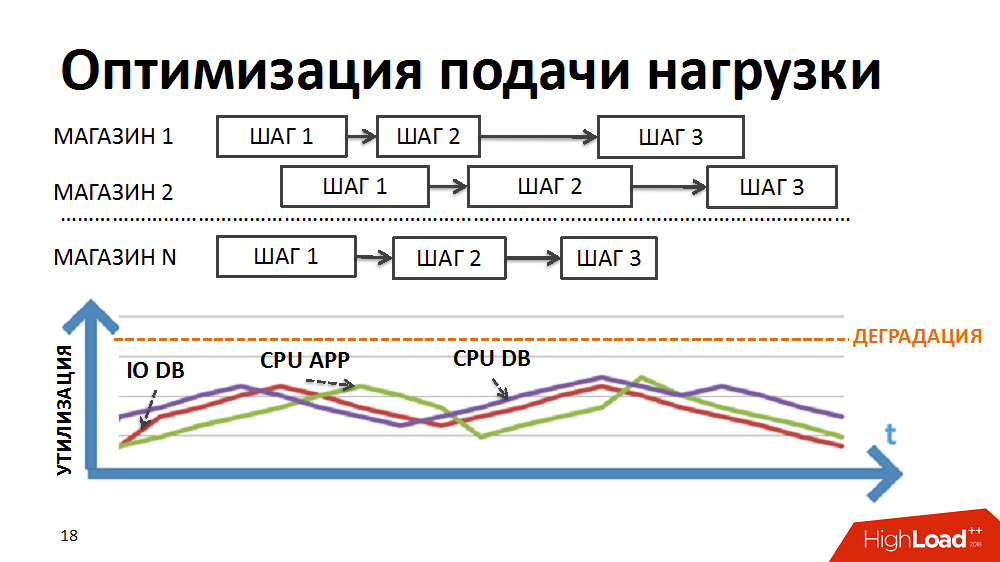
За счёт различной длительности выполнения пакетов по разным магазинам и регулируемого большого количества одновременно выполняемых процессов в рамках задач планировщика нагрузки мы достигли одновременного выполнения разнородных процессов, более плавной подачи нагрузки и устранения части узких мест.
Затем занялись оптимизацией отдельных конструкций. Каждый отдельный пакет рассматривали, профилировали и собирали неоптимальные конструкции и применяли подходы для их оптимизации. В дальнейшем эти подходы включили в регламент разработчика с целью предотвращения нежелательного роста нагрузки при развитии системы. Некоторые из них:
- избыточная нагрузка на ЦПУ серверов приложений (Часто порождалась нелинейными алгоритмами в коде программы, например, старый добрый линейный поиск в циклах либо нелинейные алгоритмы поиска пересечений множеств неупорядоченных элементов и т.п… Лечилось заменой на линейные алгоритмы: линейный поиск в циклах заменяем на двоичный; для поиска пересечений множеств используем линейные алгоритмы, предварительно упорядочив элементы и т.д.)
- идентичные обращения к БД с одними и теми же условиями в рамках одного процесса нередко приводят к избыточной утилизации CPU БД (лечится кешированием результатов первой выборки в памяти программы или на уровне сервера приложения и использованием закэшированных данных при последующих выборках)
- частые join-запросы (лучше их, конечно, выполнять на уровне БД, но иногда мы позволяли себе расщепить их на простые выборки, результат которых кэшируется, и перенести логику склеивания в приклад. Те случаи, когда лучше греть сервера приложений, а не БД.)
- тяжелые join-запросы, приводящие к большому количеству операций ввода/вывода
О последнем подробнее. В этом случае переводили модель данных в менее нормальную форму. Классический пример – выборка бухгалтерских документов за конкретную дату для отдельного магазина. Её запрашивают многие сотрудники. В master-таблице (таблице заголовков) хранятся даты документов, в таблице позиций — магазин и товар. Наиболее частые запросы – выборка всех документов по конкретному магазину за определённую дату. При таком запросе фильтр по дате по таблице заголовков выдаёт 500 тыс. записей, фильтр по магазину – аналогичный объём. При этом после склеивания по отдельному магазину за нужную дату мы имеем 3 тыс срок. Независимо от того, с какой таблицы мы начинаем фильтрацию и склеивание данных – всегда получаем много нежелательных операций ввода-вывода.
