Comments 59
Ваш вопрос относительно справочника со свойствами регистра обоюдоострый.
С одной стороны, всё это упирается в необходимость менять технологическую платформу. Это возможно. Либо нужно вводить дополнительный уровень абстракции, чтобы иметь собственный «конфигуратор» для технологической платформы. Либо существенно дополнить список допустимых объектов теми объектами, которые естественным образом возникают при решении задач, отличных от задач учёта. Состав объектов конфигурации завязан на учётные задачи, но работу по выявлению новых объектов конфигурации можно продолжить и довести до своего логического конца. Но, боюсь, это приведёт к необходимости делать такую продвинутую технологическую платформу частью операционной системы.
Представьте, что будет, если сделать операционную системы чем-то вроде 1С. Это будет означать, что прикладные программисты будут иметь дело только с объектами конфигурации (им не надо будет иметь дело даже с файлами, если операционная система сама будет документно-ориентированной!).
С другой стороны, Ваше желание совместить в одном объекте разные функции разрушает сам подход к организации объектов конфигурации. Смысл подхода заключается именно в том, чтобы каждый объект решал свою задачу. Если хотите, то тут возникает что-то вроде ортогонализации Грамма-Шмидта, которая позволяет перейти от любой линейно независимой системы векторов к ортонормированной системе, в которой скалярные произведения записываются наиболее просто без смешения разноименных элементов. Если бы кто-нибудь сумел проделать аналогичный процесс в программировании, то мы могли бы собирать любые приложения из кубиков-компонентов.
upd: чтение в другом сеансе не в транзакции. соответственно управляемые блокировки не используются (да и не хочется ожидание)
Но!
Всегда есть вероятность того, что при ином построении конфигурации какие-то вещи станет выполнять проще. Возникает вопрос: а что это за задача такая, где необходимо переписывать содержимое регистра?
удобнее набором записей, а не по записи. Вот и получается, что в момент обновления пользователь в динамическом списке видит, что данные пропали.
Это касается и перепроведения документов, в случае очистки движений. запрос в другом сеансе видит исчезновение записей
Что еще интересно. Этот подход обеспечивает постоянное развитие системы. Мы добавляем в платформу новые механизмы, и они сразу начинают работать для уже существующих объектов (без усилий разработчика приложений или с минимальными усилиями). Например, недавно мы разработали механизм хранения истории данных (версионирования). Так как система знает в общем виде о семантике данных, то разработчику достаточно поставить флажок, что он хочет хранить историю данных конкретного объекта, и платформа обеспечивает все, что нужно, от хранения истории, до визуализации — отображения пользователю истории изменений в виде различных отчетов.Здорово. А как это выглядит на практике? Речь идёт, например, о конкретном справочнике, или об объекте, который описывается отдельной строкой-записью в этом справочнике?
Пока мы все-таки стараемся удержаться от введения «просто таблиц», чтобы обеспечить чистоту модели и возможность добавлять новую функциональность, опираясь на знание о семантике всех данных. Если каких-то возможностей не будет хватать, то вначале мы все-таки будем рассматривать то, как можно развить состав типов прикладных объектов. Но, конечно, это вопрос дискуссионный и мы будем продолжать про него думать.Не надо вводить «просто таблицы». Лучше попытаться вести новые типы данных (объекты конфигурации): «НаборДанных» (для хранения самих неструкутрированных изначально данных), «МодельДанных» (для описания принципов хранения: «ключ-значение», «документ», «расширяемая запись» и т.д. и т.п.) и «РегистрМетаданныхНаборовДанных» (для описания конкретных обрабатываемых в системе данных). Для решения каждой задачи создаётся свой набор данных, выбирается для него модель, формируется своя схема данных, которая отражается в регистре. Возможно, здесь потребуется принципиально новый объект конфигурации, вроде того, который был нужен Almet'у: справочник со свойствами регистра. Здесь нужна возможность доступа по ключу (по определённой системе «разрезов»), но и возможность ссылки на объект справочника. Получается, что мы, как бы, сначала заглядываем к регистр (со связкой ключей-измерений), чтобы узнать уникальный линейный код объекта, и уже из простого линейного справочника берём всё остальное.
Таким образом, возможности, которые предоставляет в готовом виде платформа 1С: Предприятия и то повышение уровня абстракции, которое ценится прикладными разработчиками, во многом опираются именно на набор типов прикладных объектов. Это является одним из наиболее существенных отличий 1С: Предприятия от других средств разработки и одним из главных инструментов, обеспечивающих быструю и унифицированную разработку.А кто они, конкуренты? Тут одно из двух: либо конкурентов нет, потому как 1С — практически единственная компания, которая использует подход, основанный на типологии прикладных объектов, либо такой подход используется другими компаниями, но в других областях, и, поэтому, прямой конкуренции не получается. Выбранный подход кажется вполне естественным. Вроде бы, все должны заниматься этим. Может быть, всему виною ниша, выбранная 1С, и заблуждение большинства пользователей и разработчиков, что подход 1С — это удел только учётных систем? Ведь, самый главный вопрос разработки программного обеспечения — это то, какова модель управления данными. Если есть подход у правлению, то он общезначим и относится ко всем случаям и ситуациям. ЯТД.