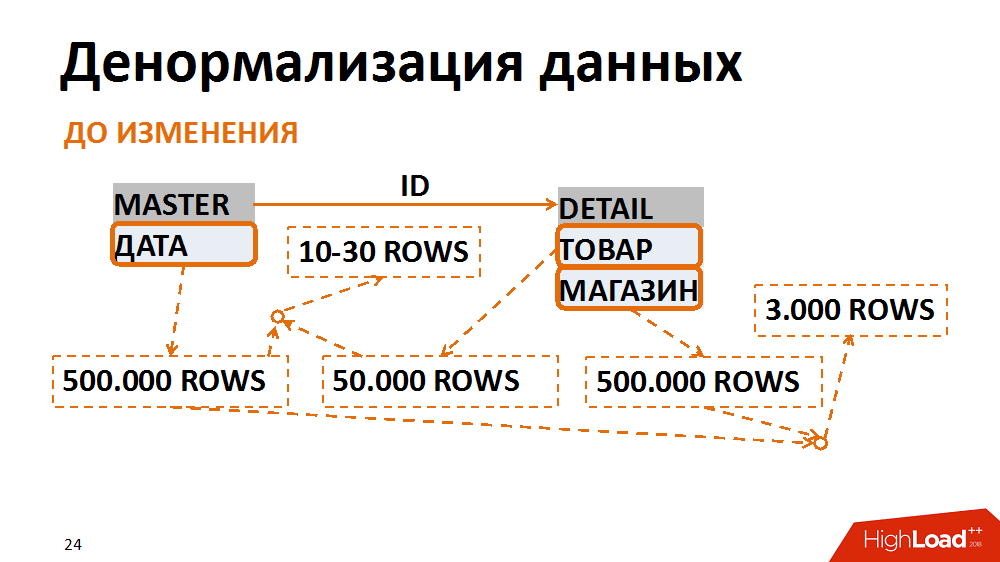
Этого можно избежать, если представить данные в менее нормальной форме. В одном случае поле даты дублировали в таблице позиций, обеспечили его заполнение при создании документов, собрали индексы для быстрого поиска и фильтровали уже по таблице позиций. Таким образом, пожертвовав незначительными накладными расходами на хранение нового поля и индексов, мы в несколько раз сократили число операций ввода/вывода, порождаемых проблемными запросами.

2015. Проблема одного сервиса
За полтора года мы проделали большую работу по оптимизации системы, она стала более прогнозируемой. Тем не менее, планы по удвоению числа магазинов оставались актуальны, поэтому вызовы все еще стояли перед нами.
По пути «вверх» мы столкнулись с разными узкими местами. Например, в конце 2015 года осознали, что уперлись в производительность одного core-сервиса платформы. Речь идет о сервисе логических блокировок SAP ABAP. Из-за него система явно не выдержала бы роста нагрузки. На горизонте замаячили потери больших денег.
Уточним, задача сервиса – выносить логическую транзакционность на уровень сервера приложений. В ABAP одна транзакция может пройти в виде нескольких шагов на разных рабочих процессах. Для того чтобы транзакция была целостной, есть сервис блокировок и сопутствующие механизмы. Операции по блокировке и разблокировке в нем происходят быстро, но они атомарные, их нельзя разделять. При этом была проблема синхронного ввода-вывода.
Сервис немного ускорился после того, как разработчики SAP выпустили специальный патч, мы перевели сервис на другое железо и поработали над системными настройками, но этого по-прежнему было мало. Потолок сервиса по паспорту составлял примерно 7 тыс операций в секунду, а нам уже давно требовалось 10 тыс.
После синтетического нагрузочного теста выяснили, что деградация происходит нелинейно и мы все-таки находимся у границы производительности сервиса выше которой проявляется неприемлемая деградация всей ERP системы. Повторные обращения к разработчикам дали лишь неутешительный вердикт — сервис работает правильно, просто мы требуем слишком многого в текущей архитектуре решения. Даже если бы мы немедленно взялись переделывать всю архитектуру решения, нам потребовалось бы несколько месяцев поддерживать работоспособность текущей системы.
Один из первых вариантов действий в попытке продлить жизнь сервису блокировок – ускорить операции ввода-вывода и их запись в файловой системе. Чем? Экспериментами с альтернативой AIX. Перенесли сервис на Linux на самой мощной Power-машине, и выиграли очень много по времени отклика. Сервис с включенной работой с файловой системой вел себя так же, как на Aix с отключенной. Далее перенесли на один из x86_64 блейдов этот код и получили еще более фантастически пологую кривую производительности, чем раньше. Выглядело это забавно.
Можно было бы предположить, что разработчики на AIX и Linux в прошлом тесте кое-что делали по-разному, но здесь уже влияние оказывала и архитектура процессора.
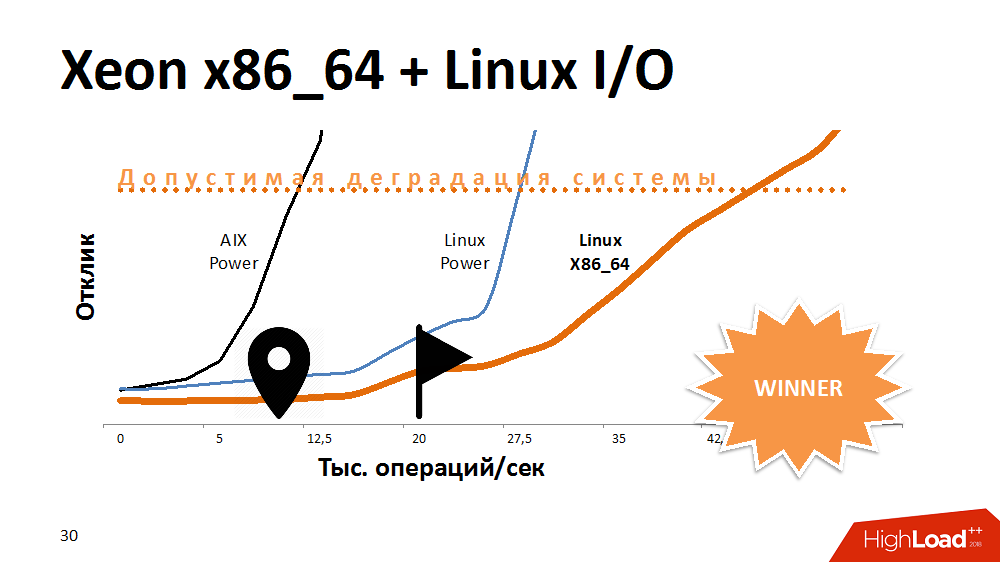
Какой был вывод? Какая-то платформа идеально подходит для многопоточных баз данных, обеспечивая и производительность, и отказоустойчивость, но со специфичными задачами процессор на другой архитектуре вполне может справиться лучше. Если на старте построения решения отказаться от кроссплатформенности, можно потерять пространство для маневров в будущем.
Тем не менее, с этой проблемой мы разобрались и сервис стал работать в 3-4 раза быстрее, что хватит на очень долгий рост.
2016. DB CPU Bottleneck
Буквально через полгода стали ощущаться экзотические проблемы с ЦПУ на БД. Вроде бы понятно, что с ростом нагрузки растет потребление ресурсов процессора. Но все большую часть его стал занимать SysTime, и явно была проблема в ядре. Стали разбираться, делать синтетические нагрузочные тесты и поняли, что наша пропускная способность – 300 тыс операций в секунду, т.е. миллиард запросов в час, а дальше – деградация.