Здорово. А как это выглядит на практике? Речь идёт, например, о конкретном справочнике, или об объекте, который описывается отдельной строкой-записью в этом справочнике?
Об объекте, который описывается отдельной строкой-записью. В статье довольно подробно описано.
Не имею понятия. Имелась ввиду идейная составляющая.
Идея может казаться сколь угодно прекрасной, но если с помощью её нет успешных реализаций требуемых задач — есть сомнения, что идея подходит для решения задач из данной предметной области.
Как можно не использовать таблицы ??? Таблица не versus модели. Заголовком вы показали или скрыли: О)))) свой уровень одинэсника. ПТУ отдыхает.
Не буду отвечать — не хочу опускаться с уровня своего ПТУ до вашего уровня.
А кто они, конкуренты?
Давайте посмотрим сюда. Например, на диаграмму из первой ссылки:
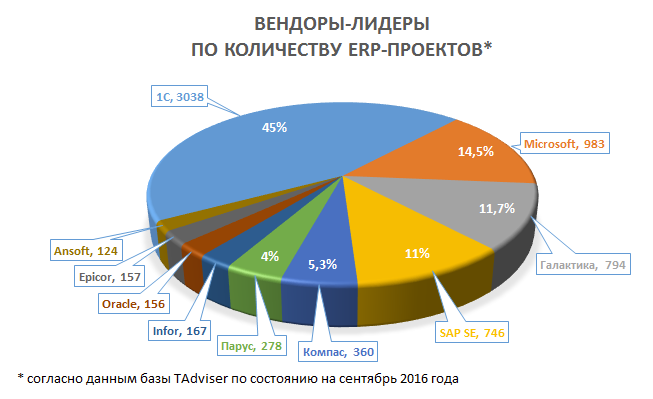
Собственно, вот и конкуренты.
А используют ли они подход, основанный на типологии прикладных объектов, или какой-то другой — конкурентами они от этого быть не перестанут.
Если говорит серьёзно, то с чем в этом списке присутствует Microsoft?
Есть Navision; недавно появилась облачная версия.
Есть Axapta.
Есть еще Solomon и Great Plains, но об их внедрениях в России я пока не слышал.
Есть еще Microsoft CRM, но тут речь про ERP продукты, CRM к ним вроде бы не относится. Хотя составители графика могли и CRM учесть.
А Oracle?
Есть Oracle E-Business Suite, есть еще Oracle Commerce, Oracle Retail, Micros и т.д…
Ещё я слышал когда-то о Компасе.
Про Компас знаю пока очень мало. Если у вас есть ссылки на профильные материалы — буду благодарен.
Про продукты Epicor знаю побольше — ранее работал в этой компании. Типологии предметной области (по крайней мере в Epicor и iScala) нет, подход к разработке прикладного кода скорее классический.
Кроме того при записи документов регистров не используется аналог Merge. А именно удаляется весь старый набор, даже если там изменена одна запись и записывается новый набор.
правда EXISTS легко заменяется через IN
— Удалять автоматически при отмене проведения
— Удалять автоматически
— Не удалять автоматически
Стандарты SQL описывают запросы к реляционным базам, а запросы 1С — запросы к объектно ориентированной модели данных. Не правильно их сравнивать по возможностям.
Есть хоть один практически необходимый пример использования OFFSET или FETCH? Или может быть Вы с помощью запросов сделать пытаетесь то, что решается архитектурно иначе?
У тебя есть набор в котором изменена 1 запись. Как этот набор запишется?
OFFSET или FETCH нужны для постраничного получения данных для сайтов и прочих выборок
Хотелось бы еще и аннотацию типов как в TypeScript
И самое интересное что этот подход работает: железо дешевле и проще приобрести чем разработчиков.
В случае с 1С, правда, срабатывает ещё и такой аргумент: лучше медленная, но прозрачная и, значит, управляемая система с устоявшейся терминологией и устоявшимся рынком поддержки, чем шустрая система с постоянно меняющейся терминологией и без толковой службы поддержки. Я могу ошибаться, но, я думаю, что консерватизм нередко заставляет отказываться от более эффективного в пользу более привычного.