В итоге мы пришли к выводу, что идеальный запрос – тот, которого нет. Расширили свою методику оптимизации новыми подходами и провели ревизию ERP-системы: стали искать запросы, например, с низким КПД (100 тыс селектов – в результате 100 строк или вообще 0) — переделывать. Если «пустые» запросы не получается убрать, то пусть они уходят в «negative cache», если уместно. Если параллельно обрабатывается много запросов одних и тех же данных о товарах, то пусть они мучают сервер приложений, а не базу — кэшируем. Также большое количество частых единичных запросов по ключу в рамках одного процесса “укрупняем”, заменяя на более редкие выборки по части ключа. Или, например, для распределения нагрузки в цепочке обработки разные шаги могли выполняться на разных серверах приложений. Это хорошо, но на разных этапах они могут спрашивать одно и то же у базы. Тогда пусть первый шаг после старта на application кэширует часть запросов, и остается там доделывать всю остальную цепочку.

С помощью таких приемов мы выигрывали везде понемногу, но в итоге серьезно разгрузили базу. Система ожила. А мы тем временем занялись Aix.
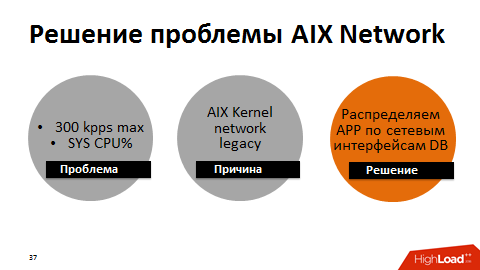
В ходе других экспериментов выяснили, что есть потолок производительности – уже упомянутые 300 000 DataBase-коллов в секунду. Корни проблемы были в производительности сетевого интерфейса, у которого был потолок – около 300 тыс пакетов в секунду в одну сторону. Как только потолок становился ближе, время системных вызовов росло. Как потом выяснилось, это также было наследие сетевого стека ядра ОС AIX.
В целом у нас никогда не было проблем с latency, ядро сети было производительным, все шнуры были собраны в большой неубиваемый канал на одном интерфейсе. Мы сделали обходное решение: разбили всю сеть между серверами приложений и базой данных на группы по разным интерфейсам. В итоге каждая группа серверов приложений общалась с БД по своему отдельному интерфейсу. Максимальная производительность каждого интерфейса немного снижалась, но суммарно мы разогнали сеть до 1 млн пакетов в секунду в одну сторону.
А принцип «Лучший запрос — тот, которого нет» был добавлен в талмуд для разработчиков, чтобы это учитывалось при написании кода.
2017. Дожить до апгрейда
Ну и последний этап оздоровления нашей системы, пройденный в 2017 году. Оставалось дожить совсем немного до апгрейда и нужно было продержать SLA всего-то ничего. Код был оптимизирован, но мы видели, что чем выше нагрузка на ЦПУ базы данных, тем медленнее работают процессы, хотя запас утилизации составлял 10-20%. Изначально рассчитывали, что 100% — это в два раза больше, чем 50%. И когда есть запас 10-20%, это и есть 10-20%. На самом деле при нагрузке выше 67-80% длительность задач нелинейно росла, т.е. срабатывал закон Амдала. У системы был лимит параллелизации и при его превышении, при вовлечении всё большего числа процессоров в работу снижалась производительность каждого отдельно взятого процессора.
На тот момент мы использовали 125 физических процессоров, или 500 логических с учётом multithreading на уровне AIX. Что бы вы предложили? Апгрейд? Даже до окончания его согласования нужно было продержаться несколько месяцев и не уронить SLA.
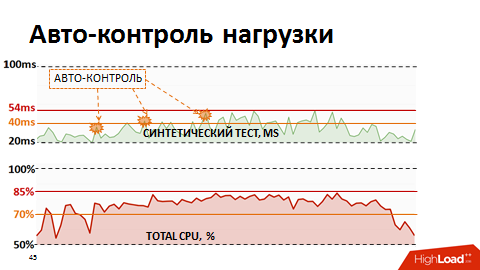
В какой-то момент поняли, что традиционные метрики утилизации процессора не показательны для нас – они не показывают фактическое начало деградации. Для реалистичной оценки здоровья системы мы начали использовать интегральную метрику – результат выполнения синтетического теста как метрики производительности процессора БД. Раз в минуту делали синтетический тест, замеряли его длительность и эту метрику выводили на наши мониторы. И реагировали, если метрика поднималась выше заявленной критической отметки. Мы немного придерживали нагрузку наших планировщиков нагрузки, чтобы она оставалась в зоне «максимального крутящего момента» базы данных.
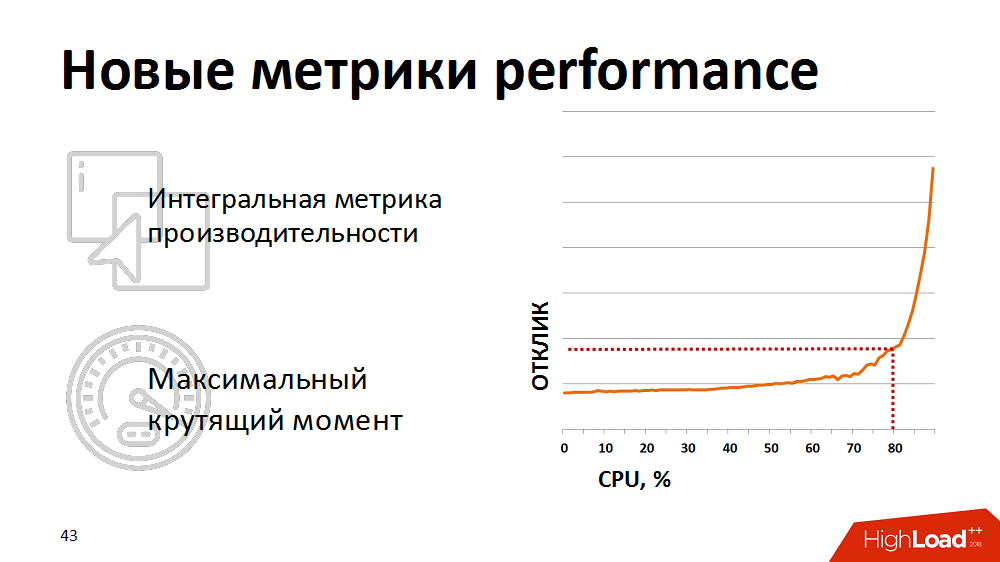
Однако ручной контроль был неэффективным, да и просыпаться по ночам нам надоело. Тогда мы переписали планировщик нагрузки так, что у него появилась обратная связь по текущим метрикам производительности. Если метрики выходили за рамки желтого порога (см. картинку), планирование низкоприоритетных пакетов замораживалось и приоритет получали только бизнес-критичные процессы. Таким образом автоматически мы смогли управлять интенсивностью подачи нагрузки и ресурсы использовались эффективно. И самое интересное, что удерживая систему в пределах 80% нагрузки, в той самой зоне максимального крутящего момента, мы в итоге получили сокращение суммарного времени выполнения бизнес-процессов, т.к. каждый поток стал работать значительно быстрее.
Пара советов тем, кто работает с высоконагруженной ERP
- Очень важно вести мониторинг производительности систем на старте проекта, особенно с собственными метриками.
- Обеспечьте линейный рост нагрузки пропорционально росту количества драйверов нагрузки (в нашем случае ими были товары и магазины).
- Устраняйте нелинейные конструкции в коде, используйте кэширование для устранения идентичных запросов к БД.
- Если нужно перенести нагрузку с ЦПУ БД на ЦПУ серверов приложений, то можно и прибегнуть к расщеплению join-запросов на простые выборки.
- При всех оптимизациях помните, что быстрый запрос – хорошо, а быстрый и частый запрос – иногда плохо.
- Старайтесь всегда прощупывать и использовать возможности гетерогенной среды решения.
- Наряду с традиционными метриками производительности используйте интегральную метрику, однозначно идентифицирующую наличие деградации; с помощью этой метрики определите зону “максимального крутящего момента” своей системы.
- Обеспечьте инструменты планирования нагрузки наличием механизмов контроля текущих показаний метрик производительности и управления интенсивностью подачи нагрузки с целью эффективного использования ресурсов системы
Благодарим организаторов Highload за возможность поделиться этим опытом не только на Хабре, но и на сцене крупнейшего мероприятия по высоконагруженным системам.
Дмитрий Цветков, Александр Лищук, эксперты по SAP в #ITX5
Кстати, #ITX5 ищет консультантов SAP.