Я когда имел неосторожность работать в конторе которая внедряла в первую очередь SAP и 1С чтобы было… Там были постоянные гонения на 1С. На SAP стояли мощнейшие сервера, а под 1С предлагали использовать файловые сервера и еще постоянно сверху письма шли мол что это отдел 1С забил весь файловый сервер… Купили бы для 1С сервера как для SAP проблем бы не было. Как будто нам было охота на медленном файловом сервере гонять базы. А потом все ноют что 1С якобы медленная.
Сейчас условие сравнения только на равенство и только для измерений, хотя поля могут быть проиндексированы.
Из-за этого часто приходится делать запрос и молотить построчно через менеджер записи.
Но когда я попробовал повторить все то же самое на 1С у меня ушло 4 часа. И все благодаря объектной модели 1С (тогда ее семерки). В те времена было вообще не принято в 1С знать как реально лежат данные. И вы хотите чтобы наоборот замедлилась разработка, но зато по было все по стандартам из других языков программирования?
мы говорим не о техническом аспекте хранения и манипулирования данными, а об описании данных как способе проектирования приложения— а как оптимизировать доступ к данным при большом их количестве? Понятно, что вы упростили жизнь себе, как архитекторам системы, но усложнили жизнь DBA и эксплуатантам!
90% проблем быстродействия связаны с некомпетентностью людей, предлагающих кастомные решения.
Сорри, не сталкивался с 1С.
Выгружать данные в какую либо отчетную систему непосрндственно не кажется правильным. Ведь та структура данных, которая положена в 1С, сделана такой для внутренних отчетов или механизмов контроля учета (например остатков) самого 1С. Отчетной системе, консолидирующей данные из разных источников, в т.ч. из 1С, может требоваться иная структура данных для формирования своих отчетов. В первую очередь следует провести сопоставление данных и формально описать правило конвертации одной строки записи 1С в строку записи таблицы DWH. Создать в 1С план обмена, в который будет включен узел, соответствующий базе данных отчетов. Включить для этого плана обмена регистрацию изменений для выгружаемой таблицы. Таким образом все новые или удаленные записи будут записаны к отправке. Далее каким либо образом DWH будет инициировать обмен, запрашивая, есть ли для нее новые данные в 1С, например можно поднять веб-сервис SOUP или HTTP прям из 1С. 1С в ответ будет формировать пакет данных, требуемый для базы отчетов. Каждый пакет должен иметь уникальный номер и после загрузки база отчетов должна послать коммит подтверждения загрузки в себя данных, после чего 1С сможет удалять у себя данные из таблицы изменений (снимать записи с регистрации) отправленные по тому номеру сообщения, который приняла база отчетов. Где будет происходить конвертация строк, в 1С или в базе отчетов не так важно, это скорее зависит от того, где дешевле выполнять доработки ззаказчику при необходимости расширить функционал.
Все перечисленные работы вполе реально сделать в одиночку за неделю. Включая составление документации и пром. тестирование.
Здесь же речь об одной строке записи прикладного объекта 1С?
>> Создать в 1С план обмена, в который будет включен узел, соответствующий базе данных отчетов. Включить для этого плана обмена регистрацию изменений для выгружаемой таблицы. Таким образом все новые или удаленные записи будут записаны к отправке.
А есть где-то описание механизма на стороне 1С? Best practice какой-нибудь? С чего стоит начать разбираться в вопросе ETL-щику, который не работал с 1С? Хочется понимать, как люди это делают правильно.
Google говорит, народ инициирует на стороне 1С выгрузку в буферную таблицу/файл, а оттуда уже забирает в DWH. Но все-равно придется как-то бить на серии «новые/обновленные/старые записи».
Здесь же речь об одной строке записи прикладного объекта 1С?
Да. Надо для одной строки записи (справочник, документ, регистр сведений или накопления или что-то еще) определить какие его измерения, реквизиты, ресурсы как должны перейти в колонки таблицы базы отчетов. Учитывая типы измерений, будет ли потеря данных, например при конвертации строк размерностью 130 символов в строки размерностью 100, или трита (булево+null) в простое булево и т.д. — это задача аналитика, который должен знать какие данные нужны для формирования отчета в базе отчетов.
Не очень понятно зачем делать какие-то буферные таблицы или файлы, когда сама платформа предлагает для этого механизм планов обмена. На низком уровне происходит так:
Если нужно выпонять какой-то тип обмена с другой системой, разработчик создает новый план обмена и включает в него те объекты 1С, которые должны передаваться в другую систему. Для каждого такого объекта платформа сама создаст таблицу изменений, в которую будет включен идентификатор записи (для справочников и документов, например — это ссылка, а для регистров — это ключ записи) и будет включен узел, в который необходимо отправить данные.
При записи объекта (например при изменении номенклатуры или создании нового документа) если для объекта есть таблица изменений, то он будет там зарегистрирован к отправке (само по себе это платформа выполняет автоматически, однако программно регистрировать и снимать с регистрации тоже можно).
Если есть несколько разных отчетных баз одного типа, то для них достаточно сделать один план обмена в котором уже в режиме предприятия создать несколько узлов, для каждой отчетной базы свой узел. Система благодаря своей структуре таблицы изменений для каждого узла будет регистрировать данные отдельно.
План обмена так же включает в себя по умолчанию номера принятых и отправленных сообщений, это необходимо для подтверждения доставки. Чтобы избежать таких случаев, когда данные в отчетную систему были отправлены, но при этом отчетная база их не приняла. При следующем обмене отправляться будут в том числе и те записи, которые отчетная база не приняла ранее, чтобы гарантировать целостность передачи. Для этого и вводится дополнительная операция — коммит подтверждения доставки. Когда 1С отправляет какие-либо данные она в таблице изменений сохраняет тот номер пакета сообщения, который она отправила и в дальнейшем когда отчетная система пришлет коммит о том, что она этот номер сообщения приняла, 1С может со спокойной совестью снять все данные с регистрации, отправленные по этому номеру сообщения.
Если обмен является двухсторонним, то обычно коммитом является получение пакета из другой базы, если обмен односторонний (как это с выгрузкой в отчетную базу) достаточно реализовать операцию подтверждения).
Сам способ отправки может быть любым. Можно создать регламентное задание, которое будет из 1С по расписанию выгружать данные в стороннюю систему, можно выгружать в файлы, можно записывать непосредственно в базу приемник (все равно какая, 1С может записывать и MySQL, MSSQL, Postgres, Oracle, IBM DB2, вообще во все, для чего есть драйвер подключения к этой базе.
Но делать непосредственные выгрузки так же как инициировать обмен из 1С — это не самая хорошая практика, лучше, когда данные запрашивает та система, которой эти данные нужны. Так же как записывать куда то в стороннее хранилище данные непосредственно тоже не очень правильно, ведь структура данных и в 1С и в сторонней базе может со временем измениться, бизнес требует частых доработок. Потому правильным считается приведение сначала к общему формату обмена, и после отправку и приемку.
Опять же что это будет за формат — не очень важно для 1С, это может быть XML, JSON, какой-то бинарный файл или просто текстовый (тот же CSV) формат, главное чтобы приемная база могла его понять и формат был согласован.
Протокол отправки то же не очень важен, сторонняя система может просто стучаться по COM, на 1С может быть реализован веб-сервис по формату SOAP или сразу передавать ответ, выполнив запрос к 1С по HTTP, ровно как и выгружать в файл на диск или ftp. Тут скорее надо определить что из этого доступно в базе которая хочет интегрироваться с 1С.
Все механизмы подробно описаны в книжке
Профессиональная разработка в системе 1С: Предприятие 8
Так же многие нюансы описаны в книжке
Настольная книга 1С: Эксперта по технологическим вопросам
Понятно что на данный момент 1С прекрасно справляется со своими задачами, но что будет дальше? Ведь даже сам по себе язык 1С никак не эволюционировал, а работа с DB запрещена пользовательским соглашением. Все этот как бы идет против течения мирового тренда.
Что произойдет когда разработка бизнесс приложений на JS станет легче 1С Предприятия?
Значит, у нас появятся конкуренты.
Одного я уже знаю — Haulmont c платформой CUBA. На мой взгляд, там все еще на порядок сложнее разрабатывать бизнес-приложения, чем на 1С. Возможно, со временем это изменится.
Я не говорю о гитхабе и open-source сообществе, которые являются двигателем прогресса…
Enterprise Development Tools позволяет хранить исходные коды конфигураций в Github. Или вы имеете в виду что-то другое?
Все этот как бы идет против течения мирового тренда.
А в какую сторону течет мировой тренд? Можете обрисовать?
отсутствие await и лямбд делает программирование «сексуально» не привлекательным, особенно для мобильных приложений или той же Розницы с колбеками.
Кроме того пора уже идти в сторону необязательной типизации «функция а(в как строка) как строка»
и дать механизм аналогичный тексовым запросам ввиде функции filter, map, fold (LINQ), не как сейчас сделано «для галочки», а удобно и с поддержкой среды и добавить туда например добавление нарастающего итога благо это есть во всех новых языках, а одинесников избавит от кучи кода и т д.
Кроме того хотелось бы иметь механизм правил обмена реализованный в мобильном приложении, да я извращенец, но когда надо быстро что то наклепать не хочется полдня заниматься "____".
Как мы в 1С: Предприятии работаем с моделями данных (или «Почему мы не работаем с таблицами?»)